Optimizing Apache Nutch For Domain Specific Crawling at Large Scale
|
|
|
- Beryl Dalton
- 6 years ago
- Views:
Transcription
1 Optimizing Apache Nutch For Domain Specific Crawling at Large Scale Luis A. Lopez, Ruth Duerr, Siri Jodha Singh Khalsa IEEE Big Data 2015, Santa Clara CA.














2 Overview BCube is a building block of NSF EarthCube, for the past 6 months we ve been crawling the Internet trying to gather all possible data that s relevant to the geosciences. Our focus is to discover scientific datasets and web services that may contain geolocated data. Mainly structured information (xml, json, csv) Greenland Aerosol Datasets Mass Spectrum Analysis in Geothermal Areas
![Understanding the problem [Focused Crawling] Big Search Space With Very Sparse Data Distribution Billions of web pages Most content](/docs-images/76/73397677/images/3-0.jpg "is not scientific data Scientific data is not well advertised Acceptable Performance With Limited Resources Scalable stack Content")
 scoring algorithm Hard Problems Distributed processing Fault tolerant Uses commodity hardware Apache")
3 Understanding the problem [Focused Crawling] Big Search Space With Very Sparse Data Distribution Billions of web pages Most content is not scientific data Scientific data is not well advertised Acceptable Performance With Limited Resources Scalable stack Content Duplication Handles TB of data Semantics Robots.txt Solution A good(enough) scoring algorithm Hard Problems Distributed processing Fault tolerant Uses commodity hardware Apache Nutch! Remote Servers Performance Malformed Metadata Bad Web Standards Implementation Cost
4 Previous Work and BCube Previous Work Finding the scoring algorithm that performs 10% better Implementing an in house(not open sourced) crawler Focusing on an specific type of data Measuring performance on thousands of pages(sometimes just hundreds) Our Work To understand where the bottlenecks are To use an open source project To improve fetching times To modify the crawler for focused crawls To use the cloud to lower operational costs To verify what happens at large scale


5 Scoring PageRank Like Scoring Focused Crawl Scoring NOAA NASA
6 BCube Customizations
7 BCube Plugins Parse-rawcontent index-links Indexes the unparsed content of a document Indexes inlinks and outlinks of a document parse-bayes index-bcube-extras Scores pages using an online naivebayes classifier Indexes HTTP responses index-bcube-filter index-xmlnamespaces Indexes all the namespaces used in xml documents Discards documents using mime types or substring matching parse-tika fixed critical bug that blocked us from parsing valid XML files
8 BCube Filtering url regex, suffix bayes scoring filters: mime type, url regex. b.edu/unknown.htm amazon.com site.org/data.xml Lucene noaa.gov/data.htm a.edu/big.is o Fetcher Nutch DB
9 Problems...
10 Performance Degradation Crawl-Delay Sparse data distribution Duplicated content Slow servers The tar pits Variable cluster performance in the cloud Idle CPU time
11 Good Scoring, Let s Celebrate! not so soon. The Tar Pit Keep indexing relevant documents from the same sites prevented us from discover new ones Well scored documents are still relevant and we should index them How often these sites are updated should be taken into account.


12 Content Duplication at large scale. Domain * The Science of Crawl: Deduplication of Web Content Documents fetched fr.climate-data.org bn.climate-data.org de.climate-data.org en.climate-data.org
13 Improving Performance Robots.txt Crawl-Delay Large files:.iso.hdf etc. SSD vs HDD Fetching Strategy Crawling at different speeds. Filtering out file extensions using Nutch s suffix-regex filter SSD instances on AWS Generate a limited number of links per host and distribute the fetch on as many nodes as possible.

14 Nutch + BCube Property Default Value BCube Value crawldb.url.filters True False db.update.max.inlinks db.injector.overwrite False True generate.max.count fetcher.server.delay 10 2 fetcher.threads.fetch fetcher.threads.per.que ue 1 2 fetcher.timelimit.mins -1 45
15 Conclusions and Future Work There are major issues in focused crawls that can only be reproduced at large scale Some issues cannot be addressed by improving the focused crawl alone We can implement mitigation techniques effectively to alleviate the problems under our control Apache Nutch can scale and be used for focused crawls Optimize scoring algorithm using the link graph and content context Develop a computationally efficient mechanism for dynamic relevance adjustment Automate cost effective cluster deployments Use the latest selenium plugins in Nutch for specific use cases More
16 References BCube at Github Apache Nutch Common Crawl Project The Science of Crawl: Deduplication of Web Content
Storm Crawler. Low latency scalable web crawling on Apache Storm. Julien Nioche digitalpebble. Berlin Buzzwords 01/06/2015
 Storm Crawler Low latency scalable web crawling on Apache Storm Julien Nioche julien@digitalpebble.com digitalpebble Berlin Buzzwords 01/06/2015 About myself DigitalPebble Ltd, Bristol (UK) Specialised
Storm Crawler Low latency scalable web crawling on Apache Storm Julien Nioche julien@digitalpebble.com digitalpebble Berlin Buzzwords 01/06/2015 About myself DigitalPebble Ltd, Bristol (UK) Specialised
Focused Crawling with
 Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
EPL660: Information Retrieval and Search Engines Lab 8
 EPL660: Information Retrieval and Search Engines Lab 8 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science What is Apache Nutch? Production ready Web Crawler Operates
EPL660: Information Retrieval and Search Engines Lab 8 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science What is Apache Nutch? Production ready Web Crawler Operates
Collective Intelligence in Action
 Collective Intelligence in Action SATNAM ALAG II MANNING Greenwich (74 w. long.) contents foreword xv preface xvii acknowledgments xix about this book xxi PART 1 GATHERING DATA FOR INTELLIGENCE 1 "1 Understanding
Collective Intelligence in Action SATNAM ALAG II MANNING Greenwich (74 w. long.) contents foreword xv preface xvii acknowledgments xix about this book xxi PART 1 GATHERING DATA FOR INTELLIGENCE 1 "1 Understanding
Focused Crawling with
 Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
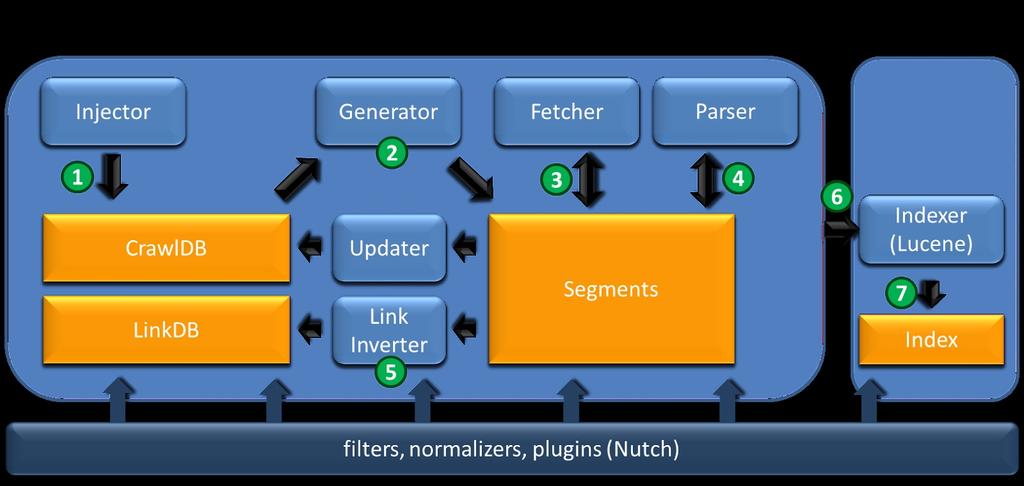
LAB 7: Search engine: Apache Nutch + Solr + Lucene
 LAB 7: Search engine: Apache Nutch + Solr + Lucene Apache Nutch Apache Lucene Apache Solr Crawler + indexer (mainly crawler) indexer + searcher indexer + searcher Lucene vs. Solr? Lucene = library, more
LAB 7: Search engine: Apache Nutch + Solr + Lucene Apache Nutch Apache Lucene Apache Solr Crawler + indexer (mainly crawler) indexer + searcher indexer + searcher Lucene vs. Solr? Lucene = library, more
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Tambako the Bixo - a webcrawler toolkit Ken Krugler, Stefan Groschupf
 Tambako the Jaguar@flickr.com Bixo - a webcrawler toolkit Ken Krugler, Stefan Groschupf Jule_Berlin@flickr.com Agenda Overview Background Motivation Goals Status Differences Architecture Data life cycle
Tambako the Jaguar@flickr.com Bixo - a webcrawler toolkit Ken Krugler, Stefan Groschupf Jule_Berlin@flickr.com Agenda Overview Background Motivation Goals Status Differences Architecture Data life cycle
Nutch as a Web mining platform the present and the future Andrzej Białecki
 Apache Nutch as a Web mining platform the present and the future Andrzej Białecki ab@sigram.com Intro Started using Lucene in 2003 (1.2-dev?) Created Luke the Lucene Index Toolbox Nutch, Lucene committer,
Apache Nutch as a Web mining platform the present and the future Andrzej Białecki ab@sigram.com Intro Started using Lucene in 2003 (1.2-dev?) Created Luke the Lucene Index Toolbox Nutch, Lucene committer,
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
BUbiNG. Massive Crawling for the Masses. Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna
 BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
Scalable Search Engine Solution
 Scalable Search Engine Solution A Case Study of BBS Yifu Huang School of Computer Science, Fudan University huangyifu@fudan.edu.cn COMP620028 Information Retrieval Project, 2013 Yifu Huang (FDU CS) COMP620028
Scalable Search Engine Solution A Case Study of BBS Yifu Huang School of Computer Science, Fudan University huangyifu@fudan.edu.cn COMP620028 Information Retrieval Project, 2013 Yifu Huang (FDU CS) COMP620028
Information Retrieval. Lecture 10 - Web crawling
 Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Building Search Applications
 Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies
 NTTS 2015 Session 6A - Big data sources: web scraping and smart meters Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies Giulio Barcaroli(*) (barcarol@istat.it),
NTTS 2015 Session 6A - Big data sources: web scraping and smart meters Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies Giulio Barcaroli(*) (barcarol@istat.it),
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS6200 Information Retreival. Crawling. June 10, 2015
 CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
This tutorial is designed for all Java enthusiasts who want to learn document type detection and content extraction using Apache Tika.
 About the Tutorial This tutorial provides a basic understanding of Apache Tika library, the file formats it supports, as well as content and metadata extraction using Apache Tika. Audience This tutorial
About the Tutorial This tutorial provides a basic understanding of Apache Tika library, the file formats it supports, as well as content and metadata extraction using Apache Tika. Audience This tutorial
Pangeo. A community-driven effort for Big Data geoscience
 Pangeo A community-driven effort for Big Data geoscience !2 What would you like to have and why? Pangeo s vision for scientific computing in the big-data era Pangeo s Website pangeo-data.org !3 Hello!
Pangeo A community-driven effort for Big Data geoscience !2 What would you like to have and why? Pangeo s vision for scientific computing in the big-data era Pangeo s Website pangeo-data.org !3 Hello!
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Around the Web in Six Weeks: Documenting a Large-Scale Crawl
 Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Around the Web in Six Weeks: Documenting a Large-Scale Crawl Sarker Tanzir Ahmed, Clint Sparkman, Hsin- Tsang Lee, and Dmitri Loguinov Internet Research Lab Department of Computer Science and Engineering
Bixo - Web Mining Toolkit 23 Sep Ken Krugler TransPac Software, Inc.
 Web Mining Toolkit Ken Krugler TransPac Software, Inc. My background - did a startup called Krugle from 2005-2008 Used Nutch to do a vertical crawl of the web, looking for technical software pages. Mined
Web Mining Toolkit Ken Krugler TransPac Software, Inc. My background - did a startup called Krugle from 2005-2008 Used Nutch to do a vertical crawl of the web, looking for technical software pages. Mined
Rok: Data Management for Data Science
 Whitepaper Rok: Data Management for Data Science At Arrikto, we are building software to empower faster and easier collaboration for data scientists working in the same or different clouds, in the same
Whitepaper Rok: Data Management for Data Science At Arrikto, we are building software to empower faster and easier collaboration for data scientists working in the same or different clouds, in the same
StormCrawler. Low Latency Web Crawling on Apache Storm.
 StormCrawler Low Latency Web Crawling on Apache Storm Julien Nioche julien@digitalpebble.com @digitalpebble @stormcrawlerapi 1 About myself DigitalPebble Ltd, Bristol (UK) Text Engineering Web Crawling
StormCrawler Low Latency Web Crawling on Apache Storm Julien Nioche julien@digitalpebble.com @digitalpebble @stormcrawlerapi 1 About myself DigitalPebble Ltd, Bristol (UK) Text Engineering Web Crawling
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
DiskSavvy Disk Space Analyzer. DiskSavvy DISK SPACE ANALYZER. User Manual. Version Dec Flexense Ltd.
 DiskSavvy DISK SPACE ANALYZER User Manual Version 10.3 Dec 2017 www.disksavvy.com info@flexense.com 1 1 Product Overview...3 2 Product Versions...7 3 Using Desktop Versions...8 3.1 Product Installation
DiskSavvy DISK SPACE ANALYZER User Manual Version 10.3 Dec 2017 www.disksavvy.com info@flexense.com 1 1 Product Overview...3 2 Product Versions...7 3 Using Desktop Versions...8 3.1 Product Installation
Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT
 Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT 1. Overview This assignment picks up where the last one left off. You will take your JSON
Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT 1. Overview This assignment picks up where the last one left off. You will take your JSON
Crawling the Web for. Sebastian Nagel. Apache Big Data Europe
 Crawling the Web for Sebastian Nagel snagel@apache.org sebastian@commoncrawl.org Apache Big Data Europe 2016 About Me computational linguist software developer, search and data matching since 2016 crawl
Crawling the Web for Sebastian Nagel snagel@apache.org sebastian@commoncrawl.org Apache Big Data Europe 2016 About Me computational linguist software developer, search and data matching since 2016 crawl
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Architectural challenges for building a low latency, scalable multi-tenant data warehouse
 Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Istat s Pilot Use Case 1
 Istat s Pilot Use Case 1 Pilot identification 1 IT 1 Reference Use case X 1) URL Inventory of enterprises 2) E-commerce from enterprises websites 3) Job advertisements on enterprises websites 4) Social
Istat s Pilot Use Case 1 Pilot identification 1 IT 1 Reference Use case X 1) URL Inventory of enterprises 2) E-commerce from enterprises websites 3) Job advertisements on enterprises websites 4) Social
A Software Architecture for Progressive Scanning of On-line Communities
 A Software Architecture for Progressive Scanning of On-line Communities Roberto Baldoni, Fabrizio d Amore, Massimo Mecella, Daniele Ucci Sapienza Università di Roma, Italy Motivations On-line communities
A Software Architecture for Progressive Scanning of On-line Communities Roberto Baldoni, Fabrizio d Amore, Massimo Mecella, Daniele Ucci Sapienza Università di Roma, Italy Motivations On-line communities
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
 Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
 Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Distributed Systems. 05r. Case study: Google Cluster Architecture. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
InfiniBand Networked Flash Storage
 InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Patent-Crawler. A real-time recursive focused web crawler to gather information on patent usage. HPC-AI Advisory Council, Lugano, April 2018
 Patent-Crawler A real-time recursive focused web crawler to gather information on patent usage HPC-AI Advisory Council, Lugano, April 2018 E. Orliac 1,2, G. Fourestey 2, D. Portabella 2, G. de Rassenfosse
Patent-Crawler A real-time recursive focused web crawler to gather information on patent usage HPC-AI Advisory Council, Lugano, April 2018 E. Orliac 1,2, G. Fourestey 2, D. Portabella 2, G. de Rassenfosse
OnCrawl Metrics. What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for.
 1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
memex-explorer Documentation
 memex-explorer Documentation Release 0.4 Andy Terrel, Christine Doig, Ben Zaitlen, Karan Dodia, Brittain Har January 19, 2016 Contents 1 User s Guide to Memex Explorer 3 1.1 Application Structure...........................................
memex-explorer Documentation Release 0.4 Andy Terrel, Christine Doig, Ben Zaitlen, Karan Dodia, Brittain Har January 19, 2016 Contents 1 User s Guide to Memex Explorer 3 1.1 Application Structure...........................................
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX
 Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Building A Billion Spatio-Temporal Object Search and Visualization Platform
 2017 2 nd International Symposium on Spatiotemporal Computing Harvard University Building A Billion Spatio-Temporal Object Search and Visualization Platform Devika Kakkar, Benjamin Lewis Goal Develop a
2017 2 nd International Symposium on Spatiotemporal Computing Harvard University Building A Billion Spatio-Temporal Object Search and Visualization Platform Devika Kakkar, Benjamin Lewis Goal Develop a
The Billion Object Platform (BOP): a system to lower barriers to support big, streaming, spatio-temporal data sources
: a system to lower barriers to support big, streaming, spatio-temporal data sources") FOSS4G 2017 Boston The Billion Object Platform (BOP): a system to lower barriers to support big, streaming, spatio-temporal data sources Devika Kakkar and Ben Lewis Harvard Center for Geographic Analysis
FOSS4G 2017 Boston The Billion Object Platform (BOP): a system to lower barriers to support big, streaming, spatio-temporal data sources Devika Kakkar and Ben Lewis Harvard Center for Geographic Analysis
Tracking Down The Bad Guys. Tom Barber - NASA JPL Big Data Conference - Vilnius Nov 2017
 Tracking Down The Bad Guys Tom Barber - NASA JPL Big Data Conference - Vilnius Nov 2017 Who am I? Tom Barber Data Nerd Open Source Business Intelligence Developer Director of Meteorite BI and Spicule LTD
Tracking Down The Bad Guys Tom Barber - NASA JPL Big Data Conference - Vilnius Nov 2017 Who am I? Tom Barber Data Nerd Open Source Business Intelligence Developer Director of Meteorite BI and Spicule LTD
I'm Charlie Hull, co-founder and Managing Director of Flax. We've been building open source search applications since 2001
 Open Source Search I'm Charlie Hull, co-founder and Managing Director of Flax We've been building open source search applications since 2001 I'm going to tell you why and how you should use open source
Open Source Search I'm Charlie Hull, co-founder and Managing Director of Flax We've been building open source search applications since 2001 I'm going to tell you why and how you should use open source
Service Oriented Performance Analysis
 Service Oriented Performance Analysis Da Qi Ren and Masood Mortazavi US R&D Center Santa Clara, CA, USA www.huawei.com Performance Model for Service in Data Center and Cloud 1. Service Oriented (end to
Service Oriented Performance Analysis Da Qi Ren and Masood Mortazavi US R&D Center Santa Clara, CA, USA www.huawei.com Performance Model for Service in Data Center and Cloud 1. Service Oriented (end to
Design and Implementation of Agricultural Information Resources Vertical Search Engine Based on Nutch
 619 A publication of CHEMICAL ENGINEERING TRANSACTIONS VOL. 51, 2016 Guest Editors: Tichun Wang, Hongyang Zhang, Lei Tian Copyright 2016, AIDIC Servizi S.r.l., ISBN 978-88-95608-43-3; ISSN 2283-9216 The
619 A publication of CHEMICAL ENGINEERING TRANSACTIONS VOL. 51, 2016 Guest Editors: Tichun Wang, Hongyang Zhang, Lei Tian Copyright 2016, AIDIC Servizi S.r.l., ISBN 978-88-95608-43-3; ISSN 2283-9216 The
A Cloud-based Web Crawler Architecture
 Volume-6, Issue-4, July-August 2016 International Journal of Engineering and Management Research Page Number: 148-152 A Cloud-based Web Crawler Architecture Poonam Maheshwar Management Education Research
Volume-6, Issue-4, July-August 2016 International Journal of Engineering and Management Research Page Number: 148-152 A Cloud-based Web Crawler Architecture Poonam Maheshwar Management Education Research
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators
 WHITE PAPER Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
WHITE PAPER Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
An Overview of Search Engine. Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia
 An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
An Overview of Search Engine Hai-Yang Xu Dev Lead of Search Technology Center Microsoft Research Asia haixu@microsoft.com July 24, 2007 1 Outline History of Search Engine Difference Between Software and
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Web Crawling. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
CS47300 Web Information Search and Management
 CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Scaling Slack. Bing Wei
 Scaling Slack Bing Wei Infrastructure@Slack 2 3 Our Mission: To make people s working lives simpler, more pleasant, and more productive. 4 From supporting small teams To serving gigantic organizations
Scaling Slack Bing Wei Infrastructure@Slack 2 3 Our Mission: To make people s working lives simpler, more pleasant, and more productive. 4 From supporting small teams To serving gigantic organizations
At Course Completion Prepares you as per certification requirements for AWS Developer Associate.
 [AWS-DAW]: AWS Cloud Developer Associate Workshop Length Delivery Method : 4 days : Instructor-led (Classroom) At Course Completion Prepares you as per certification requirements for AWS Developer Associate.
[AWS-DAW]: AWS Cloud Developer Associate Workshop Length Delivery Method : 4 days : Instructor-led (Classroom) At Course Completion Prepares you as per certification requirements for AWS Developer Associate.
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
Research Article Mobile Storage and Search Engine of Information Oriented to Food Cloud
 Advance Journal of Food Science and Technology 5(10): 1331-1336, 2013 DOI:10.19026/ajfst.5.3106 ISSN: 2042-4868; e-issn: 2042-4876 2013 Maxwell Scientific Publication Corp. Submitted: May 29, 2013 Accepted:
Advance Journal of Food Science and Technology 5(10): 1331-1336, 2013 DOI:10.19026/ajfst.5.3106 ISSN: 2042-4868; e-issn: 2042-4876 2013 Maxwell Scientific Publication Corp. Submitted: May 29, 2013 Accepted:
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 6: Information Retrieval I. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies
 Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies Giulio Barcaroli 1 (barcarol@istat.it), Monica Scannapieco 1 (scannapi@istat.it), Donato Summa
Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies Giulio Barcaroli 1 (barcarol@istat.it), Monica Scannapieco 1 (scannapi@istat.it), Donato Summa
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Administrivia. Crawlers: Nutch. Course Overview. Issues. Crawling Issues. Groups Formed Architecture Documents under Review Group Meetings CSE 454
 Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
BIG DATA TESTING: A UNIFIED VIEW
 http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
More on Testing and Large Scale Web Apps
 More on Testing and Large Scale Web Apps Testing Functionality Tests - Unit tests: E.g. Mocha - Integration tests - End-to-end - E.g. Selenium - HTML CSS validation - forms and form validation - cookies
More on Testing and Large Scale Web Apps Testing Functionality Tests - Unit tests: E.g. Mocha - Integration tests - End-to-end - E.g. Selenium - HTML CSS validation - forms and form validation - cookies
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Web scraping. Donato Summa. 3 WP1 face to face meeting September 2017 Thessaloniki (EL)
") Web scraping Donato Summa Summary Web scraping : Specific vs Generic Web scraping phases Web scraping tools Istat Web scraping chain Summary Web scraping : Specific vs Generic Web scraping phases Web scraping
Web scraping Donato Summa Summary Web scraping : Specific vs Generic Web scraping phases Web scraping tools Istat Web scraping chain Summary Web scraping : Specific vs Generic Web scraping phases Web scraping
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
EECS 395/495 Lecture 5: Web Crawlers. Doug Downey
 EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
Bringing code to the data: from MySQL to RocksDB for high volume searches
 Bringing code to the data: from MySQL to RocksDB for high volume searches Percona Live 2016 Santa Clara, CA Ivan Kruglov Senior Developer ivan.kruglov@booking.com Agenda Problem domain Evolution of search
Bringing code to the data: from MySQL to RocksDB for high volume searches Percona Live 2016 Santa Clara, CA Ivan Kruglov Senior Developer ivan.kruglov@booking.com Agenda Problem domain Evolution of search
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Dremel: Interactive Analysis of Web-Scale Database
 Dremel: Interactive Analysis of Web-Scale Database Presented by Jian Fang Most parts of these slides are stolen from here: http://bit.ly/hipzeg What is Dremel Trillion-record, multi-terabyte datasets at
Dremel: Interactive Analysis of Web-Scale Database Presented by Jian Fang Most parts of these slides are stolen from here: http://bit.ly/hipzeg What is Dremel Trillion-record, multi-terabyte datasets at
MOBIUS ONE BILLION DOCUMENT BENCHMARK TEST ON AMAZON WEB SERVICES CONTENT SERVICES PLATFORM
 MOBIUS ONE BILLION DOCUMENT BENCHMARK TEST ON AMAZON WEB SERVICES CONTENT SERVICES PLATFORM A DIGITAL WORKPLACE FOR THE MODERN ENTERPRISE Mobius is a flexible, highly scalable, performance-oriented content
MOBIUS ONE BILLION DOCUMENT BENCHMARK TEST ON AMAZON WEB SERVICES CONTENT SERVICES PLATFORM A DIGITAL WORKPLACE FOR THE MODERN ENTERPRISE Mobius is a flexible, highly scalable, performance-oriented content
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Zumobi Brand Integration(Zbi) Platform Architecture Whitepaper Table of Contents
 Platform Architecture Whitepaper Table of Contents") Zumobi Brand Integration(Zbi) Platform Architecture Whitepaper Table of Contents Introduction... 2 High-Level Platform Architecture Diagram... 3 Zbi Production Environment... 4 Zbi Publishing Engine...
Zumobi Brand Integration(Zbi) Platform Architecture Whitepaper Table of Contents Introduction... 2 High-Level Platform Architecture Diagram... 3 Zbi Production Environment... 4 Zbi Publishing Engine...
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Cloud Computing with FPGA-based NVMe SSDs
 Cloud Computing with FPGA-based NVMe SSDs Bharadwaj Pudipeddi, CTO NVXL Santa Clara, CA 1 Choice of NVMe Controllers ASIC NVMe: Fully off-loaded, consistent performance, M.2 or U.2 form factor ASIC OpenChannel:
Cloud Computing with FPGA-based NVMe SSDs Bharadwaj Pudipeddi, CTO NVXL Santa Clara, CA 1 Choice of NVMe Controllers ASIC NVMe: Fully off-loaded, consistent performance, M.2 or U.2 form factor ASIC OpenChannel:
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
White Paper. How the Meltdown and Spectre bugs work and what you can do to prevent a performance plummet. Contents
 White Paper How the Meltdown and Spectre bugs work and what you can do to prevent a performance plummet Programs that do a lot of I/O are likely to be the worst hit by the patches designed to fix the Meltdown
White Paper How the Meltdown and Spectre bugs work and what you can do to prevent a performance plummet Programs that do a lot of I/O are likely to be the worst hit by the patches designed to fix the Meltdown
BigDataBench-MT: Multi-tenancy version of BigDataBench
 BigDataBench-MT: Multi-tenancy version of BigDataBench Gang Lu Beijing Academy of Frontier Science and Technology BigDataBench Tutorial, ASPLOS 2016 Atlanta, GA, USA n Software perspective Multi-tenancy
BigDataBench-MT: Multi-tenancy version of BigDataBench Gang Lu Beijing Academy of Frontier Science and Technology BigDataBench Tutorial, ASPLOS 2016 Atlanta, GA, USA n Software perspective Multi-tenancy
JULEA: A Flexible Storage Framework for HPC
 JULEA: A Flexible Storage Framework for HPC Workshop on Performance and Scalability of Storage Systems Michael Kuhn Research Group Scientific Computing Department of Informatics Universität Hamburg 2017-06-22
JULEA: A Flexible Storage Framework for HPC Workshop on Performance and Scalability of Storage Systems Michael Kuhn Research Group Scientific Computing Department of Informatics Universität Hamburg 2017-06-22
Empowering People with Knowledge the Next Frontier for Web Search. Wei-Ying Ma Assistant Managing Director Microsoft Research Asia
 Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Performance and Scalability with Griddable.io
 Performance and Scalability with Griddable.io Executive summary Griddable.io is an industry-leading timeline-consistent synchronized data integration grid across a range of source and target data systems.
Performance and Scalability with Griddable.io Executive summary Griddable.io is an industry-leading timeline-consistent synchronized data integration grid across a range of source and target data systems.
Building a High IOPS Flash Array: A Software-Defined Approach
 Building a High IOPS Flash Array: A Software-Defined Approach Weafon Tsao Ph.D. VP of R&D Division, AccelStor, Inc. Santa Clara, CA Clarification Myth 1: S High-IOPS SSDs = High-IOPS All-Flash Array SSDs
Building a High IOPS Flash Array: A Software-Defined Approach Weafon Tsao Ph.D. VP of R&D Division, AccelStor, Inc. Santa Clara, CA Clarification Myth 1: S High-IOPS SSDs = High-IOPS All-Flash Array SSDs
Using Apache Spark for generating ElasticSearch indices offline
 Using Apache Spark for generating ElasticSearch indices offline Andrej Babolčai ESET Database systems engineer Apache: Big Data Europe 2016 Who am I Software engineer in database systems team Responsible
Using Apache Spark for generating ElasticSearch indices offline Andrej Babolčai ESET Database systems engineer Apache: Big Data Europe 2016 Who am I Software engineer in database systems team Responsible