INTRODUCTION TO GPU COMPUTING IN AALTO. Topi Siro
|
|
|
- Maximilian O’Neal’
- 5 years ago
- Views:
Transcription
1 INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro
2 OUTLINE PART I Introduction to GPUs Basics of CUDA PART II Maximizing performance Coalesced memory access Optimizing memory transfers Occupancy Overlapping computation and transfer PART III Using libraries Using the GPU resources on Triton
3 PART 1 INTRODUCTION TO GPU COMPUTING AND CUDA
4 INTRODUCTION Modern graphics processors evolved from 3D accelerators of the 80s and 90s that were needed to run computer games with increasingly demanding graphics Even today, the development is driven by the gaming industry, but general purpose applications are becoming more and more important In recent years, GPU computing in various disciplines of science has seen a rapid growth The two big players are ATI (AMD) and NVIDIA So far, the majority of general purpose GPU computations have been implemented in NVIDIA s CUDA framework

5 The evolution of the theoretical performance of CPUs and GPUs
6 CPU VS GPU In a nutshell, the CPU typically runs one or a few very fast computational threads, while the GPU runs on the order of ten thousand simultaneous (not so fast) threads The hardware in the GPU emphasizes fast data processing over cache and flow control To benefit from the GPU, the computation has to be data-parallel and arithmetically intensive data-parallel: the same instructions are executed in parallel to a large number of independent data elements arithmetic intensity: the ratio of arithmetic operations to memory operations
7 GPU PROGRAMMING There are two major frameworks that enable the programmer to use the GPU for general purpose computation, OpenCL and CUDA OpenCL is an open standard that allows writing portable programs for a variety of platforms, including GPUs (both ATI and NVIDIA) CUDA is an architecture and programming model by NVIDIA for its GPUs Should I use OpenCL or CUDA? OpenCL has the advantage of being portable to other devices, at least in theory To reach best performance, you will probably have to tune the program to the specific device anyway CUDA offers a wide package of libraries for scientific computing and the vast majority of available GPU resources are NVIDIA GPUs CUDA is currently more popular
8 When to use GPUs? GPU PROGRAMMING The best case scenario is a large data-parallel problem that can be parallelized to tens of thousands of simultaneous threads Typical examples include manipulating large matrices and vectors It might not be worth it if the data is used only once, because the speedup has to overcome the cost of data transfers to and from the GPU With an abundance of libraries for standard algorithms, one can in many cases use GPUs in a high-level code without having to know about the details (don t have to write any kernels) However, optimal performance often requires code that is tailor-made for the specific problem Some things to consider in low-level GPU programming: How to parallelize? Memory transfers between the host system and the GPU Efficient global memory access within the GPU Shared memory usage
9 CUDA Compute Unified Device Architecture is the parallel programming model by NVIDIA for its GPUs The GPUs are programmed with an extension of the C language The major difference compared to ordinary C are special functions, called kernels, that are executed on the GPU by many threads in parallel Each thread is assigned an ID number that allows different threads to operate on different data The typical structure of a CUDA program: 1. Prepare data 2. Allocate memory on the GPU 3. Transfer data to GPU 4. Perform the computation on the GPU 5. Transfer results back to the host side
10 GPU HARDWARE SM L1 cache SM L1 cache The GPU consists of multiple streaming multiprocessors (SM) that each have tens or hundreds of cores Each SM has an L1 cache / shared memory L2 cache There is also an L2 cache shared by all SMs Global memory

11 THREAD HIERARCHY Thread hierarchy in CUDA The threads are organized into blocks that form a grid Threads within a block are executed on the same multiprocessor and they can be communicate via the shared memory Threads in the same block can be synchronized but different blocks are completely independent
12 CUDA global void Vcopy( intú A, intú B ) { int id = threadidx. x ; B [ id ] = A [ id ]; } int main () { //Host... code } //Launch the kernel with N threads Vcopy<<<1, N>>>(A, B ); A simple example of a kernel that copies the vector A into vector B with one block of N threads. The kernel is launched from the host code just like any ordinary function, except that the grid configuration is specified in the angled brackets as <<<number of blocks, threads per block>>> In the kernel, defined by the global qualifier, the thread number is saved in the variable id. Then, the element in A corresponding to id is copied to the same place in B. This way, thread number 0 copies the element 0, thread number 1 copies the element 1, etc., until N, all at the same time.
13 CUDA The maximum number of threads per block in current GPUs is 1024 The thread ID in the variable threadidx can be up to 3-dimensional for convenience dim3 threadsperblock(8, 8); //2-dimensional block The grid can be 1- or 2-dimensional, and the maximum number of blocks per dimension is In addition to the thread ID, there are intrinsic variables for the block ID and the threads per block available in the kernel, called blockidx and blockdim The number of threads per block should always be divisible by 32, because
14 CUDA global void Vcopy( intú A, intú B, int N ) { int id = blockidx. x ú blockdim. x + threadidx. x ; } if ( id < N ) B [ id ] = A [ id ]; int main () { //Host... code } Vcopy<<<numBlocks, numthreadsperblock>>>(a, B, N ); A better version of the vector copy kernel for vectors of arbitrary length Each thread calculates its global ID number Removing the if statement would result in array overflow, unless N happens to be divisible by blockdim, such that we could launch exactly N threads
15 ALLOCATION AND TRANSFER The GPU memory is separate from the host memory that the CPU sees Before any kernels can be run, the necessary data has to transferred to the GPU memory via the PCIe bus Memory on the GPU can be allocated with cudamalloc cudamalloc((void**)&d_a, Nbytes,); Memory transfers can be issued with cudamemcpy cudamemcpy(d_a, A, Nbytes, cudamemcpyhosttodevice) Be careful with the order of arguments (to, from,...) The last argument can be any of cudamemcpyhosttodevice, cudamemcpydevicetohost, cudamemcpydevicetodevice or cudamemcpyhosttohost
16 ALLOCATION AND TRANSFER #include <iostream> global void Vcopy( intú A, intú B, int N ) { int id = blockidx. x ú blockdim. x + threadidx. x ; } if ( id < N ) B [ id ] = A [ id ]; int main () { int N = 1000; int numthreadsperblock = 256; int numblocks = N / ; The vector copy code including the host part where we allocate the GPU memory and transfer the data to and from the GPU intú A = new int [ N ]; intú B = new int [ N ]; intú d_a ; intú d_b ; for( int i=0; i<n ; A [ i ] = i ; i++) cudamalloc ((voidúú)&d_a, cudamalloc ((voidúú)&d_b, Núsizeof( int)); Núsizeof( int)); cudamemcpy( d_a, A, Núsizeof( int), cudamemcpyhosttodevice); Vcopy<<<numBlocks, numthreadsperblock>>>(d_a, d_b, N ); cudamemcpy( B, d_b, Núsizeof( int), cudamemcpydevicetohost); } for( int i=0; i<n ; i++) if( A [ i ]!= B [ i ]) std ::cout << "Error." << std ::endl ;
17 COMPILING CUDA programs are compiled and linked with the nvcc compiler (available in Triton with module load cuda) Files with CUDA code need to have the.cu extension The syntax is identical to compiling with gcc, for example The only thing to remember is to compile for the appropriate GPU architecture, given with the -arch option (-arch sm_20 for Fermi GPUs) To compile and link a simple program in a file main.cu nvcc -arch sm_20 -o programname main.cu
18 GPU MEMORIES Efficient use of the GPU requires some low-level knowledge about the hardware, especially the different kinds of memories that are available Global memory The main memory of the GPU that can be allocated and manipulated from the host Very slow compared to registers and shared memory, so kernels should try to minimize global memory reads and writes Cached in L1 and L2 caches in Fermi generation and newer GPUs Shared memory A fast user-managed cache that can be used in communicating between threads of the same block Ideally, the kernel should load the necessary data from the global memory into shared memory, do the computation, and then write the results back to global memory Allocated in the kernel with the shared qualifier In Fermi, can be configure to 16KB or 48KB per multiprocessor
19 GPU MEMORIES Registers Variables that are declared in the kernel are stored into registers that are very fast However, using too much registers might result in register spilling to global memory, which might kill performance Textures The texture memory offers an alternative, cached access to global memory It s a bit more complicated to use but might sometimes give better performance
20 GPU MEMORIES global void example( doubleú data, { // this variable resides in registers int A = 0; int num) // this allocates an array in shared memory shared int B [64]; int C [ num ]; //These two will give an error shared int D [ num ]; // since num is not known at //compile time } //This might lead to register spilling int E [64]; Arrays declared in the kernel might lead to register spilling if the array is not indexed by constants Dynamic shared memory allocation is possible by giving the number of bytes in the kernel call as a third parameter in the <<< >>> but then only one allocation is possible
21 PARALLEL REDUCTION 3.2 As a slightly more complicated example, let s look at an implementation of the prefix sum CUDA 3 GPU COMPUTING operation, i.e. calculating the sum of the elements of a vector CUDA int sum3.2 = intar [0]; A serial code would do it like this: 3 GPU COMPUTING for ( int i = 1 ; i < N ; i++) { int sum = intar [ 0 ] ; sum = sum + intar [ i ] ; } for ( int i = 1 ; i < N ; i++) { Figure 4: An algorithm, written in C, that calculates the sum of elements of the integer = sum sum + isintar [ i ]by ; the value of the first element, and array intar. First,sum the variable initialized then the rest }of the N elements are looped over, and sum is increased each step by the value of the current element. To get the sum of all elements, this algorithm needs N 1 iterations. Figure 4: An algorithm, written in C, look that calculates A parallel implementation could like this: the sum of elements of the integer array intar. First, the variable sum is initialized by the value of the first element, and then the rest of the N elements are looped over, and sum is increased each step by the value of the current element. To get the sum of all elements, this algorithm needs N 1 iterations.
22 PARALLEL REDUCTION global void Sum( floatú A ) { const int id = threadidx. x ; shared float As [ N ]; As [ id ] = A [ id ]; int offset = 2; for( int c=n /2; c>0; c/=2) { syncthreads () ; First we load the vector into shared memory Then we iterate according to the figure on the previous slide } if( id < c ) { int a1 = offset ú id ; int a2 = a1 + offset /2; } As [ a1 ] += As [ a2 ]; offset ú= 2; syncthreads() is a synchronization barrier that is needed here to prevent a possible race condition } if( id==0) A [0] = As [0]; A parallel prefix sum kernel for N <= 1024 Finally, the first thread writes the result back to global memory
23 SUMMARY OF PART I Modern GPUs can be used for general purpose calculations which benefit from large-scale parallelization CUDA is the programming model by NVIDIA for its GPUs, and it enables writing code that runs on the GPU with an extension of the C programming language CUDA programs consist of host code, run on the CPU, and kernels that are executed on the GPU in parallel by threads whose launch configuration is given in the kernel call In the kernels, the threads can be identified with the intrinsic variables threadidx and blockidx The most important memories are the global memory and the permultiprocessor shared memory, that can be used for communication between threads of the same block CUDA programs are compiled with nvcc
24 PART 1I MAXIMIZING PERFORMANCE

25 COALESCED MEMORY ACCESS The memory access pattern of the threads can have dramatic consequences for the memory bandwidth In Fermi and newer GPUs, the memory can be only read in 128 byte chunks In the best case scenario, the nth thread accesses the nth word in the memory, and the access is aligned so that the starting address is a multiple of 128

26 COALESCED MEMORY ACCESS In newer GPUs the requirements for coalescing are much more relaxed Still, storing and accessing data inefficiently may cripple your performance
27 0 COALESCED MEMORY ACCESS a 11 a 1N C A 0 x C A a N1 a NN x N As an example of the importance of good memory access patterns, consider a matrix-vector multiplication A simple way to parallelize the operation is to assign one thread per row that computes the dot product of the row with the vector How should we store the matrix into the memory? Let s consider the two most natural ways, row-wise and column-wise storage data = a 11 a 12 a 1N a 21 a 22 a NN data = a 11 a 21 a N1 a 12 a 22 a NN
28 COALESCED MEMORY ACCESS global void MatrixVectorRow( doubleú M, doubleú x, doubleú y, int N ) { int id = blockidx. x ú blockdim. x + threadidx. x ; double res = 0; } if ( id < N ) for( int i=0; i<n ; i++) res = res + M [ idún + i ] ú x [ i ]; y [ id ] = res ; global void MatrixVectorCol( doubleú M, doubleú x, doubleú y, int N ) { int id = blockidx. x ú blockdim. x + threadidx. x ; double res = 0; The thread id gives the row that this thread will operate with The only difference in the kernels is in the highlighted part where the row and column indices have been swapped because of the different data ordering } if ( id < N ) for( int i=0; i<n ; i++) res = res + M [ iún + id ] ú x [ i ]; y [ id ] = res ; With N ~ 10000, the column-wise version is about 13 times faster than the row-wise version!
29 COALESCED MEMORY ACCESS Why is it so much better to store the matrix column-wise instead of row-wise? In the column-wise case, the threads access the memory contiguously, while in the row-wise case, the memory accesses are scattered and the resulting memory bandwidth is crippled 0 a 11 a 12 a 1N a 21 a 22 a 2N a 31 a 32 a 2N a N1 a N2 a NN NOT like this: data = a 11 a 12 a 1N a 21 a 22 a NN But like this: data = a 11 a 21 a N1 a 12 a 22 a NN 1 C A 1st iteration 2nd iteration
30 OCCUPANCY Occupancy is the ratio of the number of resident threads to the maximum number of threads, i.e. it s a measure of how full the GPU is Occupancy depends on The number of registers needed by a thread The amount of shared memory needed by a block The block size For example, in the Tesla M2070, the maximum number of blocks per multiprocessor is 8. However, let s say our kernel is such that one block requires 20 KB of shared memory. Then only 2 blocks can fit into the SM because there s only 48 KB of shared memory available A simple tool for evaluating the occupancy of your program is the Occupancy Calculator spreadsheet by NVIDIA CUDA_Occupancy_calculator.xls
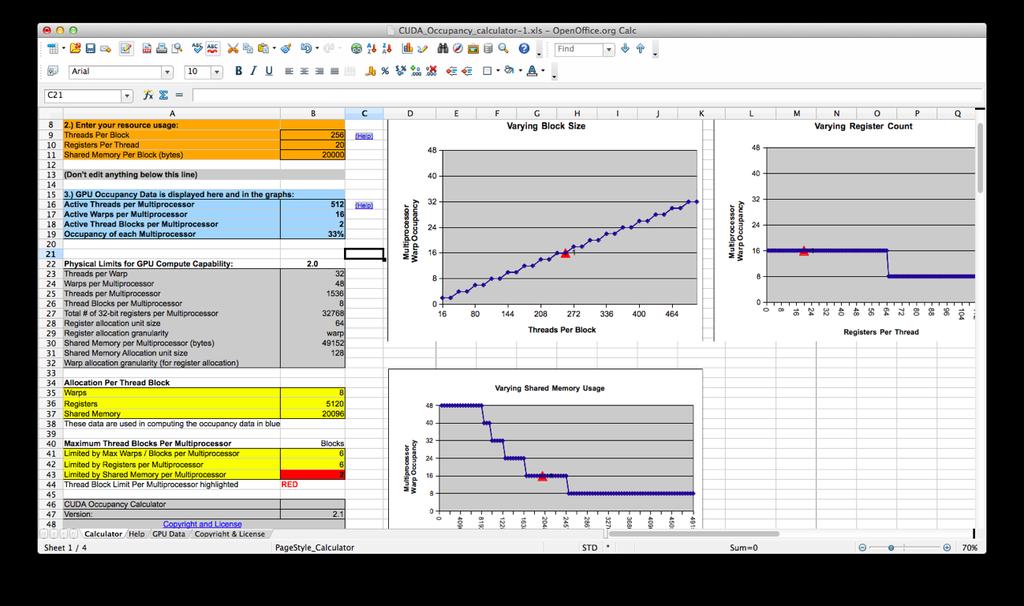
31 OCCUPANCY
32 OCCUPANCY To see you kernels resource usage, add the flag --ptxas-options=-v to nvcc when compiling and it will list the register and shared memory usage for each kernel Input the numbers along with you block size into the orange box in the occupancy calculator and it will show you the limiting factor in your occupancy If your occupancy is very low (<33%), it might be worthwhile to try to change your kernel to use less registers or shared memory so that more blocks can run concurrently However, it s not usually important to get 100% occupancy because even at lower occupancies there is enough computation to hide the memory latency
33 OPTIMIZING DATA TRANSFER A potential bottleneck in a CUDA program is the low bandwidth of the PCIe bus This means that sometimes it s useful to run kernels that have little to no speedup compared to their CPU versions in order to keep the data on the GPU and avoid transfers It s also possible to speed up the cudamemcpy by using pinned host memory When a memory transfer is issued, the CUDA driver first allocates a temporary pinned host array, copies the data there and only then from the pinned memory to the GPU We can skip the first step by explicitly allocating the pinned memory ourselves

34 OPTIMIZING DATA TRANSFER Pinned memory can be allocated with cudamallochost (same syntax as cudamalloc) You should be careful to not allocate too much pinned memory because it might crash your system cudamemcpy may be twice as fast or more with pinned memory, depending on the system
35 OPTIMIZING DATA TRANSFER int main () { int N = ; int numthreadsperblock = 256; int numblocks = N / ; intú A ; intú B ; cudamallochost ((voidúú)&a, cudamallochost ((voidúú)&b, Núsizeof( int)); Núsizeof( int)); intú d_a ; intú d_b ; cudamalloc ((voidúú)&d_a, cudamalloc ((voidúú)&d_b, Núsizeof( int)); Núsizeof( int)); for( int i=0; i<n ; A [ i ] = i ; i++) cudamemcpy( d_a, A, Núsizeof( int), cudamemcpyhosttodevice); Vcopy<<<numBlocks, numthreadsperblock>>>(d_a, d_b, N ); cudamemcpy( B, d_b, Núsizeof( int), cudamemcpydevicetohost); } for( int i=0; i<n ; i++) if( A [ i ]!= B [ i ]) std ::cout << "Error." << std ::endl ; The vector copy example with pinned host memory
36 STREAMS Streams are sequences of operations that are executed on the device in the order that they were issued Operations in different streams don t have to be synchronized, and their execution can be interleaved In the examples thus far, we have implicitly used the default stream, which is a special case in that it blocks the execution of all other streams However, kernel calls are asynchronous with respect to the CPU By using different streams, it s possible to for example overlap memory transfers and kernel execution cudastream_t stream1 ; cudastreamcreate(&stream1); cudamemcpyasync( d_a, A, N, cudamemcpyhosttodevice, stream1); kernel<<<1, N, 0, stream1>>>(d_a); cudastreamdestroy( stream1);
37 OVERLAPPING COMPUTATION AND TRANSFER By default, CUDA operations such as kernel calls and memory transfers wait until the previous operation is done before starting the next one However, it is possible to use asynchronous versions of these to for example overlap transferring memory and running a kernel To overlap, they have to be issued in different, non-default streams The host memory used in the transfer has to be pinned memory The best strategy for overlapping depends on the device but on Fermi devices (which comprise most of the GPU resources currently available) the best way is given in the following example
38 OVERLAPPING COMPUTATION AND TRANSFER int main () { doubleú A ; doubleú d_a ; int blocksize = 512; int N = 16ú1024ú1024; int nstreams = 4; int streamsize = N / nstreams ; int numblocks = streamsize / blocksize ; cudaevent_t start1, stop1 ; float time1 ; cudamallochost ((voidúú)&a, Núsizeof( double)); cudamalloc ((voidúú)&d_a, Núsizeof( double)); cudastream_tú streams = new cudastream_t [ nstreams ]; for( int i=0; i<nstreams ; i++) cudastreamcreate(&streams [ i ]) ; (& );
39 OVERLAPPING COMPUTATION AND TRANSFER cudaeventcreate(&start1); cudaeventcreate(&stop1); cudaeventrecord( start1, 0 ) ; for( int i=0; i<nstreams ; i++) { cudamemcpyasync( d_a + iústreamsize, A + iústreamsize, streamsizeúsizeof( double), cudamemcpyhosttodevice, streams [ i ]) ; kernel<<<numblocks, blocksize, 0, streams [ i]>>> ( d_a, streamsize); } cudamemcpyasync( A + iústreamsize, d_a + iústreamsize, streamsizeúsizeof( double), cudamemcpydevicetohost, streams [ i ]) ; cudaeventrecord( stop1, 0 ) ; cudaeventsynchronize( stop1 ); cudaeventelapsedtime(&time1, start1, stop1); std ::cout << "Time: " << time1/1000 << " s" << std ::endl ; } for( int i=0; i<nstreams ; i++) cudastreamdestroy( streams [ i ]) ;
40 OVERLAPPING COMPUTATION AND TRANSFER Sequential version (1 stream) 4 streams Assuming the kernel takes about the same time as the memory transfer, the execution time is roughly 50% More details at for example
41 SUMMARY OF PART II Accessing global memory in a way that allows memory transfers to be coalesced is critical for obtaining the best performance As a rule of thumb, always try to arrange your data so that threads of the same warp access data that are close to each other in the memory Managing the use of shared memory and registers is important to achieve high enough occupancy of the multiprocessors and avoid register spilling Use the occupancy calculator spreadsheet to find out your occupancy Try to minimize transferring data between the host and the device Use pinned host memory to speed up the transfers Streams can be used to overlap memory transfers with kernel execution
42 PART III GPU COMPUTING IN TRITON
43 LIBRARIES Included in CUDA are many useful libraries, for example cufft - Fast Fourier transforms CUBLAS - CUDA-accelerated linear algebra curand - Random number generation Thrust - High level interface for many parallel algorithms With these, you can use the computational power of the GPUs for many basic tasks without having to write any kernels yourself
44 CUBLAS A CUDA-accelerated version of the standard BLAS library of linear algebra routines Support single, double, complex and double complex datatypes #include <cublas.h> Remember to link cublas in the compilation CUBLAS documentation:
45 CUBLAS #include <iostream> #include <cucomplex. h> #include <cublas.h> int main () { int N = ; cucomplexú A ; cucomplexú B ; cudamallochost ((voidúú)&a, cudamallochost ((voidúú)&b, Núsizeof( cucomplex)); Núsizeof( cucomplex)); cucomplexú d_a ; cucomplexú d_b ; cudamalloc ((voidúú)&d_a, cudamalloc ((voidúú)&d_b, Núsizeof( cucomplex)); Núsizeof( cucomplex)); for( int i=0; i<n ; { A [ i ].x = 0.0; A [ i ].y = i ; } i++) cudamemcpy( d_a, A, Núsizeof( cucomplex), cudamemcpyhosttodevice); cublasccopy( N, d_a, 1, d_b, 1) ; } cudamemcpy( B, d_b, Núsizeof( cucomplex), cudamemcpydevicetohost);
 Quick start guide at http://code.google.")
46 THRUST Thrust is like a GPU version of the C++ Standard Template Library (STL) Quick start guide at
47 CURAND A library for CUDA-accelerated random number generation You can generate random numbers in bulk from the host code or generate individual numbers inside kernels Includes many different generation algorithms and distributions More information on the CURAND user guide at cuda/curand/index.html
48 CURAND EXAMPLE Let s look at a simple program that uses CURAND to approximate pi by generating random points inside a square Pi can be approximated from the probability that the point falls inside a quarter circle centered at the lower left corner of the square The probability is equal to the ratio of the areas of the quarter circle and the square which is pi/4 So we generate the points, check the fraction that falls inside the circle, and multiply that by 4 to get an approximation for pi

49 CURAND EXAMPLE

50

51

52
53
54
55 GPU COMPUTING ON TRITON Triton has 10 GPU nodes with 2 Tesla M2090 GPUs (6GB of memory) in each node GPU jobs can be run in the Slurm partition gpu For testing, log in to the gpu001 node Before anything else, load the CUDA module with module load cuda There are precompiled CUDA sample programs in /share/apps/nvidia/ cuda_samples_4.1.28/
56 GPU COMPUTING ON TRITON

57 GPU COMPUTING ON TRITON If you want to look at the source code of the samples, you can install them under you work directory compute/cuda/4_1/rel/sdk/gpucomputingsdk_4.1.28_linux.run Give the install path when prompted (in my case /triton/tfy/work/sirot1/ CUDA) The source codes can be found in <install path>/c/src

58 GPU COMPUTING ON TRITON GPU jobs can be run straight from the command line or by submitting a job script On the frontend, you can use salloc and srun: Or with a script:

59

60

61 GPU COMPUTING ON TRITON You can check the queue status with squeue -p gpu You can cancel jobs with scancel <JOBID>

62 GPU COMPUTING ON TRITON Let s recall compiling programs with nvcc To see the shared memory and register usage: These numbers can be put to the occupancy calculator

63 GPU COMPUTING ON TRITON In the new cuda 5.0 there is a very handy profiler called nvprof that you can use to check the time that is spent in kernels and memory transfers More details with --print-gpu-trace and --print-api-trace options to nvprof
64 OTHER GPU RESOURCES There are also GPUs on the Vuori machine at CSC Vuori also has the Slurm system with partitions gpu and gpu6g You need to get separate account from CSC danny, proxima etc. One new Tesla K20 on veitsi.hut.fi If you have a Geforce GPU at home you can run CUDA programs on your home computer!
65 SUMMARY OF PART III High-level usage of GPUs is possible with libraries such as CUBLAS and Thrust that are included in the CUDA installation Triton has altogether 20 GPUs with 6GB of memory each They can be accessed through the Slurm partition called gpu You can allocate and run jobs straight from the command line with salloc and srun or use a batch job script with sbatch In CUDA 5.0, there is an easy way to profile your program with nvprof
66 LEARN MORE CUDA C Programming Guide All kinds of resources including video lectures and online courses: NVIDIA Developer Blog
INTRODUCTION TO GPU COMPUTING IN AALTO. Topi Siro
 INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 11.6.2014 PART I Introduction to GPUs Basics of CUDA (and OpenACC) Running GPU jobs on Triton Hands-on 1 PART II Optimizing CUDA codes Libraries Hands-on
INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 11.6.2014 PART I Introduction to GPUs Basics of CUDA (and OpenACC) Running GPU jobs on Triton Hands-on 1 PART II Optimizing CUDA codes Libraries Hands-on
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team
 Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Don t reinvent the wheel. BLAS LAPACK Intel Math Kernel Library
 Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
Using a GPU in InSAR processing to improve performance
 Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
HPCSE II. GPU programming and CUDA
 HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
CS 179: GPU Computing. Lecture 2: The Basics
 CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Massively Parallel Computing with CUDA. Carlos Alberto Martínez Angeles Cinvestav-IPN
 Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
CUDA Memories. Introduction 5/4/11
 5/4/11 CUDA Memories James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011 Introduction
5/4/11 CUDA Memories James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011 Introduction
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
GPU Architecture and Programming. Andrei Doncescu inspired by NVIDIA
 GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA
 CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
CSE 591: GPU Programming. Programmer Interface. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
An Introduction to OpenAcc
 An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
General-purpose computing on graphics processing units (GPGPU)
") General-purpose computing on graphics processing units (GPGPU) Thomas Ægidiussen Jensen Henrik Anker Rasmussen François Rosé November 1, 2010 Table of Contents Introduction CUDA CUDA Programming Kernels
General-purpose computing on graphics processing units (GPGPU) Thomas Ægidiussen Jensen Henrik Anker Rasmussen François Rosé November 1, 2010 Table of Contents Introduction CUDA CUDA Programming Kernels
Advanced Topics: Streams, Multi-GPU, Tools, Libraries, etc.
 CSC 391/691: GPU Programming Fall 2011 Advanced Topics: Streams, Multi-GPU, Tools, Libraries, etc. Copyright 2011 Samuel S. Cho Streams Until now, we have largely focused on massively data-parallel execution
CSC 391/691: GPU Programming Fall 2011 Advanced Topics: Streams, Multi-GPU, Tools, Libraries, etc. Copyright 2011 Samuel S. Cho Streams Until now, we have largely focused on massively data-parallel execution
An Introduction to GPU Computing and CUDA Architecture
 An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Review for Midterm 3/28/11. Administrative. Parts of Exam. Midterm Exam Monday, April 4. Midterm. Design Review. Final projects
 Administrative Midterm - In class April 4, open notes - Review notes, readings and review lecture (before break) - Will post prior exams Design Review - Intermediate assessment of progress on project,
Administrative Midterm - In class April 4, open notes - Review notes, readings and review lecture (before break) - Will post prior exams Design Review - Intermediate assessment of progress on project,
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,