An Analysis of Linux Scalability to Many Cores
|
|
|
- Asher O’Neal’
- 6 years ago
- Views:
Transcription
1 An Analysis of Linux Scalability to Many Cores 1
2 What are we going to talk about? Scalability analysis of 7 system applications running on Linux on a 48 core computer Exim, memcached, Apache, PostgreSQL, gmake, Psearchy and MapReduce How can we improve the traditional Linux for better scalability 2 2 2
3 Amdahl s law If αα is the fraction of a calculation that is sequential, and 1 αα is the fraction that can be parallelized, the maximum speedup that can be achieved by using P processors is given according to Amdahl's Law Speedup = 1 αα+ 1 αα PP 3 3 3
4 Introduction Popular belief that traditional kernel designs won t scale well on multicore processors Can traditional kernel designs be used and implemented in a way that allows applications to scale? 4 4 4
5 Why Linux? Why these applications? Linux has a traditional kernel design and the Linux community has made a great progress in making it scalable The chosen applications are designed for parallel execution and stress many major Linux kernel components 5 5 5
6 How can we decide if Linux is scalable? Measure scalability of the applications on a recent Linux kernel rc5 (July 12,2010) Understand and fix scalability problems Kernel design is scalable if the changes are modest 6 6 6
7 Kind of problems Linux kernel implementation Applications user-level design Applications use of Linux kernel services 7 7 7
8 The Applications 2 Types of applications Applications that previous work has shown not to scale well on linux Memcached, Apache and Metis (MapReduce library) Applications that are designed for parallel execution gmake, PosgtreSQL, Exim and Psearchy Use synthetic user workloads to cause them to use the kernel intensively Stress the network stack, file name cache, page cache, memory manager, process manager and scheduler 8 8 8
9 Exim Exim is a mail server Single master process listens for incoming SMTP connections via TCP The master forks a new process for each connection Has a good deal of parallelism Spends 69% of its time in the kernel on a single core Stresses process creation and small file creation and deletion 9 9 9
10 memcached Object cache In-memory key-value store used to improve web application performance Has key-value hash table protected by internal lock Stresses the network stack, spending 80% of its time processing packets in the kernel at one core
11 Apache Web server Popular web server Single instance listening on port 80. One process per core each process has a thread pool to service connections On a single core, a process spends 60% of the time in the kernel Stresses network stack and the file system
12 PostgreSQL Popular open source SQL database Makes extensive internal use of shared data structures and synchronization Stores database tables as regular files accessed concurrently by all processes For read-only workload, it spends 1.5% of the time in the kernel with one core, and 82% with 48 cores
13 gmake Implementation of the standard make utility that supports executing independent build rules concurrently Unofficial default benchmark in the Linux community Creates more processes than there are core, and reads and writes many files Spends 7.6% of the time in the kernel with one core
14 Psearchy File indexexer Parallel version of searchy, a program to index and query web pages Version in the article runs searchy indexer on each core, sharing a work queue of input files
15 Metis - MapReduce MapReduce library for single multicore servers Allocates large amount of memory to hold temporary tables, stressing the kernel memory allocator Spends 3% of the time in the kernel with one core, 16% of the time with 48 cores
16 Kernel Optimizations Many of the bottlenecks are common to multiple applications The solutions have not been implemented in the standard kernel because the problem are not serious on small-scale SMPs or are masked by I/O delays
17 Quick intro to Linux file system Superblock - The superblock is essentially file system metadata and defines the file system type, size, status, and information about other metadata structures (metadata of metadata) Inode - An inode exists in a file system and represents metadata about a file. Dentry - A dentry is the glue that holds inodes and files together by relating inode numbers to file names. Dentries also play a role in directory caching which, ideally, keeps the most frequently used files on-hand for faster access. File system traversal is another aspect of the dentry as it maintains a relationship between directories and their files. Taken from: /what-is-a-superblock-inode-dentry-and-a-file
18 Common problems The tasks may lock a shared data structures, so that increasing the number of cores increase the lock wait time The tasks may write a shared memory location, so that increasing the number of cores increases the time spent waiting for the cache coherence protocol
19 Common problems - cont The tasks may compete for space in a limited size shared hardware cache, so that increasing the number of cores increases the cache miss rate The tasks may compete for other shared hardware resources such as DRAM interface There may be too few tasks to keep all cores busy
20 Cache related problems Many scaling problems are delays caused by cache misses when a core uses data that other core have written Sometimes cache coherence related operation take about the same time as loading data from off-chip RAM The cache coherence protocol serializes modifications to the same cache line
21 Multicore packet processing The Linux network stack connects different stages of packet processing with queues A received packet typically passes through multiple queues before arriving at per-socket queue The performance would be better if each packet, queue and connection be handled by just one core Avoid cache misses and queue locking Linux kernels take advantage of network cards with multiple hardware queues21 21
22 Multicore packet processing - cont Transmitting place outgoing packets on the hardware queue associated with the current core Receiving configure the hardware to enqueue incoming packets matching a particular criteria (source ip and port) on a specific queue Sample outgoing packets and update hardware s flow directing tables to deliver incoming packets from that connection directly to the core
23 Sloppy counters The problem Linux uses shared counters for reference counting and to manage various resources Lock-free atomic inc and dec do not help because of cache coherence
24 Sloppy counter The solution Each core holds a few spare references to an object It gives ownership of these references to threads running on that core when needed, without having to modify the global reference count
25 Sloppy counter - cont Core increments the sloppy counter by VV: 1. If llllllllll cccccccccc VV I. Get VV references and decrement llllllllll cccccccccc by VV and finish 2. Acquire UU VV references from the central counter and decrement the central counter by UU Core decrements the sloppy counter by VV: 1. Release VV references for local use and decrement the local counter by VV 2. If llllllllll cccccccccc tthrrrrrrhoooooo release spare references by decrementing local count and central count
26 Sloppy counter - cont Invariant: llllllllll cccccccccccccccc+number of used resources = shared counter
27 Sloppy counter - use These counters are used for counting references to: dentrys vfsmounts dst_entrys track amount of memory allocated by each network protocol (such as TCP and UDP)
28 Sloppy counters - dentry struct dentry { atomic_t d_count; /* usage count */ unsigned long d_vfs_flags; /* dentry cache flags */ spinlock_t d_lock; /* per-dentry lock */ struct inode *d_inode; /* associated inode */ struct list_head d_lru; /* unused list */ struct list_head d_child; /* list of dentries within */ struct list_head d_subdirs; /* subdirectories */ }
29 Lock-free comparison There are situations where there are bottlenecks because of low scalability of name lookups in the dentry cache The dentry cache speed ups lookup by mapping a directory and a file name to a dentry identifying the matching inode When a potential dentry is located, the lookup code acquires a per-dentry spin lock to atomically compare fields of the dentry with the arguments

30 Lock-free comparison - cont The search can be made lock-free Use generation counter which is incremented after every modification. During modification temporarily set the generation counter to 0. Comparison algorithm:
31 Per core data structures Kernel data structures that caused scaling bottlenecks: Per super-block list of open files Table of mount points Pool of free packet buffers
32 False sharing Some applications caused false sharing in the kernel A variable the kernel updated often was located on the same cache line as a variable it read often
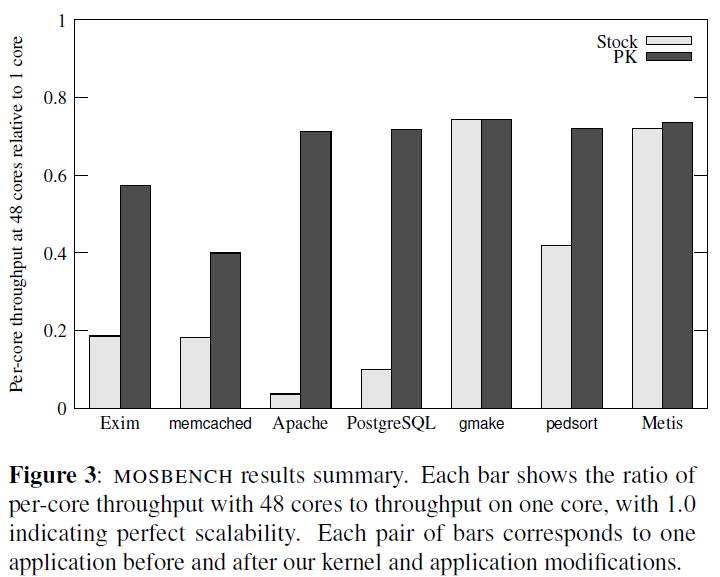
33 Evaluation
34 Technical details The experiments were made on a 48 core machine Tyan Thunder S4985 board 8*(2.4 GHz 6-core AMD Opteron 8431 chips) Each core has 64Kb L1 cache and 512Kb L2 cache The cores on each chip share 6Mb L3 cache Each chip has 8Gb of local off-chip DRAM
35 Exim
36 Exim - modifications Berkeley DB reads /proc/stat to find number of cores Modification: Cache this information aggressively Split incoming queues messages across 62 spool directories, hashing by per connection pid
37 memcached
38 memcached - modifications False read/write sharing of IXGBE device driver data in the net_device and device structures Modification: rearrange structures to isolate critical read-only members to their own cache lines Contention on dst_entry structure s reference count in the network stack s destination cache Modification: use sloppy counter
39 Apache
40 PostgreSQL
41 PostgreSQL - cont
42 gmake
43 Psearchy/pedsort
44 Metis

45 Summary of Linux scalability problems
46 Summary of Linux scalability problems - cont

47 Summary of Linux scalability problems - cont
48 Summary of Linux scalability problems - cont

49 Summary of Bottlenecks
50 Summary Most applications can scale well to many cores with modest modifications to the applications and to the kernel More bottlenecks are expected to be revealed when running on more cores
51 Thank you This presentation is based on An Analysis of Linux Scalability to Many Cores by Silas Boyd-Wickizer, Austin T. Clements, Yandong Mao, Aleksey Pesterev, M. Frans Kaashoek, Robert Morris, and Nickolai Zeldovich ( )
An Analysis of Linux Scalability to Many Cores
 An Analysis of Linux Scalability to Many Cores The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher Boyd-Wickizer,
An Analysis of Linux Scalability to Many Cores The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher Boyd-Wickizer,
Graphs speedup performance notice speedups are getting less good, but performance is improving!
 Plans: shared-memory TSP scalability on Beehive Case study: AMD CC shared memory Case study: Linux scalability BEEHIVE Scalability challanges for shared-memory TSP on Beehive work distribution master?
Plans: shared-memory TSP scalability on Beehive Case study: AMD CC shared memory Case study: Linux scalability BEEHIVE Scalability challanges for shared-memory TSP on Beehive work distribution master?
Silas Boyd-Wickizer. Doctor of Philosophy. at the. February 2014
 Optimizing Communication Bottlenecks in Multiprocessor Operating System Kernels by Silas Boyd-Wickizer B.S., Stanford University (2004) M.S., Stanford University (2006) Submitted to the Department of Electrical
Optimizing Communication Bottlenecks in Multiprocessor Operating System Kernels by Silas Boyd-Wickizer B.S., Stanford University (2004) M.S., Stanford University (2006) Submitted to the Department of Electrical
OpLog: a library for scaling update-heavy data structures
 OpLog: a library for scaling update-heavy data structures Silas Boyd-Wickizer, M. Frans Kaashoek, Robert Morris, and Nickolai Zeldovich MIT CSAIL Abstract Existing techniques (e.g., RCU) can achieve good
OpLog: a library for scaling update-heavy data structures Silas Boyd-Wickizer, M. Frans Kaashoek, Robert Morris, and Nickolai Zeldovich MIT CSAIL Abstract Existing techniques (e.g., RCU) can achieve good
D5.5 Overall system performance, scaling, and outlook on large multicores
 IOLanes Advancing the Scalability and Performance of I/O Subsystems in Multicore Platforms Contract number: Contract Start Date: Duration: Project coordinator: Partners: FP7-248615 01- Jan- 10 39 months
IOLanes Advancing the Scalability and Performance of I/O Subsystems in Multicore Platforms Contract number: Contract Start Date: Duration: Project coordinator: Partners: FP7-248615 01- Jan- 10 39 months
CPHash: A Cache-Partitioned Hash Table Zviad Metreveli, Nickolai Zeldovich, and M. Frans Kaashoek
 Computer Science and Artificial Intelligence Laboratory Technical Report MIT-CSAIL-TR-211-51 November 26, 211 : A Cache-Partitioned Hash Table Zviad Metreveli, Nickolai Zeldovich, and M. Frans Kaashoek
Computer Science and Artificial Intelligence Laboratory Technical Report MIT-CSAIL-TR-211-51 November 26, 211 : A Cache-Partitioned Hash Table Zviad Metreveli, Nickolai Zeldovich, and M. Frans Kaashoek
Mbench: Benchmarking a Multicore Operating System Using Mixed Workloads
 Mbench: Benchmarking a Multicore Operating System Using Mixed Workloads Gang Lu and Xinlong Lin Institute of Computing Technology, Chinese Academy of Sciences BPOE-6, Sep 4, 2015 Backgrounds Fast evolution
Mbench: Benchmarking a Multicore Operating System Using Mixed Workloads Gang Lu and Xinlong Lin Institute of Computing Technology, Chinese Academy of Sciences BPOE-6, Sep 4, 2015 Backgrounds Fast evolution
Improving network connection locality on multicore systems
 Improving network connection locality on multicore systems The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher
Improving network connection locality on multicore systems The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published Publisher
Kernel Synchronization I. Changwoo Min
 1 Kernel Synchronization I Changwoo Min 2 Summary of last lectures Tools: building, exploring, and debugging Linux kernel Core kernel infrastructure syscall, module, kernel data structures Process management
1 Kernel Synchronization I Changwoo Min 2 Summary of last lectures Tools: building, exploring, and debugging Linux kernel Core kernel infrastructure syscall, module, kernel data structures Process management
SMP & Locking. CPU clock-rate increase slowing. Multiprocessor System. Cache Coherency. Types of Multiprocessors (MPs)
") SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
You are free: to Share to copy, distribute and transmit the work. to Remix to adapt the work
 SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP, Multicore, Memory Ordering & Locking
 SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP & Locking. Multiprocessor System. CPU performance increases slowing. Amdahl s Law. Types of Multiprocessors (MPs)
") SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
SMP, Multicore, Memory Ordering & Locking. Multiprocessor System. CPU performance increases are slowing. Amdahl s Law. Types of Multiprocessors (MPs)
") SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP, Multicore, Memory Ordering & Locking. NICTA 2010 From imagination to impact
 SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP, Multicore, Memory Ordering & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy,
SMP & Locking. NICTA 2010 From imagination to impact
 SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
Optimizing MapReduce for Multicore Architectures Yandong Mao, Robert Morris, and Frans Kaashoek
 Computer Science and Artificial Intelligence Laboratory Technical Report MIT-CSAIL-TR-200-020 May 2, 200 Optimizing MapReduce for Multicore Architectures Yandong Mao, Robert Morris, and Frans Kaashoek
Computer Science and Artificial Intelligence Laboratory Technical Report MIT-CSAIL-TR-200-020 May 2, 200 Optimizing MapReduce for Multicore Architectures Yandong Mao, Robert Morris, and Frans Kaashoek
Tolerating Malicious Drivers in Linux. Silas Boyd-Wickizer and Nickolai Zeldovich
 XXX Tolerating Malicious Drivers in Linux Silas Boyd-Wickizer and Nickolai Zeldovich How could a device driver be malicious? Today's device drivers are highly privileged Write kernel memory, allocate memory,...
XXX Tolerating Malicious Drivers in Linux Silas Boyd-Wickizer and Nickolai Zeldovich How could a device driver be malicious? Today's device drivers are highly privileged Write kernel memory, allocate memory,...
Locating Cache Performance Bottlenecks Using Data Profiling
 Locating Cache Performance Bottlenecks Using Data Profiling The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published
Locating Cache Performance Bottlenecks Using Data Profiling The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published
SMP & Locking. NICTA 2010 From imagination to impact
 SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
SMP & Locking These slides are made distributed under the Creative Commons Attribution 3.0 License, unless otherwise noted on individual slides. You are free: to Share to copy, distribute and transmit
Corey: An Operating System for Many Cores
 Corey: An Operating System for Many Silas Boyd-Wickizer Haibo Chen Rong Chen Yandong Mao Frans Kaashoek Robert Morris Aleksey Pesterev Lex Stein Ming Wu Yuehua Dai Yang Zhang Zheng Zhang MIT Fudan University
Corey: An Operating System for Many Silas Boyd-Wickizer Haibo Chen Rong Chen Yandong Mao Frans Kaashoek Robert Morris Aleksey Pesterev Lex Stein Ming Wu Yuehua Dai Yang Zhang Zheng Zhang MIT Fudan University
CS377P Programming for Performance Multicore Performance Synchronization
 CS377P Programming for Performance Multicore Performance Synchronization Sreepathi Pai UTCS October 21, 2015 Outline 1 Synchronization Primitives 2 Blocking, Lock-free and Wait-free Algorithms 3 Transactional
CS377P Programming for Performance Multicore Performance Synchronization Sreepathi Pai UTCS October 21, 2015 Outline 1 Synchronization Primitives 2 Blocking, Lock-free and Wait-free Algorithms 3 Transactional
CS3600 SYSTEMS AND NETWORKS
 CS3600 SYSTEMS AND NETWORKS NORTHEASTERN UNIVERSITY Lecture 11: File System Implementation Prof. Alan Mislove (amislove@ccs.neu.edu) File-System Structure File structure Logical storage unit Collection
CS3600 SYSTEMS AND NETWORKS NORTHEASTERN UNIVERSITY Lecture 11: File System Implementation Prof. Alan Mislove (amislove@ccs.neu.edu) File-System Structure File structure Logical storage unit Collection
Chapter 12: File System Implementation
 Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Allocation Methods Free-Space Management
Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Allocation Methods Free-Space Management
Operating Systems. Week 9 Recitation: Exam 2 Preview Review of Exam 2, Spring Paul Krzyzanowski. Rutgers University.
 Operating Systems Week 9 Recitation: Exam 2 Preview Review of Exam 2, Spring 2014 Paul Krzyzanowski Rutgers University Spring 2015 March 27, 2015 2015 Paul Krzyzanowski 1 Exam 2 2012 Question 2a One of
Operating Systems Week 9 Recitation: Exam 2 Preview Review of Exam 2, Spring 2014 Paul Krzyzanowski Rutgers University Spring 2015 March 27, 2015 2015 Paul Krzyzanowski 1 Exam 2 2012 Question 2a One of
Heckaton. SQL Server's Memory Optimized OLTP Engine
 Heckaton SQL Server's Memory Optimized OLTP Engine Agenda Introduction to Hekaton Design Consideration High Level Architecture Storage and Indexing Query Processing Transaction Management Transaction Durability
Heckaton SQL Server's Memory Optimized OLTP Engine Agenda Introduction to Hekaton Design Consideration High Level Architecture Storage and Indexing Query Processing Transaction Management Transaction Durability
A Software Approach to Unifying Multicore Caches Silas Boyd-Wickizer, M. Frans Kaashoek, Robert Morris, and Nickolai Zeldovich
 Computer Science and Artificial Intelligence Laboratory Technical Report MIT-CSAIL-TR-2011-032 June 28, 2011 A Software Approach to Unifying Multicore Caches Silas Boyd-Wickizer, M. Frans Kaashoek, Robert
Computer Science and Artificial Intelligence Laboratory Technical Report MIT-CSAIL-TR-2011-032 June 28, 2011 A Software Approach to Unifying Multicore Caches Silas Boyd-Wickizer, M. Frans Kaashoek, Robert
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
ECE 550D Fundamentals of Computer Systems and Engineering. Fall 2017
 ECE 550D Fundamentals of Computer Systems and Engineering Fall 2017 The Operating System (OS) Prof. John Board Duke University Slides are derived from work by Profs. Tyler Bletsch and Andrew Hilton (Duke)
ECE 550D Fundamentals of Computer Systems and Engineering Fall 2017 The Operating System (OS) Prof. John Board Duke University Slides are derived from work by Profs. Tyler Bletsch and Andrew Hilton (Duke)
The Art and Science of Memory Allocation
 Logical Diagram The Art and Science of Memory Allocation Don Porter CSE 506 Binary Formats RCU Memory Management Memory Allocators CPU Scheduler User System Calls Kernel Today s Lecture File System Networking
Logical Diagram The Art and Science of Memory Allocation Don Porter CSE 506 Binary Formats RCU Memory Management Memory Allocators CPU Scheduler User System Calls Kernel Today s Lecture File System Networking
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
RadixVM: Scalable address spaces for multithreaded applications (revised )
") RadixVM: Scalable address spaces for multithreaded applications (revised 24-8-5) Austin T. Clements, M. Frans Kaashoek, and Nickolai Zeldovich MIT CSAIL ABSTRACT RadixVM is a new virtual memory system
RadixVM: Scalable address spaces for multithreaded applications (revised 24-8-5) Austin T. Clements, M. Frans Kaashoek, and Nickolai Zeldovich MIT CSAIL ABSTRACT RadixVM is a new virtual memory system
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
OPERATING SYSTEM. Chapter 12: File System Implementation
 OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
File Systems. CS170 Fall 2018
 File Systems CS170 Fall 2018 Table of Content File interface review File-System Structure File-System Implementation Directory Implementation Allocation Methods of Disk Space Free-Space Management Contiguous
File Systems CS170 Fall 2018 Table of Content File interface review File-System Structure File-System Implementation Directory Implementation Allocation Methods of Disk Space Free-Space Management Contiguous
Pay Migration Tax to Homeland: Anchor-based Scalable Reference Counting for Multicores
 Pay Migration Tax to Homeland: Anchor-based Scalable Reference Counting for Multicores Seokyong Jung, Jongbin Kim, Minsoo Ryu, Sooyong Kang, Hyungsoo Jung Hanyang University 1 Reference counting It is
Pay Migration Tax to Homeland: Anchor-based Scalable Reference Counting for Multicores Seokyong Jung, Jongbin Kim, Minsoo Ryu, Sooyong Kang, Hyungsoo Jung Hanyang University 1 Reference counting It is
Agenda Process Concept Process Scheduling Operations on Processes Interprocess Communication 3.2
 Lecture 3: Processes Agenda Process Concept Process Scheduling Operations on Processes Interprocess Communication 3.2 Process in General 3.3 Process Concept Process is an active program in execution; process
Lecture 3: Processes Agenda Process Concept Process Scheduling Operations on Processes Interprocess Communication 3.2 Process in General 3.3 Process Concept Process is an active program in execution; process
Exploring mtcp based Single-Threaded and Multi-Threaded Web Server Design
 Exploring mtcp based Single-Threaded and Multi-Threaded Web Server Design A Thesis Submitted in partial fulfillment of the requirements for the degree of Master of Technology by Pijush Chakraborty (153050015)
Exploring mtcp based Single-Threaded and Multi-Threaded Web Server Design A Thesis Submitted in partial fulfillment of the requirements for the degree of Master of Technology by Pijush Chakraborty (153050015)
Analysis of Linux UDP Sockets Concurrent Performance
 Analysis of Linux UDP Sockets Concurrent Performance Diego Rivera, Eduardo Achá, Javier Bustos-Jiménez and José Piquer Institut Telecom SudParis, France. Email: diego.rivera-villagra@telecom-sudparis.eu
Analysis of Linux UDP Sockets Concurrent Performance Diego Rivera, Eduardo Achá, Javier Bustos-Jiménez and José Piquer Institut Telecom SudParis, France. Email: diego.rivera-villagra@telecom-sudparis.eu
Chapter 11: Implementing File Systems
 Chapter 11: Implementing File Systems Operating System Concepts 99h Edition DM510-14 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation
Chapter 11: Implementing File Systems Operating System Concepts 99h Edition DM510-14 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation
Linux multi-core scalability
 Linux multi-core scalability Oct 2009 Andi Kleen Intel Corporation andi@firstfloor.org Overview Scalability theory Linux history Some common scalability trouble-spots Application workarounds Motivation
Linux multi-core scalability Oct 2009 Andi Kleen Intel Corporation andi@firstfloor.org Overview Scalability theory Linux history Some common scalability trouble-spots Application workarounds Motivation
Corey: An Operating System For Many Cores
 Corey: An Operating System For Many Cores Silas Boyd-Wickizer Haibo Chen Rong Chen Yandong Mao Frans Kaashoek Robert Morris Aleksey Pesterev Lex Stein Ming Wu Yuehua Dai Yang Zhang Zheng Zhang MIT Fudan
Corey: An Operating System For Many Cores Silas Boyd-Wickizer Haibo Chen Rong Chen Yandong Mao Frans Kaashoek Robert Morris Aleksey Pesterev Lex Stein Ming Wu Yuehua Dai Yang Zhang Zheng Zhang MIT Fudan
@ Massachusetts Institute of Technology All rights reserved.
 ..... CPHASH: A Cache-Partitioned Hash Table with LRU Eviction by Zviad Metreveli MASSACHUSETTS INSTITUTE OF TECHAC'LOGY JUN 2 1 2011 LIBRARIES Submitted to the Department of Electrical Engineering and
..... CPHASH: A Cache-Partitioned Hash Table with LRU Eviction by Zviad Metreveli MASSACHUSETTS INSTITUTE OF TECHAC'LOGY JUN 2 1 2011 LIBRARIES Submitted to the Department of Electrical Engineering and
Panu Silvasti Page 1
 Multicore support in databases Panu Silvasti Page 1 Outline Building blocks of a storage manager How do existing storage managers scale? Optimizing Shore database for multicore processors Page 2 Building
Multicore support in databases Panu Silvasti Page 1 Outline Building blocks of a storage manager How do existing storage managers scale? Optimizing Shore database for multicore processors Page 2 Building
PERFORMANCE ANALYSIS AND OPTIMIZATION OF SKIP LISTS FOR MODERN MULTI-CORE ARCHITECTURES
 PERFORMANCE ANALYSIS AND OPTIMIZATION OF SKIP LISTS FOR MODERN MULTI-CORE ARCHITECTURES Anish Athalye and Patrick Long Mentors: Austin Clements and Stephen Tu 3 rd annual MIT PRIMES Conference Sequential
PERFORMANCE ANALYSIS AND OPTIMIZATION OF SKIP LISTS FOR MODERN MULTI-CORE ARCHITECTURES Anish Athalye and Patrick Long Mentors: Austin Clements and Stephen Tu 3 rd annual MIT PRIMES Conference Sequential
Workload Optimization on Hybrid Architectures
 IBM OCR project Workload Optimization on Hybrid Architectures IBM T.J. Watson Research Center May 4, 2011 Chiron & Achilles 2003 IBM Corporation IBM Research Goal Parallelism with hundreds and thousands
IBM OCR project Workload Optimization on Hybrid Architectures IBM T.J. Watson Research Center May 4, 2011 Chiron & Achilles 2003 IBM Corporation IBM Research Goal Parallelism with hundreds and thousands
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Lecture 19: File System Implementation. Mythili Vutukuru IIT Bombay
 Lecture 19: File System Implementation Mythili Vutukuru IIT Bombay File System An organization of files and directories on disk OS has one or more file systems Two main aspects of file systems Data structures
Lecture 19: File System Implementation Mythili Vutukuru IIT Bombay File System An organization of files and directories on disk OS has one or more file systems Two main aspects of file systems Data structures
Distributed Operating Systems Memory Consistency
 Faculty of Computer Science Institute for System Architecture, Operating Systems Group Distributed Operating Systems Memory Consistency Marcus Völp (slides Julian Stecklina, Marcus Völp) SS2014 Concurrent
Faculty of Computer Science Institute for System Architecture, Operating Systems Group Distributed Operating Systems Memory Consistency Marcus Völp (slides Julian Stecklina, Marcus Völp) SS2014 Concurrent
Chapter 12: File System Implementation
 Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 24 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 Questions from last time How
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 24 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 Questions from last time How
Chapter 11: Implementing File
 Chapter 11: Implementing File Systems Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
Chapter 11: Implementing File Systems Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
Designing a True Direct-Access File System with DevFS
 Designing a True Direct-Access File System with DevFS Sudarsun Kannan, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau University of Wisconsin-Madison Yuangang Wang, Jun Xu, Gopinath Palani Huawei Technologies
Designing a True Direct-Access File System with DevFS Sudarsun Kannan, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau University of Wisconsin-Madison Yuangang Wang, Jun Xu, Gopinath Palani Huawei Technologies
NUMA replicated pagecache for Linux
 NUMA replicated pagecache for Linux Nick Piggin SuSE Labs January 27, 2008 0-0 Talk outline I will cover the following areas: Give some NUMA background information Introduce some of Linux s NUMA optimisations
NUMA replicated pagecache for Linux Nick Piggin SuSE Labs January 27, 2008 0-0 Talk outline I will cover the following areas: Give some NUMA background information Introduce some of Linux s NUMA optimisations
Multiprocessor Systems. Chapter 8, 8.1
 Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Chapter 10: File System Implementation
 Chapter 10: File System Implementation Chapter 10: File System Implementation File-System Structure" File-System Implementation " Directory Implementation" Allocation Methods" Free-Space Management " Efficiency
Chapter 10: File System Implementation Chapter 10: File System Implementation File-System Structure" File-System Implementation " Directory Implementation" Allocation Methods" Free-Space Management " Efficiency
Chapter 11: Implementing File Systems. Operating System Concepts 9 9h Edition
 Chapter 11: Implementing File Systems Operating System Concepts 9 9h Edition Silberschatz, Galvin and Gagne 2013 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory
Chapter 11: Implementing File Systems Operating System Concepts 9 9h Edition Silberschatz, Galvin and Gagne 2013 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Falcon: Scaling IO Performance in Multi-SSD Volumes. The George Washington University
 Falcon: Scaling IO Performance in Multi-SSD Volumes Pradeep Kumar H Howie Huang The George Washington University SSDs in Big Data Applications Recent trends advocate using many SSDs for higher throughput
Falcon: Scaling IO Performance in Multi-SSD Volumes Pradeep Kumar H Howie Huang The George Washington University SSDs in Big Data Applications Recent trends advocate using many SSDs for higher throughput
MultiJav: A Distributed Shared Memory System Based on Multiple Java Virtual Machines. MultiJav: Introduction
 : A Distributed Shared Memory System Based on Multiple Java Virtual Machines X. Chen and V.H. Allan Computer Science Department, Utah State University 1998 : Introduction Built on concurrency supported
: A Distributed Shared Memory System Based on Multiple Java Virtual Machines X. Chen and V.H. Allan Computer Science Department, Utah State University 1998 : Introduction Built on concurrency supported
Arrakis: The Operating System is the Control Plane
 Arrakis: The Operating System is the Control Plane Simon Peter, Jialin Li, Irene Zhang, Dan Ports, Doug Woos, Arvind Krishnamurthy, Tom Anderson University of Washington Timothy Roscoe ETH Zurich Building
Arrakis: The Operating System is the Control Plane Simon Peter, Jialin Li, Irene Zhang, Dan Ports, Doug Woos, Arvind Krishnamurthy, Tom Anderson University of Washington Timothy Roscoe ETH Zurich Building
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 22 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 Disk Structure Disk can
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 22 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 Disk Structure Disk can
MultiLanes: Providing Virtualized Storage for OS-level Virtualization on Many Cores
 MultiLanes: Providing Virtualized Storage for OS-level Virtualization on Many Cores Junbin Kang, Benlong Zhang, Tianyu Wo, Chunming Hu, and Jinpeng Huai Beihang University 夏飞 20140904 1 Outline Background
MultiLanes: Providing Virtualized Storage for OS-level Virtualization on Many Cores Junbin Kang, Benlong Zhang, Tianyu Wo, Chunming Hu, and Jinpeng Huai Beihang University 夏飞 20140904 1 Outline Background
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
An Overview of The Global File System
 An Overview of The Global File System Ken Preslan Sistina Software kpreslan@sistina.com David Teigland University of Minnesota teigland@borg.umn.edu Matthew O Keefe University of Minnesota okeefe@borg.umn.edu
An Overview of The Global File System Ken Preslan Sistina Software kpreslan@sistina.com David Teigland University of Minnesota teigland@borg.umn.edu Matthew O Keefe University of Minnesota okeefe@borg.umn.edu
Lecture 10 Midterm review
 Lecture 10 Midterm review Announcements The midterm is on Tue Feb 9 th in class 4Bring photo ID 4You may bring a single sheet of notebook sized paper 8x10 inches with notes on both sides (A4 OK) 4You may
Lecture 10 Midterm review Announcements The midterm is on Tue Feb 9 th in class 4Bring photo ID 4You may bring a single sheet of notebook sized paper 8x10 inches with notes on both sides (A4 OK) 4You may
SpanFS: A Scalable File System on Fast Storage Devices
 SpanFS: A Scalable File System on Fast Storage Devices Junbin Kang, Benlong Zhang, Tianyu Wo, Weiren Yu, Lian Du, Shuai Ma and Jinpeng Huai SKLSDE Lab, Beihang University, China {kangjb, woty, yuwr, dulian,
SpanFS: A Scalable File System on Fast Storage Devices Junbin Kang, Benlong Zhang, Tianyu Wo, Weiren Yu, Lian Du, Shuai Ma and Jinpeng Huai SKLSDE Lab, Beihang University, China {kangjb, woty, yuwr, dulian,
Filesystem. Disclaimer: some slides are adopted from book authors slides with permission
 Filesystem Disclaimer: some slides are adopted from book authors slides with permission 1 Recap Directory A special file contains (inode, filename) mappings Caching Directory cache Accelerate to find inode
Filesystem Disclaimer: some slides are adopted from book authors slides with permission 1 Recap Directory A special file contains (inode, filename) mappings Caching Directory cache Accelerate to find inode
File System Internals. Jo, Heeseung
 File System Internals Jo, Heeseung Today's Topics File system implementation File descriptor table, File table Virtual file system File system design issues Directory implementation: filename -> metadata
File System Internals Jo, Heeseung Today's Topics File system implementation File descriptor table, File table Virtual file system File system design issues Directory implementation: filename -> metadata
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Operating System. Chapter 4. Threads. Lynn Choi School of Electrical Engineering
 Operating System Chapter 4. Threads Lynn Choi School of Electrical Engineering Process Characteristics Resource ownership Includes a virtual address space (process image) Ownership of resources including
Operating System Chapter 4. Threads Lynn Choi School of Electrical Engineering Process Characteristics Resource ownership Includes a virtual address space (process image) Ownership of resources including
Today. SMP architecture. SMP architecture. Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
The Scalable Commutativity Rule: Designing Scalable Software for Multicore Processors
 The Scalable Commutativity Rule: Designing Scalable Software for Multicore Processors Austin T. Clements Thesis advisors: M. Frans Kaashoek Nickolai Zeldovich Robert Morris Eddie Kohler x86 CPU trends
The Scalable Commutativity Rule: Designing Scalable Software for Multicore Processors Austin T. Clements Thesis advisors: M. Frans Kaashoek Nickolai Zeldovich Robert Morris Eddie Kohler x86 CPU trends
Optimizing the use of the Hard Disk in MapReduce Frameworks for Multi-core Architectures*
 Optimizing the use of the Hard Disk in MapReduce Frameworks for Multi-core Architectures* Tharso Ferreira 1, Antonio Espinosa 1, Juan Carlos Moure 2 and Porfidio Hernández 2 Computer Architecture and Operating
Optimizing the use of the Hard Disk in MapReduce Frameworks for Multi-core Architectures* Tharso Ferreira 1, Antonio Espinosa 1, Juan Carlos Moure 2 and Porfidio Hernández 2 Computer Architecture and Operating
Dynamic Fine Grain Scheduling of Pipeline Parallelism. Presented by: Ram Manohar Oruganti and Michael TeWinkle
 Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Accelerate Applications Using EqualLogic Arrays with directcache
 Accelerate Applications Using EqualLogic Arrays with directcache Abstract This paper demonstrates how combining Fusion iomemory products with directcache software in host servers significantly improves
Accelerate Applications Using EqualLogic Arrays with directcache Abstract This paper demonstrates how combining Fusion iomemory products with directcache software in host servers significantly improves
CHAPTER 11: IMPLEMENTING FILE SYSTEMS (COMPACT) By I-Chen Lin Textbook: Operating System Concepts 9th Ed.
 By I-Chen Lin Textbook: Operating System Concepts 9th Ed.") CHAPTER 11: IMPLEMENTING FILE SYSTEMS (COMPACT) By I-Chen Lin Textbook: Operating System Concepts 9th Ed. File-System Structure File structure Logical storage unit Collection of related information File
CHAPTER 11: IMPLEMENTING FILE SYSTEMS (COMPACT) By I-Chen Lin Textbook: Operating System Concepts 9th Ed. File-System Structure File structure Logical storage unit Collection of related information File
Chapter 12: File System Implementation. Operating System Concepts 9 th Edition
 Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods
Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods
What's new in MySQL 5.5? Performance/Scale Unleashed
 What's new in MySQL 5.5? Performance/Scale Unleashed Mikael Ronström Senior MySQL Architect The preceding is intended to outline our general product direction. It is intended for
What's new in MySQL 5.5? Performance/Scale Unleashed Mikael Ronström Senior MySQL Architect The preceding is intended to outline our general product direction. It is intended for
Chapter 12: File System Implementation
 Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods
Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods
Accelerating Pointer Chasing in 3D-Stacked Memory: Challenges, Mechanisms, Evaluation Kevin Hsieh
 Accelerating Pointer Chasing in 3D-Stacked : Challenges, Mechanisms, Evaluation Kevin Hsieh Samira Khan, Nandita Vijaykumar, Kevin K. Chang, Amirali Boroumand, Saugata Ghose, Onur Mutlu Executive Summary
Accelerating Pointer Chasing in 3D-Stacked : Challenges, Mechanisms, Evaluation Kevin Hsieh Samira Khan, Nandita Vijaykumar, Kevin K. Chang, Amirali Boroumand, Saugata Ghose, Onur Mutlu Executive Summary
Implementation and Evaluation of Moderate Parallelism in the BIND9 DNS Server
 Implementation and Evaluation of Moderate Parallelism in the BIND9 DNS Server JINMEI, Tatuya / Toshiba Paul Vixie / Internet Systems Consortium [Supported by SCOPE of the Ministry of Internal Affairs and
Implementation and Evaluation of Moderate Parallelism in the BIND9 DNS Server JINMEI, Tatuya / Toshiba Paul Vixie / Internet Systems Consortium [Supported by SCOPE of the Ministry of Internal Affairs and
Performance and Optimization Issues in Multicore Computing
 Performance and Optimization Issues in Multicore Computing Minsoo Ryu Department of Computer Science and Engineering 2 Multicore Computing Challenges It is not easy to develop an efficient multicore program
Performance and Optimization Issues in Multicore Computing Minsoo Ryu Department of Computer Science and Engineering 2 Multicore Computing Challenges It is not easy to develop an efficient multicore program
Operating System Review
 COP 4225 Advanced Unix Programming Operating System Review Chi Zhang czhang@cs.fiu.edu 1 About the Course Prerequisite: COP 4610 Concepts and Principles Programming System Calls Advanced Topics Internals,
COP 4225 Advanced Unix Programming Operating System Review Chi Zhang czhang@cs.fiu.edu 1 About the Course Prerequisite: COP 4610 Concepts and Principles Programming System Calls Advanced Topics Internals,
Week 12: File System Implementation
 Week 12: File System Implementation Sherif Khattab http://www.cs.pitt.edu/~skhattab/cs1550 (slides are from Silberschatz, Galvin and Gagne 2013) Outline File-System Structure File-System Implementation
Week 12: File System Implementation Sherif Khattab http://www.cs.pitt.edu/~skhattab/cs1550 (slides are from Silberschatz, Galvin and Gagne 2013) Outline File-System Structure File-System Implementation
Topics. File Buffer Cache for Performance. What to Cache? COS 318: Operating Systems. File Performance and Reliability
 Topics COS 318: Operating Systems File Performance and Reliability File buffer cache Disk failure and recovery tools Consistent updates Transactions and logging 2 File Buffer Cache for Performance What
Topics COS 318: Operating Systems File Performance and Reliability File buffer cache Disk failure and recovery tools Consistent updates Transactions and logging 2 File Buffer Cache for Performance What
EI 338: Computer Systems Engineering (Operating Systems & Computer Architecture)
") EI 338: Computer Systems Engineering (Operating Systems & Computer Architecture) Dept. of Computer Science & Engineering Chentao Wu wuct@cs.sjtu.edu.cn Download lectures ftp://public.sjtu.edu.cn User:
EI 338: Computer Systems Engineering (Operating Systems & Computer Architecture) Dept. of Computer Science & Engineering Chentao Wu wuct@cs.sjtu.edu.cn Download lectures ftp://public.sjtu.edu.cn User:
OPERATING SYSTEM. Chapter 4: Threads
 OPERATING SYSTEM Chapter 4: Threads Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples Objectives To
OPERATING SYSTEM Chapter 4: Threads Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples Objectives To
File System Code Walkthrough
 File System Code Walkthrough File System An organization of data and metadata on a storage device Data expected to be retained after a program terminates by providing efficient procedures to: store, retrieve,
File System Code Walkthrough File System An organization of data and metadata on a storage device Data expected to be retained after a program terminates by providing efficient procedures to: store, retrieve,
Introducing the Cray XMT. Petr Konecny May 4 th 2007
 Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
Filesystem. Disclaimer: some slides are adopted from book authors slides with permission 1
 Filesystem Disclaimer: some slides are adopted from book authors slides with permission 1 Storage Subsystem in Linux OS Inode cache User Applications System call Interface Virtual File System (VFS) Filesystem
Filesystem Disclaimer: some slides are adopted from book authors slides with permission 1 Storage Subsystem in Linux OS Inode cache User Applications System call Interface Virtual File System (VFS) Filesystem
Background: I/O Concurrency
 Background: I/O Concurrency Brad Karp UCL Computer Science CS GZ03 / M030 5 th October 2011 Outline Worse Is Better and Distributed Systems Problem: Naïve single-process server leaves system resources
Background: I/O Concurrency Brad Karp UCL Computer Science CS GZ03 / M030 5 th October 2011 Outline Worse Is Better and Distributed Systems Problem: Naïve single-process server leaves system resources
Operating Systems Design Exam 2 Review: Fall 2010
 Operating Systems Design Exam 2 Review: Fall 2010 Paul Krzyzanowski pxk@cs.rutgers.edu 1 1. Why could adding more memory to a computer make it run faster? If processes don t have their working sets in
Operating Systems Design Exam 2 Review: Fall 2010 Paul Krzyzanowski pxk@cs.rutgers.edu 1 1. Why could adding more memory to a computer make it run faster? If processes don t have their working sets in
Kernel Scalability. Adam Belay
 Kernel Scalability Adam Belay Motivation Modern CPUs are predominantly multicore Applications rely heavily on kernel for networking, filesystem, etc. If kernel can t scale across many
Kernel Scalability Adam Belay Motivation Modern CPUs are predominantly multicore Applications rely heavily on kernel for networking, filesystem, etc. If kernel can t scale across many
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
Scalable Locking. Adam Belay
 Scalable Locking Adam Belay Problem: Locks can ruin performance 12 finds/sec 9 6 Locking overhead dominates 3 0 0 6 12 18 24 30 36 42 48 Cores Problem: Locks can ruin performance the locks
Scalable Locking Adam Belay Problem: Locks can ruin performance 12 finds/sec 9 6 Locking overhead dominates 3 0 0 6 12 18 24 30 36 42 48 Cores Problem: Locks can ruin performance the locks
CHAPTER 3 - PROCESS CONCEPT
 CHAPTER 3 - PROCESS CONCEPT 1 OBJECTIVES Introduce a process a program in execution basis of all computation Describe features of processes: scheduling, creation, termination, communication Explore interprocess
CHAPTER 3 - PROCESS CONCEPT 1 OBJECTIVES Introduce a process a program in execution basis of all computation Describe features of processes: scheduling, creation, termination, communication Explore interprocess
Chapter 10: Case Studies. So what happens in a real operating system?
 Chapter 10: Case Studies So what happens in a real operating system? Operating systems in the real world Studied mechanisms used by operating systems Processes & scheduling Memory management File systems
Chapter 10: Case Studies So what happens in a real operating system? Operating systems in the real world Studied mechanisms used by operating systems Processes & scheduling Memory management File systems