Simone Campanoni Loop transformations
|
|
|
- Roland Floyd
- 5 years ago
- Views:
Transcription



1 Simone Campanoni Loop transformations
2 Outline Simple loop transformations Loop invariants Induction variables Complex loop transformations
3 Simple loop transformations Simple loop transformations are used to Increase performance/energy savings and/or Unblock other transformations E.g., increase the number of constant propagations E.g., Extract thread-level parallelism from sequential code E.g., Generate vector instructions
4 Loop unrolling %a = 0 %a = 0 for (a=0; a < 4; a++){ } // Body %a=cmp %a, 4 branch %a Body Unrolling factor: 2 %a=cmp %a, 4 branch %a Body %a=add %a, 1 Body %a=add %a, 2
5 Loop unrolling in LLVM Dependences

6 Loop unrolling in LLVM Headers
7 Loop unrolling in LLVM Get the results of the required analyses

8 Fetch a loop
9 Loop unrolling in LLVM API

10 Loop unrolling in LLVM: example Body Body Body
11 Loop unrolling: the trip count
12 Loop unrolling: the trip multiple
13 Loop unrolling in LLVM: the runtime checks
14 Loop unrolling in LLVM: example 2 i=0 i=0 If (argc > 0) If (argc > 0) i++ Body if (i == argc) i++ Body if (i == argc) i++ Body if (i == argc) return r return r
15 Loop unrolling in LLVM: the runtime checks
16 If (argc > 0) Loop unrolling in LLVM: example 3 i_rest = i & 3 i_mul = i i_rest i++ Body if (i == argc) return r i=0 If (argc > 0) Runtime checks If (i_mul > 0) auto n=0 for (;n<i_mul; n+=4){ Body Body Body Body } for(auto m=0;m<i_rest;m++){ Body } return r
17 Loop unrolling in LLVM: example 4 trip = argc i=0 If (trip > 0) i++ Body if (i < trip) return r
18 Loop unrolling in LLVM: example 4 trip = argc i = 0 If (trip > 0) trip = argc i=0 If (trip > 0) i++ Body if (i < trip) i++ Body if (i < trip) i++ Body if (i < trip) return r return r
19 Loop peeling %a=cmp %a, 10 branch %a Body %a=add %a, 1 Peeling factor: 1 Body %a = add %a, 1 %a=cmp %a, %10 branch %a Body %a=add %a, 1
20 Loop peeling in LLVM API No trip count No flags (almost) always possible
21 Loop peeling in LLVM: example
22 Loop unrolling and peeling together
23 Outline Simple loop transformations Loop invariants Induction variables Complex loop transformations
24 Optimizations in small, hot loops Most programs: 90% of time is spent in few, small, hot loops while (){ } statement 1 statement 2 statement 3 Deleting a single statement from a small, hot loop might have a big impact (100 seconds -> 70 seconds)
25 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N); Observation: each statement in that loop will contribute to the program execution time Idea: what about moving statements from inside a loop to outside it? Which statements can be moved outside our loop? How to identify them automatically? (code analysis) How to move them? (code transformation)
26 Loop-invariant computations Let d be the following definition (d) t = x op y d is a loop-invariant of a loop L if (assuming x, y do not escape) x and y are constants or All reaching definitions of x and y are outside the loop, or Only one definition reaches x (or y), and that definition is loop-invariant
27 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N); d is a loop-invariant of a loop L if x and y are constants or All reaching definitions of x and y are outside the loop, or Only one definition reaches x (or y), and that definition is loop-invariant??

28 Loop-invariant computations in LLVM
29 Hoisting code In order to hoist a loop-invariant computation out of a loop, we need a place to put it We could copy it to all immediate predecessors of the loop header... for (auto it = pred_begin(h); it!= pred_end(h); ++it){ BasicBlock *pbb = *it; p = pbb->getterminator(); inv->movebefore(p); } n1 n2 n3 Header Is it correct?...but we can avoid code duplication (and bugs) by taking advantage of loop normalization that guarantees the existence of the pre-header
30 Hoisting code In order to hoist a loop-invariant computation out of a loop, we need a place to put it We could copy it to all immediate predecessors of the loop header... pbb = loop->getlooppreheader(); p = pbb->getterminator(); inv->movebefore(p); Exit node Pre-header Header Body...but we can avoid code duplication (and bugs) by taking advantage of loop normalization that guarantees the existence of the pre-header Latch
31 Can we hoist all invariant instructions of a loop L in the pre-header of L? Pre-header for (inv : invariants(loop)){ pbb = loop->getlooppreheader(); p = pbb->getterminator(); inv->movebefore(p); } Exit node Header Body Latch

32 Hoisting conditions For a loop-invariant definition (d) t = x op y We can hoist d into the loop s pre-header if 1. d dominates all loop exits at which t is live-out, and 2. there is only one definition?? of t in the loop, and 3. t is not live-out of the pre-header 1,3 2
33 Outline Simple loop transformations Loop invariants Induction variables Complex loop transformations
34 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N); Assuming a,b,c,m are used after our code Do we have to execute 4 for every iteration? Do we have to execute 10 for every iteration?
35 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N); y=n Do we have to execute 4 for every iteration? Compute manually values of x and y for every iteration What do you see? Do we have to execute 10 for every iteration?
36 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++;y++; 11:} while (x < N); y=n Do we have to execute 4 for every iteration? Do we have to execute 10 for every iteration?
37 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++;y++; 11:} while (y < (2*N)); y=n Do we have to execute 4 for every iteration? Do we have to execute 10 for every iteration?
38 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: y++; 11:} while (y < (2*N)); y=n Do we have to execute 4 for every iteration? Do we have to execute 10 for every iteration?
39 Loop example 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: y++; 11:} while (y < tmp); y=n;tmp=2*n; Do we have to execute 4 for every iteration? x, y are induction variables Do we have to execute 10 for every iteration?
40 Is the code transformation worth it? 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} A :y=n;tmp=2*n; do { 3: a = 1; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: y++; 11:} while (y < tmp); 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N);
41 and after Loop Invariant Code Motion... 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} A :y=n;tmp=2*n; 3 :a=1; 5 :b=k+z; 6: c=a*3; do{ 7: if (N < 0){ 8: m = 5; 9: break; } 10: y++; 11:} while (y < tmp); 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N);
42 and with a better Loop Invariant Code Motion... 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} A :y=n;tmp=2*n; 3 :a=1; 5 :b=k+z; 6: c=a*3; 7: if (N < 0){ 8: m=5; } do{ 10: y++; 11:} while (y < tmp); 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N);
43 and after dead code elimination... 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} 3 :a=1; 5 :b=k+z; 6: c=a*3; 7: if (N < 0){ 8: m=5; } Assuming a,b,c,m are used after our code 1: if (N>5){ k = 1; z = 4;} 2: else {k = 2; z = 3;} do { 3: a = 1; 4: y = x + N; 5: b = k + z; 6: c = a * 3; 7: if (N < 0){ 8: m = 5; 9: break; } 10: x++; 11:} while (x < N);
44 Induction variable observation Observation: some variables change by a constant amount on each loop iteration x initialized at 0; increments by 1 y initialized at N; increments by 1 These are all induction variables How can we identify them?
45 Induction variable elimination Suppose we have a loop variable i initially set to i 0 ; each iteration i = i + 1 and a variable that linearly depends on it x = i * c 1 + c 2 We can constants Initialize x = i o * c 1 + c 2 Increment x by c 1 each iteration
46 Is it faster? 1: i = i o 2: do { 3: i = i + 1;... A: x = i* c 1 + c 2 B:} while (i < maxi); 1: i = i o N1:x = i o * c 1 + c 2 2: do { 3: i = i + 1;... A: x = x + c 1 B:} while (i < maxi); On some hardware, adds are much faster than multiplies Strength reduction
47 Induction variables Basic induction variables i = i op c c is loop-invariant a.k.a. independent induction variable Derived induction variables j = i * c 1 + c 2 a.k.a. dependent induction variable
48 Identify induction variables: step 1 Find the basic IVs 1Scan loop body for defs of the form x = x + c, where c is loop-invariant 2Record these basic IVs as x = (x, 1, c) this represents the IV: x = x * 1 + c
49 Identify induction variables: step 2 Find derived IVs 1Scan for derived IVs of the form k = i * c1 + c2 where i is a basic IV and this is the only definition of k in the loop 2Record as k = (i, c1, c2) We say k is in the family of i
50 Identified induction variables i: basic j: basic q: derived from i k: derived from i x: derived from j z: derived from k A forest of induction variables
51 Many optimizations rely on IVs Like induction variable elimination we have seen before or like loop unrolling to compute the trip count
52 Induction variable elimination: step 1 1Iterate over IVs k = j * c1 + c2 where IV j =(i, a, b), and this is the only def of k in the loop, and there is no def of i between the def of j and the def of k i = j = i k = j 2Record as k = (i, a*c1, b*c1+c2)
53 Induction variable elimination: step 2 For an induction variable k = (i, c1, c2) 1Initialize k = i * c1 + c2 in the pre-header 2Replace k s def in the loop by k = k + c1 Make sure to do this after i s definition
54 Normalize induction variables Basic induction variables are normalized to Initial value: 0 Incremented by 1 at each iteration Explicit final value (either constant or loop-invariant) x = x*1 + 1 (x, 1, 1)
55 Normalize induction variables in LLVM indvars: normalize induction variables highlight the basic induction variables scalar-evolution: Scalar evolution analysis Represent scalar expressions (e.g., x = y op z) It supports induction variables (e.g., x = x + 1) It lowers the burden of explicitly handling the composition of expressions

56 LLVM scalar evolution example SCEV: {A, B, C}<flag>*<%D> A: Initial; B: Operator; C: Operand; D: basic block where it get defined

57 LLVM scalar evolution example SCEV: {A, B, C}<flag>*<%D> A: Initial; B: Operator; C: Operand; D: basic block where it get defined

58 LLVM scalar evolution example: pass deps
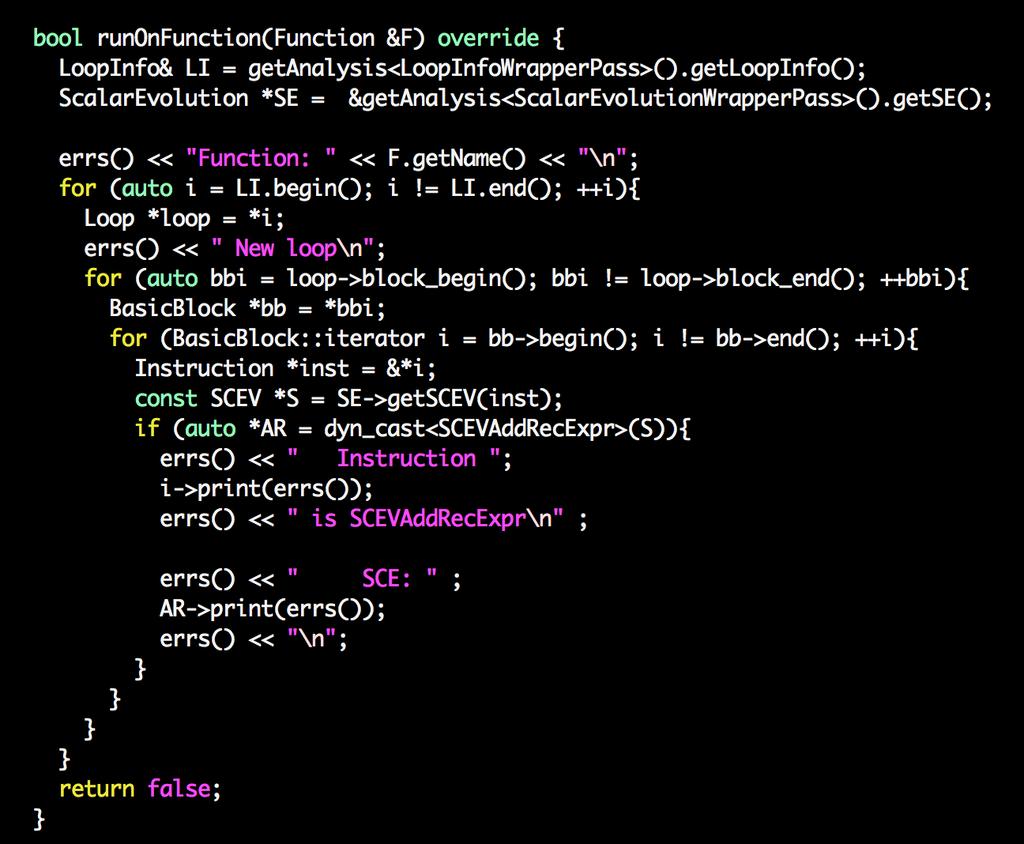
59
{ } BODY Solution for this loop: 10 Any")
60 An use of the Scalar Evaluation pass Problem: we need to infer the number of iterations that a loop will execute for (int i=0; i < 10; i++){ } BODY Solution for this loop: 10 Any idea?
61 Scalar evolution in LLVM Analysis used by Induction variable substitution Strength reduction Vectorization SCEVs are modeled by the llvm::scev class There is a sub-class for each kind of SCEV (e.g., llvm::scevaddexpr) A SCEV is a tree of SCEVs Leaves: Constant : llvm:scevconstant (e.g., 1) Unknown: llvm:scevunknown To iterate over a tree: llvm:scevvisitor
62 Outline Simple loop transformations Loop invariants Induction variables Complex loop transformations
63 Loop transformations Restructure a loop to expose more optimization opportunities and/or transform the loop overhead Loop unrolling, loop peeling, Reorganize a loop to improve memory utilization Cache blocking, skewing, loop reversal Distribute a loop over cores/processors DOACROSS, DOALL, DSWP, HELIX

64 Loop transformations for memory optimizations How many clock cycles will it take? varx = array[5];...
65 Goal: improve cache performance Temporal locality A resource that has just been referenced will more likely be referenced again in the near future Spatial locality The likelihood of referencing a resource is higher if a resource near it was just referenced Ideally, a compiler generates code with high temporal and spatial locality for the target architecture What to minimize: bad replacement decisions
66 What a compiler can do Time: When is an object accessed? Space: Where does an object exist in the address space? These are the two knobs a compiler can manipulate
67 Manipulating time and space Time: reordering computation Determine when an object will be accessed, and predict a better time to access it Space: changing data layout Determine an object s shape and location, and determine a better layout
68 First understand cache behavior... When do cache misses occur? Use locality analysis Can we change the visitation order to produce better behavior? Evaluate costs Does the new visitation order still produce correct results? Use dependence analysis
69 and then rely on loop transformations loop interchange cache blocking loop fusion loop reversal...
70 Code example double A[N][N], B[N][N]; for i = 0 to N-1{ for j = 0 to N-1{... = A[i][j]... } } Iteration space for A

![= A[j][i] Assumptions: N is large; A is](/docs-images/92/110684866/images/71-2.jpg "row-major; 2 elements per cache line A[][] in C?")
71 Loop interchange for i = 0 to N-1 for j = 0 to N-1 = A[j][i] For j = 0 to N-1 for i = 0 to N-1 = A[j][i] Assumptions: N is large; A is row-major; 2 elements per cache line A[][] in C? Java?
72 Java (similar in C) To create a matrix: double [][] A = new double[3][3]; A is an array of arrays A is not a 2 dimensional array!
73 Java (similar in C) To create a matrix: double [][] A = new double[3][]; A[0] = new double[3]; A[1] = new double[3]; A[2] = new double[3];
74 Java (similar in C) To create a matrix: double [][] A = new double[3][]; A[0] = new double[10]; A[1] = new double[5]; A[2] = new double[42]; A is a jagged array
75 C#: [][] vs. [,] double [][] A = new double[3][]; A[0] = new double[3]; A[1] = new double[3]; A[2] = new double[3]; double [,] A = new double[3,3]; The compiler can easily choose between raw-major vs. column-major

76
")
 f(a[i],")
77 Cache blocking (a.k.a. tiling) for i = 0 to N-1 for j = 0 to N-1 f(a[i], A[j]) for JJ = 0 to N-1 by B for i = 0 to N-1 for j = JJ to min(n-1,jj+b-1) f(a[i], A[j])
78 Loop fusion for i = 0 to N-1 C[i] = A[i]*2 + B[i] for i = 0 to N-1 D[i] = A[i] * 2 for i = 0 to N-1 C[i] = A[i] * 2 + B[i] D[i] = A[i] * 2 Reduce loop overhead Improve locality by combining loops that reference the same array Increase the granularity of work done in a loop
79 Locality analysis Reuse: Accessing a location that has been accessed previously Locality: Accessing a location that is in the cache Observe: Locality only occurs when there is reuse! but reuse does not imply locality
80 Steps in locality analysis Find data reuse Determine localized iteration space Set of inner loops where the data accessed by an iteration is expected to fit within the cache Find data locality Reuse localized iteration space locality
Control flow graphs and loop optimizations. Thursday, October 24, 13
 Control flow graphs and loop optimizations Agenda Building control flow graphs Low level loop optimizations Code motion Strength reduction Unrolling High level loop optimizations Loop fusion Loop interchange
Control flow graphs and loop optimizations Agenda Building control flow graphs Low level loop optimizations Code motion Strength reduction Unrolling High level loop optimizations Loop fusion Loop interchange
Loops. Lather, Rinse, Repeat. CS4410: Spring 2013
 Loops or Lather, Rinse, Repeat CS4410: Spring 2013 Program Loops Reading: Appel Ch. 18 Loop = a computation repeatedly executed until a terminating condition is reached High-level loop constructs: While
Loops or Lather, Rinse, Repeat CS4410: Spring 2013 Program Loops Reading: Appel Ch. 18 Loop = a computation repeatedly executed until a terminating condition is reached High-level loop constructs: While
Loop Optimizations. Outline. Loop Invariant Code Motion. Induction Variables. Loop Invariant Code Motion. Loop Invariant Code Motion
 Outline Loop Optimizations Induction Variables Recognition Induction Variables Combination of Analyses Copyright 2010, Pedro C Diniz, all rights reserved Students enrolled in the Compilers class at the
Outline Loop Optimizations Induction Variables Recognition Induction Variables Combination of Analyses Copyright 2010, Pedro C Diniz, all rights reserved Students enrolled in the Compilers class at the
Compiler Optimizations. Chapter 8, Section 8.5 Chapter 9, Section 9.1.7
 Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
Compiler Optimizations. Chapter 8, Section 8.5 Chapter 9, Section 9.1.7
 Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
Module 13: INTRODUCTION TO COMPILERS FOR HIGH PERFORMANCE COMPUTERS Lecture 25: Supercomputing Applications. The Lecture Contains: Loop Unswitching
 The Lecture Contains: Loop Unswitching Supercomputing Applications Programming Paradigms Important Problems Scheduling Sources and Types of Parallelism Model of Compiler Code Optimization Data Dependence
The Lecture Contains: Loop Unswitching Supercomputing Applications Programming Paradigms Important Problems Scheduling Sources and Types of Parallelism Model of Compiler Code Optimization Data Dependence
Autotuning. John Cavazos. University of Delaware UNIVERSITY OF DELAWARE COMPUTER & INFORMATION SCIENCES DEPARTMENT
 Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
CSC D70: Compiler Optimization Memory Optimizations
 CSC D70: Compiler Optimization Memory Optimizations Prof. Gennady Pekhimenko University of Toronto Winter 2018 The content of this lecture is adapted from the lectures of Todd Mowry, Greg Steffan, and
CSC D70: Compiler Optimization Memory Optimizations Prof. Gennady Pekhimenko University of Toronto Winter 2018 The content of this lecture is adapted from the lectures of Todd Mowry, Greg Steffan, and
CSE P 501 Compilers. Loops Hal Perkins Spring UW CSE P 501 Spring 2018 U-1
 CSE P 501 Compilers Loops Hal Perkins Spring 2018 UW CSE P 501 Spring 2018 U-1 Agenda Loop optimizations Dominators discovering loops Loop invariant calculations Loop transformations A quick look at some
CSE P 501 Compilers Loops Hal Perkins Spring 2018 UW CSE P 501 Spring 2018 U-1 Agenda Loop optimizations Dominators discovering loops Loop invariant calculations Loop transformations A quick look at some
Loop Transformations! Part II!
 Lecture 9! Loop Transformations! Part II! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Loop Unswitching Hoist invariant control-flow
Lecture 9! Loop Transformations! Part II! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Loop Unswitching Hoist invariant control-flow
Tiling: A Data Locality Optimizing Algorithm
 Tiling: A Data Locality Optimizing Algorithm Announcements Monday November 28th, Dr. Sanjay Rajopadhye is talking at BMAC Friday December 2nd, Dr. Sanjay Rajopadhye will be leading CS553 Last Monday Kelly
Tiling: A Data Locality Optimizing Algorithm Announcements Monday November 28th, Dr. Sanjay Rajopadhye is talking at BMAC Friday December 2nd, Dr. Sanjay Rajopadhye will be leading CS553 Last Monday Kelly
Compiler Construction 2010/2011 Loop Optimizations
 Compiler Construction 2010/2011 Loop Optimizations Peter Thiemann January 25, 2011 Outline 1 Loop Optimizations 2 Dominators 3 Loop-Invariant Computations 4 Induction Variables 5 Array-Bounds Checks 6
Compiler Construction 2010/2011 Loop Optimizations Peter Thiemann January 25, 2011 Outline 1 Loop Optimizations 2 Dominators 3 Loop-Invariant Computations 4 Induction Variables 5 Array-Bounds Checks 6
Supercomputing in Plain English Part IV: Henry Neeman, Director
 Supercomputing in Plain English Part IV: Henry Neeman, Director OU Supercomputing Center for Education & Research University of Oklahoma Wednesday September 19 2007 Outline! Dependency Analysis! What is
Supercomputing in Plain English Part IV: Henry Neeman, Director OU Supercomputing Center for Education & Research University of Oklahoma Wednesday September 19 2007 Outline! Dependency Analysis! What is
Compiler Design. Fall Control-Flow Analysis. Prof. Pedro C. Diniz
 Compiler Design Fall 2015 Control-Flow Analysis Sample Exercises and Solutions Prof. Pedro C. Diniz USC / Information Sciences Institute 4676 Admiralty Way, Suite 1001 Marina del Rey, California 90292
Compiler Design Fall 2015 Control-Flow Analysis Sample Exercises and Solutions Prof. Pedro C. Diniz USC / Information Sciences Institute 4676 Admiralty Way, Suite 1001 Marina del Rey, California 90292
Compiler Construction 2016/2017 Loop Optimizations
 Compiler Construction 2016/2017 Loop Optimizations Peter Thiemann January 16, 2017 Outline 1 Loops 2 Dominators 3 Loop-Invariant Computations 4 Induction Variables 5 Array-Bounds Checks 6 Loop Unrolling
Compiler Construction 2016/2017 Loop Optimizations Peter Thiemann January 16, 2017 Outline 1 Loops 2 Dominators 3 Loop-Invariant Computations 4 Induction Variables 5 Array-Bounds Checks 6 Loop Unrolling
Compiling for Advanced Architectures
 Compiling for Advanced Architectures In this lecture, we will concentrate on compilation issues for compiling scientific codes Typically, scientific codes Use arrays as their main data structures Have
Compiling for Advanced Architectures In this lecture, we will concentrate on compilation issues for compiling scientific codes Typically, scientific codes Use arrays as their main data structures Have
Tiling: A Data Locality Optimizing Algorithm
 Tiling: A Data Locality Optimizing Algorithm Previously Unroll and Jam Homework PA3 is due Monday November 2nd Today Unroll and Jam is tiling Code generation for fixed-sized tiles Paper writing and critique
Tiling: A Data Locality Optimizing Algorithm Previously Unroll and Jam Homework PA3 is due Monday November 2nd Today Unroll and Jam is tiling Code generation for fixed-sized tiles Paper writing and critique
Parallelisation. Michael O Boyle. March 2014
 Parallelisation Michael O Boyle March 2014 1 Lecture Overview Parallelisation for fork/join Mapping parallelism to shared memory multi-processors Loop distribution and fusion Data Partitioning and SPMD
Parallelisation Michael O Boyle March 2014 1 Lecture Overview Parallelisation for fork/join Mapping parallelism to shared memory multi-processors Loop distribution and fusion Data Partitioning and SPMD
CprE 488 Embedded Systems Design. Lecture 6 Software Optimization
 CprE 488 Embedded Systems Design Lecture 6 Software Optimization Joseph Zambreno Electrical and Computer Engineering Iowa State University www.ece.iastate.edu/~zambreno rcl.ece.iastate.edu If you lie to
CprE 488 Embedded Systems Design Lecture 6 Software Optimization Joseph Zambreno Electrical and Computer Engineering Iowa State University www.ece.iastate.edu/~zambreno rcl.ece.iastate.edu If you lie to
Loop Unrolling. Source: for i := 1 to 100 by 1 A[i] := A[i] + B[i]; endfor
![Loop Unrolling. Source: for i := 1 to 100 by 1 A[i] := A[i] + B[i]; endfor](/thumbs/74/69978897.jpg "Loop Unrolling. Source: for i := 1 to 100 by 1 A[i] := A[i] + B[i]; endfor") Source: for i := 1 to 100 by 1 A[i] := A[i] + B[i]; Loop Unrolling Transformed Code: for i := 1 to 100 by 4 A[i ] := A[i ] + B[i ]; A[i+1] := A[i+1] + B[i+1]; A[i+2] := A[i+2] + B[i+2]; A[i+3] := A[i+3]
Source: for i := 1 to 100 by 1 A[i] := A[i] + B[i]; Loop Unrolling Transformed Code: for i := 1 to 100 by 4 A[i ] := A[i ] + B[i ]; A[i+1] := A[i+1] + B[i+1]; A[i+2] := A[i+2] + B[i+2]; A[i+3] := A[i+3]
Module 18: Loop Optimizations Lecture 35: Amdahl s Law. The Lecture Contains: Amdahl s Law. Induction Variable Substitution.
 The Lecture Contains: Amdahl s Law Induction Variable Substitution Index Recurrence Loop Unrolling Constant Propagation And Expression Evaluation Loop Vectorization Partial Loop Vectorization Nested Loops
The Lecture Contains: Amdahl s Law Induction Variable Substitution Index Recurrence Loop Unrolling Constant Propagation And Expression Evaluation Loop Vectorization Partial Loop Vectorization Nested Loops
Lecture 9 Basic Parallelization
 Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
Lecture 9 Basic Parallelization
 Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
A Bad Name. CS 2210: Optimization. Register Allocation. Optimization. Reaching Definitions. Dataflow Analyses 4/10/2013
 A Bad Name Optimization is the process by which we turn a program into a better one, for some definition of better. CS 2210: Optimization This is impossible in the general case. For instance, a fully optimizing
A Bad Name Optimization is the process by which we turn a program into a better one, for some definition of better. CS 2210: Optimization This is impossible in the general case. For instance, a fully optimizing
Spring 2 Spring Loop Optimizations
 Spring 2010 Loop Optimizations Instruction Scheduling 5 Outline Scheduling for loops Loop unrolling Software pipelining Interaction with register allocation Hardware vs. Compiler Induction Variable Recognition
Spring 2010 Loop Optimizations Instruction Scheduling 5 Outline Scheduling for loops Loop unrolling Software pipelining Interaction with register allocation Hardware vs. Compiler Induction Variable Recognition
Lecture 21. Software Pipelining & Prefetching. I. Software Pipelining II. Software Prefetching (of Arrays) III. Prefetching via Software Pipelining
 III. Prefetching via Software Pipelining") Lecture 21 Software Pipelining & Prefetching I. Software Pipelining II. Software Prefetching (of Arrays) III. Prefetching via Software Pipelining [ALSU 10.5, 11.11.4] Phillip B. Gibbons 15-745: Software
Lecture 21 Software Pipelining & Prefetching I. Software Pipelining II. Software Prefetching (of Arrays) III. Prefetching via Software Pipelining [ALSU 10.5, 11.11.4] Phillip B. Gibbons 15-745: Software
Code optimization. Have we achieved optimal code? Impossible to answer! We make improvements to the code. Aim: faster code and/or less space
 Code optimization Have we achieved optimal code? Impossible to answer! We make improvements to the code Aim: faster code and/or less space Types of optimization machine-independent In source code or internal
Code optimization Have we achieved optimal code? Impossible to answer! We make improvements to the code Aim: faster code and/or less space Types of optimization machine-independent In source code or internal
Bentley Rules for Optimizing Work
 6.172 Performance Engineering of Software Systems SPEED LIMIT PER ORDER OF 6.172 LECTURE 2 Bentley Rules for Optimizing Work Charles E. Leiserson September 11, 2012 2012 Charles E. Leiserson and I-Ting
6.172 Performance Engineering of Software Systems SPEED LIMIT PER ORDER OF 6.172 LECTURE 2 Bentley Rules for Optimizing Work Charles E. Leiserson September 11, 2012 2012 Charles E. Leiserson and I-Ting
Coarse-Grained Parallelism
 Coarse-Grained Parallelism Variable Privatization, Loop Alignment, Loop Fusion, Loop interchange and skewing, Loop Strip-mining cs6363 1 Introduction Our previous loop transformations target vector and
Coarse-Grained Parallelism Variable Privatization, Loop Alignment, Loop Fusion, Loop interchange and skewing, Loop Strip-mining cs6363 1 Introduction Our previous loop transformations target vector and
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
Supercomputing and Science An Introduction to High Performance Computing
 Supercomputing and Science An Introduction to High Performance Computing Part IV: Dependency Analysis and Stupid Compiler Tricks Henry Neeman, Director OU Supercomputing Center for Education & Research
Supercomputing and Science An Introduction to High Performance Computing Part IV: Dependency Analysis and Stupid Compiler Tricks Henry Neeman, Director OU Supercomputing Center for Education & Research
Outline. Issues with the Memory System Loop Transformations Data Transformations Prefetching Alias Analysis
 Memory Optimization Outline Issues with the Memory System Loop Transformations Data Transformations Prefetching Alias Analysis Memory Hierarchy 1-2 ns Registers 32 512 B 3-10 ns 8-30 ns 60-250 ns 5-20
Memory Optimization Outline Issues with the Memory System Loop Transformations Data Transformations Prefetching Alias Analysis Memory Hierarchy 1-2 ns Registers 32 512 B 3-10 ns 8-30 ns 60-250 ns 5-20
Loops. Announcements. Loop fusion. Loop unrolling. Code motion. Array. Good targets for optimization. Basic loop optimizations:
 Announcements HW1 is available online Next Class Liang will give a tutorial on TinyOS/motes Very useful! Classroom: EADS Hall 116 This Wed ONLY Proposal is due on 5pm, Wed Email me your proposal Loops
Announcements HW1 is available online Next Class Liang will give a tutorial on TinyOS/motes Very useful! Classroom: EADS Hall 116 This Wed ONLY Proposal is due on 5pm, Wed Email me your proposal Loops
Administration. Prerequisites. Meeting times. CS 380C: Advanced Topics in Compilers
 Administration CS 380C: Advanced Topics in Compilers Instructor: eshav Pingali Professor (CS, ICES) Office: POB 4.126A Email: pingali@cs.utexas.edu TA: TBD Graduate student (CS) Office: Email: Meeting
Administration CS 380C: Advanced Topics in Compilers Instructor: eshav Pingali Professor (CS, ICES) Office: POB 4.126A Email: pingali@cs.utexas.edu TA: TBD Graduate student (CS) Office: Email: Meeting
Office Hours: Mon/Wed 3:30-4:30 GDC Office Hours: Tue 3:30-4:30 Thu 3:30-4:30 GDC 5.
 CS380C Compilers Instructor: TA: lin@cs.utexas.edu Office Hours: Mon/Wed 3:30-4:30 GDC 5.512 Jia Chen jchen@cs.utexas.edu Office Hours: Tue 3:30-4:30 Thu 3:30-4:30 GDC 5.440 January 21, 2015 Introduction
CS380C Compilers Instructor: TA: lin@cs.utexas.edu Office Hours: Mon/Wed 3:30-4:30 GDC 5.512 Jia Chen jchen@cs.utexas.edu Office Hours: Tue 3:30-4:30 Thu 3:30-4:30 GDC 5.440 January 21, 2015 Introduction
Lecture Notes on Loop Optimizations
 Lecture Notes on Loop Optimizations 15-411: Compiler Design Frank Pfenning Lecture 17 October 22, 2013 1 Introduction Optimizing loops is particularly important in compilation, since loops (and in particular
Lecture Notes on Loop Optimizations 15-411: Compiler Design Frank Pfenning Lecture 17 October 22, 2013 1 Introduction Optimizing loops is particularly important in compilation, since loops (and in particular
6.189 IAP Lecture 11. Parallelizing Compilers. Prof. Saman Amarasinghe, MIT IAP 2007 MIT
 6.189 IAP 2007 Lecture 11 Parallelizing Compilers 1 6.189 IAP 2007 MIT Outline Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Generation of Parallel
6.189 IAP 2007 Lecture 11 Parallelizing Compilers 1 6.189 IAP 2007 MIT Outline Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Generation of Parallel
Building a Runnable Program and Code Improvement. Dario Marasco, Greg Klepic, Tess DiStefano
 Building a Runnable Program and Code Improvement Dario Marasco, Greg Klepic, Tess DiStefano Building a Runnable Program Review Front end code Source code analysis Syntax tree Back end code Target code
Building a Runnable Program and Code Improvement Dario Marasco, Greg Klepic, Tess DiStefano Building a Runnable Program Review Front end code Source code analysis Syntax tree Back end code Target code
CS 701. Class Meets. Instructor. Teaching Assistant. Key Dates. Charles N. Fischer. Fall Tuesdays & Thursdays, 11:00 12: Engineering Hall
 CS 701 Charles N. Fischer Class Meets Tuesdays & Thursdays, 11:00 12:15 2321 Engineering Hall Fall 2003 Instructor http://www.cs.wisc.edu/~fischer/cs703.html Charles N. Fischer 5397 Computer Sciences Telephone:
CS 701 Charles N. Fischer Class Meets Tuesdays & Thursdays, 11:00 12:15 2321 Engineering Hall Fall 2003 Instructor http://www.cs.wisc.edu/~fischer/cs703.html Charles N. Fischer 5397 Computer Sciences Telephone:
Machine-Independent Optimizations
 Chapter 9 Machine-Independent Optimizations High-level language constructs can introduce substantial run-time overhead if we naively translate each construct independently into machine code. This chapter
Chapter 9 Machine-Independent Optimizations High-level language constructs can introduce substantial run-time overhead if we naively translate each construct independently into machine code. This chapter
Optimization Prof. James L. Frankel Harvard University
 Optimization Prof. James L. Frankel Harvard University Version of 4:24 PM 1-May-2018 Copyright 2018, 2016, 2015 James L. Frankel. All rights reserved. Reasons to Optimize Reduce execution time Reduce memory
Optimization Prof. James L. Frankel Harvard University Version of 4:24 PM 1-May-2018 Copyright 2018, 2016, 2015 James L. Frankel. All rights reserved. Reasons to Optimize Reduce execution time Reduce memory
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
Final Exam Review Questions
 EECS 665 Final Exam Review Questions 1. Give the three-address code (like the quadruples in the csem assignment) that could be emitted to translate the following assignment statement. However, you may
EECS 665 Final Exam Review Questions 1. Give the three-address code (like the quadruples in the csem assignment) that could be emitted to translate the following assignment statement. However, you may
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna16/ [ 9 ] Shared Memory Performance Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna16/ [ 9 ] Shared Memory Performance Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture
Introduction to optimizations. CS Compiler Design. Phases inside the compiler. Optimization. Introduction to Optimizations. V.
 Introduction to optimizations CS3300 - Compiler Design Introduction to Optimizations V. Krishna Nandivada IIT Madras Copyright c 2018 by Antony L. Hosking. Permission to make digital or hard copies of
Introduction to optimizations CS3300 - Compiler Design Introduction to Optimizations V. Krishna Nandivada IIT Madras Copyright c 2018 by Antony L. Hosking. Permission to make digital or hard copies of
CS 351 Final Exam Solutions
 CS 351 Final Exam Solutions Notes: You must explain your answers to receive partial credit. You will lose points for incorrect extraneous information, even if the answer is otherwise correct. Question
CS 351 Final Exam Solutions Notes: You must explain your answers to receive partial credit. You will lose points for incorrect extraneous information, even if the answer is otherwise correct. Question
Advanced optimizations of cache performance ( 2.2)
") Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
USC 227 Office hours: 3-4 Monday and Wednesday CS553 Lecture 1 Introduction 4
 CS553 Compiler Construction Instructor: URL: Michelle Strout mstrout@cs.colostate.edu USC 227 Office hours: 3-4 Monday and Wednesday http://www.cs.colostate.edu/~cs553 CS553 Lecture 1 Introduction 3 Plan
CS553 Compiler Construction Instructor: URL: Michelle Strout mstrout@cs.colostate.edu USC 227 Office hours: 3-4 Monday and Wednesday http://www.cs.colostate.edu/~cs553 CS553 Lecture 1 Introduction 3 Plan
CS 2461: Computer Architecture 1
 Next.. : Computer Architecture 1 Performance Optimization CODE OPTIMIZATION Code optimization for performance A quick look at some techniques that can improve the performance of your code Rewrite code
Next.. : Computer Architecture 1 Performance Optimization CODE OPTIMIZATION Code optimization for performance A quick look at some techniques that can improve the performance of your code Rewrite code
Lecture 3 Local Optimizations, Intro to SSA
 Lecture 3 Local Optimizations, Intro to SSA I. Basic blocks & Flow graphs II. Abstraction 1: DAG III. Abstraction 2: Value numbering IV. Intro to SSA ALSU 8.4-8.5, 6.2.4 Phillip B. Gibbons 15-745: Local
Lecture 3 Local Optimizations, Intro to SSA I. Basic blocks & Flow graphs II. Abstraction 1: DAG III. Abstraction 2: Value numbering IV. Intro to SSA ALSU 8.4-8.5, 6.2.4 Phillip B. Gibbons 15-745: Local
Computer Science 146. Computer Architecture
 Computer rchitecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 11: Software Pipelining and Global Scheduling Lecture Outline Review of Loop Unrolling Software Pipelining
Computer rchitecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 11: Software Pipelining and Global Scheduling Lecture Outline Review of Loop Unrolling Software Pipelining
PERFORMANCE OPTIMISATION
 PERFORMANCE OPTIMISATION Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Hardware design Image from Colfax training material Pipeline Simple five stage pipeline: 1. Instruction fetch get instruction
PERFORMANCE OPTIMISATION Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Hardware design Image from Colfax training material Pipeline Simple five stage pipeline: 1. Instruction fetch get instruction
Linear Loop Transformations for Locality Enhancement
 Linear Loop Transformations for Locality Enhancement 1 Story so far Cache performance can be improved by tiling and permutation Permutation of perfectly nested loop can be modeled as a linear transformation
Linear Loop Transformations for Locality Enhancement 1 Story so far Cache performance can be improved by tiling and permutation Permutation of perfectly nested loop can be modeled as a linear transformation
Exploring Parallelism At Different Levels
 Exploring Parallelism At Different Levels Balanced composition and customization of optimizations 7/9/2014 DragonStar 2014 - Qing Yi 1 Exploring Parallelism Focus on Parallelism at different granularities
Exploring Parallelism At Different Levels Balanced composition and customization of optimizations 7/9/2014 DragonStar 2014 - Qing Yi 1 Exploring Parallelism Focus on Parallelism at different granularities
Computer Science 246 Computer Architecture
 Computer Architecture Spring 2009 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Compiler ILP Static ILP Overview Have discussed methods to extract ILP from hardware Why can t some of these
Computer Architecture Spring 2009 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Compiler ILP Static ILP Overview Have discussed methods to extract ILP from hardware Why can t some of these
Tour of common optimizations
 Tour of common optimizations Simple example foo(z) { x := 3 + 6; y := x 5 return z * y } Simple example foo(z) { x := 3 + 6; y := x 5; return z * y } x:=9; Applying Constant Folding Simple example foo(z)
Tour of common optimizations Simple example foo(z) { x := 3 + 6; y := x 5 return z * y } Simple example foo(z) { x := 3 + 6; y := x 5; return z * y } x:=9; Applying Constant Folding Simple example foo(z)
Tiling: A Data Locality Optimizing Algorithm
 Tiling: A Data Locality Optimizing Algorithm Previously Performance analysis of existing codes Data dependence analysis for detecting parallelism Specifying transformations using frameworks Today Usefulness
Tiling: A Data Locality Optimizing Algorithm Previously Performance analysis of existing codes Data dependence analysis for detecting parallelism Specifying transformations using frameworks Today Usefulness
Program Transformations for the Memory Hierarchy
 Program Transformations for the Memory Hierarchy Locality Analysis and Reuse Copyright 214, Pedro C. Diniz, all rights reserved. Students enrolled in the Compilers class at the University of Southern California
Program Transformations for the Memory Hierarchy Locality Analysis and Reuse Copyright 214, Pedro C. Diniz, all rights reserved. Students enrolled in the Compilers class at the University of Southern California
ECE 5775 (Fall 17) High-Level Digital Design Automation. Static Single Assignment
 High-Level Digital Design Automation. Static Single Assignment") ECE 5775 (Fall 17) High-Level Digital Design Automation Static Single Assignment Announcements HW 1 released (due Friday) Student-led discussions on Tuesday 9/26 Sign up on Piazza: 3 students / group Meet
ECE 5775 (Fall 17) High-Level Digital Design Automation Static Single Assignment Announcements HW 1 released (due Friday) Student-led discussions on Tuesday 9/26 Sign up on Piazza: 3 students / group Meet
CS 293S Parallelism and Dependence Theory
 CS 293S Parallelism and Dependence Theory Yufei Ding Reference Book: Optimizing Compilers for Modern Architecture by Allen & Kennedy Slides adapted from Louis-Noël Pouche, Mary Hall End of Moore's Law
CS 293S Parallelism and Dependence Theory Yufei Ding Reference Book: Optimizing Compilers for Modern Architecture by Allen & Kennedy Slides adapted from Louis-Noël Pouche, Mary Hall End of Moore's Law
COMPILER DESIGN - CODE OPTIMIZATION
 COMPILER DESIGN - CODE OPTIMIZATION http://www.tutorialspoint.com/compiler_design/compiler_design_code_optimization.htm Copyright tutorialspoint.com Optimization is a program transformation technique,
COMPILER DESIGN - CODE OPTIMIZATION http://www.tutorialspoint.com/compiler_design/compiler_design_code_optimization.htm Copyright tutorialspoint.com Optimization is a program transformation technique,
Plan for Today. Concepts. Next Time. Some slides are from Calvin Lin s grad compiler slides. CS553 Lecture 2 Optimizations and LLVM 1
 Plan for Today Quiz 2 How to automate the process of performance optimization LLVM: Intro to Intermediate Representation Loops as iteration spaces Data-flow Analysis Intro Control-flow graph terminology
Plan for Today Quiz 2 How to automate the process of performance optimization LLVM: Intro to Intermediate Representation Loops as iteration spaces Data-flow Analysis Intro Control-flow graph terminology
Usually, target code is semantically equivalent to source code, but not always!
 What is a Compiler? Compiler A program that translates code in one language (source code) to code in another language (target code). Usually, target code is semantically equivalent to source code, but
What is a Compiler? Compiler A program that translates code in one language (source code) to code in another language (target code). Usually, target code is semantically equivalent to source code, but
Outline. Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities
 Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Intermediate Representation (IR)
") Intermediate Representation (IR) Components and Design Goals for an IR IR encodes all knowledge the compiler has derived about source program. Simple compiler structure source code More typical compiler
Intermediate Representation (IR) Components and Design Goals for an IR IR encodes all knowledge the compiler has derived about source program. Simple compiler structure source code More typical compiler
CSE 501: Compiler Construction. Course outline. Goals for language implementation. Why study compilers? Models of compilation
 CSE 501: Compiler Construction Course outline Main focus: program analysis and transformation how to represent programs? how to analyze programs? what to analyze? how to transform programs? what transformations
CSE 501: Compiler Construction Course outline Main focus: program analysis and transformation how to represent programs? how to analyze programs? what to analyze? how to transform programs? what transformations
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
OpenMP! baseado em material cedido por Cristiana Amza!
 OpenMP! baseado em material cedido por Cristiana Amza! www.eecg.toronto.edu/~amza/ece1747h/ece1747h.html! What is OpenMP?! Standard for shared memory programming for scientific applications.! Has specific
OpenMP! baseado em material cedido por Cristiana Amza! www.eecg.toronto.edu/~amza/ece1747h/ece1747h.html! What is OpenMP?! Standard for shared memory programming for scientific applications.! Has specific
Lecture 8: Induction Variable Optimizations
 Lecture 8: Induction Variable Optimizations I. Finding loops II. III. Overview of Induction Variable Optimizations Further details ALSU 9.1.8, 9.6, 9.8.1 Phillip B. Gibbons 15-745: Induction Variables
Lecture 8: Induction Variable Optimizations I. Finding loops II. III. Overview of Induction Variable Optimizations Further details ALSU 9.1.8, 9.6, 9.8.1 Phillip B. Gibbons 15-745: Induction Variables
A Crash Course in Compilers for Parallel Computing. Mary Hall Fall, L2: Transforms, Reuse, Locality
 A Crash Course in Compilers for Parallel Computing Mary Hall Fall, 2008 1 Overview of Crash Course L1: Data Dependence Analysis and Parallelization (Oct. 30) L2 & L3: Loop Reordering Transformations, Reuse
A Crash Course in Compilers for Parallel Computing Mary Hall Fall, 2008 1 Overview of Crash Course L1: Data Dependence Analysis and Parallelization (Oct. 30) L2 & L3: Loop Reordering Transformations, Reuse
Intermediate Representations. Reading & Topics. Intermediate Representations CS2210
 Intermediate Representations CS2210 Lecture 11 Reading & Topics Muchnick: chapter 6 Topics today: Intermediate representations Automatic code generation with pattern matching Optimization Overview Control
Intermediate Representations CS2210 Lecture 11 Reading & Topics Muchnick: chapter 6 Topics today: Intermediate representations Automatic code generation with pattern matching Optimization Overview Control
Program Op*miza*on and Analysis. Chenyang Lu CSE 467S
 Program Op*miza*on and Analysis Chenyang Lu CSE 467S 1 Program Transforma*on op#mize Analyze HLL compile assembly assemble Physical Address Rela5ve Address assembly object load executable link Absolute
Program Op*miza*on and Analysis Chenyang Lu CSE 467S 1 Program Transforma*on op#mize Analyze HLL compile assembly assemble Physical Address Rela5ve Address assembly object load executable link Absolute
Memories. CPE480/CS480/EE480, Spring Hank Dietz.
 Memories CPE480/CS480/EE480, Spring 2018 Hank Dietz http://aggregate.org/ee480 What we want, what we have What we want: Unlimited memory space Fast, constant, access time (UMA: Uniform Memory Access) What
Memories CPE480/CS480/EE480, Spring 2018 Hank Dietz http://aggregate.org/ee480 What we want, what we have What we want: Unlimited memory space Fast, constant, access time (UMA: Uniform Memory Access) What
16.10 Exercises. 372 Chapter 16 Code Improvement. be translated as
 372 Chapter 16 Code Improvement 16.10 Exercises 16.1 In Section 16.2 we suggested replacing the instruction r1 := r2 / 2 with the instruction r1 := r2 >> 1, and noted that the replacement may not be correct
372 Chapter 16 Code Improvement 16.10 Exercises 16.1 In Section 16.2 we suggested replacing the instruction r1 := r2 / 2 with the instruction r1 := r2 >> 1, and noted that the replacement may not be correct
Exploiting ILP with SW Approaches. Aleksandar Milenković, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Leftover. UMA vs. NUMA Parallel Computer Architecture. Shared-memory Distributed-memory
 Leftover Parallel Computer Architecture Shared-memory Distributed-memory 1 2 Shared- Parallel Computer Shared- Parallel Computer System Bus Main Shared Programming through threading Multiple processors
Leftover Parallel Computer Architecture Shared-memory Distributed-memory 1 2 Shared- Parallel Computer Shared- Parallel Computer System Bus Main Shared Programming through threading Multiple processors
Module 18: Loop Optimizations Lecture 36: Cycle Shrinking. The Lecture Contains: Cycle Shrinking. Cycle Shrinking in Distance Varying Loops
 The Lecture Contains: Cycle Shrinking Cycle Shrinking in Distance Varying Loops Loop Peeling Index Set Splitting Loop Fusion Loop Fission Loop Reversal Loop Skewing Iteration Space of The Loop Example
The Lecture Contains: Cycle Shrinking Cycle Shrinking in Distance Varying Loops Loop Peeling Index Set Splitting Loop Fusion Loop Fission Loop Reversal Loop Skewing Iteration Space of The Loop Example
CS553 Lecture Dynamic Optimizations 2
 Dynamic Optimizations Last time Predication and speculation Today Dynamic compilation CS553 Lecture Dynamic Optimizations 2 Motivation Limitations of static analysis Programs can have values and invariants
Dynamic Optimizations Last time Predication and speculation Today Dynamic compilation CS553 Lecture Dynamic Optimizations 2 Motivation Limitations of static analysis Programs can have values and invariants
Transforming Imperfectly Nested Loops
 Transforming Imperfectly Nested Loops 1 Classes of loop transformations: Iteration re-numbering: (eg) loop interchange Example DO 10 J = 1,100 DO 10 I = 1,100 DO 10 I = 1,100 vs DO 10 J = 1,100 Y(I) =
Transforming Imperfectly Nested Loops 1 Classes of loop transformations: Iteration re-numbering: (eg) loop interchange Example DO 10 J = 1,100 DO 10 I = 1,100 DO 10 I = 1,100 vs DO 10 J = 1,100 Y(I) =
Assignment statement optimizations
 Assignment statement optimizations 1 of 51 Constant-expressions evaluation or constant folding, refers to the evaluation at compile time of expressions whose operands are known to be constant. Interprocedural
Assignment statement optimizations 1 of 51 Constant-expressions evaluation or constant folding, refers to the evaluation at compile time of expressions whose operands are known to be constant. Interprocedural
Parallel Processing. Parallel Processing. 4 Optimization Techniques WS 2018/19
 Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
Floating Point/Multicycle Pipelining in DLX
 Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
Lecture Notes on Loop-Invariant Code Motion
 Lecture Notes on Loop-Invariant Code Motion 15-411: Compiler Design André Platzer Lecture 17 1 Introduction In this lecture we discuss an important instance of Partial Redundancy Elimination (PRE) and
Lecture Notes on Loop-Invariant Code Motion 15-411: Compiler Design André Platzer Lecture 17 1 Introduction In this lecture we discuss an important instance of Partial Redundancy Elimination (PRE) and
Lecture 6: Static ILP
 Lecture 6: Static ILP Topics: loop analysis, SW pipelining, predication, speculation (Section 2.2, Appendix G) Assignment 2 posted; due in a week 1 Loop Dependences If a loop only has dependences within
Lecture 6: Static ILP Topics: loop analysis, SW pipelining, predication, speculation (Section 2.2, Appendix G) Assignment 2 posted; due in a week 1 Loop Dependences If a loop only has dependences within
CS 426 Fall Machine Problem 4. Machine Problem 4. CS 426 Compiler Construction Fall Semester 2017
 CS 426 Fall 2017 1 Machine Problem 4 Machine Problem 4 CS 426 Compiler Construction Fall Semester 2017 Handed out: November 16, 2017. Due: December 7, 2017, 5:00 p.m. This assignment deals with implementing
CS 426 Fall 2017 1 Machine Problem 4 Machine Problem 4 CS 426 Compiler Construction Fall Semester 2017 Handed out: November 16, 2017. Due: December 7, 2017, 5:00 p.m. This assignment deals with implementing
An example of optimization in LLVM. Compiler construction Step 1: Naive translation to LLVM. Step 2: Translating to SSA form (opt -mem2reg)
") Compiler construction 2014 An example of optimization in LLVM Lecture 8 More on code optimization SSA form Constant propagation Common subexpression elimination Loop optimizations int f () { int i, j,
Compiler construction 2014 An example of optimization in LLVM Lecture 8 More on code optimization SSA form Constant propagation Common subexpression elimination Loop optimizations int f () { int i, j,
Goals of Program Optimization (1 of 2)
") Goals of Program Optimization (1 of 2) Goal: Improve program performance within some constraints Ask Three Key Questions for Every Optimization 1. Is it legal? 2. Is it profitable? 3. Is it compile-time
Goals of Program Optimization (1 of 2) Goal: Improve program performance within some constraints Ask Three Key Questions for Every Optimization 1. Is it legal? 2. Is it profitable? 3. Is it compile-time
What Do Compilers Do? How Can the Compiler Improve Performance? What Do We Mean By Optimization?
 What Do Compilers Do? Lecture 1 Introduction I What would you get out of this course? II Structure of a Compiler III Optimization Example Reference: Muchnick 1.3-1.5 1. Translate one language into another
What Do Compilers Do? Lecture 1 Introduction I What would you get out of this course? II Structure of a Compiler III Optimization Example Reference: Muchnick 1.3-1.5 1. Translate one language into another
Memory Consistency. Challenges. Program order Memory access order
 Memory Consistency Memory Consistency Memory Consistency Reads and writes of the shared memory face consistency problem Need to achieve controlled consistency in memory events Shared memory behavior determined
Memory Consistency Memory Consistency Memory Consistency Reads and writes of the shared memory face consistency problem Need to achieve controlled consistency in memory events Shared memory behavior determined
Parallel Programming & Cluster Computing Stupid Compiler Tricks
 Parallel Programming & Cluster Computing Stupid Compiler Tricks Henry Neeman, University of Oklahoma Charlie Peck, Earlham College Tuesday October 11 2011 Outline Dependency Analysis What is Dependency
Parallel Programming & Cluster Computing Stupid Compiler Tricks Henry Neeman, University of Oklahoma Charlie Peck, Earlham College Tuesday October 11 2011 Outline Dependency Analysis What is Dependency
IA-64 Compiler Technology
 IA-64 Compiler Technology David Sehr, Jay Bharadwaj, Jim Pierce, Priti Shrivastav (speaker), Carole Dulong Microcomputer Software Lab Page-1 Introduction IA-32 compiler optimizations Profile Guidance (PGOPTI)
IA-64 Compiler Technology David Sehr, Jay Bharadwaj, Jim Pierce, Priti Shrivastav (speaker), Carole Dulong Microcomputer Software Lab Page-1 Introduction IA-32 compiler optimizations Profile Guidance (PGOPTI)
Parallelization. Saman Amarasinghe. Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
CS202 Compiler Construction
 CS202 Compiler Construction April 17, 2003 CS 202-33 1 Today: more optimizations Loop optimizations: induction variables New DF analysis: available expressions Common subexpression elimination Copy propogation
CS202 Compiler Construction April 17, 2003 CS 202-33 1 Today: more optimizations Loop optimizations: induction variables New DF analysis: available expressions Common subexpression elimination Copy propogation
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
CS 33. Caches. CS33 Intro to Computer Systems XVIII 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 33 Caches CS33 Intro to Computer Systems XVIII 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Cache Performance Metrics Miss rate fraction of memory references not found in cache (misses
CS 33 Caches CS33 Intro to Computer Systems XVIII 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Cache Performance Metrics Miss rate fraction of memory references not found in cache (misses
Compiler Optimization
 Compiler Optimization The compiler translates programs written in a high-level language to assembly language code Assembly language code is translated to object code by an assembler Object code modules
Compiler Optimization The compiler translates programs written in a high-level language to assembly language code Assembly language code is translated to object code by an assembler Object code modules
Supercomputing in Plain English
 Supercomputing in Plain English An Introduction to High Performance Computing Part IV:Stupid Compiler Tricks Henry Neeman, Director OU Supercomputing Center for Education & Research Dependency Analysis
Supercomputing in Plain English An Introduction to High Performance Computing Part IV:Stupid Compiler Tricks Henry Neeman, Director OU Supercomputing Center for Education & Research Dependency Analysis
CS553 Lecture Profile-Guided Optimizations 3
 Profile-Guided Optimizations Last time Instruction scheduling Register renaming alanced Load Scheduling Loop unrolling Software pipelining Today More instruction scheduling Profiling Trace scheduling CS553
Profile-Guided Optimizations Last time Instruction scheduling Register renaming alanced Load Scheduling Loop unrolling Software pipelining Today More instruction scheduling Profiling Trace scheduling CS553
Control flow and loop detection. TDT4205 Lecture 29
 1 Control flow and loop detection TDT4205 Lecture 29 2 Where we are We have a handful of different analysis instances None of them are optimizations, in and of themselves The objective now is to Show how
1 Control flow and loop detection TDT4205 Lecture 29 2 Where we are We have a handful of different analysis instances None of them are optimizations, in and of themselves The objective now is to Show how
Topic 9: Control Flow
 Topic 9: Control Flow COS 320 Compiling Techniques Princeton University Spring 2016 Lennart Beringer 1 The Front End The Back End (Intel-HP codename for Itanium ; uses compiler to identify parallelism)
Topic 9: Control Flow COS 320 Compiling Techniques Princeton University Spring 2016 Lennart Beringer 1 The Front End The Back End (Intel-HP codename for Itanium ; uses compiler to identify parallelism)