Installing and configuring Apache Kafka
|
|
|
- Patrick Richard
- 5 years ago
- Views:
Transcription

1 3 Installing and configuring Date of Publish:
2 Contents Installing Kafka...3 Prerequisites... 3 Installing Kafka Using Ambari Preparing the Environment...9 Operating System Settings... 9 File System Selection Disk Drive Considerations...10 Java Version...10 Ethernet Bandwidth Customizing Kafka Settings on an Ambari-Managed Cluster...11 Kafka Broker Settings Connection Settings Topic Settings Log Settings Compaction Settings General Broker Settings Kafka Producer Settings Important Producer Settings Kafka Consumer Settings Configuring ZooKeeper for Use with Kafka Enabling Audit to HDFS for a Secure Cluster... 20
3 Installing Kafka Installing Kafka Although you can install Kafka on a cluster not managed by Ambari, this chapter describes how to install Kafka on an Ambari-managed cluster. Prerequisites Before installing Kafka, ZooKeeper must be installed and running on your cluster. Note that the following underlying file systems are supported for use with Kafka: EXT4: supported and recommended EXT3: supported Caution: Encrypted file systems such as SafenetFS are not supported for Kafka. Index file corruption can occur. Installing Kafka Using Ambari After Kafka is deployed and running, validate the installation. You can use the command-line interface to create a Kafka topic, send test messages, and consume the messages. Procedure 1. Click the Ambari "Services" tab. 2. In the Ambari "Actions" menu, select "Add Service." This starts the Add Service wizard, displaying the Choose Services page. Some of the services are enabled by default. 3. Scroll through the alphabetic list of components on the Choose Services page, and select "Kafka". 3
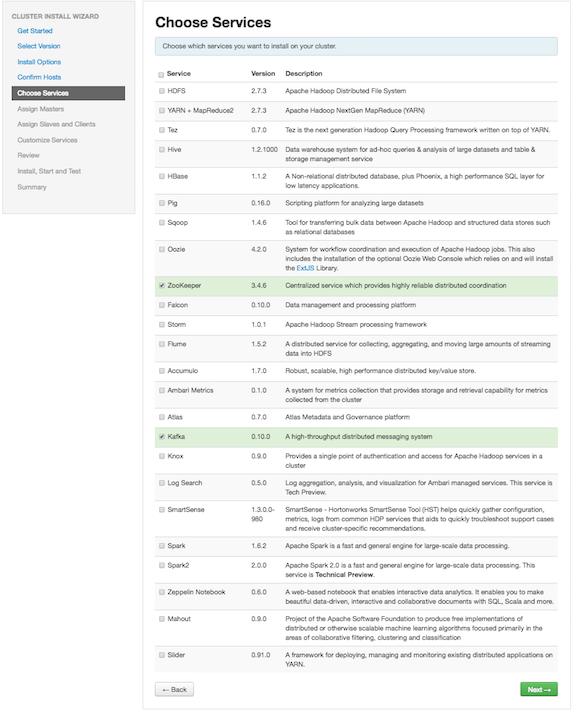
4 Installing Kafka 4

5 Installing Kafka 4. Click Next to continue. 5. On the Assign Masters page, review the node assignments for Kafka nodes. The following screen shows node assignment for a single-node Kafka cluster: 6. If you want Kafka to run with high availability, you must assign more than one node for Kafka brokers, resulting in Kafka brokers running on multiple nodes. Click the "+" symbol to add more broker nodes to the cluster: The following screen shows node assignment for a multi-node Kafka cluster: 5


6 Installing Kafka 7. Click Next to continue. 8. On the Assign Slaves and Clients page, choose the nodes that you want to run ZooKeeper clients: 9. Click Next to continue. 10. Ambari displays the Customize Services page, which lists a series of services: 6

7 Installing Kafka For your initial configuration you should use the default values set by Ambari. If Ambari prompts you with the message "Some configurations need your attention before you can proceed," review the list of properties and provide the required information. For information about optional settings that are useful in production environments, see Configuring for a Production Environment. 11. Click Next to continue. 12. When the wizard displays the Review page, ensure that all HDP components correspond to HDP 2.5 or later: 7


8 Installing Kafka 13. Click Deploy to begin installation. 14. Ambari displays the Install, Start and Test page. Monitor the status bar and messages for progress updates: 15. When the wizard presents a summary of results, click "Complete" to finish installing Kafka: 8
9 What to do next After Kafka is deployed and running, validate the installation. You can use the command-line interface to create a Kafka topic, send test messages, and consume the messages. For more information, see Validate Kafka in the Non- Ambari Cluster Installation Guide. This chapter covers topics related to Kafka configuration, including: Preparing the environment Customizing settings for brokers, producers, and consumers Configuring ZooKeeper for use with Kafka Enabling audit to HDFS when running Kafka on a secure cluster Preparing the Environment The following factors can affect Kafka performance: Operating system settings File system selection Disk drive configuration Java version Ethernet bandwidth Operating System Settings Consider the following when configuring Kafka: Kafka uses page cache memory as a buffer for active writers and readers, so after you specify JVM size (using - Xmx and -Xms Java options), leave the remaining RAM available to the operating system for page caching. Kafka needs open file descriptors for files and network connections. You should set the file descriptor limit to at least You can increase the maximum socket buffer size to enable high-performance data transfer. 9
10 File System Selection Kafka uses regular Linux disk files for storage. We recommend using the EXT4 or XFS file system. Improvements to the XFS file system show improved performance characteristics for Kafka workloads without compromising stability. Caution: Do not use mounted shared drives or any network file systems with Kafka, due to the risk of index failures and (in the case of network file systems) issues related to the use of MemoryMapped files to store the offset index. Encrypted file systems such as SafenetFS are not supported for Kafka. Index file corruption can occur. Disk Drive Considerations For throughput, we recommend dedicating multiple drives to Kafka data. More drives typically perform better with Kafka than fewer. Do not share these Kafka drives with any other application or use them for Kafka application logs. You can configure multiple drives by specifying a comma-separated list of directories for the log.dirs property in the server.properties file. Kafka uses a round-robin approach to assign partitions to directories specified in log.dirs; the default value is /tmp/kafka-logs. The num.io.threads property should be set to a value equal to or greater than the number of disks dedicated for Kafka. Recommendation: start by setting this property equal to the number of disks. Depending on how you configure flush behavior (see "Log Flush Management"), a faster disk drive is beneficial if the log.flush.interval.messages property is set to flush the log file after every 100,000 messages (approximately). Kafka performs best when data access loads are balanced among partitions, leading to balanced loads across disk drives. In addition, data distribution across disks is important. If one disk becomes full and other disks have available space, this can cause performance issues. To avoid slowdowns or interruptions to Kafka services, you should create usage alerts that notify you when available disk space is low. RAID can potentially improve load balancing among the disks, but RAID can cause performance bottleneck due to slower writes. In addition, it reduces available disk space. Although RAID can tolerate disk failures, rebuilding RAID array is I/O-intensive and effectively disables the server. Therefore, RAID does not provide substantial improvements in availability. Java Version With on HDP 2.5, you should use the latest update for Java version 1.8 and make sure that G1 garbage collection support is enabled. (G1 support is enabled by default in recent versions of Java.) If you prefer to use Java 1.7, make sure that you use update u51 or later. Here are several recommended settings for the JVM: -Xmx6g -Xms6g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80 To set JVM heap size for the Kafka broker, export KAFKA_HEAP_OPTS; for example: export KAFKA_HEAP_OPTS="-Xmx2g -Xms2g"./kafka-server-start.sh 10

11 Ethernet Bandwidth Ethernet bandwidth can have an impact on Kafka performance; make sure it is sufficient for your throughput requirements. Customizing Kafka Settings on an Ambari-Managed Cluster To customize configuration settings during the Ambari installation process, click the "Kafka" tab on the Customize Services page: If you want to access configuration settings after installing Kafka using Ambari: 1. Click Kafka on the Ambari dashboard. 2. Choose Configs. To view and modify settings, either scroll through categories and expand a category (such as "Kafka Broker", as shown in the graphic), or use the "Filter" box to search for a property. Settings in the Advanced kafka-env category are configured by Ambari; you should not modify these settings: 11
12 To add configuration properties that are not listed by default in Ambari, navigate to the Custom kafka-broker category: 12

13 Kafka Broker Settings The following subsections describe configuration settings that influence the performance of Kafka brokers. Connection Settings Review the following connection setting in the Advanced kafka-broker category, and modify as needed: zookeeper.session.timeout.ms advertised.listeners Specifies ZooKeeper session timeout, in milliseconds. The default value is ms. If the server fails to signal heartbeat to ZooKeeper within this period of time, the server is considered to be dead. If you set this value too low, the server might be falsely considered dead; if you set it too high it may take too long to recognize a truly dead server. If you see frequent disconnection from the ZooKeeper server, review this setting. If long garbage collection pauses cause Kafka to lose its ZooKeeper session, you might need to configure longer timeout values. If you have manually set listeners to advertised.listeners=plaintext://$hostname: $PORT, after enabling Kerberos, change the 13
14 listener configuration to advertised.listeners= SASL_PLAINTEXT://$HOSTNAME:$PORT. Important: Do not change the following connection settings: zookeeper.connect A comma-separated list of ZooKeeper hostname:port pairs. Ambari sets this value. Do not change this setting. Topic Settings For each topic, Kafka maintains a structured commit log with one or more partitions. These topic partitions form the basic unit of parallelism in Kafka. In general, the more partitions there are in a Kafka cluster, the more parallel consumers can be added, resulting in higher throughput. You can calculate the number of partitions based on your throughput requirements. If throughput from a producer to a single partition is P and throughput from a single partition to a consumer is C, and if your target throughput is T, the minimum number of required partitions is max (T/P, T/C). Note also that more partitions can increase latency: End-to-end latency in Kafka is defined as the difference in time from when a message is published by the producer to when the message is read by the consumer. Kafka only exposes a message to a consumer after it has been committed, after the message is replicated to all insync replicas. Replication of one thousand partitions from one broker to another can take up 20ms. This is too long for some real-time applications. In the new Kafka producer, messages are accumulated on the producer side; producers buffer the message per partition. This approach allows users to set an upper bound on the amount of memory used for buffering incoming messages. After enough data is accumulated or enough time has passed, accumulated messages are removed and sent to the broker. If you define more partitions, messages are accumulated for more partitions on the producer side. Similarly, the consumer fetches batches of messages per partition. Consumer memory requirements are proportional to the number of partitions that the consumer subscribes to. Important Topic Properties Review the following settings in the Advanced kafka-broker category, and modify as needed: auto.create.topics.enable default.replication.factor num.partitions Enable automatic creation of topics on the server. If this property is set to true, then attempts to produce, consume, or fetch metadata for a nonexistent topic automatically create the topic with the default replication factor and number of partitions. The default is enabled. Specifies default replication factors for automatically created topics. For high availability production systems, you should set this value to at least 3. Specifies the default number of log partitions per topic, for automatically created topics. The default value is 1. Change this setting based on the requirements related to your topic and partition design. 14
15 delete.topic.enable Allows users to delete a topic from Kafka using the admin tool, for Kafka versions 0.9 and later. Deleting a topic through the admin tool will have no effect if this setting is turned off. By default this feature is turned off (set to false). Log Settings Review the following settings in the Kafka Broker category, and modify as needed: log.roll.hours log.retention.hours log.dirs The maximum time, in hours, before a new log segment is rolled out. The default value is 168 hours (seven days). This setting controls the period of time after which Kafka will force the log to roll, even if the segment file is not full. This ensures that the retention process is able to delete or compact old data. The number of hours to keep a log file before deleting it. The default value is 168 hours (seven days). When setting this value, take into account your disk space and how long you would like messages to be available. An active consumer can read quickly and deliver messages to their destination. The higher the retention setting, the longer the data will be preserved. Higher settings generate larger log files, so increasing this setting might reduce your overall storage capacity. A comma-separated list of directories in which log data is kept. If you have multiple disks, list all directories under each disk. Review the following setting in the Advanced kafka-broker category, and modify as needed: log.retention.bytes log.segment.bytes The amount of data to retain in the log for each topic partition. By default, log size is unlimited. Note that this is the limit for each partition, so multiply this value by the number of partitions to calculate the total data retained for the topic. If log.retention.hours and log.retention.bytes are both set, Kafka deletes a segment when either limit is exceeded. The log for a topic partition is stored as a directory of segment files. This setting controls the maximum size of a segment file before a new segment is rolled over in the log. The default is 1 GB. Log Flush Management Kafka writes topic messages to a log file immediately upon receipt, but the data is initially buffered in page cache. A log flush forces Kafka to flush topic messages from page cache, writing the messages to disk. We recommend using the default flush settings, which rely on background flushes done by Linux and Kafka. Default settings provide high throughput and low latency, and they guarantee recovery through the use of replication. 15
16 If you decide to specify your own flush settings, you can force a flush after a period of time, or after a specified number of messages, or both (whichever limit is reached first). You can set property values globally and override them on a per-topic basis. There are several important considerations related to log file flushing: Durability: unflushed data is at greater risk of loss in the event of a crash. A failed broker can recover topic partitions from its replicas, but if a follower does not issue a fetch request or consume from the leader's log-end offset within the time specified by replica.lag.time.max.ms (which defaults to 10 seconds), the leader removes the follower from the in-sync replica ("ISR"). When this happens there is a slight chance of message loss if you do not explicitly set log.flush.interval.messages. If the leader broker fails and the follower is not caught up with the leader, the follower can still be under ISR for those 10 seconds and messages during leader transition to follower can be lost. Increased latency: data is not available to consumers until it is flushed (the fsync implementation in most Linux filesystems blocks writes to the file system). Throughput: a flush operation is typically an expensive operation. Disk usage patterns are less efficient. Page-level locking in background flushing is much more granular. log.flush.interval.messages specifies the number of messages to accumulate on a log partition before Kafka forces a flush of data to disk. log.flush.scheduler.interval.ms specifies the amount of time (in milliseconds) after which Kafka checks to see if a log needs to be flushed to disk. log.segment.bytes specifies the size of the log file. Kafka flushes the log file to disk whenever a log file reaches its maximum size. log.roll.hours specifies the maximum length of time before a new log segment is rolled out (in hours); this value is secondary to log.roll.ms. Kafka flushes the log file to disk whenever a log file reaches this time limit. Compaction Settings Review the following settings in the Advanced kafka-broker category, and modify as needed: log.cleaner.dedupe.buffer.size log.cleaner.io.buffer.size Specifies total memory used for log deduplication across all cleaner threads. By default, 128 MB of buffer is allocated. You may want to review this and other log.cleaner configuration values, and adjust settings based on your use of compacted topics ( consumer_offsets and other compacted topics). Specifies the total memory used for log cleaner I/O buffers across all cleaner threads. By default, 512 KB of buffer is allocated. You may want to review this and other log.cleaner configuration values, and adjust settings based on your usage of compacted topics ( consumer_offsets and other compacted topics). General Broker Settings Review the following settings in the Advanced kafka-broker category, and modify as needed: auto.leader.rebalance.enable unclean.leader.election.enable Enables automatic leader balancing. A background thread checks and triggers leader balancing (if needed) at regular intervals. The default is enabled. This property allows you to specify a preference of availability or durability. This is an important setting: If 16
17 availability is more important than avoiding data loss, ensure that this property is set to true. If preventing data loss is more important than availability, set this property to false. This setting operates as follows: If unclean.leader.election.enable is set to true (enabled), an out-of-sync replica will be elected as leader when there is no live in-sync replica (ISR). This preserves the availability of the partition, but there is a chance of data loss. If unclean.leader.election.enable is set to false and there are no live in-sync replicas, Kafka returns an error and the partition will be unavailable. This property is set to true by default, which favors availability. If durability is preferable to availability, set unclean.leader.election to false. controlled.shutdown.enable min.insync.replicas message.max.bytes replica.fetch.max.bytes broker.rack Enables controlled shutdown of the server. The default is enabled. When a producer sets acks to "all", min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful. If this minimum cannot be met, then the producer will raise an exception. When used together, min.insync.replicas and producer acks allow you to enforce stronger durability guarantees. You should set min.insync.replicas to 2 for replication factor equal to 3. Specifies the maximum size of message that the server can receive. It is important that this property be set with consideration for the maximum fetch size used by your consumers, or a producer could publish messages too large for consumers to consume. Note that there are currently two versions of consumer and producer APIs. The value of message.max.bytes must be smaller than the max.partition.fetch.bytes setting in the new consumer, or smaller than the fetch.message.max.bytes setting in the old consumer. In addition, the value must be smaller than replica.fetch.max.bytes. Specifies the number of bytes of messages to attempt to fetch. This value must be larger than message.max.bytes. The rack awareness feature distributes replicas of a partition across different racks. You can specify that a broker belongs to a particular rack through the "Custom kafka-broker" menu option. For more information about 17
18 the rack awareness feature, see documentation.html#basic_ops_racks. Kafka Producer Settings If performance is important and you have not yet upgraded to the new Kafka producer (client version or later), consider doing so. The new producer is generally faster and more fully featured than the previous client. To use the new producer client, add the associated maven dependency on the client jar; for example: <dependency> <groupid>org.apache.kafka</groupid> <artifactid>kafka-clients</artifactid> <version> </version> </dependency> For more information, see the KafkaProducer javadoc. The following subsections describe several types of configuration settings that influence the performance of Kafka producers. Important Producer Settings The lifecycle of a request from producer to broker involves several configuration settings: 1. The producer polls for a batch of messages from the batch queue, one batch per partition. A batch is ready when one of the following is true: batch.size is reached. Note: Larger batches typically have better compression ratios and higher throughput, but they have higher latency. linger.ms (time-based batching threshold) is reached. Note: There is no simple guideilne for setting linger.ms values; you should test settings on specific use cases. For small events (100 bytes or less), this setting does not appear to have much impact. Another batch to the same broker is ready. The producer calls flush() or close(). 2. The producer groups the batch based on the leader broker. 3. The producer sends the grouped batch to the broker. The following paragraphs list additional settings related to the request lifecycle: max.in.flight.requests.per.connection (pipelining) compression.type The maximum number of unacknowledged requests the client will send on a single connection before blocking. If this setting is greater than 1, pipelining is used when the producer sends the grouped batch to the broker. This improves throughput, but if there are failed sends there is a risk of out-of-order delivery due to retries (if retries are enabled). Note also that excessive pipelining reduces throughput. Compression is an important part of a producer s work, and the speed of different compression types differs a lot. To specify compression type, use the compression.type property. It accepts standard compression codecs ('gzip', 'snappy', 'lz4'), as well as 'uncompressed' (the default, equivalent to no compression), and 'producer' (uses the compression codec set by the producer). 18
19 Compression is handled by the user thread. If compression is slow it can help to add more threads. In addition, batching efficiency impacts the compression ratio: more batching leads to more efficient compression. acks The acks setting specifies acknowledgments that the producer requires the leader to receive before considering a request complete. This setting defines the durability level for the producer. Acks Throughput Latency Durability 0 High Low No Guarantee. The producer does not wait for acknowledgment from the server. 1 Medium Medium Leader writes the record to its local log, and responds without awaiting full acknowledgment from all followers. -1 Low High Leader waits for the full set of insync replicas (ISRs) to acknowledge the record. This guarantees that the record is not lost as long as at least one IRS is active. flush() The new Producer API supports an optional flush() call, which makes all buffered records immediately available to send (even if linger.ms is greater than 0). When using flush(), the number of bytes between two flush() calls is an important factor for performance. In microbenchmarking tests, a setting of approximately 4MB performed well for events 1KB in size. A general guideline is to set batch.size equal to the total bytes between flush()calls divided by number of partitions: (total bytes between flush()calls) / (partition count) Additional Considerations A producer thread going to the same partition is faster than a producer thread that sends messages to multiple partitions. 19
20 If a producer reaches maximum throughput but there is spare CPU and network capacity on the server, additional producer processes can increase overall throughput. Performance is sensitive to event size: larger events are more likely to have better throughput. In microbenchmarking tests, 1KB events streamed faster than 100-byte events. Kafka Consumer Settings You can usually obtain good performance from consumers without tuning configuration settings. In microbenchmarking tests, consumer performance was not as sensitive to event size or batch size as was producer performance. Both 1KG and 100B events showed similar throughput. One basic guideline for consumer performance is to keep the number of consumer threads equal to the partition count. Configuring ZooKeeper for Use with Kafka Here are several recommendations for ZooKeeper configuration with Kafka: Do not run ZooKeeper on a server where Kafka is running. When using ZooKeeper with Kafka you should dedicate ZooKeeper to Kafka, and not use ZooKeeper for any other components. Make sure you allocate sufficient JVM memory. A good starting point is 4GB. To monitor the ZooKeeper instance, use JMX metrics. Configuring ZooKeeper for Multiple Applications If you plan to use the same ZooKeeper cluster for different applications (such as Kafka cluster1, Kafka cluster2, and HBase), you should add a chroot path so that all Kafka data for a cluster appears under a specific path. The following example shows a sample chroot path: c6401.ambari.apache.org:2181:/kafka-root, c6402.ambari.apache.org:2181:/kafka-root You must create this chroot path yourself before starting the broker, and consumers must use the same connection string. Enabling Audit to HDFS for a Secure Cluster To enable audit to HDFS when running Storm on a secure cluster, perform the steps listed at the bottom of Manually Updating Ambari HDFS Audit Settings in the HDP Security Guide. 20
Hortonworks Data Platform
 Hortonworks Data Platform Apache Kafka Component Guide (June 1, 2017) docs.hortonworks.com Hortonworks Data Platform: Apache Kafka Component Guide Copyright 2012-2017 Hortonworks, Inc. Some rights reserved.
Hortonworks Data Platform Apache Kafka Component Guide (June 1, 2017) docs.hortonworks.com Hortonworks Data Platform: Apache Kafka Component Guide Copyright 2012-2017 Hortonworks, Inc. Some rights reserved.
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Intra-cluster Replication for Apache Kafka. Jun Rao
 Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
Building Durable Real-time Data Pipeline
 Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
WHITE PAPER. Reference Guide for Deploying and Configuring Apache Kafka
 WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Installing and Configuring Apache Storm
 3 Installing and Configuring Apache Storm Date of Publish: 2018-08-30 http://docs.hortonworks.com Contents Installing Apache Storm... 3...7 Configuring Storm for Supervision...8 Configuring Storm Resource
3 Installing and Configuring Apache Storm Date of Publish: 2018-08-30 http://docs.hortonworks.com Contents Installing Apache Storm... 3...7 Configuring Storm for Supervision...8 Configuring Storm Resource
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
bin/kafka-preferred-replica-election.sh --zookeeper localhost:12913/kafka --path-to-json-file topicpartitionlist.json
 Replication tools 1. Preferred Replica Leader Election Tool FAQ What happens if the preferred replica is not in the ISR? How to find if all the partitions have been moved to the "preferred replica" after
Replication tools 1. Preferred Replica Leader Election Tool FAQ What happens if the preferred replica is not in the ISR? How to find if all the partitions have been moved to the "preferred replica" after
DASH COPY GUIDE. Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 31
 DASH COPY GUIDE Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 31 DASH Copy Guide TABLE OF CONTENTS OVERVIEW GETTING STARTED ADVANCED BEST PRACTICES FAQ TROUBLESHOOTING DASH COPY PERFORMANCE TUNING
DASH COPY GUIDE Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 31 DASH Copy Guide TABLE OF CONTENTS OVERVIEW GETTING STARTED ADVANCED BEST PRACTICES FAQ TROUBLESHOOTING DASH COPY PERFORMANCE TUNING
Sizing Guidelines and Performance Tuning for Intelligent Streaming
 Sizing Guidelines and Performance Tuning for Intelligent Streaming Copyright Informatica LLC 2017. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the
Sizing Guidelines and Performance Tuning for Intelligent Streaming Copyright Informatica LLC 2017. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the
Scaling the Yelp s logging pipeline with Apache Kafka. Enrico
 Scaling the Yelp s logging pipeline with Apache Kafka Enrico Canzonieri enrico@yelp.com @EnricoC89 Yelp s Mission Connecting people with great local businesses. Yelp Stats As of Q1 2016 90M 102M 70% 32
Scaling the Yelp s logging pipeline with Apache Kafka Enrico Canzonieri enrico@yelp.com @EnricoC89 Yelp s Mission Connecting people with great local businesses. Yelp Stats As of Q1 2016 90M 102M 70% 32
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Ultra Messaging Queing Edition (Version ) Guide to Queuing
 Guide to Queuing") Ultra Messaging Queing Edition (Version 6.10.1) Guide to Queuing 2005-2017 Contents 1 Introduction 5 1.1 UMQ Overview.............................................. 5 1.2 Architecture...............................................
Ultra Messaging Queing Edition (Version 6.10.1) Guide to Queuing 2005-2017 Contents 1 Introduction 5 1.1 UMQ Overview.............................................. 5 1.2 Architecture...............................................
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Optimizing RDM Server Performance
 TECHNICAL WHITE PAPER Optimizing RDM Server Performance A Raima Inc. Technical Whitepaper Published: August, 2008 Author: Paul Johnson Director of Marketing Copyright: Raima Inc., All rights reserved Abstract
TECHNICAL WHITE PAPER Optimizing RDM Server Performance A Raima Inc. Technical Whitepaper Published: August, 2008 Author: Paul Johnson Director of Marketing Copyright: Raima Inc., All rights reserved Abstract
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Best Practices. Deploying Optim Performance Manager in large scale environments. IBM Optim Performance Manager Extended Edition V4.1.0.
 IBM Optim Performance Manager Extended Edition V4.1.0.1 Best Practices Deploying Optim Performance Manager in large scale environments Ute Baumbach (bmb@de.ibm.com) Optim Performance Manager Development
IBM Optim Performance Manager Extended Edition V4.1.0.1 Best Practices Deploying Optim Performance Manager in large scale environments Ute Baumbach (bmb@de.ibm.com) Optim Performance Manager Development
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
WHITE PAPER: BEST PRACTICES. Sizing and Scalability Recommendations for Symantec Endpoint Protection. Symantec Enterprise Security Solutions Group
 WHITE PAPER: BEST PRACTICES Sizing and Scalability Recommendations for Symantec Rev 2.2 Symantec Enterprise Security Solutions Group White Paper: Symantec Best Practices Contents Introduction... 4 The
WHITE PAPER: BEST PRACTICES Sizing and Scalability Recommendations for Symantec Rev 2.2 Symantec Enterprise Security Solutions Group White Paper: Symantec Best Practices Contents Introduction... 4 The
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
3. Monitoring Scenarios
 3. Monitoring Scenarios This section describes the following: Navigation Alerts Interval Rules Navigation Ambari SCOM Use the Ambari SCOM main navigation tree to browse cluster, HDFS and MapReduce performance
3. Monitoring Scenarios This section describes the following: Navigation Alerts Interval Rules Navigation Ambari SCOM Use the Ambari SCOM main navigation tree to browse cluster, HDFS and MapReduce performance
Administration 1. DLM Administration. Date of Publish:
 1 DLM Administration Date of Publish: 2018-07-03 http://docs.hortonworks.com Contents ii Contents Replication Concepts... 4 HDFS cloud replication...4 Hive cloud replication... 4 Cloud replication guidelines
1 DLM Administration Date of Publish: 2018-07-03 http://docs.hortonworks.com Contents ii Contents Replication Concepts... 4 HDFS cloud replication...4 Hive cloud replication... 4 Cloud replication guidelines
vsphere Replication for Disaster Recovery to Cloud vsphere Replication 8.1
 vsphere Replication for Disaster Recovery to Cloud vsphere Replication 8.1 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ If you have comments
vsphere Replication for Disaster Recovery to Cloud vsphere Replication 8.1 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ If you have comments
Hortonworks Data Platform
 Apache Ambari Operations () docs.hortonworks.com : Apache Ambari Operations Copyright 2012-2018 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open
Apache Ambari Operations () docs.hortonworks.com : Apache Ambari Operations Copyright 2012-2018 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open
Diplomado Certificación
 Diplomado Certificación Duración: 250 horas. Horario: Sabatino de 8:00 a 15:00 horas. Incluye: 1. Curso presencial de 250 horas. 2.- Material oficial de Oracle University (e-kit s) de los siguientes cursos:
Diplomado Certificación Duración: 250 horas. Horario: Sabatino de 8:00 a 15:00 horas. Incluye: 1. Curso presencial de 250 horas. 2.- Material oficial de Oracle University (e-kit s) de los siguientes cursos:
A Distributed System Case Study: Apache Kafka. High throughput messaging for diverse consumers
 A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
COS 318: Operating Systems. NSF, Snapshot, Dedup and Review
 COS 318: Operating Systems NSF, Snapshot, Dedup and Review Topics! NFS! Case Study: NetApp File System! Deduplication storage system! Course review 2 Network File System! Sun introduced NFS v2 in early
COS 318: Operating Systems NSF, Snapshot, Dedup and Review Topics! NFS! Case Study: NetApp File System! Deduplication storage system! Course review 2 Network File System! Sun introduced NFS v2 in early
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
ZooKeeper. Table of contents
 by Table of contents 1 ZooKeeper: A Distributed Coordination Service for Distributed Applications... 2 1.1 Design Goals... 2 1.2 Data model and the hierarchical namespace... 3 1.3 Nodes and ephemeral nodes...
by Table of contents 1 ZooKeeper: A Distributed Coordination Service for Distributed Applications... 2 1.1 Design Goals... 2 1.2 Data model and the hierarchical namespace... 3 1.3 Nodes and ephemeral nodes...
Source, Sink, and Processor Configuration Values
 3 Source, Sink, and Processor Configuration Values Date of Publish: 2018-12-18 https://docs.hortonworks.com/ Contents... 3 Source Configuration Values...3 Processor Configuration Values... 5 Sink Configuration
3 Source, Sink, and Processor Configuration Values Date of Publish: 2018-12-18 https://docs.hortonworks.com/ Contents... 3 Source Configuration Values...3 Processor Configuration Values... 5 Sink Configuration
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Insight Case Studies. Tuning the Beloved DB-Engines. Presented By Nithya Koka and Michael Arnold
 Insight Case Studies Tuning the Beloved DB-Engines Presented By Nithya Koka and Michael Arnold Who is Nithya Koka? Senior Hadoop Administrator Project Lead Client Engagement On-Call Engineer Cluster Ninja
Insight Case Studies Tuning the Beloved DB-Engines Presented By Nithya Koka and Michael Arnold Who is Nithya Koka? Senior Hadoop Administrator Project Lead Client Engagement On-Call Engineer Cluster Ninja
Broker Clusters. Cluster Models
 4 CHAPTER 4 Broker Clusters Cluster Models Message Queue supports the use of broker clusters: groups of brokers working together to provide message delivery services to clients. Clusters enable a Message
4 CHAPTER 4 Broker Clusters Cluster Models Message Queue supports the use of broker clusters: groups of brokers working together to provide message delivery services to clients. Clusters enable a Message
Background. 20: Distributed File Systems. DFS Structure. Naming and Transparency. Naming Structures. Naming Schemes Three Main Approaches
 Background 20: Distributed File Systems Last Modified: 12/4/2002 9:26:20 PM Distributed file system (DFS) a distributed implementation of the classical time-sharing model of a file system, where multiple
Background 20: Distributed File Systems Last Modified: 12/4/2002 9:26:20 PM Distributed file system (DFS) a distributed implementation of the classical time-sharing model of a file system, where multiple
vsphere Replication for Disaster Recovery to Cloud
 vsphere Replication for Disaster Recovery to Cloud vsphere Replication 6.0 This document supports the version of each product listed and supports all subsequent versions until the document is replaced
vsphere Replication for Disaster Recovery to Cloud vsphere Replication 6.0 This document supports the version of each product listed and supports all subsequent versions until the document is replaced
Auto Management for Apache Kafka and Distributed Stateful System in General
 Auto Management for Apache Kafka and Distributed Stateful System in General Jiangjie (Becket) Qin Data Infrastructure @LinkedIn GIAC 2017, 12/23/17@Shanghai Agenda Kafka introduction and terminologies
Auto Management for Apache Kafka and Distributed Stateful System in General Jiangjie (Becket) Qin Data Infrastructure @LinkedIn GIAC 2017, 12/23/17@Shanghai Agenda Kafka introduction and terminologies
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]
![Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]](/thumbs/96/126854374.jpg "Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]") s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Introduc)on to Apache Ka1a. Jun Rao Co- founder of Confluent
on to Apache Ka1a. Jun Rao Co- founder of Confluent") Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Installing HDF Services on an Existing HDP Cluster
 3 Installing HDF Services on an Existing HDP Cluster Date of Publish: 2018-08-13 http://docs.hortonworks.com Contents Upgrade Ambari and HDP...3 Installing Databases...3 Installing MySQL... 3 Configuring
3 Installing HDF Services on an Existing HDP Cluster Date of Publish: 2018-08-13 http://docs.hortonworks.com Contents Upgrade Ambari and HDP...3 Installing Databases...3 Installing MySQL... 3 Configuring
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
MarkLogic Server. Monitoring MarkLogic Guide. MarkLogic 9 May, Copyright 2017 MarkLogic Corporation. All rights reserved.
 Monitoring MarkLogic Guide 1 MarkLogic 9 May, 2017 Last Revised: 9.0-2, July, 2017 Copyright 2017 MarkLogic Corporation. All rights reserved. Table of Contents Table of Contents Monitoring MarkLogic Guide
Monitoring MarkLogic Guide 1 MarkLogic 9 May, 2017 Last Revised: 9.0-2, July, 2017 Copyright 2017 MarkLogic Corporation. All rights reserved. Table of Contents Table of Contents Monitoring MarkLogic Guide
vsphere Replication for Disaster Recovery to Cloud vsphere Replication 6.5
 vsphere Replication for Disaster Recovery to Cloud vsphere Replication 6.5 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ If you have comments
vsphere Replication for Disaster Recovery to Cloud vsphere Replication 6.5 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ If you have comments
Microsoft SQL Server Fix Pack 15. Reference IBM
 Microsoft SQL Server 6.3.1 Fix Pack 15 Reference IBM Microsoft SQL Server 6.3.1 Fix Pack 15 Reference IBM Note Before using this information and the product it supports, read the information in Notices
Microsoft SQL Server 6.3.1 Fix Pack 15 Reference IBM Microsoft SQL Server 6.3.1 Fix Pack 15 Reference IBM Note Before using this information and the product it supports, read the information in Notices
MarkLogic Server. Monitoring MarkLogic Guide. MarkLogic 8 February, Copyright 2015 MarkLogic Corporation. All rights reserved.
 Monitoring MarkLogic Guide 1 MarkLogic 8 February, 2015 Last Revised: 8.0-1, February, 2015 Copyright 2015 MarkLogic Corporation. All rights reserved. Table of Contents Table of Contents Monitoring MarkLogic
Monitoring MarkLogic Guide 1 MarkLogic 8 February, 2015 Last Revised: 8.0-1, February, 2015 Copyright 2015 MarkLogic Corporation. All rights reserved. Table of Contents Table of Contents Monitoring MarkLogic
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692)
") FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
Tuning Intelligent Data Lake Performance
 Tuning Intelligent Data Lake Performance 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without
Tuning Intelligent Data Lake Performance 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without
Confluent Developer Training: Building Kafka Solutions B7/801/A
 Confluent Developer Training: Building Kafka Solutions B7/801/A Kafka Fundamentals Chapter 3 Course Contents 01: Introduction 02: The Motivation for Apache Kafka >>> 03: Kafka Fundamentals 04: Kafka s
Confluent Developer Training: Building Kafka Solutions B7/801/A Kafka Fundamentals Chapter 3 Course Contents 01: Introduction 02: The Motivation for Apache Kafka >>> 03: Kafka Fundamentals 04: Kafka s
Fluentd + MongoDB + Spark = Awesome Sauce
 Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
WLS Neue Optionen braucht das Land
 WLS Neue Optionen braucht das Land Sören Halter Principal Sales Consultant 2016-11-16 Safe Harbor Statement The following is intended to outline our general product direction. It is intended for information
WLS Neue Optionen braucht das Land Sören Halter Principal Sales Consultant 2016-11-16 Safe Harbor Statement The following is intended to outline our general product direction. It is intended for information
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Using VMware vsphere Replication. vsphere Replication 6.5
 Using VMware vsphere Replication 6.5 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ If you have comments about this documentation, submit your
Using VMware vsphere Replication 6.5 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ If you have comments about this documentation, submit your
Introduction to Kafka (and why you care)
") Introduction to Kafka (and why you care) Richard Nikula VP, Product Development and Support Nastel Technologies, Inc. 2 Introduction Richard Nikula VP of Product Development and Support Involved in MQ
Introduction to Kafka (and why you care) Richard Nikula VP, Product Development and Support Nastel Technologies, Inc. 2 Introduction Richard Nikula VP of Product Development and Support Involved in MQ
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Performance Best Practices Paper for IBM Tivoli Directory Integrator v6.1 and v6.1.1
 Performance Best Practices Paper for IBM Tivoli Directory Integrator v6.1 and v6.1.1 version 1.0 July, 2007 Table of Contents 1. Introduction...3 2. Best practices...3 2.1 Preparing the solution environment...3
Performance Best Practices Paper for IBM Tivoli Directory Integrator v6.1 and v6.1.1 version 1.0 July, 2007 Table of Contents 1. Introduction...3 2. Best practices...3 2.1 Preparing the solution environment...3
CS5460: Operating Systems Lecture 20: File System Reliability
 CS5460: Operating Systems Lecture 20: File System Reliability File System Optimizations Modern Historic Technique Disk buffer cache Aggregated disk I/O Prefetching Disk head scheduling Disk interleaving
CS5460: Operating Systems Lecture 20: File System Reliability File System Optimizations Modern Historic Technique Disk buffer cache Aggregated disk I/O Prefetching Disk head scheduling Disk interleaving
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Chapter 11: Implementing File Systems
 Chapter 11: Implementing File Systems Operating System Concepts 99h Edition DM510-14 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation
Chapter 11: Implementing File Systems Operating System Concepts 99h Edition DM510-14 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation
Current Topics in OS Research. So, what s hot?
 Current Topics in OS Research COMP7840 OSDI Current OS Research 0 So, what s hot? Operating systems have been around for a long time in many forms for different types of devices It is normally general
Current Topics in OS Research COMP7840 OSDI Current OS Research 0 So, what s hot? Operating systems have been around for a long time in many forms for different types of devices It is normally general
 1 of 8 14/12/2013 11:51 Tuning long-running processes Contents 1. Reduce the database size 2. Balancing the hardware resources 3. Specifying initial DB2 database settings 4. Specifying initial Oracle database
1 of 8 14/12/2013 11:51 Tuning long-running processes Contents 1. Reduce the database size 2. Balancing the hardware resources 3. Specifying initial DB2 database settings 4. Specifying initial Oracle database
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files
 System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
Engineering Goals. Scalability Availability. Transactional behavior Security EAI... CS530 S05
 Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Esper EQC. Horizontal Scale-Out for Complex Event Processing
 Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Esper EQC Horizontal Scale-Out for Complex Event Processing Esper EQC - Introduction Esper query container (EQC) is the horizontal scale-out architecture for Complex Event Processing with Esper and EsperHA
Rhapsody Interface Management and Administration
 Rhapsody Interface Management and Administration Welcome The Rhapsody Framework Rhapsody Processing Model Application and persistence store files Web Management Console Backups Route, communication and
Rhapsody Interface Management and Administration Welcome The Rhapsody Framework Rhapsody Processing Model Application and persistence store files Web Management Console Backups Route, communication and
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
OPERATING SYSTEM. Chapter 12: File System Implementation
 OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
OPERATING SYSTEM Chapter 12: File System Implementation Chapter 12: File System Implementation File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management
Caching and reliability
 Caching and reliability Block cache Vs. Latency ~10 ns 1~ ms Access unit Byte (word) Sector Capacity Gigabytes Terabytes Price Expensive Cheap Caching disk contents in RAM Hit ratio h : probability of
Caching and reliability Block cache Vs. Latency ~10 ns 1~ ms Access unit Byte (word) Sector Capacity Gigabytes Terabytes Price Expensive Cheap Caching disk contents in RAM Hit ratio h : probability of
Installing an HDF cluster
 3 Installing an HDF cluster Date of Publish: 2018-08-13 http://docs.hortonworks.com Contents Installing Ambari...3 Installing Databases...3 Installing MySQL... 3 Configuring SAM and Schema Registry Metadata
3 Installing an HDF cluster Date of Publish: 2018-08-13 http://docs.hortonworks.com Contents Installing Ambari...3 Installing Databases...3 Installing MySQL... 3 Configuring SAM and Schema Registry Metadata
<Insert Picture Here> Filesystem Features and Performance
 Filesystem Features and Performance Chris Mason Filesystems XFS Well established and stable Highly scalable under many workloads Can be slower in metadata intensive workloads Often
Filesystem Features and Performance Chris Mason Filesystems XFS Well established and stable Highly scalable under many workloads Can be slower in metadata intensive workloads Often
StreamSets Control Hub Installation Guide
 StreamSets Control Hub Installation Guide Version 3.2.1 2018, StreamSets, Inc. All rights reserved. Table of Contents 2 Table of Contents Chapter 1: What's New...1 What's New in 3.2.1... 2 What's New in
StreamSets Control Hub Installation Guide Version 3.2.1 2018, StreamSets, Inc. All rights reserved. Table of Contents 2 Table of Contents Chapter 1: What's New...1 What's New in 3.2.1... 2 What's New in
Cloudera Kudu Introduction
 Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
Streaming Log Analytics with Kafka
 Streaming Log Analytics with Kafka Kresten Krab Thorup, Humio CTO Log Everything, Answer Anything, In Real-Time. Why this talk? Humio is a Log Analytics system Designed to run on-prem High volume, real
Streaming Log Analytics with Kafka Kresten Krab Thorup, Humio CTO Log Everything, Answer Anything, In Real-Time. Why this talk? Humio is a Log Analytics system Designed to run on-prem High volume, real
vsphere Replication for Disaster Recovery to Cloud
 vsphere Replication for Disaster Recovery to Cloud vsphere Replication 5.6 This document supports the version of each product listed and supports all subsequent versions until the document is replaced
vsphere Replication for Disaster Recovery to Cloud vsphere Replication 5.6 This document supports the version of each product listed and supports all subsequent versions until the document is replaced
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
Operating Systems. Operating Systems Professor Sina Meraji U of T
 Operating Systems Operating Systems Professor Sina Meraji U of T How are file systems implemented? File system implementation Files and directories live on secondary storage Anything outside of primary
Operating Systems Operating Systems Professor Sina Meraji U of T How are file systems implemented? File system implementation Files and directories live on secondary storage Anything outside of primary
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Chapter 11: Implementing File
 Chapter 11: Implementing File Systems Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
Chapter 11: Implementing File Systems Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory Implementation Allocation Methods Free-Space Management Efficiency
EMC RecoverPoint. EMC RecoverPoint Support
 Support, page 1 Adding an Account, page 2 RecoverPoint Appliance Clusters, page 3 Replication Through Consistency Groups, page 4 Group Sets, page 22 System Tasks, page 24 Support protects storage array
Support, page 1 Adding an Account, page 2 RecoverPoint Appliance Clusters, page 3 Replication Through Consistency Groups, page 4 Group Sets, page 22 System Tasks, page 24 Support protects storage array
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Chapter 11: Implementing File Systems. Operating System Concepts 9 9h Edition
 Chapter 11: Implementing File Systems Operating System Concepts 9 9h Edition Silberschatz, Galvin and Gagne 2013 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory
Chapter 11: Implementing File Systems Operating System Concepts 9 9h Edition Silberschatz, Galvin and Gagne 2013 Chapter 11: Implementing File Systems File-System Structure File-System Implementation Directory
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Intellicus Cluster and Load Balancing- Linux. Version: 18.1
 Intellicus Cluster and Load Balancing- Linux Version: 18.1 1 Copyright 2018 Intellicus Technologies This document and its content is copyrighted material of Intellicus Technologies. The content may not
Intellicus Cluster and Load Balancing- Linux Version: 18.1 1 Copyright 2018 Intellicus Technologies This document and its content is copyrighted material of Intellicus Technologies. The content may not