INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN
|
|
|
- Harry Gardner
- 5 years ago
- Views:
Transcription

1 INTRO TO RANDOM FOREST BY ANTHONY ANH QUOC DOAN
 Example: Ted's Cancer Thesis source: \"An Empirical Comparison of Supervised Learning Algorithms\" - https:// www.cs.")
2 MOTIVATION FOR RANDOM FOREST Random forest is a great statistical learning model. It works well with small to medium data. Unlike Neural Network which requires large data to train. (1) Example: Ted's Cancer Thesis source: "An Empirical Comparison of Supervised Learning Algorithms" ctp/ct.papers/caruana.icml06.pdf

3 EXAMPLE: PREDICTING CANCER Clinical data have few observations ranging from 5 patients to 200 patients (for phase 3). Medical data cost money. Very expensive to run trials and to find patient willing to volunteer, especially rare disease. Of course 5 is small but 200 is great for random forest. Bad for Neural Network. Ted's Thesis

4 ROADMAP SECTIONS 1. CART 2. Bagging 3. Random Forest 4. References

5 1. CART (CLASSIFICATION AND REGRESSION TREE)

6 CART SECTION OVERVIEW 1. History 2. Quick Example 3. CART Overview 4. Recursive Data Partition (CART) 5. Classifying with Terminal Nodes 6. Basis Function 7. Node Splitting 8. Tree Pruning 9. Regression Tree

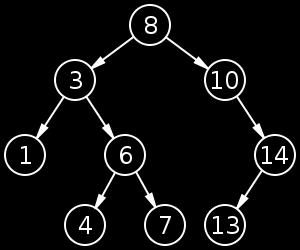

7
8 CLASSIFICATION TREE - (BINARY TREE DATA STRUCTURE)
9 CLASSIFICATION TREE - QUICK EXAMPLE We have several predictors (x's) and one response (y, the thing we're trying to predict) Let's do cancer with a simple model. 1. response Y is either 0,1 where the person have cancer or not 2. predictor - age (value range: 0 year old to 99 year old)
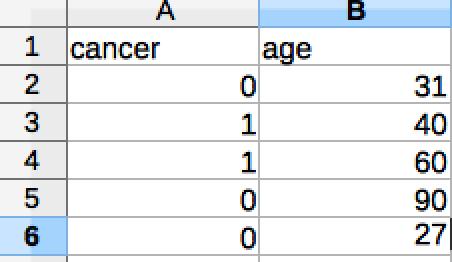
10
11
12 HOW CART (DATA PARTITION ALGORITHM) WORKS 1. For each predictor, all possible splits of the predictor values are considered 2. For each predictor, the best split is selected. (we'll get to best split criteria) 3. With the best split of each predictor is determined, we pick the best predictor in that group.
13 CART Uses Binary Tree Data Structure
14 CART - DATA PARTITION EXAMPLES Examples of step 1: marital status (categorical data: never married, married, and divorced) never married vs [married and divorced] married vs [never married and divorced] divorced vs [never married and married] age (value range: 21 to 24) So the possible split (maintaining order) 21 vs vs vs 24
15 VISUAL EXAMPLE The best way to do this is adding another predictor to our model. We're going to add exercise per week (hours) recap our response: y (0 - no cancer or 1- cancer) our predictors: age (value range: 0 to 99 year) exercise per week (value: 0 to 168 hours).
16
17
18 Note here we can either partition the data horizontally or vertically. We're choosing the best split/partition.
19
20 REPEAT DATA PARTITION ALGORITHM, CART, AGAIN FOR THE PARTITIONED DATA RECURSIVELY...
21
22
23 R - CODE flowers_data <- iris flowers_data <- flowers_data[! (flowers_data$species == 'virginica'),] library(rpart) tree.model <- rpart(species ~., data = flowers_data) library(party) library(partykit) tree.model.party <- as.party(tree.model) plot(tree.model.party)
24 R - CODE flowers_data <- iris library(rpart) tree.model <- rpart(species ~., data = flowers_data) library(party) library(partykit) tree.model.party <- as.party(tree.model) plot(tree.model.party)
25 BASIS FUNCTIONS X is a predictor M transformations of X β_m is the weight given to the mth transformation (the coefficient) h_m is the m-th transformation of X f(x) is the linear combination of transformed values of X

26 BASIS FUNCTION EXAMPLE
27 THE BASIS EXAMPLE WE CARE ABOUT
28 THIS IS CART BASIS FUNCTION The new summation is for multiple predictors. P = total number of predictors.
29

30 NODE SPLITTING
31 QUESTION HOW IS SPLIT DETERMINED? The goal is to split/partition the data until each node is homogenous in data, or as little "impurity" (few outcomes that we want in the particular node and mostly outcome that we want).
32 HOW IS NODE IMPURITY CALCULATED?
33 NODE IMPURITY - SETUP Our data to train is a random sample from a well defined population given a node, node A p(y = 1 A) impurity of node A is the probability that y = 1 given it is node A.
34 IMPURITY FUNCTION I(A) represent Impurity function that takes in a node as our parameter. The restriction tells us that the impurity function is nonnegative, symmetric when A contains all 0s or 1s, and a maximum of half of each (coin toss).
35 IMPURITY - DEFINING Φ (PHI) There are several Φ functions that people uses. The most commonly use is the Gini Index: Φ(p) = p (1-p) Others Bayes Error: Φ(p) = min(p, 1-p) Cross Entropy Function: Φ(p) = -p log(p) - (1-p) log(1-p)
36 GINI INDEX p(i t) denote the fraction of records belonging to class i at a given node t c is the number of classes (example: cancer, no cancer)
37
38
39
40

41

42

43 PRUNING TREE

44 WHY PRUNE? Reduce complexity of the model Reduce overfitting. Note: Random Forest doesn't Prune trees so we're not going to go into Tree pruning.
45 REGRESSION TREE
46 REGRESSION TREE - SPLITTING NODE The only difference is the impurity function of the node Which is just a within-node sum of squares for the response Where the summation of all cases in node τ minus the mean those cases squared. This is SSTO (sum square total) in Linear Regression
47 REGRESSION TREE EXAMPLE
48 Warning: We're going to do it on classification data as an example to show how to use the equation. Because I don't believe I have time to go over linear regression in here to do a proper example.
49
50 = (1/n)*sum(y_i) = (1/6)*( ) = 2/6 = 1/3 represents one data point in the partition (0,0,0,1,1)
51 REGRESSION TREE - PRUNING Uses AIC or some other regression criteria, it's a penalty function for using too many predictors and sacrificing degree of freedom. AIC and such are outside the scope of this talk because it's a huge topic and rabbit hole into linear regression.

52 2. BAGGING (BOOTSTRAP AGGREGATION)

53 BAGGING SECTION OVERVIEW 1. Benefit 2. Bootstrap Algorithm 3. Bootstrap example 4. Bagging Algorithm 5. Flaws 6. Why does this work?
54 WHY? BENEFITS. Reduce overfitting Reduce bias Break the bias-variance trade-off

55 BOOTSTRAP Before we dive into bagging algorithm we should go over bootstrap Bootstrap is a statistical resample method. When you can't afford to get more sample (think medical data, poor grad student, cost, etc..)
56 BOOTSTRAP ALGORITHM 1. Used in statistic when you want to estimate a statistic of a random sample (a statistic: mean, variance, mode, etc...) 2. Using bootstrap we diverge from traditional parametric statistic, we do not assume a distribution of the random sample 3. What we do is sample our only data set (aka random sample) with replacement. We take up to the number of observations in our original data. 4. We repeat step 3 for a large number of time, B times. Once done we have B number of bootstrap random samples. 5. We then take the statistic of each bootstrap random sample and average it
; mean = 1.375 {1,2,1,2,1,1,2} (n = 8); mean = 1.")
57 BOOTSTRAP EXAMPLE Original data (random sample): {1,2,3,1,2,1,1,1} (n = 8) Bootstrap random sample data: {1,2,1,2,1,1,3} (n = 8); mean = {1,1,2,2,3,1,1} (n = 8); mean = {1,2,1,2,1,1,2} (n = 8); mean = 1.25 The estimated mean for our original data is the mean of the statistic for each bootstrap sample ( )/3 = ~1.3333
58 BAGGING (BOOTSTRAP AGGREGATION) ALGORITHM 1. Take a random sample of size N with replacement from the data 2. Construct a classification tree as usual but do not prune 3. Assign a class to each terminal node, and store the class attached to each case coupled with the predictor values for each observation
59 BAGGING ALGORITHM 4. Repeat Steps 1-3 a large number of times. 5. For each observation in the dataset, count the number of times over tress that it is classified in one category and the number of times over trees it is classified in the other category 6. Assign each observation to a final category by a majority vote over the set of tress. Thus, if 51% of the time over a large number of trees a given observation is classified as a "1", that becomes its classification. 7. Construct the confusion table from these class assignments.
60 FLAWS The problem with Bagging algorithm is it's using CART. CART uses Gini-Index, a greedy algorithm to find the best split. So we end up with trees that are structurally similar to each other. The trees are highly correlated among the predictions. Random Forest address this.

61 WHY DOES THIS WORK? Outside the scope of this talk.

62 3. RANDOM FOREST

63 RANDOM FOREST SECTION OVERVIEW 1. Problem RF solve 2. Building Random Forest Algorithm 3. Breaking Down Random Forest Algorithm Parts by Parts 4. How to use Random Forest to Predict 5. R Code
64 1. PROBLEM RANDOM FOREST IS TRYING TO SOLVE
65 BAGGING PROBLEM With bagging we have an ensemble of structurally similar trees. This causes highly correlated trees.
66 RANDOM FOREST SOLUTION Create trees that have no correlation or weak correlation.

67 2. BUILDING RANDOM FOREST ALGORITHM
68 RANDOM FOREST ALGORITHM 1. Take a random sample of size N with replacement from the data. 2. Take a random sample without replacement of the predictors. 3. Construct the first CART partition of the data.
69 BUILDING RANDOM FOREST ALGORITHM 4. Repeat Step 2 for each subsequent split until the tree is as large as desired. Do not prune. 5. Repeat Steps 1 4 a large number of times (e.g., 500).
70 3. BREAKING DOWN RANDOM FOREST ALGORITHM PARTS BY PARTS
71 1. TAKE A RANDOM SAMPLE OF SIZE N WITH REPLACEMENT FROM DATA This is just bootstrapping on our data (recall bagging section)
72 2. TAKE A RANDOM SAMPLE WITHOUT REPLACEMENT OF THE PREDICTORS Predictor sampling / bootstrapping Notice this is bootstrapping our predictors and it's without replacement. This is Random Forest solution to highly correlated trees that arises from bagging algorithm.
73 Question (for step 2): Max number when sampling predictors/ features?
74 Answer: 2 to 3 sample for predictors/features
75 3. CONSTRUCT THE FIRST CART PARTITION OF DATA We partitioned our first bootstrap and use Giniindex on our bootstrapped predictors sample in step 2 to decided the split.
76 4. REPEAT STEP 2 FOR EACH SUBSEQUENT SPLIT UNTIL THE TREE IS AS LARGE AS DESIRED. DO NOT PRUNE. Self explanatory.
77 5. REPEAT STEPS 1 4 A LARGE NUMBER OF TIMES (E.G., 500). Steps 1 to 4 is to build one tree. You repeat step 1 to 4 a large number of times to build a forest. There's no magic number for large number. You can build 101, 201, 501, 1001, etc.. There's research paper that suggest certain numbers but it base on your data. So just check model performance via model evaluation using cross validation. I have no idea why suggested numbers are usually even, but I choose odd number of trees in case of ties.

78 4. HOW TO USE RANDOM FOREST TO PREDICT
79 You have an observation that you want to predict Say the observation is x = male, z = 23 year old You plug that in your your random forest. Random Forest takes those predictors and give it to each decision trees. Each decision trees give one prediction, cancer or no cancer (0,1). You take all of those predictions (aka votes) and take the majority. This is why I suggest odd number of trees to break ties for binary responses.


80 5. R CODE
81 set.seed(415) library(randomforest) iris_train <- iris[-1,] iris_test <- iris[1,] rf.model <- randomforest(species ~., data = iris_train) predict(rf.model,iris_test)

82
 \"An Empirical Comparison of Supervised Learning Algorithms\" - https://www.cs.cornell.edu/~caruana/ ctp/ct.")
83 REFERENCES Statistical Learning from a Regression Perspective by Richard A. Berk Introduction to Data Mining by Pang-Ning Tan ( index.php) From bagging to forest ( onlinecourses.science.psu.edu/stat857/node/181) "An Empirical Comparison of Supervised Learning Algorithms" - ctp/ct.papers/caruana.icml06.pdf Random Forest created and trademarked by Leo Breiman ( RandomForests/cc_home.htm#workings) "Bagging and Random Forest Ensemble Algorithms for Machine Learning" By Jason Brownlee ( machinelearningmastery.com/bagging-andrandom-forest-ensemble-algorithms-for-machinelearning/)
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Performance Evaluation of Various Classification Algorithms
 Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
The Basics of Decision Trees
 Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Classification and Regression
 Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Lecture 2 :: Decision Trees Learning
 Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Ensemble Learning. Another approach is to leverage the algorithms we have via ensemble methods
 Ensemble Learning Ensemble Learning So far we have seen learning algorithms that take a training set and output a classifier What if we want more accuracy than current algorithms afford? Develop new learning
Ensemble Learning Ensemble Learning So far we have seen learning algorithms that take a training set and output a classifier What if we want more accuracy than current algorithms afford? Develop new learning
Classification with Decision Tree Induction
 Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Introduction to Classification & Regression Trees
 Introduction to Classification & Regression Trees ISLR Chapter 8 vember 8, 2017 Classification and Regression Trees Carseat data from ISLR package Classification and Regression Trees Carseat data from
Introduction to Classification & Regression Trees ISLR Chapter 8 vember 8, 2017 Classification and Regression Trees Carseat data from ISLR package Classification and Regression Trees Carseat data from
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Nonparametric Classification Methods
 Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
Nonparametric Classification Methods We now examine some modern, computationally intensive methods for regression and classification. Recall that the LDA approach constructs a line (or plane or hyperplane)
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Random Forest Classification and Attribute Selection Program rfc3d
 Random Forest Classification and Attribute Selection Program rfc3d Overview Random Forest (RF) is a supervised classification algorithm using multiple decision trees. Program rfc3d uses training data generated
Random Forest Classification and Attribute Selection Program rfc3d Overview Random Forest (RF) is a supervised classification algorithm using multiple decision trees. Program rfc3d uses training data generated
Classification/Regression Trees and Random Forests
 Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Data Mining Lecture 8: Decision Trees
 Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
CSC 411 Lecture 4: Ensembles I
 CSC 411 Lecture 4: Ensembles I Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 04-Ensembles I 1 / 22 Overview We ve seen two particular classification algorithms:
CSC 411 Lecture 4: Ensembles I Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 04-Ensembles I 1 / 22 Overview We ve seen two particular classification algorithms:
8. Tree-based approaches
 Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Notes based on: Data Mining for Business Intelligence
 Chapter 9 Classification and Regression Trees Roger Bohn April 2017 Notes based on: Data Mining for Business Intelligence 1 Shmueli, Patel & Bruce 2 3 II. Results and Interpretation There are 1183 auction
Chapter 9 Classification and Regression Trees Roger Bohn April 2017 Notes based on: Data Mining for Business Intelligence 1 Shmueli, Patel & Bruce 2 3 II. Results and Interpretation There are 1183 auction
Decision Tree Learning
 Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
An Empirical Comparison of Ensemble Methods Based on Classification Trees. Mounir Hamza and Denis Larocque. Department of Quantitative Methods
 An Empirical Comparison of Ensemble Methods Based on Classification Trees Mounir Hamza and Denis Larocque Department of Quantitative Methods HEC Montreal Canada Mounir Hamza and Denis Larocque 1 June 2005
An Empirical Comparison of Ensemble Methods Based on Classification Trees Mounir Hamza and Denis Larocque Department of Quantitative Methods HEC Montreal Canada Mounir Hamza and Denis Larocque 1 June 2005
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
Classification and Regression Trees
 Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Classification: Basic Concepts, Decision Trees, and Model Evaluation
 Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
Evaluating generalization (validation) Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support
 Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support") Evaluating generalization (validation) Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Topics Validation of biomedical models Data-splitting Resampling Cross-validation
Evaluating generalization (validation) Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Topics Validation of biomedical models Data-splitting Resampling Cross-validation
Classification. Instructor: Wei Ding
 Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Nonparametric Approaches to Regression
 Nonparametric Approaches to Regression In traditional nonparametric regression, we assume very little about the functional form of the mean response function. In particular, we assume the model where m(xi)
Nonparametric Approaches to Regression In traditional nonparametric regression, we assume very little about the functional form of the mean response function. In particular, we assume the model where m(xi)
Statistical Methods for Data Mining
 Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying
Statistical Methods for Data Mining Kuangnan Fang Xiamen University Email: xmufkn@xmu.edu.cn Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
BIOINF 585: Machine Learning for Systems Biology & Clinical Informatics
 BIOINF 585: Machine Learning for Systems Biology & Clinical Informatics Lecture 12: Ensemble Learning I Jie Wang Department of Computational Medicine & Bioinformatics University of Michigan 1 Outline Bias
BIOINF 585: Machine Learning for Systems Biology & Clinical Informatics Lecture 12: Ensemble Learning I Jie Wang Department of Computational Medicine & Bioinformatics University of Michigan 1 Outline Bias
Supervised Learning Classification Algorithms Comparison
 Supervised Learning Classification Algorithms Comparison Aditya Singh Rathore B.Tech, J.K. Lakshmipat University -------------------------------------------------------------***---------------------------------------------------------
Supervised Learning Classification Algorithms Comparison Aditya Singh Rathore B.Tech, J.K. Lakshmipat University -------------------------------------------------------------***---------------------------------------------------------
Decision trees. Decision trees are useful to a large degree because of their simplicity and interpretability
 Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Predictive Analytics: Demystifying Current and Emerging Methodologies. Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA
 Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Lecture 5: Decision Trees (Part II)
") Lecture 5: Decision Trees (Part II) Dealing with noise in the data Overfitting Pruning Dealing with missing attribute values Dealing with attributes with multiple values Integrating costs into node choice
Lecture 5: Decision Trees (Part II) Dealing with noise in the data Overfitting Pruning Dealing with missing attribute values Dealing with attributes with multiple values Integrating costs into node choice
Ensemble Learning: An Introduction. Adapted from Slides by Tan, Steinbach, Kumar
 Ensemble Learning: An Introduction Adapted from Slides by Tan, Steinbach, Kumar 1 General Idea D Original Training data Step 1: Create Multiple Data Sets... D 1 D 2 D t-1 D t Step 2: Build Multiple Classifiers
Ensemble Learning: An Introduction Adapted from Slides by Tan, Steinbach, Kumar 1 General Idea D Original Training data Step 1: Create Multiple Data Sets... D 1 D 2 D t-1 D t Step 2: Build Multiple Classifiers
Topics in Machine Learning
 Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
Random Forests and Boosting
 Random Forests and Boosting Tree-based methods are simple and useful for interpretation. However they typically are not competitive with the best supervised learning approaches in terms of prediction accuracy.
Random Forests and Boosting Tree-based methods are simple and useful for interpretation. However they typically are not competitive with the best supervised learning approaches in terms of prediction accuracy.
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Lecture 19: Decision trees
 Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Classification: Decision Trees
 Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
7. Decision or classification trees
 7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
CS Machine Learning
 CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
Lecture 20: Bagging, Random Forests, Boosting
 Lecture 20: Bagging, Random Forests, Boosting Reading: Chapter 8 STATS 202: Data mining and analysis November 13, 2017 1 / 17 Classification and Regression trees, in a nut shell Grow the tree by recursively
Lecture 20: Bagging, Random Forests, Boosting Reading: Chapter 8 STATS 202: Data mining and analysis November 13, 2017 1 / 17 Classification and Regression trees, in a nut shell Grow the tree by recursively
Advanced and Predictive Analytics with JMP 12 PRO. JMP User Meeting 9. Juni Schwalbach
 Advanced and Predictive Analytics with JMP 12 PRO JMP User Meeting 9. Juni 2016 -Schwalbach Definition Predictive Analytics encompasses a variety of statistical techniques from modeling, machine learning
Advanced and Predictive Analytics with JMP 12 PRO JMP User Meeting 9. Juni 2016 -Schwalbach Definition Predictive Analytics encompasses a variety of statistical techniques from modeling, machine learning
Supervised Learning for Image Segmentation
 Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Part I. Instructor: Wei Ding
 Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
Classification Algorithms in Data Mining
 August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
Classification with PAM and Random Forest
 5/7/2007 Classification with PAM and Random Forest Markus Ruschhaupt Practical Microarray Analysis 2007 - Regensburg Two roads to classification Given: patient profiles already diagnosed by an expert.
5/7/2007 Classification with PAM and Random Forest Markus Ruschhaupt Practical Microarray Analysis 2007 - Regensburg Two roads to classification Given: patient profiles already diagnosed by an expert.
Example of DT Apply Model Example Learn Model Hunt s Alg. Measures of Node Impurity DT Examples and Characteristics. Classification.
 lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
Naïve Bayes for text classification
 Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Data Mining. 3.2 Decision Tree Classifier. Fall Instructor: Dr. Masoud Yaghini. Chapter 5: Decision Tree Classifier
 Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
An introduction to random forests
 An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
Oliver Dürr. Statistisches Data Mining (StDM) Woche 12. Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften
 Woche 12. Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften") Statistisches Data Mining (StDM) Woche 12 Oliver Dürr Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften oliver.duerr@zhaw.ch Winterthur, 6 Dezember 2016 1 Multitasking
Statistisches Data Mining (StDM) Woche 12 Oliver Dürr Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften oliver.duerr@zhaw.ch Winterthur, 6 Dezember 2016 1 Multitasking
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Lars Schmidt-Thieme, Information Systems and Machine Learning Lab (ISMLL), University of Hildesheim, Germany
, University of Hildesheim, Germany") Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Trade-offs in Explanatory
 1 Trade-offs in Explanatory 21 st of February 2012 Model Learning Data Analysis Project Madalina Fiterau DAP Committee Artur Dubrawski Jeff Schneider Geoff Gordon 2 Outline Motivation: need for interpretable
1 Trade-offs in Explanatory 21 st of February 2012 Model Learning Data Analysis Project Madalina Fiterau DAP Committee Artur Dubrawski Jeff Schneider Geoff Gordon 2 Outline Motivation: need for interpretable
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
DATA MINING LECTURE 9. Classification Decision Trees Evaluation
 DATA MINING LECTURE 9 Classification Decision Trees Evaluation 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K No 2 No Medium 100K No 3 No Small 70K No 4 Yes Medium
DATA MINING LECTURE 9 Classification Decision Trees Evaluation 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K No 2 No Medium 100K No 3 No Small 70K No 4 Yes Medium
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Data Mining Classification - Part 1 -
 Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Introduction to Automated Text Analysis. bit.ly/poir599
 Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
Supervised Learning. Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
 Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Leveling Up as a Data Scientist. ds/2014/10/level-up-ds.jpg
 Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
Information theory methods for feature selection
 Information theory methods for feature selection Zuzana Reitermanová Department of Computer Science Faculty of Mathematics and Physics Charles University in Prague, Czech Republic Diplomový a doktorandský
Information theory methods for feature selection Zuzana Reitermanová Department of Computer Science Faculty of Mathematics and Physics Charles University in Prague, Czech Republic Diplomový a doktorandský
Introduction to Machine Learning
 Introduction to Machine Learning Eric Medvet 16/3/2017 1/77 Outline Machine Learning: what and why? Motivating example Tree-based methods Regression trees Trees aggregation 2/77 Teachers Eric Medvet Dipartimento
Introduction to Machine Learning Eric Medvet 16/3/2017 1/77 Outline Machine Learning: what and why? Motivating example Tree-based methods Regression trees Trees aggregation 2/77 Teachers Eric Medvet Dipartimento
Machine Learning Lecture 11
 Machine Learning Lecture 11 Random Forests 23.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 11 Random Forests 23.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 10: Decision Trees colour=green? size>20cm? colour=red? watermelon size>5cm? size>5cm? colour=yellow? apple
The Curse of Dimensionality
 The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
Univariate and Multivariate Decision Trees
 Univariate and Multivariate Decision Trees Olcay Taner Yıldız and Ethem Alpaydın Department of Computer Engineering Boğaziçi University İstanbul 80815 Turkey Abstract. Univariate decision trees at each
Univariate and Multivariate Decision Trees Olcay Taner Yıldız and Ethem Alpaydın Department of Computer Engineering Boğaziçi University İstanbul 80815 Turkey Abstract. Univariate decision trees at each
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
DATA MINING LECTURE 11. Classification Basic Concepts Decision Trees Evaluation Nearest-Neighbor Classifier
 DATA MINING LECTURE 11 Classification Basic Concepts Decision Trees Evaluation Nearest-Neighbor Classifier What is a hipster? Examples of hipster look A hipster is defined by facial hair Hipster or Hippie?
DATA MINING LECTURE 11 Classification Basic Concepts Decision Trees Evaluation Nearest-Neighbor Classifier What is a hipster? Examples of hipster look A hipster is defined by facial hair Hipster or Hippie?
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation. Lecture Notes for Chapter 4. Introduction to Data Mining
 Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data
R (2) Data analysis case study using R for readily available data set using any one machine learning algorithm.
 Data analysis case study using R for readily available data set using any one machine learning algorithm.") Assignment No. 4 Title: SD Module- Data Science with R Program R (2) C (4) V (2) T (2) Total (10) Dated Sign Data analysis case study using R for readily available data set using any one machine learning
Assignment No. 4 Title: SD Module- Data Science with R Program R (2) C (4) V (2) T (2) Total (10) Dated Sign Data analysis case study using R for readily available data set using any one machine learning
Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan
 Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan Predictive Modeling Goal: learn a mapping: y = f(x;θ) Need: 1. A model structure 2. A score function
Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan Predictive Modeling Goal: learn a mapping: y = f(x;θ) Need: 1. A model structure 2. A score function
Uninformed Search Methods. Informed Search Methods. Midterm Exam 3/13/18. Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall
 Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Random Forests May, Roger Bohn Big Data Analytics
 Random Forests May, 2017 Roger Bohn Big Data Analytics This week = 2 good algorithms Thursday May 11 Lasso and Random Forests May 16 homework = case study. Kaggle, or regular? Week 7 Project: finish assignment
Random Forests May, 2017 Roger Bohn Big Data Analytics This week = 2 good algorithms Thursday May 11 Lasso and Random Forests May 16 homework = case study. Kaggle, or regular? Week 7 Project: finish assignment
An overview for regression tree
 An overview for regression tree Abstract PhD (C.) Adem Meta University Ismail Qemali Vlore, Albania Classification and regression tree is a non-parametric methodology. CART is a methodology that divides
An overview for regression tree Abstract PhD (C.) Adem Meta University Ismail Qemali Vlore, Albania Classification and regression tree is a non-parametric methodology. CART is a methodology that divides
Data Science with R. Decision Trees.
 http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/46 Data Science with R Decision Trees Graham.Williams@togaware.com Data Scientist Australian Taxation O Adjunct Professor, Australian
http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/46 Data Science with R Decision Trees Graham.Williams@togaware.com Data Scientist Australian Taxation O Adjunct Professor, Australian
A Systematic Overview of Data Mining Algorithms. Sargur Srihari University at Buffalo The State University of New York
 A Systematic Overview of Data Mining Algorithms Sargur Srihari University at Buffalo The State University of New York 1 Topics Data Mining Algorithm Definition Example of CART Classification Iris, Wine
A Systematic Overview of Data Mining Algorithms Sargur Srihari University at Buffalo The State University of New York 1 Topics Data Mining Algorithm Definition Example of CART Classification Iris, Wine
Lecture 06 Decision Trees I
 Lecture 06 Decision Trees I 08 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/33 Problem Set #2 Posted Due February 19th Piazza site https://piazza.com/ 2/33 Last time we starting fitting
Lecture 06 Decision Trees I 08 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/33 Problem Set #2 Posted Due February 19th Piazza site https://piazza.com/ 2/33 Last time we starting fitting
CS229 Lecture notes. Raphael John Lamarre Townshend
 CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
Overview. Non-Parametrics Models Definitions KNN. Ensemble Methods Definitions, Examples Random Forests. Clustering. k-means Clustering 2 / 8
 Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
International Journal of Software and Web Sciences (IJSWS)
") International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
Cyber attack detection using decision tree approach
 Cyber attack detection using decision tree approach Amit Shinde Department of Industrial Engineering, Arizona State University,Tempe, AZ, USA {amit.shinde@asu.edu} In this information age, information
Cyber attack detection using decision tree approach Amit Shinde Department of Industrial Engineering, Arizona State University,Tempe, AZ, USA {amit.shinde@asu.edu} In this information age, information
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Regularization and model selection
 CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
7. Boosting and Bagging Bagging
 Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known