Information Retrieval
|
|
|
- Susan Gregory
- 6 years ago
- Views:
Transcription
1 Information Retrieval Additional Reference Introduction to Information Retrieval, Manning, Raghavan and Schütze, online book:
2 Why Study Information Retrieval? Google Searches billions of pages Gives back personalised results in < 1 second Worth $200,000,000,000 Siri, etc IR is increasingly blending into IE IR uses very fast technology, so is a filter for performing IE at web scale First, retrieve Relevant Documents Second, Analyse these to find relevant information
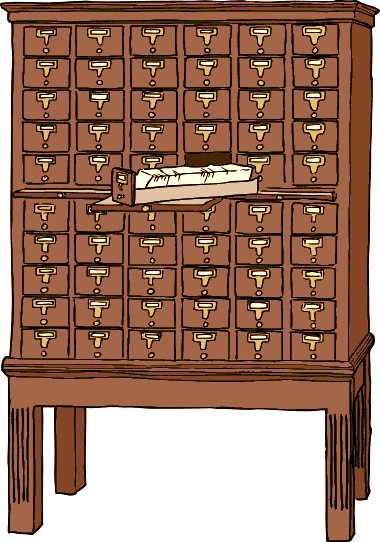
3 Library Index Card

4 Library Index Card
5 Organising documents Fields associated with a document Author, Title, Year, Publisher, Number of pages, etc. Subject Areas Curated by Librarians Creating a classification scheme for all the books in a library is a lot of work How do you search?
6
7 Search Can you search on more than one field? You could use different card collections ordered by each search field Field1: Author Field2: Title Field3: Subject
8 Edge-notched Cards (1896)
9 Key Notions Terms Values assigned to fields for each document E.g. Fields, Author, Title, Subject Index Terms Terms that have been indexed on Query Index Terms that can be combined by boolean logic operators: AND, OR, NOT Retrieval Finding documents that match query
10 Edge-notched Cards (ALASKA or GREENLAND) and NATURE Put pin through NATURE Put pin through ALASKA Collect the cards that fall out Remove ALASKA Pin Put pin through GREENLAND Collect cards that fall out
11 Boolean Search Very little has changed for Information Retrieval over closed document collections Documents labeled with terms from a domain-specific ontology Search with boolean operators permitted over these terms
12 MESH: Medical Subject Headings C11 Eye Diseases C11.93 Asthenopia C Conjunctival Diseases C Conjunctival Neoplasms C Conjunctivitis C Conjunctivitis, Allergic» C Trachoma C Pterygium C Xerophthalmia...
13 ACM Classification for CS B Hardware B.3 Memory structures B.3.1 Semiconductor Memories Dynamic memory (DRAM) Read-only memory (ROM) Static memory (SRAM) B.3.2 Design Styles B.3.3 Performance Analysis Simulation Worst-case analysis
14 Limitations Manual effort by trained catalogers: required to create classification scheme and for annotation of documents with subject classes (concepts) Users need to be aware of subject classes BUT high precision searches works well for closed collections of documents (libraries, etc.)
15 The Internet NOT a closed collection Billions of webpages Documents change on daily basis Not possible to index or search by manually constructed subject classes How does Indexing work? How does Search work?
16 Simple Indexing Model Bag-of-Words Documents and queries are represented as a bag of words Ignore order of words Ignore morphology/syntax (cat vs cats etc) Just count the number of matches between words in document and query This already works rather well!
17 Vector Space Model Ranks Documents for relevance to query Documents and queries are vectors What do vectors look like? How do you compute relevance?
18 Term Frequency D1) Athletes face dope raids: UK dope body. D2) Athletes urged to snitch on dopers at Olympics. Q) Athletes dope Olympics Athlete s face dope raids UK body Olympi cs urged snitch dopers at to on D D Q Q. D1 = 3 (Athletes + 2*dope) Q. D2 = 2 (Athletes + Olympics)
19 Similarity Metrics Each Cell is the number of times the word occurs in the document or query(simplification, more later...) Doc1 Doc2 Doc3 DocN Query Term1 ct 1 1 ct 1 2 ct 1 3 ct 1 N q 1 Term2 ct 2 1 ct 2 2 ct 2 3 ct 2 N q 2... TermM ct M 1 ct M 2 ct M 3 ct M N q M
20 Similarity Metrics Dot Product Sim DOC_N,QUERY = DOC_N. QUERY ct = 1n q 1 +ct 2n q ct mn q m ct = jn q j j But, there can be a large dot product just because documents are very long, so normalise by lengths Cosine of vectors
21 Comparison Metrics Cosine (Q,D)= Q.D / Q D Number between 0 and 1 Cosine of angles between Document and Query vectors (diagram for M=3)
22 Problems? D1) Athletes face dope raids: UK dope body. D2) Athletes urged to snitch on dopers at Olympics. Q) Athletes dope Olympics But both documents are about the London Olympics and about doping UK, Olympics London Olympics, dopers dope, etc. Indexing on words, not subject classes (concepts)
23 Problems? Dimensions are not independent Drug and Dope are closer together than Dope and London Apache could mean the server, the helicopter or the tribe. These should be different dimensions Therefore, the cosine is not necessarily an accurate reflection of similarity
24 Index terms What makes a good index term? The term should describe some aspect of the document The term should not be generic enough that it also describes all the other documents in the collection A good index term distinguishes a document from the rest of the collection
25 Text Coverage Coverage with N most frequent words 1 5% (the) 10 42% (the, and, a, he, but...) % % % Most frequent words are not informative! Least frequent words are typos or too specialised
26 Inverse Document Frequncy In a vector model, different words should have different weights Search for Query: Tom and Jerry Match on documents with Tom or Jerry should count for more than and The more documents a word appears in, the less is its use as an index term Documents are characterised by words which are relatively rare in other docs
27 Inverted Document Frequency Numerator = number of Documents in collection Denominator = number of documents containing term t i idf i =log ( D d :t i d )
28 tf*idf Normalise term frequency by length of document: (term i and document j) tf i,j = n i,j / k n k,j idf i = log ( D / {d:t i d} ) tf*idf i,j = tf i,j * idf i tf*idf is high for a term in a document if: its frequency in the document is high and its frequency in rest of collection is low


29 Cheating Hidden text Keyword Stuffing
30 Cheating the system Indexing done by algorithm, not humans No control over documents in collection Websites try to show up at the top of a search How to identify reliable websites?
31 Linear Algebra Revision Vectors are One-Dimensional Matrices X= [x 0 x 1 x 2... x n ] X = length of X = sqrt(x x 2 1 +x x n 2) = sqrt( Σ i x 2 i ) Vectors are used to represent coordinates in n-dimensional space
32 Scalar Multiplication Two vectors can be multiplied using dot product (also called scalar product) to give a scalar number. X= [x 0 x 1 x 2... x n ] Y= [y 0 y 1 y 2... y n ] X. Y = x 0 y 0 + x 1 y 1 + x 2 y x n y n = Σ i x i y i
33 Scalar Multiplication Two vectors can be multiplied using dot product (also called scalar product) to give a scalar number. X= [ ] Y= [ ] X Y X.Y = X.Y = Length of Projection of X on Y Length of Y
34 Geometric Interpretation A.A = A 2 B.B = B 2 A.B = A B cos(θ) cos(0)=1 cos(90)=0 A A Cosine function is a similarity metric θ B B
35 Vector Product Vector Product is also called cross product A m n n p = C m p 2 [1 5] = C ij = Row i. Column j Rows of C are Rows of B multiplied by scalar value from A Columns of C are columns of A multiplied by scalar value from B

36
37 Problems with Term Counts For the term IBM, how do you distinguish IBM's home page (mostly graphical; IBM occurs only a few times in the html) IBM's copyright page (IBM occurs over 100 times) A Rival's spam page (Arbitrarily large term count for IBM)
38 Hyperlinks for search Web as a graph Anchor text pointing to page B provides a description of B A Hyperlink from page A to B is a recommendation or endorsement of B Ignore Internal links? IBM computers IBM Corporation International Business Machines IBM.com
39 Links as recommendations PageRank (Brin and Page, 1998) A link from A to B is a recommendation of B Think of science Highly cited papers are considered of higher quality Backlinks are like citations But webpages aren't reviewed, so how do we know the citer A is reliable? By counting links to A of course!
40 PageRank Consider a random surfer - Clicks on links at random A 1/3 1/3 B 1/1 E 1/3 D C 1/2 1/2 F Probability of following a link
41 PageRank If you continue this random walk You will visit some pages more frequently than others These are pages with lots of links from other pages with lots of links PageRank: Pages visited more often in a random walk are more important (reliable)
42 Teleporting What if the random surfer reaches a page with no hyperlinks? Teleport: the surfer jumps from a page to any other page in the web graph at random If there are N pages in the web graph, teleporting takes the surfer to each node with probability 1/N Use teleport operation if No outgoing links from node?» With probabilty α = 1 Otherwise with some probability 0 < α < 1
43 Need for Teleporting To avoid loops where you are forced to keep visiting the same sites in the random walk
44 Steady State Given this model of a random surfer The surfer spends a fixed fraction of the time at each page that depends on The hyperlink structure of the web The value of (usually 0.1) PageRank of page : fraction of the time spent at page
45 PageRank Computation Represent Web as Adjacency matrix Adj(i,j) = 1 iff there is a link from i to j Adj(i,j) = 0 iff there is no link from i to j C A B Adj = A B C A B C
46 Transition Probabilities Divide each 1 in A by number of 1s in Row (probability of clicking on link to that page) Probability of following a link C A B 0 1/2 1/2 1/ /1 0 0
47 Transition Probabilities Lets consider teleport probability α = ½, N=3 3) Multiply cells by ½ (1-α, probability of not teleporting) 4) Add 1/6 = (α/n, probability of teleporting to that page ) to every cell Transition Probabilities C A B P = 1/6 1/4+1/6=5/12 1/4+1/6=5/12 1/2+1/6=2/3 1/6 1/6 1/2+1/6=2/3 1/6 1/6
48 Starting State Imaging, surfer starts at page B At beginning, x_0 = [0, 1, 0] Vectors x_n show proportion of time spent on pages A, B, C at time n At step one, x_1=x_0 P =[0,1,0] 1/6 5/12 5/12 2/3 1/6 1/6 2/3 1/6 1/6 X_1 = [2/3, 1/6, 1/6] 0*5/12 + 1*1/6 + 0*1/6 = 1/6
49 Iteration 2 At step one, x_1 = [2/3, 1/6, 1/6] At step 2, x_2 = x_1 P = [ 2/3, 1/6, 1/6 ] 1/6 5/12 5/12 2/3 1/6 1/6 2/3 1/6 1/6 X_2 = [2/18+2/18+2/18, 10/36+1/36+1/36, 10/36+1/36+1/36 ] = [1/3, 1/3, 1/3 ] 2/3*5/12 + 1/6*1/6 + 1/6 *1/6 =1/3
50 Iterating... A B C x_ x_1 2/3 1/6 1/6 x_2 1/3 1/3 1/3 x_3 1/2 1/4 1/4 x_4 5/12 7/24 7/ X = 4/9 5/18 5/18
51 Example Which sites have low / high pagerank? D0 D1 D2 D5 D6 D3 D4
52 Example ( = 0.14) =[ 0.05, 0.04, 0.11, 0.25, 0.21, 0.04, 0.31] D0=0.05 D1=0.04 D2=0.11 D5=0.04 D6=0.31 D3=0.25 D4=0.21
53 Properties of Page Rank New pages have to acquire Page Rank Either convince lots of sites to link to you Or convince a few high-pagerank sites Page Rank can change very fast One link on Yahoo or the BBC is enough Spamming PageRank costs money Need to create huge number of sites Google never sells PageRank
54 Web Search in a nutshell Ranking Documents for a Query Vector similarity: Cosine (Q, D) Terms from document and anchor text Terms normalised using tf*idf PageRank Independent of query: Property of Graph Measure of reliability: Collaborative trust Has nothing to do with how often real users click on links. The random user was only used to calculate a property of the graph
55 Topics not covered... Personalisation of search Increasingly IR takes into account your search history to personalise IR to your needs and interests. IR also takes into account usage data to identify: What links others clicked on for similar search queries, etc.
56 Social IR Performing IR on Social Networks searching twitter, etc Using Social Networks for IR adding collaborative aspects to web search
57 Social Model of IR (Diagram by Sebastian Marius Kirsch)
58 Features of Social IR Individuals appear in two roles: information producers and information consumers Queries and documents are essentially interchangeable Queries and/or documents may be used to model an information need or an area of expertise. Most systems will use only some of the relations in the model For a social IR systems, modelling relations between individuals is mandatory
59 Information Spaces Graph of Users Graph of Documents
60 Information Spaces Users follows/is followed by others on twitter, friends on facebook etc. User writes or views Documents
61 Social Graph Algorithms PageRank Can be used to judge reliability in same manner Tweeter is reliable if retweeted by other reliable tweeters
62 How Google ranks tweets Tweets: 140-character microblog posts sent out by Twitter members The key is to identify "reputed followers," Twitterers "follow" the comments of other Twitterers they've selected, and are themselves "followed." If lots of people follow you, and then you follow someone-- then even though this [new person] does not have lots of followers, his tweet is deemed valuable One user following another in social media is analogous to one page linking to another on the Web. Both are a form of recommendation...
63 Social Graph Algorithms PageRank for identifying authorities Not a new idea Has been used to identify most influential scientists based on citation networks.
64 Pagerank for Social IR Calculate PageRank for each User i = Π i Based on who is following whom PageRank for each Document j = Π j Based on which document links to which If User i wrote Document j, then: reliability of j is some combination of Π i and Π j
65 Collaborative Filtering for IR In addition to reliability, you can filter search results using friend networks 5.7 degrees of separation on Facebook Rerank search results to recommend documents viewed by friends, or people you follow, etc.
66 Facebook Graph Search Restaurants liked by my Italian friends in Aberdeen Filter friends by country (Italy) and Location (Aberdeen) Only use ratings by these friends Which restaurants are liked by the locals? If in Sofia, Find Restaurants in Sofia Only use ratings by Facebook users living in Sofia Pictures of Jane Look for photos of people called Jane, starting with my friends, Janes who went to my school, my university, are friends of my friends, etc. Filter out photos I don't have permission to view
Lec 8: Adaptive Information Retrieval 2
 Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Web consists of web pages and hyperlinks between pages. A page receiving many links from other pages may be a hint of the authority of the page
 Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
Information Retrieval. Lecture 11 - Link analysis
 Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Brief (non-technical) history
 history") Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Proximity Prestige using Incremental Iteration in Page Rank Algorithm
 Indian Journal of Science and Technology, Vol 9(48), DOI: 10.17485/ijst/2016/v9i48/107962, December 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Proximity Prestige using Incremental Iteration
Indian Journal of Science and Technology, Vol 9(48), DOI: 10.17485/ijst/2016/v9i48/107962, December 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Proximity Prestige using Incremental Iteration
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
COMP Page Rank
 COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Lecture #3: PageRank Algorithm The Mathematics of Google Search
 Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
How to organize the Web?
 How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Searching the Web [Arasu 01]
![Searching the Web [Arasu 01]](/thumbs/74/70312179.jpg "Searching the Web [Arasu 01]") Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
F. Aiolli - Sistemi Informativi 2007/2008. Web Search before Google
 Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
Web search before Google. (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.)
, The PageRank Citation Ranking: Bringing Order to the Web.)") ' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Link Analysis. Hongning Wang
 Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 7: Information Retrieval II. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Web Search. Lecture Objectives. Text Technologies for Data Science INFR Learn about: 11/14/2017. Instructor: Walid Magdy
 Text Technologies for Data Science INFR11145 Web Search Instructor: Walid Magdy 14-Nov-2017 Lecture Objectives Learn about: Working with Massive data Link analysis (PageRank) Anchor text 2 1 The Web Document
Text Technologies for Data Science INFR11145 Web Search Instructor: Walid Magdy 14-Nov-2017 Lecture Objectives Learn about: Working with Massive data Link analysis (PageRank) Anchor text 2 1 The Web Document
Information Retrieval. CS630 Representing and Accessing Digital Information. What is a Retrieval Model? Basic IR Processes
 CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
CS630 Representing and Accessing Digital Information Information Retrieval: Retrieval Models Information Retrieval Basics Data Structures and Access Indexing and Preprocessing Retrieval Models Thorsten
Network Centrality. Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017
 Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Vannevar Bush. Information Retrieval. Prophetic: Hypertext. Historic Vision 2/8/17
 Information Retrieval Vannevar Bush Director of the Office of Scientific Research and Development (1941-1947) Vannevar Bush,1890-1974 End of WW2 - what next big challenge for scientists? 1 Historic Vision
Information Retrieval Vannevar Bush Director of the Office of Scientific Research and Development (1941-1947) Vannevar Bush,1890-1974 End of WW2 - what next big challenge for scientists? 1 Historic Vision
Motivation. Motivation
 COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
COMP 4601 Hubs and Authorities
 COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Social Information Retrieval
 Social Information Retrieval Sebastian Marius Kirsch kirschs@informatik.uni-bonn.de th November 00 Format of this talk about my diploma thesis advised by Prof. Dr. Armin B. Cremers inspired by research
Social Information Retrieval Sebastian Marius Kirsch kirschs@informatik.uni-bonn.de th November 00 Format of this talk about my diploma thesis advised by Prof. Dr. Armin B. Cremers inspired by research
Information Retrieval
 Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Information Retrieval. Lecture 9 - Web search basics
 Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Einführung in Web und Data Science Community Analysis. Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme
 Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 16: Other Link Analysis Paul Ginsparg Cornell University, Ithaca, NY 27 Oct
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 16: Other Link Analysis Paul Ginsparg Cornell University, Ithaca, NY 27 Oct
TODAY S LECTURE HYPERTEXT AND
 LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
Advanced Computer Architecture: A Google Search Engine
 Advanced Computer Architecture: A Google Search Engine Jeremy Bradley Room 372. Office hour - Thursdays at 3pm. Email: jb@doc.ic.ac.uk Course notes: http://www.doc.ic.ac.uk/ jb/ Department of Computing,
Advanced Computer Architecture: A Google Search Engine Jeremy Bradley Room 372. Office hour - Thursdays at 3pm. Email: jb@doc.ic.ac.uk Course notes: http://www.doc.ic.ac.uk/ jb/ Department of Computing,
Unit VIII. Chapter 9. Link Analysis
 Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Representation/Indexing (fig 1.2) IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s
 IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s") Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Information Retrieval
 Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Agenda. Math Google PageRank algorithm. 2 Developing a formula for ranking web pages. 3 Interpretation. 4 Computing the score of each page
 Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Centralities (4) By: Ralucca Gera, NPS. Excellence Through Knowledge
 By: Ralucca Gera, NPS. Excellence Through Knowledge") Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
1 Starting around 1996, researchers began to work on. 2 In Feb, 1997, Yanhong Li (Scotch Plains, NJ) filed a
 filed a") !"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
!"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
MAE 298, Lecture 9 April 30, Web search and decentralized search on small-worlds
 MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
Information Retrieval: Retrieval Models
 CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
CS473: Web Information Retrieval & Management CS-473 Web Information Retrieval & Management Information Retrieval: Retrieval Models Luo Si Department of Computer Science Purdue University Retrieval Models
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
CS60092: Informa0on Retrieval
 Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Today s lecture hypertext and links We look beyond the content of documents We begin to look at the hyperlinks between them Address ques)ons
Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Today s lecture hypertext and links We look beyond the content of documents We begin to look at the hyperlinks between them Address ques)ons
2.3 Algorithms Using Map-Reduce
 28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
Graph Algorithms. Revised based on the slides by Ruoming Kent State
 Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
World Wide Web has specific challenges and opportunities
 6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Home Page. Title Page. Page 1 of 14. Go Back. Full Screen. Close. Quit
 Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Page 1 of 14 Retrieving Information from the Web Database and Information Retrieval (IR) Systems both manage data! The data of an IR system is a collection of documents (or pages) User tasks: Browsing
Natural Language Processing
 Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
CSE 494: Information Retrieval, Mining and Integration on the Internet
 CSE 494: Information Retrieval, Mining and Integration on the Internet Midterm. 18 th Oct 2011 (Instructor: Subbarao Kambhampati) In-class Duration: Duration of the class 1hr 15min (75min) Total points:
CSE 494: Information Retrieval, Mining and Integration on the Internet Midterm. 18 th Oct 2011 (Instructor: Subbarao Kambhampati) In-class Duration: Duration of the class 1hr 15min (75min) Total points:
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule
 Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Lecture 27: Learning from relational data
 Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
COMP5331: Knowledge Discovery and Data Mining
 COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
modern database systems lecture 4 : information retrieval
 modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
Generalized Social Networks. Social Networks and Ranking. How use links to improve information search? Hypertext
 Generalized Social Networs Social Networs and Raning Represent relationship between entities paper cites paper html page lins to html page A supervises B directed graph A and B are friends papers share
Generalized Social Networs Social Networs and Raning Represent relationship between entities paper cites paper html page lins to html page A supervises B directed graph A and B are friends papers share
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Link Analysis SEEM5680. Taken from Introduction to Information Retrieval by C. Manning, P. Raghavan, and H. Schutze, Cambridge University Press.
 Link Analysis SEEM5680 Taken from Introduction to Information Retrieval by C. Manning, P. Raghavan, and H. Schutze, Cambridge University Press. 1 The Web as a Directed Graph Page A Anchor hyperlink Page
Link Analysis SEEM5680 Taken from Introduction to Information Retrieval by C. Manning, P. Raghavan, and H. Schutze, Cambridge University Press. 1 The Web as a Directed Graph Page A Anchor hyperlink Page
Information Retrieval. hussein suleman uct cs
 Information Management Information Retrieval hussein suleman uct cs 303 2004 Introduction Information retrieval is the process of locating the most relevant information to satisfy a specific information
Information Management Information Retrieval hussein suleman uct cs 303 2004 Introduction Information retrieval is the process of locating the most relevant information to satisfy a specific information
Web Search Ranking. (COSC 488) Nazli Goharian Evaluation of Web Search Engines: High Precision Search
 Nazli Goharian Evaluation of Web Search Engines: High Precision Search") Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
CS 6320 Natural Language Processing
 CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
CS 6320 Natural Language Processing Information Retrieval Yang Liu Slides modified from Ray Mooney s (http://www.cs.utexas.edu/users/mooney/ir-course/slides/) 1 Introduction of IR System components, basic
Bruno Martins. 1 st Semester 2012/2013
 Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Information Retrieval and Web Search
 Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
Introduction to Information Retrieval
 Introduction to Information Retrieval (Supplementary Material) Zhou Shuigeng March 23, 2007 Advanced Distributed Computing 1 Text Databases and IR Text databases (document databases) Large collections
Introduction to Information Retrieval (Supplementary Material) Zhou Shuigeng March 23, 2007 Advanced Distributed Computing 1 Text Databases and IR Text databases (document databases) Large collections
Indexing: Part IV. Announcements (February 17) Keyword search. CPS 216 Advanced Database Systems
 Keyword search. CPS 216 Advanced Database Systems") Indexing: Part IV CPS 216 Advanced Database Systems Announcements (February 17) 2 Homework #2 due in two weeks Reading assignments for this and next week The query processing survey by Graefe Due next
Indexing: Part IV CPS 216 Advanced Database Systems Announcements (February 17) 2 Homework #2 due in two weeks Reading assignments for this and next week The query processing survey by Graefe Due next
Information Networks: PageRank
 Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 21 Link analysis
 Chapter 21 Link analysis") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 21 Link analysis Content Anchor text Link analysis for ranking Pagerank and variants HITS The Web as a Directed Graph Page A Anchor
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 21 Link analysis Content Anchor text Link analysis for ranking Pagerank and variants HITS The Web as a Directed Graph Page A Anchor
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
CSCI 5417 Information Retrieval Systems! What is Information Retrieval?
 CSCI 5417 Information Retrieval Systems! Lecture 1 8/23/2011 Introduction 1 What is Information Retrieval? Information retrieval is the science of searching for information in documents, searching for
CSCI 5417 Information Retrieval Systems! Lecture 1 8/23/2011 Introduction 1 What is Information Retrieval? Information retrieval is the science of searching for information in documents, searching for
DSCI 575: Advanced Machine Learning. PageRank Winter 2018
 DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
Calculating Web Page Authority Using the PageRank Algorithm. Math 45, Fall 2005 Levi Gill and Jacob Miles Prystowsky
 Calculating Web Page Authority Using the PageRank Algorithm Math 45, Fall 2005 Levi Gill and Jacob Miles Prystowsky Introduction In 1998 a phenomenon hit the World Wide Web: Google opened its doors. Larry
Calculating Web Page Authority Using the PageRank Algorithm Math 45, Fall 2005 Levi Gill and Jacob Miles Prystowsky Introduction In 1998 a phenomenon hit the World Wide Web: Google opened its doors. Larry
Recent Researches on Web Page Ranking
 Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
SEO and Monetizing The Content. Digital 2011 March 30 th Thinking on a different level
 SEO and Monetizing The Content Digital 2011 March 30 th 2011 Getting Found and Making the Most of It 1. Researching target Audience (Keywords) 2. On-Page Optimisation (Content) 3. Titles and Meta Tags
SEO and Monetizing The Content Digital 2011 March 30 th 2011 Getting Found and Making the Most of It 1. Researching target Audience (Keywords) 2. On-Page Optimisation (Content) 3. Titles and Meta Tags
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material.
 Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
The Ultimate Digital Marketing Glossary (A-Z) what does it all mean? A-Z of Digital Marketing Translation
 what does it all mean? A-Z of Digital Marketing Translation") The Ultimate Digital Marketing Glossary (A-Z) what does it all mean? In our experience, we find we can get over-excited when talking to clients or family or friends and sometimes we forget that not everyone
The Ultimate Digital Marketing Glossary (A-Z) what does it all mean? In our experience, we find we can get over-excited when talking to clients or family or friends and sometimes we forget that not everyone
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group Simone.Teufel@cl.cam.ac.uk Lent
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group Simone.Teufel@cl.cam.ac.uk Lent
Boolean Model. Hongning Wang
 Boolean Model Hongning Wang CS@UVa Abstraction of search engine architecture Indexed corpus Crawler Ranking procedure Doc Analyzer Doc Representation Query Rep Feedback (Query) Evaluation User Indexer
Boolean Model Hongning Wang CS@UVa Abstraction of search engine architecture Indexed corpus Crawler Ranking procedure Doc Analyzer Doc Representation Query Rep Feedback (Query) Evaluation User Indexer
CPSC 340: Machine Learning and Data Mining. Ranking Fall 2016
 CPSC 340: Machine Learning and Data Mining Ranking Fall 2016 Assignment 5: Admin 2 late days to hand in Wednesday, 3 for Friday. Assignment 6: Due Friday, 1 late day to hand in next Monday, etc. Final:
CPSC 340: Machine Learning and Data Mining Ranking Fall 2016 Assignment 5: Admin 2 late days to hand in Wednesday, 3 for Friday. Assignment 6: Due Friday, 1 late day to hand in next Monday, etc. Final:
Introduction To Graphs and Networks. Fall 2013 Carola Wenk
 Introduction To Graphs and Networks Fall 203 Carola Wenk On the Internet, links are essentially weighted by factors such as transit time, or cost. The goal is to find the shortest path from one node to
Introduction To Graphs and Networks Fall 203 Carola Wenk On the Internet, links are essentially weighted by factors such as transit time, or cost. The goal is to find the shortest path from one node to
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Link analysis in web IR CE-324: Modern Information Retrieval Sharif University of Technology
 Link analysis in web IR CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2013 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Link analysis in web IR CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2013 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Authoritative K-Means for Clustering of Web Search Results
 Authoritative K-Means for Clustering of Web Search Results Gaojie He Master in Information Systems Submission date: June 2010 Supervisor: Kjetil Nørvåg, IDI Co-supervisor: Robert Neumayer, IDI Norwegian
Authoritative K-Means for Clustering of Web Search Results Gaojie He Master in Information Systems Submission date: June 2010 Supervisor: Kjetil Nørvåg, IDI Co-supervisor: Robert Neumayer, IDI Norwegian
Social media to promote
 Social media to promote your business Fun social media facts The UK has the highest proportion of social networking users, with 52% In the UK, social media addiction is considered a disease - you can get
Social media to promote your business Fun social media facts The UK has the highest proportion of social networking users, with 52% In the UK, social media addiction is considered a disease - you can get
Mathematical Analysis of Google PageRank
 INRIA Sophia Antipolis, France Ranking Answers to User Query Ranking Answers to User Query How a search engine should sort the retrieved answers? Possible solutions: (a) use the frequency of the searched
INRIA Sophia Antipolis, France Ranking Answers to User Query Ranking Answers to User Query How a search engine should sort the retrieved answers? Possible solutions: (a) use the frequency of the searched
PageRank. CS16: Introduction to Data Structures & Algorithms Spring 2018
 PageRank CS16: Introduction to Data Structures & Algorithms Spring 2018 Outline Background The Internet World Wide Web Search Engines The PageRank Algorithm Basic PageRank Full PageRank Spectral Analysis
PageRank CS16: Introduction to Data Structures & Algorithms Spring 2018 Outline Background The Internet World Wide Web Search Engines The PageRank Algorithm Basic PageRank Full PageRank Spectral Analysis
CS 6604: Data Mining Large Networks and Time-Series
 CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
Link analysis in web IR CE-324: Modern Information Retrieval Sharif University of Technology
 Link analysis in web IR CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Link analysis in web IR CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
University of Virginia Department of Computer Science. CS 4501: Information Retrieval Fall 2015
 University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 2:00pm-3:30pm, Tuesday, December 15th Name: ComputingID: This is a closed book and closed notes exam. No electronic
University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 2:00pm-3:30pm, Tuesday, December 15th Name: ComputingID: This is a closed book and closed notes exam. No electronic
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Link Structure Analysis
 Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score
Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score