Scalable GPU Graph Traversal!
|
|
|
- Phoebe Henderson
- 6 years ago
- Views:
Transcription
1 Scalable GPU Graph Traversal Duane Merrill, Michael Garland, and Andrew Grimshaw PPoPP '12 Proceedings of the 17th ACM SIGPLAN symposium on Principles and Practice of Parallel Programming Benwen Zhang Dept of Computer & Information Sciences University of Delaware


2 Introduction Algorithms for analyzing sparse relationships represented as graphs provide crucial tools in many computational fields.
3 Introduction Breadth-first search (BFS) is a core primitive for graph traversal and a basis for many higher-level graph analysis algorithms.
4 Introduction This paper presents a BFS parallelization focused on fine-grained task management constructed from efficient prefix sum that achieves an asymptotically optimal O( V + E ) work complexity. 1. Parallelization strategy 2. Empirical performance characterization 3. High performance
5 Background We consider graphs of the form G = (V, E) with a set V of n vertices and a set E of m directed edges.
6 Background compressed sparse row (CSR) sparse matrix format
7 Background Sequential Breadth-First Search Algorithm

8 Background BFS Graph Traversal
9 Background Parallel breadth-first search 1. Quadratic parallelizations inspect every edge or every vertex during every iteration work complexity is O(n 2 +m) as there may n BFS iterations in the worst case 2. Linear parallelizations each iteration examine only the edges and vertices in that iteration s logical edge and vertex-frontiers, respectively. work-efficient parallel BFS algorithm should perform O(n+m) work 3. Distributed parallelizations partition the graph structure amongst multiple processors, particularly for very large datasets that that are too large to fit within the main memory of a single node.
10 Background Our parallelization strategy 1. our BFS strategy expands adjacent neighbors in parallel 2. implements out-of-core edge and vertex-frontiers 3. uses local prefix sum for determining enqueue offsets 4. uses a best-effort bitmask for efficient neighbor filtering

11 Background Prefix scan produces an output list where each element is computed to be the reduction of the elements occurring earlier in the input list. Prefix sum connotes a prefix scan with the addition operator. In the context of parallel BFS, parallel threads use prefix sum when assembling global edge frontiers and global vertex frontiers.

12

13 Benchmark Suite The majority of the contraction from edge-frontier down to vertex-frontier can actually be performed using duplicate-removal techniques instead of visitation-status lookup.
14 Microbenchmark Analyses A linear BFS workload is composed of two components: O(n) work related to vertex-frontier processing, and O(m) for edge-frontier processing Because the edge-frontier is dominant, we focus our attention on the two fundamental aspects of its operation: neighbor-gathering status-lookup

15 Isolated neighbor-gathering Serial gathering each thread serially expand neighbors from the column-indices array C. non-uniform degree distributions can impose significant load imbalance between threads

16 Isolated neighbor-gathering Coarse-grained, warp*-based gathering each thread enlists its entire warp to gather its assigned adjacency list this approach can suffer underutilization within the warp *Warp: the set of 32 parallel threads that execute a SIMD instruction

17 Isolated neighbor-gathering Fine-grained, scan-based gathering Threads construct a shared array of column-indices offsets corresponding to a CTA**-wide concatenation of their assigned adjacency lists. the entire CTA to gather the referenced neighbors from the column-indices array C using this perfectly packed gather vector. workload imbalance can occur in the form of underutilized cycles during offsetsharing **A CTA is an array of concurrent threads that cooperate to compute a result
18 Isolated neighbor-gathering Scan+warp+CTA gathering(hybrid) We can further mitigate inter-warp workload imbalance by introducing a third granularity of thread-enlistment: the entire CTA. CTA-wide gathering process very large adjacency lists. apply warp-based gathering to acquire adjacency smaller than the CTA size, but greater than the warp width. perform scan-based gathering to efficiently acquire the remaining loose ends.

19 neighbor-gathering analysis
20 neighbor-gathering analysis

21 neighbor-gathering analysis
22 neighbor-gathering analysis This hybrid scan+warp+cta strategy demonstrates good gathering rates. It limits all forms of load imbalance from adjacency list expansion.
23 Isolated status-lookup Bitmask reduce the size of status data from a 32-bit label to a single bit per vertex. we avoid atomic operations, our bitmask is only a conservative approximation of visitation status. Bitmask + Label If a status bit is unset, we then check the corresponding label Warp culling Using shared-memory per warp, each thread hashes in the neighbor it is currently inspecting. History culling maintaining a cache of recently- inspected vertex identifiers in local shared memory.

24 Isolated status-lookup

25 Coupling of gathering and lookup The coupled kernel requires O(m) less overall data movement The fused kernel likely suffers from TLB misses experienced by the neighborgathering workload, and it inherits the worst aspects of both
26 Single-GPU Parallelizations A complete solution must couple expansion and contraction activities. 1. Expand-contract (out-of-core vertex queue) based upon the fused gather-lookup benchmark kernel It consumes the vertex queue for the current BFS iteration and produces the vertex queue for the next requires 2n global storage and generate 5n+2m global data movement 2. Contract-expand (out-of-core edge queue) filters previously-visited and duplicate neighbors from the current edge queue, and then surviving vertices are expanded and copied out into the edge queue for the next iteration. requires 2m global storage and generate 3n+4m explicit global data movement.
27 Single-GPU Parallelizations Two-phase (out-of-core vertex and edge queues) implementation isolates the expansion and contraction workloads into separate kernels. requires n+m global storage and generates 5n+4m explicit global data movement. Hybrid combines the relative strengths of the contract-expand and two-phase approaches If the edge queue for a given BFS iteration contains more vertex identifiers than resident threads, we invoke the two-phase implementation for that iteration. Otherwise we invoke the contract-expand implementation. The hybrid approach inherits the 2m global storage requirement from the former and the 5n+4m explicit global data movement from the latter.

28 Single-GPU Parallelizations
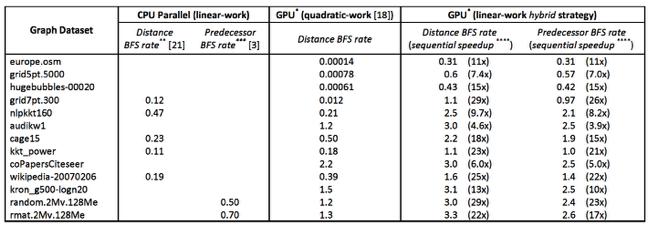
29 Single-GPU Parallelizations
30 Multi-GPU Parallelizations We implement a simple partitioning of the graph into equally- sized, disjoint subsets of V. Graph traversal proceeds in level-synchronous fashion. 1. Invoke the expansion kernel on each GPU 2. Invoke a fused filter+partition operation for each GPU that sorts neighbors within Qedgei by ownership into p bins. 3. Barrier across all GPUs 4. Invoke p-1 contraction kernels on each GPUi to stream and filter the incoming neighbors from its peers. This assembles each vertex queue Qvertexi for the next BFS iteration.

31 Multi-GPU Parallelizations slowdown for datasets having large average search depth and require more global synchronization. speedups for datasets that have small diameters and require little global synchronization.
32 Conclusion This paper has demonstrated that GPUs are well-suited for sparse graph traversal. It distills several general themes for implementing sparse and dynamic problems for the GPU machine model: Prefix sum is an effective mechanisms for coordinating shared data by threads. GPU threads should cooperatively assist each other for data movement tasks. Fusing heterogeneous tasks does not always produce the best results. The relative I/O contribution from global task redistribution can be less costly than anticipated. It is useful to provide separate implementations for saturating versus fleeting workloads.
GPU Sparse Graph Traversal. Duane Merrill
 GPU Sparse Graph Traversal Duane Merrill Breadth-first search of graphs (BFS) 1. Pick a source node 2. Rank every vertex by the length of shortest path from source Or label every vertex by its predecessor
GPU Sparse Graph Traversal Duane Merrill Breadth-first search of graphs (BFS) 1. Pick a source node 2. Rank every vertex by the length of shortest path from source Or label every vertex by its predecessor
GPU Sparse Graph Traversal
 GPU Sparse Graph Traversal Duane Merrill (NVIDIA) Michael Garland (NVIDIA) Andrew Grimshaw (Univ. of Virginia) UNIVERSITY of VIRGINIA Breadth-first search (BFS) 1. Pick a source node 2. Rank every vertex
GPU Sparse Graph Traversal Duane Merrill (NVIDIA) Michael Garland (NVIDIA) Andrew Grimshaw (Univ. of Virginia) UNIVERSITY of VIRGINIA Breadth-first search (BFS) 1. Pick a source node 2. Rank every vertex
Duane Merrill (NVIDIA) Michael Garland (NVIDIA)
 Michael Garland (NVIDIA)") Duane Merrill (NVIDIA) Michael Garland (NVIDIA) Agenda Sparse graphs Breadth-first search (BFS) Maximal independent set (MIS) 1 1 0 1 1 1 3 1 3 1 5 10 6 9 8 7 3 4 BFS MIS Sparse graphs Graph G(V, E) where
Duane Merrill (NVIDIA) Michael Garland (NVIDIA) Agenda Sparse graphs Breadth-first search (BFS) Maximal independent set (MIS) 1 1 0 1 1 1 3 1 3 1 5 10 6 9 8 7 3 4 BFS MIS Sparse graphs Graph G(V, E) where
Scalable GPU Graph Traversal
 Scalable GPU Graph Traversal Duane Merrill University of Virginia Charlottesville Virginia USA dgmd@virginia.edu Michael Garland NVIDIA Corporation Santa Clara California USA mgarland@nvidia.com Andrew
Scalable GPU Graph Traversal Duane Merrill University of Virginia Charlottesville Virginia USA dgmd@virginia.edu Michael Garland NVIDIA Corporation Santa Clara California USA mgarland@nvidia.com Andrew
High-Performance Graph Primitives on the GPU: Design and Implementation of Gunrock
 High-Performance Graph Primitives on the GPU: Design and Implementation of Gunrock Yangzihao Wang University of California, Davis yzhwang@ucdavis.edu March 24, 2014 Yangzihao Wang (yzhwang@ucdavis.edu)
High-Performance Graph Primitives on the GPU: Design and Implementation of Gunrock Yangzihao Wang University of California, Davis yzhwang@ucdavis.edu March 24, 2014 Yangzihao Wang (yzhwang@ucdavis.edu)
High Performance and Scalable GPU Graph Traversal
 High Performance and Scalable GPU Graph Traversal Duane Merrill Department of Computer Science University of Virginia Technical Report CS-- Department of Computer Science, University of Virginia Aug, Michael
High Performance and Scalable GPU Graph Traversal Duane Merrill Department of Computer Science University of Virginia Technical Report CS-- Department of Computer Science, University of Virginia Aug, Michael
Graph traversal and BFS
 Graph traversal and BFS Fundamental building block Graph traversal is part of many important tasks Connected components Tree/Cycle detection Articulation vertex finding Real-world applications Peer-to-peer
Graph traversal and BFS Fundamental building block Graph traversal is part of many important tasks Connected components Tree/Cycle detection Articulation vertex finding Real-world applications Peer-to-peer
A POWER CHARACTERIZATION AND MANAGEMENT OF GPU GRAPH TRAVERSAL
 A POWER CHARACTERIZATION AND MANAGEMENT OF GPU GRAPH TRAVERSAL ADAM MCLAUGHLIN *, INDRANI PAUL, JOSEPH GREATHOUSE, SRILATHA MANNE, AND SUDHKAHAR YALAMANCHILI * * GEORGIA INSTITUTE OF TECHNOLOGY AMD RESEARCH
A POWER CHARACTERIZATION AND MANAGEMENT OF GPU GRAPH TRAVERSAL ADAM MCLAUGHLIN *, INDRANI PAUL, JOSEPH GREATHOUSE, SRILATHA MANNE, AND SUDHKAHAR YALAMANCHILI * * GEORGIA INSTITUTE OF TECHNOLOGY AMD RESEARCH
Accelerated Load Balancing of Unstructured Meshes
 Accelerated Load Balancing of Unstructured Meshes Gerrett Diamond, Lucas Davis, and Cameron W. Smith Abstract Unstructured mesh applications running on large, parallel, distributed memory systems require
Accelerated Load Balancing of Unstructured Meshes Gerrett Diamond, Lucas Davis, and Cameron W. Smith Abstract Unstructured mesh applications running on large, parallel, distributed memory systems require
Graph Partitioning for Scalable Distributed Graph Computations
 Graph Partitioning for Scalable Distributed Graph Computations Aydın Buluç ABuluc@lbl.gov Kamesh Madduri madduri@cse.psu.edu 10 th DIMACS Implementation Challenge, Graph Partitioning and Graph Clustering
Graph Partitioning for Scalable Distributed Graph Computations Aydın Buluç ABuluc@lbl.gov Kamesh Madduri madduri@cse.psu.edu 10 th DIMACS Implementation Challenge, Graph Partitioning and Graph Clustering
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark. by Nkemdirim Dockery
 Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Introduction to Parallel Programming Models
 Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
Towards Efficient Graph Traversal using a Multi- GPU Cluster
 Towards Efficient Graph Traversal using a Multi- GPU Cluster Hina Hameed Systems Research Lab, Department of Computer Science, FAST National University of Computer and Emerging Sciences Karachi, Pakistan
Towards Efficient Graph Traversal using a Multi- GPU Cluster Hina Hameed Systems Research Lab, Department of Computer Science, FAST National University of Computer and Emerging Sciences Karachi, Pakistan
CuSha: Vertex-Centric Graph Processing on GPUs
 CuSha: Vertex-Centric Graph Processing on GPUs Farzad Khorasani, Keval Vora, Rajiv Gupta, Laxmi N. Bhuyan HPDC Vancouver, Canada June, Motivation Graph processing Real world graphs are large & sparse Power
CuSha: Vertex-Centric Graph Processing on GPUs Farzad Khorasani, Keval Vora, Rajiv Gupta, Laxmi N. Bhuyan HPDC Vancouver, Canada June, Motivation Graph processing Real world graphs are large & sparse Power
Automatic Compiler-Based Optimization of Graph Analytics for the GPU. Sreepathi Pai The University of Texas at Austin. May 8, 2017 NVIDIA GTC
 Automatic Compiler-Based Optimization of Graph Analytics for the GPU Sreepathi Pai The University of Texas at Austin May 8, 2017 NVIDIA GTC Parallel Graph Processing is not easy 299ms HD-BFS 84ms USA Road
Automatic Compiler-Based Optimization of Graph Analytics for the GPU Sreepathi Pai The University of Texas at Austin May 8, 2017 NVIDIA GTC Parallel Graph Processing is not easy 299ms HD-BFS 84ms USA Road
Practical Near-Data Processing for In-Memory Analytics Frameworks
 Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
Corolla: GPU-Accelerated FPGA Routing Based on Subgraph Dynamic Expansion
 Corolla: GPU-Accelerated FPGA Routing Based on Subgraph Dynamic Expansion Minghua Shen and Guojie Luo Peking University FPGA-February 23, 2017 1 Contents Motivation Background Search Space Reduction for
Corolla: GPU-Accelerated FPGA Routing Based on Subgraph Dynamic Expansion Minghua Shen and Guojie Luo Peking University FPGA-February 23, 2017 1 Contents Motivation Background Search Space Reduction for
An Energy-Efficient Abstraction for Simultaneous Breadth-First Searches. Adam McLaughlin, Jason Riedy, and David A. Bader
 An Energy-Efficient Abstraction for Simultaneous Breadth-First Searches Adam McLaughlin, Jason Riedy, and David A. Bader Problem Data is unstructured, heterogeneous, and vast Serious opportunities for
An Energy-Efficient Abstraction for Simultaneous Breadth-First Searches Adam McLaughlin, Jason Riedy, and David A. Bader Problem Data is unstructured, heterogeneous, and vast Serious opportunities for
Workloads Programmierung Paralleler und Verteilter Systeme (PPV)
") Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18
 Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload)
") Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
GPU Multisplit. Saman Ashkiani, Andrew Davidson, Ulrich Meyer, John D. Owens. S. Ashkiani (UC Davis) GPU Multisplit GTC / 16
 GPU Multisplit GTC / 16") GPU Multisplit Saman Ashkiani, Andrew Davidson, Ulrich Meyer, John D. Owens S. Ashkiani (UC Davis) GPU Multisplit GTC 2016 1 / 16 Motivating Simple Example: Compaction Compaction (i.e., binary split) Traditional
GPU Multisplit Saman Ashkiani, Andrew Davidson, Ulrich Meyer, John D. Owens S. Ashkiani (UC Davis) GPU Multisplit GTC 2016 1 / 16 Motivating Simple Example: Compaction Compaction (i.e., binary split) Traditional
CUB. collective software primitives. Duane Merrill. NVIDIA Research
 CUB collective software primitives Duane Merrill NVIDIA Research What is CUB?. A design model for collective primitives How to make reusable SIMT software constructs. A library of collective primitives
CUB collective software primitives Duane Merrill NVIDIA Research What is CUB?. A design model for collective primitives How to make reusable SIMT software constructs. A library of collective primitives
Enterprise. Breadth-First Graph Traversal on GPUs. November 19th, 2015
 Enterprise Breadth-First Graph Traversal on GPUs Hang Liu H. Howie Huang November 9th, 5 Graph is Ubiquitous Breadth-First Search (BFS) is Important Wide Range of Applications Single Source Shortest Path
Enterprise Breadth-First Graph Traversal on GPUs Hang Liu H. Howie Huang November 9th, 5 Graph is Ubiquitous Breadth-First Search (BFS) is Important Wide Range of Applications Single Source Shortest Path
Introduction to Parallel Computing. CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014
 Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
A Comparative Study on Exact Triangle Counting Algorithms on the GPU
 A Comparative Study on Exact Triangle Counting Algorithms on the GPU Leyuan Wang, Yangzihao Wang, Carl Yang, John D. Owens University of California, Davis, CA, USA 31 st May 2016 L. Wang, Y. Wang, C. Yang,
A Comparative Study on Exact Triangle Counting Algorithms on the GPU Leyuan Wang, Yangzihao Wang, Carl Yang, John D. Owens University of California, Davis, CA, USA 31 st May 2016 L. Wang, Y. Wang, C. Yang,
Mosaic: Processing a Trillion-Edge Graph on a Single Machine
 Mosaic: Processing a Trillion-Edge Graph on a Single Machine Steffen Maass, Changwoo Min, Sanidhya Kashyap, Woonhak Kang, Mohan Kumar, Taesoo Kim Georgia Institute of Technology Best Student Paper @ EuroSys
Mosaic: Processing a Trillion-Edge Graph on a Single Machine Steffen Maass, Changwoo Min, Sanidhya Kashyap, Woonhak Kang, Mohan Kumar, Taesoo Kim Georgia Institute of Technology Best Student Paper @ EuroSys
Breadth First Search on Cost efficient Multi GPU Systems
 Breadth First Search on Cost efficient Multi Systems Takuji Mitsuishi Keio University 3 14 1 Hiyoshi, Yokohama, 223 8522, Japan mits@am.ics.keio.ac.jp Masaki Kan NEC Corporation 1753, Shimonumabe, Nakahara
Breadth First Search on Cost efficient Multi Systems Takuji Mitsuishi Keio University 3 14 1 Hiyoshi, Yokohama, 223 8522, Japan mits@am.ics.keio.ac.jp Masaki Kan NEC Corporation 1753, Shimonumabe, Nakahara
Maximizing Face Detection Performance
 Maximizing Face Detection Performance Paulius Micikevicius Developer Technology Engineer, NVIDIA GTC 2015 1 Outline Very brief review of cascaded-classifiers Parallelization choices Reducing the amount
Maximizing Face Detection Performance Paulius Micikevicius Developer Technology Engineer, NVIDIA GTC 2015 1 Outline Very brief review of cascaded-classifiers Parallelization choices Reducing the amount
Boosting the Performance of FPGA-based Graph Processor using Hybrid Memory Cube: A Case for Breadth First Search
 Boosting the Performance of FPGA-based Graph Processor using Hybrid Memory Cube: A Case for Breadth First Search Jialiang Zhang, Soroosh Khoram and Jing Li 1 Outline Background Big graph analytics Hybrid
Boosting the Performance of FPGA-based Graph Processor using Hybrid Memory Cube: A Case for Breadth First Search Jialiang Zhang, Soroosh Khoram and Jing Li 1 Outline Background Big graph analytics Hybrid
Scalable Algorithmic Techniques Decompositions & Mapping. Alexandre David
 Scalable Algorithmic Techniques Decompositions & Mapping Alexandre David 1.2.05 adavid@cs.aau.dk Introduction Focus on data parallelism, scale with size. Task parallelism limited. Notion of scalability
Scalable Algorithmic Techniques Decompositions & Mapping Alexandre David 1.2.05 adavid@cs.aau.dk Introduction Focus on data parallelism, scale with size. Task parallelism limited. Notion of scalability
Tools and Primitives for High Performance Graph Computation
 Tools and Primitives for High Performance Graph Computation John R. Gilbert University of California, Santa Barbara Aydin Buluç (LBNL) Adam Lugowski (UCSB) SIAM Minisymposium on Analyzing Massive Real-World
Tools and Primitives for High Performance Graph Computation John R. Gilbert University of California, Santa Barbara Aydin Buluç (LBNL) Adam Lugowski (UCSB) SIAM Minisymposium on Analyzing Massive Real-World
Parallel graph traversal for FPGA
 LETTER IEICE Electronics Express, Vol.11, No.7, 1 6 Parallel graph traversal for FPGA Shice Ni a), Yong Dou, Dan Zou, Rongchun Li, and Qiang Wang National Laboratory for Parallel and Distributed Processing,
LETTER IEICE Electronics Express, Vol.11, No.7, 1 6 Parallel graph traversal for FPGA Shice Ni a), Yong Dou, Dan Zou, Rongchun Li, and Qiang Wang National Laboratory for Parallel and Distributed Processing,
Dynamic Thread Block Launch: A Lightweight Execution Mechanism to Support Irregular Applications on GPUs
 Dynamic Thread Block Launch: A Lightweight Execution Mechanism to Support Irregular Applications on GPUs Jin Wang* Norm Rubin Albert Sidelnik Sudhakar Yalamanchili* *Georgia Institute of Technology NVIDIA
Dynamic Thread Block Launch: A Lightweight Execution Mechanism to Support Irregular Applications on GPUs Jin Wang* Norm Rubin Albert Sidelnik Sudhakar Yalamanchili* *Georgia Institute of Technology NVIDIA
Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload)
") Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Today Finishing up from last time Brief discussion of graphics workload metrics
Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Today Finishing up from last time Brief discussion of graphics workload metrics
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
Scheduling the Graphics Pipeline on a GPU
 Lecture 20: Scheduling the Graphics Pipeline on a GPU Visual Computing Systems Today Real-time 3D graphics workload metrics Scheduling the graphics pipeline on a modern GPU Quick aside: tessellation Triangle
Lecture 20: Scheduling the Graphics Pipeline on a GPU Visual Computing Systems Today Real-time 3D graphics workload metrics Scheduling the graphics pipeline on a modern GPU Quick aside: tessellation Triangle
Parallel Programming Patterns Overview CS 472 Concurrent & Parallel Programming University of Evansville
 Parallel Programming Patterns Overview CS 472 Concurrent & Parallel Programming of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information
Parallel Programming Patterns Overview CS 472 Concurrent & Parallel Programming of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Parallel Breadth First Search
 CSE341T/CSE549T 11/03/2014 Lecture 18 Parallel Breadth First Search Today, we will look at a basic graph algorithm, breadth first search (BFS). BFS can be applied to solve a variety of problems including:
CSE341T/CSE549T 11/03/2014 Lecture 18 Parallel Breadth First Search Today, we will look at a basic graph algorithm, breadth first search (BFS). BFS can be applied to solve a variety of problems including:
CSE 599 I Accelerated Computing - Programming GPUS. Parallel Patterns: Graph Search
 CSE 599 I Accelerated Computing - Programming GPUS Parallel Patterns: Graph Search Objective Study graph search as a prototypical graph-based algorithm Learn techniques to mitigate the memory-bandwidth-centric
CSE 599 I Accelerated Computing - Programming GPUS Parallel Patterns: Graph Search Objective Study graph search as a prototypical graph-based algorithm Learn techniques to mitigate the memory-bandwidth-centric
Gunrock: A Fast and Programmable Multi- GPU Graph Processing Library
 Gunrock: A Fast and Programmable Multi- GPU Graph Processing Library Yangzihao Wang and Yuechao Pan with Andrew Davidson, Yuduo Wu, Carl Yang, Leyuan Wang, Andy Riffel and John D. Owens University of California,
Gunrock: A Fast and Programmable Multi- GPU Graph Processing Library Yangzihao Wang and Yuechao Pan with Andrew Davidson, Yuduo Wu, Carl Yang, Leyuan Wang, Andy Riffel and John D. Owens University of California,
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Administrative Issues. L11: Sparse Linear Algebra on GPUs. Triangular Solve (STRSM) A Few Details 2/25/11. Next assignment, triangular solve
 A Few Details 2/25/11. Next assignment, triangular solve") Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
A Simple and Practical Linear-Work Parallel Algorithm for Connectivity
 A Simple and Practical Linear-Work Parallel Algorithm for Connectivity Julian Shun, Laxman Dhulipala, and Guy Blelloch Presentation based on publication in Symposium on Parallelism in Algorithms and Architectures
A Simple and Practical Linear-Work Parallel Algorithm for Connectivity Julian Shun, Laxman Dhulipala, and Guy Blelloch Presentation based on publication in Symposium on Parallelism in Algorithms and Architectures
Parallel Variable-Length Encoding on GPGPUs
 Parallel Variable-Length Encoding on GPGPUs Ana Balevic University of Stuttgart ana.balevic@gmail.com Abstract. Variable-Length Encoding (VLE) is a process of reducing input data size by replacing fixed-length
Parallel Variable-Length Encoding on GPGPUs Ana Balevic University of Stuttgart ana.balevic@gmail.com Abstract. Variable-Length Encoding (VLE) is a process of reducing input data size by replacing fixed-length
Parallel Systems Course: Chapter VIII. Sorting Algorithms. Kumar Chapter 9. Jan Lemeire ETRO Dept. November Parallel Sorting
 Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. November 2014 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. November 2014 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Lecture 6: Input Compaction and Further Studies
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 6: Input Compaction and Further Studies 1 Objective To learn the key techniques for compacting input data for reduced consumption of
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 6: Input Compaction and Further Studies 1 Objective To learn the key techniques for compacting input data for reduced consumption of
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 9 Workload Evaluation Outline Evaluation of applications is important Simulation of sample data sets provides important information Working sets indicate
ECE 669 Parallel Computer Architecture Lecture 9 Workload Evaluation Outline Evaluation of applications is important Simulation of sample data sets provides important information Working sets indicate
Coordinating More Than 3 Million CUDA Threads for Social Network Analysis. Adam McLaughlin
 Coordinating More Than 3 Million CUDA Threads for Social Network Analysis Adam McLaughlin Applications of interest Computational biology Social network analysis Urban planning Epidemiology Hardware verification
Coordinating More Than 3 Million CUDA Threads for Social Network Analysis Adam McLaughlin Applications of interest Computational biology Social network analysis Urban planning Epidemiology Hardware verification
Fine-Grained Task Migration for Graph Algorithms using Processing in Memory
 Fine-Grained Task Migration for Graph Algorithms using Processing in Memory Paula Aguilera 1, Dong Ping Zhang 2, Nam Sung Kim 3 and Nuwan Jayasena 2 1 Dept. of Electrical and Computer Engineering University
Fine-Grained Task Migration for Graph Algorithms using Processing in Memory Paula Aguilera 1, Dong Ping Zhang 2, Nam Sung Kim 3 and Nuwan Jayasena 2 1 Dept. of Electrical and Computer Engineering University
Policy-based Tuning for Performance Portability and Library Co-optimization
 Policy-based Tuning for Performance Portability and Library Co-optimization Duane Merrill NVIDIA Corporation Santa Clara California USA dumerrill@nvdia.com Michael Garland NVIDIA Corporation Santa Clara
Policy-based Tuning for Performance Portability and Library Co-optimization Duane Merrill NVIDIA Corporation Santa Clara California USA dumerrill@nvdia.com Michael Garland NVIDIA Corporation Santa Clara
Locality-Aware Software Throttling for Sparse Matrix Operation on GPUs
 Locality-Aware Software Throttling for Sparse Matrix Operation on GPUs Yanhao Chen 1, Ari B. Hayes 1, Chi Zhang 2, Timothy Salmon 1, Eddy Z. Zhang 1 1. Rutgers University 2. University of Pittsburgh Sparse
Locality-Aware Software Throttling for Sparse Matrix Operation on GPUs Yanhao Chen 1, Ari B. Hayes 1, Chi Zhang 2, Timothy Salmon 1, Eddy Z. Zhang 1 1. Rutgers University 2. University of Pittsburgh Sparse
Performance impact of dynamic parallelism on different clustering algorithms
 Performance impact of dynamic parallelism on different clustering algorithms Jeffrey DiMarco and Michela Taufer Computer and Information Sciences, University of Delaware E-mail: jdimarco@udel.edu, taufer@udel.edu
Performance impact of dynamic parallelism on different clustering algorithms Jeffrey DiMarco and Michela Taufer Computer and Information Sciences, University of Delaware E-mail: jdimarco@udel.edu, taufer@udel.edu
Parallel Systems Course: Chapter VIII. Sorting Algorithms. Kumar Chapter 9. Jan Lemeire ETRO Dept. Fall Parallel Sorting
 Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. Fall 2017 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
Parallel Systems Course: Chapter VIII Sorting Algorithms Kumar Chapter 9 Jan Lemeire ETRO Dept. Fall 2017 Overview 1. Parallel sort distributed memory 2. Parallel sort shared memory 3. Sorting Networks
An Integrated Synchronization and Consistency Protocol for the Implementation of a High-Level Parallel Programming Language
 An Integrated Synchronization and Consistency Protocol for the Implementation of a High-Level Parallel Programming Language Martin C. Rinard (martin@cs.ucsb.edu) Department of Computer Science University
An Integrated Synchronization and Consistency Protocol for the Implementation of a High-Level Parallel Programming Language Martin C. Rinard (martin@cs.ucsb.edu) Department of Computer Science University
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Recent Advances in Heterogeneous Computing using Charm++
 Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
CSC630/COS781: Parallel & Distributed Computing
 CSC630/COS781: Parallel & Distributed Computing Algorithm Design Chapter 3 (3.1-3.3) 1 Contents Preliminaries of parallel algorithm design Decomposition Task dependency Task dependency graph Granularity
CSC630/COS781: Parallel & Distributed Computing Algorithm Design Chapter 3 (3.1-3.3) 1 Contents Preliminaries of parallel algorithm design Decomposition Task dependency Task dependency graph Granularity
Chapter 3 Parallel Software
 Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Multipredicate Join Algorithms for Accelerating Relational Graph Processing on GPUs
 Multipredicate Join Algorithms for Accelerating Relational Graph Processing on GPUs Haicheng Wu 1, Daniel Zinn 2, Molham Aref 2, Sudhakar Yalamanchili 1 1. Georgia Institute of Technology 2. LogicBlox
Multipredicate Join Algorithms for Accelerating Relational Graph Processing on GPUs Haicheng Wu 1, Daniel Zinn 2, Molham Aref 2, Sudhakar Yalamanchili 1 1. Georgia Institute of Technology 2. LogicBlox
Fast BVH Construction on GPUs
 Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Prefix Scan and Minimum Spanning Tree with OpenCL
 Prefix Scan and Minimum Spanning Tree with OpenCL U. VIRGINIA DEPT. OF COMP. SCI TECH. REPORT CS-2013-02 Yixin Sun and Kevin Skadron Dept. of Computer Science, University of Virginia ys3kz@virginia.edu,
Prefix Scan and Minimum Spanning Tree with OpenCL U. VIRGINIA DEPT. OF COMP. SCI TECH. REPORT CS-2013-02 Yixin Sun and Kevin Skadron Dept. of Computer Science, University of Virginia ys3kz@virginia.edu,
Social graphs (Facebook, Twitter, Google+, LinkedIn, etc.) Endorsement graphs (web link graph, paper citation graph, etc.)
 Endorsement graphs (web link graph, paper citation graph, etc.)") Large-Scale Graph Processing Algorithms on the GPU Yangzihao Wang, Computer Science, UC Davis John Owens, Electrical and Computer Engineering, UC Davis 1 Overview The past decade has seen a growing research
Large-Scale Graph Processing Algorithms on the GPU Yangzihao Wang, Computer Science, UC Davis John Owens, Electrical and Computer Engineering, UC Davis 1 Overview The past decade has seen a growing research
Parallel Combinatorial BLAS and Applications in Graph Computations
 Parallel Combinatorial BLAS and Applications in Graph Computations Aydın Buluç John R. Gilbert University of California, Santa Barbara SIAM ANNUAL MEETING 2009 July 8, 2009 1 Primitives for Graph Computations
Parallel Combinatorial BLAS and Applications in Graph Computations Aydın Buluç John R. Gilbert University of California, Santa Barbara SIAM ANNUAL MEETING 2009 July 8, 2009 1 Primitives for Graph Computations
State of Art and Project Proposals Intensive Computation
 State of Art and Project Proposals Intensive Computation Annalisa Massini - 2015/2016 Today s lecture Project proposals on the following topics: Sparse Matrix- Vector Multiplication Tridiagonal Solvers
State of Art and Project Proposals Intensive Computation Annalisa Massini - 2015/2016 Today s lecture Project proposals on the following topics: Sparse Matrix- Vector Multiplication Tridiagonal Solvers
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Execution Strategy and Runtime Support for Regular and Irregular Applications on Emerging Parallel Architectures
 Execution Strategy and Runtime Support for Regular and Irregular Applications on Emerging Parallel Architectures Xin Huo Advisor: Gagan Agrawal Motivation - Architecture Challenges on GPU architecture
Execution Strategy and Runtime Support for Regular and Irregular Applications on Emerging Parallel Architectures Xin Huo Advisor: Gagan Agrawal Motivation - Architecture Challenges on GPU architecture
Image-Space-Parallel Direct Volume Rendering on a Cluster of PCs
 Image-Space-Parallel Direct Volume Rendering on a Cluster of PCs B. Barla Cambazoglu and Cevdet Aykanat Bilkent University, Department of Computer Engineering, 06800, Ankara, Turkey {berkant,aykanat}@cs.bilkent.edu.tr
Image-Space-Parallel Direct Volume Rendering on a Cluster of PCs B. Barla Cambazoglu and Cevdet Aykanat Bilkent University, Department of Computer Engineering, 06800, Ankara, Turkey {berkant,aykanat}@cs.bilkent.edu.tr
Dynamic Load Balancing on Single- and Multi-GPU Systems
 Dynamic Load Balancing on Single- and Multi-GPU Systems Long Chen, Oreste Villa, Sriram Krishnamoorthy, Guang R. Gao Department of Electrical & Computer Engineering High Performance Computing University
Dynamic Load Balancing on Single- and Multi-GPU Systems Long Chen, Oreste Villa, Sriram Krishnamoorthy, Guang R. Gao Department of Electrical & Computer Engineering High Performance Computing University
Deploying Graph Algorithms on GPUs: an Adaptive Solution
 Deploying Graph Algorithms on GPUs: an Adaptive Solution Da Li Dept. of Electrical and Computer Engineering University of Missouri - Columbia dlx7f@mail.missouri.edu Abstract Thanks to their massive computational
Deploying Graph Algorithms on GPUs: an Adaptive Solution Da Li Dept. of Electrical and Computer Engineering University of Missouri - Columbia dlx7f@mail.missouri.edu Abstract Thanks to their massive computational
CS4961 Parallel Programming. Lecture 5: Data and Task Parallelism, cont. 9/8/09. Administrative. Mary Hall September 8, 2009.
 CS4961 Parallel Programming Lecture 5: Data and Task Parallelism, cont. Administrative Homework 2 posted, due September 10 before class - Use the handin program on the CADE machines - Use the following
CS4961 Parallel Programming Lecture 5: Data and Task Parallelism, cont. Administrative Homework 2 posted, due September 10 before class - Use the handin program on the CADE machines - Use the following
A Simple and Practical Linear-Work Parallel Algorithm for Connectivity
 A Simple and Practical Linear-Work Parallel Algorithm for Connectivity Julian Shun, Laxman Dhulipala, and Guy Blelloch Presentation based on publication in Symposium on Parallelism in Algorithms and Architectures
A Simple and Practical Linear-Work Parallel Algorithm for Connectivity Julian Shun, Laxman Dhulipala, and Guy Blelloch Presentation based on publication in Symposium on Parallelism in Algorithms and Architectures
BFS preconditioning for high locality, data parallel BFS algorithm N.Vasilache, B. Meister, M. Baskaran, R.Lethin. Reservoir Labs
 BFS preconditioning for high locality, data parallel BFS algorithm N.Vasilache, B. Meister, M. Baskaran, R.Lethin Problem Streaming Graph Challenge Characteristics: Large scale Highly dynamic Scale-free
BFS preconditioning for high locality, data parallel BFS algorithm N.Vasilache, B. Meister, M. Baskaran, R.Lethin Problem Streaming Graph Challenge Characteristics: Large scale Highly dynamic Scale-free
Parallel Systems Prof. James L. Frankel Harvard University. Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved.
 Parallel Systems Prof. James L. Frankel Harvard University Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved. Architectures SISD (Single Instruction, Single Data)
Parallel Systems Prof. James L. Frankel Harvard University Version of 6:50 PM 4-Dec-2018 Copyright 2018, 2017 James L. Frankel. All rights reserved. Architectures SISD (Single Instruction, Single Data)
Problem. Context. Hash table
 Problem In many problems, it is natural to use Hash table as their data structures. How can the hash table be efficiently accessed among multiple units of execution (UEs)? Context Hash table is used when
Problem In many problems, it is natural to use Hash table as their data structures. How can the hash table be efficiently accessed among multiple units of execution (UEs)? Context Hash table is used when
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Piccolo: Building Fast, Distributed Programs
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Piccolo: Building Fast, Distributed Programs
Algorithms and Applications
 Algorithms and Applications 1 Areas done in textbook: Sorting Algorithms Numerical Algorithms Image Processing Searching and Optimization 2 Chapter 10 Sorting Algorithms - rearranging a list of numbers
Algorithms and Applications 1 Areas done in textbook: Sorting Algorithms Numerical Algorithms Image Processing Searching and Optimization 2 Chapter 10 Sorting Algorithms - rearranging a list of numbers
Lecture 13: March 25
 CISC 879 Software Support for Multicore Architectures Spring 2007 Lecture 13: March 25 Lecturer: John Cavazos Scribe: Ying Yu 13.1. Bryan Youse-Optimization of Sparse Matrix-Vector Multiplication on Emerging
CISC 879 Software Support for Multicore Architectures Spring 2007 Lecture 13: March 25 Lecturer: John Cavazos Scribe: Ying Yu 13.1. Bryan Youse-Optimization of Sparse Matrix-Vector Multiplication on Emerging
Concurrency for data-intensive applications
 Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Parallel Methods for Verifying the Consistency of Weakly-Ordered Architectures. Adam McLaughlin, Duane Merrill, Michael Garland, and David A.
 Parallel Methods for Verifying the Consistency of Weakly-Ordered Architectures Adam McLaughlin, Duane Merrill, Michael Garland, and David A. Bader Challenges of Design Verification Contemporary hardware
Parallel Methods for Verifying the Consistency of Weakly-Ordered Architectures Adam McLaughlin, Duane Merrill, Michael Garland, and David A. Bader Challenges of Design Verification Contemporary hardware
Fractal: A Software Toolchain for Mapping Applications to Diverse, Heterogeneous Architecures
 Fractal: A Software Toolchain for Mapping Applications to Diverse, Heterogeneous Architecures University of Virginia Dept. of Computer Science Technical Report #CS-2011-09 Jeremy W. Sheaffer and Kevin
Fractal: A Software Toolchain for Mapping Applications to Diverse, Heterogeneous Architecures University of Virginia Dept. of Computer Science Technical Report #CS-2011-09 Jeremy W. Sheaffer and Kevin
THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT HARDWARE PLATFORMS
 Computer Science 14 (4) 2013 http://dx.doi.org/10.7494/csci.2013.14.4.679 Dominik Żurek Marcin Pietroń Maciej Wielgosz Kazimierz Wiatr THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT
Computer Science 14 (4) 2013 http://dx.doi.org/10.7494/csci.2013.14.4.679 Dominik Żurek Marcin Pietroń Maciej Wielgosz Kazimierz Wiatr THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT
Object Placement in Shared Nothing Architecture Zhen He, Jeffrey Xu Yu and Stephen Blackburn Λ
 45 Object Placement in Shared Nothing Architecture Zhen He, Jeffrey Xu Yu and Stephen Blackburn Λ Department of Computer Science The Australian National University Canberra, ACT 2611 Email: fzhen.he, Jeffrey.X.Yu,
45 Object Placement in Shared Nothing Architecture Zhen He, Jeffrey Xu Yu and Stephen Blackburn Λ Department of Computer Science The Australian National University Canberra, ACT 2611 Email: fzhen.he, Jeffrey.X.Yu,
RESOLVING FALSE DEPENDENCE ON SHARED MEMORY. Patric Zhao
 RESOLVING FALSE DEPENDENCE ON SHARED MEMORY Patric Zhao patricz@nvidia.com Agenda Background Programming Skeleton by Shared Memory False Dependence Issue Solutions to a real case Conclusions 1.Background
RESOLVING FALSE DEPENDENCE ON SHARED MEMORY Patric Zhao patricz@nvidia.com Agenda Background Programming Skeleton by Shared Memory False Dependence Issue Solutions to a real case Conclusions 1.Background
Scaling Optimistic Concurrency Control by Approximately Partitioning the Certifier and Log
 Scaling Optimistic Concurrency Control by Approximately Partitioning the Certifier and Log Philip A. Bernstein Microsoft Research Redmond, WA, USA phil.bernstein@microsoft.com Sudipto Das Microsoft Research
Scaling Optimistic Concurrency Control by Approximately Partitioning the Certifier and Log Philip A. Bernstein Microsoft Research Redmond, WA, USA phil.bernstein@microsoft.com Sudipto Das Microsoft Research
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Optimizing Cache Performance for Graph Analytics. Yunming Zhang Presentation
 Optimizing Cache Performance for Graph Analytics Yunming Zhang 6.886 Presentation Goals How to optimize in-memory graph applications How to go about performance engineering just about anything In-memory
Optimizing Cache Performance for Graph Analytics Yunming Zhang 6.886 Presentation Goals How to optimize in-memory graph applications How to go about performance engineering just about anything In-memory
18-447: Computer Architecture Lecture 30B: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013
 18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
Chí Cao Minh 28 May 2008
 Chí Cao Minh 28 May 2008 Uniprocessor systems hitting limits Design complexity overwhelming Power consumption increasing dramatically Instruction-level parallelism exhausted Solution is multiprocessor
Chí Cao Minh 28 May 2008 Uniprocessor systems hitting limits Design complexity overwhelming Power consumption increasing dramatically Instruction-level parallelism exhausted Solution is multiprocessor
Advanced Databases: Parallel Databases A.Poulovassilis
 1 Advanced Databases: Parallel Databases A.Poulovassilis 1 Parallel Database Architectures Parallel database systems use parallel processing techniques to achieve faster DBMS performance and handle larger
1 Advanced Databases: Parallel Databases A.Poulovassilis 1 Parallel Database Architectures Parallel database systems use parallel processing techniques to achieve faster DBMS performance and handle larger
DEEP DIVE INTO DYNAMIC PARALLELISM
 April 4-7, 2016 Silicon Valley DEEP DIVE INTO DYNAMIC PARALLELISM SHANKARA RAO THEJASWI NANDITALE, NVIDIA CHRISTOPH ANGERER, NVIDIA 1 OVERVIEW AND INTRODUCTION 2 WHAT IS DYNAMIC PARALLELISM? The ability
April 4-7, 2016 Silicon Valley DEEP DIVE INTO DYNAMIC PARALLELISM SHANKARA RAO THEJASWI NANDITALE, NVIDIA CHRISTOPH ANGERER, NVIDIA 1 OVERVIEW AND INTRODUCTION 2 WHAT IS DYNAMIC PARALLELISM? The ability
Performance Characterization of High-Level Programming Models for GPU Graph Analytics
 15 IEEE International Symposium on Workload Characterization Performance Characterization of High-Level Programming Models for GPU Analytics Yuduo Wu, Yangzihao Wang, Yuechao Pan, Carl Yang, and John D.
15 IEEE International Symposium on Workload Characterization Performance Characterization of High-Level Programming Models for GPU Analytics Yuduo Wu, Yangzihao Wang, Yuechao Pan, Carl Yang, and John D.
Chapter 27 Cluster Work Queues
 Chapter 27 Cluster Work Queues Part I. Preliminaries Part II. Tightly Coupled Multicore Part III. Loosely Coupled Cluster Chapter 18. Massively Parallel Chapter 19. Hybrid Parallel Chapter 20. Tuple Space
Chapter 27 Cluster Work Queues Part I. Preliminaries Part II. Tightly Coupled Multicore Part III. Loosely Coupled Cluster Chapter 18. Massively Parallel Chapter 19. Hybrid Parallel Chapter 20. Tuple Space
Lecture 9: Group Communication Operations. Shantanu Dutt ECE Dept. UIC
 Lecture 9: Group Communication Operations Shantanu Dutt ECE Dept. UIC Acknowledgement Adapted from Chapter 4 slides of the text, by A. Grama w/ a few changes, augmentations and corrections Topic Overview
Lecture 9: Group Communication Operations Shantanu Dutt ECE Dept. UIC Acknowledgement Adapted from Chapter 4 slides of the text, by A. Grama w/ a few changes, augmentations and corrections Topic Overview
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.