Big Data Analytics CSCI 4030
|
|
|
- Vernon Booker
- 6 years ago
- Views:
Transcription

1



2 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising Decision Trees Association Rules Dimensional ity reduction Spam Detection Queries on streams Perceptron, knn Duplicate document detection 2

3 A graph is a representation of a set of objects (e.g., users, computers, ) where some pairs of objects are connected by links Objects are called nodes or vertices Links are called edges The edges may be directed or undirected 3

4 Facebook social graph 4-degrees of separation [Backstrom-Boldi-Rosa-Ugander-Vigna, 2011] 4

5 Connections between political blogs Polarization of the network [Adamic-Glance, 2005] 5

6 Citation networks and Maps of science [Börner et al., 2012] 6
7 domain2 domain1 router domain3 Internet 7




8 Web as a directed graph: Nodes: Webpages Edges: Hyperlinks I teach a class on Databases. CSCI3030: Classes are in the UA building Computer Science Department at UOIT UOIT 8

9 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, 9 Web as a directed graph: Nodes: Webpages Edges: Hyperlinks I teach a class on Databases. CSCI 3030: Classes are in the UA building Computer Science Department at UOIT UOIT
10 10

11 How to make the Web accessible? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval investigates: Find relevant docs in a small and trusted set Newspaper articles, Patents, etc. But: Web is huge, full of untrusted documents, random things, web spam, etc. 11
12 2 challenges of web search: (1) Web contains many sources of information Who to trust? Trick: Trustworthy pages may point to each other! (2) What is the best answer to query newspaper? No single right answer Trick: Pages that actually know about newspapers might all be pointing to many newspapers 12
13 All web pages are not equally important vs. Let s rank the pages by the link structure! 13
14 We will cover the following Link Analysis approaches for computing importances of nodes in a graph: Page Rank Topic-Specific (Personalized) Page Rank Web Spam Detection Algorithms 14

15
16 Idea: Links as votes Page is more important if it has more links In-coming links? Out-going links? Think of in-links as votes: has 23,400 in-links has 1 in-link Are all in-links are equal? Links from important pages count more Recursive question! 16
17 A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F
18 Each link s vote is proportional to the importance of its source page If page j with importance r j has n out-links, each link gets r j / n votes Page j s own importance is the sum of the votes on its in-links r j = r i /3+r k /4 i j r j /3 k r i /3 rk /4 r j /3 r j /3 18
19 A vote from an important page is worth more A page is important if it is pointed to by other important pages Define a rank r j for page j r j i j r i d i d i out-degree of node i a/2 a The web in 1839 a/2 y/2 y y/2 m Flow equations: r y = r y /2 + r a /2 r a = r y /2 + r m r m = r a /2 m 19
20 3 equations, 3 unknowns, no constants No unique solution Flow equations: r y = r y /2 + r a /2 r a = r y /2 + r m r m = r a /2 Additional constraint forces uniqueness: r y + r a + r m = 1 Solution: r y = 2 5, r a = 2 5, r m = 1 5 Gaussian elimination method (an algorithm for solving linear equations) works for small examples, but we need a better method for large web-size graphs We need a new formulation! 20
21 Stochastic adjacency matrix M Let page i has d i out-links If i j, then M ji = 1 d i else M ji = 0 M is a column stochastic matrix Columns sum to 1 Rank vector r: vector with an entry per page r i is the importance score of page i i r i = 1 The flow equations can be written r r = M r j i j r i d i 21
22 a y m y a m y ½ ½ 0 a ½ 0 1 m 0 ½ 0 r = M r r y = r y /2 + r a /2 r a = r y /2 + r m r m = r a /2 y ½ ½ 0 y a = ½ 0 1 a m 0 ½ 0 m 22
23 Remember the flow equation: rj Flow equation in the matrix form M r = r Suppose page i links to 3 pages, including j (d i = 3) i r i i j d i 1/3 j. r i = r j M. r = r 23
24 The flow equations can be written r = M r Just a Definition x is an eigenvector with the corresponding eigenvalue λ if: Ax = λx So the rank vector r is an eigenvector of the stochastic web matrix M Largest eigenvalue of M is 1 since M is column stochastic (with non-negative entries) We can now efficiently solve for r! The method is called Power iteration 24
25 Given a web graph with n nodes, where the nodes are pages and edges are hyperlinks Power iteration: a simple iterative scheme Suppose there are N web pages Initialize: r (0) = [1/N,.,1/N] T Iterate: r (t+1) = M r (t) Stop when r (t+1) r (t) < r ( t 1) j i j ( t) i r d d i. out-degree of node i i 25
26 Power Iteration: r (0) = [1/N,.,1/N] T r (t+1) = M r (t) a y m y a m y ½ ½ 0 a ½ 0 1 m 0 ½ 0 r (t+1) r (t) 1 < r y = r y /2 + r a /2 Example: r a = r y /2 + r m r m = r a /2 r y 1/3 1/3 5/12 9/24 6/15 r a = 1/3 3/6 1/3 11/24 6/15 r m 1/3 1/6 3/12 1/6 3/15 Iteration 0, 1, 2, 26
27 Power iteration: r (1) = M r (0) r (2) = M r 1 = M Mr 1 = M 2 r 0 r (3) = M r 2 = M M 2 r 0 = M 3 r 0 Claim: Sequence M r 0, M 2 r 0, M k r 0, will converge (under which conditions?!) 27

28
29 r ( t 1) j i j r ( t) i d i or equivalently r Mr Does this converge? Does it converge to what we want? Are results reasonable? 29
30 2 problems: (1) Some pages are dead ends (have no out-links) Such pages cause importance to leak out Dead end (2) Spider traps: (all out-links are within the group) And eventually spider traps absorb all importance 30
31 Power Iteration: y y a m y ½ ½ 0 a m a ½ 0 0 m 0 ½ 1 Example: m is a spider trap r y = r y /2 + r a /2 r a = r y /2 r y 1/3 2/6 3/12 5/24 0 r a = 1/3 1/6 2/12 3/24 0 r m 1/3 3/6 7/12 16/24 1 r m = r a /2 + r m Iteration 0, 1, 2, All the PageRank score gets trapped in node m. 31
32 The Google solution for spider traps: At each time step, the random surfer has two options With probability, follow a link at random With probability 1-, jump to some random page Common values for are in the range 0.8 to 0.9 Surfer will teleport out of spider trap within a few time steps y y a m a m 32

33 Power Iteration: y y a m y ½ ½ 0 a m a ½ 0 0 m 0 ½ 0 Example: r y = r y /2 + r a /2 r a = r y /2 r m = r a /2 r y 1/3 2/6 3/12 5/24 0 r a = 1/3 1/6 2/12 3/24 0 r m 1/3 1/6 1/12 2/24 0 Iteration 0, 1, 2, Here the PageRank leaks out since the matrix is not stochastic. 33
34 Teleports: Follow random teleport links with probability 1.0 from dead-ends Adjust matrix accordingly y y a m a m y a m y ½ ½ 0 a ½ 0 0 m 0 ½ 0 y a m y ½ ½ ⅓ a ½ 0 ⅓ m 0 ½ ⅓ 34
35 Why are dead-ends and spider traps a problem and why do teleports solve the problem? Spider-traps are not a problem, but with traps PageRank scores are not what we want Solution: Never get stuck in a spider trap by teleporting out of it in a finite number of steps Dead-ends are a problem The matrix is not column stochastic so our initial assumptions are not met Solution: Make matrix column stochastic by always teleporting when there is nowhere else to go 35
36 Google s solution that does it all: At each step, random surfer has two options: With probability, follow a link at random With probability 1-, jump to some random page PageRank equation [Brin-Page, 98] r j = i j β r i d i + (1 β) 1 N d i : out-degree of node i N: total number of webpages 36
37 PageRank equation [Brin-Page, 98] r j = i j β r i d i The Google Matrix A: A = β M + 1 β + (1 β) 1 N 1 N N N [1/N] NxN N by N matrix where all entries are 1/N We have a recursive equation: r = A r And the Power method still works! What is? In practice =0.8,0.9 (make 5 steps on avg., jump) 37

38 y 7/15 M 1/2 1/ / /2 1 [1/N] NxN 1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3 a m 13/15 y 7/15 7/15 1/15 a 7/15 1/15 1/15 m 1/15 7/15 13/15 A y a = m 1/3 1/3 1/ /33 5/33 21/33 38

39
40 Key step is matrix-vector multiplication r new = A r old Easy if we have enough main memory to hold A, r old, r new Say N = 1 billion pages We need 4 bytes for each entry (say) 2 billion entries for vectors, approx 8GB Matrix A has N 2 entries is a large number! Google invented MapReduce and Hadoop mainly to calculate PageRank 40
41 Measures generic popularity of a page Biased against topic-specific authorities Solution: Topic-Specific PageRank (next) Sensitive to Link spam Artificial link topographies created in order to boost page rank Solution: TrustRank 41
42
43 Instead of generic popularity, can we measure popularity within a topic? Example: Query Trojan wants different pages depending on whether you are interested in sports, history and computer security Goal: Evaluate Web pages not just according to their popularity, but by how close they are to a particular topic, e.g. sports or history Allows search queries to be answered based on interests of the user 43
44 Random walker has a small probability of teleporting at any step Teleport can go to: Standard PageRank: Any page with equal probability To avoid dead-end and spider-trap problems Topic Specific PageRank: A topic-specific set of relevant pages (teleport set) Idea: Bias the random walk When walker teleports, she pick a page from a set S S contains only pages that are relevant to the topic E.g., Open Directory (DMOZ) pages for a given topic/query 44
45 To make this work all we need is to update the teleportation part of the PageRank formulation: A ij = β M ij + (1 β)/ S if i S β M ij + 0 otherwise A is stochastic! We weighted all pages in the teleport set S equally Could also assign different weights to pages! Compute as for regular PageRank: Multiply by M, then add a vector 45
46 Suppose S = {1}, = 0.8 Node Iteration stable S={1}, β=0.90: r=[0.17, 0.07, 0.40, 0.36] S={1}, β=0.8: r=[0.29, 0.11, 0.32, 0.26] S={1}, β=0.70: r=[0.39, 0.14, 0.27, 0.19] S={1,2,3,4}, β=0.8: r=[0.13, 0.10, 0.39, 0.36] S={1,2,3}, β=0.8: r=[0.17, 0.13, 0.38, 0.30] S={1,2}, β=0.8: r=[0.26, 0.20, 0.29, 0.23] S={1}, β=0.8: r=[0.29, 0.11, 0.32, 0.26] 46
47 Create different PageRanks for different topics The 16 DMOZ top-level categories: arts, business, sports, Which topic ranking to use? User can pick from a menu Classify query into a topic Can use the context of the query E.g., query is launched from a web page talking about a known topic History of queries e.g., basketball followed by Jordan User context, e.g., user s bookmarks, 47
48
49 Spamming: Any deliberate action to boost a web page s position in search engine results, incommensurate with page s real value Spam: Web pages that are the result of spamming This is a very broad definition SEO industry might disagree! SEO = search engine optimization Approximately 10-15% of web pages are spam 49
50 Early search engines: Crawl the Web Index pages by the words they contained Respond to search queries (lists of words) with the pages containing those words Early page ranking: Attempt to order pages matching a search query by importance First search engines considered: (1) Number of times query words appeared (2) Prominence of word position, e.g. title, header 50
51 As people began to use search engines, those with commercial interests tried to exploit search engines Example: Shirt-seller might pretend to be about movies Techniques for achieving high relevance/importance for a web page 51
52 How do you make your page appear to be about movies? (1) Add the word movie 1,000 times to your page Set text color to the background color, so only search engines would see it (2) Or, run the query movie on your target search engine See what page came first in the listings Copy it into your page, make it invisible These and similar techniques are term spam 52
53 1) Believe what people say about you, rather than what you say about yourself Use words in the anchor text (words that appear underlined to represent the link) and its surrounding text 2) PageRank as a tool to measure the importance of Web pages 53

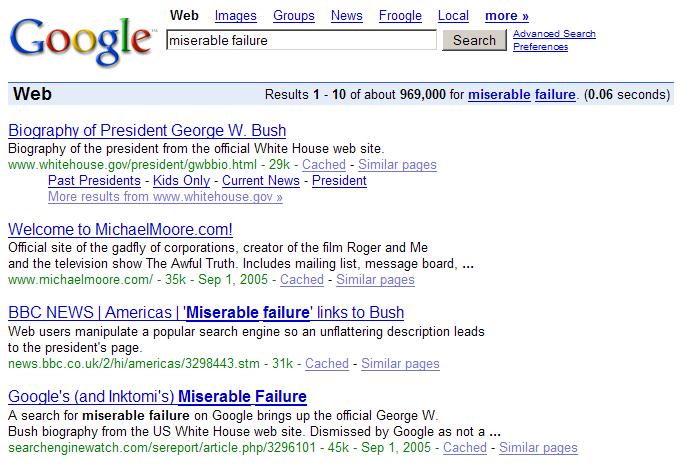
54 54

55 SPAM FARMING J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, 55

56 Once Google became the dominant search engine, spammers began to work out ways to fool Google Spam farms were developed to concentrate PageRank on a single page Link spam: Creating link structures that boost PageRank of a particular page 56

57 Three kinds of web pages from a spammer s point of view Inaccessible pages Accessible pages e.g., blog comments pages spammer can post links to his pages Owned pages Completely controlled by spammer May span multiple domain names 57

58 Accessible Owned Inaccessible 1 t 2 M Millions of farm pages Get as many links from accessible pages as possible to target page t 58

59
60 Combating link spam Detection and blacklisting of structures that look like spam farms Leads to another war hiding and detecting spam farms TrustRank Spam Mass 60
61 Basic principle: Approximate isolation It is rare for a good page to point to a bad (spam) page Choose a set of seed pages that are identified as good the trusted pages Perform a topic-sensitive PageRank with teleport set = trusted pages Propagate trust through links 61
62 Two conflicting considerations: Human has to inspect each seed page, so seed set must be as small as possible Must ensure every good page gets adequate trust rank, so we need to make all good pages reachable from seed set by short paths 62
63 Suppose we want to pick a seed set of k pages How to do that? (1) PageRank: Pick the top k pages by PageRank Theory is that you can t get a bad page s rank really high (2) Use trusted domains whose membership is controlled, like.edu,.mil,.gov 63

64 r p = PageRank of page p r p + = PageRank of p with teleport into trusted pages only Then: What fraction of a page s PageRank comes from spam pages? Spam mass of p = r p r p + r p Pages with high spam mass are spam. Web Trusted set 64
65 Given an example of the Web Compute transition matrix What is the meaning of the transition matrix? Compute Page Rank. 65
66 One way to deal with dead ends is to drop the dead ends from the graph, and also drop their incoming arcs. Doing so may create more dead ends, which have to be dropped, recursively. Apply this method on the dead ends of the following graph and draw the new graph. Compute the transition matrix of the new graph. 66
67 PageRank is an algorithm that assigns a real number, called its PageRank, to each page on the Web. The PageRank of a page is a measure of how important the page is, or how likely it is to be a good response to any search query. 67
68 Dead Ends: A dead end is a Web page with no links out. The presence of dead ends will cause the PageRank of some or all of the pages to go to 0 in the iterative computation 68
69 Spider Traps: A spider trap is a set of nodes that, while they may link to each other, have no links out to other nodes. To counter the effect of spider traps (and of dead ends, if we do not eliminate them), PageRank is normally computed in a way that modifies the simple iterative multiplication by the transition matrix (teleport) 69

70 If we know the queryer is interested in a certain topic, then it makes sense to bias the PageRank in favor of pages on that topic. TrustRank: One way to ameliorate the effect of link spam is to compute a topic-sensitive PageRank called TrustRank, where the teleport set is a collection of trusted pages 70
71 Review slides! Read Chapter 5 from course book. You can find electronic version of the book on Blackboard. 71
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today
 HW3 will be posted today") 3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Introduction to Data Mining
 Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Analysis of Large Graphs: TrustRank and WebSpam
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/6/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 High dim. data Graph data Infinite data Machine
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/6/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 High dim. data Graph data Infinite data Machine
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
How to organize the Web?
 How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Introduction to Data Mining
 Introduction to Data Mining Lecture #10: Link Analysis-2 Seoul National University 1 In This Lecture Pagerank: Google formulation Make the solution to converge Computing Pagerank for very large graphs
Introduction to Data Mining Lecture #10: Link Analysis-2 Seoul National University 1 In This Lecture Pagerank: Google formulation Make the solution to converge Computing Pagerank for very large graphs
Information Networks: PageRank
 Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University
 CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Instead of generic popularity, can we measure popularity within a topic? E.g., computer science, health Bias the random walk When
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Instead of generic popularity, can we measure popularity within a topic? E.g., computer science, health Bias the random walk When
INTRODUCTION TO DATA SCIENCE. Link Analysis (MMDS5)
") INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
Unit VIII. Chapter 9. Link Analysis
 Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
Link Analysis in Web Mining
 Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Introduction In to Info Inf rmation o Ret Re r t ie i v e a v l a LINK ANALYSIS 1
 LINK ANALYSIS 1 Today s lecture hypertext and links We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of
LINK ANALYSIS 1 Today s lecture hypertext and links We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 3 Mutually recursive definition: A hub links to many authorities; An authority is linked to by many hubs. Authorities turn out to be places where information can
Jeffrey D. Ullman Stanford University 3 Mutually recursive definition: A hub links to many authorities; An authority is linked to by many hubs. Authorities turn out to be places where information can
Link Analysis. Chapter PageRank
 Chapter 5 Link Analysis One of the biggest changes in our lives in the decade following the turn of the century was the availability of efficient and accurate Web search, through search engines such as
Chapter 5 Link Analysis One of the biggest changes in our lives in the decade following the turn of the century was the availability of efficient and accurate Web search, through search engines such as
Jeffrey D. Ullman Stanford University/Infolab
 Jeffrey D. Ullman Stanford University/Infolab Spamming = any deliberate action intended solely to boost a Web page s position in searchengine results. Web Spam = Web pages that are the result of spamming.
Jeffrey D. Ullman Stanford University/Infolab Spamming = any deliberate action intended solely to boost a Web page s position in searchengine results. Web Spam = Web pages that are the result of spamming.
CS47300 Web Information Search and Management
 CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Instructor: Dr. Mehmet Aktaş. Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
 Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Instructor: Dr. Mehmet Aktaş Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Web consists of web pages and hyperlinks between pages. A page receiving many links from other pages may be a hint of the authority of the page
 Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
Einführung in Web und Data Science Community Analysis. Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme
 Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
Brief (non-technical) history
 history") Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS
 CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network
Web search before Google. (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.)
, The PageRank Citation Ranking: Bringing Order to the Web.)") ' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
CS435 Introduction to Big Data FALL 2018 Colorado State University. 9/24/2018 Week 6-A Sangmi Lee Pallickara. Topics. This material is built based on,
 FLL 218 olorado State University 9/24/218 Week 6-9/24/218 S435 Introduction to ig ata - FLL 218 W6... PRT 1. LRGE SLE T NLYTIS WE-SLE LINK N SOIL NETWORK NLYSIS omputer Science, olorado State University
FLL 218 olorado State University 9/24/218 Week 6-9/24/218 S435 Introduction to ig ata - FLL 218 W6... PRT 1. LRGE SLE T NLYTIS WE-SLE LINK N SOIL NETWORK NLYSIS omputer Science, olorado State University
CS535 Big Data Fall 2017 Colorado State University 9/5/2017. Week 3 - A. FAQs. This material is built based on,
 S535 ig ata Fall 217 olorado State University 9/5/217 Week 3-9/5/217 S535 ig ata - Fall 217 Week 3--1 S535 IG T FQs Programming ssignment 1 We will discuss link analysis in week3 Installation/configuration
S535 ig ata Fall 217 olorado State University 9/5/217 Week 3-9/5/217 S535 ig ata - Fall 217 Week 3--1 S535 IG T FQs Programming ssignment 1 We will discuss link analysis in week3 Installation/configuration
Lecture #3: PageRank Algorithm The Mathematics of Google Search
 Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Information Retrieval. Lecture 11 - Link analysis
 Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Some Interesting Applications of Theory. PageRank Minhashing Locality-Sensitive Hashing
 Some Interesting Applications of Theory PageRank Minhashing Locality-Sensitive Hashing 1 PageRank The thing that makes Google work. Intuition: solve the recursive equation: a page is important if important
Some Interesting Applications of Theory PageRank Minhashing Locality-Sensitive Hashing 1 PageRank The thing that makes Google work. Intuition: solve the recursive equation: a page is important if important
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/12/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 3/12/2014 Jure
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/12/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 3/12/2014 Jure
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Information Retrieval and Web Search
 Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
Lec 8: Adaptive Information Retrieval 2
 Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
DS504/CS586: Big Data Analytics Graph Mining Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Graph Mining Prof. Yanhua Li Time: 6:00pm 8:50pm R Location: AK232 Fall 2016 Graph Data: Social Networks Facebook social graph 4-degrees of separation [Backstrom-Boldi-Rosa-Ugander-Vigna,
Welcome to DS504/CS586: Big Data Analytics Graph Mining Prof. Yanhua Li Time: 6:00pm 8:50pm R Location: AK232 Fall 2016 Graph Data: Social Networks Facebook social graph 4-degrees of separation [Backstrom-Boldi-Rosa-Ugander-Vigna,
Centralities (4) By: Ralucca Gera, NPS. Excellence Through Knowledge
 By: Ralucca Gera, NPS. Excellence Through Knowledge") Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
COMP Page Rank
 COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
Network Centrality. Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017
 Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Popularity of Twitter Accounts: PageRank on a Social Network
 Popularity of Twitter Accounts: PageRank on a Social Network A.D-A December 8, 2017 1 Problem Statement Twitter is a social networking service, where users can create and interact with 140 character messages,
Popularity of Twitter Accounts: PageRank on a Social Network A.D-A December 8, 2017 1 Problem Statement Twitter is a social networking service, where users can create and interact with 140 character messages,
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data: Part I Instructor: Yizhou Sun yzsun@ccs.neu.edu November 12, 2013 Announcement Homework 4 will be out tonight Due on 12/2 Next class will be canceled
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data: Part I Instructor: Yizhou Sun yzsun@ccs.neu.edu November 12, 2013 Announcement Homework 4 will be out tonight Due on 12/2 Next class will be canceled
A STUDY OF RANKING ALGORITHM USED BY VARIOUS SEARCH ENGINE
 A STUDY OF RANKING ALGORITHM USED BY VARIOUS SEARCH ENGINE Bohar Singh 1, Gursewak Singh 2 1, 2 Computer Science and Application, Govt College Sri Muktsar sahib Abstract The World Wide Web is a popular
A STUDY OF RANKING ALGORITHM USED BY VARIOUS SEARCH ENGINE Bohar Singh 1, Gursewak Singh 2 1, 2 Computer Science and Application, Govt College Sri Muktsar sahib Abstract The World Wide Web is a popular
MAE 298, Lecture 9 April 30, Web search and decentralized search on small-worlds
 MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
Bruno Martins. 1 st Semester 2012/2013
 Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
Pagerank Scoring. Imagine a browser doing a random walk on web pages:
 Ranking Sec. 21.2 Pagerank Scoring Imagine a browser doing a random walk on web pages: Start at a random page At each step, go out of the current page along one of the links on that page, equiprobably
Ranking Sec. 21.2 Pagerank Scoring Imagine a browser doing a random walk on web pages: Start at a random page At each step, go out of the current page along one of the links on that page, equiprobably
Link Analysis in the Cloud
 Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Link Analysis. Hongning Wang
 Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
CS6200 Information Retreival. The WebGraph. July 13, 2015
 CS6200 Information Retreival The WebGraph The WebGraph July 13, 2015 1 Web Graph: pages and links The WebGraph describes the directed links between pages of the World Wide Web. A directed edge connects
CS6200 Information Retreival The WebGraph The WebGraph July 13, 2015 1 Web Graph: pages and links The WebGraph describes the directed links between pages of the World Wide Web. A directed edge connects
Graph and Web Mining - Motivation, Applications and Algorithms PROF. EHUD GUDES DEPARTMENT OF COMPUTER SCIENCE BEN-GURION UNIVERSITY, ISRAEL
 Graph and Web Mining - Motivation, Applications and Algorithms PROF. EHUD GUDES DEPARTMENT OF COMPUTER SCIENCE BEN-GURION UNIVERSITY, ISRAEL Web mining - Outline Introduction Web Content Mining Web usage
Graph and Web Mining - Motivation, Applications and Algorithms PROF. EHUD GUDES DEPARTMENT OF COMPUTER SCIENCE BEN-GURION UNIVERSITY, ISRAEL Web mining - Outline Introduction Web Content Mining Web usage
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
A brief history of Google
 the math behind Sat 25 March 2006 A brief history of Google 1995-7 The Stanford days (aka Backrub(!?)) 1998 Yahoo! wouldn't buy (but they might invest...) 1999 Finally out of beta! Sergey Brin Larry Page
the math behind Sat 25 March 2006 A brief history of Google 1995-7 The Stanford days (aka Backrub(!?)) 1998 Yahoo! wouldn't buy (but they might invest...) 1999 Finally out of beta! Sergey Brin Larry Page
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
PageRank. CS16: Introduction to Data Structures & Algorithms Spring 2018
 PageRank CS16: Introduction to Data Structures & Algorithms Spring 2018 Outline Background The Internet World Wide Web Search Engines The PageRank Algorithm Basic PageRank Full PageRank Spectral Analysis
PageRank CS16: Introduction to Data Structures & Algorithms Spring 2018 Outline Background The Internet World Wide Web Search Engines The PageRank Algorithm Basic PageRank Full PageRank Spectral Analysis
1 Starting around 1996, researchers began to work on. 2 In Feb, 1997, Yanhong Li (Scotch Plains, NJ) filed a
 filed a") !"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
!"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
COMP 4601 Hubs and Authorities
 COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
Proximity Prestige using Incremental Iteration in Page Rank Algorithm
 Indian Journal of Science and Technology, Vol 9(48), DOI: 10.17485/ijst/2016/v9i48/107962, December 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Proximity Prestige using Incremental Iteration
Indian Journal of Science and Technology, Vol 9(48), DOI: 10.17485/ijst/2016/v9i48/107962, December 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Proximity Prestige using Incremental Iteration
Mining The Web. Anwar Alhenshiri (PhD)
") Mining The Web Anwar Alhenshiri (PhD) Mining Data Streams In many data mining situations, we know the entire data set in advance Sometimes the input rate is controlled externally Google queries Twitter
Mining The Web Anwar Alhenshiri (PhD) Mining Data Streams In many data mining situations, we know the entire data set in advance Sometimes the input rate is controlled externally Google queries Twitter
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
5 Choosing keywords Initially choosing keywords Frequent and rare keywords Evaluating the competition rates of search
 Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
TODAY S LECTURE HYPERTEXT AND
 LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
Lecture 27: Learning from relational data
 Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
Web Spam Detection with Anti-Trust Rank
 Web Spam Detection with Anti-Trust Rank Viay Krishnan Computer Science Department Stanford University Stanford, CA 4305 viayk@cs.stanford.edu Rashmi Ra Computer Science Department Stanford University Stanford,
Web Spam Detection with Anti-Trust Rank Viay Krishnan Computer Science Department Stanford University Stanford, CA 4305 viayk@cs.stanford.edu Rashmi Ra Computer Science Department Stanford University Stanford,
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 7: Information Retrieval II. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
Searching the Web [Arasu 01]
![Searching the Web [Arasu 01]](/thumbs/74/70312179.jpg "Searching the Web [Arasu 01]") Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Large-Scale Networks. PageRank. Dr Vincent Gramoli Lecturer School of Information Technologies
 Large-Scale Networks PageRank Dr Vincent Gramoli Lecturer School of Information Technologies Introduction Last week we talked about: - Hubs whose scores depend on the authority of the nodes they point
Large-Scale Networks PageRank Dr Vincent Gramoli Lecturer School of Information Technologies Introduction Last week we talked about: - Hubs whose scores depend on the authority of the nodes they point
Agenda. Math Google PageRank algorithm. 2 Developing a formula for ranking web pages. 3 Interpretation. 4 Computing the score of each page
 Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Recent Researches on Web Page Ranking
 Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
DSCI 575: Advanced Machine Learning. PageRank Winter 2018
 DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
COMP5331: Knowledge Discovery and Data Mining
 COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group Simone.Teufel@cl.cam.ac.uk Lent
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group Simone.Teufel@cl.cam.ac.uk Lent
Exploring both Content and Link Quality for Anti-Spamming
 Exploring both Content and Link Quality for Anti-Spamming Lei Zhang, Yi Zhang, Yan Zhang National Laboratory on Machine Perception Peking University 100871 Beijing, China zhangl, zhangyi, zhy @cis.pku.edu.cn
Exploring both Content and Link Quality for Anti-Spamming Lei Zhang, Yi Zhang, Yan Zhang National Laboratory on Machine Perception Peking University 100871 Beijing, China zhangl, zhangyi, zhy @cis.pku.edu.cn
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 12: Link Analysis January 28 th, 2016 Wolf-Tilo Balke and Younes Ghammad Institut für Informationssysteme Technische Universität Braunschweig An Overview
Information Retrieval and Web Search Engines Lecture 12: Link Analysis January 28 th, 2016 Wolf-Tilo Balke and Younes Ghammad Institut für Informationssysteme Technische Universität Braunschweig An Overview
DATA MINING - 1DL460
 DATA MINING - 1DL460 Spring 2015 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt15 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
DATA MINING - 1DL460 Spring 2015 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt15 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology, Uppsala
Unsupervised Learning. Pantelis P. Analytis. Introduction. Finding structure in graphs. Clustering analysis. Dimensionality reduction.
 March 19, 2018 1 / 40 1 2 3 4 2 / 40 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 3 / 40 4 / 40 5 / 40 Organizing the web First
March 19, 2018 1 / 40 1 2 3 4 2 / 40 What s unsupervised learning? Most of the data available on the internet do not have labels. How can we make sense of it? 3 / 40 4 / 40 5 / 40 Organizing the web First
DS504/CS586: Big Data Analytics Graph Mining Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Graph Mining Prof. Yanhua Li Time: 6:00pm 8:50pm R Location: AK 233 Spring 2018 Service Providing Improve urban planning, Ease Traffic Congestion, Save Energy,
Welcome to DS504/CS586: Big Data Analytics Graph Mining Prof. Yanhua Li Time: 6:00pm 8:50pm R Location: AK 233 Spring 2018 Service Providing Improve urban planning, Ease Traffic Congestion, Save Energy,
CS 6604: Data Mining Large Networks and Time-Series
 CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
Collaborative filtering based on a random walk model on a graph
 Collaborative filtering based on a random walk model on a graph Marco Saerens, Francois Fouss, Alain Pirotte, Luh Yen, Pierre Dupont (UCL) Jean-Michel Renders (Xerox Research Europe) Some recent methods:
Collaborative filtering based on a random walk model on a graph Marco Saerens, Francois Fouss, Alain Pirotte, Luh Yen, Pierre Dupont (UCL) Jean-Michel Renders (Xerox Research Europe) Some recent methods:
Jordan Boyd-Graber University of Maryland. Thursday, March 3, 2011
 Data-Intensive Information Processing Applications! Session #5 Graph Algorithms Jordan Boyd-Graber University of Maryland Thursday, March 3, 2011 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications! Session #5 Graph Algorithms Jordan Boyd-Graber University of Maryland Thursday, March 3, 2011 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Introduction to Data Mining
 Introduction to Data Mining Lecture #1: Course Introduction U Kang Seoul National University U Kang 1 In This Lecture Motivation to study data mining Administrative information for this course U Kang 2
Introduction to Data Mining Lecture #1: Course Introduction U Kang Seoul National University U Kang 1 In This Lecture Motivation to study data mining Administrative information for this course U Kang 2
Social Networks. Slides by : I. Koutsopoulos (AUEB), Source:L. Adamic, SN Analysis, Coursera course
, Source:L. Adamic, SN Analysis, Coursera course") Social Networks Slides by : I. Koutsopoulos (AUEB), Source:L. Adamic, SN Analysis, Coursera course Introduction Political blogs Organizations Facebook networks Ingredient networks SN representation Networks
Social Networks Slides by : I. Koutsopoulos (AUEB), Source:L. Adamic, SN Analysis, Coursera course Introduction Political blogs Organizations Facebook networks Ingredient networks SN representation Networks
The PageRank Citation Ranking
 October 17, 2012 Main Idea - Page Rank web page is important if it points to by other important web pages. *Note the recursive definition IR - course web page, Brian home page, Emily home page, Steven
October 17, 2012 Main Idea - Page Rank web page is important if it points to by other important web pages. *Note the recursive definition IR - course web page, Brian home page, Emily home page, Steven