Classification and Clustering
|
|
|
- Nickolas Whitehead
- 5 years ago
- Views:
Transcription
1 Chapter 9 Classification and Clustering
2 Classification and Clustering Classification/clustering are classical pattern recognition/ machine learning problems Classification, also referred to as categorization Asks what class does this item belong to? Supervised learning task Clustering Asks how can I group this set of items? Unsupervised learning task Items can be documents, s, queries, entities, images Useful for a wide variety of search engine tasks 2
3 Classification Classification is the task of automatically applying labels to items Useful for many search-related tasks Spam detection Sentiment classification Online advertising Two common approaches Probabilistic Geometric 3
4 How to Classify? How do humans classify items? For example, suppose you had to classify the healthiness of a food Identify set of features indicative of health: fat, cholesterol, sugar, sodium, etc. Extract features from foods Read nutritional facts, chemical analysis, etc. Combine evidence from the features into a hypothesis Add health features together to get healthiness factor Finally, classify the item based on the evidence If healthiness factor is above a certain value, then deem it healthy 4
5 Ontologies Ontology is a labeling or categorization scheme Examples Binary (spam, not spam) Multi-valued (red, green, blue) Hierarchical (news/local/sports) Different classification tasks require different ontologies 5
 Based on the term")
 P(d c) P(c) c C n i=1 c C P(w i c) P(c) n P(w i c) P(c) i=1 (Chain")
6 Naïve Bayes Classifier Probabilistic classifier based on Bayes rule: C (D) is a random variable corresponding to the class (input) Based on the term independence assumption, the Naïve Bayes rule yields: P(c d) = = P(d c) P(c) P(d c) P(c) c C n i=1 c C P(w i c) P(c) n P(w i c) P(c) i=1 (Chain rule) 6
7 Probability 101: Random Variables Random variables are non-deterministic Can be discrete (finite number of outcomes) or continues Model uncertainty in a variable P(X = x) means the probability that random variable X (i.e., its value is not fixed) ) takes on value x Examples. Let X be the outcome of a coin toss, P(X = heads) = P(X = tails) = 0.5 Y = 5-2X. If X is random/deterministic, then Y is random/ deterministic Note: Deterministic just means P(X = x) = 1.0! 7

 and P(c) P(c) is the")
")

8 Naïve Bayes Classifier Documents are classified according to Must estimate P(d c) and P(c) P(c) is the probability of observing class c P(d c) istheprobability that document d is observed given the class is known to be c 8
9 Estimating P(c) P(c) is the probability of observing class c Estimated as the proportion of training documents in class c: N c is the number of training documents in class c N is the total number of training documents 9
10 Estimating P(d c) P(d c) is the probability that document d is observed given the class is known to be c Estimate depends on the event space used to represent the documents What is an event space? The set of all possible outcomes for a given random variable e.g., g, for a coin toss random variable the event space is S = { heads, tails } The probability of an event space S A probability is assigned to each event/outcome in S The sum of fthe probabilities biliti over all the events in S must equal to one 10
11 Multiple Bernoulli Event Space Documents are represented as binary vectors One entry for every word in the vocabulary Entry i =1 1, ifwordi i occurs in the document; 0, otherwise Multiple Bernoulli distribution is a natural way to model distributions over binary vectors Same event space as used in the classical probabilistic retrieval model 11
12 Multiple Bernoulli Document Representation Example. 12
13 Multiple-Bernoulli: Estimating P(d c) P(d c) is computed (in the Multiple-Bernoulli model) as: where (w, d) = 1 iff term w occurs in d; P(d c) = 0 if w d never occurred in c in the training set, the data sparseness problem, which can be solved by the smoothing methods. Laplacian smoothed estimate: where df w,c denotes the number of documents in c including term w N c is the number of documents belonged to class c Collection smoothed estimate: where is a tunable parameter and N w is the no. of doc. including w 13
14 Multinomial Event Space Documents are represented as vectors of term frequencies One entry for every word in the vocabulary Entry i = number of times that term i occurs in the document Multinomial distribution is a natural way to model distributions over frequency vectors Same event space as used in the language modeling retrieval model 14
15 Multinomial Document Representation Example. 15


16 Multinomial: Estimating P(d c) P(d c) is computed as: Probability of Generating a document of Length d Multinomial Coefficient Document Dependent Laplacian smoothed estimate: t Dependent No. of Terms w in Class c where c is the number of terms in the training documents of class c V is the number of distinct terms in the training documents Collection smoothed estimate: Number of term w in a training set c Tunable parameter Number of terms in all training documents 16
17 Multinomial Versus Multiple-Bernoulli Model The Multinomial model is consistently outperform the Multiple-Bernoulli model Implementing both models is relatively straightforward Both classifiers are efficient, since their statistical data can be stored in memory accurate in document classification popular and attractive choice as a general-purpose classifier 17
18 Evaluating Classifiers Common classification metrics Accuracy (precision at rank 1) Precision Recall F-measure ROC curve analysis Differences from IR metrics Relevant replaced with classified correctly Micro-averaging more commonly used in classification Computes a metric ti for every test t instance (document) and then averages over all the instances, whereas Macro-averaging computes the average of the per-class metrics 18
19 Classes of Classifiers Types of classifiers Generative (e.g., Naïve-Bayes): ) assumes some underlying probability distribution on generating (writing) both documents and classes using P(c) and P(d c) Non-parametric (e.g., Nearest Neighbor) Types of learning Supervised (e.g., Naïve-Bayes, SVMs) Semi-supervised (e.g., Rocchio, Relevance models) Unsupervised (e.g., Clustering) 19
20 Generative Classification Models Generative models Assumes documents and classes are drawn from joint distribution P(d, c) Typically P(d c) decomposed to P(d c) P(c) Effectiveness depends on how P(d c) is modeled Typically more effective when little training data exists; otherwise, discriminative (e.g., SVM) or non-parameter models (e.g., nearest neighbor) should be considered 20
21 Naïve Bayes Generative Process Class 1 Class 2 Class 3 Generate class according to P(c) Generate document according to P(d c) Class 2 21
22 Nearest Neighbor Classification Non-parametric classifier: given an unseen example, find the training example that is nearest to it
23 Feature Selection Document classifiers can have a very large number of features Not all features are useful Excessive features can increase computational cost of training and testing Feature selection methods reduce the number of features by choosing the most useful features which can significantly improve efficiency (in terms of storage and processing time) while not hurting the effectiveness much (in addition to eliminating noisy) 23
24 Feature Selection Feature selection is based on entropy/information gain The law of large numbers indicates that the symbol a j will, on the average, be selected n p(a j ) times in a total of n selections The average amount of information obtained from n source outputs for each a j (j 1) with - log 2 p(a j ) bits is n p(a 1 ) log 2 p(a 1 ) n p(a j ) log 2 p(a j ) -1 bits. Divided by n obtain the average amount of information per source output symbol, which is known as uncertainty, or the entropy, E(p): E log2 i 1 p i p i 24
25 Information Gain Information gain is a commonly used feature selection measure based on information theory It tells how much information is gained (about the class labels) if we observe some feature Entropy is the expected information contained in P(c) Rank features by information gain and then train model using the top K (K is typically small) The information gain for a Multiple-Bernoulli Naïve Bayes classifier is computed as: Entropy of P(c) Conditional Entropy 25
26 Information Gain Example. The information gain for the term cheap where P(cheap) denotes P(cheap = 0) P(spam) denotes P(not spam) 0 log 0 = 0 and IG(buy) ( = , IG(banking) ( = 0.043, IG(dinner) = 0.361, IG(the) = 0 26
27 Classification Applications Classification is widely used to enhance search engines Example applications Spam detection ti Sentiment classification Semantic classification of advertisements (based on the semantically-related, not topically-related scope) Others 27
28 Spam, Spam, Spam Classification is widely used to detect various types of spam There are many types of spam Link spam Adding links to message (blog) boards (Joining) Link exchange networks Link farming (spammers buys/creates a large no. of domains/sites) Term spam URL (archive) term spam Dumping (fill documents with unrelated words) Phrase stitching (combine words/sentences from various sources) Weaving (add spam terms into a valid source and post it again) 28
29 Spam Example 29
30 Useful features Unigrams Spam Detection Formatting (invisible text, flashing, etc.) Misspellings IP address (Black list) Different features are useful for different spam detection tasks and Web page spam are by far the most widely studied, d well understood d and easily detected t d types of spam 30
31 Example. Spam Assassin Output 31
32 Sentiment Blogs, online reviews/forum posts are often opinionated Sentiment classification attempts to automatically identify the polarity of the opinion Negative opinion Neutral opinion Positive opinion Sometimes the strength th of fthe opinion i is also important t Two stars vs. four stars Weakly negative vs. strongly negative 32
33 Classifying Sentiment Useful features Unigrams Bigrams Part of speech tags Adjectives SVMs with unigram features have been shown to be outperform hand built rules 33
34 Sentiment Classification Example 34
35 Classifying Online Ads Unlike traditional search, online advertising goes beyond topical relevance A user searching for tropical fish may also be interested in pet stores, local l aquariums, or even scuba diving i lessons These are semantically related, but not topically relevant! We can bridge the semantic gap by classifying i ads and queries according to a semantic hierarchy 35
36 Semantic Classification Semantic hierarchy ontology Example: Pets / Aquariums / Supplies Training data Large number of queries and ads are manually classified into the hierarchy Nearest neighbor classification has been shown to be effective for this task Hierarchical structure of classes can be used to improve classification accuracy 36
37 Semantic Classification Aquariums Fish Supplies Rainbow Fish Resources Discount Tropical Fish Food Feed your tropical fish a gourmet diet for just pennies a day! WbP Web Page Ad 37
38 Clustering A set of unsupervised algorithms that attempt to find latent structure in a set of items Goal is to identify groups (clusters) of similar items, given a set of unlabeled instances Suppose I gave you the shape, color, vitamin C content and price of various fruits and asked you to cluster them What criteria would you use? How would you define similarity? Clustering is very sensitive to how items are represented and dhow similarity is defined! d! 38
39 Clustering General outline of clustering algorithms 1. Decide how items will be represented (e.g., feature vectors) 2. Define similarity measure between pairs or groups of items (e.g., cosine similarity) 3. Determine e what makes a good clustering 4. Iteratively construct clusters that are increasingly good 5. Stop after a local/global optimum clustering is found Steps 3 and 4 differ the most across algorithms 39
40 Hierarchical Clustering Constructs a hierarchy of clusters Starting with some initial clustering of data and iteratively trying to improve the quality of clusters The top level of the hierarchy consists of a single cluster with all items in it The bottom level of the hierarchy consists of N (# of items) singleton clusters Different objectives lead to different types of clusters Two types of hierarchical clustering Divisive ( top down ) Agglomerative ( bottom up ) Hierarchy can be visualized as a dendogram 40
41 Example Dendrogram M I L H K J Height indicates the similarity of the clusters involved A B C D E F G 41
42 Divisive & Agglomerative Hierarchical Clustering Divisive Start with a single cluster consisting of all of the items Until only singleton clusters exist Divideid an existing cluster into two (or more) new clusters Agglomerative Start with N (number of items) singleton clusters Until a single cluster exists Combine two (or more) existing cluster into a new cluster How do we know how to divide or combined clusters? Define a division or combination cost Perform the division or combination with the lowest cost 42
43 Divisive Hierarchical Clustering A D E A D E B C F G B C F G A D E A D E B C F G B C F G 43
44 Agglomerative Hierarchical Clustering A D E A D E B C F G B C F G A D E A D E B C F G B C F G 44








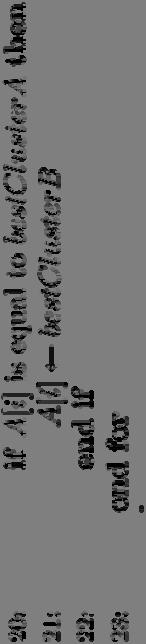

45 Agglomerative Clustering Algorithm 45


46 Clustering Costs Cost: a measure of how expensive to merge 2 clusters Single linkage Complete linkage Average linkage Average group linkage (U C = X C X / C is the centroid of cluster C) 46
47 Clustering Strategies A D Single A Complete E Linkage E Linkage D B C F G B C F G A D * Average Linkage E μ Average Group μ Linkage B C F G μ μ 47
48 K-Means Clustering Hierarchical clustering constructs a hierarchy of clusters K-means always maintains exactly K clusters Clusters represented as centroids ( center of mass ) Basic algorithm: Step 0: Choose K cluster centroids Step 1: Assign points to closet centroid Step 2: Re-compute cluster centroids Step 3: Goto Step 1 Tends to converge quickly Can be sensitive to choice of initial centroids Must choose K! 48
49 K-Means Clustering Goal: find the cluster assignments (for the assignment vectors A[1],, A[N]) that minimize the cost function: K COST(A[1],, A[N]) = dist(x i, C k ) k=1 i:a[i]=k where dist(x i, C k ) = X i - Ck 2, where Ck is the centroid of C k Strategy: = (X i - Ck ). (X i - Ck ), the Euclidean Distance 1. Randomly select K initial cluster centers (instances) as seeds 2. Move the cluster centers around to minimize i i the cost function i. Re-assign instances to the cluster with the closest centroid ii. Re-compute the cost value of each centroid based on the current members of its cluster 49
50 K-Means Clustering Example. (a) (b) (c) (d) (e) 50
51 K-Means Clustering The K-means optimization problem: A naïve approach is to try every possible combination of cluster assignments, which h is infeasible for large data sets The K-means algorithm should find an approximate, heuristic solution that iteratively tries to minimize the cost Anticipated results: 1. the solution is not guaranteed to be globally optimal 2. the solution is not even guaranteed to be locally optimal 3. despite the heuristic nature, the K-means algorithm tends to work very well in practice In practice, K-means clustering tends to converge quickly Compared to hierarchical clustering H, K-means is more efficient and produces clusters of similar quality to H Implementing K-means requires O(KN), rather than O(N 2 ) 51






52 K-Means Clustering Algorithm (* Either randomly or using some knowledge of the data *) (* Each instance is assigned to the closest cluster *) (* The cluster of an instance changes; proceeds *) 52
53 K Nearest Neighbor Clustering Hierarchical and K-Means clustering partition items into clusters Every item is in exactly one cluster K Nearest neighbor clustering forms one cluster per item The cluster for item j consists of j and the K nearest neighbors of j Clusters now overlap 53
54 5 Nearest Neighbor Clustering A A A A A A D D D B B B B B B C C C C D D D C C 54
55 K Nearest Neighbor Clustering Drawbacks of the K Nearest Neighbor Clustering method Often fails to find meaningful clusters In spare areas of the input space, the instances assigned to a cluster are father far away (e.g., D in the 5-NN example) In dense areas, some related instances may be missed if K is not large enough (e.g., B in the 5-NN example) Computational expensive (compared with K-means), since it computes distances between each pair of instances Applications of the K Nearest Neighbor Clustering method Emphasize finding a small number (rather than all) of closely related instances, i.e., precision over recall 55
56 Evaluating Clustering Evaluating clustering is challenging, since it is an unsupervised learning task If labels exist, can use standard IR metrics, e.g., precision/recall If not, then can use measures such as cluster precision, which is defined as: where K (= C ) is the total t number of resultant t clusters MaxClass(C i ) is the number of instances in cluster C i with the most instances of (human-assigned) class label C i N is the total number of instances A th ti i t l t l t i t f d t d Another option is to evaluate clustering as part of an end-to-end system, e.g., clusters to improve web ranking 56
57 How to Choose K? K-means and K nearest neighbor clustering require us to choose K, the number of clusters No theoretically appealing way of choosing K Depends on the application and data; often chosen experimentally to evaluate the quality of the resulting clusters for various values of K Can use hierarchical eac ca custe clustering gand choose the best level e Can use adaptive K for K-nearest neighbor clustering Larger (Smaller) K for dense (spare) areas Challenge: choosing the boundary size Difficult problem with no clear solution 57
58 Adaptive Nearest Neighbor Clustering A A B B B B B B C C C D C C 58
59 Cluster hypothesis Clustering and Search Closely associated documents tend to be relevant to the same requests van Rijsbergen 79 Tends to hold in practice, but not always Two retrieval modeling options (Clustered-based) Rank clusters using P(Q C j )= i=1..n P(q i C j ) Smooth documents (language g model) using K-NN clusters: where f w,d = frequency of word w in D fw,cj = frequency of word w in C j that contains D fw,coll is the frequency of word w in the collection Coll 59
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
Chapter 9. Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Search Engines. Informa1on Retrieval in Prac1ce. Annotations by Michael L. Nelson
 Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Classifica1on and Clustering Classifica1on and clustering are classical padern recogni1on
Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Classifica1on and Clustering Classifica1on and clustering are classical padern recogni1on
Information Retrieval
 Information Retrieval Clustering and Classification All slides unless specifically mentioned are Addison Wesley, 2008; Anton Leuski & Donald Metzler 2012 Clustering and Classification Classification and
Information Retrieval Clustering and Classification All slides unless specifically mentioned are Addison Wesley, 2008; Anton Leuski & Donald Metzler 2012 Clustering and Classification Classification and
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Classification. I don t like spam. Spam, Spam, Spam. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Classification applications in IR Classification! Classification is the task of automatically applying labels to items! Useful for many search-related tasks I
Information Retrieval INFO 4300 / CS 4300! Classification applications in IR Classification! Classification is the task of automatically applying labels to items! Useful for many search-related tasks I
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16)
") CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology
 Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering (COSC 416) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Clustering (COSC 488) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Natural Language Processing
 Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Semi-Supervised Clustering with Partial Background Information
 Semi-Supervised Clustering with Partial Background Information Jing Gao Pang-Ning Tan Haibin Cheng Abstract Incorporating background knowledge into unsupervised clustering algorithms has been the subject
Semi-Supervised Clustering with Partial Background Information Jing Gao Pang-Ning Tan Haibin Cheng Abstract Incorporating background knowledge into unsupervised clustering algorithms has been the subject
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
2. Design Methodology
 Content-aware Email Multiclass Classification Categorize Emails According to Senders Liwei Wang, Li Du s Abstract People nowadays are overwhelmed by tons of coming emails everyday at work or in their daily
Content-aware Email Multiclass Classification Categorize Emails According to Senders Liwei Wang, Li Du s Abstract People nowadays are overwhelmed by tons of coming emails everyday at work or in their daily
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
Classification. 1 o Semestre 2007/2008
 Classification Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 Single-Class
Classification Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 Single-Class
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Hinrich Schütze Center for Information and Language Processing, University of Munich 04-06- /86 Overview Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Hinrich Schütze Center for Information and Language Processing, University of Munich 04-06- /86 Overview Recap
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Document Clustering: Comparison of Similarity Measures
 Document Clustering: Comparison of Similarity Measures Shouvik Sachdeva Bhupendra Kastore Indian Institute of Technology, Kanpur CS365 Project, 2014 Outline 1 Introduction The Problem and the Motivation
Document Clustering: Comparison of Similarity Measures Shouvik Sachdeva Bhupendra Kastore Indian Institute of Technology, Kanpur CS365 Project, 2014 Outline 1 Introduction The Problem and the Motivation
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Introduction to Pattern Recognition Part II. Selim Aksoy Bilkent University Department of Computer Engineering
 Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Predictive Analysis: Evaluation and Experimentation. Heejun Kim
 Predictive Analysis: Evaluation and Experimentation Heejun Kim June 19, 2018 Evaluation and Experimentation Evaluation Metrics Cross-Validation Significance Tests Evaluation Predictive analysis: training
Predictive Analysis: Evaluation and Experimentation Heejun Kim June 19, 2018 Evaluation and Experimentation Evaluation Metrics Cross-Validation Significance Tests Evaluation Predictive analysis: training
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
MI example for poultry/export in Reuters. Overview. Introduction to Information Retrieval. Outline.
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 Outline 1 Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 Outline 1 Recap
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
F. Aiolli - Sistemi Informativi 2006/2007
 Text Categorization Text categorization (TC - aka text classification) is the task of buiding text classifiers, i.e. sofware systems that classify documents from a domain D into a given, fixed set C =
Text Categorization Text categorization (TC - aka text classification) is the task of buiding text classifiers, i.e. sofware systems that classify documents from a domain D into a given, fixed set C =
3. Cluster analysis Overview
 Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Classification Algorithms in Data Mining
 August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
Exploratory Analysis: Clustering
 Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University
 Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Introduction to Machine Learning
 Introduction to Machine Learning Clustering Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1 / 19 Outline
Introduction to Machine Learning Clustering Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1 / 19 Outline
Unsupervised Learning: Clustering
 Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Clustering CE-324: Modern Information Retrieval Sharif University of Technology
 Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Clustering. SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic
 Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
CLUSTERING. JELENA JOVANOVIĆ Web:
 CLUSTERING JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is clustering? Application domains K-Means clustering Understanding it through an example The K-Means algorithm
CLUSTERING JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is clustering? Application domains K-Means clustering Understanding it through an example The K-Means algorithm
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Feature Extractors. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. The Perceptron Update Rule.
 CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
K-Means Clustering 3/3/17
 K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Clustering Part 1. CSC 4510/9010: Applied Machine Learning. Dr. Paula Matuszek
 CSC 4510/9010: Applied Machine Learning 1 Clustering Part 1 Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 What is Clustering? 2 Given some instances with data:
CSC 4510/9010: Applied Machine Learning 1 Clustering Part 1 Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 What is Clustering? 2 Given some instances with data:
Clustering: K-means and Kernel K-means
 Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
Unsupervised learning, Clustering CS434
 Unsupervised learning, Clustering CS434 Unsupervised learning and pattern discovery So far, our data has been in this form: We will be looking at unlabeled data: x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,,
Unsupervised learning, Clustering CS434 Unsupervised learning and pattern discovery So far, our data has been in this form: We will be looking at unlabeled data: x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme
 Entscheidungsunterstützungssysteme") Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some