Text, Knowledge, and Information Extraction. Lizhen Qu
|
|
|
- Jayson Holt
- 6 years ago
- Views:
Transcription



1 Text, Knowledge, and Information Extraction Lizhen Qu




2 A bit about Myself PhD: Databases and Information Systems Group (MPII) Advisors: Prof. Gerhard Weikum and Prof. Rainer Gemulla Thesis: Sentiment Analysis with Limited Training Data Now: machine learning group at NICTA, adjunct research fellow at ANU.
3 Macquarie 3

4 News about Macquarie Bank 4

5 Negative News about Macquarie Bank 5
6 Simple Math Problem Bob has 15 apples. He gives 9 to Sarah. How many apples does Bob have now? 6
7 Bob has 15 apples. He gives 9 to Sarah. How many apples does Bob have now? 7


8 Information Extraction Named entity recognition Named entity disambiguation Relation extraction 8
9 Knowledge Bases (Open Linked Data) (Bob_Dylan, compose, Like_a_rolling_stone ) (The_Dark_Night, directedby, Christopher_Nolan) Entity Graph OpenIE (Ollie, Reverb) Economic Graph 9
 Economic")
10 Knowledge Bases (Open Linked Data) YAGO #classes: 350,000 #entities: 10 million #facts: 120 million #language: 10 Entity Graph OpenIE (Ollie, Reverb) Economic Graph 10

11 Knowledge Bases (Open Linked Data) DBpedia #classes: 735 #entities: 38.3 million #triples: 6.9 billion #languages: 128 Entity Graph OpenIE (Ollie, Reverb) Economic Graph 11

 Economic")
12 Knowledge Bases (Open Linked Data) Freebase #entities: 50 million #facts: 3 billion #languages: almost 70 Entity Graph OpenIE (Ollie, Reverb) Economic Graph 12



13 Construct YAGO from (Semi) Structured Data 13



14 IE Challenge: ambiguity of Natural Language I made her duck. i. I cooked waterfowl for her. ii. I cooked waterfowl belonging her. iii. I created the duck she owns. iv. I caused her to quickly lower her head or body. v. I waved my magic wand and turned her into a waterfowl. 14
15 Named Entity Recognition TASK: ORG Research at Stanford led to a search engine company, founded by Page and Brin. PER PER Machine Learning Problem: O O ORG O O O O O O O O PER O PER O Research at Stanford led to search engine company, founded by Page and Brin. 15



16 Learning and Prediction has labels train models Sentences Feature Extraction Labeled Sentences no labels prediction 16
17 Feature Extraction Use features to represent each word. w -2 Research w -2 to w -1 at w -1 a Features of Stanford : w 0 w +1 Stanford led Features of Search : w 0 w +1 search engine w +2 to w +2 company POS noun POS noun capitalized? true capitalized? false Vectorise feature representations. w -2 = research capitalized w 0 = stanford w 0 = search

18 Standard Model: Conditional Random Fields Assigns local score to different (word, label) pairs. Joint inference to find best label sequences. CRF: p(y x) = exp P T t=1 Pi if i (y t 1,y t,x t ) Z Stanford NER [1]: 86% Best system [8]: 89% 18

19 Named Entity Disambiguation TASK: ORG Research at Stanford led to a search engine company, founded by Page and Brin. PER PER Larry Page Stanford Univeristy Sergey Brin 19
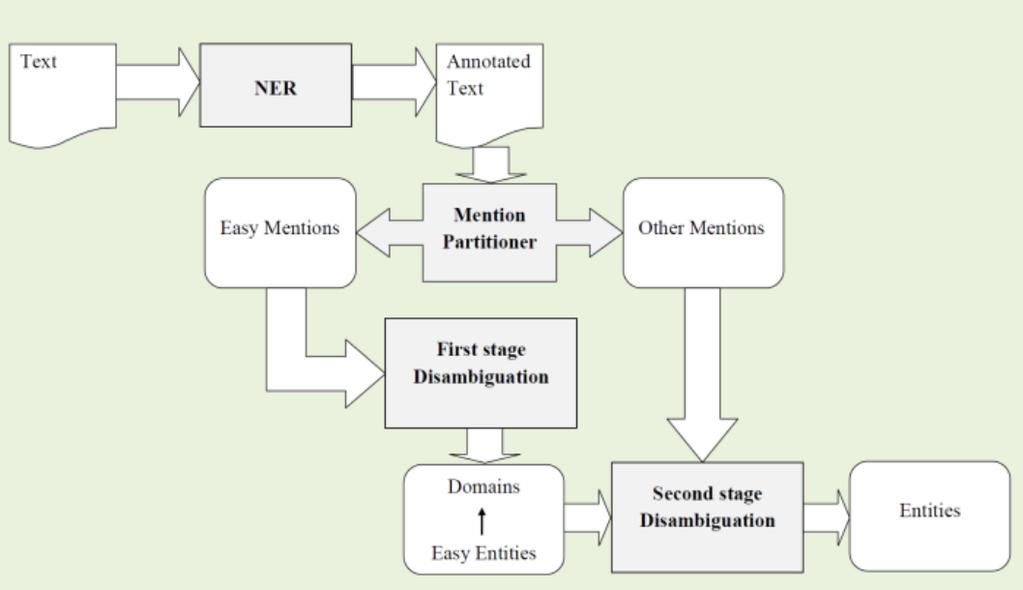
20 AIDA-light [2] 20

21 First Stage 21
22 Second Stage AIDA-light [2]: 84.8% DBPepdia spotlight: 75% 22



23 Relation Extraction Relation mention extraction. ORG: Stanford_University Research at Stanford led to a search engine company, founded by Page and Brin.? PER: Larry_Page PER: Sergey_Brin Expand knowledge bases. Larry Page? Stanford Univeristy The Dark Night? Christopher Nolan 23
24 Relation Mention Extraction Multi-class classification. Example features of a pair of entity mentions [3]. Research at Stanford led to a search engine company, founded by Page and Brin.? words between (Stanford, Page) Named entity types Number of mentions between (Stanford, Page) led, to, a, search, engine, company, founded, by (ORG, PER) 0 F-Measure on ACE: 71.2% [3] 24
![Expand Knowledge Base Multi-instance, multi-label [4,5]. Distant supervision. Freebase relation-level label Larry Page Sergey Brin mention-level label?](/docs-images/77/74877891/images/25-5.jpg "mention-level label? Research at Stanford led to a search engine company, founded by Page and Brin. Larry Page and Sergey Brin explained why they just created Alphabet.")
25 Expand Knowledge Base Multi-instance, multi-label [4,5]. Distant supervision. Freebase relation-level label Larry Page Sergey Brin mention-level label? mention-level label? Research at Stanford led to a search engine company, founded by Page and Brin. Larry Page and Sergey Brin explained why they just created Alphabet. MAP [3] : 56% MAP [4] : 66% 25
![Open Information Extraction Extract triples of any relations from the web [6].](/docs-images/77/74877891/images/26-1.jpg "It was exactly 50 years ago today that Bob Dylan walked into Studio A at Columbia Records in New York and")
 Optional: link triples to knowledge bases.")
26 Open Information Extraction Extract triples of any relations from the web [6]. It was exactly 50 years ago today that Bob Dylan walked into Studio A at Columbia Records in New York and recorded "Like a Rolling Stone. ( Bob Dylan, record, Like a rolling stone ) Optional: link triples to knowledge bases. ( Bob Dylan, record, Like a rolling stone ) The_Dark_Night record Like_a_Rolling _Stone F1 [6] : 19.6% F1 [9] : 28.3% 26
27 Harvest Domain-Specific Knowledge Deep learning. Learn cross-domain features. minimize training data. Transfer learning. source domain target domain newswire nurse handovers 27
28 Word Representation One-hot representation. stanford [ 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] university [ 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] oxford [ 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] conference [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 ] talk [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0 ] Distributed representation. stanford university oxford = [0.01, 0.3, -0.5, 0.6] conference talk 28
29 Distributed Representation 29




30 Apply Distributed Representations for NER Represent words based on positions rather than IDs. 2 nd word to the left first word to the left current word first word to the right 2 nd word to the right label Feature Matrix compare o stanford UNI university UNI and o oxford UNI 30
![Results of Named Entity Recognition [7] Reduce the amount](/docs-images/77/74877891/images/31-1.jpg "of training data. Tiny differences between word embeddings.")
31 Results of Named Entity Recognition [7] Reduce the amount of training data. Tiny differences between word embeddings. 31

32 NER for Novel Named Entity Types Goals: Minimize labeled training data. Leverage existing resources: Labeled corpora. Unlabeled text. Existing knowledge bases. source domain target domain person doctor patient location country city hotel orgnization corporation 32
33 Experimental Results on I2B2 33
34 Learn Text Representations for Relations Unsupervised pre-training. Distant supervision. Freebase co-founders Larry Page Sergey Brin Inferred mention-level label Research at Stanford led to a search engine company, founded by Page and Brin. Inferred mention-level label Larry Page and Sergey Brin explained why they just created Alphabet. 34
35 NICTA Deep Learning for IE Toolkit A fully integrated deep learning toolkit for NLP. Pipelines include both NLP preprocessing and DL components. Written in Scala/Java. Easy to write new ML component. Reuse UIMA NLP components. Scalable. Easy switch between GPUs and CPUs. Learning on GPUs. Make use of UIMA for prediction. 35
36 References [1] Jenny Rose Finkel, Trond Grenager, and Christopher Manning Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling. Proceedings of the 43nd Annual Meeting of the Association for Computational Linguistics (ACL 2005). [2] Nguyen, Dat Ba, et al. "Aida-light: High-throughput named-entity disambiguation." Linked Data on the Web at WWW2014 (2014). [3] Chan, Yee Seng, and Dan Roth. "Exploiting background knowledge for relation extraction." Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics, [4] Mihai Surdeanu, Julie Tibshirani, Ramesh Nallapati, Christopher D. Manning. Multi-instance Multi-label Learning for Relation Extraction. Proceedings of the 2012 Conference on Empirical Methods in Natural Language Processing and Natural Language Learning, [5] Riedel, Sebastian, et al. "Relation extraction with matrix factorization and universal schemas." (2013). [6] Schmitz, Michael, et al. "Open language learning for information extraction." Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics, [7] Qu, Lizhen, et al. "Big Data Small Data, In Domain Out-of Domain, Known Word Unknown Word: The Impact of Word Representation on Sequence Labelling Tasks." arxiv preprint arxiv: (2015). [8] Rie Kubota Ando and Tong Zhang A framework for learning predictive structures from multiple tasks and unlabeled data. Journal of Machine Learning Research, 6: [9] Angeli, Gabor, Melvin Johnson Premkumar, and Christopher D. Manning. "Leveraging Linguistic Structure For Open Domain Information Extraction." 36
37 Resources YAGO: research/yago-naga/yago DBPedia: Alchemy : Deep learning: Word2vec : Mallet (Java): Factorie (Scala): Stanford CoreNLP: NLP conferences. ACL, EMNLP, COLING, NAACL, EACL NLP online courses. ML online courses
JEDI: Joint Entity and Relation Detection using Type Inference
 JEDI System JEDI: Joint Entity and Relation Detection using Type Inference Johannes Kirschnick 1, Holmer Hemsen 1, Volker Markl 1,2 1 DFKI Project Office Berlin, Alt-Moabit 91c, Berlin firstname.lastname@dfki.de
JEDI System JEDI: Joint Entity and Relation Detection using Type Inference Johannes Kirschnick 1, Holmer Hemsen 1, Volker Markl 1,2 1 DFKI Project Office Berlin, Alt-Moabit 91c, Berlin firstname.lastname@dfki.de
QANUS A GENERIC QUESTION-ANSWERING FRAMEWORK
 QANUS A GENERIC QUESTION-ANSWERING FRAMEWORK NG, Jun Ping National University of Singapore ngjp@nus.edu.sg 30 November 2009 The latest version of QANUS and this documentation can always be downloaded from
QANUS A GENERIC QUESTION-ANSWERING FRAMEWORK NG, Jun Ping National University of Singapore ngjp@nus.edu.sg 30 November 2009 The latest version of QANUS and this documentation can always be downloaded from
Latent Relation Representations for Universal Schemas
 University of Massachusetts Amherst From the SelectedWorks of Andrew McCallum 2013 Latent Relation Representations for Universal Schemas Sebastian Riedel Limin Yao Andrew McCallum, University of Massachusetts
University of Massachusetts Amherst From the SelectedWorks of Andrew McCallum 2013 Latent Relation Representations for Universal Schemas Sebastian Riedel Limin Yao Andrew McCallum, University of Massachusetts
CMU System for Entity Discovery and Linking at TAC-KBP 2017
 CMU System for Entity Discovery and Linking at TAC-KBP 2017 Xuezhe Ma, Nicolas Fauceglia, Yiu-chang Lin, and Eduard Hovy Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave, Pittsburgh,
CMU System for Entity Discovery and Linking at TAC-KBP 2017 Xuezhe Ma, Nicolas Fauceglia, Yiu-chang Lin, and Eduard Hovy Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave, Pittsburgh,
CMU System for Entity Discovery and Linking at TAC-KBP 2016
 CMU System for Entity Discovery and Linking at TAC-KBP 2016 Xuezhe Ma, Nicolas Fauceglia, Yiu-chang Lin, and Eduard Hovy Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave, Pittsburgh,
CMU System for Entity Discovery and Linking at TAC-KBP 2016 Xuezhe Ma, Nicolas Fauceglia, Yiu-chang Lin, and Eduard Hovy Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave, Pittsburgh,
DBpedia Spotlight at the MSM2013 Challenge
 DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
Stanford s 2013 KBP System
 Stanford s 2013 KBP System Gabor Angeli, Arun Chaganty, Angel Chang, Kevin Reschke, Julie Tibshirani, Jean Y. Wu, Osbert Bastani, Keith Siilats, Christopher D. Manning Stanford University Stanford, CA
Stanford s 2013 KBP System Gabor Angeli, Arun Chaganty, Angel Chang, Kevin Reschke, Julie Tibshirani, Jean Y. Wu, Osbert Bastani, Keith Siilats, Christopher D. Manning Stanford University Stanford, CA
CMU System for Entity Discovery and Linking at TAC-KBP 2015
 CMU System for Entity Discovery and Linking at TAC-KBP 2015 Nicolas Fauceglia, Yiu-Chang Lin, Xuezhe Ma, and Eduard Hovy Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave, Pittsburgh,
CMU System for Entity Discovery and Linking at TAC-KBP 2015 Nicolas Fauceglia, Yiu-Chang Lin, Xuezhe Ma, and Eduard Hovy Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave, Pittsburgh,
A Korean Knowledge Extraction System for Enriching a KBox
 A Korean Knowledge Extraction System for Enriching a KBox Sangha Nam, Eun-kyung Kim, Jiho Kim, Yoosung Jung, Kijong Han, Key-Sun Choi KAIST / The Republic of Korea {nam.sangha, kekeeo, hogajiho, wjd1004109,
A Korean Knowledge Extraction System for Enriching a KBox Sangha Nam, Eun-kyung Kim, Jiho Kim, Yoosung Jung, Kijong Han, Key-Sun Choi KAIST / The Republic of Korea {nam.sangha, kekeeo, hogajiho, wjd1004109,
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
CRFVoter: Chemical Entity Mention, Gene and Protein Related Object recognition using a conglomerate of CRF based tools
 CRFVoter: Chemical Entity Mention, Gene and Protein Related Object recognition using a conglomerate of CRF based tools Wahed Hemati, Alexander Mehler, and Tolga Uslu Text Technology Lab, Goethe Universitt
CRFVoter: Chemical Entity Mention, Gene and Protein Related Object recognition using a conglomerate of CRF based tools Wahed Hemati, Alexander Mehler, and Tolga Uslu Text Technology Lab, Goethe Universitt
QuickView: NLP-based Tweet Search
 QuickView: NLP-based Tweet Search Xiaohua Liu, Furu Wei, Ming Zhou, Microsoft QuickView Team School of Computer Science and Technology Harbin Institute of Technology, Harbin, 150001, China Microsoft Research
QuickView: NLP-based Tweet Search Xiaohua Liu, Furu Wei, Ming Zhou, Microsoft QuickView Team School of Computer Science and Technology Harbin Institute of Technology, Harbin, 150001, China Microsoft Research
Automatic Domain Partitioning for Multi-Domain Learning
 Automatic Domain Partitioning for Multi-Domain Learning Di Wang diwang@cs.cmu.edu Chenyan Xiong cx@cs.cmu.edu William Yang Wang ww@cmu.edu Abstract Multi-Domain learning (MDL) assumes that the domain labels
Automatic Domain Partitioning for Multi-Domain Learning Di Wang diwang@cs.cmu.edu Chenyan Xiong cx@cs.cmu.edu William Yang Wang ww@cmu.edu Abstract Multi-Domain learning (MDL) assumes that the domain labels
Semi-Supervised Learning of Named Entity Substructure
 Semi-Supervised Learning of Named Entity Substructure Alden Timme aotimme@stanford.edu CS229 Final Project Advisor: Richard Socher richard@socher.org Abstract The goal of this project was two-fold: (1)
Semi-Supervised Learning of Named Entity Substructure Alden Timme aotimme@stanford.edu CS229 Final Project Advisor: Richard Socher richard@socher.org Abstract The goal of this project was two-fold: (1)
NLP in practice, an example: Semantic Role Labeling
 NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
INFORMATION EXTRACTION
 COMP90042 LECTURE 13 INFORMATION EXTRACTION INTRODUCTION Given this: Brasilia, the Brazilian capital, was founded in 1960. Obtain this: capital(brazil, Brasilia) founded(brasilia, 1960) Main goal: turn
COMP90042 LECTURE 13 INFORMATION EXTRACTION INTRODUCTION Given this: Brasilia, the Brazilian capital, was founded in 1960. Obtain this: capital(brazil, Brasilia) founded(brasilia, 1960) Main goal: turn
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information
 Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Introduction to Text Mining. Hongning Wang
 Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Fast and Effective System for Name Entity Recognition on Big Data
 International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
Outline. Part I. Introduction Part II. ML for DI. Part III. DI for ML Part IV. Conclusions and research direction
 Outline Part I. Introduction Part II. ML for DI ML for entity linkage ML for data extraction ML for data fusion ML for schema alignment Part III. DI for ML Part IV. Conclusions and research direction Data
Outline Part I. Introduction Part II. ML for DI ML for entity linkage ML for data extraction ML for data fusion ML for schema alignment Part III. DI for ML Part IV. Conclusions and research direction Data
Named Entity Detection and Entity Linking in the Context of Semantic Web
 [1/52] Concordia Seminar - December 2012 Named Entity Detection and in the Context of Semantic Web Exploring the ambiguity question. Eric Charton, Ph.D. [2/52] Concordia Seminar - December 2012 Challenge
[1/52] Concordia Seminar - December 2012 Named Entity Detection and in the Context of Semantic Web Exploring the ambiguity question. Eric Charton, Ph.D. [2/52] Concordia Seminar - December 2012 Challenge
Efficient Dependency-Guided Named Entity Recognition
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Efficient Dependency-Guided Named Entity Recognition Zhanming Jie, Aldrian Obaja Muis, Wei Lu Singapore University of
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Efficient Dependency-Guided Named Entity Recognition Zhanming Jie, Aldrian Obaja Muis, Wei Lu Singapore University of
Noisy Or-based model for Relation Extraction using Distant Supervision
 Noisy Or-based model for Relation Extraction using Distant Supervision Ajay Nagesh 1,2,3 1 IITB-Monash Research Academy ajaynagesh@cse.iitb.ac.in Gholamreza Haffari 2 Faculty of IT, Monash University gholamreza.haffari@monash.edu
Noisy Or-based model for Relation Extraction using Distant Supervision Ajay Nagesh 1,2,3 1 IITB-Monash Research Academy ajaynagesh@cse.iitb.ac.in Gholamreza Haffari 2 Faculty of IT, Monash University gholamreza.haffari@monash.edu
NUS-I2R: Learning a Combined System for Entity Linking
 NUS-I2R: Learning a Combined System for Entity Linking Wei Zhang Yan Chuan Sim Jian Su Chew Lim Tan School of Computing National University of Singapore {z-wei, tancl} @comp.nus.edu.sg Institute for Infocomm
NUS-I2R: Learning a Combined System for Entity Linking Wei Zhang Yan Chuan Sim Jian Su Chew Lim Tan School of Computing National University of Singapore {z-wei, tancl} @comp.nus.edu.sg Institute for Infocomm
NLATool: An Application for Enhanced Deep Text Understanding
 NLATool: An Application for Enhanced Deep Text Understanding Markus Gärtner 1, Sven Mayer 2, Valentin Schwind 2, Eric Hämmerle 2, Emine Turcan 2, Florin Rheinwald 2, Gustav Murawski 2, Lars Lischke 2,
NLATool: An Application for Enhanced Deep Text Understanding Markus Gärtner 1, Sven Mayer 2, Valentin Schwind 2, Eric Hämmerle 2, Emine Turcan 2, Florin Rheinwald 2, Gustav Murawski 2, Lars Lischke 2,
End-To-End Spam Classification With Neural Networks
 End-To-End Spam Classification With Neural Networks Christopher Lennan, Bastian Naber, Jan Reher, Leon Weber 1 Introduction A few years ago, the majority of the internet s network traffic was due to spam
End-To-End Spam Classification With Neural Networks Christopher Lennan, Bastian Naber, Jan Reher, Leon Weber 1 Introduction A few years ago, the majority of the internet s network traffic was due to spam
Module 3: GATE and Social Media. Part 4. Named entities
 Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
Introduction to Hidden Markov models
 1/38 Introduction to Hidden Markov models Mark Johnson Macquarie University September 17, 2014 2/38 Outline Sequence labelling Hidden Markov Models Finding the most probable label sequence Higher-order
1/38 Introduction to Hidden Markov models Mark Johnson Macquarie University September 17, 2014 2/38 Outline Sequence labelling Hidden Markov Models Finding the most probable label sequence Higher-order
PRIS at TAC2012 KBP Track
 PRIS at TAC2012 KBP Track Yan Li, Sijia Chen, Zhihua Zhou, Jie Yin, Hao Luo, Liyin Hong, Weiran Xu, Guang Chen, Jun Guo School of Information and Communication Engineering Beijing University of Posts and
PRIS at TAC2012 KBP Track Yan Li, Sijia Chen, Zhihua Zhou, Jie Yin, Hao Luo, Liyin Hong, Weiran Xu, Guang Chen, Jun Guo School of Information and Communication Engineering Beijing University of Posts and
Outline. Morning program Preliminaries Semantic matching Learning to rank Entities
 112 Outline Morning program Preliminaries Semantic matching Learning to rank Afternoon program Modeling user behavior Generating responses Recommender systems Industry insights Q&A 113 are polysemic Finding
112 Outline Morning program Preliminaries Semantic matching Learning to rank Afternoon program Modeling user behavior Generating responses Recommender systems Industry insights Q&A 113 are polysemic Finding
Jianyong Wang Department of Computer Science and Technology Tsinghua University
 Jianyong Wang Department of Computer Science and Technology Tsinghua University jianyong@tsinghua.edu.cn Joint work with Wei Shen (Tsinghua), Ping Luo (HP), and Min Wang (HP) Outline Introduction to entity
Jianyong Wang Department of Computer Science and Technology Tsinghua University jianyong@tsinghua.edu.cn Joint work with Wei Shen (Tsinghua), Ping Luo (HP), and Min Wang (HP) Outline Introduction to entity
Enhanced Retrieval of Web Pages using Improved Page Rank Algorithm
 Enhanced Retrieval of Web Pages using Improved Page Rank Algorithm Rekha Jain 1, Sulochana Nathawat 2, Dr. G.N. Purohit 3 1 Department of Computer Science, Banasthali University, Jaipur, Rajasthan ABSTRACT
Enhanced Retrieval of Web Pages using Improved Page Rank Algorithm Rekha Jain 1, Sulochana Nathawat 2, Dr. G.N. Purohit 3 1 Department of Computer Science, Banasthali University, Jaipur, Rajasthan ABSTRACT
Using Natural Language Processing and Machine Learning to Assist First-Level Customer Support for Contract Management
 Using Natural Language Processing and Machine Learning to Assist First-Level Customer Support for Contract Management Master thesis Final presentation Michael Legenc Advisor: Daniel Braun Munich, 08.01.2018
Using Natural Language Processing and Machine Learning to Assist First-Level Customer Support for Contract Management Master thesis Final presentation Michael Legenc Advisor: Daniel Braun Munich, 08.01.2018
Making Sense Out of the Web
 Making Sense Out of the Web Rada Mihalcea University of North Texas Department of Computer Science rada@cs.unt.edu Abstract. In the past few years, we have witnessed a tremendous growth of the World Wide
Making Sense Out of the Web Rada Mihalcea University of North Texas Department of Computer Science rada@cs.unt.edu Abstract. In the past few years, we have witnessed a tremendous growth of the World Wide
Unsupervised Improvement of Named Entity Extraction in Short Informal Context Using Disambiguation Clues
 Unsupervised Improvement of Named Entity Extraction in Short Informal Context Using Disambiguation Clues Mena B. Habib and Maurice van Keulen Faculty of EEMCS, University of Twente, Enschede, The Netherlands
Unsupervised Improvement of Named Entity Extraction in Short Informal Context Using Disambiguation Clues Mena B. Habib and Maurice van Keulen Faculty of EEMCS, University of Twente, Enschede, The Netherlands
Tokenization and Sentence Segmentation. Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017
 Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Techreport for GERBIL V1
 Techreport for GERBIL 1.2.2 - V1 Michael Röder, Ricardo Usbeck, Axel-Cyrille Ngonga Ngomo February 21, 2016 Current Development of GERBIL Recently, we released the latest version 1.2.2 of GERBIL [16] 1.
Techreport for GERBIL 1.2.2 - V1 Michael Röder, Ricardo Usbeck, Axel-Cyrille Ngonga Ngomo February 21, 2016 Current Development of GERBIL Recently, we released the latest version 1.2.2 of GERBIL [16] 1.
Name Entity Recognition and Binary Relation Detection for News Query Dan YE
 2018 International Conference on Computer, Communication and Network Technology (CCNT 2018) ISBN: 978-1-60595-561-2 Name Entity Recognition and Binary Relation Detection for News Query Dan YE Department
2018 International Conference on Computer, Communication and Network Technology (CCNT 2018) ISBN: 978-1-60595-561-2 Name Entity Recognition and Binary Relation Detection for News Query Dan YE Department
Feature Extraction and Loss training using CRFs: A Project Report
 Feature Extraction and Loss training using CRFs: A Project Report Ankan Saha Department of computer Science University of Chicago March 11, 2008 Abstract POS tagging has been a very important problem in
Feature Extraction and Loss training using CRFs: A Project Report Ankan Saha Department of computer Science University of Chicago March 11, 2008 Abstract POS tagging has been a very important problem in
Weasel: a machine learning based approach to entity linking combining different features
 Weasel: a machine learning based approach to entity linking combining different features Felix Tristram, Sebastian Walter, Philipp Cimiano, and Christina Unger Semantic Computing Group, CITEC, Bielefeld
Weasel: a machine learning based approach to entity linking combining different features Felix Tristram, Sebastian Walter, Philipp Cimiano, and Christina Unger Semantic Computing Group, CITEC, Bielefeld
The Goal of this Document. Where to Start?
 A QUICK INTRODUCTION TO THE SEMILAR APPLICATION Mihai Lintean, Rajendra Banjade, and Vasile Rus vrus@memphis.edu linteam@gmail.com rbanjade@memphis.edu The Goal of this Document This document introduce
A QUICK INTRODUCTION TO THE SEMILAR APPLICATION Mihai Lintean, Rajendra Banjade, and Vasile Rus vrus@memphis.edu linteam@gmail.com rbanjade@memphis.edu The Goal of this Document This document introduce
Knowledge Base Population and Visualization Using an Ontology based on Semantic Roles
 Knowledge Base Population and Visualization Using an Ontology based on Semantic Roles Maryam Siahbani, Ravikiran Vadlapudi, Max Whitney, and Anoop Sarkar Simon Fraser University, School of Computing Science
Knowledge Base Population and Visualization Using an Ontology based on Semantic Roles Maryam Siahbani, Ravikiran Vadlapudi, Max Whitney, and Anoop Sarkar Simon Fraser University, School of Computing Science
DHTK: The Digital Humanities ToolKit
 DHTK: The Digital Humanities ToolKit Davide Picca, Mattia Egloff University of Lausanne Abstract. Digital Humanities have the merit of connecting two very different disciplines such as humanities and computer
DHTK: The Digital Humanities ToolKit Davide Picca, Mattia Egloff University of Lausanne Abstract. Digital Humanities have the merit of connecting two very different disciplines such as humanities and computer
Towards Domain Independent Named Entity Recognition
 38 Computer Science 5 Towards Domain Independent Named Entity Recognition Fredrick Edward Kitoogo, Venansius Baryamureeba and Guy De Pauw Named entity recognition is a preprocessing tool to many natural
38 Computer Science 5 Towards Domain Independent Named Entity Recognition Fredrick Edward Kitoogo, Venansius Baryamureeba and Guy De Pauw Named entity recognition is a preprocessing tool to many natural
Disambiguating Entities Referred by Web Endpoints using Tree Ensembles
 Disambiguating Entities Referred by Web Endpoints using Tree Ensembles Gitansh Khirbat Jianzhong Qi Rui Zhang Department of Computing and Information Systems The University of Melbourne Australia gkhirbat@student.unimelb.edu.au
Disambiguating Entities Referred by Web Endpoints using Tree Ensembles Gitansh Khirbat Jianzhong Qi Rui Zhang Department of Computing and Information Systems The University of Melbourne Australia gkhirbat@student.unimelb.edu.au
EUDAMU at SemEval-2017 Task 11: Action Ranking and Type Matching for End-User Development
 EUDAMU at SemEval-2017 Task 11: Ranking and Type Matching for End-User Development Marek Kubis and Paweł Skórzewski and Tomasz Ziętkiewicz Faculty of Mathematics and Computer Science Adam Mickiewicz University
EUDAMU at SemEval-2017 Task 11: Ranking and Type Matching for End-User Development Marek Kubis and Paweł Skórzewski and Tomasz Ziętkiewicz Faculty of Mathematics and Computer Science Adam Mickiewicz University
Knowledge-based Word Sense Disambiguation using Topic Models Devendra Singh Chaplot
 Knowledge-based Word Sense Disambiguation using Topic Models Devendra Singh Chaplot Ruslan Salakhutdinov Word Sense Disambiguation Word sense disambiguation (WSD) is defined as the problem of computationally
Knowledge-based Word Sense Disambiguation using Topic Models Devendra Singh Chaplot Ruslan Salakhutdinov Word Sense Disambiguation Word sense disambiguation (WSD) is defined as the problem of computationally
An Adaptive Framework for Named Entity Combination
 An Adaptive Framework for Named Entity Combination Bogdan Sacaleanu 1, Günter Neumann 2 1 IMC AG, 2 DFKI GmbH 1 New Business Department, 2 Language Technology Department Saarbrücken, Germany E-mail: Bogdan.Sacaleanu@im-c.de,
An Adaptive Framework for Named Entity Combination Bogdan Sacaleanu 1, Günter Neumann 2 1 IMC AG, 2 DFKI GmbH 1 New Business Department, 2 Language Technology Department Saarbrücken, Germany E-mail: Bogdan.Sacaleanu@im-c.de,
Knowledge Base Population and Visualization Using an Ontology based on Semantic Roles
 Knowledge Base Population and Visualization Using an Ontology based on Semantic Roles Maryam Siahbani, Ravikiran Vadlapudi, Max Whitney, and Anoop Sarkar Simon Fraser University, School of Computing Science
Knowledge Base Population and Visualization Using an Ontology based on Semantic Roles Maryam Siahbani, Ravikiran Vadlapudi, Max Whitney, and Anoop Sarkar Simon Fraser University, School of Computing Science
Graph-based Entity Linking using Shortest Path
 Graph-based Entity Linking using Shortest Path Yongsun Shim 1, Sungkwon Yang 1, Hyunwhan Joe 1, Hong-Gee Kim 1 1 Biomedical Knowledge Engineering Laboratory, Seoul National University, Seoul, Korea {yongsun0926,
Graph-based Entity Linking using Shortest Path Yongsun Shim 1, Sungkwon Yang 1, Hyunwhan Joe 1, Hong-Gee Kim 1 1 Biomedical Knowledge Engineering Laboratory, Seoul National University, Seoul, Korea {yongsun0926,
Meaning Banking and Beyond
 Meaning Banking and Beyond Valerio Basile Wimmics, Inria November 18, 2015 Semantics is a well-kept secret in texts, accessible only to humans. Anonymous I BEG TO DIFFER Surface Meaning Step by step analysis
Meaning Banking and Beyond Valerio Basile Wimmics, Inria November 18, 2015 Semantics is a well-kept secret in texts, accessible only to humans. Anonymous I BEG TO DIFFER Surface Meaning Step by step analysis
Prakash Poudyal University of Evora ABSTRACT
 Information Retrieval Based on Extraction of Domain Specific Significant Keywords and Other Relevant Phrases from a Conceptual Semantic Network Structure Mohammad Moinul Hoque University of Evora, Portugal
Information Retrieval Based on Extraction of Domain Specific Significant Keywords and Other Relevant Phrases from a Conceptual Semantic Network Structure Mohammad Moinul Hoque University of Evora, Portugal
Extracting Relation Descriptors with Conditional Random Fields
 Extracting Relation Descriptors with Conditional Random Fields Yaliang Li, Jing Jiang, Hai Leong Chieu, Kian Ming A. Chai School of Information Systems, Singapore Management University, Singapore DSO National
Extracting Relation Descriptors with Conditional Random Fields Yaliang Li, Jing Jiang, Hai Leong Chieu, Kian Ming A. Chai School of Information Systems, Singapore Management University, Singapore DSO National
Distant Supervision via Prototype-Based. global representation learning
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Distant Supervision via Prototype-Based Global Representation Learning State Key Laboratory of Computer Science, Institute
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Distant Supervision via Prototype-Based Global Representation Learning State Key Laboratory of Computer Science, Institute
arxiv: v1 [cs.cl] 1 Aug 2017
![arxiv: v1 [cs.cl] 1 Aug 2017](/thumbs/75/72256946.jpg "arxiv: v1 [cs.cl] 1 Aug 2017") Hidekazu Oiwa * 1 Yoshihiko Suhara * 1 Jiyu Komiya 1 Andrei Lopatenko 1 arxiv:1708.00481v1 [cs.cl] 1 Aug 2017 Abstract Entity population, a task of collecting entities that belong to a particular category,
Hidekazu Oiwa * 1 Yoshihiko Suhara * 1 Jiyu Komiya 1 Andrei Lopatenko 1 arxiv:1708.00481v1 [cs.cl] 1 Aug 2017 Abstract Entity population, a task of collecting entities that belong to a particular category,
Noise reduction and targeted exploration in imitation learning for Abstract Meaning Representation parsing
 Noise reduction targeted exploration in imitation learning for Abstract Meaning Representation parsing James Goodman Andreas Vlachos Jason Naradowsky Computer Science Department, University College London
Noise reduction targeted exploration in imitation learning for Abstract Meaning Representation parsing James Goodman Andreas Vlachos Jason Naradowsky Computer Science Department, University College London
State of the Art and Trends in Search Engine Technology. Gerhard Weikum
 State of the Art and Trends in Search Engine Technology Gerhard Weikum (weikum@mpi-inf.mpg.de) Commercial Search Engines Web search Google, Yahoo, MSN simple queries, chaotic data, many results key is
State of the Art and Trends in Search Engine Technology Gerhard Weikum (weikum@mpi-inf.mpg.de) Commercial Search Engines Web search Google, Yahoo, MSN simple queries, chaotic data, many results key is
Epistemo: A Crowd-Powered Conversational Search Interface
 Epistemo: A Crowd-Powered Conversational Search Interface Saiganesh Swaminathan saiganes@cs.cmu.edu Ting-Hao (Kenneth) Huang tinghaoh@andrew.cmu.edu Irene Lin iwl@andrew.cmu.edu Anhong Guo anhongg@cs.cmu.edu
Epistemo: A Crowd-Powered Conversational Search Interface Saiganesh Swaminathan saiganes@cs.cmu.edu Ting-Hao (Kenneth) Huang tinghaoh@andrew.cmu.edu Irene Lin iwl@andrew.cmu.edu Anhong Guo anhongg@cs.cmu.edu
Shallow Parsing Swapnil Chaudhari 11305R011 Ankur Aher Raj Dabre 11305R001
 Shallow Parsing Swapnil Chaudhari 11305R011 Ankur Aher - 113059006 Raj Dabre 11305R001 Purpose of the Seminar To emphasize on the need for Shallow Parsing. To impart basic information about techniques
Shallow Parsing Swapnil Chaudhari 11305R011 Ankur Aher - 113059006 Raj Dabre 11305R001 Purpose of the Seminar To emphasize on the need for Shallow Parsing. To impart basic information about techniques
3 Data, Data Mining. Chengkai Li
 CSE4334/5334 Data Mining 3 Data, Data Mining Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2018 (Slides partly courtesy of Pang-Ning Tan, Michael Steinbach
CSE4334/5334 Data Mining 3 Data, Data Mining Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2018 (Slides partly courtesy of Pang-Ning Tan, Michael Steinbach
Scalable Machine Learning in R. with H2O
 Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
arxiv: v1 [cs.ir] 7 Nov 2017
![arxiv: v1 [cs.ir] 7 Nov 2017](/thumbs/74/70737462.jpg "arxiv: v1 [cs.ir] 7 Nov 2017") Quality-Efficiency Trade-offs in Machine Learning for Text Processing arxiv:1711.02295v1 [cs.ir] 7 Nov 2017 Abstract Nowadays, the amount of available digital documents is rapidly growing from a variety
Quality-Efficiency Trade-offs in Machine Learning for Text Processing arxiv:1711.02295v1 [cs.ir] 7 Nov 2017 Abstract Nowadays, the amount of available digital documents is rapidly growing from a variety
Semantic Web: Extracting and Mining Structured Data from Unstructured Content
 : Extracting and Mining Structured Data from Unstructured Content Web Science Lecture Besnik Fetahu L3S Research Center, Leibniz Universität Hannover May 20, 2014 1 Introduction 2 3 4 5 6 7 8 1 Introduction
: Extracting and Mining Structured Data from Unstructured Content Web Science Lecture Besnik Fetahu L3S Research Center, Leibniz Universität Hannover May 20, 2014 1 Introduction 2 3 4 5 6 7 8 1 Introduction
New York University 2014 Knowledge Base Population Systems
 New York University 2014 Knowledge Base Population Systems Thien Huu Nguyen, Yifan He, Maria Pershina, Xiang Li, Ralph Grishman Computer Science Department New York University {thien, yhe, pershina, xiangli,
New York University 2014 Knowledge Base Population Systems Thien Huu Nguyen, Yifan He, Maria Pershina, Xiang Li, Ralph Grishman Computer Science Department New York University {thien, yhe, pershina, xiangli,
Enriching an Academic Knowledge base using Linked Open Data
 Enriching an Academic Knowledge base using Linked Open Data Chetana Gavankar 1,2 Ashish Kulkarni 1 Yuan Fang Li 3 Ganesh Ramakrishnan 1 (1) IIT Bombay, Mumbai, India (2) IITB-Monash Research Academy, Mumbai,
Enriching an Academic Knowledge base using Linked Open Data Chetana Gavankar 1,2 Ashish Kulkarni 1 Yuan Fang Li 3 Ganesh Ramakrishnan 1 (1) IIT Bombay, Mumbai, India (2) IITB-Monash Research Academy, Mumbai,
High-Throughput and Language-Agnostic Entity Disambiguation and Linking on User Generated Data
 High-Throughput and Language-Agnostic Entity Disambiguation and Linking on User Generated Data Preeti Bhargava Lithium Technologies Klout San Francisco, CA preeti.bhargava@lithium.com ABSTRACT The Entity
High-Throughput and Language-Agnostic Entity Disambiguation and Linking on User Generated Data Preeti Bhargava Lithium Technologies Klout San Francisco, CA preeti.bhargava@lithium.com ABSTRACT The Entity
Domain Adaptation Using Domain Similarity- and Domain Complexity-based Instance Selection for Cross-domain Sentiment Analysis
 Domain Adaptation Using Domain Similarity- and Domain Complexity-based Instance Selection for Cross-domain Sentiment Analysis Robert Remus rremus@informatik.uni-leipzig.de Natural Language Processing Group
Domain Adaptation Using Domain Similarity- and Domain Complexity-based Instance Selection for Cross-domain Sentiment Analysis Robert Remus rremus@informatik.uni-leipzig.de Natural Language Processing Group
Word Disambiguation in Web Search
 Word Disambiguation in Web Search Rekha Jain Computer Science, Banasthali University, Rajasthan, India Email: rekha_leo2003@rediffmail.com G.N. Purohit Computer Science, Banasthali University, Rajasthan,
Word Disambiguation in Web Search Rekha Jain Computer Science, Banasthali University, Rajasthan, India Email: rekha_leo2003@rediffmail.com G.N. Purohit Computer Science, Banasthali University, Rajasthan,
Textual Emigration Analysis
 Textual Emigration Analysis Andre Blessing and Jonas Kuhn IMS - Universität Stuttgart, Germany clarin@ims.uni-stuttgart.de Abstract We present a web-based application which is called TEA (Textual Emigration
Textual Emigration Analysis Andre Blessing and Jonas Kuhn IMS - Universität Stuttgart, Germany clarin@ims.uni-stuttgart.de Abstract We present a web-based application which is called TEA (Textual Emigration
A Hybrid Approach for Entity Recognition and Linking
 A Hybrid Approach for Entity Recognition and Linking Julien Plu, Giuseppe Rizzo, Raphaël Troncy EURECOM, Sophia Antipolis, France {julien.plu,giuseppe.rizzo,raphael.troncy}@eurecom.fr Abstract. Numerous
A Hybrid Approach for Entity Recognition and Linking Julien Plu, Giuseppe Rizzo, Raphaël Troncy EURECOM, Sophia Antipolis, France {julien.plu,giuseppe.rizzo,raphael.troncy}@eurecom.fr Abstract. Numerous
Papers for comprehensive viva-voce
 Papers for comprehensive viva-voce Priya Radhakrishnan Advisor : Dr. Vasudeva Varma Search and Information Extraction Lab, International Institute of Information Technology, Gachibowli, Hyderabad, India
Papers for comprehensive viva-voce Priya Radhakrishnan Advisor : Dr. Vasudeva Varma Search and Information Extraction Lab, International Institute of Information Technology, Gachibowli, Hyderabad, India
CIRGDISCO at RepLab2012 Filtering Task: A Two-Pass Approach for Company Name Disambiguation in Tweets
 CIRGDISCO at RepLab2012 Filtering Task: A Two-Pass Approach for Company Name Disambiguation in Tweets Arjumand Younus 1,2, Colm O Riordan 1, and Gabriella Pasi 2 1 Computational Intelligence Research Group,
CIRGDISCO at RepLab2012 Filtering Task: A Two-Pass Approach for Company Name Disambiguation in Tweets Arjumand Younus 1,2, Colm O Riordan 1, and Gabriella Pasi 2 1 Computational Intelligence Research Group,
Natural Language Processing
 Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Collaborative Ranking between Supervised and Unsupervised Approaches for Keyphrase Extraction
 The 2014 Conference on Computational Linguistics and Speech Processing ROCLING 2014, pp. 110-124 The Association for Computational Linguistics and Chinese Language Processing Collaborative Ranking between
The 2014 Conference on Computational Linguistics and Speech Processing ROCLING 2014, pp. 110-124 The Association for Computational Linguistics and Chinese Language Processing Collaborative Ranking between
Discriminative Training with Perceptron Algorithm for POS Tagging Task
 Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
TEXTPRO-AL: An Active Learning Platform for Flexible and Efficient Production of Training Data for NLP Tasks
 TEXTPRO-AL: An Active Learning Platform for Flexible and Efficient Production of Training Data for NLP Tasks Bernardo Magnini 1, Anne-Lyse Minard 1,2, Mohammed R. H. Qwaider 1, Manuela Speranza 1 1 Fondazione
TEXTPRO-AL: An Active Learning Platform for Flexible and Efficient Production of Training Data for NLP Tasks Bernardo Magnini 1, Anne-Lyse Minard 1,2, Mohammed R. H. Qwaider 1, Manuela Speranza 1 1 Fondazione
Bc. Pavel Taufer. Named Entity Recognition and Linking
 MASTER THESIS Bc. Pavel Taufer Named Entity Recognition and Linking Institute of Formal and Applied Linguistics Supervisor of the master thesis: Study programme: Study branch: RNDr. Milan Straka, Ph.D.
MASTER THESIS Bc. Pavel Taufer Named Entity Recognition and Linking Institute of Formal and Applied Linguistics Supervisor of the master thesis: Study programme: Study branch: RNDr. Milan Straka, Ph.D.
Entity Linking at Web Scale
 Entity Linking at Web Scale Thomas Lin, Mausam, Oren Etzioni Computer Science & Engineering University of Washington Seattle, WA 98195, USA {tlin, mausam, etzioni}@cs.washington.edu Abstract This paper
Entity Linking at Web Scale Thomas Lin, Mausam, Oren Etzioni Computer Science & Engineering University of Washington Seattle, WA 98195, USA {tlin, mausam, etzioni}@cs.washington.edu Abstract This paper
T2KG: An End-to-End System for Creating Knowledge Graph from Unstructured Text
 The AAAI-17 Workshop on Knowledge-Based Techniques for Problem Solving and Reasoning WS-17-12 T2KG: An End-to-End System for Creating Knowledge Graph from Unstructured Text Natthawut Kertkeidkachorn, 1,2
The AAAI-17 Workshop on Knowledge-Based Techniques for Problem Solving and Reasoning WS-17-12 T2KG: An End-to-End System for Creating Knowledge Graph from Unstructured Text Natthawut Kertkeidkachorn, 1,2
Transition-Based Dependency Parsing with Stack Long Short-Term Memory
 Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
December 4, BigData 2017 Enterprise Knowledge Graphs for Large Scale Analytics 1/47
 December 4, 2017 BigData 2017 Enterprise Knowledge Graphs for Large Scale Analytics 1/47 Knowledge Graphs Analytics Knowledge Graph Analytics Finding Entities of Interest Entity Search and Recommendation
December 4, 2017 BigData 2017 Enterprise Knowledge Graphs for Large Scale Analytics 1/47 Knowledge Graphs Analytics Knowledge Graph Analytics Finding Entities of Interest Entity Search and Recommendation
The Open University s repository of research publications and other research outputs. Search Personalization with Embeddings
 Open Research Online The Open University s repository of research publications and other research outputs Search Personalization with Embeddings Conference Item How to cite: Vu, Thanh; Nguyen, Dat Quoc;
Open Research Online The Open University s repository of research publications and other research outputs Search Personalization with Embeddings Conference Item How to cite: Vu, Thanh; Nguyen, Dat Quoc;
Extracting Wikipedia Historical Attributes Data
 Extracting Wikipedia Historical Attributes Data Guillermo Garrido NLP & IR Group, UNED Madrid, Spain ggarrido@lsi.uned.es Jean-Yves Delort Google Research Zurich Switzerland jydelort@google.com Enrique
Extracting Wikipedia Historical Attributes Data Guillermo Garrido NLP & IR Group, UNED Madrid, Spain ggarrido@lsi.uned.es Jean-Yves Delort Google Research Zurich Switzerland jydelort@google.com Enrique
An Error Analysis Tool for Natural Language Processing and Applied Machine Learning
 An Error Analysis Tool for Natural Language Processing and Applied Machine Learning Apoorv Agarwal Department of Computer Science Columbia University New York, NY, USA apoorv@cs.columbia.edu Ankit Agarwal
An Error Analysis Tool for Natural Language Processing and Applied Machine Learning Apoorv Agarwal Department of Computer Science Columbia University New York, NY, USA apoorv@cs.columbia.edu Ankit Agarwal
Conclusion and review
 Conclusion and review Domain-specific search (DSS) 2 3 Emerging opportunities for DSS Fighting human trafficking Predicting cyberattacks Stopping Penny Stock Fraud Accurate geopolitical forecasting 3 General
Conclusion and review Domain-specific search (DSS) 2 3 Emerging opportunities for DSS Fighting human trafficking Predicting cyberattacks Stopping Penny Stock Fraud Accurate geopolitical forecasting 3 General
Towards Efficient and Effective Semantic Table Interpretation Ziqi Zhang
 Towards Efficient and Effective Semantic Table Interpretation Ziqi Zhang Department of Computer Science, University of Sheffield Outline Define semantic table interpretation State-of-the-art and motivation
Towards Efficient and Effective Semantic Table Interpretation Ziqi Zhang Department of Computer Science, University of Sheffield Outline Define semantic table interpretation State-of-the-art and motivation
Lightly-Supervised Attribute Extraction
 Lightly-Supervised Attribute Extraction Abstract We introduce lightly-supervised methods for extracting entity attributes from natural language text. Using those methods, we are able to extract large number
Lightly-Supervised Attribute Extraction Abstract We introduce lightly-supervised methods for extracting entity attributes from natural language text. Using those methods, we are able to extract large number
MASWS Natural Language and the Semantic Web
 MASWS Natural Language and the Semantic Web Kate Byrne School of Informatics 14 February 2011 1 / 27 Populating the Semantic Web why and how? text to RDF Organising the Triples schema design open issues
MASWS Natural Language and the Semantic Web Kate Byrne School of Informatics 14 February 2011 1 / 27 Populating the Semantic Web why and how? text to RDF Organising the Triples schema design open issues
Unstructured Data. CS102 Winter 2019
 Winter 2019 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for patterns in data
Winter 2019 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for patterns in data
QUALIBETA at the NTCIR-11 Math 2 Task: An Attempt to Query Math Collections
 QUALIBETA at the NTCIR-11 Math 2 Task: An Attempt to Query Math Collections José María González Pinto, Simon Barthel, and Wolf-Tilo Balke IFIS TU Braunschweig Mühlenpfordstrasse 23 38106 Braunschweig,
QUALIBETA at the NTCIR-11 Math 2 Task: An Attempt to Query Math Collections José María González Pinto, Simon Barthel, and Wolf-Tilo Balke IFIS TU Braunschweig Mühlenpfordstrasse 23 38106 Braunschweig,
Knowledge Graphs: In Theory and Practice
 Knowledge Graphs: In Theory and Practice Sumit Bhatia 1 and Nitish Aggarwal 2 1 IBM Research, New Delhi, India 2 IBM Watson, San Jose, CA sumitbhatia@in.ibm.com, nitish.aggarwal@ibm.com November 10, 2017
Knowledge Graphs: In Theory and Practice Sumit Bhatia 1 and Nitish Aggarwal 2 1 IBM Research, New Delhi, India 2 IBM Watson, San Jose, CA sumitbhatia@in.ibm.com, nitish.aggarwal@ibm.com November 10, 2017
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Statistical parsing. Fei Xia Feb 27, 2009 CSE 590A
 Statistical parsing Fei Xia Feb 27, 2009 CSE 590A Statistical parsing History-based models (1995-2000) Recent development (2000-present): Supervised learning: reranking and label splitting Semi-supervised
Statistical parsing Fei Xia Feb 27, 2009 CSE 590A Statistical parsing History-based models (1995-2000) Recent development (2000-present): Supervised learning: reranking and label splitting Semi-supervised
Learning a Product of Experts with Elitist Lasso
 Learning a Product of Experts with Elitist Lasso Mengqiu Wang Computer Science Department Stanford University Stanford, CA 94305, USA mengqiu@cs.stanford.edu Christopher D. Manning Computer Science Department
Learning a Product of Experts with Elitist Lasso Mengqiu Wang Computer Science Department Stanford University Stanford, CA 94305, USA mengqiu@cs.stanford.edu Christopher D. Manning Computer Science Department
Easy-First POS Tagging and Dependency Parsing with Beam Search
 Easy-First POS Tagging and Dependency Parsing with Beam Search Ji Ma JingboZhu Tong Xiao Nan Yang Natrual Language Processing Lab., Northeastern University, Shenyang, China MOE-MS Key Lab of MCC, University
Easy-First POS Tagging and Dependency Parsing with Beam Search Ji Ma JingboZhu Tong Xiao Nan Yang Natrual Language Processing Lab., Northeastern University, Shenyang, China MOE-MS Key Lab of MCC, University
Semantic Consistency: A Local Subspace Based Method for Distant Supervised Relation Extraction
 Semantic Consistency: A Local Subspace Based Method for Distant Supervised Relation Extraction Xianpei Han and Le Sun State Key Laboratory of Computer Science Institute of Software, Chinese Academy of
Semantic Consistency: A Local Subspace Based Method for Distant Supervised Relation Extraction Xianpei Han and Le Sun State Key Laboratory of Computer Science Institute of Software, Chinese Academy of
University of Sheffield, NLP. Chunking Practical Exercise
 Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Entity-centric Topic Extraction and Exploration: A Network-based Approach
 Entity-centric Topic Extraction and Exploration: A Network-based Approach Andreas Spitz and Michael Gertz March 27, 2018 ECIR 2018, Grenoble Heidelberg University, Germany Database Systems Research Group
Entity-centric Topic Extraction and Exploration: A Network-based Approach Andreas Spitz and Michael Gertz March 27, 2018 ECIR 2018, Grenoble Heidelberg University, Germany Database Systems Research Group
UBC Entity Discovery and Linking & Diagnostic Entity Linking at TAC-KBP 2014
 UBC Entity Discovery and Linking & Diagnostic Entity Linking at TAC-KBP 2014 Ander Barrena, Eneko Agirre, Aitor Soroa IXA NLP Group / University of the Basque Country, Donostia, Basque Country ander.barrena@ehu.es,
UBC Entity Discovery and Linking & Diagnostic Entity Linking at TAC-KBP 2014 Ander Barrena, Eneko Agirre, Aitor Soroa IXA NLP Group / University of the Basque Country, Donostia, Basque Country ander.barrena@ehu.es,
Lucida Sirius and DjiNN Tutorial
 Lucida Sirius and DjiNN Tutorial Speakers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang Organizers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang, Lingjia Tang, Jason Mars Before We Begin
Lucida Sirius and DjiNN Tutorial Speakers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang Organizers: Johann Hauswald, Michael A. Laurenzano, Yunqi Zhang, Lingjia Tang, Jason Mars Before We Begin