Introduc)on to Hyades
|
|
|
- Arleen Lloyd
- 6 years ago
- Views:
Transcription
1 Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC
2 Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on and Analysis 7 Q&A

3
4 Hardware Summary Component QTY Descrip1on Master Node 1 PowerEdge R820, 4x 8- core Intel Xeon E5-4620, 128GB of memory, 8x 1TB HDD Analysis Node 1 PowerEdge R820, 4x 8- core Intel Xeon E5-4640, 512GB of memory, 2x 600GB SSD Type I Compute Nodes 180 PowerEdge R620, 2x 8- core Intel Xeon E5-2650, 64GB of memory, 1TB HDD Type IIa Compute Nodes 8 PowerEdge C8220x, 2x 8- core Intel Xeon E5-2650, 64GB of memory, 2x 500GB HDD, 1x Nvidia K20 Type IIb Compute Node 1 PowerEdge R720, 2x 6- core Intel Xeon E5-2630L, 64GB of memory, 500GB HDD, 2x Xeon Phi 5110P Lustre Scratch Storage 1 Dell/Terascala solu)on, 146TB of usable storage. Huawei UDS Storage 1 1PB private cloud storage InfiniBand Mellanox QDR (40 Gb/s) non- blocking Infiniband solu)on
 128 GB memory 8x 1TB HDD in RAID- 6 o hyades.ucsc.")
5 Master Node Dell PowerEdge R820 4x Intel Xeon E (8- core, 2.2GHz) 128 GB memory 8x 1TB HDD in RAID- 6 o hyades.ucsc.edu o plumbing for the cluster o Compile and debug codes o Submit & monitor jobs, etc
6 Analysis Node Dell PowerEdge R820 4x Intel Xeon E (8- core, 2.4GHz) 512 GB memory (16GB/core)! 2x 600GB SSD in RAID- 0 o eudora.ucsc.edu o Visualiza)on/analysis & big- memory jobs
7 Type I Compute Nodes Dell PowerEdge R620 2x Intel Xeon E (8- core, 2.0GHz) 64GB memory (4GB/core, 1.6GHz RDIMMs) 1TB HDD 180 nodes
 64GB memory (4GB/core, 1.")
8 Type IIa Compute Nodes Dell PowerEdge C8220x 2x Intel Xeon E (8- core, 2.0GHz) 64GB memory (4GB/core, 1.6GHz RDIMMs) 2x 500GB HDDs 1x Nvidia Tesla K20 GPU accelerator 8 nodes
 64GB memory (5.3 GB/core, 1.")
9 Type IIb Compute Node Dell PowerEdge R720 2x Intel Xeon E (6- core, 2.0GHz) 64GB memory (5.3 GB/core, 1.6GHz RDIMMs) 500GB SAS HDD 1x Intel Xeon Phi 5110P coprocessor
10 Intel Sandy Bridge Xeon E cores / 16 threads 2GH / 2.8GHz max Turbo 20MB shared Level 3 cache 8x 256KB Level 2 cache 8x 64KB (32+32) Level 1 cache 2 QPI 8 GT/s 8 x 20/8 x 64/80 = 16 GB/s 51.2 GB/s memory 1.6 (GT/s) x 8 (Byte) x 4 (channels) = 51.2 GB/s AVX (Advanced Vector Extensions) 256- bit, 8 double- precision FLOP per cycle SSE è SSE2 è SSE3 è SSSE3 è SSE4 è AVX
 x 832 (DP units) x 2 (FMA) Single precision performance: 4.577 TFLOPS = 0.705 (GHz) x 2496 (CUDA cores) x 2 (FMA) Memory: 5.2GHz, 320- bit wide, 5GB GDDR5 5.")
11 Nvdia Tesla K20 Kepler GPU 2496 CUDA cores / 832 DP units / 13 SMX Core speed: 705 MHz Double precision performance: TFLOPS = (GHz) x 832 (DP units) x 2 (FMA) Single precision performance: TFLOPS = (GHz) x 2496 (CUDA cores) x 2 (FMA) Memory: 5.2GHz, 320- bit wide, 5GB GDDR5 5.2 (GHz) x 320 / 8 = 208 GB/s PCI express 2.0 x (MB/s) x 8/10 x 16 = 8 GB/s (16 GB/s duplex)
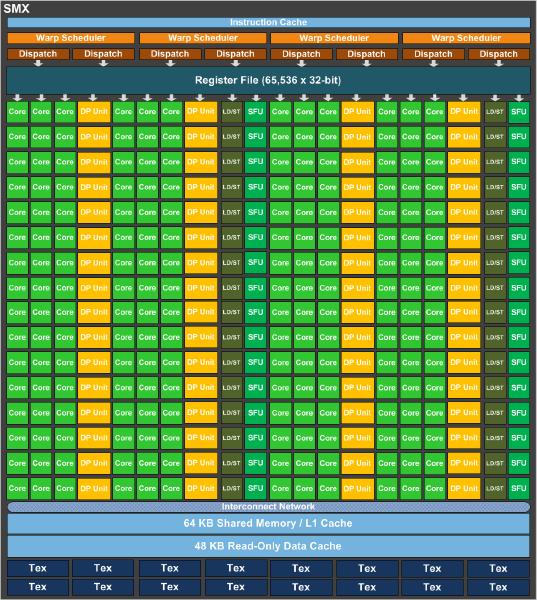
12
 x 60 (cores) x 512/64 x 2 (FMA) Memory: 8GB GDDR5 5 (GT/s) x 16 (channels) x 4 (B) = 320 GB/s PCI express 2.")
13 Intel Xeon Phi 5110P 60 cores (in- order, dual- issue x86 design) 4 threads per core Core speed: GHz 512- bit AVX Double precision performance: 1.01 TFLOPS = (GHz) x 60 (cores) x 512/64 x 2 (FMA) Memory: 8GB GDDR5 5 (GT/s) x 16 (channels) x 4 (B) = 320 GB/s PCI express 2.0 x (MB/s) x 8/10 x 16 = 8 GB/s (16 GB/s duplex)


14 hqp:// phi- larrabee- stampede- hpc, html
15 Key to performance: vectoriza)on Peak performance of Intel Xeon E = 8 (AVX) x 8 (cores) x 2.0 (GHz) = 128 GFLOPS Peak Performance of all Intel Xeon E5-2650s = 128 GFLOPS x 2 x 188 (nodes) = 48 TFLOPS Peak Performance of Nvidia K20 Peak Performance of Xeon Phi 5110P = 1.17 TFLOPS = 1.01 TFLOPS Total Peak Performance of Hyades = x = 58 TFLOPS

16 Key to performance: Data Locality / Communica)on Avoidance Bandwidth Ra1o Intel Xeon E x 4 x 2 x 8 = 8192 GB/s 1 Memory 51.2 GB/s 160 QPI 16 GB/s 512 PCIe 2.0 x16 8 GB/s 1024 QDR InfiniBand 4 GB/s 2048 SSD 500 MB/s HDD 100 MB/s 10000
17 Applica)ons Massively parallel jobs Pure MPI jobs Hybrid (MPI + OpenMP) jobs Mul)threaded jobs Embarrassingly parallel jobs Serial jobs Visualiza)on / Analysis Big data jobs Hadoop GPU compu)ng MIC compu)ng
18 Accessing Hyades Only SSH access is allowed! Master Node (hyades.ucsc.edu): ssh - l username hyades.ucsc.edu ssh username@hyades.ucsc.edu Analysis Node (eudora.ucsc.edu): ssh - l username eudora.ucsc.edu ssh username@eudora.ucsc.edu
19 Using SSH key for authen)ca)on Generate authen)ca)on key on your client computer: cd $HOME/.ssh ssh- keygen - b t rsa - f hyades Once the public key (hyades.pub) is uploaded to Hyades ssh - i ~/.ssh/hyades - l username hyades.ucsc.edu Add the following to $HOME/.ssh/config host h HostName hyades.ucsc.edu User username Iden)tyFile ~/.ssh/hyades Then a lot of keystrokes will be saved: ssh h
20 Compu)ng Environment 2 storage spaces are mounted on every node User home directories Ø NFS Ø /home/username Ø 3.6 TB total capacity Ø For source codes and scripts User work directories Ø Lustre file system Ø /pfs/username & symbolic link $HOME/pfs Ø 146 TB total capacity Ø For running simula)ons
21 Modules We use the Modules u)lity to manage souware environment To list the loaded modules: module list To list the available modules: module avail To load a module (e.g., python 2.7) module load python/2.7 To switch modules (e.g., to use a different MPI implementa)on): module switch intel_mpi/ rocks- openmpi_ib_intel To learn about a module (e.g., IDL) module help IDL module display IDL
22 Compilers Intel (default and recommended) PGI GNU
23 MPI Implementa)ons Intel MPI (default and recommended) Open MPI Mvapich Mpich
24 Compiling serial codes C icc [compiler_op)ons] hello.c C++ icpc [compiler_op)ons] hello.cpp Fortran ifort [compiler_op)ons] hello.f ifort [compiler_op)ons] hello.f90 Please consult Hyades wiki for Intel Compiler op)ons.
25 Compiling OpenMP codes C icc - openmp - o omp_hello.x omp_hello.c C++ icpc - openmp - o omp_hello.x omp_hello.cpp Fortran ifort - openmp - o omp_hello.x omp_hello.f ifort - openmp - o omp_hello.x omp_hello.f90
26 Compiling pure MPI codes C mpiicc - o mpi_hello.x mpi_hello.c C++ mpiicpc - o mpi_hello.x mpi_hello.cpp Fortran mpiifort - o mpi_hello.x mpi_hello.f mpiifort - o mpi_hello.x mpi_hello.f90
27 Compiling hybrid (MPI + OpenMP) codes C mpiicc - mt_mpi - openmp - o mpi_hello.x mpi_hello.c C++ mpiicpc - mt_mpi - openmp - o mpi_hello.x mpi_hello.cpp Fortran mpiifort - mt_mpi - openmp - o mpi_hello.x mpi_hello.f mpiifort - mt_mpi - openmp - o mpi_hello.x mpi_hello.f90
28 Running jobs Torque/PBS is the queuing system on Hyades Torque u)li)es Ø qsub ### job submission Ø qstat ### monitoring status of jobs Ø qdel ### termina)ng jobs prior to comple)on Maui is the job scheduler Maui u)li)es Ø showq ### list both ac)ve and idle jobs Ø showbf ### show what resources are immediately available Ø checkjob ### view details of a job in the queue
29 Queues on Hyades normal (default) queue Ø 16 cores per node (hyper- threading disabled) Ø 120 nodes Ø - q normal Ø - l nodes=4:ppn=16 hyper queue Ø 32 cores per node (hyper- threading enabled) Ø 60 nodes Ø - q hyper Ø - l nodes=2:ppn=32
30 Sample PBS script for MPI jobs #PBS - S /bin/bash #PBS - N hello #PBS - q normal #PBS - l nodes=4:ppn=16 #PBS - l wall)me=4:00:00 #PBS - M shaw@ucsc.edu #PBS - m abe cd $PBS_O_WORKDIR ### shell ### job name ### queue name ### 64 cores ### 4 hours wall)me ### ask Torque to send s when job aborts, starts and ends mpirun - n 64 - env I_MPI_FABRICS shm:ofa./mpi_hello.x qsub mpi.pbs
31 Sample PBS script for OpenMP jobs #PBS - S /bin/bash #PBS - N hello #PBS - q normal #PBS - l nodes=1:ppn=16 #PBS - l wall)me=4:00:00 #PBS - M shaw@ucsc.edu #PBS - m abe cd $PBS_O_WORKDIR export OMP_NUM_THREADS=16./omp_hello.x ### shell ### job name ### queue name or #PBS - l ncpus=16 ### 4 hours wall)me ### ask Torque to send s when job aborts, starts and ends qsub mpi.pbs
32 Sample PBS script for hybrid jobs #PBS - S /bin/bash #PBS - N hybrid #PBS - q normal #PBS - l nodes=4:ppn=16 #PBS - l wall)me=4:00:00 #PBS - M shaw@ucsc.edu #PBS - m abe ### shell ### job name ### queue name ### 64 cores ### 4 hours wall)me ### ask Torque to send s when job aborts, starts and ends cd $PBS_O_WORKDIR export OMP_NUM_THREADS=8 export I_MPI_PIN_DOMAIN=omp export KMP_AFFINITY=compact mpirun - env I_MPI_FABRICS shm:ofa - n 8 - ppn 2./hybrid.x qsub mpi.pbs
33 Sample PBS script for serial jobs #PBS - S /bin/bash #PBS - N hello #PBS - q normal #PBS l ncpus=1 #PBS - l wall)me=4:00:00 #PBS - M shaw@ucsc.edu #PBS - m abe cd $PBS_O_WORKDIR./hello.x ### shell ### job name ### queue name ### only 1 core ### 4 hours wall)me ### ask Torque to send s when job aborts, starts and ends qsub serial.pbs
34 Sample script for embarrassingly parallel jobs #PBS - S /bin/bash #PBS - N jobarray #PBS - q normal #PBS - l ncpus=1 #PBS - t 0-31 #PBS - j oe #PBS - l wall)me=4:00:00./hello.x 0./hello.x 1./hello.x 31 cd $PBS_O_WORKDIR./hello.x $PBS_ARRAYID qsub jobarray.pbs
35 Visualiza)on & Analysis Eudora is the dedicated viz node ssh - Y - i ~/.ssh/hyades - l username eudora.ucsc.edu Add the following to $HOME/.ssh/config host e HostName eudora.ucsc.edu User username Iden)tyFile ~/.ssh/hyades ForwardX11 yes ForwardX11Trusted yes Then a lot of keystrokes will be saved: ssh e
36 Viz tools VisIt Yt IDL module load VisIt module load yt module load IDL Python (matplotlib, SciPy, mpi4py, etc) module load python
37 Q&A Wiki: hqp://pleiades.ucsc.edu/hyades/
Cluster Clonetroop: HowTo 2014
 2014/02/25 16:53 1/13 Cluster Clonetroop: HowTo 2014 Cluster Clonetroop: HowTo 2014 This section contains information about how to access, compile and execute jobs on Clonetroop, Laboratori de Càlcul Numeric's
2014/02/25 16:53 1/13 Cluster Clonetroop: HowTo 2014 Cluster Clonetroop: HowTo 2014 This section contains information about how to access, compile and execute jobs on Clonetroop, Laboratori de Càlcul Numeric's
Introduction to GALILEO
 November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1
![Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1](/thumbs/87/95383144.jpg "Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1") Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de
Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Introduction to PICO Parallel & Production Enviroment
 Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Computing with the Moore Cluster
 Computing with the Moore Cluster Edward Walter An overview of data management and job processing in the Moore compute cluster. Overview Getting access to the cluster Data management Submitting jobs (MPI
Computing with the Moore Cluster Edward Walter An overview of data management and job processing in the Moore compute cluster. Overview Getting access to the cluster Data management Submitting jobs (MPI
SCALABLE HYBRID PROTOTYPE
 SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
Genius Quick Start Guide
 Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
UAntwerpen, 24 June 2016
 Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
Introduction to CINECA HPC Environment
 Introduction to CINECA HPC Environment 23nd Summer School on Parallel Computing 19-30 May 2014 m.cestari@cineca.it, i.baccarelli@cineca.it Goals You will learn: The basic overview of CINECA HPC systems
Introduction to CINECA HPC Environment 23nd Summer School on Parallel Computing 19-30 May 2014 m.cestari@cineca.it, i.baccarelli@cineca.it Goals You will learn: The basic overview of CINECA HPC systems
OBTAINING AN ACCOUNT:
 HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat
 Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Introduc)on to Pacman
on to Pacman") Introduc)on to Pacman Don Bahls User Consultant dmbahls@alaska.edu (Significant Slide Content from Tom Logan) Overview Connec)ng to Pacman Hardware Programming Environment Compilers Queuing System Interac)ve
Introduc)on to Pacman Don Bahls User Consultant dmbahls@alaska.edu (Significant Slide Content from Tom Logan) Overview Connec)ng to Pacman Hardware Programming Environment Compilers Queuing System Interac)ve
Leibniz Supercomputer Centre. Movie on YouTube
 SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Introduction to High Performance Computing (HPC) Resources at GACRC
 Resources at GACRC") Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
Effective Use of CCV Resources
 Effective Use of CCV Resources Mark Howison User Services & Support This talk... Assumes you have some familiarity with a Unix shell Provides examples and best practices for typical usage of CCV systems
Effective Use of CCV Resources Mark Howison User Services & Support This talk... Assumes you have some familiarity with a Unix shell Provides examples and best practices for typical usage of CCV systems
User Guide of High Performance Computing Cluster in School of Physics
 User Guide of High Performance Computing Cluster in School of Physics Prepared by Sue Yang (xue.yang@sydney.edu.au) This document aims at helping users to quickly log into the cluster, set up the software
User Guide of High Performance Computing Cluster in School of Physics Prepared by Sue Yang (xue.yang@sydney.edu.au) This document aims at helping users to quickly log into the cluster, set up the software
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Introduction to HPC Using the New Cluster at GACRC
 Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide
 - Linux Getting Started Guide") Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide Introduction What are the intended uses of the MTL? The MTL is prioritized for supporting the Intel Academic Community for the testing, validation
Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide Introduction What are the intended uses of the MTL? The MTL is prioritized for supporting the Intel Academic Community for the testing, validation
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Introduction to HPC Using the New Cluster at GACRC
 Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
GPU Computing with Fornax. Dr. Christopher Harris
 GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
Practical Introduction to
 1 2 Outline of the workshop Practical Introduction to What is ScaleMP? When do we need it? How do we run codes on the ScaleMP node on the ScaleMP Guillimin cluster? How to run programs efficiently on ScaleMP?
1 2 Outline of the workshop Practical Introduction to What is ScaleMP? When do we need it? How do we run codes on the ScaleMP node on the ScaleMP Guillimin cluster? How to run programs efficiently on ScaleMP?
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC On-class STAT8330 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 Outline What
Introduction to HPC Using zcluster at GACRC On-class STAT8330 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 Outline What
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
High Performance Computing (HPC) Using zcluster at GACRC
 Using zcluster at GACRC") High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?
High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?
Intel MIC Programming Workshop, Hardware Overview & Native Execution. Ostrava,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution Ostrava, 7-8.2.2017 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution Ostrava, 7-8.2.2017 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Transitioning to Leibniz and CentOS 7
 Transitioning to Leibniz and CentOS 7 Fall 2017 Overview Introduction: some important hardware properties of leibniz Working on leibniz: Logging on to the cluster Selecting software: toolchains Activating
Transitioning to Leibniz and CentOS 7 Fall 2017 Overview Introduction: some important hardware properties of leibniz Working on leibniz: Logging on to the cluster Selecting software: toolchains Activating
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
How to run applications on Aziz supercomputer. Mohammad Rafi System Administrator Fujitsu Technology Solutions
 How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
Introduction to HPC Numerical libraries on FERMI and PLX
 Introduction to HPC Numerical libraries on FERMI and PLX HPC Numerical Libraries 11-12-13 March 2013 a.marani@cineca.it WELCOME!! The goal of this course is to show you how to get advantage of some of
Introduction to HPC Numerical libraries on FERMI and PLX HPC Numerical Libraries 11-12-13 March 2013 a.marani@cineca.it WELCOME!! The goal of this course is to show you how to get advantage of some of
Introduction to CINECA Computer Environment
 Introduction to CINECA Computer Environment Today you will learn... Basic commands for UNIX environment @ CINECA How to submitt your job to the PBS queueing system on Eurora Tutorial #1: Example: launch
Introduction to CINECA Computer Environment Today you will learn... Basic commands for UNIX environment @ CINECA How to submitt your job to the PBS queueing system on Eurora Tutorial #1: Example: launch
Introduction to Unix Environment: modules, job scripts, PBS. N. Spallanzani (CINECA)
") Introduction to Unix Environment: modules, job scripts, PBS N. Spallanzani (CINECA) Bologna PATC 2016 In this tutorial you will learn... How to get familiar with UNIX environment @ CINECA How to submit
Introduction to Unix Environment: modules, job scripts, PBS N. Spallanzani (CINECA) Bologna PATC 2016 In this tutorial you will learn... How to get familiar with UNIX environment @ CINECA How to submit
The JANUS Computing Environment
 Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Agenda
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
High Performance Compu2ng Using Sapelo Cluster
 High Performance Compu2ng Using Sapelo Cluster Georgia Advanced Compu2ng Resource Center EITS/UGA Zhuofei Hou, Training Advisor zhuofei@uga.edu 1 Outline GACRC What is High Performance Compu2ng (HPC) Sapelo
High Performance Compu2ng Using Sapelo Cluster Georgia Advanced Compu2ng Resource Center EITS/UGA Zhuofei Hou, Training Advisor zhuofei@uga.edu 1 Outline GACRC What is High Performance Compu2ng (HPC) Sapelo
Parallel Computing at DESY Zeuthen. Introduction to Parallel Computing at DESY Zeuthen and the new cluster machines
 Parallel Computing at DESY Zeuthen. Introduction to Parallel Computing at DESY Zeuthen and the new cluster machines Götz Waschk Technical Seminar, Zeuthen April 27, 2010 > Introduction > Hardware Infiniband
Parallel Computing at DESY Zeuthen. Introduction to Parallel Computing at DESY Zeuthen and the new cluster machines Götz Waschk Technical Seminar, Zeuthen April 27, 2010 > Introduction > Hardware Infiniband
Cerebro Quick Start Guide
 Cerebro Quick Start Guide Overview of the system Cerebro consists of a total of 64 Ivy Bridge processors E5-4650 v2 with 10 cores each, 14 TB of memory and 24 TB of local disk. Table 1 shows the hardware
Cerebro Quick Start Guide Overview of the system Cerebro consists of a total of 64 Ivy Bridge processors E5-4650 v2 with 10 cores each, 14 TB of memory and 24 TB of local disk. Table 1 shows the hardware
SuperMike-II Launch Workshop. System Overview and Allocations
 : System Overview and Allocations Dr Jim Lupo CCT Computational Enablement jalupo@cct.lsu.edu SuperMike-II: Serious Heterogeneous Computing Power System Hardware SuperMike provides 442 nodes, 221TB of
: System Overview and Allocations Dr Jim Lupo CCT Computational Enablement jalupo@cct.lsu.edu SuperMike-II: Serious Heterogeneous Computing Power System Hardware SuperMike provides 442 nodes, 221TB of
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Knights Landing production environment on MARCONI
 Knights Landing production environment on MARCONI Alessandro Marani - a.marani@cineca.it March 20th, 2017 Agenda In this presentation, we will discuss - How we interact with KNL environment on MARCONI
Knights Landing production environment on MARCONI Alessandro Marani - a.marani@cineca.it March 20th, 2017 Agenda In this presentation, we will discuss - How we interact with KNL environment on MARCONI
Using Sapelo2 Cluster at the GACRC
 Using Sapelo2 Cluster at the GACRC New User Training Workshop Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Sapelo2 Cluster Diagram
Using Sapelo2 Cluster at the GACRC New User Training Workshop Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Sapelo2 Cluster Diagram
Answers to Federal Reserve Questions. Training for University of Richmond
 Answers to Federal Reserve Questions Training for University of Richmond 2 Agenda Cluster Overview Software Modules PBS/Torque Ganglia ACT Utils 3 Cluster overview Systems switch ipmi switch 1x head node
Answers to Federal Reserve Questions Training for University of Richmond 2 Agenda Cluster Overview Software Modules PBS/Torque Ganglia ACT Utils 3 Cluster overview Systems switch ipmi switch 1x head node
HPC DOCUMENTATION. 3. Node Names and IP addresses:- Node details with respect to their individual IP addresses are given below:-
 HPC DOCUMENTATION 1. Hardware Resource :- Our HPC consists of Blade chassis with 5 blade servers and one GPU rack server. a.total available cores for computing: - 96 cores. b.cores reserved and dedicated
HPC DOCUMENTATION 1. Hardware Resource :- Our HPC consists of Blade chassis with 5 blade servers and one GPU rack server. a.total available cores for computing: - 96 cores. b.cores reserved and dedicated
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Working on the NewRiver Cluster
 Working on the NewRiver Cluster CMDA3634: Computer Science Foundations for Computational Modeling and Data Analytics 22 February 2018 NewRiver is a computing cluster provided by Virginia Tech s Advanced
Working on the NewRiver Cluster CMDA3634: Computer Science Foundations for Computational Modeling and Data Analytics 22 February 2018 NewRiver is a computing cluster provided by Virginia Tech s Advanced
Introduction to HPC Using zcluster at GACRC On-Class GENE 4220
 Introduction to HPC Using zcluster at GACRC On-Class GENE 4220 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 OVERVIEW GACRC
Introduction to HPC Using zcluster at GACRC On-Class GENE 4220 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 OVERVIEW GACRC
Ambiente CINECA: moduli, job scripts, PBS. A. Grottesi (CINECA)
") Ambiente HPC @ CINECA: moduli, job scripts, PBS A. Grottesi (CINECA) Bologna 2017 In this tutorial you will learn... How to get familiar with UNIX environment @ CINECA How to submit your job to the PBS
Ambiente HPC @ CINECA: moduli, job scripts, PBS A. Grottesi (CINECA) Bologna 2017 In this tutorial you will learn... How to get familiar with UNIX environment @ CINECA How to submit your job to the PBS
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Getting started with the CEES Grid
 Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
Introduction to HPCC at MSU
 Introduction to HPCC at MSU Chun-Min Chang Research Consultant Institute for Cyber-Enabled Research Download this presentation: https://wiki.hpcc.msu.edu/display/teac/2016-03-17+introduction+to+hpcc How
Introduction to HPCC at MSU Chun-Min Chang Research Consultant Institute for Cyber-Enabled Research Download this presentation: https://wiki.hpcc.msu.edu/display/teac/2016-03-17+introduction+to+hpcc How
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Genius - introduction
 Genius - introduction HPC team ICTS, Leuven 5th June 2018 VSC HPC environment GENIUS 2 IB QDR IB QDR IB EDR IB EDR Ethernet IB IB QDR IB FDR Numalink6 /IB FDR IB IB EDR ThinKing Cerebro Accelerators Genius
Genius - introduction HPC team ICTS, Leuven 5th June 2018 VSC HPC environment GENIUS 2 IB QDR IB QDR IB EDR IB EDR Ethernet IB IB QDR IB FDR Numalink6 /IB FDR IB IB EDR ThinKing Cerebro Accelerators Genius
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System
 (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System") INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
PACE. Instructional Cluster Environment (ICE) Orientation. Research Scientist, PACE
 Orientation. Research Scientist, PACE") PACE Instructional Cluster Environment (ICE) Orientation Mehmet (Memo) Belgin, PhD Research Scientist, PACE www.pace.gatech.edu What is PACE A Partnership for an Advanced Computing Environment Provides
PACE Instructional Cluster Environment (ICE) Orientation Mehmet (Memo) Belgin, PhD Research Scientist, PACE www.pace.gatech.edu What is PACE A Partnership for an Advanced Computing Environment Provides
Genius - introduction
 Genius - introduction HPC team ICTS, Leuven 13th June 2018 VSC HPC environment GENIUS 2 IB QDR IB QDR IB EDR IB EDR Ethernet IB IB QDR IB FDR Numalink6 /IB FDR IB IB EDR ThinKing Cerebro Accelerators Genius
Genius - introduction HPC team ICTS, Leuven 13th June 2018 VSC HPC environment GENIUS 2 IB QDR IB QDR IB EDR IB EDR Ethernet IB IB QDR IB FDR Numalink6 /IB FDR IB IB EDR ThinKing Cerebro Accelerators Genius
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Running Jobs, Submission Scripts, Modules
 9/17/15 Running Jobs, Submission Scripts, Modules 16,384 cores total of about 21,000 cores today Infiniband interconnect >3PB fast, high-availability, storage GPGPUs Large memory nodes (512GB to 1TB of
9/17/15 Running Jobs, Submission Scripts, Modules 16,384 cores total of about 21,000 cores today Infiniband interconnect >3PB fast, high-availability, storage GPGPUs Large memory nodes (512GB to 1TB of
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction to NCAR HPC. 25 May 2017 Consulting Services Group Brian Vanderwende
 Introduction to NCAR HPC 25 May 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical overview of our HPC systems The NCAR computing environment Accessing software on Cheyenne
Introduction to NCAR HPC 25 May 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical overview of our HPC systems The NCAR computing environment Accessing software on Cheyenne
PACE. Instructional Cluster Environment (ICE) Orientation. Mehmet (Memo) Belgin, PhD Research Scientist, PACE
 Orientation. Mehmet (Memo) Belgin, PhD Research Scientist, PACE") PACE Instructional Cluster Environment (ICE) Orientation Mehmet (Memo) Belgin, PhD www.pace.gatech.edu Research Scientist, PACE What is PACE A Partnership for an Advanced Computing Environment Provides
PACE Instructional Cluster Environment (ICE) Orientation Mehmet (Memo) Belgin, PhD www.pace.gatech.edu Research Scientist, PACE What is PACE A Partnership for an Advanced Computing Environment Provides
Guillimin HPC Users Meeting March 17, 2016
 Guillimin HPC Users Meeting March 17, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
Guillimin HPC Users Meeting March 17, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
GPU Cluster Computing. Advanced Computing Center for Research and Education
 GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
Many-core Processor Programming for beginners. Hongsuk Yi ( 李泓錫 ) KISTI (Korea Institute of Science and Technology Information)
 KISTI (Korea Institute of Science and Technology Information)") Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
Many-core Processor Programming for beginners Hongsuk Yi ( 李泓錫 ) (hsyi@kisti.re.kr) KISTI (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Using the IAC Chimera Cluster
 Using the IAC Chimera Cluster Ángel de Vicente (Tel.: x5387) SIE de Investigación y Enseñanza Chimera overview Beowulf type cluster Chimera: a monstrous creature made of the parts of multiple animals.
Using the IAC Chimera Cluster Ángel de Vicente (Tel.: x5387) SIE de Investigación y Enseñanza Chimera overview Beowulf type cluster Chimera: a monstrous creature made of the parts of multiple animals.
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
Wednesday, August 10, 11. The Texas Advanced Computing Center Michael B. Gonzales, Ph.D. Program Director, Computational Biology
 The Texas Advanced Computing Center Michael B. Gonzales, Ph.D. Program Director, Computational Biology Computational Biology @ TACC Goal: Establish TACC as a leading center for ENABLING computational biology
The Texas Advanced Computing Center Michael B. Gonzales, Ph.D. Program Director, Computational Biology Computational Biology @ TACC Goal: Establish TACC as a leading center for ENABLING computational biology
KISTI TACHYON2 SYSTEM Quick User Guide
 KISTI TACHYON2 SYSTEM Quick User Guide Ver. 2.4 2017. Feb. SupercomputingCenter 1. TACHYON 2 System Overview Section Specs Model SUN Blade 6275 CPU Intel Xeon X5570 2.93GHz(Nehalem) Nodes 3,200 total Cores
KISTI TACHYON2 SYSTEM Quick User Guide Ver. 2.4 2017. Feb. SupercomputingCenter 1. TACHYON 2 System Overview Section Specs Model SUN Blade 6275 CPU Intel Xeon X5570 2.93GHz(Nehalem) Nodes 3,200 total Cores
Introduction to HPC Using the New Cluster at GACRC
 Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
PACE Orientation. Research Scientist, PACE
 PACE Orientation Mehmet (Memo) Belgin, PhD Research Scientist, PACE www.pace.gatech.edu What is PACE A Partnership for an Advanced Computing Environment Provides faculty and researchers vital tools to
PACE Orientation Mehmet (Memo) Belgin, PhD Research Scientist, PACE www.pace.gatech.edu What is PACE A Partnership for an Advanced Computing Environment Provides faculty and researchers vital tools to
RWTH GPU-Cluster. Sandra Wienke March Rechen- und Kommunikationszentrum (RZ) Fotos: Christian Iwainsky
 Fotos: Christian Iwainsky") RWTH GPU-Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de March 2012 Rechen- und Kommunikationszentrum (RZ) The GPU-Cluster GPU-Cluster: 57 Nvidia Quadro 6000 (29 nodes) innovative
RWTH GPU-Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de March 2012 Rechen- und Kommunikationszentrum (RZ) The GPU-Cluster GPU-Cluster: 57 Nvidia Quadro 6000 (29 nodes) innovative
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to MSI for Physical Scientists Michael Milligan MSI Scientific Computing Consultant Goals Introduction to MSI resources Show you how to access our systems
Minnesota Supercomputing Institute Introduction to MSI for Physical Scientists Michael Milligan MSI Scientific Computing Consultant Goals Introduction to MSI resources Show you how to access our systems
UF Research Computing: Overview and Running STATA
 UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
CS/Math 471: Intro. to Scientific Computing
 CS/Math 471: Intro. to Scientific Computing Getting Started with High Performance Computing Matthew Fricke, PhD Center for Advanced Research Computing Table of contents 1. The Center for Advanced Research
CS/Math 471: Intro. to Scientific Computing Getting Started with High Performance Computing Matthew Fricke, PhD Center for Advanced Research Computing Table of contents 1. The Center for Advanced Research
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
GRID Testing and Profiling. November 2017
 GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware
GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware