Adaptive Scientific Software Libraries
|
|
|
- Thomas Taylor
- 6 years ago
- Views:
Transcription
1 Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston
2 Challenges Diversity of execution environments Growing complexity of modern microprocessors. Deep memory hierarchies Out-of-order execution Instruction level parallelism Growing diversity of platform characteristics SMPs Clusters (employing a range of interconnect technologies) Grids (heterogeneity, wide range of characteristics) Wide range of application needs Dimensionality and sizes Data structures and data types Languages and programming paradigms
3 Challenges Algorithmic High arithmetic efficiency low floating-point v.s. load/store ratio Unfavorable data access patterns (big 2 n strides) Application owns the datastructures/layout Additions/multiplications unbalanced Version explosion Verification Maintenance
4 Opportunities Multiple algorithms with comparable numerical properties for many functions Improved software techniques and hardware performance Integrated performance monitors, models and data bases Run-time code construction
5 Approach Automatic algorithm selection polyalgorithmic functions (CMSSL, FFTW, ATLAS, SPIRAL,..) Exploit multiple precision options Code generation from high-level descriptions (WASSEM, CMSSL, CM-Convolution-Compiler, FFTW, UHFFT,..) Integrated performance monitoring, modeling and analysis Judicious choice between compile-time and run-time analysis and code construction Automated installation process
6 The UHFFT Program preparation at installation (platform dependent) Integrated performance models (in progress) and data bases Algorithm selection at run-time from set defined at installation Automatic multiple precision constant generation Program construction at run-time based on application and performance predictions
7 Performance Tuning Methodology Input Parameters System specifics, User options Input Parameters Size, dim., UHFFT Code generator Initialization Select best plan (factorization) Library of FFT modules Execution Calculate one or more FFTs Performance database Installation Performance Monitoring Database update Run-time
8 The UHFFT Software Architecture UHFFT Library Library of FFT Modules Initialization Routines Execution Routines Utilities FFT Code Generator Mixed-Radix (Cooly-Tukey) Prime Factor Algorithm Split-Radix Algorithm Rader's Algorithm Unparser Optimizer Scheduler Initializer (Algorithm Abstraction) Key: Fixed library code Generated code Code generator
9 The UHFFT: Code Generation Structure Algorithm abstraction Optimization Generation of a DAG Scheduling of instructions Unparsing Implementation Code generator is written in C Speed, portability and installation tuning Highly optimized straight line C code Generates FFT codelets of arbitrary size, direction, and rotation
10 The UHFFT: Code Generation (cont d) Basic structure is an Expression Constant, variable, sum, product, sign change, Basic functions Expression sum, product, assign, sign change, Derived structures Expression vectors, matrices and lists Higher level functions Matrix vector operations FFT specific operations Algorithms currently supported Rader (two versions), PFA, Split-radix, Mixed-radix
11 Equation: W Is implemented as: The UHFFT: Code Generation Mixed-Radix Algorithm n (Wr Im )Dr,m(I r Wm )Πn,r /* * FFTMixedRadix() Mixed-radix splitting. * Input: * r radix, * dir, rot direction and rotation of the transform, * u input expression vector. */ ExprVec *FFTMixedRadix(int r, int dir, int rot, ExprVec *u) { int m, n = u->n, *p; } m = n/r; p = ModRSortPermutation(n, r); u = FFTxI(r, m, dir, rot, TwiddleMult(r, m, dir, rot, IxFFT(r, m, dir, rot, PermuteExprVec(u, p)))); free(p); return u;
12 The UHFFT: Performance Modeling Analytic models Cache influence on library codes Performance measuring tools (PCL, PAPI) Prediction of composed code performance Updated from execution experience Data base Library codes. Recorded at installation time Composed codes. Recorded and updated for each execution.
13 The UHFFT: Execution Plan Generation Optimal plan search options Exhaustive Recursive Empirical Algorithms used Rader (FFTW, UHFFT) PFA (UHFFT) Split-radix (UHFFT) Mixed-radix (FFTW, SPIRAL, UHFFT)
14 Characteristics of Some Processors Processor Clock frequency Peak Performance Cache structure Intel Pentium IV 1.8 GHz 1.8 GFlops L1: 8K+8K, L2: 256K AMD Athlon 1.4 GHz 1.4 GFlops L1: 64K+64K, L2: 256K PowerPC G4 867 MHz 867 MFlops L1: 32K+32K L2: 256K, L3: 1-2M Intel Itanium 800 Mhz 3.2 GFlops L1: 16K+16K L2: 92K, L3: 2-4M IBM Power3/4 375 MHz 1.5 GFlops L1: 64K+32K, L2: 1-16M HP PA 8x MHz 3 GFlops L1: 1.5M M Alpha EV67/ MHz 1.66 GFlops L1: 64K+64K, L2: 4M MIPS R1x MHz 1 GFlop L1: 32K+32K, L2: 4M


15 Codelet efficiency Intel PIV 1.8 GHz AMD Athlon 1.4 GHz PowerPC G4 867 MHz
16 Radix-4 codelet efficiency Intel PIV 1.8 GHz AMD Athlon 1.4 GHz PowerPC G4 867 MHz
17 Radix-8 codelet efficiency Intel PIV 1.8 GHz AMD Athlon 1.4 GHz PowerPC G4 867 MHz
18 Plan Performance, 32- bit Architectures
19 Power3 plan performance MFLOPS Plan 222 MHz 888 Mflops
20 Power3 plan performance PFA sizes 800 Mflops peak
21 Itanium.. Processor Clock frequency Peak Performance Cache structure Intel Itanium 800 Mhz 3.2 GFlops Intel Itanium Mhz 3.6 GFlops Intel Itanium Mhz 4 GFlops Sun UltraSparc-III 750 Mhz 1.5 GFlops Sun UltraSparc-III 1050 Mhz 2.1 GFlops L1: 16K+16K (Data+Instruction) L2: 92K, L3: 2-4M (off-die) L1: 16K+16K (Data+Instruction) L2: 256K, L3: 1.5M (on-die) L1: 16K+16K (Data+Instruction) L2: 256K, L3: 3M (on-die) L1: 64K+32K+2K+2K (Data+Instruction+Pre-fetch+Write) L2: up to 8M (off-die) L1: 64K+32K+2K+2K (Data+Instruction+Pre-fetch+Write) L2: up to 8M (off-die) Tested configuration
22 Memory Hierarchy Itanium-2 (McKinley) Itanium L1I and L1D Size: Line size/associativity: Latency: Write Policies: 16KB + 16KB 64B/4-way 1 cycle Write through, No write allocate 16KB + 16KB 32B/4-way 1 cycle Write through, No write allocate Size: 256KB 96K B Unified L2 Line size/associativity: Integer Latency: FP Latency: 128B/8-way Min 5 cycles Min 6 cycles 64B/6-way Min 6 cycles Min 9 cycles Write Policies: Write back, write allocate Write back, write allocate Size: 3MB or 1.5MB on chip 4MB or 2MB off chip Unified L3 Line size/associativity: Integer Latency: FP Latency: 128B/12-way Min 12 cycles Min 13 cycles 64B/4-way Min 21 cycles Min 24 cycles Bandwith: 32B/cycle 16B/cycle
23 Itanium Comparison Workstation HP i2000 HP zx2000 Processor 800 MHz Intel Itanium 900 MHz Intel Itanium 2 (McKinley) Bus Speed 133 MHZ 400 MHz Bus Width 64 bit 128 bit Chipset Intel 82460GX HP zx1 Memory 2 GB SDRAM (133 MHz) 2 GB DDR SDRAM (266 MHz) OS 64-bit Red Hat Linux 7.1 HP version of the 64-bit RH Linux 7.2 Compiler Intel 6.0 Intel 6.0
 Up to 64 GB of DDR today (256 in the future) AGP 4x today (8x in the future versions) 1-8 I/O adapters supporting PCI,")
24 HP zx1 Chipset 2-way block diagram Features: 2-way and 4-way Low latency connection to the DDR memory (112 ns) Directly (112 ns latency) Through (up to 12 ) scalable memory expanders (+25 ns latency) Up to 64 GB of DDR today (256 in the future) AGP 4x today (8x in the future versions) 1-8 I/O adapters supporting PCI, PCI-X, AGP

25 UHFFT Codelet Performance

26 UHFFT Codelet Performance

27 UHFFT Codelet Performance

28 Codelet Performance Radix-2
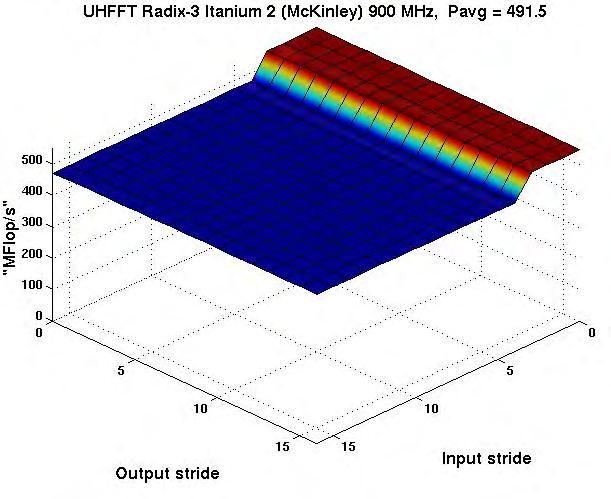
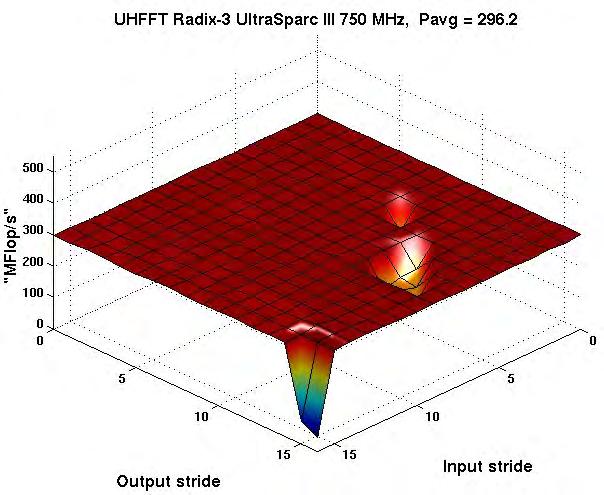
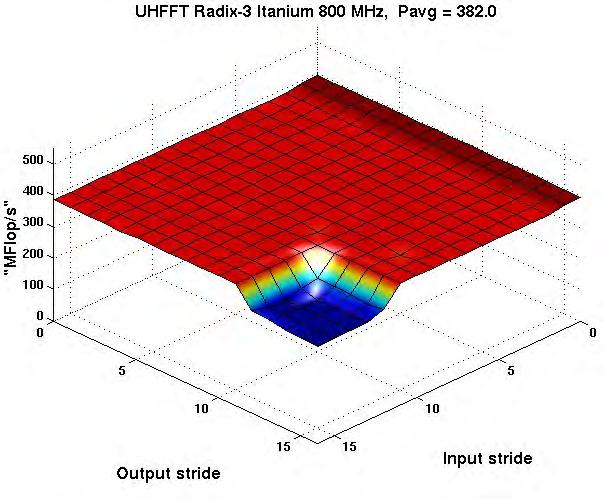
29 Codelet Performance Radix-3
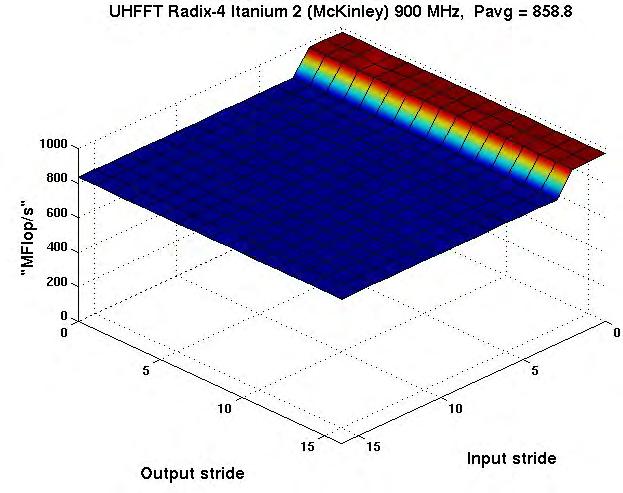
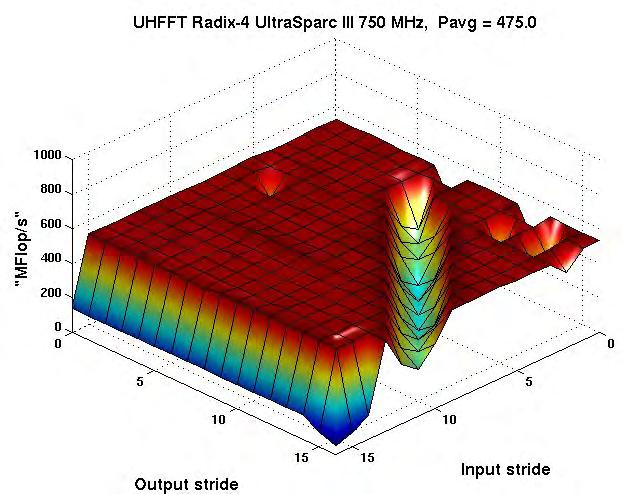
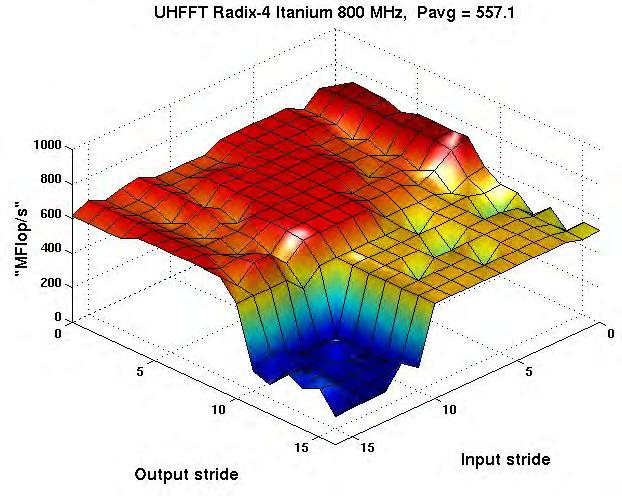
30 Codelet Performance Radix-4

31 Codelet Performance Radix-5
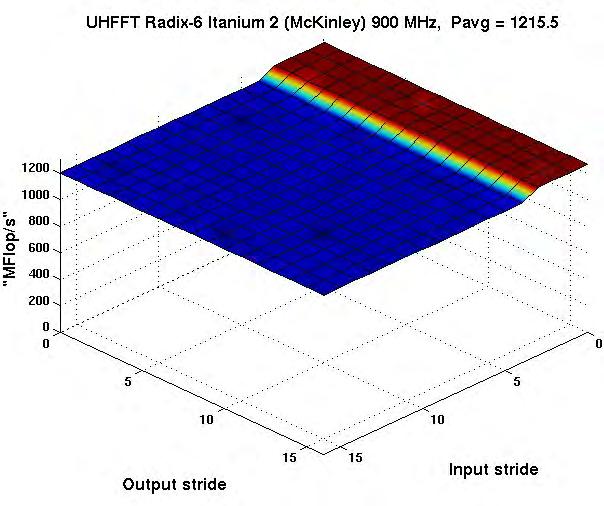
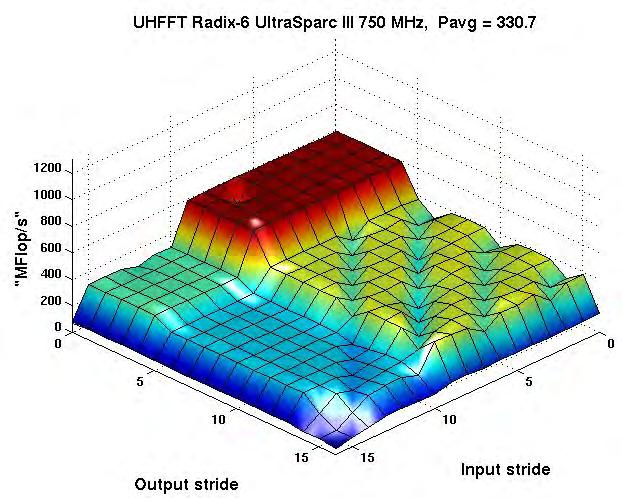
32 Codelet Performance Radix-6
33 Codelet Performance Radix-7

34 Codelet Performance Radix-8
35 Codelet Performance Radix-9
36 Codelet Performance Radix-10

37 Codelet Performance Radix-11
38 Codelet Performance Radix-12
39 Codelet Performance Radix-13
40 Codelet Performance Radix-14
41 Codelet Performance Radix-15
42 Codelet Performance Radix-16

43 Codelet Performance Radix-17
44 Codelet Performance Radix-18
45 Codelet Performance Radix-19
46 Codelet Performance Radix-20

47 Codelet Performance Radix-21

48 Codelet Performance Radix-22

49 Codelet Performance Radix-23
50 Codelet Performance Radix-24
51 Codelet Performance Radix-25
52 Codelet Performance Radix-32
53 Codelet Performance Radix-36

54 Codelet Performance Radix-45

55 Codelet Performance Radix-64
56 The UHFFT: Summary Code generator written in C Code is generated at installation Codelet library is tuned to the underlying architecture The whole library can be easily customized through parameter specification No need for laborious manual changes in the source Existing code generation infrastructure allows easy library extensions Future: Inclusion of vector/streaming instruction set extension for various architectures Implementation of new scheduling/optimization algorithms New codelet types and better execution routines Unified algorithm specification on all levels
57 New Tools for Library Code Development Generalization of the tools developed for the UHFFT library CODELAB: A Developers' Tool for Efficient Code Generation and Optimization Combination of High-level scripting language Code generator Performance measurement tools Visualization Under development Several test examples show very promising results
58 CODELAB IDE STRUCTURE CODELAB IDE Script Interpreter Code Generator Visualization Performance measurement User Input Library code Support Code Compiler Execution Operating System Application
59 CODELAB Structure Application consists of Library code Support Code Application Library code: Automatically generated and optimized collection of subroutines Supporting code: Code that binds the library routines together It could be hand-written or automatically generated Application is instrumented for performance measurements automatically
60 Script Interpreter User Input CODELAB Structure Supporting Code Application User writes: Simple script that produces the code generator or supporting code Supporting code for the application The code generator should be able to produce a large variety of code depending on a few input parameters (otherwise it is simpler to write the code by hand) Example: A single code generator for FFT codelets of different size, type, direction, rotation, Script Interpreter: Simplifies construction of the code generator Very restricted set of commands at the moment
61 CODELAB Code Generator Structure Library code Support Code Application Visualization Code generator C program that generates the application and supporting code Uses abstract expression algebra for code generation Several layers of software: Basic expressions Complex expressions algebra Vector and matrix algebra Polynomial algebra The generated code can be instrumented for performance measurements The initial expression list is transformed into DAG and optimized: Simplification of expressions Folding of constants User can get a variety of information about the generated code: Number of arithmetic ops DAG graph, etc
62 CODELAB Structure Visualization Compiler Performance measurements Execution Operating System Performance measurements The application can be compiled and executed from within the IDE The performance data are collected and visualized User can modify the code and repeat the process until a satisfactory performance is obtained Detailed performance information by using PAPI library interface
63 CODELAB Applications FFT and DSP Libraries Efficient multiple precision arithmetic Finite Element Methods Linear Algebra Other well structured applications that allow for simple parameterization few parameters define a large variety of code
64 Overview UHFFT Performance on some new architectures Intel Itanium 800 MHz, Intel Itanium 2 (McKinley) 900 MHz Sun UltraSparc-III 750 MHz New Tools for Library Code Development CODELAB Integrated Development Environment (IDE) Introduction Structure of the CODELAB IDE Applications
65 The UHFFT: An Adaptive FFT Library UHFFT employs more ways of combining codelets for execution than any other library Better coverage of the space of possible algorithms The PFA algorithm yields good performance where the Mixed-Radix algorithm (MR) performs poorly PFA algorithm requires less FP operations than MR Data access pattern in PFA is more complex than in MR, but large 2 n strides can be avoided Example IBM Power3 Good: 128-way set associative L1 data and instruction caches Bad: Direct mapped L2 cache very vulnerable to cache trashing despite the large cache size PFA execution model works better for large FFT sizes
66 Acknowledgements Contributors Dragan Mirkovic Rishad Mahasoom Fredrick Mwandia Nils Smeds Funding: Alliance (NSF) LACSI (DoE)
Advanced Computing Research Laboratory. Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
An Adaptive Framework for Scientific Software Libraries. Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston
 An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
Grid Computing: Application Development
 Grid Computing: Application Development Lennart Johnsson Department of Computer Science and the Texas Learning and Computation Center University of Houston Houston, TX Department of Numerical Analysis
Grid Computing: Application Development Lennart Johnsson Department of Computer Science and the Texas Learning and Computation Center University of Houston Houston, TX Department of Numerical Analysis
Research in High-Performance Grid Software
 Research in High-Performance Grid Software Lennart Johnsson NADA, KTH and Department of Computer Science University of Houston EU Project: Neurogenerator Collection and processing of PET and fmri data
Research in High-Performance Grid Software Lennart Johnsson NADA, KTH and Department of Computer Science University of Houston EU Project: Neurogenerator Collection and processing of PET and fmri data
Introduction to HPC. Lecture 21
 443 Introduction to HPC Lecture Dept of Computer Science 443 Fast Fourier Transform 443 FFT followed by Inverse FFT DIF DIT Use inverse twiddles for the inverse FFT No bitreversal necessary! 443 FFT followed
443 Introduction to HPC Lecture Dept of Computer Science 443 Fast Fourier Transform 443 FFT followed by Inverse FFT DIF DIT Use inverse twiddles for the inverse FFT No bitreversal necessary! 443 FFT followed
Input parameters System specifics, user options. Input parameters size, dim,... FFT Code Generator. Initialization Select fastest execution plan
 Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Grid Application Development Software
 Grid Application Development Software Department of Computer Science University of Houston, Houston, Texas GrADS Vision Goals Approach Status http://www.hipersoft.cs.rice.edu/grads GrADS Team (PIs) Ken
Grid Application Development Software Department of Computer Science University of Houston, Houston, Texas GrADS Vision Goals Approach Status http://www.hipersoft.cs.rice.edu/grads GrADS Team (PIs) Ken
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms
 Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Several Common Compiler Strategies. Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining
 Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Intel Enterprise Processors Technology
 Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
My 2 hours today: 1. Efficient arithmetic in finite fields minute break 3. Elliptic curves. My 2 hours tomorrow:
 My 2 hours today: 1. Efficient arithmetic in finite fields 2. 10-minute break 3. Elliptic curves My 2 hours tomorrow: 4. Efficient arithmetic on elliptic curves 5. 10-minute break 6. Choosing curves Efficient
My 2 hours today: 1. Efficient arithmetic in finite fields 2. 10-minute break 3. Elliptic curves My 2 hours tomorrow: 4. Efficient arithmetic on elliptic curves 5. 10-minute break 6. Choosing curves Efficient
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform
 Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
Vector IRAM: A Microprocessor Architecture for Media Processing
 IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Outline. How Fast is -fast? Performance Analysis of KKD Applications using Hardware Performance Counters on UltraSPARC-III
 Outline How Fast is -fast? Performance Analysis of KKD Applications using Hardware Performance Counters on UltraSPARC-III Peter Christen and Adam Czezowski CAP Research Group Department of Computer Science,
Outline How Fast is -fast? Performance Analysis of KKD Applications using Hardware Performance Counters on UltraSPARC-III Peter Christen and Adam Czezowski CAP Research Group Department of Computer Science,
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Formal Loop Merging for Signal Transforms
 Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
Performance Analysis of KDD Applications using Hardware Event Counters. CAP Theme 2.
 Performance Analysis of KDD Applications using Hardware Event Counters CAP Theme 2 http://cap.anu.edu.au/cap/projects/kddmemperf/ Peter Christen and Adam Czezowski Peter.Christen@anu.edu.au Adam.Czezowski@anu.edu.au
Performance Analysis of KDD Applications using Hardware Event Counters CAP Theme 2 http://cap.anu.edu.au/cap/projects/kddmemperf/ Peter Christen and Adam Czezowski Peter.Christen@anu.edu.au Adam.Czezowski@anu.edu.au
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries
 System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
Automatic Performance Tuning. Jeremy Johnson Dept. of Computer Science Drexel University
 Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Node Hardware. Performance Convergence
 Node Hardware Improved microprocessor performance means availability of desktop PCs with performance of workstations (and of supercomputers of 10 years ago) at significanty lower cost Parallel supercomputers
Node Hardware Improved microprocessor performance means availability of desktop PCs with performance of workstations (and of supercomputers of 10 years ago) at significanty lower cost Parallel supercomputers
Advanced Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
High-Performance Linear Algebra Processor using FPGA
 High-Performance Linear Algebra Processor using FPGA J. R. Johnson P. Nagvajara C. Nwankpa 1 Extended Abstract With recent advances in FPGA (Field Programmable Gate Array) technology it is now feasible
High-Performance Linear Algebra Processor using FPGA J. R. Johnson P. Nagvajara C. Nwankpa 1 Extended Abstract With recent advances in FPGA (Field Programmable Gate Array) technology it is now feasible
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Chapter 6 Caches. Computer System. Alpha Chip Photo. Topics. Memory Hierarchy Locality of Reference SRAM Caches Direct Mapped Associative
 Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Advanced Processor Architecture
 Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong
Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop
: Automatic Performance Tuning Workshop") Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
The Alpha Microprocessor: Out-of-Order Execution at 600 Mhz. R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA
 The Alpha 21264 Microprocessor: Out-of-Order ution at 600 Mhz R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA 1 Some Highlights z Continued Alpha performance leadership y 600 Mhz operation in
The Alpha 21264 Microprocessor: Out-of-Order ution at 600 Mhz R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA 1 Some Highlights z Continued Alpha performance leadership y 600 Mhz operation in
Performance Issues and Query Optimization in Monet
 Performance Issues and Query Optimization in Monet Stefan Manegold Stefan.Manegold@cwi.nl 1 Contents Modern Computer Architecture: CPU & Memory system Consequences for DBMS - Data structures: vertical
Performance Issues and Query Optimization in Monet Stefan Manegold Stefan.Manegold@cwi.nl 1 Contents Modern Computer Architecture: CPU & Memory system Consequences for DBMS - Data structures: vertical
Optimization of Vertical and Horizontal Beamforming Kernels on the PowerPC G4 Processor with AltiVec Technology
 Optimization of Vertical and Horizontal Beamforming Kernels on the PowerPC G4 Processor with AltiVec Technology EE382C: Embedded Software Systems Final Report David Brunke Young Cho Applied Research Laboratories:
Optimization of Vertical and Horizontal Beamforming Kernels on the PowerPC G4 Processor with AltiVec Technology EE382C: Embedded Software Systems Final Report David Brunke Young Cho Applied Research Laboratories:
Computer Architecture. Introduction. Lynn Choi Korea University
 Computer Architecture Introduction Lynn Choi Korea University Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, 공학관 411, lchoi@korea.ac.kr, TA: 윤창현 / 신동욱, 3290-3896,
Computer Architecture Introduction Lynn Choi Korea University Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, 공학관 411, lchoi@korea.ac.kr, TA: 윤창현 / 신동욱, 3290-3896,
Effect of memory latency
 CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Evolution of Computers & Microprocessors. Dr. Cahit Karakuş
 Evolution of Computers & Microprocessors Dr. Cahit Karakuş Evolution of Computers First generation (1939-1954) - vacuum tube IBM 650, 1954 Evolution of Computers Second generation (1954-1959) - transistor
Evolution of Computers & Microprocessors Dr. Cahit Karakuş Evolution of Computers First generation (1939-1954) - vacuum tube IBM 650, 1954 Evolution of Computers Second generation (1954-1959) - transistor
Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors
 Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors Mitchell A Cox, Robert Reed and Bruce Mellado School of Physics, University of the Witwatersrand.
Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors Mitchell A Cox, Robert Reed and Bruce Mellado School of Physics, University of the Witwatersrand.
Java Performance Analysis for Scientific Computing
 Java Performance Analysis for Scientific Computing Roldan Pozo Leader, Mathematical Software Group National Institute of Standards and Technology USA UKHEC: Java for High End Computing Nov. 20th, 2000
Java Performance Analysis for Scientific Computing Roldan Pozo Leader, Mathematical Software Group National Institute of Standards and Technology USA UKHEC: Java for High End Computing Nov. 20th, 2000
Intel released new technology call P6P
 P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
Today. SMP architecture. SMP architecture. Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Scientific Computing. Some slides from James Lambers, Stanford
 Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
PERFORMANCE MEASUREMENT
 Administrivia CMSC 411 Computer Systems Architecture Lecture 3 Performance Measurement and Reliability Homework problems for Unit 1 posted today due next Thursday, 2/12 Start reading Appendix C Basic Pipelining
Administrivia CMSC 411 Computer Systems Architecture Lecture 3 Performance Measurement and Reliability Homework problems for Unit 1 posted today due next Thursday, 2/12 Start reading Appendix C Basic Pipelining
Performance COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
Application Performance on Dual Processor Cluster Nodes
 Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
The Memory Hierarchy. Cache, Main Memory, and Virtual Memory (Part 2)
") The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Outline. 1 Reiteration. 2 Cache performance optimization. 3 Bandwidth increase. 4 Reduce hit time. 5 Reduce miss penalty. 6 Reduce miss rate
 Outline Lecture 7: EITF20 Computer Architecture Anders Ardö EIT Electrical and Information Technology, Lund University November 21, 2012 A. Ardö, EIT Lecture 7: EITF20 Computer Architecture November 21,
Outline Lecture 7: EITF20 Computer Architecture Anders Ardö EIT Electrical and Information Technology, Lund University November 21, 2012 A. Ardö, EIT Lecture 7: EITF20 Computer Architecture November 21,
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Optimizing MMM & ATLAS Library Generator
 Optimizing MMM & ATLAS Library Generator Recall: MMM miss ratios L1 Cache Miss Ratio for Intel Pentium III MMM with N = 1 1300 16 32/lock 4-way 8-byte elements IJ version (large cache) DO I = 1, N//row-major
Optimizing MMM & ATLAS Library Generator Recall: MMM miss ratios L1 Cache Miss Ratio for Intel Pentium III MMM with N = 1 1300 16 32/lock 4-way 8-byte elements IJ version (large cache) DO I = 1, N//row-major
Itanium 2 Impact Software / Systems MSC.Software. Jay Clark Director, Business Development High Performance Computing
 Itanium 2 Impact Software / Systems MSC.Software Jay Clark Director, Business Development High Performance Computing jay.clark@mscsoftware.com Agenda What MSC.Software does Software vendor point of view
Itanium 2 Impact Software / Systems MSC.Software Jay Clark Director, Business Development High Performance Computing jay.clark@mscsoftware.com Agenda What MSC.Software does Software vendor point of view
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Itanium 2 Processor Microarchitecture Overview
 Itanium 2 Processor Microarchitecture Overview Don Soltis, Mark Gibson Cameron McNairy, August 2002 Block Diagram F 16KB L1 I-cache Instr 2 Instr 1 Instr 0 M/A M/A M/A M/A I/A Template I/A B B 2 FMACs
Itanium 2 Processor Microarchitecture Overview Don Soltis, Mark Gibson Cameron McNairy, August 2002 Block Diagram F 16KB L1 I-cache Instr 2 Instr 1 Instr 0 M/A M/A M/A M/A I/A Template I/A B B 2 FMACs
The Alpha Microprocessor: Out-of-Order Execution at 600 MHz. Some Highlights
 The Alpha 21264 Microprocessor: Out-of-Order ution at 600 MHz R. E. Kessler Compaq Computer Corporation Shrewsbury, MA 1 Some Highlights Continued Alpha performance leadership 600 MHz operation in 0.35u
The Alpha 21264 Microprocessor: Out-of-Order ution at 600 MHz R. E. Kessler Compaq Computer Corporation Shrewsbury, MA 1 Some Highlights Continued Alpha performance leadership 600 MHz operation in 0.35u
Halfway! Sequoia. A Point of View. Sequoia. First half of the course is over. Now start the second half. CS315B Lecture 9
 Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
UMBC. Rubini and Corbet, Linux Device Drivers, 2nd Edition, O Reilly. Systems Design and Programming
 Systems Design and Programming Instructor: Professor Jim Plusquellic Text: Barry B. Brey, The Intel Microprocessors, 8086/8088, 80186/80188, 80286, 80386, 80486, Pentium and Pentium Pro Processor Architecture,
Systems Design and Programming Instructor: Professor Jim Plusquellic Text: Barry B. Brey, The Intel Microprocessors, 8086/8088, 80186/80188, 80286, 80386, 80486, Pentium and Pentium Pro Processor Architecture,
Bindel, Fall 2011 Applications of Parallel Computers (CS 5220) Tuning on a single core
 Tuning on a single core") Tuning on a single core 1 From models to practice In lecture 2, we discussed features such as instruction-level parallelism and cache hierarchies that we need to understand in order to have a reasonable
Tuning on a single core 1 From models to practice In lecture 2, we discussed features such as instruction-level parallelism and cache hierarchies that we need to understand in order to have a reasonable
Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks
 Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks Christos Kozyrakis Stanford University David Patterson U.C. Berkeley http://csl.stanford.edu/~christos Motivation Ideal processor
Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks Christos Kozyrakis Stanford University David Patterson U.C. Berkeley http://csl.stanford.edu/~christos Motivation Ideal processor
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
Reducing Hit Times. Critical Influence on cycle-time or CPI. small is always faster and can be put on chip
 Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Advanced School in High Performance and GRID Computing November Mathematical Libraries. Part I
 1967-10 Advanced School in High Performance and GRID Computing 3-14 November 2008 Mathematical Libraries. Part I KOHLMEYER Axel University of Pennsylvania Department of Chemistry 231 South 34th Street
1967-10 Advanced School in High Performance and GRID Computing 3-14 November 2008 Mathematical Libraries. Part I KOHLMEYER Axel University of Pennsylvania Department of Chemistry 231 South 34th Street
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply
 Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
7/28/ Prentice-Hall, Inc Prentice-Hall, Inc Prentice-Hall, Inc Prentice-Hall, Inc Prentice-Hall, Inc.
 Technology in Action Technology in Action Chapter 9 Behind the Scenes: A Closer Look a System Hardware Chapter Topics Computer switches Binary number system Inside the CPU Cache memory Types of RAM Computer
Technology in Action Technology in Action Chapter 9 Behind the Scenes: A Closer Look a System Hardware Chapter Topics Computer switches Binary number system Inside the CPU Cache memory Types of RAM Computer
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Adaptable benchmarks for register blocked sparse matrix-vector multiplication
 Adaptable benchmarks for register blocked sparse matrix-vector multiplication Berkeley Benchmarking and Optimization group (BeBOP) Hormozd Gahvari and Mark Hoemmen Based on research of: Eun-Jin Im Rich
Adaptable benchmarks for register blocked sparse matrix-vector multiplication Berkeley Benchmarking and Optimization group (BeBOP) Hormozd Gahvari and Mark Hoemmen Based on research of: Eun-Jin Im Rich
Advance CPU Design. MMX technology. Computer Architectures. Tien-Fu Chen. National Chung Cheng Univ. ! Basic concepts
 Computer Architectures Advance CPU Design Tien-Fu Chen National Chung Cheng Univ. Adv CPU-0 MMX technology! Basic concepts " small native data types " compute-intensive operations " a lot of inherent parallelism
Computer Architectures Advance CPU Design Tien-Fu Chen National Chung Cheng Univ. Adv CPU-0 MMX technology! Basic concepts " small native data types " compute-intensive operations " a lot of inherent parallelism
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computer Architecture. Fall Dongkun Shin, SKKU
 Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Technology Trends Presentation For Power Symposium
 Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Benchmarking CPU Performance
 Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed
Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Chapter 1: Introduction to the Microprocessor and Computer 1 1 A HISTORICAL BACKGROUND
 Chapter 1: Introduction to the Microprocessor and Computer 1 1 A HISTORICAL BACKGROUND The Microprocessor Called the CPU (central processing unit). The controlling element in a computer system. Controls
Chapter 1: Introduction to the Microprocessor and Computer 1 1 A HISTORICAL BACKGROUND The Microprocessor Called the CPU (central processing unit). The controlling element in a computer system. Controls
Why Parallel Architecture
 Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Mainstream Computer System Components CPU Core 2 GHz GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation
: Dynamic scheduling, Hardware speculation") Mainstream Computer System Components CPU Core 2 GHz - 3.0 GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation One core or multi-core (2-4) per chip Multiple FP, integer
Mainstream Computer System Components CPU Core 2 GHz - 3.0 GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation One core or multi-core (2-4) per chip Multiple FP, integer
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Accurate Cache and TLB Characterization Using Hardware Counters
 Accurate Cache and TLB Characterization Using Hardware Counters Jack Dongarra, Shirley Moore, Philip Mucci, Keith Seymour, and Haihang You Innovative Computing Laboratory, University of Tennessee Knoxville,
Accurate Cache and TLB Characterization Using Hardware Counters Jack Dongarra, Shirley Moore, Philip Mucci, Keith Seymour, and Haihang You Innovative Computing Laboratory, University of Tennessee Knoxville,
Mainstream Computer System Components
 Mainstream Computer System Components Double Date Rate (DDR) SDRAM One channel = 8 bytes = 64 bits wide Current DDR3 SDRAM Example: PC3-12800 (DDR3-1600) 200 MHz (internal base chip clock) 8-way interleaved
Mainstream Computer System Components Double Date Rate (DDR) SDRAM One channel = 8 bytes = 64 bits wide Current DDR3 SDRAM Example: PC3-12800 (DDR3-1600) 200 MHz (internal base chip clock) 8-way interleaved
Cache Justification for Digital Signal Processors
 Cache Justification for Digital Signal Processors by Michael J. Lee December 3, 1999 Cache Justification for Digital Signal Processors By Michael J. Lee Abstract Caches are commonly used on general-purpose
Cache Justification for Digital Signal Processors by Michael J. Lee December 3, 1999 Cache Justification for Digital Signal Processors By Michael J. Lee Abstract Caches are commonly used on general-purpose
HW Trends and Architectures
 Pavel Tvrdík, Jiří Kašpar (ČVUT FIT) HW Trends and Architectures MI-POA, 2011, Lecture 1 1/29 HW Trends and Architectures prof. Ing. Pavel Tvrdík CSc. Ing. Jiří Kašpar Department of Computer Systems Faculty
Pavel Tvrdík, Jiří Kašpar (ČVUT FIT) HW Trends and Architectures MI-POA, 2011, Lecture 1 1/29 HW Trends and Architectures prof. Ing. Pavel Tvrdík CSc. Ing. Jiří Kašpar Department of Computer Systems Faculty
Composite Metrics for System Throughput in HPC
 Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Robert Jamieson. Robs Techie PP Everything in this presentation is at your own risk!
 Robert Jamieson Robs Techie PP Everything in this presentation is at your own risk! PC s Today Basic Setup Hardware pointers PCI Express How will it effect you Basic Machine Setup Set the swap space Min
Robert Jamieson Robs Techie PP Everything in this presentation is at your own risk! PC s Today Basic Setup Hardware pointers PCI Express How will it effect you Basic Machine Setup Set the swap space Min
Alternate definition: Instruction Set Architecture (ISA) What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model
 What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model") What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 20 th Lecture Mar. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Assignment 3 - Feedback Peak Performance
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 20 th Lecture Mar. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Assignment 3 - Feedback Peak Performance
Computer Architecture s Changing Definition
 Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Gedae cwcembedded.com. The CHAMP-AV6 VPX-REDI. Digital Signal Processing Card. Maximizing Performance with Minimal Porting Effort
 Technology White Paper The CHAMP-AV6 VPX-REDI Digital Signal Processing Card Maximizing Performance with Minimal Porting Effort Introduction The Curtiss-Wright Controls Embedded Computing CHAMP-AV6 is
Technology White Paper The CHAMP-AV6 VPX-REDI Digital Signal Processing Card Maximizing Performance with Minimal Porting Effort Introduction The Curtiss-Wright Controls Embedded Computing CHAMP-AV6 is
Main Memory. EECC551 - Shaaban. Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be