A Multilingual Social Media Linguistic Corpus
|
|
|
- Veronica Cross
- 5 years ago
- Views:
Transcription
1 A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th Conference on CMC and Social Media Corpora for the Humanities, September 2016
2 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
3 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
4 The xlime Twitter Corpus A Brief Introduction Tweets German Italian Spanish Manually Annotated with: Part-of-Speech (PoS) Named Entities (NE) Sentiment
5 The xlime Twitter Corpus Some Numbers Language Tweets Tokens Annotators German Italian Spanish Total 20K 350K 7
6 Motivation Why We Created The Corpus Evaluate the performance of NLP tools on tweets tweets are harder for automatic annotation methods (Derczynski, Maynard, et al. 2013) Better Automated Methods (Ritter et al. 2011; Derczynski, Maynard, et al. 2013; Derczynski, Ritter, et al. 2013) No Corpora available: German, Spanish, and Italian Twitter at least not with manually annotated NE and PoS Sentiment classification with help from the other annotations
7 Cost vs Quality A Note Alternatives High Quality: N (e.g. N=7) expert annotators with full overlap too expensive! Cheap: Crowdsourcing time-consuming and/or low-quality We opted for using language students as annotators. With the minimum possible overlap (while still possibly getting some measure of IAA).
8 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
9 Related Work Summary NPS Chat Corpus (Forsyth et al. 2007) [English] 10K chat messages: PoS Ritter twitter corpus (Ritter et al. 2011) [English] 800 tweets ( 16K tokens): PoS, chunking tags, and NE Tweebank corpus (Owoputi et al. 2013) [English] 929 tweets ( 12K tokens): PoS clear annotation guidelines and twitter-specific tagset Semeval 2014 Task 9 corpus (Rosenthal et al. 2014) [English] 21K Twitter messages, SMS, and LiveJournal sentences message level sentiment polarity: positive, objective/neural, negative
10 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
11 Data Collection Tweets were first selected based on their reported language. The tweets were randomly sampled from the twitter public stream from late 2013 to early Rules to discard spam and low information tweets tweets: 1. Less than 5 tokens; 2. More than 3 mentions; 3. More than 2 URLs; 4. Filtered using external automatic language identification tool 1 1 langid.py (Lui et al. 2011)
12 Preprocessing 1. URLs were replaced with pre-specified tokens; were replaced with pre-specified tokens; 3. Tokenization using a variant of twokenize (O Connor et al. 2010) adapted to break apart apostrophes in Italian e.g. l amica which becomes l, amica
13 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
14 Annotation Process 50 tweets were annotated by all the annotators working on the language allows estimation of agreement measures Tokens pre-tagged with PoS labels 2 Plus some basic rules for twitter entities such as URLs and mentions. Guidelines were sent to the annotators (now distributed with the corpus) A session was organised with all the annotators to explain the guidelines and the annotation software 2 using Pattern (De Smedt et al. 2012)
15 Annotation Software Description We built an annotation tool optimised for document and token level annotation of tweets. The annotation tool included the options to mark tweets as: invalid since despite the automatic filtering performed it was still possible that tweets with incorrectly identified language, spam, or incomprehensible text might be presented to the annotators skip in case they had doubts which added the tweet to a special list to which the annotator could come back later
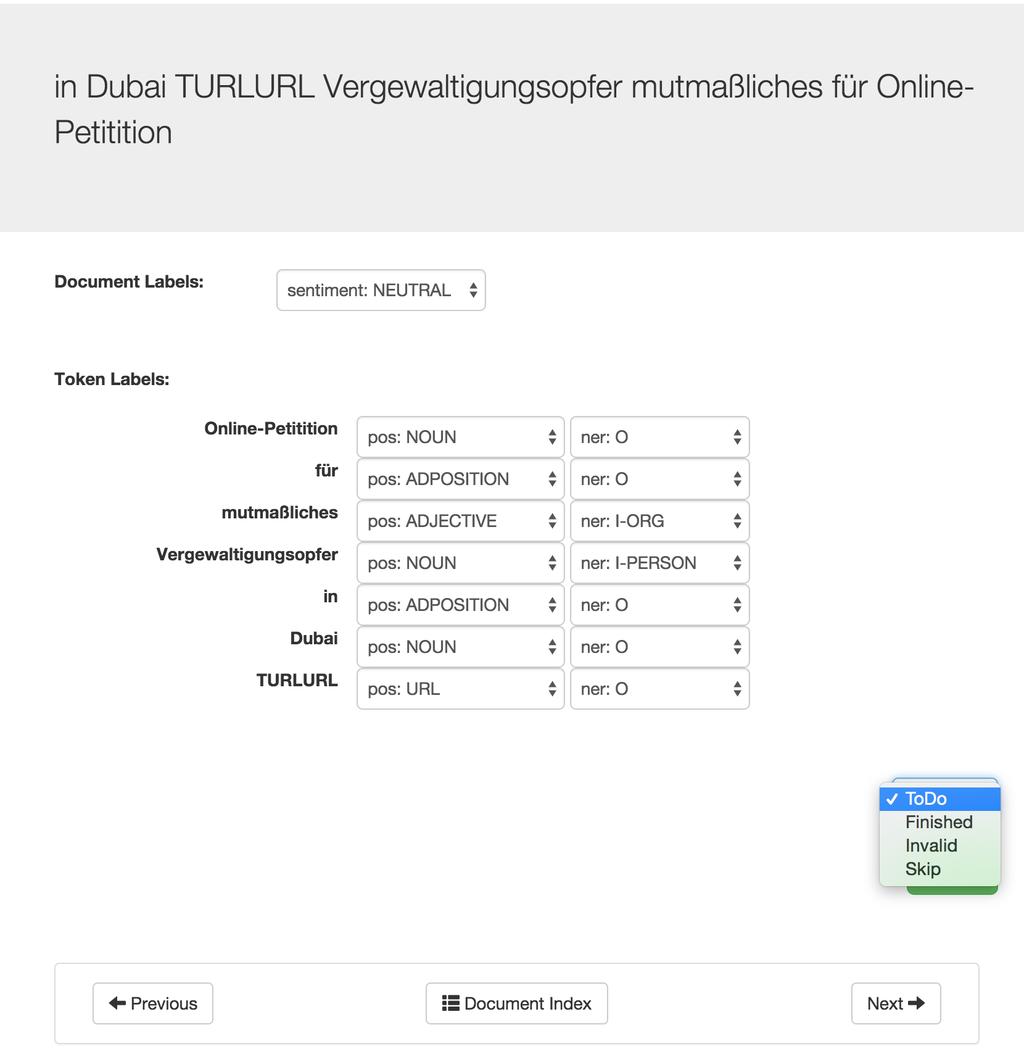
16
17 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
18 Part of Speech: Universal Tags Tagset & Counts Tag German Italian Spanish Adjective Adposition Adverb Conjunction Determiner Interjection Noun Number Other Particle Pronoun Punctuation Verb Table: Tagset (Universal) with occurrence counts per language.
19 Part of Speech: Twitter-Specific Tags Tagset & Counts Tag German Italian Spanish Continuation Emoticon Hashtag Mention URL Table: Tagset (Twitter) with occurrence counts per language.
20 Part of Speech: Twitter-Specific Tags Description Continuation indicates retweet indicators such as rt and : in twitter is cool and ellipsis that mark a truncated tweet rather than purposeful ellipsis; Emoticon this tag applies to unicode emoticons and traditional smileys, e.g. :) ; Hashtag this tag applies to the # symbol of twitter hashtags, and to the following token if and only if it is not a proper part-of-speech; Mention this indicates a such in the example above; URL indicates URLs e.g. or example.com ;
21 Named Entities Tags & Counts Named entities are phrases that contain the names of persons, organisations, and locations Entity Type German Italian Spanish Location Miscellaneous Organization Person Table: Token counts per named entity type per language
22 Sentiment Labels & Counts Each tweet is labeled with its sentiment polarity: positive, neutral/objective, or negative. The vast majority of tweets in our corpus was annotated with the Neutral/Objective Language Positive Neutral Negative Total German Italian Spanish Table: Message level sentiment polarity annotation counts.
23 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
24 Inter-Annotator Agreement Overlap In order to estimate inter-annotator agreement, for each language, the annotators were given tweets that they annotated in common. Language Tweets Tokens Annotators German Italian Spanish Table: Number of tweets and tokens annotated by all annotators for a given language.
25 Inter-Annotator Agreement Results Task German Italian Spanish PoS 0.88 (AP) 0.87 (AP) 0.85 (AP) NER 0.67 (SUB) 0.42 (MOD) 0.51 (MOD) Sentiment (Poor) 0.02 (Slight) 0.37 (Fair) Table: Inter Annotator Agreement (Cohen/Fleiss kappa) per task per language. In parenthesis, the human readable interpretation where: AP - Almost Perfect, MOD - Moderate, SUB - Substantial. The worst agreement between the human annotators occurred when labelling sentiment. Even for humans, it can be challenging to assign sentiment, without context, to a small message.
26 Table of Contents Introduction Corpus Overview Motivation Cost vs Quality Related Work Data Collection & Preprocessing Data Collection Preprocessing Annotation The Labels Part of Speech Named Entities Sentiment Agreement Availability
27 Availability Location & Content The corpus is primarily distributed online: under an Open Source License (MIT) 3 tab-separated values (TSV) files - 1 per language also task specific formats (e.g. CONLL) includes code: tokenizer pretag agreement
28 Availability File Format (Headers) token the token, e.g. levantan ; tok id a unique identifier for the token in the current message, composed of the tweet id, followed by the dash character, followed by a token id, e.g ; doc id a unique identifier for the message (tweet id), e.g.: ; doc task sentiment the sentiment label assigned by the annotator; tok task pos the Part-of-Speech tag assigned by the annotator; tok task ner the entity class label assigned by the annotator; annotator the unique identifier for the annotator.
29 Acknowledgments Thank you, Acknowledgments, Questions Thank You Questions? This work was supported by the Slovenian Research Agency and the ICT Programme of the EC under xlime (FP7-ICT ) and Symphony (FP7-ICT ). Thank to the annotators that were involved in producing the xlime Twitter Corpus. The annotators for German were M, Helbl and I. Škrjanec; for Italian, E. Derviševič, J. Jesenovec, and V. Zelj; and for Spanish, M. Kmet and E. Podobnik.
30 References I De Smedt, T. et al. Pattern for python. The Journal of Machine Learning Research (2012). Derczynski, L., Maynard, D., et al. Microblog-genre noise and impact on semantic annotation accuracy in (2013). Derczynski, L., Ritter, A., et al. Twitter Part-of-Speech Tagging for All: Overcoming Sparse and Noisy Data. in (2013). Forsyth, E. N. et al. Lexical and discourse analysis of online chat dialog in (2007). Lui, M. et al. Cross-domain feature selection for language identification in (2011). O Connor, B. et al. TweetMotif: Exploratory Search and Topic Summarization for Twitter. in (2010). Owoputi, O. et al. Improved part-of-speech tagging for online conversational text with word clusters in (2013). Ritter, A. et al. Named Entity Recognition in Tweets: An Experimental Study in (2011). Rosenthal, S. et al. SemEval-2014 Task 9: Sentiment Analysis in Twitter in (2014).
NLP Final Project Fall 2015, Due Friday, December 18
 NLP Final Project Fall 2015, Due Friday, December 18 For the final project, everyone is required to do some sentiment classification and then choose one of the other three types of projects: annotation,
NLP Final Project Fall 2015, Due Friday, December 18 For the final project, everyone is required to do some sentiment classification and then choose one of the other three types of projects: annotation,
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Download this zip file to your NLP class folder in the lab and unzip it there.
 NLP Lab Session Week 13, November 19, 2014 Text Processing and Twitter Sentiment for the Final Projects Getting Started In this lab, we will be doing some work in the Python IDLE window and also running
NLP Lab Session Week 13, November 19, 2014 Text Processing and Twitter Sentiment for the Final Projects Getting Started In this lab, we will be doing some work in the Python IDLE window and also running
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Lecture 14: Annotation
 Lecture 14: Annotation Nathan Schneider (with material from Henry Thompson, Alex Lascarides) ENLP 23 October 2016 1/14 Annotation Why gold 6= perfect Quality Control 2/14 Factors in Annotation Suppose
Lecture 14: Annotation Nathan Schneider (with material from Henry Thompson, Alex Lascarides) ENLP 23 October 2016 1/14 Annotation Why gold 6= perfect Quality Control 2/14 Factors in Annotation Suppose
Module 3: GATE and Social Media. Part 4. Named entities
 Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
Tools for Annotating and Searching Corpora Practical Session 1: Annotating
 Tools for Annotating and Searching Corpora Practical Session 1: Annotating Stefanie Dipper Institute of Linguistics Ruhr-University Bochum Corpus Linguistics Fest (CLiF) June 6-10, 2016 Indiana University,
Tools for Annotating and Searching Corpora Practical Session 1: Annotating Stefanie Dipper Institute of Linguistics Ruhr-University Bochum Corpus Linguistics Fest (CLiF) June 6-10, 2016 Indiana University,
Data Clustering Frame work using Hadoop
 Volume: 05 Issue: 09 Sep 2018 www.irjet.net p-issn: 2395-0072 Data Clustering Frame work using Hadoop Malik Sadaf Allauddin 1, Abu Sufyan Malik 2 1B.Tech, Dept. of IT, Pillai HOC College of Engineering
Volume: 05 Issue: 09 Sep 2018 www.irjet.net p-issn: 2395-0072 Data Clustering Frame work using Hadoop Malik Sadaf Allauddin 1, Abu Sufyan Malik 2 1B.Tech, Dept. of IT, Pillai HOC College of Engineering
CSC401 Natural Language Computing
 CSC401 Natural Language Computing Jan 19, 2018 TA: Willie Chang Varada Kolhatkar, Ka-Chun Won, and Aryan Arbabi) Mascots: r/sandersforpresident (left) and r/the_donald (right) To perform sentiment analysis
CSC401 Natural Language Computing Jan 19, 2018 TA: Willie Chang Varada Kolhatkar, Ka-Chun Won, and Aryan Arbabi) Mascots: r/sandersforpresident (left) and r/the_donald (right) To perform sentiment analysis
A Dependency Parser for Tweets. Lingpeng Kong, Nathan Schneider, Swabha Swayamdipta, Archna Bhatia, Chris Dyer, and Noah A. Smith
 A Dependency Parser for Tweets Lingpeng Kong, Nathan Schneider, Swabha Swayamdipta, Archna Bhatia, Chris Dyer, and Noah A. Smith NLP for Social Media Boom! Ya ur website suxx bro @SarahKSilverman michelle
A Dependency Parser for Tweets Lingpeng Kong, Nathan Schneider, Swabha Swayamdipta, Archna Bhatia, Chris Dyer, and Noah A. Smith NLP for Social Media Boom! Ya ur website suxx bro @SarahKSilverman michelle
INF FALL NATURAL LANGUAGE PROCESSING. Jan Tore Lønning, Lecture 4, 10.9
 1 INF5830 2015 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning, Lecture 4, 10.9 2 Working with texts From bits to meaningful units Today: 3 Reading in texts Character encodings and Unicode Word tokenization
1 INF5830 2015 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning, Lecture 4, 10.9 2 Working with texts From bits to meaningful units Today: 3 Reading in texts Character encodings and Unicode Word tokenization
What is this Song About?: Identification of Keywords in Bollywood Lyrics
 What is this Song About?: Identification of Keywords in Bollywood Lyrics by Drushti Apoorva G, Kritik Mathur, Priyansh Agrawal, Radhika Mamidi in 19th International Conference on Computational Linguistics
What is this Song About?: Identification of Keywords in Bollywood Lyrics by Drushti Apoorva G, Kritik Mathur, Priyansh Agrawal, Radhika Mamidi in 19th International Conference on Computational Linguistics
An open source GATE toolkit for social media analysis. Diana Maynard University of Sheffield, UK
 An open source GATE toolkit for social media analysis Diana Maynard University of Sheffield, UK GATE for text engineering Tool for developing and deployment of Text Mining technology http://gate.ac.uk
An open source GATE toolkit for social media analysis Diana Maynard University of Sheffield, UK GATE for text engineering Tool for developing and deployment of Text Mining technology http://gate.ac.uk
WASA: A Web Application for Sequence Annotation
 WASA: A Web Application for Sequence Annotation Fahad AlGhamdi, and Mona Diab Department of Computer Science The George Washington University Washington, DC {fghamdi, mtdiab}@gwu.edu Abstract Data annotation
WASA: A Web Application for Sequence Annotation Fahad AlGhamdi, and Mona Diab Department of Computer Science The George Washington University Washington, DC {fghamdi, mtdiab}@gwu.edu Abstract Data annotation
A tool for Cross-Language Pair Annotations: CLPA
 A tool for Cross-Language Pair Annotations: CLPA August 28, 2006 This document describes our tool called Cross-Language Pair Annotator (CLPA) that is capable to automatically annotate cognates and false
A tool for Cross-Language Pair Annotations: CLPA August 28, 2006 This document describes our tool called Cross-Language Pair Annotator (CLPA) that is capable to automatically annotate cognates and false
Introducing XAIRA. Lou Burnard Tony Dodd. An XML aware tool for corpus indexing and searching. Research Technology Services, OUCS
 Introducing XAIRA An XML aware tool for corpus indexing and searching Lou Burnard Tony Dodd Research Technology Services, OUCS What is XAIRA? XML Aware Indexing and Retrieval Architecture Developed from
Introducing XAIRA An XML aware tool for corpus indexing and searching Lou Burnard Tony Dodd Research Technology Services, OUCS What is XAIRA? XML Aware Indexing and Retrieval Architecture Developed from
Sentiment Analysis using Weighted Emoticons and SentiWordNet for Indonesian Language
 Sentiment Analysis using Weighted Emoticons and SentiWordNet for Indonesian Language Nur Maulidiah Elfajr, Riyananto Sarno Department of Informatics, Faculty of Information and Communication Technology
Sentiment Analysis using Weighted Emoticons and SentiWordNet for Indonesian Language Nur Maulidiah Elfajr, Riyananto Sarno Department of Informatics, Faculty of Information and Communication Technology
ASSIGNMENT 1: TWEET TOKENIZATION & NORMALIZATION
 ASSIGNMENT 1: TWEET TOKENIZATION & NORMALIZATION Motivation: The motivation of this assignment is to get an insight into data annotation (as a linguist) as well as writing rule-based NLP engines Problem
ASSIGNMENT 1: TWEET TOKENIZATION & NORMALIZATION Motivation: The motivation of this assignment is to get an insight into data annotation (as a linguist) as well as writing rule-based NLP engines Problem
Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras
 Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras Lecture - 25 Tutorial 5: Analyzing text using Python NLTK Hi everyone,
Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras Lecture - 25 Tutorial 5: Analyzing text using Python NLTK Hi everyone,
Exam III March 17, 2010
 CIS 4930 NLP Print Your Name Exam III March 17, 2010 Total Score Your work is to be done individually. The exam is worth 106 points (six points of extra credit are available throughout the exam) and it
CIS 4930 NLP Print Your Name Exam III March 17, 2010 Total Score Your work is to be done individually. The exam is worth 106 points (six points of extra credit are available throughout the exam) and it
Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels
 Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels Richa Jain 1, Namrata Sharma 2 1M.Tech Scholar, Department of CSE, Sushila Devi Bansal College of Engineering, Indore (M.P.),
Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels Richa Jain 1, Namrata Sharma 2 1M.Tech Scholar, Department of CSE, Sushila Devi Bansal College of Engineering, Indore (M.P.),
Sentiment Analysis in Twitter
 Sentiment Analysis in Twitter Mayank Gupta, Ayushi Dalmia, Arpit Jaiswal and Chinthala Tharun Reddy 201101004, 201307565, 201305509, 201001069 IIIT Hyderabad, Hyderabad, AP, India {mayank.g, arpitkumar.jaiswal,
Sentiment Analysis in Twitter Mayank Gupta, Ayushi Dalmia, Arpit Jaiswal and Chinthala Tharun Reddy 201101004, 201307565, 201305509, 201001069 IIIT Hyderabad, Hyderabad, AP, India {mayank.g, arpitkumar.jaiswal,
A Short Introduction to CATMA
 A Short Introduction to CATMA Outline: I. Getting Started II. Analyzing Texts - Search Queries in CATMA III. Annotating Texts (collaboratively) with CATMA IV. Further Search Queries: Analyze Your Annotations
A Short Introduction to CATMA Outline: I. Getting Started II. Analyzing Texts - Search Queries in CATMA III. Annotating Texts (collaboratively) with CATMA IV. Further Search Queries: Analyze Your Annotations
LAB 3: Text processing + Apache OpenNLP
 LAB 3: Text processing + Apache OpenNLP 1. Motivation: The text that was derived (e.g., crawling + using Apache Tika) must be processed before being used in an information retrieval system. Text processing
LAB 3: Text processing + Apache OpenNLP 1. Motivation: The text that was derived (e.g., crawling + using Apache Tika) must be processed before being used in an information retrieval system. Text processing
TEXT PREPROCESSING FOR TEXT MINING USING SIDE INFORMATION
 TEXT PREPROCESSING FOR TEXT MINING USING SIDE INFORMATION Ms. Nikita P.Katariya 1, Prof. M. S. Chaudhari 2 1 Dept. of Computer Science & Engg, P.B.C.E., Nagpur, India, nikitakatariya@yahoo.com 2 Dept.
TEXT PREPROCESSING FOR TEXT MINING USING SIDE INFORMATION Ms. Nikita P.Katariya 1, Prof. M. S. Chaudhari 2 1 Dept. of Computer Science & Engg, P.B.C.E., Nagpur, India, nikitakatariya@yahoo.com 2 Dept.
Morpho-syntactic Analysis with the Stanford CoreNLP
 Morpho-syntactic Analysis with the Stanford CoreNLP Danilo Croce croce@info.uniroma2.it WmIR 2015/2016 Objectives of this tutorial Use of a Natural Language Toolkit CoreNLP toolkit Morpho-syntactic analysis
Morpho-syntactic Analysis with the Stanford CoreNLP Danilo Croce croce@info.uniroma2.it WmIR 2015/2016 Objectives of this tutorial Use of a Natural Language Toolkit CoreNLP toolkit Morpho-syntactic analysis
NUSIS at TREC 2011 Microblog Track: Refining Query Results with Hashtags
 NUSIS at TREC 2011 Microblog Track: Refining Query Results with Hashtags Hadi Amiri 1,, Yang Bao 2,, Anqi Cui 3,,*, Anindya Datta 2,, Fang Fang 2,, Xiaoying Xu 2, 1 Department of Computer Science, School
NUSIS at TREC 2011 Microblog Track: Refining Query Results with Hashtags Hadi Amiri 1,, Yang Bao 2,, Anqi Cui 3,,*, Anindya Datta 2,, Fang Fang 2,, Xiaoying Xu 2, 1 Department of Computer Science, School
Parts of Speech, Named Entity Recognizer
 Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
Treex: Modular NLP Framework
 : Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
: Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
Information Extraction Techniques in Terrorism Surveillance
 Information Extraction Techniques in Terrorism Surveillance Roman Tekhov Abstract. The article gives a brief overview of what information extraction is and how it might be used for the purposes of counter-terrorism
Information Extraction Techniques in Terrorism Surveillance Roman Tekhov Abstract. The article gives a brief overview of what information extraction is and how it might be used for the purposes of counter-terrorism
TTIC 31190: Natural Language Processing
 TTIC 31190: Natural Language Processing Kevin Gimpel Winter 2016 Lecture 2: Text Classification 1 Please email me (kgimpel@ttic.edu) with the following: your name your email address whether you taking
TTIC 31190: Natural Language Processing Kevin Gimpel Winter 2016 Lecture 2: Text Classification 1 Please email me (kgimpel@ttic.edu) with the following: your name your email address whether you taking
Taming Text. How to Find, Organize, and Manipulate It MANNING GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS. Shelter Island
 Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
Taming Text How to Find, Organize, and Manipulate It GRANT S. INGERSOLL THOMAS S. MORTON ANDREW L. KARRIS 11 MANNING Shelter Island contents foreword xiii preface xiv acknowledgments xvii about this book
Automatically Annotating Text with Linked Open Data
 Automatically Annotating Text with Linked Open Data Delia Rusu, Blaž Fortuna, Dunja Mladenić Jožef Stefan Institute Motivation: Annotating Text with LOD Open Cyc DBpedia WordNet Overview Related work Algorithms
Automatically Annotating Text with Linked Open Data Delia Rusu, Blaž Fortuna, Dunja Mladenić Jožef Stefan Institute Motivation: Annotating Text with LOD Open Cyc DBpedia WordNet Overview Related work Algorithms
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
A Hybrid Unsupervised Web Data Extraction using Trinity and NLP
 IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 A Hybrid Unsupervised Web Data Extraction using Trinity and NLP Anju R
TectoMT: Modular NLP Framework
 : Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
: Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
A bit of theory: Algorithms
 A bit of theory: Algorithms There are different kinds of algorithms Vector space models. e.g. support vector machines Decision trees, e.g. C45 Probabilistic models, e.g. Naive Bayes Neural networks, e.g.
A bit of theory: Algorithms There are different kinds of algorithms Vector space models. e.g. support vector machines Decision trees, e.g. C45 Probabilistic models, e.g. Naive Bayes Neural networks, e.g.
Sentiment Analysis of Customers using Product Feedback Data under Hadoop Framework
 International Journal of Computational Intelligence Research ISSN 0973-1873 Volume 13, Number 5 (2017), pp. 1083-1091 Research India Publications http://www.ripublication.com Sentiment Analysis of Customers
International Journal of Computational Intelligence Research ISSN 0973-1873 Volume 13, Number 5 (2017), pp. 1083-1091 Research India Publications http://www.ripublication.com Sentiment Analysis of Customers
DBpedia Spotlight at the MSM2013 Challenge
 DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
DBpedia Spotlight at the MSM2013 Challenge Pablo N. Mendes 1, Dirk Weissenborn 2, and Chris Hokamp 3 1 Kno.e.sis Center, CSE Dept., Wright State University 2 Dept. of Comp. Sci., Dresden Univ. of Tech.
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Maca a configurable tool to integrate Polish morphological data. Adam Radziszewski Tomasz Śniatowski Wrocław University of Technology
 Maca a configurable tool to integrate Polish morphological data Adam Radziszewski Tomasz Śniatowski Wrocław University of Technology Outline Morphological resources for Polish Tagset and segmentation differences
Maca a configurable tool to integrate Polish morphological data Adam Radziszewski Tomasz Śniatowski Wrocław University of Technology Outline Morphological resources for Polish Tagset and segmentation differences
BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network
 BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network Roberto Navigli, Simone Paolo Ponzetto What is BabelNet a very large, wide-coverage multilingual
BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network Roberto Navigli, Simone Paolo Ponzetto What is BabelNet a very large, wide-coverage multilingual
University of Sheffield, NLP. Chunking Practical Exercise
 Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
SENTIMENT ESTIMATION OF TWEETS BY LEARNING SOCIAL BOOKMARK DATA
 IADIS International Journal on WWW/Internet Vol. 14, No. 1, pp. 15-27 ISSN: 1645-7641 SENTIMENT ESTIMATION OF TWEETS BY LEARNING SOCIAL BOOKMARK DATA Yasuyuki Okamura, Takayuki Yumoto, Manabu Nii and Naotake
IADIS International Journal on WWW/Internet Vol. 14, No. 1, pp. 15-27 ISSN: 1645-7641 SENTIMENT ESTIMATION OF TWEETS BY LEARNING SOCIAL BOOKMARK DATA Yasuyuki Okamura, Takayuki Yumoto, Manabu Nii and Naotake
Extracting Information from Social Media with GATE
 Extracting Information from Social Media with GATE Kalina BONTCHEVA 1 and Leon DERCZYNSKI 2 Abstract. Information extraction from social media content has only recently become an active research topic,
Extracting Information from Social Media with GATE Kalina BONTCHEVA 1 and Leon DERCZYNSKI 2 Abstract. Information extraction from social media content has only recently become an active research topic,
Lab II - Product Specification Outline. CS 411W Lab II. Prototype Product Specification For CLASH. Professor Janet Brunelle Professor Hill Price
 Lab II - Product Specification Outline CS 411W Lab II Prototype Product Specification For CLASH Professor Janet Brunelle Professor Hill Price Prepared by: Artem Fisan Date: 04/20/2015 Table of Contents
Lab II - Product Specification Outline CS 411W Lab II Prototype Product Specification For CLASH Professor Janet Brunelle Professor Hill Price Prepared by: Artem Fisan Date: 04/20/2015 Table of Contents
String Vector based KNN for Text Categorization
 458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
458 String Vector based KNN for Text Categorization Taeho Jo Department of Computer and Information Communication Engineering Hongik University Sejong, South Korea tjo018@hongik.ac.kr Abstract This research
Software-specific Part-of-Speech Tagging: An Experimental Study on Stack Overflow
 Software-specific Part-of-Speech Tagging: An Experimental Study on Stack Overflow Deheng Ye, Zhenchang Xing, Jing Li, and Nachiket Kapre School of Computer Engineering Nanyang Technological University,
Software-specific Part-of-Speech Tagging: An Experimental Study on Stack Overflow Deheng Ye, Zhenchang Xing, Jing Li, and Nachiket Kapre School of Computer Engineering Nanyang Technological University,
Stanbol Enhancer. Use Custom Vocabularies with the. Rupert Westenthaler, Salzburg Research, Austria. 07.
 http://stanbol.apache.org Use Custom Vocabularies with the Stanbol Enhancer Rupert Westenthaler, Salzburg Research, Austria 07. November, 2012 About Me Rupert Westenthaler Apache Stanbol and Clerezza Committer
http://stanbol.apache.org Use Custom Vocabularies with the Stanbol Enhancer Rupert Westenthaler, Salzburg Research, Austria 07. November, 2012 About Me Rupert Westenthaler Apache Stanbol and Clerezza Committer
CLEF 2017 Microblog Cultural Contextualization Lab Overview
 CLEF 2017 Microblog Cultural Contextualization Lab Overview Liana Ermakova, Lorraine Goeuriot, Josiane Mothe, Philippe Mulhem, Jian-Yun Nie, Eric SanJuan Avignon, Grenoble, Lorraine and Montréal Universities
CLEF 2017 Microblog Cultural Contextualization Lab Overview Liana Ermakova, Lorraine Goeuriot, Josiane Mothe, Philippe Mulhem, Jian-Yun Nie, Eric SanJuan Avignon, Grenoble, Lorraine and Montréal Universities
Sentiment Analysis using Support Vector Machine based on Feature Selection and Semantic Analysis
 Sentiment Analysis using Support Vector Machine based on Feature Selection and Semantic Analysis Bhumika M. Jadav M.E. Scholar, L. D. College of Engineering Ahmedabad, India Vimalkumar B. Vaghela, PhD
Sentiment Analysis using Support Vector Machine based on Feature Selection and Semantic Analysis Bhumika M. Jadav M.E. Scholar, L. D. College of Engineering Ahmedabad, India Vimalkumar B. Vaghela, PhD
Background and Context for CLASP. Nancy Ide, Vassar College
 Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
LIDER Survey. Overview. Number of participants: 24. Participant profile (organisation type, industry sector) Relevant use-cases
 Relevant use-cases") LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
Documentation and analysis of an. endangered language: aspects of. the grammar of Griko
 Documentation and analysis of an endangered language: aspects of the grammar of Griko Database and Website manual Antonis Anastasopoulos Marika Lekakou NTUA UOI December 12, 2013 Contents Introduction...............................
Documentation and analysis of an endangered language: aspects of the grammar of Griko Database and Website manual Antonis Anastasopoulos Marika Lekakou NTUA UOI December 12, 2013 Contents Introduction...............................
Topics in Opinion Mining. Dr. Paul Buitelaar Data Science Institute, NUI Galway
 Topics in Opinion Mining Dr. Paul Buitelaar Data Science Institute, NUI Galway Opinion: Sentiment, Emotion, Subjectivity OBJECTIVITY SUBJECTIVITY SPECULATION FACTS BELIEFS EMOTION SENTIMENT UNCERTAINTY
Topics in Opinion Mining Dr. Paul Buitelaar Data Science Institute, NUI Galway Opinion: Sentiment, Emotion, Subjectivity OBJECTIVITY SUBJECTIVITY SPECULATION FACTS BELIEFS EMOTION SENTIMENT UNCERTAINTY
Center for Reflected Text Analytics. Lecture 2 Annotation tools & Segmentation
 Center for Reflected Text Analytics Lecture 2 Annotation tools & Segmentation Summary of Part 1 Annotation theory Guidelines Inter-Annotator agreement Inter-subjective annotations Annotation exercise Discuss
Center for Reflected Text Analytics Lecture 2 Annotation tools & Segmentation Summary of Part 1 Annotation theory Guidelines Inter-Annotator agreement Inter-subjective annotations Annotation exercise Discuss
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2
 A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
Sentiment Analysis on Twitter Data using KNN and SVM
 Vol. 8, No. 6, 27 Sentiment Analysis on Twitter Data using KNN and SVM Mohammad Rezwanul Huq Dept. of Computer Science and Engineering East West University Dhaka, Bangladesh Ahmad Ali Dept. of Computer
Vol. 8, No. 6, 27 Sentiment Analysis on Twitter Data using KNN and SVM Mohammad Rezwanul Huq Dept. of Computer Science and Engineering East West University Dhaka, Bangladesh Ahmad Ali Dept. of Computer
Information Retrieval CS Lecture 01. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Enhancing applications with Cognitive APIs IBM Corporation
 Enhancing applications with Cognitive APIs After you complete this section, you should understand: The Watson Developer Cloud offerings and APIs The benefits of commonly used Cognitive services 2 Watson
Enhancing applications with Cognitive APIs After you complete this section, you should understand: The Watson Developer Cloud offerings and APIs The benefits of commonly used Cognitive services 2 Watson
University of Sheffield, NLP. Chunking Practical Exercise
 Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
KAF: a generic semantic annotation format
 KAF: a generic semantic annotation format Wauter Bosma & Piek Vossen (VU University Amsterdam) Aitor Soroa & German Rigau (Basque Country University) Maurizio Tesconi & Andrea Marchetti (CNR-IIT, Pisa)
KAF: a generic semantic annotation format Wauter Bosma & Piek Vossen (VU University Amsterdam) Aitor Soroa & German Rigau (Basque Country University) Maurizio Tesconi & Andrea Marchetti (CNR-IIT, Pisa)
Social Media & Text Analysis
 Social Media & Text Analysis lecture 5 - POS/NE Tagging CSE 5539-0010 Ohio State University Instructor: Alan Ritter Website: socialmedia-class.org NLP Pipeline (summary so far) classification (Naïve Bayes)
Social Media & Text Analysis lecture 5 - POS/NE Tagging CSE 5539-0010 Ohio State University Instructor: Alan Ritter Website: socialmedia-class.org NLP Pipeline (summary so far) classification (Naïve Bayes)
Text Mining for Software Engineering
 Text Mining for Software Engineering Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe (TH), Germany Department of Computer Science and Software
Text Mining for Software Engineering Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe (TH), Germany Department of Computer Science and Software
Knowledge Retrieval. Franz J. Kurfess. Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A.
 Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
16 January 2018 Ken Benoit, Kohei Watanabe & Akitaka Matsuo London School of Economics and Political Science
 16 January 2018 Ken Benoit, Kohei Watanabe & Akitaka Matsuo London School of Economics and Political Science Quantitative Analysis of Textual Data 5.5 years of development, 17 releases 6,791 commits; 719
16 January 2018 Ken Benoit, Kohei Watanabe & Akitaka Matsuo London School of Economics and Political Science Quantitative Analysis of Textual Data 5.5 years of development, 17 releases 6,791 commits; 719
Error annotation in adjective noun (AN) combinations
 combinations") Error annotation in adjective noun (AN) combinations This document describes the annotation scheme devised for annotating errors in AN combinations and explains how the inter-annotator agreement has been
Error annotation in adjective noun (AN) combinations This document describes the annotation scheme devised for annotating errors in AN combinations and explains how the inter-annotator agreement has been
Text Analytics Introduction (Part 1)
") Text Analytics Introduction (Part 1) Maha Althobaiti, Udo Kruschwitz, Massimo Poesio School of Computer Science and Electronic Engineering University of Essex udo@essex.ac.uk 23 September 2015 Text Analytics
Text Analytics Introduction (Part 1) Maha Althobaiti, Udo Kruschwitz, Massimo Poesio School of Computer Science and Electronic Engineering University of Essex udo@essex.ac.uk 23 September 2015 Text Analytics
Review Spam Analysis using Term-Frequencies
 Volume 03 - Issue 06 June 2018 PP. 132-140 Review Spam Analysis using Term-Frequencies Jyoti G.Biradar School of Mathematics and Computing Sciences Department of Computer Science Rani Channamma University
Volume 03 - Issue 06 June 2018 PP. 132-140 Review Spam Analysis using Term-Frequencies Jyoti G.Biradar School of Mathematics and Computing Sciences Department of Computer Science Rani Channamma University
ISSN: Page 74
 Extraction and Analytics from Twitter Social Media with Pragmatic Evaluation of MySQL Database Abhijit Bandyopadhyay Teacher-in-Charge Computer Application Department Raniganj Institute of Computer and
Extraction and Analytics from Twitter Social Media with Pragmatic Evaluation of MySQL Database Abhijit Bandyopadhyay Teacher-in-Charge Computer Application Department Raniganj Institute of Computer and
Package corenlp. June 3, 2015
 Type Package Title Wrappers Around Stanford CoreNLP Tools Version 0.4-1 Author Taylor Arnold, Lauren Tilton Package corenlp June 3, 2015 Maintainer Taylor Arnold Provides a minimal
Type Package Title Wrappers Around Stanford CoreNLP Tools Version 0.4-1 Author Taylor Arnold, Lauren Tilton Package corenlp June 3, 2015 Maintainer Taylor Arnold Provides a minimal
Introduction to Text Mining. Hongning Wang
 Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
A Tweet Classification Model Based on Dynamic and Static Component Topic Vectors
 A Tweet Classification Model Based on Dynamic and Static Component Topic Vectors Parma Nand, Rivindu Perera, and Gisela Klette School of Computer and Mathematical Science Auckland University of Technology
A Tweet Classification Model Based on Dynamic and Static Component Topic Vectors Parma Nand, Rivindu Perera, and Gisela Klette School of Computer and Mathematical Science Auckland University of Technology
LING/C SC/PSYC 438/538. Lecture 3 Sandiway Fong
 LING/C SC/PSYC 438/538 Lecture 3 Sandiway Fong Today s Topics Homework 4 out due next Tuesday by midnight Homework 3 should have been submitted yesterday Quick Homework 3 review Continue with Perl intro
LING/C SC/PSYC 438/538 Lecture 3 Sandiway Fong Today s Topics Homework 4 out due next Tuesday by midnight Homework 3 should have been submitted yesterday Quick Homework 3 review Continue with Perl intro
Parmenides. Semi-automatic. Ontology. construction and maintenance. Ontology. Document convertor/basic processing. Linguistic. Background knowledge
 Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
NLP in practice, an example: Semantic Role Labeling
 NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
Let s get parsing! Each component processes the Doc object, then passes it on. doc.is_parsed attribute checks whether a Doc object has been parsed
 Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
Mahek Merchant 1, Ricky Parmar 2, Nishil Shah 3, P.Boominathan 4 1,3,4 SCOPE, VIT University, Vellore, Tamilnadu, India
 Sentiment Analysis of Web Scraped Product Reviews using Hadoop Mahek Merchant 1, Ricky Parmar 2, Nishil Shah 3, P.Boominathan 4 1,3,4 SCOPE, VIT University, Vellore, Tamilnadu, India Abstract As in the
Sentiment Analysis of Web Scraped Product Reviews using Hadoop Mahek Merchant 1, Ricky Parmar 2, Nishil Shah 3, P.Boominathan 4 1,3,4 SCOPE, VIT University, Vellore, Tamilnadu, India Abstract As in the
Comparing Sentiment Engine Performance on Reviews and Tweets
 Comparing Sentiment Engine Performance on Reviews and Tweets Emanuele Di Rosa, PhD CSO, Head of Artificial Intelligence Finsa s.p.a. emanuele.dirosa@finsa.it www.app2check.com www.finsa.it Motivations
Comparing Sentiment Engine Performance on Reviews and Tweets Emanuele Di Rosa, PhD CSO, Head of Artificial Intelligence Finsa s.p.a. emanuele.dirosa@finsa.it www.app2check.com www.finsa.it Motivations
Advanced Topics in Information Retrieval Natural Language Processing for IR & IR Evaluation. ATIR April 28, 2016
 Advanced Topics in Information Retrieval Natural Language Processing for IR & IR Evaluation Vinay Setty vsetty@mpi-inf.mpg.de Jannik Strötgen jannik.stroetgen@mpi-inf.mpg.de ATIR April 28, 2016 Organizational
Advanced Topics in Information Retrieval Natural Language Processing for IR & IR Evaluation Vinay Setty vsetty@mpi-inf.mpg.de Jannik Strötgen jannik.stroetgen@mpi-inf.mpg.de ATIR April 28, 2016 Organizational
Semantics Isn t Easy Thoughts on the Way Forward
 Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Contents. List of Figures. List of Tables. Acknowledgements
 Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
Inter-Annotator Agreement for a German Newspaper Corpus
 Inter-Annotator Agreement for a German Newspaper Corpus Thorsten Brants Saarland University, Computational Linguistics D-66041 Saarbrücken, Germany thorsten@coli.uni-sb.de Abstract This paper presents
Inter-Annotator Agreement for a German Newspaper Corpus Thorsten Brants Saarland University, Computational Linguistics D-66041 Saarbrücken, Germany thorsten@coli.uni-sb.de Abstract This paper presents
Hidden Markov Models. Natural Language Processing: Jordan Boyd-Graber. University of Colorado Boulder LECTURE 20. Adapted from material by Ray Mooney
 Hidden Markov Models Natural Language Processing: Jordan Boyd-Graber University of Colorado Boulder LECTURE 20 Adapted from material by Ray Mooney Natural Language Processing: Jordan Boyd-Graber Boulder
Hidden Markov Models Natural Language Processing: Jordan Boyd-Graber University of Colorado Boulder LECTURE 20 Adapted from material by Ray Mooney Natural Language Processing: Jordan Boyd-Graber Boulder
WebAnno: a flexible, web-based annotation tool for CLARIN
 WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
Domain-specific Concept-based Information Retrieval System
 Domain-specific Concept-based Information Retrieval System L. Shen 1, Y. K. Lim 1, H. T. Loh 2 1 Design Technology Institute Ltd, National University of Singapore, Singapore 2 Department of Mechanical
Domain-specific Concept-based Information Retrieval System L. Shen 1, Y. K. Lim 1, H. T. Loh 2 1 Design Technology Institute Ltd, National University of Singapore, Singapore 2 Department of Mechanical
Parallel Concordancing and Translation. Michael Barlow
 [Translating and the Computer 26, November 2004 [London: Aslib, 2004] Parallel Concordancing and Translation Michael Barlow Dept. of Applied Language Studies and Linguistics University of Auckland Auckland,
[Translating and the Computer 26, November 2004 [London: Aslib, 2004] Parallel Concordancing and Translation Michael Barlow Dept. of Applied Language Studies and Linguistics University of Auckland Auckland,
SAPIENT Automation project
 Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
Dr Maria Liakata Leverhulme Trust Early Career fellow Department of Computer Science, Aberystwyth University Visitor at EBI, Cambridge mal@aber.ac.uk 25 May 2010, London Motivation SAPIENT Automation Project
Natural Language Processing
 Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
JU_CSE_TE: System Description 2010 ResPubliQA
 JU_CSE_TE: System Description QA@CLEF 2010 ResPubliQA Partha Pakray 1, Pinaki Bhaskar 1, Santanu Pal 1, Dipankar Das 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 Department of Computer Science & Engineering
JU_CSE_TE: System Description QA@CLEF 2010 ResPubliQA Partha Pakray 1, Pinaki Bhaskar 1, Santanu Pal 1, Dipankar Das 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 Department of Computer Science & Engineering
SAMPLE 2 This is a sample copy of the book From Words to Wisdom - An Introduction to Text Mining with KNIME
 2 Copyright 2018 by KNIME Press All Rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction, storage in a retrieval
2 Copyright 2018 by KNIME Press All Rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction, storage in a retrieval
Challenge. Case Study. The fabric of space and time has collapsed. What s the big deal? Miami University of Ohio
 Case Study Use Case: Recruiting Segment: Recruiting Products: Rosette Challenge CareerBuilder, the global leader in human capital solutions, operates the largest job board in the U.S. and has an extensive
Case Study Use Case: Recruiting Segment: Recruiting Products: Rosette Challenge CareerBuilder, the global leader in human capital solutions, operates the largest job board in the U.S. and has an extensive
GATE and Social Media: Normalisation and PoS-tagging
 GATE and Social Media: Normalisation and PoS-tagging Leon Derczynski Kalina Bontcheva The University of Sheffield, 1995-2016 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs
GATE and Social Media: Normalisation and PoS-tagging Leon Derczynski Kalina Bontcheva The University of Sheffield, 1995-2016 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs
WordNet-based User Profiles for Semantic Personalization
 PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
News Filtering and Summarization System Architecture for Recognition and Summarization of News Pages
 Bonfring International Journal of Data Mining, Vol. 7, No. 2, May 2017 11 News Filtering and Summarization System Architecture for Recognition and Summarization of News Pages Bamber and Micah Jason Abstract---
Bonfring International Journal of Data Mining, Vol. 7, No. 2, May 2017 11 News Filtering and Summarization System Architecture for Recognition and Summarization of News Pages Bamber and Micah Jason Abstract---
Implementing a Variety of Linguistic Annotations
 Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
Vision Plan. For KDD- Service based Numerical Entity Searcher (KSNES) Version 2.0
 Version 2.0") Vision Plan For KDD- Service based Numerical Entity Searcher (KSNES) Version 2.0 Submitted in partial fulfillment of the Masters of Software Engineering Degree. Naga Sowjanya Karumuri CIS 895 MSE Project
Vision Plan For KDD- Service based Numerical Entity Searcher (KSNES) Version 2.0 Submitted in partial fulfillment of the Masters of Software Engineering Degree. Naga Sowjanya Karumuri CIS 895 MSE Project
Finding Related Entities by Retrieving Relations: UIUC at TREC 2009 Entity Track
 Finding Related Entities by Retrieving Relations: UIUC at TREC 2009 Entity Track V.G.Vinod Vydiswaran, Kavita Ganesan, Yuanhua Lv, Jing He, ChengXiang Zhai Department of Computer Science University of
Finding Related Entities by Retrieving Relations: UIUC at TREC 2009 Entity Track V.G.Vinod Vydiswaran, Kavita Ganesan, Yuanhua Lv, Jing He, ChengXiang Zhai Department of Computer Science University of
@Note2 tutorial. Hugo Costa Ruben Rodrigues Miguel Rocha
 @Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
@Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
Unstructured Data. CS102 Winter 2019
 Winter 2019 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for patterns in data
Winter 2019 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for patterns in data