LyncP. Searching for a better search. LYNC Search I m Feeling Luckier. PageRank ULocalRankU UHilltopU UHITSU UAT(k)U UNORM(p)U Umore U
|
|
|
- Posy Warner
- 6 years ago
- Views:
Transcription
1 LyncP PageRank ULocalRankU UHilltopU UHITSU UAT(k)U UNORM(p)U Umore U Searching for a better search LYNC Search I m Feeling Luckier HTURadhika GuptaUTH HTUNalin MonizUTH HTUSudipto GuhaUTH th CSE 401 Senior Design. April 11P P, 2005.
2 P P U3U Lync PageRank ULocalRankU UHilltopU UHITSU UAT(k)U UNORM(p)U Umore U Searching for a better search T"for" is a very common word and was not included in your search. [HTUdetailsUTH] LYNC Search Table of Contents HTUAbstractUTH A summary of the topics covered in our paper. Pages HTUCachedUTH - HTUSimilar pagesuth Pages 1 31 for HTUSearching for a better searchuth (2 Semesters) Sponsored Links UPROBLEM SolvedU Beta Power! HTUIntroduction and DefinitionsUTH An introduction to web searching algorithms and the Link Analysis Rank Algorithms space as well as a detailed list of key definitions used in the paper. Pages HTUCachedUTH - HTUSimilar pagesuth HTUSurvey of the LiteratureUTH A detailed survey of the different classes of Link Analysis Rank algorithms including PageRank based algorithms, local interconnectivity algorithms, and HITS and the affiliated family of algorithms. This section also includes a detailed discuss of the theoretical drawbacks and benefits of each algorithm. Pages HTUCachedUTH - HTUSimilar pagesuth UFree CANDDEU Come get it. Don t be left dangling! UA PAT on the BackU The Best Authorities on Every Subject HTUPage Ranking AlgorithmsUTH An examination of the idea of a simple page rank algorithm and some of the theoretical difficulties with page ranking, as well as a discussion and analysis of Google s PageRank algorithm. Pages HTUCachedUTH - HTUSimilar pagesuth UPaging PAGE U The shortest path to perfect search. HTUIntroducing Local Inter-ConnectivityUTH A discussion of the motivation for using local connectivity in page rank algorithms, as well as an detailed discussion and analysis of both the Hilltop and the LocalRank algorithms. Pages HTUCachedUTH - HTUSimilar pagesuth HTUHub and Authority Based Ranking AlgorithmsUTH A discussion of the HITS algorithm and the ideas of hubs and authorities as well as an examinations of variations of the HITS algorithm including PHITS, Hub Averaging HITS, SALSA, BFS, and the non-linear dynamic algorithms, AT(k) and NORM(p). Pages HTUCachedUTH - HTUSimilar pagesuth Lynnnnnnnnc Result Page: 1 U2U UNextU Coming Soon! HTULYNC Goes PublicUTH: LYNC Gets Bigger and Better!!! Searching for a better search LYNC Search HTULYNC HomeUTH - HTUBusiness SolutionsUTH - HTUAbout LYNCUTH 2005 LYNC Nalin Moniz and Radhika Gupta
3 P P UNextU Lync PageRank ULocalRankU UHilltopU UHITSU UAT(k)U UNORM(p)U Umore U Searching for a better search "for" is a very common word and was not included in your search. [HTUdetailsUTH] LYNC Search Table of Contents Pages for HTUSearching for a better searchuth (2 Semesters) Sponsored Links HTUSurvey of Rank Merging and AggregationUTH A summary of our research on rank merging and aggregation including a description of key distance measures as well as rank aggregation algorithms that we use in our implementation. Pages HTUCachedUTH - HTUSimilar pagesuth HTUHybrid Algorithm ProposalsUTH A discussion of the technical details and motivations behind six of our own hybrid algorithms developed by analyzing the flaws and strengths of the different classes of Link Analysis Rank algorithms. Pages HTUCachedUTH - HTUSimilar pagesuth HTUTechnical ApproachUTH A discussion of our approach to this project including the research done in algorithms, the implementation of the algorithms, as well as the analysis of the results. Includes system architecture diagrams. Pages HTUCachedUTH - HTUSimilar pagesuth USimple Borda U Bored of Being Alone? Lets Merge UGeometric Borda U Really Bored? Like Really Bored? UMarkov Merge U Mark My Words This is really good HTUTechnical Approach AppendixUTH Samples of the XML schema of our software, sample output, and sample surveys and results. Pages HTUCachedUTH - HTUSimilar pagesuth HTUAnalysis of Survey ResultsUTH A detailed statistical analysis of the results of our survey including a discussion of the performance of different hybrid algorithms as well as possible explanations. Pages HTUCachedUTH - HTUSimilar pagesuth HTUFuture ImprovementsUTH A discussion of possible future improvements that could be made to the hybrid algorithms. Pages HTUCachedUTH - HTUSimilar pagesuth Lynnnnnnnnc Result Page: UPreviousU 1 2 U3U Coming Soon! HTULYNC Goes PublicUTH: LYNC Gets Bigger and Better!!! Searching for a better search LYNC Search HTULYNC HomeUTH - HTUBusiness SolutionsUTH - HTUAbout LYNCUTH 2005 LYNC Nalin Moniz and Radhika Gupta
4 P P U2U 3 Lync PageRank ULocalRankU UHilltopU UHITSU UAT(k)U UNORM(p)U Umore U Searching for a better search "for" is a very common word and was not included in your search. [HTUdetailsUTH] LYNC Search Table of Contents HTUMilestones and TimelineUTH The milestones and timeline for this project. Pages HTUCachedUTH - HTUSimilar pagesuth Pages for HTUSearching for a better searchuth (2 Semesters) Sponsored Links UCSE 400 U 004 Sleepless Nights HTUConclusion and ReflectionsUTH Our thoughts, reflections, and observations on this year long project. Pages HTUCachedUTH - HTUSimilar pagesuth HTUReferencesUTH A list of all our references. Pages HTUCachedUTH - HTUSimilar pagesuth UCSE 401 U 104 Sleepless Nights UCSE 401 is Over! U No More Sleepless Nights Lynnnnnnnnc Result Page: UPreviousU U1U Coming Soon! HTULYNC Goes PublicUTH: LYNC Gets Bigger and Better!!! Searching for a better search LYNC Search HTULYNC HomeUTH - HTUBusiness SolutionsUTH - HTUAbout LYNCUTH 2005 LYNC Nalin Moniz and Radhika Gupta
5 ABSTRACT Efficient and accurate ranking of web pages in response to a query is at the core of the information retrieval on the Internet. The problem of web search has been most commonly approached through Link Analysis Rank algorithms. Google s PageRank is one of the more well known algorithms in this class, and was reasonably successful, until the growth of blogs and link exchanges allowed for the manipulation of the system. These developments gave rise to the idea of rankings should focus on links coming from the relatively more important sources the notion at the heart of the LocalRank and Hilltop algorithms. At the same time, researchers began to investigate algorithms that used a dual ranking system instead of a single ranking system. Kleinberg popularized the idea of ranking pages separately for outgoing and incoming hyperlinks in his seminal paper on Hyperlink Induced Topic Distillation (HITS). HITS and related algorithms have met with some success, yet they have fundamental symmetry flaws that mandate a shift away from the linear to the non linear system paradigm if they are to be solved. The early classes of nonlinear algorithms NORM(p) and AT(k), have performed well on a small samples of queries and moderate sized systems despite their computational limitations, but have yet to gain widespread popularity. Our project looks at the work done in non linear dynamic systems for ranking web pages, and develops hybrid algorithms that bring together the simplicity and local focus of linear algorithms like LocalRank, while exploiting the benefits of the nonlinear and other interesting paradigms. The models we propose draw from Hilltop, LocalRank, HITS, and the AT(k) classes of algorithms. Our first algorithm PROBLEM, uses the concept of beta distributed user web surfing, instead of the random surfer model of PageRank, while our second algorithm, PAGE is based on a percentage of shortest path ideas. Our third algorithm, PAT(k) is a modification of the non linear dynamic algorithm, AT(k), while our fourth algorithm CANDDE, takes a new approach to dangling links. We test our algorithms in practice by implementing a demonstrative system that crawls the web on the upenn.edu domain and retrieves the top ranked pages for a particular query on a particular algorithm. We then measure our results by asking 1
6 users on the Penn campus to participate in a survey, which asks them to rate these particular different rankings. The experimental approach we will adopt is drawn from Tsaparas (Tsaparas 67) and Kleinberg and involves comparing the performance of our algorithm with PageRank, LocalRank, Hilltop, HITS, and AT(k). To explore the newer field of rank aggregation, we also include as benchmarks, three algorithms that essentially merge PageRank and HITS using different merging schemes (Borda and Markov Chain ideas). We perform a detail statistical analysis of our results, from which we gather, that for these particular queries, the algorithms tested fall into four different performance buckets. CANDDE out performed all the other algorithms, largely because of the influence of dangling links on a small graph. PROBLEM and PAT(k) fell into the second performance bucket, that included the HITS algorithm and a Borda merge. PROBLEM performed relatively well because the Beta distribution model was effectively able to capture the fact that upenn.edu has a few central pages that contain most of the information and to which users are most likely to jump to. PAT(k) on the other hand performed well because it captured the essence of the non-linear dynamical system filtering. In the third bucket, we saw Page Rank, AT(k), and the Markov algorithms, and in the fourth, and worst performing bucket, we saw PAGE and LocalRank. Our suspicion is that the poor performance of LocalRank is best attributed to an incorrect model of user behavior. 2
7 INTRODUCTION Efficient and accurate ranking of query results is central to any information retrieval problem, particularly Web search. Given the massive size of the Internet, a ranking system must be efficient, capture the information in a query accurately, and return the most relevant web sites to the user within the first few results. Ranking algorithms that solve this problem can be roughly divided into two categories: Text Analysis Algorithms and Link Analysis Rank algorithms. In this study, we focus on Link Analysis Rank (LAR) algorithms which rank pages based on the intrinsic structure of the world wide web. The structure of the web can be represented as a graph where the nodes represent web pages, and the edges represent hyperlinks between these web pages. For a given web query, the goal of a ranking system is to rank the particular pages or nodes in terms of their relevance to the query. The rank or importance of a given web page is determined by looking at the Web graph of hyperlinks and ranking a particular page or node depending on the pages linked to it and the pages that link to it. Intuitively, a hyperlink from page a to page b can be thought of as a vote for page b from page a. LAR algorithms like PageRank, LocalRank, Hilltop and HITS build upon this idea to determine the relevance of web pages related to a certain query. A LAR algorithm takes a hyperlink graph as an input and returns a measure of importance for each node as an output. In this respect, LAR algorithms are distinct from Text Analysis Rank (TAR) algorithms which rank pages based on the frequency of the query words in a particular page (Tsaparas 59). Systems based on LAR algorithms, such as Google s search engine, have proven to be more robust than TAR algorithms because LAR algorithms are innately harder to manipulate by flooding pages with popular search keywords or by maliciously manipulating the placement of text on a page. Most LAR algorithms fall into the category of dynamic systems. A dynamic system is defined as a system that begins with an initial state for each node or page, and performs a series of repeated calculations to determine a final set of weights for 3
8 the nodes. Dynamic system based algorithms run through an iterative process that updates the node weights until they converge to a steady state (Tsaparas 59). The steady state is a vector of weights indicating of the relative importance of the pages. Dynamical systems can be broken down into linear and non-linear systems, which differ in the function g (x) that is repeated applied to the original vector of weights. In the special case where the function g ( x) = Mx where M is an time invariant n n matrix, we have a linear dynamical system and the steady state solution corresponds to the principal eigenvector of the matrix M (Tsaparas 62). PageRank, LocalRank, Hilltop and HITS are all linear dynamical systems. A non-linear dynamical system is one where g (x) is anything except a time invariant matrix. TerminologyP P Below we define some of the terms we use in the context of different algorithms in the paper. The terms defined below are highlighted when they occur in the paper. Definitions are cited for sources where they occur in the document. Affiliated pages Affiliated pages are pages that are considered similar under certain criteria. The specific definition of affiliated pages is discussed in detail in the context of the Hilltop algorithm. Authority node A page that has at least one other page pointing to it. Discussed in the context of HITS and affiliated algorithms. Back link A link coming into a page Borda s Algorithm A heuristic for rank aggregation that assigns a rank to each element and sorts the candidates by cumulative total score. 4
9 Condorcet Criteria The notion that if there is an element that defeats every other element in a majority voting, it should be ranked the highest. Dangling link A link that points to a page that is not in the set of pages in the hyperlink graph. Discussed in the context of PageRank. Expert page A page that has many links to numerous non-affiliated pages on a particular topic. Discussed in the context of LocalRank and Hilltop. Full List Referring to lists in a rank aggregation problem, a full list is a list that is a permutation of the universe of ranked items. Geodesic The shortest path between two vertices in a graph. Discussed in the context of the hybrid PAGE algorithm. Hub node A page that points to at least one other page. Discussed in the context of HITS and affiliated algorithms. Linear Dynamical System Any algorithm where the iterative operator is a linear or matrix function. Link Analysis Rank (LAR) The name for the class of algorithms which rank pages based on the intrinsic structure of the web. Local Kemenization Similar to the Kemeny optimal aggregation, a solution that satisfies the Condorcet criteria but is computationally tractable. 5
10 Kemeny Optimal Aggregation A rank aggregation solution that minimizes the Kendall Tau distance between two lists. Kendall s Tau A distance measure in rank aggregation that counts the number of pairwise inversions between two ranking lists. Non-Linear Dynamical System Any algorithm where the iterative operator is not a linear or matrix function. Page Ranking Algorithms We will use this term for the general class of algorithms that take advantage of the link structure of the web to produce a global ranking of web pages. Most of these algorithms are based on Google s PageRank algorithm. Partial List Referring to lists in a rank aggregation problem, a partial list is a list that is a subset of the universe of ranked items. Rank Aggregation The process of merging two sets of ranking lists into a single list. Rank sink A web page or a set of web pages that have no outgoing links. context of PageRank. Discussed in the Scaled Footrule A distance measure in rank aggregation that weights the contribution of an element in the list based on the length of the list. Similar pages Pages that share the same domain name. 6
11 Spearman Footrule A distance measure in rank aggregation that is based on the absolute difference between the rank of an element in the lists. Text Analysis Rank (TAR) The name for the class of algorithms which rank pages based on the frequency of the query words in a particular page (Tsaparas 59). 7
12 P Ṗ SURVEY OF LITERATURE PIn this section, we survey some of the major classes of Link Analysis Rank Algorithms. We begin by examining the simplest category of page ranking algorithms, including Google s PageRank, and analyzing the theoretical benefits and drawbacks of its approach. We then look at two other classes of algorithms that build upon Google s PageRank LocalRank and Hilltop, as well as the HITS algorithm and its variations. Again we provide an analysis of the classes of algorithms, discussing some of the theoretical benefits and drawbacks of the variations. Page Ranking AlgorithmsP P In general, we will refer to page ranking algorithms as algorithms that take advantage of the link structure of the web to produce a global ranking of a set of web pages given a specific query. The algorithms rest on the assumption that a web page with a number of other web pages pointing to it, i.e. a web page with a large number of incoming links or back links, is an important page. Of course, in addition to the number of back links, the quality of those back links is also important. For instance, a page with back links from a major site such as Yahoo or MSN will clearly be relatively more important than a page with the same number of back links from an individual s blog (Craven). Simple Algorithms for Ranking Page P P Based on this intuition, we can define a rudimentary equation for calculating the page rank of a web page, v. Define F(v) as the set of pages pointed to by v (the forward links of the page) and B(v) as the set of pages that point to v (the back links of the page). The page rank PR of v can then be defined as: n PR( i) PR( v) = d (1) i B ( v) F( i) 8
13 Intuitively, this definition can be thought of as a summation of all the incoming links of a web page v, normalized by the number of outgoing links for each incoming link (Brin, Motwani, Page, and Winograd 3). A web page with a high page rank thus is a web page not only with a large number of incoming links, but also with a large number of high quality incoming links. In the equation above, the factor d is a normalization factor between 0 and 1 to account for pages with no forward links. We can restate the above equation in terms of a square matrix C with rows and columns that represent web pages. C(i, j) is 1 if there is a link from node i to j, and if 0 otherwise. The simple page rank equation (1), can then be written as a vector where: PR = dc*pr (2) The page rank matrix PR is an eigenvector of the matrix C with corresponding eigenvalue d. We can compute the value of the page rank matrix by simply repeatedly applying the matrix C to PR until the values of the page rank matrix converge and we reach a steady state solution (Brin, Motwani, Page, and Winograd 4). Theoretical Difficulties with Page Rank Algorithms The simple page rank equation, equation 1, already gives us some insight into some of the theoretical challenges of using the link structure of the web to arrive at a measure of the importance of a web page. In this section, we discuss some of the theoretical flaws inherent in the very simple page rank equation, and how they point towards Google s solution to page rank, PageRank. 9
14 The Non-Ergodic Structure of the Web P P The first interesting challenged posed by page ranking stems from the representation of the web as a hyperlinked graph. Innately, hyperlinked graphs, even undirected ones, are not ergodic. The universe of web pages can be split into multiple smaller connected components, which can be ranked separately. Computationally, this is efficient because it is cheaper than trying to calculate the principal eigenvector of the Markov matrix for the universe of pages. Each iteration involves a matrix multiplication which is O(nP2.376P) (Coppersmith and Winograd 2). The problem is that a page rank for connected components of the undirected graph is sensitive to the initial distribution of weights across the nodes. Even if the weights are uniformly distributed, there is no way to compare the page rank of two nodes in separate connected components. This appears to be a theoretical flaw in the notion of page rank based on link analysis ranking that has no immediate or obvious solution (Rogers). Rank Sinks P P Another interesting issue, and one that is a little easier to address, is the issue of rank sinks that arise within each connected component of an undirected graph. A rank sink is defined as a web page or a set of web pages that have no outgoing links. Mathematically, one can write this definition as: S = { v : v S, w F( v) w S} (3) Looking back at the simple equation we developed for page rank calculations (1), we can see that the issue of rank sinks creeps up. If we run the algorithm on a simple example of three web pages, we can see how rank sink pages accumulate rank but never distribute them. Consider a web structure where these three web pages point only to each other and to no other page, and consider an additional fourth page that points to one of these three pages. The loop of web pages forms a rank sink (Brin, Motwani, Page, and Winograd 4). 10
15 When we developed a simple equation for page ranks, we assumed that once a user enters a loop like this, they never leave it. In reality, this is not a sensible assumption because a user is unlikely to circle around in a loop more than a certain number of times. Rather they will soon leave the loop by entering a new unrelated URL into their browser. As a solution to the issue of rank sinks, Brin, Motwani, Page, and Winograd proposed the idea of a vector over all the nodes in the hyperlinked web graph, where the vector corresponded to some source of rank. A source of rank is any page that has outgoing links. Based on this additional information, the page rank equation can now be written in modified form as: PR( v) = c( i B ( v) PR( i) F( i) + E( v)) (4) The value of c is still the same normalization factor we had seen in (1) (Brin, Motwani, Page, and Winograd 4). In matrix notation, equation 2 now becomes: PR = d(c*pr + E) (5) Since R is in normalized form, this can also be written as PR = d(c + E*1)PR (6) where 1 is a vector of 1s. PR is an eigenvector of (A + E * 1). 11
16 Dangling Links Dangling links pose another problem to page ranking algorithms. A dangling link is a link that points only to pages with no outgoing links. Since the web has so many of these dangling links and it is uncertain how they actually affect a page ranking algorithm, they cannot be ignored altogether (Brin, Motwani, Page, and Winograd 5). Later in this section, we analyze the benefits and drawbacks of the manner in which Google s PageRank algorithm deals with dangling links. Google s PageRank Algorithm Brin and Page developed a formalized algorithm for page ranking, now known as Google s PageRank by drawing from the simple idea of a page rank developed in (1) and addressing some of the issues of dangling links and rank sinks raised in the previous section. The intuition behind the algorithm is best understood by thinking about the user as a random web surfer who follows links on the web accordingly to the probability distribution of a Markov chain. The probability distribution here refers to the probability distribution of a random walk on the hyperlinked graph of the web. In this paradigm, the rank of each page is represented by the steady state or stationary distribution of the Markov chain, and is based on the percentage of time the user would spend in a state or on a particular page over a long period of time (Brin and Page 7). One can incorporate the rank sink question by thinking about the web surfer occasionally getting into a small loop of web pages. Clearly, it is unlikely that the surfer will stay in the loop forever. Instead, it is likely they will jump to another page. The factor E in (4) models the user getting bored of going around in the same loop and typing a new URL into the browser. Given those assumptions, PageRank is defined in terms of the simple page rank equation (1), discussed at the beginning of the section. The normalization factor d is used again and the value 1 d is used to model the probability of the user jumping to a random web page (thus taking into account rank sinks). Brin and Page define PageRank mathematically as: 12
17 PR( T ) PR( A) = (1 d) + d (7) n i i= 1 C( Ti ) We use the original notation used by Brin and Page to define the terms below: A : The actual page to rank. This is v in our earlier discussion. T : A page pointing to A. There are n pages pointing to A. This is i in our earlier i discussion. PR : The PageRank of the page C : The number of outgoing links from a page T. This is F in our earlier discussion. d : Dampening factor, arbitrarily determined to be 0.85 by Brin and Page in their original paper. This is the normalization factor d used in our earlier discussion (Brin and Page 7). Analysis of PageRank P P In this section, we analyze the PageRank algorithm and discuss both some of its significant strengths, as well as its theoretical weaknesses and computational drawbacks. The analysis from this section is the foundation of the hybrid models developed in a later section. THEORETICAL STRENGTHS Computational Ease PageRank is easy to compute. The PageRank of the i-th webpage is the i-th element of the principal eigenvector of the Markov chain representing a 13
18 random walk on the hyperlinked web graph. PageRank is thus computationally feasible for a universe with a large number of web pages. Scalable Given the Structure of the Web PageRank improves as the universe of web pages grows larger. The number of pages on the web is increasing exponentially and every page added to the web is just another node on the hyperlinked graph. PageRank is thus scalable given the changing structure of web. Reliable Foundations PageRank relies on links which are one of the quickest and most accurate feedback loops on the web. THEORETICAL WEAKNESSES Uniform User s Preferences (E) Google s PageRank assumes the vector E in (4) to be uniform over all web pages. This is effectively assuming that the user is equally likely to jump to any particular page on the web. Although the assumption makes PageRank computationally more tractable, it is not necessarily an accurate model of a user s behavior. In general, users are more likely to jump to particular page or set of pages that they have a preference for more frequently. For example, a user is much more likely to jump to a page in his or her Favorites than to a randomly chosen page. Ignoring Dangling Links PageRank removes dangling links from the calculation until the end, thus effectively ignoring them. Since in a computation a node distributes its weight across a number of links, including dangling links, this is a problem. Ignoring dangling links from the computation means that real links from pages with dangling links receive a disproportionate weight in the normalization process. 14
19 PRACTICAL DRAWBACKS Flawed Assumption about Link Validity PageRank assumes that each link is a valid vote for a website when often links are not really valid links at all. This is particularly problematic since guest books are being used to spam PageRank (Search Marketing Information). PageRank is also vulnerable to blog optimization. Vulnerable to Manipulation Despite its theoretical soundness, PageRank has been vulnerable to manipulation. One common attack against PageRank is to leave a bogus comment in a blog with a highly optimized link. Blogs contain a large number of links interacting back and forth and are linked to a number of times. Even though blogs by themselves are harmless, their tightly linked structure leaves room for users to exploit PageRank (Zawodny). Ignoring Dangling Links PageRank removes dangling links from the calculation until the end, thus effectively ignoring them. Since in a computation a node distributes its weight across a number of links, including dangling links, this is a problem. Ignoring dangling links from the computation means that real links from pages with dangling links receive a disproportionate weight in the normalization process. Introducing Local Interconnectivity Simple Link Analysis Ranking algorithms like PageRank that analyze the hyperlinks between pages assume that pages on a particular topic link to each other, and that important or authoritative pages point to other authoritative pages. Although the assumption in itself is not unreasonable, PageRank cannot distinguish between pages that are authoritative in general and pages that authoritative on a particular query topic. In addition to the theoretical drawbacks highlighted in the previous section, PageRank is thus also query independent. Query independence may not be a correct assumption in many cases one can fathom numerous instances where a website is important in general and may contain a single page on a query topic, 15
20 but may not be authoritative on the topic on the whole. The query Indian food on the website < is one example. PageRank would not take the notion of query relevance into account and rank CNN at the top of the search results, even though the community of users who are experts on Indian food may not consider CNN a valuable resource for Indian food (SEO Rank). In this section, we examine two algorithms, Hilltop and LocalRank, that draw off this idea and try to take into account query relevance and local inter-connectivity, while trying to retain the broad appeal of PageRank. Hilltop is an algorithm developed by Krishna Bharat at Google and George Mihaila, and explicitly incorporates the query string into the ranking process. LocalRank was also developed by Krishna Bharat more recently. However, unlike Hilltop, LocalRank does not explicitly work with the query string but tries to use this notion of local interconnectivity in a two step filtering process. In this section, we analyze both algorithms, and discuss some of their more interesting theoretical strengths and weaknesses. This analysis will filter into our development of hybrid models in later sections. The Hilltop Algorithm Hilltop is a query specific algorithm, unlike PageRank and LocalRank. At a broad level, the algorithm starts from a particular search query, and then searches for a set of expert pages that are relevant to the query (Bharat and Mihaila). An expert page can be defined as one that has many links to numerous non-affiliated pages on a particular topic. Two pages are considered affiliated if they satisfy one or more of the following criteria: 1) They originate from the same domain. The pages < < and, < would be considered part of the same domain according to the Hilltop criteria. 2) They originate from the same domain but have different top level and second level suffixes. The pages < and < are examples of two pages that would be considered similar under this criteria. 16
21 3) They originate from the same IP neighborhood because they have the same first three octets in their IP addresses and along with any page whose IP address began with would be considered similar under this criterion. 4) They originate from affiliates of affiliates. If < is hosted on the same IP octet as < then < is an affiliate of < even if they are on different IP octets. This criterion ensures that affiliation is a transitive relation. The threshold number for non-affiliated pages is arbitrarily set to five (Bharat and Mihaila). Therefore, a page has to point to at least five non affiliated pages on a particular topic to be considered an expert on that topic. Given a set of expert pages, each of these expert pages have links that match the query string exactly and other links that do not. Hilltop discards the latter and only considers pages that are pointed to by links that match the search query string exactly and also are linked to from at least two expert pages that are not affiliates. This filtered subset of pages is then ranked in a manner similar to PageRank to obtain a final ranking (SEO Rank). A Closer Look at Hilltop An expert page must have at least one URL which contains all the query keywords in the key phrases that qualify it. As an approximation, we can require expert pages to contain all the query keywords. Each expert page is assigned a score that reflects the number and importance of the key phrases that contain the query keywords, as well as the degree to which these phrases match the query. (Bharat and Mihaila) Let the search query have k terms. Let S0 be the score computed from phrases containing all the query terms, S1 be the score computed from phrases containing k 1 query terms and, S2 be the score computed from phrases containing k 2 query terms. 17
22 is scores are scores. are Let PBiB the set of phrases that match (k i) of the query terms. Define, the Level Score (LS) to be the score that characterizes the type of phrase. LS(p) is 16 if p is a title phrase, 6 if p is a heading and 1 if p is anchor text. The Level Score uses the assumption that title text is more valuable than heading text which is more valuable than anchor text, to determine the relative importance of phrases (Bharat and Mihalia). The Fullness Factor (FF) is a measure of the number of terms in p covered by terms in the query, q. Let the length of the p be l and the number of terms in p that are not in the query be m. Then the Fullness Factor is defined as: FF ( p) = 1 if m 2, FF( p) m 2 1 l = if m > 2 (8) Then a page s score is defined by: S = LS( p) FF( p) i p P i (9) The goal of this weighting scheme is to prefer expert pages that match a greater proportion of the query keywords. Hence, experts are ranked by SB0B. Ties in SB0B broken by comparing SB1B and ties in SB1B broken by comparing SB2B The score of each expert is converted to a scalar by taking the weighted sum of the three scores (Bharat and Mihaila). ExpertScor e + = (10) S0 + 2 S1 S2 18
23 Analysis of Hilltop In this section, we analyze the Hilltop algorithm and discuss both some of its significant strengths, as well as its theoretical weaknesses. The analysis from this section is the foundation of the hybrid models developed in a later section. THEORETICAL STRENGTHS Query Specific Rankings As compared to PageRank, Hilltop s strength is that its rankings are query specific. It considers the hyperlink graph that is specific to the user s query and can hence evaluate relevance of content within a specific setting. Looks at All the Experts Hilltop enumerates and considers all good experts on a given subject and hence all good target pages on the subject. If a page does not appear in the output it definitely lacks the support from other pages to justify its inclusion. Incorporates Placement of Text on Page Hilltop does not ignore the text of a page and builds the relative position of a phrase on a page into its final page rank. Titles are considered to be more important than section headings, which themselves are considered more important than hyperlink anchor-text. This combination of graph and content analysis is more robust than PageRank and LocalRank. THEORETICAL WEAKNESSES Over-Filtering and Poor Performance on Narrow Queries Hilltop s biggest strength is also its biggest weakness. The stringent filtering criteria can result in no pages being returned if very few expert documents match the search query. While PageRank and LocalRank s performance improve for more specific search queries, Hilltop s performance can actually deteriorate for the same queries. 19
24 Text based manipulation Hilltop s use of relative text placement in its ranking scheme opens it up to the same text based manipulation that TAR algorithms suffered from. Local Rank While Hilltop is a powerful algorithm, it suffers from an over-filtering problem. The filtering algorithm requires the existence of a set of expert pages, and while these expert pages are easily located for broader queries, for narrow queries, it is often hard to find a set of expert pages to begin the process with. As a result, Hilltop frequently returns no results. LocalRank, an algorithm developed by Krishna Bharat, is a more recent attempt at trying to leverage the idea of unaffiliated sources used by Hilltop, while maintain a simpler two step filtering system (Bharat). At a broad level, LocalRank is a ranking, re-ranking, and weighting procedure that runs by: 1) Filtering pages according to the standard PageRank algorithm developed by Google and taking the top 1000 pages. Each of these pages is assigned an OldRank which is their standard Google PageRank. 2) Running every one of the 1000 pages in this set through a new ranking procedure, and obtaining a LocalRank for each page. 3) Obtaining a NewRank for each page which is assigned by normalizing the OldRank and LocalRank and then weighting them to get a single new rank for every page. 4) Pages are returned to the user based on the single NewRank. Thus instead of a single level of ranking, pages are passed through two independent tiers of ranking before being shown to the users (Bharat). The first tier is filter on general usefulness and authority, and the second a filter on the Hilltop notion of local connectivity. 20
25 This notion of local connectivity or LocalRank is developed by taking every page v in the selected set A of 1000 filtered web pages, and finding every page in A that has a link to v. Call this subset of pages with links to v the set B where B A. Within B, LocalRank looks for affiliated pages. The notion of affiliated pages is defined in the same way as it is in the Hilltop algorithm pages with the same three octets in the IP address and pages that contain similar or identical documents. The set B is thus partitioned into sets of affiliated pages or neighborhoods. Within each neighborhood C, again where C B, LocalRank will discard every page except the one with the largest PageRank. Thus of all the links coming into v from the same site/domain, only the single most relevant page is taken into account (Search Guild). This process of filtering out the affiliate pages of a page v is repeated for all the remaining v pages in the set B until there is only a single page from every distinct neighborhood C in B. The resulting pages are thus a collection of unaffiliated links, and from within this set of pages, the top k pages, sorted by PageRank are filtered for further consideration. The number k is an arbitrary predetermined integer. Thus while a page v may have a large number of inbound links into it, only the top k unaffiliated links will count towards its new LocalRank (Bharat). The top k pages filtered out by this tier is referred to as the BackSet of pages. At this stage the LocalRank computation is performed on each page where the LocalRank of a page is: LocalRank = k i= 1 PR m ( BackSet( i)) (11) The factor m is a factor that is set depending on the nature of the existing PageRanks (OldRank). Typically values of m have been known to be between 1 and 3. Based on the above computation of LocalRank, the NewRank which is finally presented to the user can be computed as: 21
26 NewRank a + LocalRank b + OldRank ( )( ) MaxLocalRa nk MaxOldRank = (12) where we can define the following: a,b : arbitrary constants determined by Google. MaxLocalRa nk : maximum of the LocalRank values among the top N pages or some threshold value if this is too small. MaxOldRank : the maximum values of all the PageRank values (Krishna). Analysis of Local Rank P P In this section, we analyze Bharat s LocalRank algorithm and discuss some of its significant strengths, as well as its theoretical weaknesses. The analysis from this section is the foundation of the hybrid models developed in a later section. THEORETICAL STRENGTHS Limited Set of Pages Under Consideration LocalRank is more robust in comparison to PageRank because it considers a limited set of 1000 pages in its search. Since users typically consider the top pages from a search result, this restriction is relevant. Focus on Unaffiliated Pages LocalRank like Hilltop places a greater focus on unrelated links referencing a user s page. This is relevant for two reasons. The first is that users place value of a number of unrelated results. Providing <timesofindia.com> and <cnn.com> as two query results in response to a query on the Indian election is more valuable to a user than provide two related articles on <cnn.com> because: 1) The user can easily trace one article from another, and 2) The articles are likely to provide the same perspective. 22
27 The second reason why unrelated links are relevant is that Local Rank is harder to manipulate. This was one of the fundamental flaws seen in the practical use of Google s original algorithm. With LocalRank site administrators can no longer boost PageRank by adding large number of internal links between the sites. Less Rigid Filtering than Hilltop LocalRank despite using the notion of interconnectivity provides a less rigid level of filtering than the Hilltop algorithm. LocalRank starts with the 1000 pages that are returned on a query result, as opposed to demanding that there be a set of expert pages on a particular query topic. Thus LocalRank is more likely to work for both broad and narrow queries whereas Hilltop will produce no output on narrow and uncommon queries. THEORETICAL WEAKNESSES Query Independence Even though LocalRank uses this notion of local interconnectivity, LocalRank is query independent. The algorithm ignores the fact that page relevance is query dependent. Even if page A is more relevant than page B for query q1, page B might be more relevant than page A for query q2. Hub and Authority Algorithms In this section, we survey a class of algorithms based on modifications of the Hyperlink Induced Topic Distillation (HITS) algorithm developed by Jon Kleinberg. We first look at the HITS algorithms and the concepts of hubs and authorities. We then look at some of the interesting variations to the algorithm including PHITS, SALSA, Hub Averaging HITS, and PSALSA. Finally we conclude with some of the work done by Tsaparas in the non-linear dynamical systems space, again building on Kleinberg s original HITS algorithm. 23
28 The HITS Algorithm P P The task of ranking pages has different challenges for broad and specific queries. Narrowly defined searches face a scarcity problem, since very few pages contain the information required by the query. The fundamental problem is to find the right pages that match the specific query. On the other hand, broad queries face an abundance problem. The principal challenge with broad queries is to rank the thousands of web pages that match the query s keywords and filter out the most authoritative pages. Kleinberg conceptualized HITS to effectively filter out these authorities. An authority node is a defined as a page that has at least one other page pointing to it. On the other hand, a hub node is a page that points to at least on other page. Authorities and hubs can be thought of mutually reinforcing each other in the hyperlink graph. A good authority is one that is linked to from many good hubs, while a good hub is one that links to many good authorities (Kleinberg 5). Unlike PageRank, HITS constructs query specific subgraphs. Kleinberg starts with a root set, R σ consisting of the top 200 pages returned by a TAR algorithm for the search query. For each page p R σ, Rσ is then augmented with the set of all the pages that p points to and at most d of the pages that point to p. If there are more than d pages that point to p, the d pages are chosen at random. Kleinberg set d = 50 when benchmarking the performance of HITS (Kleinberg 5). The augmented R σ is then filtered for similar pages. Two pages are defined to be similar if they share the same domain name. Finally, as Kleinberg points out a large number of pages from a single domain often all point to a single page. This could represent a mass endorsement, advertisement or a plain attempt to increase the page s ranking. This phenomenon can be eliminated by allowing only up to m pages (m 4 8) from a single domain to point to any given page p (Kleinberg 7). Mathematically, for a hyperlinked graph, define an adjacency matrix A such that: A ij = ( i, j) E 1 else 0 (13) 24
29 norm and norm. converge are Let B(i) be the set of nodes that point to node i and let F(i) i points to. Then, be the set of nodes that { j [ n] A 1} { j [ n] A 1} B ( i) = = ji F ( i) = = ij (14) Let ai and h i be the authority and hub weights of node i. The mutual reinforcement between hubs and authorities is defined so that hub and authority weights are: a = i [n] i h j j B(i) h = i [n] i a j j F (i) (15) The HITS algorithm starts with uniform vectors for both the hubs and authorities that have normalized in the LB2B and then applies (15) iteratively. At each stage, the authority and hub vectors are normalized in the LB2B The algorithm usually converges to a stable state in about 20 iterations (Kleinberg 9). The steady authority and hub vectors, ap*p hp*p to the principal eigenvectors of A T T A and AA respectively. The magnitude of the elements of a* can thought of as relevance scores. When the elements of ap*p sorted, they represent rankings of pages. Ties are broken, by ranking the elements of the eigenvector with the second largest eigenvalue (Kleinberg 11). In comparison to LocalRank, HITS calculates hub and authority weights in a complementary manner and furthermore, considers equally all the authority weights of pages that are pointed to by a page (Tsaparas 60). However, HITS has a conceptual problem in that hubs and authorities are not the same. A node with a large in-degree is likely to be an important authority but a hub node with a large out-degree is not necessarily a good hub. If this were the case, then adding links to random pages would increase the hub ranking of a page. In any ranking system, quantity should not never dominate quality. 25
30 The PHITS Algorithm PHITS is an algorithm developed by Cohn and Chang that makes a small statistical improvement to HITS. The algorithm assumes that the incoming links (i) of a page p are driven by a latent factor z. Cohn and Chang propose that there are conditional distributions P ( i z) of an incoming link i given z and conditional distributions P ( z p) of the factor z given page p. P( i z) and P ( z p) can be combined to produced a likelihood function that can be maximized to solve for z (Borodin, Roberts, Rosenthal, and Tsaparas 2). The problem with the PHITS algorithm is that it requires one to specify in advance the number of z factors that need to be considered. Cohn and Chang s approach is not computational feasible in practice has little intuition behind the number of z factors or their estimated values. Hub Averaging HITS One of the flaws of HITS is that it considers hubs that point to a lot of authorities to be good hubs. However, it makes more intuitive sense to average the authority weights to eliminate the effect of a hub pointing to many poor authorities. Under Hub Averaging HITS, another variation of Kleinberg s algorithm, a hub is superior only if it links to good authorities on average. The algorithm rightly prefers quality over quantity. As an example of a case where Hub Averaging HITS is superior to HITS, consider a graph with two hubs and a very large number of authorities. The first hub points to only the top authority, while the second hub points to all the authorities except the top one. Under HITS, it is possible that the second hub will be considered stronger because the weight of the best authority can be less than the sum of the weights of the other authorities. However, the first hub is intuitively superior. Hub Averaging HITS takes this into account by averaging authority weights and clearly indicating that the first hub is superior. 26
31 SALSA and PSALSA P P The Stochastic Approach to Link Structure Analysis or SALSA approaches the ranking problem through Kleinberg s authorities and hubs framework. However, SALSA uses a two step Markov chain model instead of PageRank and HITS one step Markov chain model. The set of authorities and hubs can be thought of vertices in a directed bipartite graph, whose edges represent links from hubs to authorities (Borodin, Roberts, Rosenthal, and Tsaparas 2). SALSA uses a random walk over this hub-authority graph where a step consists of a combination of a following a link forward and following a link backward. The algorithm constructs two Markov chains A and H for authorities and hubs. The authority Markov chain models a random walk that follows a link backward and one forward. Two authorities are connected if and only if there is a hub that points to both of them. On the other hand, the hub Markov chain models a random walk that follows a link forward and then one backward. Two hubs are connected in this model, if and only if they both point to a common authority (Lempel and Moran). Define the set of all nodes pointing to a page i (all the incoming links into page i) as: { k k i} B( i) = : (16) and all the outgoing links of page i (all the nodes we can follow out from node i) as: { k i k} F( i) = : (17) The transition probabilities of the authority Markov chain are defined as: 27
32 1 1 P a ( i, j) = (18) k: k B( i) B( j) B( i) F( k) The Markov chain for the hubs similarly has probability distribution: 1 1 P h ( i, j) = (19) k: k F ( i) F ( j) F( i) B( k) In the special case of a single connected component, the stationary distribution of the Markov chains for authorities and hubs satisfy: B( i) a i = for a = ( a1, a2,..., an ) (20) B and, H ( i) f i = for h = ( h1, h2,..., hn ) (21) H where U i B = B( i) and F = U F( i) are the set of backward and forward links respectively (Lempel and Moran). i SALSA is less vulnerable to the tightly-knit community effect than HITS. A tightly-knit community is a set of vertices that form a clique or closely approximate a clique. The tightly-knit community effect occurs when a LAR algorithm ranks the vertices in a clique or approximate clique highly even though the pages are not authoritative on the query topic. Lempel and Moran show that the authority-hub mutual reinforcement effect of HITS is vulnerable to the tightly-knit community effect, while SALSA eliminates this effect by considering the two step Markov chain (Lempel and Moran). PSALSA is an incremental improvement on SALSA that takes into account the popularity of a page within a neighborhood when computing the authority weights. 28
33 The Breadth First Search Algorithm P P Before we survey the Breadth First Search or BFS algorithm, we define some terminology. Let a B path be a path we follow if we follow a link backwards and an F path a path if we follow a link forward. A BF path is a path we follow if we follow a link backwards then forwards (Borodin, Roberts, Rosenthal, and Tsaparas 4). The BFS algorithm is a hybrid of the PSALSA and the HITS algorithm. PSALSA takes into account the popularity of a page within a neighborhood when computing the authority weights while HITS takes the structure of the graph into account rather than doing a detailed link analysis. BFS takes the idea of local popularity in PSALSA and extends it from a single link to an n-link neighborhood. Instead of n looking at the number of ( BF) paths that leave i, it considers the number of n ( BF) neighbors of node i (Borodin, Roberts, Rosenthal, and Tsaparas 5). We define n ( BF) (i) as the set of nodes that can be reached from i by following a n ( BF) path. The contribution of a node j to the weight of a node i depends on the distance of j from i. The weight of i can be written as: n 1 n 2 n 3 ai = 2 B( i) + 2 BF ( i) + 2 BFB( i) +... (21) The BFS algorithm then starts at node i and does a breadth first search on its neighbors. It takes a backward or forward step on each iteration and includes the new nodes it comes across. The weight factors are updated accordingly to compute the final weights (Borodin, Roberts, Rosenthal, and Tsaparas 5). Non-Linear Dynamic SystemsP P Many of the algorithms that we examined including PageRank, Local Rank, and HITS fall into the category of linear dynamic systems based algorithms because the iterative function we apply is a linear or matrix operator. In this section, we study 29
34 variations on HITS where the iterative operator is not a linear function, specifically looking at the AT(k) and the NORM(p) algorithms. Both algorithms fall into the category of non linear dynamic systems because the iterative function is not a matrix operator. Non-linear dynamic systems are a less researched area within Link Analysis Rank algorithms simply because the algorithms lack a closed form solution and thus the weights have to be computed through an iterative process that is computationally and memory expensive for large matrices. In addition, there is no guarantee that the algorithms converge to a steady state of weights or page relevance measures. Depending on the choice of parameters, the algorithms might converge to a cycle or the system may become chaotic and converge to a strange attractor. Since commercial systems cannot compromise on quality or speed of search results, non linear systems have not caught on, though small tests on hyperlinked graphs have shown promising results (Tsaparas 62). That said, we look at AT(k) and NORM(p) for potential ideas for improvements on the HITS algorithm that could be applied to a hybrid model. The AT(k) Algorithm P P A variation on HITS, the Authority Threshold (AT(k)) algorithm considers only the k most important authorities when calculating hub weights. Let F k (i) be the subset of F(i) that considers only the k most important authorities. Then the hubs and authorities can be calculated as: a = i [n] i h j j B(i) h = a i [n] i j j F (i) k (22) If k is greater than the maximum out-degree of the hyper link graph, AT(k) reduces to standard HITS (Tsaparas 61). The NORM(p) Algorithm P P Another non-linear dynamic variation of HITS the NORM(p) family of algorithms scale the authority weights instead of considering only a subset of authority nodes. 30
35 P Instead of choosing arbitrary scaling parameters, a NORM(p) algorithm uses the norm of authority weight vector. The hubs and authorities can be calculated as: a = i [n] i h j j B(i) p h i = a j j F ( i) 1/ p i [n] (23) As p increases, the bigger authority weights dominate increasingly. If p is 1, NORM(p) reduces to HITS (Tsaparas 61). 31
36 PḄ. B Ṗ SURVEY OF RANK MERGING AND AGGREGATION PAn interesting dimension to web page ranking is rank aggregation, the problem of merging two different rankings of a data set in an optimal manner. One could think for instance, of running a search query using two distinct ranking algorithms such as PageRank and HITS, and merging the results of those rankings into a final user ranking. Rank aggregation of results from different web search algorithms is particularly interesting given the number of different search algorithms, the fact that no single algorithm can be optimal for all users, and that no search engine is fully comprehensive in its web search. While our research is still primarily focused around the development of hybrid algorithms, we chose to explore the rank merging area, at least briefly this semester. In this section, we describe a survey of the literature on rank merging, as well as the additional algorithm ideas that stem out of this survey. Definitions and TermsP P We define a list τ with respect to a universe U as an ordering of a subset S of U, where: τ = x > x >... > x ] x S (24) [ 1 2 d i and > is an ordering relation on S. We can also denote τ(i) as the rank of i. If τ contains all the elements in U, then we call it a full list, i.e. a permutation of U. If τ is a subset of U, on the other hand, then we define it as a partial list (Dwork, Kumar, Naor and Sivakumar 2). Distance Measures P P In this section, we discuss various criteria to measure the distance between two particular list rankings. Both the Spearman footrule and Kendall tau distance 32
37 measures discussed below are common metrics of judging the performance of rank aggregation schemes. Spearman s Footrule P P The Spearman footrule distance is defined as the sum over all the elements i in S, of the difference (absolute) between the rank of element i in the two lists. Given two lists, υ and τ, we define Spearman footrule as: SF ( υ, τ ) = υ( i) τ ( i) (25) i We can normalize this value by 1 2 S to obtain the standardized footrule. 2 Spearman s footrule is a linear time computation (Dwork, Kumar, Naor and Sivakumar 2). Kendall Tau P P The Kendall Tau distance is a metric that counts the number of pairwise disagreements between two lists. Formally, we can define the Kendall tau distance between two lists, υ and τ as: KT( υ, τ ) ( i, j) : i < j, υ( i) < υ( j) τ ( i) > τ ( j) = (26) 1 2 We can normalize this value by S( S 1) to obtain the normalized Kendall tau distance. Intuitively, we can think of Kendall tau as a bubble sort distance, and hence it is easy to see that the Kendall tau distance between two lists with n elements is computed in n log n time. 33
38 We can define the Kendall tau and Spearman footrule metrics above for partial lists, as well as multiple lists (Fagin, Kumar, and Sivakumar 2). Scaled Footrule P P The scaled footrule is a metric to measure distances between a full and partial list. Scaled footrule weights the contribution of an element i in a list L based on the length of the list L. (Fagin, Kumar, and Sivakumar 2). If υ is a full list and τ a partial list, then the scaled Spearman footrule is: SSF υ, τ ) = υ( i) / υ τ ( i) / τ ( (27) i τ Optimal Rank Aggregation P P The best rank aggregation is a truly subjective term because it depends on the distance that is optimized. For instance, if we minimize the Kendall tau distance, we have a Kemeny optimal aggregation that theoretically corresponds to the geometric median of the inputs. Kemeny optimizations have a maximum likelihood interpretations, and eliminate the noise from different rankings. This notion of eliminating noise is linked to the notion of eliminating spam in the web page world and is particularly relevant to our research. Computationally, a Kemeny optimal aggregation is an NP hard problem. In their paper, Rank Aggregation Methods for the Web, Kumar and Sivakumar show that the Kemeny optimization is well approximated by the Spearman footrule optimization, which is a polynomial time computation. Mathematically, if σ is the Kemeny optimization of lists π i and ω is the footrule optimization, then (Dwork, Kumar, Naor, and Sivakumar 4) show that: K ϖ, τ,..., τ ) 2K( σ, τ,..., τ ) (28) ( 1 k 1 k 34
39 where Rank Aggregation Methods P P In this section, we discuss different algorithms for rank aggregation, some of which we use in our hybrid implementations. Borda s Algorithm P P Borda s method is a simple method of rank aggregation that assigns a score to the rank an element has, and then sorts candidates by the cumulative total score. It is computationally simple (linear time), but does not satisfy the Condorcet criterion. Formally, given lists τb1b,..., τbk Bfor every element c in the universe S, Borda s aggregation assigns a score B(i, c) for every full list B τbi B(i, c) is the number of candidates ranked below c in the full list, and the Borda score B(c) is defined as Σ B(i, c). Candidates are ranked by decreasing Borda score. Borda s method has numerous variations such as sorting on different L(p) norms, sorting by median values, sorting by geometric means, etc (Fagin, Kumar, and Sivakumar 4). Footrule and Scaled Footrule Optimization P P In the previous section, we discussed Kemeny optimal aggregation as well approximated by scaled footrule aggregation. In the case of full lists, foot rule optimal aggregation is akin to the median of values in a position vector. Given a set of full lists if the median positions of the candidates i in the lists form a permutation, then this is a footrule optimal aggregation. Computationally, the footrule optimal aggregation of a full list can be computed in polynomial time because it is equivalent to find a minimum cost perfect matching in a bipartite graph. Kumar and Sivakumar prove this in their paper. In the case of a partial list, the problem is NP hard. For full lists, Sivakumar and Kumar define a bipartite graph, where the weight W (c, p) is the scaled footrule distance from the partial lists of a ranking that places c at position p in the list, and is denoted by 35
40 i ( ( c ) / τ ) ( p / n) τ i i (29) The minimum cost matching solution gives us the scaled footrule aggregation (Fagin, Kumar, and Sivakumar 6). Markov Chain Methods P P In this section, we discuss different proposed methods for aggregation lists using Markov chain. Broadly speaking, the n candidates correspond to the states of the chain, and the transition probabilities depends on the lists. The Markov chain ranking is the aggregated final ranking. Markov chain methods have gained attention because: 1) They handle partial lists by exploiting the connectively of the chain to infer comparisons between pairs that were not explicitly ranked. 2) They are more meaningful than ad hoc majority based references. 3) They handle uneven comparisons, for instance if a page appears in the bottom half of a majority of the lists, and the top of the other minority, then the Markov chain methods look at the quality of the lists. 4) They enhance heuristics from the HITS and Page Rank algorithms. 5) They are computationally efficient, i.e. polynomial time algorithms. In this brief overview, we examine four of the Markov chains ideas proposed by Kumar and Sivakumar (Dwork, Kumar, Naor, and Sivakumar 5). 36
41 Markov Chain I Transition Matrix: If the current state is P, then the next state is chosen from the pages that were ranked higher than P by all lists that ranked P. Intuition: We move from the current page to a better page, with a 1/k probability of staying in the same page, where k is the average rank of the current page (Dwork, Kumar, Naor, and Sivakumar 7). Markov Chain II Transition Matrix: If the current state is P, then the next state is chosen by picking a ranking x from all the lists that rank P, and then picking a page Q from the set of pages Q where x(q) is at most x(p). Intuition: This chain accounts for several lists of rankings, rather than a pairwise comparison. This scheme protects minority viewpoints, and generalizes the geometric mean analogue from Borda s method (Dwork, Kumar, Naor, and Sivakumar 7). Markov Chain III Transition Matrix: If the current state is P, then the next state is chosen by picking a ranking x from the partial lists containing P, and then picking a page Q ranked by x. If x(q) < x(p), we move to Q else we stay at P. Intuition: This idea generalizes the Borda scheme, in particular if the initial state is chosen uniformly, after one step, the chain produces a ranking such that P is ranked higher than Q if the Borda score of P is higher than that of Q (Dwork, Kumar, Naor, and Sivakumar 7). Markov Chain IV Transition Matrix: If the current state is P, then the next state is chosen by picking a page Q from the union of all pages ranked by the search engines. If x(q) < x(p) for a majority of lists x, then we move to Q else we stay in P. Intuition: This idea generalizes the idea of sorting by the number of pairwise contests an element as won (Dwork, Kumar, Naor, and Sivakumar 7). 37
42 Spam Resistance and the Condorcet Criterion The Condorcet criteria refers to the simple notion that if there is an element that defeats every other in majority voting, it should be ranked the highest. The extension to this is that if there is a partition (C, D) of a universe S where for any x in C and y in D, the majority prefers x to y, then x should be ranked above y. This principle, known as the extended Condorcet criterion, has a number of properties that can be classified as spam fighting and have received much interest of late. As Kumar and Sivakumar show, spam pages are likened to Condorcet losers, and occupy the bottom partition of any aggregated ranking that satisfies the Condorcet criterion. Moreover, if good pages are preferred by the majority to bad ones, they will be Condorcet winners and ranked highly in an aggregation. The above aggregation methods do not ensure a Condorcet winner. Kumar and Sivakumar suggest a process of modifying the initial aggregation of input lists so that the Condorcet losers are pushed to the bottom of the ranking process. This method of local Kemenization has shown significant metric improvements when tested on the Borda and Markov chain aggregation methods in practice (Fagin, Kumar, and Sivakumar 8). Local Kemenization A local Kemeny optimal aggregation satisfies the Condorcet principle, and is similar to a Kemeny optimal aggregation. We can define a list M as a local Kemeny optimal aggregation of partial lists if it is impossible to reduce the total distance to the partial lists by flipping any adjacent pair. The Kemeny optimal aggregation can be calculated in n log n time. A local Kemenization of a full list with respect to a set of partial lists computes a locally Kemeny optimal aggregation of the partial lists consistent with the full list. In particular, in such an aggregation, 1) The Condorcet losers receive the lower ranks and the winners receive the higher ranks. 2) The result disagrees with the full list on any pair (i, j) if a majority of the partial lists disagree with the aggregation on (i, j). 38
43 3) For all values between 1 and the length of the aggregation x, length x prefix of the output is a local Kemenization of the top x elements in the full list (Fagin, Kumar, and Sivakumar 9). Implementation of the Rank Aggregation Algorithms We incorporate some of the above research on rank aggregation into our hybrid algorithms analysis, by testing in addition to our own hybrids and existing algorithms, rank aggregation on two existing algorithms: PageRank and HITS. We take the results of ranking web pages on PageRank and HITS, and then merge them using different schemes an arithmetic sum Borda, Borda with a geometric mean, and Markov Chain I. We compare these results to the results from our other ranking tests to see whether merging the results of existing algorithms buys us anything. The different algorithms are discussed in the section on hybrid algorithms. 39
44 PḄ. B Ṗ HYBRID ALGORITHM PROPOSALS PIn this section, we discuss the motivations and technical details behind six hybrid algorithms that represent improvements to existing LAR algorithms. Each hybrid algorithm takes the strengths of one or more of the existing PageRank, LocalRank, Hilltop, HITS and SALSA algorithms and puts them together to form more robust algorithms. The PROBLEM AlgorithmP P PageRank assumes that the user is equally likely to jump any page on the Internet not linked to the current page. However, this is not an accurate description of user s behavior. In practice, users jump to a few selected pages such Favorites with high probability and do not ever visit other pages. In the PROBLEM (Page Rank on Beta-Distributed Link E Matrix) algorithm, we model our intuition that users have different affinities for different pages by assuming that users have a probability p of jumping to any page. The probabilities p are drawn from a beta distribution. The beta distribution gives us tremendous flexibility in modeling user s preferences by using just two non-negative parameters - α and β. The probability density function for p is Pr{ p = x} = 1 x β ( α, β ) α (1 x) β 1 where β ( α, β ) = Γ( α) Γ( β ) Γ( α + β ) (30) and Γ( x) = t 0 e x 1 t dt 40
45 norm. The beta distribution is a generalization of PageRank s uniform distribution, because it reduces to the uniform distribution from 0 to 1, when α = β = 1. The elements of E can be drawn from this beta distribution and then normalized in the LB1B The beta distribution gives us the flexibility to model user s preferences. Let: α µ = and α + β φ 1 = α + β + 1 (31) The parameter µ is defined to be the mean of the beta distribution, while φ can be thought of as a dispersion index. As α and β approach 0, φ approaches 1 and the values of p become concentrated near 0 and 1. This models the fact that web pages can be segmented into broad categories. Pages that the user jumps to very frequently have p 1, while pages that the user rarely jumps to have p 0. As α and β approach, φ approaches 0 and the values of p become concentrated around µ and the normalized vector E begins to approximate Brin, Page, Motwani and Winograd s uniform vector. Hence, φ measures the polarization of a user s preference for web pages. Figures 1 and 2 illustrate the probability distribution function for the beta distribution for different combinations of α and β. Beta Distributions - I p(x) a=5,b= 5 a=1,b=1 a=0.5,b= x Figure 1 41
46 Given an intuitive model for a user s preferences, we can set values of µ and φ and then use the fact that µ ( 1 φ) α =, φ ( 1 µ )(1 φ) β = (32) φ to obtain α and β for the beta distribution to draw the values of E from. The distribution that seems the most plausible is the blue function from Figure 2, with α = 0.5 and β = 1.5. If we use this function to model the elements of E, we will have a few pages with a high probability of being jumped to and Beta Distributions - II p(x) a=1.5,b=0.5 a=0.5,b=1.5 a=2,b= x Figure 2 a large number of pages with a low probability of being jumped to. The beta distribution needs to have the reverse J-shape of the blue function in Figure 2 if our model is to make intuitive sense. 42
47 Beta Reverse J-Shaped Mode at (a-1)/(a+b-2) 1 U-Shaped J-Shaped 0 1 Alpha Figure 3 Figure 3 below illustrates the different shapes of the beta distribution for different combinations of α and β. From the graph, we can see that we need α < 1 and β > 1 in order to obtain a reverse J- shaped probability distribution function. THEORETICAL STRENGTHS Flexibility of the Beta Distribution The beta distribution gives us tremendous flexibility in modeling the heterogeneity user s preferences with just two extra parameters. Figures 1 and 2 illustrate this flexibility with 6 possible shapes that the beta distribution could take on. Stronger Jump Model The PROBLEM algorithm gives us a much more intuitive view of how people behave while actually surfing the web. THEORETICAL WEAKNESSES Difficult to estimate model parameters Even though we established that the beta distribution needs to have α < 1 and β > 1, we do not have any heuristic to determine the optimal values of α and β. 43
48 Sensitivity to model parameters The PROBLEM algorithm s rankings are sensitive to the beta distribution s parameters. Therefore, the choice of α and β is very important. PageRank s inherited flaws Since the PROBLEM algorithm is built on top of the PageRank algorithm, it inherits PageRank s shortcomings such as dangling links, query independence and link farming described in the PageRank section. The CANDDE AlgorithmP P Given an incomplete graph of the web page, it is too important to ignore dangling links like PageRank does. This artificially boosts the importance of legitimate outgoing links from pages with dangling links and can have dramatic effects on the final ranking of web pages. The CANDDE (Centralized And Neutrally Dispersed Dangling Edges) algorithm corrects the omission of dangling links, by augmenting the web graph with a central dummy vertex to which all the dummy links are assumed to point to. The central dummy vertex disperses page rank uniformly across all the vertices by linking to each of the original nodes once. The central dummy node eliminates the effect of dangling links on legitimate links from pages with dangling links. The only concern with the addition of this dummy vertex is its impact on the ranking of pages. The principal eigenvector of the PageRank Markov matrix corresponds to a steady state vector. Intuitively, we can think of the i-th element of the principal eigenvector as the proportion of time that a random walk would visit page i over a very long period of time. With the addition of the central dummy vertex, a random walk spends a smaller proportion of time in each of the real vertices of the web graph. Mathematically, this means that the elements of the principal eigenvector of the augmented web graph are smaller than their corresponding elements in the principal eigenvector of the PageRank web graph. The effect of the dummy vertex is most pronounced on vertices which have a large proportion of dangling links. The ranking of these pages will be diminished because 44

49 their links to other real pages in the web graph become less important. Similarly, pages which have a large number of incoming links from pages with dangling links will have their ranking reduced. An Example of the CANDDE Algorithm Figure 4 illustrates a graph with three pages, A, B and C. Pages A and B have dangling links that are eliminated by PageRank. Dangling Dangling A Dangling C B Figure 4: Original Graph Figure 5: PageRank Solution The PageRank graph is shown in Figure 5, while Figure 6 illustrates the graph created by the CANDDE algorithm. The principal eigenvectors are 45

50 is norm, 0 V PageRank = 0.5 and 0.5 V CANDDE 3 / / 37 = 11/ 37 9 / 37 where the last element of B VBCANDDE the dummy vertex element. After we remove the dummy vertex element and take the LB1B we get the final ranking 3 / 28 vector, V CANDDE = 14 / 28. As mentioned earlier, B s rank gets boosted and A has a 11/ 28 non-negative rank because it has an incoming link from the dummy vertex. THEORETICAL STRENGTHS Figure 6: CANDDE Solution Democratic Treatment of Dangling Links The CANDDE algorithm presents perhaps the most democratic and fair manner of dealing with dangling links. Every sample hyperlink graph can be expected to have a significant number of dangling links and hence it is important that we do not sweep them under the carpet. 46
51 P THEORETICAL WEAKNESSES PageRank s inherited flaws Since the CANDDE algorithm is built on top of the PageRank algorithm, it inherits PageRank s shortcomings such with regards to query independence ranking and link farming described in the PageRank section. Rankings are graph dependent As we increase the size of the hyperlink graph, the percentage of dangling links is expected to go down. Since, the CANDDE algorithm is sensitive to dangling links, the rankings are dependent on the size of the web graph. The Percentage Authority Threshold or the PAT(k) Algorithm P The AT(k) algorithm considers only the k most important authorities when calculating hub weights. However, if the hub links to less than k authorities, this filtration is rendered useless. The PAT(k) algorithm, corrects this problem by considering the top k% of authorities. This captures the intuition behind the AT(k) algorithm and ensures that the filtration of weak authorities when calculating hub weights always works. Let F k (i) be the subset of F(i) that considers only the k% most important authorities. Then the hubs and authorities can be calculated as: a = i [n] i h j j B(i) h = a i [n] i j j F (i) k (33) If k = 100%, PAT(k) reduces to standard HITS. THEORETICAL STRENGTHS More Intuitive Filtering of Authorities Percentage based filtering is a far more intuitive and robust way of retaining the top authority nodes than absolute number based filtering. 47
52 and THEORETICAL WEAKNESSES Hubs and Authorities Framework s inherited flaws Since the PAT(k) algorithm is built on top of the hubs and authorities framework, it has the same weaknesses as HITS and other related algorithms. The PAGE Algorithm P P As an Internet user surfs the world wide web, he/she follows hyperlinks, with the aim of getting from one page to another. A plausible model of a user s behavior is to assume the user follows the shortest path from one page to another page. The PAGE (Percentage of Aggregate Geodesic Edges) algorithm exploits this idea to rank web pages. The rank of a page is defined to be the percentage of shortest paths that pass through the page. The PAGE algorithm first reduces the unweighted hyperlink multi-graph to a weighted simple directed graph in which the weights of the edges are the number of edges between the two vertices in the original multi-graph. Given a hyperlink graph, G = ( V, E), there are O ( n 2 ) shortest path between the vertices. These shortest paths or geodesics can be computed in O( n 3 ) using the dynamic programming approach of the Floyd-Warshall algorithm. Let SBijB be the shortest path between vbib vertex, vbkb. Then, we can define: vbjb. Let σ ( i, j, k) be a binary filtration on a σ ( i, j, k) = 1, if vk Sij and 0 otherwise. (34) Also, let the total number of directed shortest paths between all the vertices be T. Then the ranking of a vertex is then defined as: R( v ) = k n n i= 1 j= 1 σ ( i, j, k) T (35) 48
53 There are O ( n 2 ) shortest paths, each of which have length O (n). Therefore, the calculation of R( v k ), k [ n] takes O( n 3 ) time. THEORETICAL STRENGTHS Computationally efficient The PAGE algorithm is more computational efficient than HITS. The algorithm runs in O( n 3 ) which is very efficient for large hyperlink graphs. THEORETICAL WEAKNESSES In Degree Dependence The PAGE algorithm s biggest weakness is that it favors pages with high in-degree. This is a direct consequence of the shortest path computation. The Percentage Local Rank Algorithm P P PLocalRank(k) and PAT(k) have a similar philosophy. LocalRank only considers the top 1000 pages, while PLocalRank(k) considers the minimum of 1000 and the top k% of pages. This makes more intuitive sense than considering a fixed number of pages for every query. If the query returns less than 1000 pages initially, LocalRank will consider all the pages and its filter becomes essentially useless. On the other hand, PLocalRank(k) s filter always works by considering the top k% of pages. PLocalRank(k) reduces to LocalRank, when k is 100% and approximates the behavior of LocalRank for broad queries. Even so, the rankings of the two algorithms can differ significantly because of subtle changes to the underlying link structure of the reduced sub graph. The Relaxed Hilltop Algorithm P P Hilltop has the most stringent filtration criteria among all the algorithms that we surveyed in this paper. As mentioned earlier, this can lead to no results being 49
54 returned if the query is too specific. To correct this flaw, Relaxed Hilltop makes the filter for affiliated pages less stringent. Instead of requiring to two pages fulfill one of the four Hilltop criteria in order to be classified as affiliated pages, the algorithm can require web pages to satisfy two, three or all four of the criteria. This ensures that the algorithm ranks a larger subset of the universe of web pages and has a lower probability of not returning any results. The Hilltop HITS Algorithm Kleinberg attempts to filter affiliated pages before running his HITS algorithm for ranking pages. However, Kleinberg s definition of affiliated pages lacks the real world rigor of Hilltop s definition. Hilltop-HITS combines Hilltop s filtration of affiliated pages with Kleinberg s powerful HITS algorithm. The analysis of Hilltop- HITS is the same as that of HITS. Implementation of the Rank Aggregation Algorithms We incorporate some of the research on rank aggregation into our hybrid algorithms analysis, by testing in addition to our own hybrids and existing algorithms, rank aggregation on two existing algorithms: PageRank and HITS. We take the results of ranking web pages on PageRank and HITS, and then merge them using different schemes simple Borda, Borda with a geometric mean, and Markov Chain I. We compare these results to the results from our other ranking tests to see whether merging the results of existing algorithms buys us anything. 50
55 B Ṗ TECHNICAL APPROACH PIn this section, we summarize the technical approach we took towards this search, as well as the technical implementations of our hybrid algorithms. We discuss the process of algorithms research, developing the hybrid models, implementing the algorithms and running the algorithms on the test graphs, and carrying out user surveys to analyze our data. Finally we describe the challenges, achievements, and learning lessons over the last one year. Our Hybrid SystemP P We spent the last one year researching and developing various algorithms for web page ranking. What we have at the end of our project is a set of hybrid algorithms, some built on existing algorithms and ideas we have researched, and some more radical in so as they represent a change in the way of thinking about this problem. We also have some early algorithms that essentially use rank aggregation to merge the results of searching with two different algorithms, notably HITS and PageRank. The following set of hybrid algorithms that we have developed, are described in detail in the section, Hybrid Algorithms. PROBLEM PAT(K) CANDDE PAGE In addition, the implementation side of our work consists of simple Java implementations of our hybrid algorithms, as well as of the existing benchmark algorithms, including Page Rank, Local Rank, ATK, and HITS. In order to run some benchmarking tests on our algorithm, we looked at different seed pages to run our algorithm on, and finally ended up choosing the upenn.edu domain. We implemented Java web parsing code to crawl the web, and output 51
56 the result of different pages into XML. We then parse this XML in Java to create web graphs, on which we run our ranking algorithms. We ran our different algorithms on different queries within this domain, and asked users how they viewed the different ranking algorithms. We created a web survey, asking users to rank these different rankings and received 103 user responses. We analyzed these responses, and made some conclusions about our hybrid algorithms, which are described in the section Statistical Analysis and Conclusions. System Breakdown: Technical Approach to the Process In this subsection, we look at the different components of our system, and describe the technical process behind the specific component. Algorithms Research Since our hybrid models stem from existing work in Link Analysis Rank algorithms, we had planned to spend a lot of time researching the literature in this space. We had initially planned to look at PageRank, LocalRank, and the non-linear algorithms developed by Tsaparas, as mentioned in Revision 1. With each algorithm, we had planned to understand in detail the mathematics of the algorithm and get a sense of the theoretical benefits and drawbacks of the solution. We began to do our research after submitting Revision 1 and started by doing a detailed study of PageRank and its precursors. Based on this we developed a sense of where PageRank was strong and weak the issue of query independence was probably the most key issue. We then looked at algorithms that addressed this issue. We did a detailed study of LocalRank as we had planned to do, and in addition we look at the Hilltop algorithm because we wanted to examine how Hilltop incorporated the query string into its ranking. Again we did an analysis of both algorithms. When doing our research we came across a lot of literature on the HITS algorithm and did a deeper study of the algorithm. Although in terms of modifications to HITS we had just planned to look at AT(k) and NORM(p), we found some interesting literature on hybrids of the HITS algorithm. This included the SALSA algorithm, Hub Averaging HITS, and BFS which we also examined in detail. 52
57 Later into the first semester, we developed our hybrid models based on this algorithms research. Our survey of the literature is concretely written into this paper, under a section Survey of Literature. The section includes most of the algorithms we surveyed and in many cases, our analysis of the benefits and drawbacks of each algorithm. Into the second semester, as we were developing our hybrid algorithms, our advisor encouraged us to look at another part of this space that of rank merging, i.e. merging the results of two different ranked lists into a single list. In the spirit of research, we spent quite some time looking at rank aggregation, and summarized our work in a separate section on Rank Aggregation. Our research included an understanding of different distance measures, theoretically optimal algorithms, and computationally feasible algorithms. We have also incorporated our work in this area into our comparison of different algorithms, by implementing hybrid algorithms that are aggregations of HITS and Page Rank. Hybrid Model Development After analyzing the space we started thinking about hybrid algorithms. We got started on this process a little later than expected because we surveyed a little more literature on HITS than we had initially planned on. We believe this survey has been valuable to us in developing hybrid algorithms. We also continued this survey in our second semester when we researched rank aggregation. In terms of algorithms, it seemed a lot of hybrid algorithms would draw from a combination of HITS, LocalRank, and PageRank. We would say there are two kinds of hybrid models we have worked on, excluding the models developed from rank aggregation. The first set of models are models that draw from some existing literature but represent a fundamental change in the assumptions of or structure of the underlying algorithm. We worked towards developing four such algorithms: 53
58 PROBLEM (Page Rank on Beta-Distributed Link E Matrix): This algorithm changes the assumptions behind the parameter E in the PageRank algorithm. E instead of a uniform value now has a beta distribution which we discuss in detail in the Hybrids section. CANDDE (Centralized And Neutrally Dispersed Dangling Edges): In CANDDE we deviate from the elimination of dangling edges in PageRank and create a new framework for dangling link analysis. PAT(k): In this algorithm we provide a non-linear dynamical solution based on Tsaparas original algorithm, changing the assumption of the parameter k. PAGE (Percentage Aggregate Geodesic Edges): In PAGE, we approach the problem of page ranking from a completely new paradigm of user behavior. All four of the algorithms are described in detail in the section on Hybrid Algorithms. Since these algorithms did represent dramatic changes in the space, we implemented them to benchmark against existing algorithms. We had initially planned to finalize a single algorithm as a hybrid, but we have chosen instead to implement and test all of the four different algorithms to gain a better of understanding of how each algorithm performs on different test cases, and what the merits and flaws of each are. The second set of models that we had developed were incremental improvements to existing algorithms. While these models did not comprise full new algorithms, they represented interesting tweaks that we could possibly incorporate into our bigger algorithms. We worked on three such incremental models (Hilltop-HITS, Relaxed Hilltop, Percentage Local Rank) and they are described in detail in the Hybrids section. Eventually when it came to a question of implementation, we chose not to implement these algorithms, firstly because they did represent only incremental changes, and secondly, because in the interest of time, we wanted to focus on new paradigm shifting ideas. 54
59 Parsing Software Development P P In Revision 1 we had planned on completing the code architecture of the parsing software. We put some time into this in the fall semester and completed the parsing software in the fall. The software now scans a given URL and creates an XML file with certain information included in the schema, crawling web pages up to 4 levels deep. The schema for the data collected and a sample instance of the schema are included at the end of this section. We chose to let our parsing software run four levels deep because we found it struck the right balance between a large amount of information sufficient enough to generate a large web graph and a small enough amount of information so that reading the data from the resulting XML was computationally feasible. To summarize the specifications of our parsing software, the software enables the user to: Users can enter in multiple search keywords separated by spaces, since we do all the string tokenization internally. Work with.html,.shtml,.htm,.jsp,.asp, cold fusion, CGI, Perl, and php web pages. All other links i.e. to Word documents and PDF files are filtered out because we cannot parse them. Continue searching if a page times out. The software is also fault tolerant with web pages loading. We use a timeout of 15 seconds on a page and retry each page 10 times before moving on to the next page. Make sure a single page is ranked only once. All redirection links to the same document (denoted with the # symbol in HTML) are eliminated. Parse relative and absolute URLs. Every URL in the final XML output is absolute. 55
60 Crawl the web page down to four levels of links. Seed Page Collection P P We had planned in Revision 1 to have a list of 100 seed pages on which we would run our algorithm, and we had a tentative list of seed pages. The approach we took to developing this seed pages is what we had planned in Revision 1, based on the methodology of Kleinberg. To recap this, we had stated that nodes in a sample graph consist of A seed node S. The set of nodes that S points to. Call this set A. The set of nodes that points to S. Call this set B. The set of nodes that point to all the nodes in A. Call this set C. The set of nodes that all the nodes in B point to. Call this set D. The vertex set V of the graph is V = S A B C D. Some of the links between nodes in V were purely for navigational purposes. Such intrinsic links are said to be between pages with the same domain name. Transverse links are links between pages not on the same domain. These links convey much more information than intrinsic links and are the essence of the problem at hand. Therefore, we can eliminate all intrinsic links from the vertex set. When we actually developed the algorithms and parsed the data, we decided it would be more instructive to run the algorithms on a single seed page with multiple queries. We decided to focus our attention to the single domain upenn.edu. We now run all our queries using as a seed page. We also chose to use this domain because the pages that would result would be familiar to the participants of the survey, and they would be able to give more instructive feedback on our results. As far as the actual query words are concerned, we tested the software on multiple different query results. We chose query words that were broad enough to be comprehensible to a wide range of users, and narrow enough so as to not have an 56
61 interesting meaning. Our Statistical Analysis section discusses the queries we ran our algorithm on. Algorithms Implementation P P We chose to implement the following algorithms (existing) in Java for the purposes of benchmarking: PageRank LocalRank ATK HITS We felt this set represented a good range of work in this area starting from the simple Page Rank algorithms to the hubs and authorities model to the non linear dynamical model. We chose to implement the algorithms in Java, rather than our original plan of implementing the algorithms in C++, because of our comparative familiarity with Java. We also implemented the following hybrid solutions in Java: PAGE CANDDE PROBLEM PATK Rank Merging Algorithms (HITS and PageRank) o Simple Borda o Geometric Mean Borda o Markov Chain I System Architecture P P Our system can be split up into the algorithms engine which contains implementations of the various algorithms that we were comparing, the parsing software and various utilities. The java files for each part are: 57
62 1) Algorithm Engine Filename ATK.java Borda.java Hits.java LocalRank.java Implements Tsaparas AT(k) and our hybrid PAT(k) algorithms Borda s simple and geometric merging schemes Kleinberg s HITS algorithm Google s LocalRank MarkovMerge.java Kumar & Sivakumar s Markov Chain Rank Merging algorithm Page.java PageRank.java Problem.java Spearman.java Our PAGE algorithm Google s PageRank algorithm Our PROBLEM algorithm Spearman s Footrule measure 2) Parsing and graph creation Filename LyncXML.java Parse.java WebPage.java Implements The conversion of parsed HTML to a storable XML format and the conversion of the XML representation of the webgraph into an adjacency matrix The recursive parsing of HTML, HTM, ASP, JSP, PHP, Cold Fusion, CGI and Perl web pages Java representation of a webpage and its outgoing links used during parsing and reading in from file 3) Utilities Filename Functions.java Lync.java Pairs.java RankHelper.java Implements Basic mathematical functions The main file which controls the overall execution of our project Helper class used to pair an element with its rank. Various utilities including converting an adjacency matrix to 58
63 StatFunctions UserInput a Markov Chain, searching, sorting and filtering A numerical approximation to the beta function which is used by PROBLEM Class to collect parameters from the user. The general order of execution is: 1) Prompt the user for input a) Prompt for the name of the file where the XML web graph will be printed. b) Prompt for the name of the file where the final rankings will be printed. c) The search query. d) The seed URL. 2) Recursively parse the HTML of webpages beginning with the seed URL and going down an arbitrarily specified number of levels. We ran our parsing 4 levels deep for all our test queries. 3) Print the parsed HTML to the XML output file. 4) Read in the XML output file. 5) Create the adjacency matrix of the web graph. 6) Run the following algorithms on the adjacency matrix: ) PageRank ) LocalRank ) HITS ) AT(k) ) PAT(k) ) PROBLEM ) CANDDE ) PAGE ) Borda Simple Rank Merging using HITS and PageRank ) Borda Geometric Rank Merging using HITS and PageRank 59
64 ) Markov Chain Rank Merging 7) Print the rankings to the output file. A diagram describing the implementation of our system is below. 60

65 LYNC System Architecture 61
66 Analysis and Surveys P P We ran the above algorithms on the upenn.edu domain for predetermined queries. In order to measure the performance of the different algorithms, we turned the question to the users, and performed a user survey of our results. For every particular query, we put forth the rankings suggested by our different algorithms, and asked the user to point out how good each ranking was. We judged the results of our survey based on high relevance ratios as Kleinberg and Tsaparas had done. The survey was created using Microsoft Word and Excel and a sample is included in the Technical Approach Appendix. We have performed a detailed statistical analysis of our findings. This is detailed in the Statistical Analysis section of our paper. Technical ChallengesP P Over the course of the two semesters, we faced numerous technical challenges as researched different algorithms, developed our hybrid model, and ultimately implemented our algorithms. Algorithms Challenges and Key Design Decisions P P One of the biggest challenges we faced while doing our research was obtaining relevant research. PageRank is a very popular algorithm, and there is some information about it, but beyond very simple layman s descriptions, there is very little strong mathematical information about it and other algorithms. Another major technical challenge was finding information on non-linear dynamical systems. While linear dynamical systems and the hubs and authorities model have been studied for a while, non linear dynamic systems are a new area of research and there is little information about them to rely on. A third major challenge we faced was that most of the existing algorithms for page ranking start from the same model of user behavior, the random surfer 62
67 model. When one looks to build on this foundation, most of the algorithms one comes up with are naturally incremental, since they derive from the same inherent model. In the process of our research, we wanted to look at new models of user behavior, many of which had not been applied to page ranking. A fourth major challenge we faced was in understanding ranking ideas not originally written for ranking web pages. Rank aggregation was one area where this came up multiple times. Borda s algorithm and the Condorcet criteria for instance were ideas developed in the seventeen and eighteen hundreds to be applied to voting. Translating these ideas to the web ranking space was a mental shift. A fifth challenge was that a lot of the research, because of the commercial nature of web page ranking, is proprietary. For example, there is very little information about patented algorithms such as LocalRank. Similarly, there are algorithms proprietary to Google, Alta Vista, MSN, and other commercial search engines, that we could not tap into as foundations for our hybrids. A sixth challenge on the algorithms side was that it is often easy to come up with an idea, but hard to refine it and prove its correctness. Arguing the correctness and rationale behind our hybrids was one of the biggest problems we faced. A more specific challenge we faced was characterizing different input parameters. The non linear dynamical systems described by PROBLEM and PAT(k) are sensitive to their input parameters. For instance, the output of PROBLEM depends on the values of α and β that determine the shape of the beta distribution. As we discussed earlier, we require α < 1 and β > 1. However, the model needs to be calibrated for different combinations of α and β. The PAT(k) algorithm depends on the value of k. In order to determine the correct values of parameters we tried to look for a user behavior rationale rather than an optimal data mining rationale. For instance on PAT(k), we identified a range of optimal percentages through small sample tests and then narrowed in on the correct value of k through research and testing. With the beta distribution algorithm, PROBLEM, we again looked at different models of 63
68 user preferences to determine what the correct values of the two parameters would be. Another problem, that we imagine occurs with algorithms in practice, is finding the correct balance between accuracy and speed. Often algorithms that compromise speed but approximate results correct, such as the scaled foot rule optimization, are what we are looking for. Convergence is a big question with Markov Chain algorithms. PageRank, PROBLEM, and a couple of other algorithms converge at some point and determining what this convergence value is and how many iterations to run an algorithm on is a challenge. One of the key decisions we made in this process was to run the tests on 4 of the original 6 algorithms. Our plan at the outset was to select one hybrid model and run the algorithm on the hybrid. At the end however we choose to discard only the two incremental improvement algorithms and run the tests on the 4 major shift algorithms. We chose to retain all four of our major algorithms because we believe no one algorithm can predict a model of user behavior. The results of the four different algorithms are constructive in that they help us understand why certain algorithms perform well on certain test cases, and looking forward there is perhaps a middle ground where we can incorporate elements of certain algorithms into yet another hybrid. Also we may be able to constructively combine some of the hybrids themselves using rank merging. Implementation Challenges and Key Design Decisions P P On the implementation side, one of the biggest questions was how many levels deep our web crawling should go. On one hand, a large number of levels gives us a larger web graph to run our results on. On the other hand, the number of entries in our XML file grows exponentially with an increase in levels, and makes the reading and writing of information extremely cumbersome. Our experience showed that the program tended to crash over 5 levels deep because of buffer limitations, and the graph was too sparse at 2 levels. We choose to run the algorithm 3-4 levels deep to make this tradeoff. 64
69 B A second big challenge was whether we needed to store HTML during our web parsing. Storing HTML we decided would have lead to very large files and mandated a database and hence we decided to do everything with XML intermediaries. However, since the ranking algorithms run just once on each hyperlink graph and the focus of our project is the hybrid algorithm, we felt that there was no need to build a database for storing the graphs. The Java program will output the hyperlink graphs as instance of the schema defined in the section on Technical Approaches. A third question was what seeds to use. Initially we had planned on using different pages identified in revision 2 as our seeds. At the end we decided on running all our algorithms on the upenn.edu domain. There were two reasons for this. Firstly we wanted to stick to a dense tight knit web graph. Secondly we felt pages in this domain would be particularly relevant to our survey participants. Two other questions that came up were what kind of files we wanted to parse and how to perform file IO. At the end in the interest of reading large files efficiently, we decided to use String Buffers in Java. Also, we chose a subset of file types that we would parse (see our implementation details). Another question, since the page ranks were often very close, was numerical precision. We tackled this problem by using arbitrary precision arithmetic (BigInteger and BigDouble) in Java. Filtering pages that match a query was also challenge. The queries are specific to a given graph and consist of commonly occurring words in the given set of web pages. For example, a graph with a medical website as its seed such as < might be associated with the query for the word doctor. The presence or absence of the query word was finally be stored as a Boolean variable along with the adjacency lists. 65
70 TECHNICAL APPROACH APPENDIX This section details the schema pages and list of seeds described in the section on Technical Approach. It also includes samples of our result sets and our survey. XSD Schema and XML Instance of the Schema Below is the schema of the data to be collected by the parsing software. <xsd:schema xmlns:xsd=" <xsd:annotation> <xsd:documentation xml:lang="en"> Schema for parsing output. Copyright 2004 Nalin Moniz and Radhika Gupta. All rights reserved. Also copyrighted by Scholes the Cat. </xsd:documentation> <xsd:annotation> <xsd:element name="document" type="documenttype"/> <xsd:complextype name="documenttype"> <xsd:sequence> <xsd:element name="query" type="querytype"/> <xsd:element name="page" type="pagetype" minoccurs="0" maxoccurs="unbounded"/> </xsd:sequence> </xsd:complextype> <xsd:complextype name="querytype"> <xsd:sequence> 66
71 <xsd:element name="queryword" type="string" minoccurs="1" maxoccurs="unbounded"/> </xsd:sequence> </xsd:complextype> <xsd:complextype name="pagetype"> <xsd:sequence> <xsd:element name="url" type="url" use="required"/> <xsd:element name="ipaddress" type="ipaddresstype" use="required"/> <xsd:element name="matchword" type="string" minoccurs="0" maxoccurs="unbounded"/> <xsd:element name="link" type="url" minoccurs="0" maxoccurs="unbounded"/> </xsd:sequence> </xsd:complextype> <xsd:simpletype name="ipaddresstype"> <xsd:restriction base="xsd:string"> <xsd:pattern value="(([1-9]?[0-9] 1[0-9][0-9] 2[0-4][0-9] 25[0-5])\.){3} ([1-9]?[0-9] 1[0-9][0-9] 2[0-4][0-9] 25[0-5])"/> </xsd:restriction> </xsd:simpletype> </xsd:schema> 67
72 Below is an instance of the schema described above, a sample set of data collected by the parsing software. <document> <query> <queryword>web</queryword> <queryword>search</queryword> <queryword>algorithms</queryword> </query> <page> <URL> <IPAddress> </IPAddress> <matchword>web</matchword> <matchword>search</matchword> <link> <link> </page> <page> <URL> <IPAddress> </IPAddress> <link> <link> </page> </document> 68
73 Sample Output from Parsing Software Below is a sample of the output generated by our software on the word bank with four levels of depth. The entire output is not shown in the interest of space. The Excel file generated basically shows a list of URLs crawled and then for the eleven different algorithms, shows the associated Page Ranks. The pages with the highest normalized page rank are the ones with the highest rank. 69

74 Query: Bank 70
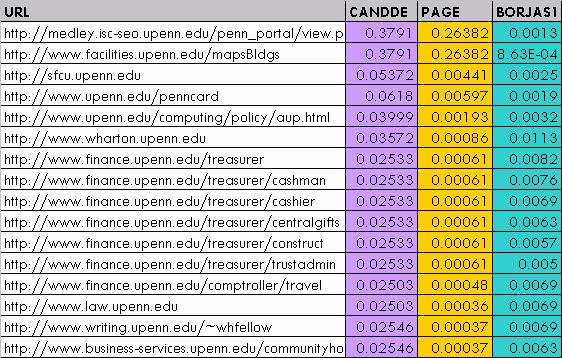

75 71



76 Sample Survey and Results Below is a sample of the survey we provided to users and a filled in response. The survey took the above output, and extracted the top 5 pages generated by the 11 different algorithms. We then removed the algorithm names for anonymous letters (which only we knew) and presented the survey for 10 different query words. For each ranking set generated by each algorithm on a particular result, we asked the participant to rank the set on a scale of The survey was administered to 103 students, faculty, and staff on our campus. We only show one query of the ten we showed to users in the interest of space. 72
77 ANALYSIS OF SURVEY RESULTS We ran a survey with the top five results of 11 algorithms on 10 different queries. The ten algorithms compared were: 1) PageRank 2) LocalRank 3) HITS 4) AT(k) 5) PAT(k) 6) PROBLEM 7) CANDDE 8) PAGE 9) Borda s Simple Rank Merging using HITS and PageRank 10) Borda s Geometric Rank Merging using HITS and PageRank 11) Markov Chain Rank Merging The ten queries run on the upenn.edu domain were: 1) Statistics 2) Technology 3) Weather 4) Safety 5) Housing 6) Health 7) Food 8) Fees 9) Bank 10) Calendar We asked users to rate each of the search results on a scale from 1 to 10, with 1 being the lowest and 10 being the highest. The users were asked to rate the search results for relevancy, accuracy and heterogeneity. The queries we tested the 73

78 algorithms on were broad enough to represent multiple spheres of interest. For example, the query Safety returned links to Building Maps, Penn s Emergency site, the office of the Vice Provost for University Life, the Penn Almanac, Facilities, the Daily Pennsylvanian and the admissions site for prospective students among others. We wanted users to consider how well a particular algorithm captured this heterogeneity. We used a blind randomized survey to prevent users from being biased for or against a particular survey. We used placeholders for the algorithm names and randomly assigned placeholders for each query. We received 103 responses to our survey. The results are summarized in the tables below. Table 1 Median Response Table 2 Mean Response 74

79 UTable 3 Standard Deviation We ran a two sample t-test to test the differences in the mean performance of the algorithms. Our null hypothesis was that the mean performance of two algorithms is the same, H 0 : x1 = x2. The t-test is calculated for every pair of algorithms in Table 4, with the mean of the algorithm in the row being x 1 and the mean of the algorithm in the column being x 2. The p-values for the test are calculated in Table 5 below. The p-values highlighted in red indicate that we reject the null hypothesis for a given pair of algorithms. The Hasse diagram below illustrates the partial ordering of the algorithm s performance based on the two sample t-test. If algorithm A lies above algorithm B, then algorithm A is statistically better than B. From Tables 4 and 5 we can see that CANDDE outperforms all the other 10 algorithms at the 5% significance level. This is probably because it is based on the robust PageRank technology and it eliminates the effect of the numerous dangling links that exist on our relative small web graphs. As we recursively parse pages more levels down, we can expect CANDDE s advantage to diminish. The second best algorithm was PROBLEM. PROBLEM s good performance suggests that the beta distribution on the E matrix accurately captures a user s behavior over a small domain such upenn.edu because most critical information is found on a few central web pages. PageRank s assumption that the user is equally likely to jump to a random page instead of following a hyperlink is a little far fetched. Instead the beta distribution captures a user s affinity for the small set of central pages when surfing the upenn.edu domain. 75
80 In contrast to CANDDE and PROBLEM which performed incredibly well, PAGE performed very poorly among users. This suggests that PAGE s model of user behavior was inadequate. PAGE returned the Course Roster as its top response for the query Statistics, Penn Safety as its top page for the query Weather and had Penn Publications as its top choice for the query Food, among its other failures. In spite of its poor performance, PAGE was able to return a few results that made survey takers take notice. For example, in response to the query Health, PAGE was the only algorithm that returned Undergraduate Admissions in response to the query Health, let alone as its top ranking. People taking our survey found this interesting because student health is a big consideration for parents considering sending their children to Penn and the undergraduate admissions page addresses this sentiment with a lot of information about health. 76
81 Borda s Geometric merging algorithm outperforms Borda s Simple merging algorithm as expected because the geometric mean is a more robust statistic than the arithmetic mean. PAT(k) and Kleinberg s HITS performed as well as PROBLEM and Borda s Geometric merging algorithm as a result of the strength of the hubs and authorities framework. PAT(k) outperformed better than AT(k) because as we mentioned in the section on algorithm design, filtering a percentage of the best authorities is a much better heuristic than filtering a fixed number of authorities, AT(k) keeps all of a hub s authorities when the number of authorities is less than the threshold k, whereas PAT(k) continues to filter only the top percentage as intended. The Markov merging algorithm outperformed Borda s Simple merging algorithm, but there was no statistical difference between its performance and that of the Borda s geometric merging algorithm. Both of Borda s rank merging heuristics used Google s PageRank and Kleinberg s HITS as a base. Since rank merging prevents spurious results, we expected Borda s algorithms to do no worse than either PageRank or HITS. However, HITS did just as well as Borda s Geometric Merging algorithm and PageRank did just as well as Borda s Simple Merging algorithm. Borda s Simple Merging algorithm actually underperformed HITS! This suggests that merging rankings might not be a good heuristic. Users tend to consider only the top couple of web pages and if merging changes the ordering of the top pages, it can produce dramatic shifts in the quality of the search results. Surprisingly, LocalRank did quite poorly on the upenn.edu. This could be because of excessively stringent filtering of pages on a small web graph. In a larger web graph, we could expect LocalRank to do much better There was no statistical difference between the performance of AT(k), Borda s Simple merging algorithm and Kumar and Sivakumar s Markov merging algorithm and PageRank. For the most part, user found that the algorithms performed at approximately the same level for most of the queries. The two outliers were the queries Housing and Bank. The algorithms performed poorly for the query Housing because most of the 77


82 algorithms returned Penn Portal as their top choice along with many spurious but interesting results such as Graduate Admissions, Campus Emergency, The School of Social Work, Philadelphia, Philadelphia Information and many more. In contrast in response to the query Bank, most of the algorithms agreed that the top websites were Penn Portal, The Student Federal Credit Union and Wharton among others. The relative stability of the performance of the algorithms over different queries suggests that there is a good chance that the performance of the algorithms might be scalable. Table 4 Differences In Algorithm Mean Performance Table 5 P-values for Algorithm Mean Performance 78


83 Table 6 Differences in Query Performance Table 7 P-values for Query Performance 79
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Information Retrieval. Lecture 11 - Link analysis
 Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
COMP 4601 Hubs and Authorities
 COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
Lecture #3: PageRank Algorithm The Mathematics of Google Search
 Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Web consists of web pages and hyperlinks between pages. A page receiving many links from other pages may be a hint of the authority of the page
 Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
1 Starting around 1996, researchers began to work on. 2 In Feb, 1997, Yanhong Li (Scotch Plains, NJ) filed a
 filed a") !"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
!"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
Web search before Google. (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.)
, The PageRank Citation Ranking: Bringing Order to the Web.)") ' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
COMP5331: Knowledge Discovery and Data Mining
 COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Einführung in Web und Data Science Community Analysis. Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme
 Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
PageRank and related algorithms
 PageRank and related algorithms PageRank and HITS Jacob Kogan Department of Mathematics and Statistics University of Maryland, Baltimore County Baltimore, Maryland 21250 kogan@umbc.edu May 15, 2006 Basic
PageRank and related algorithms PageRank and HITS Jacob Kogan Department of Mathematics and Statistics University of Maryland, Baltimore County Baltimore, Maryland 21250 kogan@umbc.edu May 15, 2006 Basic
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Roadmap. Roadmap. Ranking Web Pages. PageRank. Roadmap. Random Walks in Ranking Query Results in Semistructured Databases
 Roadmap Random Walks in Ranking Query in Vagelis Hristidis Roadmap Ranking Web Pages Rank according to Relevance of page to query Quality of page Roadmap PageRank Stanford project Lawrence Page, Sergey
Roadmap Random Walks in Ranking Query in Vagelis Hristidis Roadmap Ranking Web Pages Rank according to Relevance of page to query Quality of page Roadmap PageRank Stanford project Lawrence Page, Sergey
Link Analysis Ranking Algorithms, Theory, and Experiments
 Link Analysis Ranking Algorithms, Theory, and Experiments Allan Borodin Gareth O. Roberts Jeffrey S. Rosenthal Panayiotis Tsaparas June 28, 2004 Abstract The explosive growth and the widespread accessibility
Link Analysis Ranking Algorithms, Theory, and Experiments Allan Borodin Gareth O. Roberts Jeffrey S. Rosenthal Panayiotis Tsaparas June 28, 2004 Abstract The explosive growth and the widespread accessibility
How to organize the Web?
 How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
Link Structure Analysis
 Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score
Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score
Using Non-Linear Dynamical Systems for Web Searching and Ranking
 Using Non-Linear Dynamical Systems for Web Searching and Ranking Panayiotis Tsaparas Dipartmento di Informatica e Systemistica Universita di Roma, La Sapienza tsap@dis.uniroma.it ABSTRACT In the recent
Using Non-Linear Dynamical Systems for Web Searching and Ranking Panayiotis Tsaparas Dipartmento di Informatica e Systemistica Universita di Roma, La Sapienza tsap@dis.uniroma.it ABSTRACT In the recent
Searching the Web [Arasu 01]
![Searching the Web [Arasu 01]](/thumbs/74/70312179.jpg "Searching the Web [Arasu 01]") Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Agenda. Math Google PageRank algorithm. 2 Developing a formula for ranking web pages. 3 Interpretation. 4 Computing the score of each page
 Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
CS6200 Information Retreival. The WebGraph. July 13, 2015
 CS6200 Information Retreival The WebGraph The WebGraph July 13, 2015 1 Web Graph: pages and links The WebGraph describes the directed links between pages of the World Wide Web. A directed edge connects
CS6200 Information Retreival The WebGraph The WebGraph July 13, 2015 1 Web Graph: pages and links The WebGraph describes the directed links between pages of the World Wide Web. A directed edge connects
Pagerank Scoring. Imagine a browser doing a random walk on web pages:
 Ranking Sec. 21.2 Pagerank Scoring Imagine a browser doing a random walk on web pages: Start at a random page At each step, go out of the current page along one of the links on that page, equiprobably
Ranking Sec. 21.2 Pagerank Scoring Imagine a browser doing a random walk on web pages: Start at a random page At each step, go out of the current page along one of the links on that page, equiprobably
A STUDY OF RANKING ALGORITHM USED BY VARIOUS SEARCH ENGINE
 A STUDY OF RANKING ALGORITHM USED BY VARIOUS SEARCH ENGINE Bohar Singh 1, Gursewak Singh 2 1, 2 Computer Science and Application, Govt College Sri Muktsar sahib Abstract The World Wide Web is a popular
A STUDY OF RANKING ALGORITHM USED BY VARIOUS SEARCH ENGINE Bohar Singh 1, Gursewak Singh 2 1, 2 Computer Science and Application, Govt College Sri Muktsar sahib Abstract The World Wide Web is a popular
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Introduction to Data Mining
 Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
COMP Page Rank
 COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
Algorithms, Games, and Networks February 21, Lecture 12
 Algorithms, Games, and Networks February, 03 Lecturer: Ariel Procaccia Lecture Scribe: Sercan Yıldız Overview In this lecture, we introduce the axiomatic approach to social choice theory. In particular,
Algorithms, Games, and Networks February, 03 Lecturer: Ariel Procaccia Lecture Scribe: Sercan Yıldız Overview In this lecture, we introduce the axiomatic approach to social choice theory. In particular,
Motivation. Motivation
 COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
Bruno Martins. 1 st Semester 2012/2013
 Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Social Network Analysis
 Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
Link Analysis. Hongning Wang
 Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
A Modified Algorithm to Handle Dangling Pages using Hypothetical Node
 A Modified Algorithm to Handle Dangling Pages using Hypothetical Node Shipra Srivastava Student Department of Computer Science & Engineering Thapar University, Patiala, 147001 (India) Rinkle Rani Aggrawal
A Modified Algorithm to Handle Dangling Pages using Hypothetical Node Shipra Srivastava Student Department of Computer Science & Engineering Thapar University, Patiala, 147001 (India) Rinkle Rani Aggrawal
A brief history of Google
 the math behind Sat 25 March 2006 A brief history of Google 1995-7 The Stanford days (aka Backrub(!?)) 1998 Yahoo! wouldn't buy (but they might invest...) 1999 Finally out of beta! Sergey Brin Larry Page
the math behind Sat 25 March 2006 A brief history of Google 1995-7 The Stanford days (aka Backrub(!?)) 1998 Yahoo! wouldn't buy (but they might invest...) 1999 Finally out of beta! Sergey Brin Larry Page
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
An Improved Computation of the PageRank Algorithm 1
 An Improved Computation of the PageRank Algorithm Sung Jin Kim, Sang Ho Lee School of Computing, Soongsil University, Korea ace@nowuri.net, shlee@computing.ssu.ac.kr http://orion.soongsil.ac.kr/ Abstract.
An Improved Computation of the PageRank Algorithm Sung Jin Kim, Sang Ho Lee School of Computing, Soongsil University, Korea ace@nowuri.net, shlee@computing.ssu.ac.kr http://orion.soongsil.ac.kr/ Abstract.
CPSC 532L Project Development and Axiomatization of a Ranking System
 CPSC 532L Project Development and Axiomatization of a Ranking System Catherine Gamroth cgamroth@cs.ubc.ca Hammad Ali hammada@cs.ubc.ca April 22, 2009 Abstract Ranking systems are central to many internet
CPSC 532L Project Development and Axiomatization of a Ranking System Catherine Gamroth cgamroth@cs.ubc.ca Hammad Ali hammada@cs.ubc.ca April 22, 2009 Abstract Ranking systems are central to many internet
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Searching the Web What is this Page Known for? Luis De Alba
 Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
Brief (non-technical) history
 history") Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Proximity Prestige using Incremental Iteration in Page Rank Algorithm
 Indian Journal of Science and Technology, Vol 9(48), DOI: 10.17485/ijst/2016/v9i48/107962, December 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Proximity Prestige using Incremental Iteration
Indian Journal of Science and Technology, Vol 9(48), DOI: 10.17485/ijst/2016/v9i48/107962, December 2016 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Proximity Prestige using Incremental Iteration
Large-Scale Networks. PageRank. Dr Vincent Gramoli Lecturer School of Information Technologies
 Large-Scale Networks PageRank Dr Vincent Gramoli Lecturer School of Information Technologies Introduction Last week we talked about: - Hubs whose scores depend on the authority of the nodes they point
Large-Scale Networks PageRank Dr Vincent Gramoli Lecturer School of Information Technologies Introduction Last week we talked about: - Hubs whose scores depend on the authority of the nodes they point
The application of Randomized HITS algorithm in the fund trading network
 The application of Randomized HITS algorithm in the fund trading network Xingyu Xu 1, Zhen Wang 1,Chunhe Tao 1,Haifeng He 1 1 The Third Research Institute of Ministry of Public Security,China Abstract.
The application of Randomized HITS algorithm in the fund trading network Xingyu Xu 1, Zhen Wang 1,Chunhe Tao 1,Haifeng He 1 1 The Third Research Institute of Ministry of Public Security,China Abstract.
Information Retrieval and Web Search
 Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
Information Retrieval and Web Search Link analysis Instructor: Rada Mihalcea (Note: This slide set was adapted from an IR course taught by Prof. Chris Manning at Stanford U.) The Web as a Directed Graph
Page rank computation HPC course project a.y Compute efficient and scalable Pagerank
 Page rank computation HPC course project a.y. 2012-13 Compute efficient and scalable Pagerank 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and used by the Google Internet
Page rank computation HPC course project a.y. 2012-13 Compute efficient and scalable Pagerank 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and used by the Google Internet
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material.
 Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
TODAY S LECTURE HYPERTEXT AND
 LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
Web Structure Mining using Link Analysis Algorithms
 Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
F. Aiolli - Sistemi Informativi 2007/2008. Web Search before Google
 Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
Graph Algorithms. Revised based on the slides by Ruoming Kent State
 Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Generalized Social Networks. Social Networks and Ranking. How use links to improve information search? Hypertext
 Generalized Social Networs Social Networs and Raning Represent relationship between entities paper cites paper html page lins to html page A supervises B directed graph A and B are friends papers share
Generalized Social Networs Social Networs and Raning Represent relationship between entities paper cites paper html page lins to html page A supervises B directed graph A and B are friends papers share
PageRank Algorithm Abstract: Keywords: I. Introduction II. Text Ranking Vs. Page Ranking
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 19, Issue 1, Ver. III (Jan.-Feb. 2017), PP 01-07 www.iosrjournals.org PageRank Algorithm Albi Dode 1, Silvester
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 19, Issue 1, Ver. III (Jan.-Feb. 2017), PP 01-07 www.iosrjournals.org PageRank Algorithm Albi Dode 1, Silvester
Information Networks: PageRank
 Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Centralities (4) By: Ralucca Gera, NPS. Excellence Through Knowledge
 By: Ralucca Gera, NPS. Excellence Through Knowledge") Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
CSE 190 Lecture 16. Data Mining and Predictive Analytics. Small-world phenomena
 CSE 190 Lecture 16 Data Mining and Predictive Analytics Small-world phenomena Another famous study Stanley Milgram wanted to test the (already popular) hypothesis that people in social networks are separated
CSE 190 Lecture 16 Data Mining and Predictive Analytics Small-world phenomena Another famous study Stanley Milgram wanted to test the (already popular) hypothesis that people in social networks are separated
A ew Algorithm for Community Identification in Linked Data
 A ew Algorithm for Community Identification in Linked Data Nacim Fateh Chikhi, Bernard Rothenburger, Nathalie Aussenac-Gilles Institut de Recherche en Informatique de Toulouse 118, route de Narbonne 31062
A ew Algorithm for Community Identification in Linked Data Nacim Fateh Chikhi, Bernard Rothenburger, Nathalie Aussenac-Gilles Institut de Recherche en Informatique de Toulouse 118, route de Narbonne 31062
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
DESIGN AND ANALYSIS OF ALGORITHMS. Unit 1 Chapter 4 ITERATIVE ALGORITHM DESIGN ISSUES
 DESIGN AND ANALYSIS OF ALGORITHMS Unit 1 Chapter 4 ITERATIVE ALGORITHM DESIGN ISSUES http://milanvachhani.blogspot.in USE OF LOOPS As we break down algorithm into sub-algorithms, sooner or later we shall
DESIGN AND ANALYSIS OF ALGORITHMS Unit 1 Chapter 4 ITERATIVE ALGORITHM DESIGN ISSUES http://milanvachhani.blogspot.in USE OF LOOPS As we break down algorithm into sub-algorithms, sooner or later we shall
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Chapter 2 Basic Structure of High-Dimensional Spaces
 Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
Chapter 2 Basic Structure of High-Dimensional Spaces Data is naturally represented geometrically by associating each record with a point in the space spanned by the attributes. This idea, although simple,
Link Analysis Ranking: Algorithms, Theory, and Experiments
 Link Analysis Ranking: Algorithms, Theory, and Experiments ALLAN BORODIN University of Toronto GARETH O. ROBERTS Lancaster University JEFFREY S. ROSENTHAL University of Toronto and PANAYIOTIS TSAPARAS
Link Analysis Ranking: Algorithms, Theory, and Experiments ALLAN BORODIN University of Toronto GARETH O. ROBERTS Lancaster University JEFFREY S. ROSENTHAL University of Toronto and PANAYIOTIS TSAPARAS
PatternRank: A Software-Pattern Search System Based on Mutual Reference Importance
 PatternRank: A Software-Pattern Search System Based on Mutual Reference Importance Atsuto Kubo, Hiroyuki Nakayama, Hironori Washizaki, Yoshiaki Fukazawa Waseda University Department of Computer Science
PatternRank: A Software-Pattern Search System Based on Mutual Reference Importance Atsuto Kubo, Hiroyuki Nakayama, Hironori Washizaki, Yoshiaki Fukazawa Waseda University Department of Computer Science
Link Analysis in the Cloud
 Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Authoritative Sources in a Hyperlinked Environment
 Authoritative Sources in a Hyperlinked Environment Journal of the ACM 46(1999) Jon Kleinberg, Dept. of Computer Science, Cornell University Introduction Searching on the web is defined as the process of
Authoritative Sources in a Hyperlinked Environment Journal of the ACM 46(1999) Jon Kleinberg, Dept. of Computer Science, Cornell University Introduction Searching on the web is defined as the process of
Reading Time: A Method for Improving the Ranking Scores of Web Pages
 Reading Time: A Method for Improving the Ranking Scores of Web Pages Shweta Agarwal Asst. Prof., CS&IT Deptt. MIT, Moradabad, U.P. India Bharat Bhushan Agarwal Asst. Prof., CS&IT Deptt. IFTM, Moradabad,
Reading Time: A Method for Improving the Ranking Scores of Web Pages Shweta Agarwal Asst. Prof., CS&IT Deptt. MIT, Moradabad, U.P. India Bharat Bhushan Agarwal Asst. Prof., CS&IT Deptt. IFTM, Moradabad,
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
An Enhanced Page Ranking Algorithm Based on Weights and Third level Ranking of the Webpages
 An Enhanced Page Ranking Algorithm Based on eights and Third level Ranking of the ebpages Prahlad Kumar Sharma* 1, Sanjay Tiwari #2 M.Tech Scholar, Department of C.S.E, A.I.E.T Jaipur Raj.(India) Asst.
An Enhanced Page Ranking Algorithm Based on eights and Third level Ranking of the ebpages Prahlad Kumar Sharma* 1, Sanjay Tiwari #2 M.Tech Scholar, Department of C.S.E, A.I.E.T Jaipur Raj.(India) Asst.
TELCOM2125: Network Science and Analysis
 School of Information Sciences University of Pittsburgh TELCOM2125: Network Science and Analysis Konstantinos Pelechrinis Spring 2015 2 Part 4: Dividing Networks into Clusters The problem l Graph partitioning
School of Information Sciences University of Pittsburgh TELCOM2125: Network Science and Analysis Konstantinos Pelechrinis Spring 2015 2 Part 4: Dividing Networks into Clusters The problem l Graph partitioning
Recent Researches on Web Page Ranking
 Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
Unit VIII. Chapter 9. Link Analysis
 Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Unit 1 Chapter 4 ITERATIVE ALGORITHM DESIGN ISSUES
 DESIGN AND ANALYSIS OF ALGORITHMS Unit 1 Chapter 4 ITERATIVE ALGORITHM DESIGN ISSUES http://milanvachhani.blogspot.in USE OF LOOPS As we break down algorithm into sub-algorithms, sooner or later we shall
DESIGN AND ANALYSIS OF ALGORITHMS Unit 1 Chapter 4 ITERATIVE ALGORITHM DESIGN ISSUES http://milanvachhani.blogspot.in USE OF LOOPS As we break down algorithm into sub-algorithms, sooner or later we shall
CS 6604: Data Mining Large Networks and Time-Series
 CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
Lecture 17 November 7
 CS 559: Algorithmic Aspects of Computer Networks Fall 2007 Lecture 17 November 7 Lecturer: John Byers BOSTON UNIVERSITY Scribe: Flavio Esposito In this lecture, the last part of the PageRank paper has
CS 559: Algorithmic Aspects of Computer Networks Fall 2007 Lecture 17 November 7 Lecturer: John Byers BOSTON UNIVERSITY Scribe: Flavio Esposito In this lecture, the last part of the PageRank paper has
WEB STRUCTURE MINING USING PAGERANK, IMPROVED PAGERANK AN OVERVIEW
 ISSN: 9 694 (ONLINE) ICTACT JOURNAL ON COMMUNICATION TECHNOLOGY, MARCH, VOL:, ISSUE: WEB STRUCTURE MINING USING PAGERANK, IMPROVED PAGERANK AN OVERVIEW V Lakshmi Praba and T Vasantha Department of Computer
ISSN: 9 694 (ONLINE) ICTACT JOURNAL ON COMMUNICATION TECHNOLOGY, MARCH, VOL:, ISSUE: WEB STRUCTURE MINING USING PAGERANK, IMPROVED PAGERANK AN OVERVIEW V Lakshmi Praba and T Vasantha Department of Computer
Link Analysis SEEM5680. Taken from Introduction to Information Retrieval by C. Manning, P. Raghavan, and H. Schutze, Cambridge University Press.
 Link Analysis SEEM5680 Taken from Introduction to Information Retrieval by C. Manning, P. Raghavan, and H. Schutze, Cambridge University Press. 1 The Web as a Directed Graph Page A Anchor hyperlink Page
Link Analysis SEEM5680 Taken from Introduction to Information Retrieval by C. Manning, P. Raghavan, and H. Schutze, Cambridge University Press. 1 The Web as a Directed Graph Page A Anchor hyperlink Page
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University
 CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Instead of generic popularity, can we measure popularity within a topic? E.g., computer science, health Bias the random walk When
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Instead of generic popularity, can we measure popularity within a topic? E.g., computer science, health Bias the random walk When
Using Spam Farm to Boost PageRank p. 1/2
 Using Spam Farm to Boost PageRank Ye Du Joint Work with: Yaoyun Shi and Xin Zhao University of Michigan, Ann Arbor Using Spam Farm to Boost PageRank p. 1/2 Roadmap Introduction: Link Spam and PageRank
Using Spam Farm to Boost PageRank Ye Du Joint Work with: Yaoyun Shi and Xin Zhao University of Michigan, Ann Arbor Using Spam Farm to Boost PageRank p. 1/2 Roadmap Introduction: Link Spam and PageRank
Collaborative filtering based on a random walk model on a graph
 Collaborative filtering based on a random walk model on a graph Marco Saerens, Francois Fouss, Alain Pirotte, Luh Yen, Pierre Dupont (UCL) Jean-Michel Renders (Xerox Research Europe) Some recent methods:
Collaborative filtering based on a random walk model on a graph Marco Saerens, Francois Fouss, Alain Pirotte, Luh Yen, Pierre Dupont (UCL) Jean-Michel Renders (Xerox Research Europe) Some recent methods:
MAE 298, Lecture 9 April 30, Web search and decentralized search on small-worlds
 MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today
 HW3 will be posted today") 3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
Link Analysis in Web Mining
 Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
The PageRank Computation in Google, Randomized Algorithms and Consensus of Multi-Agent Systems
 The PageRank Computation in Google, Randomized Algorithms and Consensus of Multi-Agent Systems Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it This talk The objective of this talk is to discuss
The PageRank Computation in Google, Randomized Algorithms and Consensus of Multi-Agent Systems Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it This talk The objective of this talk is to discuss
University of Maryland. Tuesday, March 2, 2010
 Data-Intensive Information Processing Applications Session #5 Graph Algorithms Jimmy Lin University of Maryland Tuesday, March 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #5 Graph Algorithms Jimmy Lin University of Maryland Tuesday, March 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
A Survey of Google's PageRank
 http://pr.efactory.de/ A Survey of Google's PageRank Within the past few years, Google has become the far most utilized search engine worldwide. A decisive factor therefore was, besides high performance
http://pr.efactory.de/ A Survey of Google's PageRank Within the past few years, Google has become the far most utilized search engine worldwide. A decisive factor therefore was, besides high performance
Copyright 2007 Pearson Addison-Wesley. All rights reserved. A. Levitin Introduction to the Design & Analysis of Algorithms, 2 nd ed., Ch.
 Iterative Improvement Algorithm design technique for solving optimization problems Start with a feasible solution Repeat the following step until no improvement can be found: change the current feasible
Iterative Improvement Algorithm design technique for solving optimization problems Start with a feasible solution Repeat the following step until no improvement can be found: change the current feasible
Weighted Page Rank Algorithm Based on Number of Visits of Links of Web Page
 International Journal of Soft Computing and Engineering (IJSCE) ISSN: 31-307, Volume-, Issue-3, July 01 Weighted Page Rank Algorithm Based on Number of Visits of Links of Web Page Neelam Tyagi, Simple
International Journal of Soft Computing and Engineering (IJSCE) ISSN: 31-307, Volume-, Issue-3, July 01 Weighted Page Rank Algorithm Based on Number of Visits of Links of Web Page Neelam Tyagi, Simple
The PageRank Computation in Google, Randomized Algorithms and Consensus of Multi-Agent Systems
 The PageRank Computation in Google, Randomized Algorithms and Consensus of Multi-Agent Systems Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it This talk The objective of this talk is to discuss
The PageRank Computation in Google, Randomized Algorithms and Consensus of Multi-Agent Systems Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it This talk The objective of this talk is to discuss
INTRODUCTION TO DATA SCIENCE. Link Analysis (MMDS5)
") INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule
 Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Analysis of Large Graphs: TrustRank and WebSpam
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING
 Chapter 3 EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING 3.1 INTRODUCTION Generally web pages are retrieved with the help of search engines which deploy crawlers for downloading purpose. Given a query,
Chapter 3 EXTRACTION OF RELEVANT WEB PAGES USING DATA MINING 3.1 INTRODUCTION Generally web pages are retrieved with the help of search engines which deploy crawlers for downloading purpose. Given a query,
Link analysis. Query-independent ordering. Query processing. Spamming simple popularity
 Today s topic CS347 Link-based ranking in web search engines Lecture 6 April 25, 2001 Prabhakar Raghavan Web idiosyncrasies Distributed authorship Millions of people creating pages with their own style,
Today s topic CS347 Link-based ranking in web search engines Lecture 6 April 25, 2001 Prabhakar Raghavan Web idiosyncrasies Distributed authorship Millions of people creating pages with their own style,