CS 345A Data Mining Lecture 1. Introduction to Web Mining
|
|
|
- Oswin Wheeler
- 6 years ago
- Views:
Transcription
1 CS 345A Data Mining Lecture 1 Introduction to Web Mining
2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns
3 Web Mining v. Data Mining Structure (or lack of it) Textual information and linkage structure Scale Data generated per day is comparable to largest conventional data warehouses Speed Often need to react to evolving usage patterns in real-time (e.g., merchandising)
4 Web Mining topics Web graph analysis Power Laws and The Long Tail Structured data extraction Web advertising Systems Issues
5 Web Mining topics Web graph analysis Power Laws and The Long Tail Structured data extraction Web advertising Systems Issues
6 Size of the Web Number of pages Technically, infinite Much duplication (30-40%) Best estimate of unique static HTML pages comes from search engine claims Until last year, Google claimed 8 billion(?), Yahoo claimed 20 billion Google recently announced that their index contains 1 trillion pages How to explain the discrepancy?
7 The web as a graph Pages = nodes, hyperlinks = edges Ignore content Directed graph High linkage links/page on average Power-law degree distribution
8 Structure of Web graph Let s take a closer look at structure Broder et al (2000) studied a crawl of 200M pages and other smaller crawls Bow-tie structure Not a small world
9 Bow-tie Structure Source: Broder et al, 2000
10 What can the graph tell us? Distinguish important pages from unimportant ones Page rank Discover communities of related pages Hubs and Authorities Detect web spam Trust rank
11 Web Mining topics Web graph analysis Power Laws and The Long Tail Structured data extraction Web advertising Systems Issues

12 Power-law degree distribution Source: Broder et al, 2000
13 Power-laws galore Structure In-degrees Out-degrees Number of pages per site Usage patterns Number of visitors Popularity e.g., products, movies, music
")
14 The Long Tail Source: Chris Anderson (2004)
15 The Long Tail Shelf space is a scarce commodity for traditional retailers Also: TV networks, movie theaters, The web enables near-zero-cost dissemination of information about products More choice necessitates better filters Recommendation engines (e.g., Amazon) How Into Thin Air made Touching the Void a bestseller
16 Web Mining topics Web graph analysis Power Laws and The Long Tail Structured data extraction Web advertising Systems Issues

17 Extracting Structured Data

18 Extracting structured data
19 Web Mining topics Web graph analysis Power Laws and The Long Tail Structured data extraction Web advertising Systems Issues

20 Searching the Web The Web Content aggregators Content consumers

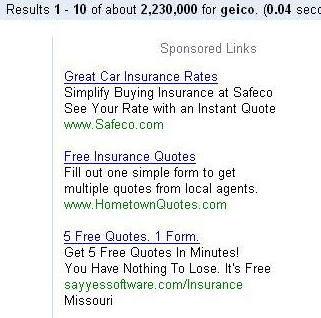
21 Ads vs. search results
22 Ads vs. search results Search advertising is the revenue model Multi-billion-dollar industry Advertisers pay for clicks on their ads Interesting problems What ads to show for a search? If I m an advertiser, which search terms should I bid on and how much to bid?
23 Web Mining topics Web graph analysis Power Laws and The Long Tail Structured data extraction Web advertising Systems Issues
24 Two Approaches to Analyzing Data Machine Learning approach Emphasizes sophisticated algorithms e.g., Support Vector Machines Data sets tend to be small, fit in memory Data Mining approach Emphasizes big data sets (e.g., in the terabytes) Data cannot even fit on a single disk! Necessarily leads to simpler algorithms
25 Philosophy In many cases, adding more data leads to better results that improving algorithms Netflix Google search Google ads More on my blog: Datawocky (datawocky.com)
26 Systems architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk
27 Very Large-Scale Data Mining CPU Mem CPU Mem CPU Mem Disk Disk Disk Cluster of commodity nodes
28 Systems Issues Web data sets can be very large Tens to hundreds of terabytes Cannot mine on a single server! Need large farms of servers How to organize hardware/software to mine multi-terabye data sets Without breaking the bank!
29 Web Mining topics Web graph analysis Power Laws and The Long Tail Structured data extraction Web advertising Systems Issues
30 Project Lots of interesting project ideas If you can t think of one please come discuss with us Infrastructure Aster Data cluster on Amazon EC2 Supports both MapReduce and SQL Data Netflix ShareThis Google WebBase TREC
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University Infinite data. Filtering data streams
 /9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
/9/7 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman
 Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Thanks to Jure Leskovec, Anand Rajaraman, Jeff Ullman http://www.mmds.org Overview of Recommender Systems Content-based Systems Collaborative Filtering J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive
Introduction to Data Mining
 Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Introduction to Data Mining Lecture #7: Recommendation Content based & Collaborative Filtering Seoul National University In This Lecture Understand the motivation and the problem of recommendation Compare
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu Customer X Buys Metalica CD Buys Megadeth CD Customer Y Does search on Metalica Recommender system suggests Megadeth
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu //8 Jure Leskovec, Stanford CS6: Mining Massive Datasets High dim. data Graph data Infinite data Machine learning
The Web: Concepts and Technology. 1 CS 584: Information Retrieval. Math & Computer Science Department, Emory University
 The Web: Concepts and Technology January 15: Course Overview 1 CS 584: Information Retrieval. Math & Computer Science Department, Emory University Today s Plan Who am I? What is this course about? Logistics
The Web: Concepts and Technology January 15: Course Overview 1 CS 584: Information Retrieval. Math & Computer Science Department, Emory University Today s Plan Who am I? What is this course about? Logistics
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
BBS654 Data Mining. Pinar Duygulu
 BBS6 Data Mining Pinar Duygulu Slides are adapted from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org Mustafa Ozdal Example: Recommender Systems Customer X Buys Metallica
BBS6 Data Mining Pinar Duygulu Slides are adapted from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org Mustafa Ozdal Example: Recommender Systems Customer X Buys Metallica
Seek and Ye shall Find
 Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2010 Adam Finkelstein Final tally: Computer $77,147, Ken Jennings $24,000, Brad Rutter $21,600. Jennings: I, for one, welcome
Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2010 Adam Finkelstein Final tally: Computer $77,147, Ken Jennings $24,000, Brad Rutter $21,600. Jennings: I, for one, welcome
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys Metallica
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys Metallica
3 Media Web. Understanding SEO WHITEPAPER
 3 Media Web WHITEPAPER WHITEPAPER In business, it s important to be in the right place at the right time. Online business is no different, but with Google searching more than 30 trillion web pages, 100
3 Media Web WHITEPAPER WHITEPAPER In business, it s important to be in the right place at the right time. Online business is no different, but with Google searching more than 30 trillion web pages, 100
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Lecture 4: Information Retrieval and Web Mining.
 Lecture 4: Information Retrieval and Web Mining http://www.cs.kent.edu/~jin/advdatabases.html 1 1 Outline Information Retrieval Chapter 19 (Database System Concepts) Web Mining (Mining the Web, Soumen
Lecture 4: Information Retrieval and Web Mining http://www.cs.kent.edu/~jin/advdatabases.html 1 1 Outline Information Retrieval Chapter 19 (Database System Concepts) Web Mining (Mining the Web, Soumen
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /7/0 Jure Leskovec, Stanford CS6: Mining Massive Datasets, http://cs6.stanford.edu High dim. data Graph data Infinite
CS6: Mining Massive Datasets Jure Leskovec, Stanford University http://cs6.stanford.edu /7/0 Jure Leskovec, Stanford CS6: Mining Massive Datasets, http://cs6.stanford.edu High dim. data Graph data Infinite
Information Retrieval. Lecture 9 - Web search basics
 Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Information Retrieval Lecture 9 - Web search basics Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Up to now: techniques for general
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Web Search Basics The Web as a graph
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Web Search Basics The Web as a graph
Scalable Web Programming. CS193S - Jan Jannink - 2/16/10
 Scalable Web Programming CS193S - Jan Jannink - 2/16/10 Administrative Stuff Submit a running website on Thursday some functionality can still be simple some placeholders acceptable Some tests required
Scalable Web Programming CS193S - Jan Jannink - 2/16/10 Administrative Stuff Submit a running website on Thursday some functionality can still be simple some placeholders acceptable Some tests required
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
CS 124/LINGUIST 180 From Languages to Information
 CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
CS /LINGUIST 80 From Languages to Information Dan Jurafsky Stanford University Recommender Systems & Collaborative Filtering Slides adapted from Jure Leskovec Recommender Systems Customer X Buys CD of
NBA 600: Day 15 Online Search 116 March Daniel Huttenlocher
 NBA 600: Day 15 Online Search 116 March 2004 Daniel Huttenlocher Today s Class Finish up network effects topic from last week Searching, browsing, navigating Reading Beyond Google No longer available on
NBA 600: Day 15 Online Search 116 March 2004 Daniel Huttenlocher Today s Class Finish up network effects topic from last week Searching, browsing, navigating Reading Beyond Google No longer available on
CS 6240: Parallel Data Processing in MapReduce: Module 1. Mirek Riedewald
 CS 6240: Parallel Data Processing in MapReduce: Module 1 Mirek Riedewald Why Parallel Processing? Answer 1: Big Data 2 How Much Information? Source: http://www2.sims.berkeley.edu/research/projects/ho w-much-info-2003/execsum.htm
CS 6240: Parallel Data Processing in MapReduce: Module 1 Mirek Riedewald Why Parallel Processing? Answer 1: Big Data 2 How Much Information? Source: http://www2.sims.berkeley.edu/research/projects/ho w-much-info-2003/execsum.htm
Computer Science 572 Midterm Prof. Horowitz Thursday, March 8, 2012, 2:00pm 3:00pm
 Computer Science 572 Midterm Prof. Horowitz Thursday, March 8, 2012, 2:00pm 3:00pm Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Computer Science 572 Midterm Prof. Horowitz Thursday, March 8, 2012, 2:00pm 3:00pm Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Myths about Links, Links and More Links:
 Myths about Links, Links and More Links: CedarValleyGroup.com Myth 1: You have to pay to be submitted to Google search engine. Well let me explode that one myth. When your website is first launched Google
Myths about Links, Links and More Links: CedarValleyGroup.com Myth 1: You have to pay to be submitted to Google search engine. Well let me explode that one myth. When your website is first launched Google
Introduction to Search Engine Technology CS , Technion, Winter 2011/12
 Introduction to Search Engine Technology CS 236621, Technion, Winter 2011/12 Ronny Lempel Yahoo! Labs, Haifa What this Course is All About Will try to sample the science that drives Web search engines,
Introduction to Search Engine Technology CS 236621, Technion, Winter 2011/12 Ronny Lempel Yahoo! Labs, Haifa What this Course is All About Will try to sample the science that drives Web search engines,
Large-Scale Data Engineering. Overview and Introduction
 Large-Scale Data Engineering Overview and Introduction Administration Blackboard Page Announcements, also via email (pardon html formatting) Practical enrollment, Turning in assignments, Check Grades Contact:
Large-Scale Data Engineering Overview and Introduction Administration Blackboard Page Announcements, also via email (pardon html formatting) Practical enrollment, Turning in assignments, Check Grades Contact:
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Knowledge Discovery & Data Mining
 Announcements ISM 50 - Business Information Systems Lecture 17 Instructor: Magdalini Eirinaki UC Santa Cruz May 29, 2007 News Folio #3 DUE Thursday 5/31 Database Assignment DUE Tuesday 6/5 Business Paper
Announcements ISM 50 - Business Information Systems Lecture 17 Instructor: Magdalini Eirinaki UC Santa Cruz May 29, 2007 News Folio #3 DUE Thursday 5/31 Database Assignment DUE Tuesday 6/5 Business Paper
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Introduction to Data Mining
 Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Ranking of ads. Sponsored Search
 Sponsored Search Ranking of ads Goto model: Rank according to how much advertiser pays Current model: Balance auction price and relevance Irrelevant ads (few click-throughs) Decrease opportunities for
Sponsored Search Ranking of ads Goto model: Rank according to how much advertiser pays Current model: Balance auction price and relevance Irrelevant ads (few click-throughs) Decrease opportunities for
Today we show how a search engine works
 How Search Engines Work Today we show how a search engine works What happens when a searcher enters keywords What was performed well in advance Also explain (briefly) how paid results are chosen If we
How Search Engines Work Today we show how a search engine works What happens when a searcher enters keywords What was performed well in advance Also explain (briefly) how paid results are chosen If we
Antonio Fernández Anta
 Antonio Fernández Anta Joint work with Luis F. Chiroque, Héctor Cordobés, Rafael A. García Leiva, Philippe Morere, Lorenzo Ornella, Fernando Pérez, and Agustín Santos Recommendation Engines (RE) suggest
Antonio Fernández Anta Joint work with Luis F. Chiroque, Héctor Cordobés, Rafael A. García Leiva, Philippe Morere, Lorenzo Ornella, Fernando Pérez, and Agustín Santos Recommendation Engines (RE) suggest
ISM 50 - Business Information Systems
 ISM 50 - Business Information Systems Lecture 17 Instructor: Magdalini Eirinaki UC Santa Cruz May 29, 2007 Announcements News Folio #3 DUE Thursday 5/31 Database Assignment DUE Tuesday 6/5 Business Paper
ISM 50 - Business Information Systems Lecture 17 Instructor: Magdalini Eirinaki UC Santa Cruz May 29, 2007 Announcements News Folio #3 DUE Thursday 5/31 Database Assignment DUE Tuesday 6/5 Business Paper
Seek and Ye shall Find
 Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2012 Adam Finkelstein Recap: Binary Representation Powers of 2 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2 7 2 8 2 9 2 10 1 2 4 8 16 32 64
Seek and Ye shall Find The continuum of computer intelligence COS 116, Spring 2012 Adam Finkelstein Recap: Binary Representation Powers of 2 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2 7 2 8 2 9 2 10 1 2 4 8 16 32 64
The Ultimate Digital Marketing Glossary (A-Z) what does it all mean? A-Z of Digital Marketing Translation
 what does it all mean? A-Z of Digital Marketing Translation") The Ultimate Digital Marketing Glossary (A-Z) what does it all mean? In our experience, we find we can get over-excited when talking to clients or family or friends and sometimes we forget that not everyone
The Ultimate Digital Marketing Glossary (A-Z) what does it all mean? In our experience, we find we can get over-excited when talking to clients or family or friends and sometimes we forget that not everyone
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson
 Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Overview Introduction Classic
Web Search Basics Introduction to Information Retrieval INF 141/ CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Overview Introduction Classic
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Desktop Crawls. Document Feeds. Document Feeds. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Site keyword analysis. Site keyword analysis
 Paieška Paieška Paieška Site keyword analysis Site keyword analysis > > The WordStream Keyword Analysis Tool takes the analysis of your website keywords a step further by not only analyzing your keywords,
Paieška Paieška Paieška Site keyword analysis Site keyword analysis > > The WordStream Keyword Analysis Tool takes the analysis of your website keywords a step further by not only analyzing your keywords,
Digital Marketing for Small Businesses. Amandine - The Marketing Cookie
 Digital Marketing for Small Businesses Amandine - The Marketing Cookie Search Engine Optimisation What is SEO? SEO stands for Search Engine Optimisation. Definition: SEO is a methodology of strategies,
Digital Marketing for Small Businesses Amandine - The Marketing Cookie Search Engine Optimisation What is SEO? SEO stands for Search Engine Optimisation. Definition: SEO is a methodology of strategies,
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Lec 8: Adaptive Information Retrieval 2
 Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Searching for Familiar Strangers on Blogosphere: Problems and Challenges. N. Agarwal, H. Liu, J. Salerno, and P. Yu
 Searching for Familiar Strangers on Blogosphere: Problems and Challenges N. Agarwal, H. Liu, J. Salerno, and P. Yu http://www.public.asu.edu/~huanliu/papers/ngdm07.pdf An Ever Evolving Field Fragmentation
Searching for Familiar Strangers on Blogosphere: Problems and Challenges N. Agarwal, H. Liu, J. Salerno, and P. Yu http://www.public.asu.edu/~huanliu/papers/ngdm07.pdf An Ever Evolving Field Fragmentation
Information retrieval
 Information retrieval Lecture 8 Special thanks to Andrei Broder, IBM Krishna Bharat, Google for sharing some of the slides to follow. Top Online Activities (Jupiter Communications, 2000) Email 96% Web
Information retrieval Lecture 8 Special thanks to Andrei Broder, IBM Krishna Bharat, Google for sharing some of the slides to follow. Top Online Activities (Jupiter Communications, 2000) Email 96% Web
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Foundations of Data Engineering
 Foundations of Data Engineering Thomas Neumann 1 / 27 About this Lecture The goal of this lecture is teaching the standard tools and techniques for large-scale data processing. Related keywords include:
Foundations of Data Engineering Thomas Neumann 1 / 27 About this Lecture The goal of this lecture is teaching the standard tools and techniques for large-scale data processing. Related keywords include:
SEO: SEARCH ENGINE OPTIMISATION
 SEO: SEARCH ENGINE OPTIMISATION SEO IN 11 BASIC STEPS EXPLAINED What is all the commotion about this SEO, why is it important? I have had a professional content writer produce my content to make sure that
SEO: SEARCH ENGINE OPTIMISATION SEO IN 11 BASIC STEPS EXPLAINED What is all the commotion about this SEO, why is it important? I have had a professional content writer produce my content to make sure that
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Thursday, 26 January, 12. Web Site Design
 Web Site Design Not Just a Pretty Face Easy to update Responsive (mobile, tablet and web-friendly) Fast loading RSS enabled Connect to social channels Easy to update To me, that means one platform, WordPress.
Web Site Design Not Just a Pretty Face Easy to update Responsive (mobile, tablet and web-friendly) Fast loading RSS enabled Connect to social channels Easy to update To me, that means one platform, WordPress.
Lecture 11: Graph algorithms! Claudia Hauff (Web Information Systems)!
!") Lecture 11: Graph algorithms!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the scenes of MapReduce:
Lecture 11: Graph algorithms!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the scenes of MapReduce:
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Sriram Srinivasan Kalpesh Jain Shankar Venkataraman
 Sriram Srinivasan Kalpesh Jain Shankar Venkataraman Introduction Business Case Functionalities Architecture Data Mining Novelty Team Contribution Agenda 2 Introduction Established team sport for hundreds
Sriram Srinivasan Kalpesh Jain Shankar Venkataraman Introduction Business Case Functionalities Architecture Data Mining Novelty Team Contribution Agenda 2 Introduction Established team sport for hundreds
ELTMaestro for Spark: Data integration on clusters
 Introduction Spark represents an important milestone in the effort to make computing on clusters practical and generally available. Hadoop / MapReduce, introduced the early 2000s, allows clusters to be
Introduction Spark represents an important milestone in the effort to make computing on clusters practical and generally available. Hadoop / MapReduce, introduced the early 2000s, allows clusters to be
CSE6331: Cloud Computing
 CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2019 by Leonidas Fegaras Cloud Computing Fundamentals Based on: J. Freire s class notes on Big Data http://vgc.poly.edu/~juliana/courses/bigdata2016/
CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2019 by Leonidas Fegaras Cloud Computing Fundamentals Based on: J. Freire s class notes on Big Data http://vgc.poly.edu/~juliana/courses/bigdata2016/
Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem
 I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
Index Construction. Dictionary, postings, scalable indexing, dynamic indexing. Web Search
 Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Acknowledgements. Beyond DBMSs. Presentation Outline
 Acknowledgements Beyond RDBMSs These slides are put together from a variety of sources (both papers and slides/tutorials available on the web) Sharma Chakravarthy Information Technology Laboratory Computer
Acknowledgements Beyond RDBMSs These slides are put together from a variety of sources (both papers and slides/tutorials available on the web) Sharma Chakravarthy Information Technology Laboratory Computer
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Web Search. Lecture Objectives. Text Technologies for Data Science INFR Learn about: 11/14/2017. Instructor: Walid Magdy
 Text Technologies for Data Science INFR11145 Web Search Instructor: Walid Magdy 14-Nov-2017 Lecture Objectives Learn about: Working with Massive data Link analysis (PageRank) Anchor text 2 1 The Web Document
Text Technologies for Data Science INFR11145 Web Search Instructor: Walid Magdy 14-Nov-2017 Lecture Objectives Learn about: Working with Massive data Link analysis (PageRank) Anchor text 2 1 The Web Document
SEO and UAEX.EDU GETTING YOUR WEB PAGES FOUND IN GOOGLE
 SEO and UAEX.EDU GETTING YOUR WEB PAGES FOUND IN GOOGLE What is Search Engine Optimization? SEO is a marketing discipline focused on growing visibility in organic (non-paid) search engine results. Why
SEO and UAEX.EDU GETTING YOUR WEB PAGES FOUND IN GOOGLE What is Search Engine Optimization? SEO is a marketing discipline focused on growing visibility in organic (non-paid) search engine results. Why
DEC Computer Technology LESSON 6: DATABASES AND WEB SEARCH ENGINES
 DEC. 1-5 Computer Technology LESSON 6: DATABASES AND WEB SEARCH ENGINES Monday Overview of Databases A web search engine is a large database containing information about Web pages that have been registered
DEC. 1-5 Computer Technology LESSON 6: DATABASES AND WEB SEARCH ENGINES Monday Overview of Databases A web search engine is a large database containing information about Web pages that have been registered
Beyond Ten Blue Links Seven Challenges
 Beyond Ten Blue Links Seven Challenges Ricardo Baeza-Yates VP of Yahoo! Research for EMEA & LatAm Barcelona, Spain Thanks to Andrei Broder, Yoelle Maarek & Prabhakar Raghavan Agenda Past and Present Wisdom
Beyond Ten Blue Links Seven Challenges Ricardo Baeza-Yates VP of Yahoo! Research for EMEA & LatAm Barcelona, Spain Thanks to Andrei Broder, Yoelle Maarek & Prabhakar Raghavan Agenda Past and Present Wisdom
AN SEO GUIDE FOR SALONS
 AN SEO GUIDE FOR SALONS AN SEO GUIDE FOR SALONS Set Up Time 2/5 The basics of SEO are quick and easy to implement. Management Time 3/5 You ll need a continued commitment to make SEO work for you. WHAT
AN SEO GUIDE FOR SALONS AN SEO GUIDE FOR SALONS Set Up Time 2/5 The basics of SEO are quick and easy to implement. Management Time 3/5 You ll need a continued commitment to make SEO work for you. WHAT
: Semantic Web (2013 Fall)
") 03-60-569: Web (2013 Fall) University of Windsor September 4, 2013 Table of contents 1 2 3 4 5 Definition of the Web The World Wide Web is a system of interlinked hypertext documents accessed via the Internet
03-60-569: Web (2013 Fall) University of Windsor September 4, 2013 Table of contents 1 2 3 4 5 Definition of the Web The World Wide Web is a system of interlinked hypertext documents accessed via the Internet
Plumbing the Web. Narayanan Shivakumar. Google Distinguished Entrepreneur & Director
 Plumbing the Web Narayanan Shivakumar Google Distinguished Entrepreneur & Director Google Developer Day 2007 powered by 3 Copyright 2007, Google Inc Developers and Google AJAX Search API Google Code Project
Plumbing the Web Narayanan Shivakumar Google Distinguished Entrepreneur & Director Google Developer Day 2007 powered by 3 Copyright 2007, Google Inc Developers and Google AJAX Search API Google Code Project
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 19: Web Search Basics Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2008.07.07 Schütze: Web
Introduction to Information Retrieval http://informationretrieval.org IIR 19: Web Search Basics Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2008.07.07 Schütze: Web
Introduction to Data Mining and Data Analytics
 1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
SEO NEWSLETTER NOVEMBER,
 SEO NEWSLETTER NOVEMBER, 2012 I 01 Google s Introduces the Much Awaited Link Disavow Tool N D E X 02 03 04 Add Authorship Rich Snippets to Claim Your Content before It Slips Out Of Your Hand Google is
SEO NEWSLETTER NOVEMBER, 2012 I 01 Google s Introduces the Much Awaited Link Disavow Tool N D E X 02 03 04 Add Authorship Rich Snippets to Claim Your Content before It Slips Out Of Your Hand Google is
~ Ian Hunneybell: WWWT Revision Notes (15/06/2006) ~
 ~") . Search Engines, history and different types In the beginning there was Archie (990, indexed computer files) and Gopher (99, indexed plain text documents). Lycos (994) and AltaVista (995) were amongst
. Search Engines, history and different types In the beginning there was Archie (990, indexed computer files) and Gopher (99, indexed plain text documents). Lycos (994) and AltaVista (995) were amongst
The Web: Concepts and Technology. January 15: Course Overview
 The Web: Concepts and Technology January 15: Course Overview 1 Today s Plan Who am I? What is this course about? Logistics Who are you? 2 Meet Your Instructor Instructor: Eugene Agichtein Web: http://www.mathcs.emory.edu/~eugene
The Web: Concepts and Technology January 15: Course Overview 1 Today s Plan Who am I? What is this course about? Logistics Who are you? 2 Meet Your Instructor Instructor: Eugene Agichtein Web: http://www.mathcs.emory.edu/~eugene
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
Data Centers and Cloud Computing
 Data Centers and Cloud Computing CS677 Guest Lecture Tim Wood 1 Data Centers Large server and storage farms 1000s of servers Many TBs or PBs of data Used by Enterprises for server applications Internet
Data Centers and Cloud Computing CS677 Guest Lecture Tim Wood 1 Data Centers Large server and storage farms 1000s of servers Many TBs or PBs of data Used by Enterprises for server applications Internet
Information Retrieval II
 Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Performance Analysis for Crawling
 Scalable Servers and Load Balancing Kai Shen Online Applications online applications Applications accessible to online users through. Examples Online keyword search engine: Google. Web email: Gmail. News:
Scalable Servers and Load Balancing Kai Shen Online Applications online applications Applications accessible to online users through. Examples Online keyword search engine: Google. Web email: Gmail. News:
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #16: Recommenda2on Systems
 Data Management Systems. B. Aditya Prakash Lecture #16: Recommenda2on Systems") CS 6: (Big) Data Management Systems B. Aditya Prakash Lecture #6: Recommendaon Systems Example: Recommender Systems Customer X Buys Metallica CD Buys Megadeth CD Customer Y Does search on Metallica Recommender
CS 6: (Big) Data Management Systems B. Aditya Prakash Lecture #6: Recommendaon Systems Example: Recommender Systems Customer X Buys Metallica CD Buys Megadeth CD Customer Y Does search on Metallica Recommender
US Patent 6,658,423. William Pugh
 US Patent 6,658,423 William Pugh Detecting duplicate and near - duplicate files Worked on this problem at Google in summer of 2000 I have no information whether this is currently being used I know that
US Patent 6,658,423 William Pugh Detecting duplicate and near - duplicate files Worked on this problem at Google in summer of 2000 I have no information whether this is currently being used I know that
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Making Money with Hubpages CA$HING IN WITH ARTICLE WRITING. Benjamin King
 Making Money with Hubpages CA$HING IN WITH ARTICLE WRITING Learn the value of Hubpages rankings within Google and how to profit from writing hubs with them. by Benjamin King http://www.makemoneyonlinefreeinfo.com
Making Money with Hubpages CA$HING IN WITH ARTICLE WRITING Learn the value of Hubpages rankings within Google and how to profit from writing hubs with them. by Benjamin King http://www.makemoneyonlinefreeinfo.com
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
Information Retrieval
 Introduction Information Retrieval Information retrieval is a field concerned with the structure, analysis, organization, storage, searching and retrieval of information Gerard Salton, 1968 J. Pei: Information
Introduction Information Retrieval Information retrieval is a field concerned with the structure, analysis, organization, storage, searching and retrieval of information Gerard Salton, 1968 J. Pei: Information
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM
 CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
CHAPTER THREE INFORMATION RETRIEVAL SYSTEM 3.1 INTRODUCTION Search engine is one of the most effective and prominent method to find information online. It has become an essential part of life for almost
Module 1: Internet Basics for Web Development (II)
") INTERNET & WEB APPLICATION DEVELOPMENT SWE 444 Fall Semester 2008-2009 (081) Module 1: Internet Basics for Web Development (II) Dr. El-Sayed El-Alfy Computer Science Department King Fahd University of
INTERNET & WEB APPLICATION DEVELOPMENT SWE 444 Fall Semester 2008-2009 (081) Module 1: Internet Basics for Web Development (II) Dr. El-Sayed El-Alfy Computer Science Department King Fahd University of
Python & Web Mining. Lecture Old Dominion University. Department of Computer Science CS 495 Fall 2012
 Python & Web Mining Lecture 6 10-10-12 Old Dominion University Department of Computer Science CS 495 Fall 2012 Hany SalahEldeen Khalil hany@cs.odu.edu Scenario So what did Professor X do when he wanted
Python & Web Mining Lecture 6 10-10-12 Old Dominion University Department of Computer Science CS 495 Fall 2012 Hany SalahEldeen Khalil hany@cs.odu.edu Scenario So what did Professor X do when he wanted
MATH36032 Problem Solving by Computer. Data Science
 MATH36032 Problem Solving by Computer Data Science NO. of jobs on jobsite 1 10000 NO. of Jobs 8000 6000 4000 2000 MATLAB Data Data Science 0 Jan 2016 Jul 2016 Jan 2017 1 http://www.jobsite.co.uk/ What
MATH36032 Problem Solving by Computer Data Science NO. of jobs on jobsite 1 10000 NO. of Jobs 8000 6000 4000 2000 MATLAB Data Data Science 0 Jan 2016 Jul 2016 Jan 2017 1 http://www.jobsite.co.uk/ What
Data Intensive Scalable Computing. Thanks to: Randal E. Bryant Carnegie Mellon University
 Data Intensive Scalable Computing Thanks to: Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Big Data Sources: Seismic Simulations Wave propagation during an earthquake Large-scale
Data Intensive Scalable Computing Thanks to: Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Big Data Sources: Seismic Simulations Wave propagation during an earthquake Large-scale