is that the question?
|
|
|
- Marion Berry
- 6 years ago
- Views:
Transcription
1 To structure or not to structure, is that the question? Paolo Atzeni Based on work done with (or by!) G. Mecca, P.Merialdo, P. Papotti, and many others Lyon, 24 August 2009
2 Content A personal (and questionable ) perspective on the role structure (and its discovery) has in the Web, especially as a replacement for semantics Two observations Especially important if we want automatic processing Something similar happened for databases many years ago and a disclaimer: I feel honored to have been invited, but I am not sure why it happened Personal means that I will refer to projects in my group (with some contradiction, as I have been personally involved only in some of them ) 24/08/2009 Paolo Atzeni 2
3 Content Questions on the Web Structures in the Web, transformations: Araneus Information extraction, wrappers: Minerva, RoadRunner Crawling, extraction and integration: Flint 24/08/2009 Paolo Atzeni 3
4 Web and Databases (1) The Web is browsed and searched Usually one page or one item at the time (may be a ranked list) Databases are (mainly) queried We are often interested in tables as results 24/08/2009 Paolo Atzeni 4
5 What do we do with the Web? Everything! We often search for specific items, and search engines are ok In other cases we need more complex things: What could be the reason for which Frederic Joliot-Curie (a French physicist and Nobel laureate, son in law of P. and M. Curie) is popular in Bulgaria (for example, the International House of Scientists in Varna is named after him)? Find a list of qualified database researchers who have never been in the VLDB PC and deserve to belong to the next one I will not provide solutions to these problems, but give hints Semantics Structure 24/08/2009 Paolo Atzeni 5
6 Questions on the Web: classification criteria (MOSES European project, FP5) Format of the response Number (and relationship) of the involved sites (one or more; of the same organization or not) Structure of the source information Extraction process 24/08/2009 Paolo Atzeni 6
7 Format of the response Asimplepiece piece of data A web page (or fragment of it) A tuple of data A "concept" A set or list of one of the above Natural language (i.e., an explanation) 24/08/2009 Paolo Atzeni 7
8 Involved sites One or more Of the same organization or not Sometimes also sites and local databases 24/08/2009 Paolo Atzeni 8
9 Structure of the source information Information directly provided by the site(s) as a whole Information available in the sites and correlated but not aggregated Information available in the site in a unrelated way 24/08/2009 Paolo Atzeni 9
10 Extraction process Explicit service: this the case for example if the site offers an address book or a search facility for finding professors One-way navigation: here the user has to navigate, but without the need for going back and forth (no trial and error ) Navigation with backtracking 24/08/2009 Paolo Atzeni 10
11 Web and Databases (2) The answer to some questions requires structure (we need to "compile" tables) databases are structured and organized how much structure and organization is there in the Web? 24/08/2009 Paolo Atzeni 11
12 Workshop on Semistructured Data at Sigmod /08/2009 Paolo Atzeni 12
13 Workshop on Semistructured Data at Sigmod /08/2009 Paolo Atzeni 13
14 Workshop on Semistructured Data at Sigmod /08/2009 Paolo Atzeni 14
15 Transformations bottom-up: accessing information from Web sources top-down: designing and maintaining Web sites global: integrating g existing sites and offering the information through new ones 24/08/2009 Paolo Atzeni 15
16 The Araneus Project At Università Roma Tre & Università della Basilicata Goals: extend database-like techniques to Web data management Several prototype systems 24/08/2009 Paolo Atzeni 16
17 Example Applications The Integrated Web Museum a site integrating g data coming from the Uffizi, Louvre and Capodimonte Web sites The ACM Sigmod Record XML Version XML+XSL Version of an existing (and currently running) Web site 24/08/2009 Paolo Atzeni 17
18 The Integrated Web Museum A new site with data coming from the Web sites of various museums Uffizi, Louvre and Capodimonte 24/08/2009 Paolo Atzeni 18
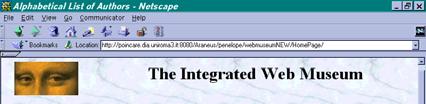

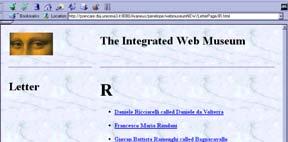

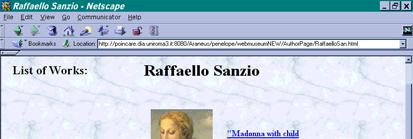
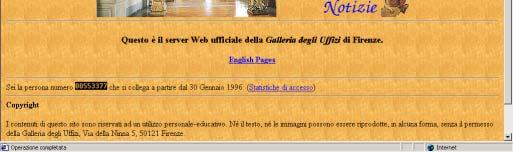

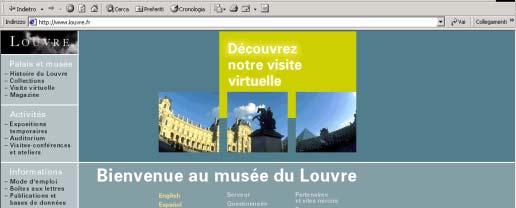


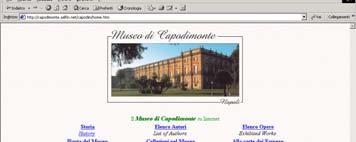

19 The Integrated Web Museum DB 24/08/2009 Paolo Atzeni 19
20 Integration of Web Sites: The Integrated Web Museum Data are re-organized: Uffizi, paintings organized by rooms Louvre, Capodimonte, works organized by collections Integrated Museum, organized by author 24/08/2009 Paolo Atzeni 20
21 Web Site Re-Engineering: ACM Sigmod Record in XML The ACM Sigmod Record Site (acm.org/sigmod/record) an existing site in HTML The ACM Sigmod Record Site, XML Edition a new site in XML with XSL Stylesheets 24/08/2009 Paolo Atzeni 21
22 24/08/2009 Paolo Atzeni 22
23 24/08/2009 Paolo Atzeni 23
24 The Araneus Approach Identification of sites of interest Wrapping of sites to extract information Navigation of site ad extraction of data Integration of data Generation of new sites Site Generation Layer Integration Layer Mediator Layer Araneus Web Site Development System (Homer) SQL and Java Araneus Query System (Ulixes) Wrapper Layer Wrapper Layer Wrapper Layer Araneus Wrapper Toolkit (Minerva) 24/08/2009 Paolo Atzeni 24
25 Building Applications in Araneus Phase A: Reverse Engineering Existing Sites Phase B: Data Integration ti Phase C: Developing New Integrated Sites 24/08/2009 Paolo Atzeni 25
26 Building Applications in Araneus Phase A: Reverse Engineering i First Step: Deriving the logical structure of data in the site ADM Scheme Second Step: Wrapping pages in order to map physical HTML sources to database objects Third Step: Extracting Data from the Site by Queries and Navigation 24/08/2009 Paolo Atzeni 26
27 Information Extraction Task Information extraction ti task source format: plain text with HTML markup (no semantics) target format: database table or XML file (adding structure, i.e., semantics ) extraction step: parse the HTML and return data items in the target format Wrapper piece of software designed to perform the extraction step 24/08/2009 Paolo Atzeni 27

 HTML page (or XML docs) Intuition: use extraction rules based")
28 Notion of Wrapper BookTitle Author Editor The HTML Sourcebook J. Graham... Computer Networks A. Tannenbaum... Wrapper Database Systems Data on the Web R. Elmasri, S. Navathe S. Abiteboul, P.Buneman, D.Suciu... database table(s) HTML page (or XML docs) Intuition: use extraction rules based on HTML markup 24/08/2009 Paolo Atzeni 28
29 Intuition Behind Extraction teamname Atalanta Inter Juventus Milan town Bergamo Milano Torino Milano <html><body> Wrapper Procedure: <h1>italian Football Teams</h1> Scan document for <ul> <ul> While there are more occurrences <li><b>atalanta</b> - <i>bergamo</i> <br> scan until <b> <li><b>inter</b> - <i>milano</i> <br> extract teamname between <b> <li><b>juventus</b> - <i>torino</i> <br> and </b> <li><b>milan</b>-<i>milano</i> i Milano /i <br> scan until <i> </ul> extract town between <i> and </i> </body></html> output [teamname, town] 24/08/2009 Paolo Atzeni 29
30 The Araneus Wrapper Toolkit Adv vantag ges Procedural Languages Flexible in presence of irregularities and exceptions Allows document restructurings Grammars Concise and declarative Simple in the case of strong regularity Drawba acks Tedious even with document strongly structured Difficult to maintain Not flexible in presence of irregularities Allow for limited restructurings 24/08/2009 Paolo Atzeni 30
31 The Araneus Wrapper Toolkit: Minerva + Editor Minerva is a Wrapper generator It couples a declarative, grammar-based approach with the flexibility of procedural programming: grammar-based procedural exception handling 24/08/2009 Paolo Atzeni 31
32 Development of wrappers Effective tools: drag and drop, example based, flexible Learning and automation (or semiautomation) Maintenance support: Web sites change quite frequently Minor changes may disrupt the extraction rules maintaining i i a wrapper is very costly this has motivated the study of (semi)- automatic wrapper generation techniques 24/08/2009 Paolo Atzeni 32
33 Observation Can XML or the Semantic Web help much? Probably not the Web is a giant legacy system and many sites will never move to the new technology (we said this ten years ago and it still seems correct ) many organizations will not be willing to expose their data in XML 24/08/2009 Paolo Atzeni 33
34 A related topic: Grammar Inference The problem given a collection of sample strings, find the language they belong to The computational model: identification in the limit [Gold, 1967] a learner is presented successively with a larger and larger corpus of examples it simultaneously makes a sequence of guesses about the language to learn if the sequence eventually converges, the inference is correct 24/08/2009 Paolo Atzeni 34
35 The RoadRunner Approach RoadRunner [Crescenzi, Mecca, Merialdo 2001] a research project on information extraction from Web sites The goal developing fully automatic, unsupervised wrapper induction techniques Contributions wrapper induction based on grammar inference techniques (suitably adapted) 24/08/2009 Paolo Atzeni 35
36 The RoadRunner Approach The target t large Web sites with HTML pages generated by programs (scripts) based on the content of an underlying data store the data store is usually a relational database The process data are extracted from the relational tables and possibly joined and nested the resulting dataset is exported in HTML format by attaching tags to values 24/08/2009 Paolo Atzeni 36





?")
37 The Schema Finding Problem A C Wrapper Output First Edition, $ Database Primer Input HTML Sources John Smith <HTML><BODY><TABLE> Computer Systems <TR> <TD><FONT>books.com<FONT></TD> XML at Work <TD><A>John Smith</A></TD> </TR> <TR> <TD><FONT>Database D Paul Primer<FONT></TD> Jones HTML and Scripts <TD><B>First Edition, Paperback</B></TD>, JavaScripts Wrapper D This book B <HTML><BODY><TABLE> An undergraduate First Edition, $ <TR> <TD><FONT>books.com<FONT></TD> A comprehensive First Edition, $ <TD><A>Paul Jones</A></TD> </TR> null $ <TR> An useful <TD><FONT>XML HTML Second Edition, at Work<FONT></TD> <TD><B>First Edition, Paperback</B></TD>, $ A must in null $ F E Second Edition, 2000 Target Schema <HTML><BODY><TABLE> <TR> SET ( <TD><FONT>books.com<FONT></TD> TUPLE (A : #PCDATA; <TD><A> #PCDATA</A></TD></TR> B : SET ( (<TR> TUPLE ( C : #PCDATA; ( <TD><FONT> #PCDATA <FONT></TD> D : #PCDATA; ( <TD><B> #PCDATA </B> )? </TD> E : SET ( ( <TR><TD><FONT> #PCDATA <FONT> TUPLE ( F: #PCDATA; <B> #PCDATA </B> </TD></TR> )+ G: #PCDATA; )+ H: #PCDATA))) 24/08/2009 Paolo Atzeni 37 G 30$ H
38 The Schema Finding Problem Page class collection of pages generated by the same script from a common dataset these pages typically share a common structure Schema finding problem given a set of sample HTML pages belonging to the same class, automatically recover the source dataset i.e., generate a wrapper capable of extracting the source dataset from the HTML code 38 24/08/2009 Paolo Atzeni
39 Contributions of RoadRunner An unsupervised learning algorithm for identifying i prefix-markup languages in the limit given a rich sample of HTML pages, the algorithm correctly identifies the language the algorithm runs in polynomial time from the language, when can infer the underlying schema and then extract the source dataset 39 24/08/2009 Paolo Atzeni
40 Data Extraction ti and Integration ti from Imprecise Web Sources Lorenzo Blanco, Mirko Bronzi, Valter Crescenzi, Paolo Merialdo, Paolo Papotti Università itàdegli listudi Roma Tre
41 Flint A novel approach for the automatic extraction and integration of web data Flint aims at exploiting an unexplored publishing pattern that frequently occurs in data intensive i web sites: large amounts of data are usually offered by pages that encode one flat tuple for each page for many disparate real world entities (e.g. stock quotes, people, travel packages, movies, books, etc) there are hundreds of web sites that deliver their data following this publishing strategy These collections of pages can be though as HTML encodings of a relation (e.g. "stock quote" relation) 24/08/2009 Paolo Atzeni 41
42 Example 24/08/2009 Paolo Atzeni 42
43 Flint goals Last Min Max StockQuote Volume 52high Open 24/08/2009 Paolo Atzeni 43
44 Flint goals q 1 Q q 2 Last Min Max StockQuote Volume 52high Open q n 24/08/2009 Paolo Atzeni 44
45 Extraction and Integration Flint builds on the observation that although structured information is spread across a myriad of sources, the web scale implies a relevant redundancy, which is apparent at tthe intensional i level: l many sources share a core set of attributes at the extensional level: many instances occur in a number of sources The extraction and integration algorithm takes advantage of the coupling of the wrapper inference and the data integration tasks 24/08/2009 Paolo Atzeni 45
46 Flint main components a crawling algorithm that gathers collections of pages containing data of interest a wrapper inference and data integration algorithm that automatically ti extracts t and integrates t data from pages collected by the crawler a framework to evaluate (in probabilistic terms) the quality of the extracted data and the reliability/trustiness of the sources 24/08/2009 Paolo Atzeni 46





47 Crawling Given as input a small set of sample pages from distinct web sites The system automatically discovers pages containing data about other instances of the conceptual entity exemplified by the input samples
48 The crawler, approach Given a bunch of sample pages crawl the web sites of the sample pages to gather other pages offering the same type of information extract a set of keywords that describe the underlying entity do launch web searches to find other sources with pages that contain instances of the target entity analyze the results to filter out irrelevant pages crawl the new sources to gather new pages while new pages are found
49 Data and Sources Reliability Redundancy among autonomous and heterogeneous sources implies inconsistencies and conflicts in the integrated data because sources can provide different values for the same property of a given object A concrete example: on April 21th 2009, the open trade for the Sun Microsystem Inc. stock quote published by the CNN Money, Google Finance, and Yahoo! Finance web sites, was 9.17, 9.15 and 9.15, respectively. 24/08/2009 Paolo Atzeni 49
50 System architecture Web Search Flint Data Extraction Data Integration The Web 24/08/2009 Paolo Atzeni 50
51 System architecture Web search Flint Extraction Integration Probability The Web 24/08/2009 Paolo Atzeni 51
52 Summary The exploitation of structure is essential for extracting information from the Web In the Web world, task automation is needed to get scalability Interaction of different activities (extraction, search, transformation, integration) is often important 24/08/2009 Paolo Atzeni 52
Databases and the World Wide Web
 Databases and the World Wide Web Paolo Atzeni D.I.A. - Università di Roma Tre http://www.dia.uniroma3.it/~atzeni thanks to the Araneus group: G. Mecca, P. Merialdo, A. Masci, V. Crescenzi, G. Sindoni,
Databases and the World Wide Web Paolo Atzeni D.I.A. - Università di Roma Tre http://www.dia.uniroma3.it/~atzeni thanks to the Araneus group: G. Mecca, P. Merialdo, A. Masci, V. Crescenzi, G. Sindoni,
Semistructured Data and Mediation
 Semistructured Data and Mediation Prof. Letizia Tanca Dipartimento di Elettronica e Informazione Politecnico di Milano SEMISTRUCTURED DATA FOR THESE DATA THERE IS SOME FORM OF STRUCTURE, BUT IT IS NOT
Semistructured Data and Mediation Prof. Letizia Tanca Dipartimento di Elettronica e Informazione Politecnico di Milano SEMISTRUCTURED DATA FOR THESE DATA THERE IS SOME FORM OF STRUCTURE, BUT IT IS NOT
Extracting Data From Web Sources. Giansalvatore Mecca
 Extracting Data From Web Sources Giansalvatore Mecca Università della Basilicata mecca@unibas.it http://www.difa.unibas.it/users/gmecca/ EDBT Summer School 2002 August, 26 2002 Outline Subject of this
Extracting Data From Web Sources Giansalvatore Mecca Università della Basilicata mecca@unibas.it http://www.difa.unibas.it/users/gmecca/ EDBT Summer School 2002 August, 26 2002 Outline Subject of this
Semistructured Data and Mediation
 Semistructured Data and Mediation Prof. Letizia Tanca Dipartimento di Elettronica e Informazione Politecnico di Milano SEMISTRUCTURED DATA FOR THESE DATA THERE IS SOME FORM OF STRUCTURE, BUT IT IS NOT
Semistructured Data and Mediation Prof. Letizia Tanca Dipartimento di Elettronica e Informazione Politecnico di Milano SEMISTRUCTURED DATA FOR THESE DATA THERE IS SOME FORM OF STRUCTURE, BUT IT IS NOT
WEB SITES NEED MODELS AND SCHEMES
 WEB SITES NEED MODELS AND SCHEMES Paolo Atzeni atzeni@dia.uniroma3.it http://www.dia.uniroma3.it/~atzeni Dipartimento di informatica e automazione Università di Roma Tre Outline Databases and information
WEB SITES NEED MODELS AND SCHEMES Paolo Atzeni atzeni@dia.uniroma3.it http://www.dia.uniroma3.it/~atzeni Dipartimento di informatica e automazione Università di Roma Tre Outline Databases and information
Handling Irregularities in ROADRUNNER
 Handling Irregularities in ROADRUNNER Valter Crescenzi Universistà Roma Tre Italy crescenz@dia.uniroma3.it Giansalvatore Mecca Universistà della Basilicata Italy mecca@unibas.it Paolo Merialdo Universistà
Handling Irregularities in ROADRUNNER Valter Crescenzi Universistà Roma Tre Italy crescenz@dia.uniroma3.it Giansalvatore Mecca Universistà della Basilicata Italy mecca@unibas.it Paolo Merialdo Universistà
XXII. Website Design. The Web
 XXII. Website Design The Web Hypertext Data Independence Data Models for Hypertext Documents The Araneus Data Model (ADM) The Navigational Conceptual Model (NCM) The Araneus Methodology for Website Design
XXII. Website Design The Web Hypertext Data Independence Data Models for Hypertext Documents The Araneus Data Model (ADM) The Navigational Conceptual Model (NCM) The Araneus Methodology for Website Design
Web Data Extraction. Craig Knoblock University of Southern California. This presentation is based on slides prepared by Ion Muslea and Kristina Lerman
 Web Data Extraction Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Kristina Lerman Extracting Data from Semistructured Sources NAME Casablanca
Web Data Extraction Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Kristina Lerman Extracting Data from Semistructured Sources NAME Casablanca
Information Discovery, Extraction and Integration for the Hidden Web
 Information Discovery, Extraction and Integration for the Hidden Web Jiying Wang Department of Computer Science University of Science and Technology Clear Water Bay, Kowloon Hong Kong cswangjy@cs.ust.hk
Information Discovery, Extraction and Integration for the Hidden Web Jiying Wang Department of Computer Science University of Science and Technology Clear Water Bay, Kowloon Hong Kong cswangjy@cs.ust.hk
Redundancy-Driven Web Data Extraction and Integration
 Redundancy-Driven Web Data Extraction and Integration Lorenzo Blanco, Mirko Bronzi, Valter Crescenzi, Paolo Merialdo, Paolo Papotti Università degli Studi Roma Tre Dipartimento di Informatica e Automazione
Redundancy-Driven Web Data Extraction and Integration Lorenzo Blanco, Mirko Bronzi, Valter Crescenzi, Paolo Merialdo, Paolo Papotti Università degli Studi Roma Tre Dipartimento di Informatica e Automazione
Manual Wrapper Generation. Automatic Wrapper Generation. Grammar Induction Approach. Overview. Limitations. Website Structure-based Approach
 Automatic Wrapper Generation Kristina Lerman University of Southern California Manual Wrapper Generation Manual wrapper generation requires user to Specify the schema of the information source Single tuple
Automatic Wrapper Generation Kristina Lerman University of Southern California Manual Wrapper Generation Manual wrapper generation requires user to Specify the schema of the information source Single tuple
MIWeb: Mediator-based Integration of Web Sources
 MIWeb: Mediator-based Integration of Web Sources Susanne Busse and Thomas Kabisch Technical University of Berlin Computation and Information Structures (CIS) sbusse,tkabisch@cs.tu-berlin.de Abstract MIWeb
MIWeb: Mediator-based Integration of Web Sources Susanne Busse and Thomas Kabisch Technical University of Berlin Computation and Information Structures (CIS) sbusse,tkabisch@cs.tu-berlin.de Abstract MIWeb
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
ISSN (Online) ISSN (Print)
 ISSN (Print)") Accurate Alignment of Search Result Records from Web Data Base 1Soumya Snigdha Mohapatra, 2 M.Kalyan Ram 1,2 Dept. of CSE, Aditya Engineering College, Surampalem, East Godavari, AP, India Abstract: Most
Accurate Alignment of Search Result Records from Web Data Base 1Soumya Snigdha Mohapatra, 2 M.Kalyan Ram 1,2 Dept. of CSE, Aditya Engineering College, Surampalem, East Godavari, AP, India Abstract: Most
EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES
 EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES Praveen Kumar Malapati 1, M. Harathi 2, Shaik Garib Nawaz 2 1 M.Tech, Computer Science Engineering, 2 M.Tech, Associate Professor, Computer Science Engineering,
EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES Praveen Kumar Malapati 1, M. Harathi 2, Shaik Garib Nawaz 2 1 M.Tech, Computer Science Engineering, 2 M.Tech, Associate Professor, Computer Science Engineering,
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Template Extraction from Heterogeneous Web Pages
 Template Extraction from Heterogeneous Web Pages 1 Mrs. Harshal H. Kulkarni, 2 Mrs. Manasi k. Kulkarni Asst. Professor, Pune University, (PESMCOE, Pune), Pune, India Abstract: Templates are used by many
Template Extraction from Heterogeneous Web Pages 1 Mrs. Harshal H. Kulkarni, 2 Mrs. Manasi k. Kulkarni Asst. Professor, Pune University, (PESMCOE, Pune), Pune, India Abstract: Templates are used by many
Universita degli Studi di Roma Tre. Dipartimento di Informatica e Automazione. Design and Maintenance of. Data-Intensive Web Sites
 Universita degli Studi di Roma Tre Dipartimento di Informatica e Automazione Via della Vasca Navale, 84 { 00146 Roma, Italy. Design and Maintenance of Data-Intensive Web Sites Paolo Atzeni y, Giansalvatore
Universita degli Studi di Roma Tre Dipartimento di Informatica e Automazione Via della Vasca Navale, 84 { 00146 Roma, Italy. Design and Maintenance of Data-Intensive Web Sites Paolo Atzeni y, Giansalvatore
A Hybrid Unsupervised Web Data Extraction using Trinity and NLP
 IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
AAAI 2018 Tutorial Building Knowledge Graphs. Craig Knoblock University of Southern California
 AAAI 2018 Tutorial Building Knowledge Graphs Craig Knoblock University of Southern California Wrappers for Web Data Extraction Extracting Data from Semistructured Sources NAME Casablanca Restaurant STREET
AAAI 2018 Tutorial Building Knowledge Graphs Craig Knoblock University of Southern California Wrappers for Web Data Extraction Extracting Data from Semistructured Sources NAME Casablanca Restaurant STREET
Keywords Data alignment, Data annotation, Web database, Search Result Record
 Volume 5, Issue 8, August 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Annotating Web
Volume 5, Issue 8, August 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Annotating Web
A survey: Web mining via Tag and Value
 A survey: Web mining via Tag and Value Khirade Rajratna Rajaram. Information Technology Department SGGS IE&T, Nanded, India Balaji Shetty Information Technology Department SGGS IE&T, Nanded, India Abstract
A survey: Web mining via Tag and Value Khirade Rajratna Rajaram. Information Technology Department SGGS IE&T, Nanded, India Balaji Shetty Information Technology Department SGGS IE&T, Nanded, India Abstract
DataRover: A Taxonomy Based Crawler for Automated Data Extraction from Data-Intensive Websites
 DataRover: A Taxonomy Based Crawler for Automated Data Extraction from Data-Intensive Websites H. Davulcu, S. Koduri, S. Nagarajan Department of Computer Science and Engineering Arizona State University,
DataRover: A Taxonomy Based Crawler for Automated Data Extraction from Data-Intensive Websites H. Davulcu, S. Koduri, S. Nagarajan Department of Computer Science and Engineering Arizona State University,
WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE
 WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE *Vidya.V.L, **Aarathy Gandhi *PG Scholar, Department of Computer Science, Mohandas College of Engineering and Technology, Anad **Assistant Professor,
WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE *Vidya.V.L, **Aarathy Gandhi *PG Scholar, Department of Computer Science, Mohandas College of Engineering and Technology, Anad **Assistant Professor,
Database Systems. Sven Helmer. Database Systems p. 1/567
 Database Systems Sven Helmer Database Systems p. 1/567 Chapter 1 Introduction and Motivation Database Systems p. 2/567 Introduction What is a database system (DBS)? Obviously a system for storing and managing
Database Systems Sven Helmer Database Systems p. 1/567 Chapter 1 Introduction and Motivation Database Systems p. 2/567 Introduction What is a database system (DBS)? Obviously a system for storing and managing
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Heading-Based Sectional Hierarchy Identification for HTML Documents
 Heading-Based Sectional Hierarchy Identification for HTML Documents 1 Dept. of Computer Engineering, Boğaziçi University, Bebek, İstanbul, 34342, Turkey F. Canan Pembe 1,2 and Tunga Güngör 1 2 Dept. of
Heading-Based Sectional Hierarchy Identification for HTML Documents 1 Dept. of Computer Engineering, Boğaziçi University, Bebek, İstanbul, 34342, Turkey F. Canan Pembe 1,2 and Tunga Güngör 1 2 Dept. of
Deep Web Crawling and Mining for Building Advanced Search Application
 Deep Web Crawling and Mining for Building Advanced Search Application Zhigang Hua, Dan Hou, Yu Liu, Xin Sun, Yanbing Yu {hua, houdan, yuliu, xinsun, yyu}@cc.gatech.edu College of computing, Georgia Tech
Deep Web Crawling and Mining for Building Advanced Search Application Zhigang Hua, Dan Hou, Yu Liu, Xin Sun, Yanbing Yu {hua, houdan, yuliu, xinsun, yyu}@cc.gatech.edu College of computing, Georgia Tech
Lessons Learned and Research Agenda for Big Data Integration of Product Specifications (Discussion Paper)
") Lessons Learned and Research Agenda for Big Data Integration of Product Specifications (Discussion Paper) Luciano Barbosa 1, Valter Crescenzi 2, Xin Luna Dong 3, Paolo Merialdo 2, Federico Piai 2, Disheng
Lessons Learned and Research Agenda for Big Data Integration of Product Specifications (Discussion Paper) Luciano Barbosa 1, Valter Crescenzi 2, Xin Luna Dong 3, Paolo Merialdo 2, Federico Piai 2, Disheng
Introduction to XML. XML: basic elements
 Introduction to XML XML: basic elements XML Trying to wrap your brain around XML is sort of like trying to put an octopus in a bottle. Every time you think you have it under control, a new tentacle shows
Introduction to XML XML: basic elements XML Trying to wrap your brain around XML is sort of like trying to put an octopus in a bottle. Every time you think you have it under control, a new tentacle shows
An Approach To Web Content Mining
 An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
Study on XML-based Heterogeneous Agriculture Database Sharing Platform
 Study on XML-based Heterogeneous Agriculture Database Sharing Platform Qiulan Wu, Yongxiang Sun, Xiaoxia Yang, Yong Liang,Xia Geng School of Information Science and Engineering, Shandong Agricultural University,
Study on XML-based Heterogeneous Agriculture Database Sharing Platform Qiulan Wu, Yongxiang Sun, Xiaoxia Yang, Yong Liang,Xia Geng School of Information Science and Engineering, Shandong Agricultural University,
Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 14-15: XML CSE 414 - Spring 2013 1 Announcements Homework 4 solution will be posted tomorrow Midterm: Monday in class Open books, no notes beyond one hand-written
Introduction to Database Systems CSE 414 Lecture 14-15: XML CSE 414 - Spring 2013 1 Announcements Homework 4 solution will be posted tomorrow Midterm: Monday in class Open books, no notes beyond one hand-written
SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES
 SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES Introduction to Information Retrieval CS 150 Donald J. Patterson This content based on the paper located here: http://dx.doi.org/10.1007/s10618-008-0118-x
SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES Introduction to Information Retrieval CS 150 Donald J. Patterson This content based on the paper located here: http://dx.doi.org/10.1007/s10618-008-0118-x
A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources
 A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources Abhilasha Bhagat, ME Computer Engineering, G.H.R.I.E.T., Savitribai Phule University, pune PUNE, India Vanita Raut
A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources Abhilasha Bhagat, ME Computer Engineering, G.H.R.I.E.T., Savitribai Phule University, pune PUNE, India Vanita Raut
Teiid Designer User Guide 7.5.0
 Teiid Designer User Guide 1 7.5.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
Teiid Designer User Guide 1 7.5.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
Knowledge discovery from XML Database
 Knowledge discovery from XML Database Pravin P. Chothe 1 Prof. S. V. Patil 2 Prof.S. H. Dinde 3 PG Scholar, ADCET, Professor, ADCET Ashta, Professor, SGI, Atigre, Maharashtra, India Maharashtra, India
Knowledge discovery from XML Database Pravin P. Chothe 1 Prof. S. V. Patil 2 Prof.S. H. Dinde 3 PG Scholar, ADCET, Professor, ADCET Ashta, Professor, SGI, Atigre, Maharashtra, India Maharashtra, India
Annotating Multiple Web Databases Using Svm
 Annotating Multiple Web Databases Using Svm M.Yazhmozhi 1, M. Lavanya 2, Dr. N. Rajkumar 3 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College, Coimbatore, India 1, 3 Head
Annotating Multiple Web Databases Using Svm M.Yazhmozhi 1, M. Lavanya 2, Dr. N. Rajkumar 3 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College, Coimbatore, India 1, 3 Head
Implementing a Numerical Data Access Service
 Implementing a Numerical Data Access Service Andrew Cooke October 2008 Abstract This paper describes the implementation of a J2EE Web Server that presents numerical data, stored in a database, in various
Implementing a Numerical Data Access Service Andrew Cooke October 2008 Abstract This paper describes the implementation of a J2EE Web Server that presents numerical data, stored in a database, in various
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A SURVEY ON WEB CONTENT MINING DEVEN KENE 1, DR. PRADEEP K. BUTEY 2 1 Research
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A SURVEY ON WEB CONTENT MINING DEVEN KENE 1, DR. PRADEEP K. BUTEY 2 1 Research
MetaNews: An Information Agent for Gathering News Articles On the Web
 MetaNews: An Information Agent for Gathering News Articles On the Web Dae-Ki Kang 1 and Joongmin Choi 2 1 Department of Computer Science Iowa State University Ames, IA 50011, USA dkkang@cs.iastate.edu
MetaNews: An Information Agent for Gathering News Articles On the Web Dae-Ki Kang 1 and Joongmin Choi 2 1 Department of Computer Science Iowa State University Ames, IA 50011, USA dkkang@cs.iastate.edu
Copyright 2014 Blue Net Corporation. All rights reserved
 a) Abstract: REST is a framework built on the principle of today's World Wide Web. Yes it uses the principles of WWW in way it is a challenge to lay down a new architecture that is already widely deployed
a) Abstract: REST is a framework built on the principle of today's World Wide Web. Yes it uses the principles of WWW in way it is a challenge to lay down a new architecture that is already widely deployed
CSE 344 MAY 7 TH EXAM REVIEW
 CSE 344 MAY 7 TH EXAM REVIEW EXAMINATION STATIONS Exam Wednesday 9:30-10:20 One sheet of notes, front and back Practice solutions out after class Good luck! EXAM LENGTH Production v. Verification Practice
CSE 344 MAY 7 TH EXAM REVIEW EXAMINATION STATIONS Exam Wednesday 9:30-10:20 One sheet of notes, front and back Practice solutions out after class Good luck! EXAM LENGTH Production v. Verification Practice
Tag-based Social Interest Discovery
 Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
XML and information exchange. XML extensible Markup Language XML
 COS 425: Database and Information Management Systems XML and information exchange 1 XML extensible Markup Language History 1988 SGML: Standard Generalized Markup Language Annotate text with structure 1992
COS 425: Database and Information Management Systems XML and information exchange 1 XML extensible Markup Language History 1988 SGML: Standard Generalized Markup Language Annotate text with structure 1992
Chapter 1: Introduction
 Chapter 1: Introduction Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Outline The Need for Databases Data Models Relational Databases Database Design Storage Manager Query
Chapter 1: Introduction Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Outline The Need for Databases Data Models Relational Databases Database Design Storage Manager Query
Home Page. Title Page. Page 1 of 14. Go Back. Full Screen. Close. Quit
 Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Getting Started with Web Services
 Getting Started with Web Services Getting Started with Web Services A web service is a set of functions packaged into a single entity that is available to other systems on a network. The network can be
Getting Started with Web Services Getting Started with Web Services A web service is a set of functions packaged into a single entity that is available to other systems on a network. The network can be
A tutorial report for SENG Agent Based Software Engineering. Course Instructor: Dr. Behrouz H. Far. XML Tutorial.
 A tutorial report for SENG 609.22 Agent Based Software Engineering Course Instructor: Dr. Behrouz H. Far XML Tutorial Yanan Zhang Department of Electrical and Computer Engineering University of Calgary
A tutorial report for SENG 609.22 Agent Based Software Engineering Course Instructor: Dr. Behrouz H. Far XML Tutorial Yanan Zhang Department of Electrical and Computer Engineering University of Calgary
Synergic Data Extraction and Crawling for Large Web Sites
 Synergic Data Extraction and Crawling for Large Web Sites Celine Badr, Paolo Merialdo, Valter Crescenzi Dipartimento di Ingegneria Università Roma Tre Rome - Italy {badr, merialdo, crescenz}@dia.uniroma3.it
Synergic Data Extraction and Crawling for Large Web Sites Celine Badr, Paolo Merialdo, Valter Crescenzi Dipartimento di Ingegneria Università Roma Tre Rome - Italy {badr, merialdo, crescenz}@dia.uniroma3.it
Database Roma Tre
 Database Group @ Roma Tre http://www.dia.uniroma3.it/db/ DIPARTIMENTO DI INFORMATICA E AUTOMAZIONE July 2012 The Database Group is one of the six research groups of the Department of Computer Science and
Database Group @ Roma Tre http://www.dia.uniroma3.it/db/ DIPARTIMENTO DI INFORMATICA E AUTOMAZIONE July 2012 The Database Group is one of the six research groups of the Department of Computer Science and
Getting Started with Web Services
 Getting Started with Web Services Getting Started with Web Services A web service is a set of functions packaged into a single entity that is available to other systems on a network. The network can be
Getting Started with Web Services Getting Started with Web Services A web service is a set of functions packaged into a single entity that is available to other systems on a network. The network can be
HERA: Automatically Generating Hypermedia Front- Ends for Ad Hoc Data from Heterogeneous and Legacy Information Systems
 HERA: Automatically Generating Hypermedia Front- Ends for Ad Hoc Data from Heterogeneous and Legacy Information Systems Geert-Jan Houben 1,2 1 Eindhoven University of Technology, Dept. of Mathematics and
HERA: Automatically Generating Hypermedia Front- Ends for Ad Hoc Data from Heterogeneous and Legacy Information Systems Geert-Jan Houben 1,2 1 Eindhoven University of Technology, Dept. of Mathematics and
RoadRunner for Heterogeneous Web Pages Using Extended MinHash
 RoadRunner for Heterogeneous Web Pages Using Extended MinHash A Suresh Babu 1, P. Premchand 2 and A. Govardhan 3 1 Department of Computer Science and Engineering, JNTUACE Pulivendula, India asureshjntu@gmail.com
RoadRunner for Heterogeneous Web Pages Using Extended MinHash A Suresh Babu 1, P. Premchand 2 and A. Govardhan 3 1 Department of Computer Science and Engineering, JNTUACE Pulivendula, India asureshjntu@gmail.com
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Enterprise Data Catalog for Microsoft Azure Tutorial
 Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Annotation Component in KiWi
 Annotation Component in KiWi Marek Schmidt and Pavel Smrž Faculty of Information Technology Brno University of Technology Božetěchova 2, 612 66 Brno, Czech Republic E-mail: {ischmidt,smrz}@fit.vutbr.cz
Annotation Component in KiWi Marek Schmidt and Pavel Smrž Faculty of Information Technology Brno University of Technology Božetěchova 2, 612 66 Brno, Czech Republic E-mail: {ischmidt,smrz}@fit.vutbr.cz
A B2B Search Engine. Abstract. Motivation. Challenges. Technical Report
 Technical Report A B2B Search Engine Abstract In this report, we describe a business-to-business search engine that allows searching for potential customers with highly-specific queries. Currently over
Technical Report A B2B Search Engine Abstract In this report, we describe a business-to-business search engine that allows searching for potential customers with highly-specific queries. Currently over
Development of an Ontology-Based Portal for Digital Archive Services
 Development of an Ontology-Based Portal for Digital Archive Services Ching-Long Yeh Department of Computer Science and Engineering Tatung University 40 Chungshan N. Rd. 3rd Sec. Taipei, 104, Taiwan chingyeh@cse.ttu.edu.tw
Development of an Ontology-Based Portal for Digital Archive Services Ching-Long Yeh Department of Computer Science and Engineering Tatung University 40 Chungshan N. Rd. 3rd Sec. Taipei, 104, Taiwan chingyeh@cse.ttu.edu.tw
Object Extraction. Output Tagging. A Generated Wrapper
 Wrapping Data into XML Wei Han, David Buttler, Calton Pu Georgia Institute of Technology College of Computing Atlanta, Georgia 30332-0280 USA fweihan, buttler, calton g@cc.gatech.edu Abstract The vast
Wrapping Data into XML Wei Han, David Buttler, Calton Pu Georgia Institute of Technology College of Computing Atlanta, Georgia 30332-0280 USA fweihan, buttler, calton g@cc.gatech.edu Abstract The vast
ESRI stylesheet selects a subset of the entire body of the metadata and presents it as if it was in a tabbed dialog.
 Creating Metadata using ArcCatalog (ACT) 1. Choosing a metadata editor in ArcCatalog ArcCatalog comes with FGDC metadata editor, which create FGDC-compliant documentation. Metadata in ArcCatalog stored
Creating Metadata using ArcCatalog (ACT) 1. Choosing a metadata editor in ArcCatalog ArcCatalog comes with FGDC metadata editor, which create FGDC-compliant documentation. Metadata in ArcCatalog stored
Basi di dati e World Wide Web
 Basi di dati e World Wide Web Paolo Atzeni 30/05/2003 Problems with many Web-sites design information is often poorly organized and difficult to access it is not even clear which pieces of information
Basi di dati e World Wide Web Paolo Atzeni 30/05/2003 Problems with many Web-sites design information is often poorly organized and difficult to access it is not even clear which pieces of information
Features and Requirements for an XML View Definition Language: Lessons from XML Information Mediation
 Page 1 of 5 Features and Requirements for an XML View Definition Language: Lessons from XML Information Mediation 1. Introduction C. Baru, B. Ludäscher, Y. Papakonstantinou, P. Velikhov, V. Vianu XML indicates
Page 1 of 5 Features and Requirements for an XML View Definition Language: Lessons from XML Information Mediation 1. Introduction C. Baru, B. Ludäscher, Y. Papakonstantinou, P. Velikhov, V. Vianu XML indicates
XML: Extensible Markup Language
 XML: Extensible Markup Language CSC 375, Fall 2015 XML is a classic political compromise: it balances the needs of man and machine by being equally unreadable to both. Matthew Might Slides slightly modified
XML: Extensible Markup Language CSC 375, Fall 2015 XML is a classic political compromise: it balances the needs of man and machine by being equally unreadable to both. Matthew Might Slides slightly modified
Database System Concepts and Architecture
 CHAPTER 2 Database System Concepts and Architecture Copyright 2017 Ramez Elmasri and Shamkant B. Navathe Slide 2-2 Outline Data Models and Their Categories History of Data Models Schemas, Instances, and
CHAPTER 2 Database System Concepts and Architecture Copyright 2017 Ramez Elmasri and Shamkant B. Navathe Slide 2-2 Outline Data Models and Their Categories History of Data Models Schemas, Instances, and
Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 13: XML and XPath 1 Announcements Current assignments: Web quiz 4 due tonight, 11 pm Homework 4 due Wednesday night, 11 pm Midterm: next Monday, May 4,
Introduction to Database Systems CSE 414 Lecture 13: XML and XPath 1 Announcements Current assignments: Web quiz 4 due tonight, 11 pm Homework 4 due Wednesday night, 11 pm Midterm: next Monday, May 4,
Speech 2 Part 2 Transcript: The role of DB2 in Web 2.0 and in the IOD World
 Speech 2 Part 2 Transcript: The role of DB2 in Web 2.0 and in the IOD World Slide 1: Cover Welcome to the speech, The role of DB2 in Web 2.0 and in the Information on Demand World. This is the second speech
Speech 2 Part 2 Transcript: The role of DB2 in Web 2.0 and in the IOD World Slide 1: Cover Welcome to the speech, The role of DB2 in Web 2.0 and in the Information on Demand World. This is the second speech
Web Presentation Patterns (controller) SWEN-343 From Fowler, Patterns of Enterprise Application Architecture
 SWEN-343 From Fowler, Patterns of Enterprise Application Architecture") Web Presentation Patterns (controller) SWEN-343 From Fowler, Patterns of Enterprise Application Architecture Objectives Look at common patterns for designing Web-based presentation layer behavior Model-View-Control
Web Presentation Patterns (controller) SWEN-343 From Fowler, Patterns of Enterprise Application Architecture Objectives Look at common patterns for designing Web-based presentation layer behavior Model-View-Control
Generalized Document Data Model for Integrating Autonomous Applications
 6 th International Conference on Applied Informatics Eger, Hungary, January 27 31, 2004. Generalized Document Data Model for Integrating Autonomous Applications Zsolt Hernáth, Zoltán Vincellér Abstract
6 th International Conference on Applied Informatics Eger, Hungary, January 27 31, 2004. Generalized Document Data Model for Integrating Autonomous Applications Zsolt Hernáth, Zoltán Vincellér Abstract
Part V. Relational XQuery-Processing. Marc H. Scholl (DBIS, Uni KN) XML and Databases Winter 2007/08 297
 XML and Databases Winter 2007/08 297") Part V Relational XQuery-Processing Marc H Scholl (DBIS, Uni KN) XML and Databases Winter 2007/08 297 Outline of this part (I) 12 Mapping Relational Databases to XML Introduction Wrapping Tables into XML
Part V Relational XQuery-Processing Marc H Scholl (DBIS, Uni KN) XML and Databases Winter 2007/08 297 Outline of this part (I) 12 Mapping Relational Databases to XML Introduction Wrapping Tables into XML
Hypertext Markup Language, or HTML, is a markup
 Introduction to HTML Hypertext Markup Language, or HTML, is a markup language that enables you to structure and display content such as text, images, and links in Web pages. HTML is a very fast and efficient
Introduction to HTML Hypertext Markup Language, or HTML, is a markup language that enables you to structure and display content such as text, images, and links in Web pages. HTML is a very fast and efficient
International Journal of Computer Science Trends and Technology (IJCST) Volume 3 Issue 4, Jul-Aug 2015
 Volume 3 Issue 4, Jul-Aug 2015") RESEARCH ARTICLE OPEN ACCESS Multi-Lingual Ontology Server (MOS) For Discovering Web Services Abdelrahman Abbas Ibrahim [1], Dr. Nael Salman [2] Department of Software Engineering [1] Sudan University
RESEARCH ARTICLE OPEN ACCESS Multi-Lingual Ontology Server (MOS) For Discovering Web Services Abdelrahman Abbas Ibrahim [1], Dr. Nael Salman [2] Department of Software Engineering [1] Sudan University
Typing Massive JSON Datasets
 Typing Massive JSON Datasets Dario Colazzo Université Paris Sud - INRIA Giorgio Ghelli Università di Pisa Carlo Sartiani Università della Basilicata Outline Introduction & Motivation Data model & Type
Typing Massive JSON Datasets Dario Colazzo Université Paris Sud - INRIA Giorgio Ghelli Università di Pisa Carlo Sartiani Università della Basilicata Outline Introduction & Motivation Data model & Type
Motivating Ontology-Driven Information Extraction
 Motivating Ontology-Driven Information Extraction Burcu Yildiz 1 and Silvia Miksch 1, 2 1 Institute for Software Engineering and Interactive Systems, Vienna University of Technology, Vienna, Austria {yildiz,silvia}@
Motivating Ontology-Driven Information Extraction Burcu Yildiz 1 and Silvia Miksch 1, 2 1 Institute for Software Engineering and Interactive Systems, Vienna University of Technology, Vienna, Austria {yildiz,silvia}@
Overview. Structured Data. The Structure of Data. Semi-Structured Data Introduction to XML Querying XML Documents. CMPUT 391: XML and Querying XML
 Database Management Systems Winter 2004 CMPUT 391: XML and Querying XML Lecture 12 Overview Semi-Structured Data Introduction to XML Querying XML Documents Dr. Osmar R. Zaïane University of Alberta Chapter
Database Management Systems Winter 2004 CMPUT 391: XML and Querying XML Lecture 12 Overview Semi-Structured Data Introduction to XML Querying XML Documents Dr. Osmar R. Zaïane University of Alberta Chapter
Research and implementation of search engine based on Lucene Wan Pu, Wang Lisha
 2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) Research and implementation of search engine based on Lucene Wan Pu, Wang Lisha Physics Institute,
2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) Research and implementation of search engine based on Lucene Wan Pu, Wang Lisha Physics Institute,
Modelling Structures in Data Mining Techniques
 Modelling Structures in Data Mining Techniques Ananth Y N 1, Narahari.N.S 2 Associate Professor, Dept of Computer Science, School of Graduate Studies- JainUniversity- J.C.Road, Bangalore, INDIA 1 Professor
Modelling Structures in Data Mining Techniques Ananth Y N 1, Narahari.N.S 2 Associate Professor, Dept of Computer Science, School of Graduate Studies- JainUniversity- J.C.Road, Bangalore, INDIA 1 Professor
ABSTRACT The Araneus project aims at developing tools for data-management on the World Wide Web. Web-based information systems deal with data of heter
 Universita degli Studi di Roma Tre Dipartimento di Informatica e Automazione Via della Vasca Navale, 84 { 00146 Roma, Italy. From Databases to Web-Bases: The Araneus Experience G. Mecca 1, P. Atzeni 2,
Universita degli Studi di Roma Tre Dipartimento di Informatica e Automazione Via della Vasca Navale, 84 { 00146 Roma, Italy. From Databases to Web-Bases: The Araneus Experience G. Mecca 1, P. Atzeni 2,
SDPL : XML Basics 2. SDPL : XML Basics 1. SDPL : XML Basics 4. SDPL : XML Basics 3. SDPL : XML Basics 5
 2 Basics of XML and XML documents 2.1 XML and XML documents Survivor's Guide to XML, or XML for Computer Scientists / Dummies 2.1 XML and XML documents 2.2 Basics of XML DTDs 2.3 XML Namespaces XML 1.0
2 Basics of XML and XML documents 2.1 XML and XML documents Survivor's Guide to XML, or XML for Computer Scientists / Dummies 2.1 XML and XML documents 2.2 Basics of XML DTDs 2.3 XML Namespaces XML 1.0
Information Retrieval CSCI
 Information Retrieval CSCI 4141-6403 My name is Anwar Alhenshiri My email is: anwar@cs.dal.ca I prefer: aalhenshiri@gmail.com The course website is: http://web.cs.dal.ca/~anwar/ir/main.html 5/6/2012 1
Information Retrieval CSCI 4141-6403 My name is Anwar Alhenshiri My email is: anwar@cs.dal.ca I prefer: aalhenshiri@gmail.com The course website is: http://web.cs.dal.ca/~anwar/ir/main.html 5/6/2012 1
Data Presentation and Markup Languages
 Data Presentation and Markup Languages MIE456 Tutorial Acknowledgements Some contents of this presentation are borrowed from a tutorial given at VLDB 2000, Cairo, Agypte (www.vldb.org) by D. Florescu &.
Data Presentation and Markup Languages MIE456 Tutorial Acknowledgements Some contents of this presentation are borrowed from a tutorial given at VLDB 2000, Cairo, Agypte (www.vldb.org) by D. Florescu &.
Form Identifying. Figure 1 A typical HTML form
 Table of Contents Form Identifying... 2 1. Introduction... 2 2. Related work... 2 3. Basic elements in an HTML from... 3 4. Logic structure of an HTML form... 4 5. Implementation of Form Identifying...
Table of Contents Form Identifying... 2 1. Introduction... 2 2. Related work... 2 3. Basic elements in an HTML from... 3 4. Logic structure of an HTML form... 4 5. Implementation of Form Identifying...
B.H.GARDI COLLEGE OF MASTER OF COMPUTER APPLICATION. Ch. 1 :- Introduction Database Management System - 1
 Basic Concepts :- 1. What is Data? Data is a collection of facts from which conclusion may be drawn. In computer science, data is anything in a form suitable for use with a computer. Data is often distinguished
Basic Concepts :- 1. What is Data? Data is a collection of facts from which conclusion may be drawn. In computer science, data is anything in a form suitable for use with a computer. Data is often distinguished
Automatic Wrapper Adaptation by Tree Edit Distance Matching
 Automatic Wrapper Adaptation by Tree Edit Distance Matching E. Ferrara 1 R. Baumgartner 2 1 Department of Mathematics University of Messina, Italy 2 Lixto Software GmbH Vienna, Austria 2nd International
Automatic Wrapper Adaptation by Tree Edit Distance Matching E. Ferrara 1 R. Baumgartner 2 1 Department of Mathematics University of Messina, Italy 2 Lixto Software GmbH Vienna, Austria 2nd International
CSCI3030U Database Models
 CSCI3030U Database Models CSCI3030U RELATIONAL MODEL SEMISTRUCTURED MODEL 1 Content Design of databases. relational model, semistructured model. Database programming. SQL, XPath, XQuery. Not DBMS implementation.
CSCI3030U Database Models CSCI3030U RELATIONAL MODEL SEMISTRUCTURED MODEL 1 Content Design of databases. relational model, semistructured model. Database programming. SQL, XPath, XQuery. Not DBMS implementation.
Ontology Based Prediction of Difficult Keyword Queries
 Ontology Based Prediction of Difficult Keyword Queries Lubna.C*, Kasim K Pursuing M.Tech (CSE)*, Associate Professor (CSE) MEA Engineering College, Perinthalmanna Kerala, India lubna9990@gmail.com, kasim_mlp@gmail.com
Ontology Based Prediction of Difficult Keyword Queries Lubna.C*, Kasim K Pursuing M.Tech (CSE)*, Associate Professor (CSE) MEA Engineering College, Perinthalmanna Kerala, India lubna9990@gmail.com, kasim_mlp@gmail.com
A General Approach to Query the Web of Data
 A General Approach to Query the Web of Data Xin Liu 1 Department of Information Science and Engineering, University of Trento, Trento, Italy liu@disi.unitn.it Abstract. With the development of the Semantic
A General Approach to Query the Web of Data Xin Liu 1 Department of Information Science and Engineering, University of Trento, Trento, Italy liu@disi.unitn.it Abstract. With the development of the Semantic
Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India
 Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India Abstract - The primary goal of the web site is to provide the
Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India Abstract - The primary goal of the web site is to provide the
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 11: XML and XPath 1 XML Outline What is XML? Syntax Semistructured data DTDs XPath 2 What is XML? Stands for extensible Markup Language 1. Advanced, self-describing
Introduction to Data Management CSE 344 Lecture 11: XML and XPath 1 XML Outline What is XML? Syntax Semistructured data DTDs XPath 2 What is XML? Stands for extensible Markup Language 1. Advanced, self-describing
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
ProFoUnd: Program-analysis based Form Understanding
 ProFoUnd: Program-analysis based Form Understanding (joint work with M. Benedikt, T. Furche, A. Savvides) PIERRE SENELLART IC2 Group Seminar, 16 May 2012 The Deep Web Definition (Deep Web, Hidden Web,
ProFoUnd: Program-analysis based Form Understanding (joint work with M. Benedikt, T. Furche, A. Savvides) PIERRE SENELLART IC2 Group Seminar, 16 May 2012 The Deep Web Definition (Deep Web, Hidden Web,
Java Framework for Database-Centric Web Site Engineering
 Java Framework for Database-Centric Web Site Engineering Beat Signer, Michael Grossniklaus and Moira C. Norrie fsigner, grossniklaus, norrieg@inf.ethz.ch Institute for Information Systems ETH Zurich CH-8092
Java Framework for Database-Centric Web Site Engineering Beat Signer, Michael Grossniklaus and Moira C. Norrie fsigner, grossniklaus, norrieg@inf.ethz.ch Institute for Information Systems ETH Zurich CH-8092
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN EFFECTIVE KEYWORD SEARCH OF FUZZY TYPE IN XML
 INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 EFFECTIVE KEYWORD SEARCH OF FUZZY TYPE IN XML Mr. Mohammed Tariq Alam 1,Mrs.Shanila Mahreen 2 Assistant Professor
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 EFFECTIVE KEYWORD SEARCH OF FUZZY TYPE IN XML Mr. Mohammed Tariq Alam 1,Mrs.Shanila Mahreen 2 Assistant Professor
CS145 Introduction. About CS145 Relational Model, Schemas, SQL Semistructured Model, XML
 CS145 Introduction About CS145 Relational Model, Schemas, SQL Semistructured Model, XML 1 Content of CS145 Design of databases. E/R model, relational model, semistructured model, XML, UML, ODL. Database
CS145 Introduction About CS145 Relational Model, Schemas, SQL Semistructured Model, XML 1 Content of CS145 Design of databases. E/R model, relational model, semistructured model, XML, UML, ODL. Database
Supporting Fuzzy Keyword Search in Databases
 I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
ISSN: (Online) Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies
 Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
ISSN: 2321-7782 (Online) Volume 3, Issue 6, June 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
XML Processing & Web Services. Husni Husni.trunojoyo.ac.id
 XML Processing & Web Services Husni Husni.trunojoyo.ac.id Based on Randy Connolly and Ricardo Hoar Fundamentals of Web Development, Pearson Education, 2015 Objectives 1 XML Overview 2 XML Processing 3
XML Processing & Web Services Husni Husni.trunojoyo.ac.id Based on Randy Connolly and Ricardo Hoar Fundamentals of Web Development, Pearson Education, 2015 Objectives 1 XML Overview 2 XML Processing 3
SEEK: Scalable Extraction of Enterprise Knowledge
 SEEK: Scalable Extraction of Enterprise Knowledge Joachim Hammer Dept. of CISE University of Florida 26-Feb-2002 1 Project Overview Faculty Joachim Hammer Mark Schmalz Computer Science Students Sangeetha
SEEK: Scalable Extraction of Enterprise Knowledge Joachim Hammer Dept. of CISE University of Florida 26-Feb-2002 1 Project Overview Faculty Joachim Hammer Mark Schmalz Computer Science Students Sangeetha