Part III: Music Context-based Similarity
|
|
|
- Darren Gilbert
- 6 years ago
- Views:
Transcription
1 RuSSIR 2013: Content- and Context-based Music Similarity and Retrieval Titelmasterformat durch Klicken bearbeiten Part III: Music Context-based Similarity Markus Schedl Peter Knees {markus.schedl, Department of Computational Perception Johannes Kepler University (JKU) Linz, Austria

 Advantages of Context Analysis Captures aspects beyond pure audio signal No audio file")
2 Music Content vs. Music Context Advantages of Content Analysis Features can be extracted from any audio file No other data or community necessary No cultural biases (i.e., no popularity bias, no subjective ratings etc.) Advantages of Context Analysis Captures aspects beyond pure audio signal No audio file necessary Usually, user-based features are closer to what users want
3 Music Content vs. Music Context Challenges for Context-Based Feature Extractors Dependence on availability of sources (Web pages, tags, playlists,...) Popularity of artists may distort results Cold start problem of community-based systems (newly added entities do not have any information associated, e.g. user tags, users playing behavior) Hacking and vandalism (cf. last.fm tag brutal death metal ) Bias towards specific user/listener groups (e.g., young, Internet-prone, metal listeners in last.fm) (Reliable) data often only available on artist level Challenge for both Content and Context Analysis Extraction of relevant features from noisy signal
4 Context- and Web-Based Methods In the following, contextual data refers to extended meta-data, usually Generated by users Unstructured data-sources Accessible via the Web Two main classes of approaches covered in the following Text processing Co-occurrence analysis As for content-based methods, similarity is the central concept for retrieval
5 Text-Based Approaches Data sources: - Web pages retrieved via Web search engines - microblogs on Twitter - product reviews - semantic tags - lyrics
6 Text-Based Similarity and Genre Classification Use Web data to transform the music similarity task into a text similarity task Allows to use the full armory of IR methods, typically Bag-of-words, Vector Space Model Stopword removal, dictionaries, term selection TF IDF Latent Semantic Indexing Part-of-Speech tagging Named Entity Detection Sentiment analysis Large range of possible similarity measures Overlap, Manhattan, Euclidean, Cosine, etc.

7 Related Web Pages as Text Source
8 Related Web Pages as Text Source Web pages features similar to...? Similarity
9 Using search engines and queries such as artist +music artist +music +review (Whitman, Lawrence; 2002) (Baumann, Hummel; 2003) (Knees et al.; 2004) Analyze Related Web Pages as Text Source result page directly or download up to top 100 Web pages (combine into one virtual document or analyze separately) Apply IR magic Applicable for similarity estimation, classification, retrieval, annotation (NB: Most discriminating terms between genres are artist names and album/track titles)
10 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): - term frequency (Schedl et al.; 2011)
11 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): - term frequency - inverse document frequency (Schedl et al.; 2011)
12 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): (Schedl et al.; 2011) - term frequency - inverse document frequency - virtual document modeling: concatenate all Web pages/posts of the artist or perform aggregation via mean, max, etc.
13 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): (Schedl et al.; 2011) - term frequency - inverse document frequency - virtual document modeling: concatenate all Web pages/posts of the artist or perform aggregation via mean, max, etc. - normalization with respect to document length
14 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): (Schedl et al.; 2011) - term frequency - inverse document frequency - virtual document modeling: concatenate all Web pages/posts of the artist or perform aggregation via mean, max, etc. - normalization with respect to document length - similarity measure
15 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): (Schedl et al.; 2011) - term frequency - inverse document frequency - virtual document modeling: concatenate all Web pages/posts of the artist or perform aggregation via mean, max, etc. - normalization with respect to document length - similarity measure - index term set
 - term frequency - inverse document frequency - virtual document modeling: concatenate all Web pages/posts of the artist or perform aggregation via mean, max, etc.")
16 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): (Schedl et al.; 2011) - term frequency - inverse document frequency - virtual document modeling: concatenate all Web pages/posts of the artist or perform aggregation via mean, max, etc. - normalization with respect to document length - similarity measure - index term set - query scheme
17 Large-Scale Study Investigating different aspects in modeling artist term profiles from Web pages (9,200 experiments): (Schedl et al.; 2011) - term frequency - inverse document frequency - virtual document modeling: concatenate all Web pages/posts of the artist or perform aggregation via mean, max, etc. - normalization with respect to document length - similarity measure - index term set - query scheme implemented in our CoMIRVA framework available from
18 Interesting Findings - modeling artists as virtual documents is preferable - using query scheme artist +music outperforms artist - normalization does not yield a statistically significant difference - standard cosine similarity measure does not yield the very best results, but the most stable ones (varying other parameters) - consistent results among the (top-ranked) variants for two collections - minor change in one parameter can have a huge impact on performance - overall winners in terms of term weighting functions: TF_C3.IDF_I TF_C3.IDF_H logarithmic formulations for TF and IDF TF_C2.IDF_I (Schedl et al.; 2011)
19 Web-Based Descriptions for Browsing MusicSun (Pampalk, Goto; 2007) Interactive Artist Recommender Recommendation is influenced/directed by selecting relevant similarity dimensions Combines different similarity measures Query artists 3 types of similarity: audio, web-based, word overall similarity = weighted average of ranks Relevant word dimension
20 Web-Based Texts for Indexing and Retrieval Use Web data to transform music retrieval into a text retrieval task Find associated (or associable) texts and use them instead of music Allows for diverse and semantic queries (e.g, chilled music, great riffs ) Search Sounds (Celma et al.; 2006) Crawl lists of RSS feeds and use Weblog entries to index pieces Squiggle (Celino et al.; 2006): Combine meta-data databases (like MusicBrainz) for rich indexing Gedoodle (Knees et al.; SIGIR 2007): Query Google and combine Web pages to index pieces

21 Gedoodle ID3 Digital audio collection Related Web pages IR Audio similarity TFIDF descriptors Audio features query TFIDF? Modified descriptors Relevance ranking
22 Gedoodle For each track: join 100 Google results of artist music artist album music review artist title music review -lyrics Combine all pages into one virtual document (Knees et al.; SIGIR 2007) Create normalized TFIDF vector for each track Include audio similarity for vector modification and dimensionality reduction

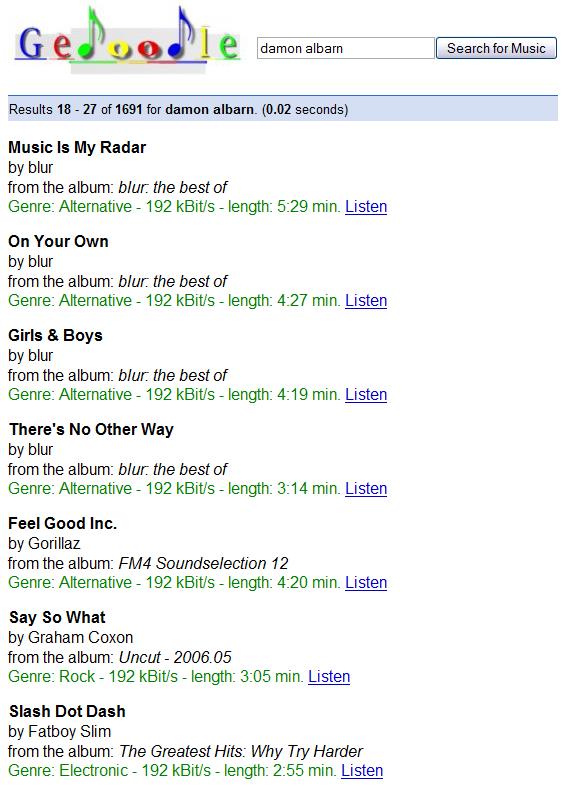
23 Gedoodle (Example queries)
24 Gedoodle Results Effects of TFIDF feature space pruning using content-similarity-based χ 2 -test (Knees et al.; SIGIR 2007) chisquare 50 chisquare 100 chisquare 150 no chisquare baseline Precision Recall
25 Gedoodle Results Alternative: Document-centered ranking (Knees et al.; ECIR 2008) Indexing of all web documents in standard index Music query addresses this index Music ranking calculated from web doc ranking according to Comparison with vector space model Precision RRS VSM approach Baseline Recall
26 Semantic Querying via Auto-Tagging Use machine learning techniques to predict tags (labels) based on song features (content, context, or combination) Automatic description of music (browsing) and automatic generation of indexing terms for retrieval Mitigates cold-start problem in social tagging Automatic Record Reviews (Whitman, Ellis; 2004) Regularized least squares learning on TFIDF-Web and cepstral features Autotagger (Bertin-Mahieux et al.; 2008) Ensemble classifier to map MFCCs, autocorrelation, Const-Q. to Web tags Semantic Music Discovery (Turnbull et al.; SIGIR 2007, 2009): Combines timbre, harmony, Web texts, and Web tags to predict user labels Semantic Annotation of Music Collections (Sordo; 2012) Propagation of tags through audio similarity



27 Auto-Tagging/Retrieval by Tag Learning indexing labels from content features (Sordo; 2012)
28 Music Information Extraction from Web Pages Web data is a rich source for all types of meta-data and semantic relations Methods from NLP, IE, Named Entity Detection for data extraction Genres, Moods, Similarities using Rule Patterns (Geleijnse, Korst; 2006) Band Members and Line-Up using Rule Patterns (Schedl, Widmer; 2007) Band Members, Discography, Artist Detection (rule based) (Krenmair; 2010) Band Members, Discography using Supervised Learning (Knees, Schedl; 2011) Album cover detection and extraction (Schedl et al., ECIR 2006)
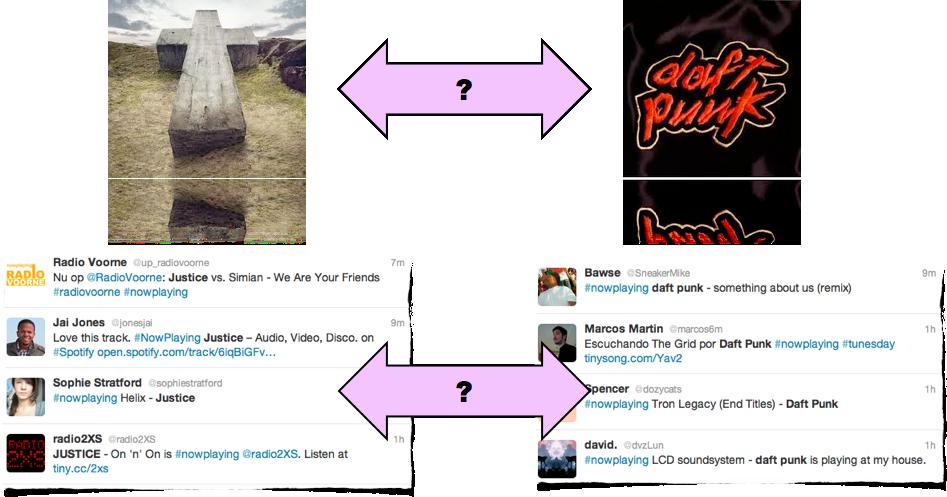

29 Microblogs as Text Sources



30 Microblogs as Text Sources: Scheme (Schedl; 2012a) Lady Gaga Mozart Alcest (+music) artist A artist B artist term profiles similarity estimate
31 Microblogs as Text Sources: Scheme Large-scale study similar to (Schedl et al.; TOIS 2011) (Schedl; 2012a) Investigating different aspects in modeling artist term profiles from microblogs (23,100 experiments): - query scheme - index term set - term frequency - inverse document frequency - normalization with respect to document length - similarity measure implemented in our CoMIRVA framework available from
32 Microblogs as text-based source: Results (Schedl; 2012a) use query scheme artist name music-specific dictionary favorable use log or Okapi BM25 use logarithmic formulations don t use Euclid; use Jeffrey or Inner Prod. no document length normalization


33 Product Reviews as Text Sources


34 Product Reviews as Text Sources Exploiting sources such as Amazon.com or Epinions.com (Hu et al.; 2005) Allows for sentiment analysis and associated rating prediction Very prone to attacks (remedy: consider helpfulness ratings)


35 Community Tags as Text Sources

 Games with a")

36 Tag Sources Community e.g., Last.fm e.g., Soundcloud (annotations along timeline) Games with a purpose (GWAP) e.g., Tag-a-Tune (Law, von Ahn; 2009) Autotags (see before)
37 Community Tags as Text Sources Treating collections of tags (e.g., from Last.fm) as documents Retrieve tags for artist or track from Last.fm Cleaning of noisy and redundant tags: manually or automatically (Geleijnse et al.; 2007) (Pohle et al.; 2007) (Levy, Sandler; 2008) (Hu et al.; 2009) List of collected terms is treated as text document and TF IDF d (Levy, Sandler; 2007) Optionally, LSA to reduce dimensionality Comparison of vectors via cosine similarity (or overlap score) Data often available in standardized fashion, dedicated terms for music Lower dimensionality e.g., 13,500 tags vs. >200,000 Web terms (Levy, Sandler; 2007) Depends on community, needs annotators Hacking and Attacks!


38 Lyrics as Text Source
39 Lyrics as Text Source Topic Features (Logan et al.; 2004) Typical topics for lyrics are distilled from a large corpus using (P)LSA ( Hate, Love, Blue, Gangsta, Spanish ) Lyrics are transformed to topic-based vectors, similarity is calculated via L 1 distance Alternative approaches use TF IDF with optional LSA and Stemming for Mood Categorization (Laurier et al.;2009) (Hu et al.; 2009) Rhyme Features (Mayer et al.; 2008) (Hirjee, Brown; 2009) Phonetic transcription is searched for patterns of rhyming lines (AA, ABAB, AABB) Frequency of patterns + statistics like words per minute, punctuation freq. etc. Other Features (Mahedero et al.; 2005) (Hirjee, Brown; 2009) Language, structure
40 Text-based Similarity Approaches: Summary Web-Terms Microblogs Reviews Tags Lyrics. Source Web pages platform shops, platform Web service portal Community-based depends depends yes yes no Level artists artists (tracks) albums artists (tracks) tracks (artists) Feature Dimensionality very high high possibly high moderate possibly high Specific Bias low low personal community none Potential Noise high high low moderate low
41 Similarity from Co-Occurrences Idea: expect entities that occur frequently in the same context to be similar Data sources considered: Page count estimates from Web search engines Shared folders/search queries on the Gnutella file sharing network Collaborative filtering on playcounts from Last.fm Occurrences in playlists
42 Search Engine Page Count Estimates (Schedl et al.; 2005) For all pairs of artists: query artist 1 artist 2 +music +review For each artist: query artist +music +review Use page counts for sim. (results in quadratic page count matrix) To avoid quadratic number of queries: download top 100 pages for each artist and parse for occurrences of other artists (linear complexity) NB: asymmetry of pc matrix can be used to identify prototypical artists!
 (Ellis et al.; 2002) Information gathered from users' shared folders (no file downloads!")
 Sparse co-occurrence matrix Experiments on Gnutella network (Shavitt, Weinsberg; 2009): meta-data highly inconsistent can be used as")
43 Shared Folders in a P2P Network Make use of meta-data transmitted as files names or ID3 tags in P2P network OpenNap (Whitman, Lawrence; 2002) (Ellis et al.; 2002) Information gathered from users' shared folders (no file downloads!) Similarities via artist co-occurrences in collections (cond. prob.) Sparse co-occurrence matrix Experiments on Gnutella network (Shavitt, Weinsberg; 2009): meta-data highly inconsistent can be used as song-based similarity measure and to estimate localized popularity/trends (matching IP addresses difficult!)
 e.g., (Resnick et al.")
44 Last.fm Playcounts Use explicit or implicit ratings of users or interpret number of plays of a song as a rating Results in a user-track rating matrix Use standard collaborative filtering approaches to predict similarities (or to recommend unknown music) e.g., (Resnick et al.; 1994) Item-based: compare tracks by calculating similarity on vectors over all users User-based: find similar users by comparing listening pattern vectors; use to find relevant/similar tracks yet unknown to user
45 Playlist Co-Occurrences Analysis of co-occurrences of artists and songs on radio station playlists and compilation CD databases (CDDB) (Pachet et al.;2001) Analysis of 29K playlists from Art of the Mix (Cano, Koppenberger;2004): artists similar if they co-occur in playlist (highly sparse) Analysis of >1M playlists from MusicStrands (Baccigalupo et al.; 2008): distance in playlists taken into account β 0 = 1, β 1 = 0.8, β 2 = 0.64 playlist prediction using case-based reasoning
46 Co-occurrence-based Approaches: Summary Web Co-Ocs Playcounts P2P nets Playlists. Source search engines, listening shared radio, compilations, Web pages service folders Web services Community-based no yes yes depends on source Level artists tracks artists (tracks) artists (tracks) Specific Bias "wikipedia"-bias popularity community low Potential Noise high low high low
CONTEXT-BASED MUSIC SIMILARITY ESTIMATION
 Context-based Music Similarity Estimation music@jku.at http://www.cp.jku.at CONTEXT-BASED MUSIC SIMILARITY ESTIMATION Peter Knees Markus Schedl Department of Computational Perception Johannes Kepler University
Context-based Music Similarity Estimation music@jku.at http://www.cp.jku.at CONTEXT-BASED MUSIC SIMILARITY ESTIMATION Peter Knees Markus Schedl Department of Computational Perception Johannes Kepler University
A Document-centered Approach to a Natural Language Music Search Engine
 A Document-centered Approach to a Natural Language Music Search Engine Peter Knees, Tim Pohle, Markus Schedl, Dominik Schnitzer, and Klaus Seyerlehner Dept. of Computational Perception, Johannes Kepler
A Document-centered Approach to a Natural Language Music Search Engine Peter Knees, Tim Pohle, Markus Schedl, Dominik Schnitzer, and Klaus Seyerlehner Dept. of Computational Perception, Johannes Kepler
Similarity by Metadata
 Similarity by Metadata Simon Putzke Mirco Semper Freie Universität Berlin Institut für Informatik Seminar Music Information Retrieval Outline Motivation Metadata Tagging Similarities Webmining Example
Similarity by Metadata Simon Putzke Mirco Semper Freie Universität Berlin Institut für Informatik Seminar Music Information Retrieval Outline Motivation Metadata Tagging Similarities Webmining Example
WHAT S HOT? ESTIMATING COUNTRY-SPECIFIC ARTIST POPULARITY
 WHAT S HOT? ESTIMATING COUNTRY-SPECIFIC ARTIST POPULARITY Markus Schedl 1, Tim Pohle 1, Noam Koenigstein 2, Peter Knees 1 1 Department of Computational Perception Johannes Kepler University, Linz, Austria
WHAT S HOT? ESTIMATING COUNTRY-SPECIFIC ARTIST POPULARITY Markus Schedl 1, Tim Pohle 1, Noam Koenigstein 2, Peter Knees 1 1 Department of Computational Perception Johannes Kepler University, Linz, Austria
From Improved Auto-taggers to Improved Music Similarity Measures
 From Improved Auto-taggers to Improved Music Similarity Measures Klaus Seyerlehner 1, Markus Schedl 1, Reinhard Sonnleitner 1, David Hauger 1, and Bogdan Ionescu 2 1 Johannes Kepler University Department
From Improved Auto-taggers to Improved Music Similarity Measures Klaus Seyerlehner 1, Markus Schedl 1, Reinhard Sonnleitner 1, David Hauger 1, and Bogdan Ionescu 2 1 Johannes Kepler University Department
Automatically Adapting the Structure of Audio Similarity Spaces
 Automatically Adapting the Structure of Audio Similarity Spaces Tim Pohle 1, Peter Knees 1, Markus Schedl 1 and Gerhard Widmer 1,2 1 Department of Computational Perception Johannes Kepler University Linz,
Automatically Adapting the Structure of Audio Similarity Spaces Tim Pohle 1, Peter Knees 1, Markus Schedl 1 and Gerhard Widmer 1,2 1 Department of Computational Perception Johannes Kepler University Linz,
FIVE APPROACHES TO COLLECTING TAGS FOR MUSIC
 FIVE APPROACHES TO COLLECTING TAGS FOR MUSIC Douglas Turnbull UC San Diego dturnbul@cs.ucsd.edu Luke Barrington UC San Diego lbarrington@ucsd.edu Gert Lanckriet UC San Diego gert@ece.ucsd.edu ABSTRACT
FIVE APPROACHES TO COLLECTING TAGS FOR MUSIC Douglas Turnbull UC San Diego dturnbul@cs.ucsd.edu Luke Barrington UC San Diego lbarrington@ucsd.edu Gert Lanckriet UC San Diego gert@ece.ucsd.edu ABSTRACT
AUGMENTING TEXT-BASED MUSIC RETRIEVAL WITH AUDIO SIMILARITY
 AUGMENTING TEXT-BASED MUSIC RETRIEVAL WITH AUDIO SIMILARITY P. Knees 1, T. Pohle 1, M. Schedl 1, D. Schnitzer 1,2, K. Seyerlehner 1, and G. Widmer 1,2 1 Department of Computational Perception, Johannes
AUGMENTING TEXT-BASED MUSIC RETRIEVAL WITH AUDIO SIMILARITY P. Knees 1, T. Pohle 1, M. Schedl 1, D. Schnitzer 1,2, K. Seyerlehner 1, and G. Widmer 1,2 1 Department of Computational Perception, Johannes
INVESTIGATING THE SIMILARITY SPACE OF MUSIC ARTISTS ON THE MICRO-BLOGOSPHERE
 12th International Society for Music Information Retrieval Conference (ISMIR 2011 INVESTIGATING THE SIMILARITY SPACE OF MUSIC ARTISTS ON THE MICRO-BLOGOSPHERE Markus Schedl, Peter Knees, Sebastian Böck
12th International Society for Music Information Retrieval Conference (ISMIR 2011 INVESTIGATING THE SIMILARITY SPACE OF MUSIC ARTISTS ON THE MICRO-BLOGOSPHERE Markus Schedl, Peter Knees, Sebastian Böck
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
FIVE APPROACHES TO COLLECTING TAGS FOR MUSIC
 FIVE APPROACHES TO COLLECTING TAGS FOR MUSIC Douglas Turnbull UC San Diego dturnbul@cs.ucsd.edu Luke Barrington UC San Diego lbarrington@ucsd.edu Gert Lanckriet UC San Diego gert@ece.ucsd.edu ABSTRACT
FIVE APPROACHES TO COLLECTING TAGS FOR MUSIC Douglas Turnbull UC San Diego dturnbul@cs.ucsd.edu Luke Barrington UC San Diego lbarrington@ucsd.edu Gert Lanckriet UC San Diego gert@ece.ucsd.edu ABSTRACT
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
Introduction to Information Retrieval
 Introduction to Information Retrieval Skiing Seminar Information Retrieval 2010/2011 Introduction to Information Retrieval Prof. Ulrich Müller-Funk, MScIS Andreas Baumgart and Kay Hildebrand Agenda 1 Boolean
Introduction to Information Retrieval Skiing Seminar Information Retrieval 2010/2011 Introduction to Information Retrieval Prof. Ulrich Müller-Funk, MScIS Andreas Baumgart and Kay Hildebrand Agenda 1 Boolean
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Introduction to Information Retrieval
 Introduction to Information Retrieval Mohsen Kamyar چهارمین کارگاه ساالنه آزمایشگاه فناوری و وب بهمن ماه 1391 Outline Outline in classic categorization Information vs. Data Retrieval IR Models Evaluation
Introduction to Information Retrieval Mohsen Kamyar چهارمین کارگاه ساالنه آزمایشگاه فناوری و وب بهمن ماه 1391 Outline Outline in classic categorization Information vs. Data Retrieval IR Models Evaluation
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most
 In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
Reading group on Ontologies and NLP:
 Reading group on Ontologies and NLP: Machine Learning27th infebruary Automated 2014 1 / 25 Te Reading group on Ontologies and NLP: Machine Learning in Automated Text Categorization, by Fabrizio Sebastianini.
Reading group on Ontologies and NLP: Machine Learning27th infebruary Automated 2014 1 / 25 Te Reading group on Ontologies and NLP: Machine Learning in Automated Text Categorization, by Fabrizio Sebastianini.
Recommender Systems: Practical Aspects, Case Studies. Radek Pelánek
 Recommender Systems: Practical Aspects, Case Studies Radek Pelánek 2017 This Lecture practical aspects : attacks, context, shared accounts,... case studies, illustrations of application illustration of
Recommender Systems: Practical Aspects, Case Studies Radek Pelánek 2017 This Lecture practical aspects : attacks, context, shared accounts,... case studies, illustrations of application illustration of
Chrome based Keyword Visualizer (under sparse text constraint) SANGHO SUH MOONSHIK KANG HOONHEE CHO
 SANGHO SUH MOONSHIK KANG HOONHEE CHO") Chrome based Keyword Visualizer (under sparse text constraint) SANGHO SUH MOONSHIK KANG HOONHEE CHO INDEX Proposal Recap Implementation Evaluation Future Works Proposal Recap Keyword Visualizer (chrome
Chrome based Keyword Visualizer (under sparse text constraint) SANGHO SUH MOONSHIK KANG HOONHEE CHO INDEX Proposal Recap Implementation Evaluation Future Works Proposal Recap Keyword Visualizer (chrome
Information Processing and Management
 Information Processing and Management 47 (2011) 426 439 Contents lists available at ScienceDirect Information Processing and Management journal homepage: www.elsevier.com/locate/infoproman A music information
Information Processing and Management 47 (2011) 426 439 Contents lists available at ScienceDirect Information Processing and Management journal homepage: www.elsevier.com/locate/infoproman A music information
Music Recommendation with Implicit Feedback and Side Information
 Music Recommendation with Implicit Feedback and Side Information Shengbo Guo Yahoo! Labs shengbo@yahoo-inc.com Behrouz Behmardi Criteo b.behmardi@criteo.com Gary Chen Vobile gary.chen@vobileinc.com Abstract
Music Recommendation with Implicit Feedback and Side Information Shengbo Guo Yahoo! Labs shengbo@yahoo-inc.com Behrouz Behmardi Criteo b.behmardi@criteo.com Gary Chen Vobile gary.chen@vobileinc.com Abstract
Information Retrieval: Retrieval Models
 CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence!
 James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence! (301) 219-4649 james.mayfield@jhuapl.edu What is Information Retrieval? Evaluation
James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence! (301) 219-4649 james.mayfield@jhuapl.edu What is Information Retrieval? Evaluation
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Instructor: Stefan Savev
 LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
Introduction to Data Mining
 Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman
 Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Multimedia Information Retrieval: Or This stuff is really hard... really! Matt Earp / Kid Kameleon
 Multimedia Information Retrieval: Or This stuff is really hard... really! Matt Earp / Kid Kameleon Setlist Review of Multimedia Information Organization MMIR in Music - Matt MMIR in Video and Photo- Yiming
Multimedia Information Retrieval: Or This stuff is really hard... really! Matt Earp / Kid Kameleon Setlist Review of Multimedia Information Organization MMIR in Music - Matt MMIR in Video and Photo- Yiming
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
THE QUEST FOR GROUND TRUTH IN MUSICAL ARTIST TAGGING IN THE SOCIAL WEB ERA
 THE QUEST FOR GROUND TRUTH IN MUSICAL ARTIST TAGGING IN THE SOCIAL WEB ERA Gijs Geleijnse Philips Research High Tech Campus 34 Eindhoven (the Netherlands) gijs.geleijnse@philips.com Markus Schedl Peter
THE QUEST FOR GROUND TRUTH IN MUSICAL ARTIST TAGGING IN THE SOCIAL WEB ERA Gijs Geleijnse Philips Research High Tech Campus 34 Eindhoven (the Netherlands) gijs.geleijnse@philips.com Markus Schedl Peter
CS 6320 Natural Language Processing
 CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
Automatic Summarization
 Automatic Summarization CS 769 Guest Lecture Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of Wisconsin, Madison February 22, 2008 Andrew B. Goldberg (CS Dept) Summarization
Automatic Summarization CS 769 Guest Lecture Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of Wisconsin, Madison February 22, 2008 Andrew B. Goldberg (CS Dept) Summarization
ACCESSING MUSIC COLLECTIONS VIA REPRESENTATIVE CLUSTER PROTOTYPES IN A HIERARCHICAL ORGANIZATION SCHEME
 ACCESSING MUSIC COLLECTIONS VIA REPRESENTATIVE CLUSTER PROTOTYPES IN A HIERARCHICAL ORGANIZATION SCHEME Markus Dopler Markus Schedl Tim Pohle Peter Knees Department of Computational Perception Johannes
ACCESSING MUSIC COLLECTIONS VIA REPRESENTATIVE CLUSTER PROTOTYPES IN A HIERARCHICAL ORGANIZATION SCHEME Markus Dopler Markus Schedl Tim Pohle Peter Knees Department of Computational Perception Johannes
Tag-based Social Interest Discovery
 Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
THE NATURAL LANGUAGE OF PLAYLISTS
 THE NATURAL LANGUAGE OF PLAYLISTS Brian McFee Computer Science and Engineering University of California, San Diego Gert Lanckriet Electrical and Computer Engineering University of California, San Diego
THE NATURAL LANGUAGE OF PLAYLISTS Brian McFee Computer Science and Engineering University of California, San Diego Gert Lanckriet Electrical and Computer Engineering University of California, San Diego
Developing Focused Crawlers for Genre Specific Search Engines
 Developing Focused Crawlers for Genre Specific Search Engines Nikhil Priyatam Thesis Advisor: Prof. Vasudeva Varma IIIT Hyderabad July 7, 2014 Examples of Genre Specific Search Engines MedlinePlus Naukri.com
Developing Focused Crawlers for Genre Specific Search Engines Nikhil Priyatam Thesis Advisor: Prof. Vasudeva Varma IIIT Hyderabad July 7, 2014 Examples of Genre Specific Search Engines MedlinePlus Naukri.com
Unstructured Data. CS102 Winter 2019
 Winter 2019 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for patterns in data
Winter 2019 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for patterns in data
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
PERSONALIZED TAG RECOMMENDATION
 PERSONALIZED TAG RECOMMENDATION Ziyu Guan, Xiaofei He, Jiajun Bu, Qiaozhu Mei, Chun Chen, Can Wang Zhejiang University, China Univ. of Illinois/Univ. of Michigan 1 Booming of Social Tagging Applications
PERSONALIZED TAG RECOMMENDATION Ziyu Guan, Xiaofei He, Jiajun Bu, Qiaozhu Mei, Chun Chen, Can Wang Zhejiang University, China Univ. of Illinois/Univ. of Michigan 1 Booming of Social Tagging Applications
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
Session 10: Information Retrieval
 INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
Multimedia Information Systems
 Multimedia Information Systems Samson Cheung EE 639, Fall 2004 Lecture 6: Text Information Retrieval 1 Digital Video Library Meta-Data Meta-Data Similarity Similarity Search Search Analog Video Archive
Multimedia Information Systems Samson Cheung EE 639, Fall 2004 Lecture 6: Text Information Retrieval 1 Digital Video Library Meta-Data Meta-Data Similarity Similarity Search Search Analog Video Archive
TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION. Prateek Verma, Yang-Kai Lin, Li-Fan Yu. Stanford University
 TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION Prateek Verma, Yang-Kai Lin, Li-Fan Yu Stanford University ABSTRACT Structural segmentation involves finding hoogeneous sections appearing
TWO-STEP SEMI-SUPERVISED APPROACH FOR MUSIC STRUCTURAL CLASSIFICATION Prateek Verma, Yang-Kai Lin, Li-Fan Yu Stanford University ABSTRACT Structural segmentation involves finding hoogeneous sections appearing
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
This lecture: IIR Sections Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes Vector space scoring
 This lecture: IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes Vector space scoring 1 Ch. 6 Ranked retrieval Thus far, our queries have all
This lecture: IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes Vector space scoring 1 Ch. 6 Ranked retrieval Thus far, our queries have all
Repositorio Institucional de la Universidad Autónoma de Madrid.
 Repositorio Institucional de la Universidad Autónoma de Madrid https://repositorio.uam.es Esta es la versión de autor de la comunicación de congreso publicada en: This is an author produced version of
Repositorio Institucional de la Universidad Autónoma de Madrid https://repositorio.uam.es Esta es la versión de autor de la comunicación de congreso publicada en: This is an author produced version of
Feature selection. LING 572 Fei Xia
 Feature selection LING 572 Fei Xia 1 Creating attribute-value table x 1 x 2 f 1 f 2 f K y Choose features: Define feature templates Instantiate the feature templates Dimensionality reduction: feature selection
Feature selection LING 572 Fei Xia 1 Creating attribute-value table x 1 x 2 f 1 f 2 f K y Choose features: Define feature templates Instantiate the feature templates Dimensionality reduction: feature selection
LabROSA Research Overview
 LabROSA Research Overview Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu 1. Music 2. Environmental sound 3.
LabROSA Research Overview Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu 1. Music 2. Environmental sound 3.
Exploiting the Diversity of User Preferences for Recommendation. Saúl Vargas and Pablo Castells {saul.vargas,
 Exploiting the Diversity of User Preferences for Recommendation Saúl Vargas and Pablo Castells {saul.vargas, pablo.castells}@uam.es Item Recommendation User A B C E F D G I H User profile You may also
Exploiting the Diversity of User Preferences for Recommendation Saúl Vargas and Pablo Castells {saul.vargas, pablo.castells}@uam.es Item Recommendation User A B C E F D G I H User profile You may also
Self-Organizing Maps (SOM)
") Overview (SOM) Basics Sequential Training (On-Line Learning) Batch SOM Visualizing the SOM - SOM Grid - Music Description Map (MDM) - Bar Plots and Chernoff's Faces - U-Matrix and Distance Matrix - Smoothed
Overview (SOM) Basics Sequential Training (On-Line Learning) Batch SOM Visualizing the SOM - SOM Grid - Music Description Map (MDM) - Bar Plots and Chernoff's Faces - U-Matrix and Distance Matrix - Smoothed
CS54701: Information Retrieval
 CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
COMP6237 Data Mining Searching and Ranking
 COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
NOVEL INTERACTIVE MUSIC SEARCH TECHNIQUES
 Mario Kubek 4FriendsOnly.com Internet Technologies AG mk@4fo.de Jürgen Nützel 4FriendsOnly.com Internet Technologies AG jn@4fo.de NOVEL INTERACTIVE MUSIC SEARCH TECHNIQUES Abstract: The discipline of finding
Mario Kubek 4FriendsOnly.com Internet Technologies AG mk@4fo.de Jürgen Nützel 4FriendsOnly.com Internet Technologies AG jn@4fo.de NOVEL INTERACTIVE MUSIC SEARCH TECHNIQUES Abstract: The discipline of finding
Social Tagging and Music Information Retrieval Paul Lamere a a
 This article was downloaded by: [Florida International University] On: 4 August 2010 Access details: Access Details: [subscription number 791500676] Publisher Routledge Informa Ltd Registered in England
This article was downloaded by: [Florida International University] On: 4 August 2010 Access details: Access Details: [subscription number 791500676] Publisher Routledge Informa Ltd Registered in England
An Oracle White Paper October Oracle Social Cloud Platform Text Analytics
 An Oracle White Paper October 2012 Oracle Social Cloud Platform Text Analytics Executive Overview Oracle s social cloud text analytics platform is able to process unstructured text-based conversations
An Oracle White Paper October 2012 Oracle Social Cloud Platform Text Analytics Executive Overview Oracle s social cloud text analytics platform is able to process unstructured text-based conversations
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval
 Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
Music Similarity Clustering
 Cognitive Science B.Sc. Program University of Osnabrück, Germany Music Similarity Clustering A Content-Based Approach in Clustering Music Files According to User Preference Thesis-Project for the Degree
Cognitive Science B.Sc. Program University of Osnabrück, Germany Music Similarity Clustering A Content-Based Approach in Clustering Music Files According to User Preference Thesis-Project for the Degree
1 Introduction. 3 Data Preprocessing. 2 Literature Review
 Rock or not? This sure does. [Category] Audio & Music CS 229 Project Report Anand Venkatesan(anand95), Arjun Parthipan(arjun777), Lakshmi Manoharan(mlakshmi) 1 Introduction Music Genre Classification continues
Rock or not? This sure does. [Category] Audio & Music CS 229 Project Report Anand Venkatesan(anand95), Arjun Parthipan(arjun777), Lakshmi Manoharan(mlakshmi) 1 Introduction Music Genre Classification continues
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Basic techniques. Text processing; term weighting; vector space model; inverted index; Web Search
 Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Query Phrase Expansion using Wikipedia for Patent Class Search
 Query Phrase Expansion using Wikipedia for Patent Class Search 1 Bashar Al-Shboul, Sung-Hyon Myaeng Korea Advanced Institute of Science and Technology (KAIST) December 19 th, 2011 AIRS 11, Dubai, UAE OUTLINE
Query Phrase Expansion using Wikipedia for Patent Class Search 1 Bashar Al-Shboul, Sung-Hyon Myaeng Korea Advanced Institute of Science and Technology (KAIST) December 19 th, 2011 AIRS 11, Dubai, UAE OUTLINE
Boolean Model. Hongning Wang
 Boolean Model Hongning Wang CS@UVa Abstraction of search engine architecture Indexed corpus Crawler Ranking procedure Doc Analyzer Doc Representation Query Rep Feedback (Query) Evaluation User Indexer
Boolean Model Hongning Wang CS@UVa Abstraction of search engine architecture Indexed corpus Crawler Ranking procedure Doc Analyzer Doc Representation Query Rep Feedback (Query) Evaluation User Indexer
MusicBox: Navigating the space of your music. Anita Lillie November 19, 2007
 MusicBox: Navigating the space of your music Anita Lillie November 19, 2007 The Problem Navigating large music libraries describing preferences with words selecting music that fits those preferences recommending
MusicBox: Navigating the space of your music Anita Lillie November 19, 2007 The Problem Navigating large music libraries describing preferences with words selecting music that fits those preferences recommending
What is this Song About?: Identification of Keywords in Bollywood Lyrics
 What is this Song About?: Identification of Keywords in Bollywood Lyrics by Drushti Apoorva G, Kritik Mathur, Priyansh Agrawal, Radhika Mamidi in 19th International Conference on Computational Linguistics
What is this Song About?: Identification of Keywords in Bollywood Lyrics by Drushti Apoorva G, Kritik Mathur, Priyansh Agrawal, Radhika Mamidi in 19th International Conference on Computational Linguistics
Learning Ontology-Based User Profiles: A Semantic Approach to Personalized Web Search
 1 / 33 Learning Ontology-Based User Profiles: A Semantic Approach to Personalized Web Search Bernd Wittefeld Supervisor Markus Löckelt 20. July 2012 2 / 33 Teaser - Google Web History http://www.google.com/history
1 / 33 Learning Ontology-Based User Profiles: A Semantic Approach to Personalized Web Search Bernd Wittefeld Supervisor Markus Löckelt 20. July 2012 2 / 33 Teaser - Google Web History http://www.google.com/history
Advanced Topics in Information Retrieval. Learning to Rank. ATIR July 14, 2016
 Advanced Topics in Information Retrieval Learning to Rank Vinay Setty vsetty@mpi-inf.mpg.de Jannik Strötgen jannik.stroetgen@mpi-inf.mpg.de ATIR July 14, 2016 Before we start oral exams July 28, the full
Advanced Topics in Information Retrieval Learning to Rank Vinay Setty vsetty@mpi-inf.mpg.de Jannik Strötgen jannik.stroetgen@mpi-inf.mpg.de ATIR July 14, 2016 Before we start oral exams July 28, the full
String Vector based KNN for Text Categorization
 458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
Multimedia Database Systems. Retrieval by Content
 Multimedia Database Systems Retrieval by Content MIR Motivation Large volumes of data world-wide are not only based on text: Satellite images (oil spill), deep space images (NASA) Medical images (X-rays,
Multimedia Database Systems Retrieval by Content MIR Motivation Large volumes of data world-wide are not only based on text: Satellite images (oil spill), deep space images (NASA) Medical images (X-rays,
SCALABLE KNOWLEDGE BASED AGGREGATION OF COLLECTIVE BEHAVIOR
 SCALABLE KNOWLEDGE BASED AGGREGATION OF COLLECTIVE BEHAVIOR P.SHENBAGAVALLI M.E., Research Scholar, Assistant professor/cse MPNMJ Engineering college Sspshenba2@gmail.com J.SARAVANAKUMAR B.Tech(IT)., PG
SCALABLE KNOWLEDGE BASED AGGREGATION OF COLLECTIVE BEHAVIOR P.SHENBAGAVALLI M.E., Research Scholar, Assistant professor/cse MPNMJ Engineering college Sspshenba2@gmail.com J.SARAVANAKUMAR B.Tech(IT)., PG
Manning Chapter: Text Retrieval (Selections) Text Retrieval Tasks. Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniques
 Text Retrieval Tasks. Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniques") Text Retrieval Readings Introduction Manning Chapter: Text Retrieval (Selections) Text Retrieval Tasks Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniues 1 2 Text Retrieval:
Text Retrieval Readings Introduction Manning Chapter: Text Retrieval (Selections) Text Retrieval Tasks Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniues 1 2 Text Retrieval:
Mining Large-Scale Music Data Sets
 Mining Large-Scale Music Data Sets Dan Ellis & Thierry Bertin-Mahieux Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,thierry}@ee.columbia.edu
Mining Large-Scale Music Data Sets Dan Ellis & Thierry Bertin-Mahieux Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,thierry}@ee.columbia.edu
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 06 Scoring, Term Weighting and the Vector Space Model 1 Recap of lecture 5 Collection and vocabulary statistics: Heaps and Zipf s laws Dictionary
Information Retrieval Suan Lee - Information Retrieval - 06 Scoring, Term Weighting and the Vector Space Model 1 Recap of lecture 5 Collection and vocabulary statistics: Heaps and Zipf s laws Dictionary
Representation/Indexing (fig 1.2) IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s
 IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s") Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Determining Song Similarity via Machine Learning Techniques and Tagging Information
 Determining Song Similarity via Machine Learning Techniques and Tagging Information 1 Renato L. F. Cunha, Evandro Caldeira Luciana Fujii, arxiv:1704.03844v1 [cs.lg] 12 Apr 2017 Universidade Federal de
Determining Song Similarity via Machine Learning Techniques and Tagging Information 1 Renato L. F. Cunha, Evandro Caldeira Luciana Fujii, arxiv:1704.03844v1 [cs.lg] 12 Apr 2017 Universidade Federal de
Knowledge Retrieval. Franz J. Kurfess. Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A.
 Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Introduction to Information Retrieval
 Introduction to Information Retrieval (Supplementary Material) Zhou Shuigeng March 23, 2007 Advanced Distributed Computing 1 Text Databases and IR Text databases (document databases) Large collections
Introduction to Information Retrieval (Supplementary Material) Zhou Shuigeng March 23, 2007 Advanced Distributed Computing 1 Text Databases and IR Text databases (document databases) Large collections
Midterm Exam Search Engines ( / ) October 20, 2015
 October 20, 2015") Student Name: Andrew ID: Seat Number: Midterm Exam Search Engines (11-442 / 11-642) October 20, 2015 Answer all of the following questions. Each answer should be thorough, complete, and relevant. Points
Student Name: Andrew ID: Seat Number: Midterm Exam Search Engines (11-442 / 11-642) October 20, 2015 Answer all of the following questions. Each answer should be thorough, complete, and relevant. Points
Learning Similarity Metrics for Event Identification in Social Media. Hila Becker, Luis Gravano
 Learning Similarity Metrics for Event Identification in Social Media Hila Becker, Luis Gravano Columbia University Mor Naaman Rutgers University Event Content in Social Media Sites Event Content in Social
Learning Similarity Metrics for Event Identification in Social Media Hila Becker, Luis Gravano Columbia University Mor Naaman Rutgers University Event Content in Social Media Sites Event Content in Social
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
Information Retrieval
 Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Moodify. 1. Introduction. 2. System Architecture. 2.1 Data Fetching Component. W205-1 Rock Baek, Saru Mehta, Vincent Chio, Walter Erquingo Pezo
 1. Introduction Moodify Moodify is an music web application that recommend songs to user based on mood. There are two ways a user can interact with the application. First, users can select a mood that
1. Introduction Moodify Moodify is an music web application that recommend songs to user based on mood. There are two ways a user can interact with the application. First, users can select a mood that
Copyright 2017 by Kevin de Wit
 Copyright 2017 by Kevin de Wit All rights reserved. No part of this publication may be reproduced, distributed, or transmitted in any form or by any means, including photocopying, recording, or other electronic
Copyright 2017 by Kevin de Wit All rights reserved. No part of this publication may be reproduced, distributed, or transmitted in any form or by any means, including photocopying, recording, or other electronic
Text Analytics (Text Mining)
") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Assistant Professor Associate Director, MS
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Text Analytics (Text Mining) Concepts, Algorithms, LSI/SVD Duen Horng (Polo) Chau Assistant Professor Associate Director, MS
COMP6237 Data Mining Making Recommendations. Jonathon Hare
 COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
COMP6237 Data Mining Making Recommendations Jonathon Hare jsh2@ecs.soton.ac.uk Introduction Recommender systems 101 Taxonomy of recommender systems Collaborative Filtering Collecting user preferences as
A Deep Relevance Matching Model for Ad-hoc Retrieval
 A Deep Relevance Matching Model for Ad-hoc Retrieval Jiafeng Guo 1, Yixing Fan 1, Qingyao Ai 2, W. Bruce Croft 2 1 CAS Key Lab of Web Data Science and Technology, Institute of Computing Technology, Chinese
A Deep Relevance Matching Model for Ad-hoc Retrieval Jiafeng Guo 1, Yixing Fan 1, Qingyao Ai 2, W. Bruce Croft 2 1 CAS Key Lab of Web Data Science and Technology, Institute of Computing Technology, Chinese
Static Pruning of Terms In Inverted Files
 In Inverted Files Roi Blanco and Álvaro Barreiro IRLab University of A Corunna, Spain 29th European Conference on Information Retrieval, Rome, 2007 Motivation : to reduce inverted files size with lossy
In Inverted Files Roi Blanco and Álvaro Barreiro IRLab University of A Corunna, Spain 29th European Conference on Information Retrieval, Rome, 2007 Motivation : to reduce inverted files size with lossy
CMSC 476/676 Information Retrieval Midterm Exam Spring 2014
 CMSC 476/676 Information Retrieval Midterm Exam Spring 2014 Name: You may consult your notes and/or your textbook. This is a 75 minute, in class exam. If there is information missing in any of the question
CMSC 476/676 Information Retrieval Midterm Exam Spring 2014 Name: You may consult your notes and/or your textbook. This is a 75 minute, in class exam. If there is information missing in any of the question
Vector Space Models: Theory and Applications
 Vector Space Models: Theory and Applications Alexander Panchenko Centre de traitement automatique du langage (CENTAL) Université catholique de Louvain FLTR 2620 Introduction au traitement automatique du
Vector Space Models: Theory and Applications Alexander Panchenko Centre de traitement automatique du langage (CENTAL) Université catholique de Louvain FLTR 2620 Introduction au traitement automatique du
Hybrid Approach for Query Expansion using Query Log
 Volume 7 No.6, July 214 www.ijais.org Hybrid Approach for Query Expansion using Query Log Lynette Lopes M.E Student, TSEC, Mumbai, India Jayant Gadge Associate Professor, TSEC, Mumbai, India ABSTRACT Web
Volume 7 No.6, July 214 www.ijais.org Hybrid Approach for Query Expansion using Query Log Lynette Lopes M.E Student, TSEC, Mumbai, India Jayant Gadge Associate Professor, TSEC, Mumbai, India ABSTRACT Web
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of