Interconnect Your Future
|
|
|
- Eustace Franklin
- 6 years ago
- Views:
Transcription
1 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting
2 Mellanox Connects the World s Fastest Supercomputer National Supercomputing Center in Wuxi, China #1 on the TOP500 Supercomputing List 93 Petaflop performance, 3X higher versus #2 on the TOP500 41K nodes, 10 million cores, 256 cores per CPU Mellanox adapter and switch solutions The TOP500 list has evolved, includes HPC & Cloud / Web2.0 Hyperscale systems Mellanox connects 41.2% of overall TOP500 systems Mellanox connects 70.4% of the TOP500 HPC platforms Mellanox connects 46 Petascale systems, Nearly 50% of the total Petascale systems InfiniBand is the Interconnect of Choice for HPC Compute and Storage Infrastructures 2016 Mellanox Technologies 2





3 Accelerating HPC Leadership Systems Summit System Sierra System Proud to Pave the Path to Exascale 2016 Mellanox Technologies 3




4 The Ever Growing Demand for Higher Performance Performance Development Terascale Petascale Exascale 1 st Roadrunner The Interconnect is the Enabling Technology HW APP SW Application Software Hardware SMP to Clusters Single-Core to Many-Core Co-Design 2016 Mellanox Technologies 4



5 The Intelligent Interconnect to Enable Exascale Performance CPU-Centric Co-Design Limited to Main CPU Usage Results in Performance Limitation Must Wait for the Data Creates Performance Bottlenecks Creating Synergies Enables Higher Performance and Scale Work on The Data as it Moves Enables Performance and Scale 2016 Mellanox Technologies 5

6 Breaking the Application Latency Wall Network 10 years ago Communication Framework Network Today Communication Framework Co-Design Network Future Communication Framework ~10 microsecond ~100 microsecond ~0.1 microsecond ~10 microsecond ~0.05 microsecond ~1 microsecond Today: Network device latencies are on the order of 100 nanoseconds Challenge: Enabling the next order of magnitude improvement in application performance Solution: Creating synergies between software and hardware intelligent interconnect Intelligent Interconnect Paves the Road to Exascale Performance 2016 Mellanox Technologies 6



7 Mellanox Smart Interconnect Solutions: Switch-IB 2 and ConnectX Mellanox Technologies 7
8 Switch-IB 2 and ConnectX-5 Smart Interconnect Solutions SHArP Enables Switch-IB 2 to Execute Data Aggregation / Reduction Operations in the Network Barrier, Reduce, All-Reduce, Broadcast Sum, Min, Max, Min-loc, max-loc, OR, XOR, AND Integer and Floating-Point, 32 / 64 bit Delivering 10X Performance Improvement for MPI and SHMEM/PAGS Communications 100Gb/s Throughput 0.6usec Latency (end-to-end) 200M Messages per Second MPI Collectives in Hardware MPI Tag Matching in Hardware In-Network Memory PCIe Gen3 and Gen4 Integrated PCIe Switch Advanced Dynamic Routing 2016 Mellanox Technologies 8




9 ConnectX-5 EDR 100G Architecture X86 Open POWER GPU ARM FPGA PCIe Gen4 Multi-Host Technology PCIe Switch PCIe Gen4 Offload Engines Memory RDMA Transport eswitch & Routing InfiniBand / Ethernet 10,20,40,50,56,100G 2016 Mellanox Technologies 9



10 Switch-IB 2 SHArP Performance Advantage MiniFE is a Finite Element mini-application Implements kernels that represent implicit finite-element applications Allreduce MPI Collective 10X to 25X Performance Improvement 2016 Mellanox Technologies 10
11 Time SHArP Performance Advantage with Intel Xeon Phi Knight Landing OSU - OSU MPI benchmark; IMB Intel MPI Benchmark Lower is better Maximizing KNL Performance 50% Reduction in Run Time (Customer Results) 2016 Mellanox Technologies 11
12 SHArP Technology Performance OpenFOAM is a popular computational fluid dynamics application SHArP Delivers 2.2X Higher Performance 2016 Mellanox Technologies 12

, SDN")




13 BlueField System-on-a-Chip (SoC) Solution NVMe Flash Storage Arrays Scale-Out Storage (NVMe over Fabric) Accelerating & Virtualizing VNFs Open vswitch (OVS), SDN Overlay networking offloads Integration of ConnectX5 + Multicore ARM State of the art capabilities 10 / 25 / 40 / 50 / 100G Ethernet & InfiniBand PCIe Gen3 / Gen4 Hardware acceleration offload - RDMA, RoCE, NVMeF, RAID Family of products Range of ARM core counts and I/O ports/speeds Price/Performance points 2016 Mellanox Technologies 13


 SB7780 Router 1U Supports up to 6 Different")
14 InfiniBand Router Solutions Isolation Between Different InfiniBand Networks (Each Network can be Managed Separately) Native InfiniBand Connectivity Between Different Network Topologies (Fat-Tree, Torus, Dragonfly, etc.) SB7780 Router 1U Supports up to 6 Different Subnets 2016 Mellanox Technologies 14
15 Technology Roadmap 100G 200G 400G 1000G Standard-based Interconnect, Same Software, Backward and Future Compatible Petascale Exascale #1 TOP500, 100Petaflop World-wide Programs Mellanox Technologies 15
16 GPUDirect RDMA Technology Maximize Performance via Accelerator and GPU Offloads 2016 Mellanox Technologies 16



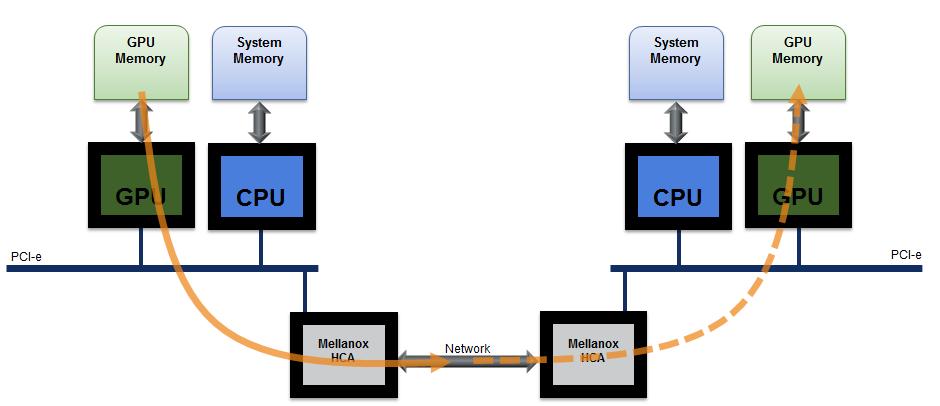
17 GPUs are Everywhere! 2016 Mellanox Technologies 17

18 Higher is Better Performance of MPI with GPUDirect RDMA GPU-GPU Internode MPI Latency GPU-GPU Internode MPI Bandwidth 10x 9.3X Lower is Better 2.18 usec Source: Prof. DK Panda 88% Lower Latency 10X Increase in Throughput 2016 Mellanox Technologies 18
19 Mellanox GPUDirect RDMA Performance Advantage HOOMD-blue is a general-purpose Molecular Dynamics simulation code accelerated on GPUs GPUDirect RDMA allows direct peer to peer GPU communications over InfiniBand Unlocks performance between GPU and InfiniBand This provides a significant decrease in GPU-GPU communication latency Provides complete CPU offload from all GPU communications across the network 102% 2X Application Performance! 2016 Mellanox Technologies 19
 direct data path between the GPU and Mellanox interconnect Control path still uses the CPU - CPU prepares and queues communication tasks on GPU - GPU triggers communication on HCA - Mellanox HCA")
20 Average time per iteration (us) GPUDirect Sync (GPUDirect 4.0) GPUDirect RDMA (3.0) direct data path between the GPU and Mellanox interconnect Control path still uses the CPU - CPU prepares and queues communication tasks on GPU - GPU triggers communication on HCA - Mellanox HCA directly accesses GPU memory GPUDirect Sync (GPUDirect 4.0) Both data path and control path go directly between the GPU and the Mellanox interconnect D stencil benchmark 27% faster 23% faster Maximum Performance For GPU Clusters Number of nodes/gpus RDMA only RDMA+PeerSync 2016 Mellanox Technologies 20
21 UCX Unified Communication X 2016 Mellanox Technologies 21




22 UCX Unified Communication - X Framework ucx-group@ .ornl.gov
23 Background MXM Developed by Mellanox Technologies HPC communication library for InfiniBand devices and shared memory Primary focus: MPI, PGAS UCCS Developed by ORNL, UH, UTK Originally based on Open MPI BTL and OPAL layers HPC communication library for InfiniBand, Cray Gemini/Aries, and shared memory Primary focus: OpenSHMEM, PGAS Also supports: MPI PAMI Developed by IBM on BG/Q, PERCS, IB VERBS Network devices and shared memory MPI, OpenSHMEM, PGAS, CHARM++, X10 C++ components Aggressive multi-threading with contexts Active Messages Non-blocking collectives with hw accleration support
24 High-level Overview Applications MPICH, Open-MPI, etc. OpenSHMEM, UPC, CAF, X10, Chapel, etc. Parsec, OCR, Legions, etc. Burst buffer, ADIOS, etc. UCP (Protocols) UCX Message Passing API Domain InfiniBand VERBs Gemini/Aries PGAS API Domain UCT (Transports) Host Memory Task Based API Domain Accelerator Memory I/O API Domain UCS (Services) RC UD XRC DCT GNI SYSV POSIX KNEM CMA XPMEM CUDA Utilities Platforms Hardware/Driver
25 Technology Roadmap 100G 200G 400G 1000G Standard-based Interconnect, Same Software, Backward and Future Compatible Petascale Exascale #1 TOP500, 100Petaflop World-wide Programs Mellanox Technologies 25
26 Thank You
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
In-Network Computing. Paving the Road to Exascale. 5th Annual MVAPICH User Group (MUG) Meeting, August 2017
 Meeting, August 2017") In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
Paving the Road to Exascale
 Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
In-Network Computing. Paving the Road to Exascale. June 2017
 In-Network Computing Paving the Road to Exascale June 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect -Centric (Onload) Data-Centric (Offload) Must Wait for the Data Creates
In-Network Computing Paving the Road to Exascale June 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect -Centric (Onload) Data-Centric (Offload) Must Wait for the Data Creates
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
In-Network Computing. Sebastian Kalcher, Senior System Engineer HPC. May 2017
 In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
Unified Communication X (UCX)
") Unified Communication X (UCX) Pavel Shamis / Pasha ARM Research SC 18 UCF Consortium Mission: Collaboration between industry, laboratories, and academia to create production grade communication frameworks
Unified Communication X (UCX) Pavel Shamis / Pasha ARM Research SC 18 UCF Consortium Mission: Collaboration between industry, laboratories, and academia to create production grade communication frameworks
Interconnect Your Future
 Interconnect Your Future Paving the Road to Exascale August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait for the Data
Interconnect Your Future Paving the Road to Exascale August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait for the Data
High Performance Computing
 High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and
High Performance Computing Dror Goldenberg, HPCAC Switzerland Conference March 2015 End-to-End Interconnect Solutions for All Platforms Highest Performance and Scalability for X86, Power, GPU, ARM and
Solutions for Scalable HPC
 Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Pavel Shamis, Manjunath Gorentla Venkata, M. Graham Lopez, Matthew B. Baker, Oscar Hernandez, Yossi Itigin, Mike Dubman, Gilad Shainer, Richard
UCX: An Open Source Framework for HPC Network APIs and Beyond Pavel Shamis, Manjunath Gorentla Venkata, M. Graham Lopez, Matthew B. Baker, Oscar Hernandez, Yossi Itigin, Mike Dubman, Gilad Shainer, Richard
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations
 The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
Interconnect Your Future Enabling the Best Datacenter Return on Investment. TOP500 Supercomputers, November 2017
 Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
The Future of Interconnect Technology
 The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
The Future of Interconnect Technology Michael Kagan, CTO HPC Advisory Council Stanford, 2014 Exponential Data Growth Best Interconnect Required 44X 0.8 Zetabyte 2009 35 Zetabyte 2020 2014 Mellanox Technologies
The Road to ExaScale. Advances in High-Performance Interconnect Infrastructure. September 2011
 The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
How to Boost the Performance of Your MPI and PGAS Applications with MVAPICH2 Libraries
 How to Boost the Performance of Your MPI and PGAS s with MVAPICH2 Libraries A Tutorial at the MVAPICH User Group (MUG) Meeting 18 by The MVAPICH Team The Ohio State University E-mail: panda@cse.ohio-state.edu
How to Boost the Performance of Your MPI and PGAS s with MVAPICH2 Libraries A Tutorial at the MVAPICH User Group (MUG) Meeting 18 by The MVAPICH Team The Ohio State University E-mail: panda@cse.ohio-state.edu
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
2008 International ANSYS Conference
 2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
Birds of a Feather Presentation
 Mellanox InfiniBand QDR 4Gb/s The Fabric of Choice for High Performance Computing Gilad Shainer, shainer@mellanox.com June 28 Birds of a Feather Presentation InfiniBand Technology Leadership Industry Standard
Mellanox InfiniBand QDR 4Gb/s The Fabric of Choice for High Performance Computing Gilad Shainer, shainer@mellanox.com June 28 Birds of a Feather Presentation InfiniBand Technology Leadership Industry Standard
Future Routing Schemes in Petascale clusters
 Future Routing Schemes in Petascale clusters Gilad Shainer, Mellanox, USA Ola Torudbakken, Sun Microsystems, Norway Richard Graham, Oak Ridge National Laboratory, USA Birds of a Feather Presentation Abstract
Future Routing Schemes in Petascale clusters Gilad Shainer, Mellanox, USA Ola Torudbakken, Sun Microsystems, Norway Richard Graham, Oak Ridge National Laboratory, USA Birds of a Feather Presentation Abstract
Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability
 Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox InfiniBand Host Channel Adapters (HCA) enable the highest data center
Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox InfiniBand Host Channel Adapters (HCA) enable the highest data center
Interconnect Your Future
 Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
Interconnect Your Future Paving the Road to Exascale
 Interconnect Your Future Paving the Road to Exascale CHPC, December 2017 90% of the World Data was Created in the Last 2 Years 2017 Mellanox Technologies 2 The Future Depends on Fastest Interconnects 1Gb/s
Interconnect Your Future Paving the Road to Exascale CHPC, December 2017 90% of the World Data was Created in the Last 2 Years 2017 Mellanox Technologies 2 The Future Depends on Fastest Interconnects 1Gb/s
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
N V M e o v e r F a b r i c s -
 N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
Maximizing Cluster Scalability for LS-DYNA
 Maximizing Cluster Scalability for LS-DYNA Pak Lui 1, David Cho 1, Gerald Lotto 1, Gilad Shainer 1 1 Mellanox Technologies, Inc. Sunnyvale, CA, USA 1 Abstract High performance network interconnect is an
Maximizing Cluster Scalability for LS-DYNA Pak Lui 1, David Cho 1, Gerald Lotto 1, Gilad Shainer 1 1 Mellanox Technologies, Inc. Sunnyvale, CA, USA 1 Abstract High performance network interconnect is an
Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning
 5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
Networking at the Speed of Light
 Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
How to Network Flash Storage Efficiently at Hyperscale. Flash Memory Summit 2017 Santa Clara, CA 1
 How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
The Exascale Architecture
 The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
Paving the Road to Exascale Computing. Yossi Avni
 Paving the Road to Exascale Computing Yossi Avni HPC@mellanox.com Connectivity Solutions for Efficient Computing Enterprise HPC High-end HPC HPC Clouds ICs Mellanox Interconnect Networking Solutions Adapter
Paving the Road to Exascale Computing Yossi Avni HPC@mellanox.com Connectivity Solutions for Efficient Computing Enterprise HPC High-end HPC HPC Clouds ICs Mellanox Interconnect Networking Solutions Adapter
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures
 Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda Department of Computer Science and Engineering
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda Department of Computer Science and Engineering
VPI / InfiniBand. Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability
 VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
Designing Shared Address Space MPI libraries in the Many-core Era
 Designing Shared Address Space MPI libraries in the Many-core Era Jahanzeb Hashmi hashmi.29@osu.edu (NBCL) The Ohio State University Outline Introduction and Motivation Background Shared-memory Communication
Designing Shared Address Space MPI libraries in the Many-core Era Jahanzeb Hashmi hashmi.29@osu.edu (NBCL) The Ohio State University Outline Introduction and Motivation Background Shared-memory Communication
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters
 Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
VPI / InfiniBand. Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability
 VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
VPI / InfiniBand Performance Accelerated Mellanox InfiniBand Adapters Provide Advanced Data Center Performance, Efficiency and Scalability Mellanox enables the highest data center performance with its
InfiniBand Networked Flash Storage
 InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR
 Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA
 MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
Mellanox Technologies Maximize Cluster Performance and Productivity. Gilad Shainer, October, 2007
 Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Introduction to Infiniband
 Introduction to Infiniband FRNOG 22, April 4 th 2014 Yael Shenhav, Sr. Director of EMEA, APAC FAE, Application Engineering The InfiniBand Architecture Industry standard defined by the InfiniBand Trade
Introduction to Infiniband FRNOG 22, April 4 th 2014 Yael Shenhav, Sr. Director of EMEA, APAC FAE, Application Engineering The InfiniBand Architecture Industry standard defined by the InfiniBand Trade
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Ethernet. High-Performance Ethernet Adapter Cards
 High-Performance Ethernet Adapter Cards Supporting Virtualization, Overlay Networks, CPU Offloads and RDMA over Converged Ethernet (RoCE), and Enabling Data Center Efficiency and Scalability Ethernet Mellanox
High-Performance Ethernet Adapter Cards Supporting Virtualization, Overlay Networks, CPU Offloads and RDMA over Converged Ethernet (RoCE), and Enabling Data Center Efficiency and Scalability Ethernet Mellanox
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience
 SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice
 InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Overview of MVAPICH2 and MVAPICH2- X: Latest Status and Future Roadmap
 Overview of MVAPICH2 and MVAPICH2- X: Latest Status and Future Roadmap MVAPICH2 User Group (MUG) MeeKng by Dhabaleswar K. (DK) Panda The Ohio State University E- mail: panda@cse.ohio- state.edu h
Overview of MVAPICH2 and MVAPICH2- X: Latest Status and Future Roadmap MVAPICH2 User Group (MUG) MeeKng by Dhabaleswar K. (DK) Panda The Ohio State University E- mail: panda@cse.ohio- state.edu h
Overview of the MVAPICH Project: Latest Status and Future Roadmap
 Overview of the MVAPICH Project: Latest Status and Future Roadmap MVAPICH2 User Group (MUG) Meeting by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Overview of the MVAPICH Project: Latest Status and Future Roadmap MVAPICH2 User Group (MUG) Meeting by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Hardened Security in the Cloud Bob Doud, Sr. Director Marketing March, 2018
 Hardened Security in the Cloud Bob Doud, Sr. Director Marketing March, 2018 1 Cloud Computing is Growing at an Astounding Rate Many compelling reasons for business to move to the cloud Cost, uptime, easy-expansion,
Hardened Security in the Cloud Bob Doud, Sr. Director Marketing March, 2018 1 Cloud Computing is Growing at an Astounding Rate Many compelling reasons for business to move to the cloud Cost, uptime, easy-expansion,
2017 Storage Developer Conference. Mellanox Technologies. All Rights Reserved.
 Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K.
 Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters
 Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters Hari Subramoni, Ping Lai, Sayantan Sur and Dhabhaleswar. K. Panda Department of
Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern Multi-Core InfiniBand Clusters Hari Subramoni, Ping Lai, Sayantan Sur and Dhabhaleswar. K. Panda Department of
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE
 MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
ROCm: An open platform for GPU computing exploration
 UCX-ROCm: ROCm Integration into UCX {Khaled Hamidouche, Brad Benton}@AMD Research ROCm: An open platform for GPU computing exploration 1 JUNE, 2018 ISC ROCm Software Platform An Open Source foundation
UCX-ROCm: ROCm Integration into UCX {Khaled Hamidouche, Brad Benton}@AMD Research ROCm: An open platform for GPU computing exploration 1 JUNE, 2018 ISC ROCm Software Platform An Open Source foundation
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand
 Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
HPC Network Stack on ARM
 HPC Network Stack on ARM Pavel Shamis (Pasha) Principal Research Engineer ARM Research ExaComm 2017 06/22/2017 HPC network stack on ARM? 2 Serious ARM HPC deployments starting in 2017 ARM Emerging CPU
HPC Network Stack on ARM Pavel Shamis (Pasha) Principal Research Engineer ARM Research ExaComm 2017 06/22/2017 HPC network stack on ARM? 2 Serious ARM HPC deployments starting in 2017 ARM Emerging CPU
OPENFABRICS INTERFACES: PAST, PRESENT, AND FUTURE
 OPENFABRICS INTERFACES: PAST, PRESENT, AND FUTURE Sean Hefty Openfabrics Interfaces Working Group Co-Chair Intel November 2016 OFIWG: develop interfaces aligned with application needs Open Source Expand
OPENFABRICS INTERFACES: PAST, PRESENT, AND FUTURE Sean Hefty Openfabrics Interfaces Working Group Co-Chair Intel November 2016 OFIWG: develop interfaces aligned with application needs Open Source Expand
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
OPEN MPI WITH RDMA SUPPORT AND CUDA. Rolf vandevaart, NVIDIA
 OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
Messaging Overview. Introduction. Gen-Z Messaging
 Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
High-Performance Training for Deep Learning and Computer Vision HPC
 High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Scaling with PGAS Languages
 Scaling with PGAS Languages Panel Presentation at OFA Developers Workshop (2013) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Scaling with PGAS Languages Panel Presentation at OFA Developers Workshop (2013) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms
 Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms Sayantan Sur, Matt Koop, Lei Chai Dhabaleswar K. Panda Network Based Computing Lab, The Ohio State
Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms Sayantan Sur, Matt Koop, Lei Chai Dhabaleswar K. Panda Network Based Computing Lab, The Ohio State
MVAPICH2 and MVAPICH2-MIC: Latest Status
 MVAPICH2 and MVAPICH2-MIC: Latest Status Presentation at IXPUG Meeting, July 214 by Dhabaleswar K. (DK) Panda and Khaled Hamidouche The Ohio State University E-mail: {panda, hamidouc}@cse.ohio-state.edu
MVAPICH2 and MVAPICH2-MIC: Latest Status Presentation at IXPUG Meeting, July 214 by Dhabaleswar K. (DK) Panda and Khaled Hamidouche The Ohio State University E-mail: {panda, hamidouc}@cse.ohio-state.edu
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications
 for Bio-Science Applications") Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
Performance Optimizations for LS-DYNA with Mellanox HPC-X Scalable Software Toolkit
 Performance Optimizations for LS-DYNA with Mellanox HPC-X Scalable Software Toolkit Pak Lui 1, David Cho 1, Gilad Shainer 1, Scot Schultz 1, Brian Klaff 1 1 Mellanox Technologies, Inc. 1 Abstract From
Performance Optimizations for LS-DYNA with Mellanox HPC-X Scalable Software Toolkit Pak Lui 1, David Cho 1, Gilad Shainer 1, Scot Schultz 1, Brian Klaff 1 1 Mellanox Technologies, Inc. 1 Abstract From
Designing High Performance Heterogeneous Broadcast for Streaming Applications on GPU Clusters
 Designing High Performance Heterogeneous Broadcast for Streaming Applications on Clusters 1 Ching-Hsiang Chu, 1 Khaled Hamidouche, 1 Hari Subramoni, 1 Akshay Venkatesh, 2 Bracy Elton and 1 Dhabaleswar
Designing High Performance Heterogeneous Broadcast for Streaming Applications on Clusters 1 Ching-Hsiang Chu, 1 Khaled Hamidouche, 1 Hari Subramoni, 1 Akshay Venkatesh, 2 Bracy Elton and 1 Dhabaleswar
Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth
 Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth by D.K. Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline Overview of MVAPICH2-GPU
Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth by D.K. Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline Overview of MVAPICH2-GPU
Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications
 Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications GPU Technology Conference GTC 2016 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
Coupling GPUDirect RDMA and InfiniBand Hardware Multicast Technologies for Streaming Applications GPU Technology Conference GTC 2016 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
MVAPICH-Aptus: Scalable High-Performance Multi-Transport MPI over InfiniBand
 MVAPICH-Aptus: Scalable High-Performance Multi-Transport MPI over InfiniBand Matthew Koop 1,2 Terry Jones 2 D. K. Panda 1 {koop, panda}@cse.ohio-state.edu trj@llnl.gov 1 Network-Based Computing Lab, The
MVAPICH-Aptus: Scalable High-Performance Multi-Transport MPI over InfiniBand Matthew Koop 1,2 Terry Jones 2 D. K. Panda 1 {koop, panda}@cse.ohio-state.edu trj@llnl.gov 1 Network-Based Computing Lab, The
GPU-centric communication for improved efficiency
 GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
Operational Robustness of Accelerator Aware MPI
 Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Unifying UPC and MPI Runtimes: Experience with MVAPICH
 Unifying UPC and MPI Runtimes: Experience with MVAPICH Jithin Jose Miao Luo Sayantan Sur D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Unifying UPC and MPI Runtimes: Experience with MVAPICH Jithin Jose Miao Luo Sayantan Sur D. K. Panda Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Introduction to High-Speed InfiniBand Interconnect
 Introduction to High-Speed InfiniBand Interconnect 2 What is InfiniBand? Industry standard defined by the InfiniBand Trade Association Originated in 1999 InfiniBand specification defines an input/output
Introduction to High-Speed InfiniBand Interconnect 2 What is InfiniBand? Industry standard defined by the InfiniBand Trade Association Originated in 1999 InfiniBand specification defines an input/output
Exploiting InfiniBand and GPUDirect Technology for High Performance Collectives on GPU Clusters
 Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Chelsio Communications. Meeting Today s Datacenter Challenges. Produced by Tabor Custom Publishing in conjunction with: CUSTOM PUBLISHING
 Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Study. Dhabaleswar. K. Panda. The Ohio State University HPIDC '09
 RDMA over Ethernet - A Preliminary Study Hari Subramoni, Miao Luo, Ping Lai and Dhabaleswar. K. Panda Computer Science & Engineering Department The Ohio State University Introduction Problem Statement
RDMA over Ethernet - A Preliminary Study Hari Subramoni, Miao Luo, Ping Lai and Dhabaleswar. K. Panda Computer Science & Engineering Department The Ohio State University Introduction Problem Statement
Infiniband and RDMA Technology. Doug Ledford
 Infiniband and RDMA Technology Doug Ledford Top 500 Supercomputers Nov 2005 #5 Sandia National Labs, 4500 machines, 9000 CPUs, 38TFlops, 1 big headache Performance great...but... Adding new machines problematic
Infiniband and RDMA Technology Doug Ledford Top 500 Supercomputers Nov 2005 #5 Sandia National Labs, 4500 machines, 9000 CPUs, 38TFlops, 1 big headache Performance great...but... Adding new machines problematic
Intra-MIC MPI Communication using MVAPICH2: Early Experience
 Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
MVAPICH2-GDR: Pushing the Frontier of HPC and Deep Learning
 MVAPICH2-GDR: Pushing the Frontier of HPC and Deep Learning Talk at Mellanox Theater (SC 16) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
MVAPICH2-GDR: Pushing the Frontier of HPC and Deep Learning Talk at Mellanox Theater (SC 16) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters
 CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY
 14th ANNUAL WORKSHOP 2018 USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY Michael Chuvelev, Software Architect Intel April 11, 2018 INTEL MPI LIBRARY Optimized MPI application performance Application-specific
14th ANNUAL WORKSHOP 2018 USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY Michael Chuvelev, Software Architect Intel April 11, 2018 INTEL MPI LIBRARY Optimized MPI application performance Application-specific
EXPERIENCES WITH NVME OVER FABRICS
 13th ANNUAL WORKSHOP 2017 EXPERIENCES WITH NVME OVER FABRICS Parav Pandit, Oren Duer, Max Gurtovoy Mellanox Technologies [ 31 March, 2017 ] BACKGROUND: NVME TECHNOLOGY Optimized for flash and next-gen
13th ANNUAL WORKSHOP 2017 EXPERIENCES WITH NVME OVER FABRICS Parav Pandit, Oren Duer, Max Gurtovoy Mellanox Technologies [ 31 March, 2017 ] BACKGROUND: NVME TECHNOLOGY Optimized for flash and next-gen
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC