arxiv: v1 [cs.cv] 6 Jul 2017
|
|
|
- Elijah Marshall
- 6 years ago
- Views:
Transcription


 methodologies. Under fully olutional architecture, RON mainly focuses on two fundamental problems: (a) multi-scale object localization and (b) negative sample mining.")
, we propose the objectness prior to significantly reduce the searching space of objects.")
1 RON: Reverse Connection with Objectness Prior Networks for Object Detection arxiv: v1 [cs.cv] 6 Jul 2017 Tao Kong 1 Fuchun Sun 1 Anbang Yao 2 Huaping Liu 1 Ming Lu 3 Yurong Chen 2 1 State Key Lab. of Intelligent Technology and Systems, Tsinghua National Laboratory for Information Science and Technology (TNList), Department of Computer Science and Technology, Tsinghua University 2 Intel Labs China 3 Department of Electronic Engineering, Tsinghua University 1 {kt14@mails,fcsun@,hpliu@}.tsinghua.edu.cn 2 {anbang.yao, yurong.chen}@.intel.com Abstract We present RON, an efficient and effective framework for generic object detection. Our motivation is to smartly associate the best of the region-based (e.g., Faster R-CNN) and region-free (e.g., SSD) methodologies. Under fully olutional architecture, RON mainly focuses on two fundamental problems: (a) multi-scale object localization and (b) negative sample mining. To address (a), we design the reverse connection, which enables the network to detect objects on multi-levels of CNNs. To deal with (b), we propose the objectness prior to significantly reduce the searching space of objects. We optimize the reverse connection, objectness prior and object detector jointly by a multi-task loss function, thus RON can directly predict final detection results from all locations of various feature maps. Extensive experiments on the challenging PASCAL VOC 2007, PASCAL VOC 2012 and MS COCO benchmarks demonstrate the competitive performance of RON. Specifically, with VGG-16 and low resolution input size, the network gets 81.3% map on PASCAL VOC 2007, 80.7% map on PASCAL VOC 2012 datasets. Its superiority increases when datasets become larger and more difficult, as demonstrated by the results on the MS COCO dataset. With 1.5G GPU memory at test phase, the speed of the network is 15 FPS, 3 faster than the Faster R-CNN counterpart. Code will be available at taokong/ron. 1. Introduction We are witnessing significant advances in object detection area, mainly thanks to the deep networks. Current top deep-networks-based object detection frameworks could be *This work was done when Tao Kong was an intern at Intel Labs China supervised by Anbang Yao who is responsible for correspondence. 3 lu-m13@mails.tsinghua.edu.cn (a) (b) (c) (d) Figure 1. Objectness prior generated from a specific image. In this example, sofa is responded at scales (a) and (b), the brown dog is responded at scale (c) and the white spotted dog is responded at scale (d). The network will generate detection results with the guidance of objectness prior. grouped into two main streams: the region-based methods [11][23][10][16] and the region-free methods [22][19]. The region-based methods divide the object detection task into two sub-problems: At the first stage, a dedicated region proposal generation network is grafted on deep olutional neural networks (CNNs) which could generate high quality candidate boxes. Then at the second stage, a region-wise subnetwork is designed to classify and refine these candidate boxes. Using very deep CNNs [14][27], the Fast R-CNN pipeline [10][23] has recently shown high accuracy on mainstream object detection benchmarks [7][24][18]. The region proposal stage could reject most of the background samples, thus the searching space for object detection is largely reduced [1][32]. Multistage training process is usually developed for joint optimization of region proposal generation and post detection (e.g., [4][23][16]). In Fast R-CNN [10], the region-wise subnetwork repeatedly evaluates thousands of region proposals to generate detection scores. Under Fast R-CNN pipeline, Faster R-CNN shares full-image olutional features with the detection network to enable nearly costfree region proposals. Recently, R-FCN [4] tries to make the unshared per-roi computation of Faster R-CNN to be sharable by adding position-sensitive score maps. Never- 1
2 theless, R-FCN still needs region proposals generated from region proposal networks [23]. To ensure detection accuracy, all methods resize the image to a large enough size (usually with the shortest side of 600 pixels). It is somewhat resource/time consuming when feeding the image into deep networks, both in training and inference time. For example, predicting with Faster R-CNN usually takes 0.2 s per image using about 5GB GPU memory for VGG-16 networks [27]. Another solution family is the region-free methods [22][19]. These methods treat object detection as a single shot problem, straight from image pixels to bounding box coordinates by fully olutional networks (FCNs). The main advantage of these detectors is high efficiency. Originated from YOLO [22], SSD [19] tries to deal object detection problem with multiple layers of deep CNNs. With low resolution input, the SSD detector could get state-of-the-art detection results. However, the detection accuracy of these methods still has room for improvement: (a) Without region proposals, the detectors have to suppress all of the negative candidate boxes only at the detection module. It will increase the difficulties on training the detection module. (b) YOLO detects objects with the top-most CNN layer, without deeply exploring the detection capacities of different layers. SSD tries to improve the detection performance by adding former layers results. However, SSD still struggles with small instances, mainly because of the limited information of middle layers. These two main bottlenecks affect the detection accuracy of the methods. Driven by the success of the two solution families, a critical question arises: is it possible to develop an elegant framework which can smartly associate the best of both methodologies and eliminate their major demerits? We answer this question by trying to bridge the gap between the region-based and region-free methodologies. To achieve this goal, we focus on two fundamental problems: (a) Multi-scale object localization. Objects of various scales could appear at any position of an image, so tens of thousands of regions with different positions/scales/aspect ratios should be considered. Prior works [16][3] show that multi-scale representation will significantly improve object detection of various scales. However, these methods always detect various scales of objects at one layer of a network [16][23][4]. With the proposed reverse connection, objects are detected on their corresponding network scales, which is more elegant and easier to optimize. (b) Negative space mining. The ratio between object and non-object samples is seriously imbalanced. So an object detector should have effective negative mining strategies [26]. In order to reduce the searching space of the objects, we create an objectness prior (Figure 1) on olutional feature maps and jointly optimize it with the detector at training phase. As a result, we propose RON (Reverse connection with Objectness prior Networks) object detection framework, which could associate the merits of region-based and region-free approaches. Furthermore, recent complementary advances such as hard example mining [26], bounding box regression [11] and multi-layer representation [16][3] could be naturally employed. Contributions. We make the following contributions: 1. We propose RON, a fully olutional framework for end-to-end object detection. Firstly, the reverse connection assists the former layers of CNNs with more semantic information. Second, the objectness prior gives an explicit guide to the searching of objects. Finally, the multi-task loss function enables us to optimize the whole network end-to-end on detection performance. 2. In order to achieve high detection accuracy, effective training strategies like negative example mining and data augmentation have been employed. With low resolution input size, RON achieves state-ofthe-art results on PASCAL VOC 2007, with a 81.3% map, VOC 2012, with a 80.7% map, and MS COCO, with a 27.4% map. 3. RON is time and resource efficient. With 1.5G GPU memory, the total feed-forward speed is 15 FPS, 3 faster than the seminal Faster R-CNN. Moreover, we conduct extensive design choices like the layers combination, with/without objectness prior, and other variations. 2. Related Work Object detection is a fundamental and heavilyresearched task in computer vision area. It aims to localize and recognize every object instance with a bounding box [7][18]. Before the success of deep CNNs [17], the widely used detection systems are based on the combination of independent components (HOG [30], SIFT [21] et al.). The DPM [8] and its variants [2][5] have been the dominant methods for years. These methods use object component descriptors as features and sweep through the entire image to find regions with a class-specific maximum response. With the great success of the deep learning on large scale object recognition, several works based on CNNs have been proposed [31][25]. R-CNN [11] and its variants usually combine region proposals (generated from Selective Search [29], Edgeboxes [32], MCG [1], et al.) and ConvNet based post-classification. These methods have brought dramatic improvement on detection accuracy [17]. After the original R-CNN, researches are improving it in a variety of ways. The SPP-Net [13] and Fast R-CNN [10] speed up the R-CNN approach with RoI-Pooling (Spatial-Pyramid- Pooling) that allows the classification layers to reuse features computed over CNN feature maps. Under Fast R-

3 n det 4 reverse connection objectness det 5 reverse connection objectness det 6 reverse connection boat boat objectness det 7 person Figure 2. RON object detection overview. Given an input image, the network firstly computes features of the backbone network. Then at each detection scale: (a) adds reverse connection; (b) generates objectness prior; (c) detects object on its corresponding CNN scales and locations. Finally, all detection results are fused and selected with non-maximum suppression. CNN pipeline, several works try to improve the detection speed and accuracy, with more effective region proposals [23], multi-layer fusion [3][16], context information [14][9] and more effective training strategy [26]. R-FCN [4] tries to reduce the computation time with position-sensitive score maps under ResNet architecture [14]. Thanks to the FCNs [20] which could give position-wise information of input images, several works are trying to solve the object detection problem by FCNs. The methods skip the region proposal generation step and predict bounding boxes and detection confidences of multiple categories directly [6]. YOLO [22] uses the top most CNN feature maps to predict both confidences and locations for multiple categories. Originated from YOLO, SSD [19] tries to predict detection results at multiple CNN layers. With carefully designed training strategies, SSD could get competitive detection results. The main advantage of these methods is high timeefficiency. For example, the feed-forward speed of YOLO is 45 FPS, 9 faster than Faster R-CNN. 3. Network Architecture This section describes RON object detection framework (Figure 2). We first introduce the reverse connection on traditional CNNs in Section 3.1, such that different network scales have effective detection capabilities. Then in Section 3.2, we explain how to generate candidate boxes on different network scales. Next, we present the objectness prior to guide the search of objects in Section 3.3 and Secction 3.4. Finally, we combine the objectness prior and object detection into a unified network for joint training and testing (Section 3.5). Network preparation We use VGG-16 as the test objectness 3 3, 512 sum rf-map n de 2 2, 512 rf-map n+1 Figure 3. A reverse connection block. case reference model, which is pre-trained with ImageNet dataset [27]. Recall that VGG-16 has 13 olutional layers and 3 fully-connected layers. We ert FC6 (14th layer) and FC7 (15th layer) to olutional layers [20], and use 2 2 olutional kernels with stride 2 to reduce the resolution of FC7 by half 1. By now, the feature map sizes used for object detection are 1/8 ( 4 3), 1/16 ( 5 3), 1/32 ( 6) and 1/64 ( 7) of the input size, both in width and height (see Figure 2 top) Reverse Connection Combining fine-grained details with highly-abstracted information helps object detection with different scales [12][20][14]. The region-based networks usually fuse multiple CNN layers into a single feature map [3][16]. Then object detection is performed on the fused maps with regionwise subnetworks [10]. As all objects need to be detected based on the fixed features, the optimization becomes much complex. SSD [19] detects objects on multiple CNN layers. However, the semantic information of former layers is limited, which affects the detection performance of these layers. This is the reason why SSD has much worse performance on smaller objects than bigger objects [19]. Inspired from the success of residual connection [14] which eases the training of much deeper networks, we propose the reverse connection on traditional CNN architectures. The reverse connection enables former features to have more semantic information. One reverse connection block is shown in Figure 3. Firstly, a deolutional layer is applied to the reverse fusion map (annotated as rf-map) n+1, and a olutional layer is grafted on backbone layer n to guarantee the inputs have the same dimension. Then the two corresponding maps are merged by element-wise addition. The reverse fusion map 7 is the olutional output (with 512 channels by 3 3 kernels) of the backbone layer 7. After this layer has been generated, each reverse connection block will be generated in the same way, as shown in Figure 2. In total, there are four reverse fusion maps with different scales. Compared with methods using single layer for object detection [16][23], multi-scale representation is more effective on locating all scales of objects (as shown in ex- 1 The last FC layer (16th layer) is not used in this paper.
4 periments). More importantly, as the reverse connection is learnable, the semantic information of former layers can be significantly enriched. This characteristic makes RON more effective in detecting all scales of objects compared with [19] Reference Boxes In this section, we describe how to generate bounding boxes on feature maps produced from Section 3.1. Feature maps from different levels within a network are known to have different receptive field sizes [13]. As the reverse connection can generate multiple feature maps with different scales. We can design the distribution of boxes so that specific feature map locations can be learned to be responsive to particular scales of objects. Denoting the minimum scale with s min, the scales S k of boxes at each feature map k are S k = {(2k 1) s min, 2k s min }, k {1, 2, 3, 4}. (1) We also impose different aspect ratios { 1 3, 1 2, 1, 2, 3} for the default boxes. The width and height of each box are computed with respect to the aspect ratio [23]. In total, there are 2 scales and 5 aspect ratios at each feature map location. The s min is 1 10 of the input size (e.g., 32 pixels for model). By combining predictions for all default boxes with different scales and aspect ratios, we have a diverse set of predictions, covering various object sizes and shapes Objectness Prior As shown in Section 3.2, we consider default boxes with different scales and aspect ratios from many feature maps. However, only a tiny fraction of boxes covers objects. In other words, the ratio between object and non-object samples is seriously imbalanced. The region-based methods overcome this problem by region proposal networks [16][23]. However, the region proposals will bring translation variance compared with the default boxes. So the Fast R-CNN pipeline usually uses region-wise networks for post detection, which brings repeated computation [4]. In contrast, we add an objectness prior for guiding the search of objects, without generating new region proposals. Concretely, we add a olutional layer followed by a Softmax function to indicate the existence of an object in each box. The channel number of objectness prior maps is 10, as there are 10 default boxes at each location. Figure 1 shows the multi-scale objectness prior generated from a specific image. For visualization, the objectness prior maps are averaged along the channel dimension. We see that the objectness prior maps could explicitly reflect the existence of an object. Thus the searching space of the objects could be dramatically reduced. Objects of various scales will respond at their corresponding feature maps, and we enable this by appropriate matching and end-to-end 3 3, 512 former layer concat latter layer 1 1, 512 Figure 4. One inception block. training. More results could be seen in the experiment section Detection and Bounding Box Regression Different from objectness prior, the detection module needs to classify regions into K+1 categories (K= 20 for PASCAL VOC dataset and K= 80 for MS COCO dataset, plus 1 for background). We employ the inception module [28] on the feature maps generated in Section 3.1 to perform detection. Concretely, we add two inception blocks (one block is shown in Figure 4) on feature maps, and classify the final inception outputs. There are many inception choices as shown in [28]. In this paper, we just use the most simple structure. With Softmax, the sub-network outputs the per-class score that indicates the presence of a class-specific instance. For bounding box regression, we predict the offsets relative to the default boxes in the cell (see Figure 5). rf-map n 3 3, 512 inception 3 3, 4 A bbox reg inception 3 3, (k+1) A softmax Figure 5. Object detection and bounding box regression modules. Top: bounding box regression; Bottom: object classification Combining Objectness Prior with Detection In this section, we explain how RON combines objectness prior with object detection. We assist object detection with objectness prior both in training and testing phases. For training the network, we firstly assign a binary class label to each candidate region generated from Section 3.2. Then if the region covers object, we also assign a classspecific label to it. For each ground truth box, we (i) match it with the candidate region with most jaccard overlap; (ii) match candidate regions to any ground truth with jaccard overlap higher than 0.5. This matching strategy guarantees that each ground truth box has at least one region box assigned to it. We assign negative labels to the boxes with jaccard overlap lower than 0.3.

5 By now, each box has its objectness label and classspecific label. The network will update the class-specific labels dynamically for assisting object detection with objectness prior at training phase. For each mini-batch at feedforward time, the network runs both the objectness prior and class-specific detection. But at the back-propagation phase, the network firstly generates the objectness prior, then for detection, samples whose objectness scores are high than threshold o p are selected (Figure 6). The extra computation only comes from the selection of samples for backpropagation. With suitable o p (we use o p = 0.03 for all models), only a small number of samples is selected for updating the detection branch, thus the complexity of backward pass has been significantly reduced. Figure 6. Mapping the objectness prior with object detection. We first binarize the objectness prior maps according to o p, then project the binary masks to the detection domain of the last olutional feature maps. The locations within the masks are collected for detecting objects. 4. Training and Testing In this section, we firstly introduce the multi-task loss function for optimizing the networks. Then we explain how to optimize the network jointly and perform inference directly Loss Function For each location, our network has three sibling output branches. The first outputs the objectness confidence score p obj = {p obj 0, pobj 1 }, computed by a Softmax over the 2 A outputs of objectness prior (A = 10 in this paper, as there are 10 types of default boxes). We denote the objectness loss with L obj. The second branch outputs the bounding-box regression loss, denoted by L loc. It targets at minimizing the smoothed L 1 loss [10] between the predicted location offsets t = (t x, t y, t w, t h ) and the target offsets t = (t x, t y, t w, t h ). Different from Fast R-CNN [10] that regresses the offsets for each of K classes, we just regress the location one time with no class-specific information. The third branch outputs the classification loss L cls obj for each box, over K+1 categories. Given the objectness confidence score p obj, the branch first excludes regions whose scores are lower than the threshold o p. Then like L obj, L cls obj is computed by a Softmax over K+1 outputs for each location p cls obj = {p cls obj 0, p cls obj 1,..., p cls obj K }. We use a multi-task loss L to jointly train the networks endto-end for objectness prior, classification and bounding-box regression: L = α 1 L obj +β 1 1 L loc +(1 α β) L cls obj. N obj N loc N cls obj (2) The hyper-parameters α and β in Equation 2 control the balance between the three losses. We normalize each loss term with its input number. Under this normalization, α = β = 1 3 works well and is used in all experiments Joint Training and Testing We optimize the models described above jointly with end-to-end training. After the matching step, most of the default boxes are negatives, especially when the number of default boxes is large. Here, we introduce a dynamic training strategy to scan the negative space. At training phase, each SGD mini-batch is constructed from N images chosen uniformly from the dataset. At each mini-batch, (a) for objectness prior, all of the positive samples are selected for training. Negative samples are randomly selected from regions with negative labels such that the ratio between positive and negative samples is 1:3; (b) for detection, we first reduce the sample number according to objectness prior scores generated at this mini-batch (as discribed in Section 3.5). Then all of the positive samples are selected. We randomly select negative samples such that the ratio between positive and negative samples is 1:3. We note that recent works such as Faster R-CNN [23] and R-FCN [4] usually use multi-stage training for joint optimization. In contrast, the loss function 2 is trained end-to-end in our implementation by back-propagation and SGD, which is more efficient at training phase. At the beginning of training, the objectness prior maps are in chaos. However, along with the training progress, the objectness prior maps are more concentrated on areas covering objects. Data augmentation To make the model more robust to various object scales, each training image is randomly sampled by one of the following options: (i) Using the original/flipped input image; (ii) Randomly sampling a patch whose edge length is { 4 10, 5 10, 6 10, 7 10, 8 10, 9 10 } of the original image and making sure that at least one object s center is within this patch. We note that the data augmentation strategy described above will increase the number of large objects, but the optimization benefit for small objects is limited. We overcome this problem by adding a small scale
![Method map aero bike bird boat bottle bus car cat chair cow table dog horse mbike person plant sheep sofa train tv Fast R-CNN[10] 70.0 77.0 78.1 69.3 59.4 38.3 81.6 78.6 86.7 42.8 78.8 68.9 84.7 82.](/docs-images/76/74371360/images/6-0.jpg "0 76.6 69.9 31.8 70.1 74.8 80.4 70.4 Faster R-CNN[23] 73.2 76.5 79.0 70.9 65.5 52.1 83.1 84.7 86.4 52.0 81.9 65.7 84.8 84.6 77.5 76.7 38.8 73.6 73.9 83.0 72.6 SSD300[19] 72.1 75.2 79.8 70.5 62.5 41.")
6 Method map aero bike bird boat bottle bus car cat chair cow table dog horse mbike person plant sheep sofa train tv Fast R-CNN[10] Faster R-CNN[23] SSD300[19] SSD500[19] RON RON RON RON Table 1. Detection results on PASCAL VOC 2007 test set. The entries with the best APs for each object category are bold-faced. Figure 7. Visualization of performance for RON384 on animals, vehicles, and furniture from VOC2007 test. The Figures show the cumulative fraction of detections that are correct (Cor) or false positive due to poor localization (Loc), confusion with similar categories (Sim), with others (Oth), or with background (BG). The solid red line reflects the change of recall with the strong criteria (0.5 jaccard overlap) as the number of detections increases. The dashed red line uses the weak criteria (0.1 jaccard overlap). for training. A large object at one scale will be smaller at smaller scales. This training strategy could effectively avoid over-fitting of objects with specific sizes. Inference At inference phase, we multiply the classconditional probability and the individual box confidence predictions. The class-specific confidence score for each box is defined as Equation 3: p cls = p obj p cls obj. (3) The scores encode both the probability of the class appearing in the box and how well the predicted box fits the object. After the final score of each box is generated, we adjust the boxes according to the bounding box regression outputs. Finally, non-maximum suppression is applied to get the final detection results. 5. Results We train and evaluate our models on three major datasets: PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO. For fair comparison, all experiments are based on the VGG-16 networks. We train all our models on a single Nvidia TitanX GPU, and demonstrate state-of-the-art results on all three datasets PASCAL VOC 2007 On this dataset, we compare RON against seminal Fast R-CNN [10], Faster R-CNN [23], and the most recently proposed SSD [19]. All methods are trained on VOC2007 trainval and VOC2012 trainval, and tested on VOC2007 test dataset. During training phase, we initialize the parameters for all the newly added layers by drawing weights from a zero-mean Gaussian distribution with standard deviation All other layers are initialized by standard VGG-16 model [10]. We use the 10 3 learning rate for the first 90k iterations, then we decay it to 10 4 and continue training for next 30k iterations. The batch size is 18 for model according to the GPU capacity. We use a momentum of 0.9 and a weight decay of Table 1 shows the result comparisons of the methods 2. With input size, RON is already better than Faster R-CNN. By increasing the input size to , RON gets 75.4% map, outperforming Faster R-CNN by a margin of 2.2%. RON384 is also better than SSD with input size Finally, RON could achieve high maps of 76.6% (RON320++) and 77.6% (RON384++) with multiscale testing, bounding box voting and flipping [3]. Small objects are challenging for detectors. As shown in Table 1, all methods have inferior performance on boat and bottle. However, RON improves performance of these categories by significant margins: 4.0 points improvement for boat and 7.1 points improvement for bottle. In sum- 2 We note that the latest SSD uses new training tricks (color distortion, random expansion and online hard example mining), which makes the results much better. We expect these tricks will also improve our results, which is beyond the focus of this paper.
7 Method map aero bike bird boat bottle bus car cat chair cow table dog horse mbike person plant sheep sofa train tv Fast R-CNN[10] OHEM[26] Faster R-CNN[23] HyperNet[16] SSD300[19] SSD500[19] RON RON RON RON Table 2. Results on PASCAL VOC 2012 test set. All methods are based on the pre-trained VGG-16 networks. mary, performance of 17 out of 20 categories has been improved by RON. To understand the performance of RON in more detail, we use the detection analysis tool from [15]. Figure 7 shows that our model can detect various object categories with high quality. The recall is higher than 85%, and is much higher with the weak (0.1 jaccard overlap) criteria PASCAL VOC 2012 We compare RON against top methods on the comp4 (outside data) track from the public leaderboard on PAS- CAL VOC The training data is the union set of all VOC 2007, VOC 2012 train and validation datasets, following [23][10][19]. We see the same performance trend as we observed on VOC 2007 test. The results, as shown in Table 2, demonstrate that our model performs the best on this dataset. Compared with Faster R-CNN and other variants [26][16], the proposed network is significantly better, mainly due to the reverse connection and the use of boxes from multiple feature maps MS COCO To further validate the proposed framework on a larger and more challenging dataset, we conduct experiments on MS COCO [18] and report results from test-dev2015 evaluation server. The evaluation metric of MS COCO dataset is different from PASCAL VOC. The average map over different IoU thresholds, from 0.5 to 0.95 (written as 0.5:0.95) is the overall performance of methods. This places a significantly larger emphasis on localization compared to the PASCAL VOC metric which only requires IoU of 0.5. We use the 80k training images and 40k validation images [23] to train our model, and validate the performance on the testdev2015 dataset which contains 20k images. We use the learning rate for 400k iterations, then we decay it to and continue training for another 150k iterations. As instances in MS COCO dataset are smaller and denser than those in PASCAL VOC dataset, the minimum scale s min of the referenced box size is 24 for model, and 32 for model. Other settings are the same as PASCAL VOC dataset. Method Train Data Average Precision :0.95 Fast R-CNN[10] train OHEM[26] trainval OHEM++[26] trainval Faster R-CNN[23] trainval SSD300[19] trainval35k SSD500[19] trainval35k RON320 trainval RON384 trainval RON320++ trainval RON384++ trainval Table 3. MS COCO test-dev2015 detection results. With the standard COCO evaluation metric, Faster R- CNN scores 21.9% AP, and RON improves it to 27.4% AP. Using the VOC overlap metric of IoU 0.5, RON384++ gives a 5.8 points boost compared with SSD500. It is also interesting to note that with input size, RON gets 26.2% AP, improving the SSD with input size by 1.8 points on the strict COCO AP evaluation metric. We also compare our method against Fast R-CNN with online hard example mining (OHEM) [26], which gives a considerable improvement on Fast R-CNN. The OHEM method also adopts recent bells and whistles to further improve the detection performance. The best result of OHEM is 25.5% AP (OHEM++). RON gets 27.4% AP, which demonstrates that the proposed network is more competitive on large dataset From MS COCO to PASCAL VOC Large-scale dataset is important for improving deep neural networks. In this experiment, we investigate how the MS COCO dataset can help with the detection performance of PASCAL VOC. As the categories on MS COCO are a superset of these on PASCAL VOC dataset, the fine-tuning process becomes easier compared with the ImageNet pretrained model. Starting from MS COCO pre-trained model, RON leads to 81.3% map on PASCAL VOC 2007 and 80.7% map on PASCAL VOC The extra data from the MS COCO dataset increases the map by 3.7% and 5.3%. Table 4 shows that the model trained on COCO+VOC has the best map on PASCAL
![Method Faster R-CNN[23] OHEM++[26] SSD512[19] RON320 RON384 RON320++ RON384++ 2007 test 78.8 78.7 80.2 80.3 81.](/docs-images/76/74371360/images/8-0.jpg "3 2012 test 75.9 80.1 80.0 76.3 79.0 78.7 80.7 Table 4. The performance on PASCAL VOC datasets.")






![We compare the proposal performance against Faster R-CNN [23] and evaluate recalls with different numbers of](/docs-images/76/74371360/images/8-7.jpg "proposals on PASCAL VOC 2007 test set, as shown in Figure 9.")







8 Method Faster R-CNN[23] OHEM++[26] SSD512[19] RON320 RON384 RON320++ RON test test Table 4. The performance on PASCAL VOC datasets. All models are pre-trained on MS COCO, and fine-tuned on PASCAL VOC. VOC 2007 and PASCAL VOC When submitting, our model with input size has been ranked as the top 1 on the VOC 2012 leaderboard among VGG-16 based models. We note that other public methods with better results are all based on much deeper networks [14]. 6. Ablation Analysis 6.1. Do Multiple Layers Help? As described in Section 3, our networks generate detection boxes from multiple layers and combine the results. In this experiment, we compare how layer combinations affect the final performance. For all of the following experiments as shown in Table 5, we use exactly the same settings and input size ( ), except for the layers for object detection. detection from layer X X X X X X X X X X map4 input map5 map6 map7 Figure 8. Objectness prior maps generated from images Generating Region Proposals After removing the detection module, our network could get region proposals. We compare the proposal performance against Faster R-CNN [23] and evaluate recalls with different numbers of proposals on PASCAL VOC 2007 test set, as shown in Figure 9. The N proposals are the topn ranked ones based on the confidence generated by these methods. r map Table 5. Combining features from different layers. From Table 5, we see that it is necessary to use all of the layer 4, 5, 6 and 7 such that the detector could get the best performance Objectness Prior As introduced in Section 3.3, the network generates objectness prior for post detection. The objectness prior maps involve not only the strength of the responses, but also their spatial positions. As shown in Figure 8, objects with various scales will respond at the corresponding maps. The maps can guide the search of different scales of objects, thus significantly reducing the searching space. We also design an experiment to verify the effect of objectness prior. In this experiment, we remove the objectness prior module and predict the detection results only from the detection module. Other settings are exactly the same as the baseline. Removing objectness prior maps leads to 69.6% map on VOC 2007 test dataset, resulting 4.6 points drop from the 74.2% map baseline. Figure 9. Recall versus number of proposals on the PASCAL VOC 2007 test set (with IoU = 0.5). Both Faster R-CNN and RON achieve promising region proposals when the region number is larger than 100. However, with fewer region proposals, the recall of RON boosts Faster R-CNN by a large margin. Specifically, with top 10 region proposals, our 320 model gets 80.7% recall, outperforming Faster R-CNN by 20 points. This validates that our model is more effective in applications with less region proposals. 7. Conclusion We have presented RON, an efficient and effective object detection framework. We design the reverse connection to enable the network to detect objects on multi-levels of CNNs. And the objectness prior is also proposed to guide the search of objects. We optimize the whole networks by a multi-task loss function, thus the networks can directly predict final detection results. On standard benchmarks, RON achieves state-of-the-art object detection performance.













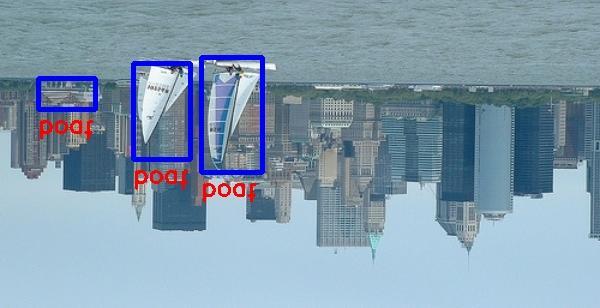
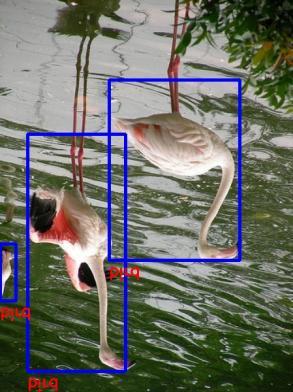




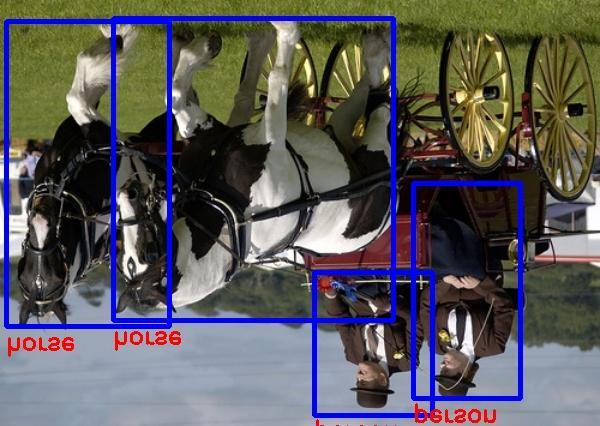





9 Figure 10. Selected examples of object detection results on the PASCAL VOC 2007 test set using the RON320 model. The training data is trainval (74.2% map on the 2007 test set).
10 References [1] P. Arbelaez, J. Pont-Tuset, J. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping. In CVPR, [2] H. Azizpour and I. Laptev. Object detection using stronglysupervised deformable part models. In ECCV, [3] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Insideoutside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, [4] J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully olutional networks. In NIPS, [5] P. Dollár, R. Appel, S. Belongie, and P. Perona. Fast feature pyramids for object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(8): , [6] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, [7] M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 111(1):98 136, [8] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained partbased models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9): , [9] S. Gidaris and N. Komodakis. Object detection via a multiregion and semantic segmentation-aware cnn model. In ICCV, [10] R. Girshick. Fast r-cnn. In ICCV, [11] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, [12] B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization. In CVPR, [13] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep olutional networks for visual recognition. In ECCV, [14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, [15] D. Hoiem, Y. Chodpathumwan, and Q. Dai. Diagnosing error in object detectors. In ECCV, [16] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection. In CVPR, [17] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep olutional neural networks. In NIPS, [18] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In ECCV, [19] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. Ssd: Single shot multibox detector. In ECCV, [20] J. Long, E. Shelhamer, and T. Darrell. Fully olutional networks for semantic segmentation. In CVPR, [21] D. G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2):91 110, [22] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, [23] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NIPS, [24] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3): , [25] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using olutional networks. In ICLR, [26] A. Shrivastava, A. Gupta, and R. Girshick. Training regionbased object detectors with online hard example mining. In CVPR, [27] K. Simonyan and A. Zisserman. Very deep olutional networks for large-scale image recognition. In ICLR, [28] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with olutions. In CVPR, [29] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. International journal of computer vision, 104(2): , [30] X. Wang, T. X. Han, and S. Yan. An hog-lbp human detector with partial occlusion handling. In CVPR, [31] Y. Zhang, K. Sohn, R. Villegas, G. Pan, and H. Lee. Improving object detection with deep olutional networks via bayesian optimization and structured prediction. In CVPR, [32] C. L. Zitnick and P. Dollár. Edge boxes: Locating object proposals from edges. In ECCV, 2014.
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v1 [cs.cv] 3 Apr 2016
![arxiv: v1 [cs.cv] 3 Apr 2016](/thumbs/77/76512524.jpg "arxiv: v1 [cs.cv] 3 Apr 2016") : Towards Accurate Region Proposal Generation and Joint Object Detection arxiv:64.6v [cs.cv] 3 Apr 26 Tao Kong Anbang Yao 2 Yurong Chen 2 Fuchun Sun State Key Lab. of Intelligent Technology and Systems
: Towards Accurate Region Proposal Generation and Joint Object Detection arxiv:64.6v [cs.cv] 3 Apr 26 Tao Kong Anbang Yao 2 Yurong Chen 2 Fuchun Sun State Key Lab. of Intelligent Technology and Systems
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Single-Shot Refinement Neural Network for Object Detection -Supplementary Material-
 Single-Shot Refinement Neural Network for Object Detection -Supplementary Material- Shifeng Zhang 1,2, Longyin Wen 3, Xiao Bian 3, Zhen Lei 1,2, Stan Z. Li 4,1,2 1 CBSR & NLPR, Institute of Automation,
Single-Shot Refinement Neural Network for Object Detection -Supplementary Material- Shifeng Zhang 1,2, Longyin Wen 3, Xiao Bian 3, Zhen Lei 1,2, Stan Z. Li 4,1,2 1 CBSR & NLPR, Institute of Automation,
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
SSD: Single Shot MultiBox Detector
 SSD: Single Shot MultiBox Detector Wei Liu 1(B), Dragomir Anguelov 2, Dumitru Erhan 3, Christian Szegedy 3, Scott Reed 4, Cheng-Yang Fu 1, and Alexander C. Berg 1 1 UNC Chapel Hill, Chapel Hill, USA {wliu,cyfu,aberg}@cs.unc.edu
SSD: Single Shot MultiBox Detector Wei Liu 1(B), Dragomir Anguelov 2, Dumitru Erhan 3, Christian Szegedy 3, Scott Reed 4, Cheng-Yang Fu 1, and Alexander C. Berg 1 1 UNC Chapel Hill, Chapel Hill, USA {wliu,cyfu,aberg}@cs.unc.edu
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
RON: Reverse Connection with Objectness Prior Networks for Object Detection
 RON: Reverse Connection with Objectness Prior Networks for Object Detection Tao Kong 1, Fuchun Sun 1, Anbang Yao 2, Huaping Liu 1, Ming Lu 3, Yurong Chen 2 1 Department of CST, Tsinghua University, 2 Intel
RON: Reverse Connection with Objectness Prior Networks for Object Detection Tao Kong 1, Fuchun Sun 1, Anbang Yao 2, Huaping Liu 1, Ming Lu 3, Yurong Chen 2 1 Department of CST, Tsinghua University, 2 Intel
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
arxiv: v2 [cs.cv] 8 Apr 2018
![arxiv: v2 [cs.cv] 8 Apr 2018](/thumbs/86/94330536.jpg "arxiv: v2 [cs.cv] 8 Apr 2018") Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
arxiv: v1 [cs.cv] 4 Jun 2015
![arxiv: v1 [cs.cv] 4 Jun 2015](/thumbs/92/109659580.jpg "arxiv: v1 [cs.cv] 4 Jun 2015") Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
G-CNN: an Iterative Grid Based Object Detector
 G-CNN: an Iterative Grid Based Object Detector Mahyar Najibi 1, Mohammad Rastegari 1,2, Larry S. Davis 1 1 University of Maryland, College Park 2 Allen Institute for Artificial Intelligence najibi@cs.umd.edu
G-CNN: an Iterative Grid Based Object Detector Mahyar Najibi 1, Mohammad Rastegari 1,2, Larry S. Davis 1 1 University of Maryland, College Park 2 Allen Institute for Artificial Intelligence najibi@cs.umd.edu
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
arxiv: v1 [cs.cv] 15 Aug 2018
![arxiv: v1 [cs.cv] 15 Aug 2018](/thumbs/83/88609179.jpg "arxiv: v1 [cs.cv] 15 Aug 2018") SAN: Learning Relationship between Convolutional Features for Multi-Scale Object Detection arxiv:88.97v [cs.cv] 5 Aug 8 Yonghyun Kim [ 8 785], Bong-Nam Kang [ 688 75], and Daijin Kim [ 86 85] Department
SAN: Learning Relationship between Convolutional Features for Multi-Scale Object Detection arxiv:88.97v [cs.cv] 5 Aug 8 Yonghyun Kim [ 8 785], Bong-Nam Kang [ 688 75], and Daijin Kim [ 86 85] Department
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL
 PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Gated Bi-directional CNN for Object Detection
 Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
arxiv: v2 [cs.cv] 18 Jul 2017
![arxiv: v2 [cs.cv] 18 Jul 2017](/thumbs/72/67294650.jpg "arxiv: v2 [cs.cv] 18 Jul 2017") PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
A MultiPath Network for Object Detection
 ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
ZAGORUYKO et al.: A MULTIPATH NETWORK FOR OBJECT DETECTION 1 A MultiPath Network for Object Detection Sergey Zagoruyko, Adam Lerer, Tsung-Yi Lin, Pedro O. Pinheiro, Sam Gross, Soumith Chintala, Piotr Dollár
arxiv: v2 [cs.cv] 30 Mar 2016
![arxiv: v2 [cs.cv] 30 Mar 2016](/thumbs/86/94159476.jpg "arxiv: v2 [cs.cv] 30 Mar 2016") arxiv:1512.2325v2 [cs.cv] 3 Mar 216 SSD: Single Shot MultiBox Detector Wei Liu 1, Dragomir Anguelov 2, Dumitru Erhan 3, Christian Szegedy 3, Scott Reed 4, Cheng-Yang Fu 1, Alexander C. Berg 1 1 UNC Chapel
arxiv:1512.2325v2 [cs.cv] 3 Mar 216 SSD: Single Shot MultiBox Detector Wei Liu 1, Dragomir Anguelov 2, Dumitru Erhan 3, Christian Szegedy 3, Scott Reed 4, Cheng-Yang Fu 1, Alexander C. Berg 1 1 UNC Chapel
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Optimizing Object Detection:
 Lecture 10: Optimizing Object Detection: A Case Study of R-CNN, Fast R-CNN, and Faster R-CNN Visual Computing Systems Today s task: object detection Image classification: what is the object in this image?
Lecture 10: Optimizing Object Detection: A Case Study of R-CNN, Fast R-CNN, and Faster R-CNN Visual Computing Systems Today s task: object detection Image classification: what is the object in this image?
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
arxiv: v1 [cs.cv] 23 Apr 2015
![arxiv: v1 [cs.cv] 23 Apr 2015](/thumbs/76/74245586.jpg "arxiv: v1 [cs.cv] 23 Apr 2015") Object Detection Networks on Convolutional Feature Maps Shaoqing Ren Kaiming He Ross Girshick Xiangyu Zhang Jian Sun Microsoft Research {v-shren, kahe, rbg, v-xiangz, jiansun}@microsoft.com arxiv:1504.06066v1
Object Detection Networks on Convolutional Feature Maps Shaoqing Ren Kaiming He Ross Girshick Xiangyu Zhang Jian Sun Microsoft Research {v-shren, kahe, rbg, v-xiangz, jiansun}@microsoft.com arxiv:1504.06066v1
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
arxiv: v2 [cs.cv] 23 Jan 2019
![arxiv: v2 [cs.cv] 23 Jan 2019](/thumbs/88/114974572.jpg "arxiv: v2 [cs.cv] 23 Jan 2019") COCO AP Consistent Optimization for Single-Shot Object Detection Tao Kong 1 Fuchun Sun 1 Huaping Liu 1 Yuning Jiang 2 Jianbo Shi 3 1 Department of Computer Science and Technology, Tsinghua University,
COCO AP Consistent Optimization for Single-Shot Object Detection Tao Kong 1 Fuchun Sun 1 Huaping Liu 1 Yuning Jiang 2 Jianbo Shi 3 1 Department of Computer Science and Technology, Tsinghua University,
Object Detection. TA : Young-geun Kim. Biostatistics Lab., Seoul National University. March-June, 2018
 Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
arxiv: v2 [cs.cv] 10 Apr 2017
![arxiv: v2 [cs.cv] 10 Apr 2017](/thumbs/80/82485703.jpg "arxiv: v2 [cs.cv] 10 Apr 2017") Fully Convolutional Instance-aware Semantic Segmentation Yi Li 1,2 Haozhi Qi 2 Jifeng Dai 2 Xiangyang Ji 1 Yichen Wei 2 1 Tsinghua University 2 Microsoft Research Asia {liyi14,xyji}@tsinghua.edu.cn, {v-haoq,jifdai,yichenw}@microsoft.com
Fully Convolutional Instance-aware Semantic Segmentation Yi Li 1,2 Haozhi Qi 2 Jifeng Dai 2 Xiangyang Ji 1 Yichen Wei 2 1 Tsinghua University 2 Microsoft Research Asia {liyi14,xyji}@tsinghua.edu.cn, {v-haoq,jifdai,yichenw}@microsoft.com
arxiv: v3 [cs.cv] 17 May 2018
![arxiv: v3 [cs.cv] 17 May 2018](/thumbs/79/79331767.jpg "arxiv: v3 [cs.cv] 17 May 2018") FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
FSSD: Feature Fusion Single Shot Multibox Detector Zuo-Xin Li Fu-Qiang Zhou Key Laboratory of Precision Opto-mechatronics Technology, Ministry of Education, Beihang University, Beijing 100191, China {lizuoxin,
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
ScratchDet: Exploring to Train Single-Shot Object Detectors from Scratch
 ScratchDet: Exploring to Train Single-Shot Object Detectors from Scratch Rui Zhu 1,4, Shifeng Zhang 3, Xiaobo Wang 1, Longyin Wen 2, Hailin Shi 1, Liefeng Bo 2, Tao Mei 1 1 JD AI Research, China. 2 JD
ScratchDet: Exploring to Train Single-Shot Object Detectors from Scratch Rui Zhu 1,4, Shifeng Zhang 3, Xiaobo Wang 1, Longyin Wen 2, Hailin Shi 1, Liefeng Bo 2, Tao Mei 1 1 JD AI Research, China. 2 JD
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
arxiv: v1 [cs.cv] 9 Aug 2017
![arxiv: v1 [cs.cv] 9 Aug 2017](/thumbs/78/78708739.jpg "arxiv: v1 [cs.cv] 9 Aug 2017") BlitzNet: A Real-Time Deep Network for Scene Understanding Nikita Dvornik Konstantin Shmelkov Julien Mairal Cordelia Schmid Inria arxiv:1708.02813v1 [cs.cv] 9 Aug 2017 Abstract Real-time scene understanding
BlitzNet: A Real-Time Deep Network for Scene Understanding Nikita Dvornik Konstantin Shmelkov Julien Mairal Cordelia Schmid Inria arxiv:1708.02813v1 [cs.cv] 9 Aug 2017 Abstract Real-time scene understanding
Adaptive Object Detection Using Adjacency and Zoom Prediction
 Adaptive Object Detection Using Adjacency and Zoom Prediction Yongxi Lu University of California, San Diego yol7@ucsd.edu Tara Javidi University of California, San Diego tjavidi@ucsd.edu Svetlana Lazebnik
Adaptive Object Detection Using Adjacency and Zoom Prediction Yongxi Lu University of California, San Diego yol7@ucsd.edu Tara Javidi University of California, San Diego tjavidi@ucsd.edu Svetlana Lazebnik
Parallel Feature Pyramid Network for Object Detection
 Parallel Feature Pyramid Network for Object Detection Seung-Wook Kim [0000 0002 6004 4086], Hyong-Keun Kook, Jee-Young Sun, Mun-Cheon Kang, and Sung-Jea Ko School of Electrical Engineering, Korea University,
Parallel Feature Pyramid Network for Object Detection Seung-Wook Kim [0000 0002 6004 4086], Hyong-Keun Kook, Jee-Young Sun, Mun-Cheon Kang, and Sung-Jea Ko School of Electrical Engineering, Korea University,
An algorithm for highway vehicle detection based on convolutional neural network
 Chen et al. EURASIP Journal on Image and Video Processing (2018) 2018:109 https://doi.org/10.1186/s13640-018-0350-2 EURASIP Journal on Image and Video Processing RESEARCH An algorithm for highway vehicle
Chen et al. EURASIP Journal on Image and Video Processing (2018) 2018:109 https://doi.org/10.1186/s13640-018-0350-2 EURASIP Journal on Image and Video Processing RESEARCH An algorithm for highway vehicle
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
arxiv: v2 [cs.cv] 23 Nov 2017
![arxiv: v2 [cs.cv] 23 Nov 2017](/thumbs/75/71682984.jpg "arxiv: v2 [cs.cv] 23 Nov 2017") Light-Head R-CNN: In Defense of Two-Stage Object Detector Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University, {lizm15@mails.tsinghua.edu.cn,
Light-Head R-CNN: In Defense of Two-Stage Object Detector Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University, {lizm15@mails.tsinghua.edu.cn,
arxiv: v2 [cs.cv] 13 Jun 2017
![arxiv: v2 [cs.cv] 13 Jun 2017](/thumbs/81/84244189.jpg "arxiv: v2 [cs.cv] 13 Jun 2017") Point Linking Network for Object Detection Xinggang Wang 1, Kaibing Chen 1, Zilong Huang 1, Cong Yao 2, Wenyu Liu 1 1 School of EIC, Huazhong University of Science and Technology, 2 Megvii Technology Inc.
Point Linking Network for Object Detection Xinggang Wang 1, Kaibing Chen 1, Zilong Huang 1, Cong Yao 2, Wenyu Liu 1 1 School of EIC, Huazhong University of Science and Technology, 2 Megvii Technology Inc.
An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b
 5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1
5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Fast Vehicle Detector for Autonomous Driving
 Fast Vehicle Detector for Autonomous Driving Che-Tsung Lin 1,2, Patrisia Sherryl Santoso 2, Shu-Ping Chen 1, Hung-Jin Lin 1, Shang-Hong Lai 1 1 Department of Computer Science, National Tsing Hua University,
Fast Vehicle Detector for Autonomous Driving Che-Tsung Lin 1,2, Patrisia Sherryl Santoso 2, Shu-Ping Chen 1, Hung-Jin Lin 1, Shang-Hong Lai 1 1 Department of Computer Science, National Tsing Hua University,
Industrial Technology Research Institute, Hsinchu, Taiwan, R.O.C ǂ
 Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
CS 1674: Intro to Computer Vision. Object Recognition. Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018
 CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
arxiv: v3 [cs.cv] 18 Oct 2017
![arxiv: v3 [cs.cv] 18 Oct 2017](/thumbs/75/72627087.jpg "arxiv: v3 [cs.cv] 18 Oct 2017") SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
SSH: Single Stage Headless Face Detector Mahyar Najibi* Pouya Samangouei* Rama Chellappa University of Maryland arxiv:78.3979v3 [cs.cv] 8 Oct 27 najibi@cs.umd.edu Larry S. Davis {pouya,rama,lsd}@umiacs.umd.edu
arxiv: v1 [cs.cv] 22 Mar 2018
![arxiv: v1 [cs.cv] 22 Mar 2018](/thumbs/89/99243655.jpg "arxiv: v1 [cs.cv] 22 Mar 2018") Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection Xiongwei Wu, Daoxin Zhang, Jianke Zhu, Steven C.H. Hoi School of Information Systems, Singapore Management University, Singapore
Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection Xiongwei Wu, Daoxin Zhang, Jianke Zhu, Steven C.H. Hoi School of Information Systems, Singapore Management University, Singapore
arxiv: v1 [cs.cv] 18 Nov 2017
![arxiv: v1 [cs.cv] 18 Nov 2017](/thumbs/71/65976358.jpg "arxiv: v1 [cs.cv] 18 Nov 2017") Single-Shot Refinement Neural Network for Object Detection Shifeng Zhang 1,2, Longyin Wen 3, Xiao Bian 3, Zhen Lei 1,2, Stan Z. Li 1,2 1 CBSR & NLPR, Institute of Automation, Chinese Academy of Sciences,
Single-Shot Refinement Neural Network for Object Detection Shifeng Zhang 1,2, Longyin Wen 3, Xiao Bian 3, Zhen Lei 1,2, Stan Z. Li 1,2 1 CBSR & NLPR, Institute of Automation, Chinese Academy of Sciences,
Towards Real-Time Automatic Number Plate. Detection: Dots in the Search Space
 Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Detection and Localization with Multi-scale Models
 Detection and Localization with Multi-scale Models Eshed Ohn-Bar and Mohan M. Trivedi Computer Vision and Robotics Research Laboratory University of California San Diego {eohnbar, mtrivedi}@ucsd.edu Abstract
Detection and Localization with Multi-scale Models Eshed Ohn-Bar and Mohan M. Trivedi Computer Vision and Robotics Research Laboratory University of California San Diego {eohnbar, mtrivedi}@ucsd.edu Abstract
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Defect Detection from UAV Images based on Region-Based CNNs
 Defect Detection from UAV Images based on Region-Based CNNs Meng Lan, Yipeng Zhang, Lefei Zhang, Bo Du School of Computer Science, Wuhan University, Wuhan, China {menglan, yp91, zhanglefei, remoteking}@whu.edu.cn
Defect Detection from UAV Images based on Region-Based CNNs Meng Lan, Yipeng Zhang, Lefei Zhang, Bo Du School of Computer Science, Wuhan University, Wuhan, China {menglan, yp91, zhanglefei, remoteking}@whu.edu.cn
arxiv: v2 [cs.cv] 19 Apr 2018
![arxiv: v2 [cs.cv] 19 Apr 2018](/thumbs/83/87325597.jpg "arxiv: v2 [cs.cv] 19 Apr 2018") arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
arxiv:1804.06215v2 [cs.cv] 19 Apr 2018 DetNet: A Backbone network for Object Detection Zeming Li 1, Chao Peng 2, Gang Yu 2, Xiangyu Zhang 2, Yangdong Deng 1, Jian Sun 2 1 School of Software, Tsinghua University,
arxiv: v1 [cs.cv] 26 May 2017
![arxiv: v1 [cs.cv] 26 May 2017](/thumbs/78/78157133.jpg "arxiv: v1 [cs.cv] 26 May 2017") arxiv:1705.09587v1 [cs.cv] 26 May 2017 J. JEONG, H. PARK AND N. KWAK: UNDER REVIEW IN BMVC 2017 1 Enhancement of SSD by concatenating feature maps for object detection Jisoo Jeong soo3553@snu.ac.kr Hyojin
arxiv:1705.09587v1 [cs.cv] 26 May 2017 J. JEONG, H. PARK AND N. KWAK: UNDER REVIEW IN BMVC 2017 1 Enhancement of SSD by concatenating feature maps for object detection Jisoo Jeong soo3553@snu.ac.kr Hyojin
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
arxiv: v1 [cs.cv] 14 Dec 2015
![arxiv: v1 [cs.cv] 14 Dec 2015](/thumbs/72/67245194.jpg "arxiv: v1 [cs.cv] 14 Dec 2015") Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com arxiv:1512.04412v1 [cs.cv] 14 Dec 2015 Abstract
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com arxiv:1512.04412v1 [cs.cv] 14 Dec 2015 Abstract
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
CAD: Scale Invariant Framework for Real-Time Object Detection
 CAD: Scale Invariant Framework for Real-Time Object Detection Huajun Zhou Zechao Li Chengcheng Ning Jinhui Tang School of Computer Science and Engineering Nanjing University of Science and Technology zechao.li@njust.edu.cn
CAD: Scale Invariant Framework for Real-Time Object Detection Huajun Zhou Zechao Li Chengcheng Ning Jinhui Tang School of Computer Science and Engineering Nanjing University of Science and Technology zechao.li@njust.edu.cn
FCHD: A fast and accurate head detector
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
Traffic Multiple Target Detection on YOLOv2
 Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Pixel Offset Regression (POR) for Single-shot Instance Segmentation
 for Single-shot Instance Segmentation") Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
CS6501: Deep Learning for Visual Recognition. Object Detection I: RCNN, Fast-RCNN, Faster-RCNN
 CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
You Only Look Once: Unified, Real-Time Object Detection
 You Only Look Once: Unified, Real-Time Object Detection Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi University of Washington, Allen Institute for AI, Facebook AI Research http://pjreddie.com/yolo/
You Only Look Once: Unified, Real-Time Object Detection Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi University of Washington, Allen Institute for AI, Facebook AI Research http://pjreddie.com/yolo/
arxiv: v2 [cs.cv] 24 Mar 2018
![arxiv: v2 [cs.cv] 24 Mar 2018](/thumbs/80/82184067.jpg "arxiv: v2 [cs.cv] 24 Mar 2018") 2018 IEEE Winter Conference on Applications of Computer Vision Context-Aware Single-Shot Detector Wei Xiang 2 Dong-Qing Zhang 1 Heather Yu 1 Vassilis Athitsos 2 1 Media Lab, Futurewei Technologies 2 University
2018 IEEE Winter Conference on Applications of Computer Vision Context-Aware Single-Shot Detector Wei Xiang 2 Dong-Qing Zhang 1 Heather Yu 1 Vassilis Athitsos 2 1 Media Lab, Futurewei Technologies 2 University
arxiv: v4 [cs.cv] 30 Nov 2016
![arxiv: v4 [cs.cv] 30 Nov 2016](/thumbs/71/65945911.jpg "arxiv: v4 [cs.cv] 30 Nov 2016") arxiv:1512.2325v4 [cs.cv] 3 Nov 216 SSD: Single Shot MultiBox Detector Wei Liu 1, Dragomir Anguelov 2, Dumitru Erhan 3, Christian Szegedy 3, Scott Reed 4, Cheng-Yang Fu 1, Alexander C. Berg 1 1 UNC Chapel
arxiv:1512.2325v4 [cs.cv] 3 Nov 216 SSD: Single Shot MultiBox Detector Wei Liu 1, Dragomir Anguelov 2, Dumitru Erhan 3, Christian Szegedy 3, Scott Reed 4, Cheng-Yang Fu 1, Alexander C. Berg 1 1 UNC Chapel
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention
 Ventral-Dorsal Neural Networks: Object Detection via Selective Attention Mohammad K. Ebrahimpour UC Merced mebrahimpour@ucmerced.edu Jiayun Li UCLA jiayunli@ucla.edu Yen-Yun Yu Ancestry.com yyu@ancestry.com
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention Mohammad K. Ebrahimpour UC Merced mebrahimpour@ucmerced.edu Jiayun Li UCLA jiayunli@ucla.edu Yen-Yun Yu Ancestry.com yyu@ancestry.com
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Project 3 Q&A. Jonathan Krause
 Project 3 Q&A Jonathan Krause 1 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations 2 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations
Project 3 Q&A Jonathan Krause 1 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations 2 Outline R-CNN Review Error metrics Code Overview Project 3 Report Project 3 Presentations
Mimicking Very Efficient Network for Object Detection
 Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
Hand Detection For Grab-and-Go Groceries
 Hand Detection For Grab-and-Go Groceries Xianlei Qiu Stanford University xianlei@stanford.edu Shuying Zhang Stanford University shuyingz@stanford.edu Abstract Hands detection system is a very critical
Hand Detection For Grab-and-Go Groceries Xianlei Qiu Stanford University xianlei@stanford.edu Shuying Zhang Stanford University shuyingz@stanford.edu Abstract Hands detection system is a very critical
DeepBox: Learning Objectness with Convolutional Networks
 DeepBox: Learning Objectness with Convolutional Networks Weicheng Kuo Bharath Hariharan Jitendra Malik University of California, Berkeley {wckuo, bharath2, malik}@eecs.berkeley.edu Abstract Existing object
DeepBox: Learning Objectness with Convolutional Networks Weicheng Kuo Bharath Hariharan Jitendra Malik University of California, Berkeley {wckuo, bharath2, malik}@eecs.berkeley.edu Abstract Existing object
R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS
 R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS JIFENG DAI YI LI KAIMING HE JIAN SUN MICROSOFT RESEARCH TSINGHUA UNIVERSITY MICROSOFT RESEARCH MICROSOFT RESEARCH SPEED/ACCURACY TRADE-OFFS
R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS JIFENG DAI YI LI KAIMING HE JIAN SUN MICROSOFT RESEARCH TSINGHUA UNIVERSITY MICROSOFT RESEARCH MICROSOFT RESEARCH SPEED/ACCURACY TRADE-OFFS
End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images
 remote sensing Article End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images Zhong Chen 1,2,3, Ting Zhang 1,2,3 and Chao Ouyang 1,2,3, * 1 School of Automation, Huazhong University
remote sensing Article End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images Zhong Chen 1,2,3, Ting Zhang 1,2,3 and Chao Ouyang 1,2,3, * 1 School of Automation, Huazhong University
arxiv: v1 [cs.cv] 11 Apr 2017
![arxiv: v1 [cs.cv] 11 Apr 2017](/thumbs/81/83129464.jpg "arxiv: v1 [cs.cv] 11 Apr 2017") A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection Xiaolong Wang Abhinav Shrivastava Abhinav Gupta The Robotics Institute, Carnegie Mellon University arxiv:1704.03414v1 [cs.cv] 11
A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection Xiaolong Wang Abhinav Shrivastava Abhinav Gupta The Robotics Institute, Carnegie Mellon University arxiv:1704.03414v1 [cs.cv] 11
WITH the recent advance [1] of deep convolutional neural
![WITH the recent advance [1] of deep convolutional neural](/thumbs/91/106774335.jpg "WITH the recent advance [1] of deep convolutional neural") 1 Action-Driven Object Detection with Top-Down Visual Attentions Donggeun Yoo, Student Member, IEEE, Sunggyun Park, Student Member, IEEE, Kyunghyun Paeng, Student Member, IEEE, Joon-Young Lee, Member,
1 Action-Driven Object Detection with Top-Down Visual Attentions Donggeun Yoo, Student Member, IEEE, Sunggyun Park, Student Member, IEEE, Kyunghyun Paeng, Student Member, IEEE, Joon-Young Lee, Member,