SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA GPUS
|
|
|
- Allen Wilson
- 5 years ago
- Views:
Transcription
1 SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018










2 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence 2





3 ACCELERATED COMPUTING Performance & Energy Efficiency HIGH PERFORMANCE COMPUTE AI / DEEP LEARNING DATA ANALYTICS ACCELERATED VDI 3



4 FACTORS DRIVING CHANGES IN HPC End$of$Dennard$Scaling$places$a$cap$on$ single$threaded$performance Increasing$application$performance$will$ require$fine$grain$parallel$code$with$ significant$computational$intensity Cloud$based$usage$models,$in?situ$ execution$and$visualization$emerging$as$ new$workflows$critical$to$the$science$ process$and$productivity Tight$coupling$of$interactive$simulation,$ visualization,$data$analysis/ai Service$Oriented$Architectures$(SOA) AI$and$Data$Science$emerging$as$ important$new$components$of$scientific$ discovery Dramatic$improvements$in$accuracy,$ completeness$and$response$time$yield$ increased$insight$from$huge$volumes$of$ data 4





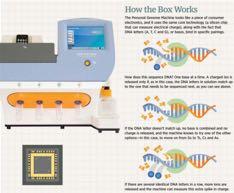
5 Multiple Experiments Coming or Upgrading In the Next 10 Years Exabyte/Day 15$TB/Day 10X$Increase$in$ Data$Volume Cryo$EM 30X$Increase$ in$power Personal$Genomics 5











6 TESLA PLATFORM ONE Data Center Platform for Accelerating HPC and AI APPLICATIONS Automotive Retail Healthcare Manufacturing Finance Defense +450 Applications INTERNET SERVICES ENTERPRISE APPLICATIONS HPC INDUSTRY FRAMEWORKS & TOOLS FRAMEWORKS ECOSYSTEM TOOLS NVIDIA SDK cudnn TensorRT NCCL cublas cusparse DeepStream SDK CUDA C/C++ FORTRAN DEEP LEARNING SDK COMPUTEWORKS TESLA & SYSTEMS TESLA NVIDIA DGX / DGX-Station NVIDIA HGX-1 SYSTEM OEM CLOUD 6
 NVIDIA Tesla V100 5120")
, 15.")



7 S FOR HPC AND DEEP LEARNING Huge$demands$on$compute$power$(FLOPS) NVIDIA Tesla V energy efficient cores + TensorCores 7.8 TF Double Precision (fp64), 15.6 TF Single Precision (fp32), 125 Tensor TFLOP/s mixed-precision Huge demands on communication and memory bandwidth CoWoS with HBM2 NVLink NCCL Direct / Direct RDMA 900 GB/s Memory Bandwidth Unifying Compute & Memory in Single Package 6 links per a 50 GB/s bidirectional for maximum scalability between s High-performance multi- and multi-node collective communication primitives optimized for NVIDIA s Direct communication between s by eliminating the CPU from the critical path 7
8 DEEP LEARNING IS A HPC WORKLOAD HPC expertise is important for success HPC and Deep Learning are using inherently parallel algorithms HPC and Deep Learning require a huge amount of compute power (FLOPS) Mainly Double Precision arithmetic for HPC Single, half or 8b precision for Deep Learning Training/Inference HPC needs less memory per FLOPS than Deep Learning HPC is more demanding on network bandwidth than Deep Learning Data scientists like dense systems (as much s as possible per node) HPC has more demand for scalability than Deep Learning up to now Distributed training frameworks like Horovod (Uber) are meanwhile available 8





9 CONTINUED DEMAND FOR COMPUTE POWER Neural$Network$complexity$is$Exploding 7 ExaFLOPS 60 Million Parameters 20 ExaFLOPS 300 Million Parameters 100 ExaFLOPS 8700 Million Parameters 2015 Microsoft ResNet Superhuman Image Recognition 2016 Baidu Deep Speech 2 Superhuman Voice Recognition 2017 Google Neural Machine Translation Near Human Language Translation 9

![* B[FP16] + C[FP32] Using Tensor cores via Volta optimized frameworks and](/docs-images/87/97344814/images/10-1.jpg "libraries (cudnn, CuBLAS, TensorRT,.")
10 TENSOR CORE Mixed Precision Matrix Math - 4x4 matrices New CUDA TensorOp instructions & data formats 4x4x4 matrix processing array D[FP32] = A[FP16] * B[FP16] + C[FP32] Using Tensor cores via Volta optimized frameworks and libraries (cudnn, CuBLAS, TensorRT,..) CUDA C++ Warp Level Matrix Operations 10
11 cublas GEMMS FOR DEEP LEARNING V100 Tensor Cores + CUDA 9: over 9x Faster Matrix-Matrix Multiply cublas Single2Precision2(FP32) cublas Mixed2Precision2(FP162Input,2FP322compute) Relative2Performance 2 1,8 1,6 1,4 1,2 1 0,8 0,6 0,4 1.8x P1002(CUDA28) V1002(CUDA29) Relative2Performance P1002(CUDA28) V1002Tensor2Cores22(CUDA29) 9.3x 0, Matrix2Size2(M=N=K) Matrix2Size2(M=N=K) Note: pre-production Tesla V100 and pre-release CUDA 9. CUDA 8 GA release. 11



12 LINEAR ALGEBRA + TENSOR CORES Tflop/s 26 FP16-TC (Tensor Cores) hgetrf LU 24 FP16 hgetrf LU FP32 sgetrf LU 22 FP64 dgetrf LU k 4k 6k 8k10k 14k 18k 22k 26k 30k 34k matrix size Data courtesy of: Azzam Haidar, Stan. Tomov & Jack Dongarra, Innovative Computing Laboratory, University of Tennessee Investigating Half Precision Arithmetic to Accelerate Dense Linear System Solvers, A. Haidar, P. Wu, S. Tomov, J. Dongarra, SC 17 GTC 2018 Poster P8237: Harnessing s Tensor Cores Fast FP16 Arithmetic to Speedup Mixed-Precision Iterative Refinement Solves Double Precision LU Decomposition! Compute initial solution in FP16! Iteratively refine to FP64 Achieved FP64 Tflops: 26 Device FP64 Tflops:
 Coherence features for NVLINK enabled CPUs Hybrid cube mesh (eg.")
13 VOLTA NVLINK 6 50 GB/s bidirectional Reduce number of lanes for lightly loaded link (Power savings) Coherence features for NVLINK enabled CPUs Hybrid cube mesh (eg. DGX1V) POWER9 based node 13
 Dual Xeon CPU, 512 GB Memory 7 TB")

14 NVIDIA DGX-1 AI supercomputer-appliance-in-a-box 8x Tesla V100 connected via NVLINK (125 TFLOPS FP32, 1 PFLOPS Tensor Core performance) Dual Xeon CPU, 512 GB Memory 7 TB SSD Deep Learning Cache Dual 10GbE, Quad IB 100Gb 3RU 3200W Optimized Deep Learning Software across the entire stack Containerized$frameworks Always$up?to?date$via$the$cloud 14

15 NVIDIA DGX-2 NVIDIA Tesla V100 32GB 1 2% Two Boards 8 V100 32GB s per board 6 NVSwitches per board 512GB Total HBM2 Memory interconnected by Plane Card Twelve NVSwitches 2.4 TB/sec bi-section bandwidth Eight EDR Infiniband/100 GigE 1600 Gb/sec Total Bi-directional Bandwidth 5 PCIe Switch Complex 30 TB NVME SSDs Internal Storage 8 6 Two Intel Xeon Platinum CPUs 7%%1.5 TB System Memory Dual 10/25 Gb/sec Ethernet 9 15


16 NVSWITCH Announced$at$GTC$US$in$March$2018 Will$be$available$in$DGX?2$systems$later$this$year 18 NVLINK GB/s per port bi-directional 900 GB/s total bi-directional Fully connected crossbar X4 PCIe Gen2 Management port GPIO I2C 2 billion transistors 16

17 FULL NON-BLOCKING BANDWIDTH 17
18 FULL 6-WAY POINT-TO-POINT NVSwitch2Fabric
19 INDEPENDENT COMMUNICATION NVSwitch2Fabric
20 LOAD & STORE TO ANY NVSwitch2Fabric


21 NVSWITCH NVLINK PROVIDES All-to-all high-bandwidth peer mapping between s Full inter- memory interconnect (incl. Atomics) UNIFIED MEMORY PROVIDES Single memory view shared by all s Automatic migration of data between s User control of data locality 21



22 SOFTWARE CHALLENGES Current DIY deep learning environments are complex and time consuming to build, test and maintain Open Source Frameworks Same issues affect HPC and other accelerated applications Need multiple jobs from different users to co-exist on the same servers NVIDIA Libraries NVIDIA Docker NVIDIA Driver NVIDIA 22


23 NVIDIA CLOUD REGISTRY Common Software stack across NVIDIA s Deep Learning All major frameworks with multi- optimizations Uses NCCL for NVLINK data exchange Multi-threaded I/O to feed the s Caffe, Caffe2,CNTK, mxnet, PyTorch, Tensorflow, Theano, Torch HPC NAMD, Gromacs, LAMMPS, GAMESS, Relion, Chroma, MILC HPC Visualization Paraview with Optix, Index and Holodeck with OpenGL visualization base on NVIDIA Docker 2.0, IndeX, VMD Single NGC Account For use on s everywhere - NVIDIA Cloud containerizes optimized frameworks, applications, runtimes, libraries, and operating system, available at no charge 23



24 NVIDIA SATURN V AI supercomputer with 660 x DGX-1V Primarily research focused Used internally for Deep Learning applied research Many using testing algorithms, networks, new approaches Embedded, robotic, auto, hyperscale, HPC Partner with university research and industry collaborations Study convergence of data science and HPC All jobs are containerized 40$PF$Peak$FP64$Performance$,$ 660$PF$DL$Tensor$Performance 24

25 DEEP LEARNING DATA CENTER Reference Architecture 25

26 NVIDIA DRIVE SIM AND CONSTELLATION AV VALIDATION SYSTEM Virtual Reality AV Simulator Same Architecture as DRIVE Computer Simulate Rare and Difficult Conditions, Recreate Scenarios, Run Regression Tests, Drive Billions of Virtual Miles 10,000 Constellations Drive 3B Miles per Year 27


27 NVIDIA ISAAC ROBOTICS PLATFORM SIMULATION TRAINING DEPLOYMENT SDK Simulation$environment$for$developing,$ testing$and$training$autonomous$ machines$in$the$virtual$world. Once$a$simulation$is$complete,$the$ trained$system$(brain)$can$be$ transferred$to$physical$robots. 28




28 COMBINING THE STRENGTHS OF HPC AND AI HPC AI Proven$algorithms$based$on$first$principles$theory Proven$statistical$models$for$accurate$results$in$ multiple$science$domains New$methods$to$improve$predictive$accuracy,$insight$ into$new$phenomena$and$response$time Develop$training$data$sets$using$first$principal$ models Incorporate$AI$models$in$semi?empirical$style$ applications$to$improve$throughput Validate$new$findings$from$AI Implement$inference$models$with$real$time$ interactivity$ Train$inference$models$to$improve$accuracy$and$ comprehend$more$of$the$physical$parameter$space Analyze$data$sets$that$are$simply$intractable$with$ classic$statistical$models Control$and$manage$complex$scientific$experiments 29
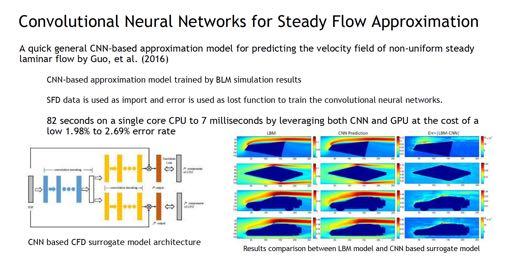
29 30
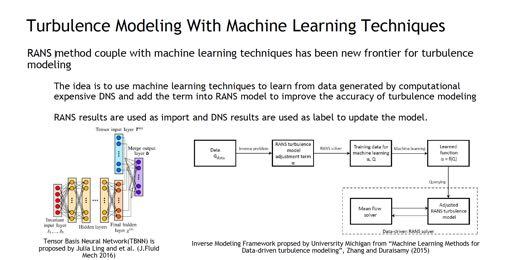
30 31

31 SUMMARY Same technology can be used for HPC and Machine Learning / deep learning Deep learning is enabling many usages in science (eg. Image recognition, classification,..) Applications can use DL to train neural networks with already simulated data and DL network can predict about the output is the right technology for HPC and DL 32
32 SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler (akoehler@nvidia.com)
CUDA: NEW AND UPCOMING FEATURES
 May 8-11, 2017 Silicon Valley CUDA: NEW AND UPCOMING FEATURES Stephen Jones, GTC 2018 CUDA ECOSYSTEM 2018 CUDA DOWNLOADS IN 2017 3,500,000 CUDA REGISTERED DEVELOPERS 800,000 GTC ATTENDEES 8,000+ 2 CUDA
May 8-11, 2017 Silicon Valley CUDA: NEW AND UPCOMING FEATURES Stephen Jones, GTC 2018 CUDA ECOSYSTEM 2018 CUDA DOWNLOADS IN 2017 3,500,000 CUDA REGISTERED DEVELOPERS 800,000 GTC ATTENDEES 8,000+ 2 CUDA
S8688 : INSIDE DGX-2. Glenn Dearth, Vyas Venkataraman Mar 28, 2018
 S8688 : INSIDE DGX-2 Glenn Dearth, Vyas Venkataraman Mar 28, 2018 Why was DGX-2 created Agenda DGX-2 internal architecture Software programming model Simple application Results 2 DEEP LEARNING TRENDS Application
S8688 : INSIDE DGX-2 Glenn Dearth, Vyas Venkataraman Mar 28, 2018 Why was DGX-2 created Agenda DGX-2 internal architecture Software programming model Simple application Results 2 DEEP LEARNING TRENDS Application
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
ACCELERATED COMPUTING: THE PATH FORWARD. Jensen Huang, Founder & CEO SC17 Nov. 13, 2017
 ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
SUPERCHARGE DEEP LEARNING WITH DGX-1. Markus Weber SC16 - November 2016
 SUPERCHARGE DEEP LEARNING WITH DGX-1 Markus Weber SC16 - November 2016 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering
SUPERCHARGE DEEP LEARNING WITH DGX-1 Markus Weber SC16 - November 2016 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering
DGX UPDATE. Customer Presentation Deck May 8, 2017
 DGX UPDATE Customer Presentation Deck May 8, 2017 NVIDIA DGX-1: The World s Fastest AI Supercomputer FASTEST PATH TO DEEP LEARNING EFFORTLESS PRODUCTIVITY REVOLUTIONARY AI PERFORMANCE Fully-integrated
DGX UPDATE Customer Presentation Deck May 8, 2017 NVIDIA DGX-1: The World s Fastest AI Supercomputer FASTEST PATH TO DEEP LEARNING EFFORTLESS PRODUCTIVITY REVOLUTIONARY AI PERFORMANCE Fully-integrated
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
POWERING THE AI REVOLUTION JENSEN HUANG, FOUNDER & CEO GTC 2017
 POWERING THE AI REVOLUTION JENSEN HUANG, FOUNDER & CEO GTC 2017 LIFE AFTER MOORE S LAW 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 Transistors (thousands) 1.1X per year 10 4 10 3 1.5X per year
POWERING THE AI REVOLUTION JENSEN HUANG, FOUNDER & CEO GTC 2017 LIFE AFTER MOORE S LAW 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 Transistors (thousands) 1.1X per year 10 4 10 3 1.5X per year
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI
 MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
MACHINE LEARNING WITH NVIDIA AND IBM POWER AI July 2017 Joerg Krall Sr. Business Ddevelopment Manager MFG EMEA jkrall@nvidia.com A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER. Markus Weber and Haiduong Vo
 DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
Cisco UCS C480 ML M5 Rack Server Performance Characterization
 White Paper Cisco UCS C480 ML M5 Rack Server Performance Characterization The Cisco UCS C480 ML M5 Rack Server platform is designed for artificial intelligence and machine-learning workloads. 2018 Cisco
White Paper Cisco UCS C480 ML M5 Rack Server Performance Characterization The Cisco UCS C480 ML M5 Rack Server platform is designed for artificial intelligence and machine-learning workloads. 2018 Cisco
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK
 Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
GPU FOR DEEP LEARNING. 周国峰 Wuhan University 2017/10/13
 GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
S8901 Quadro for AI, VR and Simulation
 S8901 Quadro for AI, VR and Simulation Carl Flygare, PNY Quadro Product Marketing Manager Allen Bourgoyne, NVIDIA Senior Product Marketing Manager The question of whether a computer can think is no more
S8901 Quadro for AI, VR and Simulation Carl Flygare, PNY Quadro Product Marketing Manager Allen Bourgoyne, NVIDIA Senior Product Marketing Manager The question of whether a computer can think is no more
Autonomous Driving Solutions
 Autonomous Driving Solutions Oct, 2017 DrivePX2 & DriveWorks Marcus Oh (moh@nvidia.com) Sr. Solution Architect, NVIDIA This work is licensed under a Creative Commons Attribution-Share Alike 4.0 (CC BY-SA
Autonomous Driving Solutions Oct, 2017 DrivePX2 & DriveWorks Marcus Oh (moh@nvidia.com) Sr. Solution Architect, NVIDIA This work is licensed under a Creative Commons Attribution-Share Alike 4.0 (CC BY-SA
S INSIDE NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORK CONTAINERS
 S8497 - INSIDE NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORK CONTAINERS Chris Lamb CUDA and NGC Engineering, NVIDIA John Barco NGC Product Management, NVIDIA NVIDIA GPU Cloud (NGC) overview AGENDA Using NGC
S8497 - INSIDE NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORK CONTAINERS Chris Lamb CUDA and NGC Engineering, NVIDIA John Barco NGC Product Management, NVIDIA NVIDIA GPU Cloud (NGC) overview AGENDA Using NGC
GPU ACCELERATED COMPUTING. 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation
 GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
GTC Jensen Huang Founder & CEO
 GTC 2018 Jensen Huang Founder & CEO 2 3 4 SCREEN-SPACE AMBIENT OCCLUSION BAKED LIGHTING 5 GLOBAL ILLUMINATION 6 SCREEN-SPACE REFLECTIONS ENVIRONMENT MAPS 7 RAY TRACED REFLECTIONS 8 SCREEN-SPACE REFRACTION
GTC 2018 Jensen Huang Founder & CEO 2 3 4 SCREEN-SPACE AMBIENT OCCLUSION BAKED LIGHTING 5 GLOBAL ILLUMINATION 6 SCREEN-SPACE REFLECTIONS ENVIRONMENT MAPS 7 RAY TRACED REFLECTIONS 8 SCREEN-SPACE REFRACTION
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC
 TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
INTRODUCING THE DGX FAMILY. Marc Domenech May 8, 2017
 INTRODUCING THE DGX FAMILY Marc Domenech May 8, 2017 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering AI computing
INTRODUCING THE DGX FAMILY Marc Domenech May 8, 2017 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering AI computing
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE
 MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU
 NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
NVDIA DGX Data Center Reference Design
 White Paper NVDIA DGX Data Center Reference Design Easy Deployment of DGX Servers for Deep Learning 2018-07-19 2018 NVIDIA Corporation. Contents Abstract ii 1. AI Workflow and Sizing 1 2. NVIDIA AI Software
White Paper NVDIA DGX Data Center Reference Design Easy Deployment of DGX Servers for Deep Learning 2018-07-19 2018 NVIDIA Corporation. Contents Abstract ii 1. AI Workflow and Sizing 1 2. NVIDIA AI Software
A NEW COMPUTING ERA. Shanker Trivedi Senior Vice President Enterprise Business at NVIDIA
 A NEW COMPUTING ERA Shanker Trivedi Senior Vice President Enterprise Business at NVIDIA THE ERA OF AI AI CLOUD MOBILE PC 2 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 5 1.1X
A NEW COMPUTING ERA Shanker Trivedi Senior Vice President Enterprise Business at NVIDIA THE ERA OF AI AI CLOUD MOBILE PC 2 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 5 1.1X
NEW NVIDIA PLATFORM FOR AI
 NEW NVIDIA PLATFORM FOR AI Pedro Mario Cruz e Silva (pcruzesilva@nvidia.com) LinkedIn Solution Architect Manager Enterprise Latin America Global Oil & Gas Team "GTC 2017: 'I AM AI' OPENING IN KEYNOTE"
NEW NVIDIA PLATFORM FOR AI Pedro Mario Cruz e Silva (pcruzesilva@nvidia.com) LinkedIn Solution Architect Manager Enterprise Latin America Global Oil & Gas Team "GTC 2017: 'I AM AI' OPENING IN KEYNOTE"
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
OpenPOWER Innovations for HPC. IBM Research. IWOPH workshop, ISC, Germany June 21, Christoph Hagleitner,
 IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
DEEP LEARNING ALISON B LOWNDES. Deep Learning Solutions Architect & Community Manager EMEA
 DEEP LEARNING ALISON B LOWNDES Deep Learning Solutions Architect & Community Manager EMEA 1 THE GPU-ACCELERATED WORLD HPC DEEP LEARNING PC VIRTUALIZATION CLOUD GAMING RENDERING 2 3 Why is Deep Learning
DEEP LEARNING ALISON B LOWNDES Deep Learning Solutions Architect & Community Manager EMEA 1 THE GPU-ACCELERATED WORLD HPC DEEP LEARNING PC VIRTUALIZATION CLOUD GAMING RENDERING 2 3 Why is Deep Learning
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS
 TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
S THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE. Presenter: Louis Capps, Solution Architect, NVIDIA,
 S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
April 4-7, 2016 Silicon Valley INSIDE PASCAL. Mark Harris, October 27,
 April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
Turing Architecture and CUDA 10 New Features. Minseok Lee, Developer Technology Engineer, NVIDIA
 Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE. Dennis Lui August 2017
 DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
NCCL 2.0. Sylvain Jeaugey
 NCCL 2.0 Sylvain Jeaugey DEE LEARNING ON GUS Making DL training times shorter Deeper neural networks, larger data sets training is a very, very long operation! CUDA NCCL 1 NCCL 2 Multi-core CU GU Multi-GU
NCCL 2.0 Sylvain Jeaugey DEE LEARNING ON GUS Making DL training times shorter Deeper neural networks, larger data sets training is a very, very long operation! CUDA NCCL 1 NCCL 2 Multi-core CU GU Multi-GU
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
IBM SpectrumAI with NVIDIA Converged Infrastructure Solutions for AI workloads
 IBM SpectrumAI with NVIDIA Converged Infrastructure Solutions for AI workloads The engine to power your AI data pipeline Introduction: Artificial intelligence (AI) including deep learning (DL) and machine
IBM SpectrumAI with NVIDIA Converged Infrastructure Solutions for AI workloads The engine to power your AI data pipeline Introduction: Artificial intelligence (AI) including deep learning (DL) and machine
GPUS FOR NGVLA. M Clark, April 2015
 S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
Towards Scalable Machine Learning
 Towards Scalable Machine Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Fraunhofer Center Machnine Larning Outline I Introduction
Towards Scalable Machine Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Fraunhofer Center Machnine Larning Outline I Introduction
GPU-Accelerated Deep Learning
 GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
The Tesla Accelerated Computing Platform
 The Tesla Accelerated Computing Platform Axel Koehler, Principal Solution Architect HPC Advisory Council Meeting Lugano 22 March 2016 Introduction TESLA Platform for HPC Agenda TESLA Platform for HYPERSCALE
The Tesla Accelerated Computing Platform Axel Koehler, Principal Solution Architect HPC Advisory Council Meeting Lugano 22 March 2016 Introduction TESLA Platform for HPC Agenda TESLA Platform for HYPERSCALE
TESLA V100 PERFORMANCE GUIDE May 2018
 TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
NVIDIA Tesla P100. Whitepaper. The Most Advanced Datacenter Accelerator Ever Built. Featuring Pascal GP100, the World s Fastest GPU
 Whitepaper NVIDIA Tesla P100 The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World s Fastest GPU NVIDIA Tesla P100 WP-08019-001_v01.2 1 Table of Contents Introduction...
Whitepaper NVIDIA Tesla P100 The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World s Fastest GPU NVIDIA Tesla P100 WP-08019-001_v01.2 1 Table of Contents Introduction...
HPC and AI Solution Overview. Garima Kochhar HPC and AI Innovation Lab
 HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
19. prosince 2018 CIIRC Praha. Milan Král, IBM Radek Špimr
 19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads. Natalia Vassilieva, Sergey Serebryakov
 HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads Natalia Vassilieva, Sergey Serebryakov Deep learning ecosystem today Software Hardware 2 HPE s portfolio for deep learning Government,
HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads Natalia Vassilieva, Sergey Serebryakov Deep learning ecosystem today Software Hardware 2 HPE s portfolio for deep learning Government,
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017
 A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
High-Performance Training for Deep Learning and Computer Vision HPC
 High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
EFFICIENT INFERENCE WITH TENSORRT. Han Vanholder
 EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
TESLA PLATFORM. Jan 2018
 TESLA PLATFORM Jan 2018 A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices MOBILE-CLOUD iphone, Amazon AWS 2.5 billion mobile users PC INTERNET WinTel, Yahoo! 1 billion PC users
TESLA PLATFORM Jan 2018 A NEW ERA OF COMPUTING AI & IOT Deep Learning, GPU 100s of billions of devices MOBILE-CLOUD iphone, Amazon AWS 2.5 billion mobile users PC INTERNET WinTel, Yahoo! 1 billion PC users
Characterization and Benchmarking of Deep Learning. Natalia Vassilieva, PhD Sr. Research Manager
 Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA PLATFORM FOR AI
 NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND. Mark Harris, May 10, 2017
 May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND Mark Harris, May 10, 2017 INTRODUCING CUDA 9 BUILT FOR VOLTA FASTER LIBRARIES Tesla V100 New GPU Architecture Tensor Cores NVLink Independent Thread Scheduling
May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND Mark Harris, May 10, 2017 INTRODUCING CUDA 9 BUILT FOR VOLTA FASTER LIBRARIES Tesla V100 New GPU Architecture Tensor Cores NVLink Independent Thread Scheduling
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
S CUDA on Xavier
 S8868 - CUDA on Xavier Anshuman Bhat CUDA Product Manager Saikat Dasadhikari CUDA Engineering 29 th March 2018 1 CUDA ECOSYSTEM 2018 CUDA DOWNLOADS IN 2017 3,500,000 CUDA REGISTERED DEVELOPERS 800,000
S8868 - CUDA on Xavier Anshuman Bhat CUDA Product Manager Saikat Dasadhikari CUDA Engineering 29 th March 2018 1 CUDA ECOSYSTEM 2018 CUDA DOWNLOADS IN 2017 3,500,000 CUDA REGISTERED DEVELOPERS 800,000
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor. 0 Copyright 2018 FUJITSU LIMITED
 FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor 0 Copyright 2018 FUJITSU LIMITED FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a compact and modular form
FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor 0 Copyright 2018 FUJITSU LIMITED FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a compact and modular form
DGX-1 DOCKER USER GUIDE Josh Park Senior Solutions Architect Contents created by Jack Han Solutions Architect
 DGX-1 DOCKER USER GUIDE 17.08 Josh Park Senior Solutions Architect Contents created by Jack Han Solutions Architect AGENDA Introduction to Docker & DGX-1 SW Stack Docker basic & nvidia-docker Docker image
DGX-1 DOCKER USER GUIDE 17.08 Josh Park Senior Solutions Architect Contents created by Jack Han Solutions Architect AGENDA Introduction to Docker & DGX-1 SW Stack Docker basic & nvidia-docker Docker image
The Exascale Era Has Arrived
 Technology Spotlight The Exascale Era Has Arrived Sponsored by NVIDIA Steve Conway, Earl Joseph, Bob Sorensen, and Alex Norton November 2018 EXECUTIVE SUMMARY Earlier this year, scientists broke the exascale
Technology Spotlight The Exascale Era Has Arrived Sponsored by NVIDIA Steve Conway, Earl Joseph, Bob Sorensen, and Alex Norton November 2018 EXECUTIVE SUMMARY Earlier this year, scientists broke the exascale
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Unified Deep Learning with CPU, GPU, and FPGA Technologies
 Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
NVIDIA Accelerators Models HPE NVIDIA GV100 Nvlink Bridge Kit HPE NVIDIA Tesla V100 FHHL 16GB Computational Accelerator
 Overview Hewlett Packard supports, on select HPE ProLiant servers, computational accelerator modules based on NVIDIA Tesla, NVIDIA GRID, and NVIDIA Quadro Graphical Processing Unit (GPU) technology. The
Overview Hewlett Packard supports, on select HPE ProLiant servers, computational accelerator modules based on NVIDIA Tesla, NVIDIA GRID, and NVIDIA Quadro Graphical Processing Unit (GPU) technology. The
TACKLING THE CHALLENGES OF NEXT GENERATION HEALTHCARE
 TACKLING THE CHALLENGES OF NEXT GENERATION HEALTHCARE Nicola Rieke, Senior Deep Learning Solution Architect Healthcare EMEA Fausto Milletari, Senior Deep Learning Solution Architect Healthcare NALA INTRODUCTION
TACKLING THE CHALLENGES OF NEXT GENERATION HEALTHCARE Nicola Rieke, Senior Deep Learning Solution Architect Healthcare EMEA Fausto Milletari, Senior Deep Learning Solution Architect Healthcare NALA INTRODUCTION
IBM Power User Group - Atlanta
 IBM Power User Group - Atlanta Wes Showfety Open Source Database & HPC strategist, North America showfety@us.ibm.com 770-617-7377 LinkedIn: https://www.linkedin.com/in/wes-showfety-2399444 Twitter: @Wes_Show
IBM Power User Group - Atlanta Wes Showfety Open Source Database & HPC strategist, North America showfety@us.ibm.com 770-617-7377 LinkedIn: https://www.linkedin.com/in/wes-showfety-2399444 Twitter: @Wes_Show
Deep Learning: Transforming Engineering and Science The MathWorks, Inc.
 Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
In partnership with. VelocityAI REFERENCE ARCHITECTURE WHITE PAPER
 In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink
 Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
DEEP NEURAL NETWORKS AND GPUS. Julie Bernauer
 DEEP NEURAL NETWORKS AND GPUS Julie Bernauer GPU Computing GPU Computing Run Computations on GPUs x86 CUDA Framework to Program NVIDIA GPUs A simple sum of two vectors (arrays) in C void vector_add(int
DEEP NEURAL NETWORKS AND GPUS Julie Bernauer GPU Computing GPU Computing Run Computations on GPUs x86 CUDA Framework to Program NVIDIA GPUs A simple sum of two vectors (arrays) in C void vector_add(int
Advancing State-of-the-Art of Autonomous Vehicles and Robotics Research using AWS GPU Instances
 Advancing State-of-the-Art of Autonomous Vehicles and Robotics Research using AWS GPU Instances Adrien Gaidon - Machine Learning Lead, Toyota Research Institute Mike Garrison - Senior Systems Engineer,
Advancing State-of-the-Art of Autonomous Vehicles and Robotics Research using AWS GPU Instances Adrien Gaidon - Machine Learning Lead, Toyota Research Institute Mike Garrison - Senior Systems Engineer,
SVM multiclass classification in 10 steps 17/32
 SVM multiclass classification in 10 steps import numpy as np # load digits dataset from sklearn import datasets digits = datasets. load_digits () # define training set size n_samples = len ( digits. images
SVM multiclass classification in 10 steps import numpy as np # load digits dataset from sklearn import datasets digits = datasets. load_digits () # define training set size n_samples = len ( digits. images
STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC. Stefan Maintz, Dr. Markus Wetzstein
 STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC Stefan Maintz, Dr. Markus Wetzstein smaintz@nvidia.com; mwetzstein@nvidia.com Companies Academia VASP USERS AND USAGE 12-25% of CPU cycles @ supercomputing
STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC Stefan Maintz, Dr. Markus Wetzstein smaintz@nvidia.com; mwetzstein@nvidia.com Companies Academia VASP USERS AND USAGE 12-25% of CPU cycles @ supercomputing
IBM Leading High Performance Computing and Deep Learning Technologies
 IBM Leading High Performance Computing and Deep Learning Technologies Yubo Li ( 李玉博 ) Chief Architect, on Cloud IBM Research -- China email: liyubobj@cn.ibm.com QQ: 395238640 GTC China 2016 Sept. 13, 2016
IBM Leading High Performance Computing and Deep Learning Technologies Yubo Li ( 李玉博 ) Chief Architect, on Cloud IBM Research -- China email: liyubobj@cn.ibm.com QQ: 395238640 GTC China 2016 Sept. 13, 2016
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive. Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center
 Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
May 8-11, 2017 Silicon Valley. CUDA 9 AND BEYOND Mark Harris, May 10, 2017
 May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND Mark Harris, May 10, 2017 INTRODUCING CUDA 9 BUILT FOR VOLTA FASTER LIBRARIES Tesla V100 New GPU Architecture Tensor Cores NVLink Independent Thread Scheduling
May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND Mark Harris, May 10, 2017 INTRODUCING CUDA 9 BUILT FOR VOLTA FASTER LIBRARIES Tesla V100 New GPU Architecture Tensor Cores NVLink Independent Thread Scheduling
Beyond Training The next steps of Machine Learning. Chris /in/chrisparsonsdev
 Beyond Training The next steps of Machine Learning Chris Parsons chrisparsons@uk.ibm.com @chrisparsonsdev /in/chrisparsonsdev What is this talk? Part 1 What is Machine Learning? AI Infrastructure PowerAI
Beyond Training The next steps of Machine Learning Chris Parsons chrisparsons@uk.ibm.com @chrisparsonsdev /in/chrisparsonsdev What is this talk? Part 1 What is Machine Learning? AI Infrastructure PowerAI