Managing Hardware Power Saving Modes for High Performance Computing
|
|
|
- Joanna Stevens
- 6 years ago
- Views:
Transcription
1 Managing Hardware Power Saving Modes for High Performance Computing Second International Green Computing Conference 2011, Orlando Timo Minartz, Michael Knobloch, Thomas Ludwig, Bernd Mohr Scientific Computing Department of Informatics University of Hamburg / 21
2 Motivation High Performance Computing Increasing performance and efficiency of calculation units But: Increasing need for calculation power increases size of installations High operational costs for large-scale high performance installations High carbon footprint of installations should be reduced for environmental and political reasons 2 / 21
3 1 Introduction 2 Hardware Power Saving Modes in HPC 3 Power Mode Control System 4 Evaluation 5 Conclusion and Future Work 3 / 21
4 Introduction (1) High Performance Computing (HPC) Important tool in natural sciences to analyze scientific questions in silico Modeling and simulation instead of performing time consuming and error prone experiments Models from weather systems to protein folding to nanotechnology Leads to new observations and unterstanding of phenomena 4 / 21
5 Introduction (2) Top500 list Since 1993 the Top500 list gathers information about achieved performance of supercomputers Exponential growth in computing performance can be observed Current (June 2011) rank #1: K computer by Fujitsu Peak performance: TFlop/s Power consumption: KW Green500 list Ranking based on energy-efficiency Energy-efficiency is defined as Flop/s per Watt K computer rank (June 2011): #6 5 / 21
6 Exascale computing Roadmap "Practical power limit" of 20 MW (U.S. Department of Energy) Energy-efficiency must be increased from different viewpoints The data-center itself including cooling facilities etc. The hardware running the scientific applications The scientific applications themselves 6 / 21
7 Hardware power saving modes Adaption of mechanism from mobile devices Idle / power saving modes of hardware Dynamic Voltage and Frequency Scaling of processors (DVFS) Adapt frequency and disable ports of network devices Spin down and flush caches of hard disks HPC related problems Synchronization problems OS Jitter increase Possible performance loss 7 / 21
8 Idle power saving potential Sheet AMD Opteron Intel Xeon Watt CPU Max Freq CPU Min Freq CPU Min Freq + CPU Min Freq + NIC 100 Mbit NIC 100 Mbit + Disk sleep Opteron: up to 11 % power savings Xeon: up to 18 % power savings Page 1 8 / 21
9 CPU power saving potential for Xeon node Sheet Load Idle Watt MHz 30 % power savings Page 1 Interesting in phases of busy-waiting or memory-boundness 9 / 21
10 When to switch which component... Performance/usage prediction Utilization based approach Instructions Per Second (IPS) Other performance counters (e.g. memory bandwidth) Knowledge about future hardware use Application developer Compiler Libraries 10 / 21
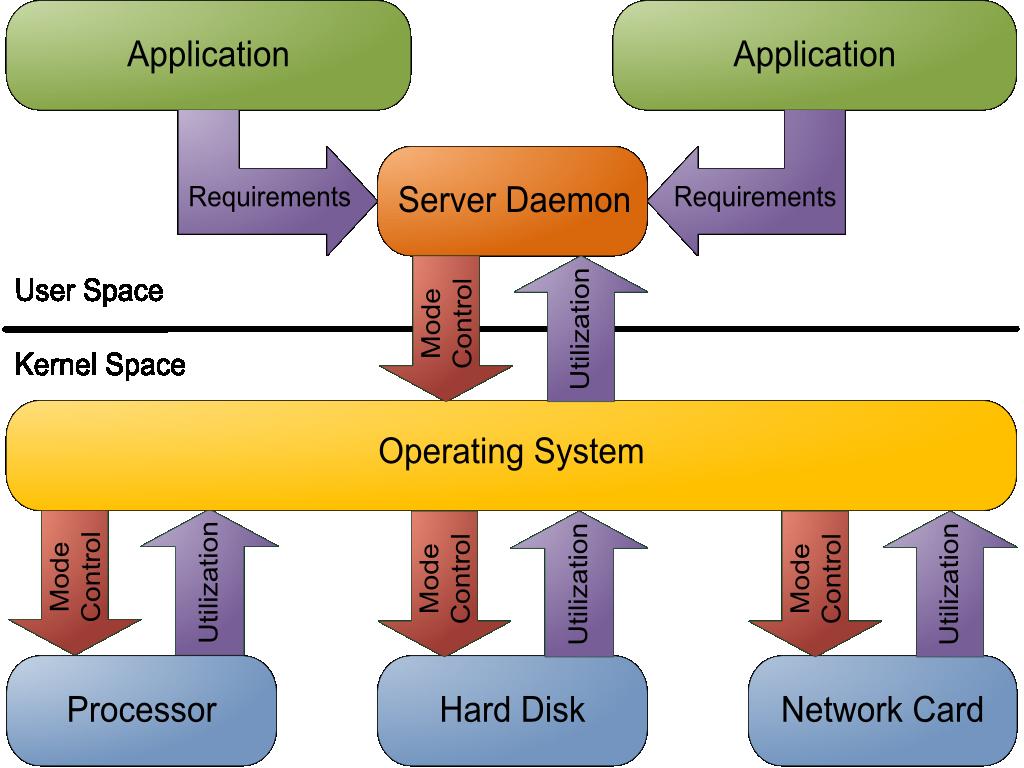
11 Daemon architecture 11 / 21
12 Daemon design Server daemon Make decision about hardware power states Processor Reduce frequency (P-States) using cpufreq Network card Reduce speed / switch duplex mode using ethtool Harddisk Reduce OS access and enforce standby modes using hdparm Client library Linked to (MPI) application Forwards desired device power state via sockets to server 12 / 21
13 Test MPI applications partdiff-par PDE solver Computation intensive phases, communication intensive phases and IO phases PEPC Pretty Efficient Parallel Coulomb-solver Computation intensive phases and communication intensive phases 13 / 21

14 Hardware Details 3 LMG 450 power meter 4 channels each up to 20 samples per second 5 AMD Opteron 6168 Dual socket 24 cores per node 5 Intel Xeon X5560 Dual socket 8 cores per node SMT disabled 14 / 21
15 Experimental setup Application test setup Instrumented: State switching dependent on phase CPU Max Freq: Processor frequency set to maximum CPU Min Freq: Processor frequency set to minimum CPU Ondemand: Processor governor set to ondemand Results Time-to-Solution (TTS): Total time for test setup Energy-to-Solution (ETS): Total energy for test setup 15 / 21
16 TTS and ETS for partdiff-par on Xeon nodes Sheet Time-to-Solution Energy-to-Solution seconds kj 0 0 Instrumented CPU Min Freq CPU Max Freq CPU Ondemand Freq 5 % savings in Energy-to-Solution Time-to-Solution increase of about 4 % Page 1 16 / 21
17 TTS and ETS for partdiff-par on Opteron nodes Sheet Time-to-Solution Energy-to-Solution seconds kj Instrumented CPU Min Freq CPU Max Freq CPU Ondemand Freq 8 % energy savings Runtime increase of 9 % Page 1 17 / 21
18 TTS and ETS for PEPC on Opteron nodes Sheet Time-to-Solution Energy-to-Solution seconds kj 0 0 Instrumented CPU Max Freq CPU Instrumented CPU Min Freq 7 % energy savings, 4 % runtime increase compared to Page 1 4 % energy savings, 2 % runtime increase 18 / 21
19 Conclusions Power consumption of idle nodes can be reduced by 11 % and 18 % respectively Power consumption can be decreased by more than 30 % in phases with unnecessary high utilization (e.g. busy-waiting) Control device power states from userspace by introducing a hardware management daemon Reduce the Energy-to-Solution by up to 8 % with an Time-to-Solution increase of about 9 % for presented applications 19 / 21
20 Future work Identify energy saving possibilities (Scalasca enhancement) Benchmark to measure power consumption in various states Enhanced measurements with larger count of applications 20 / 21
21 CPU power saving potential (C-States enabled) Sheet Load, cstates = off Load, cstates = on Idle, cstates = off Idle, cstates = on 250 Watt MHz 21 / 21
Tracing and Visualization of Energy Related Metrics
 Tracing and Visualization of Energy Related Metrics 8th Workshop on High-Performance, Power-Aware Computing 2012, Shanghai Timo Minartz, Julian Kunkel, Thomas Ludwig timo.minartz@informatik.uni-hamburg.de
Tracing and Visualization of Energy Related Metrics 8th Workshop on High-Performance, Power-Aware Computing 2012, Shanghai Timo Minartz, Julian Kunkel, Thomas Ludwig timo.minartz@informatik.uni-hamburg.de
Energy-centric DVFS Controlling Method for Multi-core Platforms
 Energy-centric DVFS Controlling Method for Multi-core Platforms Shin-gyu Kim, Chanho Choi, Hyeonsang Eom, Heon Y. Yeom Seoul National University, Korea MuCoCoS 2012 Salt Lake City, Utah Abstract Goal To
Energy-centric DVFS Controlling Method for Multi-core Platforms Shin-gyu Kim, Chanho Choi, Hyeonsang Eom, Heon Y. Yeom Seoul National University, Korea MuCoCoS 2012 Salt Lake City, Utah Abstract Goal To
Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks
 Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
POWER MANAGEMENT AND ENERGY EFFICIENCY
 POWER MANAGEMENT AND ENERGY EFFICIENCY * Adopted Power Management for Embedded Systems, Minsoo Ryu 2017 Operating Systems Design Euiseong Seo (euiseong@skku.edu) Need for Power Management Power consumption
POWER MANAGEMENT AND ENERGY EFFICIENCY * Adopted Power Management for Embedded Systems, Minsoo Ryu 2017 Operating Systems Design Euiseong Seo (euiseong@skku.edu) Need for Power Management Power consumption
Designing Power-Aware Collective Communication Algorithms for InfiniBand Clusters
 Designing Power-Aware Collective Communication Algorithms for InfiniBand Clusters Krishna Kandalla, Emilio P. Mancini, Sayantan Sur, and Dhabaleswar. K. Panda Department of Computer Science & Engineering,
Designing Power-Aware Collective Communication Algorithms for InfiniBand Clusters Krishna Kandalla, Emilio P. Mancini, Sayantan Sur, and Dhabaleswar. K. Panda Department of Computer Science & Engineering,
The Mont-Blanc Project
 http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
Power Profiling of Cholesky and QR Factorizations on Distributed Memory Systems
 International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
Energy Models for DVFS Processors
 Energy Models for DVFS Processors Thomas Rauber 1 Gudula Rünger 2 Michael Schwind 2 Haibin Xu 2 Simon Melzner 1 1) Universität Bayreuth 2) TU Chemnitz 9th Scheduling for Large Scale Systems Workshop July
Energy Models for DVFS Processors Thomas Rauber 1 Gudula Rünger 2 Michael Schwind 2 Haibin Xu 2 Simon Melzner 1 1) Universität Bayreuth 2) TU Chemnitz 9th Scheduling for Large Scale Systems Workshop July
MPI RUNTIMES AT JSC, NOW AND IN THE FUTURE
 , NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
, NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
Portable Power/Performance Benchmarking and Analysis with WattProf
 Portable Power/Performance Benchmarking and Analysis with WattProf Amir Farzad, Boyana Norris University of Oregon Mohammad Rashti RNET Technologies, Inc. Motivation Energy efficiency is becoming increasingly
Portable Power/Performance Benchmarking and Analysis with WattProf Amir Farzad, Boyana Norris University of Oregon Mohammad Rashti RNET Technologies, Inc. Motivation Energy efficiency is becoming increasingly
ENERGY-EFFICIENT VISUALIZATION PIPELINES A CASE STUDY IN CLIMATE SIMULATION
 ENERGY-EFFICIENT VISUALIZATION PIPELINES A CASE STUDY IN CLIMATE SIMULATION Vignesh Adhinarayanan Ph.D. (CS) Student Synergy Lab, Virginia Tech INTRODUCTION Supercomputers are constrained by power Power
ENERGY-EFFICIENT VISUALIZATION PIPELINES A CASE STUDY IN CLIMATE SIMULATION Vignesh Adhinarayanan Ph.D. (CS) Student Synergy Lab, Virginia Tech INTRODUCTION Supercomputers are constrained by power Power
Power Management for Embedded Systems
 Power Management for Embedded Systems Minsoo Ryu Hanyang University Why Power Management? Battery-operated devices Smartphones, digital cameras, and laptops use batteries Power savings and battery run
Power Management for Embedded Systems Minsoo Ryu Hanyang University Why Power Management? Battery-operated devices Smartphones, digital cameras, and laptops use batteries Power savings and battery run
Overview. Energy-Efficient and Power-Constrained Techniques for ExascaleComputing. Motivation: Power is becoming a leading design constraint in HPC
 Energy-Efficient and Power-Constrained Techniques for ExascaleComputing Stephanie Labasan Computer and Information Science University of Oregon 17 October 2016 Overview Motivation: Power is becoming a
Energy-Efficient and Power-Constrained Techniques for ExascaleComputing Stephanie Labasan Computer and Information Science University of Oregon 17 October 2016 Overview Motivation: Power is becoming a
Servers: Take Care of your Wattmeters!
 Solving some Mysteries in Power Monitoring of Servers: Take Care of your Wattmeters! M. Diouri 1, M. Dolz 2, O. Gluck 1, L. Lefevre 1, P. Alonso 3, S. Catalan 2, R. Mayo 2, and E. Quintana-Orti 2 1- INRIA
Solving some Mysteries in Power Monitoring of Servers: Take Care of your Wattmeters! M. Diouri 1, M. Dolz 2, O. Gluck 1, L. Lefevre 1, P. Alonso 3, S. Catalan 2, R. Mayo 2, and E. Quintana-Orti 2 1- INRIA
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms
 Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Energy Efficiency Tuning: READEX. Madhura Kumaraswamy Technische Universität München
 Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Motivation Goal Idea Proposition for users Study
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
COL862: Low Power Computing Maximizing Performance Under a Power Cap: A Comparison of Hardware, Software, and Hybrid Techniques
 COL862: Low Power Computing Maximizing Performance Under a Power Cap: A Comparison of Hardware, Software, and Hybrid Techniques Authors: Huazhe Zhang and Henry Hoffmann, Published: ASPLOS '16 Proceedings
COL862: Low Power Computing Maximizing Performance Under a Power Cap: A Comparison of Hardware, Software, and Hybrid Techniques Authors: Huazhe Zhang and Henry Hoffmann, Published: ASPLOS '16 Proceedings
Tuning Alya with READEX for Energy-Efficiency
 Tuning Alya with READEX for Energy-Efficiency Venkatesh Kannan 1, Ricard Borrell 2, Myles Doyle 1, Guillaume Houzeaux 2 1 Irish Centre for High-End Computing (ICHEC) 2 Barcelona Supercomputing Centre (BSC)
Tuning Alya with READEX for Energy-Efficiency Venkatesh Kannan 1, Ricard Borrell 2, Myles Doyle 1, Guillaume Houzeaux 2 1 Irish Centre for High-End Computing (ICHEC) 2 Barcelona Supercomputing Centre (BSC)
Overview. Idea: Reduce CPU clock frequency This idea is well suited specifically for visualization
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Challenges in HPC I/O
 Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
Matrix Computations. Enrique S. Quintana-Ortí. September 11, 2012, Hamburg, Germany
 Doing Nothing to Save Energy in Matrix Computations Enrique S. Quintana-Ortí quintana@icc.uji.esuji eeclust Workshop, Energy efficiency Motivation Doing nothing to save energy? Why at Ena-HPC then? Energy
Doing Nothing to Save Energy in Matrix Computations Enrique S. Quintana-Ortí quintana@icc.uji.esuji eeclust Workshop, Energy efficiency Motivation Doing nothing to save energy? Why at Ena-HPC then? Energy
HPC projects. Grischa Bolls
 HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
Intel profiling tools and roofline model. Dr. Luigi Iapichino
 Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
The ICARUS white paper: A scalable, energy-efficient, solar-powered HPC center based on low power GPUs
 The ICARUS white paper: A scalable, energy-efficient, solar-powered HPC center based on low power GPUs Markus Geveler, Dirk Ribbrock, Daniel Donner, Hannes Ruelmann, Christoph Höppke, David Schneider,
The ICARUS white paper: A scalable, energy-efficient, solar-powered HPC center based on low power GPUs Markus Geveler, Dirk Ribbrock, Daniel Donner, Hannes Ruelmann, Christoph Höppke, David Schneider,
Operating Systems Design 25. Power Management. Paul Krzyzanowski
 Operating Systems Design 25. Power Management Paul Krzyzanowski pxk@cs.rutgers.edu 1 Power Management Goal: Improve the battery life of mobile devices 2 CPU Voltage & Frequency Scaling Dynamic CPU Frequency
Operating Systems Design 25. Power Management Paul Krzyzanowski pxk@cs.rutgers.edu 1 Power Management Goal: Improve the battery life of mobile devices 2 CPU Voltage & Frequency Scaling Dynamic CPU Frequency
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Brand-New Vector Supercomputer
 Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
KNL tools. Dr. Fabio Baruffa
 KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
ECE 574 Cluster Computing Lecture 18
 ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
The Future of Interconnect Technology
 The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
Architecture without explicit locks for logic simulation on SIMD machines
 Architecture without explicit locks for logic on machines M. Chimeh Department of Computer Science University of Glasgow UKMAC, 2016 Contents 1 2 3 4 5 6 The Using models to replicate the behaviour of
Architecture without explicit locks for logic on machines M. Chimeh Department of Computer Science University of Glasgow UKMAC, 2016 Contents 1 2 3 4 5 6 The Using models to replicate the behaviour of
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
Performance analysis tools: Intel VTuneTM Amplifier and Advisor. Dr. Luigi Iapichino
 Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
Parallel & Cluster Computing. cs 6260 professor: elise de doncker by: lina hussein
 Parallel & Cluster Computing cs 6260 professor: elise de doncker by: lina hussein 1 Topics Covered : Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster
Parallel & Cluster Computing cs 6260 professor: elise de doncker by: lina hussein 1 Topics Covered : Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster
Energy Efficiency for Exascale. High Performance Computing, Grids and Clouds International Workshop Cetraro Italy June 27, 2012 Natalie Bates
 Energy Efficiency for Exascale High Performance Computing, Grids and Clouds International Workshop Cetraro Italy June 27, 2012 Natalie Bates The Exascale Power Challenge Where do we get a 1000x improvement
Energy Efficiency for Exascale High Performance Computing, Grids and Clouds International Workshop Cetraro Italy June 27, 2012 Natalie Bates The Exascale Power Challenge Where do we get a 1000x improvement
A2E: Adaptively Aggressive Energy Efficient DVFS Scheduling for Data Intensive Applications
 A2E: Adaptively Aggressive Energy Efficient DVFS Scheduling for Data Intensive Applications Li Tan 1, Zizhong Chen 1, Ziliang Zong 2, Rong Ge 3, and Dong Li 4 1 University of California, Riverside 2 Texas
A2E: Adaptively Aggressive Energy Efficient DVFS Scheduling for Data Intensive Applications Li Tan 1, Zizhong Chen 1, Ziliang Zong 2, Rong Ge 3, and Dong Li 4 1 University of California, Riverside 2 Texas
Static and Dynamic Frequency Scaling on Multicore CPUs
 Static and Dynamic Frequency Scaling on Multicore CPUs Wenlei Bao 1 Changwan Hong 1 Sudheer Chunduri 2 Sriram Krishnamoorthy 3 Louis-Noël Pouchet 4 Fabrice Rastello 5 P. Sadayappan 1 1 The Ohio State University
Static and Dynamic Frequency Scaling on Multicore CPUs Wenlei Bao 1 Changwan Hong 1 Sudheer Chunduri 2 Sriram Krishnamoorthy 3 Louis-Noël Pouchet 4 Fabrice Rastello 5 P. Sadayappan 1 1 The Ohio State University
Potentials and Limitations for Energy Efficiency Auto-Tuning
 Center for Information Services and High Performance Computing (ZIH) Potentials and Limitations for Energy Efficiency Auto-Tuning Parco Symposium Application Autotuning for HPC (Architectures) Robert Schöne
Center for Information Services and High Performance Computing (ZIH) Potentials and Limitations for Energy Efficiency Auto-Tuning Parco Symposium Application Autotuning for HPC (Architectures) Robert Schöne
COL862 Programming Assignment-1
 Submitted By: Rajesh Kedia (214CSZ8383) COL862 Programming Assignment-1 Objective: Understand the power and energy behavior of various benchmarks on different types of x86 based systems. We explore a laptop,
Submitted By: Rajesh Kedia (214CSZ8383) COL862 Programming Assignment-1 Objective: Understand the power and energy behavior of various benchmarks on different types of x86 based systems. We explore a laptop,
A task migration algorithm for power management on heterogeneous multicore Manman Peng1, a, Wen Luo1, b
 5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) A task migration algorithm for power management on heterogeneous multicore Manman Peng1, a, Wen Luo1, b 1 School of
5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) A task migration algorithm for power management on heterogeneous multicore Manman Peng1, a, Wen Luo1, b 1 School of
Exploring Use-cases for Non-Volatile Memories in support of HPC Resilience
 Exploring Use-cases for Non-Volatile Memories in support of HPC Resilience Onkar Patil 1, Saurabh Hukerikar 2, Frank Mueller 1, Christian Engelmann 2 1 Dept. of Computer Science, North Carolina State University
Exploring Use-cases for Non-Volatile Memories in support of HPC Resilience Onkar Patil 1, Saurabh Hukerikar 2, Frank Mueller 1, Christian Engelmann 2 1 Dept. of Computer Science, North Carolina State University
Power and Energy Management. Advanced Operating Systems, Semester 2, 2011, UNSW Etienne Le Sueur
 Power and Energy Management Advanced Operating Systems, Semester 2, 2011, UNSW Etienne Le Sueur etienne.lesueur@nicta.com.au Outline Introduction, Hardware mechanisms, Some interesting research, Linux,
Power and Energy Management Advanced Operating Systems, Semester 2, 2011, UNSW Etienne Le Sueur etienne.lesueur@nicta.com.au Outline Introduction, Hardware mechanisms, Some interesting research, Linux,
Power and Energy Management
 Power and Energy Management Advanced Operating Systems, Semester 2, 2011, UNSW Etienne Le Sueur etienne.lesueur@nicta.com.au Outline Introduction, Hardware mechanisms, Some interesting research, Linux,
Power and Energy Management Advanced Operating Systems, Semester 2, 2011, UNSW Etienne Le Sueur etienne.lesueur@nicta.com.au Outline Introduction, Hardware mechanisms, Some interesting research, Linux,
Energy Aware Scheduling in Cloud Datacenter
 Energy Aware Scheduling in Cloud Datacenter Jemal H. Abawajy, PhD, DSc., SMIEEE Director, Distributed Computing and Security Research Deakin University, Australia Introduction Cloud computing is the delivery
Energy Aware Scheduling in Cloud Datacenter Jemal H. Abawajy, PhD, DSc., SMIEEE Director, Distributed Computing and Security Research Deakin University, Australia Introduction Cloud computing is the delivery
Power Bounds and Large Scale Computing
 1 Power Bounds and Large Scale Computing Friday, March 1, 2013 Bronis R. de Supinski 1 Tapasya Patki 2, David K. Lowenthal 2, Barry L. Rountree 1 and Martin Schulz 1 2 University of Arizona This work has
1 Power Bounds and Large Scale Computing Friday, March 1, 2013 Bronis R. de Supinski 1 Tapasya Patki 2, David K. Lowenthal 2, Barry L. Rountree 1 and Martin Schulz 1 2 University of Arizona This work has
Multicore Performance and Tools. Part 1: Topology, affinity, clock speed
 Multicore Performance and Tools Part 1: Topology, affinity, clock speed Tools for Node-level Performance Engineering Gather Node Information hwloc, likwid-topology, likwid-powermeter Affinity control and
Multicore Performance and Tools Part 1: Topology, affinity, clock speed Tools for Node-level Performance Engineering Gather Node Information hwloc, likwid-topology, likwid-powermeter Affinity control and
Abhishek Pandey Aman Chadha Aditya Prakash
 Abhishek Pandey Aman Chadha Aditya Prakash System: Building Blocks Motivation: Problem: Determining when to scale down the frequency at runtime is an intricate task. Proposed Solution: Use Machine learning
Abhishek Pandey Aman Chadha Aditya Prakash System: Building Blocks Motivation: Problem: Determining when to scale down the frequency at runtime is an intricate task. Proposed Solution: Use Machine learning
Power Measurement Using Performance Counters
 Power Measurement Using Performance Counters October 2016 1 Introduction CPU s are based on complementary metal oxide semiconductor technology (CMOS). CMOS technology theoretically only dissipates power
Power Measurement Using Performance Counters October 2016 1 Introduction CPU s are based on complementary metal oxide semiconductor technology (CMOS). CMOS technology theoretically only dissipates power
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
ECE 571 Advanced Microprocessor-Based Design Lecture 7
 ECE 571 Advanced Microprocessor-Based Design Lecture 7 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 9 February 2017 Announcements HW#4 will be posted, some readings 1 Measuring
ECE 571 Advanced Microprocessor-Based Design Lecture 7 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 9 February 2017 Announcements HW#4 will be posted, some readings 1 Measuring
GPU-centric communication for improved efficiency
 GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow.
 Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Exploring Hardware Overprovisioning in Power-Constrained, High Performance Computing
 Exploring Hardware Overprovisioning in Power-Constrained, High Performance Computing Tapasya Patki 1 David Lowenthal 1 Barry Rountree 2 Martin Schulz 2 Bronis de Supinski 2 1 The University of Arizona
Exploring Hardware Overprovisioning in Power-Constrained, High Performance Computing Tapasya Patki 1 David Lowenthal 1 Barry Rountree 2 Martin Schulz 2 Bronis de Supinski 2 1 The University of Arizona
A Global Operating System for HPC Clusters
 A Global Operating System Emiliano Betti 1 Marco Cesati 1 Roberto Gioiosa 2 Francesco Piermaria 1 1 System Programming Research Group, University of Rome Tor Vergata 2 BlueGene Software Division, IBM TJ
A Global Operating System Emiliano Betti 1 Marco Cesati 1 Roberto Gioiosa 2 Francesco Piermaria 1 1 System Programming Research Group, University of Rome Tor Vergata 2 BlueGene Software Division, IBM TJ
Managing data flows. Martyn Winn Scientific Computing Dept. STFC Daresbury Laboratory Cheshire. 8th May 2014
 Managing data flows Martyn Winn Scientific Computing Dept. STFC Daresbury Laboratory Cheshire 8th May 2014 Overview Sensors continuous stream of data Store / transmit / process in situ? Do you need to
Managing data flows Martyn Winn Scientific Computing Dept. STFC Daresbury Laboratory Cheshire 8th May 2014 Overview Sensors continuous stream of data Store / transmit / process in situ? Do you need to
Power-Aware Scheduling of Virtual Machines in DVFS-enabled Clusters
 Power-Aware Scheduling of Virtual Machines in DVFS-enabled Clusters Gregor von Laszewski, Lizhe Wang, Andrew J. Younge, Xi He Service Oriented Cyberinfrastructure Lab Rochester Institute of Technology,
Power-Aware Scheduling of Virtual Machines in DVFS-enabled Clusters Gregor von Laszewski, Lizhe Wang, Andrew J. Younge, Xi He Service Oriented Cyberinfrastructure Lab Rochester Institute of Technology,
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Green Supercomputing
 Green Supercomputing On the Energy Consumption of Modern E-Science Prof. Dr. Thomas Ludwig German Climate Computing Centre Hamburg, Germany ludwig@dkrz.de Outline DKRZ 2013 and Climate Science The Exascale
Green Supercomputing On the Energy Consumption of Modern E-Science Prof. Dr. Thomas Ludwig German Climate Computing Centre Hamburg, Germany ludwig@dkrz.de Outline DKRZ 2013 and Climate Science The Exascale
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Adaptive Power Profiling for Many-Core HPC Architectures
 Adaptive Power Profiling for Many-Core HPC Architectures Jaimie Kelley, Christopher Stewart The Ohio State University Devesh Tiwari, Saurabh Gupta Oak Ridge National Laboratory State-of-the-Art Schedulers
Adaptive Power Profiling for Many-Core HPC Architectures Jaimie Kelley, Christopher Stewart The Ohio State University Devesh Tiwari, Saurabh Gupta Oak Ridge National Laboratory State-of-the-Art Schedulers
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
John Hengeveld Director of Marketing, HPC Evangelist
 MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
Application Performance on Dual Processor Cluster Nodes
 Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
MiAMI: Multi-Core Aware Processor Affinity for TCP/IP over Multiple Network Interfaces
 MiAMI: Multi-Core Aware Processor Affinity for TCP/IP over Multiple Network Interfaces Hye-Churn Jang Hyun-Wook (Jin) Jin Department of Computer Science and Engineering Konkuk University Seoul, Korea {comfact,
MiAMI: Multi-Core Aware Processor Affinity for TCP/IP over Multiple Network Interfaces Hye-Churn Jang Hyun-Wook (Jin) Jin Department of Computer Science and Engineering Konkuk University Seoul, Korea {comfact,
LEoNIDS: a Low-latency and Energyefficient Intrusion Detection System
 LEoNIDS: a Low-latency and Energyefficient Intrusion Detection System Nikos Tsikoudis Thesis Supervisor: Evangelos Markatos June 2013 Heraklion, Greece Low-Power Design Low-power systems receive significant
LEoNIDS: a Low-latency and Energyefficient Intrusion Detection System Nikos Tsikoudis Thesis Supervisor: Evangelos Markatos June 2013 Heraklion, Greece Low-Power Design Low-power systems receive significant
Thread Tailor Dynamically Weaving Threads Together for Efficient, Adaptive Parallel Applications
 Thread Tailor Dynamically Weaving Threads Together for Efficient, Adaptive Parallel Applications Janghaeng Lee, Haicheng Wu, Madhumitha Ravichandran, Nathan Clark Motivation Hardware Trends Put more cores
Thread Tailor Dynamically Weaving Threads Together for Efficient, Adaptive Parallel Applications Janghaeng Lee, Haicheng Wu, Madhumitha Ravichandran, Nathan Clark Motivation Hardware Trends Put more cores
Toward Automated Application Profiling on Cray Systems
 Toward Automated Application Profiling on Cray Systems Charlene Yang, Brian Friesen, Thorsten Kurth, Brandon Cook NERSC at LBNL Samuel Williams CRD at LBNL I have a dream.. M.L.K. Collect performance data:
Toward Automated Application Profiling on Cray Systems Charlene Yang, Brian Friesen, Thorsten Kurth, Brandon Cook NERSC at LBNL Samuel Williams CRD at LBNL I have a dream.. M.L.K. Collect performance data:
Memory Performance and Cache Coherency Effects on an Intel Nehalem Multiprocessor System
 Center for Information ervices and High Performance Computing (ZIH) Memory Performance and Cache Coherency Effects on an Intel Nehalem Multiprocessor ystem Parallel Architectures and Compiler Technologies
Center for Information ervices and High Performance Computing (ZIH) Memory Performance and Cache Coherency Effects on an Intel Nehalem Multiprocessor ystem Parallel Architectures and Compiler Technologies
Analyzing I/O Performance on a NEXTGenIO Class System
 Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
A priori power estimation of linear solvers on multi-core processors
 A priori power estimation of linear solvers on multi-core processors Dimitar Lukarski 1, Tobias Skoglund 2 Uppsala University Department of Information Technology Division of Scientific Computing 1 Division
A priori power estimation of linear solvers on multi-core processors Dimitar Lukarski 1, Tobias Skoglund 2 Uppsala University Department of Information Technology Division of Scientific Computing 1 Division
I/O at JSC. I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O. Wolfgang Frings
 Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters
 Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
LOWERING POWER CONSUMPTION OF HEVC DECODING. Chi Ching Chi Techinische Universität Berlin - AES PEGPUM 2014
 LOWERING POWER CONSUMPTION OF HEVC DECODING Chi Ching Chi Techinische Universität Berlin - AES PEGPUM 2014 Introduction How to achieve low power HEVC video decoding? Modern processors expose many low power
LOWERING POWER CONSUMPTION OF HEVC DECODING Chi Ching Chi Techinische Universität Berlin - AES PEGPUM 2014 Introduction How to achieve low power HEVC video decoding? Modern processors expose many low power
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
COL862 - Low Power Computing
 COL862 - Low Power Computing Power Measurements using performance counters and studying the low power computing techniques in IoT development board (PSoC 4 BLE Pioneer Kit) and Arduino Mega 2560 Submitted
COL862 - Low Power Computing Power Measurements using performance counters and studying the low power computing techniques in IoT development board (PSoC 4 BLE Pioneer Kit) and Arduino Mega 2560 Submitted
ECE 571 Advanced Microprocessor-Based Design Lecture 6
 ECE 571 Advanced Microprocessor-Based Design Lecture 6 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 4 February 2016 HW#3 will be posted HW#1 was graded Announcements 1 First
ECE 571 Advanced Microprocessor-Based Design Lecture 6 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 4 February 2016 HW#3 will be posted HW#1 was graded Announcements 1 First
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Modeling CPU Energy Consumption for Energy Efficient Scheduling
 Modeling CPU Energy Consumption for Energy Efficient Scheduling Abhishek Jaiantilal, Yifei Jiang, Shivakant Mishra University of Colorado - Boulder GCM '10 Proceedings of the 1st Workshop on Green Computing
Modeling CPU Energy Consumption for Energy Efficient Scheduling Abhishek Jaiantilal, Yifei Jiang, Shivakant Mishra University of Colorado - Boulder GCM '10 Proceedings of the 1st Workshop on Green Computing
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University
 EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University Material from: The Datacenter as a Computer: An Introduction to
EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University Material from: The Datacenter as a Computer: An Introduction to
in Action Fujitsu High Performance Computing Ecosystem Human Centric Innovation Innovation Flexibility Simplicity
 Fujitsu High Performance Computing Ecosystem Human Centric Innovation in Action Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Innovation Flexibility Simplicity INTERNAL USE ONLY 0 Copyright
Fujitsu High Performance Computing Ecosystem Human Centric Innovation in Action Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Innovation Flexibility Simplicity INTERNAL USE ONLY 0 Copyright
Performance Analysis and Prediction for distributed homogeneous Clusters
 Performance Analysis and Prediction for distributed homogeneous Clusters Heinz Kredel, Hans-Günther Kruse, Sabine Richling, Erich Strohmaier IT-Center, University of Mannheim, Germany IT-Center, University
Performance Analysis and Prediction for distributed homogeneous Clusters Heinz Kredel, Hans-Günther Kruse, Sabine Richling, Erich Strohmaier IT-Center, University of Mannheim, Germany IT-Center, University
Parallel Computing. Parallel Computing. Hwansoo Han
 Parallel Computing Parallel Computing Hwansoo Han What is Parallel Computing? Software with multiple threads Parallel vs. concurrent Parallel computing executes multiple threads at the same time on multiple
Parallel Computing Parallel Computing Hwansoo Han What is Parallel Computing? Software with multiple threads Parallel vs. concurrent Parallel computing executes multiple threads at the same time on multiple
Managing Data Center Power and Cooling
 Managing Data Center Power and Cooling with AMD Opteron Processors and AMD PowerNow! Technology Avoiding unnecessary energy use in enterprise data centers can be critical for success. This article discusses
Managing Data Center Power and Cooling with AMD Opteron Processors and AMD PowerNow! Technology Avoiding unnecessary energy use in enterprise data centers can be critical for success. This article discusses
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Building supercomputers from commodity embedded chips
 http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs
 Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
Meet the Increased Demands on Your Infrastructure with Dell and Intel. ServerWatchTM Executive Brief
 Meet the Increased Demands on Your Infrastructure with Dell and Intel ServerWatchTM Executive Brief a QuinStreet Excutive Brief. 2012 Doing more with less is the mantra that sums up much of the past decade,
Meet the Increased Demands on Your Infrastructure with Dell and Intel ServerWatchTM Executive Brief a QuinStreet Excutive Brief. 2012 Doing more with less is the mantra that sums up much of the past decade,
Unifying UPC and MPI Runtimes: Experience with MVAPICH
 Unifying UPC and MPI Runtimes: Experience with MVAPICH Jithin Jose Miao Luo Sayantan Sur D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Unifying UPC and MPI Runtimes: Experience with MVAPICH Jithin Jose Miao Luo Sayantan Sur D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
CHAPTER 7 IMPLEMENTATION OF DYNAMIC VOLTAGE SCALING IN LINUX SCHEDULER
 73 CHAPTER 7 IMPLEMENTATION OF DYNAMIC VOLTAGE SCALING IN LINUX SCHEDULER 7.1 INTRODUCTION The proposed DVS algorithm is implemented on DELL INSPIRON 6000 model laptop, which has Intel Pentium Mobile Processor
73 CHAPTER 7 IMPLEMENTATION OF DYNAMIC VOLTAGE SCALING IN LINUX SCHEDULER 7.1 INTRODUCTION The proposed DVS algorithm is implemented on DELL INSPIRON 6000 model laptop, which has Intel Pentium Mobile Processor