GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
|
|
|
- Susan Ramsey
- 6 years ago
- Views:
Transcription
1 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP


2 INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem we are trying to solve has also increased. From design and simulation of complex aerodynamics to the simulation of public response during a crisis. The computational power required is indeed phenomenal.
3 How about using conventional CPU s? 1. It is logical to suggest that we could use multiple CPU s to increase the calculation throughput. After all CPU s have been tried and tested since the dawn of computing. 2. Using n number of CPU s to meet our requirements does sounds like a legitimate solution. 3. CPU s have much better memory capabilities and it is more efficient at scheduling and managing the tasks performed by the computer. 4. They are also capable of very quick and efficient decision making But is that enough to qualify CPU s for high performance computing?
4 Meet the contender! 1. The GPU (Graphics processing unit) seems to be the solution for all our computationally intensive requirements. 2. The GPU will soon become a highly efficient PROCESSING FARM with multiple GPU s performing the computationally heavy functions and returning the processed data to the CPU. 3. CPU cores will still be required to act as managers and control the majority of the intensive work being carried out by the GPU. 4. The CPU becomes the brain of the system and the GPU becomes the sheer muscle power, leaving the CPU to do what it does best.
5 Is it REALLY possible? 1. Currently the GPU in a computer sits on a PCIe slot surrounded by a few GB of very fast DDR3 DDR 5 memory. 2. It does seem simple enough (and more efficient) to ditch the PCIe slot and put the complete hardware in a tightly coupled arrangement with the CPU. This tight CPU/GPU coupling is AMD s current plan for high performance supercomputing. 3. This technology, rightly called CPU assisted general computing on a GPU is a fused architecture used to allow the CPU and the GPU to collaborate by using a FUSED L3 cache. Additionally the CPU and the GPU will use the same shared off chip memory. 4. This approach increases the computational power of the GPU while taking advantage of the CPU s ability to handle complex tasks and data handling.
6 What makes a GPU so good? 1. GPU s are very good at handling large number of parallel processes. Especially where the same process has to be applied to large amount of data. 2. The long pipelines of GPU s favors the sequential streaming reads, where the number of operations to be done is far greater than the number of memory accesses required. 3. The GPU relies on the CPU s faster memory access to feed the data. 4. This implies that the GPU will have to only access the shared L3 cache, thus reducing the latency caused by GPU memory access.
7 Supercomputing The TITAN super computer uses the AMD OPTERON cores. And the nvidia TESLA series of GPU. 1.The TESLA is based on the new Kepler architecture which is the most recent update from the Fermi architecture. 2.The Kepler architecture is an improvement over Fermi in the sense that the parameters of efficiency, programmability and performance were improved. 3.The AMD OPTERON cores however use the AMD Bulldozer architecture. There are a lot of changes and enhancements over the Intel Xeon architecture that make the Opteron more desirable. 4.The Opteron has an Integrated Memory Controller that controls the CPU access to both the L3 and the main memory. This is as opposed to the Xeon that has 2 buses for Memory Memory and Memory Processor.
8 Right architecture for supercomputing A "module" has 213 million transistors in an area of 30.9 mm² (including the 2MB shared L2 cache). Each "module" has the following independent hardware resources: 2MB of L2 cache per "Module. Two dedicated integer clusters. Two symmetrical 128 bit FMAC floating point pipelines per module that can be unified into one large 256 bitwide unit if one of the integer cores dispatches AVX instruction. All "modules" present share the L3 cache as well as an Advanced Dual Channel Memory Sub System (IMC Integrated Memory Controller). Process technology 11 metal layer 32 nm SOI process. Cache and memory interface Up to 8MB of L3 shared among all Cores on the same silicon die, divided into four sub caches of 2MB each, capable of operating at 2.2 GHz.
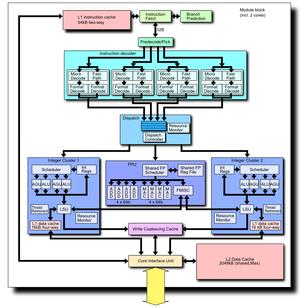
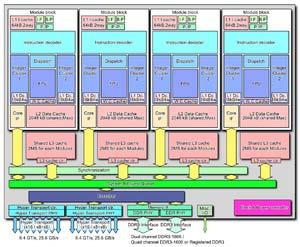
9 Pictorial representation of GPU architecture. a
10 Advantages over the Intel Xeon. 1. The Intel Xeon is the core CPU used in the Tianhe 1A super computer. There are major differences in the way a GPU works, which give it an advantage over the Xeon architecture. 2. In any conventional CPU, including the Xeon. The main memory can be accessed by each individual CPU. The main memory itself is isolated. 3. The GPU architecture however, has a NON UNIFORM MEMORY ACCESS (NUMA). Here, instead of having a unified main memory each core has its own memory. The cores can access the memory of sister cells if needed. This transaction is transparent to the user. 4. Another critical advantage that the GPU cores have over conventional CPU is the use of the Switched Fabric rather than a shared bus. In a Xeon system, the competition for the shared bus causes the efficiency to drop.
11 Switched Fabric? Figure one shows the conventional Shared data bus. It is immediately obvious what problems are faced by this Architecture. Only one instruction can access the bus at a given time. In the world of super computing and Hiper applications this can be a serious bottleneck. For applications that are not very computationally intensive, the shared data bus is a practical and easy to implement solution. But for high performance, the other powerful albeit difficult solution is a Switched fabric. Here each node is connected to a Central fabric board. This way no node is dependent on any other node for the read/write operations.
12 Lots of theory, but are there any practical implementations? Let us consider a typical network analysis problem for supercomputing. The challenge is to keep up with the increased traffic of todays large networks. (all of them dealing with real time data) The network monitoring applications typically depend on : Standard x86 processors. Custom built ASIC. But is it enough? CPU s do not have the sheer compute power required to keep track of large networks. And as a result end up dropping packets. ASIC s can be designed to have sufficient power and memory for the job. But the custom architecture is difficult and expensive to program. So is their ability to work in parallel.
13 What happens when we replace the CPU with a GPU? This is where all the architectural changes of the GPU really shine through. GPU s have high memory bandwidth and easy programmability. The task of monitoring a network means that all data packets have to be read as they cross the network. Which means that the data parallelism is the key requirement. As the name implies GPU s were originally meant to render graphics on a computer. Their architecture, which consists of many cores running in parallel and working in tandem, is perfect for use as coprocessors in tasks that can be made inherently parallel. In the ranking of the top 500 supercomputers at Out of the top 50 computers, 38 of them use nvidia GPU s to boost their performance.
14 How about at a more commercial level? We have considered the advantages of using a GPU for high performance applications. But what about at a consumer level. Do Intel, nvidia and AMD make hybrids between CPU s and GPU s? Let us consider the ultimate's of both the genres. For the GPU we shall consider the nvidia GTX 780 Ti, which is loosely based on the same architecture as the Titan supercomputer. The CPU s are represented by the Intel i7, 4 th generation processor with the Haswell architecture The cost of the GPU is around 650$. The CPU meanwhile costs 350$. Creating a machine that would integrate both the GPU and the CPU would cost around 3500$. This is phenomenal, considering that a suitable Hiper machine should not cost more than 1500$.
 3.5 GHz 3.")
15 Couple of statistics. Processor Number i a # of Cores 4 # of Threads 8 Vs. Clock Speed Max Turbo Frequency Cache Instruction Set Memory Specifications Max Memory Size (dependent on memory type) 3.5 GHz 3.9 GHz 8 MB 64 bit 32 GB Memory Types DDR3 1333/1600 Max Memory Bandwidth 25.6 GB/s values are the original figures. Without overclocking.
16 Problems faced by GPU s There are 3 fundamental problems when using GPU s. 1.Power Consumption This is the biggest concern when integrating GPU s with a CPU. GPU s are immense power sinks. Running so many cores has a disastrous effect on the power efficiency. An i7 4 th gen processor needs 84W of power. In contrast the GTX 780 Ti needs a MINIMUM of 250W and a recommended power supply of 600W. Naturally, the power hungry GPU also poses a huge temperature concern when running over prolonged periods of time. 2.Error detection and correction Mass produced GPU s are usually intended for gaming and it is pointless to engineer them such that they can detect and identify hardware problems. That task is usually performed by a more optimized CPU. However GPU s with this hardware are being developed for Hiper applications.
17 Problems (contd.) 3. The Major GPU manufacturers right now are nvidia and ATI. It is a monumental task for them to take over the market from established CPU manufacturers Intel and AMD. The current feature size of GPU s is nowhere as small as the Haswell, which is at a 22nm size. Unfortunately GPU manufacturers and designers are FABLESS industries which specialize in the design of their products. The actual fabrication is done by third party companies. Decreasing the feature size with this business model is unrealistic, because the smallest they can make is dictated by the manufacturing process of the fabricators. On the other hand, Intel and AMD are full fledged IDM s with their own Fabrication facilities and the capital to cover up an ambitious but doomed project.
18 QUESTIONS??
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
AMD Opteron 4200 Series Processor
 What s new in the AMD Opteron 4200 Series Processor (Codenamed Valencia ) and the new Bulldozer Microarchitecture? Platform Processor Socket Chipset Opteron 4000 Opteron 4200 C32 56x0 / 5100 (codenamed
What s new in the AMD Opteron 4200 Series Processor (Codenamed Valencia ) and the new Bulldozer Microarchitecture? Platform Processor Socket Chipset Opteron 4000 Opteron 4200 C32 56x0 / 5100 (codenamed
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor.
 on a single die. Also called a chip-multiprocessor.") CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
EE 7722 GPU Microarchitecture. Offered by: Prerequisites By Topic: Text EE 7722 GPU Microarchitecture. URL:
 00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Chapter 18 - Multicore Computers
 Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
Six-Core AMD Opteron Processor
 What s you should know about the Six-Core AMD Opteron Processor (Codenamed Istanbul ) Six-Core AMD Opteron Processor Versatility Six-Core Opteron processors offer an optimal mix of performance, energy
What s you should know about the Six-Core AMD Opteron Processor (Codenamed Istanbul ) Six-Core AMD Opteron Processor Versatility Six-Core Opteron processors offer an optimal mix of performance, energy
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Scaling through more cores
 Scaling through more cores From single to multi core by Thomas Walther Seminar on 30.11.2015 1/32 Index 1. Introduction 2. Scaling with single core until 2005 Problems and barriers 3. Solution through
Scaling through more cores From single to multi core by Thomas Walther Seminar on 30.11.2015 1/32 Index 1. Introduction 2. Scaling with single core until 2005 Problems and barriers 3. Solution through
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Parallelism and Concurrency. COS 326 David Walker Princeton University
 Parallelism and Concurrency COS 326 David Walker Princeton University Parallelism What is it? Today's technology trends. How can we take advantage of it? Why is it so much harder to program? Some preliminary
Parallelism and Concurrency COS 326 David Walker Princeton University Parallelism What is it? Today's technology trends. How can we take advantage of it? Why is it so much harder to program? Some preliminary
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
CS 152, Spring 2011 Section 10
 CS 152, Spring 2011 Section 10 Christopher Celio University of California, Berkeley Agenda Stuff (Quiz 4 Prep) http://3dimensionaljigsaw.wordpress.com/2008/06/18/physics-based-games-the-new-genre/ Intel
CS 152, Spring 2011 Section 10 Christopher Celio University of California, Berkeley Agenda Stuff (Quiz 4 Prep) http://3dimensionaljigsaw.wordpress.com/2008/06/18/physics-based-games-the-new-genre/ Intel
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
CS/ECE 217. GPU Architecture and Parallel Programming. Lecture 16: GPU within a computing system
 CS/ECE 217 GPU Architecture and Parallel Programming Lecture 16: GPU within a computing system Objective To understand the major factors that dictate performance when using GPU as an compute co-processor
CS/ECE 217 GPU Architecture and Parallel Programming Lecture 16: GPU within a computing system Objective To understand the major factors that dictate performance when using GPU as an compute co-processor
PC BUILDING PRESENTED BY
 PC BUILDING PRESENTED BY WHAT IS A PC General purpose Personal Computer for individual usage Macintosh 1984 WHAT IS A PC General purpose Personal Computer for individual usage IBM Personal Computer XT
PC BUILDING PRESENTED BY WHAT IS A PC General purpose Personal Computer for individual usage Macintosh 1984 WHAT IS A PC General purpose Personal Computer for individual usage IBM Personal Computer XT
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
ATS-GPU Real Time Signal Processing Software
 Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Vector Engine Processor of SX-Aurora TSUBASA
 Vector Engine Processor of SX-Aurora TSUBASA Shintaro Momose, Ph.D., NEC Deutschland GmbH 9 th October, 2018 WSSP 1 NEC Corporation 2018 Contents 1) Introduction 2) VE Processor Architecture 3) Performance
Vector Engine Processor of SX-Aurora TSUBASA Shintaro Momose, Ph.D., NEC Deutschland GmbH 9 th October, 2018 WSSP 1 NEC Corporation 2018 Contents 1) Introduction 2) VE Processor Architecture 3) Performance
CST STUDIO SUITE R Supported GPU Hardware
 CST STUDIO SUITE R 2017 Supported GPU Hardware 1 Supported Hardware CST STUDIO SUITE currently supports up to 8 GPU devices in a single host system, meaning each number of GPU devices between 1 and 8 is
CST STUDIO SUITE R 2017 Supported GPU Hardware 1 Supported Hardware CST STUDIO SUITE currently supports up to 8 GPU devices in a single host system, meaning each number of GPU devices between 1 and 8 is
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
Chapter 17 - Parallel Processing
 Chapter 17 - Parallel Processing Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 17 - Parallel Processing 1 / 71 Table of Contents I 1 Motivation 2 Parallel Processing Categories
Chapter 17 - Parallel Processing Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 17 - Parallel Processing 1 / 71 Table of Contents I 1 Motivation 2 Parallel Processing Categories
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Intel Enterprise Processors Technology
 Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
ECE 172 Digital Systems. Chapter 15 Turbo Boost Technology. Herbert G. Mayer, PSU Status 8/13/2018
 ECE 172 Digital Systems Chapter 15 Turbo Boost Technology Herbert G. Mayer, PSU Status 8/13/2018 1 Syllabus l Introduction l Speedup Parameters l Definitions l Turbo Boost l Turbo Boost, Actual Performance
ECE 172 Digital Systems Chapter 15 Turbo Boost Technology Herbert G. Mayer, PSU Status 8/13/2018 1 Syllabus l Introduction l Speedup Parameters l Definitions l Turbo Boost l Turbo Boost, Actual Performance
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Distributed Systems. 01. Introduction. Paul Krzyzanowski. Rutgers University. Fall 2013
 Distributed Systems 01. Introduction Paul Krzyzanowski Rutgers University Fall 2013 September 9, 2013 CS 417 - Paul Krzyzanowski 1 What can we do now that we could not do before? 2 Technology advances
Distributed Systems 01. Introduction Paul Krzyzanowski Rutgers University Fall 2013 September 9, 2013 CS 417 - Paul Krzyzanowski 1 What can we do now that we could not do before? 2 Technology advances
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
PacketShader: A GPU-Accelerated Software Router
 PacketShader: A GPU-Accelerated Software Router Sangjin Han In collaboration with: Keon Jang, KyoungSoo Park, Sue Moon Advanced Networking Lab, CS, KAIST Networked and Distributed Computing Systems Lab,
PacketShader: A GPU-Accelerated Software Router Sangjin Han In collaboration with: Keon Jang, KyoungSoo Park, Sue Moon Advanced Networking Lab, CS, KAIST Networked and Distributed Computing Systems Lab,
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
Robert Jamieson. Robs Techie PP Everything in this presentation is at your own risk!
 Robert Jamieson Robs Techie PP Everything in this presentation is at your own risk! PC s Today Basic Setup Hardware pointers PCI Express How will it effect you Basic Machine Setup Set the swap space Min
Robert Jamieson Robs Techie PP Everything in this presentation is at your own risk! PC s Today Basic Setup Hardware pointers PCI Express How will it effect you Basic Machine Setup Set the swap space Min
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
egfx Breakaway Box for AMD and NVIDIA GPUs
 egfx Breakaway Box for AMD and NVIDIA GPUs sonnettech.com /product/egfx-breakaway-box.html High Performance Graphics Card Connect a High-Performance Graphics Card or Other Bandwidth-Hungry PCIe Card to
egfx Breakaway Box for AMD and NVIDIA GPUs sonnettech.com /product/egfx-breakaway-box.html High Performance Graphics Card Connect a High-Performance Graphics Card or Other Bandwidth-Hungry PCIe Card to
Intel released new technology call P6P
 P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Agenda. What is Ryzen? History. Features. Zen Architecture. SenseMI Technology. Master Software. Benchmarks
 Ryzen Agenda What is Ryzen? History Features Zen Architecture SenseMI Technology Master Software Benchmarks The Ryzen Chip What is Ryzen? CPU chip family released by AMD in 2017, which uses their latest
Ryzen Agenda What is Ryzen? History Features Zen Architecture SenseMI Technology Master Software Benchmarks The Ryzen Chip What is Ryzen? CPU chip family released by AMD in 2017, which uses their latest
Best Practices for Setting BIOS Parameters for Performance
 White Paper Best Practices for Setting BIOS Parameters for Performance Cisco UCS E5-based M3 Servers May 2013 2014 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. Page
White Paper Best Practices for Setting BIOS Parameters for Performance Cisco UCS E5-based M3 Servers May 2013 2014 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. Page
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
X-Stream II. Processing Method. Operating System. Hardware Performance. Elements of Processing Speed TECHNICAL BRIEF
 X-Stream II Peter J. Pupalaikis Principal Technologist September 2, 2010 Summary This paper explains how X- Stream II techonlogy improves the speed and responsiveness of LeCroy oscilloscopes. TECHNICAL
X-Stream II Peter J. Pupalaikis Principal Technologist September 2, 2010 Summary This paper explains how X- Stream II techonlogy improves the speed and responsiveness of LeCroy oscilloscopes. TECHNICAL
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Core 2 vs I-series. How Far Have We Really Come?
 Core 2 vs I-series How Far Have We Really Come? Appendix 1. Introduction 2. Road map 3. General specifications 4. Hardware subtleties 5. Technology difference 6. Advantages of the new architecture 7. Conclusion
Core 2 vs I-series How Far Have We Really Come? Appendix 1. Introduction 2. Road map 3. General specifications 4. Hardware subtleties 5. Technology difference 6. Advantages of the new architecture 7. Conclusion
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
PC I/O. May 7, Howard Huang 1
 PC I/O Today wraps up the I/O material with a little bit about PC I/O systems. Internal buses like PCI and ISA are critical. External buses like USB and Firewire are becoming more important. Today also
PC I/O Today wraps up the I/O material with a little bit about PC I/O systems. Internal buses like PCI and ISA are critical. External buses like USB and Firewire are becoming more important. Today also
Higher Level Programming Abstractions for FPGAs using OpenCL
 Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Intel Core i7 Processor
 Intel Core i7 Processor Vishwas Raja 1, Mr. Danish Ather 2 BSc (Hons.) C.S., CCSIT, TMU, Moradabad 1 Assistant Professor, CCSIT, TMU, Moradabad 2 1 vishwasraja007@gmail.com 2 danishather@gmail.com Abstract--The
Intel Core i7 Processor Vishwas Raja 1, Mr. Danish Ather 2 BSc (Hons.) C.S., CCSIT, TMU, Moradabad 1 Assistant Professor, CCSIT, TMU, Moradabad 2 1 vishwasraja007@gmail.com 2 danishather@gmail.com Abstract--The
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
A Comparative Performance Evaluation of Different Application Domains on Server Processor Architectures
 A Comparative Performance Evaluation of Different Application Domains on Server Processor Architectures W.M. Roshan Weerasuriya and D.N. Ranasinghe University of Colombo School of Computing A Comparative
A Comparative Performance Evaluation of Different Application Domains on Server Processor Architectures W.M. Roshan Weerasuriya and D.N. Ranasinghe University of Colombo School of Computing A Comparative
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
(software agnostic) Computational Considerations
 Computational Considerations") (software agnostic) Computational Considerations The Issues CPU GPU Emerging - FPGA, Phi, Nervana Storage Networking CPU 2 Threads core core Processor/Chip Processor/Chip Computer CPU Threads vs. Cores
(software agnostic) Computational Considerations The Issues CPU GPU Emerging - FPGA, Phi, Nervana Storage Networking CPU 2 Threads core core Processor/Chip Processor/Chip Computer CPU Threads vs. Cores
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
CyberServe Atom Servers
 DA TA S HE E T S CyberServe Atom Servers Release Date: Q1 2019 Suitable For: Storage Appliance, Network Appliance Tags: CyberServe, Intel Atom Introduction: Perfect appliance servers, the CyberServe range
DA TA S HE E T S CyberServe Atom Servers Release Date: Q1 2019 Suitable For: Storage Appliance, Network Appliance Tags: CyberServe, Intel Atom Introduction: Perfect appliance servers, the CyberServe range
The Dell Precision T3620 tower as a Smart Client leveraging GPU hardware acceleration
 The Dell Precision T3620 tower as a Smart Client leveraging GPU hardware acceleration Dell IP Video Platform Design and Calibration Lab June 2018 H17415 Reference Architecture Dell EMC Solutions Copyright
The Dell Precision T3620 tower as a Smart Client leveraging GPU hardware acceleration Dell IP Video Platform Design and Calibration Lab June 2018 H17415 Reference Architecture Dell EMC Solutions Copyright
Processor Architectures
 ECPE 170 Jeff Shafer University of the Pacific Processor Architectures 2 Schedule Exam 3 Tuesday, December 6 th Caches Virtual Memory Input / Output OperaKng Systems Compilers & Assemblers Processor Architecture
ECPE 170 Jeff Shafer University of the Pacific Processor Architectures 2 Schedule Exam 3 Tuesday, December 6 th Caches Virtual Memory Input / Output OperaKng Systems Compilers & Assemblers Processor Architecture
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
Improving Packet Processing Performance of a Memory- Bounded Application
 Improving Packet Processing Performance of a Memory- Bounded Application Jörn Schumacher CERN / University of Paderborn, Germany jorn.schumacher@cern.ch On behalf of the ATLAS FELIX Developer Team LHCb
Improving Packet Processing Performance of a Memory- Bounded Application Jörn Schumacher CERN / University of Paderborn, Germany jorn.schumacher@cern.ch On behalf of the ATLAS FELIX Developer Team LHCb
소프트웨어기반고성능침입탐지시스템설계및구현
 소프트웨어기반고성능침입탐지시스템설계및구현 KyoungSoo Park Department of Electrical Engineering, KAIST M. Asim Jamshed *, Jihyung Lee*, Sangwoo Moon*, Insu Yun *, Deokjin Kim, Sungryoul Lee, Yung Yi* Department of Electrical
소프트웨어기반고성능침입탐지시스템설계및구현 KyoungSoo Park Department of Electrical Engineering, KAIST M. Asim Jamshed *, Jihyung Lee*, Sangwoo Moon*, Insu Yun *, Deokjin Kim, Sungryoul Lee, Yung Yi* Department of Electrical
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
VIA Apollo P4X400 Chipset. Enabling Total System Performance
 VIA Apollo P4X400 Chipset Enabling Total System Performance High performance DDR400 chipset platform for the Intel Pentium 4 processor Page 1 Introduction The VIA Apollo P4X400 is a core logic chipset
VIA Apollo P4X400 Chipset Enabling Total System Performance High performance DDR400 chipset platform for the Intel Pentium 4 processor Page 1 Introduction The VIA Apollo P4X400 is a core logic chipset
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
An Introduction to Graphical Processing Unit
 Vol.1, Issue.2, pp-358-363 ISSN: 2249-6645 An Introduction to Graphical Processing Unit Jayshree Ghorpade 1, Jitendra Parande 2, Rohan Kasat 3, Amit Anand 4 1 (Department of Computer Engineering, MITCOE,
Vol.1, Issue.2, pp-358-363 ISSN: 2249-6645 An Introduction to Graphical Processing Unit Jayshree Ghorpade 1, Jitendra Parande 2, Rohan Kasat 3, Amit Anand 4 1 (Department of Computer Engineering, MITCOE,
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
POST-SIEVING ON GPUs
 POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there