Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
|
|
|
- Paula Shepherd
- 5 years ago
- Views:
Transcription

1 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. 1
2 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic machines 2
3 Top 500 list Ranks computers based on performance on a linear solve 3

4 Top500 Benchmarks Spring 12 4
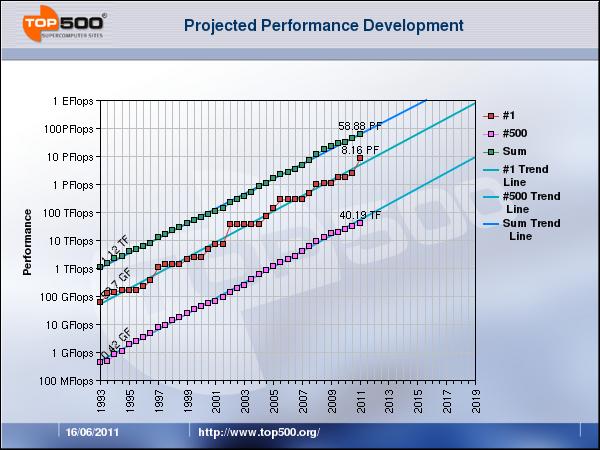
5 Trends 5
 x 2.0 E. (w) x 4.5 E. (d) Computer par11on 52 compute nodes 2 processors / node 104 AMD Magny Cours 64- bit 1.")
6 Colorado State Cray model XT6m Opera1onal January 2011 Peak performance 12 teraflops Dimensions: 7.5 E. (h) x 2.0 E. (w) x 4.5 E. (d) Computer par11on 52 compute nodes 2 processors / node 104 AMD Magny Cours 64- bit 1.9 GHz total processors 12 cores / processor; 1,248 total cores 32 GB DDR3 ECC SDRAM / node; TB total RAM 6

7 NCAR's Computational and Information Systems Laboratory (CISL) invites NSFsupported university researchers in the atmospheric, oceanic, and closely related sciences to submit large allocation requests by September 17, University researchers supported by an NSF award can request up to 30,000 GAUs as a Small Allocation request. Up to 10,000 GAUs are available to graduate students and post-docs; no NSF award is required. 7
8 NCAR & CISL systems Yellowstone A 1.5-petaflops high-performance computing system with 72,288 processor cores and 144 terabytes of memory. Production computing operations will begin in the summer of Bluefire NCAR's 77-teraflops IBM Power6 system used by the Climate Simulation Lab (CSL) and Community Computing Facilities. Janus The Janus system is a Dell Linux cluster that is housed on the CU- Boulder campus and has a high-speed networking connection to NCAR's computing and data storage systems. Lynx A Cray XT5m system deployed as a testing platform and available to NCAR users. Mirage and Storm CISL operates two data analysis and visualization clusters, with software packages including NCL, Vapor, Matlab and IDL, for its user community. GLADE The central GLADE file system significantly expands the disk space available to CISL users and allows users to access their data from both HPC and DAV systems. HPSS CISL has migrated its archival storage resource to the High-Performance Storage System (HPSS) environment, which currently stores more than 12 PB of data in support of CISL computing facilities and NCAR research activities. 8
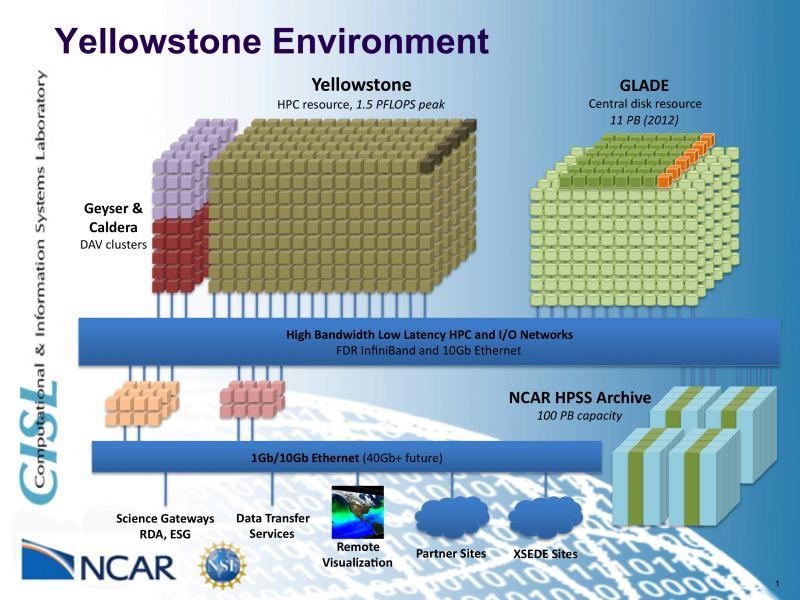
9 9
! IBM!iDataPlex!Cluster!with!Intel!Xeon!E5K2670!processors!with!Advanced!Vector! Extensions!(AVX)! 1.50!PetaFLOPs!!28.9!")
10 NCAR%Resources%!!at!the!NCAR!Wyoming!Supercompu6ng!Center!(NWSC)! Centralized!Filesystems!and!Data!Storage!(GLADE)! >90!GB/sec!aggregate!I/O!bandwidth,!GPFS!filesystems! 10.9!PetaBytes!iniJally!K>!16.4!PetaBytes!in!1Q2014! High!Performance!CompuJng!(Yellowstone)! IBM!iDataPlex!Cluster!with!Intel!Xeon!E5K2670!processors!with!Advanced!Vector! Extensions!(AVX)! 1.50!PetaFLOPs!!28.9!bluefireKequivalents!!4,518!nodes!!72,288!cores! 145!TeraBytes!total!memory! Mellanox!FDR!InfiniBand!full!fatKtree!interconnect! Data!Analysis!and!VisualizaJon!(Geyser!&!Caldera)! Large!Memory!System!with!Intel!Westmere!EX!processors! 16!nodes,!640!WestmereKEX!cores,!16!TeraBytes!memory,!16!nVIDIA!Quadro!6000!GPUs! GPUKComputaJon/Vis!System!with!Intel!Sandy!Bridge!EP!processors!with!AVX! 16!nodes,!256!E5K2670!cores,!1!TeraByte!memory,!32!nVIDIA!M2070Q!GPUs! Knights!Corner!System!with!Intel!Sandy!Bridge!EP!processors!with!AVX! 16!Knights!Corner!nodes,!256!E5K2670!cores,!>1600!KC!cores,!1!TB!memory!!Early!2013!deliver! NCAR!HPSS!Data!Archive! >100!PetaByte!capacity!(with!5!TeraByte!cartridges,!uncompressed)! 10! Codenamed! Sandy!Bridge!EP! 2
11 Yellowstone Compute 72,288 processor cores 2.6-GHz Intel Sandy Bridge EP with Advanced Vector Extensions (AVX) 8-flops clock 4,518 nodes IBM dx360 M4, dual socket, 8 cores per socket TB total system memory 2 GB/core, 32 GB/node, DDR FDR Mellanox InfiniBand interconnect Full fat tree, single plane Bandwidth 13.6 GBps bidirectional per node; latency 2.5 µs Peak bidirectional bisection bandwidth: 31.7 TBps petaflops peak 1.20 petaflops estimated HPL 11
12 XSEDE Extreme Science and Engineering Discovery Environment Mostly the same people as TeraGrid Mostly the same machines 12
13 XSEDE Machines: Yellowstone will be added to this list 13
14 Future Directions in HPC Four important concepts that will effect math software - Jack Dongarra Effective use of many-core Exploiting mixed precision in our numerical computations Self adapting / auto tuning of software Fault tolerant algorithms Barriers to progress are increasingly on the software side. Hardware has a half-life measured in years, while software has a half-life measured in decades. High performance ecosystem out of balance: HW, SW, OS, Compilers, Algorithms, Applications. 14
15 Trends Hardware Large number of cores Less memory per core More Flops/Watt Better Interconnect Software Hybrid programming Directives based 15
16 Top500 Benchmarks Spring 12 16

17 GPU GPU computing is the use of a GPU (graphics processing unit) together with a CPU to accelerate general-purpose scientific and engineering applications. GPUs do real computation Vendors have taken GPU systems and repackaged them to do computation Vendors IBM AMD Nvidia Intel NVidia Tesla M2090 GPU 17
18 Not a completely new concept Think coprocessor Main processor passes off some work to coprocessor Remember the 8087? Same issues Programs must be written to take advantage Getting data to/from coprocessor 18
19 Programming (Bottom Level) Program is written in two parts CPU GPU Computation starts on CPU Data is prepared on CPU Data is sent back to CPU Data and Program (subroutine) are sent to GPU Subroutine run on GPU as a thread 19
20 Issues Complexity Separate code for GPU Easy to write tough to get to run well Bottleneck between CPU and GPU Mixed precision Efficiency on the GPU Small amount of fast memory Massive number of threads must be managed 20

21 GPUs Many more cores Does not support normal process Expected to run multiple threads per core Very small fast memory MUCH less memory per core 21
22 Issues Complexity Directives based programming similar to OpenMP Libraries Bottleneck between CPU and GPU Getting Better Mixed precision (Some) newer GPUs have better ratio of performance Efficiency on the GPU More memory and flatter hierarchy Better thread management 22
23 CSM s old GPU node (2009) # of Tesla GPUs 4 # of Streaming Processor Cores 960 (240 per processor) Frequency of processor cores to 1.44 GHz Single Precision floating point performance (peak) 3.73 to 4.14 TFlops Double Precision floating point performance (peak) 311 to 345 GFlops Floating Point Precision IEEE 754 single & double Total Dedicated Memory 16 GB Memory Interface 512-bit Memory Bandwidth 408 GB/sec Max Power Consumption 800 W System Interface PCIe x16 or x8 Software Development Tools C-based CUDA Toolkit 23

24 Today s NVIDA offerings 24
 instruction set as other X86 When?")
25 Intel Many Integrated Core (MIC) What? Many (>50) cores on a chip Each core is x86 type processor Why? Massive parallelizm Same (MoL) instruction set as other X86 When? Knights Corner Prerelease product PCI card Available very soon as Xeon Phi, also PCI card 25
26 Intel MIC differences X86 instruction set Can in theory, run full os on the card Should most likely run threads (OpenMP) Uses the same compilers as normal Intel processors Codes optimized for current generation processor will run well on MIC Threading Vectorization 26
27 Next few slides taken from Dr. Jay Boisseau Director of TACC 27
 per core Slow operation in double precision Knights Corner (first product) 50+ cores Increased amount of RAM Details are under NDA")
28 MIC Architecture Many cores on the die L1 and L2 cache Bidirectional ring network Memory and PCIe connection MIC (KNF) architecture block diagram Knights Ferry SDP Up to 32 cores 1-2 GB of GDDR5 RAM 512-bit wide SIMD registers L1/L2 caches Multiple threads (up to 4) per core Slow operation in double precision Knights Corner (first product) 50+ cores Increased amount of RAM Details are under NDA Double precision half the speed of single precision (canonical ratio) 22 nm technology 28
29 What we at TACC like about MIC (and we think that you will like this, too) Intel s MIC is based on x86 technology x86 cores w/ caches and cache coherency SIMD instruction set Programming for MIC is similar to programming for CPUs Familiar languages: C/C++ and Fortran Familiar parallel programming models: OpenMP & MPI MPI on host and on the coprocessor Any code can run on MIC, not just kernels Optimizing for MIC is similar to optimizing for CPUs Make use of existing knowledge! Key elements of this talk highlighted! 29
30 Differences Coprocessor vs. Accelerator Architecture: x86 vs. streaming processors HPC Programming model: Threading/MPI: Programming details coherent caches vs. shared memory and caches extension to C++/C/Fortran vs. CUDA/OpenCL OpenCL support OpenMP and Multithreading vs. threads in hardware MPI on host and/or MIC vs. MPI on host only offloaded regions vs. kernels Support for any code: serial, scripting, etc. Yes No Native mode: Any code may be offloaded as a whole to the coprocessor 30
31 Programming Models Ready to use on day one! TBB s will be available to C++ programmers MKL will be available Automatic offloading by compiler for some MKL features Cilk Plus Useful for task-parallel programing (add-on to OpenMP) May become available for Fortran users as well OpenMP TACC expects that OpenMP will be the most interesting programming model for our HPC users 31
32 IBM Blue Gene Q New machine from IBM Evolution from BGL and BGP Many cores / node with less memory / core but more than L or P Very energy efficient 4 of the top 8 on top 500 list 32
33 BGQ Rack 208 Tflop 62.5 kw 1 rack 1024 nodes cores 1 node = 16+1 cores 16 Gbytes or 1Gbyte/core Footprint < 31 ft2 33
34 BGQ Proprietary Parts Processors Designed for HPC 4 threads/core Advanced speculative operation Transactional memory Networks 5D torus Collective and barrier Floating point addition in network Special IO Nodes 34

35 5D Torus What the? 35
36 Summary Core count is going up Memory / core is going down Threading will become more important Hybrid will be critical 36
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
NCAR s Data-Centric Supercomputing Environment Yellowstone. November 28, 2011 David L. Hart, CISL
 NCAR s Data-Centric Supercomputing Environment Yellowstone November 28, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
NCAR s Data-Centric Supercomputing Environment Yellowstone November 28, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
NCAR s Data-Centric Supercomputing Environment Yellowstone. November 29, 2011 David L. Hart, CISL
 NCAR s Data-Centric Supercomputing Environment Yellowstone November 29, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
NCAR s Data-Centric Supercomputing Environment Yellowstone November 29, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Cheyenne NCAR s Next-Generation Data-Centric Supercomputing Environment
 Cheyenne NCAR s Next-Generation Data-Centric Supercomputing Environment David Hart, NCAR/CISL User Services Manager June 23, 2016 1 History of computing at NCAR 2 2 Cheyenne Planned production, January
Cheyenne NCAR s Next-Generation Data-Centric Supercomputing Environment David Hart, NCAR/CISL User Services Manager June 23, 2016 1 History of computing at NCAR 2 2 Cheyenne Planned production, January
HPC. Accelerating. HPC Advisory Council Lugano, CH March 15 th, Herbert Cornelius Intel
 15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
The NCAR Yellowstone Data Centric Computing Environment. Rory Kelly ScicomP Workshop May 2013
 The NCAR Yellowstone Data Centric Computing Environment Rory Kelly ScicomP Workshop 27 31 May 2013 Computers to Data Center EVERYTHING IS NEW 2 NWSC Procurement New facility: the NWSC NCAR Wyoming Supercomputing
The NCAR Yellowstone Data Centric Computing Environment Rory Kelly ScicomP Workshop 27 31 May 2013 Computers to Data Center EVERYTHING IS NEW 2 NWSC Procurement New facility: the NWSC NCAR Wyoming Supercomputing
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
NCAR Workload Analysis on Yellowstone. March 2015 V5.0
 NCAR Workload Analysis on Yellowstone March 2015 V5.0 Purpose and Scope of the Analysis Understanding the NCAR application workload is a critical part of making efficient use of Yellowstone and in scoping
NCAR Workload Analysis on Yellowstone March 2015 V5.0 Purpose and Scope of the Analysis Understanding the NCAR application workload is a critical part of making efficient use of Yellowstone and in scoping
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
John Hengeveld Director of Marketing, HPC Evangelist
 MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Intra-MIC MPI Communication using MVAPICH2: Early Experience
 Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Overview of Parallel Computing. Timothy H. Kaiser, PH.D.
 Overview of Parallel Computing Timothy H. Kaiser, PH.D. tkaiser@mines.edu Introduction What is parallel computing? Why go parallel? The best example of parallel computing Some Terminology Slides and examples
Overview of Parallel Computing Timothy H. Kaiser, PH.D. tkaiser@mines.edu Introduction What is parallel computing? Why go parallel? The best example of parallel computing Some Terminology Slides and examples
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
The BioHPC Nucleus Cluster & Future Developments
 1 The BioHPC Nucleus Cluster & Future Developments Overview Today we ll talk about the BioHPC Nucleus HPC cluster with some technical details for those interested! How is it designed? What hardware does
1 The BioHPC Nucleus Cluster & Future Developments Overview Today we ll talk about the BioHPC Nucleus HPC cluster with some technical details for those interested! How is it designed? What hardware does
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Lecture 20: Distributed Memory Parallelism. William Gropp
 Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers
 Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT
 7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
WVU RESEARCH COMPUTING INTRODUCTION. Introduction to WVU s Research Computing Services
 WVU RESEARCH COMPUTING INTRODUCTION Introduction to WVU s Research Computing Services WHO ARE WE? Division of Information Technology Services Funded through WVU Research Corporation Provide centralized
WVU RESEARCH COMPUTING INTRODUCTION Introduction to WVU s Research Computing Services WHO ARE WE? Division of Information Technology Services Funded through WVU Research Corporation Provide centralized
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
High Performance Computing: Blue-Gene and Road Runner. Ravi Patel
 High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
Advanced High Performance Computing CSCI 580
 Advanced High Performance Computing CSCI 580 2:00 pm - 3:15 pm Tue & Thu Marquez Hall 322 Timothy H. Kaiser, Ph.D. tkaiser@mines.edu CTLM 241A http://inside.mines.edu/~tkaiser/csci580fall13/ 1 Two Similar
Advanced High Performance Computing CSCI 580 2:00 pm - 3:15 pm Tue & Thu Marquez Hall 322 Timothy H. Kaiser, Ph.D. tkaiser@mines.edu CTLM 241A http://inside.mines.edu/~tkaiser/csci580fall13/ 1 Two Similar
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures
 IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures A Future Accelerated Cognitive Distributed Hybrid Testbed for Big Data Science Analytics Milton Halem 1, John Edward
IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures A Future Accelerated Cognitive Distributed Hybrid Testbed for Big Data Science Analytics Milton Halem 1, John Edward
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
The IBM Blue Gene/Q: Application performance, scalability and optimisation
 The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
Introduction to High Performance Computing. Shaohao Chen Research Computing Services (RCS) Boston University
 Boston University") Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cray XD1 Supercomputer Release 1.3 CRAY XD1 DATASHEET
 CRAY XD1 DATASHEET Cray XD1 Supercomputer Release 1.3 Purpose-built for HPC delivers exceptional application performance Affordable power designed for a broad range of HPC workloads and budgets Linux,
CRAY XD1 DATASHEET Cray XD1 Supercomputer Release 1.3 Purpose-built for HPC delivers exceptional application performance Affordable power designed for a broad range of HPC workloads and budgets Linux,
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
The Red Storm System: Architecture, System Update and Performance Analysis
 The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
8/28/12. CSE 820 Graduate Computer Architecture. Richard Enbody. Dr. Enbody. 1 st Day 2
 CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.