Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
|
|
|
- Tamsin McKinney
- 6 years ago
- Views:
Transcription
1 Roadrunner By Diana Lleva Julissa Campos Justina Tandar
2 Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization
3 Roadrunner Background Currently fastest supercomputer in the world Completed in Phase Project: 1 Base System 76 Teraflops 2 Advanced algorithms evaluate cell 3 Roadrunner 1.3 Petaflops, cell clustered, Opteron Cluster
4 Roadrunner at a Glance Structure: 6,912 AMD Opteron 2210 Processors 12,960 IBM PowerXCell 8i cells Speed: 1.71 petaflops(peak) Rank: 1 (Top500) as of June 2008 Cost: $133 M Memory: TiB Power: 2.35 MW

5
6 On-Chip Interconnect
7 On-Chip Interconnect
8 Power Processor Element (PPE) 1 PPE/chip 1 IBM s VMX unit 32k L1 Cache 512k L2 Cache 2 way simultaneous multithreading
9 On-Chip Interconnect
10 Synergistic Processing Elements (SPE) 8 SPE s/chip 128 bit SIMD ISA 128x128 bit Register File 256k Local Store 1 Memory Flow Controller Isolation Mode (Security)
11 On-Chip Interconnect
12 Element Interconnect Bus (EIB) 1 bus/chip Bandwidth: 96 B/cycle Four 16 B data rings for internal communication Data port supports 25.6 GB/sec in each direction Command bus supports: GB/sec coherent commands GB/sec between units

13 EIB Example of EIB running 8 transactions concurrently
14 On-Chip Interconnect
15 System Memory Interface Memory Controller & RambusXDRAM Interface Bandwidth: 16 B/cycle Speed: 25.6 GB/s

16 On-Chip Interconnect
17 Input/Output Interface I/O Controller & Rambus FlexIO Bandwidth: 2*(16 B/cycle)
18 Number of Cores 6,912 dual-core AMD Opteronprocessors and 12,960 of IBM s Cell edpaccelerators Not including the cores in the operations and communication nodes: 6,120 Opteron(2 cores) + 12,240 PowerXCell8i (9 cores) = 122,400 cores
19 Pipeline Organization 6 Stages In-order Execution Dual Issue Pipeline 2 Pipes In case of instruction swap Single issue 9 Units per Pipeline
20 Pipeline Organization Floating-Point Unit Permute Unit 16 B/cycle Fixed-Point Unit Load-Store Unit Branch Unit Channel Unit Local Store (256 kb) Single Port SRAM 16 B/cycle 16 B/cycle Result Forwarding and Staging Register File 8 B/cycle Instruction Issue Unit/Instruction Line Buffer 64 B/cycle 128B Read 128B Write 8 B/cycle DMA Unit
21 Pipeline Organization
22 Pipeline Organization Permute Unit
23 Pipeline Organization Load-Store Unit
24 Pipeline Organization Channel Unit Branch Unit
25 Pipeline Organization Floating Point Unit Fixed Point Unit Note: These are not the only locations for these units
26 Instruction Issue Unit Pipeline Organization

27 Pipeline Organization Register File Unit

28 *More detailed look into the pipeline Pipeline Organization
29 SPE& PPE Cell/B.E.
30 SPE & PPE This implementation was based on issues of memory latency PPE has 32 KB L1 instruction and data caches PPE has 512 KB L2 unified (instruction and data) cache Each SPE'sDMA controllers can maintain up to 16 DMA transfers in flight simultaneously
31 PPE vs. SPE PPE: Accesses memory like a conventional processor Uses load and store commands Moves data between main storage and registers SPE: Uses direct memory access commands Moves data between main storage and a private local memory
32 PPE vs. SPE PPE: Faster at task switching SPE: More adept at compute intensive tasks Specialization is a factor for improvement in performance and power efficiency

33 Double Buffering DMA commands are processed in parallel with software execution


34 SIMD Organization IBM PowerXCell8i: 8 Synergistic Processor Elements (SPE) + 1 PowerPC Processing Elements (PPE)
35 Synergistic Processing Elements Optimized for computing intensive code using SIMD Lots of SIMD registers (128 x 128-bit) Operations (per cycle): sixteen 8-bit integers eight 16-bit integers four 32-bit integers four single-precision floating-point numbers
36 PowerPC Processing Elements Optimized for control intensive code VMX SIMD unit: 128-bit SIMD register Operations (per cycle): sixteen 8-bit integers eight 16-bit integers four 32-bit integers
37 SIMD in VMX and SPE 128 bit-wide datapath 128 bit-wide registers
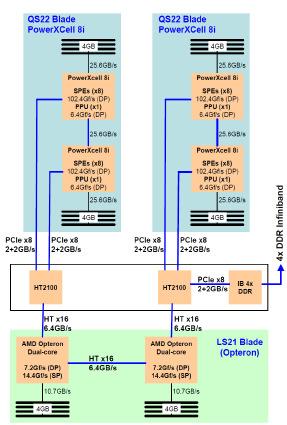
38 TriBlade One IBM LS21 Opteronblade Two IBM BladeCenter QS22 Cell/B.E. blades One blade that houses the communications fabric for the compute node
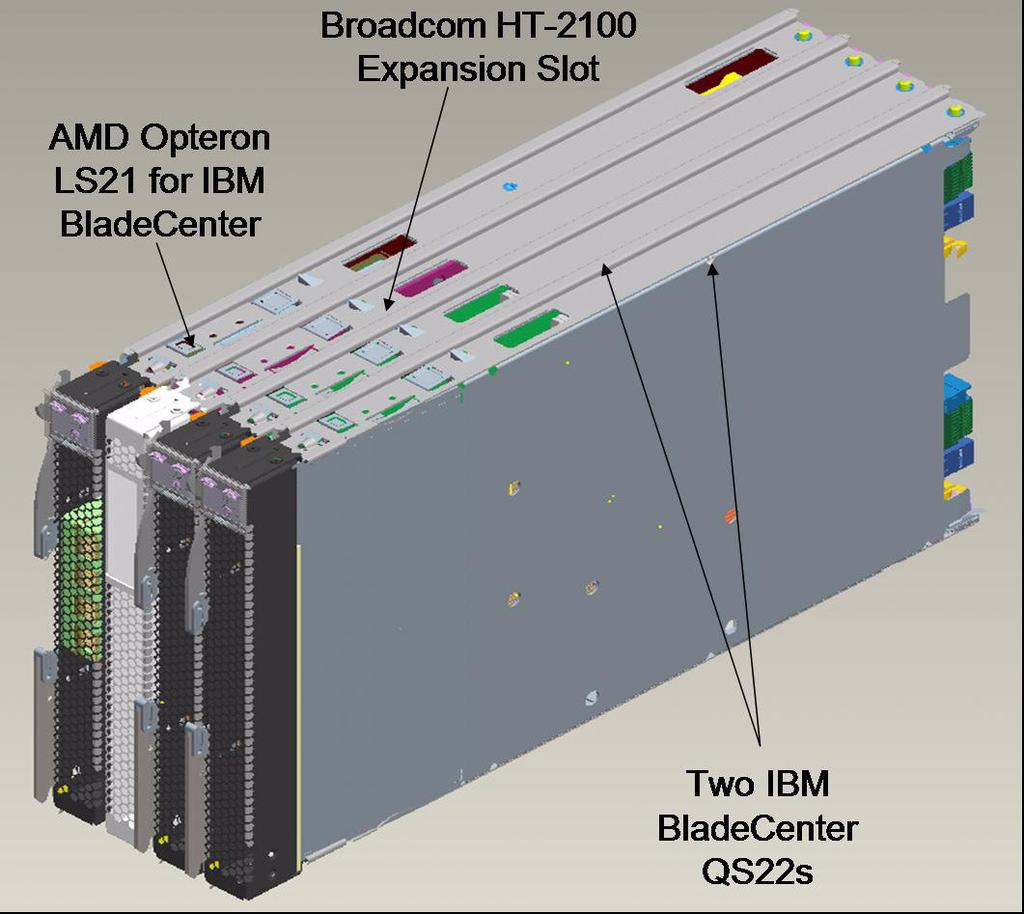
39 TriBlade
40 TriBlade
41 TriBlade One Cell/B.E. chip for each Opteroncore Hierarchy: Opteronprocessors establish a master-subordinate relationship with the Cell/B.E. processors. Each TriBladenode is capable of 400 gigaflops of double precision compute power
42 Multithreading Threads alternate fetch and dispatch cycles To run multithreaded programs, multiple SPEs run simultaneously Usually, these programs create and organize the SPE threads as needed Each SPE supports one thread The PPE can support two threads without a program creating them
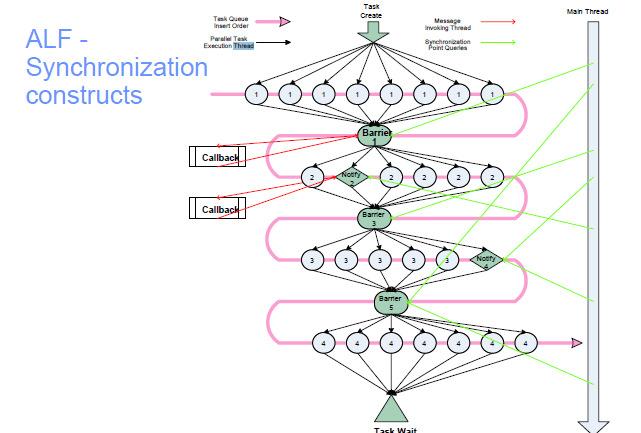
43 Multithreading
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
Cell Broadband Engine. Spencer Dennis Nicholas Barlow
 Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
Cell Processor and Playstation 3
 Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Amir Khorsandi Spring 2012
 Introduction to Amir Khorsandi Spring 2012 History Motivation Architecture Software Environment Power of Parallel lprocessing Conclusion 5/7/2012 9:48 PM ٢ out of 37 5/7/2012 9:48 PM ٣ out of 37 IBM, SCEI/Sony,
Introduction to Amir Khorsandi Spring 2012 History Motivation Architecture Software Environment Power of Parallel lprocessing Conclusion 5/7/2012 9:48 PM ٢ out of 37 5/7/2012 9:48 PM ٣ out of 37 IBM, SCEI/Sony,
Technology Trends Presentation For Power Symposium
 Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
High Performance Computing: Blue-Gene and Road Runner. Ravi Patel
 High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
( ZIH ) Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems
 Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems") ( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Sony/Toshiba/IBM (STI) CELL Processor. Scientific Computing for Engineers: Spring 2008
 CELL Processor. Scientific Computing for Engineers: Spring 2008") Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
Revisiting Parallelism
 Revisiting Parallelism Sudhakar Yalamanchili, Georgia Institute of Technology Where Are We Headed? MIPS 1000000 Multi-Threaded, Multi-Core 100000 Multi Threaded 10000 Era of Speculative, OOO 1000 Thread
Revisiting Parallelism Sudhakar Yalamanchili, Georgia Institute of Technology Where Are We Headed? MIPS 1000000 Multi-Threaded, Multi-Core 100000 Multi Threaded 10000 Era of Speculative, OOO 1000 Thread
A Brief View of the Cell Broadband Engine
 A Brief View of the Cell Broadband Engine Cris Capdevila Adam Disney Yawei Hui Alexander Saites 02 Dec 2013 1 Introduction The cell microprocessor, also known as the Cell Broadband Engine (CBE), is a Power
A Brief View of the Cell Broadband Engine Cris Capdevila Adam Disney Yawei Hui Alexander Saites 02 Dec 2013 1 Introduction The cell microprocessor, also known as the Cell Broadband Engine (CBE), is a Power
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Xbox 360 high-level architecture
 11/2/11 Xbox 360 s Xenon vs. Playstation 3 s Cell Both chips clocked at a 3.2 GHz Architectural Comparison: Xbox 360 vs. Playstation 3 Prof. Aaron Lanterman School of Electrical and Computer Engineering
11/2/11 Xbox 360 s Xenon vs. Playstation 3 s Cell Both chips clocked at a 3.2 GHz Architectural Comparison: Xbox 360 vs. Playstation 3 Prof. Aaron Lanterman School of Electrical and Computer Engineering
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to Computing and Systems Architecture
 Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP
 Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
arxiv: v1 [astro-ph.im] 2 Feb 2017
![arxiv: v1 [astro-ph.im] 2 Feb 2017](/thumbs/75/71806990.jpg "arxiv: v1 [astro-ph.im] 2 Feb 2017") International Journal of Parallel Programming manuscript No. (will be inserted by the editor) Correlating Radio Astronomy Signals with Many-Core Hardware Rob V. van Nieuwpoort John W. Romein arxiv:1702.00844v1
International Journal of Parallel Programming manuscript No. (will be inserted by the editor) Correlating Radio Astronomy Signals with Many-Core Hardware Rob V. van Nieuwpoort John W. Romein arxiv:1702.00844v1
Memory Architectures. Week 2, Lecture 1. Copyright 2009 by W. Feng. Based on material from Matthew Sottile.
 Week 2, Lecture 1 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. Directory-Based Coherence Idea Maintain pointers instead of simple states with each cache block. Ingredients Data owners
Week 2, Lecture 1 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. Directory-Based Coherence Idea Maintain pointers instead of simple states with each cache block. Ingredients Data owners
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
QDP++/Chroma on IBM PowerXCell 8i Processor
 QDP++/Chroma on IBM PowerXCell 8i Processor Frank Winter (QCDSF Collaboration) frank.winter@desy.de University Regensburg NIC, DESY-Zeuthen STRONGnet 2010 Conference Hadron Physics in Lattice QCD Paphos,
QDP++/Chroma on IBM PowerXCell 8i Processor Frank Winter (QCDSF Collaboration) frank.winter@desy.de University Regensburg NIC, DESY-Zeuthen STRONGnet 2010 Conference Hadron Physics in Lattice QCD Paphos,
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
1. Microprocessor Architectures. 1.1 Intel 1.2 Motorola
 1. Microprocessor Architectures 1.1 Intel 1.2 Motorola 1.1 Intel The Early Intel Microprocessors The first microprocessor to appear in the market was the Intel 4004, a 4-bit data bus device. This device
1. Microprocessor Architectures 1.1 Intel 1.2 Motorola 1.1 Intel The Early Intel Microprocessors The first microprocessor to appear in the market was the Intel 4004, a 4-bit data bus device. This device
Scheduling streaming applications on a complex multicore platform
 Scheduling streaming applications on a complex multicore platform Tudor David 1 Mathias Jacquelin 2 Loris Marchal 2 1 Technical University of Cluj-Napoca, Romania 2 LIP laboratory, UMR 5668, ENS Lyon CNRS
Scheduling streaming applications on a complex multicore platform Tudor David 1 Mathias Jacquelin 2 Loris Marchal 2 1 Technical University of Cluj-Napoca, Romania 2 LIP laboratory, UMR 5668, ENS Lyon CNRS
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Software Development Kit for Multicore Acceleration Version 3.0
 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
The Pennsylvania State University. The Graduate School. College of Engineering A NEURAL NETWORK BASED CLASSIFIER ON THE CELL BROADBAND ENGINE
 The Pennsylvania State University The Graduate School College of Engineering A NEURAL NETWORK BASED CLASSIFIER ON THE CELL BROADBAND ENGINE A Thesis in Electrical Engineering by Srijith Rajamohan 2009
The Pennsylvania State University The Graduate School College of Engineering A NEURAL NETWORK BASED CLASSIFIER ON THE CELL BROADBAND ENGINE A Thesis in Electrical Engineering by Srijith Rajamohan 2009
Portable Parallel Programming for Multicore Computing
 Portable Parallel Programming for Multicore Computing? Vivek Sarkar Rice University vsarkar@rice.edu FPU ISU ISU FPU IDU FXU FXU IDU IFU BXU U U IFU BXU L2 L2 L2 L3 D Acknowledgments Rice Habanero Multicore
Portable Parallel Programming for Multicore Computing? Vivek Sarkar Rice University vsarkar@rice.edu FPU ISU ISU FPU IDU FXU FXU IDU IFU BXU U U IFU BXU L2 L2 L2 L3 D Acknowledgments Rice Habanero Multicore
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
Interconnection of Clusters of Various Architectures in Grid Systems
 Journal of Applied Computer Science & Mathematics, no. 12 (6) /2012, Suceava Interconnection of Clusters of Various Architectures in Grid Systems 1 Ovidiu GHERMAN, 2 Ioan UNGUREAN, 3 Ştefan G. PENTIUC
Journal of Applied Computer Science & Mathematics, no. 12 (6) /2012, Suceava Interconnection of Clusters of Various Architectures in Grid Systems 1 Ovidiu GHERMAN, 2 Ioan UNGUREAN, 3 Ştefan G. PENTIUC
High Performance Computing. University questions with solution
 High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
Portland State University ECE 588/688. Cray-1 and Cray T3E
 Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Parallel Exact Inference on the Cell Broadband Engine Processor
 Parallel Exact Inference on the Cell Broadband Engine Processor Yinglong Xia and Viktor K. Prasanna {yinglonx, prasanna}@usc.edu University of Southern California http://ceng.usc.edu/~prasanna/ SC 08 Overview
Parallel Exact Inference on the Cell Broadband Engine Processor Yinglong Xia and Viktor K. Prasanna {yinglonx, prasanna}@usc.edu University of Southern California http://ceng.usc.edu/~prasanna/ SC 08 Overview
The Pennsylvania State University. The Graduate School. College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM
 The Pennsylvania State University The Graduate School College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM FOR THE IBM CELL BROADBAND ENGINE A Thesis in Computer Science and Engineering by
The Pennsylvania State University The Graduate School College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM FOR THE IBM CELL BROADBAND ENGINE A Thesis in Computer Science and Engineering by
FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine. David A. Bader, Virat Agarwal
 FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine David A. Bader, Virat Agarwal Cell System Features Heterogeneous multi-core system architecture Power Processor Element for control tasks
FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine David A. Bader, Virat Agarwal Cell System Features Heterogeneous multi-core system architecture Power Processor Element for control tasks
PS3 programming basics. Week 1. SIMD programming on PPE Materials are adapted from the textbook
 PS3 programming basics Week 1. SIMD programming on PPE Materials are adapted from the textbook Overview of the Cell Architecture XIO: Rambus Extreme Data Rate (XDR) I/O (XIO) memory channels The PowerPC
PS3 programming basics Week 1. SIMD programming on PPE Materials are adapted from the textbook Overview of the Cell Architecture XIO: Rambus Extreme Data Rate (XDR) I/O (XIO) memory channels The PowerPC
Parallel Hyperbolic PDE Simulation on Clusters: Cell versus GPU
 Parallel Hyperbolic PDE Simulation on Clusters: Cell versus GPU Scott Rostrup and Hans De Sterck Department of Applied Mathematics, University of Waterloo, Waterloo, Ontario, N2L 3G1, Canada Abstract Increasingly,
Parallel Hyperbolic PDE Simulation on Clusters: Cell versus GPU Scott Rostrup and Hans De Sterck Department of Applied Mathematics, University of Waterloo, Waterloo, Ontario, N2L 3G1, Canada Abstract Increasingly,
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Introduction to the Cell multiprocessor
 Introduction to the Cell multiprocessor This paper provides an introductory overview of the Cell multiprocessor. Cell represents a revolutionary extension of conventional microprocessor architecture and
Introduction to the Cell multiprocessor This paper provides an introductory overview of the Cell multiprocessor. Cell represents a revolutionary extension of conventional microprocessor architecture and
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
IBM HPC DIRECTIONS. Dr Don Grice. ECMWF Workshop November, IBM Corporation
 IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
Parallel Computer Architecture - Basics -
 Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
Programming for Performance on the Cell BE processor & Experiences at SSSU. Sri Sathya Sai University
 Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
High-Performance Modular Multiplication on the Cell Broadband Engine
 High-Performance Modular Multiplication on the Cell Broadband Engine Joppe W. Bos Laboratory for Cryptologic Algorithms EPFL, Lausanne, Switzerland joppe.bos@epfl.ch 1 / 21 Outline Motivation and previous
High-Performance Modular Multiplication on the Cell Broadband Engine Joppe W. Bos Laboratory for Cryptologic Algorithms EPFL, Lausanne, Switzerland joppe.bos@epfl.ch 1 / 21 Outline Motivation and previous
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Evaluating Multicore Architectures for Application in High Assurance Systems
 Evaluating Multicore Architectures for Application in High Assurance Systems Ryan Bradetich, Paul Oman, Jim Alves-Foss, and Theora Rice Center for Secure and Dependable Systems University of Idaho Contact:
Evaluating Multicore Architectures for Application in High Assurance Systems Ryan Bradetich, Paul Oman, Jim Alves-Foss, and Theora Rice Center for Secure and Dependable Systems University of Idaho Contact:
Cell Broadband Engine Overview
 Cell Broadband Engine Overview Course Code: L1T1H1-02 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn An overview of Cell history Cell microprocessor highlights Hardware architecture
Cell Broadband Engine Overview Course Code: L1T1H1-02 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn An overview of Cell history Cell microprocessor highlights Hardware architecture
Lecture 8: RISC & Parallel Computers. Parallel computers
 Lecture 8: RISC & Parallel Computers RISC vs CISC computers Parallel computers Final remarks Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation in computer
Lecture 8: RISC & Parallel Computers RISC vs CISC computers Parallel computers Final remarks Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation in computer
Xbox 360 Architecture. Lennard Streat Samuel Echefu
 Xbox 360 Architecture Lennard Streat Samuel Echefu Overview Introduction Hardware Overview CPU Architecture GPU Architecture Comparison Against Competing Technologies Implications of Technology Introduction
Xbox 360 Architecture Lennard Streat Samuel Echefu Overview Introduction Hardware Overview CPU Architecture GPU Architecture Comparison Against Competing Technologies Implications of Technology Introduction
Final Lecture. A few minutes to wrap up and add some perspective
 Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Portland State University ECE 588/688. IBM Power4 System Microarchitecture
 Portland State University ECE 588/688 IBM Power4 System Microarchitecture Copyright by Alaa Alameldeen 2018 IBM Power4 Design Principles SMP optimization Designed for high-throughput multi-tasking environments
Portland State University ECE 588/688 IBM Power4 System Microarchitecture Copyright by Alaa Alameldeen 2018 IBM Power4 Design Principles SMP optimization Designed for high-throughput multi-tasking environments
Applications on emerging paradigms in parallel computing
 Graduate Theses and Dissertations Iowa State University Capstones, Theses and Dissertations 2010 Applications on emerging paradigms in parallel computing Abhinav Sarje Iowa State University Follow this
Graduate Theses and Dissertations Iowa State University Capstones, Theses and Dissertations 2010 Applications on emerging paradigms in parallel computing Abhinav Sarje Iowa State University Follow this
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
Cell Programming Tips & Techniques
 Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
CS4961 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/30/11. Administrative UPDATE. Mary Hall August 30, 2011
 CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
QDP++ on Cell BE WEI WANG. June 8, 2009
 QDP++ on Cell BE WEI WANG June 8, 2009 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2009 Abstract The Cell BE provides large peak floating point performance with
QDP++ on Cell BE WEI WANG June 8, 2009 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2009 Abstract The Cell BE provides large peak floating point performance with
Towards Efficient Video Compression Using Scalable Vector Graphics on the Cell Broadband Engine
 Towards Efficient Video Compression Using Scalable Vector Graphics on the Cell Broadband Engine Andreea Sandu, Emil Slusanschi, Alin Murarasu, Andreea Serban, Alexandru Herisanu, Teodor Stoenescu University
Towards Efficient Video Compression Using Scalable Vector Graphics on the Cell Broadband Engine Andreea Sandu, Emil Slusanschi, Alin Murarasu, Andreea Serban, Alexandru Herisanu, Teodor Stoenescu University
Spring 2010 Prof. Hyesoon Kim. AMD presentations from Richard Huddy and Michael Doggett
 Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Spring 2010 Prof. Hyesoon Kim AMD presentations from Richard Huddy and Michael Doggett Radeon 2900 2600 2400 Stream Processors 320 120 40 SIMDs 4 3 2 Pipelines 16 8 4 Texture Units 16 8 4 Render Backens
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
POWER7: IBM's Next Generation Server Processor
 POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
CISC 879 Software Support for Multicore Architectures Spring Student Presentation 6: April 8. Presenter: Pujan Kafle, Deephan Mohan
 CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
POWER6 Processor and Systems
 POWER6 Processor and Systems Jim McInnes jimm@ca.ibm.com Compiler Optimization IBM Canada Toronto Software Lab Role I am a Technical leader in the Compiler Optimization Team Focal point to the hardware
POWER6 Processor and Systems Jim McInnes jimm@ca.ibm.com Compiler Optimization IBM Canada Toronto Software Lab Role I am a Technical leader in the Compiler Optimization Team Focal point to the hardware
Modeling Advanced Collective Communication Algorithms on Cell-based Systems
 Modeling Advanced Collective Communication Algorithms on Cell-based Systems Qasim Ali, Samuel P. Midkiff and Vijay S. Pai School of Electrical and Computer Engineering, Purdue University {qali, smidkiff,
Modeling Advanced Collective Communication Algorithms on Cell-based Systems Qasim Ali, Samuel P. Midkiff and Vijay S. Pai School of Electrical and Computer Engineering, Purdue University {qali, smidkiff,
PowerPC 740 and 750
 368 floating-point registers. A reorder buffer with 16 elements is used as well to support speculative execution. The register file has 12 ports. Although instructions can be executed out-of-order, in-order
368 floating-point registers. A reorder buffer with 16 elements is used as well to support speculative execution. The register file has 12 ports. Although instructions can be executed out-of-order, in-order
4. Shared Memory Parallel Architectures
 Master rogram (Laurea Magistrale) in Computer cience and Networking High erformance Computing ystems and Enabling latforms Marco Vanneschi 4. hared Memory arallel Architectures 4.4. Multicore Architectures
Master rogram (Laurea Magistrale) in Computer cience and Networking High erformance Computing ystems and Enabling latforms Marco Vanneschi 4. hared Memory arallel Architectures 4.4. Multicore Architectures
IBM Virtual Fabric Architecture
 IBM Virtual Fabric Architecture Seppo Kemivirta Product Manager Finland IBM System x & BladeCenter 2007 IBM Corporation Five Years of Durable Infrastructure Foundation for Success BladeCenter Announced
IBM Virtual Fabric Architecture Seppo Kemivirta Product Manager Finland IBM System x & BladeCenter 2007 IBM Corporation Five Years of Durable Infrastructure Foundation for Success BladeCenter Announced
W H I T E P A P E R W i t h I t s N e w P o w e r X C e l l 8i Product Line, IBM Intends to Take Accelerated Processing into the HPC Mainstream
 W H I T E P A P E R W i t h I t s N e w P o w e r X C e l l 8i Product Line, IBM Intends to Take Accelerated Processing into the HPC Mainstream Sponsored by: IBM Richard Walsh Earl C. Joseph, Ph.D. August
W H I T E P A P E R W i t h I t s N e w P o w e r X C e l l 8i Product Line, IBM Intends to Take Accelerated Processing into the HPC Mainstream Sponsored by: IBM Richard Walsh Earl C. Joseph, Ph.D. August
PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors
 PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors Peter Sandon Senior PowerPC Processor Architect IBM Microelectronics All information in these materials is subject to
PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors Peter Sandon Senior PowerPC Processor Architect IBM Microelectronics All information in these materials is subject to
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Memory Organization Part II
 ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Organization Part II Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn,
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Organization Part II Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn,
Ray Tracing on the Cell Processor
 Ray Tracing on the Cell Processor Carsten Benthin Ingo Wald Michael Scherbaum Heiko Friedrich intrace Realtime Ray Tracing GmbH SCI Institute, University of Utah Saarland University {benthin, scherbaum}@intrace.com,
Ray Tracing on the Cell Processor Carsten Benthin Ingo Wald Michael Scherbaum Heiko Friedrich intrace Realtime Ray Tracing GmbH SCI Institute, University of Utah Saarland University {benthin, scherbaum}@intrace.com,
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Driving a Hybrid in the Fast-lane: The Petascale Roadrunner System at Los Alamos
 COMPUTER, COMPUTATIONAL & STATISTICAL SCIENCES PAL LA-UR 0-06343 Driving a Hybrid in the Fast-lane: The Petascale Roadrunner System at Los Alamos Darren J. Kerbyson Performance and Architecture Laboratory
COMPUTER, COMPUTATIONAL & STATISTICAL SCIENCES PAL LA-UR 0-06343 Driving a Hybrid in the Fast-lane: The Petascale Roadrunner System at Los Alamos Darren J. Kerbyson Performance and Architecture Laboratory
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
CONSOLE ARCHITECTURE
 CONSOLE ARCHITECTURE Introduction Part 1 What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design What
CONSOLE ARCHITECTURE Introduction Part 1 What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design What
Computer Organization
 INF 101 Fundamental Information Technology Computer Organization Assistant Prof. Dr. Turgay ĐBRĐKÇĐ Course slides are adapted from slides provided by Addison-Wesley Computing Fundamentals of Information
INF 101 Fundamental Information Technology Computer Organization Assistant Prof. Dr. Turgay ĐBRĐKÇĐ Course slides are adapted from slides provided by Addison-Wesley Computing Fundamentals of Information