Visual Perception for Autonomous Driving on the NVIDIA DrivePX2 and using SYNTHIA
|
|
|
- Nancy Golden
- 6 years ago
- Views:
Transcription
1 Visual Perception for Autonomous Driving on the NVIDIA DrivePX2 and using SYNTHIA Dr. Juan C. Moure Dr. Antonio Espinosa dataset.net

 Elektra Car +")
2 Our Background & Current Research Work 2 Computer Architecture Group: GPU acceleration: Bioinformatics, CV, Image Compression Computer Vision Group: CV Algorithms + Deep Learning for Camera-based ADAS GOAL: Camera-based Perception for Autonomous Driving Robotized car GPU-accelerated algorithms Deep Learning & Simulation Infrastructure (SYNTHIA) Elektra Car + DrivePX2
 Speed up MAP estimation problem solved by DP using CNNs SYNTHIA toolkit New datasets, new ground-truth data,")
3 Overview of Presentation 3 GPU Accelerated Perception Depth Computation Semantic & Slanted stixels (Collaboration with Daimler) Speed up MAP estimation problem solved by DP using CNNs SYNTHIA toolkit New datasets, new ground-truth data, LIDARs



4 Stereo Vision for Depth Computation 4 10 meters Disparity: distance between same point in left & right images higher disparity = Objects are closer



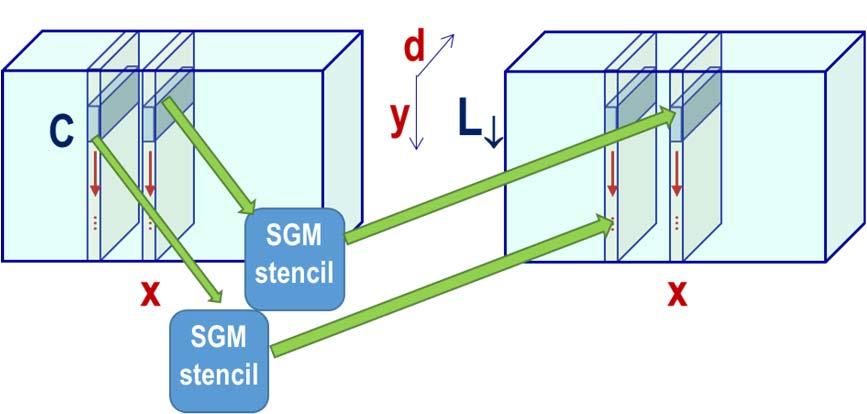
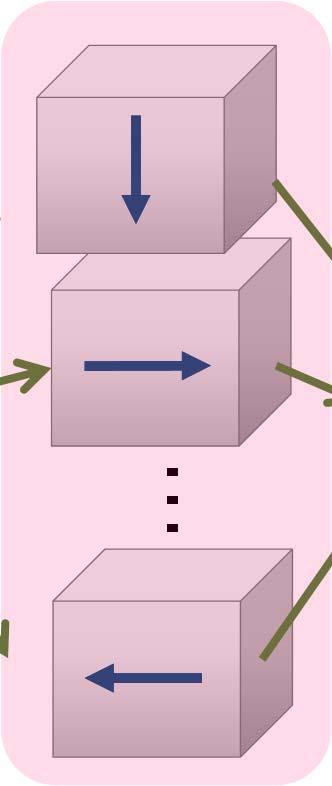
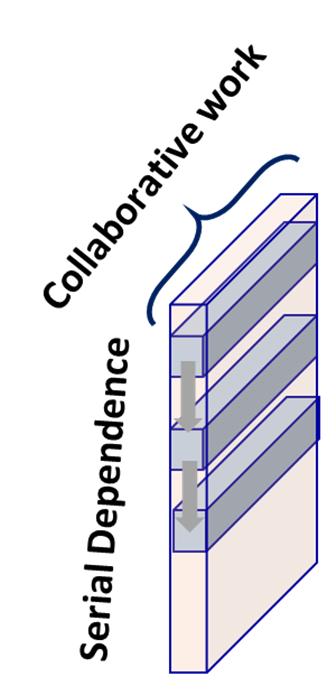
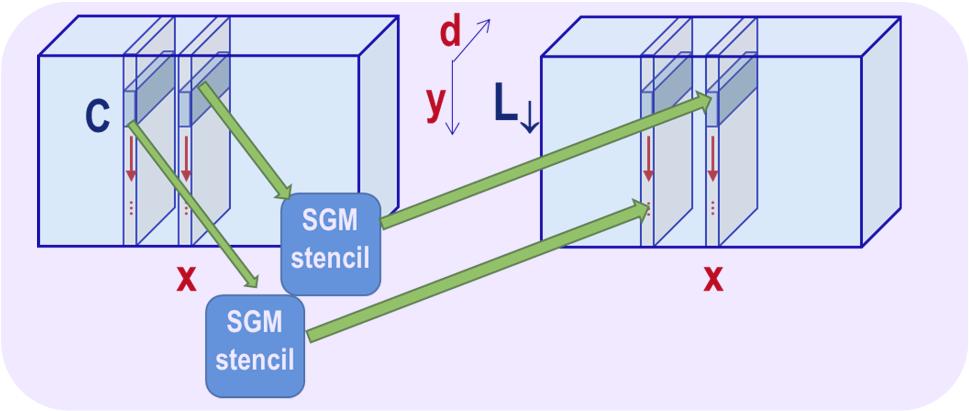
5 SemiGlobal Matching (SGM) on GPU: Parallelism 5 Large Grain Parallelism Fine Grain Parallelism Matching Cost Smoothed Cost [Hernández ICCS 2016] Medium Grain Parallelism
 Maximum Disparity= Image Height / 4 Tegra Parker improves performance 4x vs Tegra X1: 3.")
6 SGM on GPU: Results Performance ( Frames / Second, fps ) x x x720 real-time 0 Tegra X1 (DrivePX) SGM: 4 path directions Tegra Parker (DrivePX2) Maximum Disparity= Image Height / 4 Tegra Parker improves performance 4x vs Tegra X1: 3.5x Higher Effective Memory Bandwidth Higher execution overlap among kernels
7 Stixel World: Compact representation of the world Sky Obj. Stereo Images slope horizon Stereo Disparity Stixels Obj. Stixel = Stick + Pixel Obj. Fixed width, variable number of stixels per column First proposed by a Research Group in DAIMLER [Pfeiffer BMVC 2011] Grnd


8 Semantic Stixels: Unified approach Sky Buil. slope horizon Stereo Disparity Stereo Images Semantic Stixels Ped. Side Semantic segmentation [Schneider IV 2016] Road
 Stixel Disparity Model")

9 Enhanced model: Slanted Stixels 9 Stixels Slanted Stixels MAP estimation Problem joining Semantic & Depth Bayesian Model (converted to energy minimization) Stixel Disparity Model includes slant b:, Redefine Energy function (log-likelihood) : log Enforces prior assumptions: no sky below horizon, objects stand on road Best Industrial Paper [Hernández BMVC 2017]

10 New SYNTHIA-San Francisco dataset 10 SF city designed with SYNTHIA toolkit 2224 Photorealistic images featuring slanted roads, with pixel level depth & semantic ground truth Very expensive to generate equivalent real data images
 from 46 to 48.")
11 Results: Quantitative & Visual 11 Accuracy Results on SYNTHIA SF 3D representation Disparity Error (%) from 30.9 to 12.9 IoU (%) from 46 to 48.5 Accuracy remained the same for other datasets Left Image Original Stixels Slanted Stixels
12 Computation Complexity: Dynamic Programming Disparity Image Ground Object Sky h 12 Pixel Size Semantic Segmentation Each column processed independently Dynamic programming strategy for efficient evaluation of all the possible configurations Work Complexity (per column) ( h 2 ), h = image height
13 Stixel (DP) Algorithm on GPU: Parallelism 13 Large Grain parallelism CTA CTA h Medium and Fine Grain parallelism h.. Stereo Disparity step 1 step 2 step 3.. step h Sequential Operation with Decreasing Parallelism
14 Performance Results 14 Performance ( Frames/Second, fps ) Performance ( Frames/Second, fps ) x x x x x x Tegra X1 (DrivePX) Tegra Parker (DrivePX2) Tegra X1 (DrivePX) Tegra Parker (DrivePX2) Original Stixel Model Slanted + Semantic Stixel Model (includes time for semantic inference) Real time performance on DrivePX2 for all image sizes ( 6x 7x on DrivePX2 vs DrivePX ) Complex Stixel Model: 60 70% of time for Stixel algorithm % of time for semantic inference
15 Improving Computation Complexity: Pre-segmentation 15 Disparity Image Ground Object Sky h h Semantic Segmentation NAÏVE Pre-segmentation ( h ) Infer possible Stixel cuts (pre segmentation) from inputs Avoid checking all possible Stixel combinations Work Complexity (column) ( h h ), h << h Accuracy degrades 10-20% when using pre-segmentation




16 Pre-segmentation using a DNN 16 Disparity Image Ground Object Sky h h Semantic Segmentation DNN-based Pre-segmentation Infer possible Stixel cuts from inputs by using general data relations (among columns) Now accuracy improves slightly when using pre-segmentation
17 Improved Performance Results 17 Performance ( Frames/Second, fps ) Performance ( Frames/Second, fps ) x x x720 8 Tegra X1 (DrivePX) Tegra Parker (DrivePX2) x x x Tegra X1 (DrivePX) Tegra Parker (DrivePX2) Slanted + Semantic Stixel Model (includes time for semantic inference) + Pre segmentation Improves performance on both DrivePX and DrivePX2 ( 2x ) Now 15-30% of time for Stixel algorithm % of time for semantic inference Inference time increase almost neglectable ( <10% ) Most of the CNN for pre segmentation is shared with CNN for semantic segmentation


18 SYNTHIA Dataset Toolkit 18 Image generator of precise annotated data for training DNNs on Autonomous Driving tasks Ground truth data: RGB & Per pixel: depth, semantic class, optical flow, 3D rounding boxes Fully compatible with Cityscapes classes Generation of LIDAR data Problem Customization: Synthia SanFrancisco dataset.net

19 Summary: Real sequence video 19



20 Thank you Dr. Juan C. Moure Autonomous University of Barcelona
Embedded real-time stereo estimation via Semi-Global Matching on the GPU
 Embedded real-time stereo estimation via Semi-Global Matching on the GPU Daniel Hernández Juárez, Alejandro Chacón, Antonio Espinosa, David Vázquez, Juan Carlos Moure and Antonio M. López Computer Architecture
Embedded real-time stereo estimation via Semi-Global Matching on the GPU Daniel Hernández Juárez, Alejandro Chacón, Antonio Espinosa, David Vázquez, Juan Carlos Moure and Antonio M. López Computer Architecture
Training models for road scene understanding with automated ground truth Dan Levi
 Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Towards Fully-automated Driving. tue-mps.org. Challenges and Potential Solutions. Dr. Gijs Dubbelman Mobile Perception Systems EE-SPS/VCA
 Towards Fully-automated Driving Challenges and Potential Solutions Dr. Gijs Dubbelman Mobile Perception Systems EE-SPS/VCA Mobile Perception Systems 6 PhDs, 1 postdoc, 1 project manager, 2 software engineers
Towards Fully-automated Driving Challenges and Potential Solutions Dr. Gijs Dubbelman Mobile Perception Systems EE-SPS/VCA Mobile Perception Systems 6 PhDs, 1 postdoc, 1 project manager, 2 software engineers
Computing the Stereo Matching Cost with CNN
 University at Austin Figure. The of lefttexas column displays the left input image, while the right column displays the output of our stereo method. Examples are sorted by difficulty, with easy examples
University at Austin Figure. The of lefttexas column displays the left input image, while the right column displays the output of our stereo method. Examples are sorted by difficulty, with easy examples
W4. Perception & Situation Awareness & Decision making
 W4. Perception & Situation Awareness & Decision making Robot Perception for Dynamic environments: Outline & DP-Grids concept Dynamic Probabilistic Grids Bayesian Occupancy Filter concept Dynamic Probabilistic
W4. Perception & Situation Awareness & Decision making Robot Perception for Dynamic environments: Outline & DP-Grids concept Dynamic Probabilistic Grids Bayesian Occupancy Filter concept Dynamic Probabilistic
S7348: Deep Learning in Ford's Autonomous Vehicles. Bryan Goodman Argo AI 9 May 2017
 S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
Realtime Object Detection and Segmentation for HD Mapping
 Realtime Object Detection and Segmentation for HD Mapping William Raveane Lead AI Engineer Bahram Yoosefizonooz Technical Director NavInfo Europe Advanced Research Lab Presented at GTC Europe 2018 AI in
Realtime Object Detection and Segmentation for HD Mapping William Raveane Lead AI Engineer Bahram Yoosefizonooz Technical Director NavInfo Europe Advanced Research Lab Presented at GTC Europe 2018 AI in
TorontoCity: Seeing the World with a Million Eyes
 TorontoCity: Seeing the World with a Million Eyes Authors Shenlong Wang, Min Bai, Gellert Mattyus, Hang Chu, Wenjie Luo, Bin Yang Justin Liang, Joel Cheverie, Sanja Fidler, Raquel Urtasun * Project Completed
TorontoCity: Seeing the World with a Million Eyes Authors Shenlong Wang, Min Bai, Gellert Mattyus, Hang Chu, Wenjie Luo, Bin Yang Justin Liang, Joel Cheverie, Sanja Fidler, Raquel Urtasun * Project Completed
Measuring the World: Designing Robust Vehicle Localization for Autonomous Driving. Frank Schuster, Dr. Martin Haueis
 Measuring the World: Designing Robust Vehicle Localization for Autonomous Driving Frank Schuster, Dr. Martin Haueis Agenda Motivation: Why measure the world for autonomous driving? Map Content: What do
Measuring the World: Designing Robust Vehicle Localization for Autonomous Driving Frank Schuster, Dr. Martin Haueis Agenda Motivation: Why measure the world for autonomous driving? Map Content: What do
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE. Dennis Lui August 2017
 DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
GPU Coder: Automatic CUDA and TensorRT code generation from MATLAB
 GPU Coder: Automatic CUDA and TensorRT code generation from MATLAB Ram Kokku 2018 The MathWorks, Inc. 1 GPUs and CUDA programming faster Performance CUDA OpenCL C/C++ GPU Coder MATLAB Python Ease of programming
GPU Coder: Automatic CUDA and TensorRT code generation from MATLAB Ram Kokku 2018 The MathWorks, Inc. 1 GPUs and CUDA programming faster Performance CUDA OpenCL C/C++ GPU Coder MATLAB Python Ease of programming
Cloud-based Large Scale Video Analysis
 Cloud-based Large Scale Video Analysis Marcos Nieto Principal Researcher Vicomtech-IK4 Joachim Kreikemeier Manager V-Drive Valeo Schalter und Sensoren GmbH INDEX 1. Cloud-LSVA project 2. ADAS validation
Cloud-based Large Scale Video Analysis Marcos Nieto Principal Researcher Vicomtech-IK4 Joachim Kreikemeier Manager V-Drive Valeo Schalter und Sensoren GmbH INDEX 1. Cloud-LSVA project 2. ADAS validation
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Adaptive Learning of an Accurate Skin-Color Model
 Adaptive Learning of an Accurate Skin-Color Model Q. Zhu K.T. Cheng C. T. Wu Y. L. Wu Electrical & Computer Engineering University of California, Santa Barbara Presented by: H.T Wang Outline Generic Skin
Adaptive Learning of an Accurate Skin-Color Model Q. Zhu K.T. Cheng C. T. Wu Y. L. Wu Electrical & Computer Engineering University of California, Santa Barbara Presented by: H.T Wang Outline Generic Skin
Autonomous Driving Solutions
 Autonomous Driving Solutions Oct, 2017 DrivePX2 & DriveWorks Marcus Oh (moh@nvidia.com) Sr. Solution Architect, NVIDIA This work is licensed under a Creative Commons Attribution-Share Alike 4.0 (CC BY-SA
Autonomous Driving Solutions Oct, 2017 DrivePX2 & DriveWorks Marcus Oh (moh@nvidia.com) Sr. Solution Architect, NVIDIA This work is licensed under a Creative Commons Attribution-Share Alike 4.0 (CC BY-SA
Fast scene understanding and prediction for autonomous platforms. Bert De Brabandere, KU Leuven, October 2017
 Fast scene understanding and prediction for autonomous platforms Bert De Brabandere, KU Leuven, October 2017 Who am I? MSc in Electrical Engineering at KU Leuven, Belgium Last year PhD student with Luc
Fast scene understanding and prediction for autonomous platforms Bert De Brabandere, KU Leuven, October 2017 Who am I? MSc in Electrical Engineering at KU Leuven, Belgium Last year PhD student with Luc
Dense matching GPU implementation
 Dense matching GPU implementation Author: Hailong Fu. Supervisor: Prof. Dr.-Ing. Norbert Haala, Dipl. -Ing. Mathias Rothermel. Universität Stuttgart 1. Introduction Correspondence problem is an important
Dense matching GPU implementation Author: Hailong Fu. Supervisor: Prof. Dr.-Ing. Norbert Haala, Dipl. -Ing. Mathias Rothermel. Universität Stuttgart 1. Introduction Correspondence problem is an important
Layered Interpretation of Street View Images
 Layered Interpretation of Street View Images Ming-Yu Liu, Shuoxin Lin, Srikumar Ramalingam, and Oncel Tuzel Mitsubishi Electric Research Labs MERL), Cambridge, Massachusetts, USA Email: {mliu,ramalingam,oncel}@merl.com
Layered Interpretation of Street View Images Ming-Yu Liu, Shuoxin Lin, Srikumar Ramalingam, and Oncel Tuzel Mitsubishi Electric Research Labs MERL), Cambridge, Massachusetts, USA Email: {mliu,ramalingam,oncel}@merl.com
arxiv: v1 [cs.cv] 2 Apr 2017
![arxiv: v1 [cs.cv] 2 Apr 2017](/thumbs/86/93338666.jpg "arxiv: v1 [cs.cv] 2 Apr 2017") The Stixel World: A Medium-Level Representation of Traffic Scenes Marius Cordts a,c,1,, Timo Rehfeld b,c,1, Lukas Schneider a,e,1, David Pfeiffer a, Markus Enzweiler a, Stefan Roth c, Marc Pollefeys d,e,
The Stixel World: A Medium-Level Representation of Traffic Scenes Marius Cordts a,c,1,, Timo Rehfeld b,c,1, Lukas Schneider a,e,1, David Pfeiffer a, Markus Enzweiler a, Stefan Roth c, Marc Pollefeys d,e,
Training models for road scene understanding with automated ground truth Dan Levi
 Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder
Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder
RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN
 RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN Jason Bolito, Research School of Computer Science, ANU Supervisors: Yiran Zhong & Hongdong Li 2 Outline 1. Motivation and Background 2.
RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN Jason Bolito, Research School of Computer Science, ANU Supervisors: Yiran Zhong & Hongdong Li 2 Outline 1. Motivation and Background 2.
Evaluation of Different Methods for Using Colour Information in Global Stereo Matching Approaches
 Evaluation of Different Methods for Using Colour Information in Global Stereo Matching Approaches Michael Bleyer 1, Sylvie Chambon 2, Uta Poppe 1 and Margrit Gelautz 1 1 Vienna University of Technology,
Evaluation of Different Methods for Using Colour Information in Global Stereo Matching Approaches Michael Bleyer 1, Sylvie Chambon 2, Uta Poppe 1 and Margrit Gelautz 1 1 Vienna University of Technology,
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Detecting the Unexpected: The Path to Road Obstacles Prevention in Autonomous Driving
 Detecting the Unexpected: The Path to Road Obstacles Prevention in Autonomous Driving Shmoolik Mangan, PhD Algorithms Development Manager, VAYAVISION AutonomousTech TLV Israel 2018 VAYAVISION s approach
Detecting the Unexpected: The Path to Road Obstacles Prevention in Autonomous Driving Shmoolik Mangan, PhD Algorithms Development Manager, VAYAVISION AutonomousTech TLV Israel 2018 VAYAVISION s approach
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Towards Autonomous Vehicle. What is an autonomous vehicle? Vehicle driving on its own with zero mistakes How? Using sensors
 7 May 2017 Disclaimer Towards Autonomous Vehicle What is an autonomous vehicle? Vehicle driving on its own with zero mistakes How? Using sensors Why Vision Sensors? Humans use both eyes as main sense
7 May 2017 Disclaimer Towards Autonomous Vehicle What is an autonomous vehicle? Vehicle driving on its own with zero mistakes How? Using sensors Why Vision Sensors? Humans use both eyes as main sense
Deep learning in MATLAB From Concept to CUDA Code
 Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
The Stixel World - A Compact Medium Level Representation of the 3D-World
 The Stixel World - A Compact Medium Level Representation of the 3D-World Hernán Badino 1, Uwe Franke 2, and David Pfeiffer 2 hbadino@cs.cmu.edu, {uwe.franke,david.pfeiffer}@daimler.com 1 Goethe University
The Stixel World - A Compact Medium Level Representation of the 3D-World Hernán Badino 1, Uwe Franke 2, and David Pfeiffer 2 hbadino@cs.cmu.edu, {uwe.franke,david.pfeiffer}@daimler.com 1 Goethe University
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Creating Affordable and Reliable Autonomous Vehicle Systems
 Creating Affordable and Reliable Autonomous Vehicle Systems Shaoshan Liu shaoshan.liu@perceptin.io Autonomous Driving Localization Most crucial task of autonomous driving Solutions: GNSS but withvariations,
Creating Affordable and Reliable Autonomous Vehicle Systems Shaoshan Liu shaoshan.liu@perceptin.io Autonomous Driving Localization Most crucial task of autonomous driving Solutions: GNSS but withvariations,
Supplementary Material for Sparsity Invariant CNNs
 Supplementary Material for Sparsity Invariant CNNs Jonas Uhrig,1,2 Nick Schneider,1,3 Lukas Schneider 1,4 Uwe Franke 1 Thomas Brox 2 Andreas Geiger 4,5 1 Daimler R&D Sindelfingen 2 University of Freiburg
Supplementary Material for Sparsity Invariant CNNs Jonas Uhrig,1,2 Nick Schneider,1,3 Lukas Schneider 1,4 Uwe Franke 1 Thomas Brox 2 Andreas Geiger 4,5 1 Daimler R&D Sindelfingen 2 University of Freiburg
Collaborative Mapping with Streetlevel Images in the Wild. Yubin Kuang Co-founder and Computer Vision Lead
 Collaborative Mapping with Streetlevel Images in the Wild Yubin Kuang Co-founder and Computer Vision Lead Mapillary Mapillary is a street-level imagery platform, powered by collaboration and computer vision.
Collaborative Mapping with Streetlevel Images in the Wild Yubin Kuang Co-founder and Computer Vision Lead Mapillary Mapillary is a street-level imagery platform, powered by collaboration and computer vision.
National Science Foundation Engineering Research Center. Bingcai Zhang BAE Systems San Diego, CA
 Bingcai Zhang BAE Systems San Diego, CA 92127 Bingcai.zhang@BAESystems.com Introduction It is a trivial task for a five-year-old child to recognize and name an object such as a car, house or building.
Bingcai Zhang BAE Systems San Diego, CA 92127 Bingcai.zhang@BAESystems.com Introduction It is a trivial task for a five-year-old child to recognize and name an object such as a car, house or building.
ELL 788 Computational Perception & Cognition July November 2015
 ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
ELL 788 Computational Perception & Cognition July November 2015 Module 6 Role of context in object detection Objects and cognition Ambiguous objects Unfavorable viewing condition Context helps in object
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey
 Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
Scene Segmentation in Adverse Vision Conditions
 Scene Segmentation in Adverse Vision Conditions Evgeny Levinkov Max Planck Institute for Informatics, Saarbrücken, Germany levinkov@mpi-inf.mpg.de Abstract. Semantic road labeling is a key component of
Scene Segmentation in Adverse Vision Conditions Evgeny Levinkov Max Planck Institute for Informatics, Saarbrücken, Germany levinkov@mpi-inf.mpg.de Abstract. Semantic road labeling is a key component of
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Mask R-CNN. By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi
 Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Automatic Dense Semantic Mapping From Visual Street-level Imagery
 Automatic Dense Semantic Mapping From Visual Street-level Imagery Sunando Sengupta [1], Paul Sturgess [1], Lubor Ladicky [2], Phillip H.S. Torr [1] [1] Oxford Brookes University [2] Visual Geometry Group,
Automatic Dense Semantic Mapping From Visual Street-level Imagery Sunando Sengupta [1], Paul Sturgess [1], Lubor Ladicky [2], Phillip H.S. Torr [1] [1] Oxford Brookes University [2] Visual Geometry Group,
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Non-flat Road Detection Based on A Local Descriptor
 Non-flat Road Detection Based on A Local Descriptor Kangru Wang, Lei Qu, Lili Chen, Yuzhang Gu, Xiaolin Zhang Abstrct The detection of road surface and free space remains challenging for non-flat plane,
Non-flat Road Detection Based on A Local Descriptor Kangru Wang, Lei Qu, Lili Chen, Yuzhang Gu, Xiaolin Zhang Abstrct The detection of road surface and free space remains challenging for non-flat plane,
EVALUATION OF DEEP LEARNING BASED STEREO MATCHING METHODS: FROM GROUND TO AERIAL IMAGES
 EVALUATION OF DEEP LEARNING BASED STEREO MATCHING METHODS: FROM GROUND TO AERIAL IMAGES J. Liu 1, S. Ji 1,*, C. Zhang 1, Z. Qin 1 1 School of Remote Sensing and Information Engineering, Wuhan University,
EVALUATION OF DEEP LEARNING BASED STEREO MATCHING METHODS: FROM GROUND TO AERIAL IMAGES J. Liu 1, S. Ji 1,*, C. Zhang 1, Z. Qin 1 1 School of Remote Sensing and Information Engineering, Wuhan University,
Learning for Active 3D Mapping
 Learning for Active 3D Mapping Karel Zimmermann, Tomáš Petříček, Vojtěch Šalanský, Tomáš Svoboda http://cmp.felk.cvut.cz/~zimmerk/ ICCV 2017 Vision for Robotics and Autonomous Systems https://cyber.felk.cvut.cz/vras/
Learning for Active 3D Mapping Karel Zimmermann, Tomáš Petříček, Vojtěch Šalanský, Tomáš Svoboda http://cmp.felk.cvut.cz/~zimmerk/ ICCV 2017 Vision for Robotics and Autonomous Systems https://cyber.felk.cvut.cz/vras/
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features
 Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
Multiple View Geometry
 Multiple View Geometry CS 6320, Spring 2013 Guest Lecture Marcel Prastawa adapted from Pollefeys, Shah, and Zisserman Single view computer vision Projective actions of cameras Camera callibration Photometric
Multiple View Geometry CS 6320, Spring 2013 Guest Lecture Marcel Prastawa adapted from Pollefeys, Shah, and Zisserman Single view computer vision Projective actions of cameras Camera callibration Photometric
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
AUTONOMOUS DRONE NAVIGATION WITH DEEP LEARNING
 AUTONOMOUS DRONE NAVIGATION WITH DEEP LEARNING Nikolai Smolyanskiy, Alexey Kamenev, Jeffrey Smith Project Redtail May 8, 2017 100% AUTONOMOUS FLIGHT OVER 1 KM FOREST TRAIL AT 3 M/S 2 Why autonomous path
AUTONOMOUS DRONE NAVIGATION WITH DEEP LEARNING Nikolai Smolyanskiy, Alexey Kamenev, Jeffrey Smith Project Redtail May 8, 2017 100% AUTONOMOUS FLIGHT OVER 1 KM FOREST TRAIL AT 3 M/S 2 Why autonomous path
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm
 CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
GTC Interaction Simplified. Gesture Recognition Everywhere: Gesture Solutions on Tegra
 GTC 2013 Interaction Simplified Gesture Recognition Everywhere: Gesture Solutions on Tegra eyesight at a Glance Touch-free technology providing an enhanced user experience. Easy and intuitive control
GTC 2013 Interaction Simplified Gesture Recognition Everywhere: Gesture Solutions on Tegra eyesight at a Glance Touch-free technology providing an enhanced user experience. Easy and intuitive control
Priors for Stereo Vision under Adverse Weather Conditions
 2013 IEEE International Conference on Computer Vision Workshops Priors for Stereo Vision under Adverse Weather Conditions Stefan Gehrig 1 Maxim Reznitskii 2 Nicolai Schneider 3 Uwe Franke 1 Joachim Weickert
2013 IEEE International Conference on Computer Vision Workshops Priors for Stereo Vision under Adverse Weather Conditions Stefan Gehrig 1 Maxim Reznitskii 2 Nicolai Schneider 3 Uwe Franke 1 Joachim Weickert
On Board 6D Visual Sensors for Intersection Driving Assistance Systems
 On Board 6D Visual Sensors for Intersection Driving Assistance Systems S. Nedevschi, T. Marita, R. Danescu, F. Oniga, S. Bota, I. Haller, C. Pantilie, M. Drulea, C. Golban Sergiu.Nedevschi@cs.utcluj.ro
On Board 6D Visual Sensors for Intersection Driving Assistance Systems S. Nedevschi, T. Marita, R. Danescu, F. Oniga, S. Bota, I. Haller, C. Pantilie, M. Drulea, C. Golban Sergiu.Nedevschi@cs.utcluj.ro
Joint Object Detection and Viewpoint Estimation using CNN features
 Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
2 OVERVIEW OF RELATED WORK
 Utsushi SAKAI Jun OGATA This paper presents a pedestrian detection system based on the fusion of sensors for LIDAR and convolutional neural network based image classification. By using LIDAR our method
Utsushi SAKAI Jun OGATA This paper presents a pedestrian detection system based on the fusion of sensors for LIDAR and convolutional neural network based image classification. By using LIDAR our method
Exploiting Traffic Scene Disparity Statistics for Stereo Vision
 Exploiting Traffic Scene Disparity Statistics for Stereo Vision Stefan K. Gehrig Daimler AG HPC 050-G024 71059 Sindelfingen, Germany Uwe Franke Daimler AG HPC 050-G024 71059 Sindelfingen, Germany Nicolai
Exploiting Traffic Scene Disparity Statistics for Stereo Vision Stefan K. Gehrig Daimler AG HPC 050-G024 71059 Sindelfingen, Germany Uwe Franke Daimler AG HPC 050-G024 71059 Sindelfingen, Germany Nicolai
Small is the New Big: Data Analytics on the Edge
 Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
Self Driving. DNN * * Reinforcement * Unsupervised *
 CNN 응용 Methods Traditional Deep-Learning based Non-machine Learning Machine-Learning based method Supervised SVM MLP CNN RNN (LSTM) Localizati on GPS, SLAM Self Driving Perception Pedestrian detection
CNN 응용 Methods Traditional Deep-Learning based Non-machine Learning Machine-Learning based method Supervised SVM MLP CNN RNN (LSTM) Localizati on GPS, SLAM Self Driving Perception Pedestrian detection
Ground Plane Detection with a Local Descriptor
 Ground Plane Detection with a Local Descriptor Kangru Wang, Lei Qu, Lili Chen, Yuzhang Gu, Dongchen Zhu, Xiaolin Zhang Shanghai Institute of Microsystem and Information Technology (SIMIT), Chinese Academy
Ground Plane Detection with a Local Descriptor Kangru Wang, Lei Qu, Lili Chen, Yuzhang Gu, Dongchen Zhu, Xiaolin Zhang Shanghai Institute of Microsystem and Information Technology (SIMIT), Chinese Academy
Autonomous Robot Navigation: Using Multiple Semi-supervised Models for Obstacle Detection
 Autonomous Robot Navigation: Using Multiple Semi-supervised Models for Obstacle Detection Adam Bates University of Colorado at Boulder Abstract: This paper proposes a novel approach to efficiently creating
Autonomous Robot Navigation: Using Multiple Semi-supervised Models for Obstacle Detection Adam Bates University of Colorado at Boulder Abstract: This paper proposes a novel approach to efficiently creating
UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss
 UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss AAAI 2018, New Orleans, USA Simon Meister, Junhwa Hur, and Stefan Roth Department of Computer Science, TU Darmstadt 2 Deep
UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss AAAI 2018, New Orleans, USA Simon Meister, Junhwa Hur, and Stefan Roth Department of Computer Science, TU Darmstadt 2 Deep
Dense Tracking and Mapping for Autonomous Quadrocopters. Jürgen Sturm
 Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
Automatic Tracking of Moving Objects in Video for Surveillance Applications
 Automatic Tracking of Moving Objects in Video for Surveillance Applications Manjunath Narayana Committee: Dr. Donna Haverkamp (Chair) Dr. Arvin Agah Dr. James Miller Department of Electrical Engineering
Automatic Tracking of Moving Objects in Video for Surveillance Applications Manjunath Narayana Committee: Dr. Donna Haverkamp (Chair) Dr. Arvin Agah Dr. James Miller Department of Electrical Engineering
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
TERRAIN ANALYSIS FOR BLIND WHEELCHAIR USERS: COMPUTER VISION ALGORITHMS FOR FINDING CURBS AND OTHER NEGATIVE OBSTACLES
 Conference & Workshop on Assistive Technologies for People with Vision & Hearing Impairments Assistive Technology for All Ages CVHI 2007, M.A. Hersh (ed.) TERRAIN ANALYSIS FOR BLIND WHEELCHAIR USERS: COMPUTER
Conference & Workshop on Assistive Technologies for People with Vision & Hearing Impairments Assistive Technology for All Ages CVHI 2007, M.A. Hersh (ed.) TERRAIN ANALYSIS FOR BLIND WHEELCHAIR USERS: COMPUTER
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza
 Davide Scaramuzza") Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA
 sur CPU, GPU et FPGA") Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA Pierre Nowodzienski Engineer pierre.nowodzienski@mathworks.fr 2018 The MathWorks, Inc. 1 From Data to Business value Make decisions Get
Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA Pierre Nowodzienski Engineer pierre.nowodzienski@mathworks.fr 2018 The MathWorks, Inc. 1 From Data to Business value Make decisions Get
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Last update: May 4, Vision. CMSC 421: Chapter 24. CMSC 421: Chapter 24 1
 Last update: May 4, 200 Vision CMSC 42: Chapter 24 CMSC 42: Chapter 24 Outline Perception generally Image formation Early vision 2D D Object recognition CMSC 42: Chapter 24 2 Perception generally Stimulus
Last update: May 4, 200 Vision CMSC 42: Chapter 24 CMSC 42: Chapter 24 Outline Perception generally Image formation Early vision 2D D Object recognition CMSC 42: Chapter 24 2 Perception generally Stimulus
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
RGBD Occlusion Detection via Deep Convolutional Neural Networks
 1 RGBD Occlusion Detection via Deep Convolutional Neural Networks Soumik Sarkar 1,2, Vivek Venugopalan 1, Kishore Reddy 1, Michael Giering 1, Julian Ryde 3, Navdeep Jaitly 4,5 1 United Technologies Research
1 RGBD Occlusion Detection via Deep Convolutional Neural Networks Soumik Sarkar 1,2, Vivek Venugopalan 1, Kishore Reddy 1, Michael Giering 1, Julian Ryde 3, Navdeep Jaitly 4,5 1 United Technologies Research
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Introduction to Computer Vision. Srikumar Ramalingam School of Computing University of Utah
 Introduction to Computer Vision Srikumar Ramalingam School of Computing University of Utah srikumar@cs.utah.edu Course Website http://www.eng.utah.edu/~cs6320/ What is computer vision? Light source 3D
Introduction to Computer Vision Srikumar Ramalingam School of Computing University of Utah srikumar@cs.utah.edu Course Website http://www.eng.utah.edu/~cs6320/ What is computer vision? Light source 3D
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs
 In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
Stereo Human Keypoint Estimation
 Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
Segmentation Based Stereo. Michael Bleyer LVA Stereo Vision
 Segmentation Based Stereo Michael Bleyer LVA Stereo Vision What happened last time? Once again, we have looked at our energy function: E ( D) = m( p, dp) + p I < p, q > We have investigated the matching
Segmentation Based Stereo Michael Bleyer LVA Stereo Vision What happened last time? Once again, we have looked at our energy function: E ( D) = m( p, dp) + p I < p, q > We have investigated the matching
Simulation: A Must for Autonomous Driving
 Simulation: A Must for Autonomous Driving NVIDIA GTC 2018 (SILICON VALLEY) / Talk ID: S8859 Rohit Ramanna Business Development Manager Smart Virtual Prototyping, ESI North America Rodolphe Tchalekian EMEA
Simulation: A Must for Autonomous Driving NVIDIA GTC 2018 (SILICON VALLEY) / Talk ID: S8859 Rohit Ramanna Business Development Manager Smart Virtual Prototyping, ESI North America Rodolphe Tchalekian EMEA
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Vision based autonomous driving - A survey of recent methods. -Tejus Gupta
 Vision based autonomous driving - A survey of recent methods -Tejus Gupta Presently, there are three major paradigms for vision based autonomous driving: Directly map input image to driving action using
Vision based autonomous driving - A survey of recent methods -Tejus Gupta Presently, there are three major paradigms for vision based autonomous driving: Directly map input image to driving action using
arxiv: v2 [cs.cv] 12 Sep 2018
![arxiv: v2 [cs.cv] 12 Sep 2018](/thumbs/87/95388513.jpg "arxiv: v2 [cs.cv] 12 Sep 2018") Monocular Depth Estimation by Learning from Heterogeneous Datasets Akhil Gurram 1,2, Onay Urfalioglu 2, Ibrahim Halfaoui 2, Fahd Bouzaraa 2 and Antonio M. López 1 arxiv:13.018v2 [cs.cv] 12 Sep 2018 Abstract
Monocular Depth Estimation by Learning from Heterogeneous Datasets Akhil Gurram 1,2, Onay Urfalioglu 2, Ibrahim Halfaoui 2, Fahd Bouzaraa 2 and Antonio M. López 1 arxiv:13.018v2 [cs.cv] 12 Sep 2018 Abstract
CEng Computational Vision
 CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
CEng 583 - Computational Vision 2011-2012 Spring Week 4 18 th of March, 2011 Today 3D Vision Binocular (Multi-view) cues: Stereopsis Motion Monocular cues Shading Texture Familiar size etc. "God must
arxiv: v2 [cs.cv] 14 May 2018
![arxiv: v2 [cs.cv] 14 May 2018](/thumbs/79/79495201.jpg "arxiv: v2 [cs.cv] 14 May 2018") ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
Static Scene Reconstruction
 GPU supported Real-Time Scene Reconstruction with a Single Camera Jan-Michael Frahm, 3D Computer Vision group, University of North Carolina at Chapel Hill Static Scene Reconstruction 1 Capture on campus
GPU supported Real-Time Scene Reconstruction with a Single Camera Jan-Michael Frahm, 3D Computer Vision group, University of North Carolina at Chapel Hill Static Scene Reconstruction 1 Capture on campus
Stereo Vision II: Dense Stereo Matching
 Stereo Vision II: Dense Stereo Matching Nassir Navab Slides prepared by Christian Unger Outline. Hardware. Challenges. Taxonomy of Stereo Matching. Analysis of Different Problems. Practical Considerations.
Stereo Vision II: Dense Stereo Matching Nassir Navab Slides prepared by Christian Unger Outline. Hardware. Challenges. Taxonomy of Stereo Matching. Analysis of Different Problems. Practical Considerations.
Automated Driving Development
 Automated Driving Development with MATLAB and Simulink MANOHAR REDDY M 2015 The MathWorks, Inc. 1 Using Model-Based Design to develop high quality and reliable Active Safety & Automated Driving Systems
Automated Driving Development with MATLAB and Simulink MANOHAR REDDY M 2015 The MathWorks, Inc. 1 Using Model-Based Design to develop high quality and reliable Active Safety & Automated Driving Systems
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
A Study of Vehicle Detector Generalization on U.S. Highway
 26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
Stereo camera de-calibration detection based on observing kinematic attributes of detected objects and the camera rig
 Technical University of Dortmund Stereo camera de-calibration detection based on observing kinematic attributes of detected objects and the camera rig by Venkata Rama Prasad Donda A thesis submitted in
Technical University of Dortmund Stereo camera de-calibration detection based on observing kinematic attributes of detected objects and the camera rig by Venkata Rama Prasad Donda A thesis submitted in
Geometric Reconstruction Dense reconstruction of scene geometry
 Lecture 5. Dense Reconstruction and Tracking with Real-Time Applications Part 2: Geometric Reconstruction Dr Richard Newcombe and Dr Steven Lovegrove Slide content developed from: [Newcombe, Dense Visual
Lecture 5. Dense Reconstruction and Tracking with Real-Time Applications Part 2: Geometric Reconstruction Dr Richard Newcombe and Dr Steven Lovegrove Slide content developed from: [Newcombe, Dense Visual
All human beings desire to know. [...] sight, more than any other senses, gives us knowledge of things and clarifies many differences among them.
![All human beings desire to know. [...] sight, more than any other senses, gives us knowledge of things and clarifies many differences among them.](/thumbs/91/106597332.jpg "All human beings desire to know. [...] sight, more than any other senses, gives us knowledge of things and clarifies many differences among them.") All human beings desire to know. [...] sight, more than any other senses, gives us knowledge of things and clarifies many differences among them. - Aristotle University of Texas at Arlington Introduction
All human beings desire to know. [...] sight, more than any other senses, gives us knowledge of things and clarifies many differences among them. - Aristotle University of Texas at Arlington Introduction
COS Lecture 10 Autonomous Robot Navigation
 COS 495 - Lecture 10 Autonomous Robot Navigation Instructor: Chris Clark Semester: Fall 2011 1 Figures courtesy of Siegwart & Nourbakhsh Control Structure Prior Knowledge Operator Commands Localization
COS 495 - Lecture 10 Autonomous Robot Navigation Instructor: Chris Clark Semester: Fall 2011 1 Figures courtesy of Siegwart & Nourbakhsh Control Structure Prior Knowledge Operator Commands Localization
CIS 580, Machine Perception, Spring 2015 Homework 1 Due: :59AM
 CIS 580, Machine Perception, Spring 2015 Homework 1 Due: 2015.02.09. 11:59AM Instructions. Submit your answers in PDF form to Canvas. This is an individual assignment. 1 Camera Model, Focal Length and
CIS 580, Machine Perception, Spring 2015 Homework 1 Due: 2015.02.09. 11:59AM Instructions. Submit your answers in PDF form to Canvas. This is an individual assignment. 1 Camera Model, Focal Length and
Face Detection and Tracking Control with Omni Car
 Face Detection and Tracking Control with Omni Car Jheng-Hao Chen, Tung-Yu Wu CS 231A Final Report June 31, 2016 Abstract We present a combination of frontal and side face detection approach, using deep
Face Detection and Tracking Control with Omni Car Jheng-Hao Chen, Tung-Yu Wu CS 231A Final Report June 31, 2016 Abstract We present a combination of frontal and side face detection approach, using deep
Color-based Free-Space Segmentation using Online Disparity-supervised Learning
 Color-based Free-Space Segmentation using Online Disparity-supervised Learning Willem P. Sanberg, Gijs Dubbelman and Peter H.N. de With Abstract This work contributes to vision processing for Advanced
Color-based Free-Space Segmentation using Online Disparity-supervised Learning Willem P. Sanberg, Gijs Dubbelman and Peter H.N. de With Abstract This work contributes to vision processing for Advanced
Implementing Deep Learning for Video Analytics on Tegra X1.
 Implementing Deep Learning for Video Analytics on Tegra X1 research@hertasecurity.com Index Who we are, what we do Video analytics pipeline Video decoding Facial detection and preprocessing DNN: learning
Implementing Deep Learning for Video Analytics on Tegra X1 research@hertasecurity.com Index Who we are, what we do Video analytics pipeline Video decoding Facial detection and preprocessing DNN: learning
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Human Body Recognition and Tracking: How the Kinect Works. Kinect RGB-D Camera. What the Kinect Does. How Kinect Works: Overview
 Human Body Recognition and Tracking: How the Kinect Works Kinect RGB-D Camera Microsoft Kinect (Nov. 2010) Color video camera + laser-projected IR dot pattern + IR camera $120 (April 2012) Kinect 1.5 due
Human Body Recognition and Tracking: How the Kinect Works Kinect RGB-D Camera Microsoft Kinect (Nov. 2010) Color video camera + laser-projected IR dot pattern + IR camera $120 (April 2012) Kinect 1.5 due