Meaning Banking and Beyond
|
|
|
- Lindsay Armstrong
- 5 years ago
- Views:
Transcription

1 Meaning Banking and Beyond Valerio Basile Wimmics, Inria November 18, 2015
2 Semantics is a well-kept secret in texts, accessible only to humans. Anonymous I BEG TO DIFFER

3 Surface Meaning
4 Step by step analysis Dividing text into words
5 Step by step analysis Dividing text into words Labeling words
6 Emotions play an important role in p. noun verb det adjective noun prep decision making noun noun
7 Step by step analysis Dividing text into words Labeling words Finding links between words
8 Emotions play an important role in decision making subj obj attr nn
9 Step by step analysis Dividing text into words Labeling words Finding links between words Extracting the meaning
10 Emotions play an important role in decision making play(emotion, role) important(role) emotion >1...
11 Step by step analysis Dividing text into words Tokenization Labeling words Tagging Finding links between words Syntax Extracting the meaning Semantics
12 Software pipeline supervised Tokenization Elephant (Evang et al. 2013) Tagging supervised C&C tools (Curran et al. 2007) Syntax Semantics Boxer (Bos, 2008) rule-based

13 Emotions play an important role in decision making
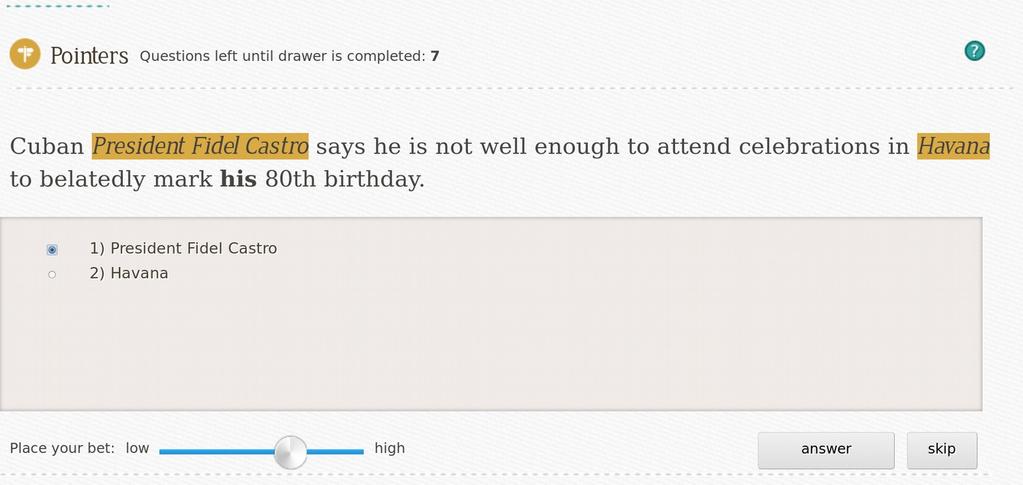
14 Supervised learning Show enough examples to the machine and it will learn and generalize. As opposed to unsupervised learning, e.g. clustering
15 Supervised learning enough examples = millions of words + annotation that is, an annotated text corpus Examples: Penn treebank (syntax) Semcor (word senses) TWITA (sentiment),...
16 What about a semantics?
17 What about a semantics? Meaning Bank (a treebank for semantics)





18
19 How to build a meaning bank Manually: Collection of texts + Expert annotation
20 How to build a meaning bank Manually: Collection of texts + Expert annotation DO NOT TRY THIS AT HOME
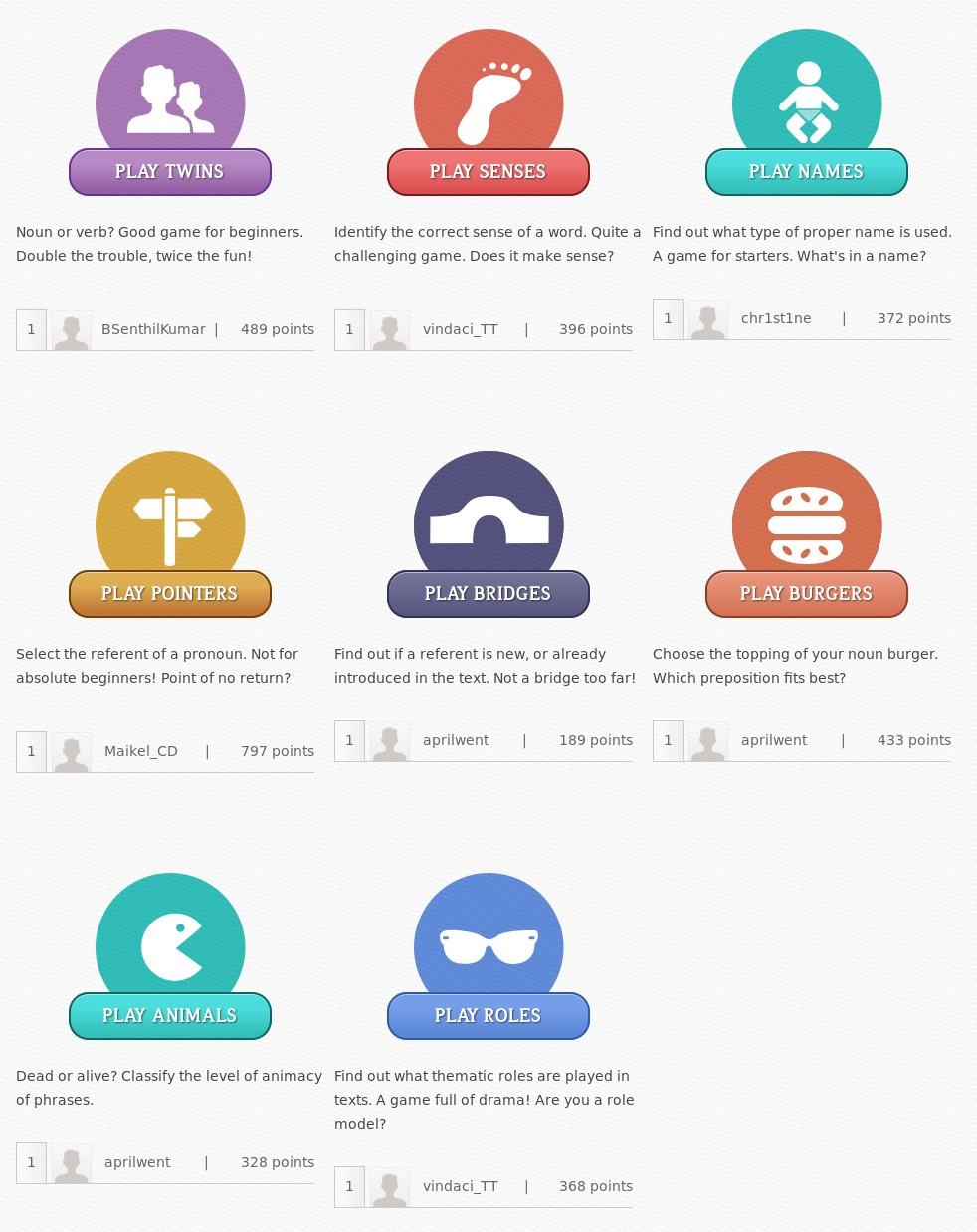
21 How to build a meaning bank By bootstrap: Collection of texts + Analysis software + Manual correction
22 Collection of texts English Public domain Whole documents Short Open domain
23 Collection of texts 73,352 documents 10,103 (accepted) 6.3 sentence per document ~90% from VoA (newswire) Jokes, legal text, fables,...




24 Analysis software GNU Make Elephant tokenization Daemon process C&C tools taggins & parsing Boxer Semantic analysis
25 Manual correction Silver standard Experts and the crowd

26 The GMB Explorer
27 The GMB Explorer 33 users 173,173 annotations (including automatically generated)
28 Gamification

29 Gamification Leaderboards Badges Agreement-based score
30 Gamification 59,413 Answers 13 Games 1,732 Players 2 Datasets
31 A semantically annotated resource that anyone can edit. Johan Bos, Valerio Basile, Kilian Evang, Noortje Venhuizen, Johannes Bjerva (forthcoming): The Groningen Meaning Bank. In Handbook of Linguistic Annotation. Berlin: Springer. Valerio Basile, Johan Bos, Kilian Evang, Noortje Venhuizen Developing a large semantically annotated corpus. LREC 2012 Valerio Basile, Johan Bos, Kilian Evang, Noortje Venhuizen A platform for collaborative semantic annotation. EACL
32 Beyond Meaning Banking
33 Beyond Meaning Banking Autonomous learning of the meaning of objects




34 Beyond Meaning Banking Autonomous learning of the meaning of objects
35 Beyond Meaning Banking Bridging semantic analysis with entity linking to build a knowledge base by reading the Web

 Patient Glass")
36 Beyond Meaning Banking When a glass or cup is emptied, The robot will ask if it should serve more serving (FrameNet) Agent Robot (DBPedia) Patient Glass (DBPedia)
37 Towards a Web Meaning Bank Better NLP tools train extract Better Linked Open Data
38 Fin Meaning Banking and Beyond Valerio Basile November 18, 2015
A platform for collaborative semantic annotation
 A platform for collaborative semantic annotation Valerio Basile and Johan Bos and Kilian Evang and Noortje Venhuizen {v.basile,johan.bos,k.evang,n.j.venhuizen}@rug.nl Center for Language and Cognition
A platform for collaborative semantic annotation Valerio Basile and Johan Bos and Kilian Evang and Noortje Venhuizen {v.basile,johan.bos,k.evang,n.j.venhuizen}@rug.nl Center for Language and Cognition
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
UGroningen: Negation detection with Discourse Representation Structures
 UGroningen: Negation detection with Discourse Representation Structures Valerio Basile and Johan Bos and Kilian Evang and Noortje Venhuizen {v.basile,johan.bos,k.evang,n.j.venhuizen}@rug.nl Center for
UGroningen: Negation detection with Discourse Representation Structures Valerio Basile and Johan Bos and Kilian Evang and Noortje Venhuizen {v.basile,johan.bos,k.evang,n.j.venhuizen}@rug.nl Center for
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF
 Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann EB Cognitive Science and SFB 632 University of Potsdam neumana@uni-potsdam.de Nancy Ide Department of Computer
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann EB Cognitive Science and SFB 632 University of Potsdam neumana@uni-potsdam.de Nancy Ide Department of Computer
NLP Final Project Fall 2015, Due Friday, December 18
 NLP Final Project Fall 2015, Due Friday, December 18 For the final project, everyone is required to do some sentiment classification and then choose one of the other three types of projects: annotation,
NLP Final Project Fall 2015, Due Friday, December 18 For the final project, everyone is required to do some sentiment classification and then choose one of the other three types of projects: annotation,
Tools for Annotating and Searching Corpora Practical Session 1: Annotating
 Tools for Annotating and Searching Corpora Practical Session 1: Annotating Stefanie Dipper Institute of Linguistics Ruhr-University Bochum Corpus Linguistics Fest (CLiF) June 6-10, 2016 Indiana University,
Tools for Annotating and Searching Corpora Practical Session 1: Annotating Stefanie Dipper Institute of Linguistics Ruhr-University Bochum Corpus Linguistics Fest (CLiF) June 6-10, 2016 Indiana University,
Lecture 14: Annotation
 Lecture 14: Annotation Nathan Schneider (with material from Henry Thompson, Alex Lascarides) ENLP 23 October 2016 1/14 Annotation Why gold 6= perfect Quality Control 2/14 Factors in Annotation Suppose
Lecture 14: Annotation Nathan Schneider (with material from Henry Thompson, Alex Lascarides) ENLP 23 October 2016 1/14 Annotation Why gold 6= perfect Quality Control 2/14 Factors in Annotation Suppose
Semantic and Multimodal Annotation. CLARA University of Copenhagen August 2011 Susan Windisch Brown
 Semantic and Multimodal Annotation CLARA University of Copenhagen 15-26 August 2011 Susan Windisch Brown 2 Program: Monday Big picture Coffee break Lexical ambiguity and word sense annotation Lunch break
Semantic and Multimodal Annotation CLARA University of Copenhagen 15-26 August 2011 Susan Windisch Brown 2 Program: Monday Big picture Coffee break Lexical ambiguity and word sense annotation Lunch break
ANC2Go: A Web Application for Customized Corpus Creation
 ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
Let s get parsing! Each component processes the Doc object, then passes it on. doc.is_parsed attribute checks whether a Doc object has been parsed
 Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
Introduction to Text Mining. Hongning Wang
 Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
UIMA-based Annotation Type System for a Text Mining Architecture
 UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
Package corenlp. June 3, 2015
 Type Package Title Wrappers Around Stanford CoreNLP Tools Version 0.4-1 Author Taylor Arnold, Lauren Tilton Package corenlp June 3, 2015 Maintainer Taylor Arnold Provides a minimal
Type Package Title Wrappers Around Stanford CoreNLP Tools Version 0.4-1 Author Taylor Arnold, Lauren Tilton Package corenlp June 3, 2015 Maintainer Taylor Arnold Provides a minimal
Hidden Markov Models. Natural Language Processing: Jordan Boyd-Graber. University of Colorado Boulder LECTURE 20. Adapted from material by Ray Mooney
 Hidden Markov Models Natural Language Processing: Jordan Boyd-Graber University of Colorado Boulder LECTURE 20 Adapted from material by Ray Mooney Natural Language Processing: Jordan Boyd-Graber Boulder
Hidden Markov Models Natural Language Processing: Jordan Boyd-Graber University of Colorado Boulder LECTURE 20 Adapted from material by Ray Mooney Natural Language Processing: Jordan Boyd-Graber Boulder
TTIC 31190: Natural Language Processing
 TTIC 31190: Natural Language Processing Kevin Gimpel Winter 2016 Lecture 2: Text Classification 1 Please email me (kgimpel@ttic.edu) with the following: your name your email address whether you taking
TTIC 31190: Natural Language Processing Kevin Gimpel Winter 2016 Lecture 2: Text Classification 1 Please email me (kgimpel@ttic.edu) with the following: your name your email address whether you taking
Refresher on Dependency Syntax and the Nivre Algorithm
 Refresher on Dependency yntax and Nivre Algorithm Richard Johansson 1 Introduction This document gives more details about some important topics that re discussed very quickly during lecture: dependency
Refresher on Dependency yntax and Nivre Algorithm Richard Johansson 1 Introduction This document gives more details about some important topics that re discussed very quickly during lecture: dependency
COMP90042 LECTURE 3 LEXICAL SEMANTICS COPYRIGHT 2018, THE UNIVERSITY OF MELBOURNE
 COMP90042 LECTURE 3 LEXICAL SEMANTICS SENTIMENT ANALYSIS REVISITED 2 Bag of words, knn classifier. Training data: This is a good movie.! This is a great movie.! This is a terrible film. " This is a wonderful
COMP90042 LECTURE 3 LEXICAL SEMANTICS SENTIMENT ANALYSIS REVISITED 2 Bag of words, knn classifier. Training data: This is a good movie.! This is a great movie.! This is a terrible film. " This is a wonderful
Deliverable D1.4 Report Describing Integration Strategies and Experiments
 DEEPTHOUGHT Hybrid Deep and Shallow Methods for Knowledge-Intensive Information Extraction Deliverable D1.4 Report Describing Integration Strategies and Experiments The Consortium October 2004 Report Describing
DEEPTHOUGHT Hybrid Deep and Shallow Methods for Knowledge-Intensive Information Extraction Deliverable D1.4 Report Describing Integration Strategies and Experiments The Consortium October 2004 Report Describing
Morpho-syntactic Analysis with the Stanford CoreNLP
 Morpho-syntactic Analysis with the Stanford CoreNLP Danilo Croce croce@info.uniroma2.it WmIR 2015/2016 Objectives of this tutorial Use of a Natural Language Toolkit CoreNLP toolkit Morpho-syntactic analysis
Morpho-syntactic Analysis with the Stanford CoreNLP Danilo Croce croce@info.uniroma2.it WmIR 2015/2016 Objectives of this tutorial Use of a Natural Language Toolkit CoreNLP toolkit Morpho-syntactic analysis
Making Sense Out of the Web
 Making Sense Out of the Web Rada Mihalcea University of North Texas Department of Computer Science rada@cs.unt.edu Abstract. In the past few years, we have witnessed a tremendous growth of the World Wide
Making Sense Out of the Web Rada Mihalcea University of North Texas Department of Computer Science rada@cs.unt.edu Abstract. In the past few years, we have witnessed a tremendous growth of the World Wide
MRD-based Word Sense Disambiguation: Extensions and Applications
 MRD-based Word Sense Disambiguation: Extensions and Applications Timothy Baldwin Joint Work with F. Bond, S. Fujita, T. Tanaka, Willy and S.N. Kim 1 MRD-based Word Sense Disambiguation: Extensions and
MRD-based Word Sense Disambiguation: Extensions and Applications Timothy Baldwin Joint Work with F. Bond, S. Fujita, T. Tanaka, Willy and S.N. Kim 1 MRD-based Word Sense Disambiguation: Extensions and
Multiword deconstruction in AnCora dependencies and final release data
 Multiword deconstruction in AnCora dependencies and final release data TECHNICAL REPORT GLICOM 2014-1 Benjamin Kolz, Toni Badia, Roser Saurí Universitat Pompeu Fabra {benjamin.kolz, toni.badia, roser.sauri}@upf.edu
Multiword deconstruction in AnCora dependencies and final release data TECHNICAL REPORT GLICOM 2014-1 Benjamin Kolz, Toni Badia, Roser Saurí Universitat Pompeu Fabra {benjamin.kolz, toni.badia, roser.sauri}@upf.edu
Ortolang Tools : MarsaTag
 Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
School of Computing and Information Systems The University of Melbourne COMP90042 WEB SEARCH AND TEXT ANALYSIS (Semester 1, 2017)
") Discussion School of Computing and Information Systems The University of Melbourne COMP9004 WEB SEARCH AND TEXT ANALYSIS (Semester, 07). What is a POS tag? Sample solutions for discussion exercises: Week
Discussion School of Computing and Information Systems The University of Melbourne COMP9004 WEB SEARCH AND TEXT ANALYSIS (Semester, 07). What is a POS tag? Sample solutions for discussion exercises: Week
Knowledge Engineering with Semantic Web Technologies
 This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
structure of the presentation Frame Semantics knowledge-representation in larger-scale structures the concept of frame
 structure of the presentation Frame Semantics semantic characterisation of situations or states of affairs 1. introduction (partially taken from a presentation of Markus Egg): i. what is a frame supposed
structure of the presentation Frame Semantics semantic characterisation of situations or states of affairs 1. introduction (partially taken from a presentation of Markus Egg): i. what is a frame supposed
Statistical parsing. Fei Xia Feb 27, 2009 CSE 590A
 Statistical parsing Fei Xia Feb 27, 2009 CSE 590A Statistical parsing History-based models (1995-2000) Recent development (2000-present): Supervised learning: reranking and label splitting Semi-supervised
Statistical parsing Fei Xia Feb 27, 2009 CSE 590A Statistical parsing History-based models (1995-2000) Recent development (2000-present): Supervised learning: reranking and label splitting Semi-supervised
Background and Context for CLASP. Nancy Ide, Vassar College
 Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Semantics Isn t Easy Thoughts on the Way Forward
 Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Yahoo! Webscope Datasets Catalog January 2009, 19 Datasets Available
 Yahoo! Webscope Datasets Catalog January 2009, 19 Datasets Available The "Yahoo! Webscope Program" is a reference library of interesting and scientifically useful datasets for non-commercial use by academics
Yahoo! Webscope Datasets Catalog January 2009, 19 Datasets Available The "Yahoo! Webscope Program" is a reference library of interesting and scientifically useful datasets for non-commercial use by academics
A Multilingual Social Media Linguistic Corpus
 A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
CMPT 755 Compilers. Anoop Sarkar.
 CMPT 755 Compilers Anoop Sarkar http://www.cs.sfu.ca/~anoop Parsing source program Lexical Analyzer token next() Parser parse tree Later Stages Lexical Errors Syntax Errors Context-free Grammars Set of
CMPT 755 Compilers Anoop Sarkar http://www.cs.sfu.ca/~anoop Parsing source program Lexical Analyzer token next() Parser parse tree Later Stages Lexical Errors Syntax Errors Context-free Grammars Set of
NLP Chain. Giuseppe Castellucci Web Mining & Retrieval a.a. 2013/2014
 NLP Chain Giuseppe Castellucci castellucci@ing.uniroma2.it Web Mining & Retrieval a.a. 2013/2014 Outline NLP chains RevNLT Exercise NLP chain Automatic analysis of texts At different levels Token Morphological
NLP Chain Giuseppe Castellucci castellucci@ing.uniroma2.it Web Mining & Retrieval a.a. 2013/2014 Outline NLP chains RevNLT Exercise NLP chain Automatic analysis of texts At different levels Token Morphological
Using Search-Logs to Improve Query Tagging
 Using Search-Logs to Improve Query Tagging Kuzman Ganchev Keith Hall Ryan McDonald Slav Petrov Google, Inc. {kuzman kbhall ryanmcd slav}@google.com Abstract Syntactic analysis of search queries is important
Using Search-Logs to Improve Query Tagging Kuzman Ganchev Keith Hall Ryan McDonald Slav Petrov Google, Inc. {kuzman kbhall ryanmcd slav}@google.com Abstract Syntactic analysis of search queries is important
Dynamic Feature Selection for Dependency Parsing
 Dynamic Feature Selection for Dependency Parsing He He, Hal Daumé III and Jason Eisner EMNLP 2013, Seattle Structured Prediction in NLP Part-of-Speech Tagging Parsing N N V Det N Fruit flies like a banana
Dynamic Feature Selection for Dependency Parsing He He, Hal Daumé III and Jason Eisner EMNLP 2013, Seattle Structured Prediction in NLP Part-of-Speech Tagging Parsing N N V Det N Fruit flies like a banana
Large-Scale Syntactic Processing: Parsing the Web. JHU 2009 Summer Research Workshop
 Large-Scale Syntactic Processing: JHU 2009 Summer Research Workshop Intro CCG parser Tasks 2 The Team Stephen Clark (Cambridge, UK) Ann Copestake (Cambridge, UK) James Curran (Sydney, Australia) Byung-Gyu
Large-Scale Syntactic Processing: JHU 2009 Summer Research Workshop Intro CCG parser Tasks 2 The Team Stephen Clark (Cambridge, UK) Ann Copestake (Cambridge, UK) James Curran (Sydney, Australia) Byung-Gyu
A Korean Knowledge Extraction System for Enriching a KBox
 A Korean Knowledge Extraction System for Enriching a KBox Sangha Nam, Eun-kyung Kim, Jiho Kim, Yoosung Jung, Kijong Han, Key-Sun Choi KAIST / The Republic of Korea {nam.sangha, kekeeo, hogajiho, wjd1004109,
A Korean Knowledge Extraction System for Enriching a KBox Sangha Nam, Eun-kyung Kim, Jiho Kim, Yoosung Jung, Kijong Han, Key-Sun Choi KAIST / The Republic of Korea {nam.sangha, kekeeo, hogajiho, wjd1004109,
Similarity Overlap Metric and Greedy String Tiling at PAN 2012: Plagiarism Detection
 Similarity Overlap Metric and Greedy String Tiling at PAN 2012: Plagiarism Detection Notebook for PAN at CLEF 2012 Arun kumar Jayapal The University of Sheffield, UK arunkumar.jeyapal@gmail.com Abstract
Similarity Overlap Metric and Greedy String Tiling at PAN 2012: Plagiarism Detection Notebook for PAN at CLEF 2012 Arun kumar Jayapal The University of Sheffield, UK arunkumar.jeyapal@gmail.com Abstract
Advanced Topics in Information Retrieval Natural Language Processing for IR & IR Evaluation. ATIR April 28, 2016
 Advanced Topics in Information Retrieval Natural Language Processing for IR & IR Evaluation Vinay Setty vsetty@mpi-inf.mpg.de Jannik Strötgen jannik.stroetgen@mpi-inf.mpg.de ATIR April 28, 2016 Organizational
Advanced Topics in Information Retrieval Natural Language Processing for IR & IR Evaluation Vinay Setty vsetty@mpi-inf.mpg.de Jannik Strötgen jannik.stroetgen@mpi-inf.mpg.de ATIR April 28, 2016 Organizational
Building Multilingual Resources and Neural Models for Word Sense Disambiguation. Alessandro Raganato March 15th, 2018
 Building Multilingual Resources and Neural Models for Word Sense Disambiguation Alessandro Raganato March 15th, 2018 About me alessandro.raganato@helsinki.fi http://wwwusers.di.uniroma1.it/~raganato ERC
Building Multilingual Resources and Neural Models for Word Sense Disambiguation Alessandro Raganato March 15th, 2018 About me alessandro.raganato@helsinki.fi http://wwwusers.di.uniroma1.it/~raganato ERC
A tool for Cross-Language Pair Annotations: CLPA
 A tool for Cross-Language Pair Annotations: CLPA August 28, 2006 This document describes our tool called Cross-Language Pair Annotator (CLPA) that is capable to automatically annotate cognates and false
A tool for Cross-Language Pair Annotations: CLPA August 28, 2006 This document describes our tool called Cross-Language Pair Annotator (CLPA) that is capable to automatically annotate cognates and false
Stack- propaga+on: Improved Representa+on Learning for Syntax
 Stack- propaga+on: Improved Representa+on Learning for Syntax Yuan Zhang, David Weiss MIT, Google 1 Transi+on- based Neural Network Parser p(action configuration) So1max Hidden Embedding words labels POS
Stack- propaga+on: Improved Representa+on Learning for Syntax Yuan Zhang, David Weiss MIT, Google 1 Transi+on- based Neural Network Parser p(action configuration) So1max Hidden Embedding words labels POS
Personalized Terms Derivative
 2016 International Conference on Information Technology Personalized Terms Derivative Semi-Supervised Word Root Finder Nitin Kumar Bangalore, India jhanit@gmail.com Abhishek Pradhan Bangalore, India abhishek.pradhan2008@gmail.com
2016 International Conference on Information Technology Personalized Terms Derivative Semi-Supervised Word Root Finder Nitin Kumar Bangalore, India jhanit@gmail.com Abhishek Pradhan Bangalore, India abhishek.pradhan2008@gmail.com
Taming Text. How to Find, Organize, and Manipulate It MANNING GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS. Shelter Island
 Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
Online Graph Planarisation for Synchronous Parsing of Semantic and Syntactic Dependencies
 Online Graph Planarisation for Synchronous Parsing of Semantic and Syntactic Dependencies Ivan Titov University of Illinois at Urbana-Champaign James Henderson, Paola Merlo, Gabriele Musillo University
Online Graph Planarisation for Synchronous Parsing of Semantic and Syntactic Dependencies Ivan Titov University of Illinois at Urbana-Champaign James Henderson, Paola Merlo, Gabriele Musillo University
Dependency grammar and dependency parsing
 Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2015-12-09 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2015-12-09 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
Ling/CSE 472: Introduction to Computational Linguistics. 5/9/17 Feature structures and unification
 Ling/CSE 472: Introduction to Computational Linguistics 5/9/17 Feature structures and unification Overview Problems with CFG Feature structures Unification Agreement Subcategorization Long-distance Dependencies
Ling/CSE 472: Introduction to Computational Linguistics 5/9/17 Feature structures and unification Overview Problems with CFG Feature structures Unification Agreement Subcategorization Long-distance Dependencies
Precise Medication Extraction using Agile Text Mining
 Precise Medication Extraction using Agile Text Mining Chaitanya Shivade *, James Cormack, David Milward * The Ohio State University, Columbus, Ohio, USA Linguamatics Ltd, Cambridge, UK shivade@cse.ohio-state.edu,
Precise Medication Extraction using Agile Text Mining Chaitanya Shivade *, James Cormack, David Milward * The Ohio State University, Columbus, Ohio, USA Linguamatics Ltd, Cambridge, UK shivade@cse.ohio-state.edu,
Dependency grammar and dependency parsing
 Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2014-12-10 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Mid-course evaluation Mostly positive
Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2014-12-10 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Mid-course evaluation Mostly positive
Dependency grammar and dependency parsing
 Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2016-12-05 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2016-12-05 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
Learning Compositional Semantics for Open Domain Semantic Parsing
 for Open Domain Semantic Parsing Institute for Logic, Language and Computation University of Amsterdam Groningen October 31, 2012 Outline Groningen Groningen Does Google understand what I mean? Groningen
for Open Domain Semantic Parsing Institute for Logic, Language and Computation University of Amsterdam Groningen October 31, 2012 Outline Groningen Groningen Does Google understand what I mean? Groningen
TechWatchTool: Innovation and Trend Monitoring
 TechWatchTool: Innovation and Trend Monitoring Hong Li Feiyu Xu Hans Uszkoreit German Research Center for Artificial Intelligence (DFKI), LT-Lab Alt-Moabit 91c, 10559 Berlin, Germany {lihong,feiyu,uszkoreit}@dfki.de
TechWatchTool: Innovation and Trend Monitoring Hong Li Feiyu Xu Hans Uszkoreit German Research Center for Artificial Intelligence (DFKI), LT-Lab Alt-Moabit 91c, 10559 Berlin, Germany {lihong,feiyu,uszkoreit}@dfki.de
CSC401 Natural Language Computing
 CSC401 Natural Language Computing Jan 19, 2018 TA: Willie Chang Varada Kolhatkar, Ka-Chun Won, and Aryan Arbabi) Mascots: r/sandersforpresident (left) and r/the_donald (right) To perform sentiment analysis
CSC401 Natural Language Computing Jan 19, 2018 TA: Willie Chang Varada Kolhatkar, Ka-Chun Won, and Aryan Arbabi) Mascots: r/sandersforpresident (left) and r/the_donald (right) To perform sentiment analysis
TectoMT: Modular NLP Framework
 : Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
: Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
slide courtesy of D. Yarowsky Splitting Words a.k.a. Word Sense Disambiguation Intro to NLP - J. Eisner 1
 Splitting Words a.k.a. Word Sense Disambiguation 600.465 - Intro to NLP - J. Eisner Representing Word as Vector Could average over many occurrences of the word... Each word type has a different vector
Splitting Words a.k.a. Word Sense Disambiguation 600.465 - Intro to NLP - J. Eisner Representing Word as Vector Could average over many occurrences of the word... Each word type has a different vector
Natural Language Processing
 Natural Language Processing Info 159/259 Lecture 5: Truth and ethics (Sept 7, 2017) David Bamman, UC Berkeley Hwæt! Wé Gárde na in géardagum, þéodcyninga þrym gefrúnon, hú ðá æþelingas ellen fremedon.
Natural Language Processing Info 159/259 Lecture 5: Truth and ethics (Sept 7, 2017) David Bamman, UC Berkeley Hwæt! Wé Gárde na in géardagum, þéodcyninga þrym gefrúnon, hú ðá æþelingas ellen fremedon.
Watson & WMR2017. (slides mostly derived from Jim Hendler and Simon Ellis, Rensselaer Polytechnic Institute, or from IBM itself)
") Watson & WMR2017 (slides mostly derived from Jim Hendler and Simon Ellis, Rensselaer Polytechnic Institute, or from IBM itself) R. BASILI A.A. 2016-17 Overview Motivations Watson Jeopardy NLU in Watson
Watson & WMR2017 (slides mostly derived from Jim Hendler and Simon Ellis, Rensselaer Polytechnic Institute, or from IBM itself) R. BASILI A.A. 2016-17 Overview Motivations Watson Jeopardy NLU in Watson
DBpedia Spotlight at the MSM2013 Challenge
 DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
Principles of Programming Languages COMP251: Syntax and Grammars
 Principles of Programming Languages COMP251: Syntax and Grammars Prof. Dekai Wu Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong, China Fall 2006
Principles of Programming Languages COMP251: Syntax and Grammars Prof. Dekai Wu Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong, China Fall 2006
EDAN20 Language Technology Chapter 13: Dependency Parsing
 EDAN20 Language Technology http://cs.lth.se/edan20/ Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ September 19, 2016 Pierre Nugues EDAN20 Language Technology http://cs.lth.se/edan20/
EDAN20 Language Technology http://cs.lth.se/edan20/ Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ September 19, 2016 Pierre Nugues EDAN20 Language Technology http://cs.lth.se/edan20/
Narrative Schema as World Knowledge for Coreference Resolution
 Narrative Schema as World Knowledge for Coreference Resolution Joseph Irwin Nara Institute of Science and Technology Nara Prefecture, Japan joseph-i@is.naist.jp Mamoru Komachi Nara Institute of Science
Narrative Schema as World Knowledge for Coreference Resolution Joseph Irwin Nara Institute of Science and Technology Nara Prefecture, Japan joseph-i@is.naist.jp Mamoru Komachi Nara Institute of Science
Text, Knowledge, and Information Extraction. Lizhen Qu
 Text, Knowledge, and Information Extraction Lizhen Qu A bit about Myself PhD: Databases and Information Systems Group (MPII) Advisors: Prof. Gerhard Weikum and Prof. Rainer Gemulla Thesis: Sentiment Analysis
Text, Knowledge, and Information Extraction Lizhen Qu A bit about Myself PhD: Databases and Information Systems Group (MPII) Advisors: Prof. Gerhard Weikum and Prof. Rainer Gemulla Thesis: Sentiment Analysis
LIDER Survey. Overview. Number of participants: 24. Participant profile (organisation type, industry sector) Relevant use-cases
 Relevant use-cases") LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
Parts of Speech, Named Entity Recognizer
 Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
A Hybrid Unsupervised Web Data Extraction using Trinity and NLP
 IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands
 AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
Web Product Ranking Using Opinion Mining
 Web Product Ranking Using Opinion Mining Yin-Fu Huang and Heng Lin Department of Computer Science and Information Engineering National Yunlin University of Science and Technology Yunlin, Taiwan {huangyf,
Web Product Ranking Using Opinion Mining Yin-Fu Huang and Heng Lin Department of Computer Science and Information Engineering National Yunlin University of Science and Technology Yunlin, Taiwan {huangyf,
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF
 Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann 1 Nancy Ide 2 Manfred Stede 1 1 EB Cognitive Science and SFB 632 University of Potsdam 2 Department of Computer
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann 1 Nancy Ide 2 Manfred Stede 1 1 EB Cognitive Science and SFB 632 University of Potsdam 2 Department of Computer
Universal Dependencies to Logical Forms with Negation Scope
 Universal Dependencies to Logical Forms with Negation Scope Federico Fancellu Siva Reddy Adam Lopez Bonnie Webber ILCC, School of Informatics, University of Edinburgh f.fancellu@sms.ed.ac.uk, siva.reddy@ed.ac.uk,
Universal Dependencies to Logical Forms with Negation Scope Federico Fancellu Siva Reddy Adam Lopez Bonnie Webber ILCC, School of Informatics, University of Edinburgh f.fancellu@sms.ed.ac.uk, siva.reddy@ed.ac.uk,
Linked Open Data Cloud. John P. McCrae, Thierry Declerck
 Linked Open Data Cloud John P. McCrae, Thierry Declerck Hitchhiker s guide to the Linked Open Data Cloud DBpedia Largest node in the linked open data cloud Nucleus for a web of open data Most data is
Linked Open Data Cloud John P. McCrae, Thierry Declerck Hitchhiker s guide to the Linked Open Data Cloud DBpedia Largest node in the linked open data cloud Nucleus for a web of open data Most data is
Machine Learning in GATE
 Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort
Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus
 Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Semantic Web and Natural Language Processing
 Semantic Web and Natural Language Processing Wiltrud Kessler Institut für Maschinelle Sprachverarbeitung Universität Stuttgart Semantic Web Winter 2014/2015 This work is licensed under a Creative Commons
Semantic Web and Natural Language Processing Wiltrud Kessler Institut für Maschinelle Sprachverarbeitung Universität Stuttgart Semantic Web Winter 2014/2015 This work is licensed under a Creative Commons
MASC: A Community Resource For and By the People
 MASC: A Community Resource For and By the People Nancy Ide Department of Computer Science Vassar College Poughkeepsie, NY, USA ide@cs.vassar.edu Christiane Fellbaum Princeton University Princeton, New
MASC: A Community Resource For and By the People Nancy Ide Department of Computer Science Vassar College Poughkeepsie, NY, USA ide@cs.vassar.edu Christiane Fellbaum Princeton University Princeton, New
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information
 Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Learning Latent Linguistic Structure to Optimize End Tasks. David A. Smith with Jason Naradowsky and Xiaoye Tiger Wu
 Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith with Jason Naradowsky and Xiaoye Tiger Wu 12 October 2012 Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith
Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith with Jason Naradowsky and Xiaoye Tiger Wu 12 October 2012 Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith
English Understanding: From Annotations to AMRs
 English Understanding: From Annotations to AMRs Nathan Schneider August 28, 2012 :: ISI NLP Group :: Summer Internship Project Presentation 1 Current state of the art: syntax-based MT Hierarchical/syntactic
English Understanding: From Annotations to AMRs Nathan Schneider August 28, 2012 :: ISI NLP Group :: Summer Internship Project Presentation 1 Current state of the art: syntax-based MT Hierarchical/syntactic
Knowledge extraction from audio content service providers' API descriptions
 Knowledge extraction from audio content service providers' API descriptions Damir Juric, György Fazekas Queen Mary University of London, London, UK {d.juric, g.fazekas}@qmul.ac.uk Abstract. Creating an
Knowledge extraction from audio content service providers' API descriptions Damir Juric, György Fazekas Queen Mary University of London, London, UK {d.juric, g.fazekas}@qmul.ac.uk Abstract. Creating an
Maximum Entropy based Natural Language Interface for Relational Database
 International Journal of Engineering Research and Technology. ISSN 0974-3154 Volume 7, Number 1 (2014), pp. 69-77 International Research Publication House http://www.irphouse.com Maximum Entropy based
International Journal of Engineering Research and Technology. ISSN 0974-3154 Volume 7, Number 1 (2014), pp. 69-77 International Research Publication House http://www.irphouse.com Maximum Entropy based
Text Mining via Information Extraction
 Ronen Feldman, Yonatan Aumann, Moshe Fresko, Orly Liphstat, Binyamin Rosenfeld, Yonatan Schler Department of Mathematics and Computer Science Bar-Ilan University Ramat-Gan, ISRAEL Tel: 972-3-5326611 Fax:
Ronen Feldman, Yonatan Aumann, Moshe Fresko, Orly Liphstat, Binyamin Rosenfeld, Yonatan Schler Department of Mathematics and Computer Science Bar-Ilan University Ramat-Gan, ISRAEL Tel: 972-3-5326611 Fax:
CS395T Project 2: Shift-Reduce Parsing
 CS395T Project 2: Shift-Reduce Parsing Due date: Tuesday, October 17 at 9:30am In this project you ll implement a shift-reduce parser. First you ll implement a greedy model, then you ll extend that model
CS395T Project 2: Shift-Reduce Parsing Due date: Tuesday, October 17 at 9:30am In this project you ll implement a shift-reduce parser. First you ll implement a greedy model, then you ll extend that model
CS 224N Assignment 2 Writeup
 CS 224N Assignment 2 Writeup Angela Gong agong@stanford.edu Dept. of Computer Science Allen Nie anie@stanford.edu Symbolic Systems Program 1 Introduction 1.1 PCFG A probabilistic context-free grammar (PCFG)
CS 224N Assignment 2 Writeup Angela Gong agong@stanford.edu Dept. of Computer Science Allen Nie anie@stanford.edu Symbolic Systems Program 1 Introduction 1.1 PCFG A probabilistic context-free grammar (PCFG)
TEXTPRO-AL: An Active Learning Platform for Flexible and Efficient Production of Training Data for NLP Tasks
 TEXTPRO-AL: An Active Learning Platform for Flexible and Efficient Production of Training Data for NLP Tasks Bernardo Magnini 1, Anne-Lyse Minard 1,2, Mohammed R. H. Qwaider 1, Manuela Speranza 1 1 Fondazione
TEXTPRO-AL: An Active Learning Platform for Flexible and Efficient Production of Training Data for NLP Tasks Bernardo Magnini 1, Anne-Lyse Minard 1,2, Mohammed R. H. Qwaider 1, Manuela Speranza 1 1 Fondazione
Transition-Based Dependency Parsing with Stack Long Short-Term Memory
 Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
Corpus Linguistics for NLP APLN550. Adam Meyers Montclair State University 9/22/2014 and 9/29/2014
 Corpus Linguistics for NLP APLN550 Adam Meyers Montclair State University 9/22/ and 9/29/ Text Corpora in NLP Corpus Selection Corpus Annotation: Purpose Representation Issues Linguistic Methods Measuring
Corpus Linguistics for NLP APLN550 Adam Meyers Montclair State University 9/22/ and 9/29/ Text Corpora in NLP Corpus Selection Corpus Annotation: Purpose Representation Issues Linguistic Methods Measuring
WebSAIL Wikifier at ERD 2014
 WebSAIL Wikifier at ERD 2014 Thanapon Noraset, Chandra Sekhar Bhagavatula, Doug Downey Department of Electrical Engineering & Computer Science, Northwestern University {nor.thanapon, csbhagav}@u.northwestern.edu,ddowney@eecs.northwestern.edu
WebSAIL Wikifier at ERD 2014 Thanapon Noraset, Chandra Sekhar Bhagavatula, Doug Downey Department of Electrical Engineering & Computer Science, Northwestern University {nor.thanapon, csbhagav}@u.northwestern.edu,ddowney@eecs.northwestern.edu
Domain Analysis. SWEN-261 Introduction to Software Engineering. Department of Software Engineering Rochester Institute of Technology.
 Domain Analysis Die 2 played with Monopoly Game played on Board Count 2 takes turn defines a using location on SWEN-261 Introduction to Software Engineering Player 2..8 represents Piece Character 0..8
Domain Analysis Die 2 played with Monopoly Game played on Board Count 2 takes turn defines a using location on SWEN-261 Introduction to Software Engineering Player 2..8 represents Piece Character 0..8
Fully Delexicalized Contexts for Syntax-Based Word Embeddings
 Fully Delexicalized Contexts for Syntax-Based Word Embeddings Jenna Kanerva¹, Sampo Pyysalo² and Filip Ginter¹ ¹Dept of IT - University of Turku, Finland ²Lang. Tech. Lab - University of Cambridge turkunlp.github.io
Fully Delexicalized Contexts for Syntax-Based Word Embeddings Jenna Kanerva¹, Sampo Pyysalo² and Filip Ginter¹ ¹Dept of IT - University of Turku, Finland ²Lang. Tech. Lab - University of Cambridge turkunlp.github.io
A Methodology for Extracting Knowledge about Controlled Vocabularies from Textual Data using FCA-Based Ontology Engineering
 A Methodology for Extracting Knowledge about Controlled Vocabularies from Textual Data using FCA-Based Ontology Engineering 1 st Simin Jabbari Information Management Institute University of Neuchâtel Neuchâtel
A Methodology for Extracting Knowledge about Controlled Vocabularies from Textual Data using FCA-Based Ontology Engineering 1 st Simin Jabbari Information Management Institute University of Neuchâtel Neuchâtel
The Multilingual Language Library
 The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
SyntaViz: Visualizing Voice Queries through a Syntax-Driven Hierarchical Ontology
 SyntaViz: Visualizing Voice Queries through a Syntax-Driven Hierarchical Ontology Md Iftekhar Tanveer University of Rochester Rochester, NY, USA itanveer@cs.rochester.edu Ferhan Ture Comcast Applied AI
SyntaViz: Visualizing Voice Queries through a Syntax-Driven Hierarchical Ontology Md Iftekhar Tanveer University of Rochester Rochester, NY, USA itanveer@cs.rochester.edu Ferhan Ture Comcast Applied AI
Language Resources and Linked Data
 Integrating NLP with Linked Data: the NIF Format Milan Dojchinovski @EKAW 2014 November 24-28, 2014, Linkoping, Sweden milan.dojchinovski@fit.cvut.cz - @m1ci - http://dojchinovski.mk Web Intelligence Research
Integrating NLP with Linked Data: the NIF Format Milan Dojchinovski @EKAW 2014 November 24-28, 2014, Linkoping, Sweden milan.dojchinovski@fit.cvut.cz - @m1ci - http://dojchinovski.mk Web Intelligence Research
Data for linguistics ALEXIS DIMITRIADIS. Contents First Last Prev Next Back Close Quit
 Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Christoph Treude. Bimodal Software Documentation
 Christoph Treude Bimodal Software Documentation Software Documentation [1985] 2 Software Documentation is everywhere [C Parnin and C Treude Measuring API Documentation on Web Web2SE 11: 2nd Int l Workshop
Christoph Treude Bimodal Software Documentation Software Documentation [1985] 2 Software Documentation is everywhere [C Parnin and C Treude Measuring API Documentation on Web Web2SE 11: 2nd Int l Workshop
A fully-automatic approach to answer geographic queries: GIRSA-WP at GikiP
 A fully-automatic approach to answer geographic queries: at GikiP Johannes Leveling Sven Hartrumpf Intelligent Information and Communication Systems (IICS) University of Hagen (FernUniversität in Hagen)
A fully-automatic approach to answer geographic queries: at GikiP Johannes Leveling Sven Hartrumpf Intelligent Information and Communication Systems (IICS) University of Hagen (FernUniversität in Hagen)
Ontology-guided Extraction of Complex Nested Relationships
 2010 22nd International Conference on Tools with Artificial Intelligence Ontology-guided Extraction of Complex Nested Relationships Sushain Pandit, Vasant Honavar Department of Computer Science Iowa State
2010 22nd International Conference on Tools with Artificial Intelligence Ontology-guided Extraction of Complex Nested Relationships Sushain Pandit, Vasant Honavar Department of Computer Science Iowa State
NLP in practice, an example: Semantic Role Labeling
 NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
WordNet-based User Profiles for Semantic Personalization
 PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
Grounded Compositional Semantics for Finding and Describing Images with Sentences
 Grounded Compositional Semantics for Finding and Describing Images with Sentences R. Socher, A. Karpathy, V. Le,D. Manning, A Y. Ng - 2013 Ali Gharaee 1 Alireza Keshavarzi 2 1 Department of Computational
Grounded Compositional Semantics for Finding and Describing Images with Sentences R. Socher, A. Karpathy, V. Le,D. Manning, A Y. Ng - 2013 Ali Gharaee 1 Alireza Keshavarzi 2 1 Department of Computational