Lecture 1: Introduction
|
|
|
- Egbert Hamilton
- 6 years ago
- Views:
Transcription



1 Lecture 1: Introduction Dr. Eng. Amr T. Abdel-Hamid Winter 2014 Computer Architecture Text book slides: Computer Architec ture: A Quantitative Approach 5 th E dition, John L. Hennessy & David A. Patterso with modifications.
: 32-bit, 5 stage pipeline, 40,760")

2 CPU History in a Flash Intel 4004 (1971): 4-bit processor, 2312 transistors, 0.4 MHz, 10 micron PMOS, 11 mm 2 chip RISC II (1983): 32-bit, 5 stage pipeline, 40,760 transistors, 3 MHz, 3 micron NMOS, 60 mm 2 chip 125 mm 2 chip, micron CMOS = 2312 RISC II+FPU+Icache+Dcache RISC II shrinks to ~ 0.02 mm 2 at 65 nm Caches via DRAM or 1 transistor SRAM Processor is the new transistor?

3 Processor Performance RISC Move to multi-processor Introduction


4 Snapdragon 805 processor specs
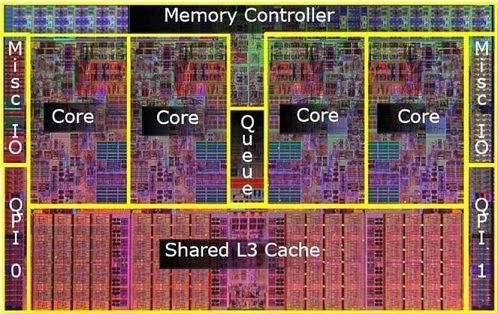
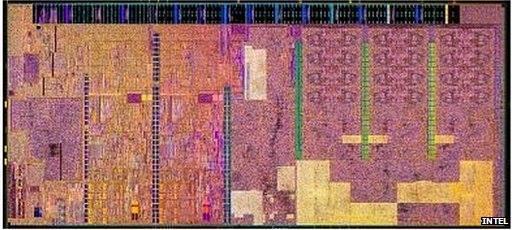
5
6 Classes of Computers Personal Mobile Device (PMD) e.g. start phones, tablet computers Emphasis on energy efficiency and real-time Desktop Computing Emphasis on price-performance Servers Emphasis on availability, scalability, throughput Clusters / Warehouse Scale Computers Used for Software as a Service (SaaS) Emphasis on availability and price-performance Sub-class: Supercomputers, emphasis: floating-point performance and fast internal networks Embedded Computers Emphasis: price
7 Instruction Set Architecture: Critical Interface software hardware instruction set Properties of a good abstraction Lasts through many generations (portability) Used in many different ways (generality) Provides convenient functionality to higher levels Permits an efficient implementation at lower levels
8 ISA vs. Computer Architecture Old definition of computer architecture = instruction set design Other aspects of computer design called implementation Insinuates implementation is uninteresting or less challenging Our view is: computer architecture >> ISA Architect s job much more than instruction set design; techni cal hurdles today more challenging than those in instruction set design


9 Computer Architecture is Design and Analysis Analysis Design Creativity Architecture is an iterative process: Searching the space of possible designs At all levels of computer systems Cost / Performance Analysis Bad Ideas Good Ideas Mediocre Ideas
10 Administrivia Instructor: Dr. Amr T. Abdel-Hamid Office: C Office Hours: Monday, 3 rd & 4 th Lectures. T. A:???


11 Administrivia
12 Course Grading Exams Quizzes 3 Quizzes: best 2 10 % Mid Term 30 % Final exam 40 % Project 20% Assignments Not Graded
13 Project Phase 0: Select your partner (17/9/2014) Submit list of your group members (2-4 per group) Submit a Comparision between Risc and Cisc Proc. Phase 1:.... Phase N: Project Implementation + Report (2 weeks before fin als) FINAL Non-Negotiable deadline
14 In time & It is too LATE Policy In phases 0, & 1: 5% of project grade penalty per day for being late In phase 2, to n: No late presentation is possible. Honor code 100% penalty for both copier and copy-giver of Any Report/CODE.
15 Quantitative Principles of Design 1. Take Advantage of Parallelism 2. Principle of Locality 3. Focus on the Common Case 4. Amdahl s Law 5. The Processor Performance Equation
16 1) Taking Advantage of Parallelism Increasing throughput of server computer via multiple processors or multi ple disks Detailed HW design (DSD course shortly) Carry lookahead adders uses parallelism to speed up computing sum s from linear to logarithmic in number of bits per operand Multiple memory banks searched in parallel in set-associative caches Pipelining: overlap instruction execution to reduce the total time to compl ete an instruction sequence. Not every instruction depends on immediate predecessor executin g instructions completely/partially in parallel possible Classic 5-stage pipeline: 1) Instruction Fetch (), 2) ister Read (), 3) Execute (), 4) Data Memory Access (Dmem), 5) ister Write ()
17 2) The Principle of Locality The Principle of Locality: Program access a relatively small portion of the address space at any instan t of time. Two Different Types of Locality: Temporal Locality (Locality in Time): If an item is referenced, it will tend to be r eferenced again soon (e.g., loops, reuse) Spatial Locality (Locality in Space): If an item is referenced, items whose addr esses are close by tend to be referenced soon (e.g., straight-line code, array access) Last 30 years, HW relied on locality for memory perf. P $ MEM
18 Capacity Access Time Cost Tape infinite sec-min Elect ~$1 / 707 GByte Levels of the Memory Hierarchy CPU isters 100s Bytes ps ( ns) L1 and L2 Cache 10s-100s K Bytes ~1 ns - ~10 ns $1000s/ GByte Main Memory G Bytes 80ns- 200ns ~ $100/ GByte Disk 10s T Bytes, 10 ms (10,000,000 ns) ~ $1 / GByte isters L1 Cache L2 Cache Memory Disk Tape Instr. Operands Blocks Blocks Pages Files Staging Xfer Unit prog./compiler 1-8 bytes cache cntl bytes cache cntl bytes OS 4K-8K bytes user/operator Mbytes Upper Level faster Larger Lower Level
19 3) Focus on the Common Case Common sense guides computer design Since its engineering, common sense is valuable In making a design trade-off, favor the frequent case over t he infrequent case E.g., Instruction fetch and decode unit used more frequently th an multiplier, so optimize it 1st E.g., If database server has 50 disks / processor, storage dep endability dominates system dependability, so optimize it 1st Frequent case is often simpler and can be done faster than the infrequent case E.g., overflow is rare when adding 2 numbers, so improve perf ormance by optimizing more common case of no overflow May slow down overflow, but overall performance improved by optimizing for the normal case What is frequent case and how much performance improve d by making case faster => Amdahl s Law
20 4) Amdahl s Law ExTimenew ExTimeold 1 Speedup overall ExTime ExTime old new 1 Best you could ever hope to do: Speedup maximum Fractionenhanced Fraction Fraction enhanced Fraction enhanced 1 enhanced Speedup enhanced Fraction Speedup enhanced enhanced
21 Amdahl s Law example New CPU 10X faster I/O bound server, so 60% time waiting for I/O Speedup overall 1 1 Fraction enhanced Fraction Speedup enhanced enhanced Apparently, its human nature to be attracted by 10X faster, vs. keeping in perspective its just 1.6X faster
22 5) Processor performance equation inst count CPI Cycle time CPU time = Seconds = Instructions x Cycles x Seconds Program Program Instruction Cycle Inst Count CPI Clock Rate Program X Compiler X (X) Inst. Set. X X Organization X X Technology X
23 5 Steps of MIPS Datapath Figure A.2, Page A-8 Next PC Address Instruction Fetch 4 Adder Memory Inst Instr. Decode. Fetch Next SEQ PC RS1 RS2 RD File Execute Addr. Calc MUX MUX Zero? Memory Access MUX Data Memory L M D Write Back MUX Imm Sign Extend WB Data
24 WB Data 5 Steps of MIPS Datapath Figure A.3, Page A-9 Next PC Address Instruction Fetch 4 Adder Memory IF/ID Instr. Decode. Fetch Next SEQ PC RS1 RS2 Imm File Sign Extend ID/EX Execute Addr. Calc Next SEQ PC MUX MUX Zero? EX/MEM RD RD RD Memory Access MUX Data Memory MEM/WB Write Back MUX
25 WB Data 5 Steps of MIPS Datapath Figure A.3, Page A-9 Next PC Address Instruction Fetch 4 Adder Memory IF/ID Instr. Decode. Fetch Next SEQ PC RS1 RS2 Imm File Sign Extend Data stationary control ID/EX Execute Addr. Calc Next SEQ PC MUX MUX Zero? EX/MEM RD RD RD local decode for each instruction phase / pipeline stage Memory Access MUX Data Memory MEM/WB Write Back MUX
26 Visualizing Pipelining Figure A.2, Page A-8 I n s t r. O r d e r Time (clock cycles) Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7
27 Pipelining is not quite that easy! Limits to pipelining: Hazards prevent next instruction from exec uting during its designated clock cycle Structural hazards: HW cannot support this combination of instruc tions (single person to fold and put clothes away) Data hazards: Instruction depends on result of prior instruction stil l in the pipeline (missing sock) Control hazards: Caused by delay between the fetching of instruct ions and decisions about changes in control flow (branches and ju mps).
28 I n s t r. O r d e r One Memory Port/Structural Hazards Figure A.4, Page A-14 Time (clock cycles) Load Instr 1 Instr 2 Instr 3 Instr 4 Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7
29 One Memory Port/Structural Hazards (Similar to Figure A.5, Page A-15) I n s t r. O r d e r Time (clock cycles) Load Instr 1 Instr 2 Stall Cycle Cycle 1 2 Cycle 3 Cycle Cycle 4 5 Cycle Cycle 6 7 Instr 3 Bubble Bubble Bubble Bubble Bubble How do you bubble the pipe?
30 Speed Up Equation for Pipelining CPI pipelined Ideal CPI Average Stall cycles per Inst Ideal CPI Pipeline depth Speedup Ideal CPI Pipeline stall CPI For simple RISC pipeline, CPI = 1: Pipeline depth Speedup 1 Pipeline stall CPI Cycle Cycle Time Cycle Time Cycle pipelined Time unpipeline d Time unpipeline d pipelined
31 Example: Dual-port vs. Single-port Machine A: Dual ported memory ( Harvard Architecture ) Machine B: Single ported memory, but its pipelined implementatio n has a 1.05 times faster clock rate Ideal CPI = 1 for both Loads are 40% of instructions executed SpeedUp A = Pipeline Depth/(1 + 0) x (clock unpipe /clock pipe ) = Pipeline Depth SpeedUp B = Pipeline Depth/( x 1) x (clock unpipe /(clock unpipe / 1.05) = (Pipeline Depth/1.4) x 1.05 = 0.75 x Pipeline Depth SpeedUp A / SpeedUp B = Pipeline Depth/(0.75 x Pipeline Depth) = 1.33 Machine A is 1.33 times faster
32 Data Hazard on R1 Figure A.6, Page A-17 I n s t r. O r d e r Time (clock cycles) add r1,r2,r3 sub r4,r1,r3 and r6,r1,r7 or r8,r1,r9 xor r10,r1,r11 IF ID/RF EX MEM WB
33 Three Generic Data Hazards Read After Write (RAW) Instr J tries to read operand before Instr I writes it I: add r1,r2,r3 J: sub r4,r1,r3 Caused by a Dependence (in compiler nomenclature). This ha zard results from an actual need for communication.
34 Three Generic Data Hazards Write After Read (WAR) Instr J writes operand before Instr I reads it I: sub r4,r1,r3 J: add r1,r2,r3 Called an anti-dependence K: mul r6,r1,r7 by compiler writers. This results from reuse of the name r1. Can t happen in MIPS 5 stage pipeline because: All instructions take 5 stages, and Reads are always in stage 2, and Writes are always in stage 5
35 Three Generic Data Hazards Write After Write (WAW) Instr J writes operand before Instr I writes it. I: sub r1,r4,r3 J: add r1,r2,r3 K: mul r6,r1,r7 Called an output dependence by compiler writers This also results from the reuse of name r1. Can t happen in MIPS 5 stage pipeline because: All instructions take 5 stages, and Writes are always in stage 5 Will see WAR and WAW in more complicated pipes
36 Forwarding to Avoid Data Hazard Figure A.7, Page A-19 I n s t r. O r d e r add r1,r2,r3 sub r4,r1,r3 and r6,r1,r7 or r8,r1,r9 xor r10,r1,r11 Time (clock cycles)
37 HW Change for Forwarding Figure A.23, Page A-37 NextPC isters Immediate ID/EX mux mux EX/MEM Data Memory MEM/WR mux What circuit detects and resolves this hazard?
38 Forwarding to Avoid LW-SW Data Hazard Figure A.8, Page A-20 I n s t r. O r d e r add r1,r2,r3 lw r4, 0(r1) sw r4,12(r1) or r8,r6,r9 xor r10,r9,r11 Time (clock cycles) 38
39 Data Hazard Even with Forwarding Figure A.9, Page A-21 I n s t r. Time (clock cycles) lw r1, 0(r2) sub r4,r1,r6 O r d e r and r6,r1,r7 or r8,r1,r9
40 Data Hazard Even with Forwarding (Similar to Figure A.10, Page A-21) I n s t r. O r d e r Time (clock cycles) lw r1, 0(r2) sub r4,r1,r6 and r6,r1,r7 or r8,r1,r9 Bubble Bubble Bubble How is this detected?
41 Control Hazard on Branches Three Stage Stall 10: beq r1,r3,36 14: and r2,r3,r5 18: or r6,r1,r7 22: add r8,r1,r9 36: xor r10,r1,r11 What do you do with the 3 instructions in between? How do you do it?
42 Branch Stall Impact If CPI = 1, 30% branch, Stall 3 cycles => new CPI = 1.9! Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier MIPS branch tests if register = 0 or 0 MIPS Solution: Move Zero test to ID/RF stage Adder to calculate new PC in ID/RF stage 1 clock cycle penalty for branch versus 3
43 WB Data Pipelined MIPS Datapath Figure A.24, page A-38 Next PC Address Instruction Fetch 4 Adder Memory IF/ID Instr. Decode. Fetch Next S EQ PC Adder Zero? File Sign Extend Execute Addr. Calc MUX EX/MEM RD RD RD Interplay of instruction set design and cycle time. RS1 RS2 Imm MUX ID/EX Memory Access Data Memory MEM/WB Write Back MUX
44 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism (ILP) Single processor performance improvement ended in 2003 New models for performance: Data-level parallelism (DLP) Thread-level parallelism (TLP) Request-level parallelism (RLP)
45 Parallelism Classes of parallelism in applications: Data-Level Parallelism (DLP) Task-Level Parallelism (TLP) Classes of architectural parallelism: Instruction-Level Parallelism (ILP) Vector architectures/graphic Processor Units (GPUs) Thread-Level Parallelism Request-Level Parallelism
46 Trends in Technology Integrated circuit technology Transistor density: 35%/year Die size: 10-20%/year Integration overall: 40-55%/year DRAM capacity: 25-40%/year (slowing) Flash capacity: 50-60%/year 15-20X cheaper/bit than DRAM Magnetic disk technology: 40%/year 15-25X cheaper/bit then Flash X cheaper/bit than DRAM
47 Bandwidth and Latency Bandwidth or throughput Total work done in a given time 10,000-25,000X improvement for processors X improvement for memory and disks Latency or response time Time between start and completion of an event 30-80X improvement for processors 6-8X improvement for memory and disks
48 Power and Energy Problem: Get power in, get power out Thermal Design Power (TDP) Characterizes sustained power consumption Used as target for power supply and cooling system Lower than peak power, higher than average power consumption Clock rate can be reduced dynamically to limit power con sumption Energy per task is often a better measurement
49 Dynamic Energy and Power Dynamic energy Transistor switch from 0 -> 1 or 1 -> 0 ½ x Capacitive load x Voltage 2 Dynamic power ½ x Capacitive load x Voltage 2 x Frequency switched Reducing clock rate reduces power, not energy

50 Power Intel consumed ~ 2 W 3.3 GHz Intel Core i7 consumes 130 W Heat must be dissipated from 1.5 x 1.5 cm chip This is the limit of what can be cooled by air
51 Reducing Power Techniques for reducing power: Do nothing well Dynamic Voltage-Frequency Scaling Low power state for DRAM, disks turning off cores
52 Reading Assignment: Chapter 1, Appendix B
CS654 Advanced Computer Architecture. Lec 2 - Introduction
 CS654 Advanced Computer Architecture Lec 2 - Introduction Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University of California,
CS654 Advanced Computer Architecture Lec 2 - Introduction Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University of California,
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Modern Computer Architecture
 Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Lecture 3. Pipelining. Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1
 Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
EECS4201 Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 1. Copyright 2012, Elsevier Inc. All rights reserved. Computer Technology
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
B649 Graduate Computer Architecture. Lec 1 - Introduction
 B649 Graduate Computer Architecture Lec 1 - Introduction http://www.cs.indiana.edu/~achauhan/teaching/ B649/2009-Spring/ 1/12/09 b649, Lec 01-intro 2 Outline Computer Science at a Crossroads Computer Architecture
B649 Graduate Computer Architecture Lec 1 - Introduction http://www.cs.indiana.edu/~achauhan/teaching/ B649/2009-Spring/ 1/12/09 b649, Lec 01-intro 2 Outline Computer Science at a Crossroads Computer Architecture
MOTIVATION. B649 Parallel Architectures and Programming
 MOTIVATION B649 Parallel Architectures and Programming Growth in Processor Performance From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, October, 2006! B649: Parallel
MOTIVATION B649 Parallel Architectures and Programming Growth in Processor Performance From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, October, 2006! B649: Parallel
Computer Architecture and System
 Computer Architecture and System 2012 Chung-Ho Chen Computer Architecture and System Laboratory Department of Electrical Engineering National Cheng-Kung University Course Focus Understanding the design
Computer Architecture and System 2012 Chung-Ho Chen Computer Architecture and System Laboratory Department of Electrical Engineering National Cheng-Kung University Course Focus Understanding the design
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Computer Architecture and System
 Computer Architecture and System Chung-Ho Chen Computer Architecture and System Laboratory Department of Electrical Engineering National Cheng-Kung University Course Focus Understanding the design techniques,
Computer Architecture and System Chung-Ho Chen Computer Architecture and System Laboratory Department of Electrical Engineering National Cheng-Kung University Course Focus Understanding the design techniques,
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Computer Systems Architecture Spring 2016
 Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
Pipelining, Instruction Level Parallelism and Memory in Processors. Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010
 Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
Introduction to Computer Architecture II
 Introduction to Computer Architecture II ECE 154B Dmitri Strukov Computer systems overview 1 Outline Course information Trends Computing classes Quantitative Principles of Design Dependability 2 Course
Introduction to Computer Architecture II ECE 154B Dmitri Strukov Computer systems overview 1 Outline Course information Trends Computing classes Quantitative Principles of Design Dependability 2 Course
Technology. Giorgio Richelli
 Technology Giorgio Richelli What Comes out of the Fab Transistor Abstractions in Logic Design In physical world Voltages, Currents Electron flow In logical world - abstraction V < V lo 0 = FALSE V > V
Technology Giorgio Richelli What Comes out of the Fab Transistor Abstractions in Logic Design In physical world Voltages, Currents Electron flow In logical world - abstraction V < V lo 0 = FALSE V > V
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
Pipelining: Hazards Ver. Jan 14, 2014
 POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
Advanced Computer Architecture
 ECE 563 Advanced Computer Architecture Fall 2010 Lecture 2: Review of Metrics and Pipelining 563 L02.1 Fall 2010 Review from Last Time Computer Architecture >> instruction sets Computer Architecture skill
ECE 563 Advanced Computer Architecture Fall 2010 Lecture 2: Review of Metrics and Pipelining 563 L02.1 Fall 2010 Review from Last Time Computer Architecture >> instruction sets Computer Architecture skill
CSE 502 Graduate Computer Architecture. Lec 3-5 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007
 CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
Advanced Computer Architecture
 ECE 563 Advanced Computer Architecture Fall 2010 Lecture 1: Introduction 563 L01.1 Fall 2010 Computing Devices Then 563 L01.2 EDSAC, University of Cambridge, UK, 1949 (The first practical stored program
ECE 563 Advanced Computer Architecture Fall 2010 Lecture 1: Introduction 563 L01.1 Fall 2010 Computing Devices Then 563 L01.2 EDSAC, University of Cambridge, UK, 1949 (The first practical stored program
Pipelining! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar DEIB! 30 November, 2017!
 Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Lecture - 4. Measurement. Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1
 Lecture - 4 Measurement Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1 Acknowledgements David Patterson Dr. Roger Kieckhafer 9/29/2009 2 Computer Architecture is Design and Analysis
Lecture - 4 Measurement Dr. Soner Onder CS 4431 Michigan Technological University 9/29/2009 1 Acknowledgements David Patterson Dr. Roger Kieckhafer 9/29/2009 2 Computer Architecture is Design and Analysis
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
COSC4201 Pipelining. Prof. Mokhtar Aboelaze York University
 COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
Processor Architecture
 Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong (jinkyu@skku.edu)
Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong (jinkyu@skku.edu)
CSE 502 Graduate Computer Architecture. Lec 3-5 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CPE Computer Architecture. Appendix A: Pipelining: Basic and Intermediate Concepts
 CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
Modern Computer Architecture
 Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation
 Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Advanced Computer Architecture Week 1: Introduction. ECE 154B Dmitri Strukov
 Advanced Computer Architecture Week 1: Introduction ECE 154B Dmitri Strukov 1 Outline Course information Trends (in technology, cost, performance) and issues 2 Course organization Class website: http://www.ece.ucsb.edu/~strukov/ece154bwint
Advanced Computer Architecture Week 1: Introduction ECE 154B Dmitri Strukov 1 Outline Course information Trends (in technology, cost, performance) and issues 2 Course organization Class website: http://www.ece.ucsb.edu/~strukov/ece154bwint
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Lecture 9. Pipeline Hazards. Christos Kozyrakis Stanford University
 Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
CSE 502 Graduate Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition CAQA5 Chapter 1 CSE 502 Graduate Computer Architecture Lec 1-3 - Introduction Fundamentals of Quantitative Design and Analysis Larry Wittie
Computer Architecture A Quantitative Approach, Fifth Edition CAQA5 Chapter 1 CSE 502 Graduate Computer Architecture Lec 1-3 - Introduction Fundamentals of Quantitative Design and Analysis Larry Wittie
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Gaduate Compute Achitectue Lectue 6 - Hazads Michela Taufe http://www.cis.udel.edu/~taufe/teaching/cis662f07 Powepoint Lectue Notes fom John Hennessy and David Patteson s: Compute Achitectue,
CISC 662 Gaduate Compute Achitectue Lectue 6 - Hazads Michela Taufe http://www.cis.udel.edu/~taufe/teaching/cis662f07 Powepoint Lectue Notes fom John Hennessy and David Patteson s: Compute Achitectue,
CSE 533: Advanced Computer Architectures. Pipelining. Instructor: Gürhan Küçük. Yeditepe University
 CSE 533: Advanced Computer Architectures Pipelining Instructor: Gürhan Küçük Yeditepe University Lecture notes based on notes by Mark D. Hill and John P. Shen Updated by Mikko Lipasti Pipelining Forecast
CSE 533: Advanced Computer Architectures Pipelining Instructor: Gürhan Küçük Yeditepe University Lecture notes based on notes by Mark D. Hill and John P. Shen Updated by Mikko Lipasti Pipelining Forecast
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. Complications With Long Instructions
 CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Memory hierarchy review. ECE 154B Dmitri Strukov
 Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Six basic optimizations Virtual memory Cache performance Opteron example Processor-DRAM gap in latency Q1. How to deal
Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Six basic optimizations Virtual memory Cache performance Opteron example Processor-DRAM gap in latency Q1. How to deal
CMSC411 Fall 2013 Midterm 1
 CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
DLX Unpipelined Implementation
 LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
Appendix C. Abdullah Muzahid CS 5513
 Appendix C Abdullah Muzahid CS 5513 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero) Single address mode for load/store: base + displacement no indirection
Appendix C Abdullah Muzahid CS 5513 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero) Single address mode for load/store: base + displacement no indirection
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Pipelining. Maurizio Palesi
 * Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
* Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
CS654 Advanced Computer Architecture. Lec 1 - Introduction
 CS654 Advanced Computer Architecture Lec 1 - Introduction Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University of California,
CS654 Advanced Computer Architecture Lec 1 - Introduction Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University of California,
Advanced Computer Architecture Pipelining
 Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
CPU Pipelining Issues
 CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CENG 3531 Computer Architecture Spring a. T / F A processor can have different CPIs for different programs.
 Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
14:332:331 Pipelined Datapath
 14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
CSE 502 Graduate Computer Architecture. Lec 4-6 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 4-6 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 4-6 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Course web site: teaching/courses/car. Piazza discussion forum:
 Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
The Big Picture Problem Focus S re r g X r eg A d, M lt2 Sub u, Shi h ft Mac2 M l u t l 1 Mac1 Mac Performance Focus Gate Source Drain BOX
 Appendix A - Pipelining 1 The Big Picture SPEC f2() { f3(s2, &j, &i); *s2->p = 10; i = *s2->q + i; } Requirements Algorithms Prog. Lang./OS ISA f1 f2 f5 f3 s q p fp j f3 f4 i1: ld r1, b i2: ld r2,
Appendix A - Pipelining 1 The Big Picture SPEC f2() { f3(s2, &j, &i); *s2->p = 10; i = *s2->q + i; } Requirements Algorithms Prog. Lang./OS ISA f1 f2 f5 f3 s q p fp j f3 f4 i1: ld r1, b i2: ld r2,
ECE 486/586. Computer Architecture. Lecture # 2
 ECE 486/586 Computer Architecture Lecture # 2 Spring 2015 Portland State University Recap of Last Lecture Old view of computer architecture: Instruction Set Architecture (ISA) design Real computer architecture:
ECE 486/586 Computer Architecture Lecture # 2 Spring 2015 Portland State University Recap of Last Lecture Old view of computer architecture: Instruction Set Architecture (ISA) design Real computer architecture:
Topics. Computer Organization CS Improving Performance. Opportunity for (Easy) Points. Three Generic Data Hazards
 Points. Three Generic Data Hazards") Computer Organization CS 231-01 Improving Performance Dr. William H. Robinson November 8, 2004 Topics Money's only important when you don't have any. Sting Cache Scoreboarding http://eecs.vanderbilt.edu/courses/cs231/
Computer Organization CS 231-01 Improving Performance Dr. William H. Robinson November 8, 2004 Topics Money's only important when you don't have any. Sting Cache Scoreboarding http://eecs.vanderbilt.edu/courses/cs231/
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Administrivia. CMSC 411 Computer Systems Architecture Lecture 8 Basic Pipelining, cont., & Memory Hierarchy. SPEC92 benchmarks
 Administrivia CMSC 4 Computer Systems Architecture Lecture 8 Basic Pipelining, cont., & Memory Hierarchy Alan Sussman als@cs.umd.edu Homework # returned today solutions posted on password protected web
Administrivia CMSC 4 Computer Systems Architecture Lecture 8 Basic Pipelining, cont., & Memory Hierarchy Alan Sussman als@cs.umd.edu Homework # returned today solutions posted on password protected web
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CISC 662 Graduate Computer Architecture Lecture 5 - Pipeline. Pipelining. Pipelining the Idea. Similar to assembly line in a factory:
 CISC 662 Graduate Computer rchitecture Lecture 5 - Pipeline ichela Taufer http://www.cis.udel.edu/~taufer/courses Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer rchitecture,
CISC 662 Graduate Computer rchitecture Lecture 5 - Pipeline ichela Taufer http://www.cis.udel.edu/~taufer/courses Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer rchitecture,
HY425 Lecture 05: Branch Prediction
 HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
第三章 Instruction-Level Parallelism and Its Dynamic Exploitation. 陈文智 浙江大学计算机学院 2014 年 10 月
 第三章 Instruction-Level Parallelism and Its Dynamic Exploitation 陈文智 chenwz@zju.edu.cn 浙江大学计算机学院 2014 年 10 月 1 3.3 The Major Hurdle of Pipelining Pipeline Hazards 本科回顾 ------- Appendix A.2 3.3.1 Taxonomy
第三章 Instruction-Level Parallelism and Its Dynamic Exploitation 陈文智 chenwz@zju.edu.cn 浙江大学计算机学院 2014 年 10 月 1 3.3 The Major Hurdle of Pipelining Pipeline Hazards 本科回顾 ------- Appendix A.2 3.3.1 Taxonomy
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
ECE 587 Advanced Computer Architecture I
 ECE 587 Advanced Computer Architecture I Instructor: Alaa Alameldeen alaa@ece.pdx.edu Spring 2015 Portland State University Copyright by Alaa Alameldeen and Haitham Akkary 2015 1 When and Where? When:
ECE 587 Advanced Computer Architecture I Instructor: Alaa Alameldeen alaa@ece.pdx.edu Spring 2015 Portland State University Copyright by Alaa Alameldeen and Haitham Akkary 2015 1 When and Where? When:
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Basic Pipelining Concepts
 Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Overview. Appendix A. Pipelining: Its Natural! Sequential Laundry 6 PM Midnight. Pipelined Laundry: Start work ASAP
 Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
ELE 375 Final Exam Fall, 2000 Prof. Martonosi
 ELE 375 Final Exam Fall, 2000 Prof. Martonosi Question Score 1 /10 2 /20 3 /15 4 /15 5 /10 6 /20 7 /20 8 /25 9 /30 10 /30 11 /30 12 /15 13 /10 Total / 250 Please write your answers clearly in the space
ELE 375 Final Exam Fall, 2000 Prof. Martonosi Question Score 1 /10 2 /20 3 /15 4 /15 5 /10 6 /20 7 /20 8 /25 9 /30 10 /30 11 /30 12 /15 13 /10 Total / 250 Please write your answers clearly in the space
Appendix A. Overview
 Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Perfect Student CS 343 Final Exam May 19, 2011 Student ID: 9999 Exam ID: 9636 Instructions Use pencil, if you have one. For multiple choice
 Instructions Page 1 of 7 Use pencil, if you have one. For multiple choice questions, circle the letter of the one best choice unless the question specifically says to select all correct choices. There
Instructions Page 1 of 7 Use pencil, if you have one. For multiple choice questions, circle the letter of the one best choice unless the question specifically says to select all correct choices. There
Computer Architecture. R. Poss
 Computer Architecture R. Poss 1 ca01-10 september 2015 Course & organization 2 ca01-10 september 2015 Aims of this course The aims of this course are: to highlight current trends to introduce the notion
Computer Architecture R. Poss 1 ca01-10 september 2015 Course & organization 2 ca01-10 september 2015 Aims of this course The aims of this course are: to highlight current trends to introduce the notion
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
ECE 2300 Digital Logic & Computer Organization. Caches
 ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
Graduate Computer Architecture. Chapter 3. Instruction Level Parallelism and Its Dynamic Exploitation
 Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
ECE154A Introduction to Computer Architecture. Homework 4 solution
 ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
Memory Hierarchy. Maurizio Palesi. Maurizio Palesi 1
 Memory Hierarchy Maurizio Palesi Maurizio Palesi 1 References John L. Hennessy and David A. Patterson, Computer Architecture a Quantitative Approach, second edition, Morgan Kaufmann Chapter 5 Maurizio
Memory Hierarchy Maurizio Palesi Maurizio Palesi 1 References John L. Hennessy and David A. Patterson, Computer Architecture a Quantitative Approach, second edition, Morgan Kaufmann Chapter 5 Maurizio
Cycle Time for Non-pipelined & Pipelined processors
 Cycle Time for Non-pipelined & Pipelined processors Fetch Decode Execute Memory Writeback 250ps 350ps 150ps 300ps 200ps For a non-pipelined processor, the clock cycle is the sum of the latencies of all
Cycle Time for Non-pipelined & Pipelined processors Fetch Decode Execute Memory Writeback 250ps 350ps 150ps 300ps 200ps For a non-pipelined processor, the clock cycle is the sum of the latencies of all
Computer Architecture Lecture 1: Fundamentals of Quantitative Design and Analysis (Chapter 1)
") Computer Architecture Lecture 1: Fundamentals of Quantitative Design and Analysis (Chapter 1) Chih Wei Liu 劉志尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Computer Technology Introduction
Computer Architecture Lecture 1: Fundamentals of Quantitative Design and Analysis (Chapter 1) Chih Wei Liu 劉志尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Computer Technology Introduction
EITF20: Computer Architecture Part2.1.1: Instruction Set Architecture
 EITF20: Computer Architecture Part2.1.1: Instruction Set Architecture Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Instruction Set Principles The Role of Compilers MIPS 2 Main Content Computer
EITF20: Computer Architecture Part2.1.1: Instruction Set Architecture Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Instruction Set Principles The Role of Compilers MIPS 2 Main Content Computer
Computer Architecture. Lecture 6.1: Fundamentals of
 CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
Review: Performance Latency vs. Throughput. Time (seconds/program) is performance measure Instructions Clock cycles Seconds.
 is performance measure Instructions Clock cycles Seconds.") Performance 980 98 982 983 984 985 986 987 988 989 990 99 992 993 994 995 996 997 998 999 2000 7/4/20 CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Instructor: Michael Greenbaum
Performance 980 98 982 983 984 985 986 987 988 989 990 99 992 993 994 995 996 997 998 999 2000 7/4/20 CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Instructor: Michael Greenbaum
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Transistors and Wires
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis Part II These slides are based on the slides provided by the publisher. The slides
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis Part II These slides are based on the slides provided by the publisher. The slides
COSC 6385 Computer Architecture. - Memory Hierarchies (I)
") COSC 6385 Computer Architecture - Hierarchies (I) Fall 2007 Slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05 Recap
COSC 6385 Computer Architecture - Hierarchies (I) Fall 2007 Slides are based on a lecture by David Culler, University of California, Berkley http//www.eecs.berkeley.edu/~culler/courses/cs252-s05 Recap