OPEN MPI WITH RDMA SUPPORT AND CUDA. Rolf vandevaart, NVIDIA
|
|
|
- Lester Martin Turner
- 6 years ago
- Views:
Transcription


1 OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA
2 OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
3 CUDA-AWARE DEFINITION Regular MPI //MPI rank 0 cudamemcpy(s_buf_h,s_buf_d,size, ); MPI_Send(s_buf_h,size, ); //MPI rank n-1 MPI_Recv(r_buf_h,size, ); cudamemcpy(r_buf_d,r_buf_h,size, ); CUDA-aware MPI //MPI rank 0 MPI_Send(s_buf_d,size, ); //MPI rank n-1 MPI_Recv(r_buf_d,size, ); CUDA-aware MPI makes MPI+CUDA easier.


4 CUDA-AWARE MPI IMPLEMENTATIONS Open MPI MVAPICH IBM Platform MPI platformcomputing/products/mpi CRAY MPT
5 HISTORY OF CUDA-AWARE OPEN MPI Open MPI released in April, 2013 Pipelining with host memory staging for large messages (utilizing asynchronous copies) over verbs layer Dynamic CUDA IPC support added GPU Direct RDMA support Use Open MPI to get all the latest features
6 MPI API SUPPORT Yes No All send and receive types All non-arithmetic collectives Reduction type operations MPI_Reduce, MPI_Allreduce, MPI_Scan Non-blocking collectives MPI-2 and MPI-3 (one sided) RMA FAQ will be updated as support changes



7 CUDA IPC SUPPORT IN OPEN MPI NODE 0 NODE 1 INTEL CPU RANK 0 RANK 1 QPI INTEL CPU RANK 2 INTEL CPU QPI INTEL CPU RANK 3 RANK 4 GPU GPU NO CUDA IPC GPU GPU CUDA IPC CUDA IPC
8 CUDA IPC SUPPORT IN OPEN MPI Open MPI dynamically detects if CUDA IPC is supported between GPUs within the same node. Enabled by default --mca btl_smcuda_use_cuda_ipc 0 To see if it is being used between two processes --mca btl_smcuda_cuda_ipc_verbose 100 CUDA 6.0 has performance fixes
9 CUDA IPC SUPPORT IN OPEN MPI
10 GPU DIRECT RDMA SUPPORT Kepler class GPUs (K10, K20, K40) Mellanox ConnectX-3, ConnectX-3 Pro, Connect-IB CUDA 6.0 (EA, RC, Final), Open MPI and Mellanox OFED 2.1 drivers. GPU Direct RDMA enabling software
11 GPU DIRECT RDMA SUPPORT Implement with RDMA type protocol Register send and receive buffers and have NIC transfer data Memory registration is not cheap need to have registration cache


12 GPU DIRECT RDMA SUPPORT Chipset implementations limit bandwidth at larger message sizes Still use pipelining with host memory staging for large messages (utilizing asynchronous copies) Final implementation is hybrid of both protocols READ GPU Chipset Network Card WRITE Memory CPU IVY BRIDGE P2P READ: 3.5 Gbyte/sec P2P WRITE: 6.4 Gbyte/sec
13 GPU DIRECT RDMA SUPPORT - PERFORMANCE
14 GPU DIRECT RDMA SUPPORT - PERFORMANCE
15 GPU DIRECT RDMA SUPPORT CONFIGURE Nothing different needs to be done at configure time > configure --with-cuda The support is configured in if CUDA 6.0 cuda.h header file is detected. To check: > ompi_info --all grep btl_openib_have_cuda_gdr MCA btl: informational "btl_openib_have_cuda_gdr" (current value: "true", data source: default, level: 4 tuner/basic, type: bool) > ompi_info -all grep btl_openib_have_driver_gdr MCA btl: informational "btl_openib_have_driver_gdr" (current value: "true", data source: default, level: 4 tuner/basic, type: bool)
16 GPU DIRECT RDMA SUPPORT TUNING PARAMETERS Runtime parameters Enable GPU Direct RDMA usage (off by default) --mca btl_openib_want_cuda_gdr 1 Adjust when we switch to pipeline transfers through host memory. Current default is 30,000 bytes --mca btl_openib_cuda_rdma_limit 60000
17 GPU DIRECT RDMA SUPPORT NUMA ISSUES Configure system so GPU and NIC are close INTEL CPU QPI INTEL CPU NIC NIC INTEL CPU QPI INTEL CPU GPU GPU BETTER
18 GPU DIRECT RDMA SUPPORT NUMA ISSUES Multi NIC - multi GPU: use hwloc to select GPU near NIC NIC CPU QPI CPU NIC GPU GPU RANK 0 RANK 1
19 LATENCY COMPARISON CLOSE VS FAR GPU AND NIC
20 CUDA-AWARE OPEN MPI AND UNIFIED MEMORY CUDA 6 Unified Memory cudamallocmanaged(buf, BUFSIZE, cudamemattachglobal) Unified Memory may not work correctly with CUDA-aware Open MPI Will fix in future release of Open MPI
21 HOOMD BLUE PERFORMANCE Highly Optimized Object-oriented Many-particle Dynamics - Blue Edition Performs general purpose particle dynamics simulations Takes advantage of NVIDIA GPU Simulations are configured and run using simple python scripts The development effort is led by Glotzer group at University of Michigan Source:
22 HOOMD CLUSTER 1 Dell PowerEdge R720xd/R720 cluster Dual-Socket Octa-core Intel E GHz CPUs (Static max Perf in BIOS), Memory: 64GB DDR MHz Dual Rank Memory Module, OS: RHEL 6.2, MLNX_OFED InfiniBand SW stack Mellanox Connect-IB FDR InfiniBand, Mellanox SwitchX SX6036 InfiniBand VPI switch, NVIDIA Tesla K40 GPUs (1 GPU per node), NVIDIA CUDA 5.5 Development Tools and Display Driver , Open MPI rc1, GPUDirect RDMA (nvidia_peer_memory tar.gz) Application: HOOMD-blue (git master 28Jan14), Benchmark datasets: Lennard-Jones Liquid Benchmarks (16K, 64K Particles) Source:

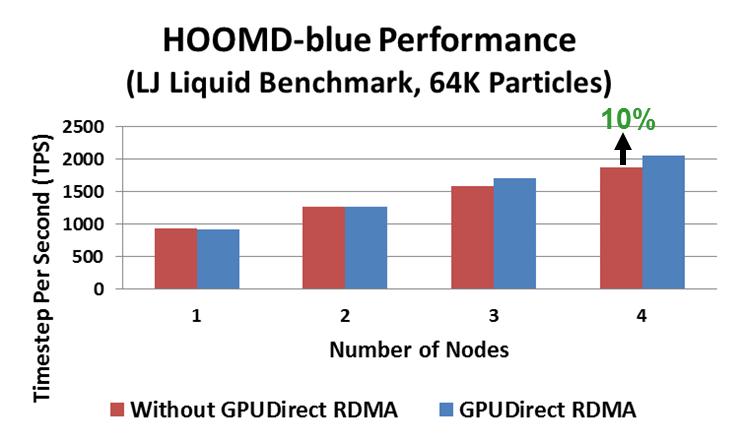
23 GPU DIRECT RDMA SUPPORT APPLICATION PERFORMANCE Higher is better Source:
24 HOOMD CLUSTER 2 Dell PowerEdge T node (1536-core) Wilkes cluster at Univ of Cambridge Dual-Socket Hexa-Core Intel E GHz CPUs, Memory: 64GB memory, DDR MHz, OS: Scientific Linux release 6.4 (Carbon), MLNX_OFED InfiniBand SW stack Mellanox Connect-IB FDR InfiniBand adapters, Mellanox SwitchX SX6036 InfiniBand VPI switch, NVIDIA Tesla K20 GPUs (2 GPUs per node), NVIDIA CUDA 5.5 Development Tools and Display Driver , Open MPI 1.7.4rc1, GPUDirect RDMA (nvidia_peer_memory tar.gz) Application: HOOMD-blue (git master 28Jan14) Benchmark datasets: Lennard-Jones Liquid Benchmarks (512K Particles) Source:
25 GPU DIRECT RDMA SUPPORT APPLICATION PERFORMANCE 102% Higher is better 20% Source:
26 OPEN MPI CUDA-AWARE Work continues to improve performance Better interactions with streams Better small message performance eager protocol CUDA-aware support for new RMA Support for reduction operations Support for non-blocking collectives Try it! Lots of information in FAQ at the Open MPI web site Questions?
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR
 Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
LAMMPSCUDA GPU Performance. April 2011
 LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
SNAP Performance Benchmark and Profiling. April 2014
 SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
OCTOPUS Performance Benchmark and Profiling. June 2015
 OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
CPMD Performance Benchmark and Profiling. February 2014
 CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
MILC Performance Benchmark and Profiling. April 2013
 MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
GROMACS (GPU) Performance Benchmark and Profiling. February 2016
 Performance Benchmark and Profiling. February 2016") GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand
 Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
LS-DYNA Performance Benchmark and Profiling. April 2015
 LS-DYNA Performance Benchmark and Profiling April 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling April 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
The Visual Computing Company
 The Visual Computing Company Update NVIDIA GPU Ecosystem Axel Koehler, Senior Solutions Architect HPC, NVIDIA Outline Tesla K40 and GPU Boost Jetson TK-1 Development Board for Embedded HPC Pascal GPU 3D
The Visual Computing Company Update NVIDIA GPU Ecosystem Axel Koehler, Senior Solutions Architect HPC, NVIDIA Outline Tesla K40 and GPU Boost Jetson TK-1 Development Board for Embedded HPC Pascal GPU 3D
ANSYS Fluent 14 Performance Benchmark and Profiling. October 2012
 ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
Adaptive MPI Multirail Tuning for Non-Uniform Input/Output Access
 Adaptive MPI Multirail Tuning for Non-Uniform Input/Output Access S. Moreaud, B. Goglin and R. Namyst INRIA Runtime team-project University of Bordeaux, France Context Multicore architectures everywhere
Adaptive MPI Multirail Tuning for Non-Uniform Input/Output Access S. Moreaud, B. Goglin and R. Namyst INRIA Runtime team-project University of Bordeaux, France Context Multicore architectures everywhere
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
Performance of Applications on Comet GPU Nodes Utilizing MVAPICH2-GDR. Mahidhar Tatineni MVAPICH User Group Meeting August 16, 2017
 Performance of Applications on Comet GPU Nodes Utilizing MVAPICH2-GDR Mahidhar Tatineni MVAPICH User Group Meeting August 16, 2017 This work supported by the National Science Foundation, award ACI-1341698.
Performance of Applications on Comet GPU Nodes Utilizing MVAPICH2-GDR Mahidhar Tatineni MVAPICH User Group Meeting August 16, 2017 This work supported by the National Science Foundation, award ACI-1341698.
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling. February 2012
 NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
Mellanox GPUDirect RDMA User Manual
 Mellanox GPUDirect RDMA User Manual Rev 1.2 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
Mellanox GPUDirect RDMA User Manual Rev 1.2 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
NAMD GPU Performance Benchmark. March 2011
 NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
Solutions for Scalable HPC
 Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
AMBER 11 Performance Benchmark and Profiling. July 2011
 AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
HPC Applications Performance and Optimizations Best Practices Pak Lui
 HPC Applications Performance and Optimizations Best Practices Pak Lui 130 Applications Best Practices Published Abaqus CPMD LS-DYNA MILC AcuSolve Dacapo minife OpenMX Amber Desmond MILC PARATEC AMG DL-POLY
HPC Applications Performance and Optimizations Best Practices Pak Lui 130 Applications Best Practices Published Abaqus CPMD LS-DYNA MILC AcuSolve Dacapo minife OpenMX Amber Desmond MILC PARATEC AMG DL-POLY
Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth
 Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth by D.K. Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline Overview of MVAPICH2-GPU
Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth by D.K. Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline Overview of MVAPICH2-GPU
HYCOM Performance Benchmark and Profiling
 HYCOM Performance Benchmark and Profiling Jan 2011 Acknowledgment: - The DoD High Performance Computing Modernization Program Note The following research was performed under the HPC Advisory Council activities
HYCOM Performance Benchmark and Profiling Jan 2011 Acknowledgment: - The DoD High Performance Computing Modernization Program Note The following research was performed under the HPC Advisory Council activities
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
ICON Performance Benchmark and Profiling. March 2012
 ICON Performance Benchmark and Profiling March 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource - HPC
ICON Performance Benchmark and Profiling March 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource - HPC
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Mellanox GPUDirect RDMA User Manual
 Mellanox GPUDirect RDMA User Manual Rev 1.0 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
Mellanox GPUDirect RDMA User Manual Rev 1.0 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
GROMACS Performance Benchmark and Profiling. August 2011
 GROMACS Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
GROMACS Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Mellanox GPUDirect RDMA User Manual
 Mellanox GPUDirect RDMA User Manual Rev 1.5 www.mellanox.com Mellanox Technologies NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX
Mellanox GPUDirect RDMA User Manual Rev 1.5 www.mellanox.com Mellanox Technologies NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX
Interconnection Network for Tightly Coupled Accelerators Architecture
 Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
Operational Robustness of Accelerator Aware MPI
 Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Altair RADIOSS Performance Benchmark and Profiling. May 2013
 Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters
 Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
CESM (Community Earth System Model) Performance Benchmark and Profiling. August 2011
 Performance Benchmark and Profiling. August 2011") CESM (Community Earth System Model) Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell,
CESM (Community Earth System Model) Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell,
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011
 The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA. NVIDIA Corporation 2012
 Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA Outline Introduction to Multi-GPU Programming Communication for Single Host, Multiple GPUs Communication for Multiple Hosts, Multiple GPUs
Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA Outline Introduction to Multi-GPU Programming Communication for Single Host, Multiple GPUs Communication for Multiple Hosts, Multiple GPUs
GROMACS Performance Benchmark and Profiling. September 2012
 GROMACS Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
GROMACS Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
MM5 Modeling System Performance Research and Profiling. March 2009
 MM5 Modeling System Performance Research and Profiling March 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center
MM5 Modeling System Performance Research and Profiling March 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
GPU-centric communication for improved efficiency
 GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters
 CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
TECHNOLOGIES FOR IMPROVED SCALING ON GPU CLUSTERS. Jiri Kraus, Davide Rossetti, Sreeram Potluri, June 23 rd 2016
 TECHNOLOGIES FOR IMPROVED SCALING ON GPU CLUSTERS Jiri Kraus, Davide Rossetti, Sreeram Potluri, June 23 rd 2016 MULTI GPU PROGRAMMING Node 0 Node 1 Node N-1 MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM
TECHNOLOGIES FOR IMPROVED SCALING ON GPU CLUSTERS Jiri Kraus, Davide Rossetti, Sreeram Potluri, June 23 rd 2016 MULTI GPU PROGRAMMING Node 0 Node 1 Node N-1 MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications
 Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications GPU Technology Conference GTC 2016 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications GPU Technology Conference GTC 2016 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
GPU- Aware Design, Implementation, and Evaluation of Non- blocking Collective Benchmarks
 GPU- Aware Design, Implementation, and Evaluation of Non- blocking Collective Benchmarks Presented By : Esthela Gallardo Ammar Ahmad Awan, Khaled Hamidouche, Akshay Venkatesh, Jonathan Perkins, Hari Subramoni,
GPU- Aware Design, Implementation, and Evaluation of Non- blocking Collective Benchmarks Presented By : Esthela Gallardo Ammar Ahmad Awan, Khaled Hamidouche, Akshay Venkatesh, Jonathan Perkins, Hari Subramoni,
Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters
 Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters Hari Subramoni, Ping Lai, Sayantan Sur and Dhabhaleswar. K. Panda Department of
Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters Hari Subramoni, Ping Lai, Sayantan Sur and Dhabhaleswar. K. Panda Department of
OpenFOAM Performance Testing and Profiling. October 2017
 OpenFOAM Performance Testing and Profiling October 2017 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Huawei, Mellanox Compute resource - HPC
OpenFOAM Performance Testing and Profiling October 2017 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Huawei, Mellanox Compute resource - HPC
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand
 Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience
 SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
NVIDIA GPUDirect Technology. NVIDIA Corporation 2011
 NVIDIA GPUDirect Technology NVIDIA GPUDirect : Eliminating CPU Overhead Accelerated Communication with Network and Storage Devices Peer-to-Peer Communication Between GPUs Direct access to CUDA memory for
NVIDIA GPUDirect Technology NVIDIA GPUDirect : Eliminating CPU Overhead Accelerated Communication with Network and Storage Devices Peer-to-Peer Communication Between GPUs Direct access to CUDA memory for
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms
 Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms Sayantan Sur, Matt Koop, Lei Chai Dhabaleswar K. Panda Network Based Computing Lab, The Ohio State
Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms Sayantan Sur, Matt Koop, Lei Chai Dhabaleswar K. Panda Network Based Computing Lab, The Ohio State
Clustering Optimizations How to achieve optimal performance? Pak Lui
 Clustering Optimizations How to achieve optimal performance? Pak Lui 130 Applications Best Practices Published Abaqus CPMD LS-DYNA MILC AcuSolve Dacapo minife OpenMX Amber Desmond MILC PARATEC AMG DL-POLY
Clustering Optimizations How to achieve optimal performance? Pak Lui 130 Applications Best Practices Published Abaqus CPMD LS-DYNA MILC AcuSolve Dacapo minife OpenMX Amber Desmond MILC PARATEC AMG DL-POLY
Paving the Road to Exascale
 Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
Speeding up the execution of numerical computations and simulations with rcuda José Duato
 Speeding up the execution of numerical computations and simulations with rcuda José Duato Universidad Politécnica de Valencia Spain Outline 1. Introduction to GPU computing 2. What is remote GPU virtualization?
Speeding up the execution of numerical computations and simulations with rcuda José Duato Universidad Politécnica de Valencia Spain Outline 1. Introduction to GPU computing 2. What is remote GPU virtualization?
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters
 Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Computing Infrastructure for Online Monitoring and Control of High-throughput DAQ Electronics
 Computing Infrastructure for Online Monitoring and Control of High-throughput DAQ S. Chilingaryan, M. Caselle, T. Dritschler, T. Farago, A. Kopmann, U. Stevanovic, M. Vogelgesang Hardware, Software, and
Computing Infrastructure for Online Monitoring and Control of High-throughput DAQ S. Chilingaryan, M. Caselle, T. Dritschler, T. Farago, A. Kopmann, U. Stevanovic, M. Vogelgesang Hardware, Software, and
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications
 for Bio-Science Applications") Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
High-Performance GPU Clustering: GPUDirect RDMA over 40GbE iwarp
 High-Performance GPU Clustering: GPUDirect RDMA over 40GbE iwarp Tom Reu Consulting Applications Engineer Chelsio Communications tomreu@chelsio.com Efficient Performance 1 Chelsio Corporate Snapshot Leader
High-Performance GPU Clustering: GPUDirect RDMA over 40GbE iwarp Tom Reu Consulting Applications Engineer Chelsio Communications tomreu@chelsio.com Efficient Performance 1 Chelsio Corporate Snapshot Leader
Unified Runtime for PGAS and MPI over OFED
 Unified Runtime for PGAS and MPI over OFED D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University, USA Outline Introduction
Unified Runtime for PGAS and MPI over OFED D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University, USA Outline Introduction
Ravindra Babu Ganapathi
 14 th ANNUAL WORKSHOP 2018 INTEL OMNI-PATH ARCHITECTURE AND NVIDIA GPU SUPPORT Ravindra Babu Ganapathi Intel Corporation [ April, 2018 ] Intel MPI Open MPI MVAPICH2 IBM Platform MPI SHMEM Intel MPI Open
14 th ANNUAL WORKSHOP 2018 INTEL OMNI-PATH ARCHITECTURE AND NVIDIA GPU SUPPORT Ravindra Babu Ganapathi Intel Corporation [ April, 2018 ] Intel MPI Open MPI MVAPICH2 IBM Platform MPI SHMEM Intel MPI Open
Tightly Coupled Accelerators Architecture
 Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning
 5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
The Future of Interconnect Technology
 The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs
 HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
Study. Dhabaleswar. K. Panda. The Ohio State University HPIDC '09
 RDMA over Ethernet - A Preliminary Study Hari Subramoni, Miao Luo, Ping Lai and Dhabaleswar. K. Panda Computer Science & Engineering Department The Ohio State University Introduction Problem Statement
RDMA over Ethernet - A Preliminary Study Hari Subramoni, Miao Luo, Ping Lai and Dhabaleswar. K. Panda Computer Science & Engineering Department The Ohio State University Introduction Problem Statement
Unifying UPC and MPI Runtimes: Experience with MVAPICH
 Unifying UPC and MPI Runtimes: Experience with MVAPICH Jithin Jose Miao Luo Sayantan Sur D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Unifying UPC and MPI Runtimes: Experience with MVAPICH Jithin Jose Miao Luo Sayantan Sur D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
High Performance Computing
 High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and
High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations
 The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K.
 Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
LAMMPS Performance Benchmark and Profiling. July 2012
 LAMMPS Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
LAMMPS Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
Overview of the MVAPICH Project: Latest Status and Future Roadmap
 Overview of the MVAPICH Project: Latest Status and Future Roadmap MVAPICH2 User Group (MUG) Meeting by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Overview of the MVAPICH Project: Latest Status and Future Roadmap MVAPICH2 User Group (MUG) Meeting by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
GRID Testing and Profiling. November 2017
 GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware
GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware
NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications
 NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications Outline RDMA Motivating trends iwarp NFS over RDMA Overview Chelsio T5 support Performance results 2 Adoption Rate of 40GbE Source: Crehan
NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications Outline RDMA Motivating trends iwarp NFS over RDMA Overview Chelsio T5 support Performance results 2 Adoption Rate of 40GbE Source: Crehan
Optimizing MPI Communication on Multi-GPU Systems using CUDA Inter-Process Communication
 Optimizing MPI Communication on Multi-GPU Systems using CUDA Inter-Process Communication Sreeram Potluri* Hao Wang* Devendar Bureddy* Ashish Kumar Singh* Carlos Rosales + Dhabaleswar K. Panda* *Network-Based
Optimizing MPI Communication on Multi-GPU Systems using CUDA Inter-Process Communication Sreeram Potluri* Hao Wang* Devendar Bureddy* Ashish Kumar Singh* Carlos Rosales + Dhabaleswar K. Panda* *Network-Based
Fermi Cluster for Real-Time Hyperspectral Scene Generation
 Fermi Cluster for Real-Time Hyperspectral Scene Generation Gary McMillian, Ph.D. Crossfield Technology LLC 9390 Research Blvd, Suite I200 Austin, TX 78759-7366 (512)795-0220 x151 gary.mcmillian@crossfieldtech.com
Fermi Cluster for Real-Time Hyperspectral Scene Generation Gary McMillian, Ph.D. Crossfield Technology LLC 9390 Research Blvd, Suite I200 Austin, TX 78759-7366 (512)795-0220 x151 gary.mcmillian@crossfieldtech.com
Unified Communication X (UCX)
") Unified Communication X (UCX) Pavel Shamis / Pasha ARM Research SC 18 UCF Consortium Mission: Collaboration between industry, laboratories, and academia to create production grade communication frameworks
Unified Communication X (UCX) Pavel Shamis / Pasha ARM Research SC 18 UCF Consortium Mission: Collaboration between industry, laboratories, and academia to create production grade communication frameworks
MPI + X programming. UTK resources: Rho Cluster with GPGPU George Bosilca CS462
 MPI + X programming UTK resources: Rho Cluster with GPGPU https://newton.utk.edu/doc/documentation/systems/rhocluster George Bosilca CS462 MPI Each programming paradigm only covers a particular spectrum
MPI + X programming UTK resources: Rho Cluster with GPGPU https://newton.utk.edu/doc/documentation/systems/rhocluster George Bosilca CS462 MPI Each programming paradigm only covers a particular spectrum
iwarp Learnings and Best Practices
 iwarp Learnings and Best Practices Author: Michael Fenn, Penn State Date: March 28, 2012 www.openfabrics.org 1 Introduction Last year, the Research Computing and Cyberinfrastructure group at Penn State
iwarp Learnings and Best Practices Author: Michael Fenn, Penn State Date: March 28, 2012 www.openfabrics.org 1 Introduction Last year, the Research Computing and Cyberinfrastructure group at Penn State
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory
 Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
The Effect of HPC Cluster Architecture on the Scalability Performance of CAE Simulations
 The Effect of HPC Cluster Architecture on the Scalability Performance of CAE Simulations Pak Lui HPC Advisory Council June 7, 2016 1 Agenda Introduction to HPC Advisory Council Benchmark Configuration
The Effect of HPC Cluster Architecture on the Scalability Performance of CAE Simulations Pak Lui HPC Advisory Council June 7, 2016 1 Agenda Introduction to HPC Advisory Council Benchmark Configuration
MPI Alltoall Personalized Exchange on GPGPU Clusters: Design Alternatives and Benefits
 MPI Alltoall Personalized Exchange on GPGPU Clusters: Design Alternatives and Benefits Ashish Kumar Singh, Sreeram Potluri, Hao Wang, Krishna Kandalla, Sayantan Sur, and Dhabaleswar K. Panda Network-Based
MPI Alltoall Personalized Exchange on GPGPU Clusters: Design Alternatives and Benefits Ashish Kumar Singh, Sreeram Potluri, Hao Wang, Krishna Kandalla, Sayantan Sur, and Dhabaleswar K. Panda Network-Based