Spring 2010 Prof. Hyesoon Kim. Thanks to Prof. Loh & Prof. Prvulovic
|
|
|
- Cori Miller
- 6 years ago
- Views:
Transcription

1 Spring 2010 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic
2 C/C++ program Compiler Assembly Code (binary) Processor





3 Memory MAR MDR INPUT Processing Unit OUTPUT ALU TEMP PC Control Unit IR Introduction to computing systems (patt&patel)
4 5ysY&feature=related
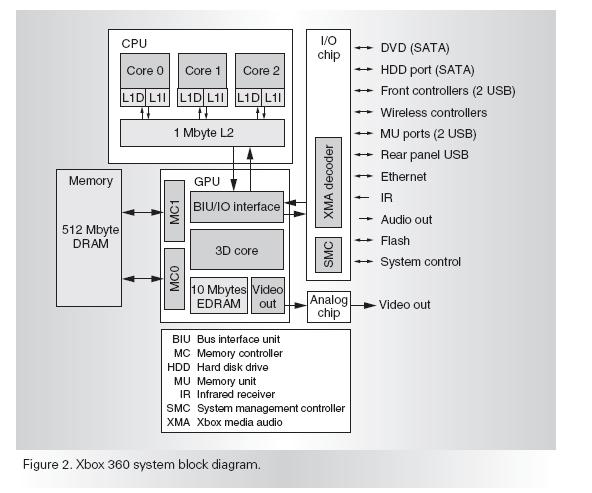
5
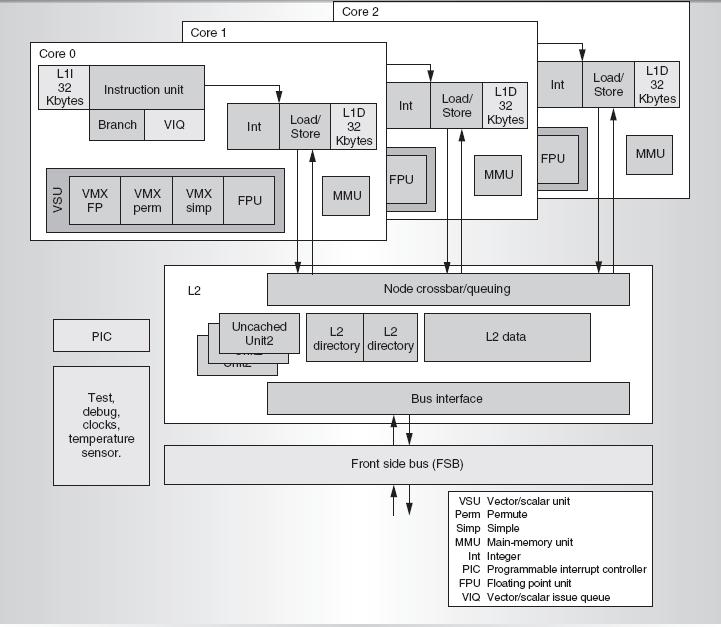
6
7
8 PC 0x0002 0x0001 0x000 0x0001 LD R1, MEM[R0] I-$ DEC RF WB 0x0002 ADD R2, R2, #1 Non-pipelined D-$ 0x000 BRZERO 0x0001 t 15 cycles Pipelined 7 cycles
9 ALU Data Dependencies RAW: Read-After-Write (True Dependence) WAR: Anti-Depedence WAW: Output Dependence Control Dependence When following instructions depend on the outcome of a previous branch/jump Ifetch Reg DMem Reg
10 ALU ALU ALU I n s t r. add r1,r2,r sub r4,r1,r Ifetch Reg Ifetch Reg DMem Reg Reg Reg DMem Reg O r d e r and r6,r2,r7 Ifetch All sources are ready? Why not execute them? Reg DMem Reg
11 Read-After-Write R1 R2 R R4 A: R1 = R2 + R B: R4 = R1 * R4 5 A 7 B 7 21 Write-After-Read R1 R2 R R4 A: R1 = R / R4 B: R = R2 * R4 5 A B -6 Write-After-Write R1 R2 R R4 A: R1 = R2 + R B: R1 = R * R4 5 A 7 B 27 R1 R2 R R4 5 B 5 15 A 7 15 R1 R2 R R4 5 B 5-6 A -6 R1 R2 R R4 5 B 27 A 7
12 WAR dependencies are from reusing registers A: R1 = R / R4 B: R = R2 * R4 A: R1 X = R / R4 B: R5 = R2 * R4 R1 R2 R R4 5 A B -6 R1 R2 R R4 5 B 5-6 A -6 R1 R2 R R4 5 B 5 A R With no dependencies, reordering still produces the correct results


13 WAW dependencies are also from reusing registers A: R1 = R2 + R B: R1 = R * R4 A: R5 X = R2 + R B: R1 = R * R4 R1 R2 R R4 5 A 7 B 27 R1 5 R2 R R4 B 27 A 7 R1 R2 R R4 5 4 B 27 A 27 R5 4 7 Same solution works
14 Give processor more registers than specified by the ISA temporarily map ISA registers ( logical or architected registers) to the physical registers to avoid overwrites Components: mapping mechanism physical registers allocated vs. free registers allocation/deallocation mechanism
15 Example I can not exec before I2 because I will overwrite R5 I5 can not go before I2 because I2, when it goes, will overwrite R2 with a stale value Program code I1: ADD R1, R2, R I2: SUB R2, R1, R5 I: AND R5, R11, R7 I4: OR R8, R5, R2 I5: XOR R2, R4, R11 RAW WAR WAW
16 Solution: Let s give I temporary name/ location (e.g., S) for the value it produces. But I4 uses that value, so we must also change that to S In fact, all uses of R5 from I to the next instruction that writes to R5 again must now be changed to S! We remove WAW deps in the same way: change R2 in I5 (and subsequent instrs) to T. I1: ADD R1, R2, R I2: SUB R2, R1, R5 I: AND R5 S, R11, R7 I4: OR R8, R5, S, R2 I5: XOR R2, T, R4, R11
17 Implementation Space for S, T, etc. How do we know when to rename a register? Simple Solution Do renaming for every instruction Change the name of a register each time we decode an instruction that will write to it. Remember what name we gave it Program code I1: ADD R1, R2, R I2: SUB R2, R1, R5 I: AND S, R11, R7 I4: OR R8, S, R2 I5: XOR T, R4, R11





18 We need some physical structure to store the register values ARF Architected Register File Outside world sees the ARF RAT One PREG per instruction in-flight PRF Register Alias Table Physical Register File

19
20 Separates architected vs. physical registers Tracks program order of all in-flight insts Enables in-order completion or commit
21 RAT Architected Register File Instruction Buffers ROB Reservation Stations and ALUs head op Qj Qk Vj Vk op Qj Qk Vj Vk op Qj Qk Vj Vk op Qj Qk Vj Vk Add op Qj Qk Vj Vk op Qj Qk Vj Vk Mult type dest value fin
 sources,")

22 Read inst from inst buffer Instruction Buffers RAT Architected Register File Check if resources available: Appropriate RS entry ROB entry Read RAT, read (available) sources, update RAT Reservation Stations and ALUs op Qj Qk Vj Vk op Qj Qk Vj Vk op Qj Qk Vj Vk op Qj Qk Vj Vk Add op Qj Qk Vj Vk op Qj Qk Vj Vk Mult ROB type dest value fin head Write to RS and ROB

23 Same as before Wait for all operands to arrive Compete to use functional unit Execute!
24 Broadcast result on CDB (any dependents will grab the value) Write result back to your ROB entry The ARF holds the official register state, which we will only update in program order Mark ready/finished bit in ROB (note that this inst has completed execution) Reservation station can be freed.

25 When an inst is the oldest in the ROB i.e., ROB-head points to it Write result (if ready/finished bit is set) If register producing instruction: write to architected register file If store: write to memory Q: What about load? Advance ROB-head to next instruction This is what the outside world sees And it s all in-order
26 Make instruction execution visible to the outside world Commit the changes to the architected state ROB A B C D E F G H J K WB result ARF Outside World sees : A executed B executed C executed D executed E executed Instructions execute out of program order, but outside world still believes it s in-order


27
28 Single thread in superscalar execution: dependences cause most of stalls Idea: when one thread stalled, other can go Different granularities of multithreading Coarse MT: can change thread every few cycles Fine MT: can change thread every cycle Simultaneous Multithreading (SMT) Instrs from different threads even in the same cycle AKA Hyperthreading
29 Uni-Processor: 4-6 wide, lucky if you get 1 IPC poor utilization SMP: 2-4 CPUs, but need independent tasks else poor utilization as well SMT: Idea is to use a single large uni-processor as a multi-processor

")




30 Regular CPU SMT (4 threads) CMP 2x HW Cost Approx 1x HW Cost
31 For an N-way (N threads) SMT, we need: Ability to fetch from N threads N sets of architectural registers (including PCs) N rename tables (RATs) N virtual memory spaces Front-end: branch predictor?: no, RAS? :yes But we don t need to replicate the entire OOO execution engine (schedulers, execution units, bypass networks, ROBs, etc.) 1






32 Multiplex the Fetch Logic RS PC 0 PC 1 PC 2 I$ fetch Decode, etc. cycle % N Can do simple round-robin between active threads, or favor some over the others based on how much each is stalling relative to the others 2


33 Thread #1 s R12!= Thread #2 s R12 separate name spaces need to disambiguate Thread 0 Register # RAT 0 PRF Thread 1 Register # RAT 1
34 No change needed After Renaming Thread 0: Add R1 = R2 + R Sub R4 = R1 R5 Xor R = R1 ^ R4 Load R2 = 0[R] Thread 1: Add R1 = R2 + R Sub R4 = R1 R5 Xor R = R1 ^ R4 Load R2 = 0[R] Thread 0: Add T12 = T20 + T8 Sub T1 = T12 T16 Xor T14 = T12 ^ T1 Load T2 = 0[T14] Thread 1: Add T17 = T2 + T Sub T5 = T17 T2 Xor T1 = T17 ^ T5 Load T25 = 0[T1] Shared RS Entries Sub T5 = T17 T2 Add T12 = T20 + T8 Load T25 = 0[T1] Xor T14 = T12 ^ T1 Load T2 = 0[T14] Sub T1 = T12 T16 Xor T1 = T17 ^ T5 Add T17 = T2 + T 4
35 Register File Management ARF/PRF organization need one ARF per thread Need to maintain interrupts, exceptions, faults on a per-thread basis like OOO needs to appear to outside world that it is in-order, SMT needs to appear as if it is actually N CPUs 5
COSC3330 Computer Architecture Lecture 14. Branch Prediction
 COSC3330 Computer Architecture Lecture 14. Branch Prediction Instructor: Weidong Shi (Larry), PhD Computer Science Department University of Houston opic Out-of-Order Execution Branch Prediction Superscalar
COSC3330 Computer Architecture Lecture 14. Branch Prediction Instructor: Weidong Shi (Larry), PhD Computer Science Department University of Houston opic Out-of-Order Execution Branch Prediction Superscalar
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Processor Architecture
 Processor Architecture Advanced Dynamic Scheduling Techniques M. Schölzel Content Tomasulo with speculative execution Introducing superscalarity into the instruction pipeline Multithreading Content Tomasulo
Processor Architecture Advanced Dynamic Scheduling Techniques M. Schölzel Content Tomasulo with speculative execution Introducing superscalarity into the instruction pipeline Multithreading Content Tomasulo
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Page 1. Recall from Pipelining Review. Lecture 15: Instruction Level Parallelism and Dynamic Execution
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
Lecture: Out-of-order Processors. Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ
 Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Graduate Computer Architecture. Chapter 3. Instruction Level Parallelism and Its Dynamic Exploitation
 Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Fall 2011 Prof. Hyesoon Kim. Thanks to Prof. Loh & Prof. Prvulovic
 Fall 2011 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic Flynn s Taxonomy of Parallel Machines How many Instruction streams? How many Data streams? SISD: Single I Stream, Single D Stream A uniprocessor
Fall 2011 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic Flynn s Taxonomy of Parallel Machines How many Instruction streams? How many Data streams? SISD: Single I Stream, Single D Stream A uniprocessor
Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1
![Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1](/thumbs/92/108067849.jpg "Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1") Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
This Set. Scheduling and Dynamic Execution Definitions From various parts of Chapter 4. Description of Three Dynamic Scheduling Methods
 10-1 Dynamic Scheduling 10-1 This Set Scheduling and Dynamic Execution Definitions From various parts of Chapter 4. Description of Three Dynamic Scheduling Methods Not yet complete. (Material below may
10-1 Dynamic Scheduling 10-1 This Set Scheduling and Dynamic Execution Definitions From various parts of Chapter 4. Description of Three Dynamic Scheduling Methods Not yet complete. (Material below may
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Tomasulo s Algorithm
 Tomasulo s Algorithm Architecture to increase ILP Removes WAR and WAW dependencies during issue WAR and WAW Name Dependencies Artifact of using the same storage location (variable name) Can be avoided
Tomasulo s Algorithm Architecture to increase ILP Removes WAR and WAW dependencies during issue WAR and WAW Name Dependencies Artifact of using the same storage location (variable name) Can be avoided
Dynamic Scheduling. Better than static scheduling Scoreboarding: Tomasulo algorithm:
 LECTURE - 13 Dynamic Scheduling Better than static scheduling Scoreboarding: Used by the CDC 6600 Useful only within basic block WAW and WAR stalls Tomasulo algorithm: Used in IBM 360/91 for the FP unit
LECTURE - 13 Dynamic Scheduling Better than static scheduling Scoreboarding: Used by the CDC 6600 Useful only within basic block WAW and WAR stalls Tomasulo algorithm: Used in IBM 360/91 for the FP unit
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
COSC4201 Instruction Level Parallelism Dynamic Scheduling
 COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,") Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Scoreboard information (3 tables) Four stages of scoreboard control
 Four stages of scoreboard control") Scoreboard information (3 tables) Instruction : issued, read operands and started execution (dispatched), completed execution or wrote result, Functional unit (assuming non-pipelined units) busy/not busy
Scoreboard information (3 tables) Instruction : issued, read operands and started execution (dispatched), completed execution or wrote result, Functional unit (assuming non-pipelined units) busy/not busy
Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
") Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Website for Students VTU NOTES QUESTION PAPERS NEWS RESULTS
 Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution. Prof. Yanjing Li University of Chicago
 CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution Prof. Yanjing Li University of Chicago Administrative Stuff! Lab2 due tomorrow " 2 free late days! Lab3 is out " Start early!! My office
CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution Prof. Yanjing Li University of Chicago Administrative Stuff! Lab2 due tomorrow " 2 free late days! Lab3 is out " Start early!! My office
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Instruction Commit The End of the Road (um Pipe) Commit is typically the last stage of the pipeline Anything an insn. does at this point is irrevocable Only actions following
CSE 502: Computer Architecture Instruction Commit The End of the Road (um Pipe) Commit is typically the last stage of the pipeline Anything an insn. does at this point is irrevocable Only actions following
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
The basic structure of a MIPS floating-point unit
 Tomasulo s scheme The algorithm based on the idea of reservation station The reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from
Tomasulo s scheme The algorithm based on the idea of reservation station The reservation station fetches and buffers an operand as soon as it is available, eliminating the need to get the operand from
CS252 Graduate Computer Architecture Lecture 8. Review: Scoreboard (CDC 6600) Explicit Renaming Precise Interrupts February 13 th, 2010
 Explicit Renaming Precise Interrupts February 13 th, 2010") CS252 Graduate Computer Architecture Lecture 8 Explicit Renaming Precise Interrupts February 13 th, 2010 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley
CS252 Graduate Computer Architecture Lecture 8 Explicit Renaming Precise Interrupts February 13 th, 2010 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism
 ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
CISC 662 Graduate Computer Architecture. Lecture 10 - ILP 3
 CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation. Types of dependences
 and its exploitation. Types of dependences") Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling)
") 18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
EECS 470 Midterm Exam Answer Key Fall 2004
 EECS 470 Midterm Exam Answer Key Fall 2004 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Part I /23 Part
EECS 470 Midterm Exam Answer Key Fall 2004 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points Part I /23 Part
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
 ece4750-t11-ooo-execution-notes.txt ========================================================================== ece4750-l12-ooo-execution-notes.txt ==========================================================================
ece4750-t11-ooo-execution-notes.txt ========================================================================== ece4750-l12-ooo-execution-notes.txt ==========================================================================
Instruction-Level Parallelism (ILP)
") Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
TDT 4260 TDT ILP Chap 2, App. C
 TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
CS 252 Graduate Computer Architecture. Lecture 4: Instruction-Level Parallelism
 CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
This Set. Scheduling and Dynamic Execution Definitions From various parts of Chapter 4. Description of Two Dynamic Scheduling Methods
 10 1 Dynamic Scheduling 10 1 This Set Scheduling and Dynamic Execution Definitions From various parts of Chapter 4. Description of Two Dynamic Scheduling Methods Not yet complete. (Material below may repeat
10 1 Dynamic Scheduling 10 1 This Set Scheduling and Dynamic Execution Definitions From various parts of Chapter 4. Description of Two Dynamic Scheduling Methods Not yet complete. (Material below may repeat
Instruction Level Parallelism
 Instruction Level Parallelism Dynamic scheduling Scoreboard Technique Tomasulo Algorithm Speculation Reorder Buffer Superscalar Processors 1 Definition of ILP ILP=Potential overlap of execution among unrelated
Instruction Level Parallelism Dynamic scheduling Scoreboard Technique Tomasulo Algorithm Speculation Reorder Buffer Superscalar Processors 1 Definition of ILP ILP=Potential overlap of execution among unrelated
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Lecture 11: Out-of-order Processors. Topics: more ooo design details, timing, load-store queue
 Lecture 11: Out-of-order Processors Topics: more ooo design details, timing, load-store queue 1 Problem 0 Show the renamed version of the following code: Assume that you have 36 physical registers and
Lecture 11: Out-of-order Processors Topics: more ooo design details, timing, load-store queue 1 Problem 0 Show the renamed version of the following code: Assume that you have 36 physical registers and
15-740/ Computer Architecture Lecture 10: Out-of-Order Execution. Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/3/2011
 5-740/8-740 Computer Architecture Lecture 0: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Fall 20, 0/3/20 Review: Solutions to Enable Precise Exceptions Reorder buffer History buffer
5-740/8-740 Computer Architecture Lecture 0: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Fall 20, 0/3/20 Review: Solutions to Enable Precise Exceptions Reorder buffer History buffer
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
References EE457. Out of Order (OoO) Execution. Instruction Scheduling (Re-ordering of instructions)
 Execution. Instruction Scheduling (Re-ordering of instructions)") EE457 Out of Order (OoO) Execution Introduction to Dynamic Scheduling of Instructions (The Tomasulo Algorithm) By Gandhi Puvvada References EE557 Textbook Prof Dubois EE557 Classnotes Prof Annavaram s
EE457 Out of Order (OoO) Execution Introduction to Dynamic Scheduling of Instructions (The Tomasulo Algorithm) By Gandhi Puvvada References EE557 Textbook Prof Dubois EE557 Classnotes Prof Annavaram s
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Multiple Instruction Issue and Hardware Based Speculation
 Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Computer Architecture Lecture 14: Out-of-Order Execution. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013
 18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
Topics. Digital Systems Architecture EECE EECE Predication, Prediction, and Speculation
 Digital Systems Architecture EECE 343-01 EECE 292-02 Predication, Prediction, and Speculation Dr. William H. Robinson February 25, 2004 http://eecs.vanderbilt.edu/courses/eece343/ Topics Aha, now I see,
Digital Systems Architecture EECE 343-01 EECE 292-02 Predication, Prediction, and Speculation Dr. William H. Robinson February 25, 2004 http://eecs.vanderbilt.edu/courses/eece343/ Topics Aha, now I see,
Advanced Computer Architecture
 Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Instruction Level Parallelism (ILP)
") Instruction Level Parallelism (ILP) Pipelining supports a limited sense of ILP e.g. overlapped instructions, out of order completion and issue, bypass logic, etc. Remember Pipeline CPI = Ideal Pipeline
Instruction Level Parallelism (ILP) Pipelining supports a limited sense of ILP e.g. overlapped instructions, out of order completion and issue, bypass logic, etc. Remember Pipeline CPI = Ideal Pipeline
Chapter. Out of order Execution
 Chapter Long EX Instruction stages We have assumed that all stages. There is a problem with the EX stage multiply (MUL) takes more time than ADD MUL ADD We can clearly delay the execution of the ADD until
Chapter Long EX Instruction stages We have assumed that all stages. There is a problem with the EX stage multiply (MUL) takes more time than ADD MUL ADD We can clearly delay the execution of the ADD until
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Lecture: Out-of-order Processors
 Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
PIPELINING: HAZARDS. Mahdi Nazm Bojnordi. CS/ECE 6810: Computer Architecture. Assistant Professor School of Computing University of Utah
 PIPELINING: HAZARDS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 1 submission deadline: Jan. 30 th This
PIPELINING: HAZARDS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 1 submission deadline: Jan. 30 th This
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
CS252 Graduate Computer Architecture Lecture 6. Recall: Software Pipelining Example
 CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
CS 152 Computer Architecture and Engineering. Lecture 13 - Out-of-Order Issue and Register Renaming
 CS 152 Computer Architecture and Engineering Lecture 13 - Out-of-Order Issue and Register Renaming Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://wwweecsberkeleyedu/~krste
CS 152 Computer Architecture and Engineering Lecture 13 - Out-of-Order Issue and Register Renaming Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://wwweecsberkeleyedu/~krste
Advanced Computer Architecture. Chapter 4: More sophisticated CPU architectures
 Advanced Computer Architecture Chapter 4: More sophisticated CPU architectures Lecturer: Paul H J Kelly Autumn 2001 Department of Computing Imperial College Room 423 email: phjk@doc.ic.ac.uk Course web
Advanced Computer Architecture Chapter 4: More sophisticated CPU architectures Lecturer: Paul H J Kelly Autumn 2001 Department of Computing Imperial College Room 423 email: phjk@doc.ic.ac.uk Course web
Lecture 8: Branch Prediction, Dynamic ILP. Topics: static speculation and branch prediction (Sections )
") Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
EECS 470 Lecture 7. Branches: Address prediction and recovery (And interrupt recovery too.)
") EECS 470 Lecture 7 Branches: Address prediction and recovery (And interrupt recovery too.) Warning: Crazy times coming Project handout and group formation today Help me to end class 12 minutes early P3
EECS 470 Lecture 7 Branches: Address prediction and recovery (And interrupt recovery too.) Warning: Crazy times coming Project handout and group formation today Help me to end class 12 minutes early P3
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Instruction Commit The End of the Road (um Pipe) Commit is typically the last stage of the pipeline Anything an insn. does at this point is irrevocable Only actions following
CSE 502: Computer Architecture Instruction Commit The End of the Road (um Pipe) Commit is typically the last stage of the pipeline Anything an insn. does at this point is irrevocable Only actions following
Lecture 9: Dynamic ILP. Topics: out-of-order processors (Sections )
") Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EECS 470 Midterm Exam Winter 2008 answers
 EECS 470 Midterm Exam Winter 2008 answers Name: KEY unique name: KEY Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: #Page Points 2 /10
EECS 470 Midterm Exam Winter 2008 answers Name: KEY unique name: KEY Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: #Page Points 2 /10
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
EECS 470. Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 7 Winter 2018
 Lecture 7 Winter 2018") EECS 470 Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 7 Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen,
EECS 470 Branches: Address prediction and recovery (And interrupt recovery too.) Lecture 7 Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen,
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
ECE 4750 Computer Architecture, Fall 2017 T10 Advanced Processors: Out-of-Order Execution
 ECE 4750 Computer Architecture, Fall 207 T0 Advanced Processors: Out-of-Order Execution School of Electrical and Computer Engineering Cornell University revision: 207--06-3-0 Incremental Approach to Exploring
ECE 4750 Computer Architecture, Fall 207 T0 Advanced Processors: Out-of-Order Execution School of Electrical and Computer Engineering Cornell University revision: 207--06-3-0 Incremental Approach to Exploring
Out of Order Processing
 Out of Order Processing Manu Awasthi July 3 rd 2018 Computer Architecture Summer School 2018 Slide deck acknowledgements : Rajeev Balasubramonian (University of Utah), Computer Architecture: A Quantitative
Out of Order Processing Manu Awasthi July 3 rd 2018 Computer Architecture Summer School 2018 Slide deck acknowledgements : Rajeev Balasubramonian (University of Utah), Computer Architecture: A Quantitative
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
" # " $ % & ' ( ) * + $ " % '* + * ' "
 * + $ % '* + * '") ! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
What is instruction level parallelism?
 Instruction Level Parallelism Sangyeun Cho Computer Science Department What is instruction level parallelism? Execute independent instructions in parallel Provide more hardware function units (e.g., adders,
Instruction Level Parallelism Sangyeun Cho Computer Science Department What is instruction level parallelism? Execute independent instructions in parallel Provide more hardware function units (e.g., adders,
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Pipelining! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar DEIB! 30 November, 2017!
 Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Announcements. ECE4750/CS4420 Computer Architecture L11: Speculative Execution I. Edward Suh Computer Systems Laboratory
 ECE4750/CS4420 Computer Architecture L11: Speculative Execution I Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab3 due today 2 1 Overview Branch penalties limit performance
ECE4750/CS4420 Computer Architecture L11: Speculative Execution I Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab3 due today 2 1 Overview Branch penalties limit performance
CS 423 Computer Architecture Spring Lecture 04: A Superscalar Pipeline
 CS 423 Computer Architecture Spring 2012 Lecture 04: A Superscalar Pipeline Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs423/ [Adapted from Computer Organization and Design, Patterson & Hennessy,
CS 423 Computer Architecture Spring 2012 Lecture 04: A Superscalar Pipeline Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs423/ [Adapted from Computer Organization and Design, Patterson & Hennessy,
CS 152 Computer Architecture and Engineering. Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming
 CS 152 Computer Architecture and Engineering Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming John Wawrzynek Electrical Engineering and Computer Sciences University of California at
CS 152 Computer Architecture and Engineering Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming John Wawrzynek Electrical Engineering and Computer Sciences University of California at