Building Mashups by Example
|
|
|
- Berenice Russell
- 5 years ago
- Views:
Transcription
1 Building Mashups by Example Craig A. Knoblock University of Southern California Work in collaboration with Rattapoom Tuchinda and Pedro Szekeley 1

![integrated experience [wikipedia] a) LA crime map b) zillow.](/docs-images/84/89546858/images/2-2.jpg "com c) Ski bonk - Crime Report from - Real Estate Listing - Weather different counties")
2 What s a Mashup? A website or application that combines content from more than one source into an integrated experience [wikipedia] a) LA crime map b) zillow.com c) Ski bonk - Crime Report from - Real Estate Listing - Weather different counties -Property Tax -Snow Report - Map -Snow Resorts Combined Data gives new insight / provides new services 2


3 Statistics and Trends Survey of top 50 Mashups Divide into five categories based on programming structures Focus of this work is on the first four categories which account for 47% of the most popular Mashups 3
4 Mashup Building Issues Data Retrieval Wrapper Wrapper Calibration -source modeling -cleaning Attribute Clean Attribute Clean Integration Combine Display Customize Display 4
5 Type 1: One Simple Source Data Retrieval Wrapper Calibration -source modeling -cleaning Attribute Clean Display Customize Display 5
6 Type 2: Union Data Retrieval Wrapper Wrapper Calibration -source modeling -cleaning Attribute Clean Attribute Clean Integration Union Display Customize Display 6
7 Type 3: One Source with Form Data Retrieval Wrapper Calibration -source modeling -cleaning Attribute Clean Display Customize Display 7
8 Type 4: Database Join Data Retrieval Wrapper Wrapper Calibration -source modeling -cleaning Attribute Clean Attribute Clean Integration Join Display Customize Display 8


9 Type 5: Customized Display Data Retrieval Wrapper Wrapper Calibration -source modeling -cleaning Attribute Clean Attribute Clean Integration Combine Display Customize Display 9

10 Existing Approaches Goal: Create Mashups without Programming Doesn t translate to not having to understand programming. Yahoo s Pipes Widget Paradigm - Widgets (i.e., 43 for Pipes, 300+ for MS) represents an operation on the data. - Locating and learning to customize widget can be time consuming - Most tools focus on particular issues and ignore others. Can we come up with a framework that addresses all of the issues while still making the Mashup building process easy? 10
11 Key Contributions A programming by demonstration approach that uses a single table for building a Mashup An integrated approach that links data extraction, source modeling, data cleaning, and data integration together. A query formulation technique that allows users to specify examples to build complicated queries. 11
12 Key Ideas Focus on data, not operations Users are more familiar with data. Leverage existing data Help source modeling, cleaning, and data integration. Consolidate as opposed to Divide-And-Conquer Solving a problem in one issue can help solve another issue. Interacting within a single spreadsheet platform 12
13 Our system: Karma Embedded Browser 13
14 Our system: Karma Embedded Browser 14
15 Our system: Karma Embedded Browser Table 15

16 Our system: Karma Embedded Browser Table Interaction Modes 16
17 Extract {Restaurant name, address, phone, Review} Extract {Restaurant name, address, Date of Inspection, Score} Clean Clean {Restaurant name, address, phone, review, Date of Inspection, Score} Map 17

18 Extract {Restaurant name, address, phone, Review} Extract {Restaurant name, address, Date of Inspection, Score} Clean Clean {Restaurant name, address, phone, review, Date of Inspection, Score} Map 18
19 Extract {Restaurant name, address, phone, Review} Clean {Restaurant name, address, phone, review, Date of Inspection, Score} Map 19
20 Extract {Restaurant name, address, phone, Review} Clean Database {Restaurant name, address, phone, review, Date of Inspection, Score} Map 20
21 Extract Database contains past Mashups and data tables {Restaurant name, address, phone, Review} Clean Database {Restaurant name, address, phone, review, Date of Inspection, Score} Map 21
22 Data Retrieval: Extraction tr TBODY tr Tbody/tr[1]/td[2]/a td td td td a br br Japon Bistro 970 E Colora Hokusai a br br 8400 Wilshir. Upscale yet affordabl Chic elegance 22
23 Data Retrieval: Extraction tr TBODY tr Tbody/tr[1]/td[2]/a td td td a br br Japon Bistro 970 E Colora td a br br Hokusai 8400 Wilshir. Tbody/tr*/td*/a Upscale yet affordabl Chic elegance 23
24 Data Retrieval: Navigation TBODY tr tr td td td td a Japon Bistro br br a Hokusai br br 970 E Colora Upscale yet affordab 8400 Wilshir. Chic elegance 24

25 Data Retrieval: Navigation TBODY tr tr td td td td a Japon Bistro br br a Hokusai br br 970 E Colora Upscale yet affordab 8400 Wilshir. Chic elegance 25

26 Data Retrieval: Navigation TBODY tr tr td td td td a Japon Bistro br br a Hokusai br br 970 E Colora Upscale yet affordab 8400 Wilshir. Chic elegance 26
27 Source Modeling (Attribute selection) restaurant name Hokusai LA Health Rating Address 8400 Health Rating 90 Newly extracted data Katana Japon Bistro Japon Bistro 927 E 95 Hokusai Sushi Sasabune artist name Hokusai Renoir Artist Info nationality Japanese French Possible Attribute {a a,s: a att (s) (val(a,s) V)} restaurant name Zagat zagat Rating restaurant name (3) artist name (1) Sushi Sasabune 27 Sushi Roku 25 Katana 23 Database 27
28 Data Cleaning: using existing values Newly extracted data restaurant name Hokusai Data repository LA Health Rating Address 8400 Health Rating 90 Japon Bistro Katana Hokusai Sushi Sasabune Japon Bistro 927 E Zagat 95 Sushi Roka restaurant name zagat Rating Restaurant name Sushi Sasabune Sushi Roku Katana 23 28
29 Data Cleaning: using existing values Newly extracted data restaurant name Hokusai Data repository LA Health Rating Address 8400 Health Rating 90 Japon Bistro Katana Hokusai Sushi Sasabune Japon Bistro 927 E Zagat 95 Sushi Roka restaurant name zagat Rating Restaurant name Sushi Sasabune Sushi Roku Katana 23 29
30 Data Cleaning: using predefined rules 31 Reviews 31 Subset Rule: (s 1 s 2 s k ) (d 1 d 2 d t ) (k <= t) s i {d 1,d 2,,d t } d i d j.. Predefined Rules. 30
 (d 1 d 2 d t ) (k <= t) s i {d 1,d 2,,d t } d i d j.. Predefined Rules.")
31 Data Cleaning: using predefined rules 31 Reviews 31 Subset Rule: (s 1 s 2 s k ) (d 1 d 2 d t ) (k <= t) s i {d 1,d 2,,d t } d i d j.. Predefined Rules. 31
32 Data Integration [tuchinda 2007] 32
33 Data Integration [tuchinda 2007] 33

34 Data Integration [tuchinda 2007] 34
35 Data Integration (cont.) restaurant name Data repository LA Health Rating Address Health Rating Hokusai Katana Japon Bistro 927 E 95 restaurant name Zagat zagat Rating Sushi Sasabune 27 Sushi Roku 25 Katana 23 35
36 Data Integration (cont.) restaurant name Data repository LA Health Rating Address Health Rating Hokusai Katana Japon Bistro 927 E 95 restaurant name Zagat zagat Rating Sushi Sasabune 27 Sushi Roku 25 Katana 23 36
37 Data Integration (cont.) restaurant name Data repository LA Health Rating Address Health Rating Hokusai Katana Japon Bistro 927 E 95 restaurant name Zagat zagat Rating Sushi Sasabune 27 Sushi Roku 25 Katana 23 37
 restaurant name Data repository LA Health Rating Address Health Rating Hokusai 8400 90 Katana 8439 99 Japon Bistro 927 E 95 Zagat {a} R = possible new attribute selection for row i.")
38 Data Integration (cont.) restaurant name Data repository LA Health Rating Address Health Rating Hokusai Katana Japon Bistro 927 E 95 Zagat {a} R = possible new attribute selection for row i. {x} = Set intersection({a}) over all the value rows. {v} = val(a,s) where a {x} s is any source where att(s) {x} {} restaurant name Sushi Sasabune Sushi Roku Katana zagat Rating
39 City Single Column Example a є all attribute Los Angeles Honolulu Can we determine the attribute now? Yes v є all value Attribute, Source Los Angeles : {(city, tax_properties), (song name, pop_music)} v є all values Λ attributeof(v) є {city, song name} Honolulu : {(city, tax_properties), (city, favorite_vacation_spot)} {x} = Set intersection({a}) over all the value rows. {v} = val(a,s) where a ε {x} Λ s is any source where att(s) {x} {} 39
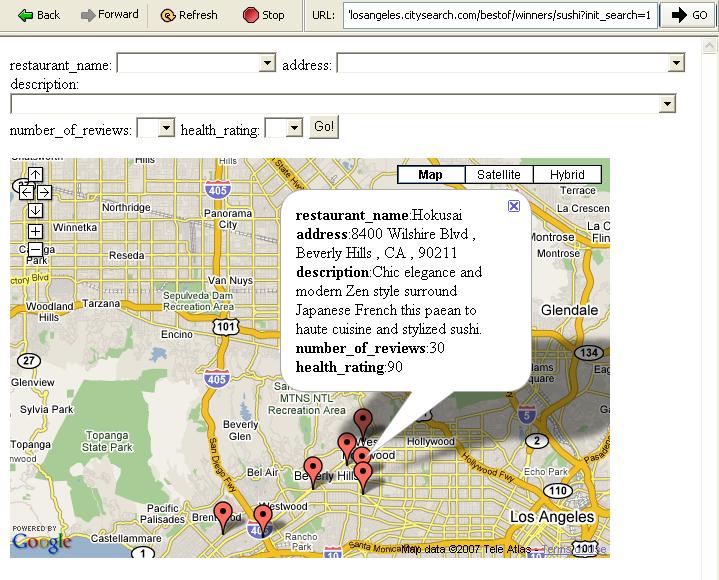
40 Map Generation 40
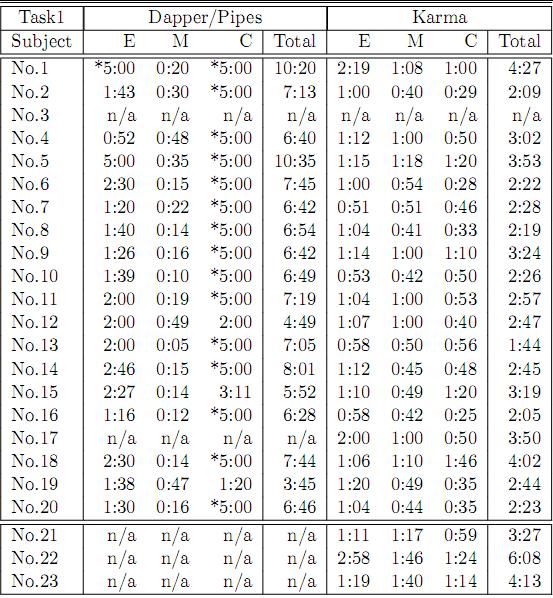
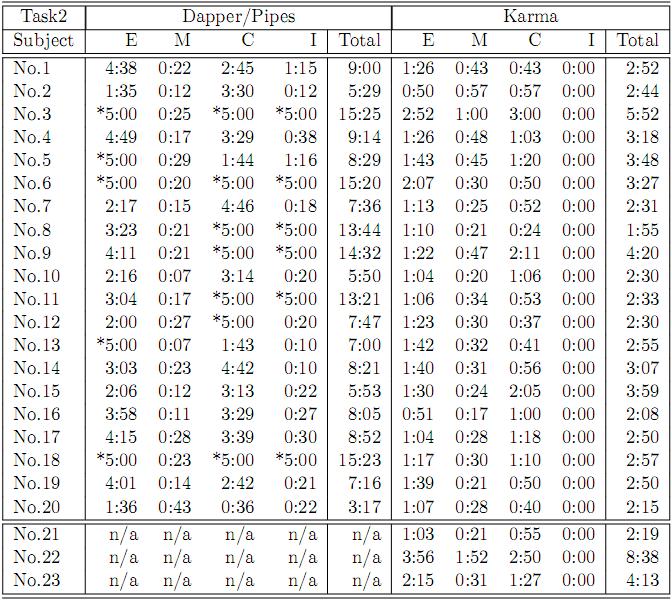
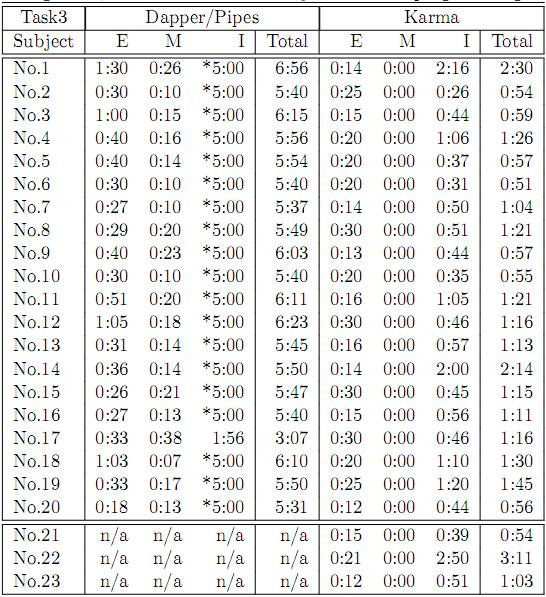
41 Evaluation Baseline: A combination of Dapper/Pipes Claims: 1. Users with no programming experiences can build all four Mashup types. 2. Karma takes less time to complete each subtask and scales better as the tasks get harder 3. Overall, the user takes less time to build the same Mashup in Karma compared to Dapper/Pipes Users: Programmers (20) Non-programmers (3) 41

42 Evaluation: Setup Familiarization -Programmers (2 assignments on DP) -Review Package -30 minutes tutorial Practice tasks using Karma Test (3 tasks) -Programmers: Alternating between Karma vs. DP for each task -Non Programmers: use only Karma -Screen are recorded using video capture software 5 minute cut off time 42
43 Evaluation: Tasks Task No. Mashup Type 1 1 (1 source) 2 2,3 (union+form) 3 4 (join 2 sources) Data Extraction Source Modeling Data Cleaning Data Integration Moderate Simple Difficult N/A Difficult Simple Simple Union (simple) Simple Simple N/A Join (difficult) Claim 1 Claim 2 Claim 3 Users with no programming experiences can build all four Mashup types. Karma takes less time to complete that subtask and scales better as the get harder Overall, the user takes less time to build the same Mashup in Karma compared to Dapper/Pipes 43
44 Claim 1: Users with no programming experiences can build all four Mashup types 44
45 Evaluation: Non-Programmers 45
46 Claim 2: Karma takes less time to complete each subtask 46
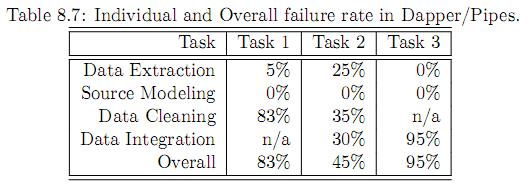
47 Karma (programmer) Evaluation: Extraction Dapper/Pipes As the extraction task gets more difficult, Dapper/Pipes takes - longer - more subjects failing to complete the task (11% for moderate and 25% for difficult) Dapper/Pipes Karma 47
48 Evaluation: Source Modeling Karma performed worse in task 1 and tasks 2 - only 30 sec difference - subjects take times selecting attributes - the saving will be realized in the data integration step. Karma performed better in task 3 because of it can automatically identify the attribute Dapper/Pipes Karma 48
49 Evaluation: Data Cleaning Karma performed better in both tasks When the cleaning task gets harder, more subjects are failing in Dapper/ Pipes (35% for simple and 83% in hard) Dapper/Pipes Karma 49
50 Evaluation: Data Integration Because of the table structure, subjects can specify union indirectly by dropping data into the right cell The time spent in source modeling step allows Karma to suggest the linking source Dapper/Pipes: 30% fail in the union case and 95% fail in the join case Dapper/Pipes Karma 50
51 Claim 3: Overall, the user takes less time to build the same Mashup in Karma compared to Dapper/Pipes 51
52 Evaluation: Overall Dapper/Pipes Karma 52
53 Evaluation: Average 3.32x 2.22x 0.67x 4.16x 6.49x Dapper/Pipes Karma 53
54 Evaluation: T-test Karma is faster than DP in data extraction subtasks t=5.35, df = 114, p < 0.01 DP is faster than Karma in source modeling subtasks t=2.54, df=114, p < 0.01 Karma is faster than DP in data cleaning subtasks t=13.54, df=74, p < 0.01 Karma is faster than DP in data integration subtasks t=7.05, df=78, p < 0.01 Karma is faster than DP overall t=13.24, df=114, p < 0.01 Not susceptible to time-bound bias because only DP s result (and not Karma) contains time-bound values. 54
55 Related Work: Mashup Systems Early work. Focus on DOM, too basic RDF / Manually specify data int Mainly focus on extraction / linear Widgets Fancier UI/ more widgets Fewer Widgets / Confusion on workflow Require an expert Create points on Map Q/A approach / linear / scalability Tuple = card. Drawing links for relations 55
56 Related Work: Mashup Systems 56
57 Related Work: Mashup Systems Require an expert 57
58 Related Work: Mashup Systems Early work. Focus on DOM, too basic Require an expert 58
59 Related Work: Mashup Systems Early work. Focus on DOM, too basic RDF / Manually specify data int Require an expert 59
60 Related Work: Mashup Systems Early work. Focus on DOM, too basic RDF / Manually specify data int Mainly focus on extraction / linear Require an expert 60
61 Related Work: Mashup Systems Early work. Focus on DOM, too basic RDF / Manually specify data int Mainly focus on extraction / linear Widgets Fancier UI/ more widgets Fewer Widgets / Confusion on workflow Require an expert 61
62 Related Work: Mashup Systems Early work. Focus on DOM, too basic RDF / Manually specify data int Mainly focus on extraction / linear Widgets Fancier UI/ more widgets Fewer Widgets / Confusion on workflow Require an expert Create points on Map 62
63 Related Work: Mashup Systems Early work. Focus on DOM, too basic RDF / Manually specify data int Mainly focus on extraction / linear Widgets Fancier UI/ more widgets Fewer Widgets / Confusion on workflow Require an expert Create points on Map Q/A approach / linear / scalability 63

64 Related Work: Mashup Systems Early work. Focus on DOM, too basic RDF / Manually specify data int Mainly focus on extraction / linear Widgets Fancier UI/ more widgets Fewer Widgets / Confusion on workflow Require an expert Create points on Map Q/A approach / linear / scalability Tuple = card. Drawing links for relations 64
65 Related Work: Data Extraction Automatic extraction: table and lists only RoadRunner (exploit HTML structure) [Crescenzi et al., 2001] Adel (grammer induction to detect rows) [Lerman+ 2001] VisualWeb (OCR technique to detect tables) [Gatterbauer+ 2007] Semi-Automatic: require more label examples WIEN (inductive less expressive than stalker) [Kushmerick 1997] Stalker (Cotesting) [Muslea+ 1999] SoftMealy (finite state transducer) [Hsu 1998] WHISK (rigid format, exact delimiter) [Soderland 1998] DOM: rely on well-formed HTML and less labeling Simile [Huynh+ 2005] Dapper Interactive Wrapper Generation (ML + prediction on DOM) [Irmak+ 2006] PLOW (add natural language) [Allen+ 2007] Cards [Dontcheva+ 2007] Karma [Tuchinda+ 2008] 65
66 Related Work: Source Modeling 1:1 mapping, N:M mapping Schema-level match TranScm [Milo+ 98] DIKE [Palopoli+ 99] Artemis [Castano+ 01] Delta [Clifton+ 97] +Instance-based matcher SemInt [Li 00] LSD [Doan 01] ILA [Etzioni 95] imapp [Dhamanka 04] Clio (interactive) [Ling 01] Inducing Source Description [Carman 07] Karma leverages existing techniques to narrow candidate matches String Similarities [Cohen+ 2003] 66
67 Related Work: Data Cleaning Commercial Tools: Focus on writing transformation ACR/Data, Migration Architect [Chaudhuri+ 1997] Discrepancy Detection: Use as a stepping stone for record linkage and cleaning system Levenshtein distance [Needleman+ 70] Vector based [Baeza-Yates+ 99] EM [Ristad+ 98] SVM [Bilenko+ 03] Record linkage & cleaning systems: Focus on ranking [Winkler 06] Fuzzy Match [Chaudhuri+ 03] Apollo [Michalowski+ 05] Phoebus [Michelson+ 07] Potter s wheel [Raman+ 01] Karma Gained reference sources through source modeling process Provided predefined transformations 67
68 Related Work: Data Integration Universal Relation: Make it easier to formulate the query but users still need to formulate the query [Ullman 1980, 1988] Query by example: Need to know which data sources to use and the query may not return results QBE [Zloof 1975] Retrieval by formulation: Need to understand domain model to formulate partial description Helgon [Fischer 1989] RABBIT [Williams 1982] Graphical Query Language: Users still need to navigate through sources (graphs) Gql [Benzi 1998, Haw 1994, Papantonakis 1988] Question-Answering Technique: Understanding about database operations required. Agent Wizard [Tuchinda+ 2004] Interactive Schema/data integration: Understanding about source schema required Clio [Ling 01] Karma is based on Programming by Demonstration [Cyper 2001; Lau2001] 68
69 Conclusion Mashup is a fast growing area Need an efficient way to for casual web users to build them Contributions A PBD approach that uses a single table for building a Mashup An integrated approach that solves four Mashup building issues A query formulation technique that allows users to specify examples to build complicated queries Evaluated the validity of the Karma approach Subjects were able to complete Mashup building tasks in Karma The overall improvement is at least a factor of
70 Future Work Customizing display by examples Interface today is limited to the table of data or a map if the points can be geocoded Learn and generalize over the task Store the integration plan so that it can be reexecuted on new data Integrate in work on machine learning of extraction tasks In collaboration with Fetch Technologies Integrate in work on automatic source modeling 70
71 Papers Building mashups by example, Rattapoom Tuchinda, Pedro Szekely, and Craig A. Knoblock. Proceedings of the 2008 International Conference on Intelligent User Interfaces, 2008 Building data integration queries by demonstration, Rattapoom Tuchinda, Pedro Szekely, and Craig A. Knoblock. In Proceedings of the International Conference on Intelligent User Interfaces,
72 Thank You! 72
73 Backup Slides 73
74 74
75 75
76 76
77 77

78 Document Object Model (DOM) Source: 78
79 Vertical Expansion 79
Building Mashups. Craig Knoblock. University of Southern California. Thanks to Rattapoom Tuchinda
 Building Mashups Craig Knoblock University of Southern California Thanks to Rattapoom Tuchinda What s a Mashup? A [wikipedia] a) LA crime map b) zillow.com c) Ski bonk Combined Data gives new insight /
Building Mashups Craig Knoblock University of Southern California Thanks to Rattapoom Tuchinda What s a Mashup? A [wikipedia] a) LA crime map b) zillow.com c) Ski bonk Combined Data gives new insight /
Building Mashups. Craig Knoblock. University of Southern California. Thanks to Rattapoom Tuchinda and
 Building Mashups Craig Knoblock University of Southern California Thanks to Rattapoom Tuchinda and What s a Mashup? A website or application that combines content from more than one source into an integrated
Building Mashups Craig Knoblock University of Southern California Thanks to Rattapoom Tuchinda and What s a Mashup? A website or application that combines content from more than one source into an integrated
Building Mashups by Demonstration
 Building Mashups by Demonstration RATTAPOOM TUCHINDA National Electronics and Computer Technology Center (Thailand) CRAIG A. KNOBLOCK University of Southern California and PEDRO SZEKELY University of Southern
Building Mashups by Demonstration RATTAPOOM TUCHINDA National Electronics and Computer Technology Center (Thailand) CRAIG A. KNOBLOCK University of Southern California and PEDRO SZEKELY University of Southern
Building Geospatial Mashups to Visualize Information for Crisis Management. Shubham Gupta and Craig A. Knoblock University of Southern California
 Building Geospatial Mashups to Visualize Information for Crisis Management Shubham Gupta and Craig A. Knoblock University of Southern California 1 WHAT IS A GEOSPATIAL MASHUP? Integrated View of data combined
Building Geospatial Mashups to Visualize Information for Crisis Management Shubham Gupta and Craig A. Knoblock University of Southern California 1 WHAT IS A GEOSPATIAL MASHUP? Integrated View of data combined
Proposal and Evaluation of Lightweight Mashup Tool to Create Information Portal
 1 1 2 2 Web Web Karma 5 6 Proposal and Evaluation of Lightweight Mashup Tool to Create Information Portal Masaki Hirayama, 1 Tomotake Niino, 1 Yoshiaki Matsuzawa 2 and Tsuyoshi Ohta 2 In recent years,
1 1 2 2 Web Web Karma 5 6 Proposal and Evaluation of Lightweight Mashup Tool to Create Information Portal Masaki Hirayama, 1 Tomotake Niino, 1 Yoshiaki Matsuzawa 2 and Tsuyoshi Ohta 2 In recent years,
Craig A. Knoblock University of Southern California
 Web-Based Learning Craig A. Knoblock University of Southern California Joint work with J. L. Ambite, K. Lerman, A. Plangprasopchok, and T. Russ, USC C. Gazen and S. Minton, Fetch Technologies M. Carman,
Web-Based Learning Craig A. Knoblock University of Southern California Joint work with J. L. Ambite, K. Lerman, A. Plangprasopchok, and T. Russ, USC C. Gazen and S. Minton, Fetch Technologies M. Carman,
Web Data Extraction. Craig Knoblock University of Southern California. This presentation is based on slides prepared by Ion Muslea and Kristina Lerman
 Web Data Extraction Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Kristina Lerman Extracting Data from Semistructured Sources NAME Casablanca
Web Data Extraction Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Kristina Lerman Extracting Data from Semistructured Sources NAME Casablanca
Kristina Lerman University of Southern California. This presentation is based on slides prepared by Ion Muslea
 Kristina Lerman University of Southern California This presentation is based on slides prepared by Ion Muslea GIVE ME: Thai food < $20 A -rated A G E N T Thai < $20 A rated Problem description: Web sources
Kristina Lerman University of Southern California This presentation is based on slides prepared by Ion Muslea GIVE ME: Thai food < $20 A -rated A G E N T Thai < $20 A rated Problem description: Web sources
AAAI 2018 Tutorial Building Knowledge Graphs. Craig Knoblock University of Southern California
 AAAI 2018 Tutorial Building Knowledge Graphs Craig Knoblock University of Southern California Wrappers for Web Data Extraction Extracting Data from Semistructured Sources NAME Casablanca Restaurant STREET
AAAI 2018 Tutorial Building Knowledge Graphs Craig Knoblock University of Southern California Wrappers for Web Data Extraction Extracting Data from Semistructured Sources NAME Casablanca Restaurant STREET
Craig Knoblock University of Southern California. These slides are based in part on slides from Sheila Tejada and Misha Bilenko
 Record Linkage Craig Knoblock University of Southern California These slides are based in part on slides from Sheila Tejada and Misha Bilenko Craig Knoblock University of Southern California 1 Record Linkage
Record Linkage Craig Knoblock University of Southern California These slides are based in part on slides from Sheila Tejada and Misha Bilenko Craig Knoblock University of Southern California 1 Record Linkage
Manual Wrapper Generation. Automatic Wrapper Generation. Grammar Induction Approach. Overview. Limitations. Website Structure-based Approach
 Automatic Wrapper Generation Kristina Lerman University of Southern California Manual Wrapper Generation Manual wrapper generation requires user to Specify the schema of the information source Single tuple
Automatic Wrapper Generation Kristina Lerman University of Southern California Manual Wrapper Generation Manual wrapper generation requires user to Specify the schema of the information source Single tuple
Wrappers & Information Agents. Wrapper Learning. Wrapper Induction. Example of Extraction Task. In this part of the lecture A G E N T
 Wrappers & Information Agents Wrapper Learning Craig Knoblock University of Southern California GIVE ME: Thai food < $20 A -rated A G E N T Thai < $20 A rated This presentation is based on slides prepared
Wrappers & Information Agents Wrapper Learning Craig Knoblock University of Southern California GIVE ME: Thai food < $20 A -rated A G E N T Thai < $20 A rated This presentation is based on slides prepared
Aligning and Integrating Data in Karma. Craig Knoblock University of Southern California
 Aligning and Integrating Data in Karma Craig Knoblock University of Southern California Data Integration Approaches 3 Data Integration Approaches Data Warehousing 4 Data Integration Approaches Data Warehousing
Aligning and Integrating Data in Karma Craig Knoblock University of Southern California Data Integration Approaches 3 Data Integration Approaches Data Warehousing 4 Data Integration Approaches Data Warehousing
Wrapper Learning. Craig Knoblock University of Southern California. This presentation is based on slides prepared by Ion Muslea and Chun-Nan Hsu
 Wrapper Learning Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Chun-Nan Hsu Wrappers & Information Agents GIVE ME: Thai food < $20 A -rated
Wrapper Learning Craig Knoblock University of Southern California This presentation is based on slides prepared by Ion Muslea and Chun-Nan Hsu Wrappers & Information Agents GIVE ME: Thai food < $20 A -rated
Snehal Thakkar, Craig A. Knoblock, Jose Luis Ambite, Cyrus Shahabi
 From: AAAI Technical Report WS-02-07. Compilation copyright 2002, AAAI (www.aaai.org). All rights reserved. Dynamically Composing Web Services from On-line Sources Snehal Thakkar, Craig A. Knoblock, Jose
From: AAAI Technical Report WS-02-07. Compilation copyright 2002, AAAI (www.aaai.org). All rights reserved. Dynamically Composing Web Services from On-line Sources Snehal Thakkar, Craig A. Knoblock, Jose
Lightweight Transformation of Tabular Open Data to RDF
 Proceedings of the I-SEMANTICS 2012 Posters & Demonstrations Track, pp. 38-42, 2012. Copyright 2012 for the individual papers by the papers' authors. Copying permitted only for private and academic purposes.
Proceedings of the I-SEMANTICS 2012 Posters & Demonstrations Track, pp. 38-42, 2012. Copyright 2012 for the individual papers by the papers' authors. Copying permitted only for private and academic purposes.
Interactive Data Integration through Smart Copy & Paste
 Interactive Data Integration through Smart Copy & Paste Zachary G. Ives 1 Craig A. Knoblock 2 Steven Minton 3 Marie Jacob 1 Partha Pratim Talukdar 1 Rattapoom Tuchinda 4 Jose Luis Ambite 2 Maria Muslea
Interactive Data Integration through Smart Copy & Paste Zachary G. Ives 1 Craig A. Knoblock 2 Steven Minton 3 Marie Jacob 1 Partha Pratim Talukdar 1 Rattapoom Tuchinda 4 Jose Luis Ambite 2 Maria Muslea
By Robin Dhamankar, Yoonkyong Lee, AnHai Doan, Alon Halevy and Pedro Domingos. Presented by Yael Kazaz
 By Robin Dhamankar, Yoonkyong Lee, AnHai Doan, Alon Halevy and Pedro Domingos Presented by Yael Kazaz Example: Merging Real-Estate Agencies Two real-estate agencies: S and T, decide to merge Schema T has
By Robin Dhamankar, Yoonkyong Lee, AnHai Doan, Alon Halevy and Pedro Domingos Presented by Yael Kazaz Example: Merging Real-Estate Agencies Two real-estate agencies: S and T, decide to merge Schema T has
Source Modeling. Kristina Lerman University of Southern California. Based on slides by Mark Carman, Craig Knoblock and Jose Luis Ambite
 Source Modeling Kristina Lerman University of Southern California Based on slides by Mark Carman, Craig Knoblock and Jose Luis Ambite Source Modeling vs. Schema Matching Schema Matching Align schemas between
Source Modeling Kristina Lerman University of Southern California Based on slides by Mark Carman, Craig Knoblock and Jose Luis Ambite Source Modeling vs. Schema Matching Schema Matching Align schemas between
A Flexible Learning System for Wrapping Tables and Lists
 A Flexible Learning System for Wrapping Tables and Lists or How to Write a Really Complicated Learning Algorithm Without Driving Yourself Mad William W. Cohen Matthew Hurst Lee S. Jensen WhizBang Labs
A Flexible Learning System for Wrapping Tables and Lists or How to Write a Really Complicated Learning Algorithm Without Driving Yourself Mad William W. Cohen Matthew Hurst Lee S. Jensen WhizBang Labs
Te Whare Wananga o te Upoko o te Ika a Maui. Computer Science
 VICTORIA UNIVERSITY OF WELLINGTON Te Whare Wananga o te Upoko o te Ika a Maui School of Mathematical and Computing Sciences Computer Science Approximately Repetitive Structure Detection for Wrapper Induction
VICTORIA UNIVERSITY OF WELLINGTON Te Whare Wananga o te Upoko o te Ika a Maui School of Mathematical and Computing Sciences Computer Science Approximately Repetitive Structure Detection for Wrapper Induction
A Scalable Architecture for Extracting, Aligning, Linking, and Visualizing Multi-Int Data
 A Scalable Architecture for Extracting, Aligning, Linking, and Visualizing Multi-Int Data Craig Knoblock & Pedro Szekely University of Southern California Introduction Massive quantities of data available
A Scalable Architecture for Extracting, Aligning, Linking, and Visualizing Multi-Int Data Craig Knoblock & Pedro Szekely University of Southern California Introduction Massive quantities of data available
WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE
 WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE *Vidya.V.L, **Aarathy Gandhi *PG Scholar, Department of Computer Science, Mohandas College of Engineering and Technology, Anad **Assistant Professor,
WEB DATA EXTRACTION METHOD BASED ON FEATURED TERNARY TREE *Vidya.V.L, **Aarathy Gandhi *PG Scholar, Department of Computer Science, Mohandas College of Engineering and Technology, Anad **Assistant Professor,
Web Data Extraction Using Tree Structure Algorithms A Comparison
 Web Data Extraction Using Tree Structure Algorithms A Comparison Seema Kolkur, K.Jayamalini Abstract Nowadays, Web pages provide a large amount of structured data, which is required by many advanced applications.
Web Data Extraction Using Tree Structure Algorithms A Comparison Seema Kolkur, K.Jayamalini Abstract Nowadays, Web pages provide a large amount of structured data, which is required by many advanced applications.
Flexible query formulation for federated search
 Flexible query formulation for federated search Matthew Michelson, Sofus A. Macskassy, and Steven N. Minton Fetch Technologies, Inc. 841 Apollo St., Suite 400 El Segundo, CA 90245 Abstract One common framework
Flexible query formulation for federated search Matthew Michelson, Sofus A. Macskassy, and Steven N. Minton Fetch Technologies, Inc. 841 Apollo St., Suite 400 El Segundo, CA 90245 Abstract One common framework
A Hybrid Unsupervised Web Data Extraction using Trinity and NLP
 IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
IBM Workplace Services Express - Technical Overview and Directions. Stuart Duguid Asia Pacific Portal & Workplace Technical Lead
 IBM Workplace Services Express - Technical Overview and Directions Stuart Duguid Asia Pacific Portal & Workplace Technical Lead Disclaimer The following material is directional in nature and does not imply
IBM Workplace Services Express - Technical Overview and Directions Stuart Duguid Asia Pacific Portal & Workplace Technical Lead Disclaimer The following material is directional in nature and does not imply
An Efficient Technique for Tag Extraction and Content Retrieval from Web Pages
 An Efficient Technique for Tag Extraction and Content Retrieval from Web Pages S.Sathya M.Sc 1, Dr. B.Srinivasan M.C.A., M.Phil, M.B.A., Ph.D., 2 1 Mphil Scholar, Department of Computer Science, Gobi Arts
An Efficient Technique for Tag Extraction and Content Retrieval from Web Pages S.Sathya M.Sc 1, Dr. B.Srinivasan M.C.A., M.Phil, M.B.A., Ph.D., 2 1 Mphil Scholar, Department of Computer Science, Gobi Arts
Kristina Lerman Anon Plangprasopchok Craig Knoblock. USC Information Sciences Institute
 Kristina Lerman Anon Plangprasopchok Craig Knoblock Check weather forecast Find hotels address Select hotel by price, features and reviews Find flights features Get distance to hotel Email agenda to attendees
Kristina Lerman Anon Plangprasopchok Craig Knoblock Check weather forecast Find hotels address Select hotel by price, features and reviews Find flights features Get distance to hotel Email agenda to attendees
Craig Knoblock University of Southern California. This talk is based in part on slides from Greg Barish
 Dataflow Execution Craig Knoblock University of Southern California This talk is based in part on slides from Greg Barish Craig Knoblock University of Southern California 1 Outline of talk Introduction
Dataflow Execution Craig Knoblock University of Southern California This talk is based in part on slides from Greg Barish Craig Knoblock University of Southern California 1 Outline of talk Introduction
EXTRACTION INFORMATION ADAPTIVE WEB. The Amorphic system works to extract Web information for use in business intelligence applications.
 By Dawn G. Gregg and Steven Walczak ADAPTIVE WEB INFORMATION EXTRACTION The Amorphic system works to extract Web information for use in business intelligence applications. Web mining has the potential
By Dawn G. Gregg and Steven Walczak ADAPTIVE WEB INFORMATION EXTRACTION The Amorphic system works to extract Web information for use in business intelligence applications. Web mining has the potential
J. Carme, R. Gilleron, A. Lemay, J. Niehren. INRIA FUTURS, University of Lille 3
 Interactive Learning o Node Selection Queries in Web Documents J. Carme, R. Gilleron, A. Lemay, J. Niehren INRIA FUTURS, University o Lille 3 Web Inormation Extraction Data organisation is : adapted to
Interactive Learning o Node Selection Queries in Web Documents J. Carme, R. Gilleron, A. Lemay, J. Niehren INRIA FUTURS, University o Lille 3 Web Inormation Extraction Data organisation is : adapted to
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Semantic annotation of unstructured and ungrammatical text
 Semantic annotation of unstructured and ungrammatical text Matthew Michelson & Craig A. Knoblock University of Southern California & Information Sciences Institute User Entered Text (on the web) User Entered
Semantic annotation of unstructured and ungrammatical text Matthew Michelson & Craig A. Knoblock University of Southern California & Information Sciences Institute User Entered Text (on the web) User Entered
A survey: Web mining via Tag and Value
 A survey: Web mining via Tag and Value Khirade Rajratna Rajaram. Information Technology Department SGGS IE&T, Nanded, India Balaji Shetty Information Technology Department SGGS IE&T, Nanded, India Abstract
A survey: Web mining via Tag and Value Khirade Rajratna Rajaram. Information Technology Department SGGS IE&T, Nanded, India Balaji Shetty Information Technology Department SGGS IE&T, Nanded, India Abstract
A KNOWLEDGE BASED ONLINE RECORD MATCHING OVER QUERY RESULTS FROM MULTIPLE WEB DATABASE
 A KNOWLEDGE BASED ONLINE RECORD MATCHING OVER QUERY RESULTS FROM MULTIPLE WEB DATABASE M.Ann Michle, K.C. Abhilash Sam Paulstin Nanjil Catholic College of Arts and Science, Kaliyakkavilai. Objective-The
A KNOWLEDGE BASED ONLINE RECORD MATCHING OVER QUERY RESULTS FROM MULTIPLE WEB DATABASE M.Ann Michle, K.C. Abhilash Sam Paulstin Nanjil Catholic College of Arts and Science, Kaliyakkavilai. Objective-The
Data Mining in the Context of Entity Resolution
 Data Mining in the Context of Entity Resolution Sofus A. Macskassy Fetch Technologies, Inc 841 Apollo Street El Segundo, CA 90245 Evan S. Gamble Fetch Technologies, Inc 841 Apollo Street El Segundo, CA
Data Mining in the Context of Entity Resolution Sofus A. Macskassy Fetch Technologies, Inc 841 Apollo Street El Segundo, CA 90245 Evan S. Gamble Fetch Technologies, Inc 841 Apollo Street El Segundo, CA
Reverse method for labeling the information from semi-structured web pages
 Reverse method for labeling the information from semi-structured web pages Z. Akbar and L.T. Handoko Group for Theoretical and Computational Physics, Research Center for Physics, Indonesian Institute of
Reverse method for labeling the information from semi-structured web pages Z. Akbar and L.T. Handoko Group for Theoretical and Computational Physics, Research Center for Physics, Indonesian Institute of
Craig Knoblock University of Southern California
 Craig Knoblock University of Southern California This talk is based in part on slides from Greg Barish Craig Knoblock University of Southern California 1 Introduction Streaming dataflow execution systems
Craig Knoblock University of Southern California This talk is based in part on slides from Greg Barish Craig Knoblock University of Southern California 1 Introduction Streaming dataflow execution systems
HTML Extraction Algorithm Based on Property and Data Cell
 IOP Conference Series: Materials Science and Engineering OPEN ACCESS HTML Extraction Algorithm Based on Property and Data Cell To cite this article: Detty Purnamasari et al 2013 IOP Conf. Ser.: Mater.
IOP Conference Series: Materials Science and Engineering OPEN ACCESS HTML Extraction Algorithm Based on Property and Data Cell To cite this article: Detty Purnamasari et al 2013 IOP Conf. Ser.: Mater.
Entity Extraction from the Web with WebKnox
 Entity Extraction from the Web with WebKnox David Urbansky, Marius Feldmann, James A. Thom and Alexander Schill Abstract This paper describes a system for entity extraction from the web. The system uses
Entity Extraction from the Web with WebKnox David Urbansky, Marius Feldmann, James A. Thom and Alexander Schill Abstract This paper describes a system for entity extraction from the web. The system uses
Identifying Maps on the World Wide Web
 Identifying Maps on the World Wide Web Matthew Michelson, Aman Goel and Craig A. Knoblock Information Sciences Institute University of Southern California 2008 Motiv Earthquake map Population density Alignment
Identifying Maps on the World Wide Web Matthew Michelson, Aman Goel and Craig A. Knoblock Information Sciences Institute University of Southern California 2008 Motiv Earthquake map Population density Alignment
Track: EXTOL Business Integrator (EBI)
") Track: EXTOL Business Integrator (EBI) Key focuses are Best Implementation Practices & Methodologies and Exploiting (Leveraging) Platform Capabilities. Attendees will take away proven strategies and practices
Track: EXTOL Business Integrator (EBI) Key focuses are Best Implementation Practices & Methodologies and Exploiting (Leveraging) Platform Capabilities. Attendees will take away proven strategies and practices
Learning High Accuracy Rules for Object Identification
 Learning High Accuracy Rules for Object Identification Sheila Tejada Wednesday, December 12, 2001 Committee Chair: Craig A. Knoblock Committee: Dr. George Bekey, Dr. Kevin Knight, Dr. Steven Minton, Dr.
Learning High Accuracy Rules for Object Identification Sheila Tejada Wednesday, December 12, 2001 Committee Chair: Craig A. Knoblock Committee: Dr. George Bekey, Dr. Kevin Knight, Dr. Steven Minton, Dr.
2009 Generic Web Services Mash-up Integrated Development Environment
 2009 Generic Web Services Mash-up Integrated Development Environment Tim Cheeseman, Ngoc Nguyen, and Jordan Osecki Final Write-up, Independent Study, Professor Regli Drexel University 9/1/2009 Page 2 Table
2009 Generic Web Services Mash-up Integrated Development Environment Tim Cheeseman, Ngoc Nguyen, and Jordan Osecki Final Write-up, Independent Study, Professor Regli Drexel University 9/1/2009 Page 2 Table
MetaNews: An Information Agent for Gathering News Articles On the Web
 MetaNews: An Information Agent for Gathering News Articles On the Web Dae-Ki Kang 1 and Joongmin Choi 2 1 Department of Computer Science Iowa State University Ames, IA 50011, USA dkkang@cs.iastate.edu
MetaNews: An Information Agent for Gathering News Articles On the Web Dae-Ki Kang 1 and Joongmin Choi 2 1 Department of Computer Science Iowa State University Ames, IA 50011, USA dkkang@cs.iastate.edu
Interactive Wrapper Generation with Minimal User Effort
 Interactive Wrapper Generation with Minimal User Effort Utku Irmak and Torsten Suel CIS Department Polytechnic University Brooklyn, NY 11201 uirmak@cis.poly.edu and suel@poly.edu Introduction Information
Interactive Wrapper Generation with Minimal User Effort Utku Irmak and Torsten Suel CIS Department Polytechnic University Brooklyn, NY 11201 uirmak@cis.poly.edu and suel@poly.edu Introduction Information
EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES
 EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES Praveen Kumar Malapati 1, M. Harathi 2, Shaik Garib Nawaz 2 1 M.Tech, Computer Science Engineering, 2 M.Tech, Associate Professor, Computer Science Engineering,
EXTRACTION AND ALIGNMENT OF DATA FROM WEB PAGES Praveen Kumar Malapati 1, M. Harathi 2, Shaik Garib Nawaz 2 1 M.Tech, Computer Science Engineering, 2 M.Tech, Associate Professor, Computer Science Engineering,
Supporting Fuzzy Keyword Search in Databases
 I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Craig Knoblock University of Southern California Joint work with Rahul Parundekar and José Luis Ambite
 Building Semantic Descriptions of Linked Data Craig Knoblock University of Southern California Joint work with Rahul Parundekar and José Luis Ambite Linked Open Data and Services Vast collection of interlinked
Building Semantic Descriptions of Linked Data Craig Knoblock University of Southern California Joint work with Rahul Parundekar and José Luis Ambite Linked Open Data and Services Vast collection of interlinked
Discovering and Building Semantic Models of Web Sources
 Discovering and Building Semantic Models of Web Sources Craig A. Knoblock University of Southern California Joint work with J. L. Ambite, K. Lerman, A. Plangprasopchok, and T. Russ, USC C. Gazen and S.
Discovering and Building Semantic Models of Web Sources Craig A. Knoblock University of Southern California Joint work with J. L. Ambite, K. Lerman, A. Plangprasopchok, and T. Russ, USC C. Gazen and S.
> Semantic Web Use Cases and Case Studies
 > Semantic Web Use Cases and Case Studies Case Study: Improving Web Search using Metadata Peter Mika, Yahoo! Research, Spain November 2008 Presenting compelling search results depends critically on understanding
> Semantic Web Use Cases and Case Studies Case Study: Improving Web Search using Metadata Peter Mika, Yahoo! Research, Spain November 2008 Presenting compelling search results depends critically on understanding
Advanced Computer Graphics CS 525M: Crowds replace Experts: Building Better Location-based Services using Mobile Social Network Interactions
 Advanced Computer Graphics CS 525M: Crowds replace Experts: Building Better Location-based Services using Mobile Social Network Interactions XIAOCHEN HUANG Computer Science Dept. Worcester Polytechnic
Advanced Computer Graphics CS 525M: Crowds replace Experts: Building Better Location-based Services using Mobile Social Network Interactions XIAOCHEN HUANG Computer Science Dept. Worcester Polytechnic
This document is downloaded from DR-NTU, Nanyang Technological University Library, Singapore.
 This document is downloaded from DR-NTU, Nanyang Technological University Library, Singapore. Title On extracting link information of relationship instances from a web site. Author(s) Naing, Myo Myo.;
This document is downloaded from DR-NTU, Nanyang Technological University Library, Singapore. Title On extracting link information of relationship instances from a web site. Author(s) Naing, Myo Myo.;
Master s Thesis Defense. Matthew Jeremy Michelson University of Southern California June 15, 2005
 Master s Thesis Defense Matthew Jeremy Michelson University of Southern California June 15, 2005 Building Queryable Datasets from Ungrammatical and Unstructured Sources Matthew Jeremy Michelson University
Master s Thesis Defense Matthew Jeremy Michelson University of Southern California June 15, 2005 Building Queryable Datasets from Ungrammatical and Unstructured Sources Matthew Jeremy Michelson University
Creating Web Mapping Applications. Nikki Golding
 Creating Web Mapping Applications Nikki Golding Agenda Web Mapping and Map Services Fundamentals ArcGIS Web Mapping Applications - ArcGIS.com Viewer - ArcGIS Explorer Online - ArcGIS Viewer for Flex -
Creating Web Mapping Applications Nikki Golding Agenda Web Mapping and Map Services Fundamentals ArcGIS Web Mapping Applications - ArcGIS.com Viewer - ArcGIS Explorer Online - ArcGIS Viewer for Flex -
DATA COLLECTION. Slides by WESLEY WILLETT 13 FEB 2014
 DATA COLLECTION Slides by WESLEY WILLETT INFO VISUAL 340 ANALYTICS D 13 FEB 2014 WHERE DOES DATA COME FROM? We tend to think of data as a thing in a database somewhere WHY DO YOU NEED DATA? (HINT: Usually,
DATA COLLECTION Slides by WESLEY WILLETT INFO VISUAL 340 ANALYTICS D 13 FEB 2014 WHERE DOES DATA COME FROM? We tend to think of data as a thing in a database somewhere WHY DO YOU NEED DATA? (HINT: Usually,
Data Extraction from Web Data Sources
 Data Extraction from Web Data Sources Jerome Robinson Computer Science Department, University of Essex, Colchester, U.K. robij@essex.ac.uk Abstract This paper provides an explanation of the basic data
Data Extraction from Web Data Sources Jerome Robinson Computer Science Department, University of Essex, Colchester, U.K. robij@essex.ac.uk Abstract This paper provides an explanation of the basic data
CA ERwin Data Modeler r9 Rick Alaras N.A. Channel Account Manager
 ERwin r9 CA ERwin Data Modeler r9 Rick Alaras N.A. Channel Account Manager In today s data-driven economy, there is an increasing disconnect between consumers and providers of data DATA VOLUMES INCREASING
ERwin r9 CA ERwin Data Modeler r9 Rick Alaras N.A. Channel Account Manager In today s data-driven economy, there is an increasing disconnect between consumers and providers of data DATA VOLUMES INCREASING
The Wargo System: Semi-Automatic Wrapper Generation in Presence of Complex Data Access Modes
 The Wargo System: Semi-Automatic Wrapper Generation in Presence of Complex Data Access Modes J. Raposo, A. Pan, M. Álvarez, Justo Hidalgo, A. Viña Denodo Technologies {apan, jhidalgo,@denodo.com University
The Wargo System: Semi-Automatic Wrapper Generation in Presence of Complex Data Access Modes J. Raposo, A. Pan, M. Álvarez, Justo Hidalgo, A. Viña Denodo Technologies {apan, jhidalgo,@denodo.com University
FedX: A Federation Layer for Distributed Query Processing on Linked Open Data
 FedX: A Federation Layer for Distributed Query Processing on Linked Open Data Andreas Schwarte 1, Peter Haase 1,KatjaHose 2, Ralf Schenkel 2, and Michael Schmidt 1 1 fluid Operations AG, Walldorf, Germany
FedX: A Federation Layer for Distributed Query Processing on Linked Open Data Andreas Schwarte 1, Peter Haase 1,KatjaHose 2, Ralf Schenkel 2, and Michael Schmidt 1 1 fluid Operations AG, Walldorf, Germany
New Face of z/os Communications Server: V2R1 Configuration Assistant
 New Face of z/os Communications Server: V2R1 Configuration Assistant Kim Bailey (ktekavec@us.ibm.com) IBM August 14, 2013 Session # 13630 Agenda What is the Configuration Assistant and how can it help
New Face of z/os Communications Server: V2R1 Configuration Assistant Kim Bailey (ktekavec@us.ibm.com) IBM August 14, 2013 Session # 13630 Agenda What is the Configuration Assistant and how can it help
Outline A Survey of Approaches to Automatic Schema Matching. Outline. What is Schema Matching? An Example. Another Example
 A Survey of Approaches to Automatic Schema Matching Mihai Virtosu CS7965 Advanced Database Systems Spring 2006 April 10th, 2006 2 What is Schema Matching? A basic problem found in many database application
A Survey of Approaches to Automatic Schema Matching Mihai Virtosu CS7965 Advanced Database Systems Spring 2006 April 10th, 2006 2 What is Schema Matching? A basic problem found in many database application
DELL POWERVAULT MD FAMILY MODULAR STORAGE THE DELL POWERVAULT MD STORAGE FAMILY
 DELL MD FAMILY MODULAR STORAGE THE DELL MD STORAGE FAMILY Simplifying IT The Dell PowerVault MD family can simplify IT by optimizing your data storage architecture and ensuring the availability of your
DELL MD FAMILY MODULAR STORAGE THE DELL MD STORAGE FAMILY Simplifying IT The Dell PowerVault MD family can simplify IT by optimizing your data storage architecture and ensuring the availability of your
AUTOMATICALLY GENERATING DATA LINKAGES USING A DOMAIN-INDEPENDENT CANDIDATE SELECTION APPROACH
 AUTOMATICALLY GENERATING DATA LINKAGES USING A DOMAIN-INDEPENDENT CANDIDATE SELECTION APPROACH Dezhao Song and Jeff Heflin SWAT Lab Department of Computer Science and Engineering Lehigh University 11/10/2011
AUTOMATICALLY GENERATING DATA LINKAGES USING A DOMAIN-INDEPENDENT CANDIDATE SELECTION APPROACH Dezhao Song and Jeff Heflin SWAT Lab Department of Computer Science and Engineering Lehigh University 11/10/2011
Slide 1. Slide 2. The Need. Using Microsoft Excel
 Slide 1 Using Microsoft Excel to Collect and Analyze Using Microsoft Excel to Collect and Analyze California California Standards Standards Text Data Test Data Presented by: Michael Nunn CTAP Region 11
Slide 1 Using Microsoft Excel to Collect and Analyze Using Microsoft Excel to Collect and Analyze California California Standards Standards Text Data Test Data Presented by: Michael Nunn CTAP Region 11
Interactively Mapping Data Sources into the Semantic Web
 Information Sciences Institute Interactively Mapping Data Sources into the Semantic Web Craig A. Knoblock, Pedro Szekely, Jose Luis Ambite, Shubham Gupta, Aman Goel, Maria Muslea, Kristina Lerman University
Information Sciences Institute Interactively Mapping Data Sources into the Semantic Web Craig A. Knoblock, Pedro Szekely, Jose Luis Ambite, Shubham Gupta, Aman Goel, Maria Muslea, Kristina Lerman University
Web Data Extraction and Generating Mashup
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 9, Issue 6 (Mar. - Apr. 2013), PP 74-79 Web Data Extraction and Generating Mashup Achala Sharma 1, Aishwarya
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 9, Issue 6 (Mar. - Apr. 2013), PP 74-79 Web Data Extraction and Generating Mashup Achala Sharma 1, Aishwarya
Information Integration for the Masses
 Information Integration for the Masses Jim Blythe Dipsy Kapoor Craig A. Knoblock Kristina Lerman USC Information Sciences Institute 4676 Admiralty Way, Marina del Rey, CA 90292 Steven Minton Fetch Technologies
Information Integration for the Masses Jim Blythe Dipsy Kapoor Craig A. Knoblock Kristina Lerman USC Information Sciences Institute 4676 Admiralty Way, Marina del Rey, CA 90292 Steven Minton Fetch Technologies
Like It Or Not Web Applications and Mashups Will Be Hot
 Like It Or Not Web Applications and Mashups Will Be Hot Tommi Mikkonen Tampere University of Technology tommi.mikkonen@tut.fi Antero Taivalsaari Sun Microsystems Laboratories antero.taivalsaari@sun.com
Like It Or Not Web Applications and Mashups Will Be Hot Tommi Mikkonen Tampere University of Technology tommi.mikkonen@tut.fi Antero Taivalsaari Sun Microsystems Laboratories antero.taivalsaari@sun.com
A B2B Search Engine. Abstract. Motivation. Challenges. Technical Report
 Technical Report A B2B Search Engine Abstract In this report, we describe a business-to-business search engine that allows searching for potential customers with highly-specific queries. Currently over
Technical Report A B2B Search Engine Abstract In this report, we describe a business-to-business search engine that allows searching for potential customers with highly-specific queries. Currently over
A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources
 A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources Abhilasha Bhagat, ME Computer Engineering, G.H.R.I.E.T., Savitribai Phule University, pune PUNE, India Vanita Raut
A Survey on Unsupervised Extraction of Product Information from Semi-Structured Sources Abhilasha Bhagat, ME Computer Engineering, G.H.R.I.E.T., Savitribai Phule University, pune PUNE, India Vanita Raut
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity
 Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Muhammed R. Baker*, Ali Minnet**, Murat Kalender**,
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Muhammed R. Baker*, Ali Minnet**, Murat Kalender**,
Natural Language Processing with PoolParty
 Natural Language Processing with PoolParty Table of Content Introduction to PoolParty 2 Resolving Language Problems 4 Key Features 5 Entity Extraction and Term Extraction 5 Shadow Concepts 6 Word Sense
Natural Language Processing with PoolParty Table of Content Introduction to PoolParty 2 Resolving Language Problems 4 Key Features 5 Entity Extraction and Term Extraction 5 Shadow Concepts 6 Word Sense
Intuitive and Interactive Query Formulation to Improve the Usability of Query Systems for Heterogeneous Graphs
 Intuitive and Interactive Query Formulation to Improve the Usability of Query Systems for Heterogeneous Graphs Nandish Jayaram University of Texas at Arlington PhD Advisors: Dr. Chengkai Li, Dr. Ramez
Intuitive and Interactive Query Formulation to Improve the Usability of Query Systems for Heterogeneous Graphs Nandish Jayaram University of Texas at Arlington PhD Advisors: Dr. Chengkai Li, Dr. Ramez
CHOOSING THE RIGHT HTML5 FRAMEWORK To Build Your Mobile Web Application
 BACKBONE.JS Sencha Touch CHOOSING THE RIGHT HTML5 FRAMEWORK To Build Your Mobile Web Application A RapidValue Solutions Whitepaper Author: Pooja Prasad, Technical Lead, RapidValue Solutions Contents Executive
BACKBONE.JS Sencha Touch CHOOSING THE RIGHT HTML5 FRAMEWORK To Build Your Mobile Web Application A RapidValue Solutions Whitepaper Author: Pooja Prasad, Technical Lead, RapidValue Solutions Contents Executive
Information Discovery, Extraction and Integration for the Hidden Web
 Information Discovery, Extraction and Integration for the Hidden Web Jiying Wang Department of Computer Science University of Science and Technology Clear Water Bay, Kowloon Hong Kong cswangjy@cs.ust.hk
Information Discovery, Extraction and Integration for the Hidden Web Jiying Wang Department of Computer Science University of Science and Technology Clear Water Bay, Kowloon Hong Kong cswangjy@cs.ust.hk
THE ARIADNE APPROACH TO WEB-BASED INFORMATION INTEGRATION
 International Journal of Cooperative Information Systems c World Scientific Publishing Company THE ARIADNE APPROACH TO WEB-BASED INFORMATION INTEGRATION CRAIG A. KNOBLOCK, STEVEN MINTON, JOSE LUIS AMBITE,
International Journal of Cooperative Information Systems c World Scientific Publishing Company THE ARIADNE APPROACH TO WEB-BASED INFORMATION INTEGRATION CRAIG A. KNOBLOCK, STEVEN MINTON, JOSE LUIS AMBITE,
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity
 Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Mohammed R. Baker*, Ali Minnet**, Murat Kalender**,
Extraction of Automatic Search Result Records Using Content Density Algorithm Based on Node Similarity Yasar Gozudeli*, Oktay Yildiz*, Hacer Karacan*, Mohammed R. Baker*, Ali Minnet**, Murat Kalender**,
Unit.9 Integer Programming
 Unit.9 Integer Programming Xiaoxi Li EMS & IAS, Wuhan University Dec. 22-29, 2016 (revised) Operations Research (Li, X.) Unit.9 Integer Programming Dec. 22-29, 2016 (revised) 1 / 58 Organization of this
Unit.9 Integer Programming Xiaoxi Li EMS & IAS, Wuhan University Dec. 22-29, 2016 (revised) Operations Research (Li, X.) Unit.9 Integer Programming Dec. 22-29, 2016 (revised) 1 / 58 Organization of this
CS 160: Lecture 15. Outline. How can we Codify Design Knowledge? Motivation for Design Patterns. Design Patterns. Example from Alexander: Night Life
 Outline CS 160: Lecture 15 Professor John Canny Fall 2004 Motivation Design patterns in architecture & SE Web design patterns Home page patterns E-commerce patterns 11/1/2004 1 11/1/2004 2 How can we Codify
Outline CS 160: Lecture 15 Professor John Canny Fall 2004 Motivation Design patterns in architecture & SE Web design patterns Home page patterns E-commerce patterns 11/1/2004 1 11/1/2004 2 How can we Codify
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
A Scalable Approach to Incrementally Building Knowledge Graphs
 A Scalable Approach to Incrementally Building Knowledge Graphs Gleb Gawriljuk 1, Andreas Harth 1, Craig A. Knoblock 2, and Pedro Szekely 2 1 Institute of Applied Informatics and Formal Description Methods
A Scalable Approach to Incrementally Building Knowledge Graphs Gleb Gawriljuk 1, Andreas Harth 1, Craig A. Knoblock 2, and Pedro Szekely 2 1 Institute of Applied Informatics and Formal Description Methods
alteryx training courses
 alteryx training courses alteryx designer 2 day course This course covers Alteryx Designer for new and intermediate Alteryx users. It introduces the User Interface and works through core Alteryx capability,
alteryx training courses alteryx designer 2 day course This course covers Alteryx Designer for new and intermediate Alteryx users. It introduces the User Interface and works through core Alteryx capability,
Course Contents: 1 Business Objects Online Training
 IQ Online training facility offers Business Objects online training by trainers who have expert knowledge in the Business Objects and proven record of training hundreds of students Our Business Objects
IQ Online training facility offers Business Objects online training by trainers who have expert knowledge in the Business Objects and proven record of training hundreds of students Our Business Objects
Automated Debugging In Data Intensive Scalable Computing Systems
 Automated Debugging In Data Intensive Scalable Computing Systems Muhammad Ali Gulzar 1, Matteo Interlandi 3, Xueyuan Han 2, Mingda Li 1, Tyson Condie 1, and Miryung Kim 1 1 University of California, Los
Automated Debugging In Data Intensive Scalable Computing Systems Muhammad Ali Gulzar 1, Matteo Interlandi 3, Xueyuan Han 2, Mingda Li 1, Tyson Condie 1, and Miryung Kim 1 1 University of California, Los
Curriculum Guide. ThingWorx
 Curriculum Guide ThingWorx Live Classroom Curriculum Guide Introduction to ThingWorx 8 ThingWorx 8 User Interface Development ThingWorx 8 Platform Administration ThingWorx 7.3 Fundamentals Applying Machine
Curriculum Guide ThingWorx Live Classroom Curriculum Guide Introduction to ThingWorx 8 ThingWorx 8 User Interface Development ThingWorx 8 Platform Administration ThingWorx 7.3 Fundamentals Applying Machine
AD406: What s New in Digital Experience Development with IBM Web Experience Factory
 AD406: What s New in Digital Experience Development with IBM Web Experience Factory Jonathan Booth, Senior Architect, Digital Experience Tooling, IBM Adam Ginsburg, Product Manager, Digital Experience
AD406: What s New in Digital Experience Development with IBM Web Experience Factory Jonathan Booth, Senior Architect, Digital Experience Tooling, IBM Adam Ginsburg, Product Manager, Digital Experience
Mapping Maintenance for Data Integration Systems
 Mapping Maintenance for Data Integration Systems R. McCann, B. AlShebli, Q. Le, H. Nguyen, L. Vu, A. Doan University of Illinois at Urbana-Champaign VLDB 2005 Laurent Charlin October 26, 2005 Mapping Maintenance
Mapping Maintenance for Data Integration Systems R. McCann, B. AlShebli, Q. Le, H. Nguyen, L. Vu, A. Doan University of Illinois at Urbana-Champaign VLDB 2005 Laurent Charlin October 26, 2005 Mapping Maintenance
Mining Data Records in Web Pages
 Mining Data Records in Web Pages Bing Liu Department of Computer Science University of Illinois at Chicago 851 S. Morgan Street Chicago, IL 60607-7053 liub@cs.uic.edu Robert Grossman Dept. of Mathematics,
Mining Data Records in Web Pages Bing Liu Department of Computer Science University of Illinois at Chicago 851 S. Morgan Street Chicago, IL 60607-7053 liub@cs.uic.edu Robert Grossman Dept. of Mathematics,
Using Text Learning to help Web browsing
 Using Text Learning to help Web browsing Dunja Mladenić J.Stefan Institute, Ljubljana, Slovenia Carnegie Mellon University, Pittsburgh, PA, USA Dunja.Mladenic@{ijs.si, cs.cmu.edu} Abstract Web browsing
Using Text Learning to help Web browsing Dunja Mladenić J.Stefan Institute, Ljubljana, Slovenia Carnegie Mellon University, Pittsburgh, PA, USA Dunja.Mladenic@{ijs.si, cs.cmu.edu} Abstract Web browsing
Enhancing Wrapper Usability through Ontology Sharing and Large Scale Cooperation
 Enhancing Wrapper Usability through Ontology Enhancing Sharing Wrapper and Large Usability Scale Cooperation through Ontology Sharing and Large Scale Cooperation Christian Schindler, Pranjal Arya, Andreas
Enhancing Wrapper Usability through Ontology Enhancing Sharing Wrapper and Large Usability Scale Cooperation through Ontology Sharing and Large Scale Cooperation Christian Schindler, Pranjal Arya, Andreas
Relational Databases. Relational Databases. SQLite Manager For Firefox. https://addons.mozilla.org/en-us/firefox/addon/sqlite-manager/
 Relational Databases Charles Severance Unless otherwise noted, the content of this course material is licensed under a Creative Commons Attribution 3.0 License. http://creativecommons.org/licenses/by/3.0/.
Relational Databases Charles Severance Unless otherwise noted, the content of this course material is licensed under a Creative Commons Attribution 3.0 License. http://creativecommons.org/licenses/by/3.0/.
Comparison of Online Record Linkage Techniques
 International Research Journal of Engineering and Technology (IRJET) e-issn: 2395-0056 Volume: 02 Issue: 09 Dec-2015 p-issn: 2395-0072 www.irjet.net Comparison of Online Record Linkage Techniques Ms. SRUTHI.
International Research Journal of Engineering and Technology (IRJET) e-issn: 2395-0056 Volume: 02 Issue: 09 Dec-2015 p-issn: 2395-0072 www.irjet.net Comparison of Online Record Linkage Techniques Ms. SRUTHI.
Designing RIA Accessibility: A Yahoo UI (YUI) Menu Case Study
 Menu Case Study") Designing RIA Accessibility: A Yahoo UI (YUI) Menu Case Study Doug Geoffray & Todd Kloots 1 Capacity Building Institute Seattle, Washington 2006.11.30 What s Happening? 2 3 Web 1.0 vs. Web 2.0 Rich Internet
Designing RIA Accessibility: A Yahoo UI (YUI) Menu Case Study Doug Geoffray & Todd Kloots 1 Capacity Building Institute Seattle, Washington 2006.11.30 What s Happening? 2 3 Web 1.0 vs. Web 2.0 Rich Internet
Asking the Right Questions in Crowd Data Sourcing
 MoDaS Mob Data Sourcing Asking the Right Questions in Crowd Data Sourcing Tova Milo Tel Aviv University Outline Introduction to crowd (data) sourcing Databases and crowds Declarative is good How to best
MoDaS Mob Data Sourcing Asking the Right Questions in Crowd Data Sourcing Tova Milo Tel Aviv University Outline Introduction to crowd (data) sourcing Databases and crowds Declarative is good How to best
Next-Generation Standards Management with IHS Engineering Workbench
 ENGINEERING & PRODUCT DESIGN Next-Generation Standards Management with IHS Engineering Workbench The addition of standards management capabilities in IHS Engineering Workbench provides IHS Standards Expert
ENGINEERING & PRODUCT DESIGN Next-Generation Standards Management with IHS Engineering Workbench The addition of standards management capabilities in IHS Engineering Workbench provides IHS Standards Expert
Business Analytics in the Oracle 12.2 Database: Analytic Views. Event: BIWA 2017 Presenter: Dan Vlamis and Cathye Pendley Date: January 31, 2017
 Business Analytics in the Oracle 12.2 Database: Analytic Views Event: BIWA 2017 Presenter: Dan Vlamis and Cathye Pendley Date: January 31, 2017 Vlamis Software Solutions Vlamis Software founded in 1992
Business Analytics in the Oracle 12.2 Database: Analytic Views Event: BIWA 2017 Presenter: Dan Vlamis and Cathye Pendley Date: January 31, 2017 Vlamis Software Solutions Vlamis Software founded in 1992
Anton van Wyk 1Spatial Australia Pty ltd Country Manager Spatial Data Infrastructure
 Anton van Wyk 1Spatial Australia Pty ltd Country Manager Anton.vanWyk@1spatial.com Spatial Data Infrastructure Industry Sectors Transportation Spatial Data Infrastructure Telecommunications Utilities Mapping
Anton van Wyk 1Spatial Australia Pty ltd Country Manager Anton.vanWyk@1spatial.com Spatial Data Infrastructure Industry Sectors Transportation Spatial Data Infrastructure Telecommunications Utilities Mapping