Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud
|
|
|
- Leo Dorsey
- 6 years ago
- Views:
Transcription
1 Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud Doug Burger Director, Hardware, Devices, & Experiences MSR NExT November 15, 2015
2 The Cloud is a Growing Disruptor for HPC Moore s Law Homogeneity Economics Disruption
3 A 2-3 Horse Race
4 Hyperscale Cloud Fabrics CS CS ToR ToR ToR CS ToR ToR
5 Accelerator Constraints of the Cloud Homogeneity Efficiency (ASICS) 5
6 Catapult Project History December 9, 2010 initial meeting Christmas break 2010: feasible to accelerate ranking? January 12, 2011 Meeting with Bing leadership 2011 v0: ported then Bing ranking stack, built BFB board 2012 v1: developed distributed architecture 2013 Took v1 to scale, Bing pilot 2014 v2: developed new architecture, commenced work with Azure 2015 Mainstreamed: production and expansion Intel announced Altera acquisition, $16.7B
7 Microsoft Open Compute Server Two 8-core Xeon 2.1 GHz CPUs 64 GB DRAM 4 HDDs, 2 SSDs 10 Gb Ethernet No cable attachments to server Microsoft Confidential 7
8 Catapult V1 Accelerator Card Altera Stratix V D K ALMs, 2014 M20Ks 457KLEs 1 KLE == ~12K gates M20K is a 2.5KB SRAM PCIe Gen 2 x8, 8GB DDR3 20 Gb network among FPGAs 8GB DDR3 Stratix V PCIe Gen3 x8 Microsoft Confidential 8



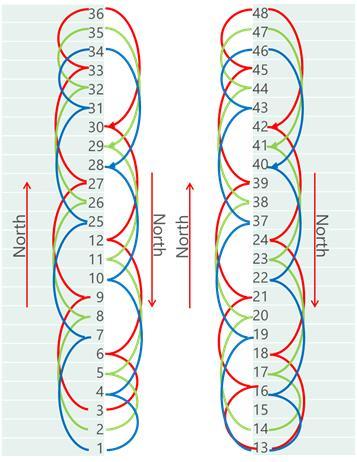


9 6x8 Torus in a 2x24 Server Layout




10 1,632 server pilot deployed in production BN datacenter
11 Target: Accelerate Ranking as a Service Selection as a Service (SaaS) Ranking as a Service (RaaS) Query SaaS SaaS SaaS Selected Documents RaaS RaaS RaaS blue links SaaS RaaS Selection-as-a-Service (SaaS) - Find all docs that contain query terms - Filter and select candidate documents for ranking Ranking-as-a-Service (RaaS) - Compute relevance scores for each selected doc - Sort the scores and return the results
12 FPGA Accelerator for Bing Ranking 12-Stage Pipeline FPGA 0 Query Augmentation Document + Query FPGA 1 Query Understanding FE: Feature Extraction Document features - Hand-coded Verilog FPGA 2 FPGA 3 Document Selection ~4K features FPGA 4 Document Ranking FFE: Free-Form Expressions FFE #1 =(2*NumberOfOccurrences_0 + NumberOfOccurrences_1) (2 * NumberOfTuples_0_1) FPGA 5 FPGA 6 Caption Generation Page Assembly MLS: Machine Learning Scoring T 2 FE9 Score ~2K Synthetic features FE7 T 3 > T 3 score score T 1 > T 1 FFE2 FFE3 > T2 T 3 > T 3 score score score Demonstrated ~2x throughput gain and stability justifying production FPGA 7 FPGA 8 FPGA 9 FPGA 10 FPGA 11
13 Throughput Throughput Pilot Results (FPGA vs. Software) Average Latency vs. Throughput 95% Latency vs. Throughput HW SW HW SW Bing s latency target at ~2X throughput Average Latency Latency
14 64 slots 2 x 16 RAMs 32B 64KB / slot Catapult V1 Shell Architecture 12V Voltage regulator 256 Mb NAND 1.5V 4 RSU 4GB SO-DIMM 120 DDR3 core 4GB SO-DIMM 120 DDR3 core Driver Reconfig JTAG Status LEDs 0.85V Gen2 x8 (Gen3 Capable) PCIe core Local application I O PCIe DMA Inter-FPGA router Xcvr config SLIII core SLIII core SLIII core SLIII core FPGA
15 Production issues at scale Build system License servers, availability of source, build machines Scale-out qualification of IP Clean interfaces for high-productivity development environment Shell/driver/application versioning and deployment Backwards compatibility Health monitoring and failure diagnostics Continuous reporting of interfaces health, soft error rate, etc. Debugging (esp. on livesite) Flight Data Recorder to replay bug-generating condition System integrity testing - many servers/vendors Scalability of verification In situ updates to drivers, golden image, shell Supply chain management
 Roll out")
 Language for programming SDN to hardware Uses connections and")

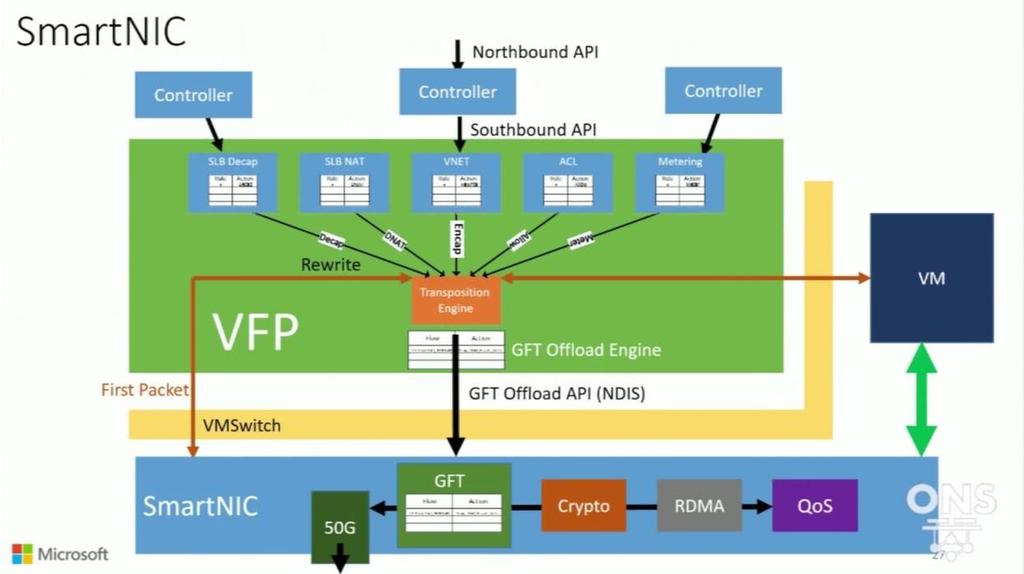
16 Azure SmartNIC Host Announced at ONS Use an FPGA for reconfigurable functions FPGAs are already used in Bing (Catapult) Roll out hardware as we do software Programmed using Generic Flow Tables (GFT) Language for programming SDN to hardware Uses connections and structured actions as primitives SmartNIC can also do Crypto, QoS, storage acceleration, and more 40Gb bidirectional AES demo NIC ASIC CPU FPGA ToR
17



18 FPGAs versus GPUs CPUs GPUs FPGAs Language C/C++ CUDA Verilog -> OpenCL (?) Performance 400 Gflops 6 Tflops -> 10T 100G -> 1T -> 4T Efficiency 5 Gflops/W -> 20 Gflops/W G/W -> G/W Scale 2M+ and growing 1s -> 10s -> 100s 10Ks -> 100Ks -> 1M+ DRAM BW 85 GB/s 2x240 GB/s 10GB/s -> 20GB/s -> GB/s
19 Large-Scale Reconfigurable Computing for HPC CS CS ToR ToR ToR ToR Deep Learning HPC / MPI Offload Bing Ranking HW Deep Compression Bing Ranking SW
20 Conclusions We are at the dawn of a new era Programmable logic playing a central role in systems at massive scale A new kind of computer Will enable new applications and services to be cost effective Will change system architecture, both in server and at cloud scale
Today s Data Centers. How can we improve efficiencies?
 Today s Data Centers O(100K) servers/data center Tens of MegaWatts, difficult to power and cool Very noisy Security taken very seriously Incrementally upgraded 3 year server depreciation, upgraded quarterly
Today s Data Centers O(100K) servers/data center Tens of MegaWatts, difficult to power and cool Very noisy Security taken very seriously Incrementally upgraded 3 year server depreciation, upgraded quarterly
A New Era of Hardware Microservices in the Cloud. Doug Burger Distinguished Engineer, Microsoft UW Cloud Workshop March 31, 2017
 A New Era of Hardware Microservices in the Cloud Doug Burger Distinguished Engineer, Microsoft UW Cloud Workshop March 31, 2017 Moore s Law Dennard Scaling has been dead for a decade Moore s La is o er
A New Era of Hardware Microservices in the Cloud Doug Burger Distinguished Engineer, Microsoft UW Cloud Workshop March 31, 2017 Moore s Law Dennard Scaling has been dead for a decade Moore s La is o er
Application-Specific Hardware. in the real world
 Application-Specific Hardware in the real world 1 http://warfarehistorynetwork.com/wp-content/uploads/military-weapons-the-catapult.jpg 2 Large-Scale Reconfigurable Computing in a Microsoft Datacenter
Application-Specific Hardware in the real world 1 http://warfarehistorynetwork.com/wp-content/uploads/military-weapons-the-catapult.jpg 2 Large-Scale Reconfigurable Computing in a Microsoft Datacenter
Enabling Flexible Network FPGA Clusters in a Heterogeneous Cloud Data Center
 Enabling Flexible Network FPGA Clusters in a Heterogeneous Cloud Data Center Naif Tarafdar, Thomas Lin, Eric Fukuda, Hadi Bannazadeh, Alberto Leon-Garcia, Paul Chow University of Toronto 1 Cloudy with
Enabling Flexible Network FPGA Clusters in a Heterogeneous Cloud Data Center Naif Tarafdar, Thomas Lin, Eric Fukuda, Hadi Bannazadeh, Alberto Leon-Garcia, Paul Chow University of Toronto 1 Cloudy with
SmartNICs: Giving Rise To Smarter Offload at The Edge and In The Data Center
 SmartNICs: Giving Rise To Smarter Offload at The Edge and In The Data Center Jeff Defilippi Senior Product Manager Arm #Arm Tech Symposia The Cloud to Edge Infrastructure Foundation for a World of 1T Intelligent
SmartNICs: Giving Rise To Smarter Offload at The Edge and In The Data Center Jeff Defilippi Senior Product Manager Arm #Arm Tech Symposia The Cloud to Edge Infrastructure Foundation for a World of 1T Intelligent
To hear the audio, please be sure to dial in: ID#
 Introduction to the HPP-Heterogeneous Processing Platform A combination of Multi-core, GPUs, FPGAs and Many-core accelerators To hear the audio, please be sure to dial in: 1-866-440-4486 ID# 4503739 Yassine
Introduction to the HPP-Heterogeneous Processing Platform A combination of Multi-core, GPUs, FPGAs and Many-core accelerators To hear the audio, please be sure to dial in: 1-866-440-4486 ID# 4503739 Yassine
LegUp: Accelerating Memcached on Cloud FPGAs
 0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
An NVMe-based Offload Engine for Storage Acceleration Sean Gibb, Eideticom Stephen Bates, Raithlin
 An NVMe-based Offload Engine for Storage Acceleration Sean Gibb, Eideticom Stephen Bates, Raithlin 1 Overview Acceleration for Storage NVMe for Acceleration How are we using (abusing ;-)) NVMe to support
An NVMe-based Offload Engine for Storage Acceleration Sean Gibb, Eideticom Stephen Bates, Raithlin 1 Overview Acceleration for Storage NVMe for Acceleration How are we using (abusing ;-)) NVMe to support
Toward a Memory-centric Architecture
 Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
Toward a Memory-centric Architecture Martin Fink EVP & Chief Technology Officer Western Digital Corporation August 8, 2017 1 SAFE HARBOR DISCLAIMERS Forward-Looking Statements This presentation contains
Hardened Security in the Cloud Bob Doud, Sr. Director Marketing March, 2018
 Hardened Security in the Cloud Bob Doud, Sr. Director Marketing March, 2018 1 Cloud Computing is Growing at an Astounding Rate Many compelling reasons for business to move to the cloud Cost, uptime, easy-expansion,
Hardened Security in the Cloud Bob Doud, Sr. Director Marketing March, 2018 1 Cloud Computing is Growing at an Astounding Rate Many compelling reasons for business to move to the cloud Cost, uptime, easy-expansion,
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Adaptable Intelligence The Next Computing Era
 Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Evolution of Rack Scale Architecture Storage
 Evolution of Rack Scale Architecture Storage Murugasamy (Sammy) Nachimuthu, Principal Engineer Mohan J Kumar, Fellow Intel Corporation August 2016 1 Agenda Introduction to Intel Rack Scale Design Storage
Evolution of Rack Scale Architecture Storage Murugasamy (Sammy) Nachimuthu, Principal Engineer Mohan J Kumar, Fellow Intel Corporation August 2016 1 Agenda Introduction to Intel Rack Scale Design Storage
An NVMe-based FPGA Storage Workload Accelerator
 An NVMe-based FPGA Storage Workload Accelerator Dr. Sean Gibb, VP Software Eideticom Santa Clara, CA 1 PCIe Bus NVMe SSD NVMe SSD Acceleration Host CPU HDD RDMA NIC NoLoad Accel. Card TM Storage I/O Bandwidth
An NVMe-based FPGA Storage Workload Accelerator Dr. Sean Gibb, VP Software Eideticom Santa Clara, CA 1 PCIe Bus NVMe SSD NVMe SSD Acceleration Host CPU HDD RDMA NIC NoLoad Accel. Card TM Storage I/O Bandwidth
The HARNESS Project. Cloud application performance modelling. Guillaume Pierre Université de Rennes 1
 The HARNESS Project Cloud application performance modelling Hardware- and Network-Enhanced Software Systems for Cloud Computing Paris Open Source Summit 18-19 November 2015 Guillaume Pierre Université
The HARNESS Project Cloud application performance modelling Hardware- and Network-Enhanced Software Systems for Cloud Computing Paris Open Source Summit 18-19 November 2015 Guillaume Pierre Université
A U G U S T 8, S A N T A C L A R A, C A
 A U G U S T 8, 2 0 1 8 S A N T A C L A R A, C A Data-Centric Innovation Summit LISA SPELMAN VICE PRESIDENT & GENERAL MANAGER INTEL XEON PRODUCTS AND DATA CENTER MARKETING Increased integration and optimization
A U G U S T 8, 2 0 1 8 S A N T A C L A R A, C A Data-Centric Innovation Summit LISA SPELMAN VICE PRESIDENT & GENERAL MANAGER INTEL XEON PRODUCTS AND DATA CENTER MARKETING Increased integration and optimization
Enabling FPGAs in Hyperscale Data Centers
 J. Weerasinghe; IEEE CBDCom 215, Beijing; 13 th August 215 Enabling s in Hyperscale Data Centers J. Weerasinghe 1, F. Abel 1, C. Hagleitner 1, A. Herkersdorf 2 1 IBM Research Zurich Laboratory 2 Technical
J. Weerasinghe; IEEE CBDCom 215, Beijing; 13 th August 215 Enabling s in Hyperscale Data Centers J. Weerasinghe 1, F. Abel 1, C. Hagleitner 1, A. Herkersdorf 2 1 IBM Research Zurich Laboratory 2 Technical
GRVI Phalanx. A Massively Parallel RISC-V FPGA Accelerator Accelerator. Jan Gray
 GRVI Phalanx A Massively Parallel RISC-V FPGA Accelerator Accelerator Jan Gray jan@fpga.org Introduction FPGA accelerators are hot MSR Catapult. Intel += Altera. OpenPOWER + Xilinx FPGAs as computers Massively
GRVI Phalanx A Massively Parallel RISC-V FPGA Accelerator Accelerator Jan Gray jan@fpga.org Introduction FPGA accelerators are hot MSR Catapult. Intel += Altera. OpenPOWER + Xilinx FPGAs as computers Massively
Colin Cunningham, Intel Kumaran Siva, Intel Sandeep Mahajan, Oracle 03-Oct :45 p.m. - 5:30 p.m. Moscone West - Room 3020
 Colin Cunningham, Intel Kumaran Siva, Intel Sandeep Mahajan, Oracle 03-Oct-2017 4:45 p.m. - 5:30 p.m. Moscone West - Room 3020 Big Data Talk Exploring New SSD Usage Models to Accelerate Cloud Performance
Colin Cunningham, Intel Kumaran Siva, Intel Sandeep Mahajan, Oracle 03-Oct-2017 4:45 p.m. - 5:30 p.m. Moscone West - Room 3020 Big Data Talk Exploring New SSD Usage Models to Accelerate Cloud Performance
Recurrent Neural Networks. Deep neural networks have enabled major advances in machine learning and AI. Convolutional Neural Networks
 Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
OpenCAPI Technology. Myron Slota Speaker name, Title OpenCAPI Consortium Company/Organization Name. Join the Conversation #OpenPOWERSummit
 OpenCAPI Technology Myron Slota Speaker name, Title OpenCAPI Consortium Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration and Innovation OpenCAPI Topics Computation
OpenCAPI Technology Myron Slota Speaker name, Title OpenCAPI Consortium Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration and Innovation OpenCAPI Topics Computation
Dr. Jean-Laurent PHILIPPE, PhD EMEA HPC Technical Sales Specialist. With Dell Amsterdam, October 27, 2016
 Dr. Jean-Laurent PHILIPPE, PhD EMEA HPC Technical Sales Specialist With Dell Amsterdam, October 27, 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration and may
Dr. Jean-Laurent PHILIPPE, PhD EMEA HPC Technical Sales Specialist With Dell Amsterdam, October 27, 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration and may
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
Overcoming the Memory System Challenge in Dataflow Processing. Darren Jones, Wave Computing Drew Wingard, Sonics
 Overcoming the Memory System Challenge in Dataflow Processing Darren Jones, Wave Computing Drew Wingard, Sonics Current Technology Limits Deep Learning Performance Deep Learning Dataflow Graph Existing
Overcoming the Memory System Challenge in Dataflow Processing Darren Jones, Wave Computing Drew Wingard, Sonics Current Technology Limits Deep Learning Performance Deep Learning Dataflow Graph Existing
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Implementing Ultra Low Latency Data Center Services with Programmable Logic
 Implementing Ultra Low Latency Data Center Services with Programmable Logic John W. Lockwood, CEO: Algo-Logic Systems, Inc. http://algo-logic.com Solutions@Algo-Logic.com (408) 707-3740 2255-D Martin Ave.,
Implementing Ultra Low Latency Data Center Services with Programmable Logic John W. Lockwood, CEO: Algo-Logic Systems, Inc. http://algo-logic.com Solutions@Algo-Logic.com (408) 707-3740 2255-D Martin Ave.,
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs
 HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
SNAP Performance Benchmark and Profiling. April 2014
 SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
Pactron FPGA Accelerated Computing Solutions
 Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor. 0 Copyright 2018 FUJITSU LIMITED
 FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor 0 Copyright 2018 FUJITSU LIMITED FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a compact and modular form
FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor 0 Copyright 2018 FUJITSU LIMITED FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a compact and modular form
SERVER. Samuli Toivola Lead HW Architect Nokia
 SERVER AirFrame Open Rack Server with Integrated HW Acceleration. Samuli Toivola Lead HW Architect Nokia Nokia in Open Compute Project Nokia is a Platinum Member of the Open Compute Project and an OCP
SERVER AirFrame Open Rack Server with Integrated HW Acceleration. Samuli Toivola Lead HW Architect Nokia Nokia in Open Compute Project Nokia is a Platinum Member of the Open Compute Project and an OCP
Martin Dubois, ing. Contents
 Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
Cloud Acceleration with FPGA s. Mike Strickland, Director, Computer & Storage BU, Altera
 Cloud Acceleration with FPGA s Mike Strickland, Director, Computer & Storage BU, Altera Agenda Mission Alignment & Data Center Trends OpenCL and Algorithm Acceleration Networking Acceleration Data Access
Cloud Acceleration with FPGA s Mike Strickland, Director, Computer & Storage BU, Altera Agenda Mission Alignment & Data Center Trends OpenCL and Algorithm Acceleration Networking Acceleration Data Access
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE
 HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
N V M e o v e r F a b r i c s -
 N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
RDMA and Hardware Support
 RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
Tightly Coupled Accelerators Architecture
 Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
Accelerating Data Centers Using NVMe and CUDA
 Accelerating Data Centers Using NVMe and CUDA Stephen Bates, PhD Technical Director, CSTO, PMC-Sierra Santa Clara, CA 1 Project Donard @ PMC-Sierra Donard is a PMC CTO project that leverages NVM Express
Accelerating Data Centers Using NVMe and CUDA Stephen Bates, PhD Technical Director, CSTO, PMC-Sierra Santa Clara, CA 1 Project Donard @ PMC-Sierra Donard is a PMC CTO project that leverages NVM Express
RapidIO.org Update. Mar RapidIO.org 1
 RapidIO.org Update rickoco@rapidio.org Mar 2015 2015 RapidIO.org 1 Outline RapidIO Overview & Markets Data Center & HPC Communications Infrastructure Industrial Automation Military & Aerospace RapidIO.org
RapidIO.org Update rickoco@rapidio.org Mar 2015 2015 RapidIO.org 1 Outline RapidIO Overview & Markets Data Center & HPC Communications Infrastructure Industrial Automation Military & Aerospace RapidIO.org
HPE ProLiant ML350 Gen10 Server
 Digital data sheet HPE ProLiant ML350 Gen10 Server ProLiant ML Servers What's new Support for Intel Xeon Scalable processors full stack. 2600 MT/s HPE DDR4 SmartMemory RDIMM/LRDIMM offering 8, 16, 32,
Digital data sheet HPE ProLiant ML350 Gen10 Server ProLiant ML Servers What's new Support for Intel Xeon Scalable processors full stack. 2600 MT/s HPE DDR4 SmartMemory RDIMM/LRDIMM offering 8, 16, 32,
Onto Petaflops with Kubernetes
 Onto Petaflops with Kubernetes Vishnu Kannan Google Inc. vishh@google.com Key Takeaways Kubernetes can manage hardware accelerators at Scale Kubernetes provides a playground for ML ML journey with Kubernetes
Onto Petaflops with Kubernetes Vishnu Kannan Google Inc. vishh@google.com Key Takeaways Kubernetes can manage hardware accelerators at Scale Kubernetes provides a playground for ML ML journey with Kubernetes
A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan
 LegoOS A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang Y 4 1 2 Monolithic Server OS / Hypervisor 3 Problems? 4 cpu mem Resource
LegoOS A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang Y 4 1 2 Monolithic Server OS / Hypervisor 3 Problems? 4 cpu mem Resource
When MPPDB Meets GPU:
 When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Thomas Lin, Naif Tarafdar, Byungchul Park, Paul Chow, and Alberto Leon-Garcia
 Thomas Lin, Naif Tarafdar, Byungchul Park, Paul Chow, and Alberto Leon-Garcia The Edward S. Rogers Sr. Department of Electrical and Computer Engineering University of Toronto, ON, Canada Motivation: IoT
Thomas Lin, Naif Tarafdar, Byungchul Park, Paul Chow, and Alberto Leon-Garcia The Edward S. Rogers Sr. Department of Electrical and Computer Engineering University of Toronto, ON, Canada Motivation: IoT
Programmable NICs. Lecture 14, Computer Networks (198:552)
") Programmable NICs Lecture 14, Computer Networks (198:552) Network Interface Cards (NICs) The physical interface between a machine and the wire Life of a transmitted packet Userspace application NIC Transport
Programmable NICs Lecture 14, Computer Networks (198:552) Network Interface Cards (NICs) The physical interface between a machine and the wire Life of a transmitted packet Userspace application NIC Transport
Service Edge Virtualization - Hardware Considerations for Optimum Performance
 Service Edge Virtualization - Hardware Considerations for Optimum Performance Executive Summary This whitepaper provides a high level overview of Intel based server hardware components and their impact
Service Edge Virtualization - Hardware Considerations for Optimum Performance Executive Summary This whitepaper provides a high level overview of Intel based server hardware components and their impact
Optimizing Efficiency of Deep Learning Workloads through GPU Virtualization
 Optimizing Efficiency of Deep Learning Workloads through GPU Virtualization Presenters: Tim Kaldewey Performance Architect, Watson Group Michael Gschwind Chief Engineer ML & DL, Systems Group David K.
Optimizing Efficiency of Deep Learning Workloads through GPU Virtualization Presenters: Tim Kaldewey Performance Architect, Watson Group Michael Gschwind Chief Engineer ML & DL, Systems Group David K.
A Cloud-Scale Acceleration Architecture
 A Cloud-Scale Acceleration Architecture Adrian M. Caulfield Eric S. Chung Andrew Putnam Hari Angepat Jeremy Fowers Michael Haselman Stephen Heil Matt Humphrey Puneet Kaur Joo-Young Kim Daniel Lo Todd Massengill
A Cloud-Scale Acceleration Architecture Adrian M. Caulfield Eric S. Chung Andrew Putnam Hari Angepat Jeremy Fowers Michael Haselman Stephen Heil Matt Humphrey Puneet Kaur Joo-Young Kim Daniel Lo Todd Massengill
HPE ProLiant ML350 Gen P 16GB-R E208i-a 8SFF 1x800W RPS Solution Server (P04674-S01)
") Digital data sheet HPE ProLiant ML350 Gen10 4110 1P 16GB-R E208i-a 8SFF 1x800W RPS Solution Server (P04674-S01) ProLiant ML Servers What's new Support for Intel Xeon Scalable processors full stack. 2600
Digital data sheet HPE ProLiant ML350 Gen10 4110 1P 16GB-R E208i-a 8SFF 1x800W RPS Solution Server (P04674-S01) ProLiant ML Servers What's new Support for Intel Xeon Scalable processors full stack. 2600
Intel SSD Data center evolution
 Intel SSD Data center evolution March 2018 1 Intel Technology Innovations Fill the Memory and Storage Gap Performance and Capacity for Every Need Intel 3D NAND Technology Lower cost & higher density Intel
Intel SSD Data center evolution March 2018 1 Intel Technology Innovations Fill the Memory and Storage Gap Performance and Capacity for Every Need Intel 3D NAND Technology Lower cost & higher density Intel
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
DataON and Intel Select Hyper-Converged Infrastructure (HCI) Maximizes IOPS Performance for Windows Server Software-Defined Storage
 Maximizes IOPS Performance for Windows Server Software-Defined Storage") Solution Brief DataON and Intel Select Hyper-Converged Infrastructure (HCI) Maximizes IOPS Performance for Windows Server Software-Defined Storage DataON Next-Generation All NVMe SSD Flash-Based Hyper-Converged
Solution Brief DataON and Intel Select Hyper-Converged Infrastructure (HCI) Maximizes IOPS Performance for Windows Server Software-Defined Storage DataON Next-Generation All NVMe SSD Flash-Based Hyper-Converged
Field Program mable Gate Arrays
 Field Program mable Gate Arrays M andakini Patil E H E P g r o u p D H E P T I F R SERC school NISER, Bhubaneshwar Nov 7-27 2017 Outline Digital electronics Short history of programmable logic devices
Field Program mable Gate Arrays M andakini Patil E H E P g r o u p D H E P T I F R SERC school NISER, Bhubaneshwar Nov 7-27 2017 Outline Digital electronics Short history of programmable logic devices
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
ANSYS Fluent 14 Performance Benchmark and Profiling. October 2012
 ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
Data-Centric Innovation Summit DAN MCNAMARA SENIOR VICE PRESIDENT GENERAL MANAGER, PROGRAMMABLE SOLUTIONS GROUP
 Data-Centric Innovation Summit DAN MCNAMARA SENIOR VICE PRESIDENT GENERAL MANAGER, PROGRAMMABLE SOLUTIONS GROUP Devices / edge network Cloud/data center Removing data Bottlenecks with Fpga acceleration
Data-Centric Innovation Summit DAN MCNAMARA SENIOR VICE PRESIDENT GENERAL MANAGER, PROGRAMMABLE SOLUTIONS GROUP Devices / edge network Cloud/data center Removing data Bottlenecks with Fpga acceleration
REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND.
 December 3-6, 2018 Santa Clara Convention Center CA, USA REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND. https://tmt.knect365.com/risc-v-summit 2018 NETRONOME SYSTEMS, INC. 1 @risc_v MASSIVELY PARALLEL
December 3-6, 2018 Santa Clara Convention Center CA, USA REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND. https://tmt.knect365.com/risc-v-summit 2018 NETRONOME SYSTEMS, INC. 1 @risc_v MASSIVELY PARALLEL
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
Deep Dive -PCIe3 RAID SAS Adapters Optimized for SSD s
 Deep Dive -PCIe3 RAID SAS Adapters Optimized for SSD s PCIe3 RAID SAS Adapter Quad-port 6Gb x8 (#EJ0J/EJ0M) PCIe3 12GB Cache RAID SAS Adapter Quad-port 6Gb x (#EJ0L) 1 Contents ASIC Overview PCIe3 RAID
Deep Dive -PCIe3 RAID SAS Adapters Optimized for SSD s PCIe3 RAID SAS Adapter Quad-port 6Gb x8 (#EJ0J/EJ0M) PCIe3 12GB Cache RAID SAS Adapter Quad-port 6Gb x (#EJ0L) 1 Contents ASIC Overview PCIe3 RAID
Industry Collaboration and Innovation
 Industry Collaboration and Innovation Industry Landscape Key changes occurring in our industry Historical microprocessor technology continues to deliver far less than the historical rate of cost/performance
Industry Collaboration and Innovation Industry Landscape Key changes occurring in our industry Historical microprocessor technology continues to deliver far less than the historical rate of cost/performance
Facilitating IP Development for the OpenCAPI Memory Interface Kevin McIlvain, Memory Development Engineer IBM. Join the Conversation #OpenPOWERSummit
 Facilitating IP Development for the OpenCAPI Memory Interface Kevin McIlvain, Memory Development Engineer IBM Join the Conversation #OpenPOWERSummit Moral of the Story OpenPOWER is the best platform to
Facilitating IP Development for the OpenCAPI Memory Interface Kevin McIlvain, Memory Development Engineer IBM Join the Conversation #OpenPOWERSummit Moral of the Story OpenPOWER is the best platform to
SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research
 SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research 1 The world s most valuable resource Data is everywhere! May. 2017 Values from Data! Need infrastructures for
SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research 1 The world s most valuable resource Data is everywhere! May. 2017 Values from Data! Need infrastructures for
33% 148% 2. at 4 years. Silo d applications & data pockets. Slow Deployment of new services. Security exploits growing. Network bottlenecks
 Outdated rate for infrastructures product innovation result in a6xslower and time to market. 1 Silo d applications & data pockets Slow Deployment of new services at 4 years server and maintenance performance
Outdated rate for infrastructures product innovation result in a6xslower and time to market. 1 Silo d applications & data pockets Slow Deployment of new services at 4 years server and maintenance performance
Maximizing heterogeneous system performance with ARM interconnect and CCIX
 Maximizing heterogeneous system performance with ARM interconnect and CCIX Neil Parris, Director of product marketing Systems and software group, ARM Teratec June 2017 Intelligent flexible cloud to enable
Maximizing heterogeneous system performance with ARM interconnect and CCIX Neil Parris, Director of product marketing Systems and software group, ARM Teratec June 2017 Intelligent flexible cloud to enable
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
New Interconnnects. Moderator: Andy Rudoff, SNIA NVM Programming Technical Work Group and Persistent Memory SW Architect, Intel
 New Interconnnects Moderator: Andy Rudoff, SNIA NVM Programming Technical Work Group and Persistent Memory SW Architect, Intel CCIX: Seamless Data Movement for Accelerated Applications TM Millind Mittal
New Interconnnects Moderator: Andy Rudoff, SNIA NVM Programming Technical Work Group and Persistent Memory SW Architect, Intel CCIX: Seamless Data Movement for Accelerated Applications TM Millind Mittal
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC
 How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
The way toward peta-flops
 The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
In-Network Computing. Sebastian Kalcher, Senior System Engineer HPC. May 2017
 In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
Zynq-7000 All Programmable SoC Product Overview
 Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
Exploring System Coherency and Maximizing Performance of Mobile Memory Systems
 Exploring System Coherency and Maximizing Performance of Mobile Memory Systems Shanghai: William Orme, Strategic Marketing Manager of SSG Beijing & Shenzhen: Mayank Sharma, Product Manager of SSG ARM Tech
Exploring System Coherency and Maximizing Performance of Mobile Memory Systems Shanghai: William Orme, Strategic Marketing Manager of SSG Beijing & Shenzhen: Mayank Sharma, Product Manager of SSG ARM Tech
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
Rack Disaggregation Using PCIe Networking
 Ethernet-based Software Defined Network (SDN) Rack Disaggregation Using PCIe Networking Cloud Computing Research Center for Mobile Applications (CCMA) Industrial Technology Research Institute 雲端運算行動應用研究中心
Ethernet-based Software Defined Network (SDN) Rack Disaggregation Using PCIe Networking Cloud Computing Research Center for Mobile Applications (CCMA) Industrial Technology Research Institute 雲端運算行動應用研究中心
Using FPGAs to accelerate NVMe-oF based Storage Networks
 Using FPGAs to accelerate NVMe-oF based Storage Networks Deboleena Sakalley IP & Solutions Architect, Xilinx Santa Clara, CA 1 Agenda NVMe-oF Offload in FPGA NVMe-oF Integrated Solution Solution Architecture
Using FPGAs to accelerate NVMe-oF based Storage Networks Deboleena Sakalley IP & Solutions Architect, Xilinx Santa Clara, CA 1 Agenda NVMe-oF Offload in FPGA NVMe-oF Integrated Solution Solution Architecture
iscsi or iser? Asgeir Eiriksson CTO Chelsio Communications Inc
 iscsi or iser? Asgeir Eiriksson CTO Chelsio Communications Inc Introduction iscsi is compatible with 15 years of deployment on all OSes and preserves software investment iser and iscsi are layered on top
iscsi or iser? Asgeir Eiriksson CTO Chelsio Communications Inc Introduction iscsi is compatible with 15 years of deployment on all OSes and preserves software investment iser and iscsi are layered on top
Developing Low Latency NVMe Systems for HyperscaleData Centers. Prepared by Engling Yeo Santa Clara, CA Date: 08/04/2017
 Developing Low Latency NVMe Systems for HyperscaleData Centers Prepared by Engling Yeo Santa Clara, CA 95054 Date: 08/04/2017 Quality of Service IOPS, Throughput, Latency Short predictable read latencies
Developing Low Latency NVMe Systems for HyperscaleData Centers Prepared by Engling Yeo Santa Clara, CA 95054 Date: 08/04/2017 Quality of Service IOPS, Throughput, Latency Short predictable read latencies
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
How to Network Flash Storage Efficiently at Hyperscale. Flash Memory Summit 2017 Santa Clara, CA 1
 How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
Solutions for Scalable HPC
 Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
Hardware Accelerated Application Integration: Challenges and Opportunities. ACM/IFIP/USENIX Middleware 2017 Daniel Ritter
 Hardware Accelerated Application Integration: Challenges and Opportunities Active @ ACM/IFIP/USENIX Middleware 2017 Daniel Ritter Application Integration EAI System, Integration Processes - De-coupling
Hardware Accelerated Application Integration: Challenges and Opportunities Active @ ACM/IFIP/USENIX Middleware 2017 Daniel Ritter Application Integration EAI System, Integration Processes - De-coupling
High-Performance Heterogeneous Computing Platform GRIFON
 High-Performance Heterogeneous Computing Platform GRIFON Purpose Input, processing and analysis of large volumes of radar and visual data. High resolution imaging and creation of virtual reality systems.
High-Performance Heterogeneous Computing Platform GRIFON Purpose Input, processing and analysis of large volumes of radar and visual data. High resolution imaging and creation of virtual reality systems.
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Simplifying FPGA Design for SDR with a Network on Chip Architecture
 Simplifying FPGA Design for SDR with a Network on Chip Architecture Matt Ettus Ettus Research GRCon13 Outline 1 Introduction 2 RF NoC 3 Status and Conclusions USRP FPGA Capability Gen
Simplifying FPGA Design for SDR with a Network on Chip Architecture Matt Ettus Ettus Research GRCon13 Outline 1 Introduction 2 RF NoC 3 Status and Conclusions USRP FPGA Capability Gen
Accelerating Data Center Workloads with FPGAs
 Accelerating Data Center Workloads with FPGAs Enno Lübbers NorCAS 2017, Linköping, Sweden Intel technologies features and benefits depend on system configuration and may require enabled hardware, software
Accelerating Data Center Workloads with FPGAs Enno Lübbers NorCAS 2017, Linköping, Sweden Intel technologies features and benefits depend on system configuration and may require enabled hardware, software
Broadberry. Artificial Intelligence Server for Fraud. Date: Q Application: Artificial Intelligence
 TM Artificial Intelligence Server for Fraud Date: Q2 2017 Application: Artificial Intelligence Tags: Artificial intelligence, GPU, GTX 1080 TI HM Revenue & Customs The UK s tax, payments and customs authority
TM Artificial Intelligence Server for Fraud Date: Q2 2017 Application: Artificial Intelligence Tags: Artificial intelligence, GPU, GTX 1080 TI HM Revenue & Customs The UK s tax, payments and customs authority
DGX UPDATE. Customer Presentation Deck May 8, 2017
 DGX UPDATE Customer Presentation Deck May 8, 2017 NVIDIA DGX-1: The World s Fastest AI Supercomputer FASTEST PATH TO DEEP LEARNING EFFORTLESS PRODUCTIVITY REVOLUTIONARY AI PERFORMANCE Fully-integrated
DGX UPDATE Customer Presentation Deck May 8, 2017 NVIDIA DGX-1: The World s Fastest AI Supercomputer FASTEST PATH TO DEEP LEARNING EFFORTLESS PRODUCTIVITY REVOLUTIONARY AI PERFORMANCE Fully-integrated
Interconnect Your Future Enabling the Best Datacenter Return on Investment. TOP500 Supercomputers, November 2017
 Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
CPMD Performance Benchmark and Profiling. February 2014
 CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting