CNAG Advanced User Training
|
|
|
- Kerry Hensley
- 6 years ago
- Views:
Transcription
1 CNAG Advanced User Training Aníbal Moreno, CNAG System Administrator Pablo Ródenas, BSC HPC Support Rubén Ramos Horta, CNAG HPC Support Barcelona,May the 5th
2 Aim Understand CNAG s cluster design HPC Cluster: Big and complex machine unlike your desktop Understand Slurm Scheduling Knowledge of Slurm s internals Slurm tips and tweaks Understand Lustre internals Complex network underneath Who to contact? cnag_support@bsc.es 2


3 Cluster Overview
4 Components The cluster consists of: 2 login nodes 108 GenC nodes (24 cores, 256 GB RAM) 12 GPU nodes (16 cores, 128 GB RAM) 20 GenB nodes (16 cores, 128 GB RAM) 94 GenA nodes (8 cores, 48 GB RAM) 1 SMP node (48 cores, 1TB RAM) Data is stored in: 1 NFS exported /home on all nodes 1 NFS exported /apps on all nodes 2 High Performance Distributed Filesystems (Lustre) (/project /scratch) Jobs are executed with: Slurm Resource Manager (Batch system) 4
5 Batch System (Slurm)

6 Slurm concepts Scheduling FIFO with priorities Backfilling Schedules less priority jobs but only those which meet free resources conditions. Increases utilization of the cluster Requires declaration of max execution time of jobs --time on srun DefaultTime or MaxTime on Partition 6


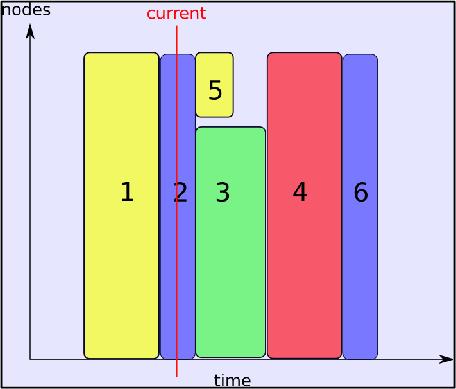
7 Backfill FIFO Scheduler Backfill Scheduler 7
8 Backfilling in the cluster $ sdiag [..-] Main schedule statistics (microseconds): Last cycle: 9773 Max cycle: Total cycles: 1081 Mean cycle: 6197 Mean depth cycle: 366 Cycles per minute: 1 Last queue length: 423 Backfilling stats Total backfilled jobs (since last slurm start): Total backfilled jobs (since last stats cycle start): 1350 Total cycles: 184 Last cycle when: Thu Apr 27 14:19: Last cycle: Max cycle: Mean cycle: Last depth cycle: 416 Last depth cycle (try sched): 416 Depth Mean: 1014 Depth Mean (try depth): 584 Last queue length: 416 Queue length mean:
9 Priorities Determining factors Age the length of time a job has been waiting in the queue, eligible to be scheduled. This factor will reach its highest value after 7 days QoS a factor specified to a specific QoS Fair-share the difference between the portion of the computing resource that has been promised and the amount of resources that has been consumed. This factor will consider only the last 14 days Job size the number of nodes or CPUs a job is allocated Partition a factor associated with each node partition Job_priority = (PriorityWeightAge) * (age_factor) + (PriorityWeightFairshare) * (fair-share_factor) + (PriorityWeightJobSize) * (job_size_factor) + (PriorityWeightPartition) * (partition_factor) + (PriorityWeightQOS) * (QOS_factor) + SUM(TRES_weight_cpu * TRES_factor_cpu, TRES_weight_<type> * TRES_factor_<type>,...) 9
10 Priorities Check the cluster weights for each factor $ sprio --weights JOBID PRIORITY AGE FAIRSHARE Weights JOBSIZE PARTITION QOS Check your job s priority that is still in the queue waiting to be scheduled $ sprio -j JOBID PRIORITY AGE 2290 FAIRSHARE JOBSIZE 22 PARTITION QOS Final priority calculated with normalized jobs priorities $ sprio -j n JOBID PRIORITY AGE PRIORITY= FAIRSHARE JOBSIZE PARTITION QOS *AGE_weight *FAIRSHARE_weight *JOBSIZE_weight *PARTITION_weight *QOS_weight =
11 Partitions alloc node allocated to one or more jobs mix node allocated but still with free resources idle node completely free drain node not available resv special reservations $ sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST main* up infinite 18 mix cnc[2,14,36-37,46-59] main* up infinite 13 alloc cnc[1,3-4,6,38-45,68] main* up infinite 77 idle cnc[5,15-35,60-67,69-108] gpu up infinite 11 resv cga[2-12] gena up infinite 17 drain* cna[21, ] gena up infinite 2 mix cna[24,49] gena up infinite 6 alloc cna[26,39,43,50-51,53] gena up infinite 51 idle cna[11-20,22-23,...,44-46,88] genb up infinite 4 mix cnb[8,10,12-13] genb up infinite 16 idle cnb[1-7,9,11,14-20] interactive up infinite 1 resv cga1 interactive up infinite 2 mix cna[1,8] interactive up infinite 3 alloc cna[5-7] interactive up infinite 5 idle cna[2-4,9-10] smp up infinite 1 alloc smp1 11
 ($ sacctmgr show")
12 Accounting Limit Enforcement Accounting of resources usage by users for controlling access to resources Fair share Maximum limits MaxCPUsPerJob, MaxJobs, MaxNodesPerJob, MaxSubmitJobs, MaxWallDurationPerJob Quality of Service (QoS) ($ sacctmgr show qos) 12

13 sview $ ssh -X login1 $ sview 13
14 Slurm tips

15 Job arrays (I) Useful when a set of jobs share logic but differ in some parameter or input Modifying slightly your jobs, intead of launching N jobs, just need to launch a single one Job script directive: #@ array=1-n 15
16 Job arrays (II) Environment variables for handling your #!/bin/bash job arrays #SBATCH --job-name=arrayjob SLURM_JOB_ID SLURM_ARRAY_JOB_ID SLURM_ARRAY_TASK_ID SLURM_ARRAY_TASK_COUNT SLURM_ARRAY_TASK_MAX SLURM_ARRAY_TASK_MIN #SBATCH #SBATCH #SBATCH #SBATCH #SBATCH #SBATCH #SBATCH --output=arrayjob_%a_%a.out --error=arrayjob_%a_%a.err --array= time=01:00:00 --partition=main --ntasks=1 --mem-per-cpu=4000 # Print this sub-job's task ID echo "My ARRAY_TASK_ID: " $SLURM_ARRAY_TASK_ID # Do some work based on the SLURM_ARRAY_TASK_ID./my_program $SLURM_ARRAY_TASK_ID 16
17 Job arrays (II) Job1 Job2 SLURM_JOB_ID=12780 SLURM_ARRAY_JOB_ID= SLURM_ARRAY_TASK_ID=1 SLURM_ARRAY_TASK_COUNT=1024 SLURM_ARRAY_TASK_MAX=1024 SLURM_ARRAY_TASK_MIN=1 SLURM_JOB_ID=12780 SLURM_ARRAY_JOB_ID= SLURM_ARRAY_TASK_ID=2 SLURM_ARRAY_TASK_COUNT=1024 SLURM_ARRAY_TASK_MAX=1024 SLURM_ARRAY_TASK_MIN=1... Job100 SLURM_JOB_ID=12780 SLURM_ARRAY_JOB_ID= SLURM_ARRAY_TASK_ID=100 SLURM_ARRAY_TASK_COUNT=1024 SLURM_ARRAY_TASK_MAX=1024 SLURM_ARRAY_TASK_MIN=1 Job1024 SLURM_JOB_ID=12780 SLURM_ARRAY_JOB_ID= SLURM_ARRAY_TASK_ID=1024 SLURM_ARRAY_TASK_COUNT=1024 SLURM_ARRAY_TASK_MAX=1024 SLURM_ARRAY_TASK_MIN=1 17
18 Job arrays (III) sbatch array= Create a job array sbatch array=0-1024%10 Only execute 10 jobs simultaneously from this job array $ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 12780_[5-1024] debug tmp mac PD 0:00 1 (Resources) 12780_1 debug tmp mac R 0:17 1 tux _2 debug tmp mac R 0:16 1 tux _3 debug tmp mac R 0:03 1 tux _4 debug tmp mac R 0:03 1 tux3 scancel _[1-3] Cancel a range of tasks from a job array 18
19 Modify your jobscript once launched and before running scontrol update jobid=<jobid> <parameter> Timelimit Qos scontrol update jobid= timelimit=9-00:00:00 scontrol update jobid= qos=highprio Partition scontrol update jobid= partition=main Prevent a job from being started scontrol hold <jobid> Scontrol uhold <jobid> 19
20 Lustre Internals
21 What is Lustre A High Performance Parallel Distributed Filesystem High Performance Fast access Parallel Many different processes in different computers can access the same file Distributed Many different servers holding different parts of the same file, working together Meaning: Formula 1, not a 4WD 21
22 Why Lustre? NFS (Network FileSystem): /home and /apps Slow access Not Parallel Not distributed All users trying to acess to resources a the same time Bottleneck 22
23 Lustre components Metadata Servers (MDS): I/O service and network request for one or more local MDT Metadata Targets (MDT): where metadata is actually stored (RAID 1 of SSD disks) Object Storage Servers (OSS): I/O service and network request for one or more local OST Object Storage Targets (OST): where data is actually stored (RAID 5+1 SATA2 disk) 23

24 Lustre s High Availability 24

25 Lustre s stripes 25

26 Lustre s stripes 26
27 Lustre s stripes Get stripes from a specific folder $ lfs getstripe pruebas/ stripe_count: stripe_offset: pruebas//2 stripe_count: stripe_offset: pruebas//1 stripe_count: stripe_offset: pruebas 4 stripe_size: stripe_size: stripe_size: Set number of stripes for a specific folder A lot of small files faster access with just one stripe Big files faster and distributed with several stripes $ mkdir pruebas/3 $ lfs setstripe -c 1 pruebas/3 $ lfs getstripe pruebas/3 pruebas/3 stripe_count: 1 stripe_size: Use carefully! Contact us in case of doubt stripe_offset: -1 27
28 GREASY
29 GREASY An easy way of creating dependecies between processes Each line is a task Lines starting with # are comments Line number = task id Each line [# optional list of dependencies #] <new_task> Only backwards dependecies are allowed More info: github.com/jonarbo/greasy/blob/master/doc/greasy_usergui de.pdf 29
30 GREASY: Example # this line is a comment /bin/sleep 2 # following task id is 4. Tasks ids 1 and 3 don t exist /bin/sleep 4 # following task will run after completion of the sleep 2 [# 2 #] /bin/sleep 6 # following task will be run after completion of the "sleep 6" [# -2 #] /bin/sleep 8 # following task is invalid because tasks 1 and 3 do not exist [#1-3#] /bin/sleep 10 # following task will be run after completion of tasks 2, 4, 8 [#2, 4, -4 #] /bin/sleep 12 30
31 Data Management
32 Data management tips Avoid intermediate steps Use bash pipelines./do_stuff./manage_stuff_1./manage_stuff_n > out Avoid replicating data Compress as much data as possible Standard compression tar -cvf name.tar.gz <path_to_file> Parallel compression ++faster (Not in login nodes!) tar -cvf <path_to_file> pigz -p N_PROC > name.tar.gz No need to untar every time zcat, zless, zgrep, zdiff 32
33 Improve performance with GPU

34 GPU nodes: Nvidia Tesla K80 GenC processors 1.92TFlops 68 GB/s of bandwidth Improve your program performace with CUDA 2.91TFlops double precision performance 8.73TFlops single precision performance 480 GB/sec of bandwidth Some developers have a version ready to run on CUDA. Ask us to install it Ask for help if you have an idea for parallelizing your program 34
35 Major incidences

36 Running out of inodes One user created 80 millions of files in scratch Non expected use of the cluster Hard to monitor everything 36

37 Major incidences Sending too many jobs Use job arrays instead Affects Slurm s scheduling Cluster runs out of resources Max jobs to be scheduled at the same time Max 3000 max jobs to be backfilled at the same time If limit is exceed, no other jobs will be scheduled until queue is emptied WallClock accuracy Smarter use of resources Allows more jobs to be scheduled 37
38 Q&A
39 Thank you! For further information please contact 39
Sherlock for IBIIS. William Law Stanford Research Computing
 Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
High Performance Computing Cluster Basic course
 High Performance Computing Cluster Basic course Jeremie Vandenplas, Gwen Dawes 30 October 2017 Outline Introduction to the Agrogenomics HPC Connecting with Secure Shell to the HPC Introduction to the Unix/Linux
High Performance Computing Cluster Basic course Jeremie Vandenplas, Gwen Dawes 30 October 2017 Outline Introduction to the Agrogenomics HPC Connecting with Secure Shell to the HPC Introduction to the Unix/Linux
High Performance Computing Cluster Advanced course
 High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
Slurm basics. Summer Kickstart June slide 1 of 49
 Slurm basics Summer Kickstart 2017 June 2017 slide 1 of 49 Triton layers Triton is a powerful but complex machine. You have to consider: Connecting (ssh) Data storage (filesystems and Lustre) Resource
Slurm basics Summer Kickstart 2017 June 2017 slide 1 of 49 Triton layers Triton is a powerful but complex machine. You have to consider: Connecting (ssh) Data storage (filesystems and Lustre) Resource
Introduction to SLURM & SLURM batch scripts
 Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 6 February 2018 Overview of Talk Basic SLURM commands SLURM batch
Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 6 February 2018 Overview of Talk Basic SLURM commands SLURM batch
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat
 Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Slurm Workload Manager Introductory User Training
 Slurm Workload Manager Introductory User Training David Bigagli david@schedmd.com SchedMD LLC Outline Roles of resource manager and job scheduler Slurm design and architecture Submitting and running jobs
Slurm Workload Manager Introductory User Training David Bigagli david@schedmd.com SchedMD LLC Outline Roles of resource manager and job scheduler Slurm design and architecture Submitting and running jobs
Introduction to SLURM on the High Performance Cluster at the Center for Computational Research
 Introduction to SLURM on the High Performance Cluster at the Center for Computational Research Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY
Introduction to SLURM on the High Performance Cluster at the Center for Computational Research Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY
Batch Usage on JURECA Introduction to Slurm. May 2016 Chrysovalantis Paschoulas HPS JSC
 Batch Usage on JURECA Introduction to Slurm May 2016 Chrysovalantis Paschoulas HPS group @ JSC Batch System Concepts Resource Manager is the software responsible for managing the resources of a cluster,
Batch Usage on JURECA Introduction to Slurm May 2016 Chrysovalantis Paschoulas HPS group @ JSC Batch System Concepts Resource Manager is the software responsible for managing the resources of a cluster,
Heterogeneous Job Support
 Heterogeneous Job Support Tim Wickberg SchedMD SC17 Submitting Jobs Multiple independent job specifications identified in command line using : separator The job specifications are sent to slurmctld daemon
Heterogeneous Job Support Tim Wickberg SchedMD SC17 Submitting Jobs Multiple independent job specifications identified in command line using : separator The job specifications are sent to slurmctld daemon
RHRK-Seminar. High Performance Computing with the Cluster Elwetritsch - II. Course instructor : Dr. Josef Schüle, RHRK
 RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
Introduction to High-Performance Computing (HPC)
") Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Case study of a computing center: Accounts, Priorities and Quotas
 Afficher le masque pour Insérer le titre ici Direction Informatique 05/02/2015 Case study of a computing center: Accounts, Priorities and Quotas Michel Ringenbach mir@unistra.fr HPC Center, Université
Afficher le masque pour Insérer le titre ici Direction Informatique 05/02/2015 Case study of a computing center: Accounts, Priorities and Quotas Michel Ringenbach mir@unistra.fr HPC Center, Université
Slurm at the George Washington University Tim Wickberg - Slurm User Group Meeting 2015
 Slurm at the George Washington University Tim Wickberg - wickberg@gwu.edu Slurm User Group Meeting 2015 September 16, 2015 Colonial One What s new? Only major change was switch to FairTree Thanks to BYU
Slurm at the George Washington University Tim Wickberg - wickberg@gwu.edu Slurm User Group Meeting 2015 September 16, 2015 Colonial One What s new? Only major change was switch to FairTree Thanks to BYU
Duke Compute Cluster Workshop. 3/28/2018 Tom Milledge rc.duke.edu
 Duke Compute Cluster Workshop 3/28/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
Duke Compute Cluster Workshop 3/28/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
ECE 574 Cluster Computing Lecture 4
 ECE 574 Cluster Computing Lecture 4 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 31 January 2017 Announcements Don t forget about homework #3 I ran HPCG benchmark on Haswell-EP
ECE 574 Cluster Computing Lecture 4 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 31 January 2017 Announcements Don t forget about homework #3 I ran HPCG benchmark on Haswell-EP
Exercises: Abel/Colossus and SLURM
 Exercises: Abel/Colossus and SLURM November 08, 2016 Sabry Razick The Research Computing Services Group, USIT Topics Get access Running a simple job Job script Running a simple job -- qlogin Customize
Exercises: Abel/Colossus and SLURM November 08, 2016 Sabry Razick The Research Computing Services Group, USIT Topics Get access Running a simple job Job script Running a simple job -- qlogin Customize
Deep Learning on SHARCNET:
 Deep Learning on SHARCNET: Best Practices Fei Mao Outlines What does SHARCNET have? - Hardware/software resources now and future How to run a job? - A torch7 example How to train in parallel: - A Theano-based
Deep Learning on SHARCNET: Best Practices Fei Mao Outlines What does SHARCNET have? - Hardware/software resources now and future How to run a job? - A torch7 example How to train in parallel: - A Theano-based
Duke Compute Cluster Workshop. 11/10/2016 Tom Milledge h:ps://rc.duke.edu/
 Duke Compute Cluster Workshop 11/10/2016 Tom Milledge h:ps://rc.duke.edu/ rescompu>ng@duke.edu Outline of talk Overview of Research Compu>ng resources Duke Compute Cluster overview Running interac>ve and
Duke Compute Cluster Workshop 11/10/2016 Tom Milledge h:ps://rc.duke.edu/ rescompu>ng@duke.edu Outline of talk Overview of Research Compu>ng resources Duke Compute Cluster overview Running interac>ve and
Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU
 Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU What is Joker? NMSU s supercomputer. 238 core computer cluster. Intel E-5 Xeon CPUs and Nvidia K-40 GPUs. InfiniBand innerconnect.
Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU What is Joker? NMSU s supercomputer. 238 core computer cluster. Intel E-5 Xeon CPUs and Nvidia K-40 GPUs. InfiniBand innerconnect.
Introduction to SLURM & SLURM batch scripts
 Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 16 Feb 2017 Overview of Talk Basic SLURM commands SLURM batch
Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 16 Feb 2017 Overview of Talk Basic SLURM commands SLURM batch
Submitting batch jobs
 Submitting batch jobs SLURM on ECGATE Xavi Abellan Xavier.Abellan@ecmwf.int ECMWF February 20, 2017 Outline Interactive mode versus Batch mode Overview of the Slurm batch system on ecgate Batch basic concepts
Submitting batch jobs SLURM on ECGATE Xavi Abellan Xavier.Abellan@ecmwf.int ECMWF February 20, 2017 Outline Interactive mode versus Batch mode Overview of the Slurm batch system on ecgate Batch basic concepts
Graham vs legacy systems
 New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
Duke Compute Cluster Workshop. 10/04/2018 Tom Milledge rc.duke.edu
 Duke Compute Cluster Workshop 10/04/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
Duke Compute Cluster Workshop 10/04/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
Training day SLURM cluster. Context Infrastructure Environment Software usage Help section SLURM TP For further with SLURM Best practices Support TP
 Training day SLURM cluster Context Infrastructure Environment Software usage Help section SLURM TP For further with SLURM Best practices Support TP Context PRE-REQUISITE : LINUX connect to «genologin»
Training day SLURM cluster Context Infrastructure Environment Software usage Help section SLURM TP For further with SLURM Best practices Support TP Context PRE-REQUISITE : LINUX connect to «genologin»
Introduction to RCC. September 14, 2016 Research Computing Center
 Introduction to HPC @ RCC September 14, 2016 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers
Introduction to HPC @ RCC September 14, 2016 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers
Introduction to GACRC Teaching Cluster
 Introduction to GACRC Teaching Cluster Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Overview Computing Resources Three Folders
Introduction to GACRC Teaching Cluster Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Overview Computing Resources Three Folders
Introduction to RCC. January 18, 2017 Research Computing Center
 Introduction to HPC @ RCC January 18, 2017 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much
Introduction to HPC @ RCC January 18, 2017 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much
Introduction to GACRC Teaching Cluster
 Introduction to GACRC Teaching Cluster Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Overview Computing Resources Three Folders
Introduction to GACRC Teaching Cluster Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Overview Computing Resources Three Folders
Slurm Birds of a Feather
 Slurm Birds of a Feather Tim Wickberg SchedMD SC17 Outline Welcome Roadmap Review of 17.02 release (Februrary 2017) Overview of upcoming 17.11 (November 2017) release Roadmap for 18.08 and beyond Time
Slurm Birds of a Feather Tim Wickberg SchedMD SC17 Outline Welcome Roadmap Review of 17.02 release (Februrary 2017) Overview of upcoming 17.11 (November 2017) release Roadmap for 18.08 and beyond Time
Introduction to GACRC Teaching Cluster PHYS8602
 Introduction to GACRC Teaching Cluster PHYS8602 Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Overview Computing Resources Three
Introduction to GACRC Teaching Cluster PHYS8602 Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Overview Computing Resources Three
The JANUS Computing Environment
 Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
Research Computing UNIVERSITY OF COLORADO The JANUS Computing Environment Monte Lunacek monte.lunacek@colorado.edu rc-help@colorado.edu What is JANUS? November, 2011 1,368 Compute nodes 16,416 processors
How to run a job on a Cluster?
 How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
Slurm and Abel job scripts. Katerina Michalickova The Research Computing Services Group SUF/USIT November 13, 2013
 Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT November 13, 2013 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT November 13, 2013 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
June Workshop Series June 27th: All About SLURM University of Nebraska Lincoln Holland Computing Center. Carrie Brown, Adam Caprez
 June Workshop Series June 27th: All About SLURM University of Nebraska Lincoln Holland Computing Center Carrie Brown, Adam Caprez Setup Instructions Please complete these steps before the lessons start
June Workshop Series June 27th: All About SLURM University of Nebraska Lincoln Holland Computing Center Carrie Brown, Adam Caprez Setup Instructions Please complete these steps before the lessons start
How to access Geyser and Caldera from Cheyenne. 19 December 2017 Consulting Services Group Brian Vanderwende
 How to access Geyser and Caldera from Cheyenne 19 December 2017 Consulting Services Group Brian Vanderwende Geyser nodes useful for large-scale data analysis and post-processing tasks 16 nodes with: 40
How to access Geyser and Caldera from Cheyenne 19 December 2017 Consulting Services Group Brian Vanderwende Geyser nodes useful for large-scale data analysis and post-processing tasks 16 nodes with: 40
New User Seminar: Part 2 (best practices)
") New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
New User Seminar: Part 2 (best practices) General Interest Seminar January 2015 Hugh Merz merz@sharcnet.ca Session Outline Submitting Jobs Minimizing queue waits Investigating jobs Checkpointing Efficiency
Submitting batch jobs Slurm on ecgate Solutions to the practicals
 Submitting batch jobs Slurm on ecgate Solutions to the practicals Xavi Abellan xavier.abellan@ecmwf.int User Support Section Com Intro 2015 Submitting batch jobs ECMWF 2015 Slide 1 Practical 1: Basic job
Submitting batch jobs Slurm on ecgate Solutions to the practicals Xavi Abellan xavier.abellan@ecmwf.int User Support Section Com Intro 2015 Submitting batch jobs ECMWF 2015 Slide 1 Practical 1: Basic job
Introduction to High-Performance Computing (HPC)
") Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Scientific Computing in practice
 Scientific Computing in practice Kickstart 2015 (cont.) Ivan Degtyarenko, Janne Blomqvist, Mikko Hakala, Simo Tuomisto School of Science, Aalto University June 1, 2015 slide 1 of 62 Triton practicalities
Scientific Computing in practice Kickstart 2015 (cont.) Ivan Degtyarenko, Janne Blomqvist, Mikko Hakala, Simo Tuomisto School of Science, Aalto University June 1, 2015 slide 1 of 62 Triton practicalities
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine
 Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Introduction to Slurm
 Introduction to Slurm Tim Wickberg SchedMD Slurm User Group Meeting 2017 Outline Roles of resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm configuration
Introduction to Slurm Tim Wickberg SchedMD Slurm User Group Meeting 2017 Outline Roles of resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm configuration
Slurm Overview. Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17. Copyright 2017 SchedMD LLC
 Slurm Overview Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17 Outline Roles of a resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm
Slurm Overview Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17 Outline Roles of a resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm
Introduction to SLURM & SLURM batch scripts
 Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 23 June 2016 Overview of Talk Basic SLURM commands SLURM batch
Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 23 June 2016 Overview of Talk Basic SLURM commands SLURM batch
Introduction to the Cluster
 Follow us on Twitter for important news and updates: @ACCREVandy Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu The Cluster We will be
Follow us on Twitter for important news and updates: @ACCREVandy Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu The Cluster We will be
Slurm and Abel job scripts. Katerina Michalickova The Research Computing Services Group SUF/USIT October 23, 2012
 Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT October 23, 2012 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT October 23, 2012 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
Training day SLURM cluster. Context. Context renewal strategy
 Training day cluster Context Infrastructure Environment Software usage Help section For further with Best practices Support Context PRE-REQUISITE : LINUX connect to «genologin» server Basic command line
Training day cluster Context Infrastructure Environment Software usage Help section For further with Best practices Support Context PRE-REQUISITE : LINUX connect to «genologin» server Basic command line
HPC Introductory Course - Exercises
 HPC Introductory Course - Exercises The exercises in the following sections will guide you understand and become more familiar with how to use the Balena HPC service. Lines which start with $ are commands
HPC Introductory Course - Exercises The exercises in the following sections will guide you understand and become more familiar with how to use the Balena HPC service. Lines which start with $ are commands
1 Bull, 2011 Bull Extreme Computing
 1 Bull, 2011 Bull Extreme Computing Table of Contents Overview. Principal concepts. Architecture. Scheduler Policies. 2 Bull, 2011 Bull Extreme Computing SLURM Overview Ares, Gerardo, HPC Team Introduction
1 Bull, 2011 Bull Extreme Computing Table of Contents Overview. Principal concepts. Architecture. Scheduler Policies. 2 Bull, 2011 Bull Extreme Computing SLURM Overview Ares, Gerardo, HPC Team Introduction
Batch Systems. Running your jobs on an HPC machine
 Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Federated Cluster Support
 Federated Cluster Support Brian Christiansen and Morris Jette SchedMD LLC Slurm User Group Meeting 2015 Background Slurm has long had limited support for federated clusters Most commands support a --cluster
Federated Cluster Support Brian Christiansen and Morris Jette SchedMD LLC Slurm User Group Meeting 2015 Background Slurm has long had limited support for federated clusters Most commands support a --cluster
Submitting batch jobs Slurm on ecgate
 Submitting batch jobs Slurm on ecgate Xavi Abellan xavier.abellan@ecmwf.int User Support Section Com Intro 2015 Submitting batch jobs ECMWF 2015 Slide 1 Outline Interactive mode versus Batch mode Overview
Submitting batch jobs Slurm on ecgate Xavi Abellan xavier.abellan@ecmwf.int User Support Section Com Intro 2015 Submitting batch jobs ECMWF 2015 Slide 1 Outline Interactive mode versus Batch mode Overview
LAB. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 LAB Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012 1 Discovery
LAB Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012 1 Discovery
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2. (Mouse over to the left to see thumbnails of all of the slides)
") STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Triton file systems - an introduction. slide 1 of 28
 Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
SLURM: Resource Management and Job Scheduling Software. Advanced Computing Center for Research and Education
 SLURM: Resource Management and Job Scheduling Software Advanced Computing Center for Research and Education www.accre.vanderbilt.edu Simple Linux Utility for Resource Management But it s also a job scheduler!
SLURM: Resource Management and Job Scheduling Software Advanced Computing Center for Research and Education www.accre.vanderbilt.edu Simple Linux Utility for Resource Management But it s also a job scheduler!
Introduction to UBELIX
 Science IT Support (ScITS) Michael Rolli, Nico Färber Informatikdienste Universität Bern 06.06.2017, Introduction to UBELIX Agenda > Introduction to UBELIX (Overview only) Other topics spread in > Introducing
Science IT Support (ScITS) Michael Rolli, Nico Färber Informatikdienste Universität Bern 06.06.2017, Introduction to UBELIX Agenda > Introduction to UBELIX (Overview only) Other topics spread in > Introducing
Data storage on Triton: an introduction
 Motivation Data storage on Triton: an introduction How storage is organized in Triton How to optimize IO Do's and Don'ts Exercises slide 1 of 33 Data storage: Motivation Program speed isn t just about
Motivation Data storage on Triton: an introduction How storage is organized in Triton How to optimize IO Do's and Don'ts Exercises slide 1 of 33 Data storage: Motivation Program speed isn t just about
Introduction to the Cluster
 Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu Follow us on Twitter for important news and updates: @ACCREVandy The Cluster We will be
Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu Follow us on Twitter for important news and updates: @ACCREVandy The Cluster We will be
The cluster system. Introduction 22th February Jan Saalbach Scientific Computing Group
 The cluster system Introduction 22th February 2018 Jan Saalbach Scientific Computing Group cluster-help@luis.uni-hannover.de Contents 1 General information about the compute cluster 2 Available computing
The cluster system Introduction 22th February 2018 Jan Saalbach Scientific Computing Group cluster-help@luis.uni-hannover.de Contents 1 General information about the compute cluster 2 Available computing
Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 FAS Research Computing
 Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 Email:plamenkrastev@fas.harvard.edu Objectives Inform you of available computational resources Help you choose appropriate computational
Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 Email:plamenkrastev@fas.harvard.edu Objectives Inform you of available computational resources Help you choose appropriate computational
Using file systems at HC3
 Using file systems at HC3 Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association www.kit.edu Basic Lustre
Using file systems at HC3 Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association www.kit.edu Basic Lustre
NERSC Site Report One year of Slurm Douglas Jacobsen NERSC. SLURM User Group 2016
 NERSC Site Report One year of Slurm Douglas Jacobsen NERSC SLURM User Group 2016 NERSC Vital Statistics 860 active projects 7,750 active users 700+ codes both established and in-development migrated production
NERSC Site Report One year of Slurm Douglas Jacobsen NERSC SLURM User Group 2016 NERSC Vital Statistics 860 active projects 7,750 active users 700+ codes both established and in-development migrated production
Using Compute Canada. Masao Fujinaga Information Services and Technology University of Alberta
 Using Compute Canada Masao Fujinaga Information Services and Technology University of Alberta Introduction to cedar batch system jobs are queued priority depends on allocation and past usage Cedar Nodes
Using Compute Canada Masao Fujinaga Information Services and Technology University of Alberta Introduction to cedar batch system jobs are queued priority depends on allocation and past usage Cedar Nodes
Computer Science Section. Computational and Information Systems Laboratory National Center for Atmospheric Research
 Computer Science Section Computational and Information Systems Laboratory National Center for Atmospheric Research My work in the context of TDD/CSS/ReSET Polynya new research computing environment Polynya
Computer Science Section Computational and Information Systems Laboratory National Center for Atmospheric Research My work in the context of TDD/CSS/ReSET Polynya new research computing environment Polynya
Slurm. Ryan Cox Fulton Supercomputing Lab Brigham Young University (BYU)
") Slurm Ryan Cox Fulton Supercomputing Lab Brigham Young University (BYU) Slurm Workload Manager What is Slurm? Installation Slurm Configuration Daemons Configuration Files Client Commands User and Account
Slurm Ryan Cox Fulton Supercomputing Lab Brigham Young University (BYU) Slurm Workload Manager What is Slurm? Installation Slurm Configuration Daemons Configuration Files Client Commands User and Account
Student HPC Hackathon 8/2018
 Student HPC Hackathon 8/2018 J. Simon, C. Plessl 22. + 23. August 2018 J. Simon - Architecture of Parallel Computer Systems SoSe 2018 < 1 > Student HPC Hackathon 8/2018 Get the most performance out of
Student HPC Hackathon 8/2018 J. Simon, C. Plessl 22. + 23. August 2018 J. Simon - Architecture of Parallel Computer Systems SoSe 2018 < 1 > Student HPC Hackathon 8/2018 Get the most performance out of
CRUK cluster practical sessions (SLURM) Part I processes & scripts
 Part I processes & scripts") CRUK cluster practical sessions (SLURM) Part I processes & scripts login Log in to the head node, clust1-headnode, using ssh and your usual user name & password. SSH Secure Shell 3.2.9 (Build 283) Copyright
CRUK cluster practical sessions (SLURM) Part I processes & scripts login Log in to the head node, clust1-headnode, using ssh and your usual user name & password. SSH Secure Shell 3.2.9 (Build 283) Copyright
Introduction to High Performance Computing at Case Western Reserve University. KSL Data Center
 Introduction to High Performance Computing at Case Western Reserve University Research Computing and CyberInfrastructure team KSL Data Center Presenters Emily Dragowsky Daniel Balagué Guardia Hadrian Djohari
Introduction to High Performance Computing at Case Western Reserve University Research Computing and CyberInfrastructure team KSL Data Center Presenters Emily Dragowsky Daniel Balagué Guardia Hadrian Djohari
Linux Clusters Institute: Scheduling
 Linux Clusters Institute: Scheduling David King, Sr. HPC Engineer National Center for Supercomputing Applications University of Illinois August 2017 1 About me Worked in HPC since 2007 Started at Purdue
Linux Clusters Institute: Scheduling David King, Sr. HPC Engineer National Center for Supercomputing Applications University of Illinois August 2017 1 About me Worked in HPC since 2007 Started at Purdue
Bash for SLURM. Author: Wesley Schaal Pharmaceutical Bioinformatics, Uppsala University
 Bash for SLURM Author: Wesley Schaal Pharmaceutical Bioinformatics, Uppsala University wesley.schaal@farmbio.uu.se Lab session: Pavlin Mitev (pavlin.mitev@kemi.uu.se) it i slides at http://uppmax.uu.se/support/courses
Bash for SLURM Author: Wesley Schaal Pharmaceutical Bioinformatics, Uppsala University wesley.schaal@farmbio.uu.se Lab session: Pavlin Mitev (pavlin.mitev@kemi.uu.se) it i slides at http://uppmax.uu.se/support/courses
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Scientific Computing in practice
 Scientific Computing in practice Winter Kickstart 2016 Ivan Degtyarenko, Janne Blomqvist, Mikko Hakala, Simo Tuomisto School of Science, Aalto University Feb 29, 2016 slide 1 of 99 What is it? Triton crash
Scientific Computing in practice Winter Kickstart 2016 Ivan Degtyarenko, Janne Blomqvist, Mikko Hakala, Simo Tuomisto School of Science, Aalto University Feb 29, 2016 slide 1 of 99 What is it? Triton crash
Brigham Young University Fulton Supercomputing Lab. Ryan Cox
 Brigham Young University Fulton Supercomputing Lab Ryan Cox SLURM User Group 2013 Fun Facts ~33,000 students ~70% of students speak a foreign language Several cities around BYU have gige at home #6 Top
Brigham Young University Fulton Supercomputing Lab Ryan Cox SLURM User Group 2013 Fun Facts ~33,000 students ~70% of students speak a foreign language Several cities around BYU have gige at home #6 Top
Working with Shell Scripting. Daniel Balagué
 Working with Shell Scripting Daniel Balagué Editing Text Files We offer many text editors in the HPC cluster. Command-Line Interface (CLI) editors: vi / vim nano (very intuitive and easy to use if you
Working with Shell Scripting Daniel Balagué Editing Text Files We offer many text editors in the HPC cluster. Command-Line Interface (CLI) editors: vi / vim nano (very intuitive and easy to use if you
Lustre Parallel Filesystem Best Practices
 Lustre Parallel Filesystem Best Practices George Markomanolis Computational Scientist KAUST Supercomputing Laboratory georgios.markomanolis@kaust.edu.sa 7 November 2017 Outline Introduction to Parallel
Lustre Parallel Filesystem Best Practices George Markomanolis Computational Scientist KAUST Supercomputing Laboratory georgios.markomanolis@kaust.edu.sa 7 November 2017 Outline Introduction to Parallel
Applications Software Example
 Applications Software Example How to run an application on Cluster? Rooh Khurram Supercomputing Laboratory King Abdullah University of Science and Technology (KAUST), Saudi Arabia Cluster Training: Applications
Applications Software Example How to run an application on Cluster? Rooh Khurram Supercomputing Laboratory King Abdullah University of Science and Technology (KAUST), Saudi Arabia Cluster Training: Applications
Using a Linux System 6
 Canaan User Guide Connecting to the Cluster 1 SSH (Secure Shell) 1 Starting an ssh session from a Mac or Linux system 1 Starting an ssh session from a Windows PC 1 Once you're connected... 1 Ending an
Canaan User Guide Connecting to the Cluster 1 SSH (Secure Shell) 1 Starting an ssh session from a Mac or Linux system 1 Starting an ssh session from a Windows PC 1 Once you're connected... 1 Ending an
Using the SLURM Job Scheduler
 Using the SLURM Job Scheduler [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2015-05-13 Overview Today we re going to cover: Part I: What is SLURM? How to use a basic
Using the SLURM Job Scheduler [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2015-05-13 Overview Today we re going to cover: Part I: What is SLURM? How to use a basic
COSC 6385 Computer Architecture. - Homework
 COSC 6385 Computer Architecture - Homework Fall 2008 1 st Assignment Rules Each team should deliver Source code (.c,.h and Makefiles files) Please: no.o files and no executables! Documentation (.pdf,.doc,.tex
COSC 6385 Computer Architecture - Homework Fall 2008 1 st Assignment Rules Each team should deliver Source code (.c,.h and Makefiles files) Please: no.o files and no executables! Documentation (.pdf,.doc,.tex
An Introduction to Gauss. Paul D. Baines University of California, Davis November 20 th 2012
 An Introduction to Gauss Paul D. Baines University of California, Davis November 20 th 2012 What is Gauss? * http://wiki.cse.ucdavis.edu/support:systems:gauss * 12 node compute cluster (2 x 16 cores per
An Introduction to Gauss Paul D. Baines University of California, Davis November 20 th 2012 What is Gauss? * http://wiki.cse.ucdavis.edu/support:systems:gauss * 12 node compute cluster (2 x 16 cores per
Slurm at UPPMAX. How to submit jobs with our queueing system. Jessica Nettelblad sysadmin at UPPMAX
 Slurm at UPPMAX How to submit jobs with our queueing system Jessica Nettelblad sysadmin at UPPMAX Slurm at UPPMAX Intro Queueing with Slurm How to submit jobs Testing How to test your scripts before submission
Slurm at UPPMAX How to submit jobs with our queueing system Jessica Nettelblad sysadmin at UPPMAX Slurm at UPPMAX Intro Queueing with Slurm How to submit jobs Testing How to test your scripts before submission
Brigham Young University
 Brigham Young University Fulton Supercomputing Lab Ryan Cox Slurm User Group September 16, 2015 Washington, D.C. Open Source Code I'll reference several codes we have open sourced http://github.com/byuhpc
Brigham Young University Fulton Supercomputing Lab Ryan Cox Slurm User Group September 16, 2015 Washington, D.C. Open Source Code I'll reference several codes we have open sourced http://github.com/byuhpc
Juropa3 Experimental Partition
 Juropa3 Experimental Partition Batch System SLURM User's Manual ver 0.2 Apr 2014 @ JSC Chrysovalantis Paschoulas c.paschoulas@fz-juelich.de Contents 1. System Information 2. Modules 3. Slurm Introduction
Juropa3 Experimental Partition Batch System SLURM User's Manual ver 0.2 Apr 2014 @ JSC Chrysovalantis Paschoulas c.paschoulas@fz-juelich.de Contents 1. System Information 2. Modules 3. Slurm Introduction
TITANI CLUSTER USER MANUAL V.1.3
 2016 TITANI CLUSTER USER MANUAL V.1.3 This document is intended to give some basic notes in order to work with the TITANI High Performance Green Computing Cluster of the Civil Engineering School (ETSECCPB)
2016 TITANI CLUSTER USER MANUAL V.1.3 This document is intended to give some basic notes in order to work with the TITANI High Performance Green Computing Cluster of the Civil Engineering School (ETSECCPB)
LAB. Preparing for Stampede: Programming Heterogeneous Many- Core Supercomputers
 LAB Preparing for Stampede: Programming Heterogeneous Many- Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012 1
LAB Preparing for Stampede: Programming Heterogeneous Many- Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012 1
Directions in Workload Management
 Directions in Workload Management Alex Sanchez and Morris Jette SchedMD LLC HPC Knowledge Meeting 2016 Areas of Focus Scalability Large Node and Core Counts Power Management Failure Management Federated
Directions in Workload Management Alex Sanchez and Morris Jette SchedMD LLC HPC Knowledge Meeting 2016 Areas of Focus Scalability Large Node and Core Counts Power Management Failure Management Federated
Scheduling By Trackable Resources
 Scheduling By Trackable Resources Morris Jette and Dominik Bartkiewicz SchedMD Slurm User Group Meeting 2018 Thanks to NVIDIA for sponsoring this work Goals More flexible scheduling mechanism Especially
Scheduling By Trackable Resources Morris Jette and Dominik Bartkiewicz SchedMD Slurm User Group Meeting 2018 Thanks to NVIDIA for sponsoring this work Goals More flexible scheduling mechanism Especially
Troubleshooting Jobs on Odyssey
 Troubleshooting Jobs on Odyssey Paul Edmon, PhD ITC Research CompuGng Associate Bob Freeman, PhD Research & EducaGon Facilitator XSEDE Campus Champion Goals Tackle PEND, FAIL, and slow performance issues
Troubleshooting Jobs on Odyssey Paul Edmon, PhD ITC Research CompuGng Associate Bob Freeman, PhD Research & EducaGon Facilitator XSEDE Campus Champion Goals Tackle PEND, FAIL, and slow performance issues
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Moab Workload Manager on Cray XT3
 Moab Workload Manager on Cray XT3 presented by Don Maxwell (ORNL) Michael Jackson (Cluster Resources, Inc.) MOAB Workload Manager on Cray XT3 Why MOAB? Requirements Features Support/Futures 2 Why Moab?
Moab Workload Manager on Cray XT3 presented by Don Maxwell (ORNL) Michael Jackson (Cluster Resources, Inc.) MOAB Workload Manager on Cray XT3 Why MOAB? Requirements Features Support/Futures 2 Why Moab?
Description of Power8 Nodes Available on Mio (ppc[ ])
![Description of Power8 Nodes Available on Mio (ppc[ ])](/thumbs/93/112992376.jpg "Description of Power8 Nodes Available on Mio (ppc[ ])") Description of Power8 Nodes Available on Mio (ppc[001-002]) Introduction: HPC@Mines has released two brand-new IBM Power8 nodes (identified as ppc001 and ppc002) to production, as part of our Mio cluster.
Description of Power8 Nodes Available on Mio (ppc[001-002]) Introduction: HPC@Mines has released two brand-new IBM Power8 nodes (identified as ppc001 and ppc002) to production, as part of our Mio cluster.
Bright Cluster Manager
 Bright Cluster Manager Using Slurm for Data Aware Scheduling in the Cloud Martijn de Vries CTO About Bright Computing Bright Computing 1. Develops and supports Bright Cluster Manager for HPC systems, server
Bright Cluster Manager Using Slurm for Data Aware Scheduling in the Cloud Martijn de Vries CTO About Bright Computing Bright Computing 1. Develops and supports Bright Cluster Manager for HPC systems, server
Kamiak Cheat Sheet. Display text file, one page at a time. Matches all files beginning with myfile See disk space on volume
 Kamiak Cheat Sheet Logging in to Kamiak ssh your.name@kamiak.wsu.edu ssh -X your.name@kamiak.wsu.edu X11 forwarding Transferring Files to and from Kamiak scp -r myfile your.name@kamiak.wsu.edu:~ Copy to
Kamiak Cheat Sheet Logging in to Kamiak ssh your.name@kamiak.wsu.edu ssh -X your.name@kamiak.wsu.edu X11 forwarding Transferring Files to and from Kamiak scp -r myfile your.name@kamiak.wsu.edu:~ Copy to
Using CSC Environment Efficiently,
 Using CSC Environment Efficiently, 17.09.2018 1 Exercises a) Log in to Taito either with your training or CSC user account, either from a terminal (with X11 forwarding) or using NoMachine client b) Go
Using CSC Environment Efficiently, 17.09.2018 1 Exercises a) Log in to Taito either with your training or CSC user account, either from a terminal (with X11 forwarding) or using NoMachine client b) Go
Feb 22, Explanatory meeting for users of supercomputer system -- Knowhow for entering jobs in UGE --
 Feb 22, 2013 Explanatory meeting for users of supercomputer system -- Knowhow for entering jobs in UGE -- Purpose of this lecture To understand the method for smoothly executing a few hundreds or thousands
Feb 22, 2013 Explanatory meeting for users of supercomputer system -- Knowhow for entering jobs in UGE -- Purpose of this lecture To understand the method for smoothly executing a few hundreds or thousands
Compiling applications for the Cray XC
 Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Bright Cluster Manager: Using the NVIDIA NGC Deep Learning Containers
 Bright Cluster Manager: Using the NVIDIA NGC Deep Learning Containers Technical White Paper Table of Contents Pre-requisites...1 Setup...2 Run PyTorch in Kubernetes...3 Run PyTorch in Singularity...4 Run
Bright Cluster Manager: Using the NVIDIA NGC Deep Learning Containers Technical White Paper Table of Contents Pre-requisites...1 Setup...2 Run PyTorch in Kubernetes...3 Run PyTorch in Singularity...4 Run
Cluster Computing in Frankfurt
 Cluster Computing in Frankfurt Goethe University in Frankfurt/Main Center for Scientific Computing December 12, 2017 Center for Scientific Computing What can we provide you? CSC Center for Scientific Computing
Cluster Computing in Frankfurt Goethe University in Frankfurt/Main Center for Scientific Computing December 12, 2017 Center for Scientific Computing What can we provide you? CSC Center for Scientific Computing