Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
|
|
|
- Luke Hunt
- 6 years ago
- Views:
Transcription
1 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
2 Overview Scalasca performance analysis toolset support for MPI & OpenMP parallel applications runtime summarization & automatic trace analysis Intel Xeon Phi (MIC architecture) parallel programming/execution models Case study TACC Stampede symmetric BT-MZ execution on 4 compute nodes Conclusion 2
3 Scalasca Scalable performance analysis toolset for most popular parallel programming paradigms supports MPI, OpenMP and hybrid OpenMP+MPI Specifically targeting large-scale parallel applications such as those running on Blue Gene or Cray systems with thousands of processes or millions of threads Integrated instrumentation, measurement & analyses runtime summarization (callpath profiling) and/or automatic event trace analysis Developed by JSC and GRS, available as open-source 3

4 Scalasca workflow Summary report Measurement library HWC Instr. target application Instrumented executable Parallel wait-state search Local event trace files Wait-state report Report manipulation Optimized measurement configuration Scalasca trace analysis Which problem? Where in the program? Which process? Instrumenter+ compiler/linker Source modules 4

5 BGQ BT-MZ.F execution imbalance 5

6 IBM BGQ 8x16x8x8x2 torus network BT-MZ.F 16384x MPI processes with 64 OpenMP threads 512 s benchmark execution (<3% dilation) 2623 s extra for 312GB trace collection+analysis 6
7 SIONlib Portable native parallel file I/O library & utilities Scalable massively parallel I/O to task-local files Manages single or multiple physical files on disk reduces meta-data server contention, optimizes bandwidth available by matching blocksizes/alignment POSIX I/O compatible sequential & parallel API Tuned for common parallel filesystems (GPFS, Lustre) Convenient for application I/O, checkpointing can be used by Scalasca tracing Developed by JSC, available as open-source 7

8 Intel Xeon Phi compute nodes 8
9 Intel Xeon Phi (MIC) Host Device Xeon E (processor) Xeon Phi SE10P (coprocessor) 2x sockets 8x 2.7 GHz cores, each 2-way HT x86_64 (cpu) 32 GB shared virtual memory 2x PCI Express cards 61x 1.1 GHz cores, each 4-way HT mic (native) 8 GB local memory per card Intel Composer XE 2013 (13.1) normal compile & link Intel MPI 4.1 N/A -mmic cross-compile & link Intel MPI 4.1 MIC = Many Integrated Core architecture (aka manycore) Xeon Phi = Intel's first product (aka Knights Corner) 9
10 MPI + OpenMP + OpenCL + pthreads + F TBB [C/C++] + Cilk Plus [C++] Device MPI + OpenMP + OpenCL + pthreads + F TBB [C/C++] + Cilk Plus [C++] device offload to host Host host offload to device MIC parallel programming models symmetric = host MPI[+MT] + device MPI[+MT] offload = automatic or compiler-assisted kernel execution on device or host LEO = language extension for offload (pragmas/directives similar to OpenMP) 10
11 Scalasca usage (basic) Host Device skin mpiifort -O -openmp *.f skin mpiifort -O -openmp -mmic *.f scan mpiexec -n 2 a.out.cpu scan mpiexec.hydra \ -host node0 -n 1 a.out.cpu \ : -host node1 -n 1 a.out.cpu ssh mic0 \ -c ''scan mpiexec -n 61 a.out.mic'' scan mpiexec.hydra \ -host mic0 -n 30 a.out.mic \ : -host mic1 -n 31 a.out.mic square epik_a_2x16_sum square epik_a_mic61x4_sum Symmetric execution: scan mpiexec.hydra -host node0 -n 2 a.out.cpu : -host mic0 -n 61 a.out.mic square epik_a_2x16+mic61x4_sum 11
12 Scalasca case study configuration TACC Stampede Dell PowerEdge C8220 6,400 compute nodes (2x Xeon + [012]x Xeon Phi) 4 compute node partition with 1x MIC for experiment NPB3.3-MZ-MPI class D: bt-mz_d.68[.cpu.mic] SLURM_TASKS_PER_NODE=2(x4) MIC_PPN=15 MIC_OMP_NUM_THREADS=OMP_NUMTHREADS=16 scan -t ibrun.symm -c bt-mz_d.68.cpu -m bt-mz_d.68.mic epik_bt-mz_d_2p8x16+mic15p60x16_trace 13
13 Scalasca usage (stampede ibrun.symm) ELG_SION_FILES=-1 SCAN_ANALYZE_OPTS=''-s -i'' scan -t ibrun.symm -c bt-mz_d.68.cpu -m bt-mz_d.68.mic S=C=A=N: Scalasca trace collection and analysis S=C=A=N:./epik_bt-mz_D_2p8x16+mic15p60x16_trace experiment archive ibrun.symm -c ''bt-mz_d.68.cpu'' -m ''bt-mz_d.68.mic'' [ ]EPIK: Created archive./epik_bt-mz_d_2p8x16+mic15p60x16_trace [ ]EPIK: ELG_SION_FILES=63 determined automatically. [ ]EPIK: Closed experiment./epik_bt-mz_d_2p8x16+mic15p60x16_trace S=C=A=N: Collect done S=C=A=N: Analyze start ibrun.symm -c ''$SCALASCA_DIR/bin/fe/scout.hyb -s -i'' \ -m ''$SCALASCA_DIR/bin/be/scout.hyb -s -i'' Analyzing experiment archive./epik_bt-mz_d_2p8x16+mic15p60x16_trace S=C=A=N:./epik_bt-mz_D_2p8x16+mic15p60x16_trace experiment complete 14
14 Scalasca experiment characteristics Activity Time Reference (uninstrumented) execution s Summary measurement execution Summary report generation s [+1.6%] 0.49 s Tracing measurement execution Event trace generation Event trace analysis (complete) s [+1.7%] s s Symmetric execution of BT-MZ class D configured with 68 MPI processes and 16 OpenMP threads per process on four Stampede Xeon Phi compute nodes. Custom instrumentation filter for Intel compiler (from preliminary score report) GB event trace data (buffered). One SION event trace file per process. 15
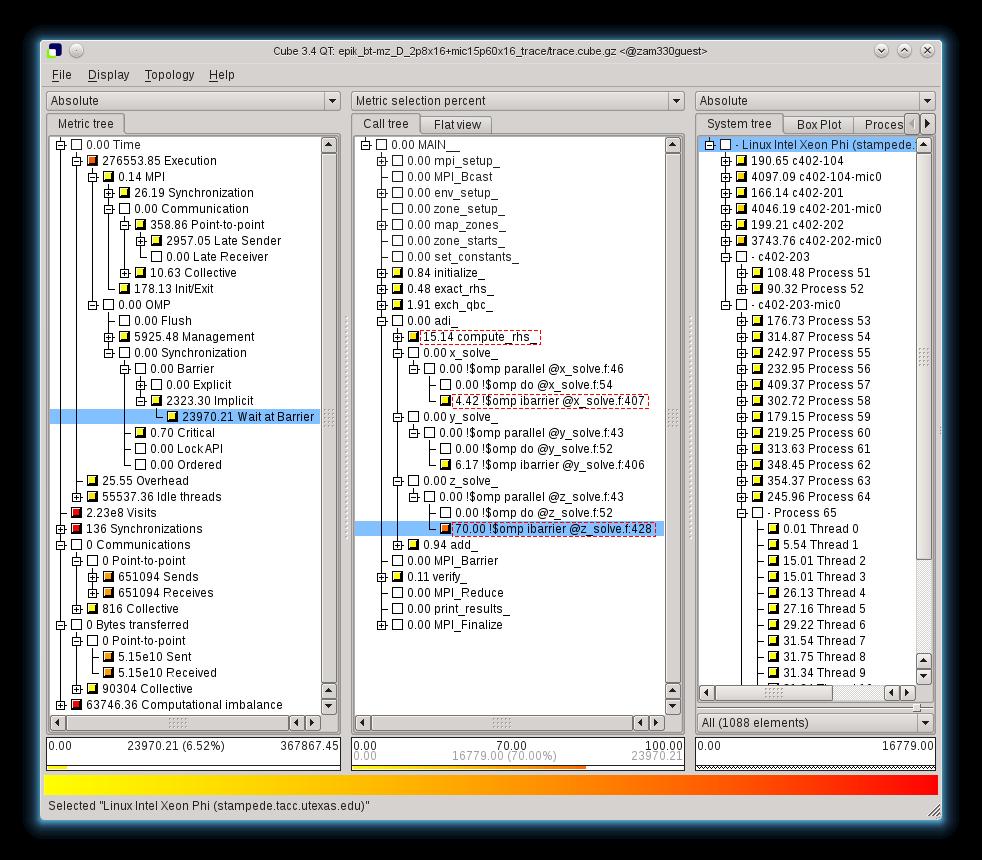
15 16

16 c mic0 c mic0 c mic0 c mic0 17
17 Scalasca BT-MZ case study insight 75% of total allocation time is actual computation 15% of time considered to be Idle threads unused compute resources outside of parallel regions 1% of total time in MPI similarly done outside of parallel regions 9% of total time in OpenMP parallelization overheads 6.5% OpenMP implicit barrier synchronization time at end of parallel regions 70% of this within Z_solve routine (lines ) unevenly distributed across threads on devices, though threads on hosts apparently well balanced maximum 43 seconds, mean 15.4±11.0 seconds 18
18 Current and future work Extend support for symmetric/heterogeneous MPMD measurement collection and analysis mpiexec.hydra consistency checks additional metrics? Migration to new Score-P measurement infrastructure support for additional threading models support for OpenMP target offload 19
19 Conclusions Port of Scalasca toolset to MIC was straightforward configuration currently somewhat complicated due to evolving/maturing environment provides familiar usage model Measurement and analysis of symmetric execution exploits combined host+device installation smart mode determination Facilitates performance analysis for tuning/optimization of MPI and/or OpenMP 20
20 Acknowledgments XSEDE (Jay Alameda) TACC (Stampede) Intel/JSC ExaCluster Laboratory DEEP Project (EU FP7) Scalasca development team 21
21 Further information Scalable performance analysis of large-scale parallel applications toolset for scalable performance measurement & analysis of MPI, OpenMP and MPI+OpenMP parallel applications supporting most popular HPC computer systems available under New BSD open-source license sources, documentation & publications: mailto: 22
Automatic trace analysis with the Scalasca Trace Tools
 Automatic trace analysis with the Scalasca Trace Tools Ilya Zhukov Jülich Supercomputing Centre Property Automatic trace analysis Idea Automatic search for patterns of inefficient behaviour Classification
Automatic trace analysis with the Scalasca Trace Tools Ilya Zhukov Jülich Supercomputing Centre Property Automatic trace analysis Idea Automatic search for patterns of inefficient behaviour Classification
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Parallel I/O on JUQUEEN
 Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
I/O Monitoring at JSC, SIONlib & Resiliency
 Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
I/O at JSC. I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O. Wolfgang Frings
 Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Performance analysis on Blue Gene/Q with
 Performance analysis on Blue Gene/Q with + other tools and debugging Michael Knobloch Jülich Supercomputing Centre scalasca@fz-juelich.de July 2012 Based on slides by Brian Wylie and Markus Geimer Performance
Performance analysis on Blue Gene/Q with + other tools and debugging Michael Knobloch Jülich Supercomputing Centre scalasca@fz-juelich.de July 2012 Based on slides by Brian Wylie and Markus Geimer Performance
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Performance analysis of Sweep3D on Blue Gene/P with Scalasca
 Mitglied der Helmholtz-Gemeinschaft Performance analysis of Sweep3D on Blue Gene/P with Scalasca 2010-04-23 Brian J. N. Wylie, David Böhme, Bernd Mohr, Zoltán Szebenyi & Felix Wolf Jülich Supercomputing
Mitglied der Helmholtz-Gemeinschaft Performance analysis of Sweep3D on Blue Gene/P with Scalasca 2010-04-23 Brian J. N. Wylie, David Böhme, Bernd Mohr, Zoltán Szebenyi & Felix Wolf Jülich Supercomputing
[Scalasca] Tool Integrations
![[Scalasca] Tool Integrations](/thumbs/95/125562042.jpg "[Scalasca] Tool Integrations") Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
SCALASCA parallel performance analyses of SPEC MPI2007 applications
 Mitglied der Helmholtz-Gemeinschaft SCALASCA parallel performance analyses of SPEC MPI2007 applications 2008-05-22 Zoltán Szebenyi Jülich Supercomputing Centre, Forschungszentrum Jülich Aachen Institute
Mitglied der Helmholtz-Gemeinschaft SCALASCA parallel performance analyses of SPEC MPI2007 applications 2008-05-22 Zoltán Szebenyi Jülich Supercomputing Centre, Forschungszentrum Jülich Aachen Institute
Symmetric Computing. ISC 2015 July John Cazes Texas Advanced Computing Center
 Symmetric Computing ISC 2015 July 2015 John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required:
Symmetric Computing ISC 2015 July 2015 John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required:
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Symmetric Computing. John Cazes Texas Advanced Computing Center
 Symmetric Computing John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host and across nodes Also called heterogeneous computing Two executables are required:
Symmetric Computing John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host and across nodes Also called heterogeneous computing Two executables are required:
Debugging Intel Xeon Phi KNC Tutorial
 Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Overview of Intel Xeon Phi Coprocessor
 Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Overview of Intel Xeon Phi Coprocessor Sept 20, 2013 Ritu Arora Texas Advanced Computing Center Email: rauta@tacc.utexas.edu This talk is only a trailer A comprehensive training on running and optimizing
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Symmetric Computing. Jerome Vienne Texas Advanced Computing Center
 Symmetric Computing Jerome Vienne Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Symmetric Computing Jerome Vienne Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Score-P. SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1
 Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
A configurable binary instrumenter
 Mitglied der Helmholtz-Gemeinschaft A configurable binary instrumenter making use of heuristics to select relevant instrumentation points 12. April 2010 Jan Mussler j.mussler@fz-juelich.de Presentation
Mitglied der Helmholtz-Gemeinschaft A configurable binary instrumenter making use of heuristics to select relevant instrumentation points 12. April 2010 Jan Mussler j.mussler@fz-juelich.de Presentation
Recent Developments in Score-P and Scalasca V2
 Mitglied der Helmholtz-Gemeinschaft Recent Developments in Score-P and Scalasca V2 Aug 2015 Bernd Mohr 9 th Scalable Tools Workshop Lake Tahoe YOU KNOW YOU MADE IT IF LARGE COMPANIES STEAL YOUR STUFF August
Mitglied der Helmholtz-Gemeinschaft Recent Developments in Score-P and Scalasca V2 Aug 2015 Bernd Mohr 9 th Scalable Tools Workshop Lake Tahoe YOU KNOW YOU MADE IT IF LARGE COMPANIES STEAL YOUR STUFF August
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede
 Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Symmetric Computing. SC 14 Jerome VIENNE
 Symmetric Computing SC 14 Jerome VIENNE viennej@tacc.utexas.edu Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Symmetric Computing SC 14 Jerome VIENNE viennej@tacc.utexas.edu Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required: CPU MIC Currently
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
IBM High Performance Computing Toolkit
 IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Bring your application to a new era:
 Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
AutoTune Workshop. Michael Gerndt Technische Universität München
 AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
SCALASCA v1.0 Quick Reference
 General SCALASCA is an open-source toolset for scalable performance analysis of large-scale parallel applications. Use the scalasca command with appropriate action flags to instrument application object
General SCALASCA is an open-source toolset for scalable performance analysis of large-scale parallel applications. Use the scalasca command with appropriate action flags to instrument application object
The DEEP (and DEEP-ER) projects
 projects") The DEEP (and DEEP-ER) projects Estela Suarez - Jülich Supercomputing Centre BDEC for Europe Workshop Barcelona, 28.01.2015 The research leading to these results has received funding from the European
The DEEP (and DEEP-ER) projects Estela Suarez - Jülich Supercomputing Centre BDEC for Europe Workshop Barcelona, 28.01.2015 The research leading to these results has received funding from the European
MIC Lab Parallel Computing on Stampede
 MIC Lab Parallel Computing on Stampede Aaron Birkland and Steve Lantz Cornell Center for Advanced Computing June 11 & 18, 2013 1 Interactive Launching This exercise will walk through interactively launching
MIC Lab Parallel Computing on Stampede Aaron Birkland and Steve Lantz Cornell Center for Advanced Computing June 11 & 18, 2013 1 Interactive Launching This exercise will walk through interactively launching
Lawrence Livermore National Laboratory Tools for High Productivity Supercomputing: Extreme-scale Case Studies
 Lawrence Livermore National Laboratory Tools for High Productivity Supercomputing: Extreme-scale Case Studies EuroPar 2013 Martin Schulz Lawrence Livermore National Laboratory Brian Wylie Jülich Supercomputing
Lawrence Livermore National Laboratory Tools for High Productivity Supercomputing: Extreme-scale Case Studies EuroPar 2013 Martin Schulz Lawrence Livermore National Laboratory Brian Wylie Jülich Supercomputing
Agenda. Optimization Notice Copyright 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Scalasca performance properties The metrics tour
 Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Native Computing and Optimization. Hang Liu December 4 th, 2013
 Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Native Computing and Optimization Hang Liu December 4 th, 2013 Overview Why run native? What is a native application? Building a native application Running a native application Setting affinity and pinning
Scalasca 1.3 User Guide
 Scalasca 1.3 User Guide Scalable Automatic Performance Analysis March 2011 The Scalasca Development Team scalasca@fz-juelich.de Copyright 1998 2011 Forschungszentrum Jülich GmbH, Germany Copyright 2009
Scalasca 1.3 User Guide Scalable Automatic Performance Analysis March 2011 The Scalasca Development Team scalasca@fz-juelich.de Copyright 1998 2011 Forschungszentrum Jülich GmbH, Germany Copyright 2009
Performance properties The metrics tour
 Performance properties The metrics tour Markus Geimer & Brian Wylie Jülich Supercomputing Centre scalasca@fz-juelich.de January 2012 Scalasca analysis result Confused? Generic metrics Generic metrics Time
Performance properties The metrics tour Markus Geimer & Brian Wylie Jülich Supercomputing Centre scalasca@fz-juelich.de January 2012 Scalasca analysis result Confused? Generic metrics Generic metrics Time
Large-scale performance analysis of PFLOTRAN with Scalasca
 Mitglied der Helmholtz-Gemeinschaft Large-scale performance analysis of PFLOTRAN with Scalasca 2011-05-26 Brian J. N. Wylie & Markus Geimer Jülich Supercomputing Centre b.wylie@fz-juelich.de Overview Dagstuhl
Mitglied der Helmholtz-Gemeinschaft Large-scale performance analysis of PFLOTRAN with Scalasca 2011-05-26 Brian J. N. Wylie & Markus Geimer Jülich Supercomputing Centre b.wylie@fz-juelich.de Overview Dagstuhl
Reusing this material
 XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
ET International HPC Runtime Software. ET International Rishi Khan SC 11. Copyright 2011 ET International, Inc.
 HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Performance properties The metrics tour
 Performance properties The metrics tour Markus Geimer & Brian Wylie Jülich Supercomputing Centre scalasca@fz-juelich.de August 2012 Scalasca analysis result Online description Analysis report explorer
Performance properties The metrics tour Markus Geimer & Brian Wylie Jülich Supercomputing Centre scalasca@fz-juelich.de August 2012 Scalasca analysis result Online description Analysis report explorer
Scalasca 1.4 User Guide
 Scalasca 1.4 User Guide Scalable Automatic Performance Analysis March 2013 The Scalasca Development Team scalasca@fz-juelich.de Copyright 1998 2013 Forschungszentrum Jülich GmbH, Germany Copyright 2009
Scalasca 1.4 User Guide Scalable Automatic Performance Analysis March 2013 The Scalasca Development Team scalasca@fz-juelich.de Copyright 1998 2013 Forschungszentrum Jülich GmbH, Germany Copyright 2009
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
Parallel I/O Libraries and Techniques
 Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Code Auto-Tuning with the Periscope Tuning Framework
 Code Auto-Tuning with the Periscope Tuning Framework Renato Miceli, SENAI CIMATEC renato.miceli@fieb.org.br Isaías A. Comprés, TUM compresu@in.tum.de Project Participants Michael Gerndt, TUM Coordinator
Code Auto-Tuning with the Periscope Tuning Framework Renato Miceli, SENAI CIMATEC renato.miceli@fieb.org.br Isaías A. Comprés, TUM compresu@in.tum.de Project Participants Michael Gerndt, TUM Coordinator
Automatic Tuning of HPC Applications with Periscope. Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München
 Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
AUTOMATIC SMT THREADING
 AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
AUTOMATIC SMT THREADING FOR OPENMP APPLICATIONS ON THE INTEL XEON PHI CO-PROCESSOR WIM HEIRMAN 1,2 TREVOR E. CARLSON 1 KENZO VAN CRAEYNEST 1 IBRAHIM HUR 2 AAMER JALEEL 2 LIEVEN EECKHOUT 1 1 GHENT UNIVERSITY
The DEEP-ER take on I/O
 Wolfgang Frings Jülich Supercomputing Centre Workshop Exascale I/O: Challenges, Innovations and Solutions SC16, Salt Lake City 18 November 2016 The research leading to these results has received funding
Wolfgang Frings Jülich Supercomputing Centre Workshop Exascale I/O: Challenges, Innovations and Solutions SC16, Salt Lake City 18 November 2016 The research leading to these results has received funding
Introduction to Parallel Performance Engineering
 Introduction to Parallel Performance Engineering Markus Geimer, Brian Wylie Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray) Performance:
Introduction to Parallel Performance Engineering Markus Geimer, Brian Wylie Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray) Performance:
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
SCALABLE HYBRID PROTOTYPE
 SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
Introduction to Parallel Performance Engineering with Score-P. Marc-André Hermanns Jülich Supercomputing Centre
 Introduction to Parallel Performance Engineering with Score-P Marc-André Hermanns Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray)
Introduction to Parallel Performance Engineering with Score-P Marc-André Hermanns Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray)
Lab MIC Offload Experiments 7/22/13 MIC Advanced Experiments TACC
 Lab MIC Offload Experiments 7/22/13 MIC Advanced Experiments TACC # pg. Subject Purpose directory 1 3 5 Offload, Begin (C) (F90) Compile and Run (CPU, MIC, Offload) offload_hello 2 7 Offload, Data Optimize
Lab MIC Offload Experiments 7/22/13 MIC Advanced Experiments TACC # pg. Subject Purpose directory 1 3 5 Offload, Begin (C) (F90) Compile and Run (CPU, MIC, Offload) offload_hello 2 7 Offload, Data Optimize
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - LRZ,
 Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
Tools for Intel Xeon Phi: VTune & Advisor Dr. Fabio Baruffa - fabio.baruffa@lrz.de LRZ, 27.6.- 29.6.2016 Architecture Overview Intel Xeon Processor Intel Xeon Phi Coprocessor, 1st generation Intel Xeon
LARGE-SCALE PERFORMANCE ANALYSIS OF SWEEP3D WITH THE SCALASCA TOOLSET
 Parallel Processing Letters Vol. 20, No. 4 (2010) 397 414 c World Scientific Publishing Company LARGE-SCALE PERFORMANCE ANALYSIS OF SWEEP3D WITH THE SCALASCA TOOLSET BRIAN J. N. WYLIE, MARKUS GEIMER, BERND
Parallel Processing Letters Vol. 20, No. 4 (2010) 397 414 c World Scientific Publishing Company LARGE-SCALE PERFORMANCE ANALYSIS OF SWEEP3D WITH THE SCALASCA TOOLSET BRIAN J. N. WYLIE, MARKUS GEIMER, BERND
Intel Parallel Studio XE 2015
 2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Hands-on / Demo: Building and running NPB-MZ-MPI / BT
 Hands-on / Demo: Building and running NPB-MZ-MPI / BT Markus Geimer Jülich Supercomputing Centre What is NPB-MZ-MPI / BT? A benchmark from the NAS parallel benchmarks suite MPI + OpenMP version Implementation
Hands-on / Demo: Building and running NPB-MZ-MPI / BT Markus Geimer Jülich Supercomputing Centre What is NPB-MZ-MPI / BT? A benchmark from the NAS parallel benchmarks suite MPI + OpenMP version Implementation
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Large-scale performance analysis of PFLOTRAN with Scalasca
 Mitglied der Helmholtz-Gemeinschaft Large-scale performance analysis of PFLOTRAN with Scalasca 2011-05-26 Brian J. N. Wylie & Markus Geimer Jülich Supercomputing Centre b.wylie@fz-juelich.de Overview Dagstuhl
Mitglied der Helmholtz-Gemeinschaft Large-scale performance analysis of PFLOTRAN with Scalasca 2011-05-26 Brian J. N. Wylie & Markus Geimer Jülich Supercomputing Centre b.wylie@fz-juelich.de Overview Dagstuhl
PRACE Project Access Technical Guidelines - 19 th Call for Proposals
 PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
Usage of the SCALASCA toolset for scalable performance analysis of large-scale parallel applications
 Usage of the SCALASCA toolset for scalable performance analysis of large-scale parallel applications Felix Wolf 1,2, Erika Ábrahám 1, Daniel Becker 1,2, Wolfgang Frings 1, Karl Fürlinger 3, Markus Geimer
Usage of the SCALASCA toolset for scalable performance analysis of large-scale parallel applications Felix Wolf 1,2, Erika Ábrahám 1, Daniel Becker 1,2, Wolfgang Frings 1, Karl Fürlinger 3, Markus Geimer
HPC code modernization with Intel development tools
 HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster
 Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster G. Jost*, H. Jin*, D. an Mey**,F. Hatay*** *NASA Ames Research Center **Center for Computing and Communication, University of
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster G. Jost*, H. Jin*, D. an Mey**,F. Hatay*** *NASA Ames Research Center **Center for Computing and Communication, University of
Message Passing Interface (MPI) on Intel Xeon Phi coprocessor
 on Intel Xeon Phi coprocessor") Message Passing Interface (MPI) on Intel Xeon Phi coprocessor Special considerations for MPI on Intel Xeon Phi and using the Intel Trace Analyzer and Collector Gergana Slavova gergana.s.slavova@intel.com
Message Passing Interface (MPI) on Intel Xeon Phi coprocessor Special considerations for MPI on Intel Xeon Phi and using the Intel Trace Analyzer and Collector Gergana Slavova gergana.s.slavova@intel.com
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Dmitry Durnov 15 February 2017
 Cовременные тенденции разработки высокопроизводительных приложений Dmitry Durnov 15 February 2017 Agenda Modern cluster architecture Node level Cluster level Programming models Tools 2/20/2017 2 Modern
Cовременные тенденции разработки высокопроизводительных приложений Dmitry Durnov 15 February 2017 Agenda Modern cluster architecture Node level Cluster level Programming models Tools 2/20/2017 2 Modern
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
Performance Analysis of Large-Scale OpenMP and Hybrid MPI/OpenMP Applications with Vampir NG
 Performance Analysis of Large-Scale OpenMP and Hybrid MPI/OpenMP Applications with Vampir NG Holger Brunst Center for High Performance Computing Dresden University, Germany June 1st, 2005 Overview Overview
Performance Analysis of Large-Scale OpenMP and Hybrid MPI/OpenMP Applications with Vampir NG Holger Brunst Center for High Performance Computing Dresden University, Germany June 1st, 2005 Overview Overview
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From