From Web Page Storage to Living Web Archives Thomas Risse
|
|
|
- Lily Scott
- 6 years ago
- Views:
Transcription
1 From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London,
2 Agenda Web Crawlingtoday& Open Issues LiWA Living Web Archives Project Selected working areas of LiWA Dynamic Pages Handling ofspam Temporal coherence of crawls Archive Interpretability Conclusions and Expected Project Results 2
3 Current Web Archiving at a Glance Quality Review Access Selection Preparation Discovery Filtering Deep Web Archiving Noise Filtering Dynamic Pages JavaScript, Flash Archivist Link Extractio on Temporal Coherence of Crawls Capture Fetching User Long-term Interpretability Index Storage Multimedia Content 3
4 LiWA Living Web Archives (EU-IST ) Next generation Web Archiving technology for: High Quality Web Archives Long-term Archive usability From Web page storage to Living Web Archives Semantic & Terminology Evolution Temporal Coherence & Consistency Noise and Spam Filtering Improved Capturing Started Feb (3 Years) Existing Web Archiving Technology 4
5 Some LiWAObjectives in more Detail Quality Review Access Selection Preparation Discovery Filtering Deep Web Archiving Noise Filtering Dynamic Pages JavaScript, Flash Archivist Link Extractio on Temporal Coherence of Crawls Capture Fetching User Long-term Interpretability Index Storage Multimedia Content 5
6 Some LiWAObjectives in more Detail Quality Review Access Selection Preparation Discovery Filtering Deep Web Archiving Noise Filtering Dynamic Pages JavaScript, Flash Archivist Link Extractio on Temporal Coherence of Crawls Capture Fetching User Long-term Interpretability Index Storage Multimedia Content 6
7 Link Extraction of Dynamic Pages Quality Review Access Selection Preparation Discovery Filtering Deep Web Archiving Noise Filtering Dynamic Pages JavaScript, Flash Archivist Link Extractio on Temporal Coherence of Crawls Capture Fetching User Long-term Interpretability Index Storage Multimedia Content 7

8 Follow the links
9 Hmm 9 9
10 Link Extraction of Dynamic Pages The Problem: links don t exist as raw text lying around user interaction and code assemble them Current Approach: guessing by assembling any fragments that look like links into URLs and trying them out Can be very noisy -lots of wrong URL s
11 Link Extraction of Dynamic Pages Approach pressing the links and see what comes out Execute code in a Javascriptengine Extract links from resulting DOM tree Implementation based on WebKit


12 Noise Filtering Quality Review Access Selection Preparation Discovery Filtering Deep Web Archiving Noise Filtering Dynamic Pages JavaScript, Flash Archivist Link Extractio on Temporal Coherence of Crawls Capture Fetching User Long-term Interpretability Index Storage Multimedia Content 12


13 Web spam: for (or against) search engines 13

14 Web Spam: indexing vs. archiving Primary target: search engines to manipulate ranking As side effect, we also archive spam But very costly if not fought against: traps crawler 10+% sites near 20% HTML pages Reputable 70.0% Unknown 0.4% Alias 0.3% Empty 0.4% Non-existent 7.9% 2004.de crawl courtesy: T. Suel Ad 3.7% Spam 16.5% 14
15 What can we do? Ideal solution Automatic identification of spam pages Requires Right selection of features to identify spam Development of new features e.g. creation and disappearance of new sites, pages Good training sets Problem: Spam is constantly changing Features need to be adapted Updated training sets are necessary Training set need to be prepared manually 15
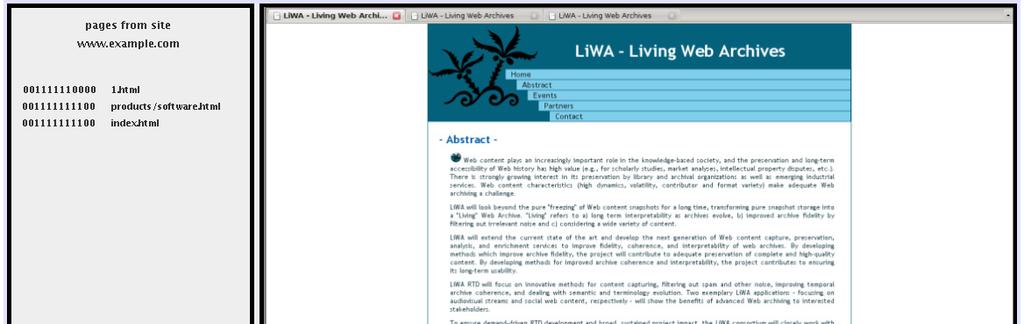
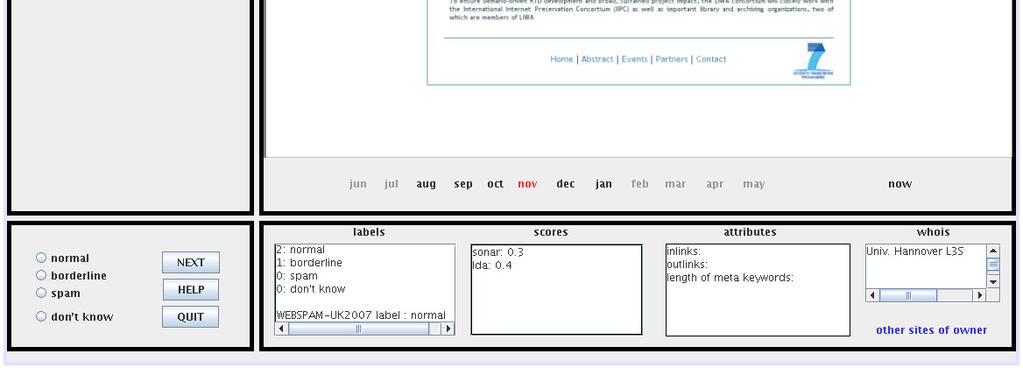
16 Spam Assessment Interface 16
17 Temporal Coherence of Crawls Quality Review Access Selection Preparation Discovery Filtering Deep Web Archiving Noise Filtering Dynamic Pages JavaScript, Flash Archivist Link Extractio on Temporal Coherence of Crawls Capture Fetching User Long-term Interpretability Index Storage Multimedia Content 17
18 Temporal Coherence Capturing Web sites as authentic as possible Make a site snapshot at once is not possible Crawlers need to be polite to web sites Slow crawling, maybe with delays Pages are changing during site crawl When Do we have a coherent crawl? 18
19 Coherence by Example t coherence = [t 2, t 3 ) p 1 p 2 p 3 p 4 t 1 = t s t 2 t 3 t 4 = t e 19/219
20 Coherence by Example t coherence p 1 p 2 p 3 p 4 t 1 = t s t 2 t 3 t 4 = t e 20/20
21 Coherence Analysis Technology Creation of automatically generated reports Visualization of coherence defects 21
22 Long-term Interpretability Quality Review Access Selection Preparation Discovery Filtering Deep Web Archiving Noise Filtering Dynamic Pages JavaScript, Flash Archivist Link Extractio on Temporal Coherence of Crawls Capture Fetching User Long-term Interpretability Index Storage Multimedia Content 22
23 Motivation Archives store content over long time ranges Content is created latest in the year of archiving Content typically creators use the language of that time St. Piter Burh 1703 St. Petersburg Petrograd Leningrad St. Petersburg present 23
24 Overview Process Find the meaning of a term in one collection at one period in time Detect evolution of terms Step 1: Word Sense Discrimination Step 2: Tracking Evolution 24
 Homogeneous language Time annotated Using Web Archives Large digital corpus At most 10 Years old Inhomogeneous with all the noise of the web Not suitable for initial evaluations")
25 Data Sets for Evaluation (1/2) Data Set Requirements Large corpus Fully digitized Long time range Increase probability of terminology evolution Not too domain specific (like the Mesh corpus) Homogeneous language Time annotated Using Web Archives Large digital corpus At most 10 Years old Inhomogeneous with all the noise of the web Not suitable for initial evaluations 25
 Spans from year 1994-2006 ~ 1.")
 Spans from year 1785-1985 ~ 20 Million articles Strategy Year 2: Initial evaluations on well known")
26 Data Sets for Evaluation (2/2) Newspaper Archives Fully digitized corpora Controlled language Clear time annotations Süddeutsche Zeitung (ger.) Spans from year ~ 1.3 Million articles London Times Archive (engl.) Spans from year ~ 20 Million articles Strategy Year 2: Initial evaluations on well known corpora Year 3: Apply technology to web archives,.gov.uk crawls provided by EA 26
27 Term. Evol- Conclusions and Future Work Terminology Extraction Find methods that are time independent for Extraction Stop word removal Lemmatization Correcting OCR errors Word Sense Discrimination Other types of clustering Metrics for evaluation Detecting Evolution Methods for comparing clusters and detecting evolution Methods for evaluation Nina Tahmasebi 27
28 Conclusions and Expected Project Results Improving Web Archiving Technology - Rich Media Capturing - Spam Processing - Archive Coherence - More general scope: Improving Archive Interpretability Selected results will be integrated in - Heritrix Crawler (our test-bed) - Hanzo Archives Crawler Evaluation in two test cases: - Streaming Media WebArchive by Sound & Vision - WebArchivistsWorkbench by European Archive and Nat. Lib. Czech Republic 28
29 Thank you! More information on 29
From Web Page Storage to Living Web Archives
 From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawling today & Open Issues LiWA Living
From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawling today & Open Issues LiWA Living
Exploiting the Social and Semantic Web for guided Web Archiving
 Exploiting the Social and Semantic Web for guided Web Archiving Thomas Risse 1, Stefan Dietze 1, Wim Peters 2, Katerina Doka 3, Yannis Stavrakas 3, and Pierre Senellart 4 1 L3S Research Center, Hannover,
Exploiting the Social and Semantic Web for guided Web Archiving Thomas Risse 1, Stefan Dietze 1, Wim Peters 2, Katerina Doka 3, Yannis Stavrakas 3, and Pierre Senellart 4 1 L3S Research Center, Hannover,
Challenges and Approaches for Web Archive Creation and Usage
 Challenges and Approaches for Web Archive Creation and Usage Thomas Risse L3S Research Center Lleida, 29. May 2015 Thomas Risse 25/11/15 1 The Web is a core part of our daily life World Wide Web = 50 Bill.
Challenges and Approaches for Web Archive Creation and Usage Thomas Risse L3S Research Center Lleida, 29. May 2015 Thomas Risse 25/11/15 1 The Web is a core part of our daily life World Wide Web = 50 Bill.
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics
 Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics Media Intelligence Business intelligence (BI) Uses data mining techniques and tools for the transformation of raw data into meaningful
Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics Media Intelligence Business intelligence (BI) Uses data mining techniques and tools for the transformation of raw data into meaningful
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
CDL s Web Archiving System
 CDL s Web Archiving System Erik Hetzner UC3, California Digital Library 16 June 2011 Erik Hetzner (UC3, California Digital Library) CDL s Web Archiving System 16 June 2011 1 / 24 Introduction We don t
CDL s Web Archiving System Erik Hetzner UC3, California Digital Library 16 June 2011 Erik Hetzner (UC3, California Digital Library) CDL s Web Archiving System 16 June 2011 1 / 24 Introduction We don t
MESH. Multimedia Semantic Syndication for Enhanced News Services. Project Overview
 MESH Multimedia Semantic Syndication for Enhanced News Services Project Overview Presentation Structure 2 Project Summary Project Motivation Problem Description Work Description Expected Result The MESH
MESH Multimedia Semantic Syndication for Enhanced News Services Project Overview Presentation Structure 2 Project Summary Project Motivation Problem Description Work Description Expected Result The MESH
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Basic techniques. Text processing; term weighting; vector space model; inverted index; Web Search
 Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Anatomy of a Semantic Virus
 Anatomy of a Semantic Virus Peyman Nasirifard Digital Enterprise Research Institute National University of Ireland, Galway IDA Business Park, Lower Dangan, Galway, Ireland peyman.nasirifard@deri.org Abstract.
Anatomy of a Semantic Virus Peyman Nasirifard Digital Enterprise Research Institute National University of Ireland, Galway IDA Business Park, Lower Dangan, Galway, Ireland peyman.nasirifard@deri.org Abstract.
Large Crawls of the Web for Linguistic Purposes
 Large Crawls of the Web for Linguistic Purposes SSLMIT, University of Bologna Birmingham, July 2005 Outline Introduction 1 Introduction 2 3 Basics Heritrix My ongoing crawl 4 Filtering and cleaning 5 Annotation
Large Crawls of the Web for Linguistic Purposes SSLMIT, University of Bologna Birmingham, July 2005 Outline Introduction 1 Introduction 2 3 Basics Heritrix My ongoing crawl 4 Filtering and cleaning 5 Annotation
What Do You Mean It Doesn t Make Sense? Redesigning Finding Aids from the Users Perspective
 What Do You Mean It Doesn t Make Sense? Redesigning Finding Aids from the Users Perspective Rethinking Finding Aids Archival patrons don t understand archival terminology Don t understand hierarchy Need
What Do You Mean It Doesn t Make Sense? Redesigning Finding Aids from the Users Perspective Rethinking Finding Aids Archival patrons don t understand archival terminology Don t understand hierarchy Need
August 14th - 18th 2005, Oslo, Norway. Web crawling : The Bibliothèque nationale de France experience
 World Library and Information Congress: 71th IFLA General Conference and Council "Libraries - A voyage of discovery" August 14th - 18th 2005, Oslo, Norway Conference Programme: http://www.ifla.org/iv/ifla71/programme.htm
World Library and Information Congress: 71th IFLA General Conference and Council "Libraries - A voyage of discovery" August 14th - 18th 2005, Oslo, Norway Conference Programme: http://www.ifla.org/iv/ifla71/programme.htm
Ranking of ads. Sponsored Search
 Sponsored Search Ranking of ads Goto model: Rank according to how much advertiser pays Current model: Balance auction price and relevance Irrelevant ads (few click-throughs) Decrease opportunities for
Sponsored Search Ranking of ads Goto model: Rank according to how much advertiser pays Current model: Balance auction price and relevance Irrelevant ads (few click-throughs) Decrease opportunities for
Crossing the Archival Borders
 IST-Africa 2008 Conference Proceedings Paul Cunningham and Miriam Cunningham (Eds) IIMC International Information Management Corporation, 2008 ISBN: 978-1-905824-07-6 Crossing the Archival Borders Fredrik
IST-Africa 2008 Conference Proceedings Paul Cunningham and Miriam Cunningham (Eds) IIMC International Information Management Corporation, 2008 ISBN: 978-1-905824-07-6 Crossing the Archival Borders Fredrik
A B2B Search Engine. Abstract. Motivation. Challenges. Technical Report
 Technical Report A B2B Search Engine Abstract In this report, we describe a business-to-business search engine that allows searching for potential customers with highly-specific queries. Currently over
Technical Report A B2B Search Engine Abstract In this report, we describe a business-to-business search engine that allows searching for potential customers with highly-specific queries. Currently over
Empowering People with Knowledge the Next Frontier for Web Search. Wei-Ying Ma Assistant Managing Director Microsoft Research Asia
 Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
Empowering People with Knowledge the Next Frontier for Web Search Wei-Ying Ma Assistant Managing Director Microsoft Research Asia Important Trends for Web Search Organizing all information Addressing user
SciVerse Scopus. Date: 21 Sept, Coen van der Krogt Product Sales Manager Presented by Andrea Kmety
 SciVerse Scopus Date: 21 Sept, 2011 Coen van der Krogt Product Sales Manager Presented by Andrea Kmety Agenda What is SciVerse? SciVerse Scopus at a glance Supporting Researchers Supporting the Performance
SciVerse Scopus Date: 21 Sept, 2011 Coen van der Krogt Product Sales Manager Presented by Andrea Kmety Agenda What is SciVerse? SciVerse Scopus at a glance Supporting Researchers Supporting the Performance
On the Change in Archivability of Websites Over Time
 Old Dominion University ODU Digital Commons Computer Science Presentations Computer Science 9-23-2013 On the Change in Archivability of Websites Over Time Mat Kelly Old Dominion University Justin F. Brunelle
Old Dominion University ODU Digital Commons Computer Science Presentations Computer Science 9-23-2013 On the Change in Archivability of Websites Over Time Mat Kelly Old Dominion University Justin F. Brunelle
DIGIT.B4 Big Data PoC
 DIGIT.B4 Big Data PoC DIGIT 01 Social Media D02.01 PoC Requirements Table of contents 1 Introduction... 5 1.1 Context... 5 1.2 Objective... 5 2 Data SOURCES... 6 2.1 Data sources... 6 2.2 Data fields...
DIGIT.B4 Big Data PoC DIGIT 01 Social Media D02.01 PoC Requirements Table of contents 1 Introduction... 5 1.1 Context... 5 1.2 Objective... 5 2 Data SOURCES... 6 2.1 Data sources... 6 2.2 Data fields...
INLS : Introduction to Information Retrieval System Design and Implementation. Fall 2008.
 INLS 490-154: Introduction to Information Retrieval System Design and Implementation. Fall 2008. 12. Web crawling Chirag Shah School of Information & Library Science (SILS) UNC Chapel Hill NC 27514 chirag@unc.edu
INLS 490-154: Introduction to Information Retrieval System Design and Implementation. Fall 2008. 12. Web crawling Chirag Shah School of Information & Library Science (SILS) UNC Chapel Hill NC 27514 chirag@unc.edu
Web Archiving Workshop
 Web Archiving Workshop Mark Phillips Texas Conference on Digital Libraries June 4, 2008 Agenda 1:00 Welcome/Introductions 1:15 Introduction to Web Archiving History Concepts/Terms Examples 2:15 Collection
Web Archiving Workshop Mark Phillips Texas Conference on Digital Libraries June 4, 2008 Agenda 1:00 Welcome/Introductions 1:15 Introduction to Web Archiving History Concepts/Terms Examples 2:15 Collection
CS6200 Information Retreival. Crawling. June 10, 2015
 CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS 425 / ECE 428 Distributed Systems Fall 2015
 CS 425 / ECE 428 Distributed Systems Fall 2015 Indranil Gupta (Indy) Measurement Studies Lecture 23 Nov 10, 2015 Reading: See links on website All Slides IG 1 Motivation We design algorithms, implement
CS 425 / ECE 428 Distributed Systems Fall 2015 Indranil Gupta (Indy) Measurement Studies Lecture 23 Nov 10, 2015 Reading: See links on website All Slides IG 1 Motivation We design algorithms, implement
OnCrawl Metrics. What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for.
 1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
Robin Wilson Director. Digital Identifiers Metadata Services
 Robin Wilson Director Digital Identifiers Metadata Services Report Digital Object Identifiers for Publishing and the e-learning Community CONTEXT elearning the the Publishing Challenge elearning the the
Robin Wilson Director Digital Identifiers Metadata Services Report Digital Object Identifiers for Publishing and the e-learning Community CONTEXT elearning the the Publishing Challenge elearning the the
Workshop W14 - Audio Gets Smart: Semantic Audio Analysis & Metadata Standards
 Workshop W14 - Audio Gets Smart: Semantic Audio Analysis & Metadata Standards Jürgen Herre for Integrated Circuits (FhG-IIS) Erlangen, Germany Jürgen Herre, hrr@iis.fhg.de Page 1 Overview Extracting meaning
Workshop W14 - Audio Gets Smart: Semantic Audio Analysis & Metadata Standards Jürgen Herre for Integrated Circuits (FhG-IIS) Erlangen, Germany Jürgen Herre, hrr@iis.fhg.de Page 1 Overview Extracting meaning
Exploring archives with probabilistic models: Topic modelling for the European Commission Archives
 Exploring archives with probabilistic models: Topic modelling for the European Commission Archives Simon Hengchen, Mathias Coeckelbergs, Seth van Hooland, Ruben Verborgh & Thomas Steiner Université libre
Exploring archives with probabilistic models: Topic modelling for the European Commission Archives Simon Hengchen, Mathias Coeckelbergs, Seth van Hooland, Ruben Verborgh & Thomas Steiner Université libre
The Black Magic of Flash SEO
 The Black Magic of Flash SEO Duane Nickull Sr. Technical Evangelist Adobe Systems July 2008 Speaker bio - Duane Nickull!! Current!! Chair - OASIS SOA Reference Model Technical Committee (OASIS Standard
The Black Magic of Flash SEO Duane Nickull Sr. Technical Evangelist Adobe Systems July 2008 Speaker bio - Duane Nickull!! Current!! Chair - OASIS SOA Reference Model Technical Committee (OASIS Standard
The 6 Most Common Website SEO Mistakes
 The 6 Most Common Website SEO Mistakes The 6 Most Common Website SEO Mistakes One of the most important weapons when it comes to expanding your business is a good website and whilst lots of websites look
The 6 Most Common Website SEO Mistakes The 6 Most Common Website SEO Mistakes One of the most important weapons when it comes to expanding your business is a good website and whilst lots of websites look
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Overview Introduction Classic
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Overview Introduction Classic
Workshop B: Archiving the Web
 Workshop B: Archiving the Web Michael Day and Maureen Pennock Digital Curation Centre UKOLN, University of Bath http://www.ukoln.ac.uk/ Driving the Long-Term Preservation of Electronic Records, London,
Workshop B: Archiving the Web Michael Day and Maureen Pennock Digital Curation Centre UKOLN, University of Bath http://www.ukoln.ac.uk/ Driving the Long-Term Preservation of Electronic Records, London,
Minghai Liu, Rui Cai, Ming Zhang, and Lei Zhang. Microsoft Research, Asia School of EECS, Peking University
 Minghai Liu, Rui Cai, Ming Zhang, and Lei Zhang Microsoft Research, Asia School of EECS, Peking University Ordering Policies for Web Crawling Ordering policy To prioritize the URLs in a crawling queue
Minghai Liu, Rui Cai, Ming Zhang, and Lei Zhang Microsoft Research, Asia School of EECS, Peking University Ordering Policies for Web Crawling Ordering policy To prioritize the URLs in a crawling queue
Web Crawling. Advanced methods of Information Retrieval. Gerhard Gossen Gerhard Gossen Web Crawling / 57
 Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Archiving dynamic websites: a considerations framework and a tool comparison
 Archiving dynamic websites: a considerations framework and a tool comparison Allard Oelen Student number: 2560801 Supervisor: Victor de Boer 30 June 2017 Vrije Universiteit Amsterdam a.b.oelen@student.vu.nl
Archiving dynamic websites: a considerations framework and a tool comparison Allard Oelen Student number: 2560801 Supervisor: Victor de Boer 30 June 2017 Vrije Universiteit Amsterdam a.b.oelen@student.vu.nl
Exam IST 441 Spring 2011
 Exam IST 441 Spring 2011 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
Exam IST 441 Spring 2011 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
The Role of Language Evolution in Digital Archives
 The Role of Language Evolution in Digital Archives Thomas Risse, Helge Holzmann (L3S) Nina Tahmasebi, Uni Gothenburg L3S Research Center Web Science @ L3S Preserving, understanding and shaping the Web
The Role of Language Evolution in Digital Archives Thomas Risse, Helge Holzmann (L3S) Nina Tahmasebi, Uni Gothenburg L3S Research Center Web Science @ L3S Preserving, understanding and shaping the Web
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
How Co-Occurrence can Complement Semantics?
 How Co-Occurrence can Complement Semantics? Atanas Kiryakov & Borislav Popov ISWC 2006, Athens, GA Semantic Annotations: 2002 #2 Semantic Annotation: How and Why? Information extraction (text-mining) for
How Co-Occurrence can Complement Semantics? Atanas Kiryakov & Borislav Popov ISWC 2006, Athens, GA Semantic Annotations: 2002 #2 Semantic Annotation: How and Why? Information extraction (text-mining) for
Conclusions. Chapter Summary of our contributions
 Chapter 1 Conclusions During this thesis, We studied Web crawling at many different levels. Our main objectives were to develop a model for Web crawling, to study crawling strategies and to build a Web
Chapter 1 Conclusions During this thesis, We studied Web crawling at many different levels. Our main objectives were to develop a model for Web crawling, to study crawling strategies and to build a Web
doc. RNDr. Tomáš Skopal, Ph.D. Department of Software Engineering, Faculty of Information Technology, Czech Technical University in Prague
 Praha & EU: Investujeme do vaší budoucnosti Evropský sociální fond course: Searching the Web and Multimedia Databases (BI-VWM) Tomáš Skopal, 2011 SS2010/11 doc. RNDr. Tomáš Skopal, Ph.D. Department of
Praha & EU: Investujeme do vaší budoucnosti Evropský sociální fond course: Searching the Web and Multimedia Databases (BI-VWM) Tomáš Skopal, 2011 SS2010/11 doc. RNDr. Tomáš Skopal, Ph.D. Department of
TEI, METS and ALTO, why we need all of them. Günter Mühlberger University of Innsbruck Digitisation and Digital Preservation
 TEI, METS and ALTO, why we need all of them Günter Mühlberger University of Innsbruck Digitisation and Digital Preservation Agenda Introduction Problem statement Proposed solution Starting point Mass digitisation
TEI, METS and ALTO, why we need all of them Günter Mühlberger University of Innsbruck Digitisation and Digital Preservation Agenda Introduction Problem statement Proposed solution Starting point Mass digitisation
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
16. HTML5, HTML Graphics, & HTML Media 웹프로그래밍 2016 년 1 학기 충남대학교컴퓨터공학과
 16. HTML5, HTML Graphics, & HTML Media 웹프로그래밍 2016 년 1 학기 충남대학교컴퓨터공학과 목차 HTML5 Introduction HTML5 Browser Support HTML5 Semantic Elements HTML5 Canvas HTML5 SVG HTML5 Multimedia 2 HTML5 Introduction What
16. HTML5, HTML Graphics, & HTML Media 웹프로그래밍 2016 년 1 학기 충남대학교컴퓨터공학과 목차 HTML5 Introduction HTML5 Browser Support HTML5 Semantic Elements HTML5 Canvas HTML5 SVG HTML5 Multimedia 2 HTML5 Introduction What
Workshop on Web Archiving
 Workshop on Web Archiving MODULE 1 A: WEB ARCHIVING Niels Brügger Asger Harlung Program, KB 10.40-11.50 Workshop part 1: Web archiving 11.50-12.10 Discussion and a short break before lunch 12.10-13.00
Workshop on Web Archiving MODULE 1 A: WEB ARCHIVING Niels Brügger Asger Harlung Program, KB 10.40-11.50 Workshop part 1: Web archiving 11.50-12.10 Discussion and a short break before lunch 12.10-13.00
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Digital Preservation in the UK. David Thomas
 Digital Preservation in the UK David Thomas Digital Preservation in the UK Main focus on National Archives Websites Datasets Electronic records Websites Contract with European Archive http://www.europarchive.org/
Digital Preservation in the UK David Thomas Digital Preservation in the UK Main focus on National Archives Websites Datasets Electronic records Websites Contract with European Archive http://www.europarchive.org/
Preservation of Web Materials
 Preservation of Web Materials Julie Dietrich INFO 560 Literature Review 7/20/13 1 Introduction Websites are a communication and informational tool that can be shared and updated across the World Wide Web.
Preservation of Web Materials Julie Dietrich INFO 560 Literature Review 7/20/13 1 Introduction Websites are a communication and informational tool that can be shared and updated across the World Wide Web.
New Issues in Near-duplicate Detection
 New Issues in Near-duplicate Detection Martin Potthast and Benno Stein Bauhaus University Weimar Web Technology and Information Systems Motivation About 30% of the Web is redundant. [Fetterly 03, Broder
New Issues in Near-duplicate Detection Martin Potthast and Benno Stein Bauhaus University Weimar Web Technology and Information Systems Motivation About 30% of the Web is redundant. [Fetterly 03, Broder
Néonaute: mining web archives for linguistic analysis
 Néonaute: mining web archives for linguistic analysis Sara Aubry, Bibliothèque nationale de France Emmanuel Cartier, LIPN, University of Paris 13 Peter Stirling, Bibliothèque nationale de France IIPC Web
Néonaute: mining web archives for linguistic analysis Sara Aubry, Bibliothèque nationale de France Emmanuel Cartier, LIPN, University of Paris 13 Peter Stirling, Bibliothèque nationale de France IIPC Web
Search Framework for a Large Digital Records Archive DLF SPRING 2007 April 23-25, 25, 2007 Dyung Le & Quyen Nguyen ERA Systems Engineering National Ar
 Search Framework for a Large Digital Records Archive DLF SPRING 2007 April 23-25, 25, 2007 Dyung Le & Quyen Nguyen ERA Systems Engineering National Archives & Records Administration Agenda ERA Overview
Search Framework for a Large Digital Records Archive DLF SPRING 2007 April 23-25, 25, 2007 Dyung Le & Quyen Nguyen ERA Systems Engineering National Archives & Records Administration Agenda ERA Overview
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
SEO. Definitions/Acronyms. Definitions/Acronyms
 Definitions/Acronyms SEO Search Engine Optimization ITS Web Services September 6, 2007 SEO: Search Engine Optimization SEF: Search Engine Friendly SERP: Search Engine Results Page PR (Page Rank): Google
Definitions/Acronyms SEO Search Engine Optimization ITS Web Services September 6, 2007 SEO: Search Engine Optimization SEF: Search Engine Friendly SERP: Search Engine Results Page PR (Page Rank): Google
An Approach To Web Content Mining
 An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
Search Engines. Charles Severance
 Search Engines Charles Severance Google Architecture Web Crawling Index Building Searching http://infolab.stanford.edu/~backrub/google.html Google Search Google I/O '08 Keynote by Marissa Mayer Usablity
Search Engines Charles Severance Google Architecture Web Crawling Index Building Searching http://infolab.stanford.edu/~backrub/google.html Google Search Google I/O '08 Keynote by Marissa Mayer Usablity
Self Adjusting Refresh Time Based Architecture for Incremental Web Crawler
 IJCSNS International Journal of Computer Science and Network Security, VOL.8 No.12, December 2008 349 Self Adjusting Refresh Time Based Architecture for Incremental Web Crawler A.K. Sharma 1, Ashutosh
IJCSNS International Journal of Computer Science and Network Security, VOL.8 No.12, December 2008 349 Self Adjusting Refresh Time Based Architecture for Incremental Web Crawler A.K. Sharma 1, Ashutosh
TECHNICAL TOOL SPECIFICATION
 TECHNICAL TOOL SPECIFICATION A. Details Institution: The University of Sheffield Contact: Michael Pidd, HRI Digital Manager Address: Humanities Research Institute, University of
TECHNICAL TOOL SPECIFICATION A. Details Institution: The University of Sheffield Contact: Michael Pidd, HRI Digital Manager Address: Humanities Research Institute, University of
Long-term preservation for INSPIRE: a metadata framework and geo-portal implementation
 Long-term preservation for INSPIRE: a metadata framework and geo-portal implementation INSPIRE 2010, KRAKOW Dr. Arif Shaon, Dr. Andrew Woolf (e-science, Science and Technology Facilities Council, UK) 3
Long-term preservation for INSPIRE: a metadata framework and geo-portal implementation INSPIRE 2010, KRAKOW Dr. Arif Shaon, Dr. Andrew Woolf (e-science, Science and Technology Facilities Council, UK) 3
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
EUDAT. Towards a pan-european Collaborative Data Infrastructure
 EUDAT Towards a pan-european Collaborative Data Infrastructure Damien Lecarpentier CSC-IT Center for Science, Finland CESSDA workshop Tampere, 5 October 2012 EUDAT Towards a pan-european Collaborative
EUDAT Towards a pan-european Collaborative Data Infrastructure Damien Lecarpentier CSC-IT Center for Science, Finland CESSDA workshop Tampere, 5 October 2012 EUDAT Towards a pan-european Collaborative
How Does a Search Engine Work? Part 1
 How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
Web Science Your Business, too!
 Web Science & Technologies University of Koblenz Landau, Germany Web Science Your Business, too! Agenda What is Web Science? An explanation by analogy What do we do about it? Understanding collective effects
Web Science & Technologies University of Koblenz Landau, Germany Web Science Your Business, too! Agenda What is Web Science? An explanation by analogy What do we do about it? Understanding collective effects
How to Crawl the Web. Hector Garcia-Molina Stanford University. Joint work with Junghoo Cho
 How to Crawl the Web Hector Garcia-Molina Stanford University Joint work with Junghoo Cho Stanford InterLib Technologies Information Overload Service Heterogeneity Interoperability Economic Concerns Information
How to Crawl the Web Hector Garcia-Molina Stanford University Joint work with Junghoo Cho Stanford InterLib Technologies Information Overload Service Heterogeneity Interoperability Economic Concerns Information
THE HISTORY & EVOLUTION OF SEARCH
 THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
THE HISTORY & EVOLUTION OF SEARCH Duration : 1 Hour 30 Minutes Let s talk about The History Of Search Crawling & Indexing Crawlers / Spiders Datacenters Answer Machine Relevancy (200+ Factors)
BUbiNG. Massive Crawling for the Masses. Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna
 BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
Knowledge Discovery and Data Mining 1 (KU)
") Knowledge Discovery and Data Mining 1 (KU) Simon Walk IICM, TU Graz October 22, 2015 Simon Walk (IICM) KDDM1 October 22, 2015 1 / 11 KDDM 1 (KU) - Introduction Introduction Institute for Information Systems
Knowledge Discovery and Data Mining 1 (KU) Simon Walk IICM, TU Graz October 22, 2015 Simon Walk (IICM) KDDM1 October 22, 2015 1 / 11 KDDM 1 (KU) - Introduction Introduction Institute for Information Systems
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Structured Data on the Web
 Structured Data on the Web Alon Halevy Google Australasian Computer Science Week January, 2010 Structured Data & The Web Andree Hudson, 4 th of July Hard to find structured data via search engines
Structured Data on the Web Alon Halevy Google Australasian Computer Science Week January, 2010 Structured Data & The Web Andree Hudson, 4 th of July Hard to find structured data via search engines
Overview of Web Mining Techniques and its Application towards Web
 Overview of Web Mining Techniques and its Application towards Web *Prof.Pooja Mehta Abstract The World Wide Web (WWW) acts as an interactive and popular way to transfer information. Due to the enormous
Overview of Web Mining Techniques and its Application towards Web *Prof.Pooja Mehta Abstract The World Wide Web (WWW) acts as an interactive and popular way to transfer information. Due to the enormous
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Search Engine Optimization (SEO) & Your Online Success
 & Your Online Success") Search Engine Optimization (SEO) & Your Online Success What Is SEO, Exactly? SEO stands for Search Engine Optimization. It is the process of attracting & keeping traffic from the free, organic, editorial
Search Engine Optimization (SEO) & Your Online Success What Is SEO, Exactly? SEO stands for Search Engine Optimization. It is the process of attracting & keeping traffic from the free, organic, editorial
Search Engine Technology. Mansooreh Jalalyazdi
 Search Engine Technology Mansooreh Jalalyazdi 1 2 Search Engines. Search engines are programs viewers use to find information they seek by typing in keywords. A list is provided by the Search engine or
Search Engine Technology Mansooreh Jalalyazdi 1 2 Search Engines. Search engines are programs viewers use to find information they seek by typing in keywords. A list is provided by the Search engine or
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
A Novel Architecture of Ontology based Semantic Search Engine
 International Journal of Science and Technology Volume 1 No. 12, December, 2012 A Novel Architecture of Ontology based Semantic Search Engine Paras Nath Gupta 1, Pawan Singh 2, Pankaj P Singh 3, Punit
International Journal of Science and Technology Volume 1 No. 12, December, 2012 A Novel Architecture of Ontology based Semantic Search Engine Paras Nath Gupta 1, Pawan Singh 2, Pankaj P Singh 3, Punit
The Functional Extension Parser (FEP) A Document Understanding Platform
 A Document Understanding Platform") The Functional Extension Parser (FEP) A Document Understanding Platform Günter Mühlberger University of Innsbruck Department for German Language and Literature Studies Introduction A book is more than
The Functional Extension Parser (FEP) A Document Understanding Platform Günter Mühlberger University of Innsbruck Department for German Language and Literature Studies Introduction A book is more than
Focused Crawling with
 Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
Weaving the Web(VTT) of Data
 of Data") Weaving the Web(VTT) of Data Thomas Steiner,1 Hannes Mühleisen,2 Ruben Verborgh,3 Pierre-Antoine Champin,1 Benoît Encelle,1 and Yannick Prié4 1 CNRS, Université de Lyon LIRIS, UMR5205 Université Lyon 1,
Weaving the Web(VTT) of Data Thomas Steiner,1 Hannes Mühleisen,2 Ruben Verborgh,3 Pierre-Antoine Champin,1 Benoît Encelle,1 and Yannick Prié4 1 CNRS, Université de Lyon LIRIS, UMR5205 Université Lyon 1,
Accessibility and Moodle: Jailbreak your LMS
 Accessibility and Moodle: Jailbreak your LMS Agenda for the Session Neil Squire who? What do these guys do? Accessibility Types and things to consider What does Moodle do? What should a teacher / instructional
Accessibility and Moodle: Jailbreak your LMS Agenda for the Session Neil Squire who? What do these guys do? Accessibility Types and things to consider What does Moodle do? What should a teacher / instructional
Focused Crawling with
 Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
Focused Crawling with ApacheCon North America Vancouver, 2016 Hello! I am Sujen Shah Computer Science @ University of Southern California Research Intern @ NASA Jet Propulsion Laboratory Member of The
Final dissemination and exploitation report
 European Commission Seventh Framework Programme Call: FP7-ICT-2007-1, Activity: ICT-1-4.1 Contract No: 216267 Final dissemination and exploitation report D10.5 Version 1.0 Editor: Work Package: Status:
European Commission Seventh Framework Programme Call: FP7-ICT-2007-1, Activity: ICT-1-4.1 Contract No: 216267 Final dissemination and exploitation report D10.5 Version 1.0 Editor: Work Package: Status:
Archiving the Web: What can Institutions learn from National and International Web Archiving Initiatives
 Archiving the Web: What can Institutions learn from National and International Web Archiving Initiatives Maureen Pennock Michael Day Lizzie Richmond UKOLN University of Bath UKOLN University of Bath University
Archiving the Web: What can Institutions learn from National and International Web Archiving Initiatives Maureen Pennock Michael Day Lizzie Richmond UKOLN University of Bath UKOLN University of Bath University
A network is a group of two or more computers that are connected to share resources and information.
 Chapter 1 Introduction to HTML, XHTML, and CSS HTML Hypertext Markup Language XHTML Extensible Hypertext Markup Language CSS Cascading Style Sheets The Internet is a worldwide collection of computers and
Chapter 1 Introduction to HTML, XHTML, and CSS HTML Hypertext Markup Language XHTML Extensible Hypertext Markup Language CSS Cascading Style Sheets The Internet is a worldwide collection of computers and
Data Mining Issues. Danushka Bollegala
 Data Mining Issues Danushka Bollegala Missing values What if we do not know the value of a particular feature of an instance? eg. the height of the 10-th student is missing although other feature values
Data Mining Issues Danushka Bollegala Missing values What if we do not know the value of a particular feature of an instance? eg. the height of the 10-th student is missing although other feature values
Design and implementation of an incremental crawler for large scale web. archives
 DEWS2007 B9-5 Web, 247 850 5 53 8505 4 6 E-mail: ttamura@acm.org, kitsure@tkl.iis.u-tokyo.ac.jp Web Web Web Web Web Web Web URL Web Web PC Web Web Design and implementation of an incremental crawler for
DEWS2007 B9-5 Web, 247 850 5 53 8505 4 6 E-mail: ttamura@acm.org, kitsure@tkl.iis.u-tokyo.ac.jp Web Web Web Web Web Web Web URL Web Web PC Web Web Design and implementation of an incremental crawler for
Wikipedia and the Web of Confusable Entities: Experience from Entity Linking Query Creation for TAC 2009 Knowledge Base Population
 Wikipedia and the Web of Confusable Entities: Experience from Entity Linking Query Creation for TAC 2009 Knowledge Base Population Heather Simpson 1, Stephanie Strassel 1, Robert Parker 1, Paul McNamee
Wikipedia and the Web of Confusable Entities: Experience from Entity Linking Query Creation for TAC 2009 Knowledge Base Population Heather Simpson 1, Stephanie Strassel 1, Robert Parker 1, Paul McNamee
National Centre for Text Mining NaCTeM. e-science and data mining workshop
 National Centre for Text Mining NaCTeM e-science and data mining workshop John Keane Co-Director, NaCTeM john.keane@manchester.ac.uk School of Informatics, University of Manchester What is text mining?
National Centre for Text Mining NaCTeM e-science and data mining workshop John Keane Co-Director, NaCTeM john.keane@manchester.ac.uk School of Informatics, University of Manchester What is text mining?
Tennessee. Trade & Industrial Course Web Page Design II - Site Designer Standards. A Guide to Web Development Using Adobe Dreamweaver CS3 2009
 Tennessee Trade & Industrial Course 655745 Web Page Design II - Site Designer Standards A Guide to Web Development Using Adobe Dreamweaver CS3 2009 ation Key SE Student Edition LE Learning Expectation
Tennessee Trade & Industrial Course 655745 Web Page Design II - Site Designer Standards A Guide to Web Development Using Adobe Dreamweaver CS3 2009 ation Key SE Student Edition LE Learning Expectation
Searching the Web What is this Page Known for? Luis De Alba
 Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
This document is for informational purposes only. PowerMapper Software makes no warranties, express or implied in this document.
 OnDemand User Manual Enterprise User Manual... 1 Overview... 2 Introduction to SortSite... 2 How SortSite Works... 2 Checkpoints... 3 Errors... 3 Spell Checker... 3 Accessibility... 3 Browser Compatibility...
OnDemand User Manual Enterprise User Manual... 1 Overview... 2 Introduction to SortSite... 2 How SortSite Works... 2 Checkpoints... 3 Errors... 3 Spell Checker... 3 Accessibility... 3 Browser Compatibility...
Enterprise Manager: Scalable Oracle Management
 Session id:xxxxx Enterprise Manager: Scalable Oracle John Kennedy System Products, Server Technologies, Oracle Corporation Enterprise Manager 10G Database Oracle World 2003 Agenda Enterprise Manager 10G
Session id:xxxxx Enterprise Manager: Scalable Oracle John Kennedy System Products, Server Technologies, Oracle Corporation Enterprise Manager 10G Database Oracle World 2003 Agenda Enterprise Manager 10G
Tambako the Bixo - a webcrawler toolkit Ken Krugler, Stefan Groschupf
 Tambako the Jaguar@flickr.com Bixo - a webcrawler toolkit Ken Krugler, Stefan Groschupf Jule_Berlin@flickr.com Agenda Overview Background Motivation Goals Status Differences Architecture Data life cycle
Tambako the Jaguar@flickr.com Bixo - a webcrawler toolkit Ken Krugler, Stefan Groschupf Jule_Berlin@flickr.com Agenda Overview Background Motivation Goals Status Differences Architecture Data life cycle
EXTRACT THE TARGET LIST WITH HIGH ACCURACY FROM TOP-K WEB PAGES
 EXTRACT THE TARGET LIST WITH HIGH ACCURACY FROM TOP-K WEB PAGES B. GEETHA KUMARI M. Tech (CSE) Email-id: Geetha.bapr07@gmail.com JAGETI PADMAVTHI M. Tech (CSE) Email-id: jageti.padmavathi4@gmail.com ABSTRACT:
EXTRACT THE TARGET LIST WITH HIGH ACCURACY FROM TOP-K WEB PAGES B. GEETHA KUMARI M. Tech (CSE) Email-id: Geetha.bapr07@gmail.com JAGETI PADMAVTHI M. Tech (CSE) Email-id: jageti.padmavathi4@gmail.com ABSTRACT:
DATA COLLECTION. Slides by WESLEY WILLETT 13 FEB 2014
 DATA COLLECTION Slides by WESLEY WILLETT INFO VISUAL 340 ANALYTICS D 13 FEB 2014 WHERE DOES DATA COME FROM? We tend to think of data as a thing in a database somewhere WHY DO YOU NEED DATA? (HINT: Usually,
DATA COLLECTION Slides by WESLEY WILLETT INFO VISUAL 340 ANALYTICS D 13 FEB 2014 WHERE DOES DATA COME FROM? We tend to think of data as a thing in a database somewhere WHY DO YOU NEED DATA? (HINT: Usually,
Temporal Analysis of Inter-Community User Flows in Online Knowledge-Sharing Networks
 Temporal Analysis of Inter-Community User Flows in Online Knowledge-Sharing Networks Anna Guimarães, Ana Paula Couto da Silva, Jussara Almeida Department of Computer Science - UFMG (Brazil) August 10,
Temporal Analysis of Inter-Community User Flows in Online Knowledge-Sharing Networks Anna Guimarães, Ana Paula Couto da Silva, Jussara Almeida Department of Computer Science - UFMG (Brazil) August 10,
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
You got a website. Now what?
 You got a website I got a website! Now what? Adriana Kuehnel Nov.2017 The majority of the traffic to your website will come through a search engine. Need to know: Best practices so ensure your information
You got a website I got a website! Now what? Adriana Kuehnel Nov.2017 The majority of the traffic to your website will come through a search engine. Need to know: Best practices so ensure your information
verapdf after PREFORMA
 PDF Days Europe 2018 verapdf after PREFORMA Real world adoption and industry needs for more PDF standards 1 History of verapdf / PREFROMA 2 The PREFORMA project verapdf development has been funded by the
PDF Days Europe 2018 verapdf after PREFORMA Real world adoption and industry needs for more PDF standards 1 History of verapdf / PREFROMA 2 The PREFORMA project verapdf development has been funded by the
Exploiting Semantics Where We Find Them
 Vrije Universiteit Amsterdam 19/06/2018 Exploiting Semantics Where We Find Them A Bottom-up Approach to the Semantic Web Prof. Dr. Christian Bizer Bizer: Exploiting Semantics Where We Find Them. VU Amsterdam,
Vrije Universiteit Amsterdam 19/06/2018 Exploiting Semantics Where We Find Them A Bottom-up Approach to the Semantic Web Prof. Dr. Christian Bizer Bizer: Exploiting Semantics Where We Find Them. VU Amsterdam,