Application I/O on Blue Waters. Rob Sisneros Kalyana Chadalavada
|
|
|
- Hilary Rich
- 5 years ago
- Views:
Transcription

1 Application I/O on Blue Waters Rob Sisneros Kalyana Chadalavada

2 I/O For Science! HDF5 I/O Library PnetCDF Adios IOBUF Scien'st Applica'on I/O Middleware U'li'es Parallel File System Darshan Blue Waters MPI- IO Damaris Lustre







3 Where the BW I/O Team Can Help HDF5 I/O Library PnetCDF Adios IOBUF Scien'st Applica'on I/O Middleware U'li'es Parallel File System Darshan Blue Waters MPI- IO Damaris Lustre



4 This Talk HDF5 I/O Library PnetCDF Adios IOBUF Scien'st Applica'on I/O Middleware MPI- IO Damaris U'li'es Parallel File System Lustre Darshan Blue Waters
5 Lustre PARALLEL I/O



6 Checkpoint files Write-close Size varies Must be written to disk Log / history / state files Simple appends Common I/O Usage Small writes (~kb - ~MB) Can be buffered Write-read not very common Op'mize for write Synchronous write Op'mize for write Asynchronous write Explicit buffer management or Use a library

7 Available File Systems home 2.2 PB 1TB quota project 2.2 PB 3TB quota scratch 22 PB 500 TB quota Three separate file systems Three separate metadata servers User operations in home won t interfere with application IO Project space controlled by the PI
8 Application I/O: Big Picture Considerations Maximize both client I/O and communication bandwidth (without breaking things) Minimize management of an unnecessarily large number of files Minimize costly post-processing Exploit parallelism in the file system Maintain portability
9 Large Scale I/O in Practice Serial I/O is limited by both the I/O bandwidth of a single process as well as that of a single OST Two ways to increase bandwidth: File File File File File File
10 File-Per-Process Each process performs I/O on its own file File File File File File Advantages Straightforward implementation Typically leads to reasonable bandwidth quickly Disadvantages Limited by single process Difficulty in managing a large number of files Likely requires post processing to acquire useful data Can be taxing on the file system metadata and ruin everybody s day
11 Shared-File There is one, large file shared among all processors which access the file concurrently File Advantages Results in easily managed data that is useful with minimal preprocessing Disadvantages Likely slower than file-per-process, if not used properly Additional (one-time!) programing investment
 Accessing multiple OSTs concurrently increases I/O")
12 Lustre File System: Striping Logical Physical File striping: single files are distributed across a series of OSTs File size can grow to the aggregate size of available OSTs (rather than a single disk) Accessing multiple OSTs concurrently increases I/O bandwidth
13 Performance Impact: Configuring File Striping lfs is the Lustre utility for viewing/setting file striping info Stripe count the number of OSTs across which the file can be striped Stripe size the size of the blocks that a file will be broken into Stripe offset the ID of an OST for Lustre to start with, when deciding which OSTs a file will be striped across Configurations should focus on stripe count/size Blue Waters defaults: $> touch test $> lfs getstripe test test lmm_stripe_count: 1 lmm_stripe_size: lmm_stripe_offset: 708 obdidx objid objid group x20faa4 0
14 Setting Striping Patterns $> lfs setstripe -c 5 -s 32m test $> lfs getstripe test test lmm_stripe_count: 5 lmm_stripe_size: lmm_stripe_offset: 1259 obdidx objid objid group x20ff7d x210c x x20fb x20fa13 0 Note: a file s striping pattern is permanent, and set upon creation lfs setstripe creates a new, 0 byte file The striping pattern can be changed for a directory; every new file or directory created within will inherit its striping pattern Simple API available for configuring striping portable to other Lustre systems

15 Striping Case Study Reading 1 TB input file using 2048 cores Func%on Stripe Count = 1 Stripe Count = 64 Improvement Total s s 94.1% loadkernel s s 98.0% loaddamp s 6.144s 81.8% loaddamp_bycol s 5.712s 81.0% Code is now CPU bound instead of I/O bound Optimization effort : lfs setstripe c 64
 Stripe size is unlikely to vary performance unless unreasonably")
16 Striping, and You When to use the default stripe count of 1 Serial I/O or small files Inefficient use of bandwidth + overhead of using multiple OSTs will degrade performance File-per-process I/O Pattern Each core interacting with a single OST reduces network costs of hitting OSTs (which can eat your lunch at large scales) Stripe size is unlikely to vary performance unless unreasonably small/large Err on the side of small This helps keep stripes aligned, or within single OSTs Can lessen OST traffic Default stripe size should be adequate
 Stripe count Should equal the number of processes performing I/O to maximize I/O bandwidth Blue Waters contains 1440 OSTs, the maximum possible for file stripe count is currently")
17 Large shared files: Processes ideally access exclusive file regions Stripe size Application dependent Should maximize stripe alignment (localize a process to an OST to reduce contention and connection overhead) Stripe count Should equal the number of processes performing I/O to maximize I/O bandwidth Blue Waters contains 1440 OSTs, the maximum possible for file stripe count is currently 160 (likely to increase soon pending a software update) $> lfs osts OBDS 0: snx11001-ost0000_uuid ACTIVE 1: snx11001-ost0001_uuid ACTIVE 1438: snx11003-ost059e_uuid ACTIVE 1439: snx11003-ost059f_uuid ACTIVE
18 And the Winner is Neither? Both patterns increase bandwidth through the addition of I/O processes There are a limited number of OSTs to stripe a file across The likelihood of OST contention grows with the ratio of I/O processes to OSTs Eventually, the benefit of another I/O process is offset by added OST traffic Both routinely use all processes to perform I/O A small subset of a node s cores can consume a node s I/O bandwidth This is an inefficient use of resources The answer? It depends but, Think aggregation, a la file-per-node


19 I/O Delegates File File Advantages More control - customize per job size Ex: One file per node, one file per OST Disadvantages Additional (one-time!) programing investment
20 Damaris, MPI-IO & IOBUF I/O MIDDLEWARE
21 Why use I/O Middleware? Derived data types Easy to work with shared files Derived types + shared files Data is now a series of objects, rather than a number of files On restart from checkpoint, the number of processors need not match the number of files Easy read-write of non-contiguous data Optimizations possible with little effort
22 I/O Middleware: Damaris Damaris -- Dedicated Adaptable Middleware for Application Resources Inline Steering Started in 2010 by Matthieu Dorier during an internship at NCSA The purpose: decouple I/O and computation to enable scalable asynchronous I/O The approach: dedicated I/O core(s) on each node Limits OST contention to the node level Leverages shared memory for efficient interaction When simulation writes data, Damaris utilizes shared memory to effectively aggregate writes to the right size
23 Application: Reducing I/O Jitter in CM1 I/O Jitter is the variability in I/O operations that arise from any number of common interferences CM1 Atmospheric simulation Current Blue Waters allocation Uses serial and parallel HDF5
24 How Damaris Helps with I/O Jitter Jitter is moved to the dedicated core Even with the reduction in number of cores performing computation, performance is not adversely affected, in fact.

25 How Damaris Helps CM Run %me (sec) Scalability factor Perfect scaling Damaris File- per- process Number of cores In these runs, Damaris spent at least 75% its time waiting! A plugin system was implemented such that this time may be used for other tasks We are collaborating with the developer to identify alternate uses Number of cores Weak scalability factor: Collec%ve- I/O S = N T base T N: number of cores T base : 'me of an itera'on on one core w/ write T: 'me of an itera'on + a write
26 I/O Middleware: MPI-IO MPI standard s implementation of collective I/O (shared-file) A file is opened by a group of processes, partitioned among them, and I/O calls are collective among all processes in the group Files are composed of native MPI data types Non-collective I/O is also possible Uses collective buffering to consolidate I/O requests All data is transferred to a subset of processes and aggregated Use MPICH_MPIIO_CB_ALIGN=2 to enable Cray s collective buffering algorithm automatic Lustre stripes alignment & minimize lock contention May not be beneficial when writing small data segments Verified to deliver 25% improvement on BlueWaters for a 1000 rank job Use MPICH_MPIIO_XSTATS [0, 1, 2] to obtain MPI-IO statistics I/O optimizations in high level libraries are often implemented here be sure any monkeying is careful monkeying


27 Exchange metadata Collective Buffering (1)

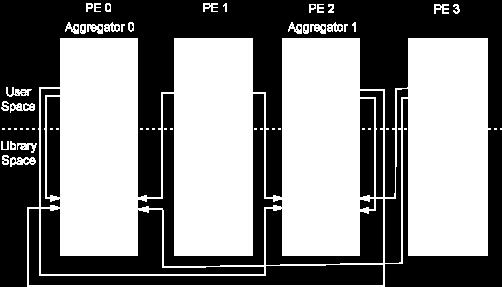
28 Collective Buffering (2) Copy user/application data


29 Collective Buffering (3) Aggregators write to disk
30 Tuning MPI-IO: CB Hints Hints are specified in application code [MPI_Info_set()] or as environment variables (MPICH_MPIIO_HINTS) Collective buffering hints Hint Descrip%on Default cb_buffer_size! set the maximum size of a single I/O opera'on cb_nodes! set maximum number of aggregators stripe count of file romio_cb_read romio_cb_write romio_no_indep_rw enable or disable collec've buffering if true, MPI- IO knows all I/O is collec've Only aggregators will open files cb_config_list a list of independent configura'ons for nodes N/A 4MB automa'c false! striping_factor Specifies the number of Lustre stripes File system striping_unit Specifies the size of the Lustre stripe File system
31 Other Useful Hints romio_lustre_co_ratio! Hint Descrip%on Default romio_lustre_coll_threshold! mpich_mpiio_hints_display tell MPI- IO the maximum number of processes (clients, here) that will access an OST Turns off collec've buffering when transfer sizes are above a certain threshold when true a summary of all hints to stderr each 'me a file is opened 1 0 (never) false!


32 IOBUF I/O Buffering Library Optimize I/O performance with minimal effort Asynchronous prefetch Write back caching stdin, stdout, stderr disabled by default No code changes needed Load module Recompile & relink the code Applica'on IOBUF Linux IO infrastructure File Systems / Lustre Ideal for sequential read or write operations
33 IOBUF I/O Buffering Library Globally (dis)enable by (un)setting IOBUF_PARAMS Fine grained control Control buffer size, count, synchronicity, prefetch Disable iobuf per file Some calls in C, C++ can be enabled using iobuf.h, use the compiler macro, USE_IOBUF_MACROS export IOBUF_PARAMS='*.in:count=4:size=32M,*.out:count=8:size=64M:preflush=1'
34 IOBUF MPI-IO Sample Output
35 HDF5 & PnetCDF I/O LIBRARIES
36 Benefits of I/O Libraries There are many benefits to using higher level I/O libraries They provide a well-defined, base structure for files that is selfdescribing and organizes data intuitively Has an API that represents data in a way similar to a simulation Often built on MPI-IO and handle (some) optimization Easy serialization/deserialization of user data structures Portable Currently supported: (Parallel) HDF5, (Parallel) netcdf, Adios
37 I/O Libraries Some Details Parallel netcdf Derived from and compatible with the original Network Common Data Format Offers collective I/O on single files Variables are typed, multidimensional, and (with files) may have associated attributes Record variables unlimited dimensions allowed if dimension size is unknown Parallel HDF5 Hierarchical Data Format with data model similar to PnetCDF, and also uses collective I/O calls Can use compression (only in serial I/O mode) Can perform data reordering Very flexible Allows some fine tuning, e.g. enabling buffering
38 Under PrgEnv-cray: Example Use on Blue Waters $> module avail hdf /opt/cray/modulefiles hdf5/1.8.7 hdf5/1.8.8(default) hdf5-parallel/1.8.7 hdf5-parallel/1.8.8 (default) $> module load hd5-parallel $> cc Dataset.c $> qsub -I -lnodes=1:ppn=16 -lwalltime=00:30:00 $> aprun n 2./a.out Application resources: utime ~0s, stime ~0s $> ls *.h5 SDS.h5 Dataset.c is a test code from the HDF Group:
39 Darshan I/O UTILITIES
40 Example I/O Utility: Darshan We will support tools for I/O Characterization Sheds light on the intricacies of an application s I/O Useful for application I/O debugging Pinpointing causes of extremes Analyzing/tuning hardware for optimizations Darshan was developed at Argonne, and is a scalable HPC I/O characterization tool designed to capture an accurate picture of application I/O behavior with minimum overhead
41 Darshan Specifics Darshan collects per-process statistics (organized by file) Counts I/O operations, e.g. unaligned and sequential accesses Times for file operations, e.g. opens and writes Accumulates read/write bandwidth info Creates data for simple visual representation More Requires no code modification (only re-linking) Small memory footprint Includes a job summary tool
42 Summary Tool Example Output jobid: 3406 uid: 1000 nprocs: 8 runtime: 1 seconds Average I/O cost per process I/O Operation Counts Percentage of run time POSIX MPI-IO Read Write Metadata Other (including application compute) I/O Sizes Ops (Total, All Processes) Read Write Open Stat Seek Mmap Fsync POSIX MPI-IO Indep. I/O Pattern MPI-IO Coll. File Count Summary type number of files avg. size max size total opened 1 128M 128M read-only files write-only files read/write files 1 128M 128M created files Most Common Access Sizes access size count Count (Total, All Procs) Ops (Total, All Procs) G+ 100M-1G 10M-100M 4M-10M 1M-4M 100K-1M 10K-100K 1K-10K 101-1K Read Write Read Write Total Sequential Consecutive
43 Timespan from first to last access on files shared by all processes read write All processes 00:00:00 00:00:00 00:00:00 00:00:00 00:00:00 00:00:01 hours:minutes:seconds Average I/O per process Cumulative time spent in I/O functions (seconds) Amount of I/O (MB) Independent reads Independent writes Independent metadata N/A Shared reads Shared writes Shared metadata N/A Data Transfer Per Filesystem Write Read File System MiB Ratio MiB Ratio / Variance in Shared Files File Processes Fastest Slowest σ Suffix Rank Time Bytes Rank Time Bytes Time Bytes...test.out M M
44 Two slides left. THE SUMMARY
45 Good Practices, Generally Opening a file for writing/appending is expensive, so: If possible, open files as read-only Avoid large numbers of small writes while(forever){ open( myfile ); write(a_byte); close( myfile ); } Be gentle with metadata (or suffer its wrath) limit the number of files in a single directory Instead opt for hierarchical directory structure ls contacts the metadata server, ls l communicates with every OST assigned to a file (for all files) Avoid wildcards: rm rf *, expanding them is expensive over many files It may even be more efficient to pass medata through MPI than have all processes hit the MDS (calling stat) Avoid updating last access time for read-only operations (NO_ATIME)
46 Lessons Learned Avoid unaligned I/O and OST contention! Use large data transfers Don t expect performance with non-contiguous, small data transfers. Use buffering when possible Consider using MPI-IO and other I/O libraries Portable data formats vs. unformatted files Use system specific hints and optimizations Exploit parallelism using striping Focus on stripe alignment, avoiding lock contention Move away from one-file-per-process model Use aggregation and reduce number of output files Talk to your POC about profiling and optimizing I/O
Lecture 33: More on MPI I/O. William Gropp
 Lecture 33: More on MPI I/O William Gropp www.cs.illinois.edu/~wgropp Today s Topics High level parallel I/O libraries Options for efficient I/O Example of I/O for a distributed array Understanding why
Lecture 33: More on MPI I/O William Gropp www.cs.illinois.edu/~wgropp Today s Topics High level parallel I/O libraries Options for efficient I/O Example of I/O for a distributed array Understanding why
Parallel I/O on Theta with Best Practices
 Parallel I/O on Theta with Best Practices Paul Coffman pcoffman@anl.gov Francois Tessier, Preeti Malakar, George Brown ALCF 1 Parallel IO Performance on Theta dependent on optimal Lustre File System utilization
Parallel I/O on Theta with Best Practices Paul Coffman pcoffman@anl.gov Francois Tessier, Preeti Malakar, George Brown ALCF 1 Parallel IO Performance on Theta dependent on optimal Lustre File System utilization
Scalable I/O. Ed Karrels,
 Scalable I/O Ed Karrels, edk@illinois.edu I/O performance overview Main factors in performance Know your I/O Striping Data layout Collective I/O 2 of 32 I/O performance Length of each basic operation High
Scalable I/O Ed Karrels, edk@illinois.edu I/O performance overview Main factors in performance Know your I/O Striping Data layout Collective I/O 2 of 32 I/O performance Length of each basic operation High
Lustre Parallel Filesystem Best Practices
 Lustre Parallel Filesystem Best Practices George Markomanolis Computational Scientist KAUST Supercomputing Laboratory georgios.markomanolis@kaust.edu.sa 7 November 2017 Outline Introduction to Parallel
Lustre Parallel Filesystem Best Practices George Markomanolis Computational Scientist KAUST Supercomputing Laboratory georgios.markomanolis@kaust.edu.sa 7 November 2017 Outline Introduction to Parallel
HPC Input/Output. I/O and Darshan. Cristian Simarro User Support Section
 HPC Input/Output I/O and Darshan Cristian Simarro Cristian.Simarro@ecmwf.int User Support Section Index Lustre summary HPC I/O Different I/O methods Darshan Introduction Goals Considerations How to use
HPC Input/Output I/O and Darshan Cristian Simarro Cristian.Simarro@ecmwf.int User Support Section Index Lustre summary HPC I/O Different I/O methods Darshan Introduction Goals Considerations How to use
Introduction to Parallel I/O
 Introduction to Parallel I/O Bilel Hadri bhadri@utk.edu NICS Scientific Computing Group OLCF/NICS Fall Training October 19 th, 2011 Outline Introduction to I/O Path from Application to File System Common
Introduction to Parallel I/O Bilel Hadri bhadri@utk.edu NICS Scientific Computing Group OLCF/NICS Fall Training October 19 th, 2011 Outline Introduction to I/O Path from Application to File System Common
Welcome! Virtual tutorial starts at 15:00 BST
 Welcome! Virtual tutorial starts at 15:00 BST Parallel IO and the ARCHER Filesystem ARCHER Virtual Tutorial, Wed 8 th Oct 2014 David Henty Reusing this material This work is licensed
Welcome! Virtual tutorial starts at 15:00 BST Parallel IO and the ARCHER Filesystem ARCHER Virtual Tutorial, Wed 8 th Oct 2014 David Henty Reusing this material This work is licensed
Analyzing the High Performance Parallel I/O on LRZ HPC systems. Sandra Méndez. HPC Group, LRZ. June 23, 2016
 Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Using file systems at HC3
 Using file systems at HC3 Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association www.kit.edu Basic Lustre
Using file systems at HC3 Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association www.kit.edu Basic Lustre
Introduction to High Performance Parallel I/O
 Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
The JANUS Computing Environment
 Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
Lustre Lockahead: Early Experience and Performance using Optimized Locking. Michael Moore
 Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Parallel I/O Libraries and Techniques
 Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Overview of High Performance Input/Output on LRZ HPC systems. Christoph Biardzki Richard Patra Reinhold Bader
 Overview of High Performance Input/Output on LRZ HPC systems Christoph Biardzki Richard Patra Reinhold Bader Agenda Choosing the right file system Storage subsystems at LRZ Introduction to parallel file
Overview of High Performance Input/Output on LRZ HPC systems Christoph Biardzki Richard Patra Reinhold Bader Agenda Choosing the right file system Storage subsystems at LRZ Introduction to parallel file
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Parallel I/O Techniques and Performance Optimization
 Parallel I/O Techniques and Performance Optimization Lonnie Crosby lcrosby1@utk.edu NICS Scientific Computing Group NICS/RDAV Spring Training 2012 March 22, 2012 2 Outline Introduction to I/O Path from
Parallel I/O Techniques and Performance Optimization Lonnie Crosby lcrosby1@utk.edu NICS Scientific Computing Group NICS/RDAV Spring Training 2012 March 22, 2012 2 Outline Introduction to I/O Path from
File Systems for HPC Machines. Parallel I/O
 File Systems for HPC Machines Parallel I/O Course Outline Background Knowledge Why I/O and data storage are important Introduction to I/O hardware File systems Lustre specifics Data formats and data provenance
File Systems for HPC Machines Parallel I/O Course Outline Background Knowledge Why I/O and data storage are important Introduction to I/O hardware File systems Lustre specifics Data formats and data provenance
Mark Pagel
 Mark Pagel pags@cray.com New features in XT MPT 3.1 and MPT 3.2 Features as a result of scaling to 150K MPI ranks MPI-IO Improvements(MPT 3.1 and MPT 3.2) SMP aware collective improvements(mpt 3.2) Misc
Mark Pagel pags@cray.com New features in XT MPT 3.1 and MPT 3.2 Features as a result of scaling to 150K MPI ranks MPI-IO Improvements(MPT 3.1 and MPT 3.2) SMP aware collective improvements(mpt 3.2) Misc
Managing Lustre TM Data Striping
 Managing Lustre TM Data Striping Metadata Server Extended Attributes and Lustre Striping APIs in a Lustre File System Sun Microsystems, Inc. February 4, 2008 Table of Contents Overview...3 Data Striping
Managing Lustre TM Data Striping Metadata Server Extended Attributes and Lustre Striping APIs in a Lustre File System Sun Microsystems, Inc. February 4, 2008 Table of Contents Overview...3 Data Striping
Introduction to HPC Parallel I/O
 Introduction to HPC Parallel I/O Feiyi Wang (Ph.D.) and Sarp Oral (Ph.D.) Technology Integration Group Oak Ridge Leadership Computing ORNL is managed by UT-Battelle for the US Department of Energy Outline
Introduction to HPC Parallel I/O Feiyi Wang (Ph.D.) and Sarp Oral (Ph.D.) Technology Integration Group Oak Ridge Leadership Computing ORNL is managed by UT-Battelle for the US Department of Energy Outline
Triton file systems - an introduction. slide 1 of 28
 Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Data storage on Triton: an introduction
 Motivation Data storage on Triton: an introduction How storage is organized in Triton How to optimize IO Do's and Don'ts Exercises slide 1 of 33 Data storage: Motivation Program speed isn t just about
Motivation Data storage on Triton: an introduction How storage is organized in Triton How to optimize IO Do's and Don'ts Exercises slide 1 of 33 Data storage: Motivation Program speed isn t just about
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Optimizing I/O on the Cray XE/XC
 Optimizing I/O on the Cray XE/XC Agenda Scaling I/O Parallel Filesystems and Lustre I/O patterns Optimising I/O Scaling I/O We tend to talk a lot about scaling application computation Nodes, network, software
Optimizing I/O on the Cray XE/XC Agenda Scaling I/O Parallel Filesystems and Lustre I/O patterns Optimising I/O Scaling I/O We tend to talk a lot about scaling application computation Nodes, network, software
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
An Overview of Fujitsu s Lustre Based File System
 An Overview of Fujitsu s Lustre Based File System Shinji Sumimoto Fujitsu Limited Apr.12 2011 For Maximizing CPU Utilization by Minimizing File IO Overhead Outline Target System Overview Goals of Fujitsu
An Overview of Fujitsu s Lustre Based File System Shinji Sumimoto Fujitsu Limited Apr.12 2011 For Maximizing CPU Utilization by Minimizing File IO Overhead Outline Target System Overview Goals of Fujitsu
Blue Waters I/O Performance
 Blue Waters I/O Performance Mark Swan Performance Group Cray Inc. Saint Paul, Minnesota, USA mswan@cray.com Doug Petesch Performance Group Cray Inc. Saint Paul, Minnesota, USA dpetesch@cray.com Abstract
Blue Waters I/O Performance Mark Swan Performance Group Cray Inc. Saint Paul, Minnesota, USA mswan@cray.com Doug Petesch Performance Group Cray Inc. Saint Paul, Minnesota, USA dpetesch@cray.com Abstract
Challenges in HPC I/O
 Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
libhio: Optimizing IO on Cray XC Systems With DataWarp
 libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
ECSS Project: Prof. Bodony: CFD, Aeroacoustics
 ECSS Project: Prof. Bodony: CFD, Aeroacoustics Robert McLay The Texas Advanced Computing Center June 19, 2012 ECSS Project: Bodony Aeroacoustics Program Program s name is RocfloCM It is mixture of Fortran
ECSS Project: Prof. Bodony: CFD, Aeroacoustics Robert McLay The Texas Advanced Computing Center June 19, 2012 ECSS Project: Bodony Aeroacoustics Program Program s name is RocfloCM It is mixture of Fortran
Guidelines for Efficient Parallel I/O on the Cray XT3/XT4
 Guidelines for Efficient Parallel I/O on the Cray XT3/XT4 Jeff Larkin, Cray Inc. and Mark Fahey, Oak Ridge National Laboratory ABSTRACT: This paper will present an overview of I/O methods on Cray XT3/XT4
Guidelines for Efficient Parallel I/O on the Cray XT3/XT4 Jeff Larkin, Cray Inc. and Mark Fahey, Oak Ridge National Laboratory ABSTRACT: This paper will present an overview of I/O methods on Cray XT3/XT4
Parallel I/O on JUQUEEN
 Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
Small File I/O Performance in Lustre. Mikhail Pershin, Joe Gmitter Intel HPDD April 2018
 Small File I/O Performance in Lustre Mikhail Pershin, Joe Gmitter Intel HPDD April 2018 Overview Small File I/O Concerns Data on MDT (DoM) Feature Overview DoM Use Cases DoM Performance Results Small File
Small File I/O Performance in Lustre Mikhail Pershin, Joe Gmitter Intel HPDD April 2018 Overview Small File I/O Concerns Data on MDT (DoM) Feature Overview DoM Use Cases DoM Performance Results Small File
Lock Ahead: Shared File Performance Improvements
 Lock Ahead: Shared File Performance Improvements Patrick Farrell Cray Lustre Developer Steve Woods Senior Storage Architect woods@cray.com September 2016 9/12/2016 Copyright 2015 Cray Inc 1 Agenda Shared
Lock Ahead: Shared File Performance Improvements Patrick Farrell Cray Lustre Developer Steve Woods Senior Storage Architect woods@cray.com September 2016 9/12/2016 Copyright 2015 Cray Inc 1 Agenda Shared
Parallel I/O from a User s Perspective
 Parallel I/O from a User s Perspective HPC Advisory Council Stanford University, Dec. 6, 2011 Katie Antypas Group Leader, NERSC User Services NERSC is DOE in HPC Production Computing Facility NERSC computing
Parallel I/O from a User s Perspective HPC Advisory Council Stanford University, Dec. 6, 2011 Katie Antypas Group Leader, NERSC User Services NERSC is DOE in HPC Production Computing Facility NERSC computing
Operating Systems. File Systems. Thomas Ropars.
 1 Operating Systems File Systems Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of these lectures is inspired by: The lecture notes of Prof. David Mazières. Operating
1 Operating Systems File Systems Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of these lectures is inspired by: The lecture notes of Prof. David Mazières. Operating
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Running Jobs on Blue Waters. Greg Bauer
 Running Jobs on Blue Waters Greg Bauer Policies and Practices Placement Checkpointing Monitoring a job Getting a nodelist Viewing the torus 2 Resource and Job Scheduling Policies Runtime limits expected
Running Jobs on Blue Waters Greg Bauer Policies and Practices Placement Checkpointing Monitoring a job Getting a nodelist Viewing the torus 2 Resource and Job Scheduling Policies Runtime limits expected
How To write(101)data on a large system like a Cray XT called HECToR
data on a large system like a Cray XT called HECToR") How To write(101)data on a large system like a Cray XT called HECToR Martyn Foster mfoster@cray.com Topics Why does this matter? IO architecture on the Cray XT Hardware Architecture Language layers OS
How To write(101)data on a large system like a Cray XT called HECToR Martyn Foster mfoster@cray.com Topics Why does this matter? IO architecture on the Cray XT Hardware Architecture Language layers OS
Damaris. In-Situ Data Analysis and Visualization for Large-Scale HPC Simulations. KerData Team. Inria Rennes,
 Damaris In-Situ Data Analysis and Visualization for Large-Scale HPC Simulations KerData Team Inria Rennes, http://damaris.gforge.inria.fr Outline 1. From I/O to in-situ visualization 2. Damaris approach
Damaris In-Situ Data Analysis and Visualization for Large-Scale HPC Simulations KerData Team Inria Rennes, http://damaris.gforge.inria.fr Outline 1. From I/O to in-situ visualization 2. Damaris approach
Leveraging Burst Buffer Coordination to Prevent I/O Interference
 Leveraging Burst Buffer Coordination to Prevent I/O Interference Anthony Kougkas akougkas@hawk.iit.edu Matthieu Dorier, Rob Latham, Rob Ross, Xian-He Sun Wednesday, October 26th Baltimore, USA Outline
Leveraging Burst Buffer Coordination to Prevent I/O Interference Anthony Kougkas akougkas@hawk.iit.edu Matthieu Dorier, Rob Latham, Rob Ross, Xian-He Sun Wednesday, October 26th Baltimore, USA Outline
Parallel I/O. Steve Lantz Senior Research Associate Cornell CAC. Workshop: Data Analysis on Ranger, January 19, 2012
 Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Data Analysis on Ranger, January 19, 2012 Based on materials developed by Bill Barth at TACC 1. Lustre 2 Lustre Components All Ranger
Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Data Analysis on Ranger, January 19, 2012 Based on materials developed by Bill Barth at TACC 1. Lustre 2 Lustre Components All Ranger
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
HDF5 I/O Performance. HDF and HDF-EOS Workshop VI December 5, 2002
 HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
Lustre overview and roadmap to Exascale computing
 HPC Advisory Council China Workshop Jinan China, October 26th 2011 Lustre overview and roadmap to Exascale computing Liang Zhen Whamcloud, Inc liang@whamcloud.com Agenda Lustre technology overview Lustre
HPC Advisory Council China Workshop Jinan China, October 26th 2011 Lustre overview and roadmap to Exascale computing Liang Zhen Whamcloud, Inc liang@whamcloud.com Agenda Lustre technology overview Lustre
API and Usage of libhio on XC-40 Systems
 API and Usage of libhio on XC-40 Systems May 24, 2018 Nathan Hjelm Cray Users Group May 24, 2018 Los Alamos National Laboratory LA-UR-18-24513 5/24/2018 1 Outline Background HIO Design HIO API HIO Configuration
API and Usage of libhio on XC-40 Systems May 24, 2018 Nathan Hjelm Cray Users Group May 24, 2018 Los Alamos National Laboratory LA-UR-18-24513 5/24/2018 1 Outline Background HIO Design HIO API HIO Configuration
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Chapter 6 Memory 11/3/2015. Chapter 6 Objectives. 6.2 Types of Memory. 6.1 Introduction
 Chapter 6 Objectives Chapter 6 Memory Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured.
Chapter 6 Objectives Chapter 6 Memory Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured.
Current Topics in OS Research. So, what s hot?
 Current Topics in OS Research COMP7840 OSDI Current OS Research 0 So, what s hot? Operating systems have been around for a long time in many forms for different types of devices It is normally general
Current Topics in OS Research COMP7840 OSDI Current OS Research 0 So, what s hot? Operating systems have been around for a long time in many forms for different types of devices It is normally general
Compiling applications for the Cray XC
 Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
PLFS and Lustre Performance Comparison
 PLFS and Lustre Performance Comparison Lustre User Group 2014 Miami, FL April 8-10, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider, Brett Kettering,
PLFS and Lustre Performance Comparison Lustre User Group 2014 Miami, FL April 8-10, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider, Brett Kettering,
Taming Parallel I/O Complexity with Auto-Tuning
 Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Filesystems on SSCK's HP XC6000
 Filesystems on SSCK's HP XC6000 Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Overview» Overview of HP SFS at SSCK HP StorageWorks Scalable File Share (SFS) based on
Filesystems on SSCK's HP XC6000 Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Overview» Overview of HP SFS at SSCK HP StorageWorks Scalable File Share (SFS) based on
File Systems. OS Overview I/O. Swap. Management. Operations CPU. Hard Drive. Management. Memory. Hard Drive. CSI3131 Topics. Structure.
 File Systems I/O Management Hard Drive Management Virtual Memory Swap Memory Management Storage and I/O Introduction CSI3131 Topics Process Management Computing Systems Memory CPU Peripherals Processes
File Systems I/O Management Hard Drive Management Virtual Memory Swap Memory Management Storage and I/O Introduction CSI3131 Topics Process Management Computing Systems Memory CPU Peripherals Processes
Parallel I/O. Steve Lantz Senior Research Associate Cornell CAC. Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012
 Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012 Based on materials developed by Bill Barth at TACC Introduction: The Parallel
Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012 Based on materials developed by Bill Barth at TACC Introduction: The Parallel
Best Practice Guide - Parallel I/O
 Sandra Mendez, LRZ, Germany Sebastian Lührs, FZJ, Germany Dominic Sloan-Murphy (Editor), EPCC, United Kingdom Andrew Turner (Editor), EPCC, United Kingdom Volker Weinberg (Editor), LRZ, Germany Version
Sandra Mendez, LRZ, Germany Sebastian Lührs, FZJ, Germany Dominic Sloan-Murphy (Editor), EPCC, United Kingdom Andrew Turner (Editor), EPCC, United Kingdom Volker Weinberg (Editor), LRZ, Germany Version
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
2. PICTURE: Cut and paste from paper
 File System Layout 1. QUESTION: What were technology trends enabling this? a. CPU speeds getting faster relative to disk i. QUESTION: What is implication? Can do more work per disk block to make good decisions
File System Layout 1. QUESTION: What were technology trends enabling this? a. CPU speeds getting faster relative to disk i. QUESTION: What is implication? Can do more work per disk block to make good decisions
New User Seminar: Part 2 (best practices)
") New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
European Lustre Workshop Paris, France September Hands on Lustre 2.x. Johann Lombardi. Principal Engineer Whamcloud, Inc Whamcloud, Inc.
 European Lustre Workshop Paris, France September 2011 Hands on Lustre 2.x Johann Lombardi Principal Engineer Whamcloud, Inc. Main Changes in Lustre 2.x MDS rewrite Client I/O rewrite New ptlrpc API called
European Lustre Workshop Paris, France September 2011 Hands on Lustre 2.x Johann Lombardi Principal Engineer Whamcloud, Inc. Main Changes in Lustre 2.x MDS rewrite Client I/O rewrite New ptlrpc API called
Do You Know What Your I/O Is Doing? (and how to fix it?) William Gropp
 William Gropp") Do You Know What Your I/O Is Doing? (and how to fix it?) William Gropp www.cs.illinois.edu/~wgropp Messages Current I/O performance is often appallingly poor Even relative to what current systems can achieve
Do You Know What Your I/O Is Doing? (and how to fix it?) William Gropp www.cs.illinois.edu/~wgropp Messages Current I/O performance is often appallingly poor Even relative to what current systems can achieve
Segmentation with Paging. Review. Segmentation with Page (MULTICS) Segmentation with Page (MULTICS) Segmentation with Page (MULTICS)
 Segmentation with Page (MULTICS) Segmentation with Page (MULTICS)") Review Segmentation Segmentation Implementation Advantage of Segmentation Protection Sharing Segmentation with Paging Segmentation with Paging Segmentation with Paging Reason for the segmentation with
Review Segmentation Segmentation Implementation Advantage of Segmentation Protection Sharing Segmentation with Paging Segmentation with Paging Segmentation with Paging Reason for the segmentation with
File Open, Close, and Flush Performance Issues in HDF5 Scot Breitenfeld John Mainzer Richard Warren 02/19/18
 File Open, Close, and Flush Performance Issues in HDF5 Scot Breitenfeld John Mainzer Richard Warren 02/19/18 1 Introduction Historically, the parallel version of the HDF5 library has suffered from performance
File Open, Close, and Flush Performance Issues in HDF5 Scot Breitenfeld John Mainzer Richard Warren 02/19/18 1 Introduction Historically, the parallel version of the HDF5 library has suffered from performance
Coordinating Parallel HSM in Object-based Cluster Filesystems
 Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Extreme I/O Scaling with HDF5
 Extreme I/O Scaling with HDF5 Quincey Koziol Director of Core Software Development and HPC The HDF Group koziol@hdfgroup.org July 15, 2012 XSEDE 12 - Extreme Scaling Workshop 1 Outline Brief overview of
Extreme I/O Scaling with HDF5 Quincey Koziol Director of Core Software Development and HPC The HDF Group koziol@hdfgroup.org July 15, 2012 XSEDE 12 - Extreme Scaling Workshop 1 Outline Brief overview of
I/O Perspectives for Earthsystem Data
 I/O Perspectives for Earthsystem Data Julian M. Kunkel kunkel@dkrz.de German Climate Computing Center (DKRZ), Research Group/Scientific Computing (WR) 05-11-2016 My High-Level Perspective on I/O Current
I/O Perspectives for Earthsystem Data Julian M. Kunkel kunkel@dkrz.de German Climate Computing Center (DKRZ), Research Group/Scientific Computing (WR) 05-11-2016 My High-Level Perspective on I/O Current
Lustre and PLFS Parallel I/O Performance on a Cray XE6
 Lustre and PLFS Parallel I/O Performance on a Cray XE6 Cray User Group 2014 Lugano, Switzerland May 4-8, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider,
Lustre and PLFS Parallel I/O Performance on a Cray XE6 Cray User Group 2014 Lugano, Switzerland May 4-8, 2014 April 2014 1 Many currently contributing to PLFS LANL: David Bonnie, Aaron Caldwell, Gary Grider,
File Systems. CS170 Fall 2018
 File Systems CS170 Fall 2018 Table of Content File interface review File-System Structure File-System Implementation Directory Implementation Allocation Methods of Disk Space Free-Space Management Contiguous
File Systems CS170 Fall 2018 Table of Content File interface review File-System Structure File-System Implementation Directory Implementation Allocation Methods of Disk Space Free-Space Management Contiguous
Advanced file systems: LFS and Soft Updates. Ken Birman (based on slides by Ben Atkin)
") : LFS and Soft Updates Ken Birman (based on slides by Ben Atkin) Overview of talk Unix Fast File System Log-Structured System Soft Updates Conclusions 2 The Unix Fast File System Berkeley Unix (4.2BSD)
: LFS and Soft Updates Ken Birman (based on slides by Ben Atkin) Overview of talk Unix Fast File System Log-Structured System Soft Updates Conclusions 2 The Unix Fast File System Berkeley Unix (4.2BSD)
Programming with MPI
 Programming with MPI p. 1/?? Programming with MPI Miscellaneous Guidelines Nick Maclaren Computing Service nmm1@cam.ac.uk, ext. 34761 March 2010 Programming with MPI p. 2/?? Summary This is a miscellaneous
Programming with MPI p. 1/?? Programming with MPI Miscellaneous Guidelines Nick Maclaren Computing Service nmm1@cam.ac.uk, ext. 34761 March 2010 Programming with MPI p. 2/?? Summary This is a miscellaneous
Improved Solutions for I/O Provisioning and Application Acceleration
 1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
The MOSIX Scalable Cluster Computing for Linux. mosix.org
 The MOSIX Scalable Cluster Computing for Linux Prof. Amnon Barak Computer Science Hebrew University http://www. mosix.org 1 Presentation overview Part I : Why computing clusters (slide 3-7) Part II : What
The MOSIX Scalable Cluster Computing for Linux Prof. Amnon Barak Computer Science Hebrew University http://www. mosix.org 1 Presentation overview Part I : Why computing clusters (slide 3-7) Part II : What
I/O in scientific applications
 COSC 4397 Parallel I/O (II) Access patterns Spring 2010 I/O in scientific applications Different classes of I/O operations Required I/O: reading input data and writing final results Checkpointing: data
COSC 4397 Parallel I/O (II) Access patterns Spring 2010 I/O in scientific applications Different classes of I/O operations Required I/O: reading input data and writing final results Checkpointing: data
Improving I/O Bandwidth With Cray DVS Client-Side Caching
 Improving I/O Bandwidth With Cray DVS Client-Side Caching Bryce Hicks Cray Inc. Bloomington, MN USA bryceh@cray.com Abstract Cray s Data Virtualization Service, DVS, is an I/O forwarder providing access
Improving I/O Bandwidth With Cray DVS Client-Side Caching Bryce Hicks Cray Inc. Bloomington, MN USA bryceh@cray.com Abstract Cray s Data Virtualization Service, DVS, is an I/O forwarder providing access
FILE SYSTEMS, PART 2. CS124 Operating Systems Fall , Lecture 24
 FILE SYSTEMS, PART 2 CS124 Operating Systems Fall 2017-2018, Lecture 24 2 Last Time: File Systems Introduced the concept of file systems Explored several ways of managing the contents of files Contiguous
FILE SYSTEMS, PART 2 CS124 Operating Systems Fall 2017-2018, Lecture 24 2 Last Time: File Systems Introduced the concept of file systems Explored several ways of managing the contents of files Contiguous
Memory Management. Reading: Silberschatz chapter 9 Reading: Stallings. chapter 7 EEL 358
 Memory Management Reading: Silberschatz chapter 9 Reading: Stallings chapter 7 1 Outline Background Issues in Memory Management Logical Vs Physical address, MMU Dynamic Loading Memory Partitioning Placement
Memory Management Reading: Silberschatz chapter 9 Reading: Stallings chapter 7 1 Outline Background Issues in Memory Management Logical Vs Physical address, MMU Dynamic Loading Memory Partitioning Placement
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete
 Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Memory. Objectives. Introduction. 6.2 Types of Memory
 Memory Objectives Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured. Master the concepts
Memory Objectives Master the concepts of hierarchical memory organization. Understand how each level of memory contributes to system performance, and how the performance is measured. Master the concepts
Operating Systems. Lecture File system implementation. Master of Computer Science PUF - Hồ Chí Minh 2016/2017
 Operating Systems Lecture 7.2 - File system implementation Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Design FAT or indexed allocation? UFS, FFS & Ext2 Journaling with Ext3
Operating Systems Lecture 7.2 - File system implementation Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Design FAT or indexed allocation? UFS, FFS & Ext2 Journaling with Ext3
On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows
 On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows Rafael Ferreira da Silva, Scott Callaghan, Ewa Deelman 12 th Workflows in Support of Large-Scale Science (WORKS) SuperComputing
On the Use of Burst Buffers for Accelerating Data-Intensive Scientific Workflows Rafael Ferreira da Silva, Scott Callaghan, Ewa Deelman 12 th Workflows in Support of Large-Scale Science (WORKS) SuperComputing
Got Burst Buffer. Now What? Early experiences, exciting future possibilities, and what we need from the system to make it work
 Got Burst Buffer. Now What? Early experiences, exciting future possibilities, and what we need from the system to make it work The Salishan Conference on High-Speed Computing April 26, 2016 Adam Moody
Got Burst Buffer. Now What? Early experiences, exciting future possibilities, and what we need from the system to make it work The Salishan Conference on High-Speed Computing April 26, 2016 Adam Moody
Memory. From Chapter 3 of High Performance Computing. c R. Leduc
 Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
Chapter 4 File Systems. Tanenbaum, Modern Operating Systems 3 e, (c) 2008 Prentice-Hall, Inc. All rights reserved
 2008 Prentice-Hall, Inc. All rights reserved") Chapter 4 File Systems File Systems The best way to store information: Store all information in virtual memory address space Use ordinary memory read/write to access information Not feasible: no enough
Chapter 4 File Systems File Systems The best way to store information: Store all information in virtual memory address space Use ordinary memory read/write to access information Not feasible: no enough
Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen
 Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen May 5, 2008 Cray Inc. Proprietary Slide 1 Goals of the Presentation Provide users an overview of the
Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen May 5, 2008 Cray Inc. Proprietary Slide 1 Goals of the Presentation Provide users an overview of the
Diagnosing Performance Issues in Cray ClusterStor Systems
 Diagnosing Performance Issues in Cray ClusterStor Systems Comprehensive Performance Analysis with Cray View for ClusterStor Patricia Langer Cray, Inc. Bloomington, MN USA planger@cray.com I. INTRODUCTION
Diagnosing Performance Issues in Cray ClusterStor Systems Comprehensive Performance Analysis with Cray View for ClusterStor Patricia Langer Cray, Inc. Bloomington, MN USA planger@cray.com I. INTRODUCTION
Toward An Integrated Cluster File System
 Toward An Integrated Cluster File System Adrien Lebre February 1 st, 2008 XtreemOS IP project is funded by the European Commission under contract IST-FP6-033576 Outline Context Kerrighed and root file
Toward An Integrated Cluster File System Adrien Lebre February 1 st, 2008 XtreemOS IP project is funded by the European Commission under contract IST-FP6-033576 Outline Context Kerrighed and root file
I/O CANNOT BE IGNORED
 LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
An Evolutionary Path to Object Storage Access
 An Evolutionary Path to Object Storage Access David Goodell +, Seong Jo (Shawn) Kim*, Robert Latham +, Mahmut Kandemir*, and Robert Ross + *Pennsylvania State University + Argonne National Laboratory Outline
An Evolutionary Path to Object Storage Access David Goodell +, Seong Jo (Shawn) Kim*, Robert Latham +, Mahmut Kandemir*, and Robert Ross + *Pennsylvania State University + Argonne National Laboratory Outline
Virtual Memory. CSCI 315 Operating Systems Design Department of Computer Science
 Virtual Memory CSCI 315 Operating Systems Design Department of Computer Science Notice: The slides for this lecture have been largely based on those from an earlier edition of the course text Operating
Virtual Memory CSCI 315 Operating Systems Design Department of Computer Science Notice: The slides for this lecture have been largely based on those from an earlier edition of the course text Operating
Parallel File Systems. John White Lawrence Berkeley National Lab
 Parallel File Systems John White Lawrence Berkeley National Lab Topics Defining a File System Our Specific Case for File Systems Parallel File Systems A Survey of Current Parallel File Systems Implementation
Parallel File Systems John White Lawrence Berkeley National Lab Topics Defining a File System Our Specific Case for File Systems Parallel File Systems A Survey of Current Parallel File Systems Implementation
CHAPTER 6 Memory. CMPS375 Class Notes Page 1/ 16 by Kuo-pao Yang
 CHAPTER 6 Memory 6.1 Memory 233 6.2 Types of Memory 233 6.3 The Memory Hierarchy 235 6.3.1 Locality of Reference 237 6.4 Cache Memory 237 6.4.1 Cache Mapping Schemes 239 6.4.2 Replacement Policies 247
CHAPTER 6 Memory 6.1 Memory 233 6.2 Types of Memory 233 6.3 The Memory Hierarchy 235 6.3.1 Locality of Reference 237 6.4 Cache Memory 237 6.4.1 Cache Mapping Schemes 239 6.4.2 Replacement Policies 247
CS 318 Principles of Operating Systems
 CS 318 Principles of Operating Systems Fall 2018 Lecture 16: Advanced File Systems Ryan Huang Slides adapted from Andrea Arpaci-Dusseau s lecture 11/6/18 CS 318 Lecture 16 Advanced File Systems 2 11/6/18
CS 318 Principles of Operating Systems Fall 2018 Lecture 16: Advanced File Systems Ryan Huang Slides adapted from Andrea Arpaci-Dusseau s lecture 11/6/18 CS 318 Lecture 16 Advanced File Systems 2 11/6/18
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
High Throughput WAN Data Transfer with Hadoop-based Storage
 High Throughput WAN Data Transfer with Hadoop-based Storage A Amin 2, B Bockelman 4, J Letts 1, T Levshina 3, T Martin 1, H Pi 1, I Sfiligoi 1, M Thomas 2, F Wuerthwein 1 1 University of California, San
High Throughput WAN Data Transfer with Hadoop-based Storage A Amin 2, B Bockelman 4, J Letts 1, T Levshina 3, T Martin 1, H Pi 1, I Sfiligoi 1, M Thomas 2, F Wuerthwein 1 1 University of California, San
Parallel IO Benchmarking
 Parallel IO Benchmarking Jia-Ying Wu August 17, 2016 MSc in High Performance Computing with Data Science The University of Edinburgh Year of Presentation: 2016 Abstract The project is aimed to investigate
Parallel IO Benchmarking Jia-Ying Wu August 17, 2016 MSc in High Performance Computing with Data Science The University of Edinburgh Year of Presentation: 2016 Abstract The project is aimed to investigate
Adaptable IO System (ADIOS)
") Adaptable IO System (ADIOS) http://www.cc.gatech.edu/~lofstead/adios Cray User Group 2008 May 8, 2008 Chen Jin, Scott Klasky, Stephen Hodson, James B. White III, Weikuan Yu (Oak Ridge National Laboratory)
Adaptable IO System (ADIOS) http://www.cc.gatech.edu/~lofstead/adios Cray User Group 2008 May 8, 2008 Chen Jin, Scott Klasky, Stephen Hodson, James B. White III, Weikuan Yu (Oak Ridge National Laboratory)