S THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE. Presenter: Louis Capps, Solution Architect, NVIDIA,
|
|
|
- Emery Dickerson
- 6 years ago
- Views:
Transcription
1 S THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com
2 A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print x 30 next x 1 FPS Run OK 2
3 DEEP LEARNING A NEW COMPUTING PLATFORM Assembly LDX #$00 dec: INX JSR printx CPX #$03 BNE dec BRK 30 FPS DL --> 3
4 SATURNV PURPOSE 124 Node Supercomputing Cluster Innovation is fueled by the right engine! Deep Learning scalability; move outside the box Drive research and Deep Learning application Partner with university research, government and industry collaborations Enable data science in HPC 4

5 NVIDIA DGX SATURNV ARCHITECTURE 124 node Cluster nvidia.com/dgx1 124 NVIDIA DGX-1 Nodes 992 P100 GPUs 8x NVIDIA Tesla P100 SXM GPUs NVLINK CubeMesh 2x Intel Xeon 20 core GPUs 512TB DDR4 System Memory SSD 7 TB scratch TB OS Mellanox 36 port EDR L1 and L2 switches 4 ports per system Fat tree topology Ubuntu 14.04, CUDA 8, OpenMPI a1, Docker, DL Frameworks NVIDIA GPU BLAS + Intel MKL (NVIDIA GPU HPL) Deep Learning applied research Many users, frameworks, algorithms, networks, new approaches Embedded, robotic, auto, hyperscale, HPC 5

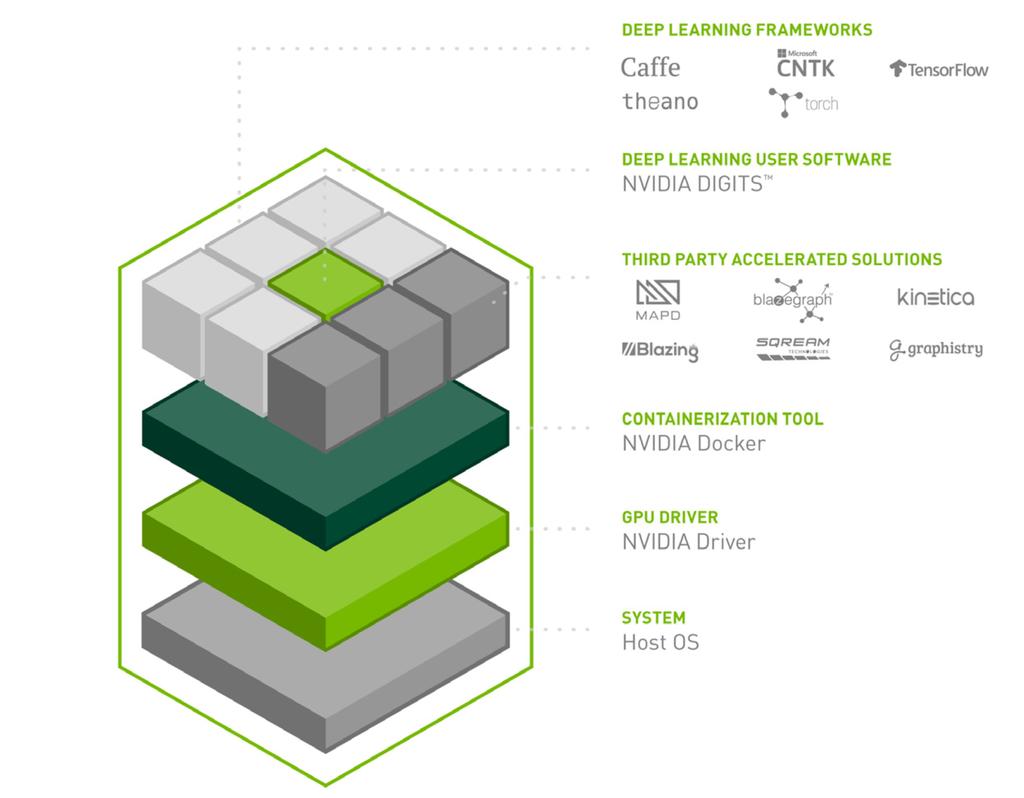
6 SATURNV STACK 6
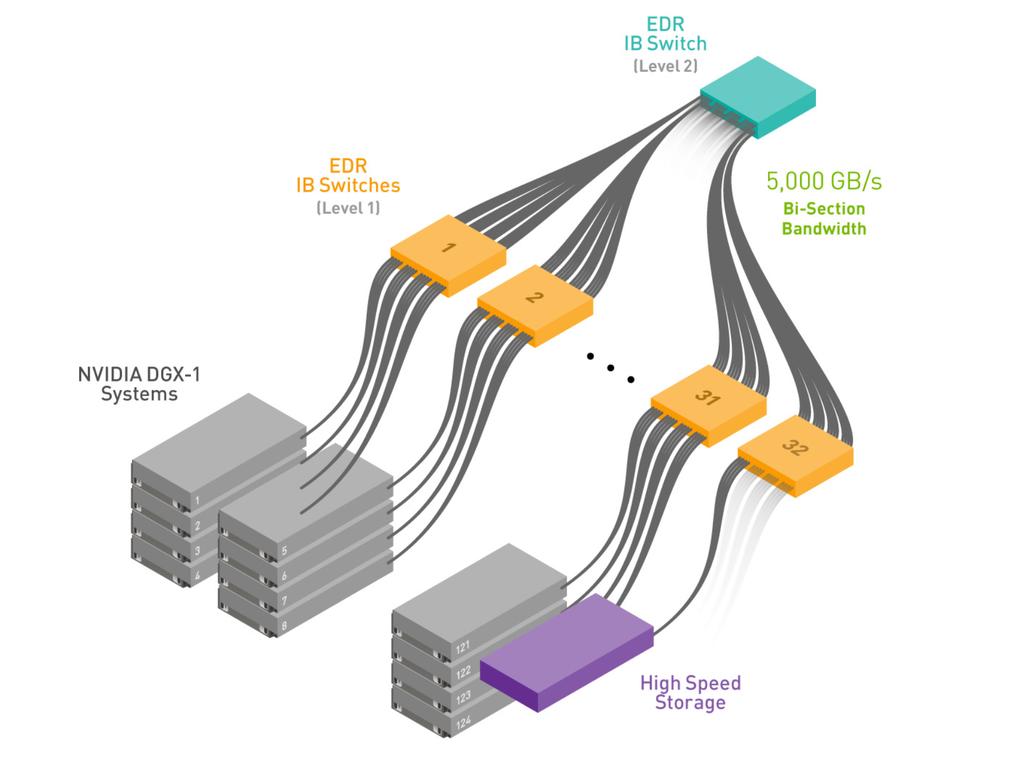

7 DGX-1 MULTI-SYSTEM 7

8 NVIDIA DGX SATURNV Greenest Supercomputer 8
9 NVIDIA DGX-1 SATURNV HPL RUN 124 node Supercomputing cluster HPL Setup Problem contained mainly in GPU memory (~16GB / GPU) 124 nodes * 8 GPU/node * 16 GB mem/gpu = 15,872 GB mem --- N = Measurement PDU input power time-stamped during full run All cluster hardware nodes, switches, storage SATURNV produced groundbreaking 9.4 GF/W at full scale --> Sets the stage for future Exascale class computing Performance HPL Rpeak 4,896 TF HPL Rmax 3,307 TF Pwr Full run avg KW Pwr Core avg KW ~15KW sustained per rack 9.4 GF / Watt 40% better than nearest competing technology 9
10 NOV2016 TOP GREEN500 SYSTEM Green500.org Top500.org SATURNV produced groundbreaking 9.4 GF/W at full scale --> Sets the stage for future Exascale class computing 10

11 WHAT IS HPL, TOP500, GREEN500? HPL High Performance Linpack Multi-system benchmark - measures optimized double-precision floating performance Solves system of dense linear equations One system or many connected in a cluster - usually Ethernet or InfiniBand Single problem split across many systems single final performance number Well designed to scale across large clusters and push limits Top500 (top500.org) List of the fastest HPL clusters in the world Updated twice a year June and Sept Published at ISC and SC conferences Green500 (green500.org) Same HPL clusters, but rank by power used during the HPL run Published at same time as Top500 11
12 DGX-1 SUPERCOMPUTER CHALLENGES Giant Leap Towards Exascale AI Compute Significant math performance FP32, FP16, INT8 Highly optimized frameworks Training, Inference Interconnect Multiple compute units inside node Multiple systems Storage Low latency, high bandwidth Equal perf to all systems Local caching for DL workloads Facilities Sufficient for bursts Maintain inlet air temp always High power density 12


13 NVIDIA DGX-1 COMPUTE NCCL Collective Library 13


14 DGX-1 COMPUTE AND MULTI-SYSTEM DGX-1 single system considerations Higher performance per system 27x to 58x faster Ingest data faster, provides faster results Also more power and heat High data ingest for DL workloads More storage and I/O into single system Cache data locally NFS cache on local SSD for training data Higher power/thermal density Example: KW vs 1,000 KW Ambient temperatures very important Silicon uses more higher temps Clocks will gate at thermal and power limits Variability lowers overall performance of multi- GPU and multi-system runs 14
15 DGX-1 COMPUTE CONSIDERATIONS #1 Recommendation - Using containers improves performance - Access to latest NVIDIA tuned codes - Latest NCCL libraries Clocking - CPUs set to performance mode to improve memory/i/o bandwidth Leave GPU clocks at default if you do set them, use base or slightly higher - Running set at max can cause extreme variation and reduced performance depending on workload - Monitor with nvidia-smi dmon 1320 Time Effects of Clocking 15
16 DGX-1 COMPUTE CONSIDERATIONS Affinity - Best performance when CPU/GPU/mem/IB affinity are aligned - E.g. cpu socket 0<->gpu0/1<->mlx5_0 Interrupt traffic can be high - Keep core 0 and core 20 free for interrupts 16
17 DGX-1 MULTI-SYSTEM CONSIDERATIONS IB Leaf Switch GPU0 GPU1 MLX0 GPU3 GPU4 MLX1 GPU5 GPU6 MLX1 GPU7 GPU8 MLX1 PCIe PCIe PCIe PCIe CPU0 CPU1 Example affinity with numactl: MEM0 MEM1 mpirun \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_0 -x CUDA_VISIBLE_DEVICES=0 numactl --physcpubind=1-4./mycode : \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_0 -x CUDA_VISIBLE_DEVICES=1 numactl --physcpubind=6-9./mycode : \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_1 -x CUDA_VISIBLE_DEVICES=2 numactl --physcpubind=10-13./mycode : \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_1 -x CUDA_VISIBLE_DEVICES=3 numactl --physcpubind=15-18./mycode : \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_2 -x CUDA_VISIBLE_DEVICES=4 numactl --physcpubind=21-24./mycode : \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_2 -x CUDA_VISIBLE_DEVICES=5 numactl --physcpubind=25-28./mycode : \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_3 -x CUDA_VISIBLE_DEVICES=6 numactl --physcpubind=30-33./mycode : \ -np 4 bind-to node -mca btl openib,sm,self --mca btl_openib_if_include mlx5_3 -x CUDA_VISIBLE_DEVICES=7 numactl --physcpubind=35-38./mycode 17

18 DGX-1 MULTI-NODE INTERCONNECT DESIGN 6,012 GB/s Design topologies that reduce latency and improve total bandwidth Fat-tree topologies for instance Equal bandwidth from a system all the way up to top level switch Ensure GPUDirect RDMA enablement DL and many computation workloads rely on fast synchronization Collectives Consistent iteration times System hierarchy - CPU0 <-> GPU0/1 <-> mlx5_0 - CPU0 <-> GPU2/3 <-> mlx5_1 - CPU1 <-> GPU4/5 <-> mlx5_2 - CPU2 <-> GPU6/7 <-> mlx5_3 If designing with only two IB ports, hook up mlx5_0, mlx5_2 18
19 DGX-1 MULTI-SYSTEM INTERCONNECT DGX-1 multi-system considerations High node to node communications DL and HPC workloads 4 IB ports à 2 ports DL: up to 5% loss Compute: up to 18% loss 1 IB port per system low performance Significant contention for many workloads Can t GPU Direct RDMA across full system Switch hierarchy critical Low bandwidth on second level Same issues as lowering ports per system Contention, lower bandwidth, variability 19
20 DGX-1 STORAGE CONSIDERATIONS Storage needs HPC needs well known Parallel FS like Lustre and Spectrum Scale well suited DL workloads just being understood Read dominated Input data rarely changes Can be raw or formatted in a DB (like LMDB) Large group of random read, then reread same data later Approaches Local caching helps significantly Can be many GB (>16GB for instance) Another approach is keep full datasets local (>100GB for ImageNet) Local SSD RAID Alternately, copy all data to nodes at beginning of job Reference designs 10Gb attached Central NFS with local caching Spectrum Scale IB attached (still evaluating) Lustre IB attached (still evaluating) 20

21 AI GRAND CHALLENGES CANDLE - Accelerate cancer research Energy / Fusion Future of low cost energy Weather and Climate Disaster Preparedness Astrophysics Our future? Autonomous Cars 21
22 Summary DGX-1 DL SCALABILITY SUMMARY DGX-1 crafted for AI and Computational workloads High compute density, but also high power and thermal density Watch ambient can cause large variability Single system has large demands in data ingest and GPU to GPU communication Multi DGX-1 systems have large demands on inter-node communication for most workloads Need at least two IB rails per system (1 EDR IB for every 2 GPU) DL Storage needs are very high But read dominated (vs writes with HPC) Many codes benefit significantly when watching affinity Align CPU/memory with GPUs and IB cards Avoid cores handling interrupts NVIDIA pre made containers significantly reduce user work Affinity is already handled Provides technologies like NCCL and the latest, tuned code and frameworks 22
23 DGX-1 DL SCALABILITY SUMMARY Thanks!!! More info at NVIDIA DGX-1 System Architecture: CANDLE sessions ( S CANDLE: PREDICTING TUMOR CELL RESPONSE TO DRUG TREATMENTS S THE DOE AND NCI PARTNERSHIP ON PRECISION ONCOLOGY AND THE CANCER MOONSHOT S BUILDLING EXASCALE DEEP LEARNING TOOLS TO HELP UNDERSTAND CANCER BIOLOGY AT THE MOLECULAR SCALE S BUILDING EXASCALE DEEP TEXT COMPREHENSION TOOLS FOR EFFECTIVE CANCER SURVEILLANCE S WHAT'S NEXT IN DGX SERVER SOLUTIONS FOR DEEP LEARNING Thursday, May 11, 10:00 AM - 10:50 AM Room 210B 23
24
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC
 TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
GROMACS (GPU) Performance Benchmark and Profiling. February 2016
 Performance Benchmark and Profiling. February 2016") GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Deep Learning Performance and Cost Evaluation
 Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Don Wang, Rene Meyer, Ph.D. info@ AMAX Corporation Publish date: October 25,
Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Don Wang, Rene Meyer, Ph.D. info@ AMAX Corporation Publish date: October 25,
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
NVDIA DGX Data Center Reference Design
 White Paper NVDIA DGX Data Center Reference Design Easy Deployment of DGX Servers for Deep Learning 2018-07-19 2018 NVIDIA Corporation. Contents Abstract ii 1. AI Workflow and Sizing 1 2. NVIDIA AI Software
White Paper NVDIA DGX Data Center Reference Design Easy Deployment of DGX Servers for Deep Learning 2018-07-19 2018 NVIDIA Corporation. Contents Abstract ii 1. AI Workflow and Sizing 1 2. NVIDIA AI Software
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
Deep Learning Performance and Cost Evaluation
 Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Rene Meyer, Ph.D. AMAX Corporation Publish date: October 25, 2018 Abstract Introduction
Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Rene Meyer, Ph.D. AMAX Corporation Publish date: October 25, 2018 Abstract Introduction
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
NAMD Performance Benchmark and Profiling. February 2012
 NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
DGX UPDATE. Customer Presentation Deck May 8, 2017
 DGX UPDATE Customer Presentation Deck May 8, 2017 NVIDIA DGX-1: The World s Fastest AI Supercomputer FASTEST PATH TO DEEP LEARNING EFFORTLESS PRODUCTIVITY REVOLUTIONARY AI PERFORMANCE Fully-integrated
DGX UPDATE Customer Presentation Deck May 8, 2017 NVIDIA DGX-1: The World s Fastest AI Supercomputer FASTEST PATH TO DEEP LEARNING EFFORTLESS PRODUCTIVITY REVOLUTIONARY AI PERFORMANCE Fully-integrated
INTRODUCING THE DGX FAMILY. Marc Domenech May 8, 2017
 INTRODUCING THE DGX FAMILY Marc Domenech May 8, 2017 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering AI computing
INTRODUCING THE DGX FAMILY Marc Domenech May 8, 2017 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering AI computing
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER. Markus Weber and Haiduong Vo
 DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
LAMMPSCUDA GPU Performance. April 2011
 LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
IBM SpectrumAI with NVIDIA Converged Infrastructure Solutions for AI workloads
 IBM SpectrumAI with NVIDIA Converged Infrastructure Solutions for AI workloads The engine to power your AI data pipeline Introduction: Artificial intelligence (AI) including deep learning (DL) and machine
IBM SpectrumAI with NVIDIA Converged Infrastructure Solutions for AI workloads The engine to power your AI data pipeline Introduction: Artificial intelligence (AI) including deep learning (DL) and machine
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Results from TSUBAME3.0 A 47 AI- PFLOPS System for HPC & AI Convergence
 Results from TSUBAME3.0 A 47 AI- PFLOPS System for HPC & AI Convergence Jens Domke Research Staff at MATSUOKA Laboratory GSIC, Tokyo Institute of Technology, Japan Omni-Path User Group 2017/11/14 Denver,
Results from TSUBAME3.0 A 47 AI- PFLOPS System for HPC & AI Convergence Jens Domke Research Staff at MATSUOKA Laboratory GSIC, Tokyo Institute of Technology, Japan Omni-Path User Group 2017/11/14 Denver,
LAMMPS and WRF on iwarp vs. InfiniBand FDR
 LAMMPS and WRF on iwarp vs. InfiniBand FDR The use of InfiniBand as interconnect technology for HPC applications has been increasing over the past few years, replacing the aging Gigabit Ethernet as the
LAMMPS and WRF on iwarp vs. InfiniBand FDR The use of InfiniBand as interconnect technology for HPC applications has been increasing over the past few years, replacing the aging Gigabit Ethernet as the
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
ACCELERATED COMPUTING: THE PATH FORWARD. Jensen Huang, Founder & CEO SC17 Nov. 13, 2017
 ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
Enabling Performance-per-Watt Gains in High-Performance Cluster Computing
 WHITE PAPER Appro Xtreme-X Supercomputer with the Intel Xeon Processor E5-2600 Product Family Enabling Performance-per-Watt Gains in High-Performance Cluster Computing Appro Xtreme-X Supercomputer with
WHITE PAPER Appro Xtreme-X Supercomputer with the Intel Xeon Processor E5-2600 Product Family Enabling Performance-per-Watt Gains in High-Performance Cluster Computing Appro Xtreme-X Supercomputer with
Inspur AI Computing Platform
 Inspur Server Inspur AI Computing Platform 3 Server NF5280M4 (2CPU + 3 ) 4 Server NF5280M5 (2 CPU + 4 ) Node (2U 4 Only) 8 Server NF5288M5 (2 CPU + 8 ) 16 Server SR BOX (16 P40 Only) Server target market
Inspur Server Inspur AI Computing Platform 3 Server NF5280M4 (2CPU + 3 ) 4 Server NF5280M5 (2 CPU + 4 ) Node (2U 4 Only) 8 Server NF5288M5 (2 CPU + 8 ) 16 Server SR BOX (16 P40 Only) Server target market
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
HPC and AI Solution Overview. Garima Kochhar HPC and AI Innovation Lab
 HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
Interconnect Your Future Enabling the Best Datacenter Return on Investment. TOP500 Supercomputers, November 2017
 Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
OpenFOAM Performance Testing and Profiling. October 2017
 OpenFOAM Performance Testing and Profiling October 2017 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Huawei, Mellanox Compute resource - HPC
OpenFOAM Performance Testing and Profiling October 2017 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Huawei, Mellanox Compute resource - HPC
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE
 MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
S8688 : INSIDE DGX-2. Glenn Dearth, Vyas Venkataraman Mar 28, 2018
 S8688 : INSIDE DGX-2 Glenn Dearth, Vyas Venkataraman Mar 28, 2018 Why was DGX-2 created Agenda DGX-2 internal architecture Software programming model Simple application Results 2 DEEP LEARNING TRENDS Application
S8688 : INSIDE DGX-2 Glenn Dearth, Vyas Venkataraman Mar 28, 2018 Why was DGX-2 created Agenda DGX-2 internal architecture Software programming model Simple application Results 2 DEEP LEARNING TRENDS Application
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA GPUS
 SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
Towards Scalable Machine Learning
 Towards Scalable Machine Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Fraunhofer Center Machnine Larning Outline I Introduction
Towards Scalable Machine Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Fraunhofer Center Machnine Larning Outline I Introduction
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
In partnership with. VelocityAI REFERENCE ARCHITECTURE WHITE PAPER
 In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
SNAP Performance Benchmark and Profiling. April 2014
 SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
April 4-7, 2016 Silicon Valley INSIDE PASCAL. Mark Harris, October 27,
 April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Atos announces the Bull sequana X1000 the first exascale-class supercomputer. Jakub Venc
 Atos announces the Bull sequana X1000 the first exascale-class supercomputer Jakub Venc The world is changing The world is changing Digital simulation will be the key contributor to overcome 21 st century
Atos announces the Bull sequana X1000 the first exascale-class supercomputer Jakub Venc The world is changing The world is changing Digital simulation will be the key contributor to overcome 21 st century
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
GROMACS Performance Benchmark and Profiling. August 2011
 GROMACS Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
GROMACS Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
HPC Innovation Lab Update. Dell EMC HPC Community Meeting 3/28/2017
 HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
19. prosince 2018 CIIRC Praha. Milan Král, IBM Radek Špimr
 19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK
 Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
NAMD GPU Performance Benchmark. March 2011
 NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
GPU FOR DEEP LEARNING. 周国峰 Wuhan University 2017/10/13
 GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
OpenPOWER Innovations for HPC. IBM Research. IWOPH workshop, ISC, Germany June 21, Christoph Hagleitner,
 IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling. April 2015
 LS-DYNA Performance Benchmark and Profiling April 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling April 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
TSUBAME-KFC : Ultra Green Supercomputing Testbed
 TSUBAME-KFC : Ultra Green Supercomputing Testbed Toshio Endo,Akira Nukada, Satoshi Matsuoka TSUBAME-KFC is developed by GSIC, Tokyo Institute of Technology NEC, NVIDIA, Green Revolution Cooling, SUPERMICRO,
TSUBAME-KFC : Ultra Green Supercomputing Testbed Toshio Endo,Akira Nukada, Satoshi Matsuoka TSUBAME-KFC is developed by GSIC, Tokyo Institute of Technology NEC, NVIDIA, Green Revolution Cooling, SUPERMICRO,
Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for ANSYS Mechanical, ANSYS Fluent, and
Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for ANSYS Mechanical, ANSYS Fluent, and
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete
 Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Innovative Alternate Architecture for Exascale Computing. Surya Hotha Director, Product Marketing
 Innovative Alternate Architecture for Exascale Computing Surya Hotha Director, Product Marketing Cavium Corporate Overview Enterprise Mobile Infrastructure Data Center and Cloud Service Provider Cloud
Innovative Alternate Architecture for Exascale Computing Surya Hotha Director, Product Marketing Cavium Corporate Overview Enterprise Mobile Infrastructure Data Center and Cloud Service Provider Cloud
Game-changing Extreme GPU computing with The Dell PowerEdge C4130
 Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
MAHA. - Supercomputing System for Bioinformatics
 MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
SUPERCHARGE DEEP LEARNING WITH DGX-1. Markus Weber SC16 - November 2016
 SUPERCHARGE DEEP LEARNING WITH DGX-1 Markus Weber SC16 - November 2016 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering
SUPERCHARGE DEEP LEARNING WITH DGX-1 Markus Weber SC16 - November 2016 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering
Mellanox GPUDirect RDMA User Manual
 Mellanox GPUDirect RDMA User Manual Rev 1.2 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
Mellanox GPUDirect RDMA User Manual Rev 1.2 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI
 MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
Interconnect Your Future
 Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
IBM Spectrum Scale IO performance
 IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
NCCL 2.0. Sylvain Jeaugey
 NCCL 2.0 Sylvain Jeaugey DEE LEARNING ON GUS Making DL training times shorter Deeper neural networks, larger data sets training is a very, very long operation! CUDA NCCL 1 NCCL 2 Multi-core CU GU Multi-GU
NCCL 2.0 Sylvain Jeaugey DEE LEARNING ON GUS Making DL training times shorter Deeper neural networks, larger data sets training is a very, very long operation! CUDA NCCL 1 NCCL 2 Multi-core CU GU Multi-GU
MILC Performance Benchmark and Profiling. April 2013
 MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
A Breakthrough in Non-Volatile Memory Technology FUJITSU LIMITED
 A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
IBM Power Systems HPC Cluster
 IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
High Performance Computing
 High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and
High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and