3D Reconstruction of Human Motion Through Video
|
|
|
- Helen Parker
- 5 years ago
- Views:
Transcription
1 3D Reconstruction of Human Motion Through Video Thomas Keemon Advisor: Professor Hao Jiang 2010 Undergraduate Honors Thesis Computer Science Department, Boston College
2 2 Abstract In this thesis, we study computer vision methods to capture 3D human movements in videos. The goal is to extract high quality movement from general videos using minimum human interaction. With a few mouse clicks on the body joints in each video frame, all the possible 3D body configurations are automatically constructed and their likelihoods are quantified using a prior trained with millions of exemplars from the CMU motion capturing database. The 3D body movement is optimized using dynamic programming using the pose hypotheses and the temporal smoothness constraints. The proposed method can be used for unconstrained motion capturing and our experiments show that it is efficient and accurate. We further study two applications based on the proposed motion capturing method. The first one is to animate characters using the motion captured from videos. The second one is for sports performance analysis. With the 3D movement information, we can measure body part speed, coordination, and various other parameters.
3 3 Contents 1. Introduction Overview Single Frame Reconstruction Collecting User Input Generating All Possible Poses Finding the Most Likely Pose Multiple Frame Reconstruction Travel Cost Dynamic Programming Results Discussion Applications Related Work Future Work Acknowledgements References Other Resources

4 4 1. Introduction Human pose estimation and action recognition are two very large areas of research within the domain of computer vision. Humans possess an uncanny ability to both detect and recognize different human poses and forms of motion, however, training a computer to do the same thing is not such a trivial task. The first person to bring the study of human motion into a laboratory setting was Gunnar Johansson [8]. Johansson s experiments involved illuminating a number of key points on the human body as it performed different types of movements including walking, running, and dancing. The results of these experiments indicate that using just illuminated points was enough to evoke a strong impression of human motion. Essentially, Johansson discovered that the collection of moving points resulted in a special response from the brain that gave structure to the entire system. Figure 1. The collection of 15 seemingly random dots in the image on the left in fact represent a human pose. The image on the right connects the dots in a meaningful way, similar to how Johansson s experiments gave structure to seemingly random patterns of dots. Images taken from BML Walker [14].
5 5 If the brain possesses this special method for recognizing biological motion, why has a computer not been used to replicate it? The answer is because the underlying mechanism for the system is not completely understood. The brain itself can be looked at as a black box. Experiments can be run on a human subject where the visual stimulus sent to the brain is controlled and the resulting subject response can be observed, however, the actual steps in the neural pathway responsible for transforming the input to the output response remain unknown. Because a computer makes such a poor human brain, problem solving that utilizes a computer often relies on computationally intensive approaches. From this sort of computational standpoint, the human body can be though of as a tree structure. With this kind of depiction, it is easy to see how the extremities are related back to the torso (the root) and how the movement and range of motion of the extremities are constrained by the intermediate joints (the intermediate nodes). Research in the area of human pose estimation has been approached from many different angles in an attempt to make a robust and accurate system. There are two parts to the problem of human pose estimation. The first is finding a pose in an image. A couple of approaches to this problem include using background subtraction, template matching [5] or detecting motion in a video sequence. The second part of the problem involves mathematically describing the pose. This has been done with both tree and non-tree [7] structures. The same two problems exist in the area of human action recognition. Detecting action can take the form of detecting movement in sequential frames, finding motion descriptors [6], or some form of template matching [13]. Recognizing actions, on the other hand, often uses some sort of probabilistic approach, the most common being Markov chains [1, 2, 12] or some more complex Bayesian based system [3].
6 6 2. Overview This thesis focuses on generating a 3D stick figure from either a single still image or a sequence of frames from a video. Section 3 details how a 3D pose is generated from a single still image, while section 4 shows how multiple 3D poses are strung together into a coherent action. Section 5 shows the results from both the single frame and multiple frame reconstructions. Finally, section 6 demonstrates a number of different applications for this system, related work in the field, and future work.

7 7 3. Single Frame Reconstruction Reconstructing a 3D pose from an image involves three steps: 1. Collecting user input 2. Generating all possible poses 3. Finding the most likely pose 3.1 Collecting user input The first step in the process involves the user marking the joints of the person in the provided image. Given an input image, the user clicks on the shoulder, elbow, and wrist for both arms, as well as the hip, knee, and ankle for both legs. In total, 12 joints are needed. If any of the joints are not visible in the image, the user must give as close an approximation as possible. As a result of the collected points, a stick figure is generated with 11 line segments. Figure 2. The image on the left shows a stick figure with all of its line segments labeled. The legend on the right image indicates assumed lengths for all line segments.
8 8 3.2 Generating all possible poses In mathematical terms, a projection is defined as the mapping of a set of points and lines from one plane to another. Within the scope of this project, the generated stick figure can be seen as a projection from a 3D plane to a 2D plane. This type of projection is characterized by a loss of depth information. Essentially, all 3D points (X,Y,Z) in the system become (X,Y). An easy way of thinking about a 3D to 2D projection is to picture someone shining a flashlight against a flat wall. If an individual were to place his hand midway between the flashlight and the wall, the hand would cast a shadow. In this situation the hand is an object in a 3D environment and the shadow is the projection of the hand onto a 2D plane. Given this setup, it is easy to imagine how either moving or rotating your hand would change the shape of the shadow against the wall. Using this logic, consider a line in 3 dimensions with the points (x 1, y 1, z 1 ) and (x 2, y 2, z 2 ) and its projection onto a 2D plane with points (x 1, y 1 ) and (x 2, y 2 ). Calculating the distance between the two points in their respective dimensions is simply an application of the Pythagorean Theorem: 2 2 C 2 D ( x 2 x 1 ) ( y 2 y 1 ) (1) C 3 D ( x 2 x 1 ) ( y 2 y 1 ) ( z 2 z 1 ) (2) Where C 2D and C 3D are distances between the two points in 2 dimensions and 3 dimensions respectively. Similarly, since C 2D and C 3D both utilize the same X and Y coordinates, they can be related to one another in the following way: C D C 2D Z (3) where Z is defined as (z 2 z 1 ).
9 9 Looking back at the stick figure, the goal is to calculate some sort of depth information. This could be done utilizing equation 3, however, there are still two unknowns. This is overcome by fixing the value of C 3D for all line segments in the stick figure (Figure 2). Solving equation 3 for Z yields: Z 2 2 3D C 2D C (4) Having the length, however, does not completely solve the problem. There is still a problem of the line segment s orientation on the Z axis. This is shown graphically in figure 3. Figure 3. The line graphed on the left represents a projection from a 3 dimensional space to the XY plane. The end points of this line are (0,1) and (0,-1). The problem with orientation on the Z-axis is demonstrated here because either of the two lines on the right could be used to create the projection on the left. The line on the top right graph has end points (0,1,-1) and (0,-1,1), while the line on the bottom right graph has points (0,-1,-1) and (0,1,1).
10 10 Given that there are 11 line segments in the stick figure and two possible solutions for each segment, there are a total of 2048 possible 3D pose configurations. 3.3 Finding the most likely pose After all 2048 possible poses are generated, a method is needed in order to determine which configuration is most likely to occur. This was accomplished through the use of a Gaussian mixture model. A Gaussian mixture model is a collection of some number of Gaussian functions in a fixed number of dimensions. Figure 4. The above graph depicts a collection of 3 Gaussian distributions in one dimension making up a Gaussian mixture model. Given any point in one dimension, the above model can numerically define how likely that point is to occur in the mixture through a probability density function (pdf). This same frame of logic is applied to describing how likely a human poses is.
11 11 In order to create a Gaussian mixture model for this project, a large database was necessary. Carnegie Melon University s Motion Capture Database (MoCap) is a database filled with millions of examples of human poses programmatically recorded using special cameras and tracking dots [15]. This database served as the source of the data for the Gaussian mixture model. In order to create the model, the poses were first extracted from the database as 12 element vectors. The vectors were then clustered in a 12D subspace using the expectationmaximization (EM) algorithm. The algorithm yielded estimates for (mean) and (standard deviation) for each cluster, which define the model. The EM algorithm was constrained to use only 50 clusters. After creating the Gaussian mixture model, quantifying the likelihood of all 2048 poses was accomplished by simply comparing each individual pose against the model. Each comparison yielded a pdf and the pose with the highest pdf constituted the most likely configuration. The above process was further optimized by utilizing two separate Gaussian mixture models; one for the upper body and one for the lower body. By doing this, only 96 unique configurations were necessary in order to describe all 2048 possible poses. After finding the largest pdf for both the upper and lower bodies, the two configurations were simply combined. Because the Gaussian mixture models were computed ahead of time, this optimization increased the speed and decreased the amount of memory used by the algorithm.
12 12 4. Multiple Frame Reconstruction Generating a 3D pose from a video sequence mirrors the procedure for the single frame reconstruction with one caveat. The ordered sequence of video frames adds a temporal aspect to the system. Because of this, a generated pose must not only be likely in its own regard, but must also be related to the poses that occur before and after it in the sequence. This essentially turns multiple frame reconstruction into a graph problem. 4.1 Travel Cost Just as in the single frame reconstruction, user input is required to label the joints in all frames of the video sequence. All possible pose configurations are then generated for each frame and quantified with a pdf. There are two conditions that need to be met in order to generate an accurate pose sequence. First of all, the pdf of the pose must be maximized, indicating that the pose is likely to occur in the first place. Second, poses in a sequence must be relatively close to one another in terms of some distance metric. In effect, the goal is to find make a series of frame to frame connections that satisfy the following equation. The travel cost to go from pose i of frame n-1 to pose j of frame n is defined by: S dist( posen 1, i, posen, j ) PDFn 1, i (5) where dist is a function representing the sum of the differences in Euclidean distances between the provided poses, PDF n-1,i is the pdf of the i th pose of frame n-1 and is some scaling factor. For each frame in the sequence, there are 2048 possible poses that could potentially connect to any of the 2048 poses in the next frame. Because of this, 4,194,304 connections need to be computed for each pair of frames.

13 Dynamic Programming This situation describes a large connected graph problem. Figure 5. The graph depicted here represents the connections of 2048 human pose configurations across n frames. Given that a video sequences can exceed 100 frames, hundreds of millions of computations are needed. This type of large computation is optimized using dynamic programming. Using equation 5, navigating the graph can be mathematically represented as: S arg min( dist( posen 1, i, posen, j ) PDFn 1, i S n 1, ) (6) n, j i i Each pose j of frame n is given a score based on equation 5. The only change is that the score from the previous frame s incoming pose is added as well. After the final frame is reached, determining the sequence of poses is simply a matter of backtracking through the graph starting with the minimum S value in the final frame.


14 14 5. Results Single Frame Reconstruction


15 15



16 Multiple Frame Reconstruction 16



17 17


18 18 6. Discussion As the above results show, this method of 3D human pose reconstruction is indeed possible in both single images as well as video sequences. Although this system is not 100% accurate, the results are good enough to be both meaningful and useful. 6.1 Applications This thesis examines two applications directly related to 3D human pose reconstruction. The first is character animation and the second is sports performance analysis. Traditionally, creating movement data for character animation is very limited. Individuals wearing suits with tracking markers were constrained to moving within small areas where special cameras monitor their actions. Because of this, trackable actions are limited in many ways. This 3D pose reconstruction offers an unconstrained form of motion capture that requires no special equipment. (a) (b) Figure 6. (a) shows person wearing trackable markers with the resulting computer generated pose next to it. (b) shows the same image with user marked joints. The resulting 3D pose is shown to the right.


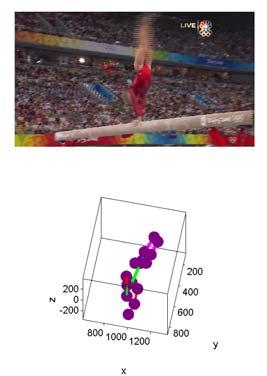
19 19 As you can see in figure 6b, without any special cameras or use of the tracking markers, a similar 3D pose is generated. In effect, this means that any video can be used to generate a series of 3D human poses. The joint locations of the poses can then simply be plugged into any kind of character animation software and the actions of the original video can be acted out by any range of characters. The second application of this type of software is for sports performance analysis. A computer is capable of conveying large amounts of data after recording and monitoring an action performed by an athlete. By simply tracking the individual points of the pose, the speed and direction of each individual joint can be calculated. Figure 7. The speed and direction of all four extremities are displayed through this gymnast s balance beam performance. Even with such a simple setup, the velocity of various body parts can be analyzed, multiple frames can be used to calculate their respective accelerations, and overall efficiency can be hypothesized. In addition to all of this, by simply including additional information with the pose, other aspects of the action can be examined. Estimating the weight of the individual could yield information such as the amount of work done by different limbs or torque experienced by different joints.
20 Related Work Within the scope of this thesis, there has recently been some work done by other individuals, the most notable of which is Jinxiang Chai. Professor Chai currently teaches in the Department of Computer Science and Engineering at Texas A&M University. His work includes generating human poses from still images [9] as well as video sequences [10]. The methods used are very similar, but differ in a few key points. Professor Chai s method still requires a user to mark key points within an image, however, 18 points of interest are necessary. As a result, the human pose is defined by 17 line segments. This system makes no assumptions about the lengths of the line segments, but as a tradeoff, five images are needed of a single pose in order to remove any ambiguity. In addition to the above publications, Professor Chai has a publication describing a system that generates human poses based on a collection of millions of example poses [11]. This approach is very similar to the Gaussian mixture model prior used in this project. 6.3 Future work There are two major potential areas of improvement for this project. The first is to have some way of automatically tracking 2D joint positions. This was a problem for two reasons. First of all, many of the videos used were not very high quality. Trying to find key points in a motion blurred image is a difficult task for a person, let alone a computer. The 3D reconstruction is very much dependant on the accuracy of the joint locations. A single outlier would almost certainly change a pose tremendously. The second problem is occlusion. This can either be the result of an object appearing between the camera and the person being recorded, or the person turning in such a way that they are only partially visible. If some joint locations are
21 21 not tracked, then a 3D reconstruction would become meaningless because the human body would not be complete when inspected from different angles. The next major improvement that should be made is some form of collision detection. This collision detection can refer to either the body as it relates to touching itself or other objects in its immediate environment. As it stands, the collection of points in a generated 3D human pose know little else than how to connect in order to form a stick figure. Because of this, poses that have legs or arm crossed sometimes have one limb passing through another. Problems like this could be avoided by adding the constraint that two limbs cannot simultaneously occupy some area in space. Overall, this software represents a good starting point for human pose reconstruction. In addition to the possible applications described above, other future directions for this project include performance analysis, tracking multi-person interaction, or efficiently creating computer simulations involving people.
22 22 7. Acknowledgements Professor Jiang Your guidance in completing this project was invaluable. There were many times when the task at hand seemed too overwhelming, yet you always had time to sit down with me and set me in the right direction. This project would not have nearly approached the scope that it did had it not been for your continued support. Professor Yu I regard working in your research lab as being one of the most beneficial and influential experiences of my college career. Thank you for taking me under your wing and teaching me the rigors of academic research. Professor Martin Your computation photography class was by far the most difficult class I have taken at Boston College. That being said, I would not be here as a computer science major nor involved with computer vision had your teaching not made me fall in love with both subjects.
23 23 8. References [1] Ahmad, M. and Lee, S. HMM-based Human Action Recognition Using Multiview Image Sequence. In Proceedings of the 18th International Conference on Pattern Recognition, [2] Brand, M., Oliver, N., Pentland, A. Coupled Hidden Markov Models for Complex Action Recognition. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, [3] Bobick, A. F. and Ivanov, Y. A. Action Recognition using Probabilistic Parsing. In Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition, [4] Chen, Y. and Chai, J. 3D Reconstruction of Human Motion and Skeleton from Uncalibrated Monocular Video. In Proceedings of IEEE Asian Conference of Computer Vision, [5] Dimitrijevic, M., Lepetit, V., Fua, P. Human Body Pose Recognition Using Spatio- Temporal Templates. In Workshop on Modeling People and Human Interaction, Beijing, China, Oct 15 21, [6] Efros, A., Berg, A., Mori, G., Malik, J. Recognizing Action at a Distance. In Proceedings of IEEE International Conference on Computer Vision, [7] Jiang, H. and Martin D. R. Global Pose Estimation Using Non-Tree Models. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, [8] Johansson, G. Visual Perception of Biological Motion and a Model for its Analysis. Perception and Psychophysics. 14, pp , 1973.
24 24 [9] Wei, X. and Chai, J. Modeling 3D Human Poses from Uncalibrated Monocular Images. In Proceedings of IEEE International Conference on Computer Vision, [10] Wei, X. and Chai, J. VideoMocap: Modeling Physically Realistic Human Motion from Monocular Video Sequence. To Appear in ACM Transactions on Graphics, [11] Wei, X., and Chai, J. Intuitive Interactive Human Character Posing with Millions of Example Poses. To Appear in IEEE Computer Graphics and Applications, [12] Yamato, J., Ohya, J., Ishii, K. Recognizing Human Action in Time-Sequential Images using Hidden Markov Model. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp , [13] Yilmaz, A. and Shah, M. Actions Sketch: A Novel Action Representation. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Other Resources [14] Biomotion Lab. [15] CMU Graphics Lab Motion Capture Database, mocap.cs.cmu.edu, developed with funding from NSF EIA
3D Human Motion Analysis and Manifolds
 D E P A R T M E N T O F C O M P U T E R S C I E N C E U N I V E R S I T Y O F C O P E N H A G E N 3D Human Motion Analysis and Manifolds Kim Steenstrup Pedersen DIKU Image group and E-Science center Motivation
D E P A R T M E N T O F C O M P U T E R S C I E N C E U N I V E R S I T Y O F C O P E N H A G E N 3D Human Motion Analysis and Manifolds Kim Steenstrup Pedersen DIKU Image group and E-Science center Motivation
Generating Different Realistic Humanoid Motion
 Generating Different Realistic Humanoid Motion Zhenbo Li,2,3, Yu Deng,2,3, and Hua Li,2,3 Key Lab. of Computer System and Architecture, Institute of Computing Technology, Chinese Academy of Sciences, Beijing
Generating Different Realistic Humanoid Motion Zhenbo Li,2,3, Yu Deng,2,3, and Hua Li,2,3 Key Lab. of Computer System and Architecture, Institute of Computing Technology, Chinese Academy of Sciences, Beijing
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Unsupervised Human Members Tracking Based on an Silhouette Detection and Analysis Scheme
 Unsupervised Human Members Tracking Based on an Silhouette Detection and Analysis Scheme Costas Panagiotakis and Anastasios Doulamis Abstract In this paper, an unsupervised, automatic video human members(human
Unsupervised Human Members Tracking Based on an Silhouette Detection and Analysis Scheme Costas Panagiotakis and Anastasios Doulamis Abstract In this paper, an unsupervised, automatic video human members(human
Thiruvarangan Ramaraj CS525 Graphics & Scientific Visualization Spring 2007, Presentation I, February 28 th 2007, 14:10 15:00. Topic (Research Paper):
:") Thiruvarangan Ramaraj CS525 Graphics & Scientific Visualization Spring 2007, Presentation I, February 28 th 2007, 14:10 15:00 Topic (Research Paper): Jinxian Chai and Jessica K. Hodgins, Performance Animation
Thiruvarangan Ramaraj CS525 Graphics & Scientific Visualization Spring 2007, Presentation I, February 28 th 2007, 14:10 15:00 Topic (Research Paper): Jinxian Chai and Jessica K. Hodgins, Performance Animation
Dynamic Human Shape Description and Characterization
 Dynamic Human Shape Description and Characterization Z. Cheng*, S. Mosher, Jeanne Smith H. Cheng, and K. Robinette Infoscitex Corporation, Dayton, Ohio, USA 711 th Human Performance Wing, Air Force Research
Dynamic Human Shape Description and Characterization Z. Cheng*, S. Mosher, Jeanne Smith H. Cheng, and K. Robinette Infoscitex Corporation, Dayton, Ohio, USA 711 th Human Performance Wing, Air Force Research
Term Project Final Report for CPSC526 Statistical Models of Poses Using Inverse Kinematics
 Term Project Final Report for CPSC526 Statistical Models of Poses Using Inverse Kinematics Department of Computer Science The University of British Columbia duanx@cs.ubc.ca, lili1987@cs.ubc.ca Abstract
Term Project Final Report for CPSC526 Statistical Models of Poses Using Inverse Kinematics Department of Computer Science The University of British Columbia duanx@cs.ubc.ca, lili1987@cs.ubc.ca Abstract
Probabilistic Tracking and Reconstruction of 3D Human Motion in Monocular Video Sequences
 Probabilistic Tracking and Reconstruction of 3D Human Motion in Monocular Video Sequences Presentation of the thesis work of: Hedvig Sidenbladh, KTH Thesis opponent: Prof. Bill Freeman, MIT Thesis supervisors
Probabilistic Tracking and Reconstruction of 3D Human Motion in Monocular Video Sequences Presentation of the thesis work of: Hedvig Sidenbladh, KTH Thesis opponent: Prof. Bill Freeman, MIT Thesis supervisors
ActivityRepresentationUsing3DShapeModels
 ActivityRepresentationUsing3DShapeModels AmitK.Roy-Chowdhury RamaChellappa UmutAkdemir University of California University of Maryland University of Maryland Riverside, CA 9252 College Park, MD 274 College
ActivityRepresentationUsing3DShapeModels AmitK.Roy-Chowdhury RamaChellappa UmutAkdemir University of California University of Maryland University of Maryland Riverside, CA 9252 College Park, MD 274 College
Recognizing Human Activities in Video by Multi-resolutional Optical Flows
 Recognizing Human Activities in Video by Multi-resolutional Optical Flows Toru Nakata Digital Human Research Center, National Institute of Advanced Industrial Science and Technology (AIST). Also Core Research
Recognizing Human Activities in Video by Multi-resolutional Optical Flows Toru Nakata Digital Human Research Center, National Institute of Advanced Industrial Science and Technology (AIST). Also Core Research
Modeling 3D Human Poses from Uncalibrated Monocular Images
 Modeling 3D Human Poses from Uncalibrated Monocular Images Xiaolin K. Wei Texas A&M University xwei@cse.tamu.edu Jinxiang Chai Texas A&M University jchai@cse.tamu.edu Abstract This paper introduces an
Modeling 3D Human Poses from Uncalibrated Monocular Images Xiaolin K. Wei Texas A&M University xwei@cse.tamu.edu Jinxiang Chai Texas A&M University jchai@cse.tamu.edu Abstract This paper introduces an
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Depth. Common Classification Tasks. Example: AlexNet. Another Example: Inception. Another Example: Inception. Depth
 Common Classification Tasks Recognition of individual objects/faces Analyze object-specific features (e.g., key points) Train with images from different viewing angles Recognition of object classes Analyze
Common Classification Tasks Recognition of individual objects/faces Analyze object-specific features (e.g., key points) Train with images from different viewing angles Recognition of object classes Analyze
Tai Chi Motion Recognition Using Wearable Sensors and Hidden Markov Model Method
 Tai Chi Motion Recognition Using Wearable Sensors and Hidden Markov Model Method Dennis Majoe 1, Lars Widmer 1, Philip Tschiemer 1 and Jürg Gutknecht 1, 1 Computer Systems Institute, ETH Zurich, Switzerland
Tai Chi Motion Recognition Using Wearable Sensors and Hidden Markov Model Method Dennis Majoe 1, Lars Widmer 1, Philip Tschiemer 1 and Jürg Gutknecht 1, 1 Computer Systems Institute, ETH Zurich, Switzerland
Graph-based High Level Motion Segmentation using Normalized Cuts
 Graph-based High Level Motion Segmentation using Normalized Cuts Sungju Yun, Anjin Park and Keechul Jung Abstract Motion capture devices have been utilized in producing several contents, such as movies
Graph-based High Level Motion Segmentation using Normalized Cuts Sungju Yun, Anjin Park and Keechul Jung Abstract Motion capture devices have been utilized in producing several contents, such as movies
Fully Automatic Methodology for Human Action Recognition Incorporating Dynamic Information
 Fully Automatic Methodology for Human Action Recognition Incorporating Dynamic Information Ana González, Marcos Ortega Hortas, and Manuel G. Penedo University of A Coruña, VARPA group, A Coruña 15071,
Fully Automatic Methodology for Human Action Recognition Incorporating Dynamic Information Ana González, Marcos Ortega Hortas, and Manuel G. Penedo University of A Coruña, VARPA group, A Coruña 15071,
Predicting 3D People from 2D Pictures
 Predicting 3D People from 2D Pictures Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ CIAR Summer School August 15-20, 2006 Leonid Sigal
Predicting 3D People from 2D Pictures Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ CIAR Summer School August 15-20, 2006 Leonid Sigal
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
Low Cost Motion Capture
 Low Cost Motion Capture R. Budiman M. Bennamoun D.Q. Huynh School of Computer Science and Software Engineering The University of Western Australia Crawley WA 6009 AUSTRALIA Email: budimr01@tartarus.uwa.edu.au,
Low Cost Motion Capture R. Budiman M. Bennamoun D.Q. Huynh School of Computer Science and Software Engineering The University of Western Australia Crawley WA 6009 AUSTRALIA Email: budimr01@tartarus.uwa.edu.au,
ROBUST OBJECT TRACKING BY SIMULTANEOUS GENERATION OF AN OBJECT MODEL
 ROBUST OBJECT TRACKING BY SIMULTANEOUS GENERATION OF AN OBJECT MODEL Maria Sagrebin, Daniel Caparròs Lorca, Daniel Stroh, Josef Pauli Fakultät für Ingenieurwissenschaften Abteilung für Informatik und Angewandte
ROBUST OBJECT TRACKING BY SIMULTANEOUS GENERATION OF AN OBJECT MODEL Maria Sagrebin, Daniel Caparròs Lorca, Daniel Stroh, Josef Pauli Fakultät für Ingenieurwissenschaften Abteilung für Informatik und Angewandte
Applications. Systems. Motion capture pipeline. Biomechanical analysis. Graphics research
 Motion capture Applications Systems Motion capture pipeline Biomechanical analysis Graphics research Applications Computer animation Biomechanics Robotics Cinema Video games Anthropology What is captured?
Motion capture Applications Systems Motion capture pipeline Biomechanical analysis Graphics research Applications Computer animation Biomechanics Robotics Cinema Video games Anthropology What is captured?
The Line of Action: an Intuitive Interface for Expressive Character Posing. Martin Guay, Marie-Paule Cani, Rémi Ronfard
 The Line of Action: an Intuitive Interface for Expressive Character Posing Martin Guay, Marie-Paule Cani, Rémi Ronfard LJK, INRIA, Université de Grenoble [S.Lee and J. Buscema, Drawing Comics the Marvel
The Line of Action: an Intuitive Interface for Expressive Character Posing Martin Guay, Marie-Paule Cani, Rémi Ronfard LJK, INRIA, Université de Grenoble [S.Lee and J. Buscema, Drawing Comics the Marvel
Tracking People. Tracking People: Context
 Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Multimedia Technology CHAPTER 4. Video and Animation
 CHAPTER 4 Video and Animation - Both video and animation give us a sense of motion. They exploit some properties of human eye s ability of viewing pictures. - Motion video is the element of multimedia
CHAPTER 4 Video and Animation - Both video and animation give us a sense of motion. They exploit some properties of human eye s ability of viewing pictures. - Motion video is the element of multimedia
Motion Interpretation and Synthesis by ICA
 Motion Interpretation and Synthesis by ICA Renqiang Min Department of Computer Science, University of Toronto, 1 King s College Road, Toronto, ON M5S3G4, Canada Abstract. It is known that high-dimensional
Motion Interpretation and Synthesis by ICA Renqiang Min Department of Computer Science, University of Toronto, 1 King s College Road, Toronto, ON M5S3G4, Canada Abstract. It is known that high-dimensional
Introduction to behavior-recognition and object tracking
 Introduction to behavior-recognition and object tracking Xuan Mo ipal Group Meeting April 22, 2011 Outline Motivation of Behavior-recognition Four general groups of behaviors Core technologies Future direction
Introduction to behavior-recognition and object tracking Xuan Mo ipal Group Meeting April 22, 2011 Outline Motivation of Behavior-recognition Four general groups of behaviors Core technologies Future direction
A novel approach to motion tracking with wearable sensors based on Probabilistic Graphical Models
 A novel approach to motion tracking with wearable sensors based on Probabilistic Graphical Models Emanuele Ruffaldi Lorenzo Peppoloni Alessandro Filippeschi Carlo Alberto Avizzano 2014 IEEE International
A novel approach to motion tracking with wearable sensors based on Probabilistic Graphical Models Emanuele Ruffaldi Lorenzo Peppoloni Alessandro Filippeschi Carlo Alberto Avizzano 2014 IEEE International
Automatic Tracking of Moving Objects in Video for Surveillance Applications
 Automatic Tracking of Moving Objects in Video for Surveillance Applications Manjunath Narayana Committee: Dr. Donna Haverkamp (Chair) Dr. Arvin Agah Dr. James Miller Department of Electrical Engineering
Automatic Tracking of Moving Objects in Video for Surveillance Applications Manjunath Narayana Committee: Dr. Donna Haverkamp (Chair) Dr. Arvin Agah Dr. James Miller Department of Electrical Engineering
9.913 Pattern Recognition for Vision. Class I - Overview. Instructors: B. Heisele, Y. Ivanov, T. Poggio
 9.913 Class I - Overview Instructors: B. Heisele, Y. Ivanov, T. Poggio TOC Administrivia Problems of Computer Vision and Pattern Recognition Overview of classes Quick review of Matlab Administrivia Instructors:
9.913 Class I - Overview Instructors: B. Heisele, Y. Ivanov, T. Poggio TOC Administrivia Problems of Computer Vision and Pattern Recognition Overview of classes Quick review of Matlab Administrivia Instructors:
A Dynamic Human Model using Hybrid 2D-3D Representations in Hierarchical PCA Space
 A Dynamic Human Model using Hybrid 2D-3D Representations in Hierarchical PCA Space Eng-Jon Ong and Shaogang Gong Department of Computer Science, Queen Mary and Westfield College, London E1 4NS, UK fongej
A Dynamic Human Model using Hybrid 2D-3D Representations in Hierarchical PCA Space Eng-Jon Ong and Shaogang Gong Department of Computer Science, Queen Mary and Westfield College, London E1 4NS, UK fongej
BSB663 Image Processing Pinar Duygulu. Slides are adapted from Selim Aksoy
 BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
lecture 10 - depth from blur, binocular stereo
 This lecture carries forward some of the topics from early in the course, namely defocus blur and binocular disparity. The main emphasis here will be on the information these cues carry about depth, rather
This lecture carries forward some of the topics from early in the course, namely defocus blur and binocular disparity. The main emphasis here will be on the information these cues carry about depth, rather
Learning Articulated Skeletons From Motion
 Learning Articulated Skeletons From Motion Danny Tarlow University of Toronto, Machine Learning with David Ross and Richard Zemel (and Brendan Frey) August 6, 2007 Point Light Displays It's easy for humans
Learning Articulated Skeletons From Motion Danny Tarlow University of Toronto, Machine Learning with David Ross and Richard Zemel (and Brendan Frey) August 6, 2007 Point Light Displays It's easy for humans
HUMAN TRACKING SYSTEM
 HUMAN TRACKING SYSTEM Kavita Vilas Wagh* *PG Student, Electronics & Telecommunication Department, Vivekanand Institute of Technology, Mumbai, India waghkav@gmail.com Dr. R.K. Kulkarni** **Professor, Electronics
HUMAN TRACKING SYSTEM Kavita Vilas Wagh* *PG Student, Electronics & Telecommunication Department, Vivekanand Institute of Technology, Mumbai, India waghkav@gmail.com Dr. R.K. Kulkarni** **Professor, Electronics
Articulated Pose Estimation with Flexible Mixtures-of-Parts
 Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Introduction to Trajectory Clustering. By YONGLI ZHANG
 Introduction to Trajectory Clustering By YONGLI ZHANG Outline 1. Problem Definition 2. Clustering Methods for Trajectory data 3. Model-based Trajectory Clustering 4. Applications 5. Conclusions 1 Problem
Introduction to Trajectory Clustering By YONGLI ZHANG Outline 1. Problem Definition 2. Clustering Methods for Trajectory data 3. Model-based Trajectory Clustering 4. Applications 5. Conclusions 1 Problem
Articulated Structure from Motion through Ellipsoid Fitting
 Int'l Conf. IP, Comp. Vision, and Pattern Recognition IPCV'15 179 Articulated Structure from Motion through Ellipsoid Fitting Peter Boyi Zhang, and Yeung Sam Hung Department of Electrical and Electronic
Int'l Conf. IP, Comp. Vision, and Pattern Recognition IPCV'15 179 Articulated Structure from Motion through Ellipsoid Fitting Peter Boyi Zhang, and Yeung Sam Hung Department of Electrical and Electronic
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering
 AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
Human Action Recognition Using Silhouette Histogram
 Human Action Recognition Using Silhouette Histogram Chaur-Heh Hsieh, *Ping S. Huang, and Ming-Da Tang Department of Computer and Communication Engineering Ming Chuan University Taoyuan 333, Taiwan, ROC
Human Action Recognition Using Silhouette Histogram Chaur-Heh Hsieh, *Ping S. Huang, and Ming-Da Tang Department of Computer and Communication Engineering Ming Chuan University Taoyuan 333, Taiwan, ROC
Human Motion Synthesis by Motion Manifold Learning and Motion Primitive Segmentation
 Human Motion Synthesis by Motion Manifold Learning and Motion Primitive Segmentation Chan-Su Lee and Ahmed Elgammal Rutgers University, Piscataway, NJ, USA {chansu, elgammal}@cs.rutgers.edu Abstract. We
Human Motion Synthesis by Motion Manifold Learning and Motion Primitive Segmentation Chan-Su Lee and Ahmed Elgammal Rutgers University, Piscataway, NJ, USA {chansu, elgammal}@cs.rutgers.edu Abstract. We
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
This blog addresses the question: how do we determine the intersection of two circles in the Cartesian plane?
 Intersecting Circles This blog addresses the question: how do we determine the intersection of two circles in the Cartesian plane? This is a problem that a programmer might have to solve, for example,
Intersecting Circles This blog addresses the question: how do we determine the intersection of two circles in the Cartesian plane? This is a problem that a programmer might have to solve, for example,
Tracking of Human Body using Multiple Predictors
 Tracking of Human Body using Multiple Predictors Rui M Jesus 1, Arnaldo J Abrantes 1, and Jorge S Marques 2 1 Instituto Superior de Engenharia de Lisboa, Postfach 351-218317001, Rua Conselheiro Emído Navarro,
Tracking of Human Body using Multiple Predictors Rui M Jesus 1, Arnaldo J Abrantes 1, and Jorge S Marques 2 1 Instituto Superior de Engenharia de Lisboa, Postfach 351-218317001, Rua Conselheiro Emído Navarro,
Vision-based Manipulator Navigation. using Mixtures of RBF Neural Networks. Wolfram Blase, Josef Pauli, and Jorg Bruske
 Vision-based Manipulator Navigation using Mixtures of RBF Neural Networks Wolfram Blase, Josef Pauli, and Jorg Bruske Christian{Albrechts{Universitat zu Kiel, Institut fur Informatik Preusserstrasse 1-9,
Vision-based Manipulator Navigation using Mixtures of RBF Neural Networks Wolfram Blase, Josef Pauli, and Jorg Bruske Christian{Albrechts{Universitat zu Kiel, Institut fur Informatik Preusserstrasse 1-9,
Mixture Models and EM
 Mixture Models and EM Goal: Introduction to probabilistic mixture models and the expectationmaximization (EM) algorithm. Motivation: simultaneous fitting of multiple model instances unsupervised clustering
Mixture Models and EM Goal: Introduction to probabilistic mixture models and the expectationmaximization (EM) algorithm. Motivation: simultaneous fitting of multiple model instances unsupervised clustering
3D Face and Hand Tracking for American Sign Language Recognition
 3D Face and Hand Tracking for American Sign Language Recognition NSF-ITR (2004-2008) D. Metaxas, A. Elgammal, V. Pavlovic (Rutgers Univ.) C. Neidle (Boston Univ.) C. Vogler (Gallaudet) The need for automated
3D Face and Hand Tracking for American Sign Language Recognition NSF-ITR (2004-2008) D. Metaxas, A. Elgammal, V. Pavlovic (Rutgers Univ.) C. Neidle (Boston Univ.) C. Vogler (Gallaudet) The need for automated
Face Tracking. Synonyms. Definition. Main Body Text. Amit K. Roy-Chowdhury and Yilei Xu. Facial Motion Estimation
 Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Skeleton based Human Action Recognition using Kinect
 Skeleton based Human Action Recognition using Kinect Ayushi Gahlot Purvi Agarwal Akshya Agarwal Vijai Singh IMS Engineering college, Amit Kumar Gautam ABSTRACT This paper covers the aspects of action recognition
Skeleton based Human Action Recognition using Kinect Ayushi Gahlot Purvi Agarwal Akshya Agarwal Vijai Singh IMS Engineering college, Amit Kumar Gautam ABSTRACT This paper covers the aspects of action recognition
3D object recognition used by team robotto
 3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
Boundary Fragment Matching and Articulated Pose Under Occlusion. Nicholas R. Howe
 Boundary Fragment Matching and Articulated Pose Under Occlusion Nicholas R. Howe Low-Budget Motion Capture Constraints (informal/archived footage): Single camera No body markers Consequent Challenges:
Boundary Fragment Matching and Articulated Pose Under Occlusion Nicholas R. Howe Low-Budget Motion Capture Constraints (informal/archived footage): Single camera No body markers Consequent Challenges:
Vehicle Occupant Posture Analysis Using Voxel Data
 Ninth World Congress on Intelligent Transport Systems, Chicago, Illinois, October Vehicle Occupant Posture Analysis Using Voxel Data Ivana Mikic, Mohan Trivedi Computer Vision and Robotics Research Laboratory
Ninth World Congress on Intelligent Transport Systems, Chicago, Illinois, October Vehicle Occupant Posture Analysis Using Voxel Data Ivana Mikic, Mohan Trivedi Computer Vision and Robotics Research Laboratory
Introduction to Computer Vision
 Introduction to Computer Vision Michael J. Black Nov 2009 Perspective projection and affine motion Goals Today Perspective projection 3D motion Wed Projects Friday Regularization and robust statistics
Introduction to Computer Vision Michael J. Black Nov 2009 Perspective projection and affine motion Goals Today Perspective projection 3D motion Wed Projects Friday Regularization and robust statistics
Human Character Animation in 3D-Graphics: The EMOTE System as a Plug-in for Maya
 Hartmann - 1 Bjoern Hartman Advisor: Dr. Norm Badler Applied Senior Design Project - Final Report Human Character Animation in 3D-Graphics: The EMOTE System as a Plug-in for Maya Introduction Realistic
Hartmann - 1 Bjoern Hartman Advisor: Dr. Norm Badler Applied Senior Design Project - Final Report Human Character Animation in 3D-Graphics: The EMOTE System as a Plug-in for Maya Introduction Realistic
Image Base Rendering: An Introduction
 Image Base Rendering: An Introduction Cliff Lindsay CS563 Spring 03, WPI 1. Introduction Up to this point, we have focused on showing 3D objects in the form of polygons. This is not the only approach to
Image Base Rendering: An Introduction Cliff Lindsay CS563 Spring 03, WPI 1. Introduction Up to this point, we have focused on showing 3D objects in the form of polygons. This is not the only approach to
1 Introduction Human activity is a continuous flow of single or discrete human action primitives in succession. An example of a human activity is a se
 Segmentation and Recognition of Continuous Human Activity Anjum Ali Computer and Vision Research Center Department of Electrical and Computer Engineering The University of Texas, Austin ali@ece.utexas.edu
Segmentation and Recognition of Continuous Human Activity Anjum Ali Computer and Vision Research Center Department of Electrical and Computer Engineering The University of Texas, Austin ali@ece.utexas.edu
Sign Language Recognition using Dynamic Time Warping and Hand Shape Distance Based on Histogram of Oriented Gradient Features
 Sign Language Recognition using Dynamic Time Warping and Hand Shape Distance Based on Histogram of Oriented Gradient Features Pat Jangyodsuk Department of Computer Science and Engineering The University
Sign Language Recognition using Dynamic Time Warping and Hand Shape Distance Based on Histogram of Oriented Gradient Features Pat Jangyodsuk Department of Computer Science and Engineering The University
Human Gait Recognition Using Bezier Curves
 Human Gait Recognition Using Bezier Curves Pratibha Mishra Samrat Ashok Technology Institute Vidisha, (M.P.) India Shweta Ezra Dhar Polytechnic College Dhar, (M.P.) India Abstract-- Gait recognition refers
Human Gait Recognition Using Bezier Curves Pratibha Mishra Samrat Ashok Technology Institute Vidisha, (M.P.) India Shweta Ezra Dhar Polytechnic College Dhar, (M.P.) India Abstract-- Gait recognition refers
Transactions on Information and Communications Technologies vol 16, 1996 WIT Press, ISSN
 ransactions on Information and Communications echnologies vol 6, 996 WI Press, www.witpress.com, ISSN 743-357 Obstacle detection using stereo without correspondence L. X. Zhou & W. K. Gu Institute of Information
ransactions on Information and Communications echnologies vol 6, 996 WI Press, www.witpress.com, ISSN 743-357 Obstacle detection using stereo without correspondence L. X. Zhou & W. K. Gu Institute of Information
Epitomic Analysis of Human Motion
 Epitomic Analysis of Human Motion Wooyoung Kim James M. Rehg Department of Computer Science Georgia Institute of Technology Atlanta, GA 30332 {wooyoung, rehg}@cc.gatech.edu Abstract Epitomic analysis is
Epitomic Analysis of Human Motion Wooyoung Kim James M. Rehg Department of Computer Science Georgia Institute of Technology Atlanta, GA 30332 {wooyoung, rehg}@cc.gatech.edu Abstract Epitomic analysis is
Face Quality Assessment System in Video Sequences
 Face Quality Assessment System in Video Sequences Kamal Nasrollahi, Thomas B. Moeslund Laboratory of Computer Vision and Media Technology, Aalborg University Niels Jernes Vej 14, 9220 Aalborg Øst, Denmark
Face Quality Assessment System in Video Sequences Kamal Nasrollahi, Thomas B. Moeslund Laboratory of Computer Vision and Media Technology, Aalborg University Niels Jernes Vej 14, 9220 Aalborg Øst, Denmark
Robot localization method based on visual features and their geometric relationship
 , pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
, pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
Lecture 17: Recursive Ray Tracing. Where is the way where light dwelleth? Job 38:19
 Lecture 17: Recursive Ray Tracing Where is the way where light dwelleth? Job 38:19 1. Raster Graphics Typical graphics terminals today are raster displays. A raster display renders a picture scan line
Lecture 17: Recursive Ray Tracing Where is the way where light dwelleth? Job 38:19 1. Raster Graphics Typical graphics terminals today are raster displays. A raster display renders a picture scan line
Video Texture. A.A. Efros
 Video Texture A.A. Efros 15-463: Computational Photography Alexei Efros, CMU, Fall 2005 Weather Forecasting for Dummies Let s predict weather: Given today s weather only, we want to know tomorrow s Suppose
Video Texture A.A. Efros 15-463: Computational Photography Alexei Efros, CMU, Fall 2005 Weather Forecasting for Dummies Let s predict weather: Given today s weather only, we want to know tomorrow s Suppose
Inverse KKT Motion Optimization: A Newton Method to Efficiently Extract Task Spaces and Cost Parameters from Demonstrations
 Inverse KKT Motion Optimization: A Newton Method to Efficiently Extract Task Spaces and Cost Parameters from Demonstrations Peter Englert Machine Learning and Robotics Lab Universität Stuttgart Germany
Inverse KKT Motion Optimization: A Newton Method to Efficiently Extract Task Spaces and Cost Parameters from Demonstrations Peter Englert Machine Learning and Robotics Lab Universität Stuttgart Germany
Visual Tracking. Image Processing Laboratory Dipartimento di Matematica e Informatica Università degli studi di Catania.
 Image Processing Laboratory Dipartimento di Matematica e Informatica Università degli studi di Catania 1 What is visual tracking? estimation of the target location over time 2 applications Six main areas:
Image Processing Laboratory Dipartimento di Matematica e Informatica Università degli studi di Catania 1 What is visual tracking? estimation of the target location over time 2 applications Six main areas:
A New Image Based Ligthing Method: Practical Shadow-Based Light Reconstruction
 A New Image Based Ligthing Method: Practical Shadow-Based Light Reconstruction Jaemin Lee and Ergun Akleman Visualization Sciences Program Texas A&M University Abstract In this paper we present a practical
A New Image Based Ligthing Method: Practical Shadow-Based Light Reconstruction Jaemin Lee and Ergun Akleman Visualization Sciences Program Texas A&M University Abstract In this paper we present a practical
A Survey of Light Source Detection Methods
 A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
Adaptive Zoom Distance Measuring System of Camera Based on the Ranging of Binocular Vision
 Adaptive Zoom Distance Measuring System of Camera Based on the Ranging of Binocular Vision Zhiyan Zhang 1, Wei Qian 1, Lei Pan 1 & Yanjun Li 1 1 University of Shanghai for Science and Technology, China
Adaptive Zoom Distance Measuring System of Camera Based on the Ranging of Binocular Vision Zhiyan Zhang 1, Wei Qian 1, Lei Pan 1 & Yanjun Li 1 1 University of Shanghai for Science and Technology, China
Construction Progress Management and Interior Work Analysis Using Kinect 3D Image Sensors
 33 rd International Symposium on Automation and Robotics in Construction (ISARC 2016) Construction Progress Management and Interior Work Analysis Using Kinect 3D Image Sensors Kosei Ishida 1 1 School of
33 rd International Symposium on Automation and Robotics in Construction (ISARC 2016) Construction Progress Management and Interior Work Analysis Using Kinect 3D Image Sensors Kosei Ishida 1 1 School of
Object Classification Using Tripod Operators
 Object Classification Using Tripod Operators David Bonanno, Frank Pipitone, G. Charmaine Gilbreath, Kristen Nock, Carlos A. Font, and Chadwick T. Hawley US Naval Research Laboratory, 4555 Overlook Ave.
Object Classification Using Tripod Operators David Bonanno, Frank Pipitone, G. Charmaine Gilbreath, Kristen Nock, Carlos A. Font, and Chadwick T. Hawley US Naval Research Laboratory, 4555 Overlook Ave.
Kinect Cursor Control EEE178 Dr. Fethi Belkhouche Christopher Harris Danny Nguyen I. INTRODUCTION
 Kinect Cursor Control EEE178 Dr. Fethi Belkhouche Christopher Harris Danny Nguyen Abstract: An XBOX 360 Kinect is used to develop two applications to control the desktop cursor of a Windows computer. Application
Kinect Cursor Control EEE178 Dr. Fethi Belkhouche Christopher Harris Danny Nguyen Abstract: An XBOX 360 Kinect is used to develop two applications to control the desktop cursor of a Windows computer. Application
Robust Model-Free Tracking of Non-Rigid Shape. Abstract
 Robust Model-Free Tracking of Non-Rigid Shape Lorenzo Torresani Stanford University ltorresa@cs.stanford.edu Christoph Bregler New York University chris.bregler@nyu.edu New York University CS TR2003-840
Robust Model-Free Tracking of Non-Rigid Shape Lorenzo Torresani Stanford University ltorresa@cs.stanford.edu Christoph Bregler New York University chris.bregler@nyu.edu New York University CS TR2003-840
Multi-Camera Calibration, Object Tracking and Query Generation
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Multi-Camera Calibration, Object Tracking and Query Generation Porikli, F.; Divakaran, A. TR2003-100 August 2003 Abstract An automatic object
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Multi-Camera Calibration, Object Tracking and Query Generation Porikli, F.; Divakaran, A. TR2003-100 August 2003 Abstract An automatic object
CS 231A Computer Vision (Fall 2012) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Fall 2012) Problem Set 3 Due: Nov. 13 th, 2012 (2:15pm) 1 Probabilistic Recursion for Tracking (20 points) In this problem you will derive a method for tracking a point of interest
CS 231A Computer Vision (Fall 2012) Problem Set 3 Due: Nov. 13 th, 2012 (2:15pm) 1 Probabilistic Recursion for Tracking (20 points) In this problem you will derive a method for tracking a point of interest
CS 231. Inverse Kinematics Intro to Motion Capture. 3D characters. Representation. 1) Skeleton Origin (root) Joint centers/ bones lengths
 Skeleton Origin (root) Joint centers/ bones lengths") CS Inverse Kinematics Intro to Motion Capture Representation D characters ) Skeleton Origin (root) Joint centers/ bones lengths ) Keyframes Pos/Rot Root (x) Joint Angles (q) Kinematics study of static
CS Inverse Kinematics Intro to Motion Capture Representation D characters ) Skeleton Origin (root) Joint centers/ bones lengths ) Keyframes Pos/Rot Root (x) Joint Angles (q) Kinematics study of static
Video based Animation Synthesis with the Essential Graph. Adnane Boukhayma, Edmond Boyer MORPHEO INRIA Grenoble Rhône-Alpes
 Video based Animation Synthesis with the Essential Graph Adnane Boukhayma, Edmond Boyer MORPHEO INRIA Grenoble Rhône-Alpes Goal Given a set of 4D models, how to generate realistic motion from user specified
Video based Animation Synthesis with the Essential Graph Adnane Boukhayma, Edmond Boyer MORPHEO INRIA Grenoble Rhône-Alpes Goal Given a set of 4D models, how to generate realistic motion from user specified
Human Action Recognition A Grand Challenge
 Human Action Recognition A Grand Challenge J. K. Aggarwal Department of Electrical and Computer Engineering The University of Texas at Austin Austin, TX 78712 1 Overview Human Action Recognition Motion
Human Action Recognition A Grand Challenge J. K. Aggarwal Department of Electrical and Computer Engineering The University of Texas at Austin Austin, TX 78712 1 Overview Human Action Recognition Motion
CS 231. Inverse Kinematics Intro to Motion Capture
 CS 231 Inverse Kinematics Intro to Motion Capture Representation 1) Skeleton Origin (root) Joint centers/ bones lengths 2) Keyframes Pos/Rot Root (x) Joint Angles (q) 3D characters Kinematics study of
CS 231 Inverse Kinematics Intro to Motion Capture Representation 1) Skeleton Origin (root) Joint centers/ bones lengths 2) Keyframes Pos/Rot Root (x) Joint Angles (q) 3D characters Kinematics study of
Recognition Rate. 90 S 90 W 90 R Segment Length T
 Human Action Recognition By Sequence of Movelet Codewords Xiaolin Feng y Pietro Perona yz y California Institute of Technology, 36-93, Pasadena, CA 925, USA z Universit a dipadova, Italy fxlfeng,peronag@vision.caltech.edu
Human Action Recognition By Sequence of Movelet Codewords Xiaolin Feng y Pietro Perona yz y California Institute of Technology, 36-93, Pasadena, CA 925, USA z Universit a dipadova, Italy fxlfeng,peronag@vision.caltech.edu
A Visualization Tool to Improve the Performance of a Classifier Based on Hidden Markov Models
 A Visualization Tool to Improve the Performance of a Classifier Based on Hidden Markov Models Gleidson Pegoretti da Silva, Masaki Nakagawa Department of Computer and Information Sciences Tokyo University
A Visualization Tool to Improve the Performance of a Classifier Based on Hidden Markov Models Gleidson Pegoretti da Silva, Masaki Nakagawa Department of Computer and Information Sciences Tokyo University
CSE/EE-576, Final Project
 1 CSE/EE-576, Final Project Torso tracking Ke-Yu Chen Introduction Human 3D modeling and reconstruction from 2D sequences has been researcher s interests for years. Torso is the main part of the human
1 CSE/EE-576, Final Project Torso tracking Ke-Yu Chen Introduction Human 3D modeling and reconstruction from 2D sequences has been researcher s interests for years. Torso is the main part of the human
SM2231 :: 3D Animation I :: Basic. Rigging
 SM2231 :: 3D Animation I :: Basic Rigging Object arrangements Hierarchical Hierarchical Separate parts arranged in a hierarchy can be animated without a skeleton Flat Flat Flat hierarchy is usually preferred,
SM2231 :: 3D Animation I :: Basic Rigging Object arrangements Hierarchical Hierarchical Separate parts arranged in a hierarchy can be animated without a skeleton Flat Flat Flat hierarchy is usually preferred,
CS4670: Computer Vision
 CS4670: Computer Vision Noah Snavely Lecture 6: Feature matching and alignment Szeliski: Chapter 6.1 Reading Last time: Corners and blobs Scale-space blob detector: Example Feature descriptors We know
CS4670: Computer Vision Noah Snavely Lecture 6: Feature matching and alignment Szeliski: Chapter 6.1 Reading Last time: Corners and blobs Scale-space blob detector: Example Feature descriptors We know
Automatic Annotation of Everyday Movements
 Automatic Annotation of Everyday Movements Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 94720 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu Abstract
Automatic Annotation of Everyday Movements Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 94720 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu Abstract
Proceedings of the 6th Int. Conf. on Computer Analysis of Images and Patterns. Direct Obstacle Detection and Motion. from Spatio-Temporal Derivatives
 Proceedings of the 6th Int. Conf. on Computer Analysis of Images and Patterns CAIP'95, pp. 874-879, Prague, Czech Republic, Sep 1995 Direct Obstacle Detection and Motion from Spatio-Temporal Derivatives
Proceedings of the 6th Int. Conf. on Computer Analysis of Images and Patterns CAIP'95, pp. 874-879, Prague, Czech Republic, Sep 1995 Direct Obstacle Detection and Motion from Spatio-Temporal Derivatives
Automatic Generation of Animatable 3D Personalized Model Based on Multi-view Images
 Automatic Generation of Animatable 3D Personalized Model Based on Multi-view Images Seong-Jae Lim, Ho-Won Kim, Jin Sung Choi CG Team, Contents Division ETRI Daejeon, South Korea sjlim@etri.re.kr Bon-Ki
Automatic Generation of Animatable 3D Personalized Model Based on Multi-view Images Seong-Jae Lim, Ho-Won Kim, Jin Sung Choi CG Team, Contents Division ETRI Daejeon, South Korea sjlim@etri.re.kr Bon-Ki
Kinematics and Orientations
 Kinematics and Orientations Hierarchies Forward Kinematics Transformations (review) Euler angles Quaternions Yaw and evaluation function for assignment 2 Building a character Just translate, rotate, and
Kinematics and Orientations Hierarchies Forward Kinematics Transformations (review) Euler angles Quaternions Yaw and evaluation function for assignment 2 Building a character Just translate, rotate, and
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos
 Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
7 Modelling and Animating Human Figures. Chapter 7. Modelling and Animating Human Figures. Department of Computer Science and Engineering 7-1
 Modelling and Animating Human Figures 7-1 Introduction Modeling and animating an articulated figure is one of the most formidable tasks that an animator can be faced with. It is especially challenging
Modelling and Animating Human Figures 7-1 Introduction Modeling and animating an articulated figure is one of the most formidable tasks that an animator can be faced with. It is especially challenging
Gait Recognition from Time-normalized Joint-angle Trajectories in the Walking Plane
 Gait Recognition from Time-normalized Joint-angle Trajectories in the Walking Plane Rawesak Tanawongsuwan and Aaron Bobick College of Computing, GVU Center, Georgia Institute of Technology Atlanta, GA
Gait Recognition from Time-normalized Joint-angle Trajectories in the Walking Plane Rawesak Tanawongsuwan and Aaron Bobick College of Computing, GVU Center, Georgia Institute of Technology Atlanta, GA
An Approach for Real Time Moving Object Extraction based on Edge Region Determination
 An Approach for Real Time Moving Object Extraction based on Edge Region Determination Sabrina Hoque Tuli Department of Computer Science and Engineering, Chittagong University of Engineering and Technology,
An Approach for Real Time Moving Object Extraction based on Edge Region Determination Sabrina Hoque Tuli Department of Computer Science and Engineering, Chittagong University of Engineering and Technology,
CS 4758: Automated Semantic Mapping of Environment
 CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
Biometrics Technology: Image Processing & Pattern Recognition (by Dr. Dickson Tong)
") Biometrics Technology: Image Processing & Pattern Recognition (by Dr. Dickson Tong) References: [1] http://homepages.inf.ed.ac.uk/rbf/hipr2/index.htm [2] http://www.cs.wisc.edu/~dyer/cs540/notes/vision.html
Biometrics Technology: Image Processing & Pattern Recognition (by Dr. Dickson Tong) References: [1] http://homepages.inf.ed.ac.uk/rbf/hipr2/index.htm [2] http://www.cs.wisc.edu/~dyer/cs540/notes/vision.html
Motion and Optical Flow. Slides from Ce Liu, Steve Seitz, Larry Zitnick, Ali Farhadi
 Motion and Optical Flow Slides from Ce Liu, Steve Seitz, Larry Zitnick, Ali Farhadi We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
Motion and Optical Flow Slides from Ce Liu, Steve Seitz, Larry Zitnick, Ali Farhadi We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
MOTION. Feature Matching/Tracking. Control Signal Generation REFERENCE IMAGE
 Head-Eye Coordination: A Closed-Form Solution M. Xie School of Mechanical & Production Engineering Nanyang Technological University, Singapore 639798 Email: mmxie@ntuix.ntu.ac.sg ABSTRACT In this paper,
Head-Eye Coordination: A Closed-Form Solution M. Xie School of Mechanical & Production Engineering Nanyang Technological University, Singapore 639798 Email: mmxie@ntuix.ntu.ac.sg ABSTRACT In this paper,
Real-Time Continuous Action Detection and Recognition Using Depth Images and Inertial Signals
 Real-Time Continuous Action Detection and Recognition Using Depth Images and Inertial Signals Neha Dawar 1, Chen Chen 2, Roozbeh Jafari 3, Nasser Kehtarnavaz 1 1 Department of Electrical and Computer Engineering,
Real-Time Continuous Action Detection and Recognition Using Depth Images and Inertial Signals Neha Dawar 1, Chen Chen 2, Roozbeh Jafari 3, Nasser Kehtarnavaz 1 1 Department of Electrical and Computer Engineering,
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Robot Vision without Calibration
 XIV Imeko World Congress. Tampere, 6/97 Robot Vision without Calibration Volker Graefe Institute of Measurement Science Universität der Bw München 85577 Neubiberg, Germany Phone: +49 89 6004-3590, -3587;
XIV Imeko World Congress. Tampere, 6/97 Robot Vision without Calibration Volker Graefe Institute of Measurement Science Universität der Bw München 85577 Neubiberg, Germany Phone: +49 89 6004-3590, -3587;
(Refer Slide Time: 00:01:27 min)
") Computer Aided Design Prof. Dr. Anoop Chawla Department of Mechanical engineering Indian Institute of Technology, Delhi Lecture No. # 01 An Introduction to CAD Today we are basically going to introduce
Computer Aided Design Prof. Dr. Anoop Chawla Department of Mechanical engineering Indian Institute of Technology, Delhi Lecture No. # 01 An Introduction to CAD Today we are basically going to introduce
Motion Analysis. Motion analysis. Now we will talk about. Differential Motion Analysis. Motion analysis. Difference Pictures
 Now we will talk about Motion Analysis Motion analysis Motion analysis is dealing with three main groups of motionrelated problems: Motion detection Moving object detection and location. Derivation of
Now we will talk about Motion Analysis Motion analysis Motion analysis is dealing with three main groups of motionrelated problems: Motion detection Moving object detection and location. Derivation of