HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
|
|
|
- Barbra Carr
- 6 years ago
- Views:
Transcription

1 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA



2 STATE OF THE ART ,688 Tesla K20X GPUs 27 PetaFLOPS

 Climate")
")
")
3 FLAGSHIP SCIENTIFIC APPLICATIONS ON TITAN Material Science (WL-LSMS) Climate Change (CAM-SE) Biofuels (LAMMPS) Astrophysics (NRDF). Combustion (S3D) Nuclear Energy (Denovo)



4 STATE OF THE ART 2017 Earth Simulator TF Top500 #1 for 3 years CORAL Summit System 5-10x Faster 1/5th the Nodes, Same Energy Use as Titan Just 1 Node in Summit Is the same performance as the Earth Simulator in 2002
5 AGENDA: 3 STORIES Heterogeneous HPC HPC System Evolution Architecture and Technology Basis for Heterogeneous Processing Architectural Optimization and NVLink Tesla Accelerated Computing Platform NVLink CORAL Punctuation Mark Optimized Fat node performance projections




6 ARE YOU CALIBRATED?.6 MPH 6 MPH 60 MPH 600 MPH 3 ORDERS OF MAGNITUDE
7 HPC SYSTEM EVOLUTION MEMORY CPU



8 CRAY-1 LATENCY-HIDING SINGLE VECTOR CPU, 160 MFLOPS PEAK

9 FIRST LINPACK LIST, JANUARY 1979
10 TOP500 SUPERCOMPUTER LIST CORAL TITAN 9 ORDERS OF MAGNITUDE CRAY-1
11 HPC SYSTEM EVOLUTION MEMORY MEMORY CPU CPU CPU




12 CRAY-2 4 LATENCY-HIDING VECTOR CPUS, 2 GFLOPS PEAK, 1985
13 HPC SYSTEM EVOLUTION MEMORY MEMORY MEMORY MEMORY CPU CPU CPU CPU CPU NETWORK

14 ATTACK OF THE KILLER MICROS


15 CRAY T3D DEC ALPHA EV4 MICROPROCESSORS, 1 TFLOPS PEAK, 1993
16 HETEROGENEOUS RESULTS



17 CRAY T3E DEC ALPHA EV5 MICROPROCESSORS, 1 TFLOPS SUSTAINED, 1995


18 FUTURE SHOCK There s hasn t really been anything truly new for 20 years except GPUs. --Thomas Schulthess, Director, CSCS
19 COMING SOON TO A NODE NEAR YOU Cray T3E 2.4 TFLOPS peak performance (2K processors) ~128 GB/s bisection bandwidth CRAY T90 56 GFLOPs peak performance (32 processors) 1 TB/s bisection bandwidth Pascal GPU (1H16) has >T3E peak with T90 memory BW





20 OPTIMIZING SERIAL/PARALLEL EXECUTION Application Code Parallel Work Serial Work GPU Majority of Ops System and Sequential Ops CPU +


21 TWO COMPUTING MODELS FOR ACCELERATORS Many-Weak-Cores (MWC) Model Single CPU Core for Both Serial & Parallel Work Heterogeneous Computing Model Complementary Processors Work Together Xeon Phi (And Others) Many Weak Serial Cores CPU Optimized for Serial Tasks GPU Accelerator Optimized for Parallel Tasks 21


22 AMDAHL S LAW ANALYSIS 98% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 22
23 AMDAHL S LAW ANALYSIS 90% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 23
24 AMDAHL S LAW ANALYSIS 80% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 24
25 AMDAHL S LAW ANALYSIS 70% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 25
26 AMDAHL S LAW ANALYSIS 60% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 26
27 AMDAHL S LAW ANALYSIS 50% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 27
28 AMDAHL S LAW ANALYSIS 40% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 28
29 AMDAHL S LAW ANALYSIS 30% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 29
30 AMDAHL S LAW ANALYSIS 20% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 30
31 AMDAHL S LAW ANALYSIS 10% Parallel Work 1 GPU+1 CPU 2 x MWC (.25x CPU) Serial Parallel Work 1x CPU Minutes Run Time 31



32 TESLA K80 WORLD S FASTEST ACCELERATOR FOR DATA ANALYTICS AND SCIENTIFIC COMPUTING Dual-GPU Accelerator for Max Throughput 2x Faster 2.9 TF 4992 Cores 480 GB/s 25x 20x 15x Deep Learning: Caffe Double the Memory Designed for Big Data Apps 24GB K40 12GB Maximum Performance Dynamically Maximize Performance for Every Application 10x 5x 0x CPU Tesla K40 Tesla K80 Oil & HPC Gas Viz Data Analytics Caffe Benchmark: AlexNet training throughput based on 20 iterations, CPU: 2.70GHz. 64GB System Memory, CentOS
33 FOCUS ON THROUGHPUT PERFORMANCE Peak Double Precision FLOPS Peak Memory Bandwidth GFLOPS 3500 GB/s K K K K M1060 K20 M2090 Ivy Bridge Sandy Bridge Westmere Haswell M1060 K20 M2090 Sandy Bridge Westmere Haswell Ivy Bridge NVIDIA GPU x86 CPU NVIDIA GPU x86 CPU 33

34 10X FASTER THAN CPU ON APPLICATIONS 15x 10x K80 CPU 5x 0x Benchmarks Molecular Dynamics Quantum Chemistry Physics CPU: 12 cores, 2.70GHz. 64GB System Memory, CentOS 6.2 GPU: Single Tesla K80, Boost enabled 34
35 TESLA PLATFORM ENABLES OPTIMIZATION Ecosystem Industry Standard CPUs and Interconnects ARM64 POWER x86 Ethernet Cray NVIDIA GPU InfiniBand Others Industry-Driven Solutions 35




36 LOGICAL VS. PHYSICAL INTEGRATION OPTIMIZING FOR EFFICIENCY + FLEXIBILITY CPU GPU Latency- Optimized Throughput- Optimized System Memory GPU Memory NVLink 36

37 UNIFIED MEMORY DRAMATICALLY LOWER DEVELOPER EFFORT Exposed Developer View (Pre-CUDA 5.5) Developer View With Unified Memory System Memory GPU Memory Unified Memory 37



38 NVLINK: NODE INTEGRATION NETWORK TESLA GPU NVLink 80 GB/s Power or ARM CPU 5x PCIe bandwidth Move data at CPU memory speed 3x lower energy/bit HBM 1 Terabyte/s Stacked Memory Throughput Optimized DDR GB/s DDR Memory Latency Optimized
39 KEPLER GPU PASCAL GPU NVLink NVLINK HIGH-SPEED NODE NETWORK POWER CPU NVLink PCIe PCIe X86 ARM64 POWER CPU 2014 X86 ARM64 POWER CPU 2016

40 NVLINK MULTI-GPU PERFORMANCE GPUs Interconnected with NVLink CPU 2.00x Over 2x Application Performance Speedup When Next-Gen GPUs Connect via NVLink Versus PCIe Speedup vs PCIe based Server 2.25x PCIe Switch 1.75x TESLA GPU TESLA GPU 1.50x 1.25x 5x Faster than PCIe Gen3 x x ANSYS Fluent Multi-GPU Sort LQCD QUDA AMBER 3D FFT 3D FFT, ANSYS: 2 GPU configuration, All other apps comparing 4 GPU 40 configuration AMBER Cellulose (256x128x128), FFT problem size (256^3)



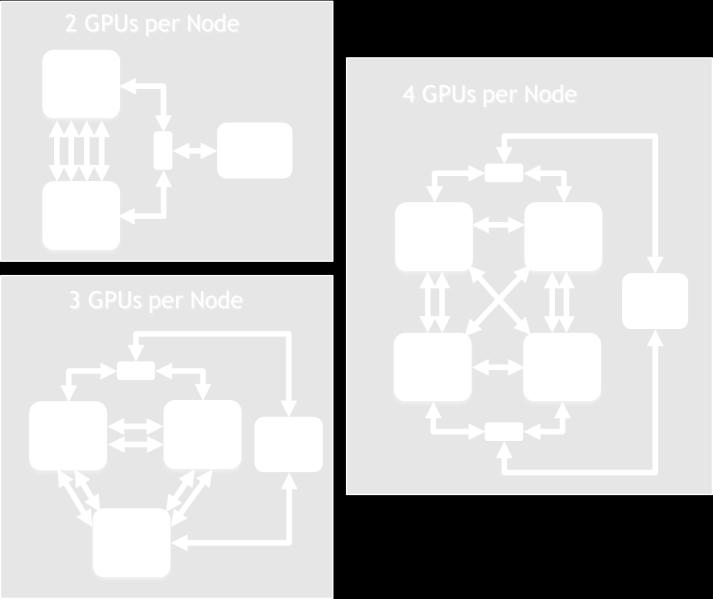

41 TESLA PLATFORM ENABLES OPTIMIZATION Scalable Nodes, ISA Choice NVLink x86 41


42 NVLINK-ENABLED HETEROGENEOUS NODE LOGICAL INTEGRATION + FLEXIBILITY + EFFICIENCY GB/s IBM POWER CPU Most Powerful Serial Processor NVIDIA NVLink Node Integration Interconnect NVIDIA Volta GPU Most Powerful Parallel Processor

 All directly")

43 CORAL SCALABLE HETEROGENEOUS NODE NVLink In Practice Approximately 3,400 nodes, each with: IBM POWER9 CPUs and multiple NVIDIA Tesla Volta GPUs CPUs and GPUs integrated on-node with high speed NVLink Large coherent memory: over 512 GB (HBM + DDR4) All directly addressable from the CPUs and GPUs An additional 800 GB of NVRAM, burst buffer or as extended memory Over 40 TF peak performance/node(!) 43


44 OPTIMIZED HETEROGENEOUS NODE CORAL Application Performance Projections 44
45 SUMMARY: Heterogeneous acceleration is powerful and efficient Latency-optimized cores for serial and system work Throughput-optimized cores for on-node parallel work High-performance integration NVLink provides a compelling node integration advantage Flexible configuration of resources in application-driven proportions Scalable performance into the future CORAL is awesome, you can buy nodes just like it. OpenPower is surprisingly affordable. It s just one example of optimized architecture for an application set and budget.
46 NVIDIA REGISTERED DEVELOPER PROGRAMS Everything you need to develop with NVIDIA products Membership is your first step in establishing a working relationship with NVIDIA Engineering Exclusive access to pre-releases Submit bugs and features requests Stay informed about latest releases and training opportunities Access to exclusive downloads Exclusive activities and special offers Interact with other developers in the NVIDIA Developer Forums REGISTER FOR FREE AT: developer.nvidia.com
47 THANK YOU
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester
 NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA ACCELERATED COMPUTING. Mike Wang Solutions Architect NVIDIA Australia & NZ
 TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
TESLA V100 PERFORMANCE GUIDE May 2018
 TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
19. prosince 2018 CIIRC Praha. Milan Král, IBM Radek Špimr
 19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA
 EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY. Peter Messmer
 NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
RECENT UPDATES ON ACCELERATING COMPUTING PLATFORM PRADEEP GUPTA SENIOR SOLUTIONS ARCHITECT, NVIDIA
 RECENT UPDATES ON ACCELERATING COMPUTING PLATFORM PRADEEP GUPTA SENIOR SOLUTIONS ARCHITECT, NVIDIA GAMING AUTO ENTERPRISE HPC & CLOUD OEM & IP THE WORLD LEADER IN VISUAL COMPUTING 2 # of GPU Developers
RECENT UPDATES ON ACCELERATING COMPUTING PLATFORM PRADEEP GUPTA SENIOR SOLUTIONS ARCHITECT, NVIDIA GAMING AUTO ENTERPRISE HPC & CLOUD OEM & IP THE WORLD LEADER IN VISUAL COMPUTING 2 # of GPU Developers
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
April 4-7, 2016 Silicon Valley INSIDE PASCAL. Mark Harris, October 27,
 April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
Exploring Emerging Technologies in the Extreme Scale HPC Co- Design Space with Aspen
 Exploring Emerging Technologies in the Extreme Scale HPC Co- Design Space with Aspen Jeffrey S. Vetter SPPEXA Symposium Munich 26 Jan 2016 ORNL is managed by UT-Battelle for the US Department of Energy
Exploring Emerging Technologies in the Extreme Scale HPC Co- Design Space with Aspen Jeffrey S. Vetter SPPEXA Symposium Munich 26 Jan 2016 ORNL is managed by UT-Battelle for the US Department of Energy
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
GPUS FOR NGVLA. M Clark, April 2015
 S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
Technologies and application performance. Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017
 Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Bigger GPUs and Bigger Nodes. Carl Pearson PhD Candidate, advised by Professor Wen-Mei Hwu
 Bigger GPUs and Bigger Nodes Carl Pearson (pearson@illinois.edu) PhD Candidate, advised by Professor Wen-Mei Hwu 1 Outline Experiences from working with domain experts to develop GPU codes on Blue Waters
Bigger GPUs and Bigger Nodes Carl Pearson (pearson@illinois.edu) PhD Candidate, advised by Professor Wen-Mei Hwu 1 Outline Experiences from working with domain experts to develop GPU codes on Blue Waters
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
HPC Architectures past,present and emerging trends
 HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
HPC Architectures past,present and emerging trends Andrew Emerson, Cineca a.emerson@cineca.it 27/09/2016 High Performance Molecular 1 Dynamics - HPC architectures Agenda Computational Science Trends in
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Present and Future Leadership Computers at OLCF
 Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
ACCELERATED COMPUTING: THE PATH FORWARD. Jensen Huang, Founder & CEO SC17 Nov. 13, 2017
 ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC and hyperscale customers deploy accelerated
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC and hyperscale customers deploy accelerated
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE
 Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Composite Metrics for System Throughput in HPC
 Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
European energy efficient supercomputer project
 http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MARCH 17 TH, MIC Workshop PAGE 1. MIC workshop Guillaume Colin de Verdière
 EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
EXASCALE COMPUTING ROADMAP IMPACT ON LEGACY CODES MIC workshop Guillaume Colin de Verdière MARCH 17 TH, 2015 MIC Workshop PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France March 17th, 2015 Overview Context
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
IBM HPC Technology & Strategy
 IBM HPC Technology & Strategy Hyperion HPC User Forum Stuttgart, October 1st, 2018 The World s Smartest Supercomputers Klaus Gottschalk gottschalk@de.ibm.com HPC Strategy Deliver End to End Solutions for
IBM HPC Technology & Strategy Hyperion HPC User Forum Stuttgart, October 1st, 2018 The World s Smartest Supercomputers Klaus Gottschalk gottschalk@de.ibm.com HPC Strategy Deliver End to End Solutions for
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
HPC Cineca Infrastructure: State of the art and towards the exascale
 HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
HPC Enabling R&D at Philip Morris International
 HPC Enabling R&D at Philip Morris International Jim Geuther*, Filipe Bonjour, Bruce O Neel, Didier Bouttefeux, Sylvain Gubian, Stephane Cano, and Brian Suomela * Philip Morris International IT Service
HPC Enabling R&D at Philip Morris International Jim Geuther*, Filipe Bonjour, Bruce O Neel, Didier Bouttefeux, Sylvain Gubian, Stephane Cano, and Brian Suomela * Philip Morris International IT Service
A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers
 A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers Maxime Martinasso, Grzegorz Kwasniewski, Sadaf R. Alam, Thomas C. Schulthess, Torsten Hoefler Swiss National Supercomputing
A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers Maxime Martinasso, Grzegorz Kwasniewski, Sadaf R. Alam, Thomas C. Schulthess, Torsten Hoefler Swiss National Supercomputing
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE
 MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Introduction to High Performance Computing. Shaohao Chen Research Computing Services (RCS) Boston University
 Boston University") Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
The Road to ExaScale. Advances in High-Performance Interconnect Infrastructure. September 2011
 The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures
 IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures A Future Accelerated Cognitive Distributed Hybrid Testbed for Big Data Science Analytics Milton Halem 1, John Edward
IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures A Future Accelerated Cognitive Distributed Hybrid Testbed for Big Data Science Analytics Milton Halem 1, John Edward
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI
 MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER. Markus Weber and Haiduong Vo
 DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
The Tesla Accelerated Computing Platform
 The Tesla Accelerated Computing Platform Axel Koehler, Principal Solution Architect HPC Advisory Council Meeting Lugano 22 March 2016 Introduction TESLA Platform for HPC Agenda TESLA Platform for HYPERSCALE
The Tesla Accelerated Computing Platform Axel Koehler, Principal Solution Architect HPC Advisory Council Meeting Lugano 22 March 2016 Introduction TESLA Platform for HPC Agenda TESLA Platform for HYPERSCALE
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA GPUS
 SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, basic tasks, data types 3 Introduction to D3, basic vis
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, basic tasks, data types 3 Introduction to D3, basic vis techniques for non-spatial data Project #1 out 4 Data
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, basic tasks, data types 3 Introduction to D3, basic vis techniques for non-spatial data Project #1 out 4 Data