Lab Exercise Three Classification with WEKA Explorer
|
|
|
- Erin Holmes
- 6 years ago
- Views:
Transcription



1 Lab Exercise Three Classification with WEKA Explorer 1. Fire up WEKA to get the GUI Chooser panel. Select Explorer from the four choices on the right side. 2. We are on Preprocess now. Click the Open file button to bring up a standard dialog through which you can select a file. Choose the customer_labthree.cvs file. 3. To perform classification with Weka, the last attribute in the dataset is taken as class label and it should be nominal. Since the last attribute of data set customer_labthree.cvs is numeric type (1/0), we should convert it to nominal type in next step.


2 4. Unsupervised attribute filter NumericToNominal is chosen to perform this conversion. Since we would like to convert the last attribute only, change the attributeindices to last. 5. After applying the filter, the last attribute becomes nominal type and it is taken as the class label for the dataset now the data set is visualized in two colors.

3 6. If the class attribute is not the last attribute, you could set it in edit window. 7. You should also to convert the types of other attributes. Attributes region, townsize, agecat, jobcat, empcat, card2tenurecat, and internet are all nominal values, however, they are treated as numeric type by Weka. And attributes gender, union, equip, wireless, called, callwait, forward, confer, ebill are binary values,


4 they are treated as numeric types as well. NumericToNominal filter should be applied to convert them. You could also normalize attribute educat to [0, 1] since education categories are rankings. Attribute Selection - Since not all attributes are relevant to the classification job, you should perform attribute selection before training the classifier. 8. You could remove irrelevant attributes by hand. For example, the first attribute custid should be removed. Select it and click Remove button to remove it.


5 9. You also could run automatic attribute selection. We have introduced two methods of evaluating attributes individually InfoGainAttributeEval and ChiSquaredAttributeEval. The default attribute selection method of Weka is CfsSubsetEval, which evaluates subsets of attributes. 10. To use evaluator InfoGainAttributeEval, a search method Ranker is selected to rank all attributes regarding the evaluation results. We use the full dataset as training dataset. The results show that the first 8 attributes are good.


6 11. Run feature selection the second time with CfsSubsetEval and BestFirst search method. Compare results of two feature selection methods.


7 12. If you decide to reduce the dataset by removing unimportant attributes, you could choose to save the reduced dataset by right-click the Result list. Save the file name as customer.arff. Naïve Bayes Classifier: bayes/naïvebayes 13. Open the saved processed data file customer.arff and then click Classify Tab on top of the window. Click Choose button under Classifier. The drop down list of all classifiers show. Choose NaiveBayes from bayes folder.


8 14. Left click the field of Classifier, choose Show Property from the drop down list. The property window of NaiveBayes opens, if you do not want to use Normal Distribution for numeric data, set usekernelestimator to ture; You also could perform supervised discretization on numeric data by setting usesuperviseddiscretization to ture. Click OK button to save all the settings. 15. To partition the training data set and test data set, choose 10-fold crossvalidation.


9 16. Click Start button on the left of the window, the algorithm begins to run. The output is showing in the right window. parameters of normal distributions for numeric attributes frequency counts of nominal values NaiveBayes avoids zero frequencies by applying the Laplace correction. Accuracy


10 K-Nearest-Neighbor: lazy/ibk 17. We would like to perform K-Nearest-Neighbor classification on the same dataset. You could try different K and see what value gives a better result. Compare the results with Naïve Bayes classifier.
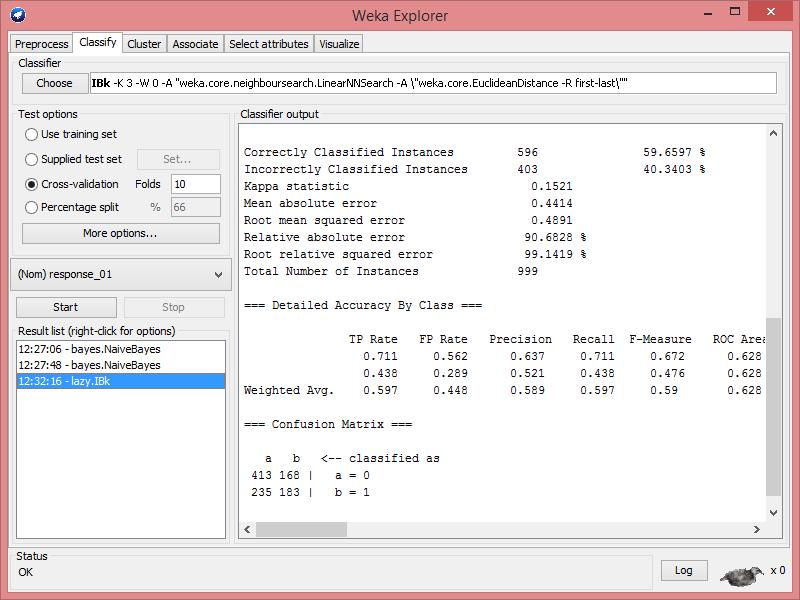
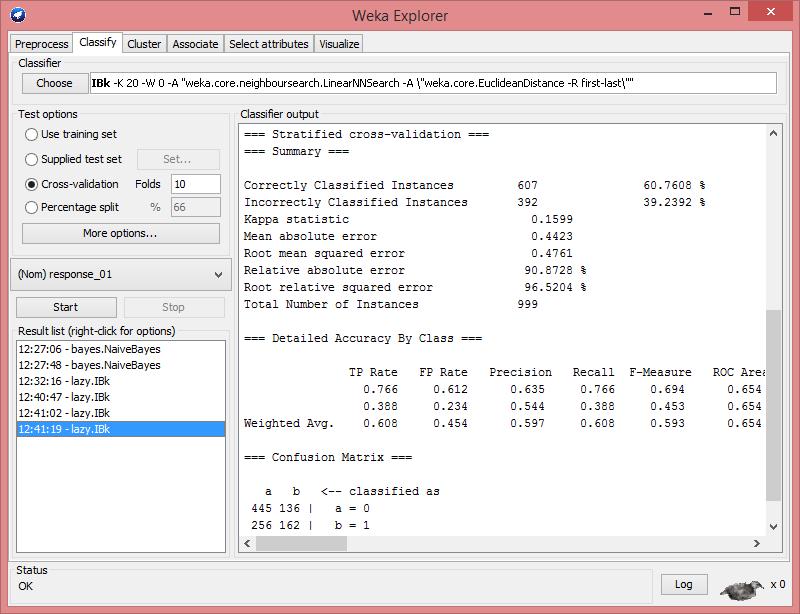
11
 18.")

12 Decision Tree: trees/j48 (Implementing C4.5) 18. We would like to build a Decision Tree model on the same given training data set. Take all default values of the parameters.
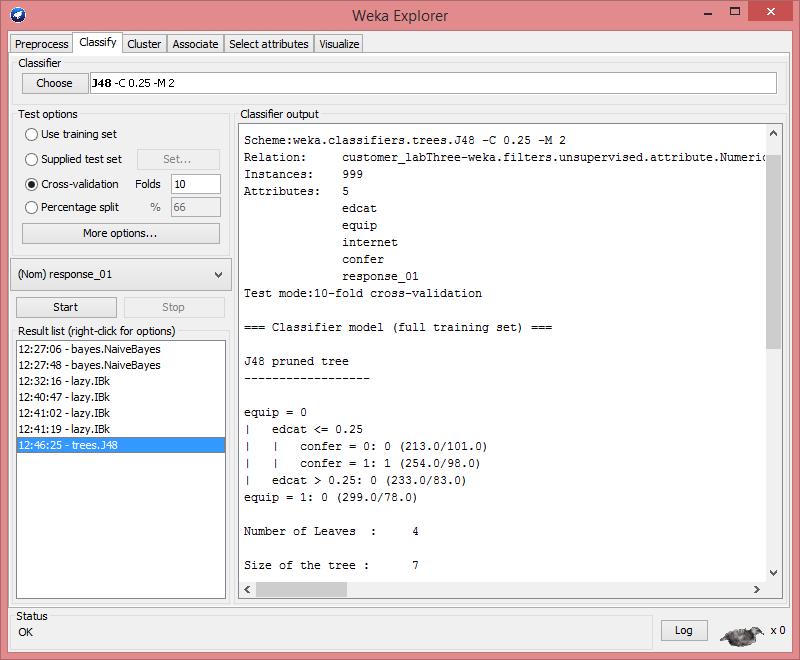
13


14 19. To visualize the decision tree we build, right-click the Result list item for J All trained classification models could be saved by right-click the Result list items.
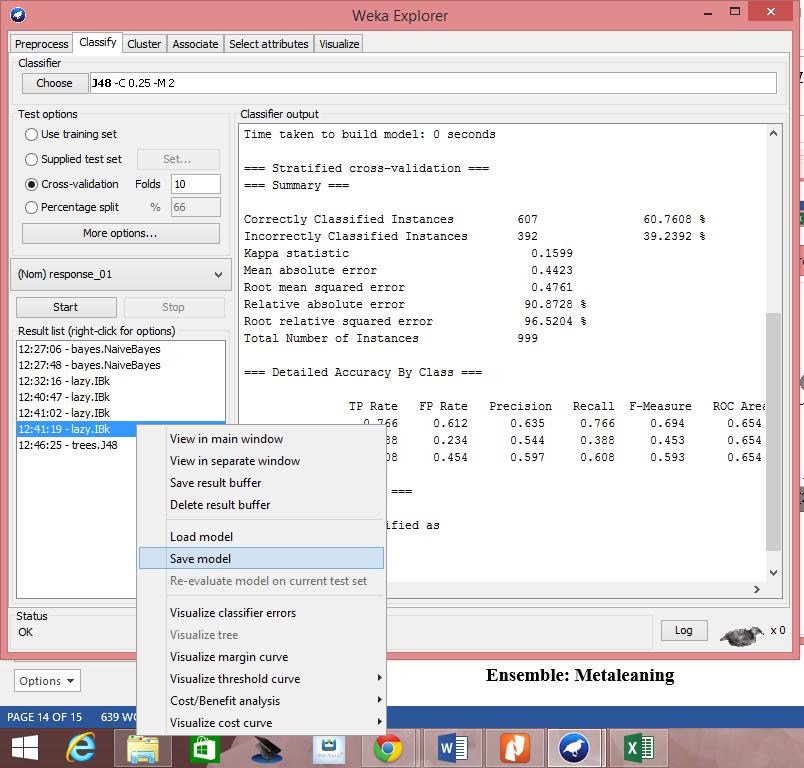
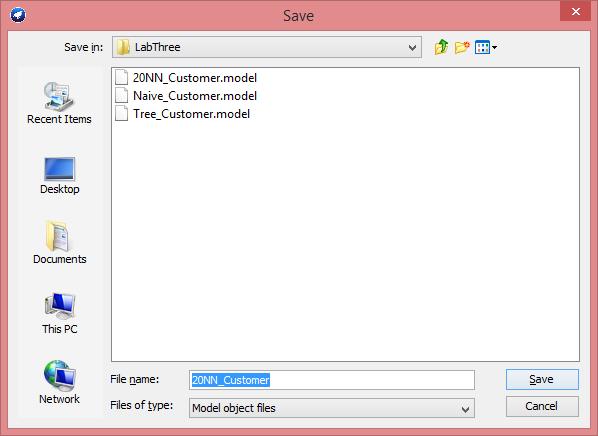
15


16 Ensemble (Metaleaning) classifier.meta.voting 21. You could combine multiple classifiers to perfrom an ensemble method.
Attribute Discretization and Selection. Clustering. NIKOLA MILIKIĆ UROŠ KRČADINAC
 Attribute Discretization and Selection Clustering NIKOLA MILIKIĆ nikola.milikic@fon.bg.ac.rs UROŠ KRČADINAC uros@krcadinac.com Naive Bayes Features Intended primarily for the work with nominal attributes
Attribute Discretization and Selection Clustering NIKOLA MILIKIĆ nikola.milikic@fon.bg.ac.rs UROŠ KRČADINAC uros@krcadinac.com Naive Bayes Features Intended primarily for the work with nominal attributes
Using Weka for Classification. Preparing a data file
 Using Weka for Classification Preparing a data file Prepare a data file in CSV format. It should have the names of the features, which Weka calls attributes, on the first line, with the names separated
Using Weka for Classification Preparing a data file Prepare a data file in CSV format. It should have the names of the features, which Weka calls attributes, on the first line, with the names separated
6.034 Design Assignment 2
 6.034 Design Assignment 2 April 5, 2005 Weka Script Due: Friday April 8, in recitation Paper Due: Wednesday April 13, in class Oral reports: Friday April 15, by appointment The goal of this assignment
6.034 Design Assignment 2 April 5, 2005 Weka Script Due: Friday April 8, in recitation Paper Due: Wednesday April 13, in class Oral reports: Friday April 15, by appointment The goal of this assignment
Data Preparation. UROŠ KRČADINAC URL:
 Data Preparation UROŠ KRČADINAC EMAIL: uros@krcadinac.com URL: http://krcadinac.com Normalization Normalization is the process of rescaling the values to a specific value scale (typically 0-1) Standardization
Data Preparation UROŠ KRČADINAC EMAIL: uros@krcadinac.com URL: http://krcadinac.com Normalization Normalization is the process of rescaling the values to a specific value scale (typically 0-1) Standardization
WEKA homepage.
 WEKA homepage http://www.cs.waikato.ac.nz/ml/weka/ Data mining software written in Java (distributed under the GNU Public License). Used for research, education, and applications. Comprehensive set of
WEKA homepage http://www.cs.waikato.ac.nz/ml/weka/ Data mining software written in Java (distributed under the GNU Public License). Used for research, education, and applications. Comprehensive set of
Practical Data Mining COMP-321B. Tutorial 4: Preprocessing
 Practical Data Mining COMP-321B Tutorial 4: Preprocessing Shevaun Ryan Mark Hall June 30, 2008 c 2006 University of Waikato 1 Introduction For this tutorial we will be using the Preprocess panel, the Classify
Practical Data Mining COMP-321B Tutorial 4: Preprocessing Shevaun Ryan Mark Hall June 30, 2008 c 2006 University of Waikato 1 Introduction For this tutorial we will be using the Preprocess panel, the Classify
Data Preparation. Nikola Milikić. Jelena Jovanović
 Data Preparation Nikola Milikić nikola.milikic@fon.bg.ac.rs Jelena Jovanović jeljov@fon.bg.ac.rs Normalization Normalization is the process of rescaling the values of an attribute to a specific value range,
Data Preparation Nikola Milikić nikola.milikic@fon.bg.ac.rs Jelena Jovanović jeljov@fon.bg.ac.rs Normalization Normalization is the process of rescaling the values of an attribute to a specific value range,
Lab Exercise Two Mining Association Rule with WEKA Explorer
 Lab Exercise Two Mining Association Rule with WEKA Explorer 1. Fire up WEKA to get the GUI Chooser panel. Select Explorer from the four choices on the right side. 2. To get a feel for how to apply Apriori,
Lab Exercise Two Mining Association Rule with WEKA Explorer 1. Fire up WEKA to get the GUI Chooser panel. Select Explorer from the four choices on the right side. 2. To get a feel for how to apply Apriori,
1. make a scenario and build a bayesian network + conditional probability table! use only nominal variable!
 Project 1 140313 1. make a scenario and build a bayesian network + conditional probability table! use only nominal variable! network.txt @attribute play {yes, no}!!! @graph! play -> outlook! play -> temperature!
Project 1 140313 1. make a scenario and build a bayesian network + conditional probability table! use only nominal variable! network.txt @attribute play {yes, no}!!! @graph! play -> outlook! play -> temperature!
Data Engineering. Data preprocessing and transformation
 Data Engineering Data preprocessing and transformation Just apply a learner? NO! Algorithms are biased No free lunch theorem: considering all possible data distributions, no algorithm is better than another
Data Engineering Data preprocessing and transformation Just apply a learner? NO! Algorithms are biased No free lunch theorem: considering all possible data distributions, no algorithm is better than another
Practical Data Mining COMP-321B. Tutorial 5: Article Identification
 Practical Data Mining COMP-321B Tutorial 5: Article Identification Shevaun Ryan Mark Hall August 15, 2006 c 2006 University of Waikato 1 Introduction This tutorial will focus on text mining, using text
Practical Data Mining COMP-321B Tutorial 5: Article Identification Shevaun Ryan Mark Hall August 15, 2006 c 2006 University of Waikato 1 Introduction This tutorial will focus on text mining, using text
Practical Data Mining COMP-321B. Tutorial 1: Introduction to the WEKA Explorer
 Practical Data Mining COMP-321B Tutorial 1: Introduction to the WEKA Explorer Gabi Schmidberger Mark Hall Richard Kirkby July 12, 2006 c 2006 University of Waikato 1 Setting up your Environment Before
Practical Data Mining COMP-321B Tutorial 1: Introduction to the WEKA Explorer Gabi Schmidberger Mark Hall Richard Kirkby July 12, 2006 c 2006 University of Waikato 1 Setting up your Environment Before
User Guide Written By Yasser EL-Manzalawy
 User Guide Written By Yasser EL-Manzalawy 1 Copyright Gennotate development team Introduction As large amounts of genome sequence data are becoming available nowadays, the development of reliable and efficient
User Guide Written By Yasser EL-Manzalawy 1 Copyright Gennotate development team Introduction As large amounts of genome sequence data are becoming available nowadays, the development of reliable and efficient
Text classification with Naïve Bayes. Lab 3
 Text classification with Naïve Bayes Lab 3 1 The Task Building a model for movies reviews in English for classifying it into positive or negative. Test classifier on new reviews Takes time 2 Sentiment
Text classification with Naïve Bayes Lab 3 1 The Task Building a model for movies reviews in English for classifying it into positive or negative. Test classifier on new reviews Takes time 2 Sentiment
Data Mining With Weka A Short Tutorial
 Data Mining With Weka A Short Tutorial Dr. Wenjia Wang School of Computing Sciences University of East Anglia (UEA), Norwich, UK Content 1. Introduction to Weka 2. Data Mining Functions and Tools 3. Data
Data Mining With Weka A Short Tutorial Dr. Wenjia Wang School of Computing Sciences University of East Anglia (UEA), Norwich, UK Content 1. Introduction to Weka 2. Data Mining Functions and Tools 3. Data
DATA ANALYSIS WITH WEKA. Author: Nagamani Mutteni Asst.Professor MERI
 DATA ANALYSIS WITH WEKA Author: Nagamani Mutteni Asst.Professor MERI Topic: Data Analysis with Weka Course Duration: 2 Months Objective: Everybody talks about Data Mining and Big Data nowadays. Weka is
DATA ANALYSIS WITH WEKA Author: Nagamani Mutteni Asst.Professor MERI Topic: Data Analysis with Weka Course Duration: 2 Months Objective: Everybody talks about Data Mining and Big Data nowadays. Weka is
Overview. Non-Parametrics Models Definitions KNN. Ensemble Methods Definitions, Examples Random Forests. Clustering. k-means Clustering 2 / 8
 Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
Tutorial Case studies
 1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Weka ( )
") Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
SSV Criterion Based Discretization for Naive Bayes Classifiers
 SSV Criterion Based Discretization for Naive Bayes Classifiers Krzysztof Grąbczewski kgrabcze@phys.uni.torun.pl Department of Informatics, Nicolaus Copernicus University, ul. Grudziądzka 5, 87-100 Toruń,
SSV Criterion Based Discretization for Naive Bayes Classifiers Krzysztof Grąbczewski kgrabcze@phys.uni.torun.pl Department of Informatics, Nicolaus Copernicus University, ul. Grudziądzka 5, 87-100 Toruń,
Data Mining. Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka. I. Data sets. I.1. Data sets characteristics and formats
 Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Homework2 Chapter4 exersices Hongying Du
 Homework2 Chapter4 exersices Hongying Du Note: use lg to denote log 2 in this whole file. 3. Consider the training examples shown in Table 4.8 for a binary classification problem. (a) The entropy of this
Homework2 Chapter4 exersices Hongying Du Note: use lg to denote log 2 in this whole file. 3. Consider the training examples shown in Table 4.8 for a binary classification problem. (a) The entropy of this
Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers
 Conditional Data-Mining Classifiers") Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers James P. Biagioni Piotr M. Szczurek Peter C. Nelson, Ph.D. Abolfazl Mohammadian, Ph.D. Agenda Background
Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers James P. Biagioni Piotr M. Szczurek Peter C. Nelson, Ph.D. Abolfazl Mohammadian, Ph.D. Agenda Background
INTRODUCTION TO ARTIFICIAL INTELLIGENCE
 v=1 v= 1 v= 1 v= 1 v= 1 v=1 optima 2) 3) 5) 6) 7) 8) 9) 12) 11) 13) INTRDUCTIN T ARTIFICIAL INTELLIGENCE DATA15001 EPISDE 7: MACHINE LEARNING TDAY S MENU 1. WHY MACHINE LEARNING? 2. KINDS F ML 3. NEAREST
v=1 v= 1 v= 1 v= 1 v= 1 v=1 optima 2) 3) 5) 6) 7) 8) 9) 12) 11) 13) INTRDUCTIN T ARTIFICIAL INTELLIGENCE DATA15001 EPISDE 7: MACHINE LEARNING TDAY S MENU 1. WHY MACHINE LEARNING? 2. KINDS F ML 3. NEAREST
Chapter 5: Summary and Conclusion CHAPTER 5 SUMMARY AND CONCLUSION. Chapter 1: Introduction
 CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
Minimum Spanning Tree
 Chapter 478 Minimum Spanning Tree Introduction A minimum spanning tree links all nodes (points or vertices) of a network with the minimum length of all arcs. This procedure finds the minimum spanning tree
Chapter 478 Minimum Spanning Tree Introduction A minimum spanning tree links all nodes (points or vertices) of a network with the minimum length of all arcs. This procedure finds the minimum spanning tree
List of Exercises: Data Mining 1 December 12th, 2015
 List of Exercises: Data Mining 1 December 12th, 2015 1. We trained a model on a two-class balanced dataset using five-fold cross validation. One person calculated the performance of the classifier by measuring
List of Exercises: Data Mining 1 December 12th, 2015 1. We trained a model on a two-class balanced dataset using five-fold cross validation. One person calculated the performance of the classifier by measuring
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
IEE 520 Data Mining. Project Report. Shilpa Madhavan Shinde
 IEE 520 Data Mining Project Report Shilpa Madhavan Shinde Contents I. Dataset Description... 3 II. Data Classification... 3 III. Class Imbalance... 5 IV. Classification after Sampling... 5 V. Final Model...
IEE 520 Data Mining Project Report Shilpa Madhavan Shinde Contents I. Dataset Description... 3 II. Data Classification... 3 III. Class Imbalance... 5 IV. Classification after Sampling... 5 V. Final Model...
WEKA Explorer User Guide for Version 3-4
 WEKA Explorer User Guide for Version 3-4 Richard Kirkby Eibe Frank July 28, 2010 c 2002-2010 University of Waikato This guide is licensed under the GNU General Public License version 2. More information
WEKA Explorer User Guide for Version 3-4 Richard Kirkby Eibe Frank July 28, 2010 c 2002-2010 University of Waikato This guide is licensed under the GNU General Public License version 2. More information
Data mining: concepts and algorithms
 Data mining: concepts and algorithms Practice Data mining Objective Exploit data mining algorithms to analyze a real dataset using the RapidMiner machine learning tool. The practice session is organized
Data mining: concepts and algorithms Practice Data mining Objective Exploit data mining algorithms to analyze a real dataset using the RapidMiner machine learning tool. The practice session is organized
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Study on Classifiers using Genetic Algorithm and Class based Rules Generation
 2012 International Conference on Software and Computer Applications (ICSCA 2012) IPCSIT vol. 41 (2012) (2012) IACSIT Press, Singapore Study on Classifiers using Genetic Algorithm and Class based Rules
2012 International Conference on Software and Computer Applications (ICSCA 2012) IPCSIT vol. 41 (2012) (2012) IACSIT Press, Singapore Study on Classifiers using Genetic Algorithm and Class based Rules
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Chapter 8 The C 4.5*stat algorithm
 109 The C 4.5*stat algorithm This chapter explains a new algorithm namely C 4.5*stat for numeric data sets. It is a variant of the C 4.5 algorithm and it uses variance instead of information gain for the
109 The C 4.5*stat algorithm This chapter explains a new algorithm namely C 4.5*stat for numeric data sets. It is a variant of the C 4.5 algorithm and it uses variance instead of information gain for the
Subject. Dataset. Copy paste feature of the diagram. Importing the dataset. Copy paste feature into the diagram.
 Subject Copy paste feature into the diagram. When we define the data analysis process into Tanagra, it is possible to copy components (or entire branches of components) towards another location into the
Subject Copy paste feature into the diagram. When we define the data analysis process into Tanagra, it is possible to copy components (or entire branches of components) towards another location into the
10/14/2017. Dejan Sarka. Anomaly Detection. Sponsors
 Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
Dejan Sarka Anomaly Detection Sponsors About me SQL Server MVP (17 years) and MCT (20 years) 25 years working with SQL Server Authoring 16 th book Authoring many courses, articles Agenda Introduction Simple
CHAPTER 6 EXPERIMENTS
 CHAPTER 6 EXPERIMENTS 6.1 HYPOTHESIS On the basis of the trend as depicted by the data Mining Technique, it is possible to draw conclusions about the Business organization and commercial Software industry.
CHAPTER 6 EXPERIMENTS 6.1 HYPOTHESIS On the basis of the trend as depicted by the data Mining Technique, it is possible to draw conclusions about the Business organization and commercial Software industry.
International Journal of Scientific Research & Engineering Trends Volume 4, Issue 6, Nov-Dec-2018, ISSN (Online): X
: X") Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Machine Learning Practical NITP Summer Course Pamela K. Douglas UCLA Semel Institute
 Machine Learning Practical NITP Summer Course 2013 Pamela K. Douglas UCLA Semel Institute Email: pamelita@g.ucla.edu Topics Covered Part I: WEKA Basics J Part II: MONK Data Set & Feature Selection (from
Machine Learning Practical NITP Summer Course 2013 Pamela K. Douglas UCLA Semel Institute Email: pamelita@g.ucla.edu Topics Covered Part I: WEKA Basics J Part II: MONK Data Set & Feature Selection (from
Computer Vision. Exercise Session 10 Image Categorization
 Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Decision Trees Using Weka and Rattle
 9/28/2017 MIST.6060 Business Intelligence and Data Mining 1 Data Mining Software Decision Trees Using Weka and Rattle We will mainly use Weka ((http://www.cs.waikato.ac.nz/ml/weka/), an open source datamining
9/28/2017 MIST.6060 Business Intelligence and Data Mining 1 Data Mining Software Decision Trees Using Weka and Rattle We will mainly use Weka ((http://www.cs.waikato.ac.nz/ml/weka/), an open source datamining
Topics In Feature Selection
 Topics In Feature Selection CSI 5388 Theme Presentation Joe Burpee 2005/2/16 Feature Selection (FS) aka Attribute Selection Witten and Frank book Section 7.1 Liu site http://athena.csee.umbc.edu/idm02/
Topics In Feature Selection CSI 5388 Theme Presentation Joe Burpee 2005/2/16 Feature Selection (FS) aka Attribute Selection Witten and Frank book Section 7.1 Liu site http://athena.csee.umbc.edu/idm02/
Predict the box office of US movies
 Predict the box office of US movies Group members: Hanqing Ma, Jin Sun, Zeyu Zhang 1. Introduction Our task is to predict the box office of the upcoming movies using the properties of the movies, such
Predict the box office of US movies Group members: Hanqing Ma, Jin Sun, Zeyu Zhang 1. Introduction Our task is to predict the box office of the upcoming movies using the properties of the movies, such
The Explorer. chapter Getting started
 chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
Machine Learning with MATLAB --classification
 Machine Learning with MATLAB --classification Stanley Liang, PhD York University Classification the definition In machine learning and statistics, classification is the problem of identifying to which
Machine Learning with MATLAB --classification Stanley Liang, PhD York University Classification the definition In machine learning and statistics, classification is the problem of identifying to which
Short instructions on using Weka
 Short instructions on using Weka G. Marcou 1 Weka is a free open source data mining software, based on a Java data mining library. Free alternatives to Weka exist as for instance R and Orange. The current
Short instructions on using Weka G. Marcou 1 Weka is a free open source data mining software, based on a Java data mining library. Free alternatives to Weka exist as for instance R and Orange. The current
2013, IJARCSSE All Rights Reserved Page 628
 Volume 3, Issue 2, December 203 ISSN: 2277 28X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Review: Mining
Volume 3, Issue 2, December 203 ISSN: 2277 28X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Review: Mining
Machine Learning Part 1
 Data Science Weekend Machine Learning Part 1 KMK Online Analytic Team Fajri Koto Data Scientist fajri.koto@kmklabs.com Machine Learning Part 1 Outline 1. Machine Learning at glance 2. Vector Representation
Data Science Weekend Machine Learning Part 1 KMK Online Analytic Team Fajri Koto Data Scientist fajri.koto@kmklabs.com Machine Learning Part 1 Outline 1. Machine Learning at glance 2. Vector Representation
Project 1 Announcement March 22th, 2016
 Project 1 Announcement March 22th, 2016 4190.408 Artificial Intelligence Course of 2016 Spring Instructor: Byoung-Tak Zhang Teaching Assistant: Seong-ho Son / Hyo-sun Chun Department of Computer Science
Project 1 Announcement March 22th, 2016 4190.408 Artificial Intelligence Course of 2016 Spring Instructor: Byoung-Tak Zhang Teaching Assistant: Seong-ho Son / Hyo-sun Chun Department of Computer Science
Tutorial on Machine Learning. Impact of dataset composition on models performance. G. Marcou, N. Weill, D. Horvath, D. Rognan, A.
 Part 1. Tutorial on Machine Learning. Impact of dataset composition on models performance G. Marcou, N. Weill, D. Horvath, D. Rognan, A. Varnek 1 Introduction Predictive performance of QSAR model depends
Part 1. Tutorial on Machine Learning. Impact of dataset composition on models performance G. Marcou, N. Weill, D. Horvath, D. Rognan, A. Varnek 1 Introduction Predictive performance of QSAR model depends
WRAPPER feature selection method with SIPINA and R (RWeka package). Comparison with a FILTER approach implemented into TANAGRA.
. Comparison with a FILTER approach implemented into TANAGRA.") 1 Topic WRAPPER feature selection method with SIPINA and R (RWeka package). Comparison with a FILTER approach implemented into TANAGRA. Feature selection. The feature selection 1 is a crucial aspect of
1 Topic WRAPPER feature selection method with SIPINA and R (RWeka package). Comparison with a FILTER approach implemented into TANAGRA. Feature selection. The feature selection 1 is a crucial aspect of
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
IMPLEMENTATION OF CLASSIFICATION ALGORITHMS USING WEKA NAÏVE BAYES CLASSIFIER
 IMPLEMENTATION OF CLASSIFICATION ALGORITHMS USING WEKA NAÏVE BAYES CLASSIFIER N. Suresh Kumar, Dr. M. Thangamani 1 Assistant Professor, Sri Ramakrishna Engineering College, Coimbatore, India 2 Assistant
IMPLEMENTATION OF CLASSIFICATION ALGORITHMS USING WEKA NAÏVE BAYES CLASSIFIER N. Suresh Kumar, Dr. M. Thangamani 1 Assistant Professor, Sri Ramakrishna Engineering College, Coimbatore, India 2 Assistant
Classifica(on and Clustering with WEKA. Classifica*on and Clustering with WEKA
 Classifica(on and Clustering with WEKA 1 Schedule: Classifica(on and Clustering with WEKA 1. Presentation of WEKA. 2. Your turn: perform classification and clustering. 2 WEKA Weka is a collec*on of machine
Classifica(on and Clustering with WEKA 1 Schedule: Classifica(on and Clustering with WEKA 1. Presentation of WEKA. 2. Your turn: perform classification and clustering. 2 WEKA Weka is a collec*on of machine
Contents. Foreword to Second Edition. Acknowledgments About the Authors
 Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Probabilistic Classifiers DWML, /27
 Probabilistic Classifiers DWML, 2007 1/27 Probabilistic Classifiers Conditional class probabilities Id. Savings Assets Income Credit risk 1 Medium High 75 Good 2 Low Low 50 Bad 3 High Medium 25 Bad 4 Medium
Probabilistic Classifiers DWML, 2007 1/27 Probabilistic Classifiers Conditional class probabilities Id. Savings Assets Income Credit risk 1 Medium High 75 Good 2 Low Low 50 Bad 3 High Medium 25 Bad 4 Medium
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
WEKA: Practical Machine Learning Tools and Techniques in Java. Seminar A.I. Tools WS 2006/07 Rossen Dimov
 WEKA: Practical Machine Learning Tools and Techniques in Java Seminar A.I. Tools WS 2006/07 Rossen Dimov Overview Basic introduction to Machine Learning Weka Tool Conclusion Document classification Demo
WEKA: Practical Machine Learning Tools and Techniques in Java Seminar A.I. Tools WS 2006/07 Rossen Dimov Overview Basic introduction to Machine Learning Weka Tool Conclusion Document classification Demo
3 Virtual attribute subsetting
 3 Virtual attribute subsetting Portions of this chapter were previously presented at the 19 th Australian Joint Conference on Artificial Intelligence (Horton et al., 2006). Virtual attribute subsetting
3 Virtual attribute subsetting Portions of this chapter were previously presented at the 19 th Australian Joint Conference on Artificial Intelligence (Horton et al., 2006). Virtual attribute subsetting
Data Mining and Knowledge Discovery Practice notes: Numeric Prediction, Association Rules
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
AI32 Guide to Weka. Andrew Roberts 1st March 2005
 AI32 Guide to Weka Andrew Roberts http://www.comp.leeds.ac.uk/andyr 1st March 2005 1 Introduction Weka is an excellent system for learning about machine learning techniques. Of course, it is a generic
AI32 Guide to Weka Andrew Roberts http://www.comp.leeds.ac.uk/andyr 1st March 2005 1 Introduction Weka is an excellent system for learning about machine learning techniques. Of course, it is a generic
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2013/12/09 1 Practice plan 2013/11/11: Predictive data mining 1 Decision trees Evaluating classifiers 1: separate
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2013/12/09 1 Practice plan 2013/11/11: Predictive data mining 1 Decision trees Evaluating classifiers 1: separate
Epitopes Toolkit (EpiT) Yasser EL-Manzalawy August 30, 2016
 Yasser EL-Manzalawy August 30, 2016") Epitopes Toolkit (EpiT) Yasser EL-Manzalawy http://www.cs.iastate.edu/~yasser August 30, 2016 What is EpiT? Epitopes Toolkit (EpiT) is a platform for developing epitope prediction tools. An EpiT developer
Epitopes Toolkit (EpiT) Yasser EL-Manzalawy http://www.cs.iastate.edu/~yasser August 30, 2016 What is EpiT? Epitopes Toolkit (EpiT) is a platform for developing epitope prediction tools. An EpiT developer
Basic Data Mining Technique
 Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
CHAPTER 5 CONTRIBUTORY ANALYSIS OF NSL-KDD CUP DATA SET
 CHAPTER 5 CONTRIBUTORY ANALYSIS OF NSL-KDD CUP DATA SET 5 CONTRIBUTORY ANALYSIS OF NSL-KDD CUP DATA SET An IDS monitors the network bustle through incoming and outgoing data to assess the conduct of data
CHAPTER 5 CONTRIBUTORY ANALYSIS OF NSL-KDD CUP DATA SET 5 CONTRIBUTORY ANALYSIS OF NSL-KDD CUP DATA SET An IDS monitors the network bustle through incoming and outgoing data to assess the conduct of data
Robot Learning. There are generally three types of robot learning: Learning from data. Learning by demonstration. Reinforcement learning
 Robot Learning 1 General Pipeline 1. Data acquisition (e.g., from 3D sensors) 2. Feature extraction and representation construction 3. Robot learning: e.g., classification (recognition) or clustering (knowledge
Robot Learning 1 General Pipeline 1. Data acquisition (e.g., from 3D sensors) 2. Feature extraction and representation construction 3. Robot learning: e.g., classification (recognition) or clustering (knowledge
CLASSIFICATION JELENA JOVANOVIĆ. Web:
 CLASSIFICATION JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is classification? Binary and multiclass classification Classification algorithms Naïve Bayes (NB) algorithm
CLASSIFICATION JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is classification? Binary and multiclass classification Classification algorithms Naïve Bayes (NB) algorithm
TUBE: Command Line Program Calls
 TUBE: Command Line Program Calls March 15, 2009 Contents 1 Command Line Program Calls 1 2 Program Calls Used in Application Discretization 2 2.1 Drawing Histograms........................ 2 2.2 Discretizing.............................
TUBE: Command Line Program Calls March 15, 2009 Contents 1 Command Line Program Calls 1 2 Program Calls Used in Application Discretization 2 2.1 Drawing Histograms........................ 2 2.2 Discretizing.............................
A Soft-Computing Approach to Knowledge Flow Synthesis and Optimization
 A Soft-Computing Approach to Knowledge Flow Synthesis and Optimization Tomáš Řehořek Pavel Kordík Computational Intelligence Group (CIG), Faculty of Information Technology (FIT), Czech Technical University
A Soft-Computing Approach to Knowledge Flow Synthesis and Optimization Tomáš Řehořek Pavel Kordík Computational Intelligence Group (CIG), Faculty of Information Technology (FIT), Czech Technical University
CIS192 Python Programming
 CIS192 Python Programming Machine Learning in Python Robert Rand University of Pennsylvania October 22, 2015 Robert Rand (University of Pennsylvania) CIS 192 October 22, 2015 1 / 18 Outline 1 Machine Learning
CIS192 Python Programming Machine Learning in Python Robert Rand University of Pennsylvania October 22, 2015 Robert Rand (University of Pennsylvania) CIS 192 October 22, 2015 1 / 18 Outline 1 Machine Learning
REMOVAL OF REDUNDANT AND IRRELEVANT DATA FROM TRAINING DATASETS USING SPEEDY FEATURE SELECTION METHOD
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 5.258 IJCSMC,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 5.258 IJCSMC,
An Introduction to WEKA Explorer. In part from: Yizhou Sun 2008
 An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
Tutorial on Machine Learning Tools
 Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
A User s Guide to Graphical-Model-based Multivariate Analysis
 A User s Guide to Graphical-Model-based Multivariate Analysis 1. Introduction Rong Chen December 2006 Graphical-Model-based Multivariate Analysis (GAMMA) is a Bayesian data mining software for structural
A User s Guide to Graphical-Model-based Multivariate Analysis 1. Introduction Rong Chen December 2006 Graphical-Model-based Multivariate Analysis (GAMMA) is a Bayesian data mining software for structural
Python With Data Science
 Course Overview This course covers theoretical and technical aspects of using Python in Applied Data Science projects and Data Logistics use cases. Who Should Attend Data Scientists, Software Developers,
Course Overview This course covers theoretical and technical aspects of using Python in Applied Data Science projects and Data Logistics use cases. Who Should Attend Data Scientists, Software Developers,
Lab A: Using Windows 2000 Help
 Lab A: Using Windows 2000 Help Slide Objective To introduce the lab. Lead-in In this lab, you will use Windows 2000 Help to locate information. Module 2: Administration of a Windows 2000 Network 7 *****************************ILLEGAL
Lab A: Using Windows 2000 Help Slide Objective To introduce the lab. Lead-in In this lab, you will use Windows 2000 Help to locate information. Module 2: Administration of a Windows 2000 Network 7 *****************************ILLEGAL
Contents. ACE Presentation. Comparison with existing frameworks. Technical aspects. ACE 2.0 and future work. 24 October 2009 ACE 2
 ACE Contents ACE Presentation Comparison with existing frameworks Technical aspects ACE 2.0 and future work 24 October 2009 ACE 2 ACE Presentation 24 October 2009 ACE 3 ACE Presentation Framework for using
ACE Contents ACE Presentation Comparison with existing frameworks Technical aspects ACE 2.0 and future work 24 October 2009 ACE 2 ACE Presentation 24 October 2009 ACE 3 ACE Presentation Framework for using
New ensemble methods for evolving data streams
 New ensemble methods for evolving data streams A. Bifet, G. Holmes, B. Pfahringer, R. Kirkby, and R. Gavaldà Laboratory for Relational Algorithmics, Complexity and Learning LARCA UPC-Barcelona Tech, Catalonia
New ensemble methods for evolving data streams A. Bifet, G. Holmes, B. Pfahringer, R. Kirkby, and R. Gavaldà Laboratory for Relational Algorithmics, Complexity and Learning LARCA UPC-Barcelona Tech, Catalonia
BerkeleyImageSeg User s Guide
 BerkeleyImageSeg User s Guide 1. Introduction Welcome to BerkeleyImageSeg! This is designed to be a lightweight image segmentation application, easy to learn and easily automated for repetitive processing
BerkeleyImageSeg User s Guide 1. Introduction Welcome to BerkeleyImageSeg! This is designed to be a lightweight image segmentation application, easy to learn and easily automated for repetitive processing
Data Cleaning and Prototyping Using K-Means to Enhance Classification Accuracy
 Data Cleaning and Prototyping Using K-Means to Enhance Classification Accuracy Lutfi Fanani 1 and Nurizal Dwi Priandani 2 1 Department of Computer Science, Brawijaya University, Malang, Indonesia. 2 Department
Data Cleaning and Prototyping Using K-Means to Enhance Classification Accuracy Lutfi Fanani 1 and Nurizal Dwi Priandani 2 1 Department of Computer Science, Brawijaya University, Malang, Indonesia. 2 Department
Classification Algorithms in Data Mining
 August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
CP365 Artificial Intelligence
 CP365 Artificial Intelligence Example Problem Problem: Does a given image contain cats? Input vector: RGB/BW pixels of the image. Output: Yes or No. Example Problem Problem: What category is a news story?
CP365 Artificial Intelligence Example Problem Problem: Does a given image contain cats? Input vector: RGB/BW pixels of the image. Output: Yes or No. Example Problem Problem: What category is a news story?
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/11/16 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/11/16 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
31 What s New in IGSS V9. Speaker Notes INSIGHT AND OVERVIEW
 31 What s New in IGSS V9 Speaker Notes INSIGHT AND OVERVIEW Contents of this lesson Topics: New IGSS Control Center Consolidated report system Redesigned Maintenance module Enhancement highlights Online
31 What s New in IGSS V9 Speaker Notes INSIGHT AND OVERVIEW Contents of this lesson Topics: New IGSS Control Center Consolidated report system Redesigned Maintenance module Enhancement highlights Online
DUE By 11:59 PM on Thursday March 15 via make turnitin on acad. The standard 10% per day deduction for late assignments applies.
 CSC 558 Data Mining and Predictive Analytics II, Spring 2018 Dr. Dale E. Parson, Assignment 2, Classification of audio data samples from assignment 1 for predicting numeric white-noise amplification level
CSC 558 Data Mining and Predictive Analytics II, Spring 2018 Dr. Dale E. Parson, Assignment 2, Classification of audio data samples from assignment 1 for predicting numeric white-noise amplification level
SUPERVISED LEARNING METHODS. Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018
 SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
Performance Evaluation of Various Classification Algorithms
 Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Empirical risk minimization (ERM) A first model of learning. The excess risk. Getting a uniform guarantee
 A first model of learning. The excess risk. Getting a uniform guarantee") A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) Empirical risk minimization (ERM) Recall the definitions of risk/empirical risk We observe the
A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) Empirical risk minimization (ERM) Recall the definitions of risk/empirical risk We observe the
Lab 11-1 Creating a Knowledge Base
 In this lab you will learn how to create and maintain a knowledge base. Knowledge bases help the trainable Group Locators improve their extraction results by providing trained extraction examples. Lab
In this lab you will learn how to create and maintain a knowledge base. Knowledge bases help the trainable Group Locators improve their extraction results by providing trained extraction examples. Lab
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
CS 539 Machine Learning Project 1
 CS 539 Machine Learning Project 1 Chris Winsor Contents: Data Preprocessing (2) Discretization (Weka) (2) Discretization (Matlab) (4) Missing Values (Weka) (12) Missing Values (Matlab) (14) Attribute Selection
CS 539 Machine Learning Project 1 Chris Winsor Contents: Data Preprocessing (2) Discretization (Weka) (2) Discretization (Matlab) (4) Missing Values (Weka) (12) Missing Values (Matlab) (14) Attribute Selection