Parallel and High Performance Computing CSE 745
|
|
|
- Lucinda Beasley
- 5 years ago
- Views:
Transcription
1 Parallel and High Performance Computing CSE 745 1
2 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel examples OpenMP MPI 2
3 Introduction to HPC computing 3
4 Overview 4
5 What is Parallel Computing? Traditionally, software has been written for serial computation: To be run on a single computer having a single Central Processing Unit (CPU); A problem is broken into a discrete series of instructions. Instructions are executed one after another. Only one instruction may execute at any moment in time. 5

6 6
7 In the simplest sense, parallel computing is the simultaneous use of multiple compute resources to solve a computational problem. To be run using multiple CPUs / cores A problem is broken into discrete parts that can be solved concurrently Each part is further broken down to a series of instructions Instructions from each part execute simultaneously on different CPUs / cores 7

8 8
9 The compute resources can include: A single computer with multiple processors; An arbitrary number of computers connected by a network; A combination of both. The computational problem usually demonstrates characteristics such as the ability to: Be broken apart into discrete pieces of work that can be solved simultaneously; Execute multiple program instructions at any moment in time; Be solved in less time with multiple compute resources than with a single compute resource. 9
10 Why Use Parallel Computing? The primary reasons for using parallel computing: Save time - wall clock time Solve larger problems Other reasons might include: Taking advantage of non-local resources - using available compute resources on a wide area network, or even the Internet when local compute resources are scarce. Cost savings - using multiple "cheap" computing resources instead of paying for time on a supercomputer. Overcoming memory constraints - single computers have very finite memory resources. For large problems, using the memories of multiple computers may overcome this obstacle. 10
11 Limits to serial computing - both physical and practical reasons pose significant constraints to simply building ever faster serial computers: Transmission speeds - the speed of a serial computer is directly dependent upon how fast data can move through hardware. Absolute limits are the speed of light (30 cm/nanosecond) and the transmission limit of copper wire (9 cm/nanosecond). Increasing speeds necessitate increasing proximity of processing elements. Limits to miniaturization - processor technology is allowing an increasing number of transistors to be placed on a chip. However, even with molecular or atomic-level components, a limit will be reached on how small components can be. Economic limitations - it is increasingly expensive to make a single processor faster. Using a larger number of moderately fast commodity processors to achieve the same (or better) performance is less expensive. 11

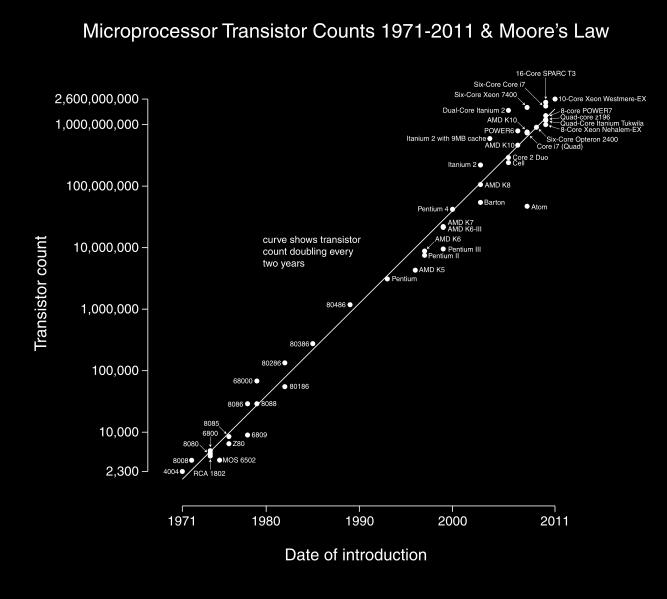
12 Moore s law 12
13 The future: during the past 15 years, the trends indicated by ever faster networks, distributed systems, and multi-processor computer architectures (even at the desktop level) suggest that parallelism is the future of computing. 13
14 von Neumann Architecture For over 40 years, virtually all computers have followed a common machine model known as the von Neumann computer. Named after the Hungarian mathematician John von Neumann. A von Neumann computer uses the stored-program concept. The CPU executes a stored program that specifies a sequence of read and write operations on the memory. 14
 gets instructions and/or data from memory, decodes the instructions and then sequentially performs them.")
15 von Neumann Architecture (2) Basic design: Memory is used to store both program and data instructions Program instructions are coded data which tell the computer to do something Data is simply information to be used by the program A central processing unit (CPU) gets instructions and/or data from memory, decodes the instructions and then sequentially performs them. 15
16 Flynn's Classical Taxonomy There are different ways to classify parallel computers. One of the more widely used classifications, in use since 1966, is called Flynn's Taxonomy. Flynn's taxonomy distinguishes multi-processor computer architectures according to how they can be classified along the two independent dimensions of Instruction and Data. Each of these dimensions can have only one of two possible states: Single or Multiple. 16
17 Flynn's Classical Taxonomy (2) The matrix below defines the 4 possible classifications according to Flynn. S I S D Single Instruction, Single Data S I M D Single Instruction, Multiple Data M I S D Multiple Instruction, Single Data M I M D Multiple Instruction, Multiple Data 17
18 Single Instruction, Single Data A serial (non-parallel) computer Single instruction: only one instruction stream is being acted on by the CPU during any one clock cycle Single data: only one data stream is being used as input during any one clock cycle Deterministic execution This is the oldest and until recently, the most prevalent form of computer 18

19 Single Instruction, Single Data (2) 19
20 Single Instruction, Multiple Data A type of parallel computer Single instruction: All processing units execute the same instruction at any given clock cycle Multiple data: Each processing unit can operate on a different data element This type of machine typically has an instruction dispatcher, a very high-bandwidth internal network, and a very large array of very small-capacity instruction units. 20
21 Single Instruction, Multiple Data (2) Best suited for specialized problems characterized by a high degree of regularity, such as image processing. Synchronous (lockstep) and deterministic execution Examples: Vector Processors: Thinking Machine CM-2, Cray Y-MP etc. MMX and SSE extensions to the x86 architecture. GPU's multiprocessors (groups of usually 32 cores) 21
22 Single Instruction, Multiple Data (3) 22
23 Multiple Instruction, Single Data A single data stream is fed into multiple processing units. Each processing unit operates on the data independently via independent instruction streams. Few actual examples of this class of parallel computer have ever existed. Some conceivable uses might be: multiple frequency filters operating on a single signal stream multiple cryptography algorithms attempting to crack a single coded message. 23

24 Multiple Instruction, Single Data (2) 24
25 Multiple Instruction, Multiple Data Currently, the most common type of parallel computer. Most modern computers fall into this category. Multiple Instruction: every processor may be executing a different instruction stream Multiple Data: every processor may be working with a different data stream Execution can be synchronous or asynchronous, deterministic or non-deterministic Examples: most current supercomputers, networked parallel computer clusters and multi-processor SMP computers; most of the current PCs. 25

26 Multiple Instruction, Multiple Data (2) 26
27 Parallel Computer Memory Architectures 27

28 Shared Memory General Characteristics: Shared memory parallel computers vary widely, but generally have in common the ability for all processors to access all memory as global address space. 28
29 Shared Memory (2) Multiple processors can operate independently but share the same memory resources. Changes in a memory location effected by one processor are visible to all other processors. Shared memory machines can be divided into two main classes based upon memory access times: UMA and NUMA. 29
30 Shared Memory (3) Uniform Memory Access (UMA): Most commonly represented today by Symmetric Multiprocessor (SMP) machines Identical processors Equal access and access times to memory Sometimes called CC-UMA - Cache Coherent UMA. Cache coherent means if one processor updates a location in shared memory, all the other processors know about the update. Cache coherency is accomplished at the hardware level. (Nearly all CPU architectures use a small amount of very fast non-shared memory known as cache to exploit locality of reference in memory accesses). 30
31 Shared Memory (4) Non-Uniform Memory Access (NUMA): Often made by physically linking two or more SMPs One SMP can directly access memory of another SMP Not all processors have equal access time to all memories Memory access across link is slower If cache coherency is maintained, then may also be called CC- NUMA - Cache Coherent NUMA 31


32 Shared Memory (5) UMA NUMA 32
33 Shared Memory (6) With NUMA, the cache coherence is typically accomplished by using inter-processor communication between cache controllers to keep a consistent memory image when more than one cache stores the same memory location. For this reason, CC-NUMA performs poorly when multiple processors attempt to access the same memory area in rapid succession. Operating-system support for NUMA attempts to reduce the frequency of this kind of access by allocating processors and memory in NUMA-friendly ways and by avoiding scheduling and locking algorithms that make NUMA-unfriendly accesses necessary. 33
34 Shared Memory (7) Advantages: Global address space provides a user-friendly programming perspective to memory Data sharing between tasks is both fast and uniform due to the proximity of memory to CPUs Disadvantages: Primary disadvantage is the lack of scalability between memory and CPUs. Adding more CPUs can geometrically increases traffic on the shared memory-cpu path, and for cache coherent systems, geometrically increase traffic associated with cache/memory management. Programmer responsibility for synchronization constructs that insure "correct" access of global memory. Expense: it becomes increasingly difficult and expensive to design and produce shared memory machines with ever increasing numbers of processors. 34
35 Distributed Memory Like shared memory systems, distributed memory systems vary widely but share a common characteristic. Distributed memory systems require a communication network to connect inter-processor memory. 35
36 Distributed Memory (2) Processors have their own local memory. Memory addresses in one processor do not map to another processor, so there is no concept of global address space across all processors. Because each processor has its own local memory, it operates independently. Changes it makes to its local memory have no effect on the memory of other processors. Hence, the concept of cache coherency does not apply. When a processor needs to access data in another processor, it is usually the task of the programmer to explicitly define how and when data is communicated. Synchronization between tasks is likewise the programmer's responsibility. The network "fabric" used for data transfer varies widely, though it can can be as simple as Ethernet. 36
37 Distributed Memory (3) Advantages: Memory is scalable with number of processors. Increase the number of processors and the size of memory increases proportionately. Each processor can rapidly access its own memory without interference and without the overhead incurred with trying to maintain cache coherency. Cost effectiveness: can use commodity, off-the-shelf processors and networking. Disadvantages: The programmer is responsible for many of the details associated with data communication between processors. It may be difficult to map existing data structures, based on global memory, to this memory organization. Non-uniform memory access (NUMA) times 37

38 Hybrid Distributed-Shared Memory The largest and fastest computers in the world today employ both shared and distributed memory architectures. 38
39 Hybrid Distributed-Shared Memory (2) The shared memory component is usually a cache coherent SMP machine. Processors on a given SMP can address that machine's memory as global. The distributed memory component is the networking of multiple SMPs. SMPs know only about their own memory - not the memory on another SMP. Therefore, network communications are required to move data from one SMP to another. Current trends seem to indicate that this type of memory architecture will continue to prevail and increase at the high end of computing for the foreseeable future. 39
40 Parallel Programming Models 40
41 Overview There are several parallel programming models in common use: Shared Memory Threads Message Passing Data Parallel Hybrid Parallel programming models exist as an abstraction above hardware and memory architectures. 41
42 Overview (2) Which model to use is often a combination of what is available and personal choice. There is no "best" model, although there certainly are better implementations of some models over others. The following slides will cover each of the models mentioned above, and will also discuss some of their actual implementations. 42
43 Shared Memory Model In the shared-memory programming model, tasks share a common address space, which they read and write asynchronously. Various mechanisms such as locks / semaphores may be used to control access to the shared memory. An advantage of this model from the programmer's point of view is that the notion of data "ownership" is lacking, so there is no need to specify explicitly the communication of data between tasks. Program development can often be simplified. An important disadvantage in terms of performance is that it becomes more difficult to understand and manage data locality. 43
44 Shared Memory Model (2) Implementations: On shared memory platforms, the native compilers translate user program variables into actual memory addresses, which are global. No common distributed memory platform implementations currently exist. 44
45 Threads Model In the threads model of parallel programming, a single process can have multiple, concurrent execution paths. Perhaps the most simple analogy that can be used to describe threads is the concept of a single program that includes a number of subroutines: The main program a.out is scheduled to run by the native operating system. a.out loads and acquires all of the necessary system and user resources to run. 45
46 Threads Model (2) a.out performs some serial work, and then creates a number of tasks (threads) that can be scheduled and run by the operating system concurrently. Each thread has local data, but also, shares the entire resources of a.out. This saves the overhead associated with replicating a program's resources for each thread. Each thread also benefits from a global memory view because it shares the memory space of a.out. A thread's work may best be described as a subroutine within the main program. Any thread can execute any subroutine at the same time as other threads. 46

47 Threads Model (3) Threads communicate with each other through global memory (updating address locations). This requires synchronization constructs to insure that more than one thread is not updating the same global address at any time. Threads can come and go, but a.out remains present to provide the necessary shared resources until the application has completed. Threads are commonly associated with shared memory architectures and operating systems. 47
48 Threads: implementations From a programming perspective, threads implementations commonly comprise: A library of subroutines that are called from within parallel source code A set of compiler directives embedded in either serial or parallel source code In both cases, the programmer is responsible for determining all parallelism. Threaded implementations are not new in computing. Historically, hardware vendors have implemented their own proprietary versions of threads. These implementations differed substantially from each other making it difficult for programmers to develop portable threaded applications. 48
49 Threads: implementations (2) Unrelated standardization efforts have resulted in two very different implementations of threads: POSIX Threads and OpenMP. POSIX Threads Library based; requires parallel coding Specified by the IEEE POSIX c standard (1995). C Language only Commonly referred to as Pthreads. Most hardware vendors now offer Pthreads in addition to their proprietary threads implementations. Very explicit parallelism; requires significant programmer attention to detail. 49
50 Threads: implementations (3) OpenMP Compiler directive based; can use serial code Jointly defined and endorsed by a group of major computer hardware and software vendors. The OpenMP Fortran API was released October 28, The C/C++ API was released in late Portable / multi-platform, including Unix and Windows NT platforms Available in C/C++ and Fortran implementations Can be very easy and simple to use - provides for "incremental parallelism" Microsoft has its own implementation for threads, which is not related to the UNIX POSIX standard or OpenMP. 50

51 Message Passing Model The message passing model demonstrates the following characteristics: A set of tasks that use their own local memory during computation. Multiple tasks can reside on the same physical machine as well across an arbitrary number of machines. Tasks exchange data through communications by sending and receiving messages. Data transfer usually requires cooperative operations to be performed by each process. For example, a send operation must have a matching receive operation. 51
52 MPI: implementations From a programming perspective, message passing implementations commonly comprise a library of subroutines that are embedded in source code. The programmer is responsible for determining all parallelism. Historically, a variety of message passing libraries have been available since the 1980s. These implementations differed substantially from each other making it difficult for programmers to develop portable applications. In 1992, the MPI Forum was formed with the primary goal of establishing a standard interface for message passing implementations. 52
53 MPI: implementations (2) Part 1 of the Message Passing Interface (MPI) was released in Part 2 (MPI-2) was released in Part 3 (not covered in this course) was released in All MPI specifications are available on the web at MPI is now the "de facto" industry standard for message passing, replacing virtually all other message passing implementations used for production work. Most, if not all of the popular parallel computing platforms offer at least one implementation of MPI. SHARCNET is using Open MPI library (open source), which has a full MPI-2 standards conformance (MPI-3 is incomplete). For shared memory architectures, MPI implementations usually don't use a network for task communications. Instead, they use shared memory (memory copies) for performance reasons. 53

54 Data Parallel Model 54
55 Data Parallel Model (2) The data parallel model demonstrates the following characteristics: Most of the parallel work focuses on performing operations on a data set. The data set is typically organized into a common structure, such as an array or cube. A set of tasks work collectively on the same data structure, however, each task works on a different partition of the same data structure. Tasks perform the same operation on their partition of work, for example, "add 4 to every array element". On shared memory architectures, all tasks may have access to the data structure through global memory. On distributed memory architectures the data structure is split up and resides as "chunks" in the local memory of each task. 55
56 Implementations Programming with the data parallel model is usually accomplished by writing a program with data parallel constructs. The constructs can be calls to a data parallel subroutine library or compiler directives recognized by a data parallel compiler. High Performance Fortran (HPF): Extensions to Fortran 90 to support data parallel programming. Contains everything in Fortran 90 Directives to tell compiler how to distribute data added Assertions that can improve optimization of generated code added Data parallel constructs added (now part of Fortran 95) Implementations are available for most common parallel platforms 56
57 Implementations (2) Coarray Fortran: An extension of Fortran 95/2003 for parallel processing created by Robert Numrich and John Reid. A Coarray Fortran program is interpreted as if it were replicated a number of times and all copies were executed asynchronously. Each copy has its own set of data objects and is termed an image. The array syntax of Fortran 95 is extended with additional trailing subscripts in square brackets to provide a concise representation of references to data that is spread across images. The Fortran 2008 standard now includes coarrays, as decided at the May 2005 meeting of the ISO Fortran Committee. 57
58 Implementations (3) UPC (Unified Parallel C): an extension of the C programming language designed for high-performance computing on large-scale parallel machines, including those with a common global address space (SMP and NUMA) and those with distributed memory (e.g. clusters). The programmer is presented with a single shared, partitioned address space, where variables may be directly read and written by any processor, but each variable is physically associated with a single processor. 58
59 Implementations (4) In order to express parallelism, UPC extends ISO C 99 with the following constructs: An explicitly parallel execution model A shared address space Synchronization primitives and a memory consistency model Memory management primitives 59
60 Hybrid In this model, any two or more parallel programming models are combined. Currently, a common example of a hybrid model is the combination of the message passing model (MPI) with either the threads model (POSIX threads) or the shared memory model (OpenMP). This hybrid model lends itself well to the increasingly common hardware environment of networked SMP machines. CUDA programming model (for GPU programming) is another example. It combines elements of the data parallel model (at the lower, block level), shared memory model (at the higher, inter-block level), and distributed memory model (between CPU and GPUs). 60
61 Single Program Multiple Data (SPMD): SPMD is actually a "high level" programming model that can be built upon any combination of the previously mentioned parallel programming models. A single program is executed by all tasks simultaneously. At any moment in time, tasks can be executing the same or different instructions within the same program. SPMD programs usually have the necessary logic programmed into them to allow different tasks to branch or conditionally execute only those parts of the program they are designed to execute. That is, tasks do not necessarily have to execute the entire program - perhaps only a portion of it. All tasks may use different data 61
. While the application is being run in parallel, each task can be executing the same or different program as other tasks.")
62 Multiple Program Multiple Data (MPMD) Like SPMD, MPMD is actually a "high level" programming model that can be built upon any combination of the previously mentioned parallel programming models. MPMD applications typically have multiple executable object files (programs). While the application is being run in parallel, each task can be executing the same or different program as other tasks. All tasks may use different data. 62
Parallel Programming Models. Parallel Programming Models. Threads Model. Implementations 3/24/2014. Shared Memory Model (without threads)
") Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
Introduction to Parallel Computing. CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014
 Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
3/24/2014 BIT 325 PARALLEL PROCESSING ASSESSMENT. Lecture Notes:
 BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
School of Parallel Programming & Parallel Architecture for HPC ICTP October, Intro to HPC Architecture. Instructor: Ekpe Okorafor
 School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Intro to HPC Architecture Instructor: Ekpe Okorafor A little about me! PhD Computer Engineering Texas A&M University Computer
School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Intro to HPC Architecture Instructor: Ekpe Okorafor A little about me! PhD Computer Engineering Texas A&M University Computer
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
High Performance Computing. Introduction to Parallel Computing
 High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
Introduction to Parallel Computing
 Tutorials Exercises Abstracts LC Workshops Comments Search Privacy & Legal Notice Tutorials Exercises Abstracts LC Workshops Comments Search Privacy & Legal Notice Introduction to Parallel Computing Blaise
Tutorials Exercises Abstracts LC Workshops Comments Search Privacy & Legal Notice Tutorials Exercises Abstracts LC Workshops Comments Search Privacy & Legal Notice Introduction to Parallel Computing Blaise
Parallel programming. Luis Alejandro Giraldo León
 Parallel programming Luis Alejandro Giraldo León Topics 1. 2. 3. 4. 5. 6. 7. 8. Philosophy KeyWords Parallel algorithm design Advantages and disadvantages Models of parallel programming Multi-processor
Parallel programming Luis Alejandro Giraldo León Topics 1. 2. 3. 4. 5. 6. 7. 8. Philosophy KeyWords Parallel algorithm design Advantages and disadvantages Models of parallel programming Multi-processor
Seminar Series on High Performance Computing:
 Seminar Series on High Performance Computing: Pragnesh Patel National Institute for Computational Sciences pragnesh@utk.edu Jan 28, 2014 Acknowledgement: Florent Nolot, Introduction to Parallel Computing,
Seminar Series on High Performance Computing: Pragnesh Patel National Institute for Computational Sciences pragnesh@utk.edu Jan 28, 2014 Acknowledgement: Florent Nolot, Introduction to Parallel Computing,
Parallel Computing Using OpenMP/MPI. Presented by - Jyotsna 29/01/2008
 Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Introduction to Parallel Computing
 Tutorials Exercises Abstracts LC Workshops Comments Search Privacy & Legal Notice Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory UCRL MI 133316 Table of
Tutorials Exercises Abstracts LC Workshops Comments Search Privacy & Legal Notice Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory UCRL MI 133316 Table of
Introduction to Parallel Computing. Yao-Yuan Chuang
 Introduction to Parallel Computing Yao-Yuan Chuang 1 Outline Overview Concepts and Terminology Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel Examples
Introduction to Parallel Computing Yao-Yuan Chuang 1 Outline Overview Concepts and Terminology Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel Examples
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Parallel Architectures
 Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
Today's Outline. In the Beginning - ENIAC
 Today's Outline System history and evolution Parallel Classification System Architecture Programming Model Design Limitations Future Technologies FPGA Cell Broadband Engine GPU In the Beginning - ENIAC
Today's Outline System history and evolution Parallel Classification System Architecture Programming Model Design Limitations Future Technologies FPGA Cell Broadband Engine GPU In the Beginning - ENIAC
Parallel Computing Introduction
 Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Introduction to Parallel Computing
 Blaise Barney, Livermore Computing 13/09/2007 https://computing.llnl.gov/tutorials/parallel_comp/ Converted into slides by Olivier Ricou Sources available on http://www.lrde.epita.fr/~ricou.
Blaise Barney, Livermore Computing 13/09/2007 https://computing.llnl.gov/tutorials/parallel_comp/ Converted into slides by Olivier Ricou Sources available on http://www.lrde.epita.fr/~ricou.
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
An Introduction to Parallel Programming
 Dipartimento di Informatica e Sistemistica University of Pavia Processor Architectures, Fall 2011 Denition Motivation Taxonomy What is parallel programming? Parallel computing is the simultaneous use of
Dipartimento di Informatica e Sistemistica University of Pavia Processor Architectures, Fall 2011 Denition Motivation Taxonomy What is parallel programming? Parallel computing is the simultaneous use of
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Introduction to Parallel Computing
 Introduction to Parallel Computing Introduction to Parallel Computing with MPI and OpenMP P. Ramieri Segrate, November 2016 Course agenda Tuesday, 22 November 2016 9.30-11.00 01 - Introduction to parallel
Introduction to Parallel Computing Introduction to Parallel Computing with MPI and OpenMP P. Ramieri Segrate, November 2016 Course agenda Tuesday, 22 November 2016 9.30-11.00 01 - Introduction to parallel
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Advanced Scientific Computing
 Advanced Scientific Computing Fall 2010 H. Zhang CS595 Overview, Page 1 Topics Fundamentals: Parallel computers (application oriented view) Parallel and distributed numerical computation MPI: message-passing
Advanced Scientific Computing Fall 2010 H. Zhang CS595 Overview, Page 1 Topics Fundamentals: Parallel computers (application oriented view) Parallel and distributed numerical computation MPI: message-passing
Introduction to Parallel Computing
 Introduction to Parallel Computing Bootcamp for SahasraT 7th September 2018 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, IISc Acknowledgments Akhila, SERC S. Ethier, PPPL P. Messina, ECP LLNL HPC tutorials
Introduction to Parallel Computing Bootcamp for SahasraT 7th September 2018 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, IISc Acknowledgments Akhila, SERC S. Ethier, PPPL P. Messina, ECP LLNL HPC tutorials
Chapter 3 Parallel Software
 Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Parallel Programming Environments. Presented By: Anand Saoji Yogesh Patel
 Parallel Programming Environments Presented By: Anand Saoji Yogesh Patel Outline Introduction How? Parallel Architectures Parallel Programming Models Conclusion References Introduction Recent advancements
Parallel Programming Environments Presented By: Anand Saoji Yogesh Patel Outline Introduction How? Parallel Architectures Parallel Programming Models Conclusion References Introduction Recent advancements
Top500 Supercomputer list
 Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Moore s Law. Computer architect goal Software developer assumption
 Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Moore s Law. Computer architect goal Software developer assumption
 Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
6.1 Multiprocessor Computing Environment
 6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow.
 Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Introduction to Parallel Programming
 Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
High Performance Computing
 The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
Parallel Computing: Overview
 Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Plan. 1: Parallel Computations. Plan. Aims of the course. Course in Scalable Computing. Vittorio Scarano. Dottorato di Ricerca in Informatica
 1: Parallel Computations Course in Scalable Computing Vittorio Scarano Università di Salerno Dottorato di Ricerca in Informatica 2 3 4 1/91 2/91 Course motivations and target Course motivations and target
1: Parallel Computations Course in Scalable Computing Vittorio Scarano Università di Salerno Dottorato di Ricerca in Informatica 2 3 4 1/91 2/91 Course motivations and target Course motivations and target
GP-GPU. General Purpose Programming on the Graphics Processing Unit
 GP-GPU General Purpose Programming on the Graphics Processing Unit Goals Learn modern GPU architectures and its advantage and disadvantage as compared to modern CPUs Learn how to effectively program the
GP-GPU General Purpose Programming on the Graphics Processing Unit Goals Learn modern GPU architectures and its advantage and disadvantage as compared to modern CPUs Learn how to effectively program the
Parallel programming models. Main weapons
 Parallel programming models Von Neumann machine model: A processor and it s memory program = list of stored instructions Processor loads program (reads from memory), decodes, executes instructions (basic
Parallel programming models Von Neumann machine model: A processor and it s memory program = list of stored instructions Processor loads program (reads from memory), decodes, executes instructions (basic
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Architecture of parallel processing in computer organization
 American Journal of Computer Science and Engineering 2014; 1(2): 12-17 Published online August 20, 2014 (http://www.openscienceonline.com/journal/ajcse) Architecture of parallel processing in computer
American Journal of Computer Science and Engineering 2014; 1(2): 12-17 Published online August 20, 2014 (http://www.openscienceonline.com/journal/ajcse) Architecture of parallel processing in computer
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
BlueGene/L (No. 4 in the Latest Top500 List)
") BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
An Overview of Parallel Computing
 An Overview of Parallel Computing Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS2101 Plan 1 Hardware 2 Types of Parallelism 3 Concurrency Platforms: Three Examples Cilk CUDA
An Overview of Parallel Computing Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) CS2101 Plan 1 Hardware 2 Types of Parallelism 3 Concurrency Platforms: Three Examples Cilk CUDA
Co-arrays to be included in the Fortran 2008 Standard
 Co-arrays to be included in the Fortran 2008 Standard John Reid, ISO Fortran Convener The ISO Fortran Committee has decided to include co-arrays in the next revision of the Standard. Aim of this talk:
Co-arrays to be included in the Fortran 2008 Standard John Reid, ISO Fortran Convener The ISO Fortran Committee has decided to include co-arrays in the next revision of the Standard. Aim of this talk:
Parallel Computing Why & How?
 Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Multi-Processor / Parallel Processing
 Parallel Processing: Multi-Processor / Parallel Processing Originally, the computer has been viewed as a sequential machine. Most computer programming languages require the programmer to specify algorithms
Parallel Processing: Multi-Processor / Parallel Processing Originally, the computer has been viewed as a sequential machine. Most computer programming languages require the programmer to specify algorithms
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Distributed Systems CS /640
 Distributed Systems CS 15-440/640 Programming Models Borrowed and adapted from our good friends at CMU-Doha, Qatar Majd F. Sakr, Mohammad Hammoud andvinay Kolar 1 Objectives Discussion on Programming Models
Distributed Systems CS 15-440/640 Programming Models Borrowed and adapted from our good friends at CMU-Doha, Qatar Majd F. Sakr, Mohammad Hammoud andvinay Kolar 1 Objectives Discussion on Programming Models
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
Multi-core Programming - Introduction
 Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
CSCI 4717 Computer Architecture
 CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
Chapter 1: Introduction to Parallel Computing
 Parallel and Distributed Computing Chapter 1: Introduction to Parallel Computing Jun Zhang Laboratory for High Performance Computing & Computer Simulation Department of Computer Science University of Kentucky
Parallel and Distributed Computing Chapter 1: Introduction to Parallel Computing Jun Zhang Laboratory for High Performance Computing & Computer Simulation Department of Computer Science University of Kentucky
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Parallel Computer Architectures. Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam
 Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Chapter 5. Thread-Level Parallelism
 Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism. Abdullah Muzahid
 Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
BİL 542 Parallel Computing
 BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
Computer Organization. Chapter 16
 William Stallings Computer Organization and Architecture t Chapter 16 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data
William Stallings Computer Organization and Architecture t Chapter 16 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data
A brief introduction to OpenMP
 A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
Introduction. CSCI 4850/5850 High-Performance Computing Spring 2018
 Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
Organisasi Sistem Komputer
 LOGO Organisasi Sistem Komputer OSK 14 Parallel Processing Pendidikan Teknik Elektronika FT UNY Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple
LOGO Organisasi Sistem Komputer OSK 14 Parallel Processing Pendidikan Teknik Elektronika FT UNY Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
ARCHITECTURAL CLASSIFICATION. Mariam A. Salih
 ARCHITECTURAL CLASSIFICATION Mariam A. Salih Basic types of architectural classification FLYNN S TAXONOMY OF COMPUTER ARCHITECTURE FENG S CLASSIFICATION Handler Classification Other types of architectural
ARCHITECTURAL CLASSIFICATION Mariam A. Salih Basic types of architectural classification FLYNN S TAXONOMY OF COMPUTER ARCHITECTURE FENG S CLASSIFICATION Handler Classification Other types of architectural
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Memory Systems in Pipelined Processors
 Advanced Computer Architecture (0630561) Lecture 12 Memory Systems in Pipelined Processors Prof. Kasim M. Al-Aubidy Computer Eng. Dept. Interleaved Memory: In a pipelined processor data is required every
Advanced Computer Architecture (0630561) Lecture 12 Memory Systems in Pipelined Processors Prof. Kasim M. Al-Aubidy Computer Eng. Dept. Interleaved Memory: In a pipelined processor data is required every
DISTRIBUTED SHARED MEMORY
 DISTRIBUTED SHARED MEMORY COMP 512 Spring 2018 Slide material adapted from Distributed Systems (Couloris, et. al), and Distr Op Systems and Algs (Chow and Johnson) 1 Outline What is DSM DSM Design and
DISTRIBUTED SHARED MEMORY COMP 512 Spring 2018 Slide material adapted from Distributed Systems (Couloris, et. al), and Distr Op Systems and Algs (Chow and Johnson) 1 Outline What is DSM DSM Design and
Computer-System Organization (cont.)
") Computer-System Organization (cont.) Interrupt time line for a single process doing output. Interrupts are an important part of a computer architecture. Each computer design has its own interrupt mechanism,
Computer-System Organization (cont.) Interrupt time line for a single process doing output. Interrupts are an important part of a computer architecture. Each computer design has its own interrupt mechanism,
Computing on GPUs. Prof. Dr. Uli Göhner. DYNAmore GmbH. Stuttgart, Germany
 Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Introduction to Parallel Computing. Lesson 1
 Introduction to Parallel Computing. Lesson 1 Adriano FESTA Dipartimento di Ingegneria e Scienze dell Informazione e Matematica, L Aquila DISIM, L Aquila, 25.02.2019 adriano.festa@univaq.it What is Parallel
Introduction to Parallel Computing. Lesson 1 Adriano FESTA Dipartimento di Ingegneria e Scienze dell Informazione e Matematica, L Aquila DISIM, L Aquila, 25.02.2019 adriano.festa@univaq.it What is Parallel
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Types of Parallel Computers
 slides1-22 Two principal types: Types of Parallel Computers Shared memory multiprocessor Distributed memory multicomputer slides1-23 Shared Memory Multiprocessor Conventional Computer slides1-24 Consists
slides1-22 Two principal types: Types of Parallel Computers Shared memory multiprocessor Distributed memory multicomputer slides1-23 Shared Memory Multiprocessor Conventional Computer slides1-24 Consists
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
FLYNN S TAXONOMY OF COMPUTER ARCHITECTURE
 FLYNN S TAXONOMY OF COMPUTER ARCHITECTURE The most popular taxonomy of computer architecture was defined by Flynn in 1966. Flynn s classification scheme is based on the notion of a stream of information.
FLYNN S TAXONOMY OF COMPUTER ARCHITECTURE The most popular taxonomy of computer architecture was defined by Flynn in 1966. Flynn s classification scheme is based on the notion of a stream of information.
Fortran Coarrays John Reid, ISO Fortran Convener, JKR Associates and Rutherford Appleton Laboratory
 Fortran Coarrays John Reid, ISO Fortran Convener, JKR Associates and Rutherford Appleton Laboratory This talk will explain the objectives of coarrays, give a quick summary of their history, describe the
Fortran Coarrays John Reid, ISO Fortran Convener, JKR Associates and Rutherford Appleton Laboratory This talk will explain the objectives of coarrays, give a quick summary of their history, describe the
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Chapter 18 Parallel Processing
 Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
COMP4510 Introduction to Parallel Computation. Shared Memory and OpenMP. Outline (cont d) Shared Memory and OpenMP
 Shared Memory and OpenMP") COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Lecture 13. Shared memory: Architecture and programming
 Lecture 13 Shared memory: Architecture and programming Announcements Special guest lecture on Parallel Programming Language Uniform Parallel C Thursday 11/2, 2:00 to 3:20 PM EBU3B 1202 See www.cse.ucsd.edu/classes/fa06/cse260/lectures/lec13
Lecture 13 Shared memory: Architecture and programming Announcements Special guest lecture on Parallel Programming Language Uniform Parallel C Thursday 11/2, 2:00 to 3:20 PM EBU3B 1202 See www.cse.ucsd.edu/classes/fa06/cse260/lectures/lec13
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Normal computer 1 CPU & 1 memory The problem of Von Neumann Bottleneck: Slow processing because the CPU faster than memory
 Parallel Machine 1 CPU Usage Normal computer 1 CPU & 1 memory The problem of Von Neumann Bottleneck: Slow processing because the CPU faster than memory Solution Use multiple CPUs or multiple ALUs For simultaneous
Parallel Machine 1 CPU Usage Normal computer 1 CPU & 1 memory The problem of Von Neumann Bottleneck: Slow processing because the CPU faster than memory Solution Use multiple CPUs or multiple ALUs For simultaneous
Multiprocessors 2007/2008
 Multiprocessors 2007/2008 Abstractions of parallel machines Johan Lukkien 1 Overview Problem context Abstraction Operating system support Language / middleware support 2 Parallel processing Scope: several
Multiprocessors 2007/2008 Abstractions of parallel machines Johan Lukkien 1 Overview Problem context Abstraction Operating system support Language / middleware support 2 Parallel processing Scope: several