JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
|
|
|
- Nancy Perkins
- 5 years ago
- Views:
Transcription

1 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA
 @ NVIDIA, Oct-Dec 2016.")
2 ABOUT ME 5th year PhD student in Stanford by day, deep learning computer vision scientist by night. Intern with Deep Learning Applied Research (Autonomous NVIDIA, Oct-Dec
3 TALK OVERVIEW (1) Problem statement and summary. (2) Dataset and preliminaries. (3) Model motivation. (4) Results and visualizations. 3
4 TALK OVERVIEW (1) Problem statement and summary. (2) Dataset and preliminaries. (3) Model motivation. (4) Results and visualizations. 4
5 FROM SINGLE TO MULTITASK LEARNING Putting deep learning to work in the real world Detection Model... Object Bounding Boxes Segmentation Model... Segmentation Mask 5
6 FROM SINGLE TO MULTITASK LEARNING Putting deep learning to work in the real world Detection Model... Object Bounding Boxes Segmentation Model... Poor scalability + inefficient use of information! Segmentation Mask 6
7 FROM SINGLE TO MULTITASK LEARNING Putting deep learning to work in the real world How do we use one model to perform multiple tasks faster and better? Shared Model... Object Bounding Boxes Segmentation Mask 7
8 FROM SINGLE TO MULTITASK LEARNING Putting deep learning to work in the real world How do we use one model to perform multiple tasks faster and better? Shared Model... Object Bounding Boxes + edge detection, + surface normals, + distance estimation Segmentation Mask 8
9 FROM SINGLE TO MULTITASK LEARNING Putting deep learning to work in the real world How do we use one model to perform multiple tasks faster and better? Shared Model... Object Bounding Boxes Segmentation Mask How do you relate various tasks to each other in a multi-task neural network? 9
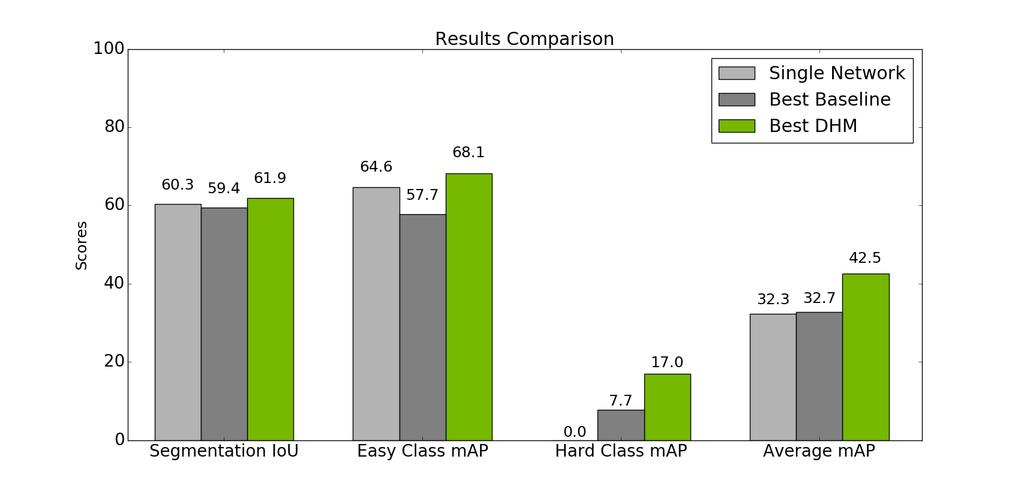
10 WHAT WE WILL SHOW By ordering tasks based on receptive field and information density, we improve segmentation and detection accuracy by ~2% and ~8% over single networks, respectively. The joint network is robust and easy to tune compared to non-hierarchical baselines. 10
11 TALK OVERVIEW (1) Problem statement and summary. (2) Dataset and preliminaries. (3) Model motivation. (4) Results and visualizations. 11
: the easy classes. Both segmentation, bounding box, and edge ground truth can be generated.")
12 CITYSCAPES DATASET 2975 Training resolution 1024 x classes for semantic segmentation, including 8 object classes. Of these 8, 4 are much more represented (car, bicycle, person, rider): the easy classes. Both segmentation, bounding box, and edge ground truth can be generated. Raw Image Semantic Seg. Edge Detection Bounding Box 12

13 HOW TO TRAIN A SEGMENTATION NETWORK Standard FCN (Shelhamer 2015) Architecture: Convolutions followed by a deconvolution to retrieve a pixel-dense prediction mask. 13

14 HOW TO TRAIN A DETECTION NETWORK Network outputs confidence that a pixel lies near the center of an object. Points of high confidence produce bounding box coordinates. Confidences are rougher than full segmentation but robust to occlusion. 14
15 TALK OVERVIEW (1) Problem statement and summary. (2) Dataset and preliminaries. (3) Model motivation. (4) Results and visualizations. 15
16 Input (1024 x 2048) Shared Feature Map (from base CNN) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv L = αl seg + (1- α)l det 16
17 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 17
18 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 18
19 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 19
20 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 20
21 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 21
22 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 22
23 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 23
24 OUR BASELINE MODEL PERFORMANCE Seg. Weight Det. Weight = α (α controls how much attention we pay to segmentation vs detection at training) 24
25 A LABEL HIERARCHY ALONG TWO AXES Required Receptive Field Object Bounding Boxes Density of Information 25
26 A LABEL HIERARCHY ALONG TWO AXES Required Receptive Field Object Bounding Boxes Object Confidence Density of Information 26
27 A LABEL HIERARCHY ALONG TWO AXES Required Receptive Field Object Bounding Boxes Object Confidence Semantic Segmentation Density of Information 27


28 A LABEL HIERARCHY ALONG TWO AXES Required Receptive Field Object Bounding Boxes Object Confidence Edge Detection (plus) Semantic Segmentation Density of Information 28
29 Input (1024 x 2048) Shared Feature Map (from base CNN) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv 29
30 Input (1024 x 2048) Shared Feature Map (from base CNN) Segmentation Obj. Confidence Obj. BBox Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv 30
31 Input (1024 x 2048) Shared Feature Map (from base CNN) Segmentation Obj. Confidence Obj. BBox Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv Decreasing information density 31
32 Input (1024 x 2048) Shared Feature Map (from base CNN) Edge Segmentation Obj. Confidence Obj. BBox Low-Res Edge Predictions (W x H x 3) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv Deconv Decreasing information density 32
33 Input (1024 x 2048) Shared Feature Map (from base CNN) Edge Segmentation Obj. Confidence Obj. BBox Low-Res Edge Predictions (W x H x 3) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv Deconv Decreasing information density 33
34 Input (1024 x 2048) Shared Feature Map (from base CNN) Edge Segmentation Obj. Confidence X Obj. BBox Low-Res Edge Predictions (W x H x 3) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv Deconv Decreasing information density 34
35 Input (1024 x 2048) Shared Feature Map (from base CNN) Edge Segmentation Obj. Confidence X Obj. BBox Low-Res Edge Predictions (W x H x 3) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Bbox Coordinate Positions Deconv Deconv Increasing receptive field 35
36 Input (1024 x 2048) Shared Feature Map (from base CNN) Edge Segmentation Obj. Confidence Obj. BBox Dilated Convs Low-Res Edge Predictions (W x H x 3) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Dilated Bbox Coordinate Positions Deconv Deconv Increasing receptive field 36
37 Input (1024 x 2048) Shared Feature Map (from base CNN) Edge Segmentation Obj. Confidence Obj. BBox Dilated Convs Low-Res Edge Predictions (W x H x 3) Low-Res Seg Predictions (W x H x 20) Obj. Confidence Positions Dilated Bbox Coordinate Positions Deconv Deconv Deep Hierarchical Network (DHM) 37
38 TALK OVERVIEW (1) Problem statement and summary. (2) Dataset and preliminaries. (3) Model motivation. (4) Results and visualizations. 38
39 RESULTS: HIGH ROBUSTNESS 39
40 RESULTS: HIGH ROBUSTNESS 40
41 41



42 RAW IMAGE Edge Predictions Bounding Box Predictions Segmentation Predictions 42
43 VISUALIZATIONS DETECTION SEGMENTAITION SINGLE NETWORK DHM (OURS) 43

44 VISUALIZATIONS SALIENCY (CAR) SEGMENTAITION SINGLE NETWORK DHM (OURS) 44
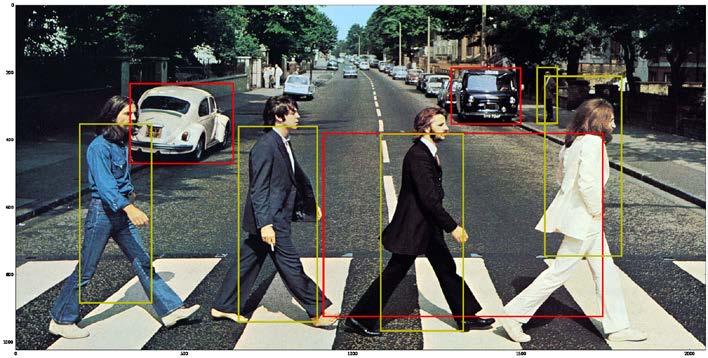
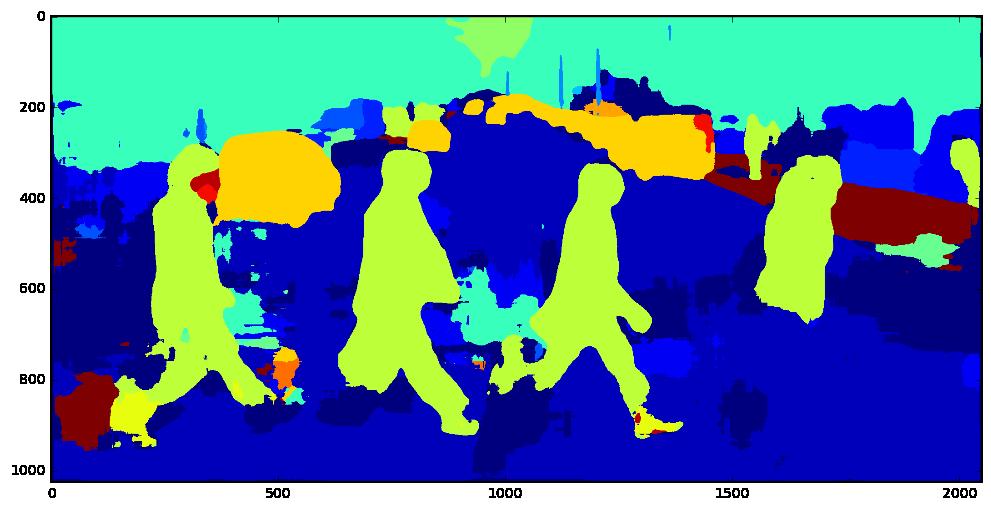
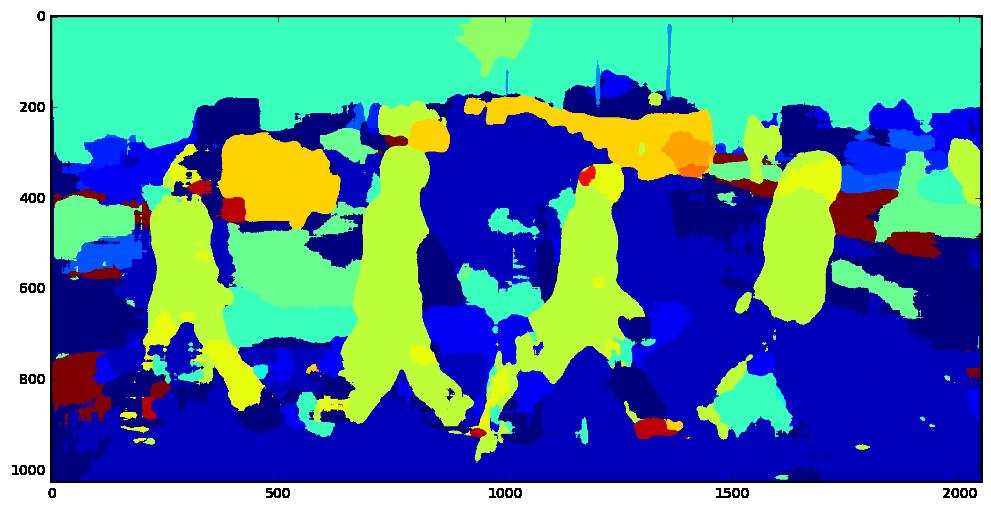
45 VISUALIZATIONS DETECTION SEGMENTAITION SINGLE NETWORK DHM (OURS) 45

46 VISUALIZATIONS DETECTION SEGMENTAITION SINGLE NETWORK DHM (OURS) 46

47 VISUALIZATIONS SALIENCY (BUS) SEGMENTAITION SINGLE NETWORK DHM (OURS) 47
48 VISUALIZATIONS DETECTION SEGMENTAITION SINGLE NETWORK DHM (OURS) 48



49 VISUALIZATIONS DETECTION SEGMENTAITION SINGLE NETWORK DHM (OURS) 49
50 VISUALIZATIONS DETECTION SEGMENTAITION SINGLE NETWORK DHM (OURS) 50
51 SUMMARY Our two hierarchies within our model allow our network to reason about intratask relationships: Information density: (Seg +) Edge > Seg > Object Conf > Bbox Receptive field: (Seg +) Edge = Bbox >> Object Conf > Seg With these relationships wired in, our network is: More accurate Robust to tuning Simultaneously better at fine detail and more instance aware Efficient and scalable (3 tasks, 1 network!) 51
52 REFERENCES J. Yao, S. Fidler, and R. Urtasun. Describing the scene as a whole: Joint object detection, scene classificationa and semantic segmentation. In CVPR, S. Gidaris and N. Komodakis. Object detection via a multiregion and semantic segmentation-aware cnn model. In ICCV, B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. Simultaneous detection and segmentation. In ECCV, S. Liu, X. Qi, J. Shi, H. Zhang, and J. Jia. Multi-scale patch aggregation (mpa) for simultaneous detection and segmentation. In CVPR, E. Shelhamer, J. Long, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and finegrained localization. In CVPR, J. Dai, K. He, and J. Sun. Instance-aware semantic segmentation via multi-task network cascades. In
53 THANK YOU! Special thanks to: My internship mentor: Jian Yao My managers: John Zedlewski and Andrew Tao All the wonderful people in DLAR/DLAV. Additional questions/comments: 53
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
arxiv: v2 [cs.cv] 18 Jul 2017
![arxiv: v2 [cs.cv] 18 Jul 2017](/thumbs/72/67294650.jpg "arxiv: v2 [cs.cv] 18 Jul 2017") PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
S7348: Deep Learning in Ford's Autonomous Vehicles. Bryan Goodman Argo AI 9 May 2017
 S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Joint Object Detection and Viewpoint Estimation using CNN features
 Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
Joint Object Detection and Viewpoint Estimation using CNN features Carlos Guindel, David Martín and José M. Armingol cguindel@ing.uc3m.es Intelligent Systems Laboratory Universidad Carlos III de Madrid
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Instance-aware Semantic Segmentation via Multi-task Network Cascades
 Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
arxiv: v1 [cs.cv] 1 Sep 2017
![arxiv: v1 [cs.cv] 1 Sep 2017](/thumbs/73/68939051.jpg "arxiv: v1 [cs.cv] 1 Sep 2017") Single Shot Text Detector with Regional Attention Pan He1, Weilin Huang2, 3, Tong He3, Qile Zhu1, Yu Qiao3, and Xiaolin Li1 arxiv:1709.00138v1 [cs.cv] 1 Sep 2017 1 National Science Foundation Center for
Single Shot Text Detector with Regional Attention Pan He1, Weilin Huang2, 3, Tong He3, Qile Zhu1, Yu Qiao3, and Xiaolin Li1 arxiv:1709.00138v1 [cs.cv] 1 Sep 2017 1 National Science Foundation Center for
Pixel Offset Regression (POR) for Single-shot Instance Segmentation
 for Single-shot Instance Segmentation") Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection
 MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection ILSVRC 2016 Object Detection from Video Byungjae Lee¹, Songguo Jin¹, Enkhbayar Erdenee¹, Mi Young Nam², Young Gui Jung², Phill Kyu
MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection ILSVRC 2016 Object Detection from Video Byungjae Lee¹, Songguo Jin¹, Enkhbayar Erdenee¹, Mi Young Nam², Young Gui Jung², Phill Kyu
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Learning to Generate Object Segmentation Proposals with Multi-modal Cues
 Learning to Generate Object Segmentation Proposals with Multi-modal Cues Haoyang Zhang 1,2, Xuming He 2,1, Fatih Porikli 1,2 1 The Australian National University, 2 Data61, CSIRO, Canberra, Australia {haoyang.zhang,xuming.he,
Learning to Generate Object Segmentation Proposals with Multi-modal Cues Haoyang Zhang 1,2, Xuming He 2,1, Fatih Porikli 1,2 1 The Australian National University, 2 Data61, CSIRO, Canberra, Australia {haoyang.zhang,xuming.he,
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
 Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Boundary-aware Instance Segmentation
 Boundary-aware Instance Segmentation Zeeshan Hayder,2, Xuming He 2, Australian National University & 2 Data6/CSIRO Mathieu Salzmann 3 3 CVLab, EPFL, Switzerland Abstract We address the problem of instance-level
Boundary-aware Instance Segmentation Zeeshan Hayder,2, Xuming He 2, Australian National University & 2 Data6/CSIRO Mathieu Salzmann 3 3 CVLab, EPFL, Switzerland Abstract We address the problem of instance-level
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Mask R-CNN. By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi
 Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
arxiv: v1 [cs.cv] 3 Apr 2016
![arxiv: v1 [cs.cv] 3 Apr 2016](/thumbs/77/76512524.jpg "arxiv: v1 [cs.cv] 3 Apr 2016") : Towards Accurate Region Proposal Generation and Joint Object Detection arxiv:64.6v [cs.cv] 3 Apr 26 Tao Kong Anbang Yao 2 Yurong Chen 2 Fuchun Sun State Key Lab. of Intelligent Technology and Systems
: Towards Accurate Region Proposal Generation and Joint Object Detection arxiv:64.6v [cs.cv] 3 Apr 26 Tao Kong Anbang Yao 2 Yurong Chen 2 Fuchun Sun State Key Lab. of Intelligent Technology and Systems
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
R-FCN: Object Detection with Really - Friggin Convolutional Networks
 R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
arxiv: v2 [cs.cv] 13 Mar 2019
![arxiv: v2 [cs.cv] 13 Mar 2019](/thumbs/94/121711710.jpg "arxiv: v2 [cs.cv] 13 Mar 2019") An End-to-End Network for Panoptic Segmentation Huanyu Liu 1, Chao Peng 2, Changqian Yu 3, Jingbo Wang 4, Xu Liu 5, Gang Yu 2, Wei Jiang 1 1 Zhejiang University, 2 Megvii Inc. (Face++), 3 Huazhong University
An End-to-End Network for Panoptic Segmentation Huanyu Liu 1, Chao Peng 2, Changqian Yu 3, Jingbo Wang 4, Xu Liu 5, Gang Yu 2, Wei Jiang 1 1 Zhejiang University, 2 Megvii Inc. (Face++), 3 Huazhong University
Pseudo Mask Augmented Object Detection
 Pseudo Mask Augmented Object Detection Xiangyun Zhao Northwestern University zhaoxiangyun915@gmail.com Shuang Liang Tongji University shuangliang@tongji.edu.cn Yichen Wei Microsoft Research yichenw@microsoft.com
Pseudo Mask Augmented Object Detection Xiangyun Zhao Northwestern University zhaoxiangyun915@gmail.com Shuang Liang Tongji University shuangliang@tongji.edu.cn Yichen Wei Microsoft Research yichenw@microsoft.com
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Internet of things that video
 Video recognition from a sentence Cees Snoek Intelligent Sensory Information Systems Lab University of Amsterdam The Netherlands Internet of things that video 45 billion cameras by 2022 [LDV Capital] 2
Video recognition from a sentence Cees Snoek Intelligent Sensory Information Systems Lab University of Amsterdam The Netherlands Internet of things that video 45 billion cameras by 2022 [LDV Capital] 2
Training models for road scene understanding with automated ground truth Dan Levi
 Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Pseudo Mask Augmented Object Detection
 Pseudo Mask Augmented Object Detection Xiangyun Zhao Northwestern University zhaoxiangyun915@gmail.com Shuang Liang Tongji University shuangliang@tongji.edu.cn Yichen Wei Microsoft Research yichenw@microsoft.com
Pseudo Mask Augmented Object Detection Xiangyun Zhao Northwestern University zhaoxiangyun915@gmail.com Shuang Liang Tongji University shuangliang@tongji.edu.cn Yichen Wei Microsoft Research yichenw@microsoft.com
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
SGN: Sequential Grouping Networks for Instance Segmentation
 SGN: Sequential Grouping Networks for Instance Segmentation Shu Liu Jiaya Jia,[ Sanja Fidler Raquel Urtasun, The Chinese University of Hong Kong [ Youtu Lab, Tencent Uber Advanced Technologies Group University
SGN: Sequential Grouping Networks for Instance Segmentation Shu Liu Jiaya Jia,[ Sanja Fidler Raquel Urtasun, The Chinese University of Hong Kong [ Youtu Lab, Tencent Uber Advanced Technologies Group University
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
arxiv: v1 [cs.cv] 14 Dec 2015
![arxiv: v1 [cs.cv] 14 Dec 2015](/thumbs/72/67245194.jpg "arxiv: v1 [cs.cv] 14 Dec 2015") Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com arxiv:1512.04412v1 [cs.cv] 14 Dec 2015 Abstract
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com arxiv:1512.04412v1 [cs.cv] 14 Dec 2015 Abstract
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Reversible Recursive Instance-level Object Segmentation
 Reversible Recursive Instance-level Object Segmentation Xiaodan Liang 1,3, Yunchao Wei 3, Xiaohui Shen 4, Zequn Jie 3, Jiashi Feng 3 Liang Lin 1, Shuicheng Yan 2,3 1 Sun Yat-sen University 2 360 AI Institute
Reversible Recursive Instance-level Object Segmentation Xiaodan Liang 1,3, Yunchao Wei 3, Xiaohui Shen 4, Zequn Jie 3, Jiashi Feng 3 Liang Lin 1, Shuicheng Yan 2,3 1 Sun Yat-sen University 2 360 AI Institute
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Deep Watershed Transform for Instance Segmentation
 Deep Watershed Transform for Instance Segmentation Min Bai Raquel Urtasun Department of Computer Science, University of Toronto {mbai, urtasun}@cs.toronto.edu Abstract Most contemporary approaches to instance
Deep Watershed Transform for Instance Segmentation Min Bai Raquel Urtasun Department of Computer Science, University of Toronto {mbai, urtasun}@cs.toronto.edu Abstract Most contemporary approaches to instance
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Illuminating Pedestrians via Simultaneous Detection & Segmentation
 Illuminating Pedestrians via Simultaneous Detection & Segmentation Garrick Brazil, Xi Yin, Xiaoming Liu Michigan State University, East Lansing, MI 48824 {brazilga, yinxi1, liuxm}@msu.edu Abstract Pedestrian
Illuminating Pedestrians via Simultaneous Detection & Segmentation Garrick Brazil, Xi Yin, Xiaoming Liu Michigan State University, East Lansing, MI 48824 {brazilga, yinxi1, liuxm}@msu.edu Abstract Pedestrian
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Mask R-CNN. Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018
 Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Dense Image Labeling Using Deep Convolutional Neural Networks
 Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
arxiv: v2 [cs.cv] 8 Apr 2018
![arxiv: v2 [cs.cv] 8 Apr 2018](/thumbs/86/94330536.jpg "arxiv: v2 [cs.cv] 8 Apr 2018") Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Scene Composition in Augmented Virtual Presenter System
 Scene Composition in Augmented Virtual Presenter System Ting-Xi Liu 1, Yao Lu 2, Li-Jing Zhang 3, Zi-Jian Wang 4 1 School of Computer Science, Beijing Institute of Technology, Beijing, China 2 School of
Scene Composition in Augmented Virtual Presenter System Ting-Xi Liu 1, Yao Lu 2, Li-Jing Zhang 3, Zi-Jian Wang 4 1 School of Computer Science, Beijing Institute of Technology, Beijing, China 2 School of
with Deep Learning A Review of Person Re-identification Xi Li College of Computer Science, Zhejiang University
 A Review of Person Re-identification with Deep Learning Xi Li College of Computer Science, Zhejiang University http://mypage.zju.edu.cn/xilics Email: xilizju@zju.edu.cn Person Re-identification Associate
A Review of Person Re-identification with Deep Learning Xi Li College of Computer Science, Zhejiang University http://mypage.zju.edu.cn/xilics Email: xilizju@zju.edu.cn Person Re-identification Associate
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL
 SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015
 CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
CS6501: Deep Learning for Visual Recognition. Object Detection I: RCNN, Fast-RCNN, Faster-RCNN
 CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
CS6501: Deep Learning for Visual Recognition Object Detection I: RCNN, Fast-RCNN, Faster-RCNN Today s Class Object Detection The RCNN Object Detector (2014) The Fast RCNN Object Detector (2015) The Faster
Supplementary Material: Unconstrained Salient Object Detection via Proposal Subset Optimization
 Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
arxiv: v1 [cs.cv] 9 Aug 2017
![arxiv: v1 [cs.cv] 9 Aug 2017](/thumbs/78/78708739.jpg "arxiv: v1 [cs.cv] 9 Aug 2017") BlitzNet: A Real-Time Deep Network for Scene Understanding Nikita Dvornik Konstantin Shmelkov Julien Mairal Cordelia Schmid Inria arxiv:1708.02813v1 [cs.cv] 9 Aug 2017 Abstract Real-time scene understanding
BlitzNet: A Real-Time Deep Network for Scene Understanding Nikita Dvornik Konstantin Shmelkov Julien Mairal Cordelia Schmid Inria arxiv:1708.02813v1 [cs.cv] 9 Aug 2017 Abstract Real-time scene understanding
3D Shape Segmentation with Projective Convolutional Networks
 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN:
 ISBN:") 2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5 Aircraft Detection in Remote Sensing Images via CNN Multi-scale Feature Representation
2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5 Aircraft Detection in Remote Sensing Images via CNN Multi-scale Feature Representation
Fast scene understanding and prediction for autonomous platforms. Bert De Brabandere, KU Leuven, October 2017
 Fast scene understanding and prediction for autonomous platforms Bert De Brabandere, KU Leuven, October 2017 Who am I? MSc in Electrical Engineering at KU Leuven, Belgium Last year PhD student with Luc
Fast scene understanding and prediction for autonomous platforms Bert De Brabandere, KU Leuven, October 2017 Who am I? MSc in Electrical Engineering at KU Leuven, Belgium Last year PhD student with Luc
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
(Deep) Learning for Robot Perception and Navigation. Wolfram Burgard
 Learning for Robot Perception and Navigation. Wolfram Burgard") (Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
(Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
CS 1674: Intro to Computer Vision. Object Recognition. Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018
 CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
EFFECTIVE OBJECT DETECTION FROM TRAFFIC CAMERA VIDEOS. Honghui Shi, Zhichao Liu*, Yuchen Fan, Xinchao Wang, Thomas Huang
 EFFECTIVE OBJECT DETECTION FROM TRAFFIC CAMERA VIDEOS Honghui Shi, Zhichao Liu*, Yuchen Fan, Xinchao Wang, Thomas Huang Image Formation and Processing (IFP) Group, University of Illinois at Urbana-Champaign
EFFECTIVE OBJECT DETECTION FROM TRAFFIC CAMERA VIDEOS Honghui Shi, Zhichao Liu*, Yuchen Fan, Xinchao Wang, Thomas Huang Image Formation and Processing (IFP) Group, University of Illinois at Urbana-Champaign
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
Semantic Soft Segmentation Supplementary Material
 Semantic Soft Segmentation Supplementary Material YAĞIZ AKSOY, MIT CSAIL and ETH Zürich TAE-HYUN OH, MIT CSAIL SYLVAIN PARIS, Adobe Research MARC POLLEFEYS, ETH Zürich and Microsoft WOJCIECH MATUSIK, MIT
Semantic Soft Segmentation Supplementary Material YAĞIZ AKSOY, MIT CSAIL and ETH Zürich TAE-HYUN OH, MIT CSAIL SYLVAIN PARIS, Adobe Research MARC POLLEFEYS, ETH Zürich and Microsoft WOJCIECH MATUSIK, MIT
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS. Mustafa Ozan Tezcan
 MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation. Deepak Pathak, Philipp Krähenbühl and Trevor Darrell
 Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in