Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
|
|
|
- Deirdre Russell
- 5 years ago
- Views:
Transcription
1 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009
2 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer absolute depth? Learn the relationship between image features and absolute depth
 fine Dense depth map")
3 coarse Mean depth (Paper #1) Geometric stage (Paper #2) fine Dense depth map (Paper #3)
4 A. Torralba, A. Oliva., Depth estimation from image structure, PAMI, 24(9): 1-13, 2002 Goal: estimate absolute mean depth of a scene based on scene structure This paper inspired the invention of GIST feature

5 Scenes at different depths have different spatial structures Panoramic views: Uniform texture zones along horizontal layers Mid-range urban environments: Dominant long horizontal and vertical contours and square patterns Close-up views of objects: Large flat surfaces with no dominant orientation
6 Global spectral signature Defined as the amplitude spectrum of the entire image Man-made and natural scenes have disparate global spectral signatures

7 Specific examples: On average: Man-made Natural
8 Local spectral signature Defined as the magnitude of the output of Gabor wavelet filters Not only differs between man-made and natural scenes, but is spatially non-stationary as well

9
10 How do the global and local spectral signatures change with the mean depth of images? The answer to this question determines if it is feasible to estimate mean depth using those spectral signatures

11 Man-made

12 Natural
13 Typical behavior of spectral signatures An increase of global roughness w.r.t. depth for man-made structures A decrease of global roughness w.r.t. depth for natural structures Local spectral signature becomes increasingly nonstationary as depth gets large More biased towards horizontal and vertical orientations as depth increases
14 Global spectral signature Amplitude spectrum is defined on a continuous 2-D frequency space Discretize it by sampling at specific frequency magnitudes and orientations Approximated by summing the energy of wavelet coefficients over the entire image at specific scales and orientations Termed as global energy, which encodes dominant orientations and scales in the image
15 Global spectral signature (another variant) Wavelet coefficients at different scales and orientations are correlated Define the magnitude correlation Magnitude correlations encode degree of clutter of edges and shapes
16 Local spectral signature The original local spectral signature has the same spatial resolution as the image Downsample it to contain only pixels Termed as local energy, which encodes local scales and orientations
17 Dimension of global energy: Dimension of magnitude correlations: Dimension of local energy: Perform PCA to reduce the feature dimension to
18 Regress the mean depth on feature vector Need to approximate the regression function Take a generative approach: Given a feature vector, use Gaussian Bayes classifier to determine if the image belongs to man-made scene group or natural scene group
19 Given each scene group, model the joint distribution of and as a two-level hierarchical mixture of Gaussians where
20 Note that the mean of given and cluster is a linear function of, suggesting that the ML estimation of and is equivalent to LS linear regression
21 Use EM algorithm to learn the mixture model E-step M-step
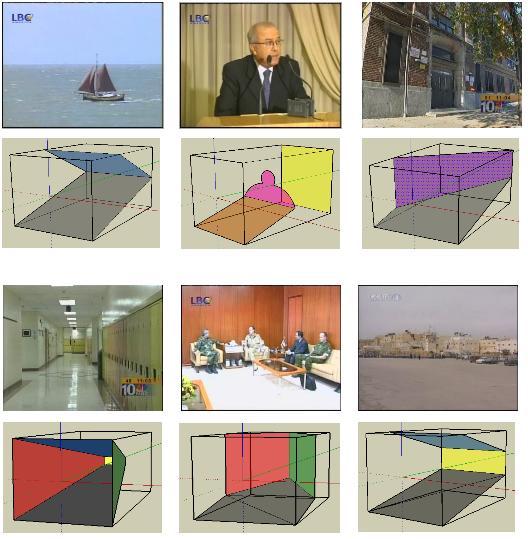
22 Having learned the model, The estimate of is given by a mixture of linear regressions The confidence of the estimate is given by
23 Ground truth generation Divide the entire training data set into man-made scene group and natural scene group Sort the images in each group according to their mean depths Humans estimate the mean depths of a portion of the images in each group Use a polynomial to fit the estimated mean depth as a function of the sorted rank

24 Using global energy features

25 Using local energy features
26 Comparison

27 Scene category recognition

28 Scale selection
29 V. Nedovic, A. W.M. Smeulders, A. Redert and J.M. Geusebroek, Depth Information by Stage Classification, ICCV, 2007 Goal: Estimate the geometric type of the global scene in an image
30 Instead of directly regressing absolute depth, it may be helpful to classify the image into relatively few 3D scene geometries (stages) first This type of scene information narrows down possible locations, scale, and identities of individual objects
31
32 Image gradient has different distributions as depth increases Makes it possible to use image gradient features to perform stage classification

33
34 Dataset Keyframes of the 2006 TRECVID video benchmark dataset Annotate 1241 TRECVID keyframes into one of the 15 stage categories For each category, half for training and half for testing
35 Evaluation Correct rate = true positives + true negatives total number of images For a class that occupies p% of the dataset, the correct rate of random guess is p/k + (1-p)(K-1)/K, where K is the total number of classes When p is small, this measure is overly optimistic
36 FN TN TP + TN TP + TN + FP + FN is pretty large! TP FP
37 Lower level of hierarchy 12 classes chance 86.42% 85.75% 84.42% 85.50% 82.71% 86.33% 87.08% 84.17% 82.71% 85.50% 80.75% 85.50% 84.74%
38 My experiments Stanford Range Image Dataset Classify 271 images into 8 stage categories For each stage, 2/3 used for training and 1/3 for testing
















39

40 Confusion matrix Overall accuracy = # all TP # all images Overall accuracy: 24.71% Recall % 40.00% 33.33% 18.18% 0.00% 26.32% 12.50% 0.00% Chance: 12.50%
41 Some misclassified examples should be classified as should be classified as
42 What if we use multi-scale features? For each image, I extracted features from 6 levels of the corresponding pyramid, and performed PCA to keep the feature dimension the same as in the paper (64) Result: the overall accuracy increases to 31.76%
43 What if we use Gist features? The Gist features also undergo PCA to keep its dimension to be 64 Still using multi-class SVM Result: the overall accuracy further increases to 40.00%

44 Confusion matrix Overall accuracy: 40.00% Recall Chance: 12.50% 28.57% 56.00% 66.67% 18.18% 22.22% 47.37% 37.50% 0.00%
45 What is we use replace multi-class SVM with simple k-nn? The accuracy turns out to be better! (42.35%) Fancy stuffs are not necessarily good
46 A. Saxena, S. H. Chung, A. Y. Ng, Learning Depth from Single Monocular Images, NIPS, 2005 Goal: recover absolute depth value for each small patch of a single monocular image
47 Texture intensity, edge directions and haze look different at different depths They can be extracted as cues to infer depth Inferring depth from the cues of an individual patch is not reliable Incorporate the cues of nearby patches Use MRF to enforce constraints
48 For each patch Apply a filter bank on the intensity channel to extract texture energy Apply a low-pass filter on the two color channels to capture haze. Apply another filter bank on the intensity channel to extract edge directions
49 The absolute and squared filter outputs are summed over all the pixels within the patch Each filter yields two values 17 filters in total Initial feature vector of dimension 34

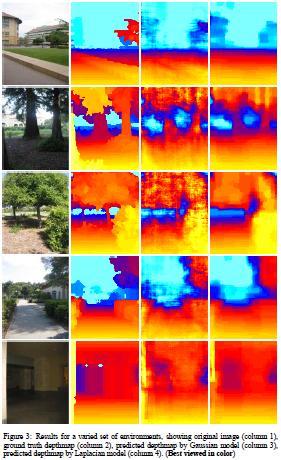
50 To incorporate contextual information Cues from the four immediate neighboring patches are included The process is repeated at three scales Cues from the column the patch lies in Final feature vector: 19*34=646 dimensional

51 These features are used to estimate how different the depths of two adjacent patches can be Measure the difference of the statistics of the two patches Uses the difference of the concatenated histograms of the 17 filter outputs 10 bins for each histogram, yielding a dimension of 170
52 The model Unary potential Linear predictor Uncertainty reflected by, which depends on the absolute depth feature of the patch Different rows have different model parameters (camera is mounted horizontally)
53 The model Pairwise potential Encourage smooth depth map Strength of smoothness constraint controlled by, which is determined by the appearance difference of neighboring patches (captured by relative depth feature) Different rows have different model parameters

54 The model Pairwise potential Multi-scale model At the smaller scale Appearance very different Allows for large discontinuity in depth At the larger scale Appearance similar Strong constraint on depth continuity
55 Learning parameters Unary parameters : linear least square problem, choose to fit the expected value of, s.t. Pairwise parameters, choose to fit the expected value of, s.t.
56 The model Replace square with absolute value Replace variance parameters with spread parameters Learning parameters Choose to minimize Fit to the expected value of Fit to the expected value of
57 Gaussian model The log-likelihood is quadratic in, the MAP estimate is found in closed form Laplacian model Use linear programming to find MAP estimate
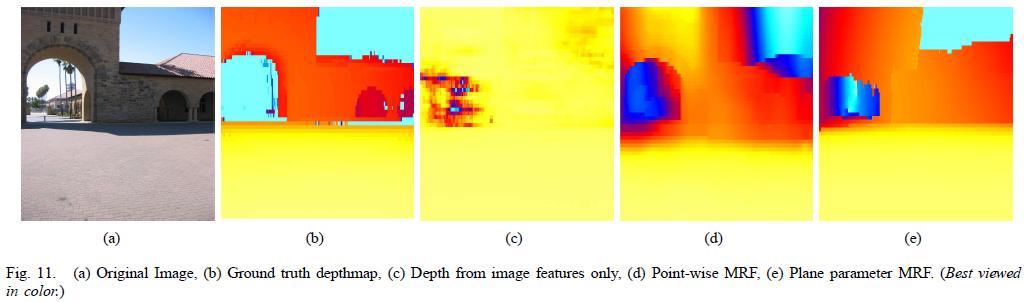
58 Ground truth depth maps collected using a 3D laser scanner 425 image+depthmap pairs 75% for training, 25% for testing Transform all the depths to a log scale before training
59 Multiscale and column features help a lot Pairwise terms further improves performance

60 Laplacian model outperforms Gaussian model empirically appears Laplacian Heavier tail more robust to outliers and errors Laplacian tends to model sharp transitions better
61
62 Not only do we want to estimate the depth map, but we want to infer the orientations of surfaces as well Follow-up paper: A. Saxena, M. Sun, A. Y. Ng, Make3D: Learning 3-D Scene Structure from a Single Still Image, PAMI, 2008
63 How to relate surface orientation with depth? Plane equation:, where represents both the 3D location and orientation of the surface : unit vector from the camera center to a point lying on the plane. This vector is known. The coordinate of the point is Therefore,
64 Modification of the model Replace image patches with superpixels For each superpixel, extract the features mentioned in the previous paper, plus shape and location features In unary potential, relative error is used is the confidence of the linear predictor, which is learned as another linear function of the superpixel features
65 Modification of the model In pairwise potential, a pair of surfaces is penalized for deviating from Being connected Being co-planar Being co-linear Strength of penalty is different under different conditions When there is evidence that two superpixels are separated by an occlusion boundary, the first two penalties are alleviated accordingly When there is evidence that two superpixels lie on a common straight long line, the third penalty is imposed accordingly

66 Quantitative comparison Spatial support is important Geometric constraints help, especially qualitatively
67 Qualitative comparison

68 More impressive results
69
Statistics of Natural Image Categories
 Statistics of Natural Image Categories Authors: Antonio Torralba and Aude Oliva Presented by: Sebastian Scherer Experiment Please estimate the average depth from the camera viewpoint to all locations(pixels)
Statistics of Natural Image Categories Authors: Antonio Torralba and Aude Oliva Presented by: Sebastian Scherer Experiment Please estimate the average depth from the camera viewpoint to all locations(pixels)
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE. Nan Hu. Stanford University Electrical Engineering
 STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
Schedule for Rest of Semester
 Schedule for Rest of Semester Date Lecture Topic 11/20 24 Texture 11/27 25 Review of Statistics & Linear Algebra, Eigenvectors 11/29 26 Eigenvector expansions, Pattern Recognition 12/4 27 Cameras & calibration
Schedule for Rest of Semester Date Lecture Topic 11/20 24 Texture 11/27 25 Review of Statistics & Linear Algebra, Eigenvectors 11/29 26 Eigenvector expansions, Pattern Recognition 12/4 27 Cameras & calibration
Mixture Models and EM
 Mixture Models and EM Goal: Introduction to probabilistic mixture models and the expectationmaximization (EM) algorithm. Motivation: simultaneous fitting of multiple model instances unsupervised clustering
Mixture Models and EM Goal: Introduction to probabilistic mixture models and the expectationmaximization (EM) algorithm. Motivation: simultaneous fitting of multiple model instances unsupervised clustering
EE795: Computer Vision and Intelligent Systems
 EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
Learning Depth from Single Monocular Images
 Learning Depth from Single Monocular Images Ashutosh Saxena, Sung H. Chung, and Andrew Y. Ng Computer Science Department Stanford University Stanford, CA 94305 asaxena@stanford.edu, {codedeft,ang}@cs.stanford.edu
Learning Depth from Single Monocular Images Ashutosh Saxena, Sung H. Chung, and Andrew Y. Ng Computer Science Department Stanford University Stanford, CA 94305 asaxena@stanford.edu, {codedeft,ang}@cs.stanford.edu
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model
 Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model Ido Ofir Computer Science Department Stanford University December 17, 2011 Abstract This project
Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model Ido Ofir Computer Science Department Stanford University December 17, 2011 Abstract This project
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Correcting User Guided Image Segmentation
 Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Correcting User Guided Image Segmentation Garrett Bernstein (gsb29) Karen Ho (ksh33) Advanced Machine Learning: CS 6780 Abstract We tackle the problem of segmenting an image into planes given user input.
Can Similar Scenes help Surface Layout Estimation?
 Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Can Similar Scenes help Surface Layout Estimation? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Robotics Institute, Carnegie Mellon University. {santosh,efros,hebert}@cs.cmu.edu Abstract We describe
Optimizing Monocular Cues for Depth Estimation from Indoor Images
 Optimizing Monocular Cues for Depth Estimation from Indoor Images Aditya Venkatraman 1, Sheetal Mahadik 2 1, 2 Department of Electronics and Telecommunication, ST Francis Institute of Technology, Mumbai,
Optimizing Monocular Cues for Depth Estimation from Indoor Images Aditya Venkatraman 1, Sheetal Mahadik 2 1, 2 Department of Electronics and Telecommunication, ST Francis Institute of Technology, Mumbai,
Learning to Reconstruct 3D from a Single Image
 Learning to Reconstruct 3D from a Single Image Mohammad Haris Baig Input Image Learning Based Learning + Constraints True Depth Prediction Contents 1- Problem Statement 2- Dataset 3- MRF Introduction 4-
Learning to Reconstruct 3D from a Single Image Mohammad Haris Baig Input Image Learning Based Learning + Constraints True Depth Prediction Contents 1- Problem Statement 2- Dataset 3- MRF Introduction 4-
Classification and Detection in Images. D.A. Forsyth
 Classification and Detection in Images D.A. Forsyth Classifying Images Motivating problems detecting explicit images classifying materials classifying scenes Strategy build appropriate image features train
Classification and Detection in Images D.A. Forsyth Classifying Images Motivating problems detecting explicit images classifying materials classifying scenes Strategy build appropriate image features train
Feature Descriptors. CS 510 Lecture #21 April 29 th, 2013
 Feature Descriptors CS 510 Lecture #21 April 29 th, 2013 Programming Assignment #4 Due two weeks from today Any questions? How is it going? Where are we? We have two umbrella schemes for object recognition
Feature Descriptors CS 510 Lecture #21 April 29 th, 2013 Programming Assignment #4 Due two weeks from today Any questions? How is it going? Where are we? We have two umbrella schemes for object recognition
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1, 2, Hongwei Qin 1,2, Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1. Dept. of Automation, Tsinghua University 2.
Robotics Programming Laboratory
 Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
ELEC Dr Reji Mathew Electrical Engineering UNSW
 ELEC 4622 Dr Reji Mathew Electrical Engineering UNSW Review of Motion Modelling and Estimation Introduction to Motion Modelling & Estimation Forward Motion Backward Motion Block Motion Estimation Motion
ELEC 4622 Dr Reji Mathew Electrical Engineering UNSW Review of Motion Modelling and Estimation Introduction to Motion Modelling & Estimation Forward Motion Backward Motion Block Motion Estimation Motion
Depth. Common Classification Tasks. Example: AlexNet. Another Example: Inception. Another Example: Inception. Depth
 Common Classification Tasks Recognition of individual objects/faces Analyze object-specific features (e.g., key points) Train with images from different viewing angles Recognition of object classes Analyze
Common Classification Tasks Recognition of individual objects/faces Analyze object-specific features (e.g., key points) Train with images from different viewing angles Recognition of object classes Analyze
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Texture. Frequency Descriptors. Frequency Descriptors. Frequency Descriptors. Frequency Descriptors. Frequency Descriptors
 Texture The most fundamental question is: How can we measure texture, i.e., how can we quantitatively distinguish between different textures? Of course it is not enough to look at the intensity of individual
Texture The most fundamental question is: How can we measure texture, i.e., how can we quantitatively distinguish between different textures? Of course it is not enough to look at the intensity of individual
Region-based Segmentation and Object Detection
 Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
Region-based Segmentation and Object Detection Stephen Gould Tianshi Gao Daphne Koller Presented at NIPS 2009 Discussion and Slides by Eric Wang April 23, 2010 Outline Introduction Model Overview Model
SuRVoS Workbench. Super-Region Volume Segmentation. Imanol Luengo
 SuRVoS Workbench Super-Region Volume Segmentation Imanol Luengo Index - The project - What is SuRVoS - SuRVoS Overview - What can it do - Overview of the internals - Current state & Limitations - Future
SuRVoS Workbench Super-Region Volume Segmentation Imanol Luengo Index - The project - What is SuRVoS - SuRVoS Overview - What can it do - Overview of the internals - Current state & Limitations - Future
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Chapter 3 Image Registration. Chapter 3 Image Registration
 Chapter 3 Image Registration Distributed Algorithms for Introduction (1) Definition: Image Registration Input: 2 images of the same scene but taken from different perspectives Goal: Identify transformation
Chapter 3 Image Registration Distributed Algorithms for Introduction (1) Definition: Image Registration Input: 2 images of the same scene but taken from different perspectives Goal: Identify transformation
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Markov Networks in Computer Vision
 Markov Networks in Computer Vision Sargur Srihari srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Some applications: 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
Markov Networks in Computer Vision Sargur Srihari srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Some applications: 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues
 2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
Global Probability of Boundary
 Global Probability of Boundary Learning to Detect Natural Image Boundaries Using Local Brightness, Color, and Texture Cues Martin, Fowlkes, Malik Using Contours to Detect and Localize Junctions in Natural
Global Probability of Boundary Learning to Detect Natural Image Boundaries Using Local Brightness, Color, and Texture Cues Martin, Fowlkes, Malik Using Contours to Detect and Localize Junctions in Natural
Context. CS 554 Computer Vision Pinar Duygulu Bilkent University. (Source:Antonio Torralba, James Hays)
") Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Context CS 554 Computer Vision Pinar Duygulu Bilkent University (Source:Antonio Torralba, James Hays) A computer vision goal Recognize many different objects under many viewing conditions in unconstrained
Dense Image-based Motion Estimation Algorithms & Optical Flow
 Dense mage-based Motion Estimation Algorithms & Optical Flow Video A video is a sequence of frames captured at different times The video data is a function of v time (t) v space (x,y) ntroduction to motion
Dense mage-based Motion Estimation Algorithms & Optical Flow Video A video is a sequence of frames captured at different times The video data is a function of v time (t) v space (x,y) ntroduction to motion
Markov Networks in Computer Vision. Sargur Srihari
 Markov Networks in Computer Vision Sargur srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Important application area for MNs 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
Markov Networks in Computer Vision Sargur srihari@cedar.buffalo.edu 1 Markov Networks for Computer Vision Important application area for MNs 1. Image segmentation 2. Removal of blur/noise 3. Stereo reconstruction
Multiple-Choice Questionnaire Group C
 Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
EE795: Computer Vision and Intelligent Systems
 EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 11 140311 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Motion Analysis Motivation Differential Motion Optical
EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 11 140311 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Motion Analysis Motivation Differential Motion Optical
Motion Tracking and Event Understanding in Video Sequences
 Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE
 OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
OCCLUSION BOUNDARIES ESTIMATION FROM A HIGH-RESOLUTION SAR IMAGE Wenju He, Marc Jäger, and Olaf Hellwich Berlin University of Technology FR3-1, Franklinstr. 28, 10587 Berlin, Germany {wenjuhe, jaeger,
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction
 Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Online structured learning for Obstacle avoidance
 Adarsh Kowdle Cornell University Zhaoyin Jia Cornell University apk64@cornell.edu zj32@cornell.edu Abstract Obstacle avoidance based on a monocular system has become a very interesting area in robotics
Adarsh Kowdle Cornell University Zhaoyin Jia Cornell University apk64@cornell.edu zj32@cornell.edu Abstract Obstacle avoidance based on a monocular system has become a very interesting area in robotics
DEPT: Depth Estimation by Parameter Transfer for Single Still Images
 DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
DEPT: Depth Estimation by Parameter Transfer for Single Still Images Xiu Li 1,2, Hongwei Qin 1,2(B), Yangang Wang 3, Yongbing Zhang 1,2, and Qionghai Dai 1 1 Department of Automation, Tsinghua University,
Supervised texture detection in images
 Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
Enabling a Robot to Open Doors Andrei Iancu, Ellen Klingbeil, Justin Pearson Stanford University - CS Fall 2007
 Enabling a Robot to Open Doors Andrei Iancu, Ellen Klingbeil, Justin Pearson Stanford University - CS 229 - Fall 2007 I. Introduction The area of robotic exploration is a field of growing interest and
Enabling a Robot to Open Doors Andrei Iancu, Ellen Klingbeil, Justin Pearson Stanford University - CS 229 - Fall 2007 I. Introduction The area of robotic exploration is a field of growing interest and
CS 4495 Computer Vision A. Bobick. CS 4495 Computer Vision. Features 2 SIFT descriptor. Aaron Bobick School of Interactive Computing
 CS 4495 Computer Vision Features 2 SIFT descriptor Aaron Bobick School of Interactive Computing Administrivia PS 3: Out due Oct 6 th. Features recap: Goal is to find corresponding locations in two images.
CS 4495 Computer Vision Features 2 SIFT descriptor Aaron Bobick School of Interactive Computing Administrivia PS 3: Out due Oct 6 th. Features recap: Goal is to find corresponding locations in two images.
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
WP1: Video Data Analysis
 Leading : UNICT Participant: UEDIN Fish4Knowledge Final Review Meeting - November 29, 2013 - Luxembourg Workpackage 1 Objectives Fish Detection: Background/foreground modeling algorithms able to deal with
Leading : UNICT Participant: UEDIN Fish4Knowledge Final Review Meeting - November 29, 2013 - Luxembourg Workpackage 1 Objectives Fish Detection: Background/foreground modeling algorithms able to deal with
BSB663 Image Processing Pinar Duygulu. Slides are adapted from Selim Aksoy
 BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
Markov Random Fields and Gibbs Sampling for Image Denoising
 Markov Random Fields and Gibbs Sampling for Image Denoising Chang Yue Electrical Engineering Stanford University changyue@stanfoed.edu Abstract This project applies Gibbs Sampling based on different Markov
Markov Random Fields and Gibbs Sampling for Image Denoising Chang Yue Electrical Engineering Stanford University changyue@stanfoed.edu Abstract This project applies Gibbs Sampling based on different Markov
Learning the Ecological Statistics of Perceptual Organization
 Learning the Ecological Statistics of Perceptual Organization Charless Fowlkes work with David Martin, Xiaofeng Ren and Jitendra Malik at University of California at Berkeley 1 How do ideas from perceptual
Learning the Ecological Statistics of Perceptual Organization Charless Fowlkes work with David Martin, Xiaofeng Ren and Jitendra Malik at University of California at Berkeley 1 How do ideas from perceptual
Chapter 9. Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Overview. Video. Overview 4/7/2008. Optical flow. Why estimate motion? Motion estimation: Optical flow. Motion Magnification Colorization.
 Overview Video Optical flow Motion Magnification Colorization Lecture 9 Optical flow Motion Magnification Colorization Overview Optical flow Combination of slides from Rick Szeliski, Steve Seitz, Alyosha
Overview Video Optical flow Motion Magnification Colorization Lecture 9 Optical flow Motion Magnification Colorization Overview Optical flow Combination of slides from Rick Szeliski, Steve Seitz, Alyosha
Image classification by a Two Dimensional Hidden Markov Model
 Image classification by a Two Dimensional Hidden Markov Model Author: Jia Li, Amir Najmi and Robert M. Gray Presenter: Tzung-Hsien Ho Hidden Markov Chain Goal: To implement a novel classifier for image
Image classification by a Two Dimensional Hidden Markov Model Author: Jia Li, Amir Najmi and Robert M. Gray Presenter: Tzung-Hsien Ho Hidden Markov Chain Goal: To implement a novel classifier for image
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi
 Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
CRFs for Image Classification
 CRFs for Image Classification Devi Parikh and Dhruv Batra Carnegie Mellon University Pittsburgh, PA 15213 {dparikh,dbatra}@ece.cmu.edu Abstract We use Conditional Random Fields (CRFs) to classify regions
CRFs for Image Classification Devi Parikh and Dhruv Batra Carnegie Mellon University Pittsburgh, PA 15213 {dparikh,dbatra}@ece.cmu.edu Abstract We use Conditional Random Fields (CRFs) to classify regions
Automatic Photo Popup
 Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS
 SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
Perceptual Grouping from Motion Cues Using Tensor Voting
 Perceptual Grouping from Motion Cues Using Tensor Voting 1. Research Team Project Leader: Graduate Students: Prof. Gérard Medioni, Computer Science Mircea Nicolescu, Changki Min 2. Statement of Project
Perceptual Grouping from Motion Cues Using Tensor Voting 1. Research Team Project Leader: Graduate Students: Prof. Gérard Medioni, Computer Science Mircea Nicolescu, Changki Min 2. Statement of Project
Visual localization using global visual features and vanishing points
 Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
Visual localization using global visual features and vanishing points Olivier Saurer, Friedrich Fraundorfer, and Marc Pollefeys Computer Vision and Geometry Group, ETH Zürich, Switzerland {saurero,fraundorfer,marc.pollefeys}@inf.ethz.ch
Stereo Vision. MAN-522 Computer Vision
 Stereo Vision MAN-522 Computer Vision What is the goal of stereo vision? The recovery of the 3D structure of a scene using two or more images of the 3D scene, each acquired from a different viewpoint in
Stereo Vision MAN-522 Computer Vision What is the goal of stereo vision? The recovery of the 3D structure of a scene using two or more images of the 3D scene, each acquired from a different viewpoint in
Revisiting Depth Layers from Occlusions
 Revisiting Depth Layers from Occlusions Adarsh Kowdle Cornell University apk64@cornell.edu Andrew Gallagher Cornell University acg226@cornell.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract
Revisiting Depth Layers from Occlusions Adarsh Kowdle Cornell University apk64@cornell.edu Andrew Gallagher Cornell University acg226@cornell.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract
Bus Detection and recognition for visually impaired people
 Bus Detection and recognition for visually impaired people Hangrong Pan, Chucai Yi, and Yingli Tian The City College of New York The Graduate Center The City University of New York MAP4VIP Outline Motivation
Bus Detection and recognition for visually impaired people Hangrong Pan, Chucai Yi, and Yingli Tian The City College of New York The Graduate Center The City University of New York MAP4VIP Outline Motivation
Lab 9. Julia Janicki. Introduction
 Lab 9 Julia Janicki Introduction My goal for this project is to map a general land cover in the area of Alexandria in Egypt using supervised classification, specifically the Maximum Likelihood and Support
Lab 9 Julia Janicki Introduction My goal for this project is to map a general land cover in the area of Alexandria in Egypt using supervised classification, specifically the Maximum Likelihood and Support
Local Image Features
 Local Image Features Computer Vision Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Flashed Face Distortion 2nd Place in the 8th Annual Best
Local Image Features Computer Vision Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Flashed Face Distortion 2nd Place in the 8th Annual Best
Range Imaging Through Triangulation. Range Imaging Through Triangulation. Range Imaging Through Triangulation. Range Imaging Through Triangulation
 Obviously, this is a very slow process and not suitable for dynamic scenes. To speed things up, we can use a laser that projects a vertical line of light onto the scene. This laser rotates around its vertical
Obviously, this is a very slow process and not suitable for dynamic scenes. To speed things up, we can use a laser that projects a vertical line of light onto the scene. This laser rotates around its vertical
Object recognition (part 2)
") Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
Object recognition (part 2) CSE P 576 Larry Zitnick (larryz@microsoft.com) 1 2 3 Support Vector Machines Modified from the slides by Dr. Andrew W. Moore http://www.cs.cmu.edu/~awm/tutorials Linear Classifiers
CS 664 Segmentation. Daniel Huttenlocher
 CS 664 Segmentation Daniel Huttenlocher Grouping Perceptual Organization Structural relationships between tokens Parallelism, symmetry, alignment Similarity of token properties Often strong psychophysical
CS 664 Segmentation Daniel Huttenlocher Grouping Perceptual Organization Structural relationships between tokens Parallelism, symmetry, alignment Similarity of token properties Often strong psychophysical
Viewpoint Invariant Features from Single Images Using 3D Geometry
 Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
Viewpoint Invariant Features from Single Images Using 3D Geometry Yanpeng Cao and John McDonald Department of Computer Science National University of Ireland, Maynooth, Ireland {y.cao,johnmcd}@cs.nuim.ie
Part III: Affinity Functions for Image Segmentation
 Part III: Affinity Functions for Image Segmentation Charless Fowlkes joint work with David Martin and Jitendra Malik at University of California at Berkeley 1 Q: What measurements should we use for constructing
Part III: Affinity Functions for Image Segmentation Charless Fowlkes joint work with David Martin and Jitendra Malik at University of California at Berkeley 1 Q: What measurements should we use for constructing
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
CSE 527: Introduction to Computer Vision
 CSE 527: Introduction to Computer Vision Week 5 - Class 1: Matching, Stitching, Registration September 26th, 2017 ??? Recap Today Feature Matching Image Alignment Panoramas HW2! Feature Matches Feature
CSE 527: Introduction to Computer Vision Week 5 - Class 1: Matching, Stitching, Registration September 26th, 2017 ??? Recap Today Feature Matching Image Alignment Panoramas HW2! Feature Matches Feature
Contents I IMAGE FORMATION 1
 Contents I IMAGE FORMATION 1 1 Geometric Camera Models 3 1.1 Image Formation............................. 4 1.1.1 Pinhole Perspective....................... 4 1.1.2 Weak Perspective.........................
Contents I IMAGE FORMATION 1 1 Geometric Camera Models 3 1.1 Image Formation............................. 4 1.1.1 Pinhole Perspective....................... 4 1.1.2 Weak Perspective.........................
CS 4495 Computer Vision Motion and Optic Flow
 CS 4495 Computer Vision Aaron Bobick School of Interactive Computing Administrivia PS4 is out, due Sunday Oct 27 th. All relevant lectures posted Details about Problem Set: You may *not* use built in Harris
CS 4495 Computer Vision Aaron Bobick School of Interactive Computing Administrivia PS4 is out, due Sunday Oct 27 th. All relevant lectures posted Details about Problem Set: You may *not* use built in Harris
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Motion and Tracking. Andrea Torsello DAIS Università Ca Foscari via Torino 155, Mestre (VE)
") Motion and Tracking Andrea Torsello DAIS Università Ca Foscari via Torino 155, 30172 Mestre (VE) Motion Segmentation Segment the video into multiple coherently moving objects Motion and Perceptual Organization
Motion and Tracking Andrea Torsello DAIS Università Ca Foscari via Torino 155, 30172 Mestre (VE) Motion Segmentation Segment the video into multiple coherently moving objects Motion and Perceptual Organization
Markov Random Fields and Segmentation with Graph Cuts
 Markov Random Fields and Segmentation with Graph Cuts Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project Proposal due Oct 27 (Thursday) HW 4 is out
Markov Random Fields and Segmentation with Graph Cuts Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project Proposal due Oct 27 (Thursday) HW 4 is out
Equation to LaTeX. Abhinav Rastogi, Sevy Harris. I. Introduction. Segmentation.
 Equation to LaTeX Abhinav Rastogi, Sevy Harris {arastogi,sharris5}@stanford.edu I. Introduction Copying equations from a pdf file to a LaTeX document can be time consuming because there is no easy way
Equation to LaTeX Abhinav Rastogi, Sevy Harris {arastogi,sharris5}@stanford.edu I. Introduction Copying equations from a pdf file to a LaTeX document can be time consuming because there is no easy way
Local Image Features
 Local Image Features Computer Vision CS 143, Brown Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial This section: correspondence and alignment
Local Image Features Computer Vision CS 143, Brown Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial This section: correspondence and alignment
Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation
 ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
ÖGAI Journal 24/1 11 Colour Segmentation-based Computation of Dense Optical Flow with Application to Video Object Segmentation Michael Bleyer, Margrit Gelautz, Christoph Rhemann Vienna University of Technology
Subpixel accurate refinement of disparity maps using stereo correspondences
 Subpixel accurate refinement of disparity maps using stereo correspondences Matthias Demant Lehrstuhl für Mustererkennung, Universität Freiburg Outline 1 Introduction and Overview 2 Refining the Cost Volume
Subpixel accurate refinement of disparity maps using stereo correspondences Matthias Demant Lehrstuhl für Mustererkennung, Universität Freiburg Outline 1 Introduction and Overview 2 Refining the Cost Volume
A MULTI-RESOLUTION APPROACH TO DEPTH FIELD ESTIMATION IN DENSE IMAGE ARRAYS F. Battisti, M. Brizzi, M. Carli, A. Neri
 A MULTI-RESOLUTION APPROACH TO DEPTH FIELD ESTIMATION IN DENSE IMAGE ARRAYS F. Battisti, M. Brizzi, M. Carli, A. Neri Università degli Studi Roma TRE, Roma, Italy 2 nd Workshop on Light Fields for Computer
A MULTI-RESOLUTION APPROACH TO DEPTH FIELD ESTIMATION IN DENSE IMAGE ARRAYS F. Battisti, M. Brizzi, M. Carli, A. Neri Università degli Studi Roma TRE, Roma, Italy 2 nd Workshop on Light Fields for Computer
Fast Edge Detection Using Structured Forests
 Fast Edge Detection Using Structured Forests Piotr Dollár, C. Lawrence Zitnick [1] Zhihao Li (zhihaol@andrew.cmu.edu) Computer Science Department Carnegie Mellon University Table of contents 1. Introduction
Fast Edge Detection Using Structured Forests Piotr Dollár, C. Lawrence Zitnick [1] Zhihao Li (zhihaol@andrew.cmu.edu) Computer Science Department Carnegie Mellon University Table of contents 1. Introduction
Classification of Protein Crystallization Imagery
 Classification of Protein Crystallization Imagery Xiaoqing Zhu, Shaohua Sun, Samuel Cheng Stanford University Marshall Bern Palo Alto Research Center September 2004, EMBC 04 Outline Background X-ray crystallography
Classification of Protein Crystallization Imagery Xiaoqing Zhu, Shaohua Sun, Samuel Cheng Stanford University Marshall Bern Palo Alto Research Center September 2004, EMBC 04 Outline Background X-ray crystallography
ECE 176 Digital Image Processing Handout #14 Pamela Cosman 4/29/05 TEXTURE ANALYSIS
 ECE 176 Digital Image Processing Handout #14 Pamela Cosman 4/29/ TEXTURE ANALYSIS Texture analysis is covered very briefly in Gonzalez and Woods, pages 66 671. This handout is intended to supplement that
ECE 176 Digital Image Processing Handout #14 Pamela Cosman 4/29/ TEXTURE ANALYSIS Texture analysis is covered very briefly in Gonzalez and Woods, pages 66 671. This handout is intended to supplement that
Multi-view Stereo. Ivo Boyadzhiev CS7670: September 13, 2011
 Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
Multi-view Stereo Ivo Boyadzhiev CS7670: September 13, 2011 What is stereo vision? Generic problem formulation: given several images of the same object or scene, compute a representation of its 3D shape
SIFT: SCALE INVARIANT FEATURE TRANSFORM SURF: SPEEDED UP ROBUST FEATURES BASHAR ALSADIK EOS DEPT. TOPMAP M13 3D GEOINFORMATION FROM IMAGES 2014
 SIFT: SCALE INVARIANT FEATURE TRANSFORM SURF: SPEEDED UP ROBUST FEATURES BASHAR ALSADIK EOS DEPT. TOPMAP M13 3D GEOINFORMATION FROM IMAGES 2014 SIFT SIFT: Scale Invariant Feature Transform; transform image
SIFT: SCALE INVARIANT FEATURE TRANSFORM SURF: SPEEDED UP ROBUST FEATURES BASHAR ALSADIK EOS DEPT. TOPMAP M13 3D GEOINFORMATION FROM IMAGES 2014 SIFT SIFT: Scale Invariant Feature Transform; transform image
EE795: Computer Vision and Intelligent Systems
 EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 10 130221 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Canny Edge Detector Hough Transform Feature-Based
EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 10 130221 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Canny Edge Detector Hough Transform Feature-Based
CORRELATION BASED CAR NUMBER PLATE EXTRACTION SYSTEM
 CORRELATION BASED CAR NUMBER PLATE EXTRACTION SYSTEM 1 PHYO THET KHIN, 2 LAI LAI WIN KYI 1,2 Department of Information Technology, Mandalay Technological University The Republic of the Union of Myanmar
CORRELATION BASED CAR NUMBER PLATE EXTRACTION SYSTEM 1 PHYO THET KHIN, 2 LAI LAI WIN KYI 1,2 Department of Information Technology, Mandalay Technological University The Republic of the Union of Myanmar
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Combining Monocular and Stereo Depth Cues
 Combining Monocular and Stereo Depth Cues Fraser Cameron December 16, 2005 Abstract A lot of work has been done extracting depth from image sequences, and relatively less has been done using only single
Combining Monocular and Stereo Depth Cues Fraser Cameron December 16, 2005 Abstract A lot of work has been done extracting depth from image sequences, and relatively less has been done using only single
Figure 1: Workflow of object-based classification
 Technical Specifications Object Analyst Object Analyst is an add-on package for Geomatica that provides tools for segmentation, classification, and feature extraction. Object Analyst includes an all-in-one
Technical Specifications Object Analyst Object Analyst is an add-on package for Geomatica that provides tools for segmentation, classification, and feature extraction. Object Analyst includes an all-in-one
Direct Methods in Visual Odometry
 Direct Methods in Visual Odometry July 24, 2017 Direct Methods in Visual Odometry July 24, 2017 1 / 47 Motivation for using Visual Odometry Wheel odometry is affected by wheel slip More accurate compared
Direct Methods in Visual Odometry July 24, 2017 Direct Methods in Visual Odometry July 24, 2017 1 / 47 Motivation for using Visual Odometry Wheel odometry is affected by wheel slip More accurate compared