GPU Cluster Computing. Advanced Computing Center for Research and Education
|
|
|
- Nicholas Cross
- 6 years ago
- Views:
Transcription


1 GPU Cluster Computing Advanced Computing Center for Research and Education 1
2 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of GPU(s) to solve scien3fic compu3ng problem. Due to their massive- parallel architecture, using GPUs enables the comple3on of computa3onally intensive assignments much faster compared with conven3onal CPUs! Hybrid CPU- GPU system: GPU: Computa3onally- intensive (massively parallel) part CPU: sequen3al part 2
3 GPU Performance Image taken from CUDA Programming Guide 3
4 GPU Performance Image taken from CUDA Programming Guide 4
 More transistors can be devoted to data processing")
5 Why is the GPU So Fast? The GPU is specialized for compute- intensive, highly data parallel computa3on (owing to its graphics rendering origin) More transistors can be devoted to data processing rather than data caching and control flow Where are GPUs good: high arithme3c intensity (the ra3o between arithme3c opera3ons and memory opera3ons) 5
6 Generic Multicore Chip Processor Memory Processor Memory Global&Memory& Handful of processors each suppor3ng ~1 hardware thread On- chip memory near processors (registers, cache) Shared global memory space (external DRAM) 6
7 Generic Manycore Chip Processor Memory Processor Memory Global&Memory& Many processors each suppor3ng many hardware threads On- chip memory near processors (register, cache, RAM) Shared global memory space (external DRAM) 7

 Multicore CPU!")
8 Heterogeneous Typically GPU and CPU coexist in a heterogeneous sesng Less computa3onally intensive part runs on CPU (coarse- grained parallelism), and more intensive parts run on GPU (fine- grained parallelism) Multicore CPU! Manycore GPU!!!! 8



9 GPUs GPU is typically a computer card, installed into a PCI Express slot Market leaders: NVIDIA, AMD (ATI) Example NVIDIA GPUs GeForce'GTX'480' Tesla&2070& 9
10 NVIDIA GPU SP:*scalar*processor** CUDA*core * * Executes*one*thread* SM# streaming*mul-processor* 32xSP**(or*16,*48*or*more)* * Fast*local* shared#memory * (shared*between*sps)* 16*KiB*(or*64*KiB)* SM* SP* SP* SP* SP* SP* SP* SP* SP* SP* SP* SP* SP* SP* SP* SP* SP* SHARED* MEMORY** GLOBAL*MEMORY* (ON*DEVICE)* 10
11 NVIDIA GPU GPU: SMs 30 SM on GT200, 15 SM on Fermi For example, GTX 480: 15 SMs x 32 cores = 480 cores on a GPU SM$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SP$ SHARED$ MEMORY$$ GDDR$memory$ $ 512$MiB$0$6$GiB$ GLOBAL$MEMORY$ (ON$DEVICE)$ 11
12 CUDA Programming Model The GPU is viewed as a compute device that: Is a co- processor to the CPU or host Has its own DRAM (device memory, or global memory in CUDA parlance) Runs many threads in parallel Data- parallel por3ons of an applica3on run on the device as kernels which are executed in parallel by many threads Differences between GPU and CPU threads GPU threads are extremely lightweight: very lidle crea3on overhead GPU needs 1000s of threads for full efficiency Mul3- core CPU needs only a few heavy ones 12
13 Software View A master process running on the CPU performs the following steps: Ini3alize card Allocates memory in host and on device Copies data from host to device memory Launches mul3ple blocks of execu3on kernel on device Copies data from device memory to host Repeats 3-5 as needed Deallocates all memory and terminates 13
14 Execution Model Serial'Code' Host' Kernel'A' Device' Serial'Code' Host' Kernel'B' Device' 14
15 Software view Threads launched for a parallel sec3on are par33oned into thread blocks Grid = all blocks for a given launch Thread block is a group of threads that can: Synchronize their execu3on Communicate via shared memory 15
16 Whole Grid Runs on GPU Many blocks of threads... SMEM SMEM SMEM SMEM Global Memory 16
17 Software View - within GPU Each block of the execu3on kernel executes on an SM If the number of blocks exceeds the number of SMs, then more than one will run at a 3me on each SM if there are enough registers and shared memory, and the others will wait in a queue and execute later All threads within one block can access local shared memory but can t see what the other blocks are doing (even if they are on the same SM) There are no guarantees on the order in which the blocks execute 17

18 Software View void function( ) { Allocate memory on the GPU Transfer input data to the GPU Launch kernel on the GPU Transfer output data to CPU }! global void kernel( ) { Code executed on the GPU goes here } CPU CPU Memory GPU Memory GPU 18
19 ACCRE GPU Nodes 48 compute nodes with: Two quad-core 2.4 GHz Intel Nehalem, 48 GB of memory 4 Nvidia GTX Gigabit Ethernet Nvidia GTX Streaming Multiprocessors per GPU 480 Compute cores per GPU Peak performance 1.35 TFLOPS SP / 168 GFLOPS DP Memory Amount 1.5 GB Memory Bandwidth GB/sec 19
20 Software Stack Operating system: CentOS 6 Batch system: SLURM All compilers and tools are available on the GPU gateway (vmps81) type: ssh vunetid@vmps81.accre.vanderbilt.edu OR rsh vmps81 if you re already logged into the cluster GCC, Intel compiler Compute nodes share the same base OS and libraries 20
21 CUDA Architecture Based on C with some extensions C++ support increasing steadily FORTRAN support provided by PGI compiler Lots of example code and good documenta3on Large user community on NVIDIA forums 21
22 CUDA Components Driver Low- level sokware that controls the graphics card Compute Capability Refers to the GPU architecture, and features supported by hardware Toolkit (CUDA version) nvcc CUDA compiler, libraries, profiling/debugging tools SDK (Sokware Development Kit) Lots of demonstra3on examples Some error- checking u3li3es Not officially supported by NVIDIA Almost no documenta3on 22
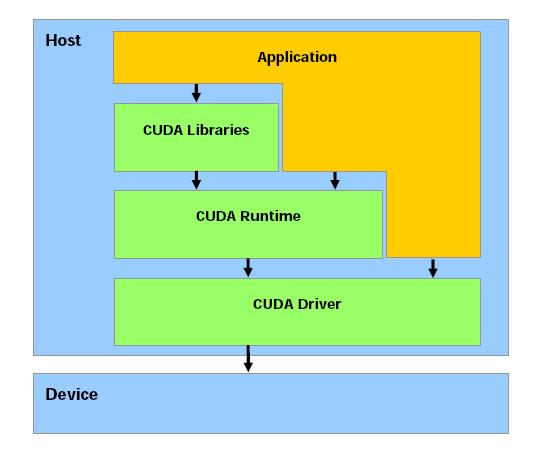
23 CUDA Architecture 23
24 CUDA Toolkit Installed at /usr/local/cuda To compile CUDA program:! export PATH="/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH="/usr/local/cuda/lib64:/usr/local/cuda/lib:LD_LIBRARY_PATH! Source files with CUDA language extensions (.cu) must be compiled with nvcc Actually, nvcc is a compile driver Works by invoking all the necessary tools and compilers like gcc, cl,... 24
 can be used to compile programs with no")
25 CUDA Toolkit $ nvcc hello_world.c $ a.out Hello World! $ NVIDIA compiler (nvcc) can be used to compile programs with no device code 25
, processed by NVIDIA compiler - Host functions, e.g. main(), processed by standard host compile, e.g. gcc, cl.")
26 CUDA Toolkit CUDA C/C++ keyword global indicates a function that: - Runs on the device - Called from host (CPU) code nvcc separates source code into host and device components - Device functions, e.g. mykernel(), processed by NVIDIA compiler - Host functions, e.g. main(), processed by standard host compile, e.g. gcc, cl.exe 26
27 CUDA SDK Provides hundreds of code samples to help you get started on the path of writing software with CUDA C/ C++ Code samples covers a wide range of applications and techniques Installed at /opt/nvidia_gpu_computing_sdk on the gpu gateway 27
28 Job Submission Should not ssh to a compute node Must use SLURM to submit jobs Either as batch or interactively Provides exclusive access to a node and all 4 GPUs Must include partition and account information If you need interactive access to a GPU for development or testing: salloc --time=6:00:00 --partition=gpu --account=<mygroup>_gpu! For batch jobs, include these lines: #SBATCH --partition=gpu! #SBATCH --account=<account>_gpu 28
29 GPU Jobs #!/bin/bash #SBATCH #SBATCH --mail-type=all #SBATCH --nodes=1 #SBATCH --ntasks=1 #SBATCH --time=2:00:00 # 2 hours #SBATCH --mem=100m #SBATCH --output=gpu-job.log #SBATCH --partition=gpu #SBATCH --account=accre_gpu # substitute appropriate group here setpkgs -a hoomd pwd date hoomd simple-script.py date Must be in a GPU group and include the --partition and --account options Single job has exclusive rights to allocated node (4 GPUs per node) See example-5 at
30 Getting help from ACCRE website FAQ and Getting Started pages: ACCRE Help Desk: Accre-forum mailing list ACCRE office hours: open a help desk ticket and mention that you would like to work personally with one of us in the office. The person most able to help you with your specific issue will contact you to schedule a date and time for your visit.
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
SLURM: Resource Management and Job Scheduling Software. Advanced Computing Center for Research and Education
 SLURM: Resource Management and Job Scheduling Software Advanced Computing Center for Research and Education www.accre.vanderbilt.edu Simple Linux Utility for Resource Management But it s also a job scheduler!
SLURM: Resource Management and Job Scheduling Software Advanced Computing Center for Research and Education www.accre.vanderbilt.edu Simple Linux Utility for Resource Management But it s also a job scheduler!
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Massively Parallel Computing with CUDA. Carlos Alberto Martínez Angeles Cinvestav-IPN
 Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Kepler Overview Mark Ebersole
 Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
SEASHORE / SARUMAN. Short Read Matching using GPU Programming. Tobias Jakobi
 SEASHORE SARUMAN Summary 1 / 24 SEASHORE / SARUMAN Short Read Matching using GPU Programming Tobias Jakobi Center for Biotechnology (CeBiTec) Bioinformatics Resource Facility (BRF) Bielefeld University
SEASHORE SARUMAN Summary 1 / 24 SEASHORE / SARUMAN Short Read Matching using GPU Programming Tobias Jakobi Center for Biotechnology (CeBiTec) Bioinformatics Resource Facility (BRF) Bielefeld University
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Graham vs legacy systems
 New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
The GPU-Cluster. Sandra Wienke Rechen- und Kommunikationszentrum (RZ) Fotos: Christian Iwainsky
 Fotos: Christian Iwainsky") The GPU-Cluster Sandra Wienke wienke@rz.rwth-aachen.de Fotos: Christian Iwainsky Rechen- und Kommunikationszentrum (RZ) The GPU-Cluster GPU-Cluster: 57 Nvidia Quadro 6000 (29 nodes) innovative computer
The GPU-Cluster Sandra Wienke wienke@rz.rwth-aachen.de Fotos: Christian Iwainsky Rechen- und Kommunikationszentrum (RZ) The GPU-Cluster GPU-Cluster: 57 Nvidia Quadro 6000 (29 nodes) innovative computer
Efficient Memory and Bandwidth Management for Industrial Strength Kirchhoff Migra<on
 Efficient Memory and Bandwidth Management for Industrial Strength Kirchhoff Migra
Efficient Memory and Bandwidth Management for Industrial Strength Kirchhoff Migra
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Introduction to the Cluster
 Follow us on Twitter for important news and updates: @ACCREVandy Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu The Cluster We will be
Follow us on Twitter for important news and updates: @ACCREVandy Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu The Cluster We will be
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Duke Compute Cluster Workshop. 11/10/2016 Tom Milledge h:ps://rc.duke.edu/
 Duke Compute Cluster Workshop 11/10/2016 Tom Milledge h:ps://rc.duke.edu/ rescompu>ng@duke.edu Outline of talk Overview of Research Compu>ng resources Duke Compute Cluster overview Running interac>ve and
Duke Compute Cluster Workshop 11/10/2016 Tom Milledge h:ps://rc.duke.edu/ rescompu>ng@duke.edu Outline of talk Overview of Research Compu>ng resources Duke Compute Cluster overview Running interac>ve and
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
RWTH GPU-Cluster. Sandra Wienke March Rechen- und Kommunikationszentrum (RZ) Fotos: Christian Iwainsky
 Fotos: Christian Iwainsky") RWTH GPU-Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de March 2012 Rechen- und Kommunikationszentrum (RZ) The GPU-Cluster GPU-Cluster: 57 Nvidia Quadro 6000 (29 nodes) innovative
RWTH GPU-Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de March 2012 Rechen- und Kommunikationszentrum (RZ) The GPU-Cluster GPU-Cluster: 57 Nvidia Quadro 6000 (29 nodes) innovative
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1
![Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1](/thumbs/87/95383144.jpg "Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1") Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de
Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
Introduction to the Cluster
 Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu Follow us on Twitter for important news and updates: @ACCREVandy The Cluster We will be
Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu Follow us on Twitter for important news and updates: @ACCREVandy The Cluster We will be
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
How to run a job on a Cluster?
 How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
Network Coding: Theory and Applica7ons
 Network Coding: Theory and Applica7ons PhD Course Part IV Tuesday 9.15-12.15 18.6.213 Muriel Médard (MIT), Frank H. P. Fitzek (AAU), Daniel E. Lucani (AAU), Morten V. Pedersen (AAU) Plan Hello World! Intra
Network Coding: Theory and Applica7ons PhD Course Part IV Tuesday 9.15-12.15 18.6.213 Muriel Médard (MIT), Frank H. P. Fitzek (AAU), Daniel E. Lucani (AAU), Morten V. Pedersen (AAU) Plan Hello World! Intra
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU Programming with CUDA. Pedro Velho
 GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Introduction to GPU Programming
 Introduction to GPU Programming Volodymyr (Vlad) Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) Tutorial Goals Become familiar with
Introduction to GPU Programming Volodymyr (Vlad) Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) Tutorial Goals Become familiar with
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
GPU Computing with Fornax. Dr. Christopher Harris
 GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT HARDWARE PLATFORMS
 Computer Science 14 (4) 2013 http://dx.doi.org/10.7494/csci.2013.14.4.679 Dominik Żurek Marcin Pietroń Maciej Wielgosz Kazimierz Wiatr THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT
Computer Science 14 (4) 2013 http://dx.doi.org/10.7494/csci.2013.14.4.679 Dominik Żurek Marcin Pietroń Maciej Wielgosz Kazimierz Wiatr THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
Duke Compute Cluster Workshop. 3/28/2018 Tom Milledge rc.duke.edu
 Duke Compute Cluster Workshop 3/28/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
Duke Compute Cluster Workshop 3/28/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
CUDA. GPU Computing. K. Cooper 1. 1 Department of Mathematics. Washington State University
 GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
Sherlock for IBIIS. William Law Stanford Research Computing
 Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Parallelizing FPGA Technology Mapping using GPUs. Doris Chen Deshanand Singh Aug 31 st, 2010
 Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
Real-Time Support for GPU. GPU Management Heechul Yun
 Real-Time Support for GPU GPU Management Heechul Yun 1 This Week Topic: Real-Time Support for General Purpose Graphic Processing Unit (GPGPU) Today Background Challenges Real-Time GPU Management Frameworks
Real-Time Support for GPU GPU Management Heechul Yun 1 This Week Topic: Real-Time Support for General Purpose Graphic Processing Unit (GPGPU) Today Background Challenges Real-Time GPU Management Frameworks
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)