Naïve Bayes Classification. Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
|
|
|
- Shawn Pope
- 5 years ago
- Views:
Transcription
1 Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
2 Things We d Like to Do Spam Classification Given an , predict whether it is spam or not Medical Diagnosis Given a list of symptoms, predict whether a patient has disease X or not Weather Based on temperature, humidity, etc predict if it will rain tomorrow
3 Bayesian Classification Problem statement: Given features X 1,X 2,,X n Predict a label Y

4 Another Application Digit Recognition Classifier 5 X 1,,X n {0,1} (Black vs. White pixels) Y {5,6} (predict whether a digit is a 5 or a 6)
5 The Bayes Classifier In class, we saw that a good strategy is to predict: (for example: what is the probability that the image represents a 5 given its pixels?) So How do we compute that?
6 The Bayes Classifier Use Bayes Rule! Likelihood Prior Normalization Constant Why did this help? Well, we think that we might be able to specify how features are generated by the class label
7 The Bayes Classifier Let s expand this for our digit recognition task: To classify, we ll simply compute these two probabilities and predict based on which one is greater
8 Model Parameters For the Bayes classifier, we need to learn two functions, the likelihood and the prior How many parameters are required to specify the prior for our digit recognition example?
9 Model Parameters How many parameters are required to specify the likelihood? (Supposing that each image is 30x30 pixels)?
10 Model Parameters The problem with explicitly modeling P(X 1,,X n Y) is that there are usually way too many parameters: We ll run out of space We ll run out of time And we ll need tons of training data (which is usually not available)
11 The Naïve Bayes Model The Naïve Bayes Assumption: Assume that all features are independent given the class label Y Equationally speaking: (We will discuss the validity of this assumption later)
12 Why is this useful? # of parameters for modeling P(X 1,,X n Y): 2(2 n -1) # of parameters for modeling P(X 1 Y),,P(X n Y) 2n


13 Naïve Bayes Training Now that we ve decided to use a Naïve Bayes classifier, we need to train it with some data: MNIST Training Data
 as the fraction of records with Y=v for which X i =u (This corresponds to Maximum Likelihood estimation of model")
14 Naïve Bayes Training Training in Naïve Bayes is easy: Estimate P(Y=v) as the fraction of records with Y=v Estimate P(X i =u Y=v) as the fraction of records with Y=v for which X i =u (This corresponds to Maximum Likelihood estimation of model parameters)
15 Naïve Bayes Training In practice, some of these counts can be zero Fix this by adding virtual counts: This is like putting a prior on parameters and doing MAP (Maximum a-posteriori) estimation instead of MLE (Maximum Liklihood Estimate) This is called Smoothing


16 Naïve Bayes Training For binary digits, training amounts to averaging all of the training fives together and all of the training sixes together.
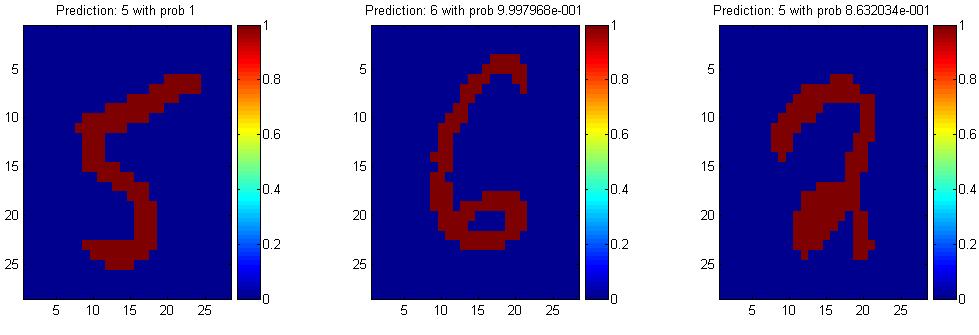
17 Naïve Bayes Classification
18 Another Example of the Naïve Bayes Classifier The weather data, with counts and probabilities outlook temperature humidity windy play yes no yes no yes no yes no yes no sunny 2 3 hot 2 2 high 3 4 false overcast 4 0 mild 4 2 normal 6 1 true 3 3 rainy 3 2 cool 3 1 sunny 2/9 3/5 hot 2/9 2/5 high 3/9 4/5 false 6/9 2/5 9/14 5/14 overcast 4/9 0/5 mild 4/9 2/5 normal 6/9 1/5 true 3/9 3/5 rainy 3/9 2/5 cool 3/9 1/5 A new day outlook temperature humidity windy play sunny cool high true?
19 Likelihood of yes Likelihood of no Therefore, the prediction is No
20 The Naive Bayes Classifier for Data Sets with Numerical Attribute Values One common practice to handle numerical attribute values is to assume normal distributions for numerical attributes.
21 The numeric weather data with summary statistics outlook temperature humidity windy play yes no yes no yes no yes no yes no sunny false overcast true 3 3 rainy sunny 2/9 3/5 mean mean false 6/9 2/5 9/14 5/14 overcast 4/9 0/5 std dev rainy 3/9 2/ std dev true 3/9 3/5
22 Let x 1, x 2,, x n be the values of a numerical attribute in the training data set ) ( w e w f x n x n n i i n i i
23 For examples, f temperature 66 Yes Likelihood of Yes = e Likelihood of No =
24 Outputting Probabilities What s nice about Naïve Bayes (and generative models in general) is that it returns probabilities These probabilities can tell us how confident the algorithm is So don t throw away those probabilities!

25 Performance on a Test Set Naïve Bayes is often a good choice if you don t have much training data!
26 Naïve Bayes Assumption Recall the Naïve Bayes assumption: that all features are independent given the class label Y Does this hold for the digit recognition problem?
27 Exclusive-OR Example For an example where conditional independence fails: Y=XOR(X 1,X 2 ) X 1 X 2 P(Y=0 X 1,X 2 ) P(Y=1 X 1,X 2 )
28 Actually, the Naïve Bayes assumption is almost never true Still Naïve Bayes often performs surprisingly well even when its assumptions do not hold
29 On naïve Bayesian classifier Advantages: Easy to implement Very efficient Good results obtained in many applications Disadvantages Assumption: class conditional independence, therefore loss of accuracy when the assumption is seriously violated (those highly correlated data sets) CS583, Bing Liu, UIC 29
30 Naïve Bayesian Classifier: Comments Advantages Easy to implement Good results obtained in most of the cases Disadvantages Assumption: class conditional independence, therefore loss of accuracy Practically, dependencies exist among variables E.g., hospitals: patients: Profile: age, family history etc Symptoms: fever, cough etc., Disease: lung cancer, diabetes etc Dependencies among these cannot be modeled by Naïve Bayesian Classifier How to deal with these dependencies? Bayesian Belief Networks
31 Numerical Stability It is often the case that machine learning algorithms need to work with very small numbers Imagine computing the probability of 2000 independent coin flips MATLAB thinks that (.5) 2000 =0
32 Underflow Prevention Multiplying lots of probabilities floating-point underflow. Recall: log(xy) = log(x) + log(y), better to sum logs of probabilities rather than multiplying probabilities.
33 Underflow Prevention Class with highest final un-normalized log probability score is still the most probable. c NB argmax c C j log P( c j ) log ipositions P( x i c j )
34 Numerical Stability Instead of comparing P(Y=5 X 1,,X n ) with P(Y=6 X 1,,X n ), Compare their logarithms
35 Recovering the Probabilities What if we want the probabilities though?? Suppose that for some constant K, we have: And How would we recover the original probabilities?


36 Recovering the Probabilities Given: Then for any constant C: One suggestion: set C such that the greatest i is shifted to zero:
37 Recap We defined a Bayes classifier but saw that it s intractable to compute P(X 1,,X n Y) We then used the Naïve Bayes assumption that everything is independent given the class label Y A natural question: is there some happy compromise where we only assume that some features are conditionally independent? Stay Tuned
38 Conclusions Naïve Bayes is: Really easy to implement and often works well Often a good first thing to try Commonly used as a punching bag for smarter algorithms
39 Evaluating classification algorithms You have designed a new classifier. You give it to me, and I try it on my image dataset
40 Evaluating classification algorithms I tell you that it achieved 95% accuracy on my data. Is your technique a success?
41 Types of errors But suppose that The 95% is the correctly classified pixels Only 5% of the pixels are actually edges It misses all the edge pixels How do we count the effect of different types of error?
42 Ground Truth Not Edge Edge Types of errors Edge Prediction Not edge True Positive False Positive False Negative True Negative
43 Two parts to each: whether you got it correct or not, and what you guessed. For example for a particular pixel, our guess might be labelled True Positive Did we get it correct? True, we did get it correct. What did we say? We said positive, i.e. edge. or maybe it was labelled as one of the others, maybe False Negative Did we get it correct? False, we did not get it correct. What did we say? We said negative, i.e. not edge.
44 Sensitivity and Specificity Count up the total number of each label (TP, FP, TN, FN) over a large dataset. In ROC analysis, we use two statistics: Sensitivity = TP TP+FN Can be thought of as the likelihood of spotting a positive case when presented with one. Or the proportion of edges we find. Specificity = TN TN+FP Can be thought of as the likelihood of spotting a negative case when presented with one. Or the proportion of non-edges that we find
45 Classifier Accuracy Measures C 1 C 2 C 1 True positive False negative C 2 False positive True negative classes buy_computer = yes buy_computer = no total recognition(%) buy_computer = yes buy_computer = no total Accuracy of a classifier M, acc(m): percentage of test set tuples that are correctly classified by the model M Error rate (misclassification rate) of M = 1 acc(m) Given m classes, CM i,j, an entry in a confusion matrix, indicates # of tuples in class i that are labeled by the classifier as class j Alternative accuracy measures (e.g., for cancer diagnosis) sensitivity = t-pos/pos /* true positive recognition rate */ specificity = t-neg/neg /* true negative recognition rate */ precision = t-pos/(t-pos + f-pos) accuracy = sensitivity * pos/(pos + neg) + specificity * neg/(pos + neg) This model can also be used for cost-benefit analysis
46 TP Sensitivity = =? TP+FN TN Specificity = =? TN+FP Ground Truth 1 0 Prediction = 90 cases in the dataset were class 1 (edge) = 100 cases in the dataset were class 0 (non-edge) = 190 examples (pixels) in the data overall
47 The ROC space 1.0 This is edge detector A This is edge detector B Sensitivity Note Specificity
48 The ROC Curve Draw a convex hull around many points: Sensitivity This point is not on the convex hull. 1 - Specificity
49 ROC Analysis All the optimal detectors lie on the convex hull. sensitivity Which of these is best depends on the ratio of edges to non-edges, and the different cost of misclassification 1 - specificity Any detector on this side can lead to a better detector by flipping its output. Take-home point : You should always quote sensitivity and specificity for your algorithm, if possible plotting an ROC graph. Remember also though, any statistic you quote should be an average over a suitable range of tests for your algorithm.
50 Predictor Error Measures Measure predictor accuracy: measure how far off the predicted value is from the actual known value Loss function: measures the error betw. y i and the predicted value y i Absolute error: y i y i Squared error: (y i y i ) 2 Test error (generalization error): the average loss over the test set Mean absolute error: Mean squared error: Relative absolute error: Relative squared error: The mean squared-error exaggerates the presence of outliers Popularly use (square) root mean-square error, similarly, root relative squared error d y y d i i i 1 ' d y y d i i i 1 2 ') ( d i i d i i i y y y y 1 1 ' d i i d i i i y y y y ) ( ') (
51 Evaluating the Accuracy of a Holdout method Classifier or Predictor (I) Given data is randomly partitioned into two independent sets Training set (e.g., 2/3) for model construction Test set (e.g., 1/3) for accuracy estimation Random sampling: a variation of holdout Repeat holdout k times, accuracy = avg. of the accuracies obtained Cross-validation (k-fold, where k = 10 is most popular) Randomly partition the data into k mutually exclusive subsets, each approximately equal size At i-th iteration, use D i as test set and others as training set Leave-one-out: k folds where k = # of tuples, for small sized data Stratified cross-validation: folds are stratified so that class dist. in each fold is approx. the same as that in the initial data
52 Holdout estimation What to do if the amount of data is limited? The holdout method reserves a certain amount for testing and uses the remainder for training Usually: one third for testing, the rest for training
53 Holdout estimation Problem: the samples might not be representative Example: class might be missing in the test data Advanced version uses stratification Ensures that each class is represented with approximately equal proportions in both subsets
54 Repeated holdout method Repeat process with different subsamples more reliable In each iteration, a certain proportion is randomly selected for training (possibly with stratificiation) The error rates on the different iterations are averaged to yield an overall error rate
55 Repeated holdout method Still not optimum: the different test sets overlap Can we prevent overlapping? Of course!
56 Cross-validation Cross-validation avoids overlapping test sets First step: split data into k subsets of equal size Second step: use each subset in turn for testing, the remainder for training Called k-fold cross-validation
57 Cross-validation Often the subsets are stratified before the crossvalidation is performed The error estimates are averaged to yield an overall error estimate
58 More on cross-validation Standard method for evaluation: stratified ten-fold cross-validation Why ten? Empirical evidence supports this as a good choice to get an accurate estimate There is also some theoretical evidence for this Stratification reduces the estimate s variance Even better: repeated stratified cross-validation E.g. ten-fold cross-validation is repeated ten times and results are averaged (reduces the variance)
59 Leave-One-Out cross-validation Leave-One-Out: a particular form of cross-validation: Set number of folds to number of training instances I.e., for n training instances, build classifier n times Makes best use of the data Involves no random subsampling Very computationally expensive (exception: NN)
60 Leave-One-Out-CV and stratification Disadvantage of Leave-One-Out-CV: stratification is not possible It guarantees a non-stratified sample because there is only one instance in the test set!
Naïve Bayes Classification. Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
 Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
ECLT 5810 Evaluation of Classification Quality
 ECLT 5810 Evaluation of Classification Quality Reference: Data Mining Practical Machine Learning Tools and Techniques, by I. Witten, E. Frank, and M. Hall, Morgan Kaufmann Testing and Error Error rate:
ECLT 5810 Evaluation of Classification Quality Reference: Data Mining Practical Machine Learning Tools and Techniques, by I. Witten, E. Frank, and M. Hall, Morgan Kaufmann Testing and Error Error rate:
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 08: Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu October 24, 2017 Learnt Prediction and Classification Methods Vector Data
CS145: INTRODUCTION TO DATA MINING 08: Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu October 24, 2017 Learnt Prediction and Classification Methods Vector Data
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
Machine Learning and Bioinformatics 機器學習與生物資訊學
 Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART V Credibility: Evaluating what s been learned 10/25/2000 2 Evaluation: the key to success How
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART V Credibility: Evaluating what s been learned 10/25/2000 2 Evaluation: the key to success How
Weka ( )
") Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
Naïve Bayes Slides are adapted from Sebastian Thrun (Udacity ), Ke Chen Jonathan Huang and H. Witten s and E. Frank s Data Mining and Jeremy Wyatt,
, Ke Chen Jonathan Huang and H. Witten s and E. Frank s Data Mining and Jeremy Wyatt,") Naïve Bayes Slides are adapted from Sebastian Thrun (Udaity ), Ke Chen Jonathan Huang and H. Witten s and E. Frank s Data Mining and Jeremy Wyatt, Bakground There are three methods to establish a lassifier
Naïve Bayes Slides are adapted from Sebastian Thrun (Udaity ), Ke Chen Jonathan Huang and H. Witten s and E. Frank s Data Mining and Jeremy Wyatt, Bakground There are three methods to establish a lassifier
Data Mining. Practical Machine Learning Tools and Techniques. Slides for Chapter 5 of Data Mining by I. H. Witten, E. Frank and M. A.
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 5 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Credibility: Evaluating what s been learned Issues: training, testing,
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 5 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Credibility: Evaluating what s been learned Issues: training, testing,
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
How do we obtain reliable estimates of performance measures?
 How do we obtain reliable estimates of performance measures? 1 Estimating Model Performance How do we estimate performance measures? Error on training data? Also called resubstitution error. Not a good
How do we obtain reliable estimates of performance measures? 1 Estimating Model Performance How do we estimate performance measures? Error on training data? Also called resubstitution error. Not a good
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
Evaluating Machine-Learning Methods. Goals for the lecture
 Evaluating Machine-Learning Methods Mark Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from
Evaluating Machine-Learning Methods Mark Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from
CS4491/CS 7265 BIG DATA ANALYTICS
 CS4491/CS 7265 BIG DATA ANALYTICS EVALUATION * Some contents are adapted from Dr. Hung Huang and Dr. Chengkai Li at UT Arlington Dr. Mingon Kang Computer Science, Kennesaw State University Evaluation for
CS4491/CS 7265 BIG DATA ANALYTICS EVALUATION * Some contents are adapted from Dr. Hung Huang and Dr. Chengkai Li at UT Arlington Dr. Mingon Kang Computer Science, Kennesaw State University Evaluation for
Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates?
 Model Evaluation Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates? Methods for Model Comparison How to
Model Evaluation Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates? Methods for Model Comparison How to
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Classification Advanced Reading: Chapter 8.4 & 8.5 Han, Chapters 4.5 & 4.6 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei. Data
CS570: Introduction to Data Mining Classification Advanced Reading: Chapter 8.4 & 8.5 Han, Chapters 4.5 & 4.6 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei. Data
Predictive Analysis: Evaluation and Experimentation. Heejun Kim
 Predictive Analysis: Evaluation and Experimentation Heejun Kim June 19, 2018 Evaluation and Experimentation Evaluation Metrics Cross-Validation Significance Tests Evaluation Predictive analysis: training
Predictive Analysis: Evaluation and Experimentation Heejun Kim June 19, 2018 Evaluation and Experimentation Evaluation Metrics Cross-Validation Significance Tests Evaluation Predictive analysis: training
Evaluating Machine Learning Methods: Part 1
 Evaluating Machine Learning Methods: Part 1 CS 760@UW-Madison Goals for the lecture you should understand the following concepts bias of an estimator learning curves stratified sampling cross validation
Evaluating Machine Learning Methods: Part 1 CS 760@UW-Madison Goals for the lecture you should understand the following concepts bias of an estimator learning curves stratified sampling cross validation
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 20: 10/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 20: 10/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis
 Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis CHAPTER 3 BEST FIRST AND GREEDY SEARCH BASED CFS AND NAÏVE BAYES ALGORITHMS FOR HEPATITIS DIAGNOSIS 3.1 Introduction
Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis CHAPTER 3 BEST FIRST AND GREEDY SEARCH BASED CFS AND NAÏVE BAYES ALGORITHMS FOR HEPATITIS DIAGNOSIS 3.1 Introduction
Evaluating Classifiers
 Evaluating Classifiers Charles Elkan elkan@cs.ucsd.edu January 18, 2011 In a real-world application of supervised learning, we have a training set of examples with labels, and a test set of examples with
Evaluating Classifiers Charles Elkan elkan@cs.ucsd.edu January 18, 2011 In a real-world application of supervised learning, we have a training set of examples with labels, and a test set of examples with
List of Exercises: Data Mining 1 December 12th, 2015
 List of Exercises: Data Mining 1 December 12th, 2015 1. We trained a model on a two-class balanced dataset using five-fold cross validation. One person calculated the performance of the classifier by measuring
List of Exercises: Data Mining 1 December 12th, 2015 1. We trained a model on a two-class balanced dataset using five-fold cross validation. One person calculated the performance of the classifier by measuring
Data Mining Algorithms: Basic Methods
 Algorithms: The basic methods Inferring rudimentary rules Data Mining Algorithms: Basic Methods Chapter 4 of Data Mining Statistical modeling Constructing decision trees Constructing rules Association
Algorithms: The basic methods Inferring rudimentary rules Data Mining Algorithms: Basic Methods Chapter 4 of Data Mining Statistical modeling Constructing decision trees Constructing rules Association
Classification with Decision Tree Induction
 Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Probabilistic Classifiers DWML, /27
 Probabilistic Classifiers DWML, 2007 1/27 Probabilistic Classifiers Conditional class probabilities Id. Savings Assets Income Credit risk 1 Medium High 75 Good 2 Low Low 50 Bad 3 High Medium 25 Bad 4 Medium
Probabilistic Classifiers DWML, 2007 1/27 Probabilistic Classifiers Conditional class probabilities Id. Savings Assets Income Credit risk 1 Medium High 75 Good 2 Low Low 50 Bad 3 High Medium 25 Bad 4 Medium
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
Regularization and model selection
 CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS
 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
Logistic Regression: Probabilistic Interpretation
 Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
Evaluation. Evaluate what? For really large amounts of data... A: Use a validation set.
 Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
INTRODUCTION TO DATA MINING. Daniel Rodríguez, University of Alcalá
 INTRODUCTION TO DATA MINING Daniel Rodríguez, University of Alcalá Outline Knowledge Discovery in Datasets Model Representation Types of models Supervised Unsupervised Evaluation (Acknowledgement: Jesús
INTRODUCTION TO DATA MINING Daniel Rodríguez, University of Alcalá Outline Knowledge Discovery in Datasets Model Representation Types of models Supervised Unsupervised Evaluation (Acknowledgement: Jesús
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
CPSC 340: Machine Learning and Data Mining. Probabilistic Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Classification Part 4
 Classification Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Model Evaluation Metrics for Performance Evaluation How to evaluate
Classification Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Model Evaluation Metrics for Performance Evaluation How to evaluate
CS 188: Artificial Intelligence Fall Machine Learning
 CS 188: Artificial Intelligence Fall 2007 Lecture 23: Naïve Bayes 11/15/2007 Dan Klein UC Berkeley Machine Learning Up till now: how to reason or make decisions using a model Machine learning: how to select
CS 188: Artificial Intelligence Fall 2007 Lecture 23: Naïve Bayes 11/15/2007 Dan Klein UC Berkeley Machine Learning Up till now: how to reason or make decisions using a model Machine learning: how to select
A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection (Kohavi, 1995)
") A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection (Kohavi, 1995) Department of Information, Operations and Management Sciences Stern School of Business, NYU padamopo@stern.nyu.edu
A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection (Kohavi, 1995) Department of Information, Operations and Management Sciences Stern School of Business, NYU padamopo@stern.nyu.edu
Evaluating Classifiers
 Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/11/16 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/11/16 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 20: Naïve Bayes 4/11/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein. W4 due right now Announcements P4 out, due Friday First contest competition
CS 188: Artificial Intelligence Spring 2011 Lecture 20: Naïve Bayes 4/11/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein. W4 due right now Announcements P4 out, due Friday First contest competition
Instance-Based Representations. k-nearest Neighbor. k-nearest Neighbor. k-nearest Neighbor. exemplars + distance measure. Challenges.
 Instance-Based Representations exemplars + distance measure Challenges. algorithm: IB1 classify based on majority class of k nearest neighbors learned structure is not explicitly represented choosing k
Instance-Based Representations exemplars + distance measure Challenges. algorithm: IB1 classify based on majority class of k nearest neighbors learned structure is not explicitly represented choosing k
CSCE 478/878 Lecture 6: Bayesian Learning and Graphical Models. Stephen Scott. Introduction. Outline. Bayes Theorem. Formulas
 ian ian ian Might have reasons (domain information) to favor some hypotheses/predictions over others a priori ian methods work with probabilities, and have two main roles: Optimal Naïve Nets (Adapted from
ian ian ian Might have reasons (domain information) to favor some hypotheses/predictions over others a priori ian methods work with probabilities, and have two main roles: Optimal Naïve Nets (Adapted from
Prediction. What is Prediction. Simple methods for Prediction. Classification by decision tree induction. Classification and regression evaluation
 Prediction Prediction What is Prediction Simple methods for Prediction Classification by decision tree induction Classification and regression evaluation 2 Prediction Goal: to predict the value of a given
Prediction Prediction What is Prediction Simple methods for Prediction Classification by decision tree induction Classification and regression evaluation 2 Prediction Goal: to predict the value of a given
Evaluating Classifiers
 Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
CS 584 Data Mining. Classification 3
 CS 584 Data Mining Classification 3 Today Model evaluation & related concepts Additional classifiers Naïve Bayes classifier Support Vector Machine Ensemble methods 2 Model Evaluation Metrics for Performance
CS 584 Data Mining Classification 3 Today Model evaluation & related concepts Additional classifiers Naïve Bayes classifier Support Vector Machine Ensemble methods 2 Model Evaluation Metrics for Performance
Artificial Intelligence Naïve Bayes
 Artificial Intelligence Naïve Bayes Instructors: David Suter and Qince Li Course Delivered @ Harbin Institute of Technology [M any slides adapted from those created by Dan Klein and Pieter Abbeel for CS188
Artificial Intelligence Naïve Bayes Instructors: David Suter and Qince Li Course Delivered @ Harbin Institute of Technology [M any slides adapted from those created by Dan Klein and Pieter Abbeel for CS188
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
CLASSIFICATION JELENA JOVANOVIĆ. Web:
 CLASSIFICATION JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is classification? Binary and multiclass classification Classification algorithms Naïve Bayes (NB) algorithm
CLASSIFICATION JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is classification? Binary and multiclass classification Classification algorithms Naïve Bayes (NB) algorithm
INTRODUCTION TO MACHINE LEARNING. Measuring model performance or error
 INTRODUCTION TO MACHINE LEARNING Measuring model performance or error Is our model any good? Context of task Accuracy Computation time Interpretability 3 types of tasks Classification Regression Clustering
INTRODUCTION TO MACHINE LEARNING Measuring model performance or error Is our model any good? Context of task Accuracy Computation time Interpretability 3 types of tasks Classification Regression Clustering
Data Mining and Knowledge Discovery Practice notes 2
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
DATA MINING LAB MANUAL
 DATA MINING LAB MANUAL Subtasks : 1. List all the categorical (or nominal) attributes and the real-valued attributes seperately. Attributes:- 1. checking_status 2. duration 3. credit history 4. purpose
DATA MINING LAB MANUAL Subtasks : 1. List all the categorical (or nominal) attributes and the real-valued attributes seperately. Attributes:- 1. checking_status 2. duration 3. credit history 4. purpose
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 21: ML: Naïve Bayes 11/10/2011 Dan Klein UC Berkeley Example: Spam Filter Input: email Output: spam/ham Setup: Get a large collection of example emails,
CS 188: Artificial Intelligence Fall 2011 Lecture 21: ML: Naïve Bayes 11/10/2011 Dan Klein UC Berkeley Example: Spam Filter Input: email Output: spam/ham Setup: Get a large collection of example emails,
Practical Data Mining COMP-321B. Tutorial 1: Introduction to the WEKA Explorer
 Practical Data Mining COMP-321B Tutorial 1: Introduction to the WEKA Explorer Gabi Schmidberger Mark Hall Richard Kirkby July 12, 2006 c 2006 University of Waikato 1 Setting up your Environment Before
Practical Data Mining COMP-321B Tutorial 1: Introduction to the WEKA Explorer Gabi Schmidberger Mark Hall Richard Kirkby July 12, 2006 c 2006 University of Waikato 1 Setting up your Environment Before
Evaluation Metrics. (Classifiers) CS229 Section Anand Avati
 CS229 Section Anand Avati") Evaluation Metrics (Classifiers) CS Section Anand Avati Topics Why? Binary classifiers Metrics Rank view Thresholding Confusion Matrix Point metrics: Accuracy, Precision, Recall / Sensitivity, Specificity,
Evaluation Metrics (Classifiers) CS Section Anand Avati Topics Why? Binary classifiers Metrics Rank view Thresholding Confusion Matrix Point metrics: Accuracy, Precision, Recall / Sensitivity, Specificity,
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 8.11.2017 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 8.11.2017 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
10 Classification: Evaluation
 CSE4334/5334 Data Mining 10 Classification: Evaluation Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2018 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
CSE4334/5334 Data Mining 10 Classification: Evaluation Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2018 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
Chapter 3: Supervised Learning
 Chapter 3: Supervised Learning Road Map Basic concepts Evaluation of classifiers Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Summary 2 An example
Chapter 3: Supervised Learning Road Map Basic concepts Evaluation of classifiers Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Summary 2 An example
CS 188: Artificial Intelligence Fall Announcements
 CS 188: Artificial Intelligence Fall 2006 Lecture 22: Naïve Bayes 11/14/2006 Dan Klein UC Berkeley Announcements Optional midterm On Tuesday 11/21 in class Review session 11/19, 7-9pm, in 306 Soda Projects
CS 188: Artificial Intelligence Fall 2006 Lecture 22: Naïve Bayes 11/14/2006 Dan Klein UC Berkeley Announcements Optional midterm On Tuesday 11/21 in class Review session 11/19, 7-9pm, in 306 Soda Projects
Announcements. CS 188: Artificial Intelligence Fall Machine Learning. Classification. Classification. Bayes Nets for Classification
 CS 88: Artificial Intelligence Fall 00 Lecture : Naïve Bayes //00 Announcements Optional midterm On Tuesday / in class Review session /9, 7-9pm, in 0 Soda Projects. due /. due /7 Dan Klein UC Berkeley
CS 88: Artificial Intelligence Fall 00 Lecture : Naïve Bayes //00 Announcements Optional midterm On Tuesday / in class Review session /9, 7-9pm, in 0 Soda Projects. due /. due /7 Dan Klein UC Berkeley
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
Partitioning Data. IRDS: Evaluation, Debugging, and Diagnostics. Cross-Validation. Cross-Validation for parameter tuning
 Partitioning Data IRDS: Evaluation, Debugging, and Diagnostics Charles Sutton University of Edinburgh Training Validation Test Training : Running learning algorithms Validation : Tuning parameters of learning
Partitioning Data IRDS: Evaluation, Debugging, and Diagnostics Charles Sutton University of Edinburgh Training Validation Test Training : Running learning algorithms Validation : Tuning parameters of learning
Data Mining Classification: Bayesian Decision Theory
 Data Mining Classification: Bayesian Decision Theory Lecture Notes for Chapter 2 R. O. Duda, P. E. Hart, and D. G. Stork, Pattern classification, 2nd ed. New York: Wiley, 2001. Lecture Notes for Chapter
Data Mining Classification: Bayesian Decision Theory Lecture Notes for Chapter 2 R. O. Duda, P. E. Hart, and D. G. Stork, Pattern classification, 2nd ed. New York: Wiley, 2001. Lecture Notes for Chapter
Pattern recognition (4)
") Pattern recognition (4) 1 Things we have discussed until now Statistical pattern recognition Building simple classifiers Supervised classification Minimum distance classifier Bayesian classifier (1D and
Pattern recognition (4) 1 Things we have discussed until now Statistical pattern recognition Building simple classifiers Supervised classification Minimum distance classifier Bayesian classifier (1D and
Representing structural patterns: Reading Material: Chapter 3 of the textbook by Witten
 Representing structural patterns: Plain Classification rules Decision Tree Rules with exceptions Relational solution Tree for Numerical Prediction Instance-based presentation Reading Material: Chapter
Representing structural patterns: Plain Classification rules Decision Tree Rules with exceptions Relational solution Tree for Numerical Prediction Instance-based presentation Reading Material: Chapter
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Introduction to Machine Learning Prof. Mr. Anirban Santara Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 Introduction to Machine Learning Prof. Mr. Anirban Santara Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 19 Python Exercise on Naive Bayes Hello everyone.
Introduction to Machine Learning Prof. Mr. Anirban Santara Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 19 Python Exercise on Naive Bayes Hello everyone.
Data Mining Practical Machine Learning Tools and Techniques
 Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 22: Naïve Bayes 11/18/2008 Dan Klein UC Berkeley 1 Machine Learning Up until now: how to reason in a model and how to make optimal decisions Machine learning:
CS 188: Artificial Intelligence Fall 2008 Lecture 22: Naïve Bayes 11/18/2008 Dan Klein UC Berkeley 1 Machine Learning Up until now: how to reason in a model and how to make optimal decisions Machine learning:
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
CSE Data Mining Concepts and Techniques STATISTICAL METHODS (REGRESSION) Professor- Anita Wasilewska. Team 13
 Professor- Anita Wasilewska. Team 13") CSE 634 - Data Mining Concepts and Techniques STATISTICAL METHODS Professor- Anita Wasilewska (REGRESSION) Team 13 Contents Linear Regression Logistic Regression Bias and Variance in Regression Model Fit
CSE 634 - Data Mining Concepts and Techniques STATISTICAL METHODS Professor- Anita Wasilewska (REGRESSION) Team 13 Contents Linear Regression Logistic Regression Bias and Variance in Regression Model Fit
Part 12: Advanced Topics in Collaborative Filtering. Francesco Ricci
 Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Part 12: Advanced Topics in Collaborative Filtering Francesco Ricci Content Generating recommendations in CF using frequency of ratings Role of neighborhood size Comparison of CF with association rules
Evaluation of different biological data and computational classification methods for use in protein interaction prediction.
 Evaluation of different biological data and computational classification methods for use in protein interaction prediction. Yanjun Qi, Ziv Bar-Joseph, Judith Klein-Seetharaman Protein 2006 Motivation Correctly
Evaluation of different biological data and computational classification methods for use in protein interaction prediction. Yanjun Qi, Ziv Bar-Joseph, Judith Klein-Seetharaman Protein 2006 Motivation Correctly
Machine Learning. Supervised Learning. Manfred Huber
 Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Nearest Neighbor Classification
 Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
The Explorer. chapter Getting started
 chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
chapter 10 The Explorer Weka s main graphical user interface, the Explorer, gives access to all its facilities using menu selection and form filling. It is illustrated in Figure 10.1. There are six different
Ensemble Methods, Decision Trees
 CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
Mining di Dati Web. Lezione 3 - Clustering and Classification
 Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
Data Mining. 3.5 Lazy Learners (Instance-Based Learners) Fall Instructor: Dr. Masoud Yaghini. Lazy Learners
 Fall Instructor: Dr. Masoud Yaghini. Lazy Learners") Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
A Critical Study of Selected Classification Algorithms for Liver Disease Diagnosis
 A Critical Study of Selected Classification s for Liver Disease Diagnosis Shapla Rani Ghosh 1, Sajjad Waheed (PhD) 2 1 MSc student (ICT), 2 Associate Professor (ICT) 1,2 Department of Information and Communication
A Critical Study of Selected Classification s for Liver Disease Diagnosis Shapla Rani Ghosh 1, Sajjad Waheed (PhD) 2 1 MSc student (ICT), 2 Associate Professor (ICT) 1,2 Department of Information and Communication
Variable Selection 6.783, Biomedical Decision Support
 6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation
 4 Model, Classification 4 Model, Regression 4 Representation") Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Data Mining: Classifier Evaluation. CSCI-B490 Seminar in Computer Science (Data Mining)
") Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
1 Machine Learning System Design
 Machine Learning System Design Prioritizing what to work on: Spam classification example Say you want to build a spam classifier Spam messages often have misspelled words We ll have a labeled training
Machine Learning System Design Prioritizing what to work on: Spam classification example Say you want to build a spam classifier Spam messages often have misspelled words We ll have a labeled training
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Universität Freiburg Lehrstuhl für Maschinelles Lernen und natürlichsprachliche Systeme. Machine Learning (SS2012)
") Universität Freiburg Lehrstuhl für Maschinelles Lernen und natürlichsprachliche Systeme Machine Learning (SS2012) Prof. Dr. M. Riedmiller, Manuel Blum Exercise Sheet 5 Exercise 5.1: Spam Detection Suppose
Universität Freiburg Lehrstuhl für Maschinelles Lernen und natürlichsprachliche Systeme Machine Learning (SS2012) Prof. Dr. M. Riedmiller, Manuel Blum Exercise Sheet 5 Exercise 5.1: Spam Detection Suppose
Probabilistic Learning Classification using Naïve Bayes
 Probabilistic Learning Classification using Naïve Bayes Weather forecasts are usually provided in terms such as 70 percent chance of rain. These forecasts are known as probabilities of precipitation reports.
Probabilistic Learning Classification using Naïve Bayes Weather forecasts are usually provided in terms such as 70 percent chance of rain. These forecasts are known as probabilities of precipitation reports.
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation. Lecture Notes for Chapter 4. Introduction to Data Mining
 Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 2017) Classification:
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Kumar (modified by Predrag Radivojac, 2017) Classification:
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Classification. Instructor: Wei Ding
 Classification Part II Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1 Practical Issues of Classification Underfitting and Overfitting Missing Values Costs of Classification
Classification Part II Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1 Practical Issues of Classification Underfitting and Overfitting Missing Values Costs of Classification
BITS F464: MACHINE LEARNING
 BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
Building Classifiers using Bayesian Networks
 Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Cross- Valida+on & ROC curve. Anna Helena Reali Costa PCS 5024
 Cross- Valida+on & ROC curve Anna Helena Reali Costa PCS 5024 Resampling Methods Involve repeatedly drawing samples from a training set and refibng a model on each sample. Used in model assessment (evalua+ng
Cross- Valida+on & ROC curve Anna Helena Reali Costa PCS 5024 Resampling Methods Involve repeatedly drawing samples from a training set and refibng a model on each sample. Used in model assessment (evalua+ng
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey