Linear Regression and K-Nearest Neighbors 3/28/18
|
|
|
- Morris Hart
- 5 years ago
- Views:
Transcription
1 Linear Regression and K-Nearest Neighbors 3/28/18
2 Linear Regression Hypothesis Space Supervised learning For every input in the data set, we know the output Regression Outputs are continuous A number, not a category label The learned model: A linear function mapping input to output A weight for each feature (including bias)
3 Linear Regression We want to find the linear model that fits our data best. Key idea: model data as linear function plus noise. Pick the weights to minimize noise magnitude. f(~x) = w b 1 w x w d x d
4 Squared Error f(~x) = 2 w b 3 w w d x x d ˆf(~x) = 2 w b 3 w w d x x d Define error for a data point to be the squared distance between correct output and predicted output: 2 f(~x) ˆf(~x) = 2 Error for the model is the sum of point errors: X y ˆf(~x) = X ~x2data ~x2data 2 ~x
5 <latexit sha1_base64="ajftwnfd3tvrioy73taufuoxv4c=">aaacknicbvfdb9mwfhuypkb4yka88xjfvdrjucuibuwdubqxhngyemvbdvu57k1nzbgz2cmrovwhfg5v/bvclcdwcsxlx+ee43t9nrzsgbtfvzx/68bnw7e37wr3791/8ddceftv6krkooza6jjjmuepfi6tsbktokswpxjp0rojdf5kiaurwn2xqwknovsokqnorknm4q+6rf5/b4i+xciiqdugeqeduqvvgjoqn9utcdeafqqsbrlbxs68/cmdyufaqqcj+gk8p3heisxqvcxodx/d66pband/tqfpb6shnnmlkxku1ot8s7axdam24dqio9ajxrzpwp90rnmvo7jcmmmmcvtyac1kk7jejqcvwylxm7baiyok5wimdtvtbvqomynrxy1lowx/ddqsn2avp06zm3tqnnnr8n+5swwzn9naqkkyqphloaysydwspwjmokru5cobxkvhegv+ykrgrfvgwa0h3nzydtb+ntwyxp9f90zvu2lsk6fkgrmqmoyteflijsmycc/09rz33sh/4h/6h/yjs6nvdz7h5er4n34dscvfmq==</latexit> <latexit sha1_base64="mbprtf7i+1x4hkw5vw+vg1scs6q=">aaac03icdvjbb9mwfhbcbyrbgudejqikwgmqbcenbeiteofxk+gwvfev45601hw7i51uvygeiff+hg/8bv4ebpoh1sgrlh/no9+5+jlkuhgbhj89/8rva9dv7nwmbt2+c/de5/6dq6plguoia6mlogegpva4ssjkjpmcwzzipeqo363jr0ssjndqg13lomnyxilucgydne38ogtmq7tu0yxy6qwebl1tbiielgijjx9aa+uzbagnovmgdgbzi6rw/fjpuxyab4gamptwrryoubdxkpbpbvdsfyvjehlemxfzwsgf7lxrnhr0pm5pmor0nu11wasec/3avgmngw7dxuayifrqja3ttzs/6ezzmknluwtgjkmwt5okfvzwixvas4m548dsjmmhfcvqtkrmuwroowygbhy3liwg/tujypkxqyxxyozzhdmorcl/xcaltv9okqhy0qlim0zpkcfqwl8wzesb3mqva4wxws0kfmekxq37b4g7hgj7yjfb6pnw1ta6enhde9pexg55rb6tponiltkj78k+grhuhxin3mfvi3/of/k/+t82ut9rcx6sc+z//w2l4+be</latexit> <latexit sha1_base64="mbprtf7i+1x4hkw5vw+vg1scs6q=">aaac03icdvjbb9mwfhbcbyrbgudejqikwgmqbcenbeiteofxk+gwvfev45601hw7i51uvygeiff+hg/8bv4ebpoh1sgrlh/no9+5+jlkuhgbhj89/8rva9dv7nwmbt2+c/de5/6dq6plguoia6mlogegpva4ssjkjpmcwzzipeqo363jr0ssjndqg13lomnyxilucgydne38ogtmq7tu0yxy6qwebl1tbiielgijjx9aa+uzbagnovmgdgbzi6rw/fjpuxyab4gamptwrryoubdxkpbpbvdsfyvjehlemxfzwsgf7lxrnhr0pm5pmor0nu11wasec/3avgmngw7dxuayifrqja3ttzs/6ezzmknluwtgjkmwt5okfvzwixvas4m548dsjmmhfcvqtkrmuwroowygbhy3liwg/tujypkxqyxxyozzhdmorcl/xcaltv9okqhy0qlim0zpkcfqwl8wzesb3mqva4wxws0kfmekxq37b4g7hgj7yjfb6pnw1ta6enhde9pexg55rb6tponiltkj78k+grhuhxin3mfvi3/of/k/+t82ut9rcx6sc+z//w2l4+be</latexit> <latexit sha1_base64="mbprtf7i+1x4hkw5vw+vg1scs6q=">aaac03icdvjbb9mwfhbcbyrbgudejqikwgmqbcenbeiteofxk+gwvfev45601hw7i51uvygeiff+hg/8bv4ebpoh1sgrlh/no9+5+jlkuhgbhj89/8rva9dv7nwmbt2+c/de5/6dq6plguoia6mlogegpva4ssjkjpmcwzzipeqo363jr0ssjndqg13lomnyxilucgydne38ogtmq7tu0yxy6qwebl1tbiielgijjx9aa+uzbagnovmgdgbzi6rw/fjpuxyab4gamptwrryoubdxkpbpbvdsfyvjehlemxfzwsgf7lxrnhr0pm5pmor0nu11wasec/3avgmngw7dxuayifrqja3ttzs/6ezzmknluwtgjkmwt5okfvzwixvas4m548dsjmmhfcvqtkrmuwroowygbhy3liwg/tujypkxqyxxyozzhdmorcl/xcaltv9okqhy0qlim0zpkcfqwl8wzesb3mqva4wxws0kfmekxq37b4g7hgj7yjfb6pnw1ta6enhde9pexg55rb6tponiltkj78k+grhuhxin3mfvi3/of/k/+t82ut9rcx6sc+z//w2l4+be</latexit> <latexit sha1_base64="mbprtf7i+1x4hkw5vw+vg1scs6q=">aaac03icdvjbb9mwfhbcbyrbgudejqikwgmqbcenbeiteofxk+gwvfev45601hw7i51uvygeiff+hg/8bv4ebpoh1sgrlh/no9+5+jlkuhgbhj89/8rva9dv7nwmbt2+c/de5/6dq6plguoia6mlogegpva4ssjkjpmcwzzipeqo363jr0ssjndqg13lomnyxilucgydne38ogtmq7tu0yxy6qwebl1tbiielgijjx9aa+uzbagnovmgdgbzi6rw/fjpuxyab4gamptwrryoubdxkpbpbvdsfyvjehlemxfzwsgf7lxrnhr0pm5pmor0nu11wasec/3avgmngw7dxuayifrqja3ttzs/6ezzmknluwtgjkmwt5okfvzwixvas4m548dsjmmhfcvqtkrmuwroowygbhy3liwg/tujypkxqyxxyozzhdmorcl/xcaltv9okqhy0qlim0zpkcfqwl8wzesb3mqva4wxws0kfmekxq37b4g7hgj7yjfb6pnw1ta6enhde9pexg55rb6tponiltkj78k+grhuhxin3mfvi3/of/k/+t82ut9rcx6sc+z//w2l4+be</latexit> ~w<latexit sha1_base64="ajftwnfd3tvrioy73taufuoxv4c=">aaacknicbvfdb9mwfhuypkb4yka88xjfvdrjucuibuwdubqxhngyemvbdvu57k1nzbgz2cmrovwhfg5v/bvclcdwcsxlx+ee43t9nrzsgbtfvzx/68bnw7e37wr3791/8ddceftv6krkooza6jjjmuepfi6tsbktokswpxjp0rojdf5kiaurwn2xqwknovsokqnorknm4q+6rf5/b4i+xciiqdugeqeduqvvgjoqn9utcdeafqqsbrlbxs68/cmdyufaqqcj+gk8p3heisxqvcxodx/d66pband/tqfpb6shnnmlkxku1ot8s7axdam24dqio9ajxrzpwp90rnmvo7jcmmmmcvtyac1kk7jejqcvwylxm7baiyok5wimdtvtbvqomynrxy1lowx/ddqsn2avp06zm3tqnnnr8n+5swwzn9naqkkyqphloaysydwspwjmokru5cobxkvhegv+ykrgrfvgwa0h3nzydtb+ntwyxp9f90zvu2lsk6fkgrmqmoyteflijsmycc/09rz33sh/4h/6h/yjs6nvdz7h5er4n34dscvfmq==</latexit> <latexit sha1_base64="ho9z9luppxjt2rx39owcnvzhppo=">aaac5hicbvjnbxmxepuux2x5akbhlioioi1uot0kcrbuqssfyysruluciq/jtax67cx2hkar3llwamsvh8wn/8khzmyrkaqjwfp85o09nnfacg5sfp31/bs3b92+s3m3uhf/wcpd1qphh40qnwv9qotssuome1yyvuvwsktqjospykfp+btl/htgtofkfrdzgg1zmpe845ryr41a/zp4smyvlui8y7s6whsdlqyw+1zygdt7lwvadkwsnfenx9ebzoxhqskw2yez/st1fw4bmzifvu0cyc4hcs7lkxcy8kilz68/upz0px0enqsexdxgkfytkbbzooicbwjqk/ebnclnhic125u8uasd9alaybvedwijxo5hrt94rgizm2mpimym4qiww4poy6lgrgwlyqwh52tcbg5kkjmzroopladjmdg4ctysfmr2/4yk5mbm89qpc2knzjo2jk+lduqbvrpwxbalzzkulspkavbbcuqw5pprk+yoekq5qxxolghcrfsygwtcvpnkbda/6l3uxscv2kdvm27socfokqprjf6ii/qeham+ol7qffw+ez/8if/n/+n/wkl9r8nzq2vm/74eyn7l0a==</latexit> <latexit sha1_base64="ho9z9luppxjt2rx39owcnvzhppo=">aaac5hicbvjnbxmxepuux2x5akbhlioioi1uot0kcrbuqssfyysruluciq/jtax67cx2hkar3llwamsvh8wn/8khzmyrkaqjwfp85o09nnfacg5sfp31/bs3b92+s3m3uhf/wcpd1qphh40qnwv9qotssuome1yyvuvwsktqjospykfp+btl/htgtofkfrdzgg1zmpe845ryr41a/zp4smyvlui8y7s6whsdlqyw+1zygdt7lwvadkwsnfenx9ebzoxhqskw2yez/st1fw4bmzifvu0cyc4hcs7lkxcy8kilz68/upz0px0enqsexdxgkfytkbbzooicbwjqk/ebnclnhic125u8uasd9alaybvedwijxo5hrt94rgizm2mpimym4qiww4poy6lgrgwlyqwh52tcbg5kkjmzroopladjmdg4ctysfmr2/4yk5mbm89qpc2knzjo2jk+lduqbvrpwxbalzzkulspkavbbcuqw5pprk+yoekq5qxxolghcrfsygwtcvpnkbda/6l3uxscv2kdvm27socfokqprjf6ii/qeham+ol7qffw+ez/8if/n/+n/wkl9r8nzq2vm/74eyn7l0a==</latexit> <latexit sha1_base64="ho9z9luppxjt2rx39owcnvzhppo=">aaac5hicbvjnbxmxepuux2x5akbhlioioi1uot0kcrbuqssfyysruluciq/jtax67cx2hkar3llwamsvh8wn/8khzmyrkaqjwfp85o09nnfacg5sfp31/bs3b92+s3m3uhf/wcpd1qphh40qnwv9qotssuome1yyvuvwsktqjospykfp+btl/htgtofkfrdzgg1zmpe845ryr41a/zp4smyvlui8y7s6whsdlqyw+1zygdt7lwvadkwsnfenx9ebzoxhqskw2yez/st1fw4bmzifvu0cyc4hcs7lkxcy8kilz68/upz0px0enqsexdxgkfytkbbzooicbwjqk/ebnclnhic125u8uasd9alaybvedwijxo5hrt94rgizm2mpimym4qiww4poy6lgrgwlyqwh52tcbg5kkjmzroopladjmdg4ctysfmr2/4yk5mbm89qpc2knzjo2jk+lduqbvrpwxbalzzkulspkavbbcuqw5pprk+yoekq5qxxolghcrfsygwtcvpnkbda/6l3uxscv2kdvm27socfokqprjf6ii/qeham+ol7qffw+ez/8if/n/+n/wkl9r8nzq2vm/74eyn7l0a==</latexit> <latexit sha1_base64="ho9z9luppxjt2rx39owcnvzhppo=">aaac5hicbvjnbxmxepuux2x5akbhlioioi1uot0kcrbuqssfyysruluciq/jtax67cx2hkar3llwamsvh8wn/8khzmyrkaqjwfp85o09nnfacg5sfp31/bs3b92+s3m3uhf/wcpd1qphh40qnwv9qotssuome1yyvuvwsktqjospykfp+btl/htgtofkfrdzgg1zmpe845ryr41a/zp4smyvlui8y7s6whsdlqyw+1zygdt7lwvadkwsnfenx9ebzoxhqskw2yez/st1fw4bmzifvu0cyc4hcs7lkxcy8kilz68/upz0px0enqsexdxgkfytkbbzooicbwjqk/ebnclnhic125u8uasd9alaybvedwijxo5hrt94rgizm2mpimym4qiww4poy6lgrgwlyqwh52tcbg5kkjmzroopladjmdg4ctysfmr2/4yk5mbm89qpc2knzjo2jk+lduqbvrpwxbalzzkulspkavbbcuqw5pprk+yoekq5qxxolghcrfsygwtcvpnkbda/6l3uxscv2kdvm27socfokqprjf6ii/qeham+ol7qffw+ez/8if/n/+n/wkl9r8nzq2vm/74eyn7l0a==</latexit> <latexit sha1_base64="ze7n0shh43t5guaznhuz21scndo=">aaac3nicbvjnj9mwehxc12742ajhlioqovralayqamfkk3hhueiulapl5bit1lrhcbzttop62qshqhvld3hjj3dgtyne2x3j8vobnzp2jjnccmoj6lfnx7t+4+atvf3g9p279w5a9x98mhmpofz5lnm9sjhbkrt2rbasb4vgliust5oznyv/6ry1ebl6bxcfjji2vsivnflhjvt/ontgbjuuqzphxp0vu8eoaxq/l2io9fnleiif5byar5ov6ybiyytmvdgqxtgcaspsxdvsoelbwg2jmiaqhuddehp10lrs/xqydabw5f91r9fqq0hdropoxy1nnzm+ommumzswub2jg7faus+qdxzb3ia2aexk3ppfjzkvm1sws2bmmi4ko6qytojldi8vdramn7epdh1ulemzqur5lkhjmam467illnts/xevy4xzziltzszozlzvrv7lg5y2ftgqhcpki4qvc6wlbjvdatgwerq5lqshgnfc3rx4jgngrfssgwtcvp3kxda/7l3sxe+ety9fn93yi4/iyxksmdwnx+qtosf9wj3qxxjfvo8+87/6p/zltdt3mpihzmp8n38byrbksw==</latexit> <latexit sha1_base64="ze7n0shh43t5guaznhuz21scndo=">aaac3nicbvjnj9mwehxc12742ajhlioqovralayqamfkk3hhueiulapl5bit1lrhcbzttop62qshqhvld3hjj3dgtyne2x3j8vobnzp2jjnccmoj6lfnx7t+4+atvf3g9p279w5a9x98mhmpofz5lnm9sjhbkrt2rbasb4vgliust5oznyv/6ry1ebl6bxcfjji2vsivnflhjvt/ontgbjuuqzphxp0vu8eoaxq/l2io9fnleiif5byar5ov6ybiyytmvdgqxtgcaspsxdvsoelbwg2jmiaqhuddehp10lrs/xqydabw5f91r9fqq0hdropoxy1nnzm+ommumzswub2jg7faus+qdxzb3ia2aexk3ppfjzkvm1sws2bmmi4ko6qytojldi8vdramn7epdh1ulemzqur5lkhjmam467illnts/xevy4xzziltzszozlzvrv7lg5y2ftgqhcpki4qvc6wlbjvdatgwerq5lqshgnfc3rx4jgngrfssgwtcvp3kxda/7l3sxe+ety9fn93yi4/iyxksmdwnx+qtosf9wj3qxxjfvo8+87/6p/zltdt3mpihzmp8n38byrbksw==</latexit> <latexit sha1_base64="ze7n0shh43t5guaznhuz21scndo=">aaac3nicbvjnj9mwehxc12742ajhlioqovralayqamfkk3hhueiulapl5bit1lrhcbzttop62qshqhvld3hjj3dgtyne2x3j8vobnzp2jjnccmoj6lfnx7t+4+atvf3g9p279w5a9x98mhmpofz5lnm9sjhbkrt2rbasb4vgliust5oznyv/6ry1ebl6bxcfjji2vsivnflhjvt/ontgbjuuqzphxp0vu8eoaxq/l2io9fnleiif5byar5ov6ybiyytmvdgqxtgcaspsxdvsoelbwg2jmiaqhuddehp10lrs/xqydabw5f91r9fqq0hdropoxy1nnzm+ommumzswub2jg7faus+qdxzb3ia2aexk3ppfjzkvm1sws2bmmi4ko6qytojldi8vdramn7epdh1ulemzqur5lkhjmam467illnts/xevy4xzziltzszozlzvrv7lg5y2ftgqhcpki4qvc6wlbjvdatgwerq5lqshgnfc3rx4jgngrfssgwtcvp3kxda/7l3sxe+ety9fn93yi4/iyxksmdwnx+qtosf9wj3qxxjfvo8+87/6p/zltdt3mpihzmp8n38byrbksw==</latexit> <latexit sha1_base64="ze7n0shh43t5guaznhuz21scndo=">aaac3nicbvjnj9mwehxc12742ajhlioqovralayqamfkk3hhueiulapl5bit1lrhcbzttop62qshqhvld3hjj3dgtyne2x3j8vobnzp2jjnccmoj6lfnx7t+4+atvf3g9p279w5a9x98mhmpofz5lnm9sjhbkrt2rbasb4vgliust5oznyv/6ry1ebl6bxcfjji2vsivnflhjvt/ontgbjuuqzphxp0vu8eoaxq/l2io9fnleiif5byar5ov6ybiyytmvdgqxtgcaspsxdvsoelbwg2jmiaqhuddehp10lrs/xqydabw5f91r9fqq0hdropoxy1nnzm+ommumzswub2jg7faus+qdxzb3ia2aexk3ppfjzkvm1sws2bmmi4ko6qytojldi8vdramn7epdh1ulemzqur5lkhjmam467illnts/xevy4xzziltzszozlzvrv7lg5y2ftgqhcpki4qvc6wlbjvdatgwerq5lqshgnfc3rx4jgngrfssgwtcvp3kxda/7l3sxe+ety9fn93yi4/iyxksmdwnx+qtosf9wj3qxxjfvo8+87/6p/zltdt3mpihzmp8n38byrbksw==</latexit> <latexit sha1_base64="uflf4ijy4ipiu3wmxujfvy+wyaq=">aaacihicbvhrbtmwfhuygcmdvsyjl1duq500qgqbyxpie7zwoctkguqqctybzppjb9vpvkx5f76jn/4gnwuidvzj8vg55/hex2elfnbf8a8g3lhzd/pe1v1o+8hdrzu9x7tfra4mxxhxups0yxaludhywklms4osycsezrcfv/mzbrortprilivocjzxihecou9nez/2kjzwsk0g6qhqbfl6stmh90btvuzrlrhqgaofaqp54gofxvyraeuz7adtrck8p/i9egugmzjtgv6av0e/0ejbmqs9jx7txbsmjdyo1tmmvx48jnua2ydpqj90ctrt/aqzzascleoswtto4tjnamac4bkbifyws8yv2bzhhipwoj3u7sqb2ppmdhw7fikhlfuvo2aftcsi88qcuxo7nlur/8unk5e/ndrclzvdxa8l5zuep2h1ltatbrmtsw8yn8l3cvycgcad/7zidyfzf/jtmho5pbomn1/1t95109git8kzmiajosqn5bm5jspcg83gihgdvam3wyq8di+upwhqez6qgxf++a1hcshy</latexit> <latexit sha1_base64="uflf4ijy4ipiu3wmxujfvy+wyaq=">aaacihicbvhrbtmwfhuygcmdvsyjl1duq500qgqbyxpie7zwoctkguqqctybzppjb9vpvkx5f76jn/4gnwuidvzj8vg55/hex2elfnbf8a8g3lhzd/pe1v1o+8hdrzu9x7tfra4mxxhxups0yxaludhywklms4osycsezrcfv/mzbrortprilivocjzxihecou9nez/2kjzwsk0g6qhqbfl6stmh90btvuzrlrhqgaofaqp54gofxvyraeuz7adtrck8p/i9egugmzjtgv6av0e/0ejbmqs9jx7txbsmjdyo1tmmvx48jnua2ydpqj90ctrt/aqzzascleoswtto4tjnamac4bkbifyws8yv2bzhhipwoj3u7sqb2ppmdhw7fikhlfuvo2aftcsi88qcuxo7nlur/8unk5e/ndrclzvdxa8l5zuep2h1ltatbrmtsw8yn8l3cvycgcad/7zidyfzf/jtmho5pbomn1/1t95109git8kzmiajosqn5bm5jspcg83gihgdvam3wyq8di+upwhqez6qgxf++a1hcshy</latexit> <latexit sha1_base64="uflf4ijy4ipiu3wmxujfvy+wyaq=">aaacihicbvhrbtmwfhuygcmdvsyjl1duq500qgqbyxpie7zwoctkguqqctybzppjb9vpvkx5f76jn/4gnwuidvzj8vg55/hex2elfnbf8a8g3lhzd/pe1v1o+8hdrzu9x7tfra4mxxhxups0yxaludhywklms4osycsezrcfv/mzbrortprilivocjzxihecou9nez/2kjzwsk0g6qhqbfl6stmh90btvuzrlrhqgaofaqp54gofxvyraeuz7adtrck8p/i9egugmzjtgv6av0e/0ejbmqs9jx7txbsmjdyo1tmmvx48jnua2ydpqj90ctrt/aqzzascleoswtto4tjnamac4bkbifyws8yv2bzhhipwoj3u7sqb2ppmdhw7fikhlfuvo2aftcsi88qcuxo7nlur/8unk5e/ndrclzvdxa8l5zuep2h1ltatbrmtsw8yn8l3cvycgcad/7zidyfzf/jtmho5pbomn1/1t95109git8kzmiajosqn5bm5jspcg83gihgdvam3wyq8di+upwhqez6qgxf++a1hcshy</latexit> <latexit sha1_base64="uflf4ijy4ipiu3wmxujfvy+wyaq=">aaacihicbvhrbtmwfhuygcmdvsyjl1duq500qgqbyxpie7zwoctkguqqctybzppjb9vpvkx5f76jn/4gnwuidvzj8vg55/hex2elfnbf8a8g3lhzd/pe1v1o+8hdrzu9x7tfra4mxxhxups0yxaludhywklms4osycsezrcfv/mzbrortprilivocjzxihecou9nez/2kjzwsk0g6qhqbfl6stmh90btvuzrlrhqgaofaqp54gofxvyraeuz7adtrck8p/i9egugmzjtgv6av0e/0ejbmqs9jx7txbsmjdyo1tmmvx48jnua2ydpqj90ctrt/aqzzascleoswtto4tjnamac4bkbifyws8yv2bzhhipwoj3u7sqb2ppmdhw7fikhlfuvo2aftcsi88qcuxo7nlur/8unk5e/ndrclzvdxa8l5zuep2h1ltatbrmtsw8yn8l3cvycgcad/7zidyfzf/jtmho5pbomn1/1t95109git8kzmiajosqn5bm5jspcg83gihgdvam3wyq8di+upwhqez6qgxf++a1hcshy</latexit> <latexit sha1_base64="4ksqatidrqcsb6hsx7cqumz9m9c=">aaacwxicdvfbb9mwfhbczspccjzyckrv1epqjqhpiebmggceh0rzuf1vjnvsmjl2sj2yksqf5g3/bjfleovgsja/853vxoytlvjyf8dnqxjt+o2be/u3ott37t6733vw8kvvlee44vpqk2bmohqkj044iwlpkbwzxops5mm2frxgy4vwx9ymxfnblkrkgjpnqxnvjk6yq/nmsnfi69nmbbr/vginrf+zacox2kexjqyd7qgwvkithumzc+0i3gg1vtgvozlqosbtib+ejud5/0qm8psizyawtiy/2vvxxzqafnvrtbxpg5prw6ses/26vhmvh4/j1uaqsdrqj50dzxu/6elzqkdlugtwtpo4dloagse4xcailcws8ro2xkmhihvoz3w7ggygnlmah8cf5abl/86owwhtpsi8smbuzxdjw/jfswnl8lezwqiycqj4eao8kua0bpcjc2gqo7nxghej/kzav8ww7vzwi/8jye6tr4lji/hrcfl5zf/wbfcb++qxeukgjceh5jb8ikdkqnjwpsbabtr8gh4py9ccs8ogy3lellly/wzwd9kp</latexit> <latexit sha1_base64="4ksqatidrqcsb6hsx7cqumz9m9c=">aaacwxicdvfbb9mwfhbczspccjzyckrv1epqjqhpiebmggceh0rzuf1vjnvsmjl2sj2yksqf5g3/bjfleovgsja/853vxoytlvjyf8dnqxjt+o2be/u3ott37t6733vw8kvvlee44vpqk2bmohqkj044iwlpkbwzxops5mm2frxgy4vwx9ymxfnblkrkgjpnqxnvjk6yq/nmsnfi69nmbbr/vginrf+zacox2kexjqyd7qgwvkithumzc+0i3gg1vtgvozlqosbtib+ejud5/0qm8psizyawtiy/2vvxxzqafnvrtbxpg5prw6ses/26vhmvh4/j1uaqsdrqj50dzxu/6elzqkdlugtwtpo4dloagse4xcailcws8ro2xkmhihvoz3w7ggygnlmah8cf5abl/86owwhtpsi8smbuzxdjw/jfswnl8lezwqiycqj4eao8kua0bpcjc2gqo7nxghej/kzav8ww7vzwi/8jye6tr4lji/hrcfl5zf/wbfcb++qxeukgjceh5jb8ikdkqnjwpsbabtr8gh4py9ccs8ogy3lellly/wzwd9kp</latexit> <latexit sha1_base64="4ksqatidrqcsb6hsx7cqumz9m9c=">aaacwxicdvfbb9mwfhbczspccjzyckrv1epqjqhpiebmggceh0rzuf1vjnvsmjl2sj2yksqf5g3/bjfleovgsja/853vxoytlvjyf8dnqxjt+o2be/u3ott37t6733vw8kvvlee44vpqk2bmohqkj044iwlpkbwzxops5mm2frxgy4vwx9ymxfnblkrkgjpnqxnvjk6yq/nmsnfi69nmbbr/vginrf+zacox2kexjqyd7qgwvkithumzc+0i3gg1vtgvozlqosbtib+ejud5/0qm8psizyawtiy/2vvxxzqafnvrtbxpg5prw6ses/26vhmvh4/j1uaqsdrqj50dzxu/6elzqkdlugtwtpo4dloagse4xcailcws8ro2xkmhihvoz3w7ggygnlmah8cf5abl/86owwhtpsi8smbuzxdjw/jfswnl8lezwqiycqj4eao8kua0bpcjc2gqo7nxghej/kzav8ww7vzwi/8jye6tr4lji/hrcfl5zf/wbfcb++qxeukgjceh5jb8ikdkqnjwpsbabtr8gh4py9ccs8ogy3lellly/wzwd9kp</latexit> <latexit sha1_base64="4ksqatidrqcsb6hsx7cqumz9m9c=">aaacwxicdvfbb9mwfhbczspccjzyckrv1epqjqhpiebmggceh0rzuf1vjnvsmjl2sj2yksqf5g3/bjfleovgsja/853vxoytlvjyf8dnqxjt+o2be/u3ott37t6733vw8kvvlee44vpqk2bmohqkj044iwlpkbwzxops5mm2frxgy4vwx9ymxfnblkrkgjpnqxnvjk6yq/nmsnfi69nmbbr/vginrf+zacox2kexjqyd7qgwvkithumzc+0i3gg1vtgvozlqosbtib+ejud5/0qm8psizyawtiy/2vvxxzqafnvrtbxpg5prw6ses/26vhmvh4/j1uaqsdrqj50dzxu/6elzqkdlugtwtpo4dloagse4xcailcws8ro2xkmhihvoz3w7ggygnlmah8cf5abl/86owwhtpsi8smbuzxdjw/jfswnl8lezwqiycqj4eao8kua0bpcjc2gqo7nxghej/kzav8ww7vzwi/8jye6tr4lji/hrcfl5zf/wbfcb++qxeukgjceh5jb8ikdkqnjwpsbabtr8gh4py9ccs8ogy3lellly/wzwd9kp</latexit> Error as a function X : input examples Y : output examples X ~x Y f(x) 8~x 2 X : learned weights ˆf(~x) : model prediction ˆf(~x) ~w ~x Error depends on the data and the weights. (X, Y, ~w) = X f(x) ~w ~x 2 ~x2x For a given data set, error is a function of the weights. ( ~w) = X f(x) ~w ~x 2 ~x2x
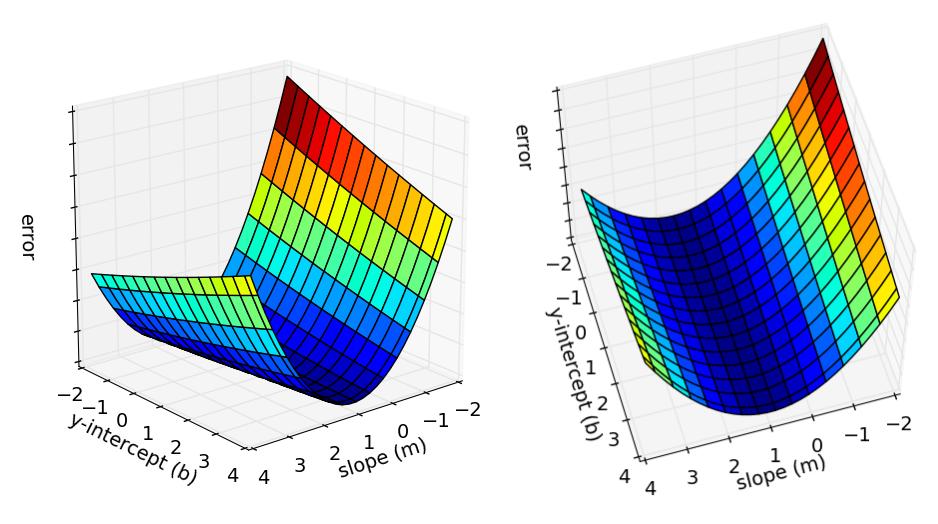
6 <latexit sha1_base64="bbis2j/7lmdsrkdqenaoxgcsgig=">aaab8hicbvbns8naej34wetx1aoxxsiiqkleua9c0yvhcsyw21a22027dhctdjdicp0xxjyoepxneppfug1z0nyha4/3zpizfyacaeo6387c4tlyympprby+sbm1xdnzvddxqgj1scxj1qqxppxj6htmog0limirctomh9djv/lilwaxvdnzqgob+5jfjgbjpycmxslxhi5r2k1u3zo7azonxkgqukdrrxx1ejfjbzwgckx123mte+ryguy4hzu7qayjjkpcp21ljrzub/nk4he6teoprbgyjq2aql8nciy0zkroowu2az3rjcx/vhzqovmgzzjjdzvkuihkotixgr+pekxrynhmcsak2vsrgwcfibehlw0i3uzl88q/qv3uvnvtav2qskme+3aar+dbgdthbhrgawejz/akb452xpx352pauuaum3vwb87nd/wxj1o=</latexit> <latexit sha1_base64="bbis2j/7lmdsrkdqenaoxgcsgig=">aaab8hicbvbns8naej34wetx1aoxxsiiqkleua9c0yvhcsyw21a22027dhctdjdicp0xxjyoepxneppfug1z0nyha4/3zpizfyacaeo6387c4tlyympprby+sbm1xdnzvddxqgj1scxj1qqxppxj6htmog0limirctomh9djv/lilwaxvdnzqgob+5jfjgbjpycmxslxhi5r2k1u3zo7azonxkgqukdrrxx1ejfjbzwgckx123mte+ryguy4hzu7qayjjkpcp21ljrzub/nk4he6teoprbgyjq2aql8nciy0zkroowu2az3rjcx/vhzqovmgzzjjdzvkuihkotixgr+pekxrynhmcsak2vsrgwcfibehlw0i3uzl88q/qv3uvnvtav2qskme+3aar+dbgdthbhrgawejz/akb452xpx352pauuaum3vwb87nd/wxj1o=</latexit> <latexit sha1_base64="bbis2j/7lmdsrkdqenaoxgcsgig=">aaab8hicbvbns8naej34wetx1aoxxsiiqkleua9c0yvhcsyw21a22027dhctdjdicp0xxjyoepxneppfug1z0nyha4/3zpizfyacaeo6387c4tlyympprby+sbm1xdnzvddxqgj1scxj1qqxppxj6htmog0limirctomh9djv/lilwaxvdnzqgob+5jfjgbjpycmxslxhi5r2k1u3zo7azonxkgqukdrrxx1ejfjbzwgckx123mte+ryguy4hzu7qayjjkpcp21ljrzub/nk4he6teoprbgyjq2aql8nciy0zkroowu2az3rjcx/vhzqovmgzzjjdzvkuihkotixgr+pekxrynhmcsak2vsrgwcfibehlw0i3uzl88q/qv3uvnvtav2qskme+3aar+dbgdthbhrgawejz/akb452xpx352pauuaum3vwb87nd/wxj1o=</latexit> <latexit sha1_base64="bbis2j/7lmdsrkdqenaoxgcsgig=">aaab8hicbvbns8naej34wetx1aoxxsiiqkleua9c0yvhcsyw21a22027dhctdjdicp0xxjyoepxneppfug1z0nyha4/3zpizfyacaeo6387c4tlyympprby+sbm1xdnzvddxqgj1scxj1qqxppxj6htmog0limirctomh9djv/lilwaxvdnzqgob+5jfjgbjpycmxslxhi5r2k1u3zo7azonxkgqukdrrxx1ejfjbzwgckx123mte+ryguy4hzu7qayjjkpcp21ljrzub/nk4he6teoprbgyjq2aql8nciy0zkroowu2az3rjcx/vhzqovmgzzjjdzvkuihkotixgr+pekxrynhmcsak2vsrgwcfibehlw0i3uzl88q/qv3uvnvtav2qskme+3aar+dbgdthbhrgawejz/akb452xpx352pauuaum3vwb87nd/wxj1o=</latexit> 1D Inputs: y = mx + b
7 Minimizing Squared Error Goal: pick weights that minimize squared error. Approach #1: gradient descent Your reading derived this for 1D inputs. Does this look familiar?
8 Minimizing Squared Error Goal: pick weights that minimize squared error. Approach #2 (the right way): analytical solution The gradient is 0 at the error minimum. For linear regression, there is a unique global minimum with a closed formula: 1 ~w = X X T X T ~y 2 X ~x 0 ~x 1...~x n x 00 x x 0n x 10 x x 1n x d0 x d1... x dn
9 Change of Basis Polynomial regression is just linear regression with a change of basis x 0 3 x ! x d 2 x 0 3 (x 0 ) 2 x 1 (x 1 ) x d 5 (x d ) 2 quadratic basis Perform linear regression on the new representation. 2 x 0 3 x ! x d x 0 (x 0 ) 2 (x 0 ) 3 x 1 (x 1 ) 2 (x 1 ) 3. 6 x d 7 4(x d ) 2 5 (x d ) 3 cubic basis
10 Change of Basis Demo
11 K-Nearest Neighbors Hypothesis Space Supervised learning For every input in the data set, we know the output Classification Outputs are discrete Category labels The learned model: We ll talk about this in a bit.
12 K-nearest neighbors algorithm Training: Store all of the test points and their labels. Can use a data structure like a kd-tree that speeds up localized lookup. Prediction: Find the k training inputs closest to the test input. Output the most common label among them.
13 KNN implementation decisions How should we measure distance? (Euclidean distance between input vectors.) (and possible answers) What if there s a tie for the nearest points? (Include all points that are tied.) What if there s a tie for the most-common label? (Remove the most-distant point until a plurality is achieved.) What if there s a tie for both? (We need some arbitrary tie-breaking rule.)


14 KNN Hypothesis Space What does the learned model look like?
15 Weighted nearest neighbors Idea: closer points should matter more. Solution: weight the vote by Instead of contributing one vote for its label, each neighbor contributes votes for its label.
16 Why do we even need k neighbors? Idea: if we re weighting by distance, we can give all training points a vote. Points that are far away will just have really small weight. Why might this be a bad idea? Slow: we have to sum over every point in the training set. If we re using a kd-tree, we can get the neighbors quickly and sum over a small set.
17 The same ideas can apply to regression. K-nearest neighbors setting: Supervised learning (we know the correct output for each test point). Classification (small number of discrete labels). vs. Locally-weighted regression setting: Supervised learning (we know the correct output for each test point). Regression (outputs are continuous).
18 Locally-Weighted Average Instead of taking a majority vote, average the y-values. We could average over the k nearest neighbors. We could weight the average by distance. Better yet, do both.
19 Locally Weighted Regression Key idea: For any point we want to predict, compute a linear regression with error weighted by distance. As before, we find the linear function that minimizes total error, but we redefine total error, so that closer points count more: X ~x2data y ˆf(~x) dist( ~x t, ~x) = X ~x2data 2 ~x ~x t ~x 2
20 Supervised Learning Phases Fitting (a.k.a. training) Process data Create the model that will be used for prediction Prediction (a.k.a. testing) Evaluate the model on new inputs Compare models Describe the work done in each phase: Linear regression KNN
CS178: Machine Learning and Data Mining. Complexity & Nearest Neighbor Methods
 + CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
+ CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
Distribution-free Predictive Approaches
 Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
CP365 Artificial Intelligence
 CP365 Artificial Intelligence Example Problem Problem: Does a given image contain cats? Input vector: RGB/BW pixels of the image. Output: Yes or No. Example Problem Problem: What category is a news story?
CP365 Artificial Intelligence Example Problem Problem: Does a given image contain cats? Input vector: RGB/BW pixels of the image. Output: Yes or No. Example Problem Problem: What category is a news story?
REGRESSION ANALYSIS : LINEAR BY MAUAJAMA FIRDAUS & TULIKA SAHA
 REGRESSION ANALYSIS : LINEAR BY MAUAJAMA FIRDAUS & TULIKA SAHA MACHINE LEARNING It is the science of getting computer to learn without being explicitly programmed. Machine learning is an area of artificial
REGRESSION ANALYSIS : LINEAR BY MAUAJAMA FIRDAUS & TULIKA SAHA MACHINE LEARNING It is the science of getting computer to learn without being explicitly programmed. Machine learning is an area of artificial
Nearest Neighbor Classification. Machine Learning Fall 2017
 Nearest Neighbor Classification Machine Learning Fall 2017 1 This lecture K-nearest neighbor classification The basic algorithm Different distance measures Some practical aspects Voronoi Diagrams and Decision
Nearest Neighbor Classification Machine Learning Fall 2017 1 This lecture K-nearest neighbor classification The basic algorithm Different distance measures Some practical aspects Voronoi Diagrams and Decision
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 6: k-nn Cross-validation Regularization
 SS18. Lecture 6: k-nn Cross-validation Regularization") COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
k-nearest Neighbor (knn) Sept Youn-Hee Han
 Sept Youn-Hee Han") k-nearest Neighbor (knn) Sept. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²Eager Learners Eager vs. Lazy Learning when given a set of training data, it will construct a generalization model before receiving
k-nearest Neighbor (knn) Sept. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²Eager Learners Eager vs. Lazy Learning when given a set of training data, it will construct a generalization model before receiving
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance and case-based reasoning
 Instance and case-based reasoning ML for NLP Lecturer: Kevin Koidl Assist. Lecturer Alfredo Maldonado https://www.scss.tcd.ie/kevin.koidl/cs462/ kevin.koidl@scss.tcd.ie, maldonaa@tcd.ie 27 Instance-based
Instance and case-based reasoning ML for NLP Lecturer: Kevin Koidl Assist. Lecturer Alfredo Maldonado https://www.scss.tcd.ie/kevin.koidl/cs462/ kevin.koidl@scss.tcd.ie, maldonaa@tcd.ie 27 Instance-based
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Approximate Q-Learning 3/23/18
 Approximate Q-Learning 3/23/18 On-Policy Learning (SARSA) Instead of updating based on the best action from the next state, update based on the action your current policy actually takes from the next state.
Approximate Q-Learning 3/23/18 On-Policy Learning (SARSA) Instead of updating based on the best action from the next state, update based on the action your current policy actually takes from the next state.
Classification and K-Nearest Neighbors
 Classification and K-Nearest Neighbors Administrivia o Reminder: Homework 1 is due by 5pm Friday on Moodle o Reading Quiz associated with today s lecture. Due before class Wednesday. NOTETAKER 2 Regression
Classification and K-Nearest Neighbors Administrivia o Reminder: Homework 1 is due by 5pm Friday on Moodle o Reading Quiz associated with today s lecture. Due before class Wednesday. NOTETAKER 2 Regression
Mathematics of Data. INFO-4604, Applied Machine Learning University of Colorado Boulder. September 5, 2017 Prof. Michael Paul
 Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11. Nearest Neighbour Classifier. Keywords: K Neighbours, Weighted, Nearest Neighbour
 MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11 Nearest Neighbour Classifier Keywords: K Neighbours, Weighted, Nearest Neighbour 1 Nearest neighbour classifiers This is amongst the simplest
MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11 Nearest Neighbour Classifier Keywords: K Neighbours, Weighted, Nearest Neighbour 1 Nearest neighbour classifiers This is amongst the simplest
Topics in Machine Learning
 Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Going nonparametric: Nearest neighbor methods for regression and classification
 Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
Perceptron as a graph
 Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
k-nearest Neighbors + Model Selection
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
Nearest neighbors classifiers
 Nearest neighbors classifiers James McInerney Adapted from slides by Daniel Hsu Sept 11, 2017 1 / 25 Housekeeping We received 167 HW0 submissions on Gradescope before midnight Sept 10th. From a random
Nearest neighbors classifiers James McInerney Adapted from slides by Daniel Hsu Sept 11, 2017 1 / 25 Housekeeping We received 167 HW0 submissions on Gradescope before midnight Sept 10th. From a random
Machine Learning. Supervised Learning. Manfred Huber
 Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Supervised Learning (contd) Linear Separation. Mausam (based on slides by UW-AI faculty)
 Linear Separation. Mausam (based on slides by UW-AI faculty)") Supervised Learning (contd) Linear Separation Mausam (based on slides by UW-AI faculty) Images as Vectors Binary handwritten characters Treat an image as a highdimensional vector (e.g., by reading pixel
Supervised Learning (contd) Linear Separation Mausam (based on slides by UW-AI faculty) Images as Vectors Binary handwritten characters Treat an image as a highdimensional vector (e.g., by reading pixel
Data Preprocessing. Supervised Learning
 Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2015
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
Nearest Neighbor Methods
 Nearest Neighbor Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Nearest Neighbor Methods Learning Store all training examples Classifying a
Nearest Neighbor Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Nearest Neighbor Methods Learning Store all training examples Classifying a
Machine Learning: Think Big and Parallel
 Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
CSC 411: Lecture 05: Nearest Neighbors
 CSC 411: Lecture 05: Nearest Neighbors Raquel Urtasun & Rich Zemel University of Toronto Sep 28, 2015 Urtasun & Zemel (UofT) CSC 411: 05-Nearest Neighbors Sep 28, 2015 1 / 13 Today Non-parametric models
CSC 411: Lecture 05: Nearest Neighbors Raquel Urtasun & Rich Zemel University of Toronto Sep 28, 2015 Urtasun & Zemel (UofT) CSC 411: 05-Nearest Neighbors Sep 28, 2015 1 / 13 Today Non-parametric models
K-Nearest Neighbour Classifier. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 K-Nearest Neighbour Classifier Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Reminder Supervised data mining Classification Decision Trees Izabela
K-Nearest Neighbour Classifier Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Reminder Supervised data mining Classification Decision Trees Izabela
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation
 Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Lecture 3. Oct
 Lecture 3 Oct 3 2008 Review of last lecture A supervised learning example spam filter, and the design choices one need to make for this problem use bag-of-words to represent emails linear functions as
Lecture 3 Oct 3 2008 Review of last lecture A supervised learning example spam filter, and the design choices one need to make for this problem use bag-of-words to represent emails linear functions as
Gradient Descent. Wed Sept 20th, James McInenrey Adapted from slides by Francisco J. R. Ruiz
 Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
A Brief Look at Optimization
 A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
MLCC 2018 Local Methods and Bias Variance Trade-Off. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 Local Methods and Bias Variance Trade-Off Lorenzo Rosasco UNIGE-MIT-IIT About this class 1. Introduce a basic class of learning methods, namely local methods. 2. Discuss the fundamental concept
MLCC 2018 Local Methods and Bias Variance Trade-Off Lorenzo Rosasco UNIGE-MIT-IIT About this class 1. Introduce a basic class of learning methods, namely local methods. 2. Discuss the fundamental concept
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
CS 584 Data Mining. Classification 1
 CS 584 Data Mining Classification 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for
CS 584 Data Mining Classification 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for
3 Nonlinear Regression
 3 Linear models are often insufficient to capture the real-world phenomena. That is, the relation between the inputs and the outputs we want to be able to predict are not linear. As a consequence, nonlinear
3 Linear models are often insufficient to capture the real-world phenomena. That is, the relation between the inputs and the outputs we want to be able to predict are not linear. As a consequence, nonlinear
Announcements. CS 188: Artificial Intelligence Spring Classification: Feature Vectors. Classification: Weights. Learning: Binary Perceptron
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM. Mingon Kang, PhD Computer Science, Kennesaw State University
 CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM Mingon Kang, PhD Computer Science, Kennesaw State University KNN K-Nearest Neighbors (KNN) Simple, but very powerful classification algorithm Classifies
CS7267 MACHINE LEARNING NEAREST NEIGHBOR ALGORITHM Mingon Kang, PhD Computer Science, Kennesaw State University KNN K-Nearest Neighbors (KNN) Simple, but very powerful classification algorithm Classifies
CSC411/2515 Tutorial: K-NN and Decision Tree
 CSC411/2515 Tutorial: K-NN and Decision Tree Mengye Ren csc{411,2515}ta@cs.toronto.edu September 25, 2016 Cross-validation K-nearest-neighbours Decision Trees Review: Motivation for Validation Framework:
CSC411/2515 Tutorial: K-NN and Decision Tree Mengye Ren csc{411,2515}ta@cs.toronto.edu September 25, 2016 Cross-validation K-nearest-neighbours Decision Trees Review: Motivation for Validation Framework:
CS5670: Computer Vision
 CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
Kernels and Clustering
 Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
CS273 Midterm Exam Introduction to Machine Learning: Winter 2015 Tuesday February 10th, 2014
 CS273 Midterm Eam Introduction to Machine Learning: Winter 2015 Tuesday February 10th, 2014 Your name: Your UCINetID (e.g., myname@uci.edu): Your seat (row and number): Total time is 80 minutes. READ THE
CS273 Midterm Eam Introduction to Machine Learning: Winter 2015 Tuesday February 10th, 2014 Your name: Your UCINetID (e.g., myname@uci.edu): Your seat (row and number): Total time is 80 minutes. READ THE
SUPERVISED LEARNING METHODS. Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018
 SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
COMPUTATIONAL INTELLIGENCE (CS) (INTRODUCTION TO MACHINE LEARNING) SS16. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions
 (INTRODUCTION TO MACHINE LEARNING) SS16. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions") COMPUTATIONAL INTELLIGENCE (CS) (INTRODUCTION TO MACHINE LEARNING) SS16 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Regression
COMPUTATIONAL INTELLIGENCE (CS) (INTRODUCTION TO MACHINE LEARNING) SS16 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Regression
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation
 Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions
 SS18. Lecture 2: Linear Regression Gradient Descent Non-linear basis functions") COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Simplest
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 2: Linear Regression Gradient Descent Non-linear basis functions LINEAR REGRESSION MOTIVATION Why Linear Regression? Simplest
Lecture 17: Smoothing splines, Local Regression, and GAMs
 Lecture 17: Smoothing splines, Local Regression, and GAMs Reading: Sections 7.5-7 STATS 202: Data mining and analysis November 6, 2017 1 / 24 Cubic splines Define a set of knots ξ 1 < ξ 2 < < ξ K. We want
Lecture 17: Smoothing splines, Local Regression, and GAMs Reading: Sections 7.5-7 STATS 202: Data mining and analysis November 6, 2017 1 / 24 Cubic splines Define a set of knots ξ 1 < ξ 2 < < ξ K. We want
Voronoi Region. K-means method for Signal Compression: Vector Quantization. Compression Formula 11/20/2013
 Voronoi Region K-means method for Signal Compression: Vector Quantization Blocks of signals: A sequence of audio. A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1) A vector quantizer
Voronoi Region K-means method for Signal Compression: Vector Quantization Blocks of signals: A sequence of audio. A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1) A vector quantizer
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 15 th, 2007 2005-2007 Carlos Guestrin 1 1-Nearest Neighbor Four things make a memory based learner:
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 15 th, 2007 2005-2007 Carlos Guestrin 1 1-Nearest Neighbor Four things make a memory based learner:
6.034 Quiz 2, Spring 2005
 6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
Machine Learning Classifiers and Boosting
 Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
COMS 4771 Clustering. Nakul Verma
 COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
Model Selection Introduction to Machine Learning. Matt Gormley Lecture 4 January 29, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Model Selection Matt Gormley Lecture 4 January 29, 2018 1 Q&A Q: How do we deal
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Model Selection Matt Gormley Lecture 4 January 29, 2018 1 Q&A Q: How do we deal
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
k Nearest Neighbors Super simple idea! Instance-based learning as opposed to model-based (no pre-processing)
") k Nearest Neighbors k Nearest Neighbors To classify an observation: Look at the labels of some number, say k, of neighboring observations. The observation is then classified based on its nearest neighbors
k Nearest Neighbors k Nearest Neighbors To classify an observation: Look at the labels of some number, say k, of neighboring observations. The observation is then classified based on its nearest neighbors
DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS
 DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes and a class attribute
DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes and a class attribute
K- Nearest Neighbors(KNN) And Predictive Accuracy
 And Predictive Accuracy") Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.
Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.
Naïve Bayes for text classification
 Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Supervised Learning: Nearest Neighbors
 CS 2750: Machine Learning Supervised Learning: Nearest Neighbors Prof. Adriana Kovashka University of Pittsburgh February 1, 2016 Today: Supervised Learning Part I Basic formulation of the simplest classifier:
CS 2750: Machine Learning Supervised Learning: Nearest Neighbors Prof. Adriana Kovashka University of Pittsburgh February 1, 2016 Today: Supervised Learning Part I Basic formulation of the simplest classifier:
Function Approximation. Pieter Abbeel UC Berkeley EECS
 Function Approximation Pieter Abbeel UC Berkeley EECS Outline Value iteration with function approximation Linear programming with function approximation Value Iteration Algorithm: Start with for all s.
Function Approximation Pieter Abbeel UC Berkeley EECS Outline Value iteration with function approximation Linear programming with function approximation Value Iteration Algorithm: Start with for all s.
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
Going nonparametric: Nearest neighbor methods for regression and classification
 Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 8, 28 Locality sensitive hashing for approximate NN
Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 8, 28 Locality sensitive hashing for approximate NN
Notes and Announcements
 Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
Data Mining and Machine Learning: Techniques and Algorithms
 Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Instance-Based Learning. Goals for the lecture
 Instance-Based Learning Mar Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Instance-Based Learning Mar Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Lecture 7: Linear Regression (continued)
") Lecture 7: Linear Regression (continued) Reading: Chapter 3 STATS 2: Data mining and analysis Jonathan Taylor, 10/8 Slide credits: Sergio Bacallado 1 / 14 Potential issues in linear regression 1. Interactions
Lecture 7: Linear Regression (continued) Reading: Chapter 3 STATS 2: Data mining and analysis Jonathan Taylor, 10/8 Slide credits: Sergio Bacallado 1 / 14 Potential issues in linear regression 1. Interactions
LARGE MARGIN CLASSIFIERS
 Admin Assignment 5 LARGE MARGIN CLASSIFIERS David Kauchak CS 451 Fall 2013 Midterm Download from course web page when you re ready to take it 2 hours to complete Must hand-in (or e-mail in) by 11:59pm
Admin Assignment 5 LARGE MARGIN CLASSIFIERS David Kauchak CS 451 Fall 2013 Midterm Download from course web page when you re ready to take it 2 hours to complete Must hand-in (or e-mail in) by 11:59pm
Nearest Neighbor Predictors
 Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Cost Functions in Machine Learning
 Cost Functions in Machine Learning Kevin Swingler Motivation Given some data that reflects measurements from the environment We want to build a model that reflects certain statistics about that data Something
Cost Functions in Machine Learning Kevin Swingler Motivation Given some data that reflects measurements from the environment We want to build a model that reflects certain statistics about that data Something
CS489/698 Lecture 2: January 8 th, 2018
 CS489/698 Lecture 2: January 8 th, 2018 Nearest Neighbour [RN] Sec. 18.8.1, [HTF] Sec. 2.3.2, [D] Chapt. 3, [B] Sec. 2.5.2, [M] Sec. 1.4.2 CS489/698 (c) 2018 P. Poupart 1 Inductive Learning (recap) Induction
CS489/698 Lecture 2: January 8 th, 2018 Nearest Neighbour [RN] Sec. 18.8.1, [HTF] Sec. 2.3.2, [D] Chapt. 3, [B] Sec. 2.5.2, [M] Sec. 1.4.2 CS489/698 (c) 2018 P. Poupart 1 Inductive Learning (recap) Induction
Data Mining Classification: Alternative Techniques. Lecture Notes for Chapter 4. Instance-Based Learning. Introduction to Data Mining, 2 nd Edition
 Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Instance Based Classifiers
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Instance Based Classifiers
7. Nearest neighbors. Learning objectives. Foundations of Machine Learning École Centrale Paris Fall 2015
 Foundations of Machine Learning École Centrale Paris Fall 2015 7. Nearest neighbors Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr Learning
Foundations of Machine Learning École Centrale Paris Fall 2015 7. Nearest neighbors Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr Learning
Data Mining. 3.5 Lazy Learners (Instance-Based Learners) Fall Instructor: Dr. Masoud Yaghini. Lazy Learners
 Fall Instructor: Dr. Masoud Yaghini. Lazy Learners") Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
3 Nonlinear Regression
 CSC 4 / CSC D / CSC C 3 Sometimes linear models are not sufficient to capture the real-world phenomena, and thus nonlinear models are necessary. In regression, all such models will have the same basic
CSC 4 / CSC D / CSC C 3 Sometimes linear models are not sufficient to capture the real-world phenomena, and thus nonlinear models are necessary. In regression, all such models will have the same basic
Assignment 4 (Sol.) Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran
 Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran") Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
PROBLEM 4
 PROBLEM 2 PROBLEM 4 PROBLEM 5 PROBLEM 6 PROBLEM 7 PROBLEM 8 PROBLEM 9 PROBLEM 10 PROBLEM 11 PROBLEM 12 PROBLEM 13 PROBLEM 14 PROBLEM 16 PROBLEM 17 PROBLEM 22 PROBLEM 23 PROBLEM 24 PROBLEM 25
PROBLEM 2 PROBLEM 4 PROBLEM 5 PROBLEM 6 PROBLEM 7 PROBLEM 8 PROBLEM 9 PROBLEM 10 PROBLEM 11 PROBLEM 12 PROBLEM 13 PROBLEM 14 PROBLEM 16 PROBLEM 17 PROBLEM 22 PROBLEM 23 PROBLEM 24 PROBLEM 25
CPSC 340: Machine Learning and Data Mining. More Regularization Fall 2017
 CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
CISC 4631 Data Mining
 CISC 4631 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F.
CISC 4631 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F.
Large Scale Data Analysis Using Deep Learning
 Large Scale Data Analysis Using Deep Learning Machine Learning Basics - 1 U Kang Seoul National University U Kang 1 In This Lecture Overview of Machine Learning Capacity, overfitting, and underfitting
Large Scale Data Analysis Using Deep Learning Machine Learning Basics - 1 U Kang Seoul National University U Kang 1 In This Lecture Overview of Machine Learning Capacity, overfitting, and underfitting
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Decision Tree (Continued) and K-Nearest Neighbour. Dr. Xiaowei Huang
 and K-Nearest Neighbour. Dr. Xiaowei Huang") Decision Tree (Continued) and K-Nearest Neighbour Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Recap basic knowledge Decision tree learning How to split Identify the best feature to
Decision Tree (Continued) and K-Nearest Neighbour Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Recap basic knowledge Decision tree learning How to split Identify the best feature to
Neural Network Neurons
 Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Fitting: The Hough transform
 Fitting: The Hough transform Voting schemes Let each feature vote for all the models that are compatible with it Hopefully the noise features will not vote consistently for any single model Missing data
Fitting: The Hough transform Voting schemes Let each feature vote for all the models that are compatible with it Hopefully the noise features will not vote consistently for any single model Missing data
UVA CS 6316/4501 Fall 2016 Machine Learning. Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff. Dr. Yanjun Qi. University of Virginia
 UVA CS 6316/4501 Fall 2016 Machine Learning Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 11/9/16 1 Rough Plan HW5
UVA CS 6316/4501 Fall 2016 Machine Learning Lecture 15: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 11/9/16 1 Rough Plan HW5
UVA CS 4501: Machine Learning. Lecture 10: K-nearest-neighbor Classifier / Bias-Variance Tradeoff. Dr. Yanjun Qi. University of Virginia
 UVA CS 4501: Machine Learning Lecture 10: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 1 Where are we? è Five major secfons
UVA CS 4501: Machine Learning Lecture 10: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 1 Where are we? è Five major secfons
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Learning from Data: Adaptive Basis Functions
 Learning from Data: Adaptive Basis Functions November 21, 2005 http://www.anc.ed.ac.uk/ amos/lfd/ Neural Networks Hidden to output layer - a linear parameter model But adapt the features of the model.
Learning from Data: Adaptive Basis Functions November 21, 2005 http://www.anc.ed.ac.uk/ amos/lfd/ Neural Networks Hidden to output layer - a linear parameter model But adapt the features of the model.
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2017
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2017 Assignment 3: 2 late days to hand in tonight. Admin Assignment 4: Due Friday of next week. Last Time: MAP Estimation MAP
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2017 Assignment 3: 2 late days to hand in tonight. Admin Assignment 4: Due Friday of next week. Last Time: MAP Estimation MAP
Announcements. CS 188: Artificial Intelligence Spring Generative vs. Discriminative. Classification: Feature Vectors. Project 4: due Friday.
 CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted
CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted