Lesson 3. Prof. Enza Messina
|
|
|
- Alvin Dickerson
- 6 years ago
- Views:
Transcription

1 Lesson 3 Prof. Enza Messina
2 Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical structure HIERARCHICAL ALGORITHMS Groups data with a sequence of nested partitions, either from singleton clusters to a cluster containing all elements, or viceversa DENSITY-BASED Divides the feature space in order to find dense areas separated by empty space GRID-BASED Based on a multiple-level granularity structure MODEL-BASED Based on a model hypothesis in which the clusters can fit
3 Hierarchical clustering is usually represented by a tree-like structure called dendrogram 45
4 The root node of the dendrogram represents the whole data set, each leaf node is regarded as a data point The intermediate nodes describe the extent to which the objects are proximal to each other The height of the dendrogram expresses the distance between each pair of data points or clusters, or a data point and a cluster. The clustering results can be obtained by cutting the dendrogram at different levels 46
5 There are two general approaches to hierarchical clustering: AGGLOMERATIVE APPROACH Starts from a set of singleton clusters (where each cluster contains a single element), and progressively aggregate them into bigger clusters until the desired number of cluster is reached or there is a single cluster containing all the elements. DIVISIVE APPROACH Starts from a single cluster containing all the elements, and progressively splits it into smaller clusters, until the desidered number of clusters is reached or there are only singleton clusters. 47
6 48
7 {Put every point in a cluster by itself. For i=1 to N-1 do{ let C 1 and C 2 be the most mergeable pair of clusters Create C 1,2 as parent of C 1 and C 2 } Example: For simplicity, we still use 1-dimensional objects. Numerical difference is used as the distance Objects: 1, 2, 5, 6,7 agglomerative clustering: find two closest objects and merge; => {1,2}, so we have now {1.5,5, 6,7}; => {1,2}, {5,6}, so {1.5, 5.5,7}; => {1,2}, {{5,6},7}
8 The merge of a pair of clusters or the formation of a new cluster is dependent on the definition of the distance function between two clusters Which proximity measure we use? 50
9 The merge of a pair of clusters or the formation of a new cluster is dependent on the definition of the distance function between two clusters Which proximity measure we use? Euclidean, Mahalanobis, Pearson, Cosine, etc. 50
10 The merge of a pair of clusters or the formation of a new cluster is dependent on the definition of the distance function between two clusters Which proximity measure we use? But. Euclidean, Mahalanobis, Pearson, Cosine, etc. Proximity measure can compute distance between two elements; how do we compute distance between two groups of elements? 50
11 The merge of a pair of clusters or the formation of a new cluster is dependent on the definition of the distance function between two clusters Which proximity measure we use? But. Euclidean, Mahalanobis, Pearson, Cosine, etc. Proximity measure can compute distance between two elements; how do we compute distance between two groups of elements? LINKAGE 50
12 Linkage defines how we measure the proximity of two groups of elements There are several choices of linkages: Single Linkage Complete Linkage Group Average Linkage Weighted Average Linkage Centroid Linkage Median Linkage 51

13 Single Linkage The distance between a pair of clusters is determined by the two closest objects to the different clusters 52
14 Single Linkage The distance between a pair of clusters is determined by the two closest objects to the different clusters When two clusters C i and C j are merged, the distance to a third cluster C l can be recomputed as: 53
15 Single Link Example
16 Single Link Example
17 Single Link Example
18 Single Link Example
19 Single Link Example
20 Single Link Example
21 Single Link Example
22 Single Link Example
23 Single Linkage Single linkage clustering tends to generate elongated clusters As a result, two clusters with quite different properties may be connected due to the existence of noise However, if the clusters are separated far from each other, the single linkage method works well 55

24 Complete Linkage This method uses the farthest distance of a pair of objects to define inter-cluster distance 56
25 Complete Linkage This method uses the farthest distance of a pair of objects to define inter-cluster distance When two clusters C i and C j are merged, the distance to a third cluster C l can be recomputed as: It is effective in uncovering small and compact clusters 57
26 Complete Link Example
27 Complete Link Example
28 Complete Link Example
29 Complete Link Example
30 Complete Link Example
31 Complete Link Example
32 Complete Link Example
33 Complete Link Example
34 Group Average Linkage This method is also known as the unweighted pair group method average (UPGMA) The distance between two clusters is defined as the average of the distance between all pairs of data points, each of which comes from a different group. When two clusters C i and C j are merged, the distance to a third cluster C l can be recomputed as: 59
35 Weighted Group Average Linkage This method is also known as the weighted pair group method average (WPGMA) 60
36 Weighted Group Average Linkage This method is also known as the weighted pair group method average (WPGMA) The distance between two clusters is defined as the average of the distance between all pairs of data points, each of which comes from a different group The difference is that the distances between the newly formed cluster and the rest are weighted based on the number of data points in each cluster 61
37 Weighted Group Average Linkage This method is also known as the weighted pair group method average (WPGMA) When two clusters C i and C j are merged, the distance to a third cluster C l can be recomputed as: 62
38 Centroid Linkage This method is also known as the unweighted pair group method centroid (UPGMC) The centroid is the mean of all points in a cluster 63
39 Centroid Linkage This method is also known as the unweighted pair group method centroid (UPGMC) When two clusters C i and C j are merged, the distance to a third cluster C l can be recomputed as: 64
40 Median Linkage Similar to the centroid linkage, except that equal weight is given to the clusters to be merged When two clusters C i and C j are merged, the distance to a third cluster C l can be recomputed as: 65

41 Single linkage, complete linkage, and average linkage consider all points of a pair of clusters when calculating their inter-cluster distance, so they are also called graph methods The others are called geometric methods because they use geometric centers to represent clusters and determine their distances Equivalence to graph theory If the dissimilarity matrix is defined as ìï D ij = í îï 1 if d(x i, x j ) < d 0 0 otherwise Both the single linkage method and the complete linkage method can be described on the basis of the threshold graph: Single linkage clustering is equivalent to seeking maximally connected sub-graphs (components), while complete linkage clustering corresponds to finding maximally complete subgraphs (cliques). 66
42 Example of agglomerative approach Try to cluster this dataset with single and complete linkage 67


43 Example Problem: clustering analysis with agglomerative algorithm data matrix Euclidean distance distance matrix 68


44 Example Merge two closest clusters (iteration 1) 69


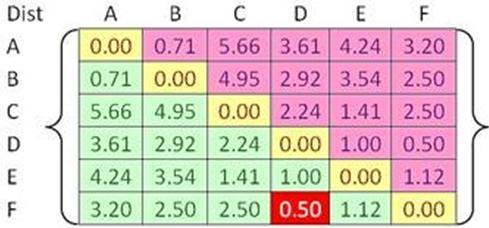
45 Example Update distance matrix (iteration 1) 70
 71")
46 Example Merge two closest clusters (iteration 2) 71
47 Example Update distance matrix (iteration 2) 72

48 Example Merge two closest clusters/update distance matrix (iteration 3) 73


49 Example Merge two closest clusters/update distance matrix (iteration 4) 74

50 Example Final result (meeting termination condition) 75
51 Example of agglomerative approach Try to cluster this dataset with single and complete linkage 77
52 Example of agglomerative approach 78
53 Combines HAC and K-Means clustering. First randomly take a sample of instances of size N Run group-average HAC on this sample, which takes only O(N) time. Use the results of HAC as initial seeds for K-means. Overall algorithm is O(N) and avoids problems of bad seed selection. Cut where You have k clusters Uses HAC to bootstrap K-means
54 Compared to agglomerative hierarchical clustering, divisive clustering proceeds in the opposite way. In the beginning, the entire data set belongs to a cluster, and a procedure successively divides it until all clusters are singletons. For a data set with N objects, a divisive hierarchical algorithm would start by considering possible divisions of the data into two nonempty subsets, which is computationally expensive even for small-scale data sets. Therefore, divisive clustering is not a common choice in practice. 80
55 However, the divisive clustering algorithms do provide clearer insights of the main structure of the data The larger clusters are generated at the early stage of the clustering process It is less likely to suffer from the accumulated erroneous decisions, which cannot be corrected by the successive process Given the computational burden of this approach, we rely on heuristic methods 81
56 DIANA (Divisive Analysis) considers only a part of all the possible divisions DIANA consists of a series of iterative steps in order to move the closer objects into the splinter group, which is seeded with the object that is farthest from the others in the cluster to be divided. The cluster with the largest diameter, defined as the largest distance between any pair of objects, is selected for further division 82

 For the remaining iterations, compute the")
57 Suppose that cluster C l is going to be split into clusters C i and C j : 1. Start with C i = C l and C j empty 2. For each data object x m in C i : a) For the first iteration, compute its average distance to all the other objects: b) For the remaining iterations, compute the difference between the average distance to C i and the average distance to C j : 83
58 3. Decide whether to move element x m to cluster C j or keep it in cluster C i : a) For the first iteration, move the object with the maximum value to C j (that is, the element farther from every other element is separated from the others) b) For the remaining iterations, if the maximum difference value is greater than zero, move the data object with the maximum difference into C j, then repeat steps 2b and 3b. If the maximum value is less than zero, stop. 84

59 During each division of DIANA, all features are used; hence the divisive algorithm is called polythetic On the other hand, if the division is on a one-feature-onestep basis, the corresponding algorithm is said to be monothetic. One such algorithm is called MONA (Monothetic Analysis) and is used for data objects with binary features The criterion for selecting a feature to divide the data is based on its similarity with other features, through measures of association. 87
60 Criticisms of classical hierarchical clustering algorithms: lack of robustness (sensitivity to noise and outliers) not capable of correcting possible previous misclassification computational complexity, which is at least O(N 2 ) 88
61 New clustering methods, with hierarchical cluster results, have appeared and have greatly improved the clustering performance. BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) (Zhang, et al., 1996) CURE (Clustering Using REpresentatives) (Guha et al., 1998) ROCK (RObust Clustering using links) (Guha et al., 2000) Chameleon (Karypis et al., 1999) 89
62 Designed for very large data sets Time and memory are limited Incremental and dynamic clustering of incoming objects Only one scan of data is necessary Does not need the whole data set in advance Two key phases: Scans the database to build an in-memory tree Applies clustering algorithm to cluster the leaf nodes 90

63 Given a cluster of instances, we define: Centroid: Radius: average distance from member points to centroid Diameter: average pair-wise distance within a cluster 91
64 centroid Euclidean distance: centroid Manhattan distance: average inter-cluster: average intra-cluster: variance increase: 92



65 centroid Euclidean distance: centroid Manhattan distance: average inter-cluster: average intra-cluster: variance increase: To calculate centroid, radius, diameter, D 0, D 1, D 2, D 3 and D 4, NOT ALL POINTS ARE NEEDED! 93
66 The Birch algorithm builds a dendrogram called clustering feature tree (CF tree) while scanning the data set. Each entry in the CF tree represents a cluster of objects and is characterized by a 3-tuple: (Ni, LSi, SSi), where Ni is the number of objects in the i-th cluster and LS i = N å i x i j =1 N å i j =1 SS i = x i 2 linear sum of the data points square sum of the data points 94
67 CF entry is more compact Stores significantly less than all of the data points in the sub-cluster A CF entry has sufficient information to calculate D0-D4 Additivity theorem allows us to merge sub-clusters incrementally & consistently 95
68 CF entry is more compact Stores significantly less than all of the data points in the sub-cluster A CF entry has sufficient information to calculate D0-D4 Additivity theorem allows us to merge sub-clusters incrementally & consistently 95
 (2,6) (4,5) (4,7) (3,8) 96 of")
69 Example: CF = (5, (16,30),(54,190)) (3,4) (2,6) (4,5) (4,7) (3,8) 96 of 28
70 Each non-leaf node has at most B entries Each leaf node has at most L CF entries, each of which satisfies threshold T Node size is determined by dimensionality of data space and input parameter P (page size) 97
71 Each non-leaf node has at most B entries Each leaf node has at most L CF entries, each of which satisfies threshold T Node size is determined by dimensionality of data space and input parameter P (page size) 97


72 Each non-leaf node has at most B entries Each leaf node has at most L CF entries, each of which satisfies threshold T Node size is determined by dimensionality of data space and input parameter P (page size) 97
73 The tree size is a function of T (the larger the T is, the smaller the tree is) We require a node to fit in a page of size of P B and L are determined by P (P can be varied for performance tuning ) Very compact representation of the dataset because each entry in a leaf node is not a single data point but a subcluster.
74 Phase 1: Scan dataset once, build a CF tree in memory Phase 2: (Optional) Condense the CF tree to a smaller CF tree Phase 3: Global Clustering Phase 4: (Optional) Clustering Refining (require scan of dataset)
75 100 May 2, 2014
76 CF of a data point (3,4) is (1,(3,4),25) Insert a point to the tree Find the path (based on D 0, D 1, D 2, D 3, D 4 between CF of children in a non-leaf node) Modify the leaf Find closest leaf node entry (based on D 0, D 1, D 2, D 3, D 4 of CF in leaf node) Check if it can absorb the new data point Modify the path to the leaf Splitting if leaf node is full, split into two leaf node, add one more entry in parent
77 Recurse down from root, find the appropriate leaf Follow the "closest"-cf path, w.r.t. D0 / / D4 Modify the leaf If the closest-cf leaf cannot absorb, make a new CF entry. If there is no room for new leaf, split the parent node Traverse back Updating CFs on the path or splitting nodes 102 May 2, 2014
78 Sum of CF(N,LS,SS) of all children Non-leaf node CF(N,LS,SS) under condition D<T or R<T Leaf node
79 If we run out of space, increase threshold T By increasing the threshold, CFs absorb more data Rebuilding "pushes" CFs over The larger T allows different CFs to group together Reducibility theorem Increasing T will result in a CF-tree smaller than the original Rebuilding needs at most h extra pages of memory
80 New subcluster sc1 sc8 sc3 sc4 sc5 sc6 sc7 sc2 LN2 LN3 LN1 LN1 Root LN2 LN3 sc8 sc1 sc2 sc3 sc4 sc5 sc6 sc7 105 May 2, 2014
81 If the branching factor of a leaf node can not exceed 3, then LN1 is split. sc1 sc8 sc3 sc4 sc5 sc6 sc7 LN1 sc2 LN2 LN3 LN1 LN1 Root LN1 LN2 LN3 sc8 sc1 sc2 sc3 sc4 sc5 sc6 sc7 106 May 2, 2014
82 If the branching factor of a non-leaf node can not exceed 3, then the root is split and the height of the CF Tree increases by one. sc1 sc8 sc3 sc4 sc5 sc6 sc7 sc2 LN1 LN2 LN3 LN1 NLN1 Root NLN2 LN1 LN1 LN2 LN3 sc8 sc1 sc2 sc3 sc4 sc5 sc6 sc7 107 May 2, 2014
83 Merge Operation in BIRCH Assume that the subclusters are numbered according to the order of formation sc6 sc5 sc3 root sc1 sc2 LN2 sc4 LN1 LN2 LN1 sc1 sc2 sc3 sc4 sc5 sc6 Vladimir Jelić 19 of 28
84 Merge Operation in BIRCH If the branching factor of a leaf node can not exceed 3, then LN2 is split sc3 sc6 sc5 sc4 root sc1 sc2 LN1 LN2 LN2 LN1 LN2 LN2 sc1 sc2 sc5 sc4 sc3 sc6 Vladimir Jelić (jelicvladimir5@gmail.com) 19 of 28
85 Merge Operation in BIRCH LN2 and LN1 will be merged, and the newly formed node wil be split immediately sc6 sc5 sc2 sc3 sc4 sc1 LN3 LN2 LN3 root LN3 LN3 LN2 sc2 sc1 sc5 sc4 sc3 sc6 Vladimir Jelić 19 of 28
86 Chose a larger T (threshold) Consider entries in leaf nodes Reinsert CF entries in the new tree If new path is before original path, move it to new path If new path is the same as original path, leave it unchanged
87 Consider CF entries in leaf nodes only Use centroid as the representative of a cluster Perform traditional clustering (e.g. agglomerative hierarchy (complete link == D 2 ) or K-mean or CL ) Cluster CF instead of data points
88 Require scan of dataset one more time Use clusters found in phase 3 as seeds Redistribute data points to their closest seeds and form new clusters Removal of outliers Acquisition of membership information
89 A CF tree is a height-balanced tree that stores the clustering features for a hierarchical clustering. Given a limited amount of main memory, BIRCH can minimize the time required for I/O. BIRCH is a scalable clustering algorithm with respect to the number of objects, and good quality of clustering of the data. A clustering algorithm taking consideration of I/O costs, memory limitation Utilize local information (each clustering decision is made without scanning all data points) Not every data point is equally important for clustering purpose
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Parallelization of Hierarchical Density-Based Clustering using MapReduce. Talat Iqbal Syed
 Parallelization of Hierarchical Density-Based Clustering using MapReduce by Talat Iqbal Syed A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science Department
Parallelization of Hierarchical Density-Based Clustering using MapReduce by Talat Iqbal Syed A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science Department
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Hierarchy. No or very little supervision Some heuristic quality guidances on the quality of the hierarchy. Jian Pei: CMPT 459/741 Clustering (2) 1
 1") Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
3. Cluster analysis Overview
 Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
3. Cluster analysis Overview
 Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Hierarchical Clustering Lecture 9
 Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Machine Learning: Symbol-based
 10d Machine Learning: Symbol-based More clustering examples 10.5 Knowledge and Learning 10.6 Unsupervised Learning 10.7 Reinforcement Learning 10.8 Epilogue and References 10.9 Exercises Additional references
10d Machine Learning: Symbol-based More clustering examples 10.5 Knowledge and Learning 10.6 Unsupervised Learning 10.7 Reinforcement Learning 10.8 Epilogue and References 10.9 Exercises Additional references
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Clustering (COSC 416) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Clustering in Ratemaking: Applications in Territories Clustering
 Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Clustering (COSC 488) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
4. Ad-hoc I: Hierarchical clustering
 4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 06 07 Department of CS - DM - UHD Road map Cluster Analysis: Basic
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 06 07 Department of CS - DM - UHD Road map Cluster Analysis: Basic
Clustering & Bootstrapping
 Clustering & Bootstrapping Jelena Prokić University of Groningen The Netherlands March 25, 2009 Groningen Overview What is clustering? Various clustering algorithms Bootstrapping Application in dialectometry
Clustering & Bootstrapping Jelena Prokić University of Groningen The Netherlands March 25, 2009 Groningen Overview What is clustering? Various clustering algorithms Bootstrapping Application in dialectometry
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Hierarchical clustering
 Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
Aprendizagem Automática Hierarchical clustering Ludwig Krippahl Hierarchical clustering Summary Hierarchical Clustering Agglomerative Clustering Divisive Clustering Clustering Features 1 Aprendizagem Automática
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Objective of clustering
 Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Lecture 10: Semantic Segmentation and Clustering
 Lecture 10: Semantic Segmentation and Clustering Vineet Kosaraju, Davy Ragland, Adrien Truong, Effie Nehoran, Maneekwan Toyungyernsub Department of Computer Science Stanford University Stanford, CA 94305
Lecture 10: Semantic Segmentation and Clustering Vineet Kosaraju, Davy Ragland, Adrien Truong, Effie Nehoran, Maneekwan Toyungyernsub Department of Computer Science Stanford University Stanford, CA 94305
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
Multivariate analyses in ecology. Cluster (part 2) Ordination (part 1 & 2)
 Ordination (part 1 & 2)") Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Community Detection. Community
 Community Detection Community In social sciences: Community is formed by individuals such that those within a group interact with each other more frequently than with those outside the group a.k.a. group,
Community Detection Community In social sciences: Community is formed by individuals such that those within a group interact with each other more frequently than with those outside the group a.k.a. group,
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
CSE494 Information Retrieval Project C Report
 CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Unsupervised: no target value to predict
 Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Clustering from Data Streams
 Clustering from Data Streams João Gama LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting
Clustering from Data Streams João Gama LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting
CHAPTER 4 K-MEANS AND UCAM CLUSTERING ALGORITHM
 CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
Hierarchical and Ensemble Clustering
 Hierarchical and Ensemble Clustering Ke Chen Reading: [7.8-7., EA], [25.5, KPM], [Fred & Jain, 25] COMP24 Machine Learning Outline Introduction Cluster Distance Measures Agglomerative Algorithm Example
Hierarchical and Ensemble Clustering Ke Chen Reading: [7.8-7., EA], [25.5, KPM], [Fred & Jain, 25] COMP24 Machine Learning Outline Introduction Cluster Distance Measures Agglomerative Algorithm Example
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
A Comparison of Document Clustering Techniques
 A Comparison of Document Clustering Techniques M. Steinbach, G. Karypis, V. Kumar Present by Leo Chen Feb-01 Leo Chen 1 Road Map Background & Motivation (2) Basic (6) Vector Space Model Cluster Quality
A Comparison of Document Clustering Techniques M. Steinbach, G. Karypis, V. Kumar Present by Leo Chen Feb-01 Leo Chen 1 Road Map Background & Motivation (2) Basic (6) Vector Space Model Cluster Quality
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Automatic Cluster Number Selection using a Split and Merge K-Means Approach
 Automatic Cluster Number Selection using a Split and Merge K-Means Approach Markus Muhr and Michael Granitzer 31st August 2009 The Know-Center is partner of Austria's Competence Center Program COMET. Agenda
Automatic Cluster Number Selection using a Split and Merge K-Means Approach Markus Muhr and Michael Granitzer 31st August 2009 The Know-Center is partner of Austria's Competence Center Program COMET. Agenda
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
TRANSACTIONAL CLUSTERING. Anna Monreale University of Pisa
 TRANSACTIONAL CLUSTERING Anna Monreale University of Pisa Clustering Clustering : Grouping of objects into different sets, or more precisely, the partitioning of a data set into subsets (clusters), so
TRANSACTIONAL CLUSTERING Anna Monreale University of Pisa Clustering Clustering : Grouping of objects into different sets, or more precisely, the partitioning of a data set into subsets (clusters), so
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY
 VISHAL BHARTI Computer Science Dept. GC, CUNY") Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY Clustering Algorithm Clustering is an unsupervised machine learning algorithm that divides a data into meaningful sub-groups,
Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY Clustering Algorithm Clustering is an unsupervised machine learning algorithm that divides a data into meaningful sub-groups,
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering