ECE 154A Introduction to. Fall 2012
|
|
|
- Rosemary Henry
- 5 years ago
- Views:
Transcription
1 ECE 154A Introduction to Computer Architecture Fall 2012 Dmitri Strukov Lecture 10 Floating point review Pipelined design
2 IEEE Floating Point Format single: 8 bits double: 11 bits single: 23 bits double: 52 bits S Exponent Fraction x ( 1) S (1 Fraction) 2 (Exponent Bias) S: sign bit (0 non negative, 1 negative) Normalized significand: 1.0 significand < 2.0 Always has a leading pre binary point 1 bit, so no need to represent it explicitly (hidden bit) Significand is Fraction with the 1. restored Exponent: excess representation: actual exponent + Bias Ensures exponent is unsigned Single: Bias = 127; Double: Bias = 1203
3 Floating Point Addition Consider a 4 digit decimal example Align decimal points Shiftnumber withsmallerexponent exponent Add significands = Normalize result & check for over/underflow Round and renormalize if necessary






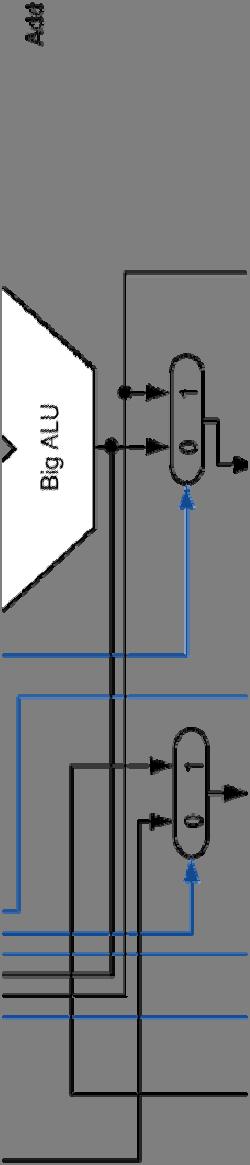
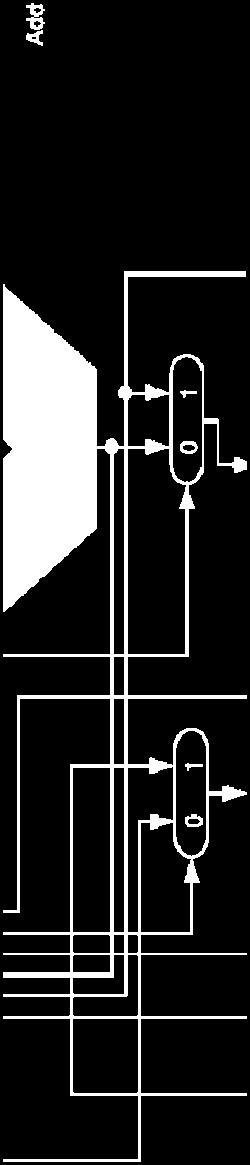
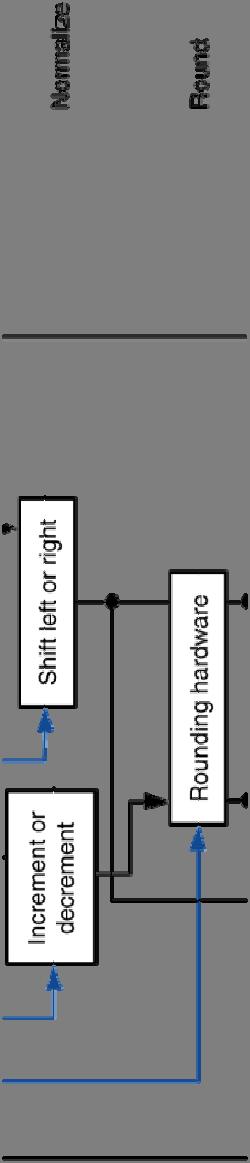
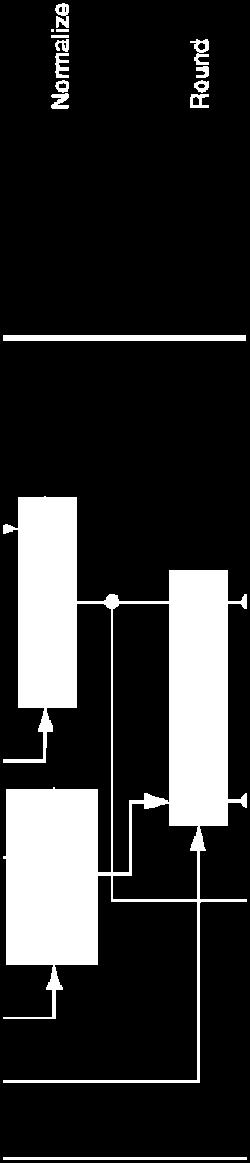
4 FP Adder Hardware Step 1 Step 2 Step 3 Step 4
5 Floating Point Multiplication Consider a 4 digit decimal example Add exponents For biased exponents, subtract bias from sum New exponent = = 5 2. Multiply significands = Normalize result & check for over/underflow Round and renormalize if necessary Determine sign of result from signs of operands
6 Accurate Arithmetic IEEE Std 754 specifies additional rounding control Extra bits of precision (guard, round, sticky) Choice of rounding modes Allows programmer to fine tune numerical behavior of a computation Not allfp units implement alloptions Most programming languages and FP libraries just use defaults Trade off between hardware complexity, performance, and market requirements
7 Interpretation of Data The BIG Picture Bits have no inherent meaning Interpretation depends on the instructions applied Computer representations of numbers Finite range and precision Need to account for this in programs
8 Associativity Parallel programs may interleave operations in unexpected orders Assumptions of associativity may fail (x+y)+z x -1.50E+38 y 1.50E E+0000E+00 z E+00 x+(y+z) -1.50E E E+00 Need to validate parallel programs under varying degrees of parallelism
9 Pipelined datapath
10 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions smallnumber of instruction formats opcode always the first 6 bits Smaller is faster limited instruction set limited number of registers in register file limitednumber ofaddressing modes Make the common case fast arithmetic operands from the register file (load store machine) allow instructions to contain immediate operands Good design demands good compromises three instruction formats






11 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non stop: Speedup p = 2n/0.5n = number of stages 4.5 An Overview of Pipelining Chapter 4 The Processor 11
12 The Five Stages of Load Instruction Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 lw IFetch Dec Exec Mem WB IFetch: Instruction Fetch and Update PC Dec: Registers Fetch and Instruction Decode Exec: Execute R type; calculate l memory address Mem: Read/write the data from/to the Data Memory WB: Write the result data into the register file
13 A Pipelined MIPS Processor Start the next instruction before the current one has completed improves throughput total amount of work done in a given time instruction latency (execution time, delay time, response time time from the start of an instruction to its completion) is not reduced Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 lw IFetch Dec Exec Mem WB sw IFetch Dec Exec Mem WB R type IFetch Dec Exec Mem WB clock cycle (pipeline stage time) is limited by the slowest stage for some stages don t need the whole clock cycle (e.g., WB) for some instructions, some stages are wasted cycles (i.e., nothing is done during that cycle for that instruction)





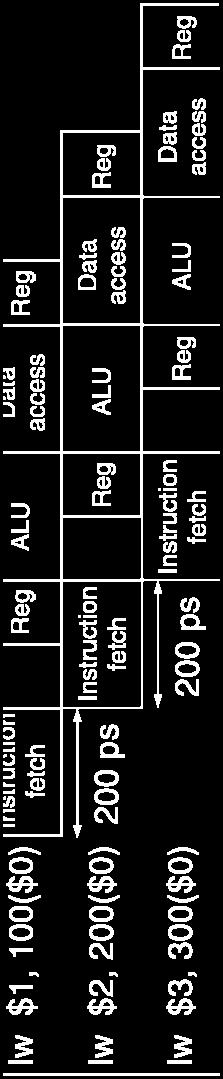
14 Pipeline Performance Single cycle (T c = 800ps) Pipelined (T c = 200ps) p) Chapter 4 The Processor 14
15 Pipeline Speedup If all stages are balanced i.e., all take the same time Time between instructions pipelined = Time between instructions nonpipelined Number of stages If not bl balanced, speedup is less Speedup due to increased throughput Latency (time for each instruction) does not decrease Chapter 4 The Processor 15
16 Single Cycle vs. Multicycle vs. Pipelined Clock Time needed Time allotted Instr 1 Instr 2 Instr 3 Instr 4 Clock Time needed Time allotted 3 cycles 5 cycles 3 cycles 4 cycles Instr 1 Instr 2 Instr 3 Instr 4 Time saved f r a d w Cycle 1 f f f f f f f Cycle 2 3 f r f a r d a w d w 2 3 r r r r r r r a a a a a a a Drainage region 4 f = Fetch f r a d w 5 r = Reg read a = op f r a d w 6 d = Data access w = Writeback f r a d w 7 f r a d Instruction (a) Task-time diagram w 4 5 Start-up region Pipeline stage d d d d d d d w w w w w w w (b) Space-time diagram
17 MIPS Pipeline Five stages, one step per stage 1. IF: Instruction fetch from memory 2. ID: Instruction decode & register read 3. EX: Execute operation or calculate address 4. MEM: Access memory operand 5. WB: Write result back to register lw Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 IFetch Dec Exec Mem WB Chapter 4 The Processor 17
18 Pipelining and ISA Design MIPS ISA designed for pipelining pp All instructions are 32 bits Easier to fetch and decode in one cycle c.f. x86: 1 to 17 byte instructions i Few and regular instruction formats Can decode and read registers in one step Load/store addressing Can calculate address in 3 rd stage, access memory in 4 th stage Alignment of memory operands Memory access takes only one cycle Chapter 4 The Processor 18
19 Graphically Representing MIPS Pipeline Can help with answering questions like: How many cycles does it take to execute this code? What is the doing during cycle 4? Is there a hazard, why does it occur, and how can it be fixed?
20 Why Pipeline? For Performance! Time (l (clock cycles) I n s t r. Inst 0 Inst 1 A LU Once the pipeline is full, one instruction is completed every cycle, so CPI = 1 O Inst 2 r d e r Inst 3 Inst 4 Timeto fillthe pipeline
21 Hazards Situations that prevent starting the next instruction in the next cycle Structure hazards A required resource is busy Data hazard Need to wait for previous instruction to complete its data read/write Control hazard Deciding on control action depends on previous instruction Chapter 4 The Processor 21
22 Structure Hazards Conflict for use of a resource In MIPS pipeline with a single memory Load/store requires dt data access Instruction fetch would have to stall for that cycle Would cause a pipeline bubble bbl Hence, pipelined datapaths require separate instruction/data i memories Or separate instruction/data caches Chapter 4 The Processor 22
23 A Single Memory Would Be a Structural Hazard Time (l (clock cycles) I n s t r. lw Inst 1 A LU Mem Reg Mem Reg Mem Reg Mem Reg Reading data from memory O Inst 2 r d e r Inst 3 Mem Reg Mem Reg Mem Reg Mem Reg Inst 4 Reading instruction from memory Mem Reg Mem Reg Fix with separate instr and data memories (I$ and D$)
24 Data Hazards An instruction depends on completion of data access by a previous instruction add $s0, $t0, $t1 sub $t2, $s0, $t3 Chapter 4 The Processor 24
25 Register Usage Can Cause Data Hazards Dependencies backward in time cause hazards I n s t r. O r d e r add $1, sub $4,$1,$5 and $6,$1,$7 or $8,$1,$9 xor $4,$1,$5 AL LU Read before write data hazard
26 Register Usage Can Cause Data Hazards Dependencies backward in time cause hazards add $1, AL LU $,$,$ Usub $4,$1,$5 and $6,$1,$7 or $8,$1,$9 xor $4,$1,$5 Read before write data hazard
27 Loads Can Cause Data Hazards Dependencies backward in time cause hazards I n s t r. O r d e r lw $1,4($2) sub $4,$1,$5 and $6,$1,$7 or $8,$1,$9 xor $4,$1,$5 AL LU Load use data hazard
28 How About Register File Access? Time (clock cycles) I n s add $1, t Inst 1 r. Fix register file access hazard by doing reads in the second half of the cycle and writes in the first half O r d e r Inst 2 add $2,$1, clock edge that controls register writing clock edge that t controls loading of pipeline state registers
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CO Computer Architecture and Programming Languages CAPL. Lecture 18 & 19
 CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Computer Architecture. Lecture 6.1: Fundamentals of
 CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Computer Architecture and IC Design Lab. Chapter 3 Part 2 Arithmetic for Computers Floating Point
 Chapter 3 Part 2 Arithmetic for Computers Floating Point Floating Point Representation for non integral numbers Including very small and very large numbers 4,600,000,000 or 4.6 x 10 9 0.0000000000000000000000000166
Chapter 3 Part 2 Arithmetic for Computers Floating Point Floating Point Representation for non integral numbers Including very small and very large numbers 4,600,000,000 or 4.6 x 10 9 0.0000000000000000000000000166
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Full Datapath. CSCI 402: Computer Architectures. The Processor (2) 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI
 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI") CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
Floating Point Arithmetic
 Floating Point Arithmetic Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Floating Point Arithmetic Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
ECE260: Fundamentals of Computer Engineering
 Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Chapter 4 (Part II) Sequential Laundry
 Sequential Laundry") Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
CSCI 402: Computer Architectures. Fengguang Song Department of Computer & Information Science IUPUI. Today s Content
 3/6/8 CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Today s Content We have looked at how to design a Data Path. 4.4, 4.5 We will design
3/6/8 CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Today s Content We have looked at how to design a Data Path. 4.4, 4.5 We will design
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Computer Architecture Review. Jo, Heeseung
 Computer Architecture Review Jo, Heeseung Computer Abstractions and Technology Jo, Heeseung Below Your Program Application software Written in high-level language System software Compiler: translates HLL
Computer Architecture Review Jo, Heeseung Computer Abstractions and Technology Jo, Heeseung Below Your Program Application software Written in high-level language System software Compiler: translates HLL
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
CSCI 402: Computer Architectures. Arithmetic for Computers (4) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Arithmetic for Computers (4) Fengguang Song Department of Computer & Information Science IUPUI Homework 4 Assigned on Feb 22, Thursday Due Time: 11:59pm, March 5 on Monday
CSCI 402: Computer Architectures Arithmetic for Computers (4) Fengguang Song Department of Computer & Information Science IUPUI Homework 4 Assigned on Feb 22, Thursday Due Time: 11:59pm, March 5 on Monday
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Written Homework 3. Floating-Point Example (1/2)
") Written Homework 3 Assigned on Tuesday, Feb 19 Due Time: 11:59pm, Feb 26 on Tuesday Problems: 3.22, 3.23, 3.24, 3.41, 3.43 Note: You have 1 week to work on homework 3. 3 Floating-Point Example (1/2) Q:
Written Homework 3 Assigned on Tuesday, Feb 19 Due Time: 11:59pm, Feb 26 on Tuesday Problems: 3.22, 3.23, 3.24, 3.41, 3.43 Note: You have 1 week to work on homework 3. 3 Floating-Point Example (1/2) Q:
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Chapter 3. Arithmetic Text: P&H rev
 Chapter 3 Arithmetic Text: P&H rev3.29.16 Arithmetic for Computers Operations on integers Addition and subtraction Multiplication and division Dealing with overflow Floating-point real numbers Representation
Chapter 3 Arithmetic Text: P&H rev3.29.16 Arithmetic for Computers Operations on integers Addition and subtraction Multiplication and division Dealing with overflow Floating-point real numbers Representation
COMP2611: Computer Organization. The Pipelined Processor
 COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
Floating Point. The World is Not Just Integers. Programming languages support numbers with fraction
 1 Floating Point The World is Not Just Integers Programming languages support numbers with fraction Called floating-point numbers Examples: 3.14159265 (π) 2.71828 (e) 0.000000001 or 1.0 10 9 (seconds in
1 Floating Point The World is Not Just Integers Programming languages support numbers with fraction Called floating-point numbers Examples: 3.14159265 (π) 2.71828 (e) 0.000000001 or 1.0 10 9 (seconds in
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
CO Computer Architecture and Programming Languages CAPL. Lecture 15
 CO20-320241 Computer Architecture and Programming Languages CAPL Lecture 15 Dr. Kinga Lipskoch Fall 2017 How to Compute a Binary Float Decimal fraction: 8.703125 Integral part: 8 1000 Fraction part: 0.703125
CO20-320241 Computer Architecture and Programming Languages CAPL Lecture 15 Dr. Kinga Lipskoch Fall 2017 How to Compute a Binary Float Decimal fraction: 8.703125 Integral part: 8 1000 Fraction part: 0.703125
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Operations on integers Addition and subtraction Multiplication and division Dealing with overflow Floating-point real numbers VO
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Operations on integers Addition and subtraction Multiplication and division Dealing with overflow Floating-point real numbers VO
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
14:332:331 Pipelined Datapath
 14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
COMPUTER ORGANIZATION AND DESIGN
 ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
CPS104 Computer Organization and Programming Lecture 19: Pipelining. Robert Wagner
 CPS104 Computer Organization and Programming Lecture 19: Pipelining Robert Wagner cps 104 Pipelining..1 RW Fall 2000 Lecture Overview A Pipelined Processor : Introduction to the concept of pipelined processor.
CPS104 Computer Organization and Programming Lecture 19: Pipelining Robert Wagner cps 104 Pipelining..1 RW Fall 2000 Lecture Overview A Pipelined Processor : Introduction to the concept of pipelined processor.
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
CSE 141 Computer Architecture Summer Session Lecture 3 ALU Part 2 Single Cycle CPU Part 1. Pramod V. Argade
 CSE 141 Computer Architecture Summer Session 1 2004 Lecture 3 ALU Part 2 Single Cycle CPU Part 1 Pramod V. Argade Reading Assignment Announcements Chapter 5: The Processor: Datapath and Control, Sec. 5.3-5.4
CSE 141 Computer Architecture Summer Session 1 2004 Lecture 3 ALU Part 2 Single Cycle CPU Part 1 Pramod V. Argade Reading Assignment Announcements Chapter 5: The Processor: Datapath and Control, Sec. 5.3-5.4
Pipelining: Hazards Ver. Jan 14, 2014
 POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
Introduction to Pipelined Datapath
 14:332:331 Computer Architecture and Assembly Language Week 12 Introduction to Pipelined Datapath [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 W12.1 Review:
14:332:331 Computer Architecture and Assembly Language Week 12 Introduction to Pipelined Datapath [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 W12.1 Review:
Pipelined Datapath. One register file is enough
 ipelined path The goal of pipelining is to allow multiple instructions execute at the same time We may need to perform several operations in a cycle Increment the and add s at the same time. Fetch one
ipelined path The goal of pipelining is to allow multiple instructions execute at the same time We may need to perform several operations in a cycle Increment the and add s at the same time. Fetch one
Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Divide: Paper & Pencil
 Divide: Paper & Pencil 1001 Quotient Divisor 1000 1001010 Dividend -1000 10 101 1010 1000 10 Remainder See how big a number can be subtracted, creating quotient bit on each step Binary => 1 * divisor or
Divide: Paper & Pencil 1001 Quotient Divisor 1000 1001010 Dividend -1000 10 101 1010 1000 10 Remainder See how big a number can be subtracted, creating quotient bit on each step Binary => 1 * divisor or
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 15: Midterm 1 Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Basics Midterm to cover Book Sections (inclusive) 1.1 1.5
ECE331: Hardware Organization and Design Lecture 15: Midterm 1 Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Basics Midterm to cover Book Sections (inclusive) 1.1 1.5
TDT4255 Computer Design. Lecture 4. Magnus Jahre
 1 TDT4255 Computer Design Lecture 4 Magnus Jahre 2 Chapter 3 Computer Arithmetic ti Acknowledgement: Slides are adapted from Morgan Kaufmann companion material 3 Arithmetic for Computers Operations on
1 TDT4255 Computer Design Lecture 4 Magnus Jahre 2 Chapter 3 Computer Arithmetic ti Acknowledgement: Slides are adapted from Morgan Kaufmann companion material 3 Arithmetic for Computers Operations on
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 11: Floating Point & Floating Point Addition Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Last time: Single Precision Format
ECE232: Hardware Organization and Design Lecture 11: Floating Point & Floating Point Addition Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Last time: Single Precision Format
SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Chapter 6 ADMIN. Reading for Chapter 6: 6.1,
 Life. Chapter 6 ADMIN. Reading for Chapter 6: 6.1,") SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Chapter 6 ADMIN ing for Chapter 6: 6., 6.9-6.2 2 Midnight Laundry Task order A 6 PM 7 8 9 0 2 2 AM B C D 3 Smarty
SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Chapter 6 ADMIN ing for Chapter 6: 6., 6.9-6.2 2 Midnight Laundry Task order A 6 PM 7 8 9 0 2 2 AM B C D 3 Smarty
COSC4201 Pipelining. Prof. Mokhtar Aboelaze York University
 COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
Processor Architecture
 Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong (jinkyu@skku.edu)
Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong (jinkyu@skku.edu)
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 4: Datapath and Control
 ELEC 52/62 Computer Architecture and Design Spring 217 Lecture 4: Datapath and Control Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn, AL 36849
ELEC 52/62 Computer Architecture and Design Spring 217 Lecture 4: Datapath and Control Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn, AL 36849
Modern Computer Architecture
 Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Midnight Laundry. IC220 Set #19: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Return to Chapter 4
 Life. Return to Chapter 4") IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CS 230 Practice Final Exam & Actual Take-home Question. Part I: Assembly and Machine Languages (22 pts)
") Part I: Assembly and Machine Languages (22 pts) 1. Assume that assembly code for the following variable definitions has already been generated (and initialization of A and length). int powerof2; /* powerof2
Part I: Assembly and Machine Languages (22 pts) 1. Assume that assembly code for the following variable definitions has already been generated (and initialization of A and length). int powerof2; /* powerof2
Floating Point Arithmetic. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Floating Point Arithmetic Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Floating Point (1) Representation for non-integral numbers Including very
Floating Point Arithmetic Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Floating Point (1) Representation for non-integral numbers Including very
Computer Systems Architecture Spring 2016
 Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
CS 61C: Great Ideas in Computer Architecture. Lecture 13: Pipelining. Krste Asanović & Randy Katz
 CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
Single-Cycle Examples, Multi-Cycle Introduction
 Single-Cycle Examples, ulti-cycle Introduction 1 Today s enu Single cycle examples Single cycle machines vs. multi-cycle machines Why multi-cycle? Comparative performance Physical and Logical Design of
Single-Cycle Examples, ulti-cycle Introduction 1 Today s enu Single cycle examples Single cycle machines vs. multi-cycle machines Why multi-cycle? Comparative performance Physical and Logical Design of
These actions may use different parts of the CPU. Pipelining is when the parts run simultaneously on different instructions.
 MIPS Pipe Line 2 Introduction Pipelining To complete an instruction a computer needs to perform a number of actions. These actions may use different parts of the CPU. Pipelining is when the parts run simultaneously
MIPS Pipe Line 2 Introduction Pipelining To complete an instruction a computer needs to perform a number of actions. These actions may use different parts of the CPU. Pipelining is when the parts run simultaneously
Lecture 3. Pipelining. Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1
 Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Math 230 Assembly Programming (AKA Computer Organization) Spring 2008
 Spring 2008") Math 230 Assembly Programming (AKA Computer Organization) Spring 2008 MIPS Intro II Lect 10 Feb 15, 2008 Adapted from slides developed for: Mary J. Irwin PSU CSE331 Dave Patterson s UCB CS152 M230 L10.1
Math 230 Assembly Programming (AKA Computer Organization) Spring 2008 MIPS Intro II Lect 10 Feb 15, 2008 Adapted from slides developed for: Mary J. Irwin PSU CSE331 Dave Patterson s UCB CS152 M230 L10.1
Improving Performance: Pipelining
 Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Pipeline Review. Review
 Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
EE260: Logic Design, Spring n Integer multiplication. n Booth s algorithm. n Integer division. n Restoring, non-restoring
 EE 260: Introduction to Digital Design Arithmetic II Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Overview n Integer multiplication n Booth s algorithm n Integer division
EE 260: Introduction to Digital Design Arithmetic II Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Overview n Integer multiplication n Booth s algorithm n Integer division
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 15 April 1, 2009 martha@cs.columbia.edu and the rest of the semester Source code (e.g., *.java, *.c) (software) Compiler MIPS instruction set architecture
CSEE 3827: Fundamentals of Computer Systems Lecture 15 April 1, 2009 martha@cs.columbia.edu and the rest of the semester Source code (e.g., *.java, *.c) (software) Compiler MIPS instruction set architecture
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
CPE 335. Basic MIPS Architecture Part II
 CPE 335 Computer Organization Basic MIPS Architecture Part II Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Architecture
CPE 335 Computer Organization Basic MIPS Architecture Part II Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Architecture
Pipelining! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar DEIB! 30 November, 2017!
 Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
ECE 4750 Computer Architecture, Fall 2017 T05 Integrating Processors and Memories
 ECE 4750 Computer Architecture, Fall 2017 T05 Integrating Processors and Memories School of Electrical and Computer Engineering Cornell University revision: 2017-10-17-12-06 1 Processor and L1 Cache Interface
ECE 4750 Computer Architecture, Fall 2017 T05 Integrating Processors and Memories School of Electrical and Computer Engineering Cornell University revision: 2017-10-17-12-06 1 Processor and L1 Cache Interface
What is Pipelining? Time per instruction on unpipelined machine Number of pipe stages
 What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm