Department of Electronic Engineering FINAL YEAR PROJECT REPORT
|
|
|
- Ernest Barnett
- 5 years ago
- Views:
Transcription
1 Department of Electronic Engineering FINAL YEAR PROJECT REPORT BEngCE-2007/08-HCS-HCS-03-BECE Natural Language Understanding for Query in Web Search 1 Student Name: Sit Wing Sum Student ID: Supervisor: Dr. So, H C Assessor: Dr. Wong, K W Bachelor of Engineering (Honours) in Computer Engineering - 1 -
2 Student Final Year Project Declaration I have read the student handbook and I understand the meaning of academic dishonesty, in particular plagiarism and collusion. I declare that the work submitted for the final year project does not involve academic dishonesty. I give permission for my final year project work to be electronically scanned and if found to involve academic dishonesty, I am aware of the consequences as stated in the Student Handbook. Project Title: Natural Language Understanding for Query in Web search - 1 Student Name: Sit Wing Sum Student ID: Signature Date: No part of this report may be reproduced, stored in a retrieval system, or transcribed in any form or by any means electronic, mechanical, photocopying, recording or otherwise without the prior written permission of City University of Hong Kong
3 Content 1. Abstract P Objectives P Product Introduction 3.1 Function of the search engine 3.2 User interface of the search engine P. 2 P Theory 4.1 Web Searching 4.2 Natural Language Processing 4.3 Information Retrieval 4.4 Natural Language Processing in Information Retrieval Process 4.5 Evaluation Statistical Hypothesis Tests P P P P. 19 P Methodology 5.1 Querying 5.2 Web Searching 5.3 Reprioritize retrieved documents based on nutrition lexicon database 5.4 Evaluation & Modification P. 23 P. 23 P P Evaluation Results 6.1 Probability of retrieving relevant documents (detection probability) 6.2 Probability of retrieving irrelevant documents (false alarm probability) P P Discussion P Improvements P Working Schedule P Conclusion P References P Appendix A P. 76 Appendix B P i
4 List of Figures Figure 3.1 User interface of search engine (before search) P. 3 Figure 3.2 User interface of search engine (after search) P.4 Figure 3.3 Interface to see original search results (before ranking) P. 5 Figure 3.4 User interface of search engine (Help How to use) P. 6 Figure 3.5 User interface of search engine (Help Boolean search operators) P. 7 Figure 3.6 User interface of search engine (Help Advanced search operators) P. 8 Figure The retrieval process P. 14 Figure Cosine angle between document and query vector P. 16 Figure Google API Timeout Error Message P. 29 Figure Evaluation (test case and corresponding expected search result -- 1) P. 30 Figure Evaluation (test case and corresponding expected search result -- 2) P. 31 Figure Evaluation (evaluate on each test case) P. 32 Figure Evaluation (ratio of relevant document & irrelevant document 1) P. 33 Figure Evaluation (ratio of relevant document & irrelevant document 2) P. 34 Figure Evaluation (ratio of relevant document & irrelevant document 3) P. 35 Figure Evaluation (ratio of relevant document & irrelevant document 4) P. 36 Figure Evaluation (input data in SPSS -- Top 50 results -- relevant) P. 38 Figure Evaluation (input data in SPSS -- Top 10 results -- relevant) P. 39 Figure Evaluation (input data in SPSS -- Top 50 results irrelevant) P. 41 Figure Evaluation (input data in SPSS -- Top 10 results -- irrelevant) P. 42 Figure Result of KS-Test (top 50 results relevant) P. 45 Figure Result of modified KS-Test (top 50 results relevant) P. 45 Figure Histograms (top 50 results relevant) P. 46 Figure Independent samples T-Test (Top 50 results relevant static query approach) P. 47 ii
5 Figure Independent samples T-Test (Top 50 results relevant dynamic query approach) P. 48 Figure Paired samples T-Test (Top 50 results relevant) P. 49 Figure Result of KS-Test (top 10 results relevant) P. 51 Figure Result of modified KS-Test (top 10 results relevant) P. 51 Figure Histograms (top 10 results relevant) P. 52 Figure independent samples test (top 10 results relevant static query approach) Figure independent samples test (top 10 results relevant dynamic query approach) P. 53 P. 54 Figure Result of KS-Test (top 50 results irrelevant) P. 56 Figure Result of modified KS-Test (top 50 results irrelevant) P. 56 Figure Histograms (top 50 results irrelevant) P. 57 Figure Independent samples T-Test (Top 50 results irrelevant static query approach) Figure Independent samples T-Test (Top 50 results irrelevant dynamic query approach) P. 58 P. 59 Figure Paired samples T-Test (Top 50 results irrelevant) P. 60 Figure Result of KS-Test (top 10 results irrelevant) P. 62 Figure Result of modified KS-Test (top 10 results irrelevant) P. 62 Figure Histograms (top 10 results irrelevant) P. 63 Figure independent samples test (top 10 results irrelevant static query approach) Figure independent samples test (top 10 results irrelevant dynamic query approach) P. 64 P. 65 Figure 9.1 Working Schedule (Semester A 07/08) P. 71 Figure 9.2 Working Schedule (Semester B 07/08) P. 72 List of Table Table 7.1 Comparison between Google s search engine and my search engine P. 66 iii
6 1. Abstract In this project, a search engine is developed for searching the nutritional information in a more effective manner. It is written in Microsoft.NET environment with C# language, and based on a nutrition lexicon database. To obtain better search results, natural language is applied in processing the web query. To implement a search engine, it involves several processes: querying, crawling, information retrieval and ranking. Natural language processing is applied in the querying process by expanding the query entered by users. Google API is used in the crawling process to access the web document database of Google. Vector space model is applied in the information retrieval process with three different approaches: 1) Static query 2) Dynamic query 3) Dynamic query with relevance feedback. By using vector space model, a weight is then calculated for each retrieved document and these weights are eventually used to reprioritize the documents in the ranking process. In order to select the best approach, a software SPSS is used to evaluate the search results. Among the three approaches, the third one is time inefficient with Google API timeout problem whereas the others obtain a better retrieval performance when compared with Google s search results
7 2. Objectives There are five main project objectives: Develop a specialized field search engine in Microsoft.NET environment. Apply natural language in processing the web query. Familiar with Google API for web searching. Familiar with different information retrieval techniques to re-rank the retrieved documents. Familiar with web searching performance evaluation techniques. 3. Product Introduction 3.1 Function of the search engine This is a search engine for searching nutritional information. That is, those web documents which are more relevant to nutrition will be placed at the top priority. When compared to Google s search engine, the advantage of this search engine is that users can find nutritional information in a more effective manner, that is, users can find more nutritional relevant documents in top ranked results than that in Google s search results - 2 -
 With information: 1) How to use 2) Boolean operators for search engine 3) Advanced operators for search engine Press exit to quit Fig. 3.1 User interface of search engine (before search) - 3 -")
8 3.2 User interface of the search engine Before search: Text box for search query input Press search to start searching Search Results display in here Press more to see original search results (before ranking) With information: 1) How to use 2) Boolean operators for search engine 3) Advanced operators for search engine Press exit to quit Fig. 3.1 User interface of search engine (before search) - 3 -
 The progress bar")
9 After search: No. of results found is displayed in here Click here to go to next page (10 results in each page) The progress bar indicates that the search process is finished Fig. 3.2 User interface of search engine (after search) - 4 -
 The upper text box shows the frequencies, weights,")
10 After pressing more button: Fig. 3.3 Interface to see original search results (before ranking) The upper text box shows the frequencies, weights, ranking scores, etc. The lower table displays the original search results

11 After pressing help button: i. About how to use the search engine Fig. 3.4 User interface of search engine (Help How to use?) - 6 -
![ii. About Boolean search operators [5] Fig. 3.](/docs-images/95/125603178/images/12-0.jpg "5 User interface of search engine (Help Boolean search")
12 ii. About Boolean search operators [5] Fig. 3.5 User interface of search engine (Help Boolean search operators) - 7 -
![iii. About advanced search engine operators [5] Fig. 3.](/docs-images/95/125603178/images/13-0.jpg "6 User interface of search engine (Help advanced search")
13 iii. About advanced search engine operators [5] Fig. 3.6 User interface of search engine (Help advanced search operators) - 8 -
14 4. Theory 4.1 Web Searching Basic concept The World Wide Web (WWW) is a very huge database which is public accessible. To search the information in the WWW, search engines are developed and implemented Search engines Basic concept of search engines Search engines are applications which are used to search web documents in the WWW and then provide the documents which match the search query entered by users Operation of search engines [13] The operation of a search engine involves a few steps. First, a program named as spider will be delivered to all pages of all websites to retrieve as many web documents as possible. Then, indexing is done to obtain the IDs of the retrieved pages which contain the query terms. Lastly, a ranking algorithm is implemented to rank the pages, according to their relevance to the search terms entered by users. Sometimes it is found that different search engines produce different results as they adopt different ranking algorithms. One of the approaches is to find out the frequencies and positions of the search terms in a webpage. For those with greater frequency and in key positions will have a higher ranking score. Another common approach - 9 -
15 is to determine if the linked pages of a website contain the relevant keywords or not. If so, that website obtains a higher ranking score Common search engines and corresponding approaches [11] i) Google, Lycos, Yahoo These search engines are in a general search manner. That is, not being searched in a specific field. ii) Ask Jeeves Apart from general search, it allows users to ask questions in natural language as well. That is, it attempts to answer the questions requested by users. iii) Medline Plus It is a kind of specialized field search engine which focuses on specific topic. My search engine is also a kind of specialized field search engine (in terms of nutrition). iv) Search engines in individual websites They search and retrieve the information only in their own sites Google API [8] Google API can be used in implementing a search engine. By using Google API, we are able to access Google s database which is automatically updated and then the relevant documents can be retrieved for further implementation. Using Google API is simple, but it is limited to 1000 queries per day
16 4.2 Natural Language Processing (NLP) Basic concept The aim of using natural language processing is to allow computers to understand human language so that we can find the information in a more effective and efficient way How natural language processing works [6] Different ways in applying natural language processing: i) Phonetic Speech recognition -- human speech is cut into pieces, that is, the phonetic units. ii) Morphological Some search engines put morphologies into searches, for example, oranges and orange are morphologies and both of them are put into searches. iii) Syntactic Part of speech is analysed for each word in this application. iv) Semantic When semantic is applied in search engine, it means that synonyms of each search term are put into searches. The search query is expanded in this way
17 v) Discourse It is used to extract the meaning of a large piece of paragraph or a whole text. It is useful in automatic abstracting. vi) Pragmatic It allows a search engine to understand some blurred meanings. For example, when a user searches for George Bush s birthday, a pragmatic search understands that a passage with content George Bush was born on is referred to George Bush s birthday and this document is relevant to user s search request Natural language processing in search engines Natural language processing can be applied in several ways: i) Allow users to use natural language in searching process. ii) iii) Answer the questions requested by users. Part of speech and synonyms are found for expanding the search queries. iv) Extract relevant information from a retrieved document which matches users requirements Tools of applying natural language processing in web querying process i) WordNet [10] WordNet is a powerful electronic lexical database. It can be used to find out the part of speech, synonyms, etc. for each search term in query. In this way, search queries can be expanded and then the
18 chances of finding relevant documents can be increased. To conclude, WordNet is a useful tool in query expansion. ii) SharpNLP [4] SharpNLP is a program with different kinds of NLP tools, including sentence splitter, tokenzier, part of speech tagger, chunker, etc. These tools are very useful in implementing the search engine, especially the tokenizer and part of speech tagger, which can reduce our workload in analysing the terms in documents
19 4.3 Information Retrieval Basic concept [2] Information retrieval is useful in finding the relevant information from a large group of data, according to the user s search queries. To apply in search engine, information retrieval can be used in comparing the search query with the retrieved documents from web page database. After that, the documents which are relevant to user s search requirements will be returned to users where the priority of documents is according to its relevance to users search queries Retrieval process [2] Fig The retrieval process Information retrieval models Information retrieval (IR) models are used to find out which documents are relevant to users search requirements and therefore to prioritize the documents from the most relevant to least relevant. There are different IR models and each of them has different weight calculation method
20 Three classic IR models: Boolean model [2, 3] Boolean model is a combination of set theory and Boolean algebra calculation. It only considers whether no search terms present in a document or has search terms present in a document. Therefore, the weight of each document after calculation is binary (0 means not relevant and 1 means relevant ). Mathematical expression: The disadvantage of Boolean model is that, the retrieved documents cannot be ranked as we can only know the document is relevant or irrelevant, not a ranking score Vector space model [2, 3, 9] In vector space modeling, document dj and query q are both vectors: Mathematical expression to find the similarity between document vector and query vector:
21 According to the figure below, it means that the smaller the angle, the more the document is similar to the query. Figure Cosine angle between document and query vector Calculation in details: where Normalized frequency: Inverse document frequency:
22 If the word appears in each document, = log (1) will be equal to 0. The lower the occurrence (ni), the higher the value will be. It means this word is more significant. The calculation of Wi,q is similar to that of Wi,j. However, a constant 0.5 is added as the weight of term in query is always a smaller value
23 Probabilistic model [2] Probabilistic model estimates the probability of a document dj will be relevant to user s search query. The calculation is complicated. Also, the frequencies of terms which occur in the documents are ignored:
24 4.4 Natural Language Processing in Information Retrieval Process [12] Tokenization The content of retrieved documents is cut into pieces (usually cut into single words and without punctuation). In this way, the text size can be reduced for faster indexing and therefore shorter processing time Stopwords elimination Stopwords (e.g. a, an, the) are eliminated for further smaller text size and faster indexing and therefore shorter processing time Stemming Stemming maps different variants of a term in one word and this word is then added in the document term list in vector space modeling Part of speech tagging It is used to distinguish the part of speech of each word in documents. For example, it is applied in considering whether boats is a verb or a noun
25 4.5 Evaluation Statistical Hypothesis Tests The function of applying statistical hypothesis tests in evaluation is to analyze the result data statistically and therefore to identify which search approach is the best, according to the tests results. Principle of statistical hypothesis test In a statistical hypothesis test associated with a null hypothesis, four cases may be happened: i) Null hypothesis is true and not rejected ii) Null hypothesis is false and rejected iii) Null hypothesis is true but rejected iv) Null hypothesis is false but not rejected. The first two cases are normal but the last two cases are abnormal and we considered them as type I error and type II error respectively [15]. Null hypothesis is a hypothesis there is no significant difference or there is no significant effect This null hypothesis is regarded as false when the p value is near to zero. Statistically, this null hypothesis is regarded as true when the p value is higher than the significance level (the common levels are: 5% (0.05), 1% (0.01), 0.1% (0.001)) [14]. P value is actually the probability of occurrence of type I error. That is, if p value is 5%, the probability is 5% that we reject a true null hypothesis. In other words, the probability is 95% that we correctly reject a wrong hypothesis. In this way, p value can be calculated to see if the hypothesis is rejected by tested data or not. In these hypothesis tests, we assume the null hypothesis is true initially. If we find that the p value is lower than the significance level, we can conclude that the data are likely to reject a wrong hypothesis (the chance of rejecting a false hypothesis is > 95%) [15]. Significantly different is a condition that the difference between two groups of data is not happened by chance. To satisfy this condition, the p value mentioned above
26 should be lower than the significance level (normally set at alpha level: 5%). Reversely, no significant difference means that the difference is likely to have happened by chance and therefore the null hypothesis is accepted [14]. The difference between our search engine s search results and Google s search results is desired to be statistically significant, to indicate that the good performance of our search engine is stable and consistent. The followings are the statistical tests to be used in the part of evaluation: Kolmogorov Smirnov Test (KS-Test) [1] It is a common method to test whether the data is normally, uniformly, poisson or exponentially distributed. For example, if we let the null hypothesis as There is no significant difference in between data A and normal distribution curve. When p value is lower than the critical level (5%), this hypothesis is rejected at the 5% significance level and it means that data are not normally distributed. Reversely, data are normally distributed when p > It is an essential process to decide which test (T-Test or 2-Indpendent Samples Test) to be performed later T-Test [1] T-Test is a compare mean method to test whether there is a significant difference in between the means of 2 groups of data. For example, we let the null hypothesis as There is no significant difference between data A and data B. When p-value is lower than the critical level (5%), this hypothesis is rejected at the 5% significance level and it means that data A is significantly different from data B. The requirement of performing this test is that the data should be normally distributed
27 There are two types of T-Test: i) Independent Samples T-Test The means of two groups of data are compared in Independent Samples T-Test in which the assumptions included 1) The data are normally distributed; 2) These two groups of data are independent of each other. ii) Paired Samples T-Test The means of two groups of data are compared in paired samples T- Test. The difference between paired samples T-Test and independent samples T-Test is that it calculates the difference between each pair (e.g. Data A case 1 vs Data B case 1), in order to find out whether the average difference between Data A and Data B is significantly different from 0 or not. If the average difference between Data A and Data B is not significantly different from 0, the two groups of data should have no significant difference; otherwise, the two groups of data should have significant difference Independent Samples Test [1] It is another common method to test whether there is a significant difference in between 2 groups of data. For example, we let the null hypothesis as There is no significant difference between data A and data B. When p value is lower than the critical level (5%), this hypothesis is rejected at the 5% significance level and it means that data A is significantly different from data B. The difference between this method and T-Test is that the data are not needed to be normally distributed
28 5. Methodology The developed search engine was a kind of specialized field search engine, which focused on the topic of nutrition. To implement a search engine, several processes were involved. 5.1 Querying The methodology used in this part was to apply natural language processing in web query. In this part, we had used WordNet to expand the query entered by users. Through WordNet, first, we analyzed the part of speech for each word in the query. Then, the synonyms of each word were found. A web query was then expanded and formed. The next step was to pass this query to web searching 5.2 Web searching The methodology implemented in this part was using Google API to retrieve the web documents from Google s web documents database. Through Google API, Google s web documents database can be accessed. Several results were returned, including the title, summary, url and estimated number of retrieved documents. These results were then used in the procedure of reprioritizing retrieved web documents. 5.3 Reprioritize retrieved documents based on nutrition lexicon database The methodology adopted in this part was using information retrieval techniques. Three approaches were tried and the best one was selected through evaluation:
29 5.3.1 Static query approach 1) Tokenize all summaries and titles of the retrieved documents by using sharpnlp. 2) Eliminate all stop words from the tokenized documents. 3) Perform indexing 3.1) For each document, find the terms which match the nutrition lexicon database. 3.2) For each term found in each document, find its occurrence frequency. 4) Implement information retrieval models in calculating ranking score: Among the three models, vector space model was applied. Boolean model was not used as it only told us the document was relevant or not, no ranking was performed. Probabilistic model was better than Boolean model, however, its calculation was much more complicated than that of vector space model and therefore might require longer processing time in calculating the ranking score. Therefore, among these models, vector space model was selected. For vector space model, several steps were involved: (In following steps, calculations corresponding to summaries and titles were done separately) 4.1) Weights were calculated for every term found in step 3 by applying this equation:
30 4.2) The words in nutrition lexicon database were considered as query terms. (i.e., the query was static). The frequency of each query term was preset and then the weight of each term was calculated by applying this formula: 4.3)For each document, the similarity value between the document vector and query vector was calculated for summary and title respectively: 5) The two similarity values were added together to form the ranking score. 6) Documents were reprioritized with respect to their ranking score. For higher ranking score, higher the priority will be Dynamic query approach The method of approach 2 was similar to that of approach 1. There was only a slight difference in step 4. 1) Tokenize all summaries and titles of the retrieved documents by using sharpnlp. 2) Eliminate all stop words from the tokenized documents. 3) Perform indexing
31 3.1) For each document, find the terms which match the nutrition lexicon database. 3.2) For each term found in each document, find its occurrence frequency. 4) Implement information retrieval modeling in calculating ranking score: Vector space model was applied. (In following steps, calculations corresponding to summaries and titles were done separately) 4.1) Weights were calculated for every term found in step 3 by applying this equation: 4.2) The words which match the terms in nutrition lexicon database (that were found in step 3.1) were considered as query terms. In this case, the query terms were different every time as we started a new search (i.e. dynamic query). The weight of each query term was calculated by applying this equation: 4.3)For each document, the similarity value between the document vector and query vector was calculated for summary and title respectively:
32 5) The two similarity values were added together to form the ranking score. 6) Documents were reprioritized with respect to their ranking score Dynamic query with relevance feedback approach For this approach, relevance feedback (i.e. user feedback) was included. Actually, it was a method based on dynamic query approach. 1) Tokenize all summaries and titles of the retrieved documents by using sharpnlp. 2) Eliminate all stop words from the tokenized documents. 3) Perform indexing 3.1) For each document, find the terms which match the nutrition lexicon database. 3.2) For each term found in each document, find its occurrence frequency. 4) Implement information retrieval modeling in calculating ranking score: Vector space model was applied. (In following steps, calculations corresponding to summaries and titles were done separately) 4.1) Weights were calculated for every terms found in step 3 by applying this equation:
33 4.2) The words which match the terms in nutrition lexicon database (that were found in step 3.1) were considered as query terms. In this case, the query terms were different every time as we started a new search (i.e. dynamic query). The weight of each query term was calculated by applying this equation: 4.3)For each document, the similarity value between the document vector and query vector was calculated for summary and title respectively: 5) The two similarity values were added together to form the ranking score. 6) Documents were reprioritized with respect to their ranking score. 7) For the documents ranked in top 10, three feedback terms were chosen according to the following equation: 8) These three feedback terms were added into the initial search query to search again. 9) Steps 1 to 6 were repeated for the modified search query
 was selected in this part. Among the three approaches mentioned in 5.")
34 5.4 Evaluation & Modification The methodology used in this part was writing test cases and then the results were evaluated statistically by using software called SPSS. The best approach (static query, dynamic query, dynamic query with relevance feedback) was selected in this part. Among the three approaches mentioned in 5.3, it was found that there was a Google API timeout problem happened in approach 3 as the program running time was too long. The running time of approach 3 was much longer than the others because it searched twice. Due to the Google API timeout problem, approach 3 was no longer considered and only the other two approaches were evaluated. Fig Google API Timeout Error Message

35 Step 1: 42 test cases were written and the expected search result was written for each test case. Fig Evaluation (test case and corresponding expected search result -- 1)

36 Fig Evaluation (test case and corresponding expected search result -- 2) Step 2: Search for each test case by approach 1 and 2. View at the summaries and titles and then modify the program to enhance relevancy in this stage. The modifications made including: 1) Ranking score is increased if the words in summaries or titles are exactly the same as the search terms. 2) Ranking score is increased when the summary or title of a web page contains more search terms than others. 3) Ranking score is decreased when the summary or title of a web page contains none of the search terms
 the content of each web page, 4) identify whether the web page is relevant to user s search requirement or not, according to the expectations written in step 1.")
37 Step 3: For both approach 1 and 2, view at the top 50 results again and then find out 1) the words which match our nutrition lexicon database, 2) the occurrence frequencies of each word which match our nutrition lexicon database, 3) the content of each web page, 4) identify whether the web page is relevant to user s search requirement or not, according to the expectations written in step 1. It was found that the priority order of Google s search results changed a little for every search, therefore, Google s search results in static query approach was different from that in dynamic query approach. One of the test case examples: 1) The words which match our nutrition lexicon database 2) The occurrence frequencies of each word which match our nutrition lexicon database 3) The content of each web page 4) Yellow indicate relevant Fig Evaluation (evaluate on each test case) Grey indicate irrelevant

38 Step 4: For each test case, the no. of relevant documents, the no. of irrelevant documents and the no. of dead links were counted for top 10, top 20 and top 50 results respectively. 6 values (no. of relevant documents / 10; no. of relevant documents / 20; no. of relevant documents / 50; no. of irrelevant documents / 10; no. of irrelevant documents / 20; no. of irrelevant documents / 50) were calculated for each test case in each approach. Fig Evaluation (ratio of relevant document & irrelevant document 1)

39 Fig Evaluation (ratio of relevant document & irrelevant document 2)

40 Fig Evaluation (ratio of relevant document & irrelevant document 3)

41 Fig Evaluation (ratio of relevant document & irrelevant document 4)
 Probability of retrieving relevant documents (detection probability) Top 10 results and top 50 results were considered to see if there was significant improvement")
42 Step 5: With the values calculated in step 4, these data were then passed to the software SPSS for statistical evaluation. Two directions were evaluated: i) Probability of retrieving relevant documents (detection probability) Top 10 results and top 50 results were considered to see if there was significant improvement when compared to Google s search results. That is, to see if our search engine retrieves more relevant documents in top ranked results than Google s and is not happened by chance. Top 50 results: First, input the data (values calculated in step 4 -- no. of relevant documents / 50). No. of relevant / 50 e.g. 30 / 50 =
 and dynamic query approach (Google & our search engine) respectively.")
43 Fig Evaluation (input data in SPSS -- Top 50 results -- relevant) Second, identify if the data were normally distributed by KS-Test. KS-Test was done for static query approach (Google & our search engine) and dynamic query approach (Google & our search engine) respectively. Third, T-Test (Independent samples T-Test and Paired samples T-Test) was performed if data were normally distributed. Otherwise, 2-Independent Samples Test was performed. Lastly, through the results from T-Test / 2-Independent Samples Test, it is able to determine if there is any significant difference when compared to Google s search results

44 Top 10 results: First, input the data (values calculated in step 4 -- no. of relevant documents / 10). No. of relevant / 10 e.g. 6 / 10 = 0.6 Fig Evaluation (input data in SPSS -- Top 10 results -- relevant)
 and dynamic query approach (Google & our search engine) respectively.")
45 Second, identify if the data were normally distributed by KS-Test. KS-Test was done for static query approach (Google & our search engine) and dynamic query approach (Google & our search engine) respectively. Third, T-Test (Independent samples T-Test and Paired samples T-Test) was performed if data were normally distributed. Otherwise, 2-Independent Samples Test was performed. Lastly, through the results from T-Test / 2-Independent Samples Test, it is able to determine if there is any significant difference when compared to Google s search results. ii) Probability of retrieving irrelevant documents (false alarm probability) Top 10 results and top 50 results were considered to see if there was significant improvement when compared to Google s search results. That is, to see if our search engine retrieves less irrelevant documents in top ranked results than Google s. Top 50 results: First, input the data (values calculated in step 4 -- no. of irrelevant documents / 50). No. of irrelevant / 50 e.g. 17 / 50 =
 and dynamic query approach (Google & our search engine) respectively.")
46 Fig Evaluation (input data in SPSS -- Top 50 results -- irrelevant) Second, identify if the data were normally distributed by KS-Test. KS-Test was done for static query approach (Google & our search engine) and dynamic query approach (Google & our search engine) respectively. Third, T-Test (Independent samples T-Test and Paired samples T-Test) was performed if data were normally distributed. Otherwise, 2-Independent Samples Test was performed. Lastly, through the results from T-Test / 2-Independent Samples Test, it is able to determine if there is any significant difference when compared to Google s search results
 - 42 -")
47 Top 10 results: First, input the data (values calculated in step 4 -- no. of irrelevant documents / 10). No. of irrelevant/ 10 e.g. 4 / 10 = 0.4 Fig Evaluation (input data in SPSS -- Top 10 results -- irrelevant)
48 Second, identify if the data were normally distributed by KS-Test. KS-Test was done for static query approach (Google & our search engine) and dynamic query approach (Google & our search engine) respectively. Third, T-Test (Independent samples T-Test and Paired samples T-Test) was performed if data were normally distributed. Otherwise, 2-Independent Samples Test was performed. Lastly, through the results from T-Test / 2-Independent Samples Test, it is able to determine if there is any significant difference when compared to Google s search results. Step 6: By integrating the results from all the tests taken in step 5, the best approach can be selected and we can conclude if there is statistical significant improvement of our search engine when compared to Google s search results
49 6. Evaluation Results Evaluation results in two directions are shown as the followings: 6.1 Probability of retrieving relevant documents (detection probability) Top 50 results were evaluated: i) Kolmogorov Smirnov Test (KS-Test) Data A (Static_Google): Google s top 50 results in static query approach (no. of relevant documents / 50) Data B (Static_FYP): Our search engine s top 50 results in static query approach (no. of relevant documents / 50) Data C (Dynamic_Google): Google s top 50 results in dynamic query approach (no. of relevant documents / 50) Data D (Dynamic_FYP): Our search engine s top 50 results in dynamic query approach (no. of relevant documents / 50) Null hypothesis A: There is no significant difference between data A and normal distribution curve. Null hypothesis B: There is no significant difference between data B and normal distribution curve. Null hypothesis C: There is no significant difference between data C and normal distribution curve. Null hypothesis D: There is no significant difference between data D and normal distribution curve
50 Original KS-Test: Fig Result of KS-Test (top 50 results relevant) All p values are > 0.05 and near to 1 that we can regard null hypothesis A, B, C and D as true. That is, all the data are normally distributed. Modified KS-Test with Lilliefors-significance correction: Fig Result of modified KS-Test (top 50 results relevant) All p values are > 0.05 that we can regard null hypothesis A, B, C and D as true. That is, all the data are normally distributed
 As all the data are normally")

: Data A (Static_Google):")
 Data B (Static_FYP): Our search engine s top 50")
51 Fig Histograms (top 50 results relevant) As all the data are normally distributed, T-Test is used to compare the means to see if there is significant difference. ii) T-Test (Independent Samples T-Test and Paired Samples T-Test) Independent Samples T-Test (Static Query Appraoch): Data A (Static_Google): Google s top 50 results in static query approach (no. of relevant documents / 50) Data B (Static_FYP): Our search engine s top 50 results in static query approach (no. of relevant documents / 50) Null hypothesis: There is no significant difference between the mean of data A and data B
52 Fig Independent samples T-Test (Top 50 results relevant static query approach) As the p value of Levene s test is > 0.05 (0.463), we look at the upper row where equal variance is assumed. P value of independent samples T-Test is < 0.05 (0.002), that means there is significant difference between Google s and our top 50 search results (static query approach) As the mean of our search results (0.6467) is higher than that of google s (0.5076), we can conclude our search engine (static query approach) retrieve more relevant documents than Google in top 50 results. Independent Samples T-Test (Dynamic Query Approach) Data C (Dynamic_Google): Google s top 50 results in dynamic query approach (no. of relevant documents / 50) Data D (Dynamic_FYP): Our search engine s top 50 results in dynamic query approach (no. of relevant documents / 50) Null hypothesis: There is no significant difference between the mean of data C and data D
53 Fig Independent samples T-Test (Top 50 results relevant dynamic query approach) As the p value of Levene s test is > 0.05 (0.656), we look at the upper row where equal variance is assumed. P value is < (0.000), that means there is statiscally highly significant difference between Google s and our top 50 search results (dynamic query approach) As the mean of our search results (0.6929) is higher than that of google s (0.5162), we can conclude our search engine (dynamic query approach) retrieve more relevant documents than Google in top 50 results. As the mean of dynamic query approach results (0.6929) is higher than that of static query approach results (0.6467), also the p value of dynamic query approach is smaller, we can conclude dynamic query approach retrieve more relevant documents than static query approach in top 50 results
54 Paired Samples T-Test: Data A (Static_Google): Google s top 50 results in static query approach (no. of relevant documents / 50) Data B (Static_FYP): Our search engine s top 50 results in static query approach (no. of relevant documents / 50) Data C (Dynamic_Google): Google s top 50 results in dynamic query approach (no. of relevant documents / 50) Data D (Dynamic_FYP): Our search engine s top 50 results in dynamic query approach (no. of relevant documents / 50) Null hypothesis A: There is no significant difference between data A and data B. Null hypothesis B: There is no significant difference between data C and data D. Fig Paired samples T-Test (Top 50 results relevant)
55 For paired samples t-test, p values for both approaches is < 0.001, it means that there is statiscally significant difference between Google s and our top 50 search results (both approaches). To compare the mean values, dynamic query approach is better. Top 10 results were evaluated: i) Kolmogorov Smirnov Test (KS-Test) Data A (Static_Google) : Google s top 10 results in static query approach (no. of relevant documents / 10) Data B (Static_FYP): Our search engine s top 10 results in static query approach (no. of relevant documents / 10) Data C (Dynamic_Google): Google s top 10 results in dynamic query approach (no. of relevant documents / 10) Data D (Dynamic_FYP): Our search engine s top 10 results in dynamic query approach (no. of relevant documents / 10) Null hypothesis A: There is no significant difference between data A and normal distribution curve. Null hypothesis B: There is no significant difference between data B and normal distribution curve. Null hypothesis C: There is no significant difference between data C and normal distribution curve. Null hypothesis D: There is no significant difference between data D and normal distribution curve
56 Original KS-Test: Fig Result of KS-Test (top 10 results relevant) All p values are > 0.05 that we can regard null hypothesis A, B, C and D as true. That is, all the data are normally distributed. Modified KS-Test with Lilliefors-significance correction: Fig Result of modified KS-Test (top 10 results relevant) However, according to this modifed KS-Test, all p values are < 0.05 except for Dynamic_Google, that means, the data (Static_Google, Static_FYP and Dynamic_FYP) reject the hypothesis and they are not normally distributed




57 Fig Histograms (top 10 results relevant) As not all the data are normally distributed, non-parametric test is used to compare the mean to see if there is significant difference
58 2-independent samples test (non-parametric test) Static query approach: Data A (Static_Google): Google s top 10 results in static query approach (no. of relevant documents / 10) Data B (Static_FYP): Our search engine s top 10 results in static query approach (no. of relevant documents / 10) Null hypothesis: There is no significant difference between data A and data B. Fig independent sample test (top 10 results relevant static query approach) As p value > 0.05 (0.200), the null hypothesis is true and there is no significant difference between Google s search results and our top 10 search results (static query approach)
59 Dynamic query approach: Data C (Dynamic_Google): Google s top 10 results in dynamic query approach (no. of relevant documents / 10) Data D (Dynamic_FYP): Our search engine s top 10 results in dynamic query approach (no. of relevant documents / 10) Null hypothesis: There is no significant difference between data C and data D. Fig independent sample test (top 10 results relevant dynamic query approach) As p value < 0.05 (0.004), there is significant difference between Google s search results and our search results (dynamic query approach) When mean values are compared (please see Fig ; dynamic query approach: ; google s search engine: ), dynamic query approach is better as it retrieve more relevant documents than Google in top 10 results. To conclude, dynamic query approach (0.7881) is better as it retrieve more relevant documents than static query approach (0.7024) in top 10 results. Also, there is a significant improvement when compared to Google s search results
60 6.2 Probability of retrieving irrelevant documents (false alarm probability) Top 50 results were evaluated: i) Kolmogorov Smirnov Test (KS-Test) Data A (Static_Google): Google s top 50 results in static query approach (no. of irrelevant documents / 50) Data B (Static_FYP): Our search engine s top 50 results in static query approach (no. of irrelevant documents / 50) Data C (Dynamic_Google): Google s top 50 results in dynamic query approach (no. of irrelevant documents / 50) Data D (Dynamic_FYP): Our search engine s top 50 results in dynamic query approach (no. of irrelevant documents / 50) Null hypothesis A: There is no significant difference between data A and normal distribution curve. Null hypothesis B: There is no significant difference between data B and normal distribution curve. Null hypothesis C: There is no significant difference between data C and normal distribution curve. Null hypothesis D: There is no significant difference between data D and normal distribution curve
61 Original KS-Test: Fig Result of KS-Test (top 50 results irrelevant) All p values are > 0.05 and near to 1 that we can regard null hypothesis A, B, C and D as true. That is, all the data are normally distributed. Modified KS-Test with Lilliefors-significance correction: Fig Result of modified KS-Test (top 50 results irrelevant) All p values are > 0.05 that we can regard null hypothesis A, B, C and D as true. That is, all the data are normally distributed
 As all the data are")

: Data A")
62 Fig Histograms (top 50 results irrelevant) As all the data are normally distributed, T-Test is used to compare the means to see if there is significant difference. ii) T-Test (Independent Samples T-Test and Paired Samples T-Test) Independent Samples T-Test (Static Query Appraoch): Data A (Static_Google): Google s top 50 results in static query approach (no. of irrelevant documents / 50)
63 Data B (Static_FYP): Our search engine s top 50 results in static query approach (no. of irrelevant documents / 50) Null hypothesis: There is no significant difference between the mean of data A and data B. Fig Independent samples T-Test (Top 50 results irrelevant static query approach) As the p value of Levene s test is > 0.05 (0.419), we look at the upper row where equal variance is assumed. P value of independent samples T-Test is < 0.05 (0.001), that means there is significant difference between Google s and our top 50 search results (static query approach) As the mean of our search results (0.3048) is lower than that of google s (0.4490), we can conclude our search engine (static query approach) retrieve less irrelevant documents than google in top 50 results. Independent Samples T-Test (Dynamic Query Approach) Data C (Dynamic_Google): Google s top 50 results in dynamic query approach (no. of irrelevant documents / 50)
64 Data D (Dynamic_FYP): Our search engine s top 50 results in dynamic query approach (no. of irrelevant documents / 50) Null hypothesis: There is no significant difference between the mean of data C and data D. Fig Independent samples T-Test (Top 50 results irrelevant dynamic query approach) As the p value of Levene s test is > 0.05 (0.539), we look at the upper row where equal variance is assumed. P value is < 0.001, that means there is statiscally highly significant difference between Google s and our top 50 search results (dynamic query approach) As the mean of our search results (0.2610) is lower than that of google s (0.4424), we can conclude our search engine (dynamic query approach) retrieve less irrelevant documents than google in top 50 results. As the mean of dynamic query approach results (0.2610) is lower than that of static query approach results (0.3048), also the p value of dynamic query approach is smaller, we can conclude dynamic query approach retrieve less irrelevant documents than static query approach in top 50 results
65 Paired Samples T-Test: Data A (Static_Google): Google s top 50 results in static query approach (no. of irrelevant documents / 50) Data B (Static_FYP): Our search engine s top 50 results in static query approach (no. of irrelevant documents / 50) Data C (Dynamic_Google): Google s top 50 results in dynamic query approach (no. of irrelevant documents / 50) Data D (Dynamic_FYP): Our search engine s top 50 results in dynamic query approach (no. of irrelevant documents / 50) Null hypothesis A: There is no significant difference between data A and data B. Null hypothesis B: There is no significant difference between data C and data D. Fig Paired samples T-Test (Top 50 results irrelevant) For paired samples t-test, p values for both approaches is < 0.001, that means
66 there is statiscally significant difference between Google s and our top 50 search results (both approaches). To compare the mean values, dynamic query approach is better as it retrieve less irrelevent documents than static approach in top 50 results. Top 10 results were evaluated: i) Kolmogorov Smirnov Test (KS-Test) Data A (Static_Google): Google s top 10 results in static query approach (no. of irrelevant documents / 10) Data B (Static_FYP): Our search engine s top 10 results in static query approach (no. of irrelevant documents / 10) Data C (Dynamic_Google): Google s top 10 results in dynamic query approach (no. of irrelevant documents / 10) Data D (Dynamic_FYP): Our search engine s top 10 results in dynamic query approach (no. of irrelevant documents / 10) Null hypothesis A: There is no significant difference between data A and normal distribution curve. Null hypothesis B: There is no significant difference between data B and normal distribution curve. Null hypothesis C: There is no significant difference between data C and normal distribution curve. Null hypothesis D: There is no significant difference between data D and normal distribution curve
67 Original KS-Test: Fig Result of KS-Test (top 10 results irrelevant) All p values are > 0.05 that we can regard null hypothesis A, B, C and D as true. That is, all the data are normally distributed. Modified KS-Test with Lilliefors-significance correction: Fig Result of modified KS-Test (top 10 results irrelevant) However, according to this modifed KS-Test, all p values are < 0.05, that means, all data reject the hypothesis and they are not normally distributed




68 Fig Histograms (top 10 results irrelevant) As all the data are not normally distributed, non-parametric test is used to compare the mean to see if there is significant difference
69 2-independent samples test (non-parametric test) Static query approach: Data A (Static_Google): Google s top 10 results in static query approach (no. of irrelevant documents / 10) Data B (Static_FYP): Our search engine s top 10 results in static query approach (no. of irrelevant documents / 10) Null hypothesis: There is no significant difference between data A and data B. Fig independent samples test (top 10 results irrelevant static query approach) As p value < 0.05 (0.038), there is significant difference between Google s search results and our search results (static query approach) When mean values are compared (please see Fig ; static query approach: ; Google: ), static query approach is better as it retrieve less irrelevant documents than Google in top 10 results
70 Dynamic query approach: Data C (Dynamic_Google): Google s top 10 results in dynamic query approach (no. of irrelevant documents / 10) Data D (Dynamic_FYP): Our search engine s top 10 results in dynamic query approach (no. of irrelevant documents / 10) Null hypothesis: There is no significant difference between data C and data D. Fig independent samples test (top 10 results irrelevant dynamic query approach) As p value < 0.05 (0.004), there is significant difference between Google s search results and our search results (dynamic query approach) When mean values are compared (please see Fig ; dynamic query approach: ; static query approach: ), dynamic query approach is better as it retrieves less irrelevant documents than static query approach in top 10 results. Conclusion Dynamic query approach is better than static query approach after compared to p values and mean values from different statistical tests. More importnatly, there is significant improvement of our search results when compared to Google s search results, in terms of the amount of relevant and irrelevant documents retrieved respectively
71 7. Discussion Comparison between Google s search engine and my search engine: Table 7.1 Comparison between Google s search engine and my search engine To conclude, the advantage of my search engine is that it can be used to search specified field information with a better result than using Google s search engine. Also, users are able to search in any specialized field by changing the lexicon database themselves, which is a.txt file. However, my search engine requires a longer time for searching and re-ranking which makes its efficiency lower than Google s search engine. The reason for longer searching time is that, by using Google API, it only allows us to return 10 results each time. Therefore, we need to request 75 times for 750 results. That is why a longer time is required in web searching. Indeed, this is one of the disadvantages of using Google API. Discussion for each part in methodology: Part I: Querying It is found that the advantage of expanding the web query by applying natural language processing is that it can maximize the search range. When we search eating apple is
72 healthy, in which good for you is the synonym of healthy, the results relevant to eating apple is good for you or eating apple is healthy will be returned. Part II: Web searching Building an own web document database is very complicated, time-consuming and may be expensive. However, by using Google API, it is not only free to use, but also let us to retrieve data from Google s web document database in an easier and convenient way. Despite of the advantages, there are some limitations: 1) Only 10 results can be returned each time; we have to request 75 times in order to obtain 750 results. 2) Only the first 1000 results can be returned in total. 3) It is limited to 1000 queries each day. 4) Google API timeout in a short period of time. Although it is more convenient to use Google API in retrieving the web documents, it would be better to retrieve documents from own database in a long term. For example, we can put nutritional related documents only in own database to minimize the retrieval of irrelevant documents and therefore enhance the relevancy. Moreover, Google API is no longer required and therefore no limitations exist. Part III: Reprioritize the retrieved documents It is found that natural language processing is not only useful in expanding the web query to retrieve more relevant results, it is also essential in information retrieval process. With tokenizing the summaries and titles, we can perform the matching with the nutrition lexicon database in an easier manner. Without eliminating the stopwords, lots of useless words (e.g. a, an, the) will be stored and hence require more unnecessary storage. However, tokenization sometimes may not perform in a desired way. For
73 example, we would like to consider junk food as one term, but it will be regarded as two terms ( junk & food ) after tokenization. Problems encountered: 1) When we tried to tokenize all the retrieved web content, we found that the speed was very slow as there was too much text to be tokenized. Therefore, we decided to tokenize the titles and summaries of all web documents only. 2) The idea of including relevance feedback in approach 3 is: it is believed that the three most frequently occurred terms in top 10 results which match the nutrition lexicon database are most relevant to user s search requirement, therefore, by adding these terms in the original query and search again may enhance the relevancy. However, the running time of approach 3 became much longer than the others because it searched twice. That is why Google API timeout problem happened in approach 3. Part IV: Evaluation In this part, the results were evaluated by statistical hypothesis tests rather than just comparing the sample means to draw conclusion. It is do so as we want to prove that the improvement is not happened by chance. It is found that the data of top 10 results are not normally distributed. It is due to two main reasons: 1) There are only 11 feasible values (0, 0.1, 0.2,.0.9, 1.0) 2) In both Google and my search engine, the top 10 documents will be most relevant and therefore no. of relevant documents / 10 is always a large value ( > 0.7)
74 Apart from relying on the t-test provided by SPSS, we can calculate the t value and then determine the p value according to this equation [7]: The larger the t value, the smaller the p value will be. According to t sig / probability table, for 42 documents, t value must be > ( ) or < ( ) for p value < From this equation, it is found that when the difference between the means increases or when the standard deviation decreases, the t value will then increase. In most of the test cases, we found that the difference between the mean of dynamic query approach and the mean of Google s search results is larger than that between static query approach and Google s. Also, the standard deviation value of dynamic query approach is smaller than that of static query approach. From these two clues, we can also estimate that dynamic query approach is better. However, due to the assumption (data are normally distributed) of T-Test, it is still required performing KS test first. Problems encountered: 1) It is found that the summaries or titles of the web page obtained from Google are occasionally different from the main idea of the web page and therefore it may sometimes affect the actual relevancy. The solution of this problem may be retrieving the first 100 words of the main content of each web page as well to ensure the main idea of the top ranked results are nutritional relevant
75 8. Improvements 1) Try retrieving the first 100 words of the main content of each web page or even the whole passage to maximize the amount of information for re-ranking. 2) Develop own web document database. Google API is no longer required and therefore no limitations will be existed. Efficiency may also be enhanced as it is no longer required to build connection to Google s web documents database. 3) For specialized content search engine, try to only put field-related documents in web document database to minimize the retrieval of irrelevant documents in order to enhance relevancy. 4) Available for Chinese (or any other languages) web searching 5) To include more functions in the future. For example, searching for pictures, news, videos, etc
76 9. Working Schedule Fig. 9.1 Working Schedule (Semester A 07/08)
77 Fig. 9.2 Working Schedule (Semester B 07/08)
78 10. Conclusion Throughout this year, all five project objectives have been achieved. First, I have developed a specialized content search engine in Microsoft.NET environment. Second, I have successfully applied natural language processing in web query to retrieve more relevant results. Third, I have successfully applied Google API in web searching. Fourth, I have tried three different approaches in information retrieval to re-rank the retrieved documents, including static query approach, dynamic query approach and dynamic query with relevance feedback approach. Lastly, I have learnt how to perform KS-Test, T-Test and 2 independent samples test in web document retrieval performance evaluation. Through this project, I found that natural language processing is not only useful in expanding the web query to retrieve more relevant results, it is also essential in information retrieval process. On the other hand, as different ranking algorithms produce different results, an appropriate evaluation is required to select the best ranking method
79 11. References [1] 林傑斌 林川雄 劉明德著 (2004), SPSS 12 統計建模與應用實務, 台北 : 博碩文化, 頁 , , [2] Baeza-Yates R. & Ribeiro-Neto B. (1999), Modern Information Retrieval, New York : ACM Press ; Harlow, England : Addison-Wesley, pp.24-33, , [3] Christopher D. M., Prabhakar R. & Hinrich S. (2008), Introduction to Information Retrieval, Cambridge University Press, retrieved on 10 November 2007, from [4] CodePlex: Open source natural language processing tools. Retrieved on 12 September, from [5] Eileen Kowalski (2004), Back to basics: Researching with Search Engine Operators, retrieved on 6 April 2008, from [6] Network Computing: What is Natural-Language Searching? Retrieved on 24 June, 2007, from [7] Psychology world: t-test example. Retrieved on 3 April 2008, from [8] Rank for Sales: The Google API s and their uses. Retrieved on 11 July, 2007, from [9] Rich Ackerman (2003), Theory of Information Retrieval, Florida State University LIS (Fall, 2003), retrieved on 10 November 2007, from [10] Rila Mandala, Tokunaga Takenobu & Tanaka Hozumi, The Use of WordNet in Information Retrieval, retrieved on 15 November 2007, from [11] SearchSOA.com: What is search engine? Retrieved on 24 June 2007, from
80 [12] Thorsten Brants, Natural Language Processing in Information Retrieval, retrieved on 15 November 2007, from [13] Webopedia: How Web Search Engines Work. Retrieved on 24 June 2007, from sp [14] Wikipedia: Statistical significance. Retrieved on 2 April 2008, from [15] Yahoo! 知識 : 統計數上 p-value 是什麼意思呀? Retrieved on 2 April 2008, from -
")

81 Appendix A: Stopword List (Source: 何修維, Information Retrieval and Extraction Final Project IR Model Implementation) Appendix B: (Source: Delores C.S. James, 2004, Nutrition Well-Being A to Z, USA: Thomson Gale) Nutrition Lexicon Database

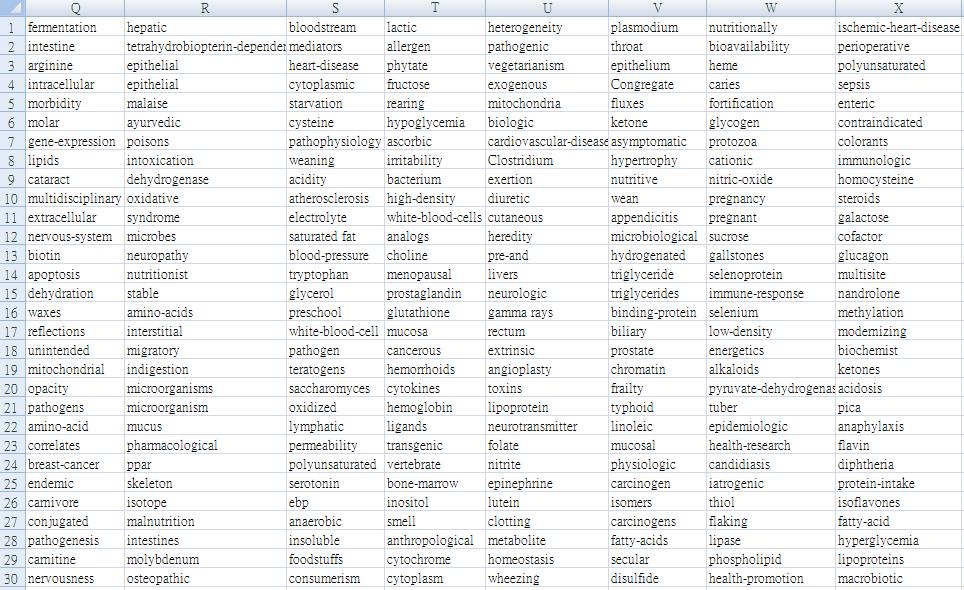
82 Nutrition Lexicon Database -- 2 Nutrition Lexicon Database


83 Nutrition Lexicon Database 4 Nutrition Lexicon Database
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most
 In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
In = number of words appearing exactly n times N = number of words in the collection of words A = a constant. For example, if N=100 and the most common word appears 10 times then A = rn*n/n = 1*10/100
Web Search Engine Question Answering
 Web Search Engine Question Answering Reena Pindoria Supervisor Dr Steve Renals Com3021 07/05/2003 This report is submitted in partial fulfilment of the requirement for the degree of Bachelor of Science
Web Search Engine Question Answering Reena Pindoria Supervisor Dr Steve Renals Com3021 07/05/2003 This report is submitted in partial fulfilment of the requirement for the degree of Bachelor of Science
Introduction to Information Retrieval
 Introduction to Information Retrieval Mohsen Kamyar چهارمین کارگاه ساالنه آزمایشگاه فناوری و وب بهمن ماه 1391 Outline Outline in classic categorization Information vs. Data Retrieval IR Models Evaluation
Introduction to Information Retrieval Mohsen Kamyar چهارمین کارگاه ساالنه آزمایشگاه فناوری و وب بهمن ماه 1391 Outline Outline in classic categorization Information vs. Data Retrieval IR Models Evaluation
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval
 Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
Web Information Retrieval using WordNet
 Web Information Retrieval using WordNet Jyotsna Gharat Asst. Professor, Xavier Institute of Engineering, Mumbai, India Jayant Gadge Asst. Professor, Thadomal Shahani Engineering College Mumbai, India ABSTRACT
Web Information Retrieval using WordNet Jyotsna Gharat Asst. Professor, Xavier Institute of Engineering, Mumbai, India Jayant Gadge Asst. Professor, Thadomal Shahani Engineering College Mumbai, India ABSTRACT
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM
 CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
Information Retrieval and Web Search
 Information Retrieval and Web Search Introduction to IR models and methods Rada Mihalcea (Some of the slides in this slide set come from IR courses taught at UT Austin and Stanford) Information Retrieval
Information Retrieval and Web Search Introduction to IR models and methods Rada Mihalcea (Some of the slides in this slide set come from IR courses taught at UT Austin and Stanford) Information Retrieval
Information Retrieval. Information Retrieval and Web Search
 Information Retrieval and Web Search Introduction to IR models and methods Information Retrieval The indexing and retrieval of textual documents. Searching for pages on the World Wide Web is the most recent
Information Retrieval and Web Search Introduction to IR models and methods Information Retrieval The indexing and retrieval of textual documents. Searching for pages on the World Wide Web is the most recent
Instructor: Stefan Savev
 LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
CS 6320 Natural Language Processing
 CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
Information Retrieval
 Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES
 TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES Mu. Annalakshmi Research Scholar, Department of Computer Science, Alagappa University, Karaikudi. annalakshmi_mu@yahoo.co.in Dr. A.
TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES Mu. Annalakshmi Research Scholar, Department of Computer Science, Alagappa University, Karaikudi. annalakshmi_mu@yahoo.co.in Dr. A.
Semantic Extensions to Syntactic Analysis of Queries Ben Handy, Rohini Rajaraman
 Semantic Extensions to Syntactic Analysis of Queries Ben Handy, Rohini Rajaraman Abstract We intend to show that leveraging semantic features can improve precision and recall of query results in information
Semantic Extensions to Syntactic Analysis of Queries Ben Handy, Rohini Rajaraman Abstract We intend to show that leveraging semantic features can improve precision and recall of query results in information
Information Retrieval. CS630 Representing and Accessing Digital Information. What is a Retrieval Model? Basic IR Processes
 CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Information Retrieval CS Lecture 01. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Question Answering Systems
 Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Designing and Building an Automatic Information Retrieval System for Handling the Arabic Data
 American Journal of Applied Sciences (): -, ISSN -99 Science Publications Designing and Building an Automatic Information Retrieval System for Handling the Arabic Data Ibrahiem M.M. El Emary and Ja'far
American Journal of Applied Sciences (): -, ISSN -99 Science Publications Designing and Building an Automatic Information Retrieval System for Handling the Arabic Data Ibrahiem M.M. El Emary and Ja'far
Optimal Query. Assume that the relevant set of documents C r. 1 N C r d j. d j. Where N is the total number of documents.
 Optimal Query Assume that the relevant set of documents C r are known. Then the best query is: q opt 1 C r d j C r d j 1 N C r d j C r d j Where N is the total number of documents. Note that even this
Optimal Query Assume that the relevant set of documents C r are known. Then the best query is: q opt 1 C r d j C r d j 1 N C r d j C r d j Where N is the total number of documents. Note that even this
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Information Extraction Techniques in Terrorism Surveillance
 Information Extraction Techniques in Terrorism Surveillance Roman Tekhov Abstract. The article gives a brief overview of what information extraction is and how it might be used for the purposes of counter-terrorism
Information Extraction Techniques in Terrorism Surveillance Roman Tekhov Abstract. The article gives a brief overview of what information extraction is and how it might be used for the purposes of counter-terrorism
Duke University. Information Searching Models. Xianjue Huang. Math of the Universe. Hubert Bray
 Duke University Information Searching Models Xianjue Huang Math of the Universe Hubert Bray 24 July 2017 Introduction Information searching happens in our daily life, and even before the computers were
Duke University Information Searching Models Xianjue Huang Math of the Universe Hubert Bray 24 July 2017 Introduction Information searching happens in our daily life, and even before the computers were
Representation of Documents and Infomation Retrieval
 Representation of s and Infomation Retrieval Pavel Brazdil LIAAD INESC Porto LA FEP, Univ. of Porto http://www.liaad.up.pt Escola de verão Aspectos de processamento da LN F. Letras, UP, th June 9 Overview.
Representation of s and Infomation Retrieval Pavel Brazdil LIAAD INESC Porto LA FEP, Univ. of Porto http://www.liaad.up.pt Escola de verão Aspectos de processamento da LN F. Letras, UP, th June 9 Overview.
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Document Searching Engine Using Term Similarity Vector Space Model on English and Indonesian Document
 Document Searching Engine Using Term Similarity Vector Space Model on English and Indonesian Document Andreas Handojo, Adi Wibowo, Yovita Ria Informatics Engineering Department Faculty of Industrial Technology,
Document Searching Engine Using Term Similarity Vector Space Model on English and Indonesian Document Andreas Handojo, Adi Wibowo, Yovita Ria Informatics Engineering Department Faculty of Industrial Technology,
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Search Engine Architecture II
 Search Engine Architecture II Primary Goals of Search Engines Effectiveness (quality): to retrieve the most relevant set of documents for a query Process text and store text statistics to improve relevance
Search Engine Architecture II Primary Goals of Search Engines Effectiveness (quality): to retrieve the most relevant set of documents for a query Process text and store text statistics to improve relevance
TIC: A Topic-based Intelligent Crawler
 2011 International Conference on Information and Intelligent Computing IPCSIT vol.18 (2011) (2011) IACSIT Press, Singapore TIC: A Topic-based Intelligent Crawler Hossein Shahsavand Baghdadi and Bali Ranaivo-Malançon
2011 International Conference on Information and Intelligent Computing IPCSIT vol.18 (2011) (2011) IACSIT Press, Singapore TIC: A Topic-based Intelligent Crawler Hossein Shahsavand Baghdadi and Bali Ranaivo-Malançon
Natural Language Processing
 Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Domain Specific Search Engine for Students
 Domain Specific Search Engine for Students Domain Specific Search Engine for Students Wai Yuen Tang The Department of Computer Science City University of Hong Kong, Hong Kong wytang@cs.cityu.edu.hk Lam
Domain Specific Search Engine for Students Domain Specific Search Engine for Students Wai Yuen Tang The Department of Computer Science City University of Hong Kong, Hong Kong wytang@cs.cityu.edu.hk Lam
A Linguistic Approach for Semantic Web Service Discovery
 A Linguistic Approach for Semantic Web Service Discovery Jordy Sangers 307370js jordysangers@hotmail.com Bachelor Thesis Economics and Informatics Erasmus School of Economics Erasmus University Rotterdam
A Linguistic Approach for Semantic Web Service Discovery Jordy Sangers 307370js jordysangers@hotmail.com Bachelor Thesis Economics and Informatics Erasmus School of Economics Erasmus University Rotterdam
Modern information retrieval
 Modern information retrieval Modelling Saif Rababah 1 Introduction IR systems usually adopt index terms to process queries Index term: a keyword or group of selected words any word (more general) Stemming
Modern information retrieval Modelling Saif Rababah 1 Introduction IR systems usually adopt index terms to process queries Index term: a keyword or group of selected words any word (more general) Stemming
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Information Retrieval
 s Information Retrieval Information system management system Model Processing of queries/updates Queries Answer Access to stored data Patrick Lambrix Department of Computer and Information Science Linköpings
s Information Retrieval Information system management system Model Processing of queries/updates Queries Answer Access to stored data Patrick Lambrix Department of Computer and Information Science Linköpings
Authoritative K-Means for Clustering of Web Search Results
 Authoritative K-Means for Clustering of Web Search Results Gaojie He Master in Information Systems Submission date: June 2010 Supervisor: Kjetil Nørvåg, IDI Co-supervisor: Robert Neumayer, IDI Norwegian
Authoritative K-Means for Clustering of Web Search Results Gaojie He Master in Information Systems Submission date: June 2010 Supervisor: Kjetil Nørvåg, IDI Co-supervisor: Robert Neumayer, IDI Norwegian
Handout 9: Imperative Programs and State
 06-02552 Princ. of Progr. Languages (and Extended ) The University of Birmingham Spring Semester 2016-17 School of Computer Science c Uday Reddy2016-17 Handout 9: Imperative Programs and State Imperative
06-02552 Princ. of Progr. Languages (and Extended ) The University of Birmingham Spring Semester 2016-17 School of Computer Science c Uday Reddy2016-17 Handout 9: Imperative Programs and State Imperative
doi: / _32
 doi: 10.1007/978-3-319-12823-8_32 Simple Document-by-Document Search Tool Fuwatto Search using Web API Masao Takaku 1 and Yuka Egusa 2 1 University of Tsukuba masao@slis.tsukuba.ac.jp 2 National Institute
doi: 10.1007/978-3-319-12823-8_32 Simple Document-by-Document Search Tool Fuwatto Search using Web API Masao Takaku 1 and Yuka Egusa 2 1 University of Tsukuba masao@slis.tsukuba.ac.jp 2 National Institute
SYSTEMS FOR NON STRUCTURED INFORMATION MANAGEMENT
 SYSTEMS FOR NON STRUCTURED INFORMATION MANAGEMENT Prof. Dipartimento di Elettronica e Informazione Politecnico di Milano INFORMATION SEARCH AND RETRIEVAL Inf. retrieval 1 PRESENTATION SCHEMA GOALS AND
SYSTEMS FOR NON STRUCTURED INFORMATION MANAGEMENT Prof. Dipartimento di Elettronica e Informazione Politecnico di Milano INFORMATION SEARCH AND RETRIEVAL Inf. retrieval 1 PRESENTATION SCHEMA GOALS AND
Improving Relevance Prediction for Focused Web Crawlers
 2012 IEEE/ACIS 11th International Conference on Computer and Information Science Improving Relevance Prediction for Focused Web Crawlers Mejdl S. Safran 1,2, Abdullah Althagafi 1 and Dunren Che 1 Department
2012 IEEE/ACIS 11th International Conference on Computer and Information Science Improving Relevance Prediction for Focused Web Crawlers Mejdl S. Safran 1,2, Abdullah Althagafi 1 and Dunren Che 1 Department
INFSCI 2140 Information Storage and Retrieval Lecture 6: Taking User into Account. Ad-hoc IR in text-oriented DS
 INFSCI 2140 Information Storage and Retrieval Lecture 6: Taking User into Account Peter Brusilovsky http://www2.sis.pitt.edu/~peterb/2140-051/ Ad-hoc IR in text-oriented DS The context (L1) Querying and
INFSCI 2140 Information Storage and Retrieval Lecture 6: Taking User into Account Peter Brusilovsky http://www2.sis.pitt.edu/~peterb/2140-051/ Ad-hoc IR in text-oriented DS The context (L1) Querying and
IMPROVING THE RELEVANCY OF DOCUMENT SEARCH USING THE MULTI-TERM ADJACENCY KEYWORD-ORDER MODEL
 IMPROVING THE RELEVANCY OF DOCUMENT SEARCH USING THE MULTI-TERM ADJACENCY KEYWORD-ORDER MODEL Lim Bee Huang 1, Vimala Balakrishnan 2, Ram Gopal Raj 3 1,2 Department of Information System, 3 Department
IMPROVING THE RELEVANCY OF DOCUMENT SEARCH USING THE MULTI-TERM ADJACENCY KEYWORD-ORDER MODEL Lim Bee Huang 1, Vimala Balakrishnan 2, Ram Gopal Raj 3 1,2 Department of Information System, 3 Department
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
CS377: Database Systems Text data and information. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
A Document Graph Based Query Focused Multi- Document Summarizer
 A Document Graph Based Query Focused Multi- Document Summarizer By Sibabrata Paladhi and Dr. Sivaji Bandyopadhyay Department of Computer Science and Engineering Jadavpur University Jadavpur, Kolkata India
A Document Graph Based Query Focused Multi- Document Summarizer By Sibabrata Paladhi and Dr. Sivaji Bandyopadhyay Department of Computer Science and Engineering Jadavpur University Jadavpur, Kolkata India
A Deep Relevance Matching Model for Ad-hoc Retrieval
 A Deep Relevance Matching Model for Ad-hoc Retrieval Jiafeng Guo 1, Yixing Fan 1, Qingyao Ai 2, W. Bruce Croft 2 1 CAS Key Lab of Web Data Science and Technology, Institute of Computing Technology, Chinese
A Deep Relevance Matching Model for Ad-hoc Retrieval Jiafeng Guo 1, Yixing Fan 1, Qingyao Ai 2, W. Bruce Croft 2 1 CAS Key Lab of Web Data Science and Technology, Institute of Computing Technology, Chinese
Semantic Search in s
 Semantic Search in Emails Navneet Kapur, Mustafa Safdari, Rahul Sharma December 10, 2010 Abstract Web search technology is abound with techniques to tap into the semantics of information. For email search,
Semantic Search in Emails Navneet Kapur, Mustafa Safdari, Rahul Sharma December 10, 2010 Abstract Web search technology is abound with techniques to tap into the semantics of information. For email search,
68A8 Multimedia DataBases Information Retrieval - Exercises
 68A8 Multimedia DataBases Information Retrieval - Exercises Marco Gori May 31, 2004 Quiz examples for MidTerm (some with partial solution) 1. About inner product similarity When using the Boolean model,
68A8 Multimedia DataBases Information Retrieval - Exercises Marco Gori May 31, 2004 Quiz examples for MidTerm (some with partial solution) 1. About inner product similarity When using the Boolean model,
IN4325 Query refinement. Claudia Hauff (WIS, TU Delft)
") IN4325 Query refinement Claudia Hauff (WIS, TU Delft) The big picture Information need Topic the user wants to know more about The essence of IR Query Translation of need into an input for the search engine
IN4325 Query refinement Claudia Hauff (WIS, TU Delft) The big picture Information need Topic the user wants to know more about The essence of IR Query Translation of need into an input for the search engine
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
Basic techniques. Text processing; term weighting; vector space model; inverted index; Web Search
 Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Outline. Possible solutions. The basic problem. How? How? Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity
 Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
Digital Libraries: Language Technologies
 Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
Chapter 3 - Text. Management and Retrieval
 Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 3 - Text Management and Retrieval Literature: Baeza-Yates, R.;
Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 3 - Text Management and Retrieval Literature: Baeza-Yates, R.;
Section 001. Read this before starting!
 Points missed: Student's Name: Total score: / points East Tennessee State University Department of Computer and Information Sciences CSCI 25 (Tarnoff) Computer Organization TEST 2 for Fall Semester, 25
Points missed: Student's Name: Total score: / points East Tennessee State University Department of Computer and Information Sciences CSCI 25 (Tarnoff) Computer Organization TEST 2 for Fall Semester, 25
vector space retrieval many slides courtesy James Amherst
 vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
vector space retrieval many slides courtesy James Allan@umass Amherst 1 what is a retrieval model? Model is an idealization or abstraction of an actual process Mathematical models are used to study the
Recovering Traceability Links between Code and Documentation
 Recovering Traceability Links between Code and Documentation Paper by: Giuliano Antoniol, Gerardo Canfora, Gerardo Casazza, Andrea De Lucia, and Ettore Merlo Presentation by: Brice Dobry and Geoff Gerfin
Recovering Traceability Links between Code and Documentation Paper by: Giuliano Antoniol, Gerardo Canfora, Gerardo Casazza, Andrea De Lucia, and Ettore Merlo Presentation by: Brice Dobry and Geoff Gerfin
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval
 Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Enhanced Retrieval of Web Pages using Improved Page Rank Algorithm
 Enhanced Retrieval of Web Pages using Improved Page Rank Algorithm Rekha Jain 1, Sulochana Nathawat 2, Dr. G.N. Purohit 3 1 Department of Computer Science, Banasthali University, Jaipur, Rajasthan ABSTRACT
Enhanced Retrieval of Web Pages using Improved Page Rank Algorithm Rekha Jain 1, Sulochana Nathawat 2, Dr. G.N. Purohit 3 1 Department of Computer Science, Banasthali University, Jaipur, Rajasthan ABSTRACT
THE WEB SEARCH ENGINE
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
Better Contextual Suggestions in ClueWeb12 Using Domain Knowledge Inferred from The Open Web
 Better Contextual Suggestions in ClueWeb12 Using Domain Knowledge Inferred from The Open Web Thaer Samar 1, Alejandro Bellogín 2, and Arjen P. de Vries 1 1 Centrum Wiskunde & Informatica, {samar,arjen}@cwi.nl
Better Contextual Suggestions in ClueWeb12 Using Domain Knowledge Inferred from The Open Web Thaer Samar 1, Alejandro Bellogín 2, and Arjen P. de Vries 1 1 Centrum Wiskunde & Informatica, {samar,arjen}@cwi.nl
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
CS54701: Information Retrieval
 CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
Using NLP and context for improved search result in specialized search engines
 Mälardalen University School of Innovation Design and Engineering Västerås, Sweden Thesis for the Degree of Bachelor of Science in Computer Science DVA331 Using NLP and context for improved search result
Mälardalen University School of Innovation Design and Engineering Västerås, Sweden Thesis for the Degree of Bachelor of Science in Computer Science DVA331 Using NLP and context for improved search result
Knowledge Retrieval. Franz J. Kurfess. Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A.
 Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
To search and summarize on Internet with Human Language Technology
 To search and summarize on Internet with Human Language Technology Hercules DALIANIS Department of Computer and System Sciences KTH and Stockholm University, Forum 100, 164 40 Kista, Sweden Email:hercules@kth.se
To search and summarize on Internet with Human Language Technology Hercules DALIANIS Department of Computer and System Sciences KTH and Stockholm University, Forum 100, 164 40 Kista, Sweden Email:hercules@kth.se
CS/INFO 1305 Summer 2009
 Information Retrieval Information Retrieval (Search) IR Search Using a computer to find relevant pieces of information Text search Idea popularized in the article As We May Think by Vannevar Bush in 1945
Information Retrieval Information Retrieval (Search) IR Search Using a computer to find relevant pieces of information Text search Idea popularized in the article As We May Think by Vannevar Bush in 1945
CHAPTER 5 SEARCH ENGINE USING SEMANTIC CONCEPTS
 82 CHAPTER 5 SEARCH ENGINE USING SEMANTIC CONCEPTS In recent years, everybody is in thirst of getting information from the internet. Search engines are used to fulfill the need of them. Even though the
82 CHAPTER 5 SEARCH ENGINE USING SEMANTIC CONCEPTS In recent years, everybody is in thirst of getting information from the internet. Search engines are used to fulfill the need of them. Even though the
Documents Retrieval Using the Combination of Two Keywords
 Documents Retrieval Using the Combination of Two Keywords Rohitash Chandra Bhensle, Saikiran Chepuri, Menta Snjeeva Avinash M. Tech. Scholar (Software Technology) VIT University Vellore, Tmilnadu, India
Documents Retrieval Using the Combination of Two Keywords Rohitash Chandra Bhensle, Saikiran Chepuri, Menta Snjeeva Avinash M. Tech. Scholar (Software Technology) VIT University Vellore, Tmilnadu, India
Multimedia Information Systems
 Multimedia Information Systems Samson Cheung EE 639, Fall 2004 Lecture 6: Text Information Retrieval 1 Digital Video Library Meta-Data Meta-Data Similarity Similarity Search Search Analog Video Archive
Multimedia Information Systems Samson Cheung EE 639, Fall 2004 Lecture 6: Text Information Retrieval 1 Digital Video Library Meta-Data Meta-Data Similarity Similarity Search Search Analog Video Archive
Chapter 8. Evaluating Search Engine
 Chapter 8 Evaluating Search Engine Evaluation Evaluation is key to building effective and efficient search engines Measurement usually carried out in controlled laboratory experiments Online testing can
Chapter 8 Evaluating Search Engine Evaluation Evaluation is key to building effective and efficient search engines Measurement usually carried out in controlled laboratory experiments Online testing can
Query Expansion Based on Crowd Knowledge for Code Search
 PAGE 1 Query Expansion Based on Crowd Knowledge for Code Search Liming Nie, He Jiang*, Zhilei Ren, Zeyi Sun, Xiaochen Li Abstract As code search is a frequent developer activity in software development
PAGE 1 Query Expansion Based on Crowd Knowledge for Code Search Liming Nie, He Jiang*, Zhilei Ren, Zeyi Sun, Xiaochen Li Abstract As code search is a frequent developer activity in software development
Ranking in a Domain Specific Search Engine
 Ranking in a Domain Specific Search Engine CS6998-03 - NLP for the Web Spring 2008, Final Report Sara Stolbach, ss3067 [at] columbia.edu Abstract A search engine that runs over all domains must give equal
Ranking in a Domain Specific Search Engine CS6998-03 - NLP for the Web Spring 2008, Final Report Sara Stolbach, ss3067 [at] columbia.edu Abstract A search engine that runs over all domains must give equal
Search Engines Chapter 8 Evaluating Search Engines Felix Naumann
 Search Engines Chapter 8 Evaluating Search Engines 9.7.2009 Felix Naumann Evaluation 2 Evaluation is key to building effective and efficient search engines. Drives advancement of search engines When intuition
Search Engines Chapter 8 Evaluating Search Engines 9.7.2009 Felix Naumann Evaluation 2 Evaluation is key to building effective and efficient search engines. Drives advancement of search engines When intuition
Assignment No. 1. Abdurrahman Yasar. June 10, QUESTION 1
 COMPUTER ENGINEERING DEPARTMENT BILKENT UNIVERSITY Assignment No. 1 Abdurrahman Yasar June 10, 2014 1 QUESTION 1 Consider the following search results for two queries Q1 and Q2 (the documents are ranked
COMPUTER ENGINEERING DEPARTMENT BILKENT UNIVERSITY Assignment No. 1 Abdurrahman Yasar June 10, 2014 1 QUESTION 1 Consider the following search results for two queries Q1 and Q2 (the documents are ranked
University of Virginia Department of Computer Science. CS 4501: Information Retrieval Fall 2015
 University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 5:00pm-6:15pm, Monday, October 26th Name: ComputingID: This is a closed book and closed notes exam. No electronic
University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 5:00pm-6:15pm, Monday, October 26th Name: ComputingID: This is a closed book and closed notes exam. No electronic
Web Structure Mining using Link Analysis Algorithms
 Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Query Phrase Expansion using Wikipedia for Patent Class Search
 Query Phrase Expansion using Wikipedia for Patent Class Search 1 Bashar Al-Shboul, Sung-Hyon Myaeng Korea Advanced Institute of Science and Technology (KAIST) December 19 th, 2011 AIRS 11, Dubai, UAE OUTLINE
Query Phrase Expansion using Wikipedia for Patent Class Search 1 Bashar Al-Shboul, Sung-Hyon Myaeng Korea Advanced Institute of Science and Technology (KAIST) December 19 th, 2011 AIRS 11, Dubai, UAE OUTLINE
WordNet-based User Profiles for Semantic Personalization
 PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
Better Contextual Suggestions in ClueWeb12 Using Domain Knowledge Inferred from The Open Web
 Better Contextual Suggestions in ClueWeb12 Using Domain Knowledge Inferred from The Open Web Thaer Samar 1, Alejandro Bellogín 2, and Arjen P. de Vries 1 1 Centrum Wiskunde & Informatica, {samar,arjen}@cwi.nl
Better Contextual Suggestions in ClueWeb12 Using Domain Knowledge Inferred from The Open Web Thaer Samar 1, Alejandro Bellogín 2, and Arjen P. de Vries 1 1 Centrum Wiskunde & Informatica, {samar,arjen}@cwi.nl
California Open Online Library for Education & Accessibility
 California Open Online Library for Education & Accessibility COOL4Ed (the California Open Online Library for Education) was created so that faculty can easily find, adopt, utilize, review and/or modify
California Open Online Library for Education & Accessibility COOL4Ed (the California Open Online Library for Education) was created so that faculty can easily find, adopt, utilize, review and/or modify
AUTOMATED STUDENT S ATTENDANCE ENTERING SYSTEM BY ELIMINATING FORGE SIGNATURES
 AUTOMATED STUDENT S ATTENDANCE ENTERING SYSTEM BY ELIMINATING FORGE SIGNATURES K. P. M. L. P. Weerasinghe 149235H Faculty of Information Technology University of Moratuwa June 2017 AUTOMATED STUDENT S
AUTOMATED STUDENT S ATTENDANCE ENTERING SYSTEM BY ELIMINATING FORGE SIGNATURES K. P. M. L. P. Weerasinghe 149235H Faculty of Information Technology University of Moratuwa June 2017 AUTOMATED STUDENT S
Deep Web Content Mining
 Deep Web Content Mining Shohreh Ajoudanian, and Mohammad Davarpanah Jazi Abstract The rapid expansion of the web is causing the constant growth of information, leading to several problems such as increased
Deep Web Content Mining Shohreh Ajoudanian, and Mohammad Davarpanah Jazi Abstract The rapid expansion of the web is causing the constant growth of information, leading to several problems such as increased
Web-Page Indexing Based on the Prioritized Ontology Terms
 Web-Page Indexing Based on the Prioritized Ontology Terms Sukanta Sinha 1,2, Rana Dattagupta 2, and Debajyoti Mukhopadhyay 1,3 1 WIDiCoReL Research Lab, Green Tower, C-9/1, Golf Green, Kolkata 700095,
Web-Page Indexing Based on the Prioritized Ontology Terms Sukanta Sinha 1,2, Rana Dattagupta 2, and Debajyoti Mukhopadhyay 1,3 1 WIDiCoReL Research Lab, Green Tower, C-9/1, Golf Green, Kolkata 700095,
Session 10: Information Retrieval
 INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
INFM 63: Information Technology and Organizational Context Session : Information Retrieval Jimmy Lin The ischool University of Maryland Thursday, November 7, 23 Information Retrieval What you search for!
Outline. Lecture 3: EITN01 Web Intelligence and Information Retrieval. Query languages - aspects. Previous lecture. Anders Ardö.
 Outline Lecture 3: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University February 5, 2013 A. Ardö, EIT Lecture 3: EITN01 Web Intelligence
Outline Lecture 3: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University February 5, 2013 A. Ardö, EIT Lecture 3: EITN01 Web Intelligence
TEXT MINING APPLICATION PROGRAMMING
 TEXT MINING APPLICATION PROGRAMMING MANU KONCHADY CHARLES RIVER MEDIA Boston, Massachusetts Contents Preface Acknowledgments xv xix Introduction 1 Originsof Text Mining 4 Information Retrieval 4 Natural
TEXT MINING APPLICATION PROGRAMMING MANU KONCHADY CHARLES RIVER MEDIA Boston, Massachusetts Contents Preface Acknowledgments xv xix Introduction 1 Originsof Text Mining 4 Information Retrieval 4 Natural
Exam IST 441 Spring 2014
 Exam IST 441 Spring 2014 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
Exam IST 441 Spring 2014 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
An Ontology-Based Information Retrieval Model for Domesticated Plants
 An Ontology-Based Information Retrieval Model for Domesticated Plants Ruban S 1, Kedar Tendolkar 2, Austin Peter Rodrigues 2, Niriksha Shetty 2 Assistant Professor, Department of IT, AIMIT, St Aloysius
An Ontology-Based Information Retrieval Model for Domesticated Plants Ruban S 1, Kedar Tendolkar 2, Austin Peter Rodrigues 2, Niriksha Shetty 2 Assistant Professor, Department of IT, AIMIT, St Aloysius
Taming Text. How to Find, Organize, and Manipulate It MANNING GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS. Shelter Island
 Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
Information Retrieval
 Introduction Information Retrieval Information retrieval is a field concerned with the structure, analysis, organization, storage, searching and retrieval of information Gerard Salton, 1968 J. Pei: Information
Introduction Information Retrieval Information retrieval is a field concerned with the structure, analysis, organization, storage, searching and retrieval of information Gerard Salton, 1968 J. Pei: Information
Graph-based Entity Linking using Shortest Path
 Graph-based Entity Linking using Shortest Path Yongsun Shim 1, Sungkwon Yang 1, Hyunwhan Joe 1, Hong-Gee Kim 1 1 Biomedical Knowledge Engineering Laboratory, Seoul National University, Seoul, Korea {yongsun0926,
Graph-based Entity Linking using Shortest Path Yongsun Shim 1, Sungkwon Yang 1, Hyunwhan Joe 1, Hong-Gee Kim 1 1 Biomedical Knowledge Engineering Laboratory, Seoul National University, Seoul, Korea {yongsun0926,
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri
 Dr. Anwar Alhenshiri") Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Near Neighbor Search in High Dimensional Data (1) Dr. Anwar Alhenshiri Scene Completion Problem The Bare Data Approach High Dimensional Data Many real-world problems Web Search and Text Mining Billions
Information Retrieval and Data Mining Part 1 Information Retrieval
 Information Retrieval and Data Mining Part 1 Information Retrieval 2005/6, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Information Retrieval - 1 1 Today's Question 1. Information
Information Retrieval and Data Mining Part 1 Information Retrieval 2005/6, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Information Retrieval - 1 1 Today's Question 1. Information
Web-page Indexing based on the Prioritize Ontology Terms
 Web-page Indexing based on the Prioritize Ontology Terms Sukanta Sinha 1, 4, Rana Dattagupta 2, Debajyoti Mukhopadhyay 3, 4 1 Tata Consultancy Services Ltd., Victoria Park Building, Salt Lake, Kolkata
Web-page Indexing based on the Prioritize Ontology Terms Sukanta Sinha 1, 4, Rana Dattagupta 2, Debajyoti Mukhopadhyay 3, 4 1 Tata Consultancy Services Ltd., Victoria Park Building, Salt Lake, Kolkata
International Journal of Advance Foundation and Research in Science & Engineering (IJAFRSE) Volume 1, Issue 2, July 2014.
 Volume 1, Issue 2, July 2014.") A B S T R A C T International Journal of Advance Foundation and Research in Science & Engineering (IJAFRSE) Information Retrieval Models and Searching Methodologies: Survey Balwinder Saini*,Vikram Singh,Satish
A B S T R A C T International Journal of Advance Foundation and Research in Science & Engineering (IJAFRSE) Information Retrieval Models and Searching Methodologies: Survey Balwinder Saini*,Vikram Singh,Satish
Information Retrieval CS Lecture 06. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Information Retrieval CS 6900 Lecture 06 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Boolean Retrieval vs. Ranked Retrieval Many users (professionals) prefer
Web Page Similarity Searching Based on Web Content
 Web Page Similarity Searching Based on Web Content Gregorius Satia Budhi Informatics Department Petra Chistian University Siwalankerto 121-131 Surabaya 60236, Indonesia (62-31) 2983455 greg@petra.ac.id
Web Page Similarity Searching Based on Web Content Gregorius Satia Budhi Informatics Department Petra Chistian University Siwalankerto 121-131 Surabaya 60236, Indonesia (62-31) 2983455 greg@petra.ac.id