INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
|
|
|
- Rodney McBride
- 6 years ago
- Views:
Transcription
1 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian
2 Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers got faster by increasing the frequency Voltage was decreased to keep power reasonable. Now, voltage cannot be decreased any further 1s and 0s in a system are represented by different voltages Reducing overall voltage further would reduce this difference to a point where 0s and 1s cannot be properly distinguished Other performance issues too Capacitance increases with complexity Speed of light, size of atoms, dissipation of heat And practical issues Developing new chips is incredibly expensive Must make maximum use of existing technology Now parallelism explicit in chip design Beyond implicit parallelism of pipelines, multi-issue and vector units
3 Multicore processors
4 Accelerators Need a chip which can perform many parallel operations every clock cycle Many cores and/or many operations per core Floating Point operations (FLOPS) what is generally crucial for computational simulation Want to keep power/core as low as possible Much of the power expended by CPU cores is on functionality not generally that useful for HPC Branch prediction, out-of-order execution etc
5 Accelerators So, for HPC, we want chips with simple, low power, number-crunching cores But we need our machine to do other things as well as the number crunching Run an operating system, perform I/O, set up calculation etc Solution: Hybrid system containing both CPU and accelerator chips
6 AMD 12-core CPU Not much space on CPU is dedicated to compute = compute unit (= core)
7 NVIDIA Fermi GPU = compute unit (= SM = 32 CUDA cores)

8 Intel Xeon Phi (KNC) As does Xeon Phi = compute unit (= core)
.")
9 Intel Xeon Phi - KNC Intel Larrabee: A Many-Core x86 Architecture for Visual Computing Release delayed such that the chip missed competitive window of opportunity. Larrabee was not released as a competitive product, but instead a platform for research and development (Knight s Ferry). 1 st Gen Xeon Phi Knights Corner derivative chip Intel Xeon Phi co-processor Many Integrated Cores (MIC) architecture. No longer aimed at graphics market Instead Accelerating Science and Discovery PCIe Card 60 cores/240 threads/1.054 GHz 8 GB/320 GB/s 512-bit SIMD instructions Hybrid between GPU and many-core CPU

10 KNC Each core has a private L2 cache ring interconnect connects components together cache coherent
11 KNC Intel Pentium P54C cores were originally used in CPUs in 1993 Simplistic and low-power compared to today s high-end CPUs Philosophy behind Phi is to dedicate large fraction of silicone to many of these cores And, similar to GPUs, Phi uses Graphics GDDR Memory Higher memory bandwidth that standard DDR memory used by CPUs
12 KNC Each core has been augmented with a wide 512-bit vector unit For each clock cycle, each core can operate vectors of size 8 (in double precision) Twice the width of 256-bit AVX instructions supported by current CPUs Multiple cores, each performing multiple operations per cycle
13 KNC 3100 series 5100 series 7100 series cores Clock frequency GHz GHz GHz DP Performance 1 Tflops 1.01 TFlops 1.2 TFlops Memory Bandwidth 240 GB/s 320 GB/s 352 GB/s Memory 6 GB 8 GB 16 GB
14 KNC Systems Unlike GPUs, Each KNC runs an operating system User can log directly into KNC and run code native mode But any serial parts of the application will be very slow relative to running on modern CPU Typically, each node in a system will contain at least one regular CPU in addition to one (or more) KNC KNC acts as an accelerator, in exactly the same way as already described for GPU systems. Offload mode : run most source code on main CPU, and offload computationally intensive parts to KNC
15 KNC: Achievable Performance 1 to 1.2 TFlop/s double precision performance Dependent on using 512-bit vector units And FMA instructions 240 to 352 GB/s peak memory bandwidth ~60 physical cores Each can run 4 threads Must run at least 2 threads to get full instruction issue rate Don t think of it as 240 threads, think of it as 120 plus more if beneficial 2.5x speedup over host is good performance Highly vectorised code, no communications costs MPI performance Can be significantly slower than host


16 Xeon Phi Knights Landing (KNL) Intel s latest many-core processor Knights Landing 2 nd generation Xeon Phi Successor to the Knights Corner 1 st generation Xeon Phi New operation modes New processor architecture New memory systems New cores
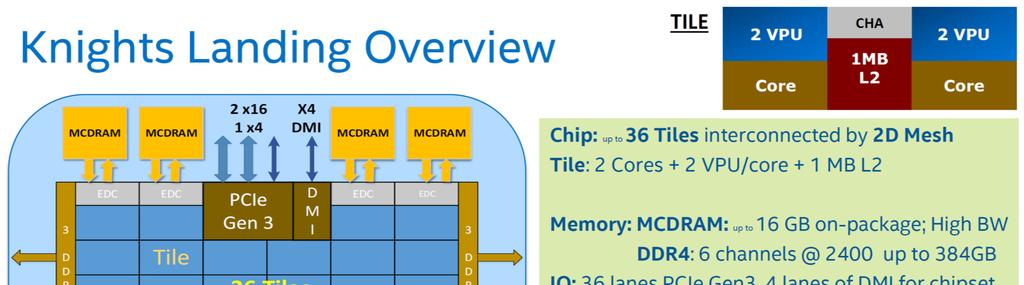

17 KNL


18 Picture from Avinash Sodani s talk from hot chips 2016



19 KNL

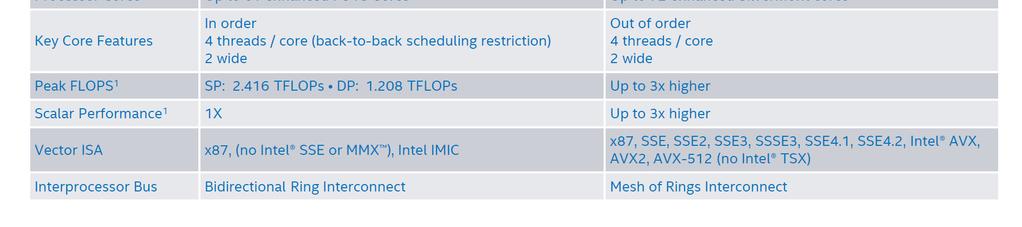

20 KNL vs KNC
21 L2 cache sharing L2 cache is shared between cores on a tile Capacity depends on data locality No sharing of data between core: 512kb per core Sharing data: 1MB for 2 cores Gives fast communication mechanism for processes/threads on same tile May lend itself to blocking or nested parallelism
22 Hyperthreading KNC required at least 2 threads per core for sensible compute performance Back to back instruction issues were not possible KNL does not Can run up to 4 threads per core efficiently Running 3 threads per core is not sensible Resource partitioning reduces available resources for all threads A lot of applications don t need any hyperthreads Much more like ARCHER Ivybridge hyperthreading now



23 KNL hemisphere
24 Memory Two levels of memory for KNL Main memory KNL has direct access to all of main memory Similar latency/bandwidth as you d see from a standard processors 6 DDR channels MCDRAM High bandwidth memory on chip: 16 GB Slightly higher latency than main memory (~10% slower) 8 MCDRAM controllers/16 channels
25 Memory Modes Cache mode MCDRAM cache for DRAM Only DRAM address space Done in hardware (applications don t need modified) Misses more expensive (DRAM and MCDRAM access) Flat mode MCDRAM and DRAM are both available MCDRAM is just memory, in same address space Software managed (applications need to do it themselves) Hybrid Part cache/part memory 25% or 50% cache Processor MCDRAM Processor DRAM MCDRAM DRAM
26 Compiling for the KNL Standard KNL compilation targets the KNL vector instruction set This won t run on standard processor Binaries that run on standard processors will run on the KNL If your build process executes programs this may be an issue Can build a fat binary using Intel compilers -ax MIC-AVX-512,AVX For other compilers can do initial compile with KNL instruction set Then re-compile specific executables with KNL instruction set i.e. aavx for Intel, -hcpu= for Cray, -march= for GNU
27 ARCHER KNL 12 nodes in test system ARCHER users get access Non-ARCHER users can get access through driving test Initial access will be unrestricted Charging will come in soon (near end of November) Charging will be same as ARCHER (i.e. 1 node hour = 0.36 kaus) Each node has 1 x Intel(R) Xeon Phi(TM) CPU 1.30GHz 64 core/4 hyperthreads 16GB MCDRAM 96GB DDR4@2133 MT/s
28 System setup XC40 system integrated with ARCHER Shares /home file system KNL system has it s own login nodes: knl-login Not accessible from the outside world Have to login in to the ARCHER login nodes first ssh to login.archer.ac.uk then ssh to knl-login Username is same as ARCHER account username Compile jobs there Different versions of the system software from the standard ARCHER nodes Submit jobs using PBS from those nodes Has it s own /work filesystem (scratch space) /work/knl-users/$user
29 Programming the KNL Standard HPC - parallelism MPI OpenMP Default OMP_NUM_THREADS may be 256 mkl Standard HPC compilers module craype-mic-knl (loaded by default on knl-login nodes) Intel compilers xmic-avx512 (without the module) Cray compilers -hcpu=mic-knl (without the module) GNU compilers -march=knl or -mavx512f -mavx512cd -mavx512er -mavx512pf (without the module)
30 Running applications on the XC40 You will have a separate budget on the KNL system Name is: k01-$user i.e. k01-adrianj Use PBS and aprun as in ARCHER Standard PBS script, with one extra for selecting memory/communication setup (more later) Standard aprun, run 64 MPI processes on the 64 KNL cores: aprun n 64./my_app 256 threads per KNL processor Numbering wraps, i.e the hardware cores, wraps onto the cores again, etc Meaning core 0 has threads 0,64,128,192, core 1 has threads 1,65,129,193, etc
31 Running applications on the XC40 For hyperthreading (using more than 64 cores): OMP_NUM_THREADS=4 aprun n 256 j 4./my_app or aprun n 128 j 2./my_other_app Should also be possible to control thread placement with OMP_PROC_BIND: OMP_PROC_BIND=true OMP_NUM_THREADS=4 aprun n 64 cc none j 4./my_app
32 Configuring KNL Different memory modes and cluster options Configured at boot time Switching between cache and flat mode Switching cluster modes For ARCHER XC40 Cluster configuration is done through batch system (PBS) Modes can be requested as a resource: #PBS l select=4:aoe=quad_100 #PBS l select=4:aoe=snc2_50 This is in the form :aoe=numa_cfg_hbm_cache_pct Available modes are: For the NUMA configuration (numa_cfg): a2a, snc2, snc4, hemi, quad For the MCDRAM cache configuration (hbm_cache_pct): 0, 25, 50, 100 So for quadrant mode and flat memory (MCDRAM and DRAM separate) this would be: #PBS l select=4:aoe=quad_0 Currently not enabling changing KNL setup
33 Current configuration apstat -M NID Memory(MB) HBM(MB) Cache(MB) NumaCfg quad quad quad quad quad quad quad quad quad quad quad quad adrianj@login:~>
34 Test data hardware Same KNL as the ARCHER ones Intel(R) Xeon Phi(TM) CPU 1.30GHz 64 core 16GB MCDRAM 215W TDP 1.3Ghz TDP, 1.1Ghz AVX 1.6Ghz Mesh 6.4GT/s OPIO 96GB DDR4@2133 MT/s
35 Performance Initial performance experiences with a single KNL
36 CP2K Results courtesy of Fiona Reid
37 CP2K Results courtesy of Fiona Reid
38 LU factorisation (KNC) 3 Relative performance ARCHER node to one Xeon Phi 2.5 Relative performance (>1 Xeon Phi better, <1 ARCHER better) Relative Performance Ratio
39 LU Factorisation 9 Relative performance ARCHER node to one Knights Landing Xeon Phi (>1 Xeon Phi better, <1 ARCHER better) 8 7 SIMD Ivdep Cilk MKL Performance Ratio
40 LU factorisation 1.2 Comparison between 64 and 64 with HBM 1 > HBM threads better 1 Ivdep SIMD Cilk MKL Performance Ratio
41 Performance multi-node COSA - Fluid dynamics code Harmonic balance (frequency domain approach) Unsteady navier-stokes solver Optimise performance of turbo-machinery like problems Multi-grid, multi-level, multi-block code ARCHER Broadwell KNL KNL HB KNL 2 Node HB GS2 ARCHER Broadwell KNL KNL HB KNL 2 Node KNL 2 Node HB
42 MPI Performance - PingPong
43 MPI Performance - Allreduce
44 MPI Performance - Allreduce
45 Questions? mwuj1rxyw8t8
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Welcome. Virtual tutorial starts at BST
 Welcome Virtual tutorial starts at 15.00 BST Using KNL on ARCHER Adrian Jackson With thanks to: adrianj@epcc.ed.ac.uk @adrianjhpc Harvey Richardson from Cray Slides from Intel Xeon Phi Knights Landing
Welcome Virtual tutorial starts at 15.00 BST Using KNL on ARCHER Adrian Jackson With thanks to: adrianj@epcc.ed.ac.uk @adrianjhpc Harvey Richardson from Cray Slides from Intel Xeon Phi Knights Landing
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system. Piero Lanucara
 HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
HPC Issues for DFT Calculations. Adrian Jackson EPCC
 HC Issues for DFT Calculations Adrian Jackson ECC Scientific Simulation Simulation fast becoming 4 th pillar of science Observation, Theory, Experimentation, Simulation Explore universe through simulation
HC Issues for DFT Calculations Adrian Jackson ECC Scientific Simulation Simulation fast becoming 4 th pillar of science Observation, Theory, Experimentation, Simulation Explore universe through simulation
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures
 Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Benchmark results on Knight Landing (KNL) architecture
 architecture") Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
Introduction to KNL and Parallel Computing
 Introduction to KNL and Parallel Computing Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2,
Introduction to KNL and Parallel Computing Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2,
Intel Xeon PhiTM Knights Landing (KNL) System Software Clark Snyder, Peter Hill, John Sygulla
 System Software Clark Snyder, Peter Hill, John Sygulla") Intel Xeon PhiTM Knights Landing (KNL) System Software Clark Snyder, Peter Hill, John Sygulla Motivation The Intel Xeon Phi TM Knights Landing (KNL) has 20 different configurations 5 NUMA modes X 4 memory
Intel Xeon PhiTM Knights Landing (KNL) System Software Clark Snyder, Peter Hill, John Sygulla Motivation The Intel Xeon Phi TM Knights Landing (KNL) has 20 different configurations 5 NUMA modes X 4 memory
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Comparing Performance and Power Consumption on Different Architectures
 Comparing Performance and Power Consumption on Different Architectures Andriani Mappoura August 18, 2017 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2017 Abstract
Comparing Performance and Power Consumption on Different Architectures Andriani Mappoura August 18, 2017 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2017 Abstract
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Single-thread optimization Parallelization Common pitfalls
KNL Performance Comparison: CP2K. March 2017
 KNL Performance Comparison: CP2K March 2017 1. Compilation, Setup and Input 2 Compilation CP2K and its supporting libraries libint, libxsmm, libgrid, and libxc were compiled following the instructions
KNL Performance Comparison: CP2K March 2017 1. Compilation, Setup and Input 2 Compilation CP2K and its supporting libraries libint, libxsmm, libgrid, and libxc were compiled following the instructions
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
1. Many Core vs Multi Core. 2. Performance Optimization Concepts for Many Core. 3. Performance Optimization Strategy for Many Core
 1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
KNL Performance Comparison: R and SPRINT. Adrian Jackson March 2017
 KNL Performance Comparison: R and SPRINT Adrian Jackson a.jackson@epcc.ed.ac.uk March 2017 1. Introduction R (https://www.r-project.org/) is a statistical programming language widely used for data analytics
KNL Performance Comparison: R and SPRINT Adrian Jackson a.jackson@epcc.ed.ac.uk March 2017 1. Introduction R (https://www.r-project.org/) is a statistical programming language widely used for data analytics
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Deep Learning with Intel DAAL
 Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
HPCF Cray Phase 2. User Test period. Cristian Simarro User Support. ECMWF April 18, 2016
 HPCF Cray Phase 2 User Test period Cristian Simarro User Support advisory@ecmwf.int ECMWF April 18, 2016 Content Introduction Upgrade timeline Changes Hardware Software Steps for the testing on CCB Possible
HPCF Cray Phase 2 User Test period Cristian Simarro User Support advisory@ecmwf.int ECMWF April 18, 2016 Content Introduction Upgrade timeline Changes Hardware Software Steps for the testing on CCB Possible
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
Scientific Computing with Intel Xeon Phi Coprocessors
 Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
Scientific Computing with Intel Xeon Phi Coprocessors Andrey Vladimirov Colfax International HPC Advisory Council Stanford Conference 2015 Compututing with Xeon Phi Welcome Colfax International, 2014 Contents
Leibniz Supercomputer Centre. Movie on YouTube
 SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
Introduction to tuning on KNL platforms
 Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
Introduction to tuning on KNL platforms Gilles Gouaillardet RIST gilles@rist.or.jp 1 Agenda Why do we need many core platforms? KNL architecture Post-K overview Single-thread optimization Parallelization
Opportunities and Challenges in Sparse Linear Algebra on Many-Core Processors with High-Bandwidth Memory
 Opportunities and Challenges in Sparse Linear Algebra on Many-Core Processors with High-Bandwidth Memory Jongsoo Park, Parallel Computing Lab, Intel Corporation with contributions from MKL team 1 Algorithm/
Opportunities and Challenges in Sparse Linear Algebra on Many-Core Processors with High-Bandwidth Memory Jongsoo Park, Parallel Computing Lab, Intel Corporation with contributions from MKL team 1 Algorithm/
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
MEMORY ON THE KNL. Adrian Some slides from Intel Presentations
 MEMORY ON THE KNL Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Some slides from Intel Presentations Memory Two levels of memory for KNL Main memory KNL has direct access to all of main memory Similar
MEMORY ON THE KNL Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Some slides from Intel Presentations Memory Two levels of memory for KNL Main memory KNL has direct access to all of main memory Similar
VLPL-S Optimization on Knights Landing
 VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.
VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
Today. SMP architecture. SMP architecture. Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Benchmark results on Knight Landing architecture
 Benchmark results on Knight Landing architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Milano, 21/04/2017 KNL vs BDW A1 BDW A2 KNL cores per node 2 x 18 @2.3 GHz 1 x 68
Benchmark results on Knight Landing architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Milano, 21/04/2017 KNL vs BDW A1 BDW A2 KNL cores per node 2 x 18 @2.3 GHz 1 x 68
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MARCH 17 TH, MIC Workshop PAGE 1. MIC workshop Guillaume Colin de Verdière
 EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
Manycore Processors. Manycore Chip: A chip having many small CPUs, typically statically scheduled and 2-way superscalar or scalar.
 phi 1 Manycore Processors phi 1 Definition Manycore Chip: A chip having many small CPUs, typically statically scheduled and 2-way superscalar or scalar. Manycore Accelerator: [Definition only for this
phi 1 Manycore Processors phi 1 Definition Manycore Chip: A chip having many small CPUs, typically statically scheduled and 2-way superscalar or scalar. Manycore Accelerator: [Definition only for this
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Multi-core today: Intel Xeon 600v4 (016) Xeon E5-600v4 Broadwell
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Multi-core today: Intel Xeon 600v4 (016) Xeon E5-600v4 Broadwell
Using GPUs for unstructured grid CFD
 Using GPUs for unstructured grid CFD Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Schlumberger Abingdon Technology Centre, February 17th, 2011
Using GPUs for unstructured grid CFD Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Schlumberger Abingdon Technology Centre, February 17th, 2011
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - LRZ,
 Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
MANY-CORE COMPUTING. 7-Oct Ana Lucia Varbanescu, UvA. Original slides: Rob van Nieuwpoort, escience Center
 MANY-CORE COMPUTING 7-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics & analysis 2. Programming: basics (10-10-2013)
MANY-CORE COMPUTING 7-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics & analysis 2. Programming: basics (10-10-2013)
Advanced Job Launching. mapping applications to hardware
 Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Geant4 MT Performance. Soon Yung Jun (Fermilab) 21 st Geant4 Collaboration Meeting, Ferrara, Italy Sept , 2016
 21 st Geant4 Collaboration Meeting, Ferrara, Italy Sept , 2016") Geant4 MT Performance Soon Yung Jun (Fermilab) 21 st Geant4 Collaboration Meeting, Ferrara, Italy Sept. 12-16, 2016 Introduction Geant4 multi-threading (Geant4 MT) capabilities Event-level parallelism
Geant4 MT Performance Soon Yung Jun (Fermilab) 21 st Geant4 Collaboration Meeting, Ferrara, Italy Sept. 12-16, 2016 Introduction Geant4 multi-threading (Geant4 MT) capabilities Event-level parallelism
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture
 Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Overview of High Performance Computing
 Overview of High Performance Computing Timothy H. Kaiser, PH.D. tkaiser@mines.edu http://inside.mines.edu/~tkaiser/csci580fall13/ 1 Near Term Overview HPC computing in a nutshell? Basic MPI - run an example
Overview of High Performance Computing Timothy H. Kaiser, PH.D. tkaiser@mines.edu http://inside.mines.edu/~tkaiser/csci580fall13/ 1 Near Term Overview HPC computing in a nutshell? Basic MPI - run an example
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Reusing this material
 XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data